Graph強化学習による原子微細構造決定の加速
Atomic data determined by analysis of observed atomic spectra are essential for plasma diagnostics.
背景と学術的系譜
起源と学術的系譜
本稿で扱う「項解析」として知られる問題は、元素の原子構造を理解するという根本的な必要性から生じている。具体的には、観測された原子スペクトルからエネルギー準位のエネルギーおよび全電子角運動量 ($J$) を抽出し、これらの準位に適切な項記号を割り当てることを含む。この研究分野は、エネルギー準位や遷移波数などの結果として得られる原子データが、プラズマ診断、照明・金属産業、磁場閉じ込め核融合研究、核研究、医療用同位体製造、そして特に中性子星合体のような事象からの重元素起源の理解といった、幅広い応用にとって不可欠であるため、極めて重要である。
歴史的に、項解析のプロセスは、深い原子分光学的専門知識と広範な人的労力を要求する、逐次的で複雑な意思決定タスクであった。1970年代にフーリエ変換 (FT) 分光項解析が導入されて以来、その応用は主に鉄族元素(原子番号 $Z$ が23から28の間)に限定されてきた。この課題は、個々のエネルギー準位の決定を、精度が低い理論的予測のみに頼って行うことを困難にする、膨大な数の観測可能なスペクトル線(各元素でしばしば数万本)に起因する。
従来のアプローチの根本的な限界、すなわち「ペインポイント」は、その極端な非効率性と専門家への依存である。単一の原子種に対するスペクトル測定と理論計算の初期段階は数週間で完了できるが、その後の項解析、すなわち観測データからエネルギー準位を特定するという重要なステップは、数ヶ月から数年かかることがある。この手動で労働集約的なプロセスは、様々な科学的および産業分野における増大する需要を満たすために必要な原子データの迅速な生成を妨げる、主要なボトルネックとなっている。さらに、既存の ab initio(第一原理)計算は、しばしば数パーセントの精度しかなく、高いスペクトル分解能を必要とする応用には不十分である。項解析は、人的コストにもかかわらず、桁違いに高い精度を提供し、理論モデルに信頼できる制約を与える。この非効率性と、理論的手法だけでは十分な精度を提供できないという事実は、著者らが自動化された人工知能駆動型ソリューションを開発する主要な動機となっている。
直感的なドメイン用語
-
原子微細構造決定 / 項解析: 複雑な楽器、例えばグランドピアノを想像してみてほしい。しかし、鍵盤やその配置を見ることはできず、鳴る音しか聞くことができない。「原子微細構造決定」とは、聞こえるメロディーだけを頼りに、そのピアノのすべての鍵盤の正確な位置と識別、そしてそれらが互いにどのように関連しているかを解き明かすようなものである。これは、観測されたスペクトル「音符」を、原子の基本的な「鍵」(エネルギー準位)にマッピングするプロセスである。
-
スペクトル線 / 波長 ($\sigma$): ピアノのアナロジーを続けると、「スペクトル線」は、私たちが聞く単一の、明確な音符のようなものである。原子内の電子が高いエネルギー準位から低いエネルギー準位に遷移する際に、非常に特定の「ピッチ」で光を放出する。「波数」($\sigma$) は、そのピッチの正確な測定値であり、その電子遷移で放出されたエネルギー量を正確に示している。これは、2つの原子状態間のエネルギー差の直接的な尺度である。
-
マルコフ決定過程 (MDP): MDPを宝探しゲームと考えてほしい。あなた(「エージェント」)は特定の場所(「状態」)にいて、いくつかの経路(「行動」)を選択できる。あなたが選ぶ各経路は、新しい場所(新しい状態)にあなたを導き、いくらかの金(「報酬」)を与えるかもしれない。ゲームの目標は、ゲーム全体を通して収集する金の総量を最大化する戦略(「方策」)を見つけることである。たとえ一部の経路が即座に小さな報酬をもたらしても、後で行き止まりになる可能性があるとしても。
-
強化学習 (RL): これは、ロボットに明示的な指示を与えることなく、宝探しゲームをプレイするように教えるようなものである。代わりに、ロボットにさまざまな経路を試させる。金を見つけたとき、「よくやった!」(正の報酬)と伝える。行き止まりにぶつかったとき、「あまり良くない」(負の報酬)と伝える。多くの試行錯誤を通じて、ロボットはどの状態でのどの行動が最も多くの金につながるかを試行錯誤で学び、最終的には熟練した宝探し屋になる。
-
グラフニューラルネットワーク (GNN): それぞれがユニークな特性(人口、産業など)を持つ相互接続された都市の広大なネットワークと、それらを接続する各道路の特性(長さ、交通量など)を考えてほしい。GNNは、このようなネットワーク内の関係性と特徴を理解し、そこから学習するために設計された特殊な人工知能である。それはAIが都市と道路に関する情報に基づいた決定を下すことを可能にし、原子エネルギー準位とスペクトル線の複雑なウェブを分析するのに役立つ。
記法表
| 記法 | 説明 |
|---|---|
| $J$ | 全電子角運動量 |
| $Z$ | 原子番号 |
| $\sigma$ | 波長 |
| $\sigma_{obs}$ | 観測された波長 |
| $\delta\sigma_{obs}$ | 標準波長不確かさ |
| $I_{obs}$ | 相対強度 |
| $S/N_{obs}$ | 信号対雑音比 |
| $E_{obs}$ | 原子準位の観測エネルギー |
| $E_{calc}$ | 原子準位の理論エネルギー |
| $\Delta E$ | エネルギー準位の理論的不確かさ |
| $\Delta I$ | 線強度の理論的不確かさ |
| $E_u$ | 上部エネルギー準位 |
| $E_l$ | 下部エネルギー準位 |
| $E_0$ | 基底エネルギー準位(ゼロに固定) |
| $s_t$ | MDPにおける時刻 $t$ の状態 |
| $a_t$ | MDPにおける時刻 $t$ で取られた行動 |
| $r_t$ | 時刻 $t$ で受け取った報酬 |
| $G_t$ | 時刻 $t$ からの割引累積報酬 |
| $\gamma$ | 割引因子 |
| $H$ | MDPにおける有限ホライズン(エピソード長) |
| $Q(s, a)$ | Q値(状態 $s$ で行動 $a$ を取った場合の期待累積報酬) |
| $Q_{\theta}$ | パラメータ $\theta$ を持つオンラインQネットワーク |
| $Q_{\bar{\theta}}$ | パラメータ $\bar{\theta}$ を持つターゲットQネットワーク |
| $L$ | 損失関数 |
| $TD[n]$ | nステップ時間差誤差 |
| $r^{[n]}$ | nステップリターン |
| $w_m$ | 最小二乗最適化における線 $m$ の重み |
| $S_{mn}$ | エネルギー準位と線 $m$ を関連付ける係数行列 |
| $M$ | 知られている線の総数 |
| $N$ | 知られている準位の総数 |
| $D$ | 行動 $a^{(2)}$ の選好スコア |
| $h_v$ | 準位 $v$ のノード埋め込みベクトル |
| $S_{agg}$ | グローバルグラフ状態埋め込みベクトル |
| $V(s)$ | 状態価値関数 |
| $A(s, a)$ | アドバンテージ関数 |
| MLP | 多層パーセプトロン |
| GNN | グラフニューラルネットワーク |
| $N_c$ | 正しく決定されたエネルギー準位の数 |
| $R_{max}$ | 最大累積報酬 |
| Acc. | 決定された準位の精度 |
| PER | Prioritized Experience Replay(優先経験再生) |
| MCTS | Monte-Carlo Tree Search(モンテカルロ木探索) |
| UCT | Upper Confidence Bound for Trees(木のための上限信頼度) |
問題定義と制約
コア問題定式化とジレンマ
本稿で取り上げるコア問題は、原子微細構造決定の加速である。これは原子分光学における重要なタスクであり、プラズマ診断から天体物理学まで、様々な科学的および産業的応用における基礎データを提供する。
この分析の出発点(入力/現在の状態)は、観測された原子スペクトルのコレクションであり、これは「線リスト」として前処理される。この線リストは、特定の原子種に対して約 $10^4$ 本の観測可能なスペクトル線を含み、それぞれが観測された波数 ($\sigma_{obs}$)、標準波数不確かさ ($\delta\sigma_{obs}$)、相対強度 ($I_{obs}$)、および信号対雑音比 ($S/N_{obs}$) によって特徴付けられる。さらに、現在の状態には、既知の(経験的に決定された)エネルギー準位と遷移、および理論的に予測された準位と線とのグラフ表現が含まれる。これらの既知の準位は通常接続されており、固定されたゼロエネルギー基底準位に対する観測エネルギー ($E_{obs}$) を持つ。
望ましい終点(出力/目標状態)は、未知の原子エネルギー準位の観測エネルギー ($E_{obs}$) を正確に決定し、実験的不確かさ内で理論的予測に最もよく一致するスペクトル線を分類することである。これには、未知の準位を既知の準位に接続する少なくとも2つの観測スペクトル線を特定して一致させることにより、既知準位のサブグラフを拡張し、それによって未知の準位のエネルギーを決定することが含まれる。
本稿が橋渡ししようとする正確な欠落リンクまたは数学的ギャップは、生のスペクトル線データと精度が低い理論的予測から、正確で経験的に検証された原子エネルギー準位への移行にある。歴史的に、この「項解析」として知られるプロセスは、広範な人的労力と原子分光学的専門知識を必要とする、逐次的で複雑な意思決定タスクであり、単一の原子種に対して数ヶ月から数年かかることが多かった。数学的ギャップは、理論的だがしばしば不正確な計算によって導かれる、観測されたエネルギー差の膨大な数からこれらのエネルギー準位を推論するための、自動化され、スケーラブルで、正確な方法の欠如である。本稿ではこれをグラフ強化学習 (GRL) によって解決されるマルコフ決定過程 (MDP) として定式化する。
過去の研究者を閉じ込めてきた痛みを伴うトレードオフまたはジレンマは、精度と効率の間の厳しい選択である。人間主導の項解析は高い精度(ab initio 計算よりも桁違いに高い)と信頼できる理論的制約をもたらすが、それは非常に遅く労働集約的であり、原子データに対する増大する需要を満たすのに苦労している。逆に、ab initio 理論計算は高速であるが、通常は数パーセントの精度しかなく、より高いスペクトル分解能を必要とする応用には不十分である。ジレンマは、分析速度の向上は伝統的に必要な精度を犠牲にすることを意味したか、またはその逆であったということである。本稿では、プロセスの部分的な自動化を目指し、大幅に加速されたペースで人間レベルの精度を達成することを目指し、データ需要と分析能力の間のギャップを埋めることを目指している。
制約と失敗モード
原子微細構造決定の加速という問題は、いくつかの厳しい現実的な制約により、非常に困難である。
-
物理的およびドメイン固有の制約:
- データの量と複雑さ: 低イオン化の開殻dおよびfサブシェル原子種ごとに、約 $10^3$ 個の微細構造エネルギー準位を決定するには、約 $10^4$ 本の観測スペクトル線を分析する必要がある。主な課題は、「膨大な数の観測されたエネルギー差」から正確なエネルギー準位を抽出することである(セクション1、p.3)。
- 不正確な理論的ガイダンス: 既存の理論的予測はしばしば「精度が低い」(セクション1、p.3)ため、正確な値を提供するのではなく、大まかなガイドを提供するにすぎない。Ab initio 計算は通常、数パーセントの精度しかなく、多くの応用には不十分である。
- 曖昧さと不確かさ: 決定されたエネルギー準位はしばしば「曖昧な値」を持つ(セクション2.5、p.5)。人間の専門家は、観測された線強度と理論的線強度の間の合意、および波数不確かさ内での繰り返し $E_{obs}$ 値の一貫性を考慮する必要がある。「遷移確率の不確かさやスペクトル線フィッティングのエラー、特に広範囲にわたる弱線や/または混合線の場合」(セクション2.5、p.6)によって、この判断は複雑になる。
- 限られた使用可能な遷移: 「高次の多重極遷移は実験室スペクトルではめったに観測されない」(セクション2.2、p.4)ため、分析に利用可能なデータが制限されるため、電気双極子微細構造遷移のみが考慮される。
- 外れ値とノイズ: 「外れ値の波数(例:未知の線混合またはスペクトル線プロファイルのフィッティング不良)」(セクション3、p.8)の存在は、たとえ $\delta E$ 公差内であっても、決定されたエネルギー準位のシフトにつながる可能性がある。
- 困難なシナリオ: 「単線準位決定や切断された既知準位サブグラフの結合、既知準位が全くない項解析の開始」(セクション3、p.8)などの最も困難な状況は、MDPの複雑さを大幅に増加させ、現在の方法からはしばしば省略される。
-
計算的およびアルゴリズム的制約:
- 計算可能性と時間ホライズン: 人間の分析プロセスには「数ヶ月から数年」(セクション1、p.3)かかる。計算可能性のために、MDPは有限ホライズン $H$ を持つエピソード的であり(セクション2.1、p.4)、1つのエピソードで決定できる未知のエネルギー準位の数を制限する。
- 大きな状態空間と行動空間: 問題は「大きな状態空間と行動空間」(セクション2.7、p.7)を伴い、関数近似のために深層ニューラルネットワークを必要とする。未知の準位を選択するための行動空間 ($A^{(1)}$) は0から200まで、線を一致させるための行動空間 ($A^{(2)}$) は、より大きな $k$(接続する既知準位の数)に対して $10^3$ に達する可能性があるが、中央値は10未満である(セクション2.3、p.5)。単線決定を許可すると、「実行不可能なほど大きな $A^{(1)}$」(セクション2.3、p.5)につながる。
- MDP複雑性の管理: 「MDP複雑性の低減は、実行可能性とRLパフォーマンスの鍵である」(セクション2.6、p.6)。これには、信号対雑音比の低いグラフエッジの削除、既に一致した線の除外、スペクトル範囲の制限などの戦略が含まれる。「$|A^{(2)}|$ の最大キャップ」は、「効率的な探索とメモリ制御」を支援するために強制される(セクション2.6、p.6)。
- 探索効率: モンテカルロ木探索 (MCTS) における従来の探索方法、例えばランダム行動サンプリングは、「正しい行動が1つしかない大きな行動空間では非効率的である」(セクション4.6、p.11)。
- 計算コスト: ハイパーパラメータチューニングや複数シード実行を含む包括的な実験は、非常にリソース集約的であり、約 $10^5$ 時間(約11年)の仮説的なシングルコアCPU時間を必要とする(セクション4.7、p.11)。
-
データ駆動型学習の制約:
- 人間のデータへの依存: 報酬関数は、「逆強化学習を通じて過去の人間の決定に基づいて部分的に学習される」(Abstract, p.2)ものであり、専門家によって生成されたMDP状態遷移に依存する。
- 報酬関数学習のための訓練データ不足: 選好スコア $D$ を予測するMLPモデルは、Co II から115件、Nd III から23件の比較的少ない専門家 $a^{(2)}$ MDP状態遷移のデータセットで訓練された(セクション4.3、p.9)。
- 訓練データのバイアス: 「弱い線は訓練データセットで過小評価されており、未知の線は通常弱い」(セクション4.3、p.9)ため、これらの目立たない線に対するモデルのパフォーマンスに影響を与える可能性がある。
- 初期状態の質: 「初期MDP状態」の質は変動する可能性がある。例えば、Nd II の Rmax エピソードからのデータは「暫定的」と見なされ、「質の低いMDP初期状態」(セクション3、p.8)として扱われるが、人間の検証が行われるまでである。
なぜこのアプローチなのか
選択の必然性
グラフ強化学習 (GRL)、特に項解析とグラフ深層Qネットワーク (TAG-DQN) の選択は、単なる好みではなく、原子微細構造決定の本質的な性質によって駆動された必然的な選択であった。この複雑な問題は、本質的にグラフ構造データ上で動作する逐次的意思決定タスクである。著者らが問題定式化から推測できる「実現の正確な瞬間」は明示されていないが、彼らは解析手順を、原子エネルギー準位がノード、スペクトル線がエッジであるマルコフ決定過程 (MDP) として捉えた。
標準的な「SOTA」手法、例えば標準的な畳み込みニューラルネットワーク (CNN)、基本的な拡散モデル、またはTransformerは、それらの典型的な応用では、この特定の課題には不向きである。CNNはグリッド状データ(画像)に優れているが、不規則なグラフ構造には苦労する。拡散モデルは主に生成モデルであり、グラフ上の逐次的意思決定や組み合わせ最適化のために設計されていない。Transformerはシーケンスデータには強力であるが、項解析に固有の動的なグラフベースの状態表現と逐次的意思決定プロセスを処理するために、大幅な適応が必要となるだろう。根本的な問題は、固定グリッドでのパターン認識、新しいデータの生成、または単純なシーケンス翻訳の問題ではない。むしろ、未知のエネルギー準位を特定するために動的に進化するグラフ上で一連の相互依存的な選択を行うことであり、これはグラフ上の強化学習の強みに自然にマッピングされるタスクである。著者らは明確に、「スケーラビリティの達成の鍵は、この広範な文献で成功を収めた手法を採用することである。これには、行動空間の分解、ドメイン知識による有効な行動の制限、および学習表現としてのグラフニューラルネットワーク (GNN) の使用が含まれる [32]」と述べており、問題のグラフ構造と組み合わせ的な性質がこの特殊なアプローチを必要としたことを強調している。
比較優位性
単純なパフォーマンス指標を超えて、TAG-DQNは、主に広範な人的労力とあまり洗練されていない探索アルゴリズムに依存していた以前のゴールドスタンダードと比較して、質的および構造的な利点を提供する。最も顕著な利点は、分析時間の劇的な短縮である。TAG-DQNは、数ヶ月から数年を要するタスクを、数時間で数百のエネルギー準位を決定できる。これは効率において桁違いの改善である。
構造的には、TAG-DQNの優位性は、以下の能力に起因する。
1. グラフ構造データのネイティブな処理: 学習表現としてグラフニューラルネットワーク (GNN) を採用することにより、TAG-DQNは原子準位(ノード)とスペクトル線(エッジ)の固有のグラフ構造を直接処理する。これは、データを平坦化または高度に前処理する必要がある方法とは異なり、重要な情報を失う可能性があるため、自然な適合である。
2. 逐次的意思決定の学習: 強化学習エージェントとして、TAG-DQNは、累積報酬を最大化するために、一連の最適な決定(未知の準位の選択、スペクトル線のマッチング)を行う方策を学習する。これは、「逐次的で複雑な意思決定タスク」である項解析にとって極めて重要である。
3. 専門知識と不確実性の組み込み: 報酬関数は、逆強化学習を通じて過去の人間の決定から部分的に学習されるため、モデルは人間の専門家の微妙な好みやヒューリスティックを捉えることができる。さらに、行動空間は理論的および実験的不確かさ ($\Delta E$, $\Delta I$) を組み込んでおり、モデルが現実に即した物理的制約内で動作することを可能にする。
4. 長期的な一貫性の達成: モンテカルロ木探索 (MCTS) のようなベースライン探索アルゴリズムと比較して、TAG-DQNは、特にNd IIのような複雑なケースにおいて、正しくラベル付けされた準位の決定において優れた精度を示す。MCTSはより高い即時報酬を見つけるかもしれないが、大きな状態行動空間での浅いロールアウトは「近視眼的な行動」と一貫性のない長期的な結果につながる可能性がある。TAG-DQNは、エピソード全体を通して観測と理論との一貫性が「より高い」レベルのアイデンティティにつながる方策を学習する能力を持っており、これは重要な質的利点である。
本稿では、$O(N^2)$ 対 $O(N)$ のメモリ複雑性や、報酬関数の設計による高次元ノイズ処理(高信号対雑音比 (S/N) 線を優先し、測定不良の線を除外する)以外の特定の高次元ノイズ処理については明示的に議論していない。しかし、GNNと行動空間分解によるスケーラビリティの達成は、暗黙的に大規模で高次元の入力空間の課題に対処している。
制約との整合性
選択されたTAG-DQN手法は、原子微細構造決定の本質的な制約と要件に完全に整合しており、問題と解決策の強力な「結婚」を形成している。
- 逐次的意思決定: 問題は「逐次的で複雑な意思決定タスク」として記述されている。強化学習は、その定義により、離散時間ステップにわたる最適な方策を学習することによって、このような問題を解決するために設計されている。
- グラフ構造データ: 原子エネルギー準位とスペクトル線は自然にグラフを形成し、準位はノード、線はエッジである。TAG-DQNのコアコンポーネントであるGNNは、このような関係性データを処理および学習するために特別に設計されており、問題の構造的完全性を維持している。
- 膨大な探索空間: タスクは、「観測されたエネルギー差の膨大な数」からエネルギー準位を決定することを含む。効率的な状態表現のためのGNNと、大きな状態行動空間での学習のためのDQNの組み合わせは、この広大な組み合わせランドスケープをナビゲートするために必要なメカニズムを提供する。
- ドメイン知識と人間の専門知識の組み込み: 項解析は「本質的に経験的」であり、人間の専門知識に依存している。この手法は、逆強化学習を通じて「過去の人間の決定から部分的に学習された」報酬関数を使用することにより、これを処理し、専門知識をAIの意思決定プロセスに効果的に埋め込む。ドメイン知識は、有効な行動を制限し、MDPを単純化するためにも使用される。
- 計算可能性とスケーラビリティ: 主要な制約は、人間の労力が「数ヶ月から数年」かかることである。TAG-DQNは「数時間で最大102個の暫定的な微細構造エネルギー準位を決定できる」ため、加速の必要性に直接対応している。著者らはまた、「MDP複雑性の低減は、実行可能性とRLパフォーマンスの鍵である」と明示的に述べており、問題空間を(例:低S/Nエッジの削除、スペクトル範囲の制限)切り詰めて、解決策を管理可能にする方法を詳述している。
- 不確実性の処理: 問題は「精度が低い理論的予測」と実験的不確かさを伴う。行動空間と報酬関数は、理論的不確かさ ($\Delta E$, $\Delta I$) を考慮し、高信号対雑音比を持つ線に優先順位を付けるように設計されており、ノイズの多いデータに対して堅牢な解決策となっている。
代替案の却下
本稿では、特に探索アルゴリズムや一般的な強化学習パラダイムの範囲内で、特定の代替アプローチを却下する明確な理由を提供している。
- 貪欲探索: 著者らは、「貪欲探索はRLエージェントと比較して一貫して劣っていた」と明確に述べている。これは、貪欲アプローチは定義上、即時報酬のみを考慮し、項解析のような逐次的意思決定タスクにとって重要な長期的な結果を計画できないためである。
- モンテカルロ木探索 (MCTS): MCTSはより洗練された探索アルゴリズムであるが、本稿では「MCTSはTAG-DQNよりも高いRmaxを達成したが、TAG-DQNはNeの上限をより高く達成し、特にNd IIの場合に顕著であった」と述べている。解釈は、「MCTSのロールアウトは浅く、短期的な報酬を好んだ」ため、「累積報酬」は高かったが、「正しくラベル付けされた準位の精度」は低かったということである。これは、この問題では、長期的な一貫性と精度(TAG-DQNがより良く達成した)が、即時報酬の最大化よりも重要であることを示唆している。大きな状態行動空間は、深いMCTSロールアウトを計算コストが高くノイズに弱いものにする。
- 方策勾配法: 著者らは、「我々は、方策勾配法 [40] と比較してサンプル効率が高いという理由で、このアルゴリズムクラス [DQN] を選択した」と述べている。方策勾配法は通常、効果的な方策を学習するために環境とのより多くの相互作用を必要とし、これは原子データ分析の複雑で潜在的にコストのかかるシミュレーションまたは現実世界への応用において大きな欠点となるだろう。
- その他の深層学習アーキテクチャ(暗黙的な却下): GAN、拡散モデル、または標準的なCNN/Transformerが失敗したと明示的に述べているわけではないが、GNNとRLの選択は、コア問題に対してこれらを暗黙的に却下している。問題は画像生成、シーケンス翻訳、またはグリッド状データでの単純な分類ではない。原子準位と線の固有のグラフ構造と逐次的意思決定の性質の組み合わせにより、GRLは最も適切で効果的なパラダイムとなっている。これらの他の方法は、問題の適合に大幅な、おそらく不自然な再定式化を必要とし、最適性能の低下または複雑性の増加につながる可能性が高い。
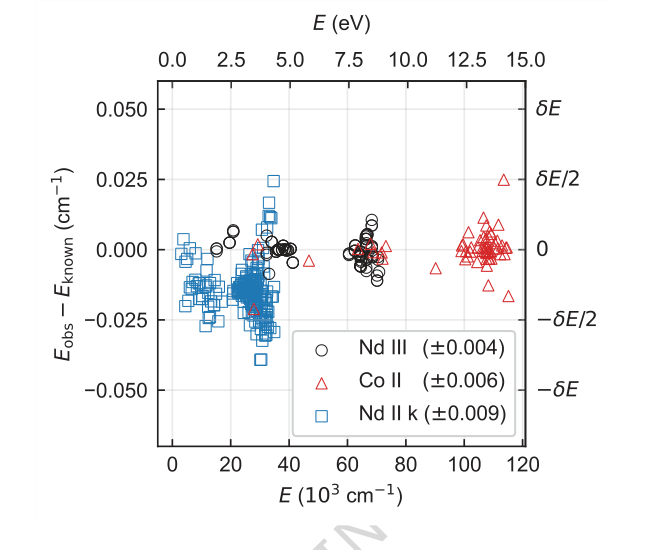 Figure 4. Difference between energy levels determined from a single seed and their known (ac- cepted) values for each species. Only levels contributing to Nc are shown. Energy differences for Nd III, Co II, and Nd II k are shown in circles, triangles, and squares, respectively. The root-mean-square energy differences are given in parentheses in the legend. Typical energy level uncertainty by FT spectroscopy is of order 0.001 cm−1. The offset and higher spread of Nd II k energies are expected and within uncertainties as their known values were derived by lower-precision grating spectroscopy [4]
Figure 4. Difference between energy levels determined from a single seed and their known (ac- cepted) values for each species. Only levels contributing to Nc are shown. Energy differences for Nd III, Co II, and Nd II k are shown in circles, triangles, and squares, respectively. The root-mean-square energy differences are given in parentheses in the legend. Typical energy level uncertainty by FT spectroscopy is of order 0.001 cm−1. The offset and higher spread of Nd II k energies are expected and within uncertainties as their known values were derived by lower-precision grating spectroscopy [4]
数学的および論理的メカニズム
マスター方程式
本稿のメカニズムの中核は、エージェントが最大化を目指すマルコフ決定過程 (MDP) の目的関数と、基盤となるニューラルネットワークの学習を駆動する損失関数という、2つの基本的な方程式を中心に展開されている。さらに、エネルギー準位を決定するための重要な計算は、状態更新メカニズムの不可欠な部分を形成する。
強化学習エージェントの主な目的は、有限ホライズン $H$ における期待累積割引報酬を最大化することである。
$$ E[G_t] = E\left[\sum_{k=0}^{H} \gamma^k r_{t+k}\right] \quad (1) $$
この方程式は、エージェントが何を達成しようとしているかを定義している。すなわち、将来の報酬の合計が可能な限り高くなるような一連の決定を下すことである。ただし、より早く受け取った報酬は、より遅く受け取った報酬よりも高く評価される。
深層Qネットワーク (DQN) エージェントの学習プロセスは、特にnステップ時間差 (TD) エラーの二乗である損失関数を最小化することによって駆動される。
$$ L = [TD[n]]^2 = \left[r^{[n]} + \gamma^n Q_{\bar{\theta}}(s_{t+n}, \text{argmax}_{a_{t+n}} Q_{\theta}(s_{t+n}, a_{t+n})) – Q_{\theta}(s_t, a_t)\right]^2 \quad (15) $$
この損失関数は、ニューラルネットワークが行動の「質」を正確に予測するように導き、その推定値が実際の将来の報酬と一致することを保証する。
最後に、状態更新、特に観測エネルギーレベル ($E_{obs}$) の決定を支える重要な計算は、重み付き最小二乗最小化によって実行される。
$$ E_{obs} = \text{argmin}_{E_n} \sum_{m=0}^{M-1} w_m \left( \sum_{n=0}^{N-1} S_{mn}E_n - \sigma_m \right)^2 \quad (9) $$
この方程式は、観測されたスペクトル線に基づいて既知のエネルギー準位のエネルギー値を洗練する方法であり、原子データを処理および更新する「数学的エンジン」の中心的なコンポーネントとなっている。
項ごとの解剖
これらの各方程式を詳細に分析し、個々のコンポーネントとその役割を理解しよう。
方程式 (1): 期待累積割引報酬
- $E[G_t]$: これは、時刻 $t$ から始まる期待累積割引報酬を表す。
- 数学的定義: 多くの可能な軌道にわたる $G_t$ の平均値。
- 物理的/論理的役割: これは強化学習エージェントの究極の目的関数である。エージェントの方策は、この量を最大化する行動を選択するように設計されており、実質的に原子微細構造を決定するための最良の一連の決定を見つける。
- $E[\cdot]$: これは期待値演算子である。
- 数学的定義: 確率変数の平均値を計算する。
- 物理的/論理的役割: 強化学習では、エージェントは正確な将来の報酬や状態遷移を決定論的に知らない。この演算子は、環境に固有の不確実性を考慮し、エージェントが平均的な結果を最適化することを保証する。
- $G_t$: これは、時刻 $t$ からの累積割引報酬である。
- 数学的定義: 将来のすべての報酬の合計であり、各報酬は $\gamma$ のべき乗で割引される。
- 物理的/論理的役割: 時刻 $t$ から始まる特定の一連の行動と状態の「良さ」の総量を定量化する。
- $\sum_{k=0}^{H} \gamma^k r_{t+k}$: これは割引将来報酬の合計である。
- 数学的定義: 各報酬 $r_{t+k}$ が $\gamma^k$ で乗算される有限の合計。
- 物理的/論理的役割: $t+k$ 時刻に得られた報酬を合計し、即時報酬を遠い報酬よりも価値のあるものにするために割引を適用する。合計は、総報酬が個々の報酬の蓄積であるため使用される。
- $\gamma$: これは割引因子である。
- 数学的定義: 0から1までのスカラー値(包括)、$\gamma \in [0, 1]$。
- 物理的/論理的役割: 即時報酬と将来の報酬の重要性のバランスを取る。0に近い $\gamma$ はエージェントを「近視眼的」にし、即時的な利益に焦点を当てる一方、1に近い $\gamma$ は「遠視的」にし、長期的な結果を考慮させる。著者らは合計に加算を選択したのは、総価値が個々の報酬の蓄積であるためである。
- $k$: これは $t$ に対する相対的な時間ステップインデックスである。
- 数学的定義: 時刻 $t$ からの将来のステップ数を表す整数。
- 物理的/論理的役割: 特定の報酬 $r_{t+k}$ がいつ受け取られるかを追跡し、割引のための $\gamma$ のべき乗を決定する。
- $r_{t+k}$: これは時刻 $t+k$ で受け取った報酬である。
- 数学的定義: 行動を取った後に環境から得られる即時のフィードバックを表すスカラー値。
- 物理的/論理的役割: 本稿では、報酬は決定されたエネルギー準位に対する信頼度、理論および観測との一致、および将来の準位決定を可能にする能力を反映するように設計されている(方程式6および7)。
方程式 (15): TAG-DQNの損失関数
- $L$: これは損失関数である。
- 数学的定義: 予測されたQ値とターゲットQ値の間の誤差を定量化するスカラー値。
- 物理的/論理的役割: トレーニングの目標は、この損失を最小化することであり、それによってQネットワークの予測がより正確になる。
- $[TD[n]]^2$: これはnステップ時間差 (TD) エラーの二乗である。
- 数学的定義: nステップリターン(将来の報酬の推定値)と現在のQ値予測の差の二乗。
- 物理的/論理的役割: エラーを二乗することにより、正と負の両方のエラーが損失に寄与し、より大きなエラーをより強く罰することで、収束を促進する。
- $r^{[n]}$: これはnステップリターンである。
- 数学的定義: 最初の $n$ 個の報酬の合計(割引済み)、それに $n$ ステップ後に到達した状態の割引Q値が加算される。
- 物理的/論理的役割: Q値推定値からブートストラップする前に短いホライズンにわたる実際の報酬を組み込むことにより、1ステップリターンよりも安定した、バイアスの少ない将来の報酬の推定値を提供する。
- $\gamma^n$: これは割引因子を $n$ 乗したものである。
- 数学的定義: 割引因子 $\gamma$ を $n$ 回掛けたもの。
- 物理的/論理的役割: 状態 $s_{t+n}$ における将来のQ値推定値を時刻 $t$ に戻して割引し、 $n$ ステップにわたって受け取った報酬と値を一致させる。
- $Q_{\bar{\theta}}(s_{t+n}, \text{argmax}_{a_{t+n}} Q_{\theta}(s_{t+n}, a_{t+n}))$: これはターゲットQ値である。
- 数学的定義: ターゲットネットワーク $Q_{\bar{\theta}}$ によって予測された、状態 $s_{t+n}$ におけるQ値と、その状態でQ値を最大化する行動。
- 物理的/論理的役割: この項は、学習するための安定したターゲットを提供する。遅延更新 ($\bar{\theta}$) を持つ別のターゲットネットワークを使用することにより、Q値推定値が動くターゲットを追いかけるのを防ぎ、トレーニングの不安定性を回避する。$\text{argmax}$ 部分は、ターゲットがオンラインネットワークの現在の理解に従って、次の状態からの最良の行動の価値を反映することを保証する。
- $Q_{\theta}(s_t, a_t)$: これは現在のQ値予測である。
- 数学的定義: オンラインネットワーク $Q_{\theta}$ によって予測された、現在の状態行動ペア $(s_t, a_t)$ のQ値。
- 物理的/論理的役割: これは、ネットワークが現在状態 $s_t$ で行動 $a_t$ を取ることに対して予測している値である。損失関数は、この予測がターゲットQ値に一致するように $\theta$ を調整することを目指す。
- $s_t$: これは時刻 $t$ における状態である。
- 数学的定義: 時刻 $t$ における環境の表現であり、グラフノードとエッジの特徴(方程式2および3)を含む。
- 物理的/論理的役割: 現在の項解析の進捗状況、例えば既知/未知の準位、観測されたスペクトル線、および理論計算など、関連するすべての情報を含む。
- $a_t$: これは時刻 $t$ で取られた行動である。
- 数学的定義: エージェントによって行われる離散的な選択であり、未知の準位 ($a^{(1)}$) を選択するか、エネルギーを決定するために線を一致させるか ($a^{(2)}$) のいずれかである。
- 物理的/論理的役割: 項解析プロセスにおけるエージェントの決定を表す。
- $\theta$: これらはオンラインQネットワークのパラメータである。
- 数学的定義: 現在Q値を予測するニューラルネットワークの重みとバイアス。
- 物理的/論理的役割: これらは、エージェントの方策を改善するためにトレーニング中に積極的に更新されるパラメータである。
- $\bar{\theta}$: これらはターゲットQネットワークのパラメータである。
- 数学的定義: Qネットワークのコピーの重みとバイアスであり、より頻繁に、またはスムーズに更新される。
- 物理的/論理的役割: 学習プロセスの安定性に不可欠な、ターゲットQ値の安定した参照を提供する。
- $\text{argmax}_{a_{t+n}} Q_{\theta}(s_{t+n}, a_{t+n})$: この演算子は、オンラインネットワークに従って、状態 $s_{t+n}$ でQ値を最大化する行動を見つける。
- 数学的定義: オンラインネットワークパラメータ $\theta$ を使用して、状態 $s_{t+n}$ に対して最も高いQ値をもたらす行動 $a_{t+n}$ を返す。
- 物理的/論理的役割: これはDouble DQNの重要なコンポーネントであり、オンラインネットワークがターゲット値計算のための行動を選択するが、ターゲットネットワークがその値を評価する。これはQ学習における過大評価バイアスを軽減するのに役立つ。
方程式 (9): レベルエネルギー最適化
- $E_{obs}$: これは準位の観測エネルギーを表す。
- 数学的定義: $N$ 個の既知準位に対するエネルギー値 $E_n$ のベクトル。
- 物理的/論理的役割: これらは、項解析が確立しようとする経験的に決定されたエネルギー準位である。
- $\text{argmin}_{E_n}$: これは最小化演算子である。
- 数学的定義: 後続の式を最小化する $E_n$ の値を検索する。
- 物理的/論理的役割: 観測されたエネルギー準位は、観測されたスペクトル線への不一致を最小化することによって、エネルギー準位のセットを見つけることによって決定されることを意味する。
- $\sum_{m=0}^{M-1} w_m \left( \sum_{n=0}^{N-1} S_{mn}E_n - \sigma_m \right)^2$: これは重み付き二乗残差の合計である。
- 数学的定義: $M$ 個の既知線すべてにわたる合計であり、各項は予測された波数と観測された波数との二乗差であり、$w_m$ で重み付けされる。
- 物理的/論理的役割: これは最小二乗最適化の目的関数である。現在のエネルギー準位のセットと観測されたスペクトル線との全体的な不一致を定量化する。この合計を最小化することは、観測されたスペクトルを最もよく説明するエネルギー準位のセットを見つけることを意味する。合計は、総誤差が個々の線からの誤差の集計であるため使用される。
- $M$: これは既知線の総数である。
- 数学的定義: 既知エネルギー準位間の遷移に一致したスペクトル線の整数カウント。
- 物理的/論理的役割: エネルギー準位を制約するために利用可能な経験的データの量を示す。
- $N$: これは既知準位の総数である。
- 数学的定義: 値が最適化されているエネルギー準位の整数カウント。
- 物理的/論理的役割: 値が洗練されている原子状態の数を表す。
- $w_m$: これは線 $m$ の重みである。
- 数学的定義: $w_m = (\delta\sigma_m)^{-2}$、線 $m$ の波数不確かさの逆二乗。
- 物理的/論理的役割: より正確に測定されたスペクトル線($\delta\sigma_m$ が小さいもの)に高い重要性を割り当て、不確かさが大きい線には低い重要性を割り当てる。これにより、信頼できるデータが決定されたエネルギー準位に大きな影響を与えることが保証される。逆二乗は、重みが測定誤差の分散に反比例する場合、重み付き最小二乗法における標準的な選択である。
- $\left( \sum_{n=0}^{N-1} S_{mn}E_n - \sigma_m \right)^2$: これは線 $m$ の二乗差(残差)である。
- 数学的定義: 現在のエネルギー準位によって予測された波数と線 $m$ の観測された波数との差の二乗。
- 物理的/論理的役割: 現在のエネルギー準位のセットが特定の観測スペクトル線をどの程度よく説明しているかを測定する。二乗することにより、正の値が保証され、より大きな偏差がより強く罰せられる。
- $S_{mn}$: これはエネルギー準位と線 $m$ の関係を定義する係数である。
- 数学的定義: 係数行列要素であり、準位 $n$ が遷移 $m$ の上部準位の場合は1、準位 $n$ が遷移 $m$ の下部準位の場合は-1、それ以外の場合は0である。
- 物理的/論理的役割: この係数は、スペクトル線の波数 ($\sigma_m$) が、遷移に関与する上部 ($E_u$) および下部 ($E_l$) エネルギー準位間の差であるという基本的な関係をエンコードする:$\sigma_m = E_u - E_l$。
- $E_n$: これは準位 $n$ のエネルギーである。
- 数学的定義: 特定の原子準位のエネルギーを表すスカラー値。
- 物理的/論理的役割: これらは、最適化プロセスが決定しようとする未知のパラメータである。
- $\sigma_m$: これは線 $m$ の観測波数である。
- 数学的定義: スペクトル線の波数を示す測定されたスカラー値。
- 物理的/論理的役割: これは、スペクトル線リストからの経験的入力データであり、エネルギー準位はこれに適合する必要がある。
ステップバイステップの流れ
項解析を、抽象的なデータポイントが一連の操作を通過する動的な組立ラインとして想像してみよう。
-
初期状態入力: プロセスは、初期のグラフ状態 $s_t$ から始まる。この状態は、ノード $V$ が原子エネルギー準位(一部は既知、一部は未知)、エッジ $E$ が潜在的または観測されたスペクトル線(遷移)であるリッチなデータ構造、グラフ $G=(V, E)$ である。各ノードとエッジは、特徴のセット(例:理論エネルギー、観測波数、不確かさ、既知または選択されたフラグのバイナリフラグ)を持つ。これに加えて、すべての観測された遷移を含む包括的なスペクトル線リストがある。
-
行動 $a^{(1)}$: 準位選択: エージェントは最初にタイプ $a^{(1)}$ の行動を実行する。それは、少なくとも2つの潜在的な接続(エッジ)が既知準位に接続されている未知のすべての準位を調査する。このプールから、エージェントは決定の対象となる特定の未知の準位を1つ選択する。この選択は、エージェントの学習済みQ値に基づいており、そのレベルを選択することの長期的な報酬を推定する。選択されると、このノードの「選択済み」フラグが反転され、それが現在のターゲットであることを示す。
-
行動 $a^{(2)}$: 線マッチングとエネルギー仮説: 次に、エージェントはタイプ $a^{(2)}$ の行動を実行する。選択された未知の準位に対して、既知の準位に接続するすべての可能なエッジを考慮する。各エッジについて、スペクトル線リスト全体($10^4$ 本の線を含む可能性がある)をフィルタリングして、候補となる観測線を見つける。このフィルタリングは厳密である。
- 波数マッチ: 観測された波数 $\sigma_{obs}$ は、遷移の理論的な波数 $\sigma_{calc}$ とエネルギー不確かさ $\Delta E$ の範囲 $[\sigma_{calc} \pm \Delta E]$ 内にある必要がある。
- 強度マッチ: 観測された強度 $I_{obs}$ は、理論的な範囲 $[I_{calc} \pm \Delta I]$ 内にある必要がある。
- 候補 $E_{obs}$ 生成: フィルタリングされた各線について、選択された未知の準位の候補観測エネルギー $E_{obs}$ は、接続された準位の既知のエネルギーに線の波数(選択された準位が上部か下部かによる)を加算または減算することによって計算される。
- 統合: 複数の線が未知の準位に対して同じエネルギーを示唆する可能性があるため、候補はグループ化され、小さな許容誤差 $\delta E$ 内で繰り返される $E_{obs}$ 値のみが考慮される。次に、エージェントはこれらの統合された $E_{obs}$ 値のいずれか(または適切な候補が存在しない場合は「何もしない」)を選択する。
-
状態遷移とグラフ更新: $E_{obs}$ 値が ($a^{(2)}$ を介して) 選択された準位に対して選択されると、グラフ状態 $s_t$ は決定論的に新しい状態 $s_{t+1}$ に遷移する。
- 「選択された」未知の準位は、現在「既知」の準位となり、その $E_{obs}$ 特徴は選択された値で更新される。
- 一致したスペクトル線に対応するエッジも「既知」エッジとなり、その特徴(例:$\sigma_{obs}$, $I_{obs}$)は線リストから更新される。これらの一致した線は、このエピソードでの将来の $a^{(2)}$ 考慮から除外される。
- グローバル再最適化: 重要なのは、新しい準位が決定された後、現在既知のすべての準位(新しく決定されたものを含む)の観測エネルギー $E_{obs}$ が、重み付き最小二乗最小化(方程式9)を使用して再最適化されることである。これにより、既知のレベルシステム全体の一貫性が保証される。基底エネルギー準位 $E_0$ は、参照としてゼロに固定される。
-
報酬計算: 新しい状態 $s_{t+1}$ と取られた行動に基づいて、報酬 $r_t$ が計算される。この報酬は複合的であり、決定された準位の信頼度、理論との一致、および将来の決定を可能にする可能性を反映する。$a^{(1)}$ については、接続線の信号対雑音比(方程式6)に基づいている。$a^{(2)}$ については、人間の決定から学習された選好スコア $D$(方程式7)が組み込まれている。
-
経験の保存: タプル $(s_t, a_t, r_t, s_{t+1})$、すなわち古い状態、取られた行動、受け取った報酬、新しい状態を表すものは、リプレイバッファに保存される。このバッファはメモリとして機能し、過去の経験を蓄積する。
-
反復: プロセスはステップ2に戻り、エージェントは別の未知の準位を選択するか、現在の準位の洗練を続ける。これは、有限ホライズン $H$ に達するか、またはそれ以上有効な行動が取れなくなるまで続く。
この全体的なシーケンスは、生のスペクトルデータが継続的に洗練され、自己整合的な原子エネルギー準位のモデルに統合される、抽象的な数学を動く機械組立ラインのように感じさせる。
最適化ダイナミクス
TAG-DQNメカニズムは、主に時間差 (TD) エラーを最小化することによって駆動される、深層強化学習技術の洗練された相互作用を通じて学習および収束する。その仕組みは以下の通りである。
-
グラフ表現学習: 基盤となるのはグラフニューラルネットワーク (GNN) である。グラフ状態 $s_t$(現在の既知/未知準位と線のセットを表す)が提示されると、GNNはノード(準位)とエッジ(線)およびそれらに関連付けられた特徴(例:$E_{calc}$, $\sigma_{obs}$, $I_{obs}$)を処理する。それはマルチヘッドグラフアテンションレイヤーを使用して、各ノードの局所的な近傍の構造的および特徴的な情報を捉える、リッチで文脈化されたノード埋め込みベクトル $h_v$ を学習する(方程式11)。次に、単純にこれらのノード埋め込みを平均することによって、グローバルなグラフ状態埋め込みベクトル $S_{agg}$ が取得される。この $S_{agg}$ は、グラフ全体の現在の状態を効果的に要約する。
-
Q値推定(デュエリングDQN): 学習されたグラフ埋め込みは、次に多層パーセプトロン (MLP) に供給され、Q値を推定する。アーキテクチャはデュエリングDQN設計を採用しており、状態価値関数 $V(s)$ とアドバンテージ関数 $A(s, a)$ の推定を分離する。
- 行動タイプ $a^{(1)}$(未知の準位の選択)の場合、各有効な準位選択に対するQ値は、グローバル $S_{agg}$(状態価値用)と選択された準位のノード埋め込み(アドバンテージ用)を組み合わせることによって推定される(方程式12)。
- 行動タイプ $a^{(2)}$(エネルギーを決定するための線のマッチング)の場合、Q値は同様に推定されるが、アドバンテージ関数 $A(s,a)$ は、状態行動値と状態値の差を取ることによって計算される(方程式13)。この分離は、ネットワークがどの状態が行動とは独立に価値があるかを学習するのに役立ち、効率を向上させる。
-
方策と探索: エージェントの方策は、推定Q値に対する貪欲である。各ステップで、それは最も高い予測Q値を持つ行動($a^{(1)}$ または $a^{(2)}$ のいずれか)を選択する。探索のために、従来のイプシロン貪欲法の代わりに、著者らはノイズネットワークを使用する。これは、ノイズがMLP出力層の重みに直接追加されることを意味し、エージェントが明示的な $\epsilon$ パラメータを必要とせずに自然に異なる行動を探索することを奨励する。ノイズは学習され、時間とともに適応され、複雑な環境でのより効率的な探索を可能にする。
-
経験からの学習(リプレイバッファとnステップリターン): 学習するために、エージェントは最新の経験のみを使用しない。代わりに、過去の経験(状態、行動、報酬、次の状態のタプル)をリプレイバッファに保存する。トレーニング中、これらの経験のバッチがバッファからランダムにサンプリングされる。これにより、連続する経験間の相関が壊れ、学習プロセスが安定する。損失計算(方程式15)はnステップリターン ($r^{[n]}$)を使用する。これは、即時報酬 $r_t$ と次の状態 $s_{t+1}$ のQ値のみを考慮するのではなく、ブートストラップする前に短い軌道にわたる実際の報酬を組み込むことにより、学習のためのより正確なターゲットを提供する。
-
安定性のためのターゲットネットワーク: Q学習における主な課題は、ターゲット値(ネットワークが予測しようとしているもの)が更新されているネットワーク自体に依存しており、不安定性を引き起こすことである。これを解決するために、TAG-DQNはターゲットネットワーク $Q_{\bar{\theta}}$ を使用する。これはオンラインQネットワーク ($Q_{\theta}$) の別のコピーであり、そのパラメータ $\bar{\theta}$ は $\theta$ よりもはるかに遅く更新される。具体的には、$\bar{\theta}$ は各ステップでオンラインネットワークのパラメータの小さな割合をターゲットネットワークのパラメータにブレンドすることによってソフト更新(方程式14)される。これにより、オンラインネットワークが学習するための安定したターゲットが作成され、振動と発散が防止される。Double DQNの使用は、ターゲット値計算のための最良の行動を選択するためにオンラインネットワークを使用するが、その値を評価するためにターゲットネットワークを使用することにより、これをさらに洗練させ、過大評価バイアスを軽減するのに役立つ。
-
報酬関数学習(逆強化学習): ユニークな側面は、行動 $a^{(2)}$ の報酬関数(選好スコア $D$)が手作業でコーディングされていないことである。代わりに、それは過去の人間の専門家の決定から学習される、一種の逆強化学習を使用する。単純な多層パーセプトロン (MLP) は、候補線の特徴から $D$ を予測するように訓練される(方程式8)。このMLPは、人間の決定が肯定的な例としてラベル付けされた専門家によって生成されたMDP状態遷移のデータセットで訓練される。これにより、システムは、線の一致の「良さ」に関する人間の専門家の微妙な判断を暗黙的に捉え、専門家の直感と一致する行動を好むように損失ランドスケープを形成することができる。
-
最適化アルゴリズム: ネットワークパラメータ $\theta$ は、深層学習タスクにおいて効率性と良好なパフォーマンスで知られる一般的な確率的勾配降下法であるAdamオプティマイザを使用して最適化される。この反復的な最適化プロセスは、損失関数を最小化するように重みとバイアスを調整し、それによってQ値予測の精度を向上させ、結果としてエージェントの方策を向上させる。
本質的に、最適化ダイナミクスは連続的なサイクルを含んでいる。エージェントは環境で行動し、経験を収集し、それを保存し、次にこの経験のバッチから学習する。この学習プロセスは、ターゲットネットワーク、nステップリターン、およびデュエリングアーキテクチャのような技術によって安定化され、探索はノイズネットワークによって処理される。人間の専門知識から導き出された学習済み報酬関数は、エージェントを物理的に意味のある解にさらに導き、専門家の好みと不確かさを反映するように損失ランドスケープを形成する。この反復的な洗練により、エージェントは原子微細構造を効率的かつ正確に決定する方策に収束できる。
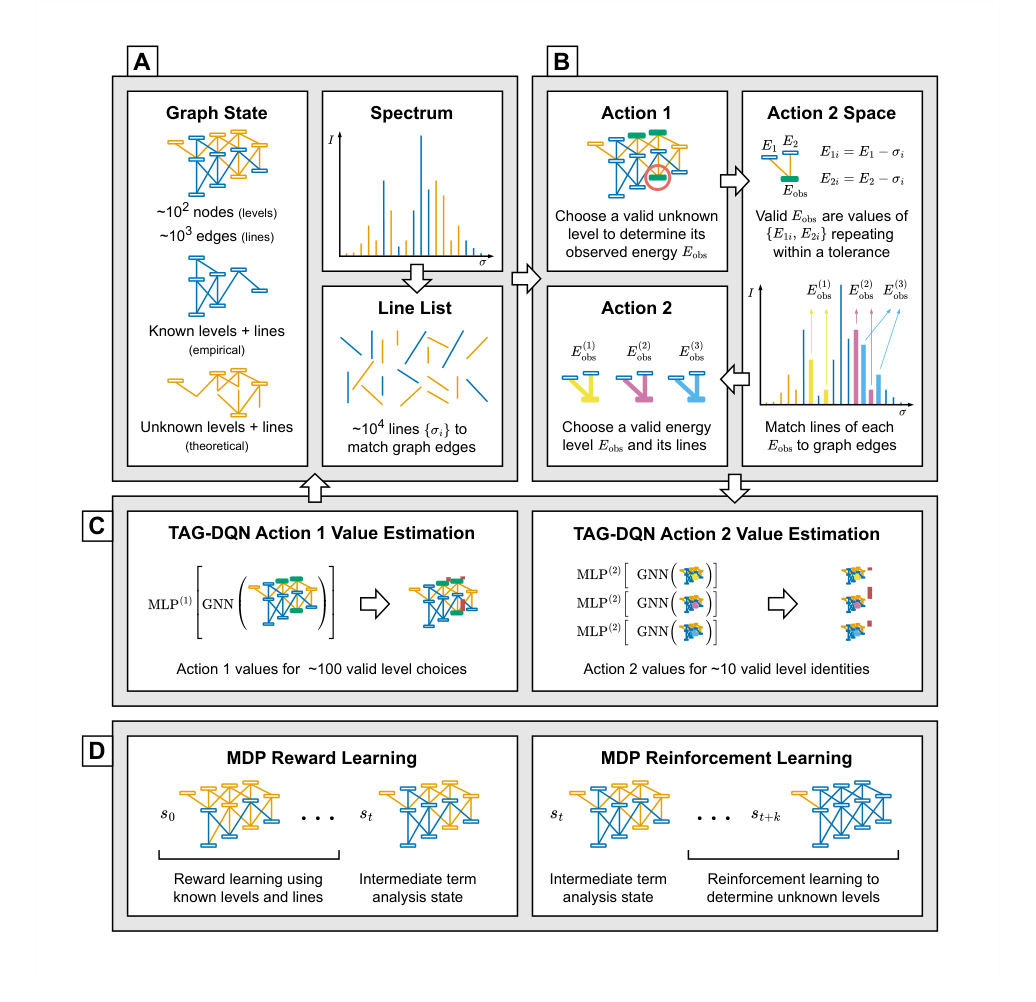 Figure 1. Illustration of the MDP environment and TAG-DQN. A The term analysis state is represented as a graph with node and edge features, alongside the spectral line list. B Actions alternate between two regimes; each pair of actions leads to the determination of the observed energy Eobs for one level by matching at least two lines from the line list to unknown edges in the graph. C TAG-DQN employs a GNN to embed graph representations, which are inputs for multilayer perceptrons (MLPs) estimating Q-values for each action (vertical bars); the highest Q-value action advances the MDP to the next state. D Given a term analysis state st, the MDP trajectory leading to st involving known levels is used for reward learning, while RL with the learned reward function guides the discovery of unknown levels in future states st+k
Figure 1. Illustration of the MDP environment and TAG-DQN. A The term analysis state is represented as a graph with node and edge features, alongside the spectral line list. B Actions alternate between two regimes; each pair of actions leads to the determination of the observed energy Eobs for one level by matching at least two lines from the line list to unknown edges in the graph. C TAG-DQN employs a GNN to embed graph representations, which are inputs for multilayer perceptrons (MLPs) estimating Q-values for each action (vertical bars); the highest Q-value action advances the MDP to the next state. D Given a term analysis state st, the MDP trajectory leading to st involving known levels is used for reward learning, while RL with the learned reward function guides the discovery of unknown levels in future states st+k
結果、限界、および結論
実験設計とベースライン
数学的主張を厳密に検証するために、著者らはTAG-DQN (Term Analysis with Graph Deep Q-Network) を、貪欲探索エージェントと標準的なモンテカルロ木探索 (MCTS) エージェント(Upper Confidence Bound for Trees (UCT) 戦略を使用)という2つのベースラインモデルと比較する一連の実験を設計した。中心的な考えは、TAG-DQNが原子微細構造決定の複雑で逐次的な意思決定タスクを効果的に自動化および加速できることを実証することであった。
実験設定は、Co II、Nd III、およびNd IIの2つのバリアント(ab initio 計算用のNd II u、およびCowanコード計算用のNd II k)の実際の原子項解析から派生した4つの異なるマルコフ決定過程 (MDP) 環境を使用した。これらの環境は、実際の項解析の課題を反映するように慎重に構築され、既存のフーリエ変換 (FT) スペクトル線リストと理論的計算が使用された。例えば、Co II 環境は、改訂された公開データから141個の既知準位で初期化された一方、Nd III は40個の準位を使用した。Nd II 環境は、6つの基底項準位、5つの 6K 準位、および11個の遷移で開始され、理論計算方法が異なっていた。
公平で堅牢な比較を保証するために、TAG-DQNとMCTSは、25個の異なるランダムシードで評価され、平均パフォーマンスと95%信頼区間が報告された。決定論的である貪欲探索は一度実行された。パフォーマンスは、3つの主要な指標で測定された。
1. $R_{max}$: MDPエピソード長 $H$ 内でエージェントが達成した最大累積報酬。
2. $N_c$: $R_{max}$ エピソードで正しく決定されたエネルギー準位の数。準位は、その観測エネルギー ($E_{obs}$) が以前に公開されたエネルギー準位 ($E_{known}$) から $\pm \delta E$ 以内にある場合に正しいと見なされた。
3. 精度 (Acc.): $R_{max}$ エピソードで決定された総準位数に対する $N_c$ の比率として定義される。
MDP環境は、実行可能性とRLパフォーマンスを向上させるために慎重に簡略化された。これには、低信号対雑音比 ($S/N_{calc} < 2$) のグラフエッジの枝刈り、既に一致した線リストエントリの除外、エネルギー最適化中の初期既知準位の固定、およびスペクトル範囲の制限が含まれた。線マッチングの行動空間 ($|A^{(2)}|$) の最大キャップも、効率的な探索とメモリ管理を支援するために課された。エピソード長 $H$ は、計算コストとエージェントが長期的な結果を学習する能力とのバランスを取るために、種ごとに変化した(例:Nd III および Co II では $H=128$、Nd II u では $H=64$、Nd II k では $H=512$)。
さらに、Nd III 環境でアブレーション研究が行われ、TAG-DQNの全体的なパフォーマンスに対する様々な深層Qネットワーク (DQN) 拡張(二重Q学習、優先経験再生、デュエリング、多ステップリターン、および探索のためのノイズネットワークなど)の寄与を解明した。これにより、どのアーキテクチャコンポーネントがモデルの成功した操作に最も重要であるかを特定することができた。
証拠が証明するもの
実験結果は、TAG-DQNが、伝統的に数ヶ月から数年の人間の努力を必要とする原子微細構造決定を大幅に加速できることを説得力のある証拠を提供している。このシステムは、数時間で数百のエネルギー準位を特定および決定することができた。
具体的には、項解析をグラフ強化学習で解決されるマルコフ決定過程として捉え、人間の決定から部分的に学習された報酬関数を使用するというTAG-DQNの中核メカニズムが、現実世界で実証された。決定的な証拠は、公開値との高い一致率にある。Co II では95%、Nd II および Nd III では54%から87%である。この精度のレベルは、わずかな時間で達成されており、手法の有効性の強力な指標となっている。
ベースラインモデル(表2)と比較すると、TAG-DQNはすべての指標で貪欲探索エージェントを常に上回った。さらに重要なのは、5つのケーススタディのうち3つで、$N_c$(正しく決定された準位の数)においてMCTSエージェントよりも優れたパフォーマンスを示したことである。MCTSは時折より高い最大累積報酬 ($R_{max}$) を達成したが、TAG-DQNは常に $N_c$ の上限をより高く達成し、特にNd II のケースで顕著であった。これは、TAG-DQNが、MCTSの浅いロールアウトが全体的な精度を犠牲にして短期的な報酬を好んだ可能性があるのに対し、エピソード全体を通して観測と理論と一貫性を保つ準位のアイデンティティを選択するのに優れていたことを示唆している。Nd II k の場合、TAG-DQNはMCTS(130 $\pm$ 11)と比較して大幅に多い数の準位(169 $\pm$ 10)を正しくラベル付けした。これはこの解釈をさらに強化する。
学習曲線(図2A、B)は、累積報酬と正しく決定された準位の数 ($N_c$) との間の整合性を明確に示しており、学習された報酬関数がエージェントを正確な準位決定に効果的に導いていることを示している。ボルツマンプロット(図2C)は、TAG-DQNが異なる電子構成の準位を決定できること、およびボルツマンレベル集団に基づいた線強度フィルタリングが問題のある線を排除するのに効果的であることを確認した。
アブレーション研究(図3)は、TAG-DQNのアーキテクチャに関する重要な洞察を提供した。それらは、ほとんどのDQN拡張がパフォーマンスに肯定的に貢献し、特にデュエリングネットワークアーキテクチャと探索のためのノイズネットワークが非常に重要であることを明らかにした。これは、問題に固有の大きな行動空間のためである可能性が高い。興味深いことに、優先経験再生 (PER) はパフォーマンスをわずかに低下させた。これは、バッファサイズとトレーニングステップがこの特定の環境でのPERの利点に対して最適にスケーリングされていなかったためである可能性がある。エネルギー準位差(図4)は、手法の精度をさらに裏付け、決定された準位の小さな割合が受け入れられた値から逸脱したものの、これらの逸脱は一般的に実験的不確かさ $\delta E$ 内(例:Nd III では $\pm 0.004$ cm$^{-1}$、Co II では $\pm 0.006$ cm$^{-1}$、Nd II k では $\pm 0.009$ cm$^{-1}$)であり、ほとんどの応用には無視できるものであったことを示している。
限界と今後の方向性
TAG-DQNアプローチは、原子微細構造決定の自動化において大きな進歩を示しているが、現在の限界を認識し、将来の開発の方向性を考慮することが重要である。
主な限界の1つは、現在の手法が、その印象的な速度にもかかわらず、人間の専門家と比較して精度が低下しており、原子構造計算に依存していることである。決定された準位、特にNd II k のようなケースでは、暫定的なものと見なされ、最終的な出版前に人間の検証を必要とする。さらに、現在のフレームワークは、単線準位の決定、切断された既知準位サブグラフの結合、または完全に未知の状態からの分析の開始など、最も困難なシナリオにはまだ対処していない。これらの状況はMDPの複雑さを大幅に増加させ、大幅な再設計を必要とするだろう。報酬関数は、現在主にCo II データで訓練されているが、異なる原子種や条件全体での一般化を改善するために、より多様で広範な訓練データセットで利益を得る可能性がある。
将来を見据えると、いくつかの有望な方向性がこれらの発見をさらに進化させる可能性がある。
- MDPの状態と行動空間の充実: 現在のMDPは、より詳細な情報を含めるように拡張できる。例えば、生のスペクトルと線プロファイル分析をMDPに直接統合することで、エージェントが同位体シフト、超微細構造、および異なるスペクトル間の比較のような追加要因を考慮できるようになる。波動関数に関する情報、例えば主要な構成ラベル、電子確率密度、および特定のパリティとJ値内の局所的な準位密度なども、線プロファイルと強度に関するエージェントの決定に情報を提供し、より堅牢で正確な準位決定につながる可能性がある。
- より堅牢な報酬関数の開発: 前述のように、現在の報酬関数が限られたデータセットに依存していることは制約である。将来の研究では、多様な原子種の線リストとMDPの広大な配列を使用して、より一般的な報酬関数を訓練することに焦点を当てるべきである。これにより、エージェントが新しい状況を処理する能力が向上し、全体的なパフォーマンスが向上する。
- 人間参加型ループの統合: 著者らは、AIの出力が中間ステップとして機能する協調的なアプローチを構想している。エピソードの最終的なMDP状態は、人間の専門家がスペクトルを検査し、誤って決定された準位を枝刈りし、半経験的計算を洗練し、報酬関数を再訓練するための新しい初期状態となる可能性がある。この反復的な人間-AI協力は、AIが骨の折れる初期識別を処理し、人間の専門家が重要な検証と洗練を提供するという、両者の強みを活用できる可能性がある。
- 複雑なシナリオへの対処: 将来の研究では、現在省略されている困難な状況に対処するためにMDPを再設計することに焦点を当てるべきである。これには、増加する複雑性を管理するために、新しいグラフ表現または行動空間分解が必要になる可能性があり、項解析の最も困難な側面さえも自動化する能力を解き放つ可能性がある。
- 他の実験手法への拡張: このアプローチは本質的に柔軟であり、環境パラメータ($\delta E$, $\Delta I$、および報酬関数)のマイナーな調整で、格子分光法のような他の実験手法に適合させることができる。これにより、様々な分光技術にわたるグラフ強化学習の適用範囲が広がるだろう。
- 計算効率とインフラストラクチャ: TAG-DQNはシングルシード実行のために汎用ハードウェアで実行できるが、広範なハイパーパラメータチューニングと複数シード評価を含む包括的な実験は、かなりの計算リソースを必要とする。将来の研究では、広範な研究に必要な計算コストと時間を削減するために、より効率的なハイパーパラメータ最適化手法または分散コンピューティングフレームワークを検討する可能性がある。
最終的に、この作品は、原子物理学における科学的発見、特にデータ集約型および労働集約型分野における、グラフ強化学習および一般的にAIの可能性の証である。提案された進歩は、原子データの需要と現在の決定効率との間のギャップを埋める、加速された原子物理学研究の新時代への道を開く可能性がある。
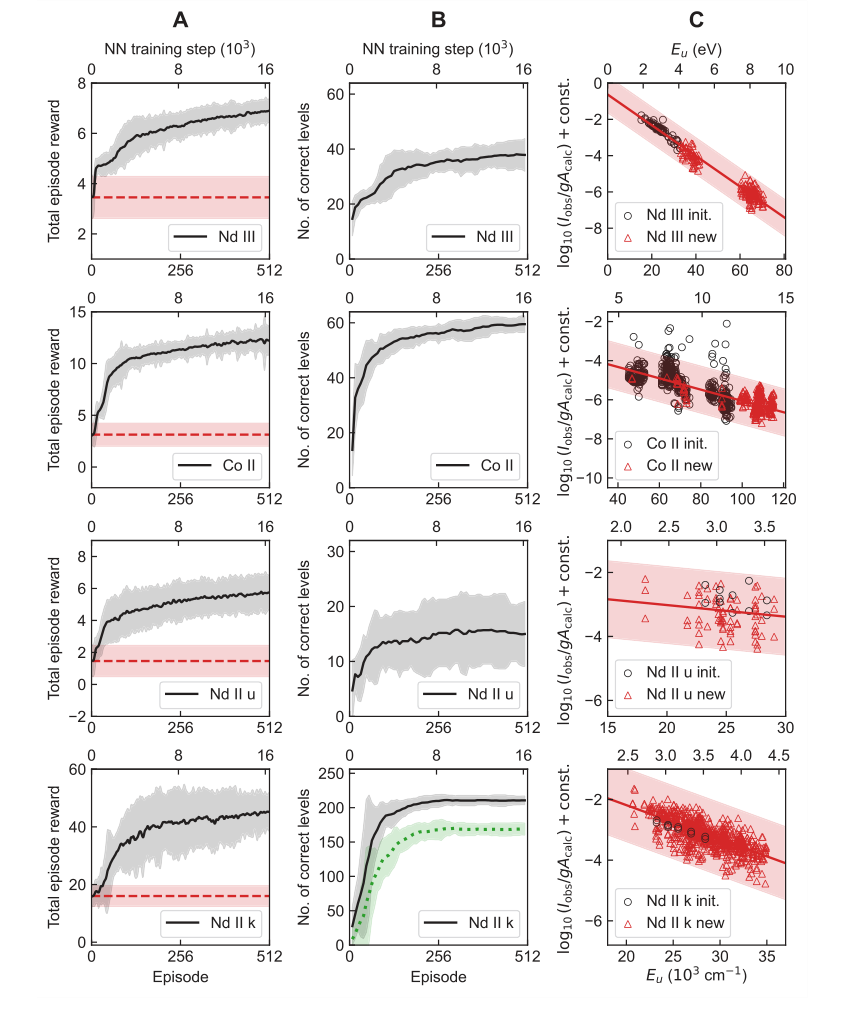 Figure 2. Learning results of TAG-DQN agent in the four case studies of Table 1. A Average learning curves, i.e., mean cumulative rewards obtained as a function of neural network (NN) training steps. The dashed horizontal lines show reward obtained during the pre-training episodes and correspond to rewards obtained by choosing actions in the MDP uniformly at random. The shaded regions show ±2 standard deviations across 25 random seeds. B Average Nc of the final state of the most recent maximum reward episode. The dotted curve for Nd II k shows the number of correct levels that also match human chosen level labels, and the y-axes limits are H
Figure 2. Learning results of TAG-DQN agent in the four case studies of Table 1. A Average learning curves, i.e., mean cumulative rewards obtained as a function of neural network (NN) training steps. The dashed horizontal lines show reward obtained during the pre-training episodes and correspond to rewards obtained by choosing actions in the MDP uniformly at random. The shaded regions show ±2 standard deviations across 25 random seeds. B Average Nc of the final state of the most recent maximum reward episode. The dotted curve for Nd II k shows the number of correct levels that also match human chosen level labels, and the y-axes limits are H
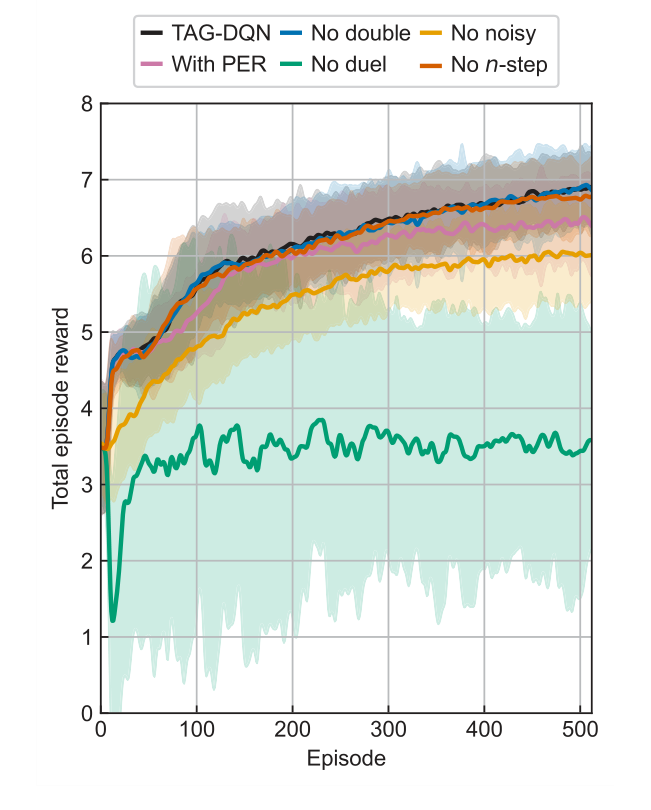 Figure 3. Learning curves of TAG-DQN (black) and its variants in the Nd III environment. Average total episode reward during training of TAG-DQN and its designs with or without particular deep Q-network extensions: without double Q-learning (blue), without noisy networks for exploration (yellow), with prioritised experience replay (PER, pink), without duelling deep Q-network (green), and without multi(n)-step return (orange). Shaded regions show ±2 standard deviations across 16 seeds. The duelling extension and noisy networks for exploration are key for TAG-DQN, while using PER reduced performance slightly
Figure 3. Learning curves of TAG-DQN (black) and its variants in the Nd III environment. Average total episode reward during training of TAG-DQN and its designs with or without particular deep Q-network extensions: without double Q-learning (blue), without noisy networks for exploration (yellow), with prioritised experience replay (PER, pink), without duelling deep Q-network (green), and without multi(n)-step return (orange). Shaded regions show ±2 standard deviations across 16 seeds. The duelling extension and noisy networks for exploration are key for TAG-DQN, while using PER reduced performance slightly
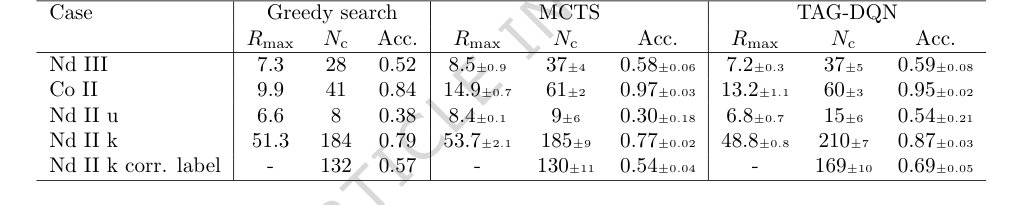 Table 2. Results and comparisons with benchmark agents. TAG-DQN matches MCTS performance as judged by downstream metrics in 2/5 cases and outperforms it in 3/5 cases, while Greedy search is worse overall
Table 2. Results and comparisons with benchmark agents. TAG-DQN matches MCTS performance as judged by downstream metrics in 2/5 cases and outperforms it in 3/5 cases, while Greedy search is worse overall
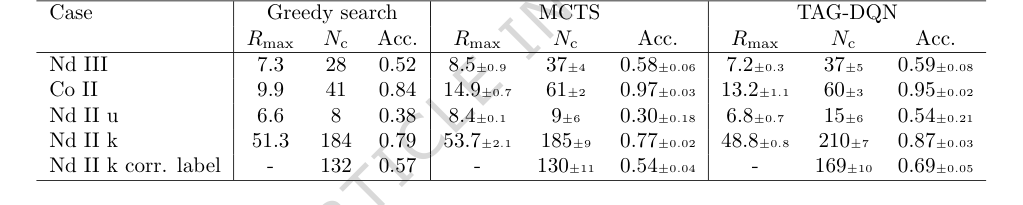 Table 1. Key term analysis MDP environment parameters
Table 1. Key term analysis MDP environment parameters