그래프 강화학습을 이용한 원자 미세구조 결정 가속화
Atomic data determined by analysis of observed atomic spectra are essential for plasma diagnostics.
배경 및 학문적 계보
기원 및 학문적 계보
본 논문에서 다루는 "항목 분석(term analysis)"이라 알려진 문제는 원소의 원자 구조를 이해하려는 근본적인 필요성에서 비롯된다. 구체적으로, 이는 관측된 원자 스펙트럼으로부터 에너지 준위의 에너지와 총 전자 각운동량($J$)을 추출하고, 이러한 준위에 적절한 항목 기호(term symbol)를 부여하는 것을 포함한다. 이 연구 분야는 에너지 준위 및 전이 파수(wavenumber)와 같은 결과적인 원자 데이터가 광범위한 응용 분야에 필수적이기 때문에 매우 중요하다. 이러한 응용 분야에는 플라즈마 진단, 조명 및 금속 산업, 자기 가둠 핵융합 연구, 핵 연구, 의료 동위원소 생산, 그리고 특히 중성자별 병합과 같은 사건으로부터 무거운 원소의 기원을 이해하는 천문학이 포함된다.
역사적으로 항목 분석 과정은 깊은 원자 분광학 전문 지식과 광범위한 인간의 노력을 요구하는 순차적이고 복잡한 의사 결정 작업이었다. 1970년대 푸리에 변환(FT) 분광학적 항목 분석이 도입된 이후, 그 적용은 주로 철족 원소(원자 번호 $Z$가 23에서 28 사이인 원소)에 국한되었다. 이러한 어려움은 에너지 준위 간의 에너지 차이를 나타내는 엄청나게 많은 관측 가능한 스펙트럼 선(각 원소에 대해 종종 수만 개) 때문에 개별 에너지 준위 결정이 덜 정확한 이론적 예측에만 의존하는 어려운 작업이 된다.
이전 접근 방식의 근본적인 한계점, 즉 "고충점(pain point)"은 극도의 비효율성과 인간 전문가에 대한 의존성이다. 단일 원자 종에 대한 스펙트럼 측정 및 이론적 계산의 초기 단계는 몇 주 안에 완료될 수 있지만, 관측된 데이터로부터 에너지 준위를 식별하는 중요한 단계인 후속 항목 분석은 몇 달에서 몇 년이 걸릴 수 있다. 이러한 수동적이고 노동 집약적인 과정은 다양한 과학 및 산업 분야에서 증가하는 수요를 충족시키는 데 필요한 원자 데이터의 신속한 생성을 방해하는 주요 병목 현상이 되었다. 더욱이, 기존의 ab initio (최초 원리) 계산은 종종 몇 퍼센트 정도의 정확도만 가지는데, 이는 높은 스펙트럼 분해능을 요구하는 응용 분야에는 충분하지 않다. 항목 분석은 인간의 비용에도 불구하고 수십 배 더 높은 정확도를 제공하며 이론적 모델에 대한 신뢰할 수 있는 제약을 제공한다. 이러한 비효율성과 이론적 방법만으로는 충분한 정확도를 제공할 수 없다는 점이 저자들이 인공지능 기반의 자동화된 솔루션을 개발하도록 동기를 부여하는 주요 요인이다.
직관적인 도메인 용어
-
원자 미세구조 결정 / 항목 분석: 복잡한 악기, 예를 들어 그랜드 피아노가 있다고 상상해 보세요. 하지만 건반이나 그 배열 방식은 볼 수 없고 오직 연주되는 음만 들을 수 있습니다. "원자 미세구조 결정"은 오직 소리만 듣고 그 피아노의 모든 건반의 정확한 위치와 정체를 파악하고 서로 어떻게 관련되는지 알아내는 것과 같습니다. 이는 관측된 스펙트럼 "음"을 원자의 근본적인 "건반"(에너지 준위)으로 되돌려 매핑하는 과정입니다.
-
스펙트럼 선 / 파수 ($\sigma$): 피아노 비유를 계속하자면, "스펙트럼 선"은 우리가 듣는 단일하고 뚜렷한 음과 같습니다. 원자 내의 전자가 높은 에너지 준위에서 낮은 에너지 준위로 점프할 때, 매우 특정한 "음높이"의 빛을 방출합니다. "파수"($\sigma$)는 그 음높이의 정확한 측정값으로, 해당 전자 점프에서 방출된 에너지의 양을 정확히 알려줍니다. 이는 두 원자 상태 간의 에너지 차이를 직접적으로 측정하는 것입니다.
-
마르코프 결정 과정 (MDP): MDP를 보물찾기 게임이라고 생각하세요. 당신( "에이전트")은 특정 위치( "상태")에 있고, 여러 경로( "행동")를 선택할 수 있습니다. 당신이 선택하는 각 경로는 새로운 위치(새로운 상태)로 이어지고 약간의 금( "보상")을 줄 수 있습니다. 게임의 목표는 전체 사냥 동안 수집하는 금의 총량을 최대화하는 전략( "정책")을 찾는 것입니다. 일부 경로는 즉각적인 작은 보상을 주지만 나중에 막다른 길로 이어질 수도 있습니다.
-
강화학습 (RL): 이것은 로봇에게 명시적인 지시를 주지 않고 보물찾기 게임을 하도록 가르치는 것과 같습니다. 대신 로봇이 여러 경로를 시도하도록 합니다. 금을 찾으면 "잘했어!"(긍정적인 보상)라고 말합니다. 막다른 길에 부딪히면 "별로 좋지 않아"(부정적인 보상)라고 말합니다. 수많은 시도를 통해 로봇은 시행착오를 거쳐 어떤 상태에서 어떤 행동이 가장 많은 금으로 이어지는지 학습하여 결국 보물 사냥 전문가가 됩니다.
-
그래프 신경망 (GNNs): 각 도시가 고유한 특징(인구, 산업 등)을 가지고 있고, 그 도시들을 연결하는 각 도로가 속성(길이, 교통량 등)을 가지는 상호 연결된 도시들의 거대한 네트워크를 고려해 보세요. GNN은 이러한 네트워크 내의 관계와 특징을 이해하고 학습하도록 설계된 특별한 유형의 인공 지능입니다. 이는 AI가 전체 구조와 지역 연결을 "볼" 수 있도록 도와주며, 원자 에너지 준위와 스펙트럼 선의 복잡한 웹을 분석하는 데 도움이 되는 것처럼 도시와 도로에 대한 정보에 입각한 결정을 내릴 수 있도록 합니다.
표기법 표
| 표기법 | 설명 |
|---|---|
| $J$ | 총 전자 각운동량 |
| $Z$ | 원자 번호 |
| $\sigma$ | 파수 |
| $\sigma_{obs}$ | 관측된 파수 |
| $\delta\sigma_{obs}$ | 표준 파수 불확실성 |
| $I_{obs}$ | 상대 강도 |
| $S/N_{obs}$ | 신호 대 잡음비 |
| $E_{obs}$ | 원자 준위의 관측된 에너지 |
| $E_{calc}$ | 원자 준위의 이론적 에너지 |
| $\Delta E$ | 에너지 준위의 이론적 불확실성 |
| $\Delta I$ | 선 강도의 이론적 불확실성 |
| $E_u$ | 상위 에너지 준위 |
| $E_l$ | 하위 에너지 준위 |
| $E_0$ | 기준 에너지 준위 (0으로 고정) |
| $s_t$ | MDP에서의 시간 $t$에서의 상태 |
| $a_t$ | MDP에서의 시간 $t$에서의 행동 |
| $r_t$ | 시간 $t$에서의 보상 |
| $G_t$ | 시간 $t$부터의 할인된 누적 보상 |
| $\gamma$ | 할인율 |
| $H$ | MDP에서의 유한 호라이즌 (에피소드 길이) |
| $Q(s, a)$ | Q-값 (상태 $s$에서 행동 $a$를 취했을 때 예상되는 누적 보상) |
| $Q_{\theta}$ | 파라미터 $\theta$를 가진 온라인 Q-네트워크 |
| $Q_{\bar{\theta}}$ | 파라미터 $\bar{\theta}$를 가진 타겟 Q-네트워크 |
| $L$ | 손실 함수 |
| $TD[n]$ | n-스텝 시간차 오차 |
| $r^{[n]}$ | n-스텝 반환 |
| $w_m$ | 최소 제곱 최적화에서 선 $m$의 가중치 |
| $S_{mn}$ | 에너지 준위와 선 $m$을 연결하는 계수 행렬 |
| $M$ | 알려진 선의 총 개수 |
| $N$ | 알려진 준위의 총 개수 |
| $D$ | 행동 $a^{(2)}$에 대한 선호도 점수 |
| $h_v$ | 준위 $v$의 노드 임베딩 벡터 |
| $S_{agg}$ | 전역 그래프 상태 임베딩 벡터 |
| $V(s)$ | 상태-가치 함수 |
| $A(s, a)$ | 장점 함수 |
| MLP | 다층 퍼셉트론 |
| GNN | 그래프 신경망 |
| $N_c$ | 정확하게 결정된 에너지 준위의 수 |
| $R_{max}$ | 최대 누적 보상 |
| Acc. | 결정된 준위의 정확도 |
| PER | 우선순위 경험 리플레이 |
| MCTS | 몬테카를로 트리 탐색 |
| UCT | 트리 상한 신뢰도 |
문제 정의 및 제약 조건
핵심 문제 공식화 및 딜레마
본 논문에서 다루는 핵심 문제는 원자 미세구조 결정의 가속화이다. 이는 원자 분광학에서 플라즈마 진단부터 천체 물리학에 이르기까지 다양한 과학 및 산업 응용 분야에 대한 기본 데이터를 제공하는 중요한 작업이다.
이 분석의 시작점 (입력/현재 상태)은 관측된 원자 스펙트럼의 모음으로, 이는 "선 목록(line list)"으로 사전 처리된다. 이 선 목록은 주어진 원자 종에 대해 약 $10^4$개의 관측 가능한 스펙트럼 선을 포함하며, 각 선은 관측된 파수($\sigma_{obs}$), 표준 파수 불확실성($\delta\sigma_{obs}$), 상대 강도($I_{obs}$), 그리고 신호 대 잡음비($S/N_{obs}$)로 특징지어진다. 또한, 현재 상태에는 알려진 (경험적으로 결정된) 에너지 준위와 전이, 그리고 이론적으로 예측된 준위와 선의 그래프 표현이 포함된다. 이러한 알려진 준위는 일반적으로 연결되어 있으며, 관측된 에너지($E_{obs}$)는 0 에너지 기준 준위로부터 상대적이다.
원하는 종점 (출력/목표 상태)은 미지의 원자 에너지 준위에 대한 관측된 에너지($E_{obs}$)를 정확하게 결정하고, 실험적 불확실성 내에서 이론적 예측과 가장 잘 일치하는 스펙트럼 선을 분류하는 것이다. 이는 알려진 준위의 하위 그래프를 확장하는 것을 포함하는데, 이는 미지의 준위와 알려진 준위를 연결하는 최소 두 개의 관측된 스펙트럼 선을 식별하고 일치시킴으로써 미지의 준위의 에너지를 결정한다.
본 논문이 연결하고자 하는 정확한 누락된 연결 또는 수학적 격차는 원시 스펙트럼 선 데이터와 덜 정확한 이론적 예측에서 정확하고 경험적으로 검증된 원자 에너지 준위로의 전환에 있다. 역사적으로 "항목 분석"으로 알려진 이 과정은 광범위한 인간의 노력과 원자 분광학 전문 지식을 요구하는 순차적이고 복잡한 의사 결정 작업이었으며, 종종 단일 원자 종에 대해 몇 달에서 몇 년이 걸렸다. 수학적 격차는 이론적으로는 부정확하지만, 방대한 수의 관측된 스펙트럼 선 차이로부터 이러한 에너지 준위를 추론하는 자동화되고 확장 가능하며 정확한 방법의 부재이다. 본 논문은 이를 그래프 강화학습(GRL)으로 해결해야 할 마르코프 결정 과정(MDP)으로 프레임화한다.
이전 연구자들이 갇혀 있던 고통스러운 상충 관계 또는 딜레마는 정확성과 효율성 사이의 극명한 선택이다. 인간 주도의 항목 분석은 높은 정확도( ab initio 계산보다 수십 배 높음)와 신뢰할 수 있는 이론적 제약을 제공하지만, 극도로 느리고 노동 집약적이어서 원자 데이터에 대한 증가하는 수요를 충족시키는 데 어려움을 겪는다. 반대로, ab initio 이론적 계산은 빠르지만 일반적으로 몇 퍼센트 정도의 정확도만 가지므로 더 높은 스펙트럼 분해능을 요구하는 응용 분야에는 충분하지 않다. 딜레마는 분석 속도를 향상시키는 것이 전통적으로 필요한 정밀도를 희생하는 것을 의미하거나 그 반대였다는 것이다. 본 논문은 프로세스를 부분적으로 자동화하여 훨씬 더 빠른 속도로 인간 수준의 정확도를 달성하는 것을 목표로 하여 데이터 수요와 분석 능력 간의 격차를 해소하고자 한다.
제약 조건 및 실패 모드
원자 미세구조 결정 가속화 문제는 다음과 같은 여러 가지 가혹하고 현실적인 제약 조건으로 인해 매우 어렵다.
-
물리적 및 도메인별 제약 조건:
- 데이터 양 및 복잡성: 각 저이온화 개방형 d- 및 f-부껍질 원자 종의 경우, 약 $10^3$개의 미세구조 에너지 준위를 결정하는 것은 약 $10^4$개의 관측 가능한 스펙트럼 선을 분석하는 것을 포함한다. 주요 과제는 "엄청나게 많은 관측된 에너지 차이"에서 정확한 에너지 준위를 추출하는 것이다 (섹션 1, p.3).
- 부정확한 이론적 안내: 기존 이론적 예측은 종종 "덜 정확하여"(섹션 1, p.3) 정확한 값이 아닌 대략적인 안내만 제공한다. Ab initio 계산은 일반적으로 몇 퍼센트 정도의 정확도만 가지므로 많은 응용 분야에 충분하지 않다.
- 모호성 및 불확실성: 결정된 에너지 준위는 종종 "모호한 값을 갖는다"(섹션 2.5, p.5). 인간 전문가는 관측된 선 강도와 이론적 선 강도 간의 일치와 파수 불확실성 내에서의 반복적인 $E_{obs}$ 값의 일관성을 저울질해야 한다. 이 판단은 "전이 확률의 불확실성과 스펙트럼 선 피팅 오류, 특히 광범위하게 약하거나/또는 혼합된 선의 경우"(섹션 2.5, p.6)로 인해 복잡해진다.
- 제한된 사용 가능한 전이: "실험실 스펙트럼에서는 고차 다중극 전이가 거의 관측되지 않기 때문에"(섹션 2.2, p.4) 전기 쌍극자 미세구조 전이만 고려되며, 이는 분석에 사용할 수 있는 데이터를 제한한다.
- 이상치 및 노이즈: "이상치 파수(예: 알려지지 않은 선 혼합 또는 스펙트럼 선 프로파일의 잘못된 피팅)"(섹션 3, p.8)의 존재는 $\delta E$ 허용 오차 내에 있더라도 결정된 에너지 준위의 이동으로 이어질 수 있다.
- 어려운 시나리오: "단일 선 준위 결정 또는 연결되지 않은 알려진 준위 하위 그래프 연결, 알려진 준위가 없는 항목 분석 시작 포함"(섹션 3, p.8)과 같은 가장 어려운 상황은 MDP 복잡성을 크게 증가시키며 현재 접근 방식에서 종종 생략된다.
-
계산 및 알고리즘 제약 조건:
- 계산 가능성 및 시간 호라이즌: 인간 분석 과정은 "몇 달에서 몇 년"(섹션 1, p.3)이 걸린다. 계산 가능성을 위해 MDP는 유한 호라이즌 $H$를 가진 에피소드이며, 단일 에피소드에서 결정될 수 있는 미지의 에너지 준위 수를 제한한다.
- 대규모 상태 및 행동 공간: 이 문제는 "대규모 상태 및 행동 공간"(섹션 2.7, p.7)을 포함하므로 함수 근사를 위해 심층 신경망이 필요하다. 미지의 준위를 선택하는 행동 공간 ($A^{(1)}$)은 0에서 200까지 다양할 수 있으며, 선을 일치시키는 행동 공간 ($A^{(2)}$)은 $k$ (연결된 알려진 준위 수)가 클 경우 $10^3$에 달할 수 있으며, 중앙값은 10 미만이다 (섹션 2.3, p.5). 단일 선 결정을 허용하면 "실현 불가능하게 큰 $A^{(1)}$"(섹션 2.3, p.5)이 발생한다.
- MDP 복잡성 관리: "MDP 복잡성 감소는 실현 가능성과 RL 성능에 핵심적이다"(섹션 2.6, p.6). 여기에는 낮은 신호 대 잡음비의 그래프 에지 제거, 이미 일치된 선 제외, 스펙트럼 범위 제한과 같은 전략이 포함된다. "$|A^{(2)}|$의 최대 상한"은 "효율적인 탐색 및 메모리 제어"(섹션 2.6, p.6)를 돕기 위해 시행된다.
- 탐색 효율성: 몬테카를로 트리 탐색(MCTS)의 전통적인 탐색 방법은 "하나의 행동만 올바른 대규모 행동 공간에서 비효율적이다"(섹션 4.6, p.11).
- 계산 비용: 하이퍼파라미터 튜닝 및 다중 시드 실행을 포함한 포괄적인 실험은 약 $10^5$ 시간 (약 11년)의 가상 단일 코어 CPU 시간을 요구하는 극도로 리소스 집약적이다 (섹션 4.7, p.11).
-
데이터 기반 학습 제약 조건:
- 인간 데이터에 대한 의존성: 보상 함수는 역 강화 학습을 통해 "과거 인간 결정에서 부분적으로 학습된다"(초록, p.2)는 것은 전문가 생성 MDP 상태 전이에 의존한다.
- 보상 함수 훈련 데이터 제한: 선호도 점수 $D$를 예측하는 MLP 모델은 Co II에서 115개의 전문가 $a^{(2)}$ MDP 상태 전이와 Nd III에서 23개의 비교적 작은 데이터셋으로 훈련되었다 (섹션 4.3, p.9).
- 훈련 데이터의 편향: "약한 선은 훈련 데이터셋에서 과소 표현되었고 미지의 선은 일반적으로 약하다"(섹션 4.3, p.9)는 것은 이러한 덜 두드러진 선에 대한 모델 성능에 영향을 미칠 수 있다.
- 초기 상태 품질: "초기 MDP 상태"의 품질은 다양할 수 있다. 예를 들어, Rmax 에피소드의 Nd II 데이터는 "잠정적"으로 간주되며 "저품질 MDP 초기 상태"(섹션 3, p.8)로 간주된다.
왜 이 접근 방식인가
선택의 불가피성
그래프 강화학습(GRL), 특히 그래프 심층 Q-네트워크(TAG-DQN)를 이용한 항목 분석의 선택은 원자 미세구조 결정의 본질적인 특성에 의해 주도된 단순한 선호가 아니라 불가피한 선택이었다. 이 복잡한 문제는 본질적으로 그래프 구조 데이터에서 작동하는 순차적 의사 결정 작업이다. 저자들의 문제 공식화에서 추론할 수 있듯이, 저자들이 "정확한 순간"을 깨달은 것은 명시적으로 언급되지 않았지만, 그들은 분석 절차를 그래프를 포함하는 마르코프 결정 과정(MDP)으로 설정했다. 여기서 원자 에너지 준위는 노드이고 스펙트럼 선은 에지이다.
표준 CNN, 기본 확산 모델 또는 트랜스포머와 같은 전통적인 "SOTA" 방법은 일반적인 응용 분야에서 이 특정 과제에 적합하지 않다. CNN은 격자형 데이터(이미지)에 뛰어나지만 불규칙한 그래프 구조에는 어려움을 겪는다. 확산 모델은 주로 생성적이며 그래프에서의 순차적 의사 결정 또는 조합 최적화를 위해 설계되지 않았다. 트랜스포머는 시퀀스 데이터에 강력하지만, 항목 분석에 내재된 동적이고 그래프 기반의 상태 표현 및 순차적 의사 결정 프로세스를 처리하기 위해 상당한 조정이 필요할 것이다. 핵심 문제는 고정된 격자에서의 패턴 인식, 새로운 데이터 생성 또는 단순 시퀀스 번역에 관한 것이 아니다. 대신, 이는 미지의 에너지 준위를 식별하기 위해 동적으로 진화하는 그래프에서 상호 의존적인 일련의 결정을 내리는 것에 관한 것으로, 이는 그래프에서의 강화학습의 강점에 자연스럽게 매핑되는 작업이다. 저자들은 명시적으로 "확장성을 달성하는 데 핵심은 이 광범위한 문헌에서 성공적인 것으로 입증된 기법을 채택하는 것인데, 여기에는 행동 공간 분해, 도메인 지식을 통한 유효 행동 제한, 학습 표현으로 그래프 신경망(GNN) 사용이 포함된다 [32]"라고 명시하여 문제의 그래프 구조와 조합적 특성이 이 전문화된 접근 방식을 필요로 했음을 강조한다.
비교 우위
단순한 성능 지표를 넘어, TAG-DQN은 광범위한 인간의 노력과 덜 정교한 탐색 알고리즘에 주로 의존했던 이전의 황금 표준에 비해 질적 및 구조적 이점을 제공한다. 가장 두드러진 이점은 분석 시간의 극적인 감소이다. TAG-DQN은 전통적으로 수개월에서 수년이 걸렸던 작업을 몇 시간 만에 수백 개의 에너지 준위를 결정할 수 있다. 이는 효율성에서 수십 배의 개선을 나타낸다.
구조적으로 TAG-DQN의 우수성은 다음을 수행할 수 있는 능력에서 비롯된다.
1. 그래프 구조 데이터 네이티브 처리: 학습 표현으로 그래프 신경망(GNN)을 사용함으로써 TAG-DQN은 원자 준위(노드)와 스펙트럼 선(에지)의 내재된 그래프 구조를 직접 처리한다. 이는 이러한 관계형 데이터를 평탄화하거나 과도하게 사전 처리하여 중요한 정보를 잠재적으로 손실할 수 있는 방법과는 달리 자연스러운 적합이다.
2. 순차적 의사 결정 학습: 강화학습 에이전트로서 TAG-DQN은 누적 보상을 최대화하기 위해 일련의 최적 결정을 내리는 정책을 학습한다(미지의 준위 선택, 스펙트럼 선 일치). 이는 "순차적이고 복잡한 의사 결정 작업"인 항목 분석에 중요하다.
3. 전문가 지식 및 불확실성 통합: 보상 함수는 역 강화 학습을 통해 과거 인간 결정에서 부분적으로 학습되어 모델이 인간 전문가의 미묘한 선호도와 휴리스틱을 포착할 수 있도록 한다. 또한, 행동 공간은 이론적 및 실험적 불확실성($\Delta E$, $\Delta I$)을 통합하여 모델이 현실적인 물리적 제약 조건 내에서 작동할 수 있도록 한다.
4. 장기적 일관성 달성: 몬테카를로 트리 탐색(MCTS)과 같은 기준 탐색 알고리즘과 비교할 때, TAG-DQN은 특히 Nd II와 같은 복잡한 경우에 올바르게 레이블이 지정된 준위를 결정하는 데 있어 우수한 정확도를 보여준다. MCTS는 즉각적인 보상을 더 높게 찾을 수 있지만, 대규모 상태-행동 공간에서의 얕은 롤아웃은 "근시안적 행동"과 덜 일관된 장기 결과를 초래할 수 있다. TAG-DQN은 "에피소드 전체에 걸쳐 관측 및 이론과 일관성을 유지할 가능성이 높은" 준위 식별로 이어지는 장기적 영향을 고려하는 정책을 학습할 수 있는 능력은 핵심적인 질적 이점이다.
본 논문은 $O(N^2)$ 대 $O(N)$의 메모리 복잡성 또는 특정 고차원 노이즈 처리에 대해 명시적으로 논의하지는 않지만, 보상 함수의 설계가 높은 신호 대 잡음비(S/N) 선을 우선시하고 측정되지 않은 선을 제외하도록 설계되었다. 그러나 GNN 및 행동 공간 분해를 통한 확장성은 대규모 고차원 입력 공간의 문제를 암묵적으로 해결한다.
제약 조건과의 정렬
선택된 TAG-DQN 방법은 원자 미세구조 결정의 내재된 제약 조건 및 요구 사항과 완벽하게 정렬되어 문제와 해결책 간의 강력한 "결합"을 형성한다.
- 순차적 의사 결정: 이 문제는 "순차적이고 복잡한 의사 결정 작업"으로 설명된다. 강화학습은 정의상 이산 시간 단계에 걸쳐 최적 정책을 학습하여 이러한 문제를 해결하도록 설계되었다.
- 그래프 구조 데이터: 원자 에너지 준위와 스펙트럼 선은 자연스럽게 그래프를 형성하며, 준위는 노드이고 선은 에지이다. TAG-DQN의 핵심 구성 요소인 GNN은 이러한 관계형 데이터를 처리하고 학습하도록 특별히 설계되어 문제의 구조적 무결성을 보존한다.
- 엄청난 탐색 공간: 이 작업은 "엄청나게 많은 관측된 에너지 차이"에서 에너지 준위를 결정하는 것을 포함한다. 효율적인 상태 표현을 위한 GNN과 대규모 상태-행동 공간에서의 학습을 위한 DQN의 조합은 이 방대한 조합적 환경을 탐색하는 데 필요한 메커니즘을 제공한다.
- 도메인 지식 및 인간 전문성 통합: 항목 분석은 "본질적으로 경험적"이며 인간 전문성에 의존한다. 이 방법은 "과거 인간 결정에서 부분적으로 학습된" 보상 함수를 역 강화 학습을 통해 사용하여 전문가 지식을 AI의 의사 결정 프로세스에 효과적으로 내장함으로써 이를 해결한다. 도메인 지식은 유효 행동을 제한하고 MDP를 단순화하는 데에도 사용된다.
- 계산 가능성 및 확장성: 주요 제약 조건은 인간 노동에 "수개월에서 수년"이 걸린다는 것이다. TAG-DQN은 "몇 시간 만에 최대 102개의 잠정적인 미세구조 에너지 준위를" 결정하여 가속화 요구 사항을 직접적으로 해결한다. 저자들은 또한 "MDP 복잡성 감소는 실현 가능성과 RL 성능에 핵심적"이라고 명시적으로 언급하며, 문제를 해결 가능하게 만들기 위해 문제 공간을 가지치기하는 방법(예: 낮은 S/N 에지 제거, 스펙트럼 범위 제한)을 자세히 설명한다.
- 불확실성 처리: 이 문제는 "덜 정확한 이론적 예측"과 실험적 불확실성을 포함한다. 행동 공간과 보상 함수는 이론적 불확실성($\Delta E$, $\Delta I$)을 고려하고 높은 신호 대 잡음비의 선을 우선시하도록 설계되어 노이즈가 있는 데이터에 대해 솔루션을 견고하게 만든다.
대안의 기각
본 논문은 특히 탐색 알고리즘 및 일반 강화학습 패러다임 내에서 특정 대안적 접근 방식을 기각하는 명확한 이유를 제공한다.
- 탐욕적 탐색: 저자들은 "탐욕적 탐색은 RL 에이전트에 비해 일관되게 성능이 떨어졌다"고 명시적으로 언급한다. 이는 탐욕적 접근 방식이 정의상 즉각적인 보상만 고려하고 장기적인 결과를 계획할 수 없기 때문인데, 이는 항목 분석과 같이 초기 선택이 미래 가능성에 영향을 미치는 순차적 의사 결정 작업에 중요하다.
- 몬테카를로 트리 탐색 (MCTS): MCTS는 더 정교한 탐색 알고리즘이지만, 본 논문은 "MCTS는 TAG-DQN보다 높은 Rmax를 달성했지만, TAG-DQN은 특히 Nd II 사례에서 Ne의 더 높은 상한에 도달했다"고 언급한다. 해석은 "MCTS 롤아웃이 얕았고 단기 보상을 선호했다"는 것으로, 이는 전체적인 정확도보다 더 높은 궤적 보상으로 이어졌지만, 올바르게 레이블이 지정된 준위의 정확도는 낮았다. 이는 이 문제에 대해 장기적인 일관성과 정확도(TAG-DQN이 더 잘 달성한 것)가 즉각적인 보상 최대화보다 더 중요하다는 것을 강조한다. 대규모 상태 및 행동 공간으로 인해 깊은 MCTS 롤아웃은 계산 비용이 많이 들고 노이즈에 취약하다.
- 정책 기울기 방법: 저자들은 "우리는 이 알고리즘 클래스 [DQN]를 정책 기울기 접근 방식 [40]에 비해 샘플 효율성이 높기 때문에 선택했다"고 말한다. 정책 기울기 방법은 일반적으로 효과적인 정책을 학습하기 위해 환경과의 더 많은 상호 작용이 필요하며, 이는 원자 데이터 분석의 복잡하고 잠재적으로 비용이 많이 드는 시뮬레이션 또는 실제 응용 분야에서 상당한 단점이 될 것이다.
- 기타 심층 학습 아키텍처 (암묵적 기각): GAN, 확산 모델 또는 표준 CNN/트랜스포머가 실패했다고 명시적으로 언급하지는 않지만, GNN 및 RL의 선택은 핵심 문제에 대해 암묵적으로 이러한 방법을 기각한다. 이 문제는 이미지 생성, 시퀀스 번역 또는 격자형 데이터에 대한 단순 분류가 아니다. 원자 준위와 선의 내재된 그래프 구조와 순차적 의사 결정 특성이 결합되어 GRL이 가장 적절하고 효과적인 패러다임이 된다. 이러한 다른 방법들은 문제에 대한 상당한, 아마도 부자연스러운 재구성으로 그들의 아키텍처에 맞추어야 할 것이며, 이는 아마도 최적이 아닌 성능이나 증가된 복잡성으로 이어질 것이다.
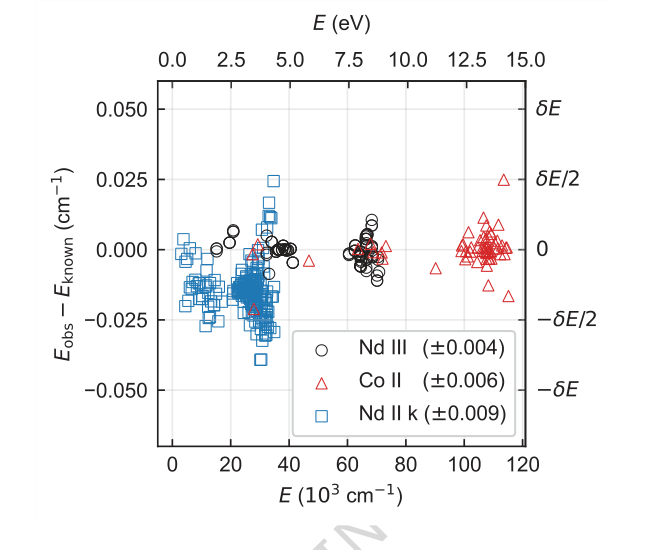 Figure 4. Difference between energy levels determined from a single seed and their known (ac- cepted) values for each species. Only levels contributing to Nc are shown. Energy differences for Nd III, Co II, and Nd II k are shown in circles, triangles, and squares, respectively. The root-mean-square energy differences are given in parentheses in the legend. Typical energy level uncertainty by FT spectroscopy is of order 0.001 cm−1. The offset and higher spread of Nd II k energies are expected and within uncertainties as their known values were derived by lower-precision grating spectroscopy [4]
Figure 4. Difference between energy levels determined from a single seed and their known (ac- cepted) values for each species. Only levels contributing to Nc are shown. Energy differences for Nd III, Co II, and Nd II k are shown in circles, triangles, and squares, respectively. The root-mean-square energy differences are given in parentheses in the legend. Typical energy level uncertainty by FT spectroscopy is of order 0.001 cm−1. The offset and higher spread of Nd II k energies are expected and within uncertainties as their known values were derived by lower-precision grating spectroscopy [4]
수학적 및 논리적 메커니즘
마스터 방정식
본 논문의 메커니즘의 핵심은 두 가지 기본 방정식에 집중되어 있다. 에이전트가 최대화하려는 마르코프 결정 과정(MDP)의 목적 함수와 기본 신경망의 학습을 주도하는 손실 함수이다. 또한, 에너지 준위를 결정하는 중요한 계산은 상태 업데이트 메커니즘의 필수적인 부분을 형성한다.
강화학습 에이전트의 주요 목표는 유한 호라이즌 $H$에 걸쳐 예상되는 누적 할인 보상을 최대화하는 것이다.
$$ E[G_t] = E\left[\sum_{k=0}^{H} \gamma^k r_{t+k}\right] \quad (1) $$
이 방정식은 에이전트가 달성하고자 하는 것을 정의한다. 즉, 미래 보상의 총합을 최대화하는 일련의 결정을 내리는 것으로, 더 빨리 받은 보상은 나중에 받은 보상보다 더 높은 가치를 갖는다.
심층 Q-네트워크(DQN) 에이전트의 학습 과정은 시간차(TD) 오차의 n-스텝 제곱을 최소화하는 손실 함수를 통해 구동된다.
$$ L = [TD[n]]^2 = \left[r^{[n]} + \gamma^n Q_{\bar{\theta}}(s_{t+n}, \text{argmax}_{a_{t+n}} Q_{\theta}(s_{t+n}, a_{t+n})) – Q_{\theta}(s_t, a_t)\right]^2 \quad (15) $$
이 손실 함수는 신경망이 행동의 "품질"을 정확하게 예측하도록 안내하여, 그 추정치가 실제 미래 보상과 일치하도록 보장한다.
마지막으로, 관측된 에너지 준위($E_{obs}$) 결정과 같은 상태 업데이트를 뒷받침하는 중요한 계산은 가중 최소 제곱 최소화를 통해 수행된다.
$$ E_{obs} = \text{argmin}_{E_n} \sum_{m=0}^{M-1} w_m \left( \sum_{n=0}^{N-1} S_{mn}E_n - \sigma_m \right)^2 \quad (9) $$
이 방정식은 관측된 스펙트럼 선에 따라 알려진 준위의 에너지 값을 정제하는 방법이며, 이는 원자 데이터를 처리하고 업데이트하는 "수학적 엔진"의 핵심 구성 요소가 된다.
항별 분석
이러한 각 방정식을 분해하여 개별 구성 요소와 역할을 이해해 보자.
방정식 (1): 예상 누적 할인 보상
- $E[G_t]$: 이는 시간 단계 $t$부터 시작하는 예상 누적 할인 보상을 나타낸다.
- 수학적 정의: 여러 가능한 궤적에 걸친 $G_t$의 평균값.
- 물리적/논리적 역할: 이것이 강화학습 에이전트의 궁극적인 목적 함수이다. 에이전트의 정책은 이 양을 최대화하는 행동을 선택하도록 설계되어, 원자 미세구조를 결정하는 최적의 일련의 결정을 찾는다.
- $E[\cdot]$: 이것은 기대 연산자이다.
- 수학적 정의: 확률 변수의 평균값을 계산한다.
- 물리적/논리적 역할: 강화학습에서 에이전트는 정확한 미래 보상이나 상태 전이를 결정론적으로 알지 못한다. 이 연산자는 환경의 내재된 불확실성을 고려하여 에이전트가 평균 결과에 대해 최적화하도록 보장한다.
- $G_t$: 이것은 시간 $t$부터의 누적 할인 보상이다.
- 수학적 정의: 미래의 모든 보상의 합으로, 각 보상은 미래로의 단계 수에 해당하는 $\gamma$의 거듭제곱으로 할인된다.
- 물리적/논리적 역할: 시간 $t$부터 시작하는 특정 행동 및 상태 시퀀스의 총 "좋음"을 정량화한다.
- $\sum_{k=0}^{H} \gamma^k r_{t+k}$: 이것은 할인된 미래 보상의 합이다.
- 수학적 정의: 각 보상 $r_{t+k}$가 $\gamma^k$로 곱해지는 유한 합.
- 물리적/논리적 역할: 미래 시간 단계 $t+k$에서 얻은 보상을 집계하며, 즉각적인 보상을 먼 보상보다 더 가치 있게 만들기 위해 할인을 적용한다. 합계는 총 보상이 개별 보상의 누적이기 때문에 사용된다.
- $\gamma$: 이것은 할인율이다.
- 수학적 정의: 0과 1 사이의 스칼라 값, $\gamma \in [0, 1]$.
- 물리적/논리적 역할: 즉각적인 보상과 미래 보상의 중요성을 균형 있게 조절한다. 0에 가까운 $\gamma$는 에이전트를 "근시안적"으로 만들어 즉각적인 이득에 집중하게 하고, 1에 가까운 $\gamma$는 "원시안적"으로 만들어 장기적인 결과를 고려하게 한다. 저자들은 총 가치가 개별 보상의 누적이기 때문에 합계를 위해 덧셈을 선택했다.
- $k$: 이것은 $t$에 대한 시간 단계 인덱스이다.
- 수학적 정의: 시간 $t$로부터 미래로 몇 단계 떨어진지를 나타내는 정수.
- 물리적/논리적 역할: 특정 보상 $r_{t+k}$가 수신되는 시점을 추적하며, 이는 할인을 위해 $\gamma$를 올릴 거듭제곱을 결정한다.
- $r_{t+k}$: 이것은 시간 $t+k$에서 수신된 보상이다.
- 수학적 정의: 행동을 취한 후 환경으로부터 받은 즉각적인 피드백을 나타내는 스칼라 값.
- 물리적/논리적 역할: 본 논문에서 보상은 결정된 에너지 준위에 대한 신뢰도, 이론 및 관측과의 일치, 그리고 미래 준위 결정을 가능하게 하는 능력(방정식 6 및 7)을 반영하도록 설계되었다.
방정식 (15): TAG-DQN의 손실 함수
- $L$: 이것은 손실 함수이다.
- 수학적 정의: 예측된 Q-값과 타겟 Q-값 간의 오차를 정량화하는 스칼라 값.
- 물리적/논리적 역할: 훈련의 목표는 이 손실을 최소화하는 것이며, 이는 Q-네트워크의 예측을 더 정확하게 만든다.
- $[TD[n]]^2$: 이것은 n-스텝 시간차(TD) 오차의 제곱이다.
- 수학적 정의: n-스텝 반환(미래 보상의 추정치)과 현재 Q-값 예측 간의 차이의 제곱.
- 물리적/논리적 역할: 오차를 제곱하면 양수 및 음수 오차 모두 손실에 기여하고 더 큰 오차에 더 큰 페널티를 부과하여 수렴을 촉진한다.
- $r^{[n]}$: 이것은 n-스텝 반환이다.
- 수학적 정의: 처음 $n$개의 보상 합계(할인됨)와 $n$ 단계 후에 도달한 상태의 할인된 Q-값.
- 물리적/논리적 역할: Q-값 추정치에서 부트스트랩하기 전에 짧은 호라이즌에 걸쳐 실제 보상을 통합함으로써, 단일 스텝 반환에 비해 더 안정적이고 편향이 적은 가치 추정치를 제공한다.
- $\gamma^n$: 이것은 할인율이 $n$의 거듭제곱으로 올라간 것이다.
- 수학적 정의: 할인율 $\gamma$가 $n$번 곱해진 것이다.
- 물리적/논리적 역할: 상태 $s_{t+n}$에서의 미래 Q-값 추정치를 시간 $t$로 할인하여 $n$ 단계 동안 받은 보상과 일치시킨다.
- $Q_{\bar{\theta}}(s_{t+n}, \text{argmax}_{a_{t+n}} Q_{\theta}(s_{t+n}, a_{t+n}))$: 이것은 타겟 Q-값이다.
- 수학적 정의: 타겟 네트워크 $Q_{\bar{\theta}}$에 의해 예측된 대로, 상태 $s_{t+n}$에서 Q-값을 최대화하는 행동 $a_{t+n}$의 Q-값.
- 물리적/논리적 역할: 이 항은 온라인 네트워크가 학습할 안정적인 타겟을 제공한다. 지연된 업데이트($\bar{\theta}$)를 가진 별도의 타겟 네트워크를 사용함으로써, Q-값 추정치가 움직이는 타겟을 쫓는 것을 방지하여 학습 불안정을 초래할 수 있다. $\text{argmax}$ 부분은 타겟이 온라인 네트워크의 현재 이해에 따라 다음 상태에서 가능한 최선의 행동의 가치를 반영하도록 보장한다.
- $Q_{\theta}(s_t, a_t)$: 이것은 현재 Q-값 예측이다.
- 수학적 정의: 온라인 네트워크 $Q_{\theta}$에 의해 예측된 현재 상태-행동 쌍 $(s_t, a_t)$의 Q-값.
- 물리적/논리적 역할: 이것은 네트워크가 현재 상태 $s_t$에서 행동 $a_t$를 취하는 것으로 예측하는 값이다. 손실 함수는 이 예측이 타겟 Q-값과 일치하도록 $\theta$를 조정하는 것을 목표로 한다.
- $s_t$: 이것은 시간 $t$에서의 상태이다.
- 수학적 정의: 시간 $t$에서의 환경 표현, 그래프 노드 및 에지 특징 포함(방정식 2 및 3).
- 물리적/논리적 역할: 알려진/미지의 준위, 관측된 스펙트럼 선, 이론적 계산과 같은 현재 항목 분석 진행 상황에 대한 모든 관련 정보를 포함한다.
- $a_t$: 이것은 시간 $t$에서 취해진 행동이다.
- 수학적 정의: 에이전트가 내리는 이산적인 선택, 미지의 준위($a^{(1)}$)를 선택하거나 에너지 결정을 위해 선을 일치시키는 것($a^{(2)}$).
- 물리적/논리적 역할: 항목 분석 프로세스에서 에이전트의 결정을 나타낸다.
- $\theta$: 이것은 온라인 Q-네트워크의 파라미터이다.
- 수학적 정의: 현재 Q-값을 예측하는 신경망의 가중치와 편향.
- 물리적/논리적 역할: 에이전트의 정책을 개선하기 위해 훈련 중에 적극적으로 업데이트되는 파라미터이다.
- $\bar{\theta}$: 이것은 타겟 Q-네트워크의 파라미터이다.
- 수학적 정의: Q-네트워크의 복사본의 가중치와 편향으로, 덜 자주 또는 부드럽게 업데이트된다.
- 물리적/논리적 역할: 학습 프로세스의 안정성을 위해 타겟 Q-값에 대한 안정적인 참조를 제공한다.
- $\text{argmax}_{a_{t+n}} Q_{\theta}(s_{t+n}, a_{t+n})$: 이 연산자는 온라인 네트워크에 따라 상태 $s_{t+n}$에서 Q-값을 최대화하는 행동을 찾는다.
- 수학적 정의: 온라인 네트워크 파라미터 $\theta$를 사용하여 상태 $s_{t+n}$에 대해 가장 높은 Q-값을 산출하는 행동 $a_{t+n}$을 반환한다.
- 물리적/논리적 역할: 이것은 Double DQN의 핵심 구성 요소로, 온라인 네트워크가 타겟 값 계산을 위한 행동을 선택하지만 타겟 네트워크가 그 가치를 평가한다. 이는 Q-학습에서 과대평가 편향을 완화하는 데 도움이 된다.
방정식 (9): 준위 에너지 최적화
- $E_{obs}$: 이것은 준위의 관측된 에너지를 나타낸다.
- 수학적 정의: $N$개의 알려진 준위에 대한 에너지 값 $E_n$의 벡터.
- 물리적/논리적 역할: 이는 항목 분석이 확립하고자 하는 경험적으로 결정된 에너지 준위이다.
- $\text{argmin}_{E_n}$: 이것은 최소화 연산자이다.
- 수학적 정의: 후속 표현식을 최소화하는 $E_n$ 값을 찾는다.
- 물리적/논리적 역할: 관측된 에너지 준위는 관측된 스펙트럼 선에 대한 불일치를 최소화함으로써 가장 잘 맞는 에너지 세트를 찾아 결정됨을 의미한다.
- $\sum_{m=0}^{M-1} w_m \left( \sum_{n=0}^{N-1} S_{mn}E_n - \sigma_m \right)^2$: 이것은 가중 제곱 잔차 합이다.
- 수학적 정의: $M$개의 알려진 선에 대한 합으로, 각 항은 예측된 파수와 관측된 파수 간의 제곱 차이이며 $w_m$으로 가중치가 부여된다.
- 물리적/논리적 역할: 이것은 최소 제곱 최적화의 목적 함수이다. 현재 에너지 준위 세트와 관측된 스펙트럼 선 간의 전반적인 불일치를 정량화한다. 이 합을 최소화하는 것은 관측된 스펙트럼을 가장 잘 설명하는 에너지 준위 세트를 찾는 것을 의미한다. 합계는 총 오차가 개별 선의 오차의 집계이기 때문에 사용된다.
- $M$: 이것은 알려진 선의 총 개수이다.
- 수학적 정의: 알려진 에너지 준위 간의 전이에 일치된 스펙트럼 선의 정수 개수.
- 물리적/논리적 역할: 에너지 준위를 제약하는 데 사용할 수 있는 경험적 데이터의 양을 나타낸다.
- $N$: 이것은 알려진 준위의 총 개수이다.
- 수학적 정의: 값이 최적화되는 에너지 준위의 정수 개수.
- 물리적/논리적 역할: 값이 정제되는 원자 상태의 수를 나타낸다.
- $w_m$: 이것은 선 $m$의 가중치이다.
- 수학적 정의: $w_m = (\delta\sigma_m)^{-2}$, 선 $m$의 파수 불확실성의 역제곱.
- 물리적/논리적 역할: 더 정확하게 측정된 스펙트럼 선(작은 $\delta\sigma_m$를 가진 선)에 더 높은 중요성을 부여하고 불확실성이 높은 선에는 더 적은 중요성을 부여한다. 이는 신뢰할 수 있는 데이터가 결정된 에너지 준위에 더 큰 영향을 미치도록 보장한다. 역제곱은 가중치가 측정 오차의 분산에 반비례하는 가중 최소 제곱에서 표준 선택이다.
- $\left( \sum_{n=0}^{N-1} S_{mn}E_n - \sigma_m \right)^2$: 이것은 선 $m$에 대한 제곱 차이(잔차)이다.
- 수학적 정의: 현재 에너지 준위로 예측된 파수와 선 $m$에 대한 관측된 파수 간의 차이의 제곱.
- 물리적/논리적 역할: 현재 에너지 준위 세트가 특정 관측된 스펙트럼 선을 얼마나 잘 설명하는지를 측정한다. 제곱은 양수 값을 보장하고 더 큰 편차에 더 큰 페널티를 부과한다.
- $S_{mn}$: 이것은 에너지 준위와 선 $m$ 간의 관계를 정의하는 계수이다.
- 수학적 정의: 준위 $n$이 선 $m$의 상위 준위이면 1, 준위 $n$이 선 $m$의 하위 준위이면 -1, 그렇지 않으면 0인 행렬 요소.
- 물리적/논리적 역할: 이 계수는 스펙트럼 선의 파수($\sigma_m$)가 전이에 관련된 상위 ($E_u$) 및 하위 ($E_l$) 에너지 준위의 차이임을 나타내는 기본 관계를 인코딩한다: $\sigma_m = E_u - E_l$.
- $E_n$: 이것은 준위 $n$의 에너지이다.
- 수학적 정의: 특정 원자 준위의 에너지를 나타내는 스칼라 값.
- 물리적/논리적 역할: 이는 최적화 프로세스가 결정하고자 하는 미지의 매개변수이다.
- $\sigma_m$: 이것은 선 $m$에 대한 관측된 파수이다.
- 수학적 정의: 스펙트럼 선의 파수를 나타내는 측정된 스칼라 값.
- 물리적/논리적 역할: 이는 에너지 준위가 준수해야 하는 스펙트럼 선 목록에서 얻은 경험적 입력 데이터이다.
단계별 흐름
항목 분석을 일련의 연산을 통해 이동하는 추상적인 데이터 포인트인 동적 조립 라인으로 상상해 보세요.
-
초기 상태 입력: 프로세스는 초기 그래프 상태 $s_t$로 시작된다. 이 상태는 노드 $V$가 원자 에너지 준위(일부는 알려지고 일부는 미지)이고 에지 $E$가 잠재적 또는 관측된 스펙트럼 선(전이)인 풍부한 데이터 구조, 즉 그래프 $G=(V, E)$이다. 각 노드와 에지는 일련의 특징(예: 이론적 에너지, 관측된 파수, 불확실성, "알려짐" 또는 "선택됨"의 이진 플래그)을 전달한다. 이와 함께 모든 관측된 전이를 포함하는 포괄적인 스펙트럼 선 목록이 있다.
-
행동 $a^{(1)}$: 준위 선택: 에이전트는 먼저 $a^{(1)}$ 유형의 행동을 수행한다. 이는 알려지지 않은 준위 중에서 알려진 준위로 최소 두 개의 잠재적 연결(에지)을 가진 모든 준위를 조사한다. 이 풀에서 에이전트는 결정을 위해 집중할 특정 미지의 준위 하나를 선택한다. 이 선택은 해당 준위를 선택하는 장기 보상을 추정하는 에이전트의 학습된 Q-값을 기반으로 한다. 선택되면 이 노드의 "선택됨" 플래그가 현재 대상임을 나타내도록 전환된다.
-
행동 $a^{(2)}$: 선 일치 및 에너지 가설: 다음으로, 에이전트는 $a^{(2)}$ 유형의 행동을 실행한다. "선택된" 미지의 준위에 대해, 알려진 준위와 연결하는 모든 가능한 에지를 고려한다. 각 에지에 대해 전체 스펙트럼 선 목록(10^4개의 선을 포함할 수 있음)을 필터링하여 후보 관측 선을 찾는다. 이 필터링은 엄격하다.
- 파수 일치: 관측된 파수 $\sigma_{obs}$는 이론적 범위 $[\sigma_{calc} \pm \Delta E]$ 내에 있어야 하며, 여기서 $\sigma_{calc}$는 전이에 대한 이론적 파수이고 $\Delta E$는 에너지 불확실성이다.
- 강도 일치: 관측된 강도 $I_{obs}$는 이론적 범위 $[I_{calc} \pm \Delta I]$ 내에 있어야 한다.
- 후보 $E_{obs}$ 생성: 필터링된 각 선에 대해, 선택된 미지의 준위에 대한 후보 관측 에너지 $E_{obs}$는 연결된 준위의 알려진 에너지에 선의 파수를 더하거나 빼서 계산된다(선택된 준위가 상위인지 하위인지에 따라 다름).
- 통합: 여러 선이 미지의 준위에 대해 동일한 에너지를 제안할 수 있으므로, 후보는 그룹화되고 작은 허용 오차 $\delta E$ 내에서 반복되는 $E_{obs}$ 값만 고려된다. 그런 다음 에이전트는 이러한 통합된 $E_{obs}$ 값 중 하나를 선택한다(적절한 후보가 없으면 "작업 없음").
-
상태 전이 및 그래프 업데이트: $E_{obs}$ 값이 $a^{(2)}$를 통해 선택된 준위에 대해 선택되면, 그래프 상태 $s_t$는 결정론적으로 새로운 상태 $s_{t+1}$로 전환된다.
- "선택된" 미지의 준위는 이제 "알려진" 준위가 되고, 해당 $E_{obs}$ 특징은 선택된 값으로 업데이트된다.
- 일치된 스펙트럼 선에 해당하는 에지도 "알려진" 에지가 되고, 해당 특징(예: $\sigma_{obs}$, $I_{obs}$)은 선 목록에서 업데이트된다. 이러한 일치된 선은 이 에피소드에서 향후 $a^{(2)}$ 고려 사항에서 제외된다.
- 전역 재최적화: 중요한 것은, 새로운 준위가 결정된 후, 현재 알려진 모든 준위(새로 결정된 준위 포함)의 관측된 에너지 $E_{obs}$는 가중 최소 제곱 최소화(방정식 9)를 사용하여 재최적화된다. 이는 전체 알려진 준위 시스템에 걸쳐 일관성을 보장한다. 기준 에너지 준위 $E_0$는 참조로 0으로 고정된다.
-
보상 계산: 새로운 상태 $s_{t+1}$와 취해진 행동을 기반으로 보상 $r_t$가 계산된다. 이 보상은 결정된 준위에 대한 신뢰도, 이론과의 일치, 그리고 미래 결정을 가능하게 하는 능력에 반영되는 복합체이다. $a^{(1)}$의 경우, 이는 연결 선의 신호 대 잡음비(방정식 6)를 기반으로 한다. $a^{(2)}$의 경우, 이는 인간 전문가 결정에서 부분적으로 학습된 학습된 선호도 점수 $D$(방정식 7)를 포함한다.
-
경험 저장: 튜플 $(s_t, a_t, r_t, s_{t+1})$ - 이전 상태, 취해진 행동, 받은 보상, 새로운 상태를 나타내는 -가 리플레이 버퍼에 저장된다. 이 버퍼는 메모리 역할을 하며 과거 경험을 축적한다.
-
반복: 그런 다음 프로세스는 에이전트가 다른 미지의 준위를 선택하거나 현재 준위를 계속 정제하면서 단계 2로 돌아간다. 유한 호라이즌 $H$에 도달하거나 더 이상 유효한 행동을 취할 수 없을 때까지 반복된다.
이 전체 시퀀스는 추상적인 수학을 원시 스펙트럼 데이터가 지속적으로 정제되고 원자 에너지 준위의 성장하는 자체 일관적인 모델로 통합되는 움직이는 기계 조립 라인처럼 느끼게 한다.
최적화 역학
TAG-DQN 메커니즘은 주로 시간차(TD) 오차를 최소화함으로써 주도되는 심층 강화학습 기법의 정교한 상호 작용을 통해 학습하고 수렴한다. 작동 방식은 다음과 같다.
-
그래프 표현 학습: 기초는 그래프 신경망(GNN)이다. 그래프 상태 $s_t$(현재 알려진/미지의 준위 및 선의 집합을 나타냄)가 제시되면, GNN은 노드(준위)와 에지(선) 및 관련 특징(예: $E_{calc}$, $\sigma_{obs}$, $I_{obs}$)을 처리한다. 다중 헤드 그래프 어텐션 레이어를 사용하여 각 노드 주변의 지역적 이웃의 구조적 및 특징적 정보를 포착하는 풍부하고 맥락적인 노드 임베딩 벡터 $h_v$를 학습한다. 그런 다음 전역 그래프 상태 임베딩 벡터 $S_{agg}$는 단순히 이러한 노드 임베딩을 평균하여 얻는다(방정식 11). 이 $S_{agg}$는 전체 그래프의 현재 상태를 효과적으로 요약한다.
-
Q-값 추정 (듀얼링 DQN): 학습된 그래프 임베딩은 다층 퍼셉트론(MLP)으로 공급되어 Q-값을 추정한다. 아키텍처는 상태-가치 함수 $V(s)$와 장점 함수 $A(s, a)$의 추정을 분리하는 듀얼링 DQN 설계를 사용한다.
- 행동 유형 $a^{(1)}$(미지의 준위 선택)의 경우, 각 유효 준위 선택에 대한 Q-값은 전역 $S_{agg}$(상태-가치용)와 선택된 준위의 노드 임베딩(장점용)을 결합하여 추정된다(방정식 12 참조).
- 행동 유형 $a^{(2)}$(에너지 결정을 위한 선 일치)의 경우, Q-값은 유사하게 추정되지만, 장점 함수 $A(s,a)$는 상태-행동 값과 상태 값의 차이를 취하여 계산된다(방정식 13 참조). 이 분리는 상태가 취해진 행동과 독립적으로 가치 있다는 것을 학습하는 데 도움이 되어 효율성을 향상시킨다.
-
정책 및 탐색: 에이전트의 정책은 예측된 Q-값에 대해 탐욕적이다. 각 단계에서 가장 높은 예측 Q-값을 가진 행동( $a^{(1)}$ 또는 $a^{(2)}$)을 선택한다. 탐색을 위해 전통적인 엡실론-탐욕적 방법 대신, 저자들은 노이즈 네트워크를 사용한다. 이는 MLP 출력 레이어의 가중치에 직접 노이즈가 추가되어 에이전트가 명시적인 $\epsilon$ 매개변수 없이 자연스럽게 다른 행동을 탐색하도록 장려한다. 노이즈는 시간이 지남에 따라 학습되고 조정되어 복잡한 환경에서 더 효율적인 탐색을 가능하게 한다.
-
경험으로부터 학습 (리플레이 버퍼 및 n-스텝 반환): 학습을 위해 에이전트는 가장 최근 경험만 사용하지 않는다. 대신, 과거 경험(상태, 행동, 보상, 다음 상태 튜플)을 리플레이 버퍼에 저장한다. 훈련 중에 이러한 경험의 배치가 버퍼에서 무작위로 샘플링된다. 이는 연속적인 경험 간의 상관 관계를 끊어 학습 프로세스를 안정화시킨다. 손실 계산(방정식 15)은 n-스텝 반환($r^{[n]}$)을 사용하는데, 이는 즉각적인 보상 $r_t$와 다음 상태 $s_{t+1}$의 Q-값만 고려하는 대신, Q-값 추정치에서 부트스트랩하기 전에 짧은 궤적에 걸쳐 실제 보상을 통합하여 학습을 위한 더 정확한 타겟을 제공한다.
-
안정성을 위한 타겟 네트워크: Q-학습의 주요 과제는 타겟 값(네트워크가 예측하려고 하는 것)이 업데이트되는 동일한 네트워크에 의존하여 불안정을 초래한다는 것이다. 이를 해결하기 위해 TAG-DQN은 타겟 네트워크 $Q_{\bar{\theta}}$를 사용한다. 이것은 온라인 Q-네트워크($Q_{\theta}$)의 별도 복사본으로, 그 파라미터 $\bar{\theta}$는 $\theta$보다 훨씬 느리게 업데이트된다. 구체적으로, $\bar{\theta}$는 각 단계에서 온라인 네트워크의 파라미터의 작은 부분을 타겟 네트워크의 파라미터에 혼합하여 부드럽게 업데이트된다(방정식 14). 이는 온라인 네트워크가 학습할 안정적인 타겟을 생성하여 진동과 발산을 방지한다. Double DQN의 사용은 온라인 네트워크를 사용하여 다음 상태에 대한 최적의 행동을 선택하지만 타겟 네트워크가 그 가치를 평가하도록 함으로써 이점을 더욱 개선하여 과대평가 편향을 완화하는 데 도움이 된다.
-
보상 함수 학습 (역 강화 학습): 독특한 측면은 행동 $a^{(2)}$에 대한 보상 함수(선호도 점수 $D$)가 수동으로 코딩되지 않는다는 것이다. 대신, 역 강화 학습의 한 형태를 사용하여 과거 인간 전문가 결정에서 학습된다. 간단한 다층 퍼셉트론(MLP)은 후보 선의 특징으로부터 $D$를 예측하도록 훈련된다(방정식 8). 이 MLP는 인간의 선택이 긍정적인 예로 레이블이 지정된 전문가 생성 MDP 상태 전이 데이터셋으로 훈련된다. 이를 통해 시스템은 특정 선 일치의 "좋음"에 관한 인간 전문가의 미묘한 판단을 암묵적으로 포착하여 전문가의 직관과 일치하는 행동을 선호하는 손실 풍경을 형성할 수 있다.
-
최적화 알고리즘: 네트워크 파라미터 $\theta$는 심층 학습 작업에서 효율성과 좋은 성능으로 유명한 인기 있는 확률적 경사 하강법 방법인 Adam 옵티마이저를 사용하여 최적화된다. 이 반복적인 최적화 프로세스는 가중치와 편향을 조정하여 손실 함수를 최소화하고 결과적으로 에이전트의 정책을 개선한다.
본질적으로 최적화 역학은 에이전트가 환경에서 행동하고, 경험을 수집하고, 저장하고, 그런 다음 이러한 경험의 배치에서 학습하는 연속적인 주기를 포함한다. 이 학습 프로세스는 타겟 네트워크, n-스텝 반환 및 듀얼링 아키텍처와 같은 기술을 사용하여 안정화되는 반면, 탐색은 노이즈 네트워크에 의해 처리된다. 인간 전문성에서 파생된 학습된 보상 함수는 에이전트를 물리적으로 의미 있는 솔루션으로 더욱 안내하여 전문가의 선호도와 불확실성을 반영하도록 손실 풍경을 형성한다. 이러한 반복적인 개선은 에이전트가 원자 미세구조를 효율적이고 정확하게 결정하는 정책으로 수렴할 수 있도록 한다.
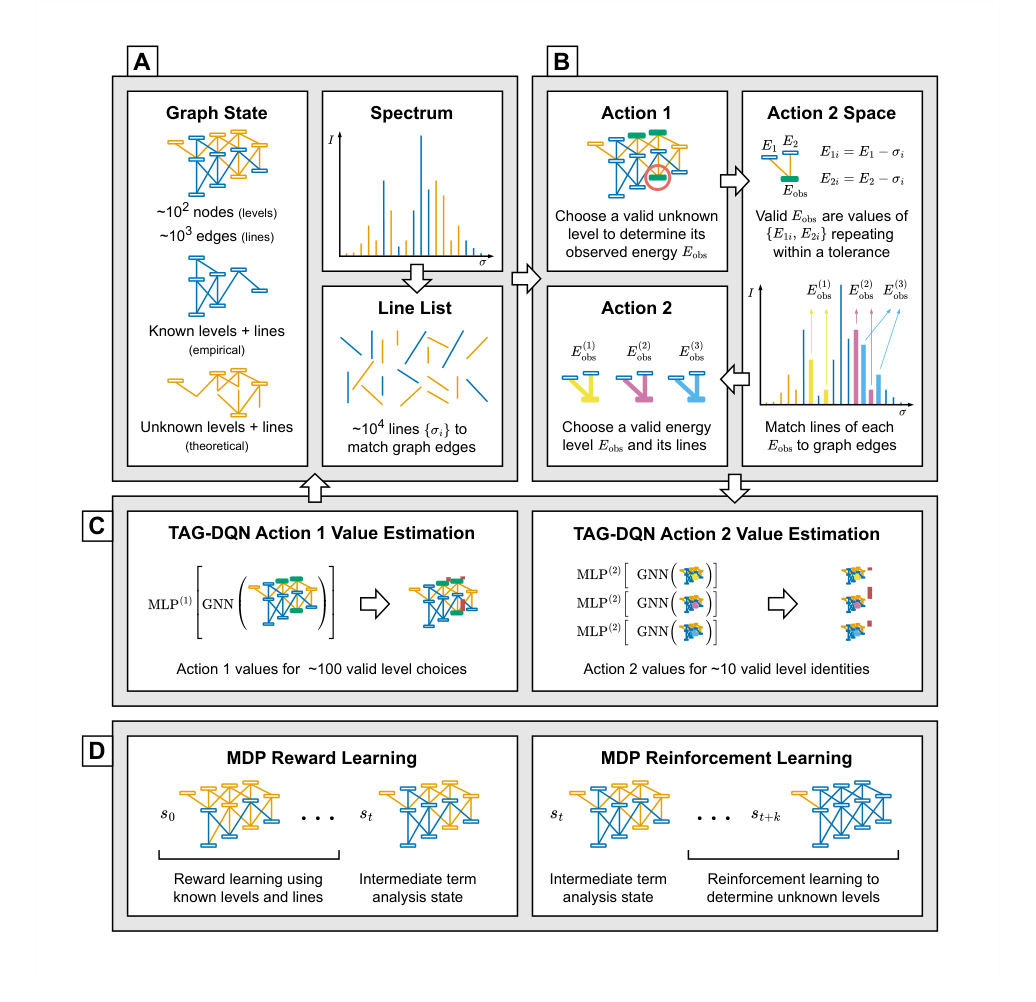 Figure 1. Illustration of the MDP environment and TAG-DQN. A The term analysis state is represented as a graph with node and edge features, alongside the spectral line list. B Actions alternate between two regimes; each pair of actions leads to the determination of the observed energy Eobs for one level by matching at least two lines from the line list to unknown edges in the graph. C TAG-DQN employs a GNN to embed graph representations, which are inputs for multilayer perceptrons (MLPs) estimating Q-values for each action (vertical bars); the highest Q-value action advances the MDP to the next state. D Given a term analysis state st, the MDP trajectory leading to st involving known levels is used for reward learning, while RL with the learned reward function guides the discovery of unknown levels in future states st+k
Figure 1. Illustration of the MDP environment and TAG-DQN. A The term analysis state is represented as a graph with node and edge features, alongside the spectral line list. B Actions alternate between two regimes; each pair of actions leads to the determination of the observed energy Eobs for one level by matching at least two lines from the line list to unknown edges in the graph. C TAG-DQN employs a GNN to embed graph representations, which are inputs for multilayer perceptrons (MLPs) estimating Q-values for each action (vertical bars); the highest Q-value action advances the MDP to the next state. D Given a term analysis state st, the MDP trajectory leading to st involving known levels is used for reward learning, while RL with the learned reward function guides the discovery of unknown levels in future states st+k
결과, 한계 및 결론
실험 설계 및 기준선
수학적 주장을 엄격하게 검증하기 위해 저자들은 TAG-DQN(그래프 심층 Q-네트워크를 이용한 항목 분석)을 탐욕적 탐색 에이전트 및 몬테카를로 트리 탐색(MCTS) 에이전트(트리 상한 신뢰도(UCT) 전략 사용)와 비교하는 일련의 실험을 설계했다. 핵심 아이디어는 TAG-DQN이 원자 미세구조 결정의 복잡하고 순차적인 의사 결정 작업을 효과적으로 자동화하고 가속화할 수 있음을 입증하는 것이었다.
실험 설정은 Co II, Nd III 및 Nd II의 두 가지 변형( ab initio 계산용 Nd II u 및 Cowan 코드 계산용 Nd II k)에 대한 실제 원자 항목 분석에서 파생된 네 가지 서로 다른 마르코프 결정 과정(MDP) 환경을 포함했다. 이러한 환경은 기존 푸리에 변환(FT) 스펙트럼 선 목록 및 이론적 계산을 사용하여 실제 항목 분석의 과제를 반영하도록 신중하게 구성되었다. 예를 들어, Co II 환경은 수정된 출판 데이터를 기반으로 141개의 알려진 준위로 초기화되었으며, Nd III는 40개의 준위를 사용했다. Nd II 환경은 6개의 기본 항 준위, 5개의 6K 준위 및 11개의 전이로 시작했으며, 이론적 계산 방법이 달랐다.
공정하고 강력한 비교를 보장하기 위해 TAG-DQN과 MCTS는 25개의 서로 다른 무작위 시드에 걸쳐 평가되었으며, 평균 성능과 95% 신뢰 구간이 보고되었다. 결정론적인 탐욕적 탐색은 한 번 실행되었다. 성능은 세 가지 주요 지표를 사용하여 측정되었다.
1. $R_{max}$: MDP 에피소드 길이 $H$ 내에서 에이전트가 달성한 최대 누적 보상.
2. $N_c$: $R_{max}$ 에피소드에서 정확하게 결정된 에너지 준위의 수. 여기서 준위는 관측된 에너지($E_{obs}$)가 이전에 출판된 에너지 준위($E_{known}$)로부터 $\pm \delta E$ 이내에 있을 때 정확한 것으로 간주되었다.
3. 정확도 (Acc.): $R_{max}$ 에피소드에서 결정된 총 준위 수에 대한 $N_c$의 비율.
MDP 환경은 실현 가능성과 RL 성능을 향상시키기 위해 신중하게 단순화되었다. 여기에는 낮은 신호 대 잡음비($S/N_{calc} < 2$)의 그래프 에지 가지치기, 이미 일치된 선 목록 항목 제외, 에너지 최적화 중 초기 알려진 준위 고정, 스펙트럼 범위 제한이 포함되었다. 또한 효율적인 탐색 및 메모리 관리를 돕기 위해 선 일치에 대한 행동 공간의 최대 상한($|A^{(2)}|$)이 부과되었다. 에피소드 길이 $H$는 계산 비용과 에이전트의 장기적인 결과 학습 능력을 균형 있게 조절하기 위해 종별로 다양했다(예: Nd III 및 Co II의 경우 $H=128$, Nd II u의 경우 $H=64$, Nd II k의 경우 $H=512$).
또한, Nd III 환경에 대한 축소 실험을 수행하여 TAG-DQN의 전반적인 성능에 대한 심층 Q-네트워크(DQN) 확장(예: 이중 Q-학습, 우선순위 경험 리플레이, 듀얼링, 다중 스텝 반환 및 노이즈 네트워크 탐색)의 기여를 분석했다. 이를 통해 연구자들은 모델의 성공적인 작동에 가장 중요한 아키텍처 구성 요소를 파악할 수 있었다.
증거가 증명하는 것
실험 결과는 TAG-DQN이 전통적으로 수개월에서 수년의 인간 노력이 필요한 원자 미세구조 결정 작업을 크게 가속화할 수 있다는 설득력 있는 증거를 제공한다. 이 시스템은 몇 시간 만에 수백 개의 에너지 준위를 식별하고 결정할 수 있었다.
구체적으로, 항목 분석을 인간 결정에서 부분적으로 학습된 보상 함수로 해결되는 그래프 강화학습으로 캐스팅하는 TAG-DQN의 핵심 메커니즘은 실제로 작동했음이 입증되었다. 결정적인 증거는 높은 일치율에 있다. Co II의 경우 95%, Nd II 및 Nd III의 경우 54%에서 87% 사이이다. 이 정도의 정확도는 시간의 일부만으로 달성되었으며, 방법의 효과를 강력하게 나타낸다.
기준 모델(표 2)과 비교할 때, TAG-DQN은 모든 지표에서 탐욕적 탐색 에이전트보다 일관되게 우수했다. 더 중요한 것은, 5가지 사례 연구 중 3가지에서 $N_c$(정확하게 결정된 에너지 준위 수) 측면에서 MCTS 에이전트보다 우수한 성능을 보였다는 것이다. MCTS가 때때로 더 높은 최대 누적 보상($R_{max}$)을 달성했지만, TAG-DQN은 특히 Nd II 사례에서 $N_c$의 더 높은 상한에 도달했다. 이는 TAG-DQN이 에피소드 전체에 걸쳐 관측 및 이론과 일관성을 유지하는 준위 식별을 더 잘 선택했음을 시사하며, 반면 MCTS의 얕은 롤아웃은 전반적인 정확도를 희생하고 단기 보상을 선호했을 수 있다. Nd II k의 경우, TAG-DQN은 MCTS(130 $\pm$ 11)보다 훨씬 더 많은 수의 준위(169 $\pm$ 10)를 정확하게 레이블링하여 이러한 해석을 더욱 강화했다.
학습 곡선(그림 2A, B)은 누적 보상과 정확하게 결정된 준위 수($N_c$) 간의 정렬을 명확하게 보여주며, 이는 학습된 보상 함수가 에이전트를 정확한 준위 결정으로 효과적으로 안내함을 나타낸다. 볼츠만 플롯(그림 2C)은 TAG-DQN이 다른 전자 구성에 걸쳐 준위를 결정할 수 있으며, 볼츠만 준위 분포에 기반한 선 강도 필터링이 문제가 되는 선을 제외하는 데 효과적임을 확인했다.
축소 실험(그림 3)은 TAG-DQN 아키텍처에 대한 중요한 통찰력을 제공했다. 대부분의 DQN 확장이 성능에 긍정적으로 기여했으며, 듀얼링 네트워크 아키텍처와 탐색을 위한 노이즈 네트워크가 특히 중요했음을 보여주었다. 이는 이 특정 환경에서 내재된 대규모 행동 공간 때문일 가능성이 높다. 흥미롭게도, 우선순위 경험 리플레이(PER)는 버퍼 크기와 훈련 단계가 이 특정 환경에서 PER의 이점에 대해 최적으로 확장되지 않았기 때문에 성능을 약간 감소시켰다. 에너지 준위 차이(그림 4)는 방법의 정밀도를 더욱 뒷받침했으며, 결정된 준위의 작은 비율이 승인된 값에서 벗어났지만, 이러한 편차는 일반적으로 실험적 불확실성 $\delta E$ (예: Nd III의 경우 $\pm 0.004$ cm$^{-1}$, Co II의 경우 $\pm 0.006$ cm$^{-1}$, Nd II k의 경우 $\pm 0.009$ cm$^{-1}$) 내에 있어 대부분의 응용 분야에서 무시할 수 있음을 보여주었다.
한계 및 향후 방향
TAG-DQN 접근 방식은 원자 미세구조 결정 자동화에서 상당한 발전을 이루었지만, 현재의 한계를 인정하고 향후 개발을 위한 길을 고려하는 것이 중요하다.
주요 한계 중 하나는 현재 방법이 인상적인 속도에도 불구하고 인간 전문가에 비해 정확도가 감소했으며 원자 구조 계산에 의존한다는 것이다. 결정된 준위, 특히 Nd II k와 같은 경우에 대한 것은 잠정적인 것으로 간주되며 최종 출판 전에 인간의 검증이 필요하다. 또한, 현재 프레임워크는 단일 선 준위 결정, 연결되지 않은 알려진 준위 하위 그래프 연결 또는 완전히 알려지지 않은 상태에서 분석 시작과 같은 가장 어려운 시나리오를 아직 다루지 않는다. 이러한 상황은 MDP 복잡성을 상당히 증가시키며 상당한 재설계가 필요하다. 현재 Co II 데이터를 기반으로 훈련된 보상 함수는 다양한 원자 종 및 조건에 대한 일반화를 개선하기 위해 더 다양하고 광범위한 훈련 데이터셋을 활용할 수 있다.
앞으로 몇 가지 유망한 방향은 이러한 결과를 더욱 발전시킬 수 있다.
- MDP 상태 및 행동 공간 풍부화: 현재 MDP는 더 세분화된 정보를 통합하도록 확장될 수 있다. 예를 들어, 원시 스펙트럼 및 선 프로파일 분석을 MDP에 직접 통합하면 에이전트가 동위원소 이동, 초미세 구조 및 다른 스펙트럼 간의 비교와 같은 추가 요소를 고려할 수 있다. 파동 함수에 대한 정보, 예를 들어 선도 구성 레이블, 전자 확률 밀도 및 특정 패리티 및 J 값 내의 국부 준위 밀도는 선 프로파일 및 강도에 대한 에이전트의 결정을 알릴 수 있으며, 잠재적으로 더 강력하고 정확한 준위 결정을 초래할 수 있다.
- 더욱 강력한 보상 함수 개발: 언급했듯이, 현재 보상 함수는 제한된 데이터셋에 의존한다는 한계가 있다. 향후 연구는 다양한 원자 종의 방대한 라인 목록 및 MDP를 사용하여 더 일반화된 보상 함수를 훈련하는 데 중점을 두어야 한다. 이는 에이전트가 새로운 상황을 처리하는 능력을 향상시키고 전반적인 성능을 개선할 것이다.
- 인간-루프 통합: 저자들은 AI의 출력이 중간 단계 역할을 하는 협업적 접근 방식을 구상한다. 에피소드의 최종 MDP 상태는 인간 전문가가 스펙트럼을 검사하고, 잘못 결정된 준위를 가지치기하고, 반경험적 계산을 정제하고, 보상 함수를 재훈련하는 새로운 초기 상태가 될 수 있다. 이러한 반복적인 인간-AI 협업은 AI가 노동 집약적인 초기 식별을 처리하고 인간 전문가가 중요한 검증 및 정제를 제공하는 등 양쪽의 강점을 활용할 수 있다.
- 복잡한 시나리오 처리: 향후 연구는 현재 생략된 어려운 상황을 처리하기 위해 MDP를 재설계하는 데 중점을 두어야 한다. 이는 증가된 복잡성을 관리하기 위해 새로운 그래프 표현 또는 행동 공간 분해를 포함할 수 있으며, 잠재적으로 항목 분석의 가장 어려운 측면을 자동화하는 능력을 발휘할 수 있다.
- 다른 실험 방법으로 확장: 이 접근 방식은 본질적으로 유연하며 환경 매개변수($\delta E$, $\Delta I$, 보상 함수)를 약간 조정하여 격자 분광학과 같은 다른 실험 방법으로 조정될 수 있다. 이는 그래프 강화학습의 적용 범위를 다양한 분광학 기술에 걸쳐 확장할 것이다.
- 계산 효율성 및 인프라: TAG-DQN은 단일 시드 실행의 경우 일반 하드웨어에서 실행될 수 있지만, 광범위한 하이퍼파라미터 튜닝 및 다중 시드 평가를 포함하는 포괄적인 실험은 상당한 계산 리소스를 요구한다. 향후 연구는 광범위한 연구에 필요한 계산 비용 및 시간을 줄이기 위해 더 효율적인 하이퍼파라미터 최적화 기술 또는 분산 컴퓨팅 프레임워크를 탐색할 수 있다.
궁극적으로 이 작업은 데이터 및 노동 집약적인 분야에서 과학적 발견을 지원하는 그래프 강화학습 및 AI의 잠재력에 대한 증거이다. 제안된 발전은 원자 물리학 연구의 새로운 시대를 열어 원자 데이터에 대한 수요와 현재 결정 효율성 간의 격차를 해소할 수 있다.
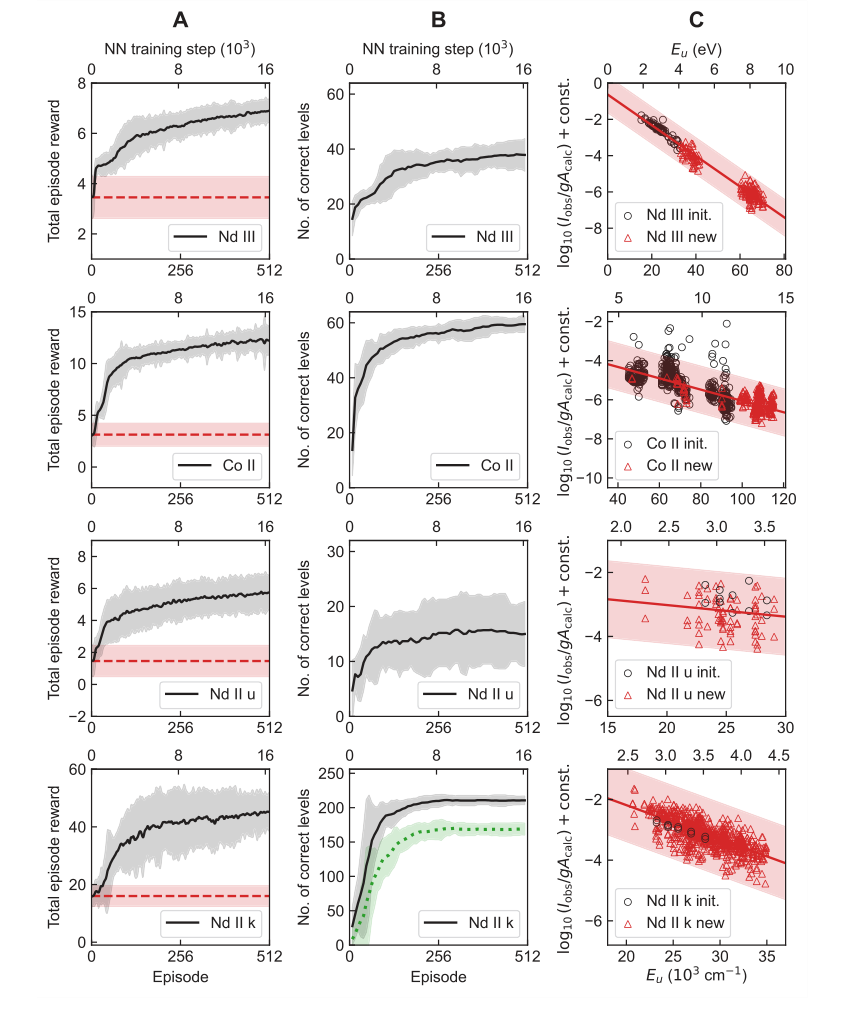 Figure 2. Learning results of TAG-DQN agent in the four case studies of Table 1. A Average learning curves, i.e., mean cumulative rewards obtained as a function of neural network (NN) training steps. The dashed horizontal lines show reward obtained during the pre-training episodes and correspond to rewards obtained by choosing actions in the MDP uniformly at random. The shaded regions show ±2 standard deviations across 25 random seeds. B Average Nc of the final state of the most recent maximum reward episode. The dotted curve for Nd II k shows the number of correct levels that also match human chosen level labels, and the y-axes limits are H
Figure 2. Learning results of TAG-DQN agent in the four case studies of Table 1. A Average learning curves, i.e., mean cumulative rewards obtained as a function of neural network (NN) training steps. The dashed horizontal lines show reward obtained during the pre-training episodes and correspond to rewards obtained by choosing actions in the MDP uniformly at random. The shaded regions show ±2 standard deviations across 25 random seeds. B Average Nc of the final state of the most recent maximum reward episode. The dotted curve for Nd II k shows the number of correct levels that also match human chosen level labels, and the y-axes limits are H
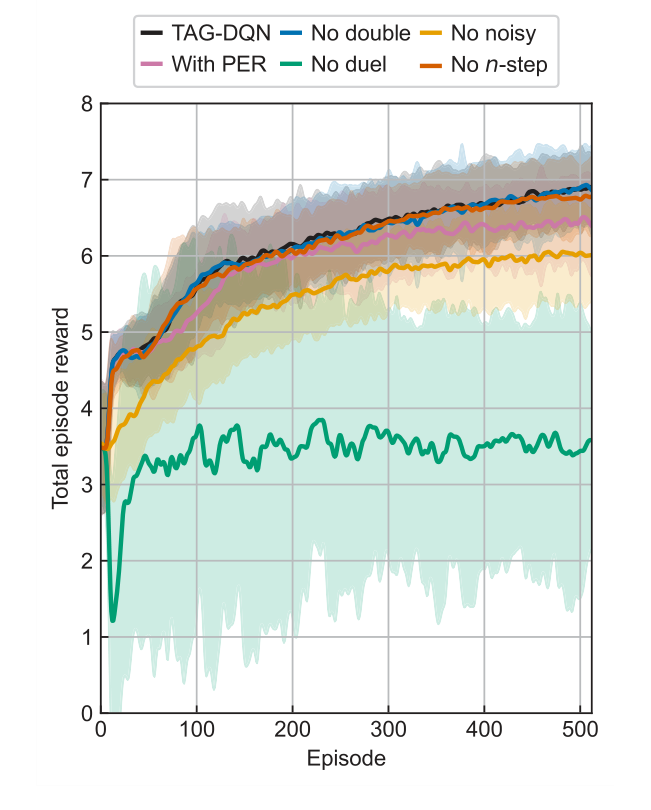 Figure 3. Learning curves of TAG-DQN (black) and its variants in the Nd III environment. Average total episode reward during training of TAG-DQN and its designs with or without particular deep Q-network extensions: without double Q-learning (blue), without noisy networks for exploration (yellow), with prioritised experience replay (PER, pink), without duelling deep Q-network (green), and without multi(n)-step return (orange). Shaded regions show ±2 standard deviations across 16 seeds. The duelling extension and noisy networks for exploration are key for TAG-DQN, while using PER reduced performance slightly
Figure 3. Learning curves of TAG-DQN (black) and its variants in the Nd III environment. Average total episode reward during training of TAG-DQN and its designs with or without particular deep Q-network extensions: without double Q-learning (blue), without noisy networks for exploration (yellow), with prioritised experience replay (PER, pink), without duelling deep Q-network (green), and without multi(n)-step return (orange). Shaded regions show ±2 standard deviations across 16 seeds. The duelling extension and noisy networks for exploration are key for TAG-DQN, while using PER reduced performance slightly
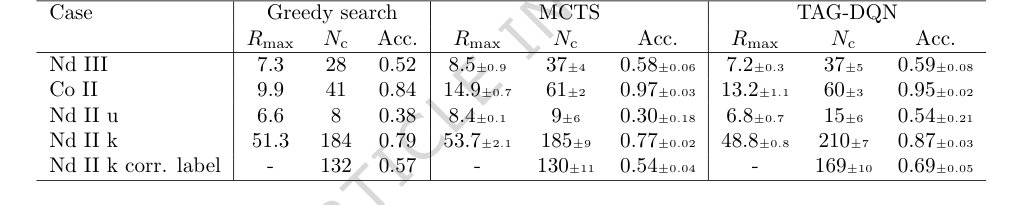 Table 2. Results and comparisons with benchmark agents. TAG-DQN matches MCTS performance as judged by downstream metrics in 2/5 cases and outperforms it in 3/5 cases, while Greedy search is worse overall
Table 2. Results and comparisons with benchmark agents. TAG-DQN matches MCTS performance as judged by downstream metrics in 2/5 cases and outperforms it in 3/5 cases, while Greedy search is worse overall
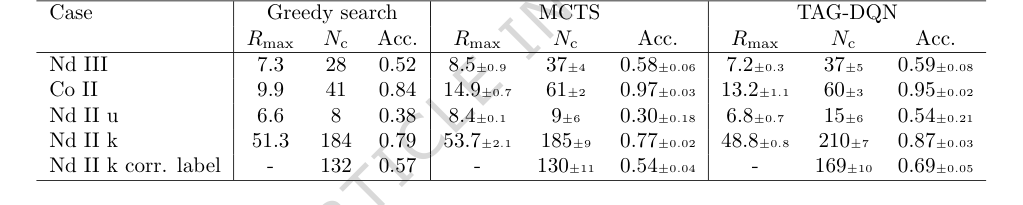 Table 1. Key term analysis MDP environment parameters
Table 1. Key term analysis MDP environment parameters