利用图强化学习加速原子精细结构测定
Atomic data determined by analysis of observed atomic spectra are essential for plasma diagnostics.
背景与学术渊源
起源与学术渊源
本文所解决的问题,即“谱项分析”(term analysis),源于理解元素原子结构的根本需求。具体而言,它涉及从观测到的原子光谱中提取能级能量和总电子角动量($J$),并将适当的谱项符号分配给这些能级。这一研究领域至关重要,因为由此产生的原子数据,如能级和跃迁波数,对于广泛的应用至关重要。这些应用包括等离子体诊断、照明和金属工业、磁约束聚变研究、核研究、医用同位素生产以及天文学,尤其是在理解中子星合并等事件产生的重元素起源方面。
历史上,谱项分析过程是一项顺序的、复杂的决策任务,需要深厚的原子光谱学专业知识和大量的人工劳动。自20世纪70年代引入傅里叶变换(FT)光谱谱项分析以来,其应用主要局限于铁族元素(原子序数$Z$在23到28之间)。挑战源于可观测光谱线的数量巨大(每种元素通常有数万条),这些谱线代表了能级之间的能量差,使得确定单个能级成为一项艰巨的任务,仅能依赖于不太精确的理论预测。
先前方法的根本局限性或“痛点”在于其极低的效率和对人类专家的依赖。虽然对单个原子物种进行光谱测量和理论计算的初始步骤可以在几周内完成,但随后的谱项分析——从观测数据中识别能级的关键步骤——可能需要数月到数年。这种手动、劳动密集型的过程已成为一个主要瓶颈,阻碍了满足各科学和工业领域日益增长需求的原子数据的快速生成。此外,现有的从头算(first-principles)计算通常仅能达到几个百分点的精度,这对于需要高光谱分辨率的应用来说是不足的。谱项分析尽管人力成本高昂,但能提供数量级更高的精度,并为理论模型提供可靠的约束。这种低效率以及理论方法本身无法提供足够精度是作者开发自动化、人工智能驱动解决方案的主要动机。
直观的领域术语
-
原子精细结构测定 / 谱项分析:想象一下你有一个复杂的乐器,比如一架大钢琴,但你只能听到它演奏的音符,而看不到琴键或它们的排列方式。“原子精细结构测定”就像是通过听旋律来精确确定钢琴上每一个琴键的位置和身份,以及它们之间的相互关系。它是通过将观测到的光谱“音符”映射回原子基本“琴键”(能级)的过程。
-
光谱线 / 波数($\sigma$):继续钢琴的比喻,“光谱线”就像你听到的一个单独的、清晰的音符。当原子中的电子从较高的能级跃迁到较低的能级时,它会以非常特定的“音高”发射光。“波数”($\sigma$)是该音高的精确测量值,告诉我们该电子跃迁释放了多少能量。它是两个原子态之间能量差的直接度量。
-
马尔可夫决策过程(MDP):将 MDP 想象成一个寻宝游戏。你(“智能体”)处于某个位置(“状态”),并且有几种路径可供选择(“动作”)。你选择的每条路径都可能将你带到一个新的位置(新状态)并给你一些金币(“奖励”)。游戏的目标是找到一个“策略”(“策略”),以最大化整个寻宝过程中收集到的金币总量,即使某些路径有即时的小奖励但之后会导向死胡同。
-
强化学习(RL):这就像在不给出明确指令的情况下教机器人玩寻宝游戏。相反,你让机器人尝试不同的路径。当它找到金币时,你告诉它“做得好!”(正奖励)。当它撞到死胡同时,你告诉它“不太好”(负奖励)。经过多次尝试,机器人通过试错学会了在哪些状态下采取哪些动作可以获得最多的金币,最终成为一名专家寻宝者。
-
图神经网络(GNNs):考虑一个由相互连接的城市组成的庞大网络,每个城市都有独特的特征(如人口、工业),连接它们的每条道路都有属性(如长度、交通流量)。GNN 是一种特殊的人工智能,旨在理解和学习这种网络中的关系和特征。它帮助 AI “看到”整体结构和局部连接,使其能够就城市和道路做出明智的决策,就像它帮助分析原子能级和光谱线复杂网络一样。
符号表
| 符号 | 描述 |
|---|---|
| $J$ | 总电子角动量 |
| $Z$ | 原子序数 |
| $\sigma$ | 波数 |
| $\sigma_{obs}$ | 观测波数 |
| $\delta\sigma_{obs}$ | 标准波数不确定度 |
| $I_{obs}$ | 相对强度 |
| $S/N_{obs}$ | 信噪比 |
| $E_{obs}$ | 原子能级的观测能量 |
| $E_{calc}$ | 原子能级的理论能量 |
| $\Delta E$ | 能级理论不确定度 |
| $\Delta I$ | 线强度理论不确定度 |
| $E_u$ | 上能级 |
| $E_l$ | 下能级 |
| $E_0$ | 基态能量(固定为零) |
| $s_t$ | MDP 中时间 $t$ 的状态 |
| $a_t$ | MDP 中时间 $t$ 采取的动作 |
| $r_t$ | 时间 $t$ 收到的奖励 |
| $G_t$ | 时间 $t$ 起的折扣累积奖励 |
| $\gamma$ | 折扣因子 |
| $H$ | MDP 中有限的视野(回合长度) |
| $Q(s, a)$ | Q 值(在状态 $s$ 中采取动作 $a$ 的预期累积奖励) |
| $Q_{\theta}$ | 参数为 $\theta$ 的在线 Q 网络 |
| $Q_{\bar{\theta}}$ | 参数为 $\bar{\theta}$ 的目标 Q 网络 |
| $L$ | 损失函数 |
| $TD[n]$ | n 步时序差分误差 |
| $r^{[n]}$ | n 步回报 |
| $w_m$ | 最小二乘优化中第 $m$ 条线的权重 |
| $S_{mn}$ | 将能级与第 $m$ 条线关联的系数矩阵 |
| $M$ | 已知线的总数 |
| $N$ | 已知能级的总数 |
| $D$ | 动作 $a^{(2)}$ 的偏好得分 |
| $h_v$ | 能级 $v$ 的节点嵌入向量 |
| $S_{agg}$ | 全局图状态嵌入向量 |
| $V(s)$ | 状态值函数 |
| $A(s, a)$ | 优势函数 |
| MLP | 多层感知机 |
| GNN | 图神经网络 |
| $N_c$ | 正确确定的能级数量 |
| $R_{max}$ | 最大累积奖励 |
| Acc. | 确定能级的准确率 |
| PER | 优先经验回放 |
| MCTS | 蒙特卡洛树搜索 |
| UCT | 树的上限置信界 |
问题定义与约束
核心问题构建与困境
本文所解决的核心问题是加速原子精细结构测定。这是原子光谱学中的一项关键任务,为从等离子体诊断到天体物理学的各种科学和工业应用提供基础数据。
该分析的起点(输入/当前状态)是一系列观测到的原子光谱,这些光谱被预处理成一个“谱线列表”。该谱线列表包含给定原子物种大约 $10^4$ 条可观测光谱线,每条线都具有观测波数($\sigma_{obs}$)、标准波数不确定度($\delta\sigma_{obs}$)、相对强度($I_{obs}$)和信噪比($S/N_{obs}$)。此外,当前状态还包括已知(经验确定)能级和跃迁的图表示,以及理论预测的能级和谱线。这些已知能级通常是相互连接的,其观测能量($E_{obs}$)相对于固定的零能量基态。
期望的终点(输出/目标状态)是准确确定未知原子能级的观测能量($E_{obs}$),并根据实验不确定度将光谱线与理论预测进行最佳匹配。这包括通过识别和匹配至少两条观测光谱线与连接未知能级与已知能级的相应边,来扩展已知能级的子图,从而确定未知能级的能量。
本文试图弥合的确切缺失环节或数学鸿沟在于从原始光谱线数据和不太精确的理论预测过渡到精确的、经验验证的原子能级。历史上,这个过程被称为“谱项分析”,它是一项顺序的、复杂的决策任务,需要大量的人工劳动和原子光谱学专业知识,通常需要数月到数年才能完成一个原子物种的分析。数学鸿沟在于缺乏一种自动化、可扩展且准确的方法,可以在理论上但通常不精确的计算指导下,从大量的观测光谱线差值中推断出这些能级。本文将其框架化为通过图强化学习(GRL)解决的马尔可夫决策过程(MDP)。
过去研究人员陷入的痛苦的权衡或困境是精度与效率之间的严峻选择。虽然人工驱动的谱项分析能产生高精度(比从头算计算高几个数量级)并提供可靠的理论约束,但它极其缓慢且劳动密集,难以满足日益增长的原子数据需求。相反,从头算理论计算速度很快,但通常仅能达到几个百分点的精度,这对于需要更高光谱分辨率的应用来说是不足的。困境在于,提高分析速度传统上意味着牺牲必要的精度,反之亦然。本文旨在部分自动化该过程,目标是以显著加快的速度实现人类水平的精度,从而缩小数据需求与分析能力之间的差距。
约束与失败模式
原子精细结构测定加速问题由于几个严峻的、现实的约束而变得异常困难:
-
物理与领域特定约束:
- 数据量与复杂性: 对于每个低电离的开放 d 和 f 亚壳原子物种,确定约 $10^3$ 个精细结构能级涉及分析约 $10^4$ 条可观测光谱线。主要挑战在于从“海量的观测能量差值”(第1节,第3页)中提取精确的能级。
- 不精确的理论指导: 现有的理论预测通常“不太精确”(第1节,第3页),仅提供粗略的指导而非精确值。从头算计算通常仅能达到几个百分点的精度,这对于许多应用来说是不足的。
- 歧义与不确定性: 确定的能级通常具有“模糊值”(第2.5节,第5页)。人类专家必须权衡观测到的谱线强度与理论预测的强度之间的一致性,以及在波数不确定度内重复的 $E_{obs}$ 值的稳定性。这种判断因“跃迁概率的不确定性以及光谱线拟合中的误差而变得复杂,特别是对于广泛分布的弱线和/或混合线”(第2.5节,第6页)。
- 有限的可用跃迁: 仅考虑电偶极精细结构跃迁,因为“实验室光谱中很少观测到更高阶的多极跃迁”(第2.2节,第4页),这限制了可用于分析的数据。
- 异常值与噪声: “异常波数(例如,未知的谱线混合或光谱线轮廓的糟糕拟合)”(第3节,第8页)的存在可能导致确定的能级发生偏移,即使在 $\delta E$ 容差范围内。
- 挑战性场景: 最困难的情况,例如“单线能级确定或连接不相连的已知能级子图,包括从没有已知能级开始的谱项分析”(第3节,第8页),显著增加了 MDP 的复杂性,并且通常被排除在当前方法之外。
-
计算与算法约束:
- 计算可行性与时间范围: 人工分析过程需要“数月到数年”(第1节,第3页)。为了计算可行性,MDP 是回合制的,具有“有限的视野 $H$”(第2.1节,第4页),限制了单个回合中可以确定的未知能级数量。
- 庞大的状态与动作空间: 该问题涉及“庞大的状态与动作空间”(第2.7节,第7页),需要深度神经网络进行函数逼近。选择未知能级($A^{(1)}$)的动作空间范围可以从 0 到 200,而匹配谱线($A^{(2)}$)的动作空间对于较大的 $k$(连接的已知能级数量)可以达到 $10^3$,中位数低于 10(第2.3节,第5页)。允许单线确定将导致“不切实际的巨大 $A^{(1)}$”(第2.3节,第5页)。
- MDP 复杂性管理: “降低 MDP 复杂性是可行性和 RL 性能的关键”(第2.6节,第6页)。这包括诸如移除低信噪比的图边、排除已匹配的谱线以及限制光谱范围等策略。强制执行“对 $|A^{(2)}|$ 的最大上限”有助于“高效的探索和内存控制”(第2.6节,第6页)。
- 探索效率: 蒙特卡洛树搜索(MCTS)等传统探索方法在动作空间巨大的情况下“效率低下,因为只有一个动作是正确的”(第4.6节,第11页)。
- 计算成本: 全面的实验,包括超参数调优和多种子运行,需要极高的资源,大约需要 $10^5$ 小时(约 11 年)的假设单核 CPU 时间(第4.7节,第11页)。
-
数据驱动学习约束:
- 依赖于人类数据: 奖励函数“部分基于历史人类决策通过逆强化学习进行学习”(摘要,第2页),这依赖于专家生成的 MDP 状态转换。
- 奖励函数训练数据有限: 用于预测偏好得分 $D$ 的 MLP 模型是在一个相对较小的数据集上训练的,该数据集包含来自 Co II 的 115 个专家 $a^{(2)}$ MDP 状态转换和来自 Nd III 的 23 个(第4.3节,第9页)。
- 训练数据中的偏差: “较弱的谱线在训练数据集中代表性不足,而未知谱线通常较弱”(第4.3节,第9页),这可能会影响模型在这些不太显著的谱线上的性能。
- 初始状态质量: “初始 MDP 状态”的质量可能有所不同;例如,来自 Rmax 回合的 Nd II 数据被视为“暂定”的,并且是“低质量的 MDP 初始状态”(第3节,第8页),直到人工验证。
为什么选择此方法
选择的必然性
选择图强化学习(GRL),特别是带有图深度 Q 网络(TAG-DQN)的谱项分析,并非仅仅是偏好,而是由原子精细结构测定的内在性质驱动的必然选择。这个复杂的问题本质上是在图结构数据上进行顺序决策的任务。“作者们真正意识到这一点的那一刻”,虽然没有明确说明,但可以从他们的问题构建中推断出来:他们将分析过程构建为涉及图的马尔可夫决策过程(MDP),其中原子能级是节点,光谱线是边。
传统的“SOTA”方法,如标准的卷积神经网络(CNN)、基本的扩散模型或 Transformer,在其典型应用中,并不适合这一特定挑战。CNN 在网格状数据(图像)上表现出色,但在处理不规则图结构时遇到困难。扩散模型主要是生成性的,并非为图上的顺序决策或组合优化而设计。Transformer 虽然在序列数据方面功能强大,但需要大量调整才能处理原子谱项分析中固有的动态、基于图的状态表示和顺序决策过程。核心问题在于,该问题不是关于固定网格中的模式识别,也不是生成新数据或简单的序列翻译。相反,它是在动态演化的图上做出了一系列相互依赖的决策,以识别未知的能级,这项任务自然地映射到图上强化学习的优势。作者明确指出,“实现可扩展性的关键在于采用在更广泛文献中已被证明成功的技术,包括动作空间分解、通过领域知识限制有效动作,以及使用图神经网络(GNNs)作为学习表示[32]”,这强调了问题的图结构和组合性质需要这种专门的方法。
相对优越性
除了简单的性能指标外,TAG-DQN 还提供了定性和结构上的优势,使其在传统上依赖于大量人工劳动和不太复杂的搜索算法的先前黄金标准方面具有压倒性的优势。最显著的优势是分析时间的急剧缩短:TAG-DQN 可以在数小时内确定数百个能级,而传统上需要数月到数年的人工努力。这代表了效率上的数量级提升。
在结构上,TAG-DQN 的优越性源于其能够:
1. 原生处理图结构数据: 通过使用图神经网络(GNNs)作为学习表示,TAG-DQN 直接处理原子能级(节点)和光谱线(边)的固有图结构。这是一种自然的匹配,不像那些需要展平或对这类关系数据进行大量预处理的方法,可能会丢失关键信息。
2. 学习顺序决策: 作为强化学习智能体,TAG-DQN 学习一个策略来做出最优决策序列(选择未知能级、匹配光谱线),以最大化累积奖励。这对于谱项分析至关重要,它是一个“顺序的、复杂的决策任务”。
3. 整合专家知识和不确定性: 奖励函数部分通过逆强化学习从历史人类决策中学习,使模型能够捕捉人类专家的细微偏好和启发式方法。此外,动作空间包含了理论和实验不确定性($\Delta E$、$\Delta I$),使模型能够在现实的物理约束下运行。
4. 实现长期一致性: 与蒙特卡洛树搜索(MCTS)等基线搜索算法相比,TAG-DQN 在确定正确标记的能级方面表现出优越的准确性,尤其是在 Nd II 等复杂情况下。虽然 MCTS 可能找到更高的即时奖励,但其在庞大的状态-动作空间中的浅层回溯可能导致“短视的动作”和不太一致的长期结果。TAG-DQN 学习一个考虑其选择的长期影响的策略的能力,从而使能级身份“在整个回合中更有可能与观测和理论保持一致”,这是一个关键的定性优势。
本文没有明确讨论内存复杂度(例如 $O(N^2)$ vs $O(N)$)或特定的高维噪声处理(除了奖励函数设计以优先考虑高信噪比(S/N)谱线并排除测量不佳的谱线)。然而,通过 GNN 和动作空间分解实现的可扩展性隐式地解决了大型、高维输入空间的挑战。
与约束的对齐
所选的 TAG-DQN 方法完美地符合原子精细结构测定的固有约束和要求,形成了问题与解决方案之间的强大“联姻”。
- 顺序决策: 该问题被描述为“顺序的、复杂的决策任务”。强化学习,顾名思义,旨在通过学习离散时间步上的最优策略来解决此类问题。
- 图结构数据: 原子能级和光谱线自然形成一个图,能级为节点,谱线为边。GNN,作为 TAG-DQN 的核心组成部分,专门用于处理和学习此类关系数据,保留问题的结构完整性。
- 巨大的搜索空间: 该任务涉及从“海量的观测能量差值”中确定能级。GNN 用于高效状态表示和 DQN 用于在大状态-动作空间中学习的组合提供了导航这个巨大组合景观的必要机制。
- 整合领域知识和人类专业知识: 谱项分析是“本质上是经验性的”,并且依赖于人类专业知识。该方法通过使用“部分基于历史人类决策通过逆强化学习学习”的奖励函数来解决这个问题,有效地将专家知识嵌入到 AI 的决策过程中。领域知识也用于限制有效动作并简化 MDP。
- 计算可行性与可扩展性: 主要的约束是所需的人工劳动“数月到数年”。TAG-DQN 可以在数小时内实现“多达 102 个暂定的精细结构能级确定”,直接解决了加速的需求。作者还明确提到“降低 MDP 复杂性是可行性和 RL 性能的关键”,详细说明了他们如何修剪问题空间(例如,移除低 S/N 边,限制光谱范围)以使解决方案可处理。
- 不确定性处理: 该问题涉及“不太精确的理论预测”和实验不确定性。动作空间和奖励函数被设计为考虑理论不确定性($\Delta E$、$\Delta I$)并优先考虑高信噪比的谱线,使解决方案对噪声数据具有鲁棒性。
备选方案的拒绝
本文为拒绝某些备选方案提供了清晰的理由,特别是在搜索算法和通用强化学习范式领域。
- 贪婪搜索: 作者明确指出“贪婪搜索在所有指标上持续表现不如 RL 智能体”。这是因为贪婪方法,顾名思义,只考虑即时奖励,而无法规划长期后果,这对于像谱项分析这样的顺序决策任务至关重要,因为早期选择会影响未来的可能性。
- 蒙特卡洛树搜索(MCTS): 虽然 MCTS 是一种更复杂的搜索算法,但本文指出“MCTS 实现了比 TAG-DQN 更高的 Rmax,但 TAG-DQN 达到了更高的 Ne 上限,尤其是在 Nd II 的情况下”。解释是“MCTS 的回溯较浅,偏爱短期奖励”,导致了更高的轨迹奖励但更低的正确标记能级的准确性。这表明对于这个问题,长期一致性和准确性(TAG-DQN 在这方面做得更好)比最大化即时奖励更重要。庞大的状态和动作空间使得深度 MCTS 回溯在计算上成本高昂且容易受到噪声影响。
- 策略梯度方法: 作者表示,“我们选择此类算法[DQN]是因为与策略梯度方法[40]相比,它具有更高的样本效率。”策略梯度方法通常需要更多的与环境的交互才能学习有效的策略,这在这种复杂且可能成本高昂的原子数据分析模拟或实际应用中将是一个显著的缺点。
- 其他深度学习架构(隐含拒绝): 虽然没有明确说明 GAN、扩散模型或标准的 CNN/Transformer 失败,但 GNN 和 RL 的选择隐含地拒绝了它们用于核心问题。该问题不是图像生成、序列翻译或网格状数据上的简单分类。原子能级和谱线的固有图结构,加上顺序决策的性质,使得 GRL 成为最合适且有效的范式。这些其他方法需要对问题进行重大、可能不自然的重新构建以适应它们的架构,很可能导致次优性能或增加复杂性。
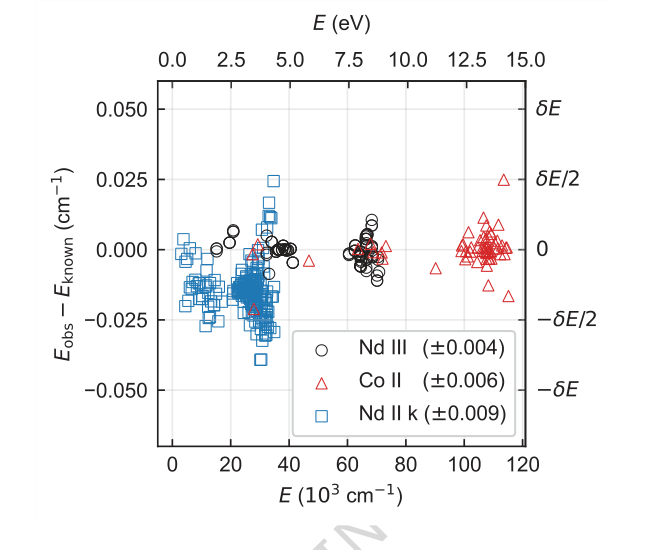 Figure 4. Difference between energy levels determined from a single seed and their known (ac- cepted) values for each species. Only levels contributing to Nc are shown. Energy differences for Nd III, Co II, and Nd II k are shown in circles, triangles, and squares, respectively. The root-mean-square energy differences are given in parentheses in the legend. Typical energy level uncertainty by FT spectroscopy is of order 0.001 cm−1. The offset and higher spread of Nd II k energies are expected and within uncertainties as their known values were derived by lower-precision grating spectroscopy [4]
Figure 4. Difference between energy levels determined from a single seed and their known (ac- cepted) values for each species. Only levels contributing to Nc are shown. Energy differences for Nd III, Co II, and Nd II k are shown in circles, triangles, and squares, respectively. The root-mean-square energy differences are given in parentheses in the legend. Typical energy level uncertainty by FT spectroscopy is of order 0.001 cm−1. The offset and higher spread of Nd II k energies are expected and within uncertainties as their known values were derived by lower-precision grating spectroscopy [4]
数学与逻辑机制
主方程
本文机制的核心围绕两个基本方程:智能体旨在最大化的马尔可夫决策过程(MDP)的目标函数,以及驱动底层神经网络学习的损失函数。此外,一个关键的能级确定计算构成了状态更新机制的重要组成部分。
强化学习智能体的首要目标是最大化有限视野 $H$ 内的预期累积折扣奖励:
$$ E[G_t] = E\left[\sum_{k=0}^{H} \gamma^k r_{t+k}\right] \quad (1) $$
该方程定义了智能体试图实现的目标:做出一个决策序列,以获得尽可能高的未来奖励总和,其中较早获得的奖励比稍晚获得的奖励更有价值。
深度 Q 网络(DQN)智能体的学习过程通过最小化损失函数来驱动,特别是平方 n 步时序差分(TD)误差:
$$ L = [TD[n]]^2 = \left[r^{[n]} + \gamma^n Q_{\bar{\theta}}(s_{t+n}, \text{argmax}_{a_{t+n}} Q_{\theta}(s_{t+n}, a_{t+n})) – Q_{\theta}(s_t, a_t)\right]^2 \quad (15) $$
该损失函数指导神经网络准确预测动作的“质量”,确保其估计与实际未来奖励保持一致。
最后,支撑状态更新的关键计算,特别是观测能级($E_{obs}$)的确定,是通过加权最小二乘最小化进行的:
$$ E_{obs} = \text{argmin}_{E_n} \sum_{m=0}^{M-1} w_m \left( \sum_{n=0}^{N-1} S_{mn}E_n - \sigma_m \right)^2 \quad (9) $$
这个方程是如何系统根据观测到的光谱线精炼已知能级能量的,使其成为处理和更新原子数据的“数学引擎”的核心组成部分。
逐项解剖
让我们逐一剖析这些方程,以理解它们的各个组成部分及其作用。
方程 (1):预期累积折扣奖励
- $E[G_t]$:这代表从时间步 $t$ 开始的预期累积折扣奖励。
- 数学定义:在许多可能轨迹上的 $G_t$ 的平均值。
- 物理/逻辑作用:这是强化学习智能体的最终目标函数。智能体的策略旨在选择最大化此数量的动作,从而有效地找到确定原子精细结构的最佳决策序列。
- $E[\cdot]$:这是期望算子。
- 数学定义:计算随机变量的平均值。
- 物理/逻辑作用:在强化学习中,智能体不知道确切的未来奖励或状态转换是确定性的。该算子考虑了环境中固有的不确定性,确保智能体针对平均结果进行优化。
- $G_t$:这是从时间 $t$ 开始的累积折扣奖励。
- 数学定义:所有未来奖励的总和,每个奖励都乘以折扣因子 $\gamma$ 的幂次,该幂次等于未来步数。
- 物理/逻辑作用:它量化了从时间 $t$ 开始的一系列特定动作和状态的总体“好度”。
- $\sum_{k=0}^{H} \gamma^k r_{t+k}$:这是折扣未来奖励的总和。
- 数学定义:一个有限和,其中每个奖励 $r_{t+k}$ 都乘以 $\gamma^k$。
- 物理/逻辑作用:它聚合了在未来时间步 $t+k$ 获得的奖励,应用折扣使即时奖励比遥远奖励更有价值。求和用于因为总奖励是单个奖励的累积。
- $\gamma$:这是折扣因子。
- 数学定义:一个介于 0 和 1 之间(含)的标量值,$\gamma \in [0, 1]$。
- 物理/逻辑作用:它平衡了即时奖励与未来奖励的重要性。$\gamma$ 接近 0 使智能体变得“短视”,专注于即时收益;而 $\gamma$ 接近 1 使其变得“远见”,考虑长期后果。作者选择加法求和是因为总值是各个奖励的累积。
- $k$:这是相对于 $t$ 的时间步索引。
- 数学定义:一个整数,表示从时间 $t$ 开始的未来步数。
- 物理/逻辑作用:它跟踪在时间 $t+k$ 获得的特定奖励 $r_{t+k}$ 的未来程度,这决定了 $\gamma$ 的幂次用于折扣。
- $r_{t+k}$:这是在时间 $t+k$ 收到的奖励。
- 数学定义:一个标量值,表示采取动作后从环境中获得的即时反馈。
- 物理/逻辑作用:在本文中,奖励被设计为反映确定能级的置信度、与理论和观测的一致性以及未来能级确定的能力(方程 6 和 7)。
方程 (15):TAG-DQN 的损失函数
- $L$:这是损失函数。
- 数学定义:量化预测 Q 值与目标 Q 值之间误差的标量值。
- 物理/逻辑作用:训练的目标是最小化此损失,从而使 Q 网络预测更准确。
- $[TD[n]]^2$:这是平方 n 步时序差分(TD)误差。
- 数学定义:n 步回报(未来奖励的估计)与当前 Q 值预测之间差值的平方。
- 物理/逻辑作用:平方误差确保正负误差都计入损失,并对较大的误差进行更严厉的惩罚,促进收敛。
- $r^{[n]}$:这是n 步回报。
- 数学定义:前 $n$ 个奖励的总和,经过折扣,加上在 $n$ 步后到达的状态的折扣 Q 值。
- 物理/逻辑作用:它通过结合短期内的实际奖励,然后从 Q 值估计进行引导(bootstrapping),提供比单步回报更稳定、偏差更小的真实值估计。
- $\gamma^n$:这是折扣因子的 $n$ 次幂。
- 数学定义:折扣因子 $\gamma$ 自身乘以 $n$ 次。
- 物理/逻辑作用:它将状态 $s_{t+n}$ 下的未来 Q 值估计折扣回时间 $t$,使其值与 $n$ 步内获得的奖励保持一致。
- $Q_{\bar{\theta}}(s_{t+n}, \text{argmax}_{a_{t+n}} Q_{\theta}(s_{t+n}, a_{t+n}))$:这是目标 Q 值。
- 数学定义:状态 $s_{t+n}$ 和最大化该状态下 Q 值的动作的 Q 值,由目标网络 $Q_{\bar{\theta}}$ 预测。
- 物理/逻辑作用:该项为在线网络提供了一个稳定的学习目标。通过使用单独的目标网络进行延迟更新($\bar{\theta}$),可以防止 Q 值估计追逐一个移动的目标,这可能导致训练不稳定。$\text{argmax}$ 部分确保目标反映了根据在线网络当前理解,从下一个状态获得最佳动作的价值。
- $Q_{\theta}(s_t, a_t)$:这是当前 Q 值预测。
- 数学定义:当前状态-动作对 $(s_t, a_t)$ 的 Q 值,由在线网络 $Q_{\theta}$ 预测。
- 物理/逻辑作用:这是网络当前预测的在状态 $s_t$ 中采取动作 $a_t$ 的值。损失函数旨在调整 $\theta$,使此预测与目标 Q 值匹配。
- $s_t$:这是时间 $t$ 的状态。
- 数学定义:时间 $t$ 时环境的表示,包括图节点和边特征(方程 2 和 3)。
- 物理/逻辑作用:它包含了关于当前谱项分析进展的所有相关信息,例如已知/未知能级、观测光谱线和理论计算。
- $a_t$:这是时间 $t$ 采取的动作。
- 数学定义:智能体做出的离散选择,要么选择一个未知能级($a^{(1)}$),要么匹配谱线以确定其能量($a^{(2)}$)。
- 物理/逻辑作用:它代表了智能体在谱项分析过程中的决策。
- $\theta$:这些是在线 Q 网络的参数。
- 数学定义:当前预测 Q 值的神经网络的权重和偏置。
- 物理/逻辑作用:这些是在训练过程中主动更新的参数,以改进智能体的策略。
- $\bar{\theta}$:这些是目标 Q 网络的参数。
- 数学定义:一个 Q 网络副本的权重和偏置,更新频率较低或平滑更新。
- 物理/逻辑作用:为目标 Q 值提供稳定的参考,这对于学习过程的稳定性至关重要。
- $\text{argmax}_{a_{t+n}} Q_{\theta}(s_{t+n}, a_{t+n})$:该算子在状态 $s_{t+n}$ 下找到最大化 Q 值的动作,根据在线网络。
- 数学定义:使用在线网络参数 $\theta$ 返回在状态 $s_{t+n}$ 下产生最高 Q 值的动作 $a_{t+n}$。
- 物理/逻辑作用:这是 Double DQN 的一个关键组成部分,其中在线网络选择用于目标值计算的动作,但目标网络评估其值。这有助于减轻 Q 学习中的高估偏差。
方程 (9):能级能量优化
- $E_{obs}$:这代表能级的观测能量。
- 数学定义:$N$ 个已知能级的能量值 $E_n$ 的向量。
- 物理/逻辑作用:这些是谱项分析旨在确定的经验确定的能级。
- $\text{argmin}_{E_n}$:这是最小化算子。
- 数学定义:找到最小化后续表达式的 $E_n$ 值。
- 物理/逻辑作用:它表示观测能级是通过找到最适合观测光谱线的能量集来确定的,从而最小化差异。
- $\sum_{m=0}^{M-1} w_m \left( \sum_{n=0}^{N-1} S_{mn}E_n - \sigma_m \right)^2$:这是加权平方残差和。
- 数学定义:对所有 $M$ 条已知谱线求和,其中每项是预测波数与观测波数之间的平方差,由 $w_m$ 加权。
- 物理/逻辑作用:这是最小二乘优化的目标函数。它量化了当前能级集与观测光谱线之间的总体不一致性。最小化此总和意味着找到最能解释观测光谱的能量集。求和用于因为总误差是来自单个谱线的误差的聚合。
- $M$:这是已知线的总数。
- 数学定义:已匹配到已知能级之间跃迁的光谱线数量的整数计数。
- 物理/逻辑作用:代表了约束能级的经验数据量。
- $N$:这是已知能级的总数。
- 数学定义:正在优化其值的能级数量的整数计数。
- 物理/逻辑作用:代表正在精炼其值的原子状态的数量。
- $w_m$:这是第 $m$ 条线的权重。
- 数学定义:$w_m = (\delta\sigma_m)^{-2}$,第 $m$ 条线的波数不确定度的倒数平方。
- 物理/逻辑作用:它为更精确测量的光谱线($\delta\sigma_m$ 较小)分配更高的重要性,为不确定度较高的谱线分配较低的重要性。这确保了可靠数据对确定能级的影响更大。倒数平方是加权最小二乘中的标准选择,其中权重与测量误差的方差成反比。
- $\left( \sum_{n=0}^{N-1} S_{mn}E_n - \sigma_m \right)^2$:这是第 $m$ 条线的平方差(残差)。
- 数学定义:由当前能级预测的波数与第 $m$ 条线的观测波数之间的差值的平方。
- 物理/逻辑作用:它衡量当前能级集在多大程度上解释了特定的观测光谱线。平方确保值为正,并对较大的偏差进行更严厉的惩罚。
- $S_{mn}$:这是定义能级与第 $m$ 条线之间关系的系数。
- 数学定义:一个矩阵元素,如果能级 $n$ 是跃迁 $m$ 的上能级,则为 1;如果能级 $n$ 是跃迁 $m$ 的下能级,则为 -1;否则为 0。
- 物理/逻辑作用:该系数编码了基本关系,即光谱线波数($\sigma_m$)是跃迁涉及的上能级($E_u$)和下能级($E_l$)之间的差值:$\sigma_m = E_u - E_l$。
- $E_n$:这是能级 $n$ 的能量。
- 数学定义:表示特定原子能级能量的标量值。
- 物理/逻辑作用:这些是优化过程旨在确定的未知参数。
- $\sigma_m$:这是第 $m$ 条线的观测波数。
- 数学定义:表示光谱线波数的测量标量值。
- 物理/逻辑作用:这是来自光谱线列表的经验输入数据,能级必须符合这些数据。
分步流程
将谱项分析想象成一个动态的装配线,其中一个代表原子能级确定当前状态的抽象数据点通过一系列操作。
-
初始状态输入:过程以初始图状态 $s_t$ 开始。此状态是一个丰富的数据结构,一个图 $G=(V, E)$,其中节点 $V$ 是原子能级(有些已知,有些未知),边 $E$ 是潜在的或观测到的光谱线(跃迁)。每个节点和边都带有特征集(例如,理论能量、观测波数、不确定度、表示“已知”或“已选”的二进制标志)。此外,还有一个包含所有观测跃迁的综合光谱线列表。
-
动作 $a^{(1)}$:能级选择:智能体首先执行 $a^{(1)}$ 类动作。它检查所有当前未知的、至少有两个潜在连接(边)到已知能级的能级。从这个池中,智能体选择一个特定的未知能级作为当前焦点。此选择基于智能体学习到的 Q 值,这些 Q 值估计选择该能级的长期奖励。一旦被选中,该节点的“已选”标志将被翻转,表示它是当前目标。
-
动作 $a^{(2)}$:谱线匹配与能量假设:接下来,智能体执行 $a^{(2)}$ 类动作。对于“已选”的未知能级,它考虑所有连接到已知能级的潜在边。对于每条这样的边,它会过滤整个光谱线列表(其中可能包含 $10^4$ 条谱线)以查找候选观测谱线。此过滤非常严格:
- 波数匹配:观测波数 $\sigma_{obs}$ 必须落在理论范围 $[\sigma_{calc} \pm \Delta E]$ 内,其中 $\sigma_{calc}$ 是跃迁的理论波数,$\Delta E$ 是能量不确定度。
- 强度匹配:观测强度 $I_{obs}$ 必须落在理论范围 $[I_{calc} \pm \Delta I]$ 内。
- 候选 $E_{obs}$ 生成:对于每条过滤后的谱线,通过将谱线的波数加或减已连接已知能级的能量来计算所选未知能级的候选观测能量 $E_{obs}$(取决于所选能级是上能级还是下能级)。
- 合并:由于多条谱线可能暗示未知能级的相同能量,因此将候选能量分组,并且只有在小容差 $\delta E$ 内重复出现的 $E_{obs}$ 值才被考虑。然后,智能体选择这些合并的 $E_{obs}$ 值之一(如果不存在合适的候选者,则选择“无操作”)。
-
状态转换与图更新:一旦通过 $a^{(2)}$ 为所选能级选择了 $E_{obs}$ 值,图状态 $s_t$ 将确定性地转换到新状态 $s_{t+1}$:
- “已选”的未知能级现在成为“已知”能级,其 $E_{obs}$ 特征将使用选定的值进行更新。
- 对应于匹配光谱线的边也成为“已知”边,其特征(例如,$\sigma_{obs}$、$I_{obs}$)将从谱线列表中更新。这些匹配的谱线随后在本回合的后续 $a^{(2)}$ 考虑中被排除。
- 全局重新优化:至关重要的是,在确定新能级后,所有当前已知能级(包括新确定的能级)的观测能量 $E_{obs}$ 将使用加权最小二乘最小化(方程 9)进行重新优化。这确保了整个已知能级系统的一致性。基态能量 $E_0$ 被固定为零作为参考。
-
奖励计算:根据新状态 $s_{t+1}$ 和采取的动作,计算奖励 $r_t$。该奖励是复合的,反映了确定能级的置信度、其与理论的一致性以及其未来能级确定的潜力。对于 $a^{(1)}$,它基于连接谱线的信噪比(方程 6)。对于 $a^{(2)}$,它包含一个学习到的偏好得分 $D$(方程 7),该得分源自人类专家的决策。
-
经验存储:元组 $(s_t, a_t, r_t, s_{t+1})$——代表旧状态、采取的动作、收到的奖励和新状态——被存储在回放缓冲区中。该缓冲区充当内存,累积过去的经验。
-
迭代:然后过程循环回步骤 2,智能体选择另一个未知能级或继续精炼当前能级,直到达到有限视野 $H$ 或无法采取更多有效动作。
整个序列使得抽象的数学感觉像一个移动的机械装配线,其中原始光谱数据被不断精炼并整合到一个不断增长的、自洽的原子能级模型中。
优化动力学
TAG-DQN 机制通过深度强化学习技术的复杂相互作用进行学习和收敛,主要由最小化时序差分(TD)误差驱动。其工作原理如下:
-
图表示学习:基础是图神经网络(GNN)。当呈现图状态 $s_t$(代表当前已知/未知能级和谱线的集合)时,GNN 处理其节点(能级)和边(谱线)及其相关特征(例如,$E_{calc}$、$\sigma_{obs}$、$I_{obs}$)。它使用多头图注意力层来学习丰富的、上下文相关的节点嵌入向量 $h_v$,用于每个能级 $v$。这些嵌入捕获了每个节点周围局部邻域的结构和特征信息。然后通过简单地平均这些节点嵌入(方程 11)获得全局图状态嵌入向量 $S_{agg}$。这个 $S_{agg}$ 有效地总结了整个图的当前状态。
-
Q 值估计(双网络 DQN):学习到的图嵌入随后被输入到多层感知机(MLPs)中以估计 Q 值。该架构采用了双网络 DQN 设计,该设计将状态值函数 $V(s)$ 和优势函数 $A(s, a)$ 的估计分离开来。
- 对于动作类型 $a^{(1)}$(选择未知能级),每个有效能级选择的 Q 值是通过将全局 $S_{agg}$(用于状态值)与所选能级的节点嵌入(用于优势)相结合来估计的,如方程(12)所示。
- 对于动作类型 $a^{(2)}$(匹配谱线以确定能量),Q 值的估计方式类似,但优势函数 $A(s,a)$ 是通过取状态-动作值与状态值之间的差值来计算的,如方程(13)所示。这种分离有助于网络独立于所采取的动作学习哪些状态是有价值的,从而提高效率。
-
策略与探索:智能体的策略是相对于估计的 Q 值进行贪婪的。在每一步,它选择具有最高预测 Q 值的动作($a^{(1)}$ 或 $a^{(2)}$)。对于探索,作者没有使用传统的 epsilon-greedy 方法,而是使用了噪声网络。这意味着噪声直接添加到 MLP 输出层的权重中,鼓励智能体自然地探索不同的动作,而无需显式的 $\epsilon$ 参数。噪声是学习到的并随时间自适应,允许在复杂环境中进行更有效的探索。
-
从经验中学习(回放缓冲区与 n 步回报):为了学习,智能体不仅仅使用其最近的经验。相反,它将过去的经验(状态、动作、奖励、下一个状态元组)存储在回放缓冲区中。在训练期间,从缓冲区中随机采样这些经验的批次。这打破了连续经验之间的相关性,稳定了学习过程。损失计算(方程 15)使用n 步回报($r^{[n]}$),这意味着它不仅考虑即时奖励 $r_t$ 和下一个状态 $s_{t+1}$ 的 Q 值,还向前看 $n$ 步。通过在从 Q 值估计进行引导(bootstrapping)之前纳入短期轨迹的实际奖励,这提供了对真实值更准确的估计。
-
目标网络以实现稳定性:Q 学习中的一个关键挑战是目标值(网络试图预测的值)依赖于正在更新的同一网络,这会导致不稳定。为了解决这个问题,TAG-DQN 使用了一个目标网络 $Q_{\bar{\theta}}$。这是在线 Q 网络 $Q_{\theta}$ 的一个单独副本,其参数 $\bar{\theta}$ 的更新速度远慢于 $\theta$。具体来说,$\bar{\theta}$ 在每一步通过将在线网络参数的一小部分混合到目标网络的参数中进行软更新(方程 14)。这为在线网络提供了稳定的学习目标,防止了振荡和发散。双 DQN 的使用进一步完善了这一点,它使用在线网络选择下一个状态的最佳动作,但使用目标网络评估其值,这有助于减轻高估偏差。
-
奖励函数学习(逆强化学习):一个独特的方面是,动作 $a^{(2)}$ 的奖励函数(偏好得分 $D$)不是手动编码的。相反,它通过一种逆强化学习的形式从历史人类专家决策中学习。一个简单的多层感知机(MLP)被训练来从候选谱线的特征预测 $D$(方程 8)。该 MLP 在专家生成的人类决策被标记为正例的 MDP 状态转换上进行训练。这使得系统能够隐式地捕捉人类专家关于特定谱线匹配“好坏”的细微判断,从而塑造损失景观,使其倾向于与专家直觉一致的动作。
-
优化算法:网络参数 $\theta$ 使用Adam 优化器进行优化,这是一个流行的随机梯度下降方法,以其效率和在深度学习任务中的良好性能而闻名。这种迭代优化过程调整 GNN 和 MLP 的权重和偏置以最小化损失函数,从而提高 Q 值预测的准确性,进而提高智能体的策略。
本质上,优化动力学涉及一个连续的循环:智能体在环境中行动,收集经验,存储它,然后从经验批次中学习,通过最小化精心构建的损失函数。这个学习过程通过目标网络、n 步回报和双网络架构等技术得到稳定,而探索则由噪声网络处理。从人类专业知识中获得的学习奖励函数,进一步引导智能体走向物理上有意义的解决方案,塑造损失景观以反映专家偏好和不确定性。这种迭代精炼使智能体能够收敛到一个能够高效且准确地确定原子精细结构的策略。
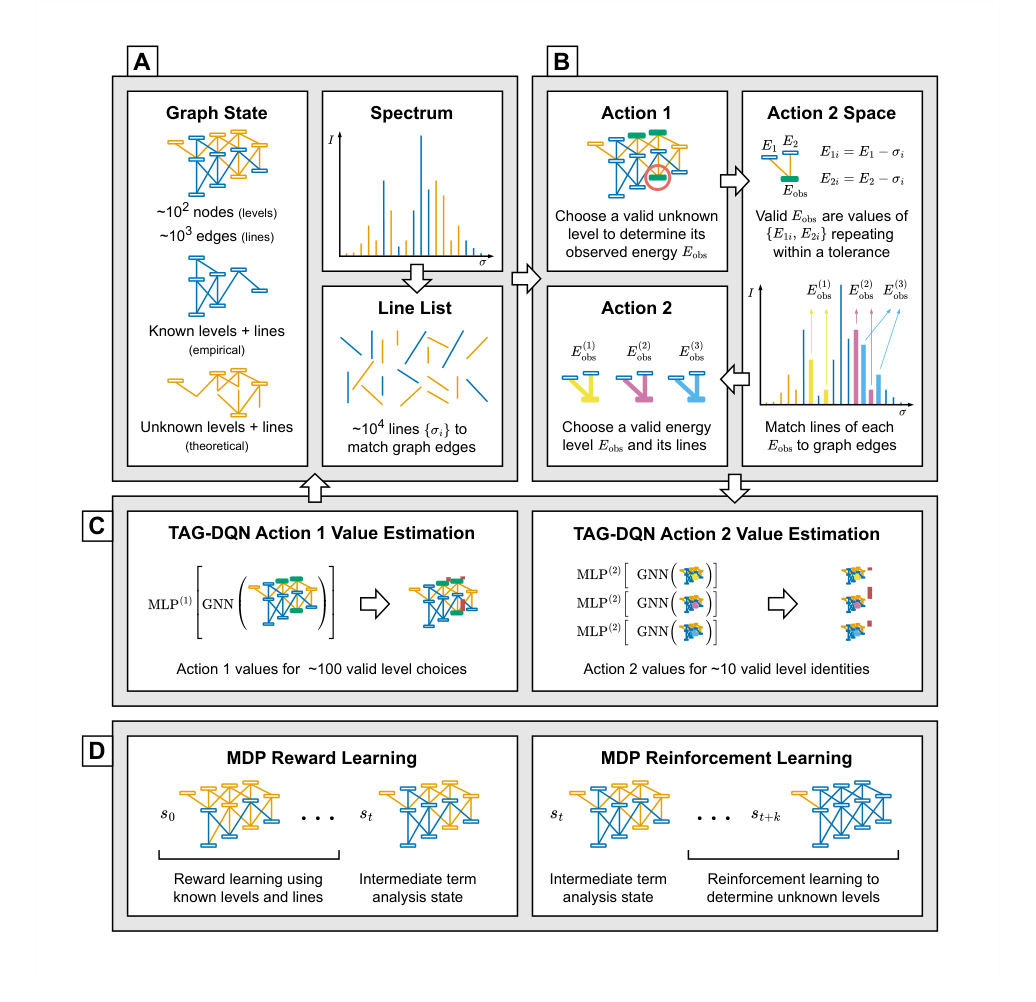 Figure 1. Illustration of the MDP environment and TAG-DQN. A The term analysis state is represented as a graph with node and edge features, alongside the spectral line list. B Actions alternate between two regimes; each pair of actions leads to the determination of the observed energy Eobs for one level by matching at least two lines from the line list to unknown edges in the graph. C TAG-DQN employs a GNN to embed graph representations, which are inputs for multilayer perceptrons (MLPs) estimating Q-values for each action (vertical bars); the highest Q-value action advances the MDP to the next state. D Given a term analysis state st, the MDP trajectory leading to st involving known levels is used for reward learning, while RL with the learned reward function guides the discovery of unknown levels in future states st+k
Figure 1. Illustration of the MDP environment and TAG-DQN. A The term analysis state is represented as a graph with node and edge features, alongside the spectral line list. B Actions alternate between two regimes; each pair of actions leads to the determination of the observed energy Eobs for one level by matching at least two lines from the line list to unknown edges in the graph. C TAG-DQN employs a GNN to embed graph representations, which are inputs for multilayer perceptrons (MLPs) estimating Q-values for each action (vertical bars); the highest Q-value action advances the MDP to the next state. D Given a term analysis state st, the MDP trajectory leading to st involving known levels is used for reward learning, while RL with the learned reward function guides the discovery of unknown levels in future states st+k
结果、局限性与结论
实验设计与基线
为了严格验证其数学声明,作者设计了一系列实验,将其谱项分析图深度 Q 网络(TAG-DQN)与两种基线模型进行了比较:贪婪搜索智能体和标准的蒙特卡洛树搜索(MCTS)智能体(采用了树的上限置信界(UCT)策略)。核心思想是证明 TAG-DQN 能够有效自动化和加速传统上需要数月到数年人类努力的复杂顺序决策任务。
实验设置涉及四个不同的马尔可夫决策过程(MDP)环境,每个环境都源自 Co II、Nd III 以及 Nd II 的两个变体(Nd II u 用于从头算计算,Nd II k 用于 Cowan 代码计算)的实际原子谱项分析。这些环境经过精心构建,以反映实际谱项分析的挑战,使用了现有的傅里叶变换(FT)光谱线列表和理论计算。例如,Co II 环境以已修订的已发布数据中的 141 个已知能级初始化,而 Nd III 使用 40 个能级。Nd II 环境以六个基态谱项能级、五个 6K 能级和 11 个跃迁开始,其理论计算方法不同。
为了确保公平和稳健的比较,TAG-DQN 和 MCTS 在 25 个不同的随机种子下进行了评估,并报告了平均性能和 95% 置信区间。贪婪搜索是确定性的,运行一次。性能使用三个关键指标进行衡量:
1. $R_{max}$:智能体在 MDP 回合长度 $H$ 内达到的最大累积奖励。
2. $N_c$:在 $R_{max}$ 回合中正确确定的能级数量,如果其观测能量($E_{obs}$)在 $\pm \delta E$ 内与先前发布的能量水平($E_{known}$)一致,则该能级被认为是正确的。
3. 准确率(Acc.):定义为 $N_c$ 与 $R_{max}$ 回合中确定的总能级数量之比。
MDP 环境经过精心简化,以增强可行性和 RL 性能。这包括修剪信噪比低于 2 的图边($S/N_{calc} < 2$)、排除已匹配的谱线列表条目、在能量优化期间固定初始已知能级,以及限制光谱范围。还对匹配谱线的动作空间($|A^{(2)}|$)施加了最大上限,以帮助高效探索和管理内存。每个物种的回合长度 $H$ 都不同(例如,Nd III 和 Co II 为 $H=128$,Nd II u 为 $H=64$,Nd II k 为 $H=512$),以平衡计算成本与智能体学习长期后果的能力。
此外,对 Nd III 环境进行了消融研究,以剖析各种深度 Q 网络(DQN)扩展(如双 Q 学习、优先经验回放、双网络、多步回报和用于探索的噪声网络)对 TAG-DQN 整体性能的贡献。这使得研究人员能够确定哪些架构组件对模型的成功运行最为关键。
证据证明的内容
实验结果提供了令人信服的证据,表明 TAG-DQN 能够显著加速原子精细结构测定,这项任务传统上需要数月到数年的努力。该系统能够在数小时内识别和确定数百个能级。
具体而言,TAG-DQN 的核心机制,即将谱项分析构建为通过图强化学习解决的马尔可夫决策过程,并采用部分从人类决策中学习的奖励函数,在实践中得到了有效验证。决定性证据在于与已发布值的极高一致率:Co II 为 95%,Nd II 和 Nd III 之间为 54% 至 87%。这种精度水平,在极短的时间内实现,是该方法有效性的有力指标。
与基线模型(表 2)相比,TAG-DQN 在所有指标上都持续优于贪婪搜索智能体。更重要的是,在五项案例研究中的三项中,它在 $N_c$(正确确定的能级数量)方面表现优于 MCTS 智能体。虽然 MCTS 有时实现了更高的最大累积奖励($R_{max}$),但 TAG-DQN 持续达到了更高的 $N_c$ 上限,尤其是在 Nd II 情况中。这表明 TAG-DQN 更擅长选择在整个回合中与观测和理论保持一致的能级身份,而 MCTS 的浅层回溯可能以牺牲整体准确性为代价偏爱短期奖励。对于 Nd II k,TAG-DQN 正确标记的能级数量(169 $\pm$ 10)显著多于 MCTS(130 $\pm$ 11),进一步证实了这一解释。
学习曲线(图 2A、B)清晰地说明了累积奖励与正确确定的能级数量($N_c$)之间的对齐,表明学习到的奖励函数有效地引导智能体进行准确的能级确定。玻尔兹曼图(图 2C)证实了 TAG-DQN 能够确定不同电子构型的能级,并且其基于玻尔兹曼能级分布的谱线强度过滤有效地排除了有问题的谱线。
消融研究(图 3)提供了对 TAG-DQN 架构的关键见解。它们显示大多数 DQN 扩展都对性能产生了积极影响,其中双网络架构和用于探索的噪声网络尤为关键。这可能是由于该问题固有的庞大动作空间。有趣的是,优先经验回放(PER)略微降低了性能,可能是因为缓冲区大小和训练步数没有针对 PER 在此特定环境中的优势进行最佳缩放。能级差值(图 4)进一步支持了该方法的精度,显示虽然一小部分确定的能级偏离了公认值,但这些偏差通常在实验不确定度 $\delta E$ 的范围内(例如,Nd III 为 $\pm 0.004$ cm$^{-1}$,Co II 为 $\pm 0.006$ cm$^{-1}$,Nd II k 为 $\pm 0.009$ cm$^{-1}$),对于大多数应用来说可以忽略不计。
局限性与未来方向
尽管 TAG-DQN 方法在自动化原子精细结构测定方面取得了重大进展,但认识到其当前局限性并考虑未来发展方向至关重要。
一个主要局限是,当前方法尽管速度惊人,但与人类专家相比,其精度仍然有所下降,并且依赖于原子结构计算。确定的能级,尤其是在 Nd II k 等情况下,被认为是暂定的,在最终发布前需要人工验证。此外,当前框架尚未解决谱项分析中最具挑战性的场景,例如确定单线能级、连接不相连的已知能级子图,或从完全未知状态开始分析。这些情况将显著增加 MDP 的复杂性,并需要进行大量重新设计。奖励函数目前主要基于 Co II 数据进行训练,可以受益于更广泛、更丰富的数据集,以提高其在不同原子物种和条件下的泛化能力。
展望未来,几个有希望的方向可以进一步发展这些发现:
- 丰富 MDP 状态和动作空间:当前的 MDP 可以扩展以包含更精细的信息。例如,将原始光谱和谱线轮廓分析直接整合到 MDP 中,将使智能体能够考虑同位素位移、超精细结构和不同光谱比较等额外因素。波函数的输入,如前导构型标签、电子概率密度以及特定奇偶性和 J 值内的局部能级密度,也可以为智能体在谱线轮廓和强度上的决策提供信息,可能导致更鲁棒和准确的能级确定。
- 开发更鲁棒的奖励函数:如前所述,当前奖励函数依赖于有限的数据集是一个限制。未来的工作应侧重于使用来自不同原子物种的大量谱线列表和 MDP 来训练更通用的奖励函数。这将增强智能体处理新情况的能力并提高整体性能。
- 人机协同集成:作者设想了一种协作方法,其中 AI 的输出作为中间步骤。一个回合的最终 MDP 状态可以成为人类专家检查光谱、修剪错误确定的能级、精炼半经验计算并重新训练奖励函数的新初始状态。这种迭代的人机协同可以利用两者的优势,AI 处理繁琐的初始识别,人类专家提供关键的验证和精炼。
- 处理复杂场景:未来的研究应侧重于重新设计 MDP 以处理当前被忽略的挑战性情况。这可能需要新颖的图表示或动作空间分解来管理增加的复杂性,从而可能解锁自动化谱项分析中最困难方面的能力。
- 扩展到其他实验方法:该方法本质上是灵活的,可以通过对环境参数(如 $\delta E$、$\Delta I$)和奖励函数的微小调整来适应其他实验方法,如光栅光谱学。这将拓宽图强化学习在各种光谱技术中的适用性。
- 计算效率和基础设施:虽然 TAG-DQN 可以在单种子运行时在普通硬件上运行,但涉及广泛超参数调优和多种子评估的全面实验需要大量的计算资源。未来的工作可以探索更有效的超参数优化技术或分布式计算框架,以减少广泛研究所需的计算成本和时间。
最终,这项工作证明了图强化学习和人工智能在科学发现中的潜力,特别是在数据和劳动密集型领域。拟议的进展可能为加速原子物理学研究的新时代铺平道路,缩小原子数据需求与当前确定效率之间的差距。
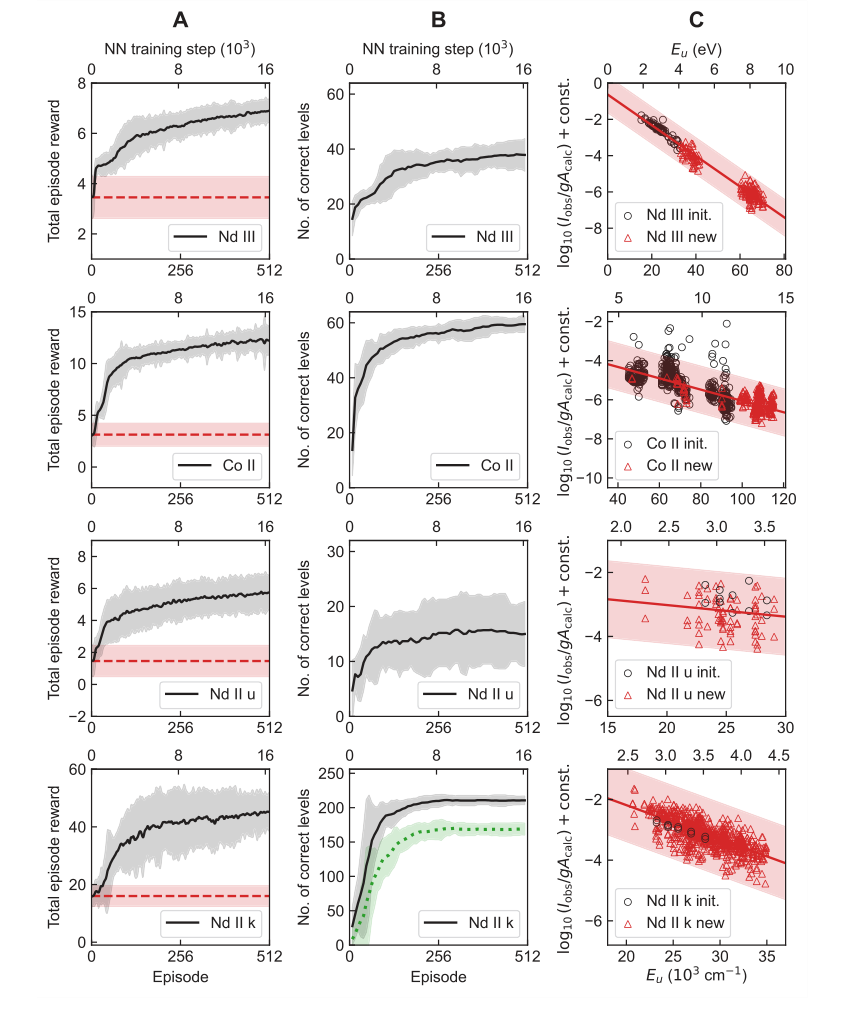 Figure 2. Learning results of TAG-DQN agent in the four case studies of Table 1. A Average learning curves, i.e., mean cumulative rewards obtained as a function of neural network (NN) training steps. The dashed horizontal lines show reward obtained during the pre-training episodes and correspond to rewards obtained by choosing actions in the MDP uniformly at random. The shaded regions show ±2 standard deviations across 25 random seeds. B Average Nc of the final state of the most recent maximum reward episode. The dotted curve for Nd II k shows the number of correct levels that also match human chosen level labels, and the y-axes limits are H
Figure 2. Learning results of TAG-DQN agent in the four case studies of Table 1. A Average learning curves, i.e., mean cumulative rewards obtained as a function of neural network (NN) training steps. The dashed horizontal lines show reward obtained during the pre-training episodes and correspond to rewards obtained by choosing actions in the MDP uniformly at random. The shaded regions show ±2 standard deviations across 25 random seeds. B Average Nc of the final state of the most recent maximum reward episode. The dotted curve for Nd II k shows the number of correct levels that also match human chosen level labels, and the y-axes limits are H
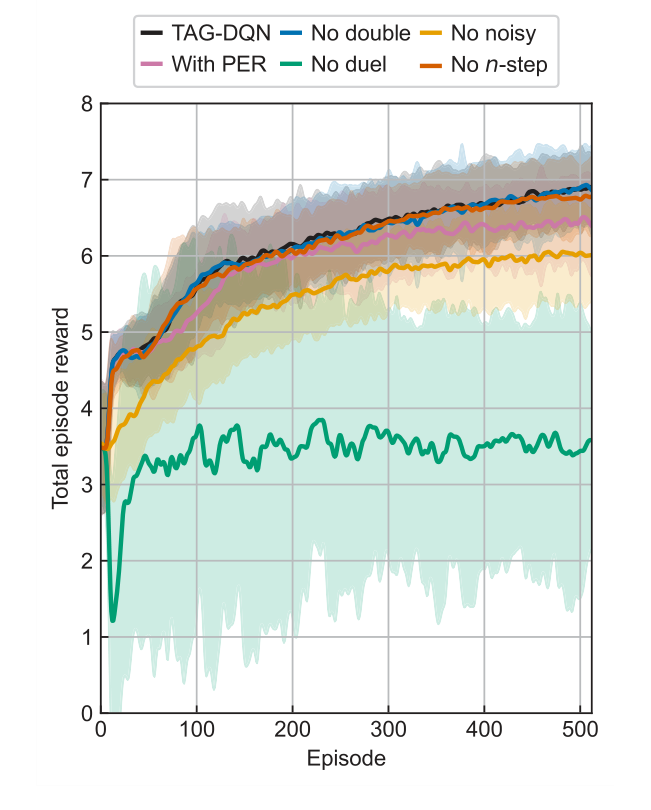 Figure 3. Learning curves of TAG-DQN (black) and its variants in the Nd III environment. Average total episode reward during training of TAG-DQN and its designs with or without particular deep Q-network extensions: without double Q-learning (blue), without noisy networks for exploration (yellow), with prioritised experience replay (PER, pink), without duelling deep Q-network (green), and without multi(n)-step return (orange). Shaded regions show ±2 standard deviations across 16 seeds. The duelling extension and noisy networks for exploration are key for TAG-DQN, while using PER reduced performance slightly
Figure 3. Learning curves of TAG-DQN (black) and its variants in the Nd III environment. Average total episode reward during training of TAG-DQN and its designs with or without particular deep Q-network extensions: without double Q-learning (blue), without noisy networks for exploration (yellow), with prioritised experience replay (PER, pink), without duelling deep Q-network (green), and without multi(n)-step return (orange). Shaded regions show ±2 standard deviations across 16 seeds. The duelling extension and noisy networks for exploration are key for TAG-DQN, while using PER reduced performance slightly
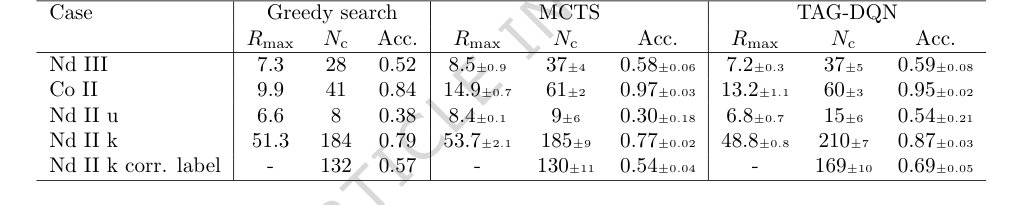 Table 2. Results and comparisons with benchmark agents. TAG-DQN matches MCTS performance as judged by downstream metrics in 2/5 cases and outperforms it in 3/5 cases, while Greedy search is worse overall
Table 2. Results and comparisons with benchmark agents. TAG-DQN matches MCTS performance as judged by downstream metrics in 2/5 cases and outperforms it in 3/5 cases, while Greedy search is worse overall
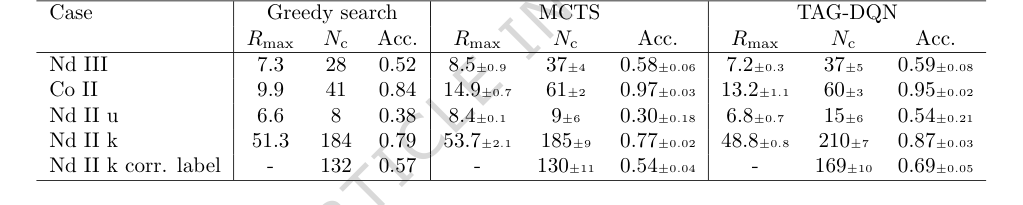 Table 1. Key term analysis MDP environment parameters
Table 1. Key term analysis MDP environment parameters
与其他领域的同构性
结构骨架
本文的核心提出了一种机制,该机制通过学习到的奖励函数指导,以最优地匹配观测数据与潜在连接,从而顺序地扩展已知实体图。