छद्म विशेषताओं का स्मरण कैसे होता है: यादृच्छिक और NTK विशेषताओं के लिए सटीक विश्लेषण
डीप लर्निंग मॉडल द्वारा छद्म विशेषताओं (spurious features) का स्मरण एक महत्वपूर्ण और सुप्रलेखित घटना है, फिर भी इसे सटीक रूप से मापने के लिए एक कठोर सैद्धांतिक ढांचा काफी हद तक अनुपस्थित रहा है। यह समस्या इसलिए...
पृष्ठभूमि और अकादमिक वंश
उत्पत्ति और अकादमिक वंश
डीप लर्निंग मॉडल द्वारा छद्म विशेषताओं (spurious features) का स्मरण एक महत्वपूर्ण और सुप्रलेखित घटना है, फिर भी इसे सटीक रूप से मापने के लिए एक कठोर सैद्धांतिक ढांचा काफी हद तक अनुपस्थित रहा है। यह समस्या इसलिए उत्पन्न होती है क्योंकि न्यूरल नेटवर्क अक्सर प्रशिक्षण डेटा में उन विशेषताओं से सीखते हैं जो स्वाभाविक रूप से इच्छित कार्य के लिए प्रासंगिक नहीं होती हैं। यह कुछ पैटर्न और सीखने के कार्य के बीच सकारात्मक छद्म सहसंबंधों (positive spurious correlations) के कारण हो सकता है (Geirhos et al., 2020; Xiao et al., 2021), या तब भी जब ये विशेषताएं दुर्लभ (Yang et al., 2022) या बस अप्रासंगिक (Hermann & Lampinen, 2020) हों। इस तरह का स्मरण मॉडल को छद्म संबंधों को सीखने की ओर ले जाता है, जो वितरण बदलावों (distribution shifts) के प्रति उनकी मजबूती (robustness) (Geirhos et al., 2019; Zhou et al., 2021), निष्पक्षता (fairness) (Zliobaite, 2015), और डेटा गोपनीयता (data privacy) (Leino & Fredrikson, 2020) को प्रभावित करता है।
ऐतिहासिक रूप से, अनुभवजन्य प्रयासों ने इस घटना को कम करने पर ध्यान केंद्रित किया है (Plumb et al., 2022; Chang et al., 2021)। हालांकि, स्मरण से बचना हमेशा संभव नहीं होता है, क्योंकि यह कभी-कभी अति-पैरामीट्रिक मॉडल (over-parameterized models) में सटीकता के लिए इष्टतम हो सकता है, जो अक्सर शून्य प्रशिक्षण त्रुटि (zero training error) तक प्रशिक्षित होने पर अपना सर्वश्रेष्ठ प्रदर्शन प्राप्त करते हैं (Nakkiran et al., 2020; Feldman, 2020)। पिछले सैद्धांतिक कार्यों ने सौम्य अति-फिटिंग (benign overfitting) (Belkin, 2021; Bartlett et al., 2020) और यादृच्छिक विशेषताओं (random features) और न्यूरल टेंगेंट कर्नेल (neural tangent kernels) (Mei & Montanari, 2022; Ghorbani et al., 2021; Montanari & Zhong, 2022) जैसे इंटरपोलेटिंग मॉडल के इन-डिस्ट्रीब्यूशन सामान्यीकरण (in-distribution generalization) जैसी संबंधित अवधारणाओं को चित्रित किया है।
इन पिछले दृष्टिकोणों की मौलिक सीमा, या "दर्द बिंदु" (pain point), यह है कि वे आम तौर पर शोर (noise) को लेबल में निवास करने के रूप में मॉडल करते हैं, न कि इनपुट डेटा में ही। परिणामस्वरूप, यह शक्तिशाली सैद्धांतिक मशीनरी सीधे इनपुट में अंतर्निहित छद्म विशेषताओं के स्मरण को कवर नहीं करती है। जबकि व्यावहारिक अनुसंधान ने छद्म विशेषताओं के प्रभाव की खोज की है और उन्हें मुख्य विशेषताओं से अलग करने का प्रयास किया है (Hermann & Lampinen, 2020; Singla & Feizi, 2022), सैद्धांतिक विश्लेषणों ने मुख्य रूप से इस बात पर ध्यान केंद्रित किया है कि सीखने को विशेषता जटिलता (feature complexity) (Qiu et al., 2023) या अति-पैरामीट्राइजेशन की डिग्री (degree of overparameterization) (Sagawa et al., 2020) से कैसे प्रभावित किया जाता है, अक्सर मॉडल के आर्किटेक्चर की भूमिका को पूरी तरह से कैप्चर किए बिना। यह पत्र इस अंतर को एक विश्लेषणात्मक रूप से सुलभ ढांचा प्रदान करके पाटने का लक्ष्य रखता है ताकि छद्म विशेषताओं के स्मरण को समझा और मापा जा सके, विशेष रूप से जब वे नमूने के वास्तविक लेबल से असंबद्ध (uncorrelated) हों।
डीप लर्निंग में छद्म विशेषताओं के स्मरण की समस्या की सबसे सटीक उत्पत्ति अति-पैरामीट्रिक व्यवस्थाओं में प्रशिक्षण डेटा के लिए डीप लर्निंग मॉडल के अनुभवजन्य अवलोकनों का पता लगाया जा सकता है। जबकि डीप लर्निंग ने उल्लेखनीय सफलता हासिल की, शोधकर्ताओं ने अवांछित व्यवहारों को नोटिस करना शुरू कर दिया जहां मॉडल ऐसे पैटर्न सीखते थे जो कार्य से सहसंबद्ध थे लेकिन कारण रूप से संबंधित नहीं थे, या यहां तक कि पूरी तरह से अप्रासंगिक पैटर्न भी।
इसके उद्भव के पीछे का "क्यों" बहुआयामी है:
1. अति-पैरामीट्राइजेशन (Over-parameterization): आधुनिक डीप लर्निंग मॉडल में अक्सर प्रशिक्षण डेटा बिंदुओं की तुलना में बहुत अधिक पैरामीटर होते हैं। यह क्षमता उन्हें शून्य प्रशिक्षण त्रुटि प्राप्त करने की अनुमति देती है, लेकिन उन्हें प्रशिक्षण डेटा को "स्मरण" करने में भी सक्षम बनाती है, जिसमें अप्रासंगिक विवरण शामिल हैं। Nakkiran et al. (2020) और Feldman (2020) ने इस बात पर प्रकाश डाला कि शून्य प्रशिक्षण त्रुटि प्राप्त करने के लिए अक्सर लंबे प्रशिक्षण समय की आवश्यकता होती है, जिससे स्मरण हो सकता है।
2. डेटा में छद्म सहसंबंध (Spurious Correlations in Data): वास्तविक दुनिया के डेटासेट में अक्सर ऐसी विशेषताएं होती हैं जो सांख्यिकीय रूप से वास्तविक लेबल से सहसंबद्ध होती हैं लेकिन कारण रूप से जुड़ी नहीं होती हैं। उदाहरण के लिए, यदि किसी डेटासेट में "बिल्लियों" की सभी छवियों में एक विशिष्ट "नीली पृष्ठभूमि" होती है, तो एक मॉडल "नीली पृष्ठभूमि" को "बिल्ली" से जोड़ना सीख सकता है (Geirhos et al., 2020; Xiao et al., 2021)। यह विशेष रूप से समस्याग्रस्त है जब ये छद्म सहसंबंध वास्तविक नमूना वितरण (sampling distribution) के भविष्यवक्ता नहीं होते हैं।
3. अप्रासंगिक या दुर्लभ पैटर्न (Irrelevant or Rare Patterns): समस्या तब भी उत्पन्न होती है जब छद्म पैटर्न दुर्लभ या कार्य के लिए बस अप्रासंगिक होते हैं (Yang et al., 2022; Hermann & Lampinen, 2020)। मॉडल अभी भी इन पैटर्न को उठा सकते हैं, जिससे स्मरण हो सकता है।
4. मजबूती, निष्पक्षता और गोपनीयता के लिए परिणाम (Consequences for Robustness, Fairness, and Privacy): इस स्मरण के व्यावहारिक निहितार्थ - जैसे खराब आउट-ऑफ-डिस्ट्रीब्यूशन मजबूती (poor out-of-distribution robustness) (Geirhos et al., 2019; Zhou et al., 2021), पक्षपातपूर्ण भविष्यवाणियां जो निष्पक्षता को प्रभावित करती हैं (biased predictions affecting fairness) (Zliobaite, 2015), और सूचना निष्कर्षण के माध्यम से संभावित डेटा गोपनीयता उल्लंघन (potential data privacy breaches through information extraction) (Leino & Fredrikson, 2020) - ने गहरी समझ की तत्काल आवश्यकता पर प्रकाश डाला।
ऐतिहासिक संदर्भ अति-फिटिंग के अनुभवजन्य अवलोकनों से एक मान्यता की ओर प्रगति दिखाता है कि यह अति-फिटिंग अक्सर यादृच्छिक शोर के बजाय "छद्म विशेषताओं" को शामिल करती है। अकादमिक क्षेत्र ने तब गुणात्मक विवरणों और अनुभवजन्य शमन रणनीतियों से परे एक कठोर सैद्धांतिक ढांचे की ओर बढ़ने की मांग की।
पिछले दृष्टिकोणों की मौलिक सीमा या "दर्द बिंदु" जिसने लेखकों को यह पत्र लिखने के लिए मजबूर किया, वह है इनपुट डेटा में अंतर्निहित छद्म विशेषताओं के स्मरण को मापने के लिए एक सटीक सैद्धांतिक ढांचे की कमी, बजाय इसके कि उन्हें लेबल में शोर के रूप में मॉडल किया जाए।
पिछले कार्यों के निकाय, शक्तिशाली होने के बावजूद, मुख्य रूप से इन पर केंद्रित थे:
* सौम्य अति-फिटिंग (Benign Overfitting): उन मॉडलों को चित्रित करना जो प्रशिक्षण डेटा को अति-फिट करते हैं लेकिन फिर भी इन-डिस्ट्रीब्यूशन परीक्षण डेटा पर अच्छी तरह से सामान्यीकृत होते हैं (Belkin, 2021; Bartlett et al., 2020)।
* इन-डिस्ट्रीब्यूशन सामान्यीकरण (In-distribution Generalization): यादृच्छिक विशेषताओं (RF) और न्यूरल टेंगेंट कर्नेल (NTK) जैसे इंटरपोलेटिंग मॉडल का विश्लेषण करना जहां शोर को आम तौर पर लेबल में माना जाता है, न कि इनपुट विशेषताओं में (Mei & Montanari, 2022; Ghorbani et al., 2021)।
महत्वपूर्ण अंतर यह था कि ये सैद्धांतिक उपकरण "छद्म विशेषताओं के स्मरण को कवर नहीं करते हैं, क्योंकि शोर को आम तौर पर लेबल में मॉडल किया जाता है, न कि इनपुट डेटा में।" इसके अलावा, जबकि व्यावहारिक कार्य ने छद्म विशेषताओं को समझने और अलग करने का प्रयास किया, सैद्धांतिक दृष्टिकोण काफी हद तक विशेषता जटिलता या अति-पैरामीट्राइजेशन पर केंद्रित रहे, "आर्किटेक्चर की भूमिका को कैप्चर किए बिना।" यह पत्र सीधे इस दर्द बिंदु को संबोधित करता है, छद्म विशेषता स्मरण को समझने और मापने के लिए एक विश्लेषणात्मक रूप से सुलभ ढांचा प्रदान करके, विशेष रूप से मॉडल के आर्किटेक्चर और सक्रियण फ़ंक्शन (activation function) पर विचार करते हुए।
सहज डोमेन शब्द (Intuitive Domain Terms)
जटिल अवधारणाओं को शून्य-आधारित पाठक के लिए सुलभ बनाने के लिए, आइए कुछ अत्यधिक विशिष्ट शब्दों को रोजमर्रा की उपमाओं का उपयोग करके तोड़ें:
- छद्म विशेषताएँ ($y$): कल्पना करें कि आप एक स्मार्ट रोबोट को तस्वीरों में "सेब" की पहचान करना सिखा रहे हैं। "मुख्य विशेषता" स्वयं सेब है (उसका आकार, रंग, तना)। एक "छद्म विशेषता" वह विशिष्ट रसोई काउंटर हो सकती है जिस पर सेब की आपकी सभी प्रशिक्षण तस्वीरें ली गई थीं। काउंटर तस्वीरों में मौजूद है, लेकिन इसका सेब होने के लिए जो कुछ भी आवश्यक है उससे कोई लेना-देना नहीं है।
- स्मरण (छद्म विशेषताओं का): यह तब होता है जब रोबोट, केवल सेब के बारे में सीखने के बजाय, रसोई काउंटर को भी "याद" कर लेता है। यदि आप बाद में उसे किसी भिन्न सतह पर एक सेब दिखाते हैं, तो वह हिचकिचा सकता है या उसे पहचानने में विफल भी हो सकता है क्योंकि उसने गलती से "रसोई काउंटर" को "सेब-पन" से जोड़ दिया है। रोबोट ने एक अप्रासंगिक विवरण "स्मरण" किया है।
- विशेषता संरेखण ($F_\phi(z^s, z)$): यह मापता है कि "अप्रासंगिक भाग" (केवल रसोई काउंटर, $z^s$) "पूरी तस्वीर" (रसोई काउंटर पर सेब, $z$) के समान कितना दिखता है रोबोट के आंतरिक प्रसंस्करण परिप्रेक्ष्य से। यदि रोबोट की दृश्य प्रणाली पृष्ठभूमि को बहुत अधिक संसाधित करती है, तो केवल रसोई काउंटर को देखना उस काउंटर पर सेब की स्मृति के साथ दृढ़ता से "संरेखित" हो सकता है।
- स्थिरता ($S_{z_1}$): यह संदर्भित करता है कि यदि आप एक विशिष्ट प्रशिक्षण तस्वीर (जैसे, रसोई काउंटर पर एक सेब) जोड़ते या हटाते हैं तो सेब की रोबोट की समग्र समझ कितनी बदल जाती है। एक "स्थिर" रोबोट का ज्ञान नाटकीय रूप से नहीं बदलेगा। यदि रोबोट का "रसोई काउंटर = सेब" विश्वास बहुत अस्थिर है, तो केवल एक तस्वीर को हटाने से यह पूरी तरह से संघ को छोड़ सकता है। यदि यह स्थिर है, तो यह अपने प्रशिक्षण उदाहरणों में मामूली बदलाव के साथ भी विश्वास बनाए रखेगा।
संकेतन तालिका (Notation Table)
| संकेतन (Notation) | विवरण (Description) |
|---|---|
| $z = [x, y]$ | एक इनपुट नमूना, एक मुख्य विशेषता $x$ और एक छद्म विशेषता $y$ में विघटित। |
| $x$ | एक नमूने की मुख्य विशेषता, वास्तविक लेबल पर निर्भर करती है। |
| $y$ | एक नमूने की छद्म विशेषता, वास्तविक लेबल से असंबद्ध। |
| $g(x)$ | वास्तविक लेबल, जो केवल मुख्य विशेषता $x$ पर निर्भर करता है। |
| $z^s = [-, y]$ | एक नमूने का "छद्म प्रतिरूप" (spurious counterpart), जहां मुख्य विशेषता $x$ को हटा दिया जाता है (जैसे, सभी शून्य से प्रतिस्थापित किया जाता है), केवल छद्म विशेषता $y$ को छोड़ दिया जाता है। |
| $f(z, \theta^*)$ | इष्टतम मापदंडों $\theta^*$ के साथ इनपुट $z$ के लिए मॉडल का भविष्यवाणी फ़ंक्शन। |
| $\phi(z)$ | इनपुट $z$ का विशेषता मानचित्र (feature map) (या विशेषता वेक्टर), कच्चे डेटा को उच्च-आयामी प्रतिनिधित्व में परिवर्तित करता है। |
| $\theta^*$ | पूर्ण प्रशिक्षण डेटासेट से सीखे गए मॉडल के इष्टतम पैरामीटर। |
| $\theta^*_{-1}$ | प्रशिक्षण डेटासेट को छोड़कर नमूना $z_1$ से सीखे गए मॉडल के इष्टतम पैरामीटर। |
| $S_{z_1}$ | प्रशिक्षण नमूना $z_1$ के संबंध में मॉडल की स्थिरता, जब $z_1$ को हटा दिया जाता है तो आउटपुट में परिवर्तन को मापता है। |
| $F_\phi(z, z_1)$ | $\phi$ द्वारा प्रेरित विशेषता मैट्रिक्स के स्पैन में नमूना $z$ और $z_1$ के बीच विशेषता संरेखण। |
| $P_{\Phi_{-1}}$ | विशेषता मैट्रिक्स $\Phi_{-1}$ की पंक्तियों के स्पैन पर प्रोजेक्टर (सभी प्रशिक्षण नमूने $z_1$ को छोड़कर)। |
| $R_{Z_{-1}}$ | डेटासेट $Z_{-1}$ ( $z_1$ को छोड़कर) पर प्रशिक्षित मॉडल की सामान्यीकरण त्रुटि। |
| $\gamma_\phi$ | विशेषता संरेखण से संबंधित एक आनुपातिकता स्थिरांक, विशेषता मानचित्र $\phi$ और सक्रियण फ़ंक्शन पर निर्भर करता है। |
| $\alpha = d_y/d$ | छद्म विशेषता के लिए जिम्मेदार इनपुट आयाम का अंश। |
| $h_i$ | $i$-वीं हर्माइट बहुपद (Hermite polynomial), सक्रियण कार्यों को चित्रित करने के लिए उपयोग किया जाता है। |
| $N$ | प्रशिक्षण नमूनों की संख्या। |
| $k$ | न्यूरॉन्स की संख्या (RF के लिए) या चौड़ाई (NTK के लिए)। |
| $d$ | कुल इनपुट आयाम। |
| $d_x$ | मुख्य विशेषता $x$ का आयाम। |
| $d_y$ | छद्म विशेषता $y$ का आयाम। |
| RF | यादृच्छिक विशेषता मॉडल (Random Features model)। |
| NTK | न्यूरल टेंगेंट कर्नेल मॉडल (Neural Tangent Kernel model)। |
समस्या परिभाषा और बाधाएँ
मुख्य समस्या सूत्रीकरण और दुविधा (Core Problem Formulation & The Dilemma)
डीप लर्निंग मॉडल, विशेष रूप से अति-पैरामीट्रिक वाले, अपने प्रशिक्षण डेटा में मौजूद "छद्म विशेषताओं" को याद करने के लिए जाने जाते हैं। ये विशेषताएं पैटर्न या विशेषताएँ हैं जो नमूने के वास्तविक लेबल से असंबद्ध हैं, लेकिन प्रशिक्षण सेट में इसके साथ सह-घटित हो सकती हैं। उदाहरण के लिए, यदि किसी मॉडल को बिल्लियों की पहचान करने के लिए प्रशिक्षित किया जाता है, और बिल्लियों की सभी प्रशिक्षण छवियों में एक विशिष्ट पृष्ठभूमि (छद्म विशेषता) होती है, तो मॉडल बिल्ली के बजाय पृष्ठभूमि को "बिल्ली" लेबल से जोड़ना सीख सकता है।
इस पत्र द्वारा संबोधित मुख्य समस्या इन छद्म विशेषताओं को कैसे सटीक रूप से मापा और समझा जाए, इसके लिए एक कठोर सैद्धांतिक ढांचे की कमी है। पिछले सैद्धांतिक कार्यों ने काफी हद तक "सौम्य अति-फिटिंग" पर ध्यान केंद्रित किया है, जहां लेबल में शोर को मॉडल किया जाता है, या विशेषताओं की जटिलता और अति-पैरामीट्राइजेशन पर, विशेष रूप से इनपुट डेटा में अंतर्निहित छद्म विशेषताओं या मॉडल आर्किटेक्चर की भूमिका को संबोधित किए बिना।
इनपुट/वर्तमान स्थिति (Input/Current State): हम डीप लर्निंग मॉडल से शुरू करते हैं जो ऐसे डेटासेट पर प्रशिक्षित होते हैं जहां प्रत्येक नमूना $z$ एक मुख्य विशेषता $x$ और एक छद्म विशेषता $y$ से बना होता है, औपचारिक रूप से $z = [x, y]$। एक नमूना $z_i$ के लिए वास्तविक लेबल $g$ $g_i = g(x_i)$ है, जिसका अर्थ है कि यह केवल मुख्य विशेषता $x_i$ पर निर्भर करता है और छद्म विशेषता $y_i$ से स्वतंत्र है। ये मॉडल आम तौर पर अति-पैरामीट्रिक होते हैं और तब तक प्रशिक्षित होते हैं जब तक वे शून्य प्रशिक्षण त्रुटि प्राप्त नहीं कर लेते, जिसका अर्थ है कि वे प्रशिक्षण डेटा को पूरी तरह से फिट करते हैं। औपचारिक रूप से, हम नमूना $z$ को दो अलग-अलग भागों से बना मॉडल करते हैं, अर्थात, $z = [x, y]$, जहां $x$ मुख्य विशेषता है और $y$ छद्म है, चित्र 1 देखें। छद्म विशेषताओं का स्मरण मॉडल के आउटपुट पर छद्म नमूना $z^s = [-, y]$ पर पूछे जाने पर वास्तविक लेबल $g_i$ और मॉडल के आउटपुट के बीच सहसंबंध द्वारा कैप्चर किया जाता है, जहां "-" मुख्य विशेषता $x$ को हटाने (जैसे, इसे सभी शून्य से प्रतिस्थापित करना) के अनुरूप है।
आउटपुट/लक्ष्य स्थिति (Output/Goal State): वांछित परिणाम एक विश्लेषणात्मक रूप से सुलभ ढांचा है जो छद्म विशेषताओं के स्मरण को सटीक रूप से चित्रित कर सकता है। इसमें शामिल हैं:
1. नमूने के "छद्म प्रतिरूप" ($z_i^s = [x, y_i]$, जहां $x$ को एक स्वतंत्र विशेषता, जैसे, सभी शून्य से प्रतिस्थापित किया जाता है) के साथ मॉडल के आउटपुट के बीच सहप्रसरण (covariance) जैसे मीट्रिक का उपयोग करके स्मरण की सीमा को मापना।
2. इस स्मरण को दो प्रमुख घटकों में विघटित करना: व्यक्तिगत प्रशिक्षण नमूनों के संबंध में मॉडल की स्थिरता और "विशेषता संरेखण" नामक एक नवीन अवधारणा।
3. यह उजागर करना कि मॉडल विकल्प (जैसे यादृच्छिक विशेषताएँ या न्यूरल टेंगेंट कर्नेल आर्किटेक्चर) और सक्रियण फ़ंक्शन इस विशेषता संरेखण और, परिणामस्वरूप, छद्म विशेषताओं के स्मरण को कैसे प्रभावित करते हैं।
4. अंततः, लक्ष्य ऐसे अंतर्दृष्टि प्रदान करना है जो मशीन लर्निंग मॉडल के डिजाइन को सक्षम करते हैं जो छद्म सहसंबंधों को याद करने की संभावना कम रखते हैं, जिससे वितरण बदलावों के प्रति मजबूती, निष्पक्षता और डेटा गोपनीयता में सुधार होता है।
दुविधा (The Dilemma): दर्दनाक व्यापार-बंद जिसने पिछले शोधकर्ताओं को फंसाया है, और जिसे यह पत्र नेविगेट करने का प्रयास करता है, यह है कि छद्म विशेषताओं के स्मरण से बचना अक्सर उच्च सटीकता प्राप्त करने के साथ विरोध में होता है। अति-पैरामीट्रिक डीप लर्निंग मॉडल, जो आज प्रचलित हैं, अक्सर अपना सर्वश्रेष्ठ प्रदर्शन तब प्राप्त करते हैं जब वे शून्य प्रशिक्षण त्रुटि तक पहुंचने के लिए लंबे समय तक प्रशिक्षित होते हैं। प्रशिक्षण डेटा को पूरी तरह से फिट करने की यह प्रक्रिया अक्सर छद्म सहसंबंधों को याद करने को शामिल करती है, क्योंकि यह मॉडल के लिए प्रशिक्षण हानि को कम करने का एक "आसान" तरीका है। इसलिए, एक पहलू में सुधार (छद्म स्मरण को कम करना) आम तौर पर दूसरे (समग्र प्रशिक्षण सटीकता या मुख्य विशेषताओं पर सामान्यीकरण) को खराब करने का जोखिम उठाता है, जिससे एक कठिन संतुलन कार्य बनता है।
बाधाएँ और विफलता मोड (Constraints & Failure Modes)
डीप लर्निंग में छद्म विशेषता स्मरण को सैद्धांतिक रूप से मापने की समस्या कई कठोर, यथार्थवादी बाधाओं के कारण स्वाभाविक रूप से चुनौतीपूर्ण है:
- कम्प्यूटेशनल और सैद्धांतिक सुगमता (Computational and Theoretical Tractability): पूर्ण डीप न्यूरल नेटवर्क कुख्यात रूप से जटिल होते हैं, जिससे उनका सैद्धांतिक विश्लेषण अत्यंत कठिन हो जाता है। यह पत्र दो सरलीकृत लेकिन शक्तिशाली सैद्धांतिक मॉडल पर ध्यान केंद्रित करके इसे संबोधित करता है: यादृच्छिक विशेषताएँ (RF) और न्यूरल टेंगेंट कर्नेल (NTK) प्रतिगमन। इन मॉडलों को इसलिए चुना जाता है क्योंकि वे "विश्लेषणात्मक रूप से सुलभ" और "सैद्धांतिक साहित्य में व्यापक रूप से विश्लेषणित" हैं, जो सटीक गणितीय लक्षण वर्णन की अनुमति देते हैं। इसका तात्पर्य है कि मनमानी, जटिल डीप लर्निंग आर्किटेक्चर के लिए सटीक विश्लेषणात्मक परिणामों का विस्तार एक महत्वपूर्ण बाधा बनी हुई है।
- छद्म विशेषताओं की विशिष्ट परिभाषा (Specific Definition of Spurious Features): विश्लेषण सख्ती से उन छद्म विशेषताओं तक सीमित है जो वास्तविक सीखने के कार्य से असंबद्ध हैं। यदि छद्म विशेषताओं में सहसंबंध होता, तो समस्या शुद्ध "स्मरण" से "शॉर्टकट लर्निंग" या "छद्म सहसंबंध शोषण" में बदल जाती, जिसके लिए एक अलग सैद्धांतिक उपचार की आवश्यकता होती है। यह वर्तमान ढांचे के लिए एक महत्वपूर्ण सीमा शर्त है।
- डेटा वितरण धारणाएँ (Data Distribution Assumptions): सैद्धांतिक परिणाम डेटा वितरण के बारे में विशिष्ट मान्यताओं पर निर्भर करते हैं। उदाहरण के लिए, इनपुट नमूने $z_i = [x_i, y_i]$ एक उत्पाद वितरण $P_z = P_x \times P_y$ से स्वतंत्र और समान रूप से वितरित (i.i.d.) माने जाते हैं, जिसका अर्थ है कि मुख्य विशेषताएं $x_i$ और छद्म विशेषताएं $y_i$ स्वतंत्र हैं। इसके अलावा, शून्य माध्य और नियंत्रित $L_2$ मानदंड ($||x||_2 = \sqrt{d_x}$, $||y||_2 = \sqrt{d_y}$) जैसी विशिष्ट गुणों को $x$ और $y$ के लिए माना जाता है। दोनों $P_x$ और $P_y$ को लिप्सचिट्ज़ एकाग्रता (Lipschitz concentration) को संतुष्ट करना चाहिए। ये धारणाएँ विश्लेषण को सरल बनाती हैं लेकिन सभी वास्तविक दुनिया के डेटासेट के लिए सार्वभौमिक रूप से मान्य नहीं हो सकती हैं।
- अति-पैरामीट्राइजेशन और उच्च-आयामीता धारणाएँ (Over-parameterization and High-Dimensionality Assumptions): ढांचा अति-पैरामीट्राइजेशन और उच्च-आयामीता के विशिष्ट व्यवस्थाओं के भीतर संचालित होता है। RF मॉडल के लिए, $N \log^3 N = o(k)$, $\sqrt{d} \log d = o(k)$, और $k \log^4 k = o(d^2)$ जैसी स्थितियाँ आवश्यक हैं, जो डेटा बिंदुओं $N$ और इनपुट आयाम $d$ की तुलना में न्यूरॉन्स $k$ की एक बड़ी संख्या का संकेत देती हैं। NTK मॉडल के लिए, स्थितियाँ $N \log^3 N = o(kd)$, $N > d$, और $k = O(d)$ हैं। ये स्थितियाँ कर्नेल व्युत्क्रमणीयता (kernel invertibility) और डेटा को इंटरपोलेट करने की मॉडल की क्षमता सुनिश्चित करने के लिए आवश्यक हैं, लेकिन वे एक विशिष्ट परिचालन व्यवस्था को परिभाषित करती हैं।
- सक्रियण फ़ंक्शन गुण (Activation Function Properties): सक्रियण फ़ंक्शन $\phi$ (या NTK के लिए इसके व्युत्पन्न $\phi'$) को गैर-रैखिक और L-लिप्सचिट्ज़ माना जाता है। ये गुण गणितीय व्युत्पत्तियों के लिए महत्वपूर्ण हैं, विशेष रूप से हर्माइट गुणांक (Hermite coefficients) और एकाग्रता असमानताओं (concentration inequalities) से जुड़े।
- कर्नेल व्युत्क्रमणीयता (Kernel Invertibility): सामान्यीकृत रैखिक प्रतिगमन मॉडल के लिए एक मौलिक बाधा यह है कि प्रेरित कर्नेल $K$ प्रशिक्षण सेट पर व्युत्क्रमणीय होना चाहिए। यह सुनिश्चित करता है कि मॉडल किसी भी लेबल सेट $G$ को पूरी तरह से फिट कर सकता है और इष्टतम पैरामीटर $\theta^*$ के समाधान में उपयोग किया जाने वाला मूर-पेनरोज़ व्युत्क्रम (Moore-Penrose inverse) अच्छी तरह से परिभाषित है।
- वास्तविक दुनिया के परिदृश्यों के लिए सामान्यीकरण (Generalization to Real-World Scenarios): जबकि पत्र मानक डेटासेट (MNIST, CIFAR-10) और विभिन्न न्यूरल नेटवर्क आर्किटेक्चर (पूरी तरह से जुड़े, संवादात्मक, ResNet) पर संख्यात्मक प्रयोग प्रदान करता है ताकि यह दिखाया जा सके कि सैद्धांतिक भविष्यवाणियां स्थानांतरित होती हैं, विश्लेषणात्मक प्रमाण मुख्य रूप से सरलीकृत मॉडल और सिंथेटिक डेटा के लिए हैं। जटिल, वास्तविक दुनिया के डीप लर्निंग सिस्टम के लिए पूर्ण सैद्धांतिक कठोरता के साथ इस अंतर को पाटना एक खुला चुनौती बनी हुई है। वर्तमान विश्लेषण एक महत्वपूर्ण कदम है लेकिन व्यावहारिक डीप लर्निंग सेटअपों की विशाल विविधता को पूरी तरह से शामिल नहीं करता है।
यह दृष्टिकोण क्यों (Why This Approach)
चुनाव की अनिवार्यता (The Inevitability of the Choice)
यादृच्छिक विशेषताएँ (RF) और न्यूरल टेंगेंट कर्नेल (NTK) प्रतिगमन मॉडल का चयन मनमाना नहीं था, बल्कि एक रणनीतिक आवश्यकता थी जो इस पत्र द्वारा पाटे जाने वाले विशिष्ट सैद्धांतिक अंतर से प्रेरित थी। मुख्य समस्या उन छद्म विशेषताओं के स्मरण को समझना और मापना है जो वास्तविक सीखने के कार्य से असंबद्ध हैं, जहां ये विशेषताएं लेबल में शोर के बजाय इनपुट डेटा में ही प्रकट होती हैं।
मौजूदा सैद्धांतिक ढांचे, यहां तक कि वे भी जो सौम्य अति-फिटिंग या इन-डिस्ट्रीब्यूशन सामान्यीकरण जैसी घटनाओं के लिए RF और NTK जैसे शक्तिशाली उपकरणों का लाभ उठाते हैं, मुख्य रूप से लेबल में शोर को मॉडल करते हैं। इस मौलिक अंतर का मतलब था कि जबकि ये मॉडल (RF और NTK) विश्लेषणात्मक सुगमता के लिए सैद्धांतिक रूप से आकर्षक थे, उनकी स्थापित सैद्धांतिक मशीनरी ने सीधे इनपुट-स्तरीय छद्म विशेषता स्मरण समस्या को संबोधित नहीं किया। लेखकों ने महसूस किया कि पारंपरिक "SOTA" विधियों, जो अक्सर अनुभवजन्य प्रकृति की होती हैं (जैसे, मानक CNN, डिफ्यूजन मॉडल, या ट्रांसफार्मर), व्यावहारिक कार्यों के लिए शक्तिशाली होने के बावजूद, इस विशिष्ट स्मरण घटना के सटीक, मात्रात्मक सैद्धांतिक लक्षण वर्णन के लिए आवश्यक विश्लेषणात्मक पारदर्शिता की कमी थी। इसलिए, RF और NTK के सैद्धांतिक विश्लेषण का विस्तार, जो सीखने के सिद्धांत से संबंधित क्षेत्रों में अपनी विश्लेषणात्मक सुगमता के लिए जाने जाते हैं, आवश्यक कठोर ढांचा विकसित करने का एकमात्र व्यवहार्य मार्ग बन गया।
तुलनात्मक श्रेष्ठता (Comparative Superiority)
यह विधि न केवल प्रदर्शन मेट्रिक्स के माध्यम से गुणात्मक श्रेष्ठता प्रदान करती है, बल्कि सैद्धांतिक समझ में एक अभूतपूर्व संरचनात्मक लाभ प्रदान करके भी प्रदान करती है। पत्र एक नवीन अवधारणा का परिचय देता है: "विशेषता संरेखण" ($F_\phi(z, z_1)$), जो एक प्रशिक्षण नमूने और उसके छद्म प्रतिरूप के बीच विशेषता स्थान में समानता को मापता है। यह, मॉडल स्थिरता ($S_{z_1}$) की शास्त्रीय धारणा के साथ मिलकर, छद्म विशेषताओं को सटीक रूप से चित्रित करने के लिए एक दो-तरफा दृष्टिकोण बनाता है।
संरचनात्मक लाभ RF और NTK मॉडल की विश्लेषणात्मक सुगमता में निहित है, इस ढांचे के भीतर। वे स्मरण को सामान्यीकरण त्रुटि से जोड़ने वाले आनुपातिकता स्थिरांक ($\gamma_\phi$) के लिए बंद-रूप अभिव्यक्तियों (closed-form expressions) की अनुमति देते हैं। गणितीय व्याख्यात्मकता का यह स्तर पिछले अनुभवजन्य स्वर्ण मानकों की तुलना में अत्यधिक श्रेष्ठ है, जो अक्सर अंतर्निहित स्मरण तंत्र में गहरी अंतर्दृष्टि के बिना प्रदर्शन लाभ प्रदान करते हैं। जबकि विधि कम्प्यूटेशनल अर्थ में $O(N^2)$ से $O(N)$ तक मेमोरी जटिलता को कम नहीं करती है या स्पष्ट रूप से उच्च-आयामी शोर को बेहतर ढंग से संभालती नहीं है, यह इस प्रक्रिया में छद्म विशेषताओं (इनपुट शोर के रूप में मॉडल) को कैसे याद किया जाता है, इसका एक मात्रात्मक माप प्रदान करता है, जो मॉडल आर्किटेक्चर और उसके सक्रियण फ़ंक्शन की महत्वपूर्ण भूमिका को उजागर करता है।
बाधाओं के साथ संरेखण (Alignment with Constraints)
चुना गया दृष्टिकोण यादृच्छिक विशेषताओं और न्यूरल टेंगेंट कर्नेल के अद्वितीय गुणों का लाभ उठाकर समस्या की कठोर आवश्यकताओं के साथ पूरी तरह से संरेखित होता है। प्राथमिक बाधा एक विश्लेषणात्मक रूप से सुलभ ढांचा विकसित करना था ताकि छद्म विशेषताओं के स्मरण को मापा जा सके जो वास्तविक लेबल से असंबद्ध हैं और इनपुट डेटा में अंतर्निहित हैं।
सामान्यीकृत रैखिक प्रतिगमन सेटिंग, RF और NTK मॉडल के साथ संयुक्त, ठीक यही विश्लेषणात्मक सुगमता प्रदान करती है। एक नमूना $z$ को मुख्य विशेषता $x$ और छद्म विशेषता $y$ ($z = [x, y]$) में औपचारिक विघटन, जहां $y$ वास्तविक लेबल $g(x)$ से स्वतंत्र है, सीधे समस्या परिभाषा को दर्शाता है। स्थिरता और नवीन विशेषता संरेखण शब्द के माध्यम से स्मरण को सटीक रूप से चित्रित करने की ढांचे की क्षमता, घटना के प्रत्यक्ष मापन की अनुमति देती है। इसके अलावा, की गई धारणाएँ (जैसे, डेटा वितरण, अति-पैरामीट्राइजेशन, सक्रियण फ़ंक्शन गुण) सावधानीपूर्वक चुनी जाती हैं ताकि यह सुनिश्चित किया जा सके कि गणितीय विश्लेषण व्यवहार्य बना रहे और सार्थक, बंद-रूप अभिव्यक्तियाँ उत्पन्न करे, इस प्रकार समस्या की सैद्धांतिक मांगों और समाधान की विश्लेषणात्मक क्षमताओं के बीच एक आदर्श "विवाह" बनाया जा सके।
विकल्पों का अस्वीकरण (Rejection of Alternatives)
यह पत्र स्पष्ट रूप से GANs या डिफ्यूजन मॉडल जैसे अन्य लोकप्रिय डीप लर्निंग आर्किटेक्चर को सभी कार्यों के लिए निम्नतर मानने के अर्थ में "अस्वीकार" नहीं करता है। इसके बजाय, निहित अस्वीकरण इनपुट डेटा में छद्म विशेषता स्मरण को सटीक रूप से मापने के लिए एक कठोर, विश्लेषणात्मक रूप से सुलभ सैद्धांतिक ढांचे की वर्तमान कमी से उपजा है।
लेखक इस बात पर प्रकाश डालते हैं कि जबकि व्यावहारिक कार्य ने छद्म विशेषताओं की खोज की है, ये दृष्टिकोण अक्सर आर्किटेक्चर की भूमिका को कैप्चर करने या मात्रात्मक सैद्धांतिक समझ प्रदान करने में विफल रहते हैं। RF और NTK जैसे मॉडलों के लिए मौजूदा सैद्धांतिक मशीनरी, जब सौम्य अति-फिटिंग जैसी समस्याओं पर लागू होती है, तो आम तौर पर लेबल में शोर को मॉडल करती है, न कि इनपुट में छद्म विशेषताओं के रूप में। इसका मतलब है कि जबकि ये मॉडल (RF/NTK) स्वयं शक्तिशाली हैं, उनका मौजूदा सैद्धांतिक विश्लेषण इनपुट-स्तरीय छद्म विशेषता स्मरण की विशिष्ट समस्या के लिए अपर्याप्त था। पत्र का योगदान RF और NTK के लिए इस सैद्धांतिक विश्लेषण का विस्तार करना है ताकि छद्म विशेषता स्मरण को कवर किया जा सके, बजाय इसके कि पूरी तरह से नया मॉडल प्रस्तावित किया जाए। इसलिए, "अस्वीकरण" स्वयं मॉडल का नहीं है, बल्कि वर्तमान सैद्धांतिक उपकरणों की अपर्याप्तता का है जो इस पत्र द्वारा मांगी गई इनपुट-स्तरीय छद्म विशेषता स्मरण की विशिष्ट समस्या के लिए गहरी, मात्रात्मक अंतर्दृष्टि प्रदान करते हैं।
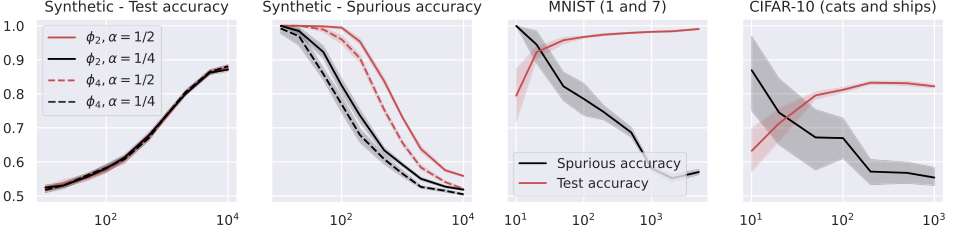 Figure 2. Test and spurious accuracies as a function of the number of training samples N, for various binary classification tasks. In the first two plots, we consider the RF model in (14) with k = 105 trained over Gaussian data with d = 1000. The labeling function is g(x) = sign(u⊤x). We repeat the experiments for α = {0.25, 0.5} and for the two activations ϕ2 = h1 + h2 and ϕ4 = h1 + h4, where hi denotes the i-th Hermite polynomial (see Appendix A.1). In the last two plots, we consider the same model with ReLU activation, trained over two MNIST and CIFAR-10 classes. The width of the noise background is 10 pixels for MNIST and 8 pixels for CIFAR-10, see Figure 1. The spurious accuracy is obtained by querying the model only with the noise background from the training set, replacing all the other pixels with 0, and taking the sign of the output. As we consider binary classification, an accuracy of 0.5 is achieved by random guessing. We plot the average over 10 independent trials and the confidence band at 1 standard deviation
Figure 2. Test and spurious accuracies as a function of the number of training samples N, for various binary classification tasks. In the first two plots, we consider the RF model in (14) with k = 105 trained over Gaussian data with d = 1000. The labeling function is g(x) = sign(u⊤x). We repeat the experiments for α = {0.25, 0.5} and for the two activations ϕ2 = h1 + h2 and ϕ4 = h1 + h4, where hi denotes the i-th Hermite polynomial (see Appendix A.1). In the last two plots, we consider the same model with ReLU activation, trained over two MNIST and CIFAR-10 classes. The width of the noise background is 10 pixels for MNIST and 8 pixels for CIFAR-10, see Figure 1. The spurious accuracy is obtained by querying the model only with the noise background from the training set, replacing all the other pixels with 0, and taking the sign of the output. As we consider binary classification, an accuracy of 0.5 is achieved by random guessing. We plot the average over 10 independent trials and the confidence band at 1 standard deviation
गणितीय और तार्किक तंत्र (Mathematical & Logical Mechanism)
मास्टर समीकरण (The Master Equation)
मॉडल स्थिरता, नमूनों के बीच विशेषता संरेखण, और उन्हें एक साथ जोड़ने वाले संबंध की तीन परस्पर जुड़ी गणितीय परिभाषाओं पर छद्म विशेषताओं को कैसे याद किया जाता है, यह समझने के लिए पत्र का मुख्य तंत्र टिका है। ये समीकरण सामूहिक रूप से व्यक्तिगत प्रशिक्षण बिंदुओं के प्रति प्रशिक्षित मॉडल की संवेदनशीलता का वर्णन करते हैं और यह संवेदनशीलता कैसे विशेषता स्थान में समानता से संशोधित होती है।
सबसे पहले, प्रशिक्षण नमूना $z_1$ के संबंध में मॉडल की स्थिरता को इस प्रकार परिभाषित किया गया है:
$$S_{z_1} := f(\cdot, \theta^*) - f(\cdot, \theta^*_{-1}) \quad (5)$$
यह मात्रा मापती है कि एक विशिष्ट प्रशिक्षण नमूना $z_1$ को प्रशिक्षण डेटासेट में शामिल करने या बाहर करने पर मॉडल के आउटपुट में कितना परिवर्तन होता है।
दूसरे, विशेषता मानचित्र $\phi$ द्वारा प्रेरित विशेषता स्थान में दो नमूनों, $z$ और $z_1$, के बीच विशेषता संरेखण दिया गया है:
$$F_\phi(z, z_1) := \frac{\phi(z)^\top P_{\Phi_{-1}} \phi(z_1)}{\|P_{\Phi_{-1}}\phi(z_1)\|_2^2} \quad (8)$$
यह पद एक सामान्य नमूना $z$ के विशेषता प्रतिनिधित्व की एक विशिष्ट प्रशिक्षण नमूना $z_1$ के साथ समानता या "संरेखण" को मापता है, शेष प्रशिक्षण डेटा द्वारा परिभाषित उप-स्थान पर प्रक्षेपण के बाद।
अंत में, स्थिरता और विशेषता संरेखण के बीच महत्वपूर्ण कड़ी लेम्मा 4.1 द्वारा स्थापित की गई है, जो बताती है:
$$S_{z_1}(z) = F_\phi(z, z_1) S_{z_1}(z_1) \quad (9)$$
यह समीकरण बताता है कि किसी भी नमूना $z$ के लिए मॉडल के आउटपुट की स्थिरता (जब $z_1$ को हटा दिया जाता है) स्वयं $z_1$ पर स्थिरता के सीधे आनुपातिक होती है, जो उनके विशेषता संरेखण से स्केल की जाती है। यह सुरुचिपूर्ण संबंध स्मरण के विश्लेषण के लिए पत्र की नींव बनाता है।
पद-दर-पद विच्छेदन (Term-by-Term Autopsy)
आइए इन मास्टर समीकरणों के प्रत्येक घटक को उनके सटीक गणितीय परिभाषा, मॉडल में उनकी भौतिक या तार्किक भूमिका और चुने गए गणितीय संचालन के पीछे के तर्क को समझने के लिए विच्छेदित करें।
समीकरण (5): स्थिरता $S_{z_1}$
* $S_{z_1}$: यह प्रतीक प्रशिक्षण नमूना $z_1$ के संबंध में मॉडल की स्थिरता का प्रतिनिधित्व करता है।
* गणितीय परिभाषा: मॉडल भविष्यवाणियों में परिवर्तन का प्रतिनिधित्व करने वाला एक स्केलर मान।
* भौतिक/तार्किक भूमिका: यह एक एकल प्रशिक्षण नमूना $z_1$ के मॉडल के आउटपुट पर प्रभाव को मापता है। एक बड़ा $S_{z_1}$ का अर्थ है कि $z_1$ को हटाने से मॉडल की भविष्यवाणियां काफी बदल जाती हैं, जो इंगित करता है कि $z_1$ "स्मरण" किया गया है या इसका एक मजबूत प्रभाव है।
* $f(\cdot, \theta^*)$: यह पूर्ण डेटासेट पर प्रशिक्षित मॉडल का भविष्यवाणी फ़ंक्शन है।
* गणितीय परिभाषा: $f(z, \theta^*) = \phi(z)\theta^*$, जहां $\phi(z)$ इनपुट $z$ के लिए विशेषता वेक्टर है और $\theta^*$ पूरे प्रशिक्षण सेट $Z$ से सीखे गए इष्टतम पैरामीटर हैं।
* भौतिक/तार्किक भूमिका: इसके मापदंडों को सीखने के लिए सभी उपलब्ध प्रशिक्षण डेटा का उपयोग करने पर मॉडल के आउटपुट का प्रतिनिधित्व करता है।
* $f(\cdot, \theta^*_{-1})$: यह डेटासेट बिना $z_1$ के प्रशिक्षित मॉडल का भविष्यवाणी फ़ंक्शन है।
* गणितीय परिभाषा: $f(z, \theta^*_{-1}) = \phi(z)\theta^*_{-1}$, जहां $\theta^*_{-1}$ प्रशिक्षण सेट $Z_{-1}$ (जो $Z$ को $z_1$ को छोड़कर है) से सीखे गए इष्टतम पैरामीटर हैं।
* भौतिक/तार्किक भूमिका: प्रशिक्षण प्रक्रिया से एक विशिष्ट प्रशिक्षण नमूना $z_1$ को छोड़ने पर मॉडल के आउटपुट का प्रतिनिधित्व करता है।
* $- (घटाव)$:
* क्यों उपयोग किया जाता है: $z_1$ की उपस्थिति या अनुपस्थिति के कारण मॉडल के आउटपुट में परिवर्तन या अंतर को सीधे मापने के लिए घटाव का उपयोग किया जाता है। यह प्रभाव या संवेदनशीलता को मापने का एक मानक तरीका है। यदि गुणा का उपयोग किया जाता, तो यह एक अनुपात को मापता, जो "परिवर्तन" के लिए वांछित मीट्रिक नहीं है।
समीकरण (8): विशेषता संरेखण $F_\phi(z, z_1)$
* $F_\phi(z, z_1)$: यह प्रतीक नमूना $z$ और प्रशिक्षण नमूना $z_1$ के बीच विशेषता संरेखण को दर्शाता है।
* गणितीय परिभाषा: एक सामान्यीकृत प्रक्षेपण का प्रतिनिधित्व करने वाला एक स्केलर मान।
* भौतिक/तार्किक भूमिका: यह मापता है कि एक सामान्य नमूना $z$ का विशेषता प्रतिनिधित्व एक विशिष्ट प्रशिक्षण नमूना $z_1$ के कितना "समान" है, विशेषता स्थान के भीतर। यह समानता महत्वपूर्ण है क्योंकि यह इंगित करता है कि $z_1$ के बारे में कितनी जानकारी मॉडल के आंतरिक प्रतिनिधित्व में "स्थानांतरित" या "संरेखित" हो सकती है।
* $\phi(z)$: इनपुट नमूना $z$ का विशेषता मानचित्र।
* गणितीय परिभाषा: एक वेक्टर $\phi(z) \in \mathbb{R}^p$ जो इनपुट $z \in \mathbb{R}^d$ पर एक विशेषता मानचित्र फ़ंक्शन $\phi: \mathbb{R}^d \to \mathbb{R}^p$ लागू करके प्राप्त किया जाता है।
* भौतिक/तार्किक भूमिका: यह कच्चे इनपुट डेटा $z$ को एक उच्च-आयामी विशेषता प्रतिनिधित्व में परिवर्तित करता है जिस पर रैखिक मॉडल संचालित होता है। यह इनपुट की मॉडल की आंतरिक "समझ" है।
* $\phi(z_1)$: प्रशिक्षण नमूना $z_1$ का विशेषता मानचित्र।
* गणितीय परिभाषा: विशिष्ट प्रशिक्षण नमूना $z_1$ के लिए, $\phi(z)$ के समान।
* भौतिक/तार्किक भूमिका: उस प्रशिक्षण नमूने के मॉडल के आंतरिक विशेषता प्रतिनिधित्व का प्रतिनिधित्व करता है जिसके प्रभाव का अध्ययन किया जा रहा है।
* $P_{\Phi_{-1}}$: $\Phi_{-1}$ की पंक्तियों के स्पैन पर प्रोजेक्टर।
* गणितीय परिभाषा: एक प्रक्षेपण मैट्रिक्स $P_{\Phi_{-1}} \in \mathbb{R}^{p \times p}$ जैसे कि $P_{\Phi_{-1}} = \Phi_{-1}^\top (\Phi_{-1}\Phi_{-1}^\top)^{-1} \Phi_{-1}$ (यदि $\Phi_{-1}\Phi_{-1}^\top$ व्युत्क्रमणीय है)। यह $\Phi_{-1}$ की पंक्ति स्थान पर वैक्टर को प्रोजेक्ट करता है।
* भौतिक/तार्किक भूमिका: यह प्रोजेक्टर प्रभावी रूप से विशेषता वैक्टर को "फ़िल्टर आउट" या "सामान्यीकृत" करता है, अन्य सभी प्रशिक्षण नमूनों ( $z_1$ को छोड़कर) की विशेषताओं के स्पैन पर विचार करके। यह सुनिश्चित करता है कि संरेखण बाकी डेटासेट से सामूहिक जानकारी के सापेक्ष मापा जाता है, जिससे यह अद्वितीय संरेखण का अधिक मजबूत माप बन जाता है।
* $\top$ (ट्रांसपोज़):
* क्यों उपयोग किया जाता है: दो वैक्टर, $\phi(z)$ और $P_{\Phi_{-1}}\phi(z_1)$ के बीच एक आंतरिक उत्पाद (डॉट उत्पाद) करने के लिए ट्रांसपोज़ का उपयोग किया जाता है। यह ऑपरेशन दो विशेषता वैक्टर के बीच रैखिक सहसंबंध या समानता को मापता है।
* $\cdot$ (गुणा):
* क्यों उपयोग किया जाता है: मैट्रिक्स-वेक्टर गुणन (जैसे, $P_{\Phi_{-1}}\phi(z_1)$) प्रोजेक्टर द्वारा परिभाषित रैखिक परिवर्तन लागू करता है। वेक्टर-वेक्टर गुणन (डॉट उत्पाद) समानता को मापता है।
* $\|\cdot\|_2^2$: वर्गित L2 मानदंड।
* गणितीय परिभाषा: एक वेक्टर $v$ के लिए, $\|v\|_2^2 = v^\top v = \sum_i v_i^2$।
* भौतिक/तार्किक भूमिका: हर में यह पद संरेखण को सामान्यीकृत करता है। यह सुनिश्चित करता है कि $F_\phi(z, z_1)$ सापेक्ष संरेखण का माप है, जो इसे विशेषता वैक्टर के पैमाने के प्रति अपरिवर्तनीय बनाता है। यह अनिवार्य रूप से विशेषता स्थान में कोसाइन समानता (या एक संबंधित प्रक्षेपण) को मापता है।
* $/$ (विभाजन):
* क्यों उपयोग किया जाता है: वर्गित L2 मानदंड द्वारा विभाजन एक सामान्यीकरण कदम है, जो प्रक्षेपण या समानताओं को परिभाषित करने में आम है, यह सुनिश्चित करता है कि संरेखण मीट्रिक ठीक से स्केल किया गया है।
समीकरण (9): संबंध $S_{z_1}(z) = F_\phi(z, z_1) S_{z_1}(z_1)$
* $S_{z_1}(z)$: एक सामान्य नमूना $z$ पर मॉडल के आउटपुट की स्थिरता।
* गणितीय परिभाषा: $f(z, \theta^*) - f(z, \theta^*_{-1})$।
* भौतिक/तार्किक भूमिका: यह $z_1$ को हटाने पर नमूना $z$ के लिए मॉडल की भविष्यवाणी में परिवर्तन है।
* $S_{z_1}(z_1)$: प्रशिक्षण नमूना $z_1$ पर ही मॉडल के आउटपुट की स्थिरता।
* गणितीय परिभाषा: $f(z_1, \theta^*) - f(z_1, \theta^*_{-1})$।
* भौतिक/तार्किक भूमिका: यह $z_1$ के अपने भविष्यवाणी पर $z_1$ के प्रत्यक्ष प्रभाव का प्रतिनिधित्व करता है। यदि मॉडल पूरी तरह से इंटरपोलेट करता है, तो $f(z_1, \theta^*) = g_1$, इसलिए यह पद $g_1 - f(z_1, \theta^*_{-1})$ बन जाता है, जो $z_1$ के लेबल के "स्मरण" का प्रतिनिधित्व करता है।
* $\cdot$ (गुणा):
* क्यों उपयोग किया जाता है: प्रत्यक्ष आनुपातिकता दिखाने के लिए गुणा का उपयोग किया जाता है। $z$ के लिए भविष्यवाणी में परिवर्तन $z_1$ के लिए परिवर्तन का एक स्केल किया गया संस्करण है, जहां स्केलिंग कारक विशेषता संरेखण है। यह एक रैखिक संबंध का तात्पर्य है: यदि $z$ विशेषता स्थान में $z_1$ के साथ अत्यधिक संरेखित है, तो $z_1$ को हटाने से $z$ की भविष्यवाणी पर उसी तरह प्रभाव पड़ेगा जैसे $z_1$ की भविष्यवाणी पर।
चरण-दर-चरण प्रवाह (Step-by-Step Flow)
कल्पना करें कि एक डेटा बिंदु $z$ इस गणितीय इंजन में प्रवेश करता है, साथ ही एक विशिष्ट प्रशिक्षण नमूना $z_1$ और उसका छद्म प्रतिरूप $z^s$ भी। लक्ष्य यह समझना है कि $z^s$ के लिए मॉडल का आउटपुट $z_1$ से कैसे प्रभावित हो सकता है, जो स्मरण का संकेत देता है।
- विशेषता निष्कर्षण (Feature Extraction): सबसे पहले, कच्चे इनपुट $z$ और विशिष्ट प्रशिक्षण नमूना $z_1$ को मॉडल के विशेषता मानचित्र $\phi$ में फीड किया जाता है। यह उन्हें उनके आंतरिक विशेषता प्रतिनिधित्व, क्रमशः $\phi(z)$ और $\phi(z_1)$ में परिवर्तित करता है। इसे प्रारंभिक प्रसंस्करण इकाई के रूप में सोचें, जो कच्चे डेटा को ऐसे प्रारूप में परिवर्तित करती है जिसे मॉडल "समझ" सकता है।
- उप-स्थान प्रक्षेपण (Subspace Projection): अगला, $\phi(z_1)$ को अन्य प्रशिक्षण नमूनों, $\Phi_{-1}$ की विशेषताओं द्वारा फैले उप-स्थान पर प्रोजेक्ट किया जाता है, प्रोजेक्टर $P_{\Phi_{-1}}$ का उपयोग करके। यह कदम बाकी प्रशिक्षण डेटा की पृष्ठभूमि को ध्यान में रखते हुए, $z_1$ की विशेषताओं के अद्वितीय योगदान को अलग करता है।
- विशेषता संरेखण गणना (Feature Alignment Calculation): प्रोजेक्टेड $\phi(z_1)$ की तुलना फिर डॉट उत्पाद के माध्यम से $\phi(z)$ से की जाती है, और प्रोजेक्टेड $\phi(z_1)$ के परिमाण द्वारा सामान्यीकृत की जाती है। यह $F_\phi(z, z_1)$, विशेषता संरेखण की गणना करता है। यह इकाई निर्धारित करती है कि मॉडल के विशेषता स्थान में $z$, $z_1$ के कितना "समान" है, अन्य प्रशिक्षण डेटा की पृष्ठभूमि को ध्यान में रखते हुए।
- मॉडल प्रशिक्षण (अंतर्निहित) (Model Training (Implicit)): समानांतर में, मॉडल के दो संस्करण "प्रशिक्षित" होते हैं। एक, $f(\cdot, \theta^*)$, संपूर्ण प्रशिक्षण डेटासेट $Z$ ( $z_1$ सहित) का उपयोग करता है। दूसरा, $f(\cdot, \theta^*_{-1})$, डेटासेट $Z_{-1}$ ( $z_1$ को छोड़कर) का उपयोग करता है। पैरामीटर $\theta^*$ और $\theta^*_{-1}$ इन प्रशिक्षण प्रक्रियाओं से प्राप्त होते हैं।
- $z_1$ पर स्थिरता मापन (Stability Measurement at $z_1$): $z_1$ के लिए मॉडल का आउटपुट दोनों पैरामीटर सेट का उपयोग करके गणना की जाती है: $f(z_1, \theta^*)$ और $f(z_1, \theta^*_{-1})$। इन दो आउटपुट के बीच का अंतर, $S_{z_1}(z_1) = f(z_1, \theta^*) - f(z_1, \theta^*_{-1})$, गणना की जाती है। यह इकाई मापती है कि $z_1$ स्वयं $z_1$ के लिए मॉडल की भविष्यवाणी को कितना बदलता है। यदि मॉडल पूरी तरह से इंटरपोलेट करता है, तो $f(z_1, \theta^*) = g_1$, इसलिए यह पद $g_1 - f(z_1, \theta^*_{-1})$ बन जाता है, जो $z_1$ के लेबल के "स्मरण" का प्रतिनिधित्व करता है।
- स्थिरता का प्रसार (Propagating Stability): अब, विशेषता संरेखण $F_\phi(z, z_1)$ और $z_1$ पर स्थिरता, $S_{z_1}(z_1)$, को $S_{z_1}(z) = F_\phi(z, z_1) S_{z_1}(z_1)$ प्राप्त करने के लिए गुणा किया जाता है। इसका मतलब है कि एक सामान्य नमूना $z$ पर $z_1$ का प्रभाव सीधे तौर पर $z_1$ के साथ $z$ के संरेखण के समानुपाती होता है, जो $z_1$ के स्वयं के प्रभाव से स्केल किया जाता है।
- स्मरण का मापन (Quantifying Memorization): अंत में, छद्म विशेषताओं के स्मरण को मापने के लिए, पत्र सहप्रसरण
Cov(f(z^s, θ*), g_i)पर विचार करता है। इसमें एक छद्म नमूना $z^s = [-, y]$ (जहां मुख्य विशेषता $x$ को हटा दिया जाता है या शून्य कर दिया जाता है, केवल छद्म विशेषता $y$ को छोड़ दिया जाता है) पर मॉडल का मूल्यांकन करना और इसके आउटपुट को वास्तविक लेबल $g_i$ (जो केवल $x_i$ पर निर्भर करता है) के साथ सहसंबंधित करना शामिल है। व्युत्पन्न संबंध (समीकरण 11) दिखाता है कि यह सहप्रसरण $\gamma_\phi \sqrt{R_{Z_{-1}}} \sqrt{\text{Var}(g_i)}$ द्वारा सीमित है, जहां $\gamma_\phi$ विशेषता संरेखण से संबंधित एक स्थिरांक है और $R_{Z_{-1}}$ सामान्यीकरण त्रुटि है। यह अंतिम चरण विशेषता प्रसंस्करण और स्थिरता की यांत्रिक असेंबली लाइन को छद्म विशेषता स्मरण के अंतिम माप से जोड़ता है।
अनुकूलन गतिकी (Optimization Dynamics)
यह पत्र सामान्यीकृत रैखिक प्रतिगमन के ढांचे के भीतर संचालित होता है, जहां मॉडल पैरामीटर $\theta$ को समीकरण (2) में दिखाए गए एक द्विघात हानि के साथ अनुभवजन्य जोखिम को कम करके सीखा जाता है: $\min_\theta \| \Phi \theta - G \|_2^2$ । इस सेटिंग में, अनुकूलन प्रक्रिया इष्टतम पैरामीटर $\theta^*$ के लिए एक बंद-रूप समाधान की ओर ले जाती है, जिसे समीकरण (3) द्वारा दिया गया है: $\theta^* = \theta_0 + \Phi^+(G - f(Z, \theta_0))$।
इसका मतलब है कि "सीखने" या "अनुकूलन गतिकी" जटिल हानि परिदृश्य का पता लगाने वाली पुनरावृत्ति ग्रेडिएंट वंश प्रक्रिया के बारे में नहीं है, बल्कि इस प्रत्यक्ष, इंटरपोलेटिंग समाधान के गुणों के बारे में है। पत्र स्पष्ट रूप से बताता है कि "ग्रेडिएंट वंश आरंभीकरण के लिए एल2 मानदंड के निकटतम इंटरपोलेटर में परिवर्तित होता है।" इसका तात्पर्य है कि मॉडल को शून्य प्रशिक्षण त्रुटि प्राप्त करने के लिए प्रशिक्षित किया जाता है, जो अति-पैरामीट्रिक मॉडल की एक विशेषता है।
यहां विश्लेषण की जाने वाली प्रमुख "गतिकी" हैं:
1. इंटरपोलेशन (Interpolation): प्रशिक्षण डेटा को पूरी तरह से फिट करने की मॉडल की क्षमता (शून्य प्रशिक्षण त्रुटि प्राप्त करना) अति-पैरामीट्रिक व्यवस्था और चुने गए अनुकूलन उद्देश्य का प्रत्यक्ष परिणाम है। यह इंटरपोलेशन छद्म विशेषताओं के स्मरण की अनुमति देता है।
2. सामान्यीकरण त्रुटि की भूमिका (Generalization Error's Role): पत्र का मुख्य परिणाम (समीकरण 11) दिखाता है कि छद्म विशेषताओं का स्मरण ( Cov(f(z^s, θ*), g_i) द्वारा मापा जाता है) सीधे सामान्यीकरण त्रुटि $R_{Z_{-1}}$ के समानुपाती होता है। इसका मतलब है कि जैसे-जैसे मॉडल की अनदेखे डेटा पर सामान्यीकरण करने की क्षमता में सुधार होता है (अर्थात, $R_{Z_{-1}}$ घटता है), छद्म विशेषताओं को याद करने की उसकी प्रवृत्ति भी कमजोर हो जाती है। यह इंटरपोलेटिंग समाधान के व्यवहार में एक महत्वपूर्ण अंतर्दृष्टि है।
3. विशेषता संरेखण का प्रभाव (Feature Alignment's Influence): स्मरण सीमा (समीकरण 11) में आनुपातिकता स्थिरांक $\gamma_\phi$ विशेषता संरेखण $F_\phi(z_1, z_1)$ से प्राप्त होता है। यह स्थिरांक, जो विशेषता मानचित्र $\phi$ और सक्रियण फ़ंक्शन पर निर्भर करता है, "हानि परिदृश्य" को इस तरह से आकार देता है जो यह निर्धारित करता है कि मॉडल सामान्यीकरण के बावजूद छद्म विशेषताओं को कितनी दृढ़ता से याद करता है। एक उच्च $\gamma_\phi$ का अर्थ है एक दिए गए सामान्यीकरण त्रुटि के लिए अधिक स्मरण। RF और NTK मॉडल के विश्लेषण में इस $\gamma_\phi$ का सटीक लक्षण वर्णन, यह बताता है कि मॉडल आर्किटेक्चर और सक्रियण फ़ंक्शन स्मरण की गतिशीलता को कैसे प्रभावित करते हैं।
4. स्थिरता एक प्रॉक्सी के रूप में (Stability as a Proxy): स्थिरता $S_{z_1}(z_1)$ एक माप के रूप में कार्य करती है कि मॉडल इंटरपोलेशन प्राप्त करने के लिए व्यक्तिगत प्रशिक्षण बिंदुओं पर कितना निर्भर करता है। यदि $S_{z_1}(z_1)$ बड़ा है, तो मॉडल $z_1$ के प्रति अत्यधिक संवेदनशील है, जो इंगित करता है कि $z_1$ दृढ़ता से "स्मरण" किया गया है। अनुकूलन प्रक्रिया, एक इंटरपोलेटिंग समाधान ढूंढकर, स्वाभाविक रूप से यह स्थिरता बनाती है, जो तब छद्म स्मरण को प्रभावित करने के लिए विशेषता संरेखण के माध्यम से प्रचारित होती है।
संक्षेप में, "अनुकूलन गतिकी" को इसे खोजने के पुनरावृत्ति चरणों के बजाय इंटरपोलेटिंग समाधान $\theta^*$ के विशेषताओं के लेंस के माध्यम से समझा जाता है। मॉडल डेटा को पूरी तरह से फिट करना सीखता है, और पत्र इस सीखने की रणनीति के अंतर्निहित व्यापार-बंद और परिणामों का विश्लेषण करता है, विशेष रूप से अप्रासंगिक जानकारी के स्मरण के संबंध में। ग्रेडिएंट, जबकि $\theta^*$ की ओर ले जाते हैं, उनके पुनरावृत्ति व्यवहार में स्पष्ट रूप से विश्लेषण नहीं किए जाते हैं, बल्कि उनके अंतिम स्थिति के गुणों का विश्लेषण किया जाता है।
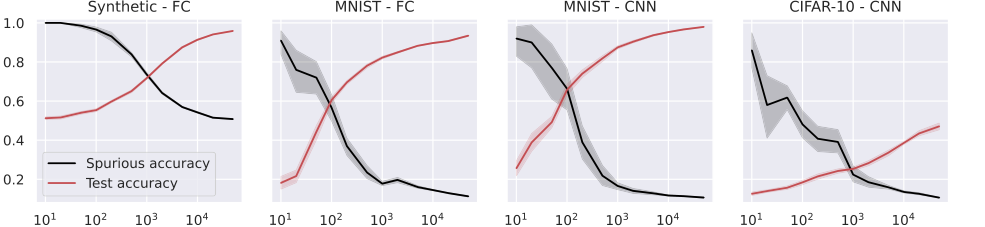 Figure 4. Test and spurious accuracies as a function of the number of training samples N, for a fully connected (FC, first two plots), and a small convolutional neural network (CNN, last two plots). In the first plot, we use synthetic (Gaussian) data with d = 1000, and the labeling function is g(x) = sign(u⊤x). As we consider binary classification, the accuracy of random guessing is 0.5. The other plots use subsets of the MNIST and CIFAR-10 datasets, with an external layer of noise added to images, see Figure 1. As we consider 10 classes, the accuracy of random guessing is 0.1. We plot the average over 10 independent trials and the confidence band at 1 standard deviation
Figure 4. Test and spurious accuracies as a function of the number of training samples N, for a fully connected (FC, first two plots), and a small convolutional neural network (CNN, last two plots). In the first plot, we use synthetic (Gaussian) data with d = 1000, and the labeling function is g(x) = sign(u⊤x). As we consider binary classification, the accuracy of random guessing is 0.5. The other plots use subsets of the MNIST and CIFAR-10 datasets, with an external layer of noise added to images, see Figure 1. As we consider 10 classes, the accuracy of random guessing is 0.1. We plot the average over 10 independent trials and the confidence band at 1 standard deviation
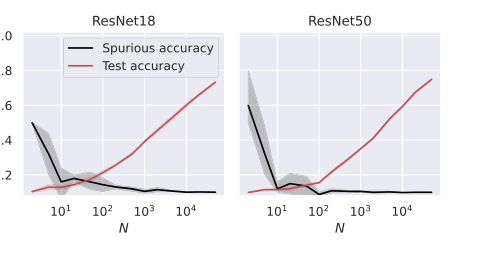 Figure 5. Test and spurious accuracies as a function of the number of training samples N, for two ResNet architectures. We use subsets of the CIFAR-10 dataset, with an external layer of noise added to images, see Figure 1. As we consider 10 classes, the accuracy of random guessing is 0.1. We plot the average over 10 independent trials and the confidence band at 1 standard deviation
Figure 5. Test and spurious accuracies as a function of the number of training samples N, for two ResNet architectures. We use subsets of the CIFAR-10 dataset, with an external layer of noise added to images, see Figure 1. As we consider 10 classes, the accuracy of random guessing is 0.1. We plot the average over 10 independent trials and the confidence band at 1 standard deviation
परिणाम, सीमाएँ और निष्कर्ष (Results, Limitations & Conclusion)
प्रयोगात्मक डिजाइन और बेसलाइन (Experimental Design & Baselines)
अपने सैद्धांतिक दावों को कठोरता से मान्य करने के लिए, लेखकों ने विभिन्न मॉडल प्रकारों और डेटासेट पर अपने गणितीय भविष्यवाणियों को अनुभवजन्य अवलोकनों के खिलाफ खड़ा करते हुए प्रयोगों की एक श्रृंखला को सावधानीपूर्वक डिजाइन किया। मुख्य विचार छद्म विशेषताओं - अप्रासंगिक शोर या पृष्ठभूमि जानकारी - को प्रशिक्षण डेटा में मौजूद परिदृश्यों को बनाना था, लेकिन वास्तविक लेबल के भविष्यवक्ता नहीं थे। फिर, उन्होंने मापा कि मॉडल इन अप्रासंगिक विशेषताओं को कितना "स्मरण" करते हैं।
इन प्रयोगों में "पीड़ित" पारंपरिक अर्थों में वैकल्पिक मॉडल नहीं थे, बल्कि स्वयं यादृच्छिक विशेषताएँ (RF) और न्यूरल टेंगेंट कर्नेल (NTK) मॉडल थे, साथ ही पूरी तरह से जुड़े (FC), संवादात्मक तंत्रिका नेटवर्क (CNNs), और ResNets (ResNet18, ResNet50) जैसे अधिक जटिल डीप लर्निंग आर्किटेक्चर थे। लक्ष्य यह प्रदर्शित करना था कि ये मॉडल, जब प्रशिक्षित होते हैं, तो अनिवार्य रूप से छद्म सहसंबंधों को उठाएंगे और उन पर भरोसा करेंगे, और इस व्यवहार को कैसे सटीक रूप से चित्रित किया जा सकता है।
प्रयोगात्मक सेटअप में शामिल थे:
- डेटा जनरेशन (Data Generation):
- सिंथेटिक डेटा (Synthetic Data): बाइनरी वर्गीकरण कार्यों के लिए इनपुट आयाम $d=1000$ के साथ गॉसियन डेटा का उपयोग किया गया था। इसने डेटा गुणों पर सटीक नियंत्रण की अनुमति दी।
- मानक डेटासेट (Standard Datasets): MNIST (अंक '1' और '7' को वर्गीकृत करने के लिए) और CIFAR-10 ( 'बिल्लियों' और 'जहाजों' को वर्गीकृत करने के लिए) का उपयोग सिद्धांत की वास्तविक दुनिया की छवि डेटा पर प्रयोज्यता का परीक्षण करने के लिए किया गया था।
- छद्म विशेषता इंजेक्शन (Spurious Feature Injection): सभी डेटासेट के लिए, एक छद्म विशेषता $y$ पेश की गई थी। यह आम तौर पर मूल छवि $x$ के चारों ओर जोड़ा गया एक शोर पृष्ठभूमि था, जो इनपुट नमूना $z = [x, y]$ बनाता है (जैसा कि चित्र 1 में दर्शाया गया है)। महत्वपूर्ण रूप से, यह $y$ असंबद्ध होने के लिए डिज़ाइन किया गया था वास्तविक लेबल $g(x)$ से। MNIST और CIFAR-10 के लिए, छद्म सटीकता के लिए पूछे जाने पर मुख्य विशेषता $x$ को शून्य से बदल दिया गया था, जिसका अर्थ है कि मॉडल का परीक्षण केवल शोर घटक पर किया गया था।
- मॉडल आर्किटेक्चर (Model Architectures):
- RF और NTK मॉडल (RF and NTK Models): ये प्राथमिक सैद्धांतिक लक्ष्य थे, जिनमें न्यूरॉन्स की विभिन्न संख्याएँ ($k$) और विभिन्न संख्या में नमूने ($N$) पर प्रशिक्षित थे।
- डीप न्यूरल नेटवर्क (Deep Neural Networks): FC, CNN, और ResNet आर्किटेक्चर का भी परीक्षण किया गया ताकि यह दिखाया जा सके कि सैद्धांतिक अंतर्दृष्टि RF/NTK व्यवस्थाओं से परे जटिल, विशेषता-सीखने वाले मॉडल तक विस्तारित होती है।
- प्रमुख प्रयोगात्मक पैरामीटर (Key Experimental Parameters):
- प्रशिक्षण नमूनों की संख्या ($N$) (Number of Training Samples): सामान्यीकरण और स्मरण दोनों पर इसके प्रभाव को देखने के लिए इसे काफी हद तक (जैसे, $10^1$ से $10^4$ तक) भिन्न किया गया था।
- सक्रियण फ़ंक्शन ($\phi$) (Activation Functions): विभिन्न सक्रियण कार्यों का उपयोग किया गया था, जिन्हें उनके हर्माइट गुणांकों द्वारा चित्रित किया गया था (जैसे, RF के लिए $\phi_2 = h_1 + h_2$, $\phi_4 = h_1 + h_4$; NTK के लिए $\phi_2 = h_0 + h_1$, $\phi_4 = h_0 + h_3$, जहां $h_i$ हर्माइट बहुपद हैं)। ReLU सक्रियण का भी परीक्षण किया गया था। सक्रियण फ़ंक्शन की पसंद को स्मरण को प्रभावित करने की भविष्यवाणी की गई थी।
- छद्म विशेषता अंश ($\alpha$) (Spurious Feature Fraction): $d_y/d$ के रूप में परिभाषित, यह पैरामीटर छद्म विशेषता के लिए जिम्मेदार इनपुट आयाम के अनुपात का प्रतिनिधित्व करता है। स्मरण पर इसके प्रभाव की भी जांच की गई थी।
- स्मरण का मापन (Measurement of Memorization): स्मरण को साबित करने का सबसे सीधा और "क्रूर" तरीका "छद्म सटीकता" के माध्यम से था। यह प्रशिक्षित मॉडल को एक नमूने के केवल छद्म घटक ($y$) को फीड करके (जैसे, मुख्य विशेषता $x$ को शून्य से बदलकर) और यह जांच कर गणना की गई थी कि क्या मॉडल अभी भी सही लेबल $g(x)$ की भविष्यवाणी करता है। यदि मॉडल केवल छद्म भाग पर उच्च सटीकता प्राप्त करता है, तो यह निश्चित रूप से स्मरण साबित करता है।
- सटीकता के लिए बेसलाइन (Baselines for Accuracy): बाइनरी वर्गीकरण कार्यों के लिए, 0.5 की यादृच्छिक अनुमान सटीकता एक निचली सीमा के रूप में कार्य करती है। 10-वर्ग वर्गीकरण (CIFAR-10, MNIST) के लिए, यादृच्छिक अनुमान 0.1 सटीकता देता है। मॉडल के प्रदर्शन की तुलना इन तुच्छ बेसलाइन से की गई थी। सभी प्रयोगों को 1 मानक विचलन का संकेत देने वाले आत्मविश्वास बैंड के साथ 10 स्वतंत्र परीक्षणों पर औसत किया गया था।
साक्ष्य क्या साबित करते हैं (What the Evidence Proves)
अनुभवजन्य साक्ष्य भारी रूप से पत्र के केंद्रीय सैद्धांतिक दावों का समर्थन करते हैं, यह निश्चित, निर्विवाद प्रमाण प्रदान करते हैं कि प्रस्तावित गणितीय ढांचा छद्म विशेषताओं के स्मरण की जटिल घटना को सटीक रूप से चित्रित करता है। मुख्य तंत्र, जो मानता है कि स्मरण मॉडल स्थिरता (सामान्यीकरण त्रुटि से संबंधित) और "विशेषता संरेखण" नामक एक नवीन अवधारणा दोनों का परिणाम है, को मजबूती से मान्य किया गया था।
यहाँ वह है जो साक्ष्य निश्चित रूप से साबित करते हैं:
-
सामान्यीकरण और स्मरण के बीच विपरीत संबंध (Inverse Relationship Between Generalization and Memorization): चित्र 2, 3, 4, और 5 लगातार एक स्पष्ट और विपरीत संबंध प्रदर्शित करते हैं: जैसे-जैसे प्रशिक्षण नमूनों ($N$) की संख्या बढ़ती है, मॉडल की परीक्षण सटीकता (सामान्यीकरण क्षमता का एक प्रॉक्सी) में सुधार होता है, जबकि इसकी छद्म सटीकता (स्मरण का एक प्रत्यक्ष माप) घट जाती है। यह इस सैद्धांतिक भविष्यवाणी का कठोर प्रमाण है कि "सामान्यीकरण क्षमता बढ़ने पर छद्म विशेषताओं का स्मरण कमजोर हो जाता है" (सार, पृष्ठ 1), और यह कि स्मरण सामान्यीकरण त्रुटि के समानुपाती होता है (समीकरण 11, 18, 27)। मॉडल, उनके आर्किटेक्चर की परवाह किए बिना, इस व्यापार-बंद के "पीड़ित" थे, यह दिखाते हुए कि बेहतर सामान्यीकरण अनिवार्य रूप से छद्म संकेतों पर निर्भरता को कम करता है।
-
सक्रियण कार्यों की महत्वपूर्ण भूमिका (The Critical Role of Activation Functions): प्रयोगों ने इस सैद्धांतिक अंतर्दृष्टि के मजबूत सत्यापन प्रदान किए कि सक्रियण फ़ंक्शन स्मरण में एक महत्वपूर्ण भूमिका निभाता है।
- यादृच्छिक विशेषता (RF) मॉडल के लिए सिंथेटिक डेटा पर (चित्र 2), छद्म सटीकता $\alpha$ (इनपुट का छद्म अंश) के साथ और निम्न-क्रम हर्माइट गुणांकों के प्रमुख प्रमुख सक्रियण कार्यों का उपयोग करते समय बढ़ती हुई देखी गई। यह सीधे प्रमेय 5.4 और समीकरण 17 में सैद्धांतिक भविष्यवाणी के साथ संरेखित होता है, जो दिखाता है कि $\gamma_{RF}$ (विशेषता संरेखण स्थिरांक) इन गुणांकों पर निर्भर करता है।
- न्यूरल टेंगेंट कर्नेल (NTK) मॉडल के लिए MNIST और CIFAR-10 पर (चित्र 3), परिणामों से पता चला कि उच्च-क्रम हर्माइट गुणांकों के प्रमुख प्रमुख सक्रियणों वाले सक्रियणों ने कम स्मरण किया। यह प्रमेय 6.3 और समीकरण 26 के अनुरूप है, जो सक्रियण फ़ंक्शन के व्युत्पन्न के हर्माइट गुणांकों पर $\gamma_{NTK}$ की निर्भरता को चित्रित करता है। यह दर्शाता है कि सक्रियण फ़ंक्शन के विशिष्ट गणितीय गुण, जैसा कि इसके हर्माइट विस्तार द्वारा कैप्चर किया गया है, सीधे मॉडल की स्मरण की प्रवृत्ति को निर्धारित करते हैं।
-
छद्म विशेषता अंश ($\alpha$) पर निर्भरता (Dependence on the Spurious Feature Fraction ($\alpha$)): चित्र 7 एक सम्मोहक प्रमाण प्रदान करता है कि छद्म सटीकता मोनोटोनिक रूप से $\alpha$ (इनपुट का छद्म अंश) के साथ बढ़ती है। यह RF और NTK मॉडल दोनों के लिए सिंथेटिक डेटा पर देखा गया था। महत्वपूर्ण रूप से, परीक्षण सटीकता $\alpha$ से काफी हद तक अप्रभावित रही। यह सीधे प्रमेय 5.4 और 6.3 में स्थापित $\alpha$ पर विशेषता संरेखण स्थिरांक ($\gamma_{RF}$, $\gamma_{NTK}$) की सैद्धांतिक निर्भरता की पुष्टि करता है। जितना अधिक छद्म जानकारी मौजूद होती है, उतना ही अधिक मॉडल इसे याद करता है, बिना आवश्यक रूप से इसके मुख्य कार्य प्रदर्शन में सुधार किए।
-
आर्किटेक्चर में व्यापक प्रयोज्यता (Broad Applicability Across Architectures): सरलीकृत RF और NTK मॉडल से परे, पत्र ने FC, CNN, और ResNet (चित्र 4 और 5) सहित अधिक जटिल डीप लर्निंग आर्किटेक्चर के लिए अपने अनुभवजन्य सत्यापन का विस्तार किया। इन प्रयोगों से पता चला कि देखी गई प्रवृत्तियाँ - अधिक प्रशिक्षण नमूनों के साथ परीक्षण सटीकता में वृद्धि और छद्म सटीकता में कमी - इन विविध मॉडलों में सच रही। यह बताता है कि स्मरण और सामान्यीकरण से इसके संबंध के अंतर्निहित सिद्धांत, जैसा कि विशेषता संरेखण और स्थिरता द्वारा स्पष्ट किया गया है, रैखिक मॉडल तक सीमित नहीं हैं, बल्कि आधुनिक डीप लर्निंग पर व्यापक रूप से लागू होते हैं। यह सैद्धांतिक ढांचे की अंतर्दृष्टि की सामान्यता के लिए मजबूत समर्थन प्रदान करता है, भले ही सटीक गणितीय लक्षण वर्णन सरल मॉडल के लिए प्राप्त किया गया हो।
संक्षेप में, प्रयोगों को छद्म विशेषताओं के प्रभाव को अलग करने और मापने के लिए डिज़ाइन किया गया था, और विभिन्न सेटिंग्स में लगातार रुझान निर्विवाद प्रमाण प्रदान करते हैं कि प्रस्तावित सैद्धांतिक ढांचा मशीन लर्निंग मॉडल में छद्म विशेषता स्मरण की जटिल घटना को सटीक रूप से कैप्चर करता है।
सीमाएँ और भविष्य की दिशाएँ (Limitations & Future Directions)
जबकि यह पत्र छद्म विशेषताओं को याद करने के तरीके को समझने के लिए एक शानदार और सटीक सैद्धांतिक ढांचा प्रदान करता है, इसके वर्तमान सीमाओं को स्वीकार करना और इन निष्कर्षों को कैसे आगे विकसित किया जा सकता है, इस पर विचार करना महत्वपूर्ण है। लेखक स्वयं भविष्य के अनुसंधान के लिए अंतर्दृष्टिपूर्ण रास्ते प्रदान करते हैं, जो इस क्षेत्र के विकास के बारे में महत्वपूर्ण सोच को प्रेरित कर सकते हैं।
विश्लेषण की वर्तमान सीमाएँ:
- छद्म विशेषताओं का दायरा (Scope of Spurious Features): इस कार्य का प्राथमिक ध्यान उन छद्म विशेषताओं पर है जो वास्तविक सीखने के कार्य से असंबद्ध हैं। जबकि यह विश्लेषण को सरल बनाता है और एक मजबूत नींव प्रदान करता है, कई वास्तविक दुनिया के छद्म सहसंबंधों में लेबल के साथ कुछ डिग्री का सहसंबंध हो सकता है, जिससे उन्हें अलग करना अधिक चुनौतीपूर्ण हो जाता है।
- सामान्यीकृत रैखिक प्रतिगमन सेटिंग (Generalized Linear Regression Setting): विशेषता संरेखण के लिए कठोर गणितीय प्रमाण मुख्य रूप से सामान्यीकृत रैखिक प्रतिगमन के संदर्भ में स्थापित किए गए हैं, विशेष रूप से यादृच्छिक विशेषताएँ (RF) और न्यूरल टेंगेंट कर्नेल (NTK) मॉडल के लिए। यद्यपि अनुभवजन्य परिणाम बताते हैं कि अंतर्दृष्टि अधिक जटिल डीप न्यूरल नेटवर्क (FC, CNN, ResNet) तक विस्तारित होती है, इन आर्किटेक्चर के लिए एक पूर्ण सैद्धांतिक लक्षण वर्णन एक खुला चुनौती बनी हुई है।
- विशिष्ट मॉडल प्रकार (Specific Model Types): विशेषता संरेखण स्थिरांक ($\gamma_{RF}$, $\gamma_{NTK}$) के लिए सटीक बंद-रूप अभिव्यक्तियाँ RF और NTK मॉडल के लिए प्राप्त की जाती हैं। अन्य प्रकार के मॉडल, विशेष रूप से जो गतिशील रूप से विशेषताओं को सीखते हैं, के लिए इस सटीक मापन का विस्तार करने के लिए महत्वपूर्ण अतिरिक्त सैद्धांतिक कार्य की आवश्यकता होगी।
भविष्य की दिशाएँ और चर्चा विषय (Future Directions & Discussion Topics):
- लेबल सहसंबंध के साथ छद्म विशेषताएँ (Spurious Features with Label Correlation): यदि छद्म विशेषताओं में ग्राउंड-ट्रूथ लेबल के साथ आंशिक सहसंबंध होता तो स्मरण की गतिशीलता कैसे बदलती? यह कई अनुप्रयोगों में एक अधिक यथार्थवादी परिदृश्य है। क्या वर्तमान ढांचे को "सौम्य" बनाम "दुर्भावनापूर्ण" स्मरण की डिग्री को मापने के लिए विस्तारित किया जा सकता है? इसके लिए "छद्म" की अधिक सूक्ष्म परिभाषा की आवश्यकता होगी जो इसकी भविष्य कहनेवाला शक्ति को ध्यान में रखे।
- आउट-ऑफ-डिस्ट्रीब्यूशन (OOD) छद्म विशेषताएँ (Out-of-Distribution (OOD) Spurious Features): यह पत्र मुख्य रूप से प्रशिक्षण सेट में मौजूद छद्म विशेषताओं के स्मरण की जांच करता है। क्या होता है यदि कोई मॉडल परीक्षण समय पर नए छद्म विशेषताओं का सामना करता है जो प्रशिक्षण के दौरान नहीं देखे गए थे लेकिन पहले से याद की गई छद्म विशेषताओं से सहसंबद्ध हैं? यह सीधे वितरण बदलाव मजबूती से संबंधित है। क्या हम इस तरह के OOD छद्म विशेषताओं के प्रति मॉडल की भेद्यता की भविष्यवाणी कर सकते हैं, जो उसके सीखे हुए विशेषता संरेखण के आधार पर?
- "सरलता पूर्वाग्रह" का एकीकरण (Integrating "Simplicity Bias"): पत्र "सरलता पूर्वाग्रह" का उल्लेख करता है - मॉडल की पहले "आसान" पैटर्न सीखने की प्रवृत्ति - एक संबंधित घटना के रूप में। इस वर्तमान ढांचे को औपचारिक रूप से सरलता पूर्वाग्रह को कैसे शामिल या समझाया जा सकता है? क्या विशेषता संरेखण एक तंत्र है जिसके माध्यम से सरलता पूर्वाग्रह प्रकट होता है, या वे अलग लेकिन परस्पर क्रिया करने वाली घटनाएं हैं? इस अंतःक्रिया को समझना अधिक मजबूत सीखने के एल्गोरिदम को जन्म दे सकता है।
- जटिल आर्किटेक्चर के लिए विशेषता संरेखण का लक्षण वर्णन (Characterizing Feature Alignment for Complex Architectures): अनुभवजन्य परिणाम बताते हैं कि रुझान FC, CNN, और ResNet मॉडल के लिए मान्य हैं। एक महत्वपूर्ण अगला कदम इन जटिल, विशेषता-सीखने वाले आर्किटेक्चर के लिए विशेषता संरेखण $F_\phi(z^s, z)$ को सैद्धांतिक रूप से चित्रित करना है। इसमें यह समझना शामिल होगा कि पूरी तरह से जुड़े, संवादात्मक, या ध्यान परतों द्वारा उत्पन्न विशेषता मानचित्र स्मरण को कैसे प्रभावित करते हैं। इस तरह का लक्षण वर्णन विभिन्न डीप लर्निंग मॉडल की अंतर्निहित छद्म सहसंबंधों के प्रति संवेदनशीलता की सीधी तुलना की अनुमति देगा।
- स्मरण-प्रतिरोधी मॉडल डिजाइन करना (Designing Memorization-Resistant Models): इस विश्लेषणात्मक ढांचे से लैस होकर, हम ऐसे मॉडल या प्रशिक्षण रणनीतियों को कैसे डिजाइन कर सकते हैं जो स्वाभाविक रूप से छद्म विशेषताओं को याद करने की संभावना कम रखते हैं? पत्र सक्रियण कार्यों और उनके हर्माइट गुणांकों की भूमिका पर प्रकाश डालता है। क्या हम सक्रियण कार्यों या आर्किटेक्चरल विकल्पों को इंजीनियर कर सकते हैं जो उच्च-क्रम विशेषता सीखने को बढ़ावा देते हैं, जिससे छद्म स्मरण कम हो जाता है? इसमें नवीन नियमितीकरण तकनीकों या आर्किटेक्चरल प्रेरण पूर्वाग्रहों को शामिल किया जा सकता है।
- व्यापक सामाजिक प्रभाव (Broader Societal Impact): जबकि पत्र स्पष्ट रूप से बताता है कि यह सैद्धांतिक है और सामाजिक परिणामों में गहराई से नहीं उतरता है, निष्कर्षों के निष्पक्षता, गोपनीयता और मजबूती के लिए गहन निहितार्थ हैं। उदाहरण के लिए, यदि कोई मॉडल किसी मुख्य कार्य के साथ-साथ संवेदनशील जनसांख्यिकीय जानकारी (एक छद्म विशेषता) को याद करता है, तो यह गोपनीयता संबंधी चिंताएं पैदा करता है। यदि यह भविष्यवाणियों के लिए छद्म सहसंबंधों पर निर्भर करता है, तो यह पक्षपातपूर्ण या अनुचित परिणाम दे सकता है। भविष्य का काम छद्म स्मरण के ऑडिट के लिए मौजूदा मॉडल के लिए इस ढांचे का उपयोग करने और इन जोखिमों को कम करने के लिए हस्तक्षेप विकसित करने का पता लगा सकता है, जिससे अधिक नैतिक और भरोसेमंद एआई सिस्टम में योगदान होता है। इसमें गोपनीयता रिसाव या निष्पक्षता उल्लंघनों को मापने के लिए विशेषता संरेखण के आधार पर मेट्रिक्स या उपकरण विकसित करना शामिल हो सकता है।
- इंटरपोलेशन से परे (Beyond Interpolation): यह पत्र अति-पैरामीट्रिक व्यवस्था में संचालित होता है जहां मॉडल प्रशिक्षण डेटा को इंटरपोलेट करते हैं। ये निष्कर्ष कम-पैरामीट्रिक मॉडल या उन मॉडलों पर कैसे लागू होते हैं जो शून्य प्रशिक्षण त्रुटि प्राप्त नहीं करते हैं? क्या स्थिरता और विशेषता संरेखण की अवधारणाएं उन व्यवस्थाओं में समान व्याख्यात्मक शक्ति रखती हैं?
ये चर्चा बिंदु इस बात पर प्रकाश डालते हैं कि यह पत्र एक मजबूत सैद्धांतिक आधार रखता है, जो डीप लर्निंग की अवांछित पहलुओं को समझने और कम करने में दोनों सैद्धांतिक और व्यावहारिक अनुसंधान के लिए कई रोमांचक और चुनौतीपूर्ण रास्ते खोलता है।