虚假特征的记忆机制:随机特征与NTK特征的精确分析
This paper offers a theoretical explanation for why AI models memorize irrelevant data, revealing how model stability and feature alignment play key roles.
背景与学术渊源
起源与学术渊源
深度学习模型记忆虚假特征的问题是该领域一个显著且有充分文献记载的现象,但迄今为止,缺乏一个严格的理论框架来精确量化它。这个问题之所以出现,是因为神经网络经常从训练数据中与预期任务无关的特征中学习。这可能是由于某些模式与学习任务之间存在正虚假相关性(Geirhos et al., 2020; Xiao et al., 2021),甚至是当这些模式稀少(Yang et al., 2022)或完全不相关时(Hermann & Lampinen, 2020)。这种记忆会导致模型学习到虚假关系,从而影响其在分布偏移下的鲁棒性(Geirhos et al., 2019; Zhou et al., 2021)、公平性(Zliobaite, 2015)和数据隐私(Leino & Fredrikson, 2020)。
历史上,实证研究主要集中在缓解这一现象(Plumb et al., 2022; Chang et al., 2021)。然而,避免记忆并非总是可行,因为在过参数化模型中,有时为了准确性而记忆可能是最优的,这些模型通常在被训练至零训练误差时达到最佳性能(Nakkiran et al., 2020; Feldman, 2020)。先前的理论工作已经描述了诸如良性过拟合(Belkin, 2021; Bartlett et al., 2020)以及随机特征和神经切线核(NTK)等内插模型在分布内泛化(Mei & Montanari, 2022; Ghorbani et al., 2021; Montanari & Zhong, 2022)等相关概念。
这些先前方法的根本局限性或“痛点”在于,它们通常将噪声建模为存在于标签中,而不是数据本身。因此,这种强大的理论机制并不直接涵盖输入数据中嵌入的虚假特征的记忆。尽管实际研究探索了虚假特征的影响并试图将其与核心特征分离(Hermann & Lampinen, 2020; Singla & Feizi, 2022),但理论分析主要集中在学习如何受到特征复杂度(Qiu et al., 2023)或过参数化程度(Sagawa et al., 2020)的影响,而往往未能充分捕捉模型架构的作用。本文旨在通过提供一个分析上可处理的框架来理解和量化虚假特征的记忆,特别是当它们与样本的真实标签不相关时,从而弥合这一差距。
深度学习中记忆虚假特征问题的最精确起源可以追溯到深度学习模型在训练数据上过拟合的实证观察,尤其是在过参数化区域。尽管深度学习取得了显著的成功,但研究人员开始注意到一些不良行为,即模型会学习到与任务相关但并非因果关联的模式,甚至是完全不相关的模式。
其出现背后的“原因”是多方面的:
1. 过参数化:现代深度学习模型通常拥有远超训练数据点的参数。这种容量允许它们实现零训练误差,但也使它们能够“记忆”训练数据,包括不相关的细节。Nakkiran等人(2020)和Feldman(2020)强调,实现零训练误差通常需要长时间的训练,这可能导致记忆。
2. 数据中的虚假相关性:现实世界的数据集经常包含与真实标签统计相关但并非因果关联的特征。例如,如果数据集中所有“猫”的图像恰好具有特定的“蓝色背景”,模型可能会学会将“蓝色背景”与“猫”相关联(Geirhos et al., 2020; Xiao et al., 2021)。当这些虚假相关性无法预测真实采样分布时,问题尤其严重。
3. 不相关或稀有模式:即使虚假模式稀少或与任务完全不相关,问题也会出现(Yang et al., 2022; Hermann & Lampinen, 2020)。模型仍然可以捕捉到这些模式,导致记忆。
4. 对鲁棒性、公平性和隐私的影响:这种记忆的实际影响——例如,在分布外鲁棒性差(Geirhos et al., 2019; Zhou et al., 2021)、影响公平性的有偏预测(Zliobaite, 2015)以及通过信息提取可能导致的数据隐私泄露(Leino & Fredrikson, 2020)——凸显了深入理解的紧迫性。
历史背景显示了一个从过拟合的实证观察到认识到这种过拟合通常涉及“虚假特征”而非仅仅是随机噪声的进展。然后,学术界寻求超越定性描述和实证缓解策略,转向严格的理论框架。
促使作者撰写本文的先前方法的根本局限性或“痛点”是缺乏一个精确的理论框架来量化虚假特征在嵌入输入数据中时的记忆,而不是将其建模为标签中的噪声。
先前的工作虽然强大,但主要集中在:
* 良性过拟合:描述了过拟合训练数据但仍在分布内测试数据上泛化良好的模型(Belkin, 2021; Bartlett et al., 2020)。
* 分布内泛化:分析了诸如随机特征(RF)和神经切线核(NTK)等内插模型,其中噪声通常假设存在于标签中,而不是输入特征中(Mei & Montanari, 2022; Ghorbani et al., 2021)。
关键的差距在于,这些理论工具“不涵盖虚假特征的记忆,因为噪声通常被建模为存在于标签中,而不是输入数据中。” 此外,尽管实际工作试图理解和分离虚假特征,但理论方法主要集中在特征复杂度或过参数化上,“未能捕捉架构的作用。” 本文通过提供一个分析上可处理的框架来理解和量化虚假特征记忆,明确考虑了模型架构和激活函数,直接解决了这一痛点。
直观的领域术语
为了使复杂概念对零基础读者易于理解,让我们使用日常类比来分解一些高度专业化的术语:
- 虚假特征 ($y$):想象一下您正在教一个智能机器人识别照片中的“苹果”。“核心特征”是苹果本身(它的形状、颜色、茎)。“虚假特征”可能是您所有苹果训练照片拍摄的特定厨房台面。台面存在于照片中,但与苹果的本质无关。
- 记忆(虚假特征的):当机器人不仅仅学习苹果,还“记住”了厨房台面时,就会发生这种情况。如果您稍后向它展示一个放在不同表面的苹果,它可能会犹豫甚至无法识别它,因为它错误地将“厨房台面”与“苹果性”关联起来了。机器人“记住”了一个不相关的细节。
- 特征对齐 ($F_\phi(z^s, z)$):这衡量了“无关部分”(仅厨房台面,$z^s$)在机器人内部处理视角下,与“整个画面”(放在厨房台面上的苹果,$z$)的相似程度。如果机器人的视觉系统大量处理背景,那么仅看到厨房台面可能会强烈地“对齐”其对放在该台面上的苹果的记忆。
- 稳定性 ($S_{z_1}$):这指的是如果添加或删除一个特定的训练照片(例如,一个放在厨房台面上的苹果),机器人对苹果的整体理解会发生多大的变化。“稳定”的机器人的知识不会发生剧烈变化。如果机器人“厨房台面=苹果”的信念非常不稳定,删除一张照片可能会使其完全放弃这种关联。如果它稳定,即使训练样本发生微小变化,它也会保留这种信念。
符号表
| 符号 | 描述 |
|---|---|
| $z = [x, y]$ | 一个输入样本,分解为核心特征 $x$ 和虚假特征 $y$。 |
| $x$ | 样本的核心特征,与真实标签相关。 |
| $y$ | 样本的虚假特征,与真实标签不相关。 |
| $g(x)$ | 真实标签,仅取决于核心特征 $x$。 |
| $z^s = [-, y]$ | 样本的“虚假对应体”,其中核心特征 $x$ 被移除(例如,替换为零),只留下虚假特征 $y$。 |
| $f(z, \theta^*)$ | 输入 $z$ 具有最优参数 $\theta^*$ 的模型预测函数。 |
| $\phi(z)$ | 输入 $z$ 的特征图(或特征向量),将原始数据转换为高维表示。 |
| $\theta^*$ | 从完整训练数据集中学习到的模型的最优参数。 |
| $\theta^*_{-1}$ | 从训练数据集排除样本 $z_1$ 后学习到的模型的最优参数。 |
| $S_{z_1}$ | 模型相对于训练样本 $z_1$ 的稳定性,衡量移除 $z_1$ 时输出的变化。 |
| $F_\phi(z, z_1)$ | 在 $\phi$ 诱导的特征空间中样本 $z$ 和 $z_1$ 之间的特征对齐。 |
| $P_{\Phi_{-1}}$ | 投影到特征矩阵 $\Phi_{-1}$ 的行张成的子空间上的投影算子。 |
| $R_{Z_{-1}}$ | 在数据集 $Z_{-1}$(排除 $z_1$)上训练的模型的泛化误差。 |
| $\gamma_\phi$ | 与特征对齐相关的比例常数,取决于特征图 $\phi$ 和激活函数。 |
| $\alpha = d_y/d$ | 归因于虚假特征的输入维度的比例。 |
| $h_i$ | 第 $i$ 个埃尔米特多项式,用于表征激活函数。 |
| $N$ | 训练样本的数量。 |
| $k$ | 神经元数量(对于RF)或宽度(对于NTK)。 |
| $d$ | 总输入维度。 |
| $d_x$ | 核心特征 $x$ 的维度。 |
| $d_y$ | 虚假特征 $y$ 的维度。 |
| RF | 随机特征模型。 |
| NTK | 神经切线核模型。 |
问题定义与约束
核心问题表述与困境
深度学习模型,特别是过参数化的模型,以记忆训练数据中存在的“虚假特征”而闻名。这些特征是与样本的真实标签不相关的模式或属性,但可能在训练集中与真实标签共同出现。例如,如果一个模型被训练来识别猫,而所有猫的训练图像恰好具有特定的背景(虚假特征),模型可能会学会将背景与“猫”标签关联起来,而不是猫本身。
本文旨在解决的核心问题是,缺乏一个严格的理论框架来精确量化和理解如何记忆这些虚假特征。先前的理论工作主要集中在“良性过拟合”,即噪声被建模在标签中,或者关注特征的复杂性和过参数化,而没有专门解决嵌入在输入数据中的虚假特征或模型架构的作用。
输入/当前状态:我们从在数据集中训练的深度学习模型开始,其中每个样本 $z$ 由核心特征 $x$ 和虚假特征 $y$ 组成,形式为 $z = [x, y]$。样本 $z_i$ 的真实标签 $g$ 为 $g_i = g(x_i)$,这意味着它仅取决于核心特征 $x_i$ 且与虚假特征 $y_i$ 无关。这些模型通常是过参数化的,并且训练直到它们达到零训练误差,这意味着它们完美地拟合了训练数据。形式上,我们将样本 $z$ 建模为由两个独立部分组成,即 $z = [x, y]$,其中 $x$ 是核心特征,$y$ 是虚假特征,参见图1的说明。虚假特征的记忆通过真实标签 $g$ 与模型在虚假样本 $z^s = [-, y]$(其中"-"表示移除核心特征 $x$,例如替换为全零)上的输出之间的协方差来捕捉。
输出/目标状态:期望的结果是一个分析上可处理的框架,能够精确地表征虚假特征的记忆。这包括:
1. 使用一个度量来量化记忆的程度,例如真实标签 $g_i$ 与模型在查询“虚假对应体”样本 $z_i^s = [x, y_i]$(其中 $x$ 被替换为独立特征,例如全零)时的输出之间的协方差。
2. 将这种记忆分解为两个关键组成部分:模型相对于单个训练样本的稳定性和一个新概念——原始样本和虚假样本之间的“特征对齐”。
3. 揭示模型选择(如随机特征或神经切线核架构)和激活函数如何影响这种特征对齐,进而影响虚假特征的记忆。
4. 最终目标是提供见解,从而能够设计出不易记忆虚假相关性的机器学习模型,从而提高对分布偏移的鲁棒性、公平性和数据隐私。
困境:先前研究人员陷入的痛苦的权衡,也是本文试图解决的,即避免记忆虚假特征通常与实现高精度相悖。当今普遍存在的过参数化深度学习模型,在训练至零训练误差时通常能达到最佳性能。这个完美拟合训练数据的过程常常涉及记忆虚假相关性,因为这是模型降低训练损失的“简单”方法。因此,改进一个方面(减少虚假记忆)通常会冒着损害另一个方面(整体训练准确性或核心特征的泛化能力)的风险,从而造成一个困难的平衡。
约束与失效模式
由于几个严峻的现实约束,在理论上量化深度学习中虚假特征记忆的问题本质上是具有挑战性的:
- 计算和理论可处理性:完整的深度神经网络以其复杂性而闻名,这使得它们的理论分析极其困难。本文通过关注两个简化但强大的理论模型来解决这个问题:随机特征(RF)和神经切线核(NTK)回归。选择这些模型是因为它们是“分析上可处理的”并且“在理论文献中被广泛分析”,允许精确的数学表征。这意味着将精确的分析结果扩展到任意复杂的深度学习架构仍然是一个重大障碍。
- 虚假特征的特定定义:分析严格限制在与真实学习任务不相关的虚假特征。如果虚假特征相关,问题将从纯粹的“记忆”转变为“捷径学习”或“虚假相关性利用”,这需要不同的理论处理。这是当前框架的一个关键边界条件。
- 数据分布假设:理论结果依赖于特定的数据分布假设。例如,输入样本 $z_i = [x_i, y_i]$ 被假定为独立同分布(i.i.d.)来自一个乘积分布 $P_z = P_x \times P_y$,意味着核心特征 $x_i$ 和虚假特征 $y_i$ 是独立的。此外,还假设了 $x$ 和 $y$ 的特定属性,如零均值和受控的 $L_2$ 范数($||x||_2 = \sqrt{d_x}$,$||y||_2 = \sqrt{d_y}$)。$P_x$ 和 $P_y$ 都必须满足 Lipschitz 集中性。这些假设简化了分析,但可能不适用于所有现实世界的数据集。
- 过参数化和高维性假设:该框架在特定的过参数化和高维性区域内运行。对于RF模型,需要满足条件如 $N \log^3 N = o(k)$、$\sqrt{d} \log d = o(k)$ 和 $k \log^4 k = o(d^2)$,这意味着神经元数量 $k$ 相对于数据点 $N$ 和输入维度 $d$ 很大。对于NTK模型,条件为 $N \log^3 N = o(kd)$、$N > d$ 和 $k = O(d)$。这些条件对于确保核的可逆性和模型内插数据的能力至关重要,但它们定义了一个特定的操作区域。
- 激活函数属性:激活函数 $\phi$(或其导数 $\phi'$ 对于NTK)被假定为非线性和 L-Lipschitz。这些属性对于数学推导至关重要,特别是涉及埃尔米特系数和集中不等式的内容。
- 核的可逆性:广义线性回归模型的一个基本约束是训练集上的诱导核 $K$ 必须是可逆的。这确保了模型可以完美地拟合任何一组标签 $G$,并且用于最优参数 $\theta^*$ 解的摩尔-彭罗斯逆是明确定义的。
- 泛化到现实场景:尽管本文在标准数据集(MNIST、CIFAR-10)和不同神经网络架构(全连接、卷积、ResNet)上进行了数值实验,以表明理论预测是可迁移的,但分析证明主要针对简化模型和合成数据。将这一差距与复杂、现实世界的深度学习系统进行严格的理论证明仍然是一个开放的挑战。当前的分析是一个重要的步骤,但并未完全涵盖实际深度学习设置的巨大多样性。
为什么选择这种方法
选择的必然性
选择随机特征(RF)和神经切线核(NTK)回归模型并非随意,而是由本文旨在弥合的特定理论差距驱动的战略性必要性。核心问题是理解和量化与真实学习任务不相关的虚假特征的记忆,这些特征作为噪声本身存在于输入数据中,而不仅仅是标签中。
现有的理论框架,即使是那些利用强大的工具如RF和NTK来处理良性过拟合或分布内泛化等现象的,也主要将噪声建模为存在于标签中。这种根本性的差异意味着,尽管这些模型(RF和NTK)在理论上因其分析可处理性而具有吸引力,但它们已建立的理论机制并不直接解决输入级别的虚假特征记忆问题。作者意识到,传统的“SOTA”方法,通常是实证性的(例如,标准的CNN、扩散模型或Transformer),虽然在实际任务中功能强大,但缺乏精确、可量化的理论表征这一特定记忆现象所需的分析透明度。因此,扩展RF和NTK的理论理解,它们以在相关学习理论中的分析可处理性而闻名,成为开发所需严格框架的唯一可行途径。
相对优越性
这种方法不仅通过性能指标提供了定性优势,而且通过提供前所未有的结构性优势来增强理论理解。本文引入了一个新概念:“特征对齐”($F_\phi(z, z_1)$),它量化了训练样本与其虚假对应体在特征空间中的相似性。这与经典的“模型稳定性”($S_{z_1}$)概念相结合,形成了一个双管齐下的方法来精确表征虚假特征的记忆方式。
结构优势在于该框架内RF和NTK模型的分析可处理性。它们允许为将记忆与泛化误差联系起来的比例常数($\gamma_\phi$)提供封闭形式的表达式。这种数学可解释性水平远远优于先前的实证黄金标准,后者通常在提供性能提升的同时,对底层记忆机制缺乏深入的见解。虽然该方法在计算意义上并未将内存复杂度从 $O(N^2)$ 降低到 $O(N)$ 或显式地更好地处理高维噪声,但它提供了虚假特征(建模为输入噪声)如何被记忆的可量化度量,揭示了模型架构及其激活函数在此过程中起到的关键作用。
与约束的一致性
所选方法通过利用随机特征和神经切线核的独特属性,完美地符合问题的严苛要求。主要约束是开发一个分析上可处理的框架来量化那些与真实标签不相关且嵌入在输入数据中的虚假特征的记忆。
广义线性回归设置,结合RF和NTK模型,恰恰提供了这种分析可处理性。将样本 $z$ 分解为核心特征 $x$ 和虚假特征 $y$($z = [x, y]$)的形式,其中 $y$ 与真实标签 $g(x)$ 无关,直接呼应了问题定义。该框架通过稳定性以及新颖的特征对齐项精确表征记忆的能力,允许对该现象进行直接量化。此外,所做的假设(例如,数据分布、过参数化、激活函数属性)经过精心选择,以确保数学分析的可行性并产生有意义的封闭形式表达式,从而在问题的理论需求与解决方案的分析能力之间实现了完美的“结合”。
替代方案的拒绝
本文并未明确地将GANs或扩散模型等其他流行的深度学习架构“拒绝”为在所有任务上都劣等。相反,其隐含的拒绝源于它们目前缺乏一个严格的、分析上可处理的理论框架来精确量化输入数据中的虚假特征记忆。
作者强调,尽管实际工作已经探索了虚假特征,但这些方法通常未能捕捉架构的作用或提供可量化的理论理解。现有针对RF和NTK等模型的理论机制,当应用于良性过拟合等问题时,通常将噪声建模在标签中,而不是作为输入中的虚假特征。这意味着,尽管这些模型(RF/NTK)本身功能强大,但它们现有的理论分析不足以解决手头上的特定问题。本文的贡献是扩展RF和NTK的理论分析,以涵盖虚假特征记忆,而不是提出一个全新的模型。因此,“拒绝”的不是模型本身,而是当前理论工具的不足,无法提供本文所寻求的关于输入级别虚假特征记忆的深刻、可量化的见解。
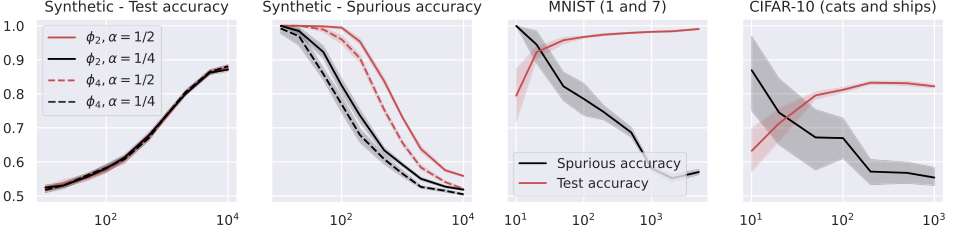 Figure 2. Test and spurious accuracies as a function of the number of training samples N, for various binary classification tasks. In the first two plots, we consider the RF model in (14) with k = 105 trained over Gaussian data with d = 1000. The labeling function is g(x) = sign(u⊤x). We repeat the experiments for α = {0.25, 0.5} and for the two activations ϕ2 = h1 + h2 and ϕ4 = h1 + h4, where hi denotes the i-th Hermite polynomial (see Appendix A.1). In the last two plots, we consider the same model with ReLU activation, trained over two MNIST and CIFAR-10 classes. The width of the noise background is 10 pixels for MNIST and 8 pixels for CIFAR-10, see Figure 1. The spurious accuracy is obtained by querying the model only with the noise background from the training set, replacing all the other pixels with 0, and taking the sign of the output. As we consider binary classification, an accuracy of 0.5 is achieved by random guessing. We plot the average over 10 independent trials and the confidence band at 1 standard deviation
Figure 2. Test and spurious accuracies as a function of the number of training samples N, for various binary classification tasks. In the first two plots, we consider the RF model in (14) with k = 105 trained over Gaussian data with d = 1000. The labeling function is g(x) = sign(u⊤x). We repeat the experiments for α = {0.25, 0.5} and for the two activations ϕ2 = h1 + h2 and ϕ4 = h1 + h4, where hi denotes the i-th Hermite polynomial (see Appendix A.1). In the last two plots, we consider the same model with ReLU activation, trained over two MNIST and CIFAR-10 classes. The width of the noise background is 10 pixels for MNIST and 8 pixels for CIFAR-10, see Figure 1. The spurious accuracy is obtained by querying the model only with the noise background from the training set, replacing all the other pixels with 0, and taking the sign of the output. As we consider binary classification, an accuracy of 0.5 is achieved by random guessing. We plot the average over 10 independent trials and the confidence band at 1 standard deviation
数学与逻辑机制
主方程
本文理解虚假特征如何被记忆的核心机制,依赖于三个相互关联的数学定义:模型的稳定性、样本之间的特征对齐,以及将它们联系起来的关系。这些方程共同描述了训练模型对单个训练点的敏感性,以及这种敏感性如何被特征空间中特征的相似性所调节。
首先,模型相对于训练样本 $z_1$ 的稳定性定义为:
$$S_{z_1} := f(\cdot, \theta^*) - f(\cdot, \theta^*_{-1}) \quad (5)$$
该量衡量了当一个特定的训练样本 $z_1$ 被包含或排除在训练数据集之外时,模型输出的变化程度。
其次,在由特征图 $\phi$ 诱导的特征空间中,两个样本 $z$ 和 $z_1$ 之间的特征对齐定义为:
$$F_\phi(z, z_1) := \frac{\phi(z)^\top P_{\Phi_{-1}} \phi(z_1)}{\|P_{\Phi_{-1}}\phi(z_1)\|_2^2} \quad (8)$$
该项量化了通用样本 $z$ 的特征表示与特定训练样本 $z_1$ 的特征表示在投影到由其余训练数据定义的子空间后的相似性或“对齐度”。
最后,稳定性与特征对齐之间的关键联系由引理4.1建立,该引理指出:
$$S_{z_1}(z) = F_\phi(z, z_1) S_{z_1}(z_1) \quad (9)$$
该方程揭示了模型对任何样本 $z$ 的输出稳定性(当 $z_1$ 被移除时)直接与其自身 $z_1$ 的稳定性成正比,并由它们的特征对齐进行缩放。这种优雅的关系构成了本文对记忆分析的基石。
按项解剖
让我们仔细分析这些主方程的每个组成部分,以理解它们的精确数学定义、在模型中的物理或逻辑作用,以及选择特定数学运算的理由。
方程 (5):稳定性 $S_{z_1}$
* $S_{z_1}$:该符号代表模型相对于训练样本 $z_1$ 的稳定性。
* 数学定义:表示模型预测差异的标量值。
* 物理/逻辑作用:它量化了单个训练样本 $z_1$ 对模型输出的影响。较大的 $S_{z_1}$ 意味着移除 $z_1$ 会显著改变模型的预测,表明 $z_1$ 被“记忆”或具有强烈影响。
* $f(\cdot, \theta^*)$:这是在完整数据集上训练的模型的预测函数。
* 数学定义:$f(z, \theta^*) = \phi(z)\theta^*$,其中 $\phi(z)$ 是输入 $z$ 的特征向量,$\theta^*$ 是从整个训练集 $Z$ 中学习到的最优参数。
* 物理/逻辑作用:表示在所有可用训练数据都用于学习其参数时模型的输出。
* $f(\cdot, \theta^*_{-1})$:这是在不包含 $z_1$ 的数据集上训练的模型的预测函数。
* 数学定义:$f(z, \theta^*_{-1}) = \phi(z)\theta^*_{-1}$,其中 $\theta^*_{-1}$ 是从训练集 $Z_{-1}$(即 $Z$ 排除 $z_1$)学习到的最优参数。
* 物理/逻辑作用:表示在训练过程中省略特定训练样本 $z_1$ 时的模型输出。
* $- (减法)$:
* 为何使用:减法用于直接衡量模型输出由于 $z_1$ 的存在或不存在而产生的变化或差异。这是量化影响或敏感性的标准方法。如果使用乘法,它将衡量比率,这并非所需的“变化”度量。
方程 (8):特征对齐 $F_\phi(z, z_1)$
* $F_\phi(z, z_1)$:该符号表示样本 $z$ 和训练样本 $z_1$ 之间的特征对齐。
* 数学定义:表示归一化投影的标量值。
* 物理/逻辑作用:它衡量了通用样本 $z$ 的特征表示与特定训练样本 $z_1$ 的特征表示在特征空间中的“相似度”。这种相似度至关重要,因为它表明关于 $z_1$ 的信息可能在模型的内部表示中被“转移”或“对齐”。
* $\phi(z)$:输入样本 $z$ 的特征图。
* 数学定义:通过将特征图函数 $\phi: \mathbb{R}^d \to \mathbb{R}^p$ 应用于输入 $z \in \mathbb{R}^d$ 得到的向量 $\phi(z) \in \mathbb{R}^p$。
* 物理/逻辑作用:它将原始输入数据 $z$ 转换为线性模型操作的更高维特征表示。这是模型对输入的“理解”。
* $\phi(z_1)$:训练样本 $z_1$ 的特征图。
* 数学定义:与 $\phi(z)$ 类似,但针对特定训练样本 $z_1$。
* 物理/逻辑作用:表示模型对正在研究其影响的训练样本的内部特征表示。
* $P_{\Phi_{-1}}$:投影到 $\Phi_{-1}$ 行张成的子空间上的投影算子。
* 数学定义:一个投影矩阵 $P_{\Phi_{-1}} \in \mathbb{R}^{p \times p}$,使得 $P_{\Phi_{-1}} = \Phi_{-1}^\top (\Phi_{-1}\Phi_{-1}^\top)^{-1} \Phi_{-1}$(如果 $\Phi_{-1}\Phi_{-1}^\top$ 可逆)。它将向量投影到 $\Phi_{-1}$ 的行空间。
* 物理/逻辑作用:该投影算子通过考虑其余训练样本(排除 $z_1$)的特征子空间来有效地“过滤掉”或“归一化”特征向量。这确保了对齐是相对于数据集中其他信息的集体度量的,使其成为衡量独特对齐的更稳健的度量。
* $\top (转置)$:
* 为何使用:转置用于执行两个向量 $\phi(z)$ 和 $P_{\Phi_{-1}}\phi(z_1)$ 之间的内积(点积)。此操作量化了两个特征向量之间的线性相关性或相似性。
* $\cdot$ (乘法):
* 为何使用:矩阵-向量乘法(例如,$P_{\Phi_{-1}}\phi(z_1)$)应用投影算子定义的线性变换。向量-向量乘法(点积)量化相似性。
* $\|\cdot\|_2^2$:平方 L2 范数。
* 数学定义:对于向量 $v$,$\|v\|_2^2 = v^\top v = \sum_i v_i^2$。
* 物理/逻辑作用:分母中的这一项对齐进行了归一化。它确保 $F_\phi(z, z_1)$ 是一个相对对齐的度量,使其对特征向量本身的尺度不变。它本质上衡量了特征空间中的余弦相似度(或相关的投影)。
* $/$ (除法):
* 为何使用:除以平方 L2 范数是归一化步骤,在定义投影或相似度时很常见,确保对齐度量被正确缩放。
方程 (9):关系 $S_{z_1}(z) = F_\phi(z, z_1) S_{z_1}(z_1)$
* $S_{z_1}(z)$:模型在通用样本 $z$ 上的输出稳定性。
* 数学定义:$f(z, \theta^*) - f(z, \theta^*_{-1})$。
* 物理/逻辑作用:这是当 $z_1$ 被移除时,模型对样本 $z$ 的预测的具体变化。
* $S_{z_1}(z_1)$:模型在训练样本 $z_1$ 本身上的输出稳定性。
* 数学定义:$f(z_1, \theta^*) - f(z_1, \theta^*_{-1})$。
* 物理/逻辑作用:这代表了 $z_1$ 对其自身预测的直接影响。如果模型完美内插,则 $f(z_1, \theta^*) = g_1$,因此该项变为 $g_1 - f(z_1, \theta^*_{-1})$,表示 $z_1$ 标签的“记忆”。
* $\cdot$ (乘法):
* 为何使用:乘法用于表示直接比例关系。对 $z$ 的预测变化是 $z_1$ 变化的缩放版本,缩放因子是特征对齐。这暗示了线性关系:如果 $z$ 在特征空间中与 $z_1$ 高度对齐,那么移除 $z_1$ 将像影响 $z_1$ 的预测一样影响 $z$ 的预测。
分步流程
想象一个数据点 $z$ 进入这个数学引擎,以及一个特定的训练样本 $z_1$ 及其虚假对应体 $z^s$。目标是理解 $z^s$ 的模型输出可能如何受到 $z_1$ 的影响,这表明了记忆。
- 特征提取:首先,原始输入 $z$ 和特定训练样本 $z_1$ 被馈送到模型的特征图 $\phi$ 中。这会将它们转换为内部特征表示 $\phi(z)$ 和 $\phi(z_1)$。可以将其视为初始处理单元,将原始数据转换为模型可以“理解”的格式。
- 子空间投影:接下来,使用投影算子 $P_{\Phi_{-1}}$ 将 $\phi(z_1)$ 投影到由其他所有训练样本 $\Phi_{-1}$ 的特征张成的子空间上。此步骤将 $z_1$ 特征的独特贡献与其余训练数据隔离开来。
- 特征对齐计算:然后,通过内积将投影后的 $\phi(z_1)$ 与 $\phi(z)$ 进行比较,并除以投影后的 $\phi(z_1)$ 的幅度进行归一化。这计算出 $F_\phi(z, z_1)$,即特征对齐。此单元确定 $z$ 在模型特征空间中与 $z_1$ 的“相似度”,同时考虑了其他训练数据的背景。
- 模型训练(隐式):同时,“训练”了两个模型版本。一个版本 $f(\cdot, \theta^*)$ 使用整个训练数据集 $Z$(包括 $z_1$)。另一个版本 $f(\cdot, \theta^*_{-1})$ 使用数据集 $Z_{-1}$(排除 $z_1$)。参数 $\theta^*$ 和 $\theta^*_{-1}$ 来自这些训练过程。
- 在 $z_1$ 处的稳定性测量:使用两种参数集计算模型在 $z_1$ 处的输出:$f(z_1, \theta^*)$ 和 $f(z_1, \theta^*_{-1})$。计算这两个输出之间的差值 $S_{z_1}(z_1) = f(z_1, \theta^*) - f(z_1, \theta^*_{-1})$。此单元衡量 $z_1$ 本身改变模型对 $z_1$ 的预测的程度。如果模型完美内插,则 $f(z_1, \theta^*) = g_1$,因此该项变为 $g_1 - f(z_1, \theta^*_{-1})$,表示 $z_1$ 标签的“记忆”。
- 传播稳定性:现在,将特征对齐 $F_\phi(z, z_1)$ 和 $z_1$ 处的稳定性 $S_{z_1}(z_1)$ 相乘,得到 $S_{z_1}(z) = F_\phi(z, z_1) S_{z_1}(z_1)$。这意味着 $z_1$ 对通用样本 $z$ 的影响直接与其在特征空间中与 $z_1$ 的对齐程度成正比,并由 $z_1$ 本身的影响进行缩放。
- 量化记忆:最后,为了量化虚假特征的记忆,本文考虑了协方差
Cov(f(z^s, θ*), g_i)。这包括在虚假样本 $z^s = [-, y]$(其中核心特征 $x$ 被移除或置零,只留下虚假特征 $y$)上评估模型,并将其输出与真实标签 $g_i$(仅取决于 $x_i$)进行关联。推导出的关系(方程11)表明,该协方差受 $\gamma_\phi \sqrt{R_{Z_{-1}}} \sqrt{\text{Var}(g_i)}$ 的界限约束,其中 $\gamma_\phi$ 是与特征对齐相关的常数,$R_{Z_{-1}}$ 是泛化误差。这一最终步骤将特征处理和稳定性的机械组装线与虚假特征记忆的最终度量联系起来。
优化动力学
本文在广义线性回归框架内运行,其中模型参数 $\theta$ 通过最小化二次损失的经验风险来学习,如方程 (2) 所示:$\min_\theta \| \Phi \theta - G \|_2^2$。在此设置下,优化过程导致最优参数 $\theta^*$ 的封闭形式解,由方程 (3) 给出:$\theta^* = \theta_0 + \Phi^+(G - f(Z, \theta_0))$。
这意味着“学习”或“优化动力学”不是关于在传统意义上探索复杂损失景观的迭代梯度下降过程,而是关于这个直接的、内插解的属性。本文明确指出,“梯度下降收敛到最接近初始化 $l_2$ 范数的内插器。”这表明模型被训练以实现零训练误差,这是过参数化模型的一个特征。
这里分析的关键“动力学”是:
1. 内插:模型完美拟合训练数据的能力(实现零训练误差)是过参数化区域和所选优化目标的结果。这种内插允许记忆虚假特征。
2. 泛化误差的作用:本文的主要结果(方程11)表明,虚假特征的记忆(由 Cov(f(z^s, θ*), g_i) 量化)与泛化误差 $R_{Z_{-1}}$ 成正比。这意味着随着模型泛化到未见数据的能力提高(即 $R_{Z_{-1}}$ 减小),其记忆虚假特征的倾向也减弱。这是对内插解行为的一个关键见解。
3. 特征对齐的影响:记忆边界(方程11)中的比例常数 $\gamma_\phi$ 来自特征对齐 $F_\phi(z_1, z_1)$。该常数取决于特征图 $\phi$ 和激活函数,它塑造了“损失景观”,从而决定了即使模型泛化良好,虚假特征的记忆强度。较高的 $\gamma_\phi$ 意味着给定泛化误差下记忆程度更高。本文对RF和NTK模型的分析精确地表征了这一 $\gamma_\phi$,揭示了模型架构和激活函数如何影响记忆。
4. 稳定性作为代理:稳定性 $S_{z_1}(z_1)$ 作为模型为实现内插而依赖单个训练点的度量。如果 $S_{z_1}(z_1)$ 很大,则模型对 $z_1$ 高度敏感,表明 $z_1$ 被强烈“记忆”。优化过程通过找到一个内插解,固有地产生了这种稳定性,然后这种稳定性通过特征对齐传播,影响虚假记忆。
本质上,“优化动力学”是通过内插解 $\theta^*$ 的特性来理解的,而不是通过寻找它的迭代步骤。模型学会完美地拟合数据,本文分析了这种学习策略的固有权衡和后果,特别是关于无关信息的记忆。虽然梯度会导向 $\theta^*$,但它们在迭代行为中的表现并未被明确分析,而是分析了其最终状态的特性。
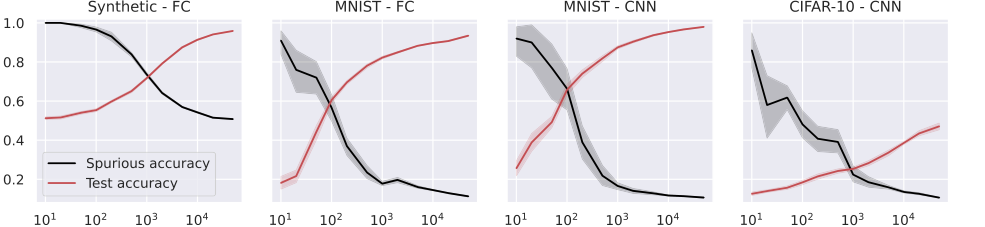 Figure 4. Test and spurious accuracies as a function of the number of training samples N, for a fully connected (FC, first two plots), and a small convolutional neural network (CNN, last two plots). In the first plot, we use synthetic (Gaussian) data with d = 1000, and the labeling function is g(x) = sign(u⊤x). As we consider binary classification, the accuracy of random guessing is 0.5. The other plots use subsets of the MNIST and CIFAR-10 datasets, with an external layer of noise added to images, see Figure 1. As we consider 10 classes, the accuracy of random guessing is 0.1. We plot the average over 10 independent trials and the confidence band at 1 standard deviation
Figure 4. Test and spurious accuracies as a function of the number of training samples N, for a fully connected (FC, first two plots), and a small convolutional neural network (CNN, last two plots). In the first plot, we use synthetic (Gaussian) data with d = 1000, and the labeling function is g(x) = sign(u⊤x). As we consider binary classification, the accuracy of random guessing is 0.5. The other plots use subsets of the MNIST and CIFAR-10 datasets, with an external layer of noise added to images, see Figure 1. As we consider 10 classes, the accuracy of random guessing is 0.1. We plot the average over 10 independent trials and the confidence band at 1 standard deviation
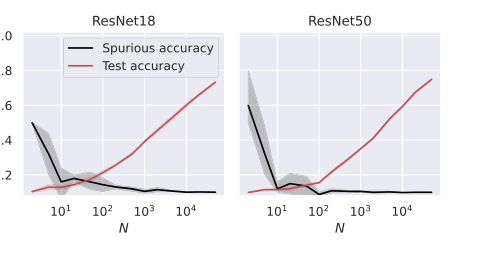 Figure 5. Test and spurious accuracies as a function of the number of training samples N, for two ResNet architectures. We use subsets of the CIFAR-10 dataset, with an external layer of noise added to images, see Figure 1. As we consider 10 classes, the accuracy of random guessing is 0.1. We plot the average over 10 independent trials and the confidence band at 1 standard deviation
Figure 5. Test and spurious accuracies as a function of the number of training samples N, for two ResNet architectures. We use subsets of the CIFAR-10 dataset, with an external layer of noise added to images, see Figure 1. As we consider 10 classes, the accuracy of random guessing is 0.1. We plot the average over 10 independent trials and the confidence band at 1 standard deviation
结果、局限性与结论
实验设计与基线
为了严格验证其理论主张,作者精心设计了一系列实验,将他们的数学预测与各种模型类型和数据集上的实证观察进行对比。核心思想是创建存在虚假特征(不相关的噪声或背景信息)但对真实标签不具预测性的训练数据场景。然后,他们测量了模型“记忆”这些不相关特征的程度。
这些实验中的“受害者”并非传统意义上的替代模型,而是所研究的随机特征(RF)和神经切线核(NTK)模型本身,以及更复杂的深度学习架构,如全连接(FC)、卷积神经网络(CNN)和ResNet(ResNet18、ResNet50)。目标是展示这些模型在训练时如何不可避免地捕捉并依赖虚假相关性,以及这种行为如何被精确表征。
实验设置包括:
- 数据生成:
- 合成数据:使用具有输入维度 $d=1000$ 的高斯数据进行二分类任务。这允许精确控制数据属性。
- 标准数据集:使用MNIST(用于分类数字“1”和“7”)和CIFAR-10(用于分类“猫”和“船”)来测试理论对真实图像数据的适用性。
- 虚假特征注入:对于所有数据集,都引入了一个虚假特征 $y$。这通常是在原始图像 $x$ 周围添加的噪声背景,形成输入样本 $z = [x, y]$(如图1所示)。关键是,这个 $y$ 被设计为与真实标签 $g(x)$ 不相关。对于MNIST和CIFAR-10,在查询虚假准确性时,核心特征 $x$ 被替换为零,这意味着模型仅在噪声分量上进行测试。
- 模型架构:
- RF和NTK模型:这些是主要的理论目标,具有不同数量的神经元($k$)和在不同数量的样本($N$)上进行训练。
- 深度神经网络:还测试了FC、CNN和ResNet架构,以表明理论见解不仅限于简化的RF/NTK区域,还扩展到更复杂的、学习特征的模型。
- 关键实验参数:
- 训练样本数量($N$):显著变化(例如,从 $10^1$ 到 $10^4$),以观察其对泛化和记忆的影响。
- 激活函数($\phi$):使用了不同的激活函数,其特点是埃尔米特系数(例如,RF的 $\phi_2 = h_1 + h_2$、$\phi_4 = h_1 + h_4$;NTK的 $\phi_2 = h_0 + h_1$、$\phi_4 = h_0 + h_3$,其中 $h_i$ 是埃尔米特多项式)。还测试了ReLU激活函数。选择激活函数被预测会影响记忆。
- 虚假特征比例($\alpha$):定义为 $d_y/d$,该参数表示归因于虚假特征的输入维度比例。也研究了其对记忆的影响。
- 记忆测量:证明记忆的最直接和“无情”的方法是通过“虚假准确性”。这是通过将训练好的模型仅输入样本的虚假分量($y$)(例如,将核心特征 $x$ 替换为零)并检查模型是否仍然预测正确标签 $g(x)$ 来计算的。如果模型仅在虚假分量上实现了高准确性,则明确证明了记忆。
- 准确性基线:对于二分类任务,随机猜测准确性0.5作为下限。对于10类分类(CIFAR-10、MNIST),随机猜测的准确性为0.1。将模型的性能与这些平凡基线进行比较。所有实验都经过10次独立试验的平均,置信区间表示1个标准差。
证据证明的内容
实证证据压倒性地支持了本文的核心理论主张,提供了确凿、无可辩驳的证明,即所提出的数学框架能够准确地表征虚假特征的记忆。核心机制,即记忆是模型稳定性和所谓的“特征对齐”概念共同作用的结果,得到了有力验证。
以下是证据明确证明的内容:
-
泛化与记忆之间的反比关系:图2、3、4和5一致地展示了一个清晰的反比关系:随着训练样本数量($N$)的增加,模型的测试准确性(泛化能力的代理)提高,而其虚假准确性(记忆的直接度量)则降低。这是理论预测“随着泛化能力提高,虚假特征的记忆减弱”(摘要,第1页)以及记忆与泛化误差成正比(方程11、18、27)的有力证据。模型,无论其架构如何,都是这种权衡的“受害者”,表明更好的泛化能力会固有地减少对虚假线索的依赖。
-
激活函数的关键作用:实验为激活函数在记忆中起关键作用的理论见解提供了强有力的验证。
- 对于合成数据上的随机特征(RF)模型(图2),观察到虚假准确性随着 $\alpha$(虚假输入比例)的增加以及使用具有主导低阶埃尔米特系数的激活函数时而增加。这直接符合定理5.4和方程17中的理论预测,该预测显示 $\gamma_{RF}$(特征对齐常数)取决于这些系数。
- 对于MNIST和CIFAR-10上的神经切线核(NTK)模型(图3),结果表明具有主导高阶埃尔米特系数的激活函数导致记忆减少。这与定理6.3和方程26一致,该定理描述了 $\gamma_{NTK}$ 对激活函数导数埃尔米特系数的依赖性。这表明激活函数的特定数学属性,如其埃尔米特展开所捕捉到的,直接决定了模型记忆的倾向。
-
对虚假特征比例($\alpha$)的依赖性:图7提供了令人信服的证据,表明虚假准确性随 $\alpha$(输入中虚假部分的比例)单调增长。这在RF和NTK模型在合成数据上都观察到了。关键是,测试准确性在很大程度上不受 $\alpha$ 的影响。这直接证实了特征对齐常数($\gamma_{RF}$、$\gamma_{NTK}$)对 $\alpha$ 的理论依赖性,如定理5.4和6.3所建立的。虚假信息越多,模型记忆的就越多,而核心任务性能并未必然提高。
-
跨架构的广泛适用性:除了简化的RF和NTK模型之外,本文还将其实证验证扩展到更复杂的深度学习架构,包括全连接(FC)、卷积神经网络(CNN)和ResNet(图4和5)。这些实验表明,随着训练样本的增加,观察到的趋势——测试准确性提高,虚假准确性降低——在这些不同的模型中都成立。这表明,由特征对齐和稳定性框架阐明的记忆及其与泛化关系的潜在原理,不仅限于线性模型,而且广泛适用于现代深度学习。这为理论框架见解的普遍性提供了有力支持,即使精确的数学表征是为更简单的模型推导的。
总之,实验被设计用来隔离和衡量虚假特征的影响,并且在各种设置中一致的趋势提供了无可辩驳的证据,表明所提出的理论框架能够准确地捕捉机器学习模型中虚假特征记忆的复杂现象。
局限性与未来方向
尽管本文为理解虚假特征的记忆方式提供了一个出色且精确的理论框架,但认识到其当前的界限并考虑如何进一步发展这些发现至关重要。作者自己也提供了对未来研究的富有洞察力的方向,这可以激发对该领域演变的批判性思考。
当前分析的局限性:
- 虚假特征的范围:本工作的主要重点是与真实学习任务不相关的虚假特征。虽然这简化了分析并提供了一个坚实的基础,但许多现实世界的虚假相关性可能与标签具有一定程度的相关性,这使得它们更难分离。
- 广义线性回归设置:特征对齐的严格数学证明主要在广义线性回归的背景下建立,特别是针对随机特征(RF)和神经切线核(NTK)模型。尽管实证结果表明这些见解可以扩展到更复杂的深度神经网络(FC、CNN、ResNet),但对这些架构进行完整的理论表征仍然是一个开放的挑战。
- 特定模型类型:特征对齐常数($\gamma_{RF}$、$\gamma_{NTK}$)的精确封闭形式表达式是为RF和NTK模型推导的。将这种精确量化扩展到其他类型的模型,特别是那些动态学习特征的模型,将需要大量的额外理论工作。
未来方向与讨论主题:
- 具有标签相关性的虚假特征:如果虚假特征与真实标签部分相关,记忆动力学将如何变化?在许多应用中,这种情况更为现实。能否扩展当前框架来量化在这种情况下“良性”与“恶意”记忆的程度?这将需要对“虚假”进行更细致的定义,以考虑其预测能力。
- 分布外(OOD)虚假特征:本文主要研究训练集中存在的虚假特征的记忆。如果模型在测试时遇到新颖的虚假特征,这些特征在训练时未见过但与先前记忆的虚假特征相关,会发生什么?这直接关系到分布偏移鲁棒性。能否根据模型学习到的特征对齐来预测模型对这种 OOD 虚假特征的脆弱性?
- 整合“简单性偏见”:本文提到了“简单性偏见”——模型倾向于先学习“简单”模式——作为一个相关现象。当前框架如何正式地整合或解释简单性偏见?特征对齐是简单性偏见表现出来的机制,还是它们是不同但相互作用的现象?理解这种相互作用可能导致更鲁棒的学习算法。
- 复杂架构的特征对齐表征:实证结果表明,趋势对于FC、CNN和ResNet模型是成立的。一个关键的下一步是理论上表征这些复杂、学习特征的架构的特征对齐 $F_\phi(z^s, z)$。这将涉及理解由多个全连接、卷积或注意力层生成的特征图如何影响记忆。这种表征将允许直接比较不同深度学习模型固有的对虚假相关性的易感性。
- 设计抗记忆模型:有了这个分析框架,我们如何设计模型或训练策略,使其固有地不易记忆虚假特征?本文强调了激活函数及其埃尔米特系数的作用。能否设计激活函数或架构选择,以促进高阶特征学习,从而减少虚假记忆?这可能涉及新颖的正则化技术或架构归纳偏置。
- 更广泛的社会影响:尽管本文明确声明其理论性质且不深入探讨社会后果,但其研究结果对公平性、隐私和鲁棒性具有深远影响。例如,如果一个模型在核心任务之外记忆了敏感的统计信息(虚假特征),就会引发隐私担忧。如果它依赖虚假相关性进行预测,则可能导致不公平或有偏见的结果。未来的工作可以探索如何利用该框架来审计现有模型是否存在虚假记忆,并开发干预措施来缓解这些风险,从而为更值得信赖和合乎道德的 AI 系统做出贡献。这可能涉及开发基于特征对齐的度量或工具来量化隐私泄露或公平性违规。
- 超越内插:本文在模型内插训练数据的过参数化区域内运行。这些发现如何转化为欠参数化模型或不实现零训练误差的模型?在这些区域,稳定性和特征对齐的概念是否仍然具有相同的解释力?
这些讨论点表明,本文奠定了一个坚实的理论基础,为理解和缓解深度学习的不足之处开辟了许多令人兴奋且充满挑战的理论和应用研究途径。
与其他领域的同构性
结构骨架
其核心在于,本文提出了一种机制,用于量化高维特征空间中完整数据样本与其虚假分量之间的对齐,并将这种对齐与模型稳定性和无关信息“记忆”联系起来。