Как запоминаются ложные признаки: Точный анализ случайных признаков и признаков нейронного касательного ядра
Проблема запоминания ложных признаков моделями глубокого обучения является значительным и хорошо документированным явлением в данной области, однако строгая теоретическая основа для его точной количественной оценки в...
Предпосылки и академическая родословная
Истоки и академическая родословная
Проблема запоминания ложных признаков моделями глубокого обучения является значительным и хорошо документированным явлением в данной области, однако строгая теоретическая основа для его точной количественной оценки в значительной степени отсутствовала. Эта проблема возникает из-за того, что нейронные сети часто обучаются на признаках в обучающих данных, которые не имеют непосредственного отношения к поставленной задаче. Это может происходить из-за положительных ложных корреляций между определенными паттернами и задачей обучения (Geirhos et al., 2020; Xiao et al., 2021), или даже когда эти паттерны редки (Yang et al., 2022) или просто нерелевантны (Hermann & Lampinen, 2020). Такое запоминание приводит к тому, что модели изучают ложные взаимосвязи, что влияет на их устойчивость к сдвигам распределения (Geirhos et al., 2019; Zhou et al., 2021), справедливость (Zliobaite, 2015) и конфиденциальность данных (Leino & Fredrikson, 2020).
Исторически эмпирические усилия были сосредоточены на смягчении этого явления (Plumb et al., 2022; Chang et al., 2021). Однако избегание запоминания не всегда возможно, поскольку иногда оно может быть оптимальным для точности в перепараметризованных моделях, которые часто достигают наилучшей производительности при обучении до нулевой ошибки на обучающей выборке (Nakkiran et al., 2020; Feldman, 2020). Предыдущие теоретические работы характеризовали связанные понятия, такие как доброкачественное переобучение (benign overfitting) (Belkin, 2021; Bartlett et al., 2020) и обобщение в пределах распределения (in-distribution generalization) для интерполирующих моделей, таких как случайные признаки (random features) и нейронные касательные ядра (neural tangent kernels) (Mei & Montanari, 2022; Ghorbani et al., 2021; Montanari & Zhong, 2022).
Фундаментальным ограничением или "болевой точкой" этих предыдущих подходов является то, что они обычно моделируют шум как присущий меткам, а не самим входным данным. Следовательно, этот мощный теоретический аппарат не охватывает напрямую запоминание ложных признаков, встроенных во входные данные. В то время как практические исследования изучали влияние ложных признаков и пытались отделить их от основных признаков (Hermann & Lampinen, 2020; Singla & Feizi, 2022), теоретический анализ преимущественно фокусировался на том, как обучение зависит от сложности признаков (Qiu et al., 2023) или степени перепараметризации (Sagawa et al., 2020), часто без полного охвата роли архитектуры модели. Данная работа направлена на устранение этого пробела путем предоставления аналитически управляемой структуры для понимания и количественной оценки запоминания ложных признаков, особенно когда они некоррелированы с истинной меткой выборки.
Наиболее точное происхождение проблемы запоминания ложных признаков в глубоком обучении можно проследить до эмпирических наблюдений моделей глубокого обучения, переобучающихся на обучающих данных, особенно в режимах перепараметризации. В то время как глубокое обучение достигло замечательных успехов, исследователи начали замечать нежелательное поведение, при котором модели изучали паттерны, коррелированные с задачей, но не причинно связанные с ней, или даже совершенно нерелевантные паттерны.
"Почему" его возникновения многогранно:
1. Перепараметризация: Современные модели глубокого обучения часто имеют гораздо больше параметров, чем точек обучающих данных. Эта мощность позволяет им достигать нулевой ошибки на обучающей выборке, но также позволяет им "запоминать" обучающие данные, включая нерелевантные детали. Nakkiran et al. (2020) и Feldman (2020) подчеркнули, что достижение нулевой ошибки на обучающей выборке часто требует длительного времени обучения, что может привести к запоминанию.
2. Ложные корреляции в данных: Реальные наборы данных часто содержат признаки, которые статистически коррелированы с истинной меткой, но не связаны причинно. Например, если все изображения "кошек" в наборе данных случайно имеют определенный "синий фон", модель может научиться ассоциировать "синий фон" с "кошкой" (Geirhos et al., 2020; Xiao et al., 2021). Это особенно проблематично, когда эти ложные корреляции не являются предиктивными для истинного распределения выборки.
3. Нерелевантные или редкие паттерны: Проблема также возникает даже тогда, когда ложные паттерны редки или просто нерелевантны для задачи (Yang et al., 2022; Hermann & Lampinen, 2020). Модели все еще могут улавливать эти паттерны, что приводит к запоминанию.
4. Последствия для устойчивости, справедливости и конфиденциальности: Практические последствия этого запоминания — такие как плохая устойчивость вне распределения (out-of-distribution robustness) (Geirhos et al., 2019; Zhou et al., 2021), предвзятые прогнозы, влияющие на справедливость (Zliobaite, 2015), и потенциальные нарушения конфиденциальности данных через извлечение информации (Leino & Fredrikson, 2020) — подчеркнули острую необходимость более глубокого понимания.
Исторический контекст показывает прогресс от эмпирических наблюдений переобучения к признанию того, что это переобучение часто включает "ложные признаки", а не просто случайный шум. Затем академическая область стремилась выйти за рамки качественных описаний и эмпирических стратегий смягчения последствий к строгой теоретической основе.
Фундаментальным ограничением или "болевой точкой" предыдущих подходов, которые побудили авторов написать эту статью, является отсутствие точной теоретической основы для количественной оценки запоминания ложных признаков, когда они встроены во входные данные, а не моделируются как шум в метках.
Предыдущие работы, хотя и мощные, в основном фокусировались на:
* Доброкачественное переобучение (Benign Overfitting): Характеристика моделей, которые переобучаются на обучающих данных, но все же хорошо обобщаются на тестовых данных в пределах распределения (Belkin, 2021; Bartlett et al., 2020).
* Обобщение в пределах распределения (In-distribution Generalization): Анализ интерполирующих моделей, таких как случайные признаки (RF) и нейронные касательные ядра (NTK), где шум обычно предполагается в метках, а не во входных признаках (Mei & Montanari, 2022; Ghorbani et al., 2021).
Ключевым пробелом было то, что эти теоретические инструменты "не охватывают запоминание ложных признаков, поскольку шум обычно моделируется как присутствующий в метках, а не во входных данных." Кроме того, в то время как практическая работа пыталась понять и отделить ложные признаки, теоретические подходы в основном оставались сосредоточенными на сложности признаков или перепараметризации, "без охвата роли архитектуры." Данная статья напрямую решает эту болевую точку, предоставляя аналитически управляемую основу для понимания и количественной оценки запоминания ложных признаков, явно учитывая архитектуру модели и функцию активации.
Интуитивные термины предметной области
Чтобы сделать сложные концепции доступными для читателя с нулевой базой, давайте разберем некоторые высокоспециализированные термины с помощью повседневных аналогий:
- Ложные признаки ($y$): Представьте, что вы учите умного робота распознавать "яблоки" на фотографиях. "Основной признак" — это само яблоко (его форма, цвет, стебель). "Ложный признак" может быть конкретной кухонной столешницей, на которой были сделаны все ваши обучающие фотографии яблок. Столешница присутствует на фотографиях, но она не имеет никакого отношения к тому, что делает яблоко яблоком.
- Запоминание (ложных признаков): Это происходит, когда робот, вместо того чтобы просто учиться яблокам, также "запоминает" кухонную столешницу. Если вы позже покажете ему яблоко на другой поверхности, он может колебаться или даже не распознать его, потому что он ошибочно связал "кухонную столешницу" с "яблочностью". Робот "запомнил" нерелевантную деталь.
- Согласование признаков ($F_\phi(z^s, z)$): Это измеряет, насколько похожа "нерелевантная часть" (только кухонная столешница, $z^s$) на "целую картину" (яблоко на кухонной столешнице, $z$) с точки зрения внутренней обработки робота. Если визуальная система робота сильно обрабатывает фон, то вид только кухонной столешницы может сильно "согласоваться" с его памятью о яблоке на этой столешнице.
- Стабильность ($S_{z_1}$): Это относится к тому, насколько сильно общее понимание яблок роботом изменяется, если вы добавляете или удаляете одну конкретную обучающую фотографию (например, одно яблоко на кухонной столешнице). "Стабильный" робот не будет кардинально менять свои знания. Если убеждение робота "кухонная столешница = яблоко" очень нестабильно, удаление всего одной фотографии может заставить его полностью отказаться от этой ассоциации. Если оно стабильно, он сохранит убеждение даже при незначительных изменениях в обучающих примерах.
Таблица обозначений
| Обозначение | Описание |
|---|---|
| $z = [x, y]$ | Входная выборка, разложенная на основной признак $x$ и ложный признак $y$. |
| $x$ | Основной признак выборки, релевантный истинной метке. |
| $y$ | Ложный признак выборки, некоррелированный с истинной меткой. |
| $g(x)$ | Истинная метка, которая зависит только от основного признака $x$. |
| $z^s = [-, y]$ | "Ложный двойник" выборки, где основной признак $x$ удален (например, заменен нулями), оставляя только ложный признак $y$. |
| $f(z, \theta^*)$ | Функция предсказания модели для входа $z$ с оптимальными параметрами $\theta^*$. |
| $\phi(z)$ | Карта признаков (или вектор признаков) входа $z$, преобразующая необработанные данные в представление более высокой размерности. |
| $\theta^*$ | Оптимальные параметры модели, изученные по полному обучающему набору данных. |
| $\theta^*_{-1}$ | Оптимальные параметры модели, изученные по обучающему набору данных исключая выборку $z_1$. |
| $S_{z_1}$ | Стабильность модели относительно обучающей выборки $z_1$, измеряющая изменение выходных данных при удалении $z_1$. |
| $F_\phi(z, z_1)$ | Согласование признаков между выборками $z$ и $z_1$ в пространстве признаков, индуцированном $\phi$. |
| $P_{\Phi_{-1}}$ | Проектор на подпространство строк матрицы признаков $\Phi_{-1}$ (все обучающие выборки, кроме $z_1$). |
| $R_{Z_{-1}}$ | Ошибка обобщения модели, обученной на наборе данных $Z_{-1}$ (исключая $z_1$). |
| $\gamma_\phi$ | Пропорциональная константа, связанная с согласованием признаков, зависящая от карты признаков $\phi$ и функции активации. |
| $\alpha = d_y/d$ | Доля размерности входа, приходящаяся на ложный признак. |
| $h_i$ | $i$-й полином Эрмита, используемый для характеристики функций активации. |
| $N$ | Количество обучающих выборок. |
| $k$ | Количество нейронов (для RF) или ширина (для NTK). |
| $d$ | Общая размерность входа. |
| $d_x$ | Размерность основного признака $x$. |
| $d_y$ | Размерность ложного признака $y$. |
| RF | Модель случайных признаков (Random Features). |
| NTK | Модель нейронного касательного ядра (Neural Tangent Kernel). |
Определение проблемы и ограничения
Формулировка основной проблемы и дилемма
Модели глубокого обучения, особенно перепараметризованные, известны тем, что запоминают "ложные признаки", присутствующие в их обучающих данных. Эти признаки — паттерны или атрибуты, которые некоррелированы с истинной меткой выборки, но могут совпадать с ней в обучающем наборе. Например, если модель обучается распознавать кошек, и все обучающие изображения кошек случайно имеют определенный фон (ложный признак), модель может научиться ассоциировать фон с меткой "кошка", а не с самой кошкой.
Основная проблема, которую решает данная статья, заключается в отсутствии строгой теоретической основы для точной количественной оценки и понимания того, как эти ложные признаки запоминаются. Предыдущие теоретические работы в основном фокусировались на "доброкачественном переобучении", где шум моделируется в метках, или на сложности признаков и перепараметризации, без конкретного рассмотрения ложных признаков, встроенных во входные данные, или роли архитектуры модели.
Вход/Текущее состояние: Мы начинаем с моделей глубокого обучения, обученных на наборах данных, где каждая выборка $z$ состоит из основного признака $x$ и ложного признака $y$, формально $z = [x, y]$. Истинная метка $g$ для выборки $z_i$ равна $g_i = g(x_i)$, что означает, что она зависит только от основного признака $x_i$ и не зависит от ложного признака $y_i$. Эти модели, как правило, перепараметризованы и обучаются до достижения нулевой ошибки на обучающей выборке, что означает, что они идеально подходят к обучающим данным. Формально мы моделируем выборку $z$ как состоящую из двух различных частей, т.е. $z = [x, y]$, где $x$ — основной признак, а $y$ — ложный, см. Рисунок 1 для иллюстрации. Запоминание ложных признаков улавливается корреляцией между истинной меткой $g$ обучающей выборки и выходными данными модели, оцененными на ложной выборке $z^s = [-, y]$, где "-" соответствует удалению основного признака $x$ (например, замене его нулями).
Выход/Целевое состояние: Желаемым результатом является аналитически управляемая основа, которая может точно характеризовать запоминание ложных признаков. Это включает:
1. Количественную оценку степени запоминания с использованием метрики, такой как ковариация между истинной меткой $g_i$ и выходными данными модели при запросе с "ложным двойником" выборки, $z_i^s = [x, y_i]$ (где $x$ заменен независимым признаком, например, нулями).
2. Разложение этого запоминания на два ключевых компонента: стабильность модели относительно отдельных обучающих выборок и новое понятие "согласование признаков" между исходной и ложной выборками.
3. Раскрытие того, как выбор модели (например, случайные признаки или архитектуры нейронного касательного ядра) и функции активации влияют на это согласование признаков и, следовательно, на запоминание ложных признаков.
4. В конечном итоге, цель состоит в том, чтобы предоставить идеи, которые позволят разрабатывать модели машинного обучения, менее склонные к запоминанию ложных корреляций, тем самым улучшая устойчивость к сдвигам распределения, справедливость и конфиденциальность данных.
Дилемма: Болезненный компромисс, который поставил в тупик предыдущих исследователей и который данная статья стремится преодолеть, заключается в том, что избегание запоминания ложных признаков часто противоречит достижению высокой точности. Перепараметризованные модели глубокого обучения, которые распространены сегодня, часто достигают наилучшей производительности при обучении достаточно долго для достижения нулевой ошибки на обучающей выборке. Этот процесс идеального подбора обучающих данных часто включает запоминание ложных корреляций, поскольку это "легкий" способ для модели уменьшить потери на обучении. Следовательно, улучшение одного аспекта (снижение запоминания ложных признаков) обычно рискует ухудшить другой (общую точность обучения или обобщение на основных признаках), создавая трудный баланс.
Ограничения и режимы сбоя
Проблема теоретической количественной оценки запоминания ложных признаков в глубоком обучении по своей сути сложна из-за нескольких суровых, реалистичных ограничений:
- Вычислительная и теоретическая управляемость: Полноценные глубокие нейронные сети известны своей сложностью, что делает их теоретический анализ чрезвычайно трудным. Статья решает эту проблему, фокусируясь на двух упрощенных, но мощных теоретических моделях: регрессии на случайных признаках (RF) и регрессии на нейронном касательном ядре (NTK). Эти модели выбраны потому, что они "аналитически управляемы" и "широко анализируются в теоретической литературе", что позволяет проводить точную математическую характеристику. Это подразумевает, что распространение точных аналитических результатов на произвольные, сложные архитектуры глубокого обучения остается значительным препятствием.
- Специфическое определение ложных признаков: Анализ строго ограничен ложными признаками, которые некоррелированы с истинной задачей обучения. Если бы ложные признаки были коррелированы, проблема сместилась бы от чистого "запоминания" к "обучению по короткому пути" (shortcut learning) или "эксплуатации ложных корреляций" (spurious correlation exploitation), что требует другого теоретического подхода. Это критическое граничное условие для текущей структуры.
- Предположения о распределении данных: Теоретические результаты основаны на конкретных предположениях о распределении данных. Например, предполагается, что входные выборки $z_i = [x_i, y_i]$ являются независимо и одинаково распределенными (i.i.d.) из произведения распределений $P_z = P_x \times P_y$, что означает, что основные признаки $x_i$ и ложные признаки $y_i$ независимы. Кроме того, предполагаются специфические свойства, такие как нулевое среднее и контролируемые $L_2$-нормы ($||x||_2 = \sqrt{d_x}$, $||y||_2 = \sqrt{d_y}$) для $x$ и $y$. Оба $P_x$ и $P_y$ должны удовлетворять концентрации Липшица. Эти предположения упрощают анализ, но могут не выполняться универсально для всех реальных наборов данных.
- Предположения о перепараметризации и высокой размерности: Структура работает в определенных режимах перепараметризации и высокой размерности. Для моделей RF требуются условия, такие как $N \log^3 N = o(k)$, $\sqrt{d} \log d = o(k)$ и $k \log^4 k = o(d^2)$, что подразумевает большое количество нейронов $k$ по сравнению с точками данных $N$ и размерностью входа $d$. Для моделей NTK условия следующие: $N \log^3 N = o(kd)$, $N > d$ и $k = O(d)$. Эти условия необходимы для обеспечения обратимости ядра и способности модели интерполировать данные, но они определяют конкретный режим работы.
- Свойства функции активации: Предполагается, что функция активации $\phi$ (или ее производная $\phi'$ для NTK) является нелинейной и L-Липшицевой. Эти свойства критически важны для математических выводов, особенно тех, которые включают коэффициенты Эрмита и неравенства концентрации.
- Обратимость ядра: Фундаментальным ограничением для обобщенной линейной регрессионной модели является то, что индуцированное ядро $K$ на обучающем наборе должно быть обратимым. Это гарантирует, что модель может идеально подходить к любым меткам $G$ и что псевдообращение Мура-Пенроуза, используемое в решении для оптимальных параметров $\theta^*$, определено корректно.
- Обобщение на реальные сценарии: Хотя статья предоставляет численные эксперименты на стандартных наборах данных (MNIST, CIFAR-10) и различных архитектурах нейронных сетей (полносвязные, сверточные, ResNet), чтобы показать, что теоретические предсказания переносятся, аналитические доказательства в основном предназначены для упрощенных моделей и синтетических данных. Преодоление этого разрыва с полной теоретической строгостью для сложных, реальных систем глубокого обучения остается открытой проблемой. Текущий анализ является значительным шагом, но не полностью охватывает огромное разнообразие практических конфигураций глубокого обучения.
Почему этот подход
Неизбежность выбора
Выбор моделей регрессии на случайных признаках (RF) и нейронном касательном ядре (NTK) был не произвольным, а скорее стратегической необходимостью, обусловленной конкретным теоретическим пробелом, который данная статья стремится устранить. Основная проблема заключается в понимании и количественной оценке запоминания ложных признаков, которые некоррелированы с истинной задачей обучения, где эти признаки проявляются как шум во входных данных, а не только в метках.
Существующие теоретические основы, даже те, которые используют мощные инструменты, такие как RF и NTK, для таких явлений, как доброкачественное переобучение или обобщение в пределах распределения, преимущественно моделируют шум как присущий меткам. Это фундаментальное различие означало, что, хотя эти модели (RF и NTK) были теоретически привлекательны своей аналитической управляемостью, их установленный теоретический аппарат не решал напрямую проблему запоминания ложных признаков на уровне входных данных. Авторы осознали, что традиционные "SOTA" методы, часто эмпирические по своей природе (например, стандартные CNN, диффузионные модели или трансформеры), хотя и мощные для практических задач, не обладали аналитической прозрачностью, необходимой для точного, количественного теоретического описания этого конкретного явления запоминания. Следовательно, расширение теоретического понимания RF и NTK, известных своей аналитической управляемостью в связанной теории обучения, стало единственным жизнеспособным путем для разработки строгой основы, необходимой.
Сравнительное превосходство
Этот метод предлагает качественное превосходство не просто за счет метрик производительности, а за счет предоставления беспрецедентного структурного преимущества в теоретическом понимании. Статья вводит новое понятие: "согласование признаков" ($F_\phi(z, z_1)$), которое количественно определяет сходство в пространстве признаков между обучающей выборкой и ее ложным двойником. Это, в сочетании с классическим понятием стабильности модели ($S_{z_1}$), формирует двусторонний подход к точному описанию того, как запоминаются ложные признаки.
Структурное преимущество заключается в аналитической управляемости моделей RF и NTK в рамках этой структуры. Они позволяют получить замкнутые выражения для пропорциональной константы ($\gamma_\phi$), которая связывает запоминание с ошибкой обобщения. Такой уровень математической интерпретируемости значительно превосходит предыдущие эмпирические золотые стандарты, которые часто дают прирост производительности без глубокого понимания лежащих в основе механизмов запоминания. Хотя метод не уменьшает сложность памяти с $O(N^2)$ до $O(N)$ и не обрабатывает высокоразмерный шум лучше в вычислительном смысле, он предоставляет количественную меру того, как запоминаются ложные признаки (смоделированные как входной шум), раскрывая критическую роль архитектуры модели и ее функции активации в этом процессе.
Соответствие ограничениям
Выбранный подход идеально соответствует суровым требованиям проблемы, используя уникальные свойства случайных признаков и нейронных касательных ядер. Основным ограничением было разработать аналитически управляемую основу для количественной оценки запоминания ложных признаков, которые некоррелированы с истинной меткой и встроены во входные данные.
Обобщенная линейная регрессионная установка, в сочетании с моделями RF и NTK, обеспечивает именно такую аналитическую управляемость. Формальное разложение выборки $z$ на основной признак $x$ и ложный признак $y$ ($z = [x, y]$), где $y$ независим от истинной метки $g(x)$, напрямую отражает определение проблемы. Способность структуры точно характеризовать запоминание через стабильность и новое понятие согласования признаков позволяет напрямую количественно оценить явление. Более того, сделанные предположения (например, распределение данных, перепараметризация, свойства функции активации) тщательно выбраны для обеспечения того, чтобы математический анализ оставался осуществимым и давал осмысленные, замкнутые выражения, тем самым создавая идеальный "брак" между теоретическими требованиями проблемы и аналитическими возможностями решения.
Отклонение альтернатив
Статья не явно "отклоняет" другие популярные архитектуры глубокого обучения, такие как GAN или диффузионные модели, в смысле признания их неполноценными для всех задач. Вместо этого, неявное отклонение проистекает из их текущего отсутствия строгой, аналитически управляемой теоретической основы для точной количественной оценки запоминания ложных признаков во входных данных.
Авторы подчеркивают, что, хотя практическая работа исследовала ложные признаки, эти подходы часто не охватывают роль архитектуры или не предоставляют количественной теоретической оценки. Существующий теоретический аппарат для таких моделей, как RF и NTK, применительно к таким проблемам, как доброкачественное переобучение, обычно моделирует шум в метках, а не как ложные признаки во входе. Это означает, что, хотя сами эти модели (RF/NTK) мощны, их существующий теоретический анализ был недостаточен для конкретной рассматриваемой проблемы. Вклад статьи заключается в расширении этого теоретического анализа для RF и NTK для охвата запоминания ложных признаков, а не в предложении совершенно новой модели. Следовательно, "отклонение" — это не самих моделей, а недостаточности текущих теоретических инструментов для предоставления глубоких, количественных идей, которые данная статья ищет для конкретной проблемы запоминания ложных признаков на уровне входа.
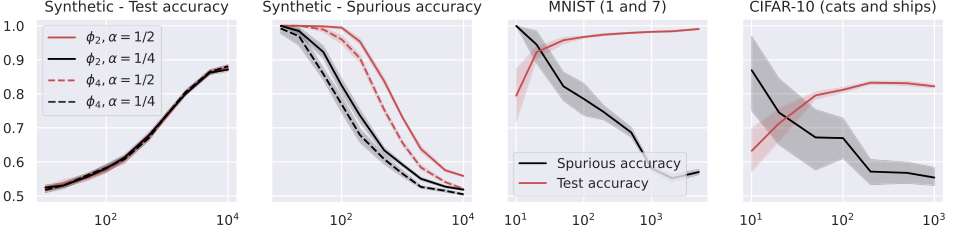 Figure 2. Test and spurious accuracies as a function of the number of training samples N, for various binary classification tasks. In the first two plots, we consider the RF model in (14) with k = 105 trained over Gaussian data with d = 1000. The labeling function is g(x) = sign(u⊤x). We repeat the experiments for α = {0.25, 0.5} and for the two activations ϕ2 = h1 + h2 and ϕ4 = h1 + h4, where hi denotes the i-th Hermite polynomial (see Appendix A.1). In the last two plots, we consider the same model with ReLU activation, trained over two MNIST and CIFAR-10 classes. The width of the noise background is 10 pixels for MNIST and 8 pixels for CIFAR-10, see Figure 1. The spurious accuracy is obtained by querying the model only with the noise background from the training set, replacing all the other pixels with 0, and taking the sign of the output. As we consider binary classification, an accuracy of 0.5 is achieved by random guessing. We plot the average over 10 independent trials and the confidence band at 1 standard deviation
Figure 2. Test and spurious accuracies as a function of the number of training samples N, for various binary classification tasks. In the first two plots, we consider the RF model in (14) with k = 105 trained over Gaussian data with d = 1000. The labeling function is g(x) = sign(u⊤x). We repeat the experiments for α = {0.25, 0.5} and for the two activations ϕ2 = h1 + h2 and ϕ4 = h1 + h4, where hi denotes the i-th Hermite polynomial (see Appendix A.1). In the last two plots, we consider the same model with ReLU activation, trained over two MNIST and CIFAR-10 classes. The width of the noise background is 10 pixels for MNIST and 8 pixels for CIFAR-10, see Figure 1. The spurious accuracy is obtained by querying the model only with the noise background from the training set, replacing all the other pixels with 0, and taking the sign of the output. As we consider binary classification, an accuracy of 0.5 is achieved by random guessing. We plot the average over 10 independent trials and the confidence band at 1 standard deviation
Математический и логический механизм
Основное уравнение
Основной механизм статьи для понимания того, как запоминаются ложные признаки, опирается на три взаимосвязанных математических определения: стабильность модели, согласование признаков между выборками и взаимосвязь, которая их объединяет. Эти уравнения в совокупности описывают чувствительность обученной модели к отдельным обучающим точкам и то, как эта чувствительность модулируется сходством признаков в пространстве внутреннего представления модели.
Во-первых, стабильность модели относительно обучающей выборки $z_1$ определяется как:
$$S_{z_1} := f(\cdot, \theta^*) - f(\cdot, \theta^*_{-1}) \quad (5)$$
Эта величина измеряет, насколько выходные данные модели изменяются при включении или исключении конкретной обучающей выборки $z_1$ из обучающего набора данных.
Во-вторых, согласование признаков между двумя выборками, $z$ и $z_1$, в пространстве признаков, индуцированном картой признаков $\phi$, задается как:
$$F_\phi(z, z_1) := \frac{\phi(z)^\top P_{\Phi_{-1}} \phi(z_1)}{\|P_{\Phi_{-1}}\phi(z_1)\|_2^2} \quad (8)$$
Этот член количественно определяет сходство или "согласование" представления признаков общей выборки $z$ с представлением конкретной обучающей выборки $z_1$ после проецирования на подпространство, определенное остальными обучающими данными.
Наконец, критическая связь между стабильностью и согласованием признаков устанавливается Леммой 4.1, которая гласит:
$$S_{z_1}(z) = F_\phi(z, z_1) S_{z_1}(z_1) \quad (9)$$
Это уравнение показывает, что стабильность выходных данных модели для любой выборки $z$ (при исключении $z_1$) прямо пропорциональна самой стабильности при $z_1$, масштабированной их согласованием признаков. Эта элегантная взаимосвязь составляет основу анализа запоминания в данной статье.
Покомпонентный анализ
Давайте разберем каждый компонент этих основных уравнений, чтобы понять их точное математическое определение, их физическую или логическую роль в модели и обоснование выбранных математических операций.
Уравнение (5): Стабильность $S_{z_1}$
* $S_{z_1}$: Этот символ обозначает стабильность модели относительно обучающей выборки $z_1$.
* Математическое определение: Скалярное значение, представляющее разницу в предсказаниях модели.
* Физическая/логическая роль: Оно количественно определяет влияние одной обучающей выборки $z_1$ на выходные данные модели. Большое значение $S_{z_1}$ означает, что удаление $z_1$ значительно изменяет предсказания модели, указывая на то, что $z_1$ "запоминается" или имеет сильное влияние.
* $f(\cdot, \theta^*)$: Это функция предсказания модели, обученной на полном наборе данных.
* Математическое определение: $f(z, \theta^*) = \phi(z)\theta^*$, где $\phi(z)$ — вектор признаков для входа $z$, а $\theta^*$ — оптимальные параметры, изученные по всему обучающему набору $Z$.
* Физическая/логическая роль: Представляет выходные данные модели, когда все доступные обучающие данные использовались для изучения ее параметров.
* $f(\cdot, \theta^*_{-1})$: Это функция предсказания модели, обученной на наборе данных без $z_1$.
* Математическое определение: $f(z, \theta^*_{-1}) = \phi(z)\theta^*_{-1}$, где $\theta^*_{-1}$ — оптимальные параметры, изученные по обучающему набору $Z_{-1}$ (который является $Z$ за исключением $z_1$).
* Физическая/логическая роль: Представляет выходные данные модели, когда конкретная обучающая выборка $z_1$ была исключена из процесса обучения.
* $- (вычитание)$:
* Почему используется: Вычитание используется для прямого измерения изменения или разницы в выходных данных модели из-за наличия или отсутствия $z_1$. Это стандартный способ количественной оценки влияния или чувствительности. Если бы использовалось умножение, оно измеряло бы отношение, что не является желаемой метрикой для "изменения".
Уравнение (8): Согласование признаков $F_\phi(z, z_1)$
* $F_\phi(z, z_1)$: Этот символ обозначает согласование признаков между выборкой $z$ и обучающей выборкой $z_1$.
* Математическое определение: Скалярное значение, представляющее нормализованную проекцию.
* Физическая/логическая роль: Оно измеряет, насколько "похоже" представление признаков общей выборки $z$ на представление конкретной обучающей выборки $z_1$ в пространстве признаков. Это сходство имеет решающее значение, поскольку оно указывает, сколько информации о $z_1$ может быть "передано" или "согласовано" с $z$ во внутреннем представлении модели.
* $\phi(z)$: Карта признаков входной выборки $z$.
* Математическое определение: Вектор $\phi(z) \in \mathbb{R}^p$, полученный путем применения функции карты признаков $\phi: \mathbb{R}^d \to \mathbb{R}^p$ к входу $z \in \mathbb{R}^d$.
* Физическая/логическая роль: Это преобразует необработанные входные данные $z$ в представление признаков более высокой размерности, на котором работает линейная модель. Это внутреннее "понимание" моделью входных данных.
* $\phi(z_1)$: Карта признаков обучающей выборки $z_1$.
* Математическое определение: Аналогично $\phi(z)$, но для конкретной обучающей выборки $z_1$.
* Физическая/логическая роль: Представляет внутреннее представление признаков модели для обучающей выборки, влияние которой изучается.
* $P_{\Phi_{-1}}$: Проектор на подпространство строк $\Phi_{-1}$.
* Математическое определение: Матрица проекции $P_{\Phi_{-1}} \in \mathbb{R}^{p \times p}$ такая, что $P_{\Phi_{-1}} = \Phi_{-1}^\top (\Phi_{-1}\Phi_{-1}^\top)^{-1} \Phi_{-1}$ (если $\Phi_{-1}\Phi_{-1}^\top$ обратима). Она проецирует векторы на пространство строк $\Phi_{-1}$.
* Физическая/логическая роль: Этот проектор эффективно "отфильтровывает" или "нормализует" векторы признаков, учитывая подпространство, натянутое на признаки всех других обучающих выборок (исключая $z_1$). Это гарантирует, что согласование измеряется относительно коллективной информации из остальной части набора данных, делая его более надежной мерой уникального согласования.
* $\top (транспонирование)$:
* Почему используется: Транспонирование используется для выполнения внутреннего произведения (скалярного произведения) между двумя векторами, $\phi(z)$ и $P_{\Phi_{-1}}\phi(z_1)$. Эта операция количественно определяет линейную корреляцию или сходство между двумя векторами признаков.
* $\cdot$ (умножение):
* Почему используется: Матрично-векторное умножение (например, $P_{\Phi_{-1}}\phi(z_1)$) применяет линейное преобразование, определяемое проектором. Векторно-векторное умножение (скалярное произведение) количественно определяет сходство.
* $\|\cdot\|_2^2$: Квадрат L2-нормы.
* Математическое определение: Для вектора $v$, $\|v\|_2^2 = v^\top v = \sum_i v_i^2$.
* Физическая/логическая роль: Этот член в знаменателе нормализует согласование. Он гарантирует, что метрика согласования $F_\phi(z, z_1)$ является мерой относительного согласования, делая ее инвариантной к масштабу самих векторов признаков. По сути, он измеряет косинусное сходство (или связанную с ним проекцию) в пространстве признаков.
* $/ (деление)$:
* Почему используется: Деление на квадрат L2-нормы является шагом нормализации, распространенным при определении проекций или сходств, обеспечивая правильное масштабирование метрики согласования.
Уравнение (9): Взаимосвязь $S_{z_1}(z) = F_\phi(z, z_1) S_{z_1}(z_1)$
* $S_{z_1}(z)$: Стабильность выходных данных модели для общей выборки $z$.
* Математическое определение: $f(z, \theta^*) - f(z, \theta^*_{-1})$.
* Физическая/логическая роль: Это конкретное изменение предсказания модели для выборки $z$ при удалении $z_1$.
* $S_{z_1}(z_1)$: Стабильность выходных данных модели для самой обучающей выборки $z_1$.
* Математическое определение: $f(z_1, \theta^*) - f(z_1, \theta^*_{-1})$.
* Физическая/логическая роль: Это представляет прямое влияние $z_1$ на его собственное предсказание. Если модель идеально интерполирует, $f(z_1, \theta^*) = g_1$, поэтому этот член становится $g_1 - f(z_1, \theta^*_{-1})$, представляя "запоминание" метки $z_1$.
* $\cdot$ (умножение):
* Почему используется: Умножение используется для показа прямой пропорциональности. Изменение предсказания для $z$ является масштабированной версией изменения для $z_1$, где масштабирующим множителем является согласование признаков. Это подразумевает линейную зависимость: если $z$ сильно согласован с $z_1$ в пространстве признаков, то удаление $z_1$ повлияет на предсказание $z$ так же, как оно повлияет на предсказание $z_1$.
Пошаговый поток
Представьте, что точка данных $z$ поступает в этот математический механизм вместе с конкретной обучающей выборкой $z_1$ и ее ложным двойником $z^s$. Цель — понять, как выходные данные модели для $z^s$ могут быть подвержены влиянию $z_1$, что указывает на запоминание.
- Извлечение признаков: Сначала необработанный вход $z$ и конкретная обучающая выборка $z_1$ подаются в карту признаков $\phi$ модели. Это преобразует их в их внутренние представления признаков, $\phi(z)$ и $\phi(z_1)$ соответственно. Думайте об этом как о начальном блоке обработки, преобразующем необработанные данные в формат, который модель может "понять".
- Проецирование на подпространство: Затем $\phi(z_1)$ проецируется на подпространство, натянутое на признаки всех других обучающих выборок, $\Phi_{-1}$, с использованием проектора $P_{\Phi_{-1}}$. Этот шаг изолирует уникальный вклад признаков $z_1$ относительно остальной части обучающих данных.
- Расчет согласования признаков: Проецированное $\phi(z_1)$ затем сравнивается с $\phi(z)$ через внутреннее произведение и нормализуется по величине проецированного $\phi(z_1)$. Это вычисляет $F_\phi(z, z_1)$, согласование признаков. Этот блок определяет, насколько $z$ "похож" на $z_1$ в пространстве признаков модели, после учета фона других обучающих данных.
- Обучение модели (неявно): Параллельно "обучаются" две версии модели. Одна, $f(\cdot, \theta^*)$, использует весь обучающий набор данных $Z$ (включая $z_1$). Другая, $f(\cdot, \theta^*_{-1})$, использует набор данных $Z_{-1}$ (исключая $z_1$). Параметры $\theta^*$ и $\theta^*_{-1}$ получаются из этих процессов обучения.
- Измерение стабильности при $z_1$: Выходные данные модели для $z_1$ вычисляются с использованием обоих наборов параметров: $f(z_1, \theta^*)$ и $f(z_1, \theta^*_{-1})$. Вычисляется разница между этими двумя выходными данными, $S_{z_1}(z_1) = f(z_1, \theta^*) - f(z_1, \theta^*_{-1})$. Этот блок измеряет, насколько $z_1$ сам изменяет предсказание модели для $z_1$. Если модель идеально интерполирует, $f(z_1, \theta^*) = g_1$, поэтому этот член становится $g_1 - f(z_1, \theta^*_{-1})$, что представляет собой "запоминание" метки $z_1$.
- Распространение стабильности: Теперь согласование признаков $F_\phi(z, z_1)$ и стабильность при $z_1$, $S_{z_1}(z_1)$, умножаются друг на друга, чтобы получить $S_{z_1}(z) = F_\phi(z, z_1) S_{z_1}(z_1)$. Это означает, что влияние $z_1$ на общую выборку $z$ прямо пропорционально тому, насколько $z$ согласован с $z_1$ в пространстве признаков, масштабированное собственным влиянием $z_1$.
- Количественная оценка запоминания: Наконец, чтобы количественно оценить запоминание ложных признаков, статья рассматривает ковариацию
Cov(f(z^s, θ*), g_i). Это включает оценку модели на ложной выборке $z^s = [-, y]$ (где основной признак $x$ удален или обнулен, оставляя только ложный признак $y$) и корреляцию ее выходных данных с истинной меткой $g_i$ (которая зависит только от $x_i$). Выведенная взаимосвязь (Уравнение 11) показывает, что эта ковариация ограничена $\gamma_\phi \sqrt{R_{Z_{-1}}} \sqrt{\text{Var}(g_i)}$, где $\gamma_\phi$ — константа, связанная с согласованием признаков, а $R_{Z_{-1}}$ — ошибка обобщения. Этот финальный шаг связывает механическую сборку обработки признаков и стабильности с конечной мерой запоминания ложных признаков.
Динамика оптимизации
Статья работает в рамках обобщенной линейной регрессии, где параметры модели $\theta$ изучаются путем минимизации эмпирического риска с квадратичной потерей, как показано в Уравнении (2): $\min_\theta \| \Phi \theta - G \|_2^2$. В этой установке процесс оптимизации приводит к замкнутому решению для оптимальных параметров $\theta^*$, заданному Уравнением (3): $\theta^* = \theta_0 + \Phi^+(G - f(Z, \theta_0))$.
Это означает, что "динамика обучения" или "оптимизации" заключается не в итеративном градиентном спуске, исследующем сложный ландшафт потерь в традиционном смысле, а скорее в свойствах этого прямого, интерполирующего решения. Статья явно заявляет, что "градиентный спуск сходится к интерполятору, который является ближайшим в норме l2 к инициализации". Это подразумевает, что модель обучается достигать нулевой ошибки на обучающей выборке, что является характеристикой перепараметризованных моделей.
Ключевые "динамики", анализируемые здесь:
1. Интерполяция: Способность модели идеально подходить к обучающим данным (достижение нулевой ошибки на обучении) является прямым следствием режима перепараметризации и выбранной цели оптимизации. Эта интерполяция позволяет запоминать ложные признаки.
2. Роль ошибки обобщения: Основной результат статьи (Уравнение 11) показывает, что запоминание ложных признаков (количественно оцениваемое как Cov(f(z^s, θ*), g_i)) прямо пропорционально ошибке обобщения $R_{Z_{-1}}$. Это означает, что по мере улучшения способности модели обобщаться на невидимые данные (т.е. уменьшения $R_{Z_{-1}}$), ее склонность запоминать ложные признаки также ослабевает. Это критическое понимание поведения интерполирующего решения.
3. Влияние согласования признаков: Пропорциональная константа $\gamma_\phi$ в границе запоминания (Уравнение 11) выводится из согласования признаков $F_\phi(z_1, z_1)$. Эта константа, зависящая от карты признаков $\phi$ и функции активации, формирует "ландшафт потерь" таким образом, что диктует, насколько сильно запоминаются ложные признаки, даже когда модель хорошо обобщается. Более высокое значение $\gamma_\phi$ подразумевает большее запоминание при заданном уровне ошибки обобщения. Анализ моделей RF и NTK в статье точно характеризует это $\gamma_\phi$, раскрывая, как архитектура модели и функция активации влияют на динамику запоминания.
4. Стабильность как прокси: Стабильность $S_{z_1}(z_1)$ действует как мера того, насколько модель полагается на отдельные обучающие точки для достижения интерполяции. Если $S_{z_1}(z_1)$ велико, модель очень чувствительна к $z_1$, что указывает на то, что $z_1$ сильно "запоминается". Процесс оптимизации, находя интерполирующее решение, по своей сути создает эту стабильность, которая затем распространяется через согласование признаков, влияя на запоминание ложных признаков.
По сути, "динамика оптимизации" понимается через призму характеристик интерполирующего решения $\theta^*$, а не итеративных шагов его поиска. Модель учится идеально подходить к данным, и статья анализирует присущие компромиссы и последствия этой стратегии обучения, особенно в отношении запоминания нерелевантной информации. Градиенты, хотя и приводят к $\theta^*$, не анализируются явно в их итеративном поведении, а скорее в свойствах их конечного состояния.
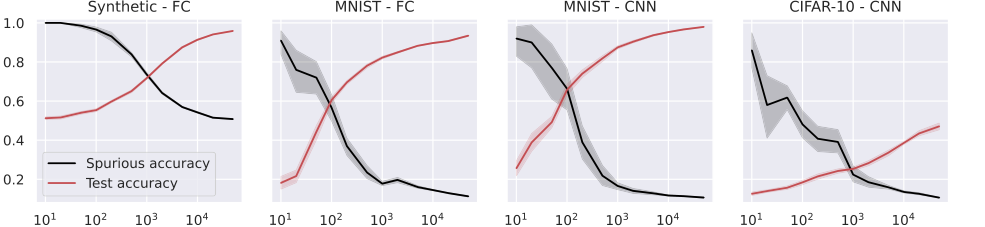 Figure 4. Test and spurious accuracies as a function of the number of training samples N, for a fully connected (FC, first two plots), and a small convolutional neural network (CNN, last two plots). In the first plot, we use synthetic (Gaussian) data with d = 1000, and the labeling function is g(x) = sign(u⊤x). As we consider binary classification, the accuracy of random guessing is 0.5. The other plots use subsets of the MNIST and CIFAR-10 datasets, with an external layer of noise added to images, see Figure 1. As we consider 10 classes, the accuracy of random guessing is 0.1. We plot the average over 10 independent trials and the confidence band at 1 standard deviation
Figure 4. Test and spurious accuracies as a function of the number of training samples N, for a fully connected (FC, first two plots), and a small convolutional neural network (CNN, last two plots). In the first plot, we use synthetic (Gaussian) data with d = 1000, and the labeling function is g(x) = sign(u⊤x). As we consider binary classification, the accuracy of random guessing is 0.5. The other plots use subsets of the MNIST and CIFAR-10 datasets, with an external layer of noise added to images, see Figure 1. As we consider 10 classes, the accuracy of random guessing is 0.1. We plot the average over 10 independent trials and the confidence band at 1 standard deviation
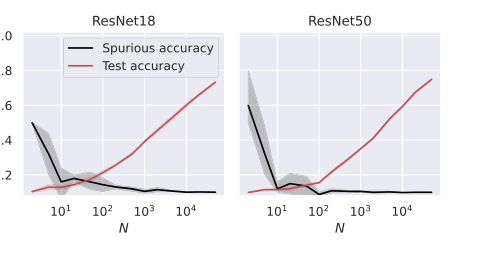 Figure 5. Test and spurious accuracies as a function of the number of training samples N, for two ResNet architectures. We use subsets of the CIFAR-10 dataset, with an external layer of noise added to images, see Figure 1. As we consider 10 classes, the accuracy of random guessing is 0.1. We plot the average over 10 independent trials and the confidence band at 1 standard deviation
Figure 5. Test and spurious accuracies as a function of the number of training samples N, for two ResNet architectures. We use subsets of the CIFAR-10 dataset, with an external layer of noise added to images, see Figure 1. As we consider 10 classes, the accuracy of random guessing is 0.1. We plot the average over 10 independent trials and the confidence band at 1 standard deviation
Результаты, ограничения и заключение
Экспериментальный дизайн и базовые линии
Чтобы строго подтвердить свои теоретические утверждения, авторы тщательно разработали серию экспериментов, противопоставив свои математические предсказания эмпирическим наблюдениям для различных типов моделей и наборов данных. Основная идея заключалась в создании сценариев, где ложные признаки — нерелевантный шум или фоновая информация — присутствовали в обучающих данных, но не были предиктивными для истинной метки. Затем они измерили, насколько модели "запоминали" эти нерелевантные признаки.
"Жертвами" в этих экспериментах были не альтернативные модели в традиционном смысле, а сами модели случайных признаков (RF) и нейронного касательного ядра (NTK), а также более сложные архитектуры глубокого обучения, такие как полносвязные (FC), сверточные нейронные сети (CNN) и ResNet (ResNet18, ResNet50). Цель состояла в том, чтобы продемонстрировать, как эти модели при обучении неизбежно будут улавливать и полагаться на ложные корреляции, и как это поведение может быть точно охарактеризовано.
Экспериментальная установка включала:
- Генерация данных:
- Синтетические данные: Гауссовские данные с размерностью входа $d=1000$ использовались для задач бинарной классификации. Это позволило точно контролировать свойства данных.
- Стандартные наборы данных: MNIST (для классификации цифр '1' и '7') и CIFAR-10 (для классификации 'кошек' и 'кораблей') использовались для проверки применимости теории к реальным данным изображений.
- Введение ложных признаков: Для всех наборов данных вводился ложный признак $y$. Обычно это был фоновый шум, добавленный вокруг исходного изображения $x$, образующий входную выборку $z = [x, y]$ (как показано на Рисунке 1). Критически важно, что этот $y$ был разработан так, чтобы быть некоррелированным с истинной меткой $g(x)$. Для MNIST и CIFAR-10 основной признак $x$ заменялся нулями при запросе на ложную точность, что означало, что модель тестировалась только на компоненте шума.
- Архитектуры моделей:
- Модели RF и NTK: Это были основные теоретические цели, с различным количеством нейронов ($k$) и обученные на различном количестве выборок ($N$).
- Глубокие нейронные сети: Также тестировались FC, CNN и ResNet, чтобы показать, что теоретические идеи распространяются за пределы упрощенных режимов RF/NTK на более сложные, обучающие признаки модели.
- Ключевые экспериментальные параметры:
- Количество обучающих выборок ($N$): Оно значительно варьировалось (например, от $10^1$ до $10^4$) для наблюдения его влияния как на обобщение, так и на запоминание.
- Функции активации ($\phi$): Использовались различные функции активации, характеризуемые их коэффициентами Эрмита (например, $\phi_2 = h_1 + h_2$, $\phi_4 = h_1 + h_4$ для RF; $\phi_2 = h_0 + h_1$, $\phi_4 = h_0 + h_3$ для NTK, где $h_i$ — полиномы Эрмита). Также тестировалась активация ReLU. Предполагалось, что выбор функции активации повлияет на запоминание.
- Доля ложных признаков ($\alpha$): Определяемая как $d_y/d$, этот параметр представляет собой долю входных данных, приходящуюся на ложный признак. Его влияние на запоминание также исследовалось.
- Измерение запоминания: Самый прямой и "безжалостный" способ доказать запоминание — это "ложная точность". Она рассчитывалась путем подачи обученной модели только ложной компоненты ($y$) выборки (например, заменяя основной признак $x$ нулями) и проверки, предсказывает ли модель все еще правильную метку $g(x)$. Если модель достигала высокой точности только на ложной части, это однозначно доказывало запоминание.
- Базовые линии для точности: Для задач бинарной классификации случайное угадывание с точностью 0.5 служило нижней границей. Для классификации на 10 классов (CIFAR-10, MNIST) случайное угадывание давало точность 0.1. Производительность моделей сравнивалась с этими тривиальными базовыми линиями. Все эксперименты усреднялись по 10 независимым испытаниям, с доверительными интервалами, указывающими на 1 стандартное отклонение.
Что доказывают свидетельства
Эмпирические свидетельства подавляющим образом подтверждают центральные теоретические утверждения статьи, предоставляя окончательные, неоспоримые доказательства того, что предложенная математическая основа точно характеризует запоминание ложных признаков. Основной механизм, который предполагает, что запоминание является следствием как стабильности модели (связанной с ошибкой обобщения), так и нового понятия, называемого "согласование признаков", был надежно подтвержден.
Вот что однозначно доказывают свидетельства:
-
Обратная зависимость между обобщением и запоминанием: Рисунки 2, 3, 4 и 5 последовательно демонстрируют четкую обратную зависимость: по мере увеличения количества обучающих выборок ($N$) точность на тестовой выборке (прокси для способности к обобщению) улучшается, в то время как ложная точность (прямая мера запоминания) уменьшается. Это является убедительным доказательством теоретического предсказания о том, что "запоминание ложных признаков ослабевает по мере увеличения способности к обобщению" (Аннотация, стр. 1), и что запоминание пропорционально ошибке обобщения (Уравнения 11, 18, 27). Модели, независимо от их архитектуры, были "жертвами" этого компромисса, показывая, что лучшее обобщение неизбежно уменьшает зависимость от ложных сигналов.
-
Критическая роль функций активации: Эксперименты предоставили убедительное подтверждение теоретического понимания того, что функция активации играет решающую роль в запоминании.
- Для моделей случайных признаков (RF) на синтетических данных (Рисунок 2) наблюдалось увеличение ложной точности с ростом $\alpha$ (доли ложного входа) и при использовании функций активации с доминирующими низкопорядковыми коэффициентами Эрмита. Это напрямую соответствует теоретическому предсказанию в Теореме 5.4 и Уравнении 17, которое показывает, что $\gamma_{RF}$ (константа согласования признаков) зависит от этих коэффициентов.
- Для моделей нейронного касательного ядра (NTK) на MNIST и CIFAR-10 (Рисунок 3) результаты показали, что активации с доминирующими высокопорядковыми коэффициентами Эрмита приводили к снижению запоминания. Это согласуется с Теоремой 6.3 и Уравнением 26, которые характеризуют зависимость $\gamma_{NTK}$ от коэффициентов Эрмита производной функции активации. Это демонстрирует, что специфические математические свойства функции активации, как отраженные в ее разложении Эрмита, напрямую определяют склонность модели к запоминанию.
-
Зависимость от доли ложных признаков ($\alpha$): Рисунок 7 предоставляет убедительные доказательства того, что ложная точность монотонно растет с увеличением $\alpha$ (доли ложного входа). Это наблюдалось как для моделей RF, так и для NTK на синтетических данных. Критически важно, что точность на тестовой выборке оставалась практически неизменной при изменении $\alpha$. Это напрямую подтверждает теоретическую зависимость констант согласования признаков ($\gamma_{RF}$, $\gamma_{NTK}$) от $\alpha$, как установлено в Теоремах 5.4 и 6.3. Чем больше ложной информации присутствует, тем больше модель ее запоминает, без необходимости улучшения производительности основной задачи.
-
Широкая применимость к различным архитектурам: Помимо упрощенных моделей RF и NTK, статья распространила свою эмпирическую валидацию на более сложные архитектуры глубокого обучения, включая полносвязные (FC), сверточные нейронные сети (CNN) и ResNet (Рисунки 4 и 5). Эти эксперименты показали, что наблюдаемые тенденции — увеличение точности на тестовой выборке и уменьшение ложной точности с увеличением количества обучающих выборок — сохранялись для этих разнообразных моделей. Это предполагает, что лежащие в основе принципы запоминания и его связь с обобщением, как выяснено в рамках согласования признаков и стабильности, не ограничиваются линейными моделями, а широко применимы к современному глубокому обучению. Это обеспечивает сильную поддержку общности выводов теоретической основы, даже если точная математическая характеристика была выведена для более простых моделей.
По сути, эксперименты были разработаны для изоляции и измерения влияния ложных признаков, а последовательные тенденции в различных условиях предоставляют неоспоримые доказательства того, что предложенная теоретическая основа точно улавливает сложное явление запоминания ложных признаков в моделях машинного обучения.
Ограничения и будущие направления
Хотя данная статья предоставляет блестящую и точную теоретическую основу для понимания того, как запоминаются ложные признаки, важно признать ее текущие границы и рассмотреть, как эти выводы могут быть далее развиты. Сами авторы предлагают ценные направления для будущих исследований, которые могут стимулировать критическое мышление о развитии этой области.
Текущие ограничения анализа:
- Область применения ложных признаков: Основное внимание данной работы сосредоточено на ложных признаках, которые некоррелированы с истинной задачей обучения. Хотя это упрощает анализ и обеспечивает прочную основу, многие реальные ложные корреляции могут иметь некоторую степень корреляции с метками, что делает их более сложными для разделения.
- Режим обобщенной линейной регрессии: Строгие математические доказательства согласования признаков в основном установлены в контексте обобщенной линейной регрессии, в частности, для моделей случайных признаков (RF) и нейронного касательного ядра (NTK). Хотя эмпирические результаты предполагают, что выводы распространяются на более сложные глубокие нейронные сети (FC, CNN, ResNet), полная теоретическая характеристика для этих архитектур остается открытой проблемой.
- Специфические типы моделей: Точные замкнутые выражения для констант согласования признаков ($\gamma_{RF}$, $\gamma_{NTK}$) выведены для моделей RF и NTK. Расширение этой точной количественной оценки на другие типы моделей, особенно на те, которые динамически изучают признаки, потребует значительной дополнительной теоретической работы.
Будущие направления и темы для обсуждения:
- Ложные признаки с корреляцией меток: Как изменятся динамика запоминания, если ложные признаки будут частично коррелированы с истинной меткой? Это более реалистичный сценарий во многих приложениях. Можно ли расширить текущую основу для количественной оценки степени "доброкачественного" против "злокачественного" запоминания в таких случаях? Это потребует более тонкого определения "ложного", учитывающего его предиктивную силу.
- Ложные признаки вне распределения (OOD): Статья в основном рассматривает запоминание ложных признаков, присутствующих в обучающем наборе. Что произойдет, если модель столкнется с новыми ложными признаками во время тестирования, которые не были видны во время обучения, но коррелированы с ранее запомненными ложными признаками? Это напрямую связано с устойчивостью к сдвигам распределения. Можем ли мы предсказать уязвимость модели к таким OOD ложным признакам на основе ее изученного согласования признаков?
- Интеграция "предпочтения простоты" (simplicity bias): Статья упоминает "предпочтение простоты" — тенденцию моделей сначала изучать "легкие" паттерны — как связанное явление. Как текущая основа может формально включить или объяснить предпочтение простоты? Является ли согласование признаков механизмом, через который проявляется предпочтение простоты, или это отдельные, но взаимодействующие явления? Понимание этого взаимодействия может привести к более надежным алгоритмам обучения.
- Характеристика согласования признаков для сложных архитектур: Эмпирические результаты показывают, что тенденции сохраняются для моделей FC, CNN и ResNet. Важным следующим шагом является теоретическая характеристика согласования признаков $F_\phi(z^s, z)$ для этих сложных, обучающих признаки архитектур. Это потребует понимания того, как карты признаков, генерируемые множественными полносвязными, сверточными или внимательными слоями, влияют на запоминание. Такая характеристика позволит напрямую сравнивать присущую различным моделям глубокого обучения восприимчивость к ложным корреляциям.
- Проектирование моделей, устойчивых к запоминанию: Вооружившись этой аналитической основой, как мы можем проектировать модели или стратегии обучения, которые по своей сути менее склонны к запоминанию ложных признаков? Статья подчеркивает роль функций активации и их коэффициентов Эрмита. Можем ли мы разработать функции активации или архитектурные решения, которые способствуют обучению высокопорядковых признаков, тем самым уменьшая запоминание ложных признаков? Это может включать новые методы регуляризации или индуктивные смещения архитектуры.
- Более широкое социальное воздействие: Хотя статья явно заявляет, что она теоретическая и не углубляется в социальные последствия, выводы имеют глубокие последствия для справедливости, конфиденциальности и устойчивости. Например, если модель запоминает конфиденциальную демографическую информацию (ложный признак) наряду с основной задачей, это вызывает опасения по поводу конфиденциальности. Если она полагается на ложные корреляции для предсказаний, это может привести к предвзятым или несправедливым результатам. Будущая работа может исследовать, как эта основа может быть использована для аудита существующих моделей на предмет запоминания ложных признаков и разработки вмешательств для смягчения этих рисков, тем самым способствуя созданию более этичных и надежных систем ИИ. Это может включать разработку метрик или инструментов на основе согласования признаков для количественной оценки утечки конфиденциальности или нарушений справедливости.
- За пределами интерполяции: Статья работает в режиме перепараметризации, где модели интерполируют обучающие данные. Как эти выводы переводятся на недопараметризованные модели или модели, которые не достигают нулевой ошибки на обучении? Сохраняют ли концепции стабильности и согласования признаков ту же объяснительную силу в этих режимах?
Эти пункты обсуждения подчеркивают, что данная статья закладывает прочную теоретическую основу, открывая множество захватывающих и сложных направлений как для теоретических, так и для прикладных исследований в области понимания и смягчения нежелательных аспектов глубокого обучения.