스퓨리어스 특징의 암기: 랜덤 특징 및 NTK 특징에 대한 정밀 분석
This paper offers a theoretical explanation for why AI models memorize irrelevant data, revealing how model stability and feature alignment play key roles.
배경 및 학문적 계보
기원 및 학문적 계보
딥러닝 모델이 스퓨리어스 특징을 암기하는 문제는 해당 분야에서 중요하고 잘 문서화된 현상이지만, 이를 정밀하게 정량화할 수 있는 엄격한 이론적 프레임워크는 대체로 부재했다. 이 문제는 신경망이 종종 의도된 작업과 본질적으로 관련 없는 훈련 데이터의 특징으로부터 학습하기 때문에 발생한다. 이는 특정 패턴과 학습 작업 간의 긍정적인 스퓨리어스 상관관계(Geirhos et al., 2020; Xiao et al., 2021) 때문에 발생할 수 있으며, 이러한 패턴이 드물거나(Yang et al., 2022) 단순히 관련이 없는 경우에도(Hermann & Lampinen, 2020) 발생할 수 있다. 이러한 암기는 모델이 스퓨리어스 관계를 학습하게 하여, 분포 변화에 대한 강건성(Geirhos et al., 2019; Zhou et al., 2021), 공정성(Zliobaite, 2015), 데이터 프라이버시(Leino & Fredrikson, 2020)에 영향을 미친다.
역사적으로 경험적 노력은 이 현상을 완화하는 데 초점을 맞추어 왔다(Plumb et al., 2022; Chang et al., 2021). 그러나 암기를 피하는 것이 항상 가능한 것은 아니다. 왜냐하면 과대적합된 모델의 정확도에 때때로 최적이 될 수 있으며, 이러한 모델은 종종 훈련 오류를 0으로 훈련될 때 최고의 성능을 달성하기 때문이다(Nakkiran et al., 2020; Feldman, 2020). 이전의 이론적 연구는 양성 과대적합(benign overfitting, Belkin, 2021; Bartlett et al., 2020) 및 랜덤 특징 및 신경망 접선 커널(Neural Tangent Kernels, NTK)과 같은 보간 모델의 분포 내 일반화(Mei & Montanari, 2022; Ghorbani et al., 2021; Montanari & Zhong, 2022)와 같은 관련 개념을 특징지었다.
이러한 이전 접근 방식의 근본적인 한계, 즉 "고충점(pain point)"은 일반적으로 노이즈가 입력 데이터 자체에 존재하는 것이 아니라 레이블에 존재한다고 모델링한다는 것이다. 결과적으로, 이 강력한 이론적 장치는 입력에 내재된 스퓨리어스 특징의 암기를 직접적으로 다루지 않는다. 실질적인 연구는 스퓨리어스 특징의 영향을 탐구하고 핵심 특징으로부터 이를 분리하려고 시도했지만(Hermann & Lampinen, 2020; Singla & Feizi, 2022), 이론적 분석은 주로 특징 복잡성(Qiu et al., 2023) 또는 과대적합 정도(Sagawa et al., 2020)가 학습에 미치는 영향에 초점을 맞추었으며, 종종 모델 아키텍처의 역할을 완전히 포착하지 못했다. 본 논문은 샘플의 실제 레이블과 상관관계가 없는 스퓨리어스 특징의 암기를 이해하고 정량화하기 위한 분석적으로 다루기 쉬운 프레임워크를 제공함으로써 이 격차를 해소하는 것을 목표로 한다.
딥러닝에서 스퓨리어스 특징을 암기하는 문제의 가장 정확한 기원은 과대적합된 영역에서 딥러닝 모델이 훈련 데이터를 과대적합하는 경험적 관찰로 거슬러 올라간다. 딥러닝이 놀라운 성공을 거두었지만, 연구자들은 작업과 상관관계가 있지만 인과적으로 관련이 없는 패턴을 학습하거나 완전히 관련 없는 패턴을 학습하는 바람직하지 않은 동작을 인지하기 시작했다.
그 출현의 "이유"는 다면적이다:
1. 과대적합(Over-parameterization): 현대 딥러닝 모델은 종종 훈련 데이터 포인트보다 훨씬 더 많은 매개변수를 가진다. 이 용량은 훈련 오류를 0으로 달성할 수 있게 하지만, 관련 없는 세부 사항을 포함하여 훈련 데이터를 "암기"할 수 있게 한다. Nakkiran et al. (2020) 및 Feldman (2020)은 훈련 오류를 0으로 달성하는 데 종종 긴 훈련 시간이 필요하며, 이는 암기로 이어질 수 있다고 강조했다.
2. 데이터 내 스퓨리어스 상관관계: 실제 데이터셋은 종종 실제 레이블과 통계적으로 상관관계가 있지만 인과적으로 연결되지 않은 특징을 포함한다. 예를 들어, 데이터셋에서 "고양이" 이미지의 모든 이미지가 특정 "파란색 배경"을 가지고 있다면, 모델은 "고양이" 자체보다는 "파란색 배경"을 "고양이"와 연관시키는 것을 학습할 수 있다(Geirhos et al., 2020; Xiao et al., 2021). 이는 이러한 스퓨리어스 상관관계가 실제 샘플링 분포를 예측하지 못할 때 특히 문제가 된다.
3. 관련 없는 또는 희귀한 패턴: 스퓨리어스 패턴이 희귀하거나 단순히 작업과 관련이 없는 경우에도 문제가 발생한다(Yang et al., 2022; Hermann & Lampinen, 2020). 모델은 여전히 이러한 패턴을 파악하여 암기로 이어질 수 있다.
4. 강건성, 공정성 및 프라이버시에 대한 결과: 이러한 암기의 실질적인 영향—분포 외 강건성 부족(Geirhos et al., 2019; Zhou et al., 2021), 공정성에 영향을 미치는 편향된 예측(Zliobaite, 2015), 정보 추출을 통한 잠재적 데이터 프라이버시 침해(Leino & Fredrikson, 2020)—은 더 깊은 이해에 대한 긴급한 필요성을 강조했다.
역사적 맥락은 과대적합의 경험적 관찰에서 이러한 과대적합이 종종 무작위 노이즈보다는 "스퓨리어스 특징"을 포함한다는 인식으로의 발전을 보여준다. 그런 다음 학계는 질적 설명과 경험적 완화 전략을 넘어 엄격한 이론적 프레임워크를 추구했다.
저자들이 이 논문을 작성하게 만든 근본적인 한계 또는 "고충점"은 입력 데이터에 내재된 스퓨리어스 특징의 암기를 정량화할 수 있는 정밀한 이론적 프레임워크의 부족이다.
이전의 연구들은 강력했지만 주로 다음 사항에 초점을 맞추었다:
* 양성 과대적합(Benign Overfitting): 훈련 데이터를 과대적합하지만 분포 내 테스트 데이터에서는 여전히 잘 일반화되는 모델을 특징짓는다(Belkin, 2021; Bartlett et al., 2020).
* 분포 내 일반화(In-distribution Generalization): 노이즈가 일반적으로 레이블에 있다고 가정되는 랜덤 특징(RF) 및 신경망 접선 커널(NTK)과 같은 보간 모델을 분석한다. 입력 특징이 아닌 레이블에 노이즈가 있다고 가정한다(Mei & Montanari, 2022; Ghorbani et al., 2021).
핵심적인 격차는 이러한 이론적 도구가 "노이즈가 일반적으로 입력 데이터가 아닌 레이블에 있다고 모델링되기 때문에 스퓨리어스 특징의 암기를 다루지 않는다"는 것이었다. 또한, 실질적인 연구는 스퓨리어스 특징을 이해하고 분리하려고 시도했지만, 이론적 접근 방식은 특징 복잡성 또는 과대적합에 주로 초점을 맞추었으며, "아키텍처의 역할을 포착하지 못했다." 본 논문은 모델 아키텍처와 활성화 함수를 명시적으로 고려하여 스퓨리어스 특징 암기를 이해하고 정량화하기 위한 분석적으로 다루기 쉬운 프레임워크를 제공함으로써 이 고충점을 직접적으로 해결한다.
직관적 도메인 용어
복잡한 개념을 기초 독자에게 접근 가능하게 만들기 위해 일상적인 비유를 사용하여 매우 전문적인 용어를 분석해 보자:
- 스퓨리어스 특징 ($y$): 사진에서 "사과"를 식별하도록 똑똑한 로봇을 가르친다고 상상해 보자. "핵심 특징"은 사과 자체이다(모양, 색깔, 줄기). "스퓨리어스 특징"은 훈련 사진의 모든 사과 사진이 찍힌 특정 주방 카운터일 수 있다. 카운터는 사진에 존재하지만, 사과를 사과로 만드는 것과는 아무 관련이 없다.
- 암기 (스퓨리어스 특징의): 로봇이 사과에 대해 배우는 것 외에 주방 카운터도 "기억"할 때 발생한다. 나중에 다른 표면의 사과를 보여주면, "주방 카운터"를 "사과스러움"과 잘못 연관시켰기 때문에 망설이거나 인식하지 못할 수도 있다. 로봇은 관련 없는 세부 사항을 "암기"했다.
- 특징 정렬 ($F_\phi(z^s, z)$): 이것은 "관련 없는 부분" (단지 주방 카운터, $z^s$)이 "전체 그림" (주방 카운터 위의 사과, $z$)과 로봇의 내부 처리 관점에서 얼마나 유사한지를 측정한다. 로봇의 시각 시스템이 배경을 많이 처리한다면, 주방 카운터만 보는 것이 그 카운터 위의 사과에 대한 기억과 강하게 "정렬"될 수 있다.
- 안정성 ($S_{z_1}$): 이것은 특정 훈련 사진 (예: 주방 카운터 위의 사과 사진 하나)을 추가하거나 제거할 때 사과에 대한 로봇의 전반적인 이해가 얼마나 변하는지를 나타낸다. "안정적인" 로봇의 지식은 크게 변하지 않을 것이다. 로봇의 "주방 카운터 = 사과"라는 믿음이 매우 불안정하다면, 사진 하나를 제거하면 그 연관성을 완전히 버릴 수도 있다. 믿음이 안정적이라면, 훈련 예제의 사소한 변화에도 불구하고 믿음을 유지할 것이다.
표기법 표
| 표기법 | 설명 |
|---|---|
| $z = [x, y]$ | 핵심 특징 $x$와 스퓨리어스 특징 $y$로 분해된 입력 샘플. |
| $x$ | 실제 레이블과 관련된 샘플의 핵심 특징. |
| $y$ | 실제 레이블과 상관관계가 없는 샘플의 스퓨리어스 특징. |
| $g(x)$ | 핵심 특징 $x$에만 의존하는 실제 레이블. |
| $z^s = [-, y]$ | 핵심 특징 $x$가 제거된 (예: 0으로 대체된) 샘플의 "스퓨리어스 대응물", 스퓨리어스 특징 $y$만 남김. |
| $f(z, \theta^*)$ | 최적 매개변수 $\theta^*$를 가진 입력 $z$에 대한 모델의 예측 함수. |
| $\phi(z)$ | 입력 $z$의 특징 맵 (또는 특징 벡터), 원시 데이터를 고차원 표현으로 변환. |
| $\theta^*$ | 전체 훈련 데이터셋으로부터 학습된 모델의 최적 매개변수. |
| $\theta^*_{-1}$ | 훈련 데이터셋에서 샘플 $z_1$을 제외하고 학습된 모델의 최적 매개변수. |
| $S_{z_1}$ | 훈련 샘플 $z_1$에 대한 모델의 안정성, $z_1$을 제거했을 때 출력 변화를 측정. |
| $F_\phi(z, z_1)$ | $\phi$에 의해 유도된 특징 공간에서 샘플 $z$와 $z_1$ 간의 특징 정렬. |
| $P_{\Phi_{-1}}$ | 특징 행렬 $\Phi_{-1}$의 행의 스팬에 대한 투영기 ($z_1$을 제외한 모든 훈련 샘플). |
| $R_{Z_{-1}}$ | 데이터셋 $Z_{-1}$ ($z_1$ 제외)으로 훈련된 모델의 일반화 오류. |
| $\gamma_\phi$ | 특징 맵 $\phi$ 및 활성화 함수에 의존하는 특징 정렬과 관련된 비례 상수. |
| $\alpha = d_y/d$ | 스퓨리어스 특징에 기인하는 입력 차원의 비율. |
| $h_i$ | 활성화 함수를 특징짓는 데 사용되는 $i$번째 에르미트 다항식. |
| $N$ | 훈련 샘플 수. |
| $k$ | 뉴런 수 (RF의 경우) 또는 너비 (NTK의 경우). |
| $d$ | 총 입력 차원. |
| $d_x$ | 핵심 특징 $x$의 차원. |
| $d_y$ | 스퓨리어스 특징 $y$의 차원. |
| RF | 랜덤 특징 모델. |
| NTK | 신경망 접선 커널 모델. |
문제 정의 및 제약 조건
핵심 문제 공식화 및 딜레마
딥러닝 모델, 특히 과대적합된 모델은 훈련 데이터에 존재하는 "스퓨리어스 특징"을 암기하는 것으로 알려져 있다. 이러한 특징은 샘플의 실제 레이블과 상관관계가 없는 패턴 또는 속성이지만, 훈련 세트에서 해당 레이블과 함께 발생할 수 있다. 예를 들어, 모델이 고양이를 식별하도록 훈련되었고 모든 훈련 이미지에 특정 배경(스퓨리어스 특징)이 있다면, 모델은 고양이 자체보다는 배경을 "고양이" 레이블과 연관시키는 것을 학습할 수 있다.
이 논문이 다루는 핵심 문제는 이러한 스퓨리어스 특징이 어떻게 암기되는지를 정밀하게 정량화하고 이해하기 위한 엄격한 이론적 프레임워크의 부족이다. 이전의 이론적 연구는 주로 노이즈가 레이블에 모델링되는 "양성 과대적합"에 초점을 맞추거나, 입력 데이터 자체에 내재된 스퓨리어스 특징 또는 모델 아키텍처의 역할을 특정하지 않고 특징의 복잡성과 과대적합에 초점을 맞추었다.
입력/현재 상태: 우리는 각 샘플 $z$가 핵심 특징 $x$와 스퓨리어스 특징 $y$로 구성된 데이터셋으로 훈련된 딥러닝 모델로 시작한다. 즉, $z = [x, y]$이다. 샘플 $z_i$에 대한 실제 레이블 $g$는 $g_i = g(x_i)$이며, 이는 오직 핵심 특징 $x_i$에만 의존하고 스퓨리어스 특징 $y_i$와는 독립적임을 의미한다. 이러한 모델은 일반적으로 과대적합되며 훈련 오류를 0으로 달성할 때까지 훈련된다. 즉, 훈련 데이터를 완벽하게 맞춘다. 형식적으로, 우리는 샘플 $z$를 두 개의 별도 부분으로 구성된 것으로 모델링한다. 즉, $z = [x, y]$이며, 여기서 $x$는 핵심 특징이고 $y$는 스퓨리어스 특징이다. 그림 1을 참조하라. 스퓨리어스 특징의 암기는 실제 레이블 $g_i$와 "스퓨리어스 대응물" $z_i^s = [x, y_i]$ (여기서 $x$는 독립적인 특징으로 대체됨, 예: 모든 0)로 쿼리했을 때 모델의 출력 간의 공분산으로 포착된다.
출력/목표 상태: 원하는 결과는 스퓨리어스 특징의 암기를 정밀하게 특징지을 수 있는 분석적으로 다루기 쉬운 프레임워크이다. 여기에는 다음이 포함된다:
1. 실제 레이블 $g_i$와 "스퓨리어스 대응물" $z_i^s = [x, y_i]$ (여기서 $x$는 독립적인 특징으로 대체됨, 예: 모든 0)로 쿼리했을 때 모델의 출력 간의 공분산과 같은 메트릭을 사용하여 암기 정도를 정량화한다.
2. 이 암기를 모델의 안정성과 원본 및 스퓨리어스 샘플 간의 새로운 개념인 "특징 정렬"의 두 가지 주요 구성 요소로 분해한다.
3. 모델 선택 (예: 랜덤 특징 또는 신경망 접선 커널 아키텍처) 및 활성화 함수가 이 특징 정렬에, 결과적으로 스퓨리어스 특징의 암기에 어떻게 영향을 미치는지 밝힌다.
4. 궁극적으로, 목표는 분포 변화, 공정성 및 데이터 프라이버시에 대한 강건성을 개선하기 위해 스퓨리어스 상관관계를 덜 암기하는 기계 학습 모델을 설계할 수 있는 통찰력을 제공하는 것이다.
딜레마: 이전 연구자들이 갇혀 있었고 이 논문이 해결하고자 하는 고통스러운 절충점은 스퓨리어스 특징의 암기를 피하는 것이 종종 높은 정확도를 달성하는 것과 상충된다는 것이다. 오늘날 널리 사용되는 과대적합된 딥러닝 모델은 종종 훈련 오류를 0으로 달성할 때까지 장기간 훈련될 때 최고의 성능을 달성한다. 훈련 데이터를 완벽하게 맞추는 이 과정은 종종 스퓨리어스 상관관계를 암기하는 것을 포함한다. 왜냐하면 모델이 훈련 손실을 줄이는 "쉬운" 방법이기 때문이다. 따라서 한 측면(스퓨리어스 암기 감소)을 개선하는 것은 일반적으로 다른 측면(전반적인 훈련 정확도 또는 핵심 특징에 대한 일반화)을 저하시킬 위험이 있어 어려운 균형 잡기 행위가 된다.
제약 조건 및 실패 모드
딥러닝에서 스퓨리어스 특징 암기를 이론적으로 정량화하는 문제는 몇 가지 가혹하고 현실적인 제약 조건으로 인해 본질적으로 어렵다:
- 계산 및 이론적 다루기 쉬움: 완전한 심층 신경망은 악명 높게 복잡하여 이론적 분석이 매우 어렵다. 본 논문은 두 가지 단순화되었지만 강력한 이론적 모델인 랜덤 특징(RF) 및 신경망 접선 커널(NTK) 회귀에 초점을 맞춤으로써 이를 해결한다. 이러한 모델은 "분석적으로 다루기 쉬우며" "이론 문헌에서 널리 분석"되어 정밀한 수학적 특성화를 가능하게 하기 때문에 선택되었다. 이는 임의의 복잡한 딥러닝 아키텍처에 대한 정확한 분석 결과의 확장이 여전히 상당한 장애물로 남아 있음을 시사한다.
- 스퓨리어스 특징의 특정 정의: 분석은 실제 학습 작업과 상관관계가 없는 스퓨리어스 특징으로 엄격하게 제한된다. 스퓨리어스 특징이 상관관계가 있다면, 문제는 순수한 "암기"에서 "단축 학습" 또는 "스퓨리어스 상관관계 착취"로 전환되며, 이는 다른 이론적 처리가 필요하다. 이것은 현재 프레임워크의 중요한 경계 조건이다.
- 데이터 분포 가정: 이론적 결과는 데이터 분포에 대한 특정 가정에 의존한다. 예를 들어, 입력 샘플 $z_i = [x_i, y_i]$는 곱셈 분포 $P_z = P_x \times P_y$에서 독립적이고 동일하게 분포(i.i.d.)된다고 가정된다. 즉, 핵심 특징 $x_i$와 스퓨리어스 특징 $y_i$는 독립적이다. 또한, $x$와 $y$에 대한 0 평균 및 제어된 $L_2$ 노름($||x||_2 = \sqrt{d_x}$, $||y||_2 = \sqrt{d_y}$)과 같은 특정 속성이 가정된다. $P_x$와 $P_y$ 모두 Lipschitz 농도를 만족해야 한다. 이러한 가정은 분석을 단순화하지만 모든 실제 데이터셋에 보편적으로 적용되지 않을 수 있다.
- 과대적합 및 고차원성 가정: 프레임워크는 과대적합 및 고차원성의 특정 영역 내에서 작동한다. RF 모델의 경우, $N \log^3 N = o(k)$, $\sqrt{d} \log d = o(k)$, $k \log^4 k = o(d^2)$와 같은 조건이 요구되며, 이는 데이터 포인트 $N$ 및 입력 차원 $d$에 비해 많은 뉴런 $k$를 의미한다. NTK 모델의 경우, 조건은 $N \log^3 N = o(kd)$, $N > d$, $k = O(d)$이다. 이러한 조건은 커널의 역행렬 가능성을 보장하고 모델이 데이터를 보간할 수 있도록 하는 데 필수적이지만, 특정 작동 영역을 정의한다.
- 활성화 함수 속성: 활성화 함수 $\phi$ (또는 NTK의 경우 도함수 $\phi'$)는 비선형이고 L-Lipschitz라고 가정된다. 이러한 속성은 에르미트 계수 및 농도 불평등을 포함하는 수학적 유도에 매우 중요하다.
- 커널 역행렬 가능성: 일반화된 선형 회귀 모델의 기본 제약 조건은 훈련 세트의 유도된 커널 $K$가 역행렬 가능해야 한다는 것이다. 이는 모델이 임의의 레이블 $G$를 완벽하게 맞출 수 있고 최적 매개변수 $\theta^*$의 해에 사용되는 무어-펜로즈 역행렬이 잘 정의됨을 보장한다.
- 실제 시나리오로의 일반화: 본 논문은 이론적 예측이 이전된다는 것을 보여주기 위해 표준 데이터셋(MNIST, CIFAR-10) 및 다양한 신경망 아키텍처(전결합, 컨볼루션, ResNet)에 대한 수치 실험을 제공하지만, 분석적 증명은 주로 단순화된 모델 및 합성 데이터에 대한 것이다. 복잡한 실제 딥러닝 시스템에 대한 정확한 이론적 엄밀함으로 이 격차를 해소하는 것은 여전히 중요한 과제로 남아 있다. 현재 분석은 중요한 단계이지만 실제 딥러닝 설정의 방대한 다양성을 완전히 포괄하지는 않는다.
왜 이 접근 방식인가
선택의 불가피성
랜덤 특징(RF) 및 신경망 접선 커널(NTK) 회귀 모델의 선택은 임의적인 것이 아니라, 본 논문이 해결하고자 하는 특정 이론적 격차에 의해 주도된 전략적 필요성이었다. 핵심 문제는 실제 학습 작업과 상관관계가 없는 스퓨리어스 특징의 암기를 이해하고 정량화하는 것이며, 이러한 특징은 레이블뿐만 아니라 입력 데이터 자체 내의 노이즈로 나타난다.
RF 및 NTK와 같은 강력한 도구를 활용하는 현존하는 이론적 프레임워크조차도 양성 과대적합 또는 분포 내 일반화와 같은 현상에 대해, 주로 레이블의 노이즈를 모델링한다. 이 근본적인 차이는 이러한 모델(RF 및 NTK)이 이론적으로 매력적이고 분석적으로 다루기 쉬웠음에도 불구하고, 그들의 확립된 이론적 장치는 입력 수준의 스퓨리어스 특징 암기 문제를 직접적으로 다루지 않았다는 것을 의미했다. 저자들은 전통적인 "SOTA" 방법, 종종 경험적인 성격의 방법(예: 표준 CNN, 확산 모델 또는 트랜스포머)이 실제 작업에 강력하지만, 이 특정 암기 현상에 대한 정밀하고 정량화 가능한 이론적 특성화에 필요한 분석적 투명성이 부족하다는 것을 깨달았다. 따라서 관련 학습 이론에서 분석적 다루기 쉬움으로 알려진 RF 및 NTK의 이론적 이해를 확장하는 것이 필요한 엄격한 프레임워크를 개발하는 유일하게 실행 가능한 경로가 되었다.
비교 우위
이 방법은 성능 지표를 통한 단순한 질적 우위가 아니라, 이론적 이해에서 전례 없는 구조적 이점을 제공한다. 본 논문은 훈련 샘플과 그 스퓨리어스 대응물 간의 특징 공간에서의 유사성을 정량화하는 새로운 개념인 "특징 정렬"($F_\phi(z, z_1)$)을 도입한다. 이것은 고전적인 모델 안정성 ($S_{z_1}$) 개념과 결합되어 스퓨리어스 특징이 암기되는 방식을 정밀하게 특징짓는 이중 접근 방식을 형성한다.
구조적 이점은 이 프레임워크 내에서 RF 및 NTK 모델의 분석적 다루기 쉬움에 있다. 이들은 암기를 일반화 오류에 연결하는 비례 상수($\gamma_\phi$)에 대한 닫힌 형태의 표현을 허용한다. 이러한 수준의 수학적 해석 가능성은 근본적인 암기 메커니즘에 대한 깊은 통찰력 없이 종종 성능 향상을 제공하는 이전의 경험적 금본위제보다 압도적으로 우수하다. 이 방법이 메모리 복잡성을 $O(N^2)$에서 $O(N)$으로 줄이거나 고차원 노이즈를 계산적으로 더 잘 처리하지는 않지만, 스퓨리어스 특징(입력 노이즈로 모델링됨)이 암기되는 정량화 가능한 측정값을 제공하며, 이 과정에서 모델 아키텍처와 활성화 함수의 중요한 역할을 밝힌다.
제약 조건과의 일치
선택된 접근 방식은 랜덤 특징 및 신경망 접선 커널의 고유한 속성을 활용함으로써 문제의 가혹한 요구 사항과 완벽하게 일치한다. 주요 제약 조건은 실제 레이블과 상관관계가 없는 입력 데이터에 내재된 스퓨리어스 특징의 암기를 정량화하기 위한 분석적으로 다루기 쉬운 프레임워크를 개발하는 것이었다.
일반화된 선형 회귀 설정은 RF 및 NTK 모델과 결합되어 정확히 이러한 분석적 다루기 쉬움을 제공한다. 샘플 $z$를 핵심 특징 $x$와 스퓨리어스 특징 $y$로 분해하는 형식($z = [x, y]$), 여기서 $y$는 실제 레이블 $g(x)$와 독립적이라는 것은 문제 정의를 직접적으로 반영한다. 안정성과 새로운 특징 정렬 항을 통해 암기를 정밀하게 특징짓는 프레임워크의 능력은 현상의 직접적인 정량화를 허용한다. 또한, 가정된 것들(예: 데이터 분포, 과대적합, 활성화 함수 속성)은 수학적 분석이 실현 가능하고 의미 있는 닫힌 형태의 표현을 산출하도록 신중하게 선택되어, 문제의 이론적 요구 사항과 해결책의 분석적 능력 사이에 완벽한 "결합"을 생성한다.
대안의 거부
본 논문은 모든 작업에 대해 다른 인기 있는 딥러닝 아키텍처(예: GAN 또는 확산 모델)를 열등하다고 간주하는 의미에서 명시적으로 "거부"하지 않는다. 대신, 암묵적인 거부는 스퓨리어스 특징 암기를 정밀하게 정량화하기 위한 엄격하고 분석적으로 다루기 쉬운 이론적 프레임워크의 현재 부족에서 비롯된다.
저자들은 실질적인 연구가 스퓨리어스 특징을 탐구했지만, 이러한 접근 방식은 종종 아키텍처의 역할을 포착하지 못하거나 정량화 가능한 이론적 이해를 제공하지 못한다고 강조한다. 양성 과대적합과 같은 문제에 적용될 때 RF 및 NTK와 같은 모델에 대한 기존 이론적 장치는 일반적으로 입력의 스퓨리어스 특징이 아닌 레이블의 노이즈를 모델링한다. 이는 이러한 모델(RF/NTK) 자체가 강력하지만, 그들의 기존 이론적 분석은 이 특정 문제에 대해 불충분했다는 것을 의미한다. 본 논문의 기여는 이 논문이 스퓨리어스 특징 암기에 대해 추구하는 깊고 정량화 가능한 통찰력을 제공하기 위해 RF 및 NTK에 대한 이 이론적 분석을 확장하는 것이지, 완전히 새로운 모델을 제안하는 것이 아니다. 따라서 "거부"는 모델 자체에 대한 것이 아니라, 입력 수준의 스퓨리어스 특징 암기에 대한 이 논문이 추구하는 깊고 정량화 가능한 통찰력을 제공하기 위한 현재 이론적 도구의 불충분성에 대한 것이다.
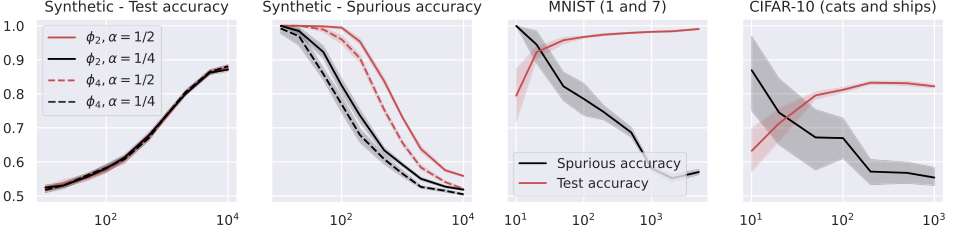 Figure 2. Test and spurious accuracies as a function of the number of training samples N, for various binary classification tasks. In the first two plots, we consider the RF model in (14) with k = 105 trained over Gaussian data with d = 1000. The labeling function is g(x) = sign(u⊤x). We repeat the experiments for α = {0.25, 0.5} and for the two activations ϕ2 = h1 + h2 and ϕ4 = h1 + h4, where hi denotes the i-th Hermite polynomial (see Appendix A.1). In the last two plots, we consider the same model with ReLU activation, trained over two MNIST and CIFAR-10 classes. The width of the noise background is 10 pixels for MNIST and 8 pixels for CIFAR-10, see Figure 1. The spurious accuracy is obtained by querying the model only with the noise background from the training set, replacing all the other pixels with 0, and taking the sign of the output. As we consider binary classification, an accuracy of 0.5 is achieved by random guessing. We plot the average over 10 independent trials and the confidence band at 1 standard deviation
Figure 2. Test and spurious accuracies as a function of the number of training samples N, for various binary classification tasks. In the first two plots, we consider the RF model in (14) with k = 105 trained over Gaussian data with d = 1000. The labeling function is g(x) = sign(u⊤x). We repeat the experiments for α = {0.25, 0.5} and for the two activations ϕ2 = h1 + h2 and ϕ4 = h1 + h4, where hi denotes the i-th Hermite polynomial (see Appendix A.1). In the last two plots, we consider the same model with ReLU activation, trained over two MNIST and CIFAR-10 classes. The width of the noise background is 10 pixels for MNIST and 8 pixels for CIFAR-10, see Figure 1. The spurious accuracy is obtained by querying the model only with the noise background from the training set, replacing all the other pixels with 0, and taking the sign of the output. As we consider binary classification, an accuracy of 0.5 is achieved by random guessing. We plot the average over 10 independent trials and the confidence band at 1 standard deviation
수학적 및 논리적 메커니즘
마스터 방정식
스퓨리어스 특징이 암기되는 방식을 이해하기 위한 본 논문의 핵심 메커니즘은 모델의 안정성, 샘플 간의 특징 정렬, 그리고 이들을 연결하는 관계를 정의하는 세 가지 상호 연결된 수학적 정의에 달려 있다. 이러한 방정식은 훈련 포인트에 대한 훈련된 모델의 민감성을 집합적으로 설명하고, 이 민감성이 고차원 특징 공간에서 특징의 유사성에 의해 어떻게 조절되는지를 설명한다.
첫째, 훈련 샘플 $z_1$에 대한 모델의 안정성은 다음과 같이 정의된다:
$$S_{z_1} := f(\cdot, \theta^*) - f(\cdot, \theta^*_{-1}) \quad (5)$$
이 양은 특정 훈련 샘플 $z_1$이 훈련 데이터셋에 포함되거나 제외될 때 모델의 출력 변화를 측정한다.
둘째, 특징 맵 $\phi$에 의해 유도된 특징 공간에서 두 샘플 $z$와 $z_1$ 간의 특징 정렬은 다음과 같이 주어진다:
$$F_\phi(z, z_1) := \frac{\phi(z)^\top P_{\Phi_{-1}} \phi(z_1)}{\|P_{\Phi_{-1}}\phi(z_1)\|_2^2} \quad (8)$$
이 항은 나머지 훈련 데이터로 정의된 부분 공간에 투영된 후, 특정 훈련 샘플 $z_1$의 특징 표현과 일반 샘플 $z$의 특징 표현 간의 유사성 또는 "정렬"을 정량화한다.
마지막으로, 안정성과 특징 정렬 사이의 중요한 연결은 보조 정리 4.1에 의해 확립된다:
$$S_{z_1}(z) = F_\phi(z, z_1) S_{z_1}(z_1) \quad (9)$$
이 방정식은 임의의 샘플 $z$에 대한 모델 출력의 변화( $z_1$이 제거되었을 때)가 $z_1$ 자체의 안정성에 직접 비례하며, 특징 정렬에 의해 스케일링된다는 것을 보여준다. 이 우아한 관계는 암기 분석의 기반을 형성한다.
항별 분석
이러한 마스터 방정식의 각 구성 요소를 분해하여 정확한 수학적 정의, 모델에서의 물리적 또는 논리적 역할, 그리고 선택된 수학적 연산의 근거를 이해해 보자.
방정식 (5): 안정성 $S_{z_1}$
* $S_{z_1}$: 이것은 훈련 샘플 $z_1$에 대한 모델의 안정성을 나타내는 기호이다.
* 수학적 정의: 모델 예측의 차이를 나타내는 스칼라 값.
* 물리적/논리적 역할: 단일 훈련 샘플 $z_1$이 모델 출력에 미치는 영향을 정량화한다. 큰 $S_{z_1}$은 $z_1$을 제거하면 모델 예측이 크게 변한다는 것을 의미하며, 이는 $z_1$이 "암기"되었거나 강한 영향을 미친다는 것을 나타낸다.
* $f(\cdot, \theta^*)$: 이것은 전체 데이터셋으로 훈련된 모델의 예측 함수이다.
* 수학적 정의: $f(z, \theta^*) = \phi(z)\theta^*$, 여기서 $\phi(z)$는 입력 $z$의 특징 벡터이고 $\theta^*$는 전체 훈련 세트 $Z$로부터 학습된 최적 매개변수이다.
* 물리적/논리적 역할: 모든 사용 가능한 훈련 데이터를 사용하여 매개변수를 학습한 모델의 출력을 나타낸다.
* $f(\cdot, \theta^*_{-1})$: 이것은 $z_1$을 제외한 데이터셋으로 훈련된 모델의 예측 함수이다.
* 수학적 정의: $f(z, \theta^*_{-1}) = \phi(z)\theta^*_{-1}$, 여기서 $\theta^*_{-1}$는 훈련 세트 $Z_{-1}$ ( $z_1$을 제외한 $Z$)으로부터 학습된 최적 매개변수이다.
* 물리적/논리적 역할: 특정 훈련 샘플 $z_1$이 훈련 과정에서 제외되었을 때 모델의 출력을 나타낸다.
* $- (빼기)$:
* 사용 이유: 빼기는 $z_1$의 존재 또는 부재로 인한 모델 출력의 변화 또는 차이를 직접 측정하는 데 사용된다. 이것은 영향 또는 민감도를 정량화하는 표준적인 방법이다. 곱셈을 사용하면 비율을 측정하게 되는데, 이는 "변화"에 대한 원하는 측정값이 아니다.
방정식 (8): 특징 정렬 $F_\phi(z, z_1)$
* $F_\phi(z, z_1)$: 이것은 샘플 $z$와 훈련 샘플 $z_1$ 간의 특징 정렬을 나타내는 기호이다.
* 수학적 정의: 정규화된 투영을 나타내는 스칼라 값.
* 물리적/논리적 역할: 특징 공간에서 $z$의 특징 표현이 $z_1$의 특징 표현과 얼마나 "유사한지"를 측정한다. 이 유사성은 중요하며, 이는 $z_1$에 대한 정보가 $z$에 어떻게 "전달"되거나 "정렬"될 수 있는지를 나타내기 때문이다.
* $\phi(z)$: 입력 샘플 $z$의 특징 맵.
* 수학적 정의: 입력 $z \in \mathbb{R}^d$에 특징 맵 함수 $\phi: \mathbb{R}^d \to \mathbb{R}^p$를 적용하여 얻은 벡터 $\phi(z) \in \mathbb{R}^p$.
* 물리적/논리적 역할: 원시 입력 데이터 $z$를 선형 모델이 작동하는 고차원 특징 표현으로 변환한다. 이것은 모델의 입력에 대한 내부 "이해"이다.
* $\phi(z_1)$: 훈련 샘플 $z_1$의 특징 맵.
* 수학적 정의: 특정 훈련 샘플 $z_1$에 대해 $\phi(z)$와 유사하다.
* 물리적/논리적 역할: 영향이 연구되는 훈련 샘플의 모델 내부 특징 표현을 나타낸다.
* $P_{\Phi_{-1}}$: $\Phi_{-1}$의 행의 스팬에 대한 투영기.
* 수학적 정의: $P_{\Phi_{-1}} \in \mathbb{R}^{p \times p}$인 투영 행렬이며, $P_{\Phi_{-1}} = \Phi_{-1}^\top (\Phi_{-1}\Phi_{-1}^\top)^{-1} \Phi_{-1}$ (만약 $\Phi_{-1}\Phi_{-1}^\top$가 역행렬 가능하면). 이는 벡터를 $\Phi_{-1}$의 행 공간으로 투영한다.
* 물리적/논리적 역할: 이 투영기는 다른 모든 훈련 샘플( $z_1$ 제외)의 특징으로 정의된 부분 공간을 고려하여 특징 벡터를 효과적으로 "필터링"하거나 "정규화"한다. 이는 나머지 훈련 데이터의 집합적 정보에 대해 정렬이 측정되도록 보장하여 고유한 정렬의 보다 강력한 측정값을 만든다.
* $\top (전치)$:
* 사용 이유: 전치는 두 벡터, $\phi(z)$와 $P_{\Phi_{-1}}\phi(z_1)$ 간의 내적(점곱)을 수행하는 데 사용된다. 이 연산은 두 특징 벡터 간의 선형 상관관계 또는 유사성을 정량화한다.
* $\cdot$ (곱셈):
* 사용 이유: 행렬-벡터 곱셈 (예: $P_{\Phi_{-1}}\phi(z_1)$)은 투영기에 의해 정의된 선형 변환을 적용한다. 벡터-벡터 곱셈(점곱)은 유사성을 정량화한다.
* $\|\cdot\|_2^2$: 제곱 L2 노름.
* 수학적 정의: 벡터 $v$에 대해 $\|v\|_2^2 = v^\top v = \sum_i v_i^2$.
* 물리적/논리적 역할: 이 분모의 항은 정렬을 정규화한다. 이는 $F_\phi(z, z_1)$가 특징 벡터 자체의 스케일에 불변인 상대적 정렬의 측정값이 되도록 보장한다. 본질적으로 특징 공간에서 코사인 유사성(또는 관련 투영)을 측정한다.
* $/ (나눗셈)$:
* 사용 이유: 제곱 L2 노름으로 나누는 것은 투영 또는 유사성을 정의하는 데 일반적인 정규화 단계이며, 정렬 측정값이 올바르게 스케일링되도록 보장한다.
방정식 (9): 관계 $S_{z_1}(z) = F_\phi(z, z_1) S_{z_1}(z_1)$
* $S_{z_1}(z)$: 일반 샘플 $z$에서의 모델 출력의 안정성.
* 수학적 정의: $f(z, \theta^*) - f(z, \theta^*_{-1})$.
* 물리적/논리적 역할: 이것은 샘플 $z$에 대한 모델 예측의 변화이다 ( $z_1$이 제거되었을 때).
* $S_{z_1}(z_1)$: 훈련 샘플 $z_1$ 자체에서의 모델 출력의 안정성.
* 수학적 정의: $f(z_1, \theta^*) - f(z_1, \theta^*_{-1})$.
* 물리적/논리적 역할: 이것은 $z_1$이 자신의 예측에 미치는 직접적인 영향을 나타낸다. 모델이 완벽하게 보간하면 $f(z_1, \theta^*) = g_1$이므로, 이 항은 $g_1 - f(z_1, \theta^*_{-1})$이 된다. 이는 $z_1$의 레이블을 "암기"하는 것을 나타낸다.
* $\cdot$ (곱셈):
* 사용 이유: 곱셈은 직접적인 비례 관계를 보여주는 데 사용된다. $z$에 대한 변화는 $z_1$에 대한 변화의 스케일링된 버전이며, 스케일링 인자는 특징 정렬이다. 이는 선형 관계를 시사한다: $z$가 특징 공간에서 $z_1$과 높은 정렬을 보이면, $z_1$을 제거하면 $z$의 예측에 $z_1$의 예측에 영향을 미치는 방식과 유사하게 영향을 미친다.
단계별 흐름
데이터 포인트 $z$가 이 수학적 엔진에 들어가고, 특정 훈련 샘플 $z_1$과 그 스퓨리어스 대응물 $z^s$가 함께 들어간다고 상상해 보자. 목표는 $z^s$에 대한 모델의 출력이 $z_1$에 의해 어떻게 영향을 받을 수 있는지 이해하는 것이며, 이는 암기를 나타낸다.
- 특징 추출: 먼저, 원시 입력 $z$와 특정 훈련 샘플 $z_1$이 모델의 특징 맵 $\phi$에 공급된다. 이것은 이들을 내부 특징 표현 $\phi(z)$ 및 $\phi(z_1)$으로 변환한다. 이것을 초기 처리 단위로 생각하면, 원시 데이터를 모델이 "이해할 수 있는" 형식으로 변환한다.
- 부분 공간 투영: 다음으로, $\phi(z_1)$은 다른 모든 훈련 샘플의 특징으로 생성된 부분 공간, $\Phi_{-1}$으로 투영된다. 이 단계는 나머지 훈련 데이터에 비해 $z_1$ 특징의 고유한 기여를 분리한다.
- 특징 정렬 계산: 그런 다음 투영된 $\phi(z_1)$은 정규화된 $\phi(z_1)$의 크기로 나누고 $\phi(z)$와 내적을 통해 비교된다. 이것은 $F_\phi(z, z_1)$를 계산하며, 특징 정렬이다. 이 단위는 모델의 특징 공간에서 $z$가 $z_1$과 얼마나 "유사한지"를 결정한다.
- 모델 훈련 (암시적): 병렬로, 모델의 두 가지 버전이 "훈련"된다. 하나는 전체 훈련 데이터셋 $Z$ ( $z_1$ 포함)를 사용한다. 다른 하나는 $z_1$을 제외한 데이터셋 $Z_{-1}$을 사용한다. 매개변수 $\theta^*$와 $\theta^*_{-1}$은 이러한 훈련 과정에서 파생된다.
- $z_1$에서의 안정성 측정: $z_1$에 대한 모델의 출력은 두 매개변수 세트: $f(z_1, \theta^*)$ 및 $f(z_1, \theta^*_{-1})$를 사용하여 계산된다. 이 두 출력의 차이, $S_{z_1}(z_1) = f(z_1, \theta^*) - f(z_1, \theta^*_{-1})$가 계산된다. 이 단위는 $z_1$이 $z_1$ 자체의 예측에 얼마나 영향을 미치는지를 측정한다. 모델이 완벽하게 보간하면 $f(z_1, \theta^*) = g_1$이므로, 이 항은 $g_1 - f(z_1, \theta^*_{-1})$이 되어 $z_1$의 레이블 "암기"를 나타낸다.
- 안정성 전파: 이제 특징 정렬 $F_\phi(z, z_1)$와 $z_1$에서의 안정성 $S_{z_1}(z_1)$이 곱해져 $S_{z_1}(z) = F_\phi(z, z_1) S_{z_1}(z_1)$이 된다. 이는 일반 샘플 $z$에 대한 예측의 변화가 $z_1$에서의 변화에 직접 비례하며, 특징 정렬에 의해 스케일링됨을 의미한다. 이는 선형 관계를 시사한다: $z$가 특징 공간에서 $z_1$과 높은 정렬을 보이면, $z_1$을 제거하면 $z$의 예측에 $z_1$의 예측에 영향을 미치는 방식과 유사하게 영향을 미친다.
- 암기 정량화: 마지막으로, 스퓨리어스 특징의 암기를 정량화하기 위해, 논문은 공분산
Cov(f(z^s, θ*), g_i)를 고려한다. 여기에는 스퓨리어스 샘플 $z^s = [-, y]$ (핵심 특징 $x$가 제거되거나 0으로 설정되어 스퓨리어스 특징 $y$만 남음)에서 모델을 평가하고 그 출력을 실제 레이블 $g_i$ ( $x_i$에만 의존함)와 상관시키는 것이 포함된다. 유도된 관계 (방정식 11)는 이 공분산이 $\gamma_\phi \sqrt{R_{Z_{-1}}} \sqrt{\text{Var}(g_i)}$로 제한된다는 것을 보여준다. 여기서 $\gamma_\phi$는 특징 정렬과 관련된 상수이고 $R_{Z_{-1}}$는 일반화 오류이다. 이 최종 단계는 특징 처리 및 안정성의 기계적 조립 라인을 스퓨리어스 특징 암기의 궁극적인 측정값으로 연결한다.
최적화 역학
본 논문은 일반화된 선형 회귀 프레임워크 내에서 작동하며, 여기서 모델 매개변수 $\theta$는 방정식 (2)에서와 같이 경험적 위험을 이차 손실로 최소화함으로써 학습된다: $\min_\theta \| \Phi \theta - G \|_2^2$. 이 설정에서 최적화 과정은 최적 매개변수 $\theta^*$에 대한 닫힌 형태의 해로 이어진다. 방정식 (3): $\theta^* = \theta_0 + \Phi^+(G - f(Z, \theta_0))$로 주어진다.
이는 "학습" 또는 "최적화 역학"이 복잡한 손실 지형을 탐색하는 반복적인 경사 하강 과정에 관한 것이 아니라, 이 직접적인 보간 솔루션의 속성에 관한 것임을 의미한다. 본 논문은 "경사 하강은 초기화에 $l_2$ 노름에서 가장 가까운 보간기로 수렴한다"고 명시적으로 명시한다. 이는 모델이 훈련 오류를 0으로 달성하도록 훈련되었음을 시사하며, 이는 과대적합된 모델의 특징이다.
여기서 분석되는 핵심 "역학"은 다음과 같다:
1. 보간(Interpolation): 모델이 훈련 데이터를 완벽하게 맞추는 능력(훈련 오류 0 달성)은 과대적합된 영역과 선택된 최적화 목표의 직접적인 결과이다. 이 보간은 스퓨리어스 특징을 암기할 수 있게 한다.
2. 일반화 오류의 역할: 본 논문의 주요 결과(방정식 11)는 스퓨리어스 특징의 암기(Cov(f(z^s, θ*), g_i))가 일반화 오류 $R_{Z_{-1}}$에 직접 비례한다는 것을 보여준다. 이는 모델의 보이지 않는 데이터에 대한 일반화 능력이 향상될수록(즉, $R_{Z_{-1}}$이 감소할수록) 스퓨리어스 특징을 암기하는 경향도 약해진다는 것을 의미한다. 이것은 보간 솔루션의 행동에 대한 중요한 통찰력이다.
3. 특징 정렬의 영향: 암기 바운드(방정식 11)의 비례 상수 $\gamma_\phi$는 특징 정렬 $F_\phi(z_1, z_1)$에서 파생된다. 이 상수는 특징 맵 $\phi$ 및 활성화 함수에 따라 달라지며, 모델이 잘 일반화될 때에도 스퓨리어스 특징이 얼마나 강하게 암기되는지를 결정하는 방식으로 "손실 지형"을 형성한다. 더 높은 $\gamma_\phi$는 주어진 일반화 오류에 대해 더 큰 암기를 의미한다. RF 및 NTK 모델에 대한 본 논문의 분석은 이 $\gamma_\phi$를 정확하게 특징지어, 모델 아키텍처와 활성화 함수가 암기 역학에 어떻게 영향을 미치는지 밝힌다.
4. 안정성을 프록시로 사용: 안정성 $S_{z_1}(z_1)$은 모델이 보간을 달성하기 위해 개별 훈련 포인트에 얼마나 "의존"하는지를 측정하는 척도 역할을 한다. $S_{z_1}(z_1)$이 크면 모델이 $z_1$에 매우 민감하다는 것을 나타내며, 이는 $z_1$이 강하게 "암기"되었음을 나타낸다. 보간 솔루션을 찾는 최적화 과정은 본질적으로 이 안정성을 생성하며, 이는 특징 정렬을 통해 스퓨리어스 암기에 영향을 미치도록 전파된다.
본질적으로, "최적화 역학"은 이를 찾는 반복 단계보다는 보간 솔루션 $\theta^*$의 특성을 통해 이해된다. 모델은 데이터를 완벽하게 맞추도록 학습되며, 본 논문은 특히 관련 없는 정보의 암기에 관한 한 이 학습 전략의 고유한 절충점과 결과를 분석한다. 경사 하강은 $\theta^*$로 이어지지만, 반복적인 행동은 명시적으로 분석되지 않고 최종 상태의 속성만 분석된다.
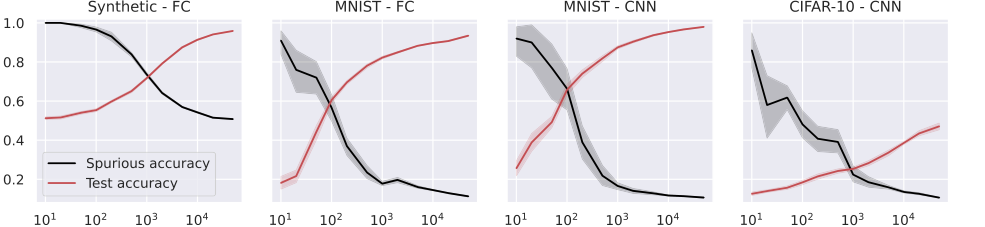 Figure 4. Test and spurious accuracies as a function of the number of training samples N, for a fully connected (FC, first two plots), and a small convolutional neural network (CNN, last two plots). In the first plot, we use synthetic (Gaussian) data with d = 1000, and the labeling function is g(x) = sign(u⊤x). As we consider binary classification, the accuracy of random guessing is 0.5. The other plots use subsets of the MNIST and CIFAR-10 datasets, with an external layer of noise added to images, see Figure 1. As we consider 10 classes, the accuracy of random guessing is 0.1. We plot the average over 10 independent trials and the confidence band at 1 standard deviation
Figure 4. Test and spurious accuracies as a function of the number of training samples N, for a fully connected (FC, first two plots), and a small convolutional neural network (CNN, last two plots). In the first plot, we use synthetic (Gaussian) data with d = 1000, and the labeling function is g(x) = sign(u⊤x). As we consider binary classification, the accuracy of random guessing is 0.5. The other plots use subsets of the MNIST and CIFAR-10 datasets, with an external layer of noise added to images, see Figure 1. As we consider 10 classes, the accuracy of random guessing is 0.1. We plot the average over 10 independent trials and the confidence band at 1 standard deviation
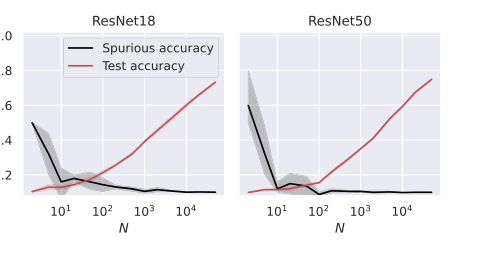 Figure 5. Test and spurious accuracies as a function of the number of training samples N, for two ResNet architectures. We use subsets of the CIFAR-10 dataset, with an external layer of noise added to images, see Figure 1. As we consider 10 classes, the accuracy of random guessing is 0.1. We plot the average over 10 independent trials and the confidence band at 1 standard deviation
Figure 5. Test and spurious accuracies as a function of the number of training samples N, for two ResNet architectures. We use subsets of the CIFAR-10 dataset, with an external layer of noise added to images, see Figure 1. As we consider 10 classes, the accuracy of random guessing is 0.1. We plot the average over 10 independent trials and the confidence band at 1 standard deviation
결과, 한계 및 결론
실험 설계 및 기준선
이론적 주장을 엄격하게 검증하기 위해 저자들은 다양한 모델 유형과 데이터셋에 걸쳐 수학적 예측과 경험적 관찰을 비교하는 일련의 실험을 세심하게 설계했다. 핵심 아이디어는 훈련 데이터에 존재하지만 실제 레이블을 예측하지 않는 스퓨리어스 특징—관련 없는 노이즈 또는 배경 정보—을 생성하는 시나리오를 만드는 것이었다. 그런 다음 모델이 이러한 관련 없는 특징을 얼마나 "암기"했는지 측정했다.
이러한 실험의 "희생자"는 전통적인 의미의 대안 모델이 아니라, 랜덤 특징(RF) 및 신경망 접선 커널(NTK) 모델 자체였으며, 전결합(FC), 컨볼루션 신경망(CNN) 및 ResNet과 같은 더 복잡한 딥러닝 아키텍처도 포함되었다. 목표는 이러한 모델이 훈련될 때 스퓨리어스 상관관계를 불가피하게 파악하고 의존하게 되는 방식과, 이 동작이 어떻게 정밀하게 특징지어질 수 있는지를 보여주는 것이었다.
실험 설정은 다음을 포함했다:
- 데이터 생성:
- 합성 데이터: 이진 분류 작업을 위해 입력 차원 $d=1000$인 가우시안 데이터가 사용되었다. 이를 통해 데이터 속성을 정밀하게 제어할 수 있었다.
- 표준 데이터셋: MNIST(숫자 '1'과 '7' 분류용) 및 CIFAR-10( '고양이'와 '배' 분류용)은 이론의 실제 이미지 데이터 적용을 테스트하는 데 사용되었다.
- 스퓨리어스 특징 주입: 모든 데이터셋에 대해 스퓨리어스 특징 $y$가 도입되었다. 이것은 일반적으로 원본 이미지 $x$ 주위에 추가된 노이즈 배경이었으며, 입력 샘플 $z = [x, y]$를 형성했다(그림 1 참조). 중요하게도, 이 $y$는 실제 레이블 $g(x)$와 상관관계가 없도록 설계되었다. MNIST 및 CIFAR-10의 경우, 스퓨리어스 정확도를 쿼리할 때 핵심 특징 $x$는 0으로 대체되었으며, 이는 모델이 오직 노이즈 구성 요소에 대해서만 테스트되었음을 의미한다.
- 모델 아키텍처:
- RF 및 NTK 모델: 이들은 다양한 뉴런 수($k$)와 다양한 샘플 수($N$)로 훈련된 주요 이론적 대상이었다.
- 심층 신경망: FC, CNN 및 ResNet 아키텍처도 테스트되어 이론적 통찰력이 단순화된 RF/NTK 영역을 넘어 더 복잡한 특징 학습 모델로 확장된다는 것을 보여주었다.
- 주요 실험 매개변수:
- 훈련 샘플 수 ($N$): 일반화 및 암기 모두에 미치는 영향을 관찰하기 위해 상당히 다양했다(예: $10^1$에서 $10^4$까지).
- 활성화 함수 ($\phi$): 에르미트 계수로 특징지어진 다양한 활성화 함수가 사용되었다(예: RF의 경우 $\phi_2 = h_1 + h_2$, $\phi_4 = h_1 + h_4$; NTK의 경우 $\phi_2 = h_0 + h_1$, $\phi_4 = h_0 + h_3$, 여기서 $h_i$는 에르미트 다항식). ReLU 활성화 함수도 테스트되었다. 활성화 함수 선택은 암기에 영향을 미칠 것으로 예측되었다.
- 스퓨리어스 특징 비율 ($\alpha$): $d_y/d$로 정의되며, 입력 차원에서 스퓨리어스 특징에 기인하는 비율을 나타낸다. 스퓨리어스 암기에 미치는 영향도 조사되었다.
- 암기 측정: 암기를 증명하는 가장 직접적이고 "무자비한" 방법은 "스퓨리어스 정확도"를 통하는 것이었다. 이것은 훈련된 모델에 샘플의 스퓨리어스 구성 요소만 (예: 핵심 특징 $x$를 0으로 대체) 공급하고 모델이 여전히 올바른 레이블 $g(x)$를 예측하는지 확인하여 계산되었다. 모델이 오직 스퓨리어스 부분에 대해 높은 정확도를 달성했다면, 이는 암기를 명확하게 증명했다.
- 정확도 기준선: 이진 분류 작업의 경우, 무작위 추측 정확도 0.5가 하한선 역할을 했다. 10개 클래스 분류(CIFAR-10, MNIST)의 경우, 무작위 추측은 0.1의 정확도를 산출했다. 모델의 성능은 이러한 사소한 기준선과 비교되었다. 모든 실험은 10번의 독립적인 시도에 대해 평균되었으며, 신뢰 구간은 1 표준 편차를 나타낸다.
증거가 증명하는 것
경험적 증거는 본 논문의 핵심 이론적 주장을 압도적으로 지지하며, 제안된 수학적 프레임워크가 스퓨리어스 특징 암기 현상을 정확하게 특징짓는다는 것을 결정적이고 부인할 수 없는 증거를 제공한다. 모델 안정성(일반화 오류와 관련됨)과 "특징 정렬"이라는 새로운 개념의 조합으로 암기가 발생하는 핵심 메커니즘은 강력하게 검증되었다.
증거가 명확하게 증명하는 것은 다음과 같다:
-
일반화와 암기 간의 반비례 관계: 그림 2, 3, 4, 5는 훈련 샘플 수($N$)가 증가함에 따라 모델의 테스트 정확도(일반화 능력의 프록시)가 향상되는 반면, 스퓨리어스 정확도(암기의 직접적인 측정값)는 감소하는 명확하고 반비례 관계를 일관되게 보여준다. 이것은 "일반화 능력이 증가함에 따라 스퓨리어스 특징의 암기가 약해진다"(초록, 1쪽)는 이론적 예측과 암기가 일반화 오류에 비례한다는 것(방정식 11, 18, 27)에 대한 강력한 증거이다. 모델 아키텍처에 관계없이 이러한 절충점의 "희생자"였으며, 더 나은 일반화가 본질적으로 스퓨리어스 단서에 대한 의존성을 줄인다는 것을 보여준다.
-
활성화 함수의 결정적 역할: 실험은 활성화 함수가 암기에 중요한 역할을 한다는 이론적 통찰력에 대한 강력한 검증을 제공했다.
- 랜덤 특징(RF) 모델의 합성 데이터(그림 2)의 경우, $\alpha$(스퓨리어스 입력의 비율)가 증가하고 저차수 에르미트 계수가 지배적인 활성화 함수를 사용할 때 스퓨리어스 정확도가 증가하는 것으로 관찰되었다. 이것은 $\gamma_{RF}$(특징 정렬 상수)가 이러한 계수에 의존한다는 이론적 예측인 정리 5.4 및 방정식 17과 직접적으로 일치한다.
- 신경망 접선 커널(NTK) 모델의 MNIST 및 CIFAR-10(그림 3)의 경우, 고차수 에르미트 계수가 지배적인 활성화 함수가 감소된 암기를 초래한다는 결과가 나왔다. 이것은 정리 6.3 및 방정식 26과 일치하며, 이는 활성화 함수의 에르미트 전개로 포착된 활성화 함수의 수학적 속성이 모델의 암기 성향을 직접적으로 결정한다는 것을 보여준다.
-
스퓨리어스 특징 비율 ($\alpha$)에 대한 의존성: 그림 7은 스퓨리어스 정확도가 $\alpha$(입력 중 스퓨리어스 부분의 비율)와 함께 단조롭게 증가한다는 강력한 증거를 제공한다. 이것은 합성 데이터에 대한 RF 및 NTK 모델 모두에서 관찰되었다. 중요하게도, 테스트 정확도는 $\alpha$에 의해 거의 영향을 받지 않았다. 이것은 정리 5.4 및 6.3에 확립된 바와 같이 $\alpha$에 대한 특징 정렬 상수($\gamma_{RF}$, $\gamma_{NTK}$)의 이론적 의존성을 직접적으로 확인한다. 더 많은 스퓨리어스 정보가 존재할수록 모델은 핵심 작업 성능을 향상시키지 않고도 이를 더 많이 암기한다.
-
아키텍처 전반에 걸친 광범위한 적용 가능성: 단순화된 RF 및 NTK 모델을 넘어, 본 논문은 전결합(FC), 컨볼루션 신경망(CNN) 및 ResNet(그림 4 및 5)을 포함한 더 복잡한 딥러닝 아키텍처로 경험적 검증을 확장했다. 이러한 실험은 관찰된 추세—훈련 샘플이 더 많을수록 테스트 정확도가 증가하고 스퓨리어스 정확도가 감소하는 것—가 이러한 다양한 모델 전반에 걸쳐 유지된다는 것을 보여주었다. 이것은 특징 정렬 및 안정성 프레임워크에 의해 설명된 암기 및 일반화와의 관계에 대한 기본 원리가 선형 모델에 국한되지 않고 현대 딥러닝에 광범위하게 적용된다는 것을 시사한다. 이것은 정확한 수학적 특성화가 단순화된 모델에 대해 유도되었더라도 이론적 프레임워크의 통찰력의 일반성에 대한 강력한 지원을 제공한다.
본질적으로, 실험은 스퓨리어스 특징의 영향을 분리하고 측정하도록 설계되었으며, 다양한 설정에 걸친 일관된 추세는 제안된 이론적 프레임워크가 기계 학습 모델에서 스퓨리어스 특징 암기라는 복잡한 현상을 정확하게 포착한다는 부인할 수 없는 증거를 제공한다.
한계 및 향후 방향
이 논문은 스퓨리어스 특징이 암기되는 방식을 이해하기 위한 훌륭하고 정밀한 이론적 프레임워크를 제공하지만, 현재의 경계를 인정하고 이러한 발견이 어떻게 더 발전될 수 있는지 고려하는 것이 중요하다. 저자들 스스로가 비판적 사고를 자극할 수 있는 통찰력 있는 미래 연구 방향을 제시한다.
현재 분석의 한계:
- 스퓨리어스 특징의 범위: 본 연구의 주요 초점은 실제 학습 작업과 상관관계가 없는 스퓨리어스 특징이다. 이것은 분석을 단순화하고 강력한 기반을 제공하지만, 많은 실제 스퓨리어스 상관관계는 레이블과 어느 정도 상관관계가 있을 수 있으며, 이는 이를 분리하기 더 어렵게 만든다.
- 일반화된 선형 회귀 설정: 특징 정렬에 대한 엄격한 수학적 증명은 주로 일반화된 선형 회귀의 맥락에서, 특히 랜덤 특징(RF) 및 신경망 접선 커널(NTK) 모델에 대해 확립된다. 경험적 결과는 이러한 통찰력이 더 복잡한 심층 신경망(FC, CNN, ResNet)으로 확장된다는 것을 시사하지만, 이러한 아키텍처에 대한 완전한 이론적 특성화는 여전히 열린 과제로 남아 있다.
- 특정 모델 유형: 특징 정렬 상수($\gamma_{RF}$, $\gamma_{NTK}$)에 대한 정확한 닫힌 형태의 표현은 RF 및 NTK 모델에 대해 유도된다. 동적으로 특징을 학습하는 모델을 포함한 다른 유형의 모델로 이 정확한 정량화를 확장하려면 상당한 추가 이론적 작업이 필요하다.
향후 방향 및 토론 주제:
- 레이블 상관관계가 있는 스퓨리어스 특징: 스퓨리어스 특징이 실제 레이블과 부분적으로 상관관계가 있는 경우 암기 역학은 어떻게 변할까? 이것은 많은 응용 분야에서 더 현실적인 시나리오이다. 이러한 경우 "양성" 대 "악성" 암기의 정도를 정량화하기 위해 현재 프레임워크를 확장할 수 있을까? 이는 예측력이 있는 스퓨리어스의 정의를 더 미묘하게 조정해야 할 것이다.
- 분포 외 (OOD) 스퓨리어스 특징: 본 논문은 주로 훈련 세트에 존재하는 스퓨리어스 특징의 암기에 초점을 맞춘다. 훈련 중에 보지 못했지만 이전에 암기된 스퓨리어스 특징과 상관관계가 있는 새로운 스퓨리어스 특징을 테스트 시점에 만나는 경우 어떻게 될까? 이것은 분포 변화 강건성과 직접적으로 관련된다. 이 프레임워크를 사용하여 이러한 OOD 스퓨리어스 특징에 대한 모델의 취약성을 예측할 수 있을까?
- "단순성 편향" 통합: 본 논문은 "단순성 편향"—모델이 "쉬운" 패턴을 먼저 학습하는 경향—을 관련 현상으로 언급한다. 현재 프레임워크는 단순성 편향을 어떻게 공식적으로 통합하거나 설명할 수 있을까? 특징 정렬은 단순성 편향이 나타나는 메커니즘인가, 아니면 별개의 상호 작용하는 현상인가? 이 상호 작용을 이해하면 더 강력한 학습 알고리즘을 개발할 수 있을 것이다.
- 복잡한 아키텍처에 대한 특징 정렬 특성화: 경험적 결과는 추세가 FC, CNN 및 ResNet 모델에 대해 유지된다는 것을 보여준다. 중요한 다음 단계는 이러한 복잡한 특징 학습 아키텍처에 대한 특징 정렬 $F_\phi(z^s, z)$를 이론적으로 특성화하는 것이다. 여기에는 다중 전결합, 컨볼루션 또는 주의 계층에 의해 생성된 특징 맵이 암기에 어떻게 영향을 미치는지 이해하는 것이 포함될 것이다. 이러한 특성화는 다양한 딥러닝 모델의 스퓨리어스 상관관계에 대한 고유한 취약성을 직접 비교할 수 있게 할 것이다.
- 암기 저항 모델 설계: 이 분석 프레임워크를 무장하여, 스퓨리어스 특징을 암기하는 데 덜 취약한 모델이나 훈련 전략을 어떻게 설계할 수 있을까? 본 논문은 활성화 함수와 그 에르미트 계수의 역할을 강조한다. 스퓨리어스 암기를 줄이기 위해 고차 특징 학습을 촉진하는 활성화 함수나 아키텍처 선택을 엔지니어링할 수 있을까? 여기에는 새로운 정규화 기술이나 아키텍처 귀납적 편향이 포함될 수 있다.
- 더 넓은 사회적 영향: 본 논문은 이론적이며 사회적 결과를 자세히 다루지 않지만, 그 발견은 공정성, 프라이버시 및 강건성에 대한 심오한 영향을 미친다. 예를 들어, 모델이 핵심 작업과 함께 민감한 인구 통계 정보(스퓨리어스 특징)를 암기하면 프라이버시 문제가 발생한다. 예측을 위해 스퓨리어스 상관관계에 의존하면 편향되거나 불공정한 결과로 이어질 수 있다. 미래 연구는 이 프레임워크를 사용하여 기존 모델을 스퓨리어스 암기에 대해 감사하고 이러한 위험을 완화하기 위한 개입을 개발하는 방법을 탐구할 수 있으며, 따라서 더 윤리적이고 신뢰할 수 있는 AI 시스템에 기여할 수 있다. 여기에는 프라이버시 누출 또는 공정성 위반을 정량화하기 위해 특징 정렬을 기반으로 하는 측정 또는 도구를 개발하는 것이 포함될 수 있다.
- 보간 너머: 본 논문은 모델이 훈련 데이터를 보간하는 과대적합된 영역에서 작동한다. 이러한 발견은 저차원 모델이나 훈련 오류를 달성하지 못하는 모델에 어떻게 적용될까? 안정성과 특징 정렬의 개념은 이러한 영역에서도 동일한 설명력을 유지할까?
이러한 토론 지점은 이 논문이 강력한 이론적 기반을 마련하고, 딥러닝의 바람직하지 않은 측면을 이해하고 완화하는 데 있어 이론적 및 응용 연구 모두에 대해 많은 흥미롭고 도전적인 길을 열어준다는 것을 강조한다.