偽の特徴が記憶されるメカニズム:ランダム特徴量とNTK特徴量に対する厳密な分析
This paper offers a theoretical explanation for why AI models memorize irrelevant data, revealing how model stability and feature alignment play key roles.
背景と学術的系譜
起源と学術的系譜
深層学習モデルが偽の特徴を記憶するという問題は、この分野において重要かつ十分に文書化された現象であるが、それを厳密に定量化するための理論的枠組みは、これまでほとんど欠如していた。この問題は、ニューラルネットワークがしばしば、意図されたタスクに本来関連のない訓練データの特徴から学習してしまうことに起因する。これは、特定のパターンと学習タスクとの間に正の偽相関が生じる場合(Geirhos et al., 2020; Xiao et al., 2021)、あるいはこれらのパターンが稀である場合(Yang et al., 2022)や単に関連性がない場合(Hermann & Lampinen, 2020)に発生しうる。このような記憶は、モデルが偽の関係性を学習することを招き、分布シフトに対するロバスト性(Geirhos et al., 2019; Zhou et al., 2021)、公平性(Zliobaite, 2015)、データプライバシー(Leino & Fredrikson, 2020)に影響を与える。
歴史的に、経験的な努力は、この現象を軽減することに焦点を当ててきた(Plumb et al., 2022; Chang et al., 2021)。しかし、記憶を回避することが常に可能であるとは限らない。なぜなら、過剰パラメータ化されたモデルでは、訓練誤差ゼロを達成したときに最高の性能を発揮することが多く、その場合に記憶が精度にとって最適となることがあるからである(Nakkiran et al., 2020; Feldman, 2020)。過去の理論的研究では、偽の過剰適合(benign overfitting)(Belkin, 2021; Bartlett et al., 2020)や、ランダム特徴量およびニューラルタンジェントカーネル(NTK)のような補間モデルの分布内汎化(in-distribution generalization)(Mei & Montanari, 2022; Ghorbani et al., 2021; Montanari & Zhong, 2022)といった関連概念が特徴づけられてきた。
これらの先行アプローチの根本的な限界、すなわち「ペインポイント」は、それらが通常、ノイズをラベルに存在するものとしてモデル化しており、入力データ自体に存在するノイズとしてはモデル化していないことである。その結果、この強力な理論的機構は、入力に埋め込まれた偽の特徴の記憶に直接対応しない。実用的な研究では、偽の特徴の影響を調査し、それらをコア特徴から分離しようと試みてきた(Hermann & Lampinen, 2020; Singla & Feizi, 2022)が、理論的分析は主に特徴の複雑さ(Qiu et al., 2023)や過剰パラメータ化の度合い(Sagawa et al., 2020)が学習に与える影響に焦点を当てており、モデルのアーキテクチャの役割を完全に捉えていないことが多い。本稿は、サンプルから真のラベルと相関しない偽の特徴が埋め込まれている場合に、偽の特徴の記憶を理解し定量化するための解析的に扱いやすい枠組みを提供することで、このギャップを埋めることを目指す。
深層学習における偽の特徴記憶問題の最も厳密な起源は、深層学習モデルが訓練データに過剰適合する経験的な観察、特に過剰パラメータ化された領域における観察に遡ることができる。深層学習が目覚ましい成功を収める一方で、研究者たちは、タスクと相関しているが因果関係のないパターン、あるいは完全に無関係なパターンをモデルが学習するという望ましくない挙動に気づき始めた。
その出現の背後にある「なぜ」は多岐にわたる。
1. 過剰パラメータ化: 最新の深層学習モデルは、訓練データ点よりもはるかに多くのパラメータを持つことが多い。この能力により、モデルは訓練誤差ゼロを達成できるが、無関係な詳細を含む訓練データを「記憶」することも可能になる。Nakkiran et al. (2020) および Feldman (2020) は、訓練誤差ゼロを達成するにはしばしば長い訓練時間が必要であり、それが記憶につながる可能性があることを強調した。
2. データにおける偽相関: 実世界のデータセットには、真のラベルと統計的に相関しているが因果関係のない特徴が含まれていることが多い。例えば、データセット中の「猫」の画像がすべて特定の「青い背景」を持っている場合、モデルは「猫」そのものではなく、「青い背景」を「猫」と関連付けることを学習する可能性がある(Geirhos et al., 2020; Xiao et al., 2021)。これは、これらの偽相関が真のサンプリング分布を予測しない場合に特に問題となる。
3. 無関係または稀なパターン: 偽のパターンが稀であるか、単に関連性がない場合でも問題は発生する(Yang et al., 2022; Hermann & Lampinen, 2020)。モデルはこれらのパターンを拾い上げ、記憶につながる可能性がある。
4. ロバスト性、公平性、プライバシーへの影響: この記憶がもたらす実用的な影響――分布外ロバスト性の低下(Geirhos et al., 2019; Zhou et al., 2021)、公平性に影響を与えるバイアスのかかった予測(Zliobaite, 2015)、情報抽出を通じたデータプライバシー侵害の可能性(Leino & Fredrikson, 2020)――は、より深い理解の緊急の必要性を浮き彫りにした。
歴史的文脈は、過剰適合の経験的な観察から、この過剰適合が単なるランダムノイズではなく「偽の特徴」を含むことが多いという認識への進展を示している。その後、学術分野は定性的な記述や経験的な軽減戦略を超えて、厳密な理論的枠組みを求めるようになった。
本稿の著者らが本稿を執筆するに至った根本的な限界、すなわち「ペインポイント」は、入力データに埋め込まれた偽の特徴を、ラベルのノイズとしてモデル化するのではなく、厳密に定量化する理論的枠組みの欠如である。
先行研究は、強力ではあるものの、主に以下に焦点を当てていた。
* 偽の過剰適合 (Benign Overfitting): 訓練データに過剰適合するが、分布内テストデータに対しては依然として良好に汎化するモデルの特徴づけ(Belkin, 2021; Bartlett et al., 2020)。
* 分布内汎化 (In-distribution Generalization): ランダム特徴量(RF)やニューラルタンジェントカーネル(NTK)のような補間モデルの分析。これらのモデルでは、ノイズは通常、入力特徴量ではなくラベルに存在すると仮定される(Mei & Montanari, 2022; Ghorbani et al., 2021)。
重要なギャップは、これらの理論的ツールが「ノイズは一般的にラベルにモデル化されるため、入力データではなく、偽の特徴の記憶をカバーしていない」という点であった。さらに、実用的な研究は偽の特徴を理解し分離しようと試みてきたが、理論的なアプローチは主に特徴の複雑さや過剰パラメータ化に焦点を当てており、「アーキテクチャの役割を捉えていない」という状況であった。本稿は、モデルのアーキテクチャと活性化関数を明示的に考慮した、偽の特徴記憶を理解し定量化するための解析的に扱いやすい枠組みを提供することで、このペインポイントに直接対処する。
直感的なドメイン用語
複雑な概念をゼロベースの読者にも理解できるように、日常的なアナロジーを用いて高度に専門的な用語を分解してみよう。
- 偽の特徴 ($y$): スマートロボットに写真の中の「リンゴ」を識別するように教えていると想像してほしい。「コア特徴」はリンゴそのもの(その形、色、茎)である。「偽の特徴」は、訓練写真のリンゴがすべて撮影された特定のキッチンカウンターかもしれない。カウンターは写真に存在するが、リンゴをリンゴたらしめるものとは全く関係がない。
- 記憶(偽の特徴の): これは、ロボットがリンゴについて学ぶだけでなく、キッチンカウンターも「記憶」してしまう場合に発生する。後で別の表面にあるリンゴを見せられた場合、ロボットは「キッチンカウンター=リンゴらしさ」という関連付けを誤って行ったため、ためらったり、認識に失敗したりするかもしれない。ロボットは無関係な詳細を「記憶」してしまったのだ。
- 特徴アライメント ($F_\phi(z^s, z)$): これは、「無関係な部分」(キッチンカウンターのみ、$z^s$)が、「全体像」(キッチンカウンターの上のリンゴ、$z$)と、ロボットの内部処理の観点から、どれだけ似ているかを測定する。ロボットの視覚システムが背景を強く処理する場合、キッチンカウンターだけを見ると、そのカウンター上のリンゴの記憶と強く「整列」するかもしれない。
- 安定性 ($S_{z_1}$): これは、特定の訓練写真(例:キッチンカウンターの上のリンゴの写真)を1枚追加または削除した場合に、ロボットのリンゴ全体に対する理解がどれだけ変化するかを指す。「安定した」ロボットの知識は劇的に変化しない。ロボットの「キッチンカウンター=リンゴ」という信念が非常に不安定な場合、1枚の写真を取り除くだけで、その関連付けを完全にドロップしてしまうかもしれない。安定している場合、訓練例のわずかな変更にもかかわらず、信念を保持するだろう。
記法表
| 記法 | 説明 |
|---|---|
| $z = [x, y]$ | コア特徴 $x$ と偽の特徴 $y$ に分解された入力サンプル。 |
| $x$ | 真のラベルに関連する、サンプルのコア特徴。 |
| $y$ | 真のラベルと相関しない、サンプルの偽の特徴。 |
| $g(x)$ | コア特徴 $x$ のみに依存する真のラベル。 |
| $z^s = [-, y]$ | コア特徴 $x$ が除去された(例:ゼロに置き換えられた)サンプルの「偽の対応物」、偽の特徴 $y$ のみ残る。 |
| $f(z, \theta^*)$ | 最適パラメータ $\theta^*$ を持つ入力 $z$ に対するモデルの予測関数。 |
| $\phi(z)$ | 入力 $z$ の特徴マップ(または特徴ベクトル)、生データを高次元表現に変換する。 |
| $\theta^*$ | 完全な訓練データセットから学習されたモデルの最適パラメータ。 |
| $\theta^*_{-1}$ | 訓練データセットからサンプル $z_1$ を除外して学習されたモデルの最適パラメータ。 |
| $S_{z_1}$ | 訓練サンプル $z_1$ に対するモデルの安定性。$z_1$ を除外した場合の出力の変化を測定する。 |
| $F_\phi(z, z_1)$ | $\phi$ によって誘導される特徴空間におけるサンプル $z$ と $z_1$ の間の特徴アライメント。 |
| $P_{\Phi_{-1}}$ | 特徴行列 $\Phi_{-1}$ の行の線形部分空間への射影($z_1$ を除くすべての訓練サンプル)。 |
| $R_{Z_{-1}}$ | データセット $Z_{-1}$($z_1$ を除く)で訓練されたモデルの汎化誤差。 |
| $\gamma_\phi$ | 特徴アライメントに関連する比例定数。特徴マップ $\phi$ と活性化関数に依存する。 |
| $\alpha = d_y/d$ | 偽の特徴に帰属する入力次元の割合。 |
| $h_i$ | $i$ 番目のエルミート多項式。活性化関数を特徴づけるために使用される。 |
| $N$ | 訓練サンプルの数。 |
| $k$ | ニューロンの数(RFの場合)または幅(NTKの場合)。 |
| $d$ | 全入力次元。 |
| $d_x$ | コア特徴 $x$ の次元。 |
| $d_y$ | 偽の特徴 $y$ の次元。 |
| RF | ランダム特徴量モデル。 |
| NTK | ニューラルタンジェントカーネルモデル。 |
問題定義と制約
コア問題の定式化とジレンマ
深層学習モデル、特に過剰パラメータ化されたモデルは、訓練データに含まれる「偽の特徴」を記憶することで知られている。これらの特徴は、サンプルの真のラベルとは相関しない属性やパターンであるが、訓練セットではそれと共起する可能性がある。例えば、モデルが猫を識別するように訓練されており、猫のすべての訓練画像が特定の背景(偽の特徴)を持っている場合、モデルは猫そのものではなく、背景を「猫」ラベルと関連付けることを学習するかもしれない。
本稿が取り組むコア問題は、これらの偽の特徴がどのように記憶されるかを厳密に定量化し、理解するための理論的枠組みが欠如していることである。過去の理論的研究は、主に「偽の過剰適合」に焦点を当てており、そこではノイズがラベルにモデル化されるか、あるいは特徴の複雑さや過剰パラメータ化に焦点を当てていたが、入力データ自体に埋め込まれた偽の特徴やモデルアーキテクチャの役割を特に扱っていなかった。
入力/現在の状態: 各サンプル $z$ がコア特徴 $x$ と偽の特徴 $y$ から構成されるデータセット $z = [x, y]$ で訓練された深層学習モデルから開始する。サンプル $z_i$ の真のラベル $g$ は $g_i = g(x_i)$ であり、これはコア特徴 $x_i$ のみに依存し、偽の特徴 $y_i$ には依存しない。これらのモデルは通常、過剰パラメータ化されており、訓練誤差ゼロを達成するまで訓練される。すなわち、訓練データを完全に適合させる。形式的には、サンプル $z$ を2つの異なる部分から構成されるものとしてモデル化する。すなわち、$z = [x, y]$ であり、$x$ がコア特徴、$y$ が偽の特徴である。偽の特徴の記憶は、訓練サンプルの真のラベル $g$ と、偽のサンプル $z^s = [-, y]$(ここで「-」はコア特徴 $x$ を除去すること(例:すべてゼロに置き換えること)に対応する)で評価されたモデルの出力との間の共分散によって捉えられる。
出力/目標状態: 望ましい結果は、偽の特徴の記憶を厳密に特徴づけることができる解析的に扱いやすい枠組みである。これには以下が含まれる。
1. 真のラベル $g_i$ と、サンプルの「偽の対応物」$z_i^s = [x, y_i]$(ここで $x$ は独立した特徴、例:すべてゼロに置き換えられる)でクエリされたモデルの出力との間の共分散のような指標を用いて、記憶の範囲を定量化する。
2. この記憶を、個々の訓練サンプルに対するモデルの安定性と、「元のサンプルと偽のサンプル」間の「特徴アライメント」という新しい概念の2つの主要な構成要素に分解する。
3. モデルの選択(ランダム特徴量またはニューラルタンジェントカーネルアーキテクチャなど)と活性化関数が、この特徴アライメント、ひいては偽の特徴の記憶にどのように影響するかを明らかにする。
4. 最終的には、機械学習モデルが偽の相関を記憶しにくくなるように設計するための洞察を提供し、それによって分布シフトに対するロバスト性、公平性、データプライバシーを改善することを目指す。
ジレンマ: 過去の研究者を閉じ込めてきた痛みを伴うトレードオフであり、本稿が解決しようとしているのは、偽の特徴の記憶を回避することが、しばしば高い精度を達成することと相反するということである。現在普及している過剰パラメータ化された深層学習モデルは、訓練誤差ゼロに達するまで長く訓練された場合に最高の性能を発揮することが多い。訓練データを完全に適合させるこのプロセスは、モデルが訓練損失を減らすための「簡単な」方法であるため、しばしば偽の相関を記憶することを含む。したがって、一方の側面(偽の記憶の低減)を改善することは、通常、もう一方(全体的な訓練精度またはコア特徴に対する汎化)を低下させるリスクを伴い、困難なバランス調整を生み出す。
制約と失敗モード
深層学習における偽の特徴記憶の理論的な定量化という問題は、いくつかの厳しい現実的な制約により、本質的に困難である。
- 計算的および理論的な扱いやすさ: 完全な深層ニューラルネットワークは、その理論的分析が極めて困難なことで悪名高い。本稿は、2つの単純化された強力な理論モデル、すなわちランダム特徴量(RF)とニューラルタンジェントカーネル(NTK)回帰に焦点を当てることで、この問題に対処する。これらのモデルは、「解析的に扱いやすく」、「理論的文献で広く分析されている」ため、厳密な数学的特徴づけが可能である。これは、任意の複雑な深層学習アーキテクチャへの正確な解析結果の拡張が依然として大きなハードルであることを意味する。
- 偽の特徴の特定の定義: 分析は、真の学習タスクと相関しない偽の特徴に厳密に限定される。偽の特徴が相関していた場合、問題は純粋な「記憶」から「ショートカット学習」または「偽相関の悪用」に移行し、異なる理論的処理が必要となる。これは、現在の枠組みにおける重要な境界条件である。
- データ分布の仮定: 理論的結果は、データ分布に関する特定の仮定に依存する。例えば、入力サンプル $z_i = [x_i, y_i]$ は、積分布 $P_z = P_x \times P_y$ から独立かつ同一に分布している(i.i.d.)と仮定される。すなわち、コア特徴 $x_i$ と偽の特徴 $y_i$ は独立である。さらに、ゼロ平均や制御された $L_2$ ノルム($||x||_2 = \sqrt{d_x}$、$||y||_2 = \sqrt{d_y}$)といった特定の性質が $x$ と $y$ に仮定される。$P_x$ と $P_y$ の両方がリプシッツ濃度を満たす必要がある。これらの仮定は分析を単純化するが、すべての実世界のデータセットに普遍的に当てはまるわけではない可能性がある。
- 過剰パラメータ化と高次元性の仮定: 枠組みは、過剰パラメータ化と高次元性の特定の領域内で動作する。RFモデルの場合、$N \log^3 N = o(k)$、$ \sqrt{d} \log d = o(k)$、$k \log^4 k = o(d^2)$ といった条件が必要であり、これはデータ点 $N$ および入力次元 $d$ に対してニューロン数 $k$ が大きいことを意味する。NTKモデルの場合、条件は $N \log^3 N = o(kd)$、$N > d$、$k = O(d)$ である。これらの条件は、カーネルの可逆性を保証し、モデルがデータを補間する能力を保証するために不可欠であるが、特定の動作領域を定義する。
- 活性化関数の性質: 活性化関数 $\phi$(またはNTKの場合はその導関数 $\phi'$)は、非線形かつL-リプシッツ連続であると仮定される。これらの性質は、特にエルミート係数や濃度不等式を含む数学的導出に不可欠である。
- カーネルの可逆性: 一般化線形回帰モデルの基本的な制約は、誘導されるカーネル $K$ が訓練セット上で可逆であることである。これにより、モデルは任意のラベル集合 $G$ を完全に適合させることができ、最適パラメータ $\theta^*$ の解に使用されるムーア・ペンローズ逆が正しく定義される。
- 実世界シナリオへの汎化: 本稿は、標準的なデータセット(MNIST、CIFAR-10)および異なるニューラルネットワークアーキテクチャ(全結合、畳み込み、ResNet)に対する数値実験を提供し、理論的予測が転移することを示すが、解析的な証明は主に単純化されたモデルと合成データに対するものである。複雑な実世界の深層学習システムに対する厳密な理論的厳密性とのギャップを埋めることは、依然として開かれた課題である。現在の分析は重要な一歩であるが、実世界の深層学習セットアップの広範な多様性を完全に包含するものではない。
なぜこのアプローチなのか
選択の必然性
ランダム特徴量(RF)およびニューラルタンジェントカーネル(NTK)回帰モデルの選択は、本稿が橋渡ししようとする特定の理論的ギャップによって駆動される戦略的な必要性であり、任意のものではなかった。コア問題は、真の学習タスクと相関しない偽の特徴の記憶を定量化し、理解することであり、これらの特徴はラベルだけでなく、入力データ自体におけるノイズとして現れる。
RFおよびNTKといった強力なツールを活用した既存の理論的枠組みでさえ、偽の過剰適合や分布内汎化といった現象に対しては、主にノイズをラベルにモデル化していた。この根本的な違いは、これらのモデル(RFおよびNTK)が理論的に魅力的で解析的に扱いやすかったとしても、確立された理論的機構が入力レベルの偽の特徴記憶問題に直接対応していなかったことを意味した。著者らは、従来の「SOTA」手法、すなわち経験的な性質のもの(例:標準的なCNN、拡散モデル、またはTransformer)は、実用的なタスクには強力であるが、「正確な、定量化可能な理論的特徴づけ」に必要な解析的な透明性を、この特定の記憶現象に対して欠いていると認識した。したがって、関連する学習理論において解析的な扱いやすさで知られるRFおよびNTKの理論的分析を拡張することが、必要な厳密な枠組みを開発するための唯一の実行可能な道となった。
比較優位性
このアプローチは、単なる性能指標を通じてではなく、理論的理解における前例のない構造的優位性によって、質的な優位性を提供する。本稿は、「元のサンプルと偽のサンプル」の特徴空間における類似性を定量化する新しい概念、「特徴アライメント」($F_\phi(z, z_1)$)を導入する。これは、モデルの安定性という古典的な概念と組み合わされ、偽の特徴がどのように記憶されるかを厳密に特徴づけるための二重のアプローチを形成する。
構造的な優位性は、RFおよびNTKモデルのこの枠組み内での解析的な扱いやすさにある。これにより、記憶と汎化誤差を結びつける比例定数($\gamma_\phi$)の閉形式表現が可能になる。このレベルの数学的解釈可能性は、根本的な記憶メカニズムの深い洞察なしに性能向上をしばしば提供する、以前の経験的なゴールドスタンダードよりも圧倒的に優れている。この手法は計算的な意味でメモリ複雑性を $O(N^2)$ から $O(N)$ に削減したり、高次元ノイズを明示的により良く扱ったりするわけではないが、偽の特徴(入力ノイズとしてモデル化される)がどのように記憶されるかの定量化可能な尺度を提供し、このプロセスにおけるモデルアーキテクチャとその活性化関数の重要な役割を明らかにする。
制約との整合性
選択されたアプローチは、ランダム特徴量とニューラルタンジェントカーネルのユニークな特性を活用することで、問題の厳しい要件と完全に整合する。主な制約は、真のラベルと相関しない入力データに埋め込まれた偽の特徴の記憶を定量化するための解析的に扱いやすい枠組みを開発することであった。
一般化線形回帰の設定は、RFおよびNTKモデルと組み合わされることで、まさにこの解析的な扱いやすさを提供する。サンプル $z$ をコア特徴 $x$ と偽の特徴 $y$ に分解する形式的な分解 ($z = [x, y]$)、ここで $y$ は真のラベル $g(x)$ から独立していることは、問題定義に直接対応する。安定性と新しい特徴アライメント項を通じて記憶を厳密に特徴づける枠組みの能力は、現象の直接的な定量化を可能にする。さらに、なされた仮定(例:データ分布、過剰パラメータ化、活性化関数の性質)は、数学的分析が実行可能であり、意味のある閉形式表現を生み出すことを保証するために慎重に選択されており、それによって問題の理論的要求と解の解析能力との完璧な「結婚」が生まれる。
代替案の却下
本稿は、GANや拡散モデルのような他の一般的な深層学習アーキテクチャを、すべてのタスクにおいて劣っていると見なす意味で、それらを明示的に「却下」しているわけではない。むしろ、暗黙的な却下は、偽の特徴記憶を入力データで厳密に定量化するための、厳密で解析的に扱いやすい理論的枠組みの現在の欠如に起因する。
著者らは、実用的な研究が偽の特徴を調査してきた一方で、これらのアプローチはしばしばアーキテクチャの役割を捉えたり、定量化可能な理論的理解を提供したりすることに失敗していると指摘している。RFおよびNTKのようなモデルに対する既存の理論的機構は、偽の過剰適合のような問題に適用される場合、通常、入力における偽の特徴ではなく、ラベルにおけるノイズをモデル化する。これは、これらのモデル(RF/NTK)自体は強力であるが、それらの既存の理論的分析は、本稿が求める特定の課題には不十分であったことを意味する。本稿の貢献は、偽の特徴記憶の入力レベルという特定の課題に対して、この論文が求める深い定量化可能な洞察を提供するために、RFおよびNTKの理論的分析を拡張することであり、全く新しいモデルを提案することではない。したがって、「却下」はモデル自体ではなく、入力レベルの偽の特徴記憶という特定の課題に対して、この論文が求める深い定量化可能な洞察を提供する現在の理論的ツールの不十分さに対するものである。
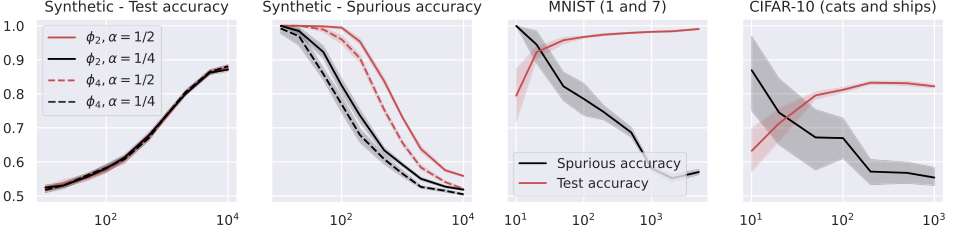 Figure 2. Test and spurious accuracies as a function of the number of training samples N, for various binary classification tasks. In the first two plots, we consider the RF model in (14) with k = 105 trained over Gaussian data with d = 1000. The labeling function is g(x) = sign(u⊤x). We repeat the experiments for α = {0.25, 0.5} and for the two activations ϕ2 = h1 + h2 and ϕ4 = h1 + h4, where hi denotes the i-th Hermite polynomial (see Appendix A.1). In the last two plots, we consider the same model with ReLU activation, trained over two MNIST and CIFAR-10 classes. The width of the noise background is 10 pixels for MNIST and 8 pixels for CIFAR-10, see Figure 1. The spurious accuracy is obtained by querying the model only with the noise background from the training set, replacing all the other pixels with 0, and taking the sign of the output. As we consider binary classification, an accuracy of 0.5 is achieved by random guessing. We plot the average over 10 independent trials and the confidence band at 1 standard deviation
Figure 2. Test and spurious accuracies as a function of the number of training samples N, for various binary classification tasks. In the first two plots, we consider the RF model in (14) with k = 105 trained over Gaussian data with d = 1000. The labeling function is g(x) = sign(u⊤x). We repeat the experiments for α = {0.25, 0.5} and for the two activations ϕ2 = h1 + h2 and ϕ4 = h1 + h4, where hi denotes the i-th Hermite polynomial (see Appendix A.1). In the last two plots, we consider the same model with ReLU activation, trained over two MNIST and CIFAR-10 classes. The width of the noise background is 10 pixels for MNIST and 8 pixels for CIFAR-10, see Figure 1. The spurious accuracy is obtained by querying the model only with the noise background from the training set, replacing all the other pixels with 0, and taking the sign of the output. As we consider binary classification, an accuracy of 0.5 is achieved by random guessing. We plot the average over 10 independent trials and the confidence band at 1 standard deviation
数学的・論理的メカニズム
マスター方程式
偽の特徴がどのように記憶されるかを理解するための本稿のコアメカニズムは、モデルの安定性、サンプル間の特徴アライメント、そしてそれらを結びつける関係という、3つの相互に関連する数学的定義に依存している。これらの式は、個々の訓練ポイントに対する訓練済みモデルの感度と、この感度が特徴空間におけるアライメントの類似性によってどのように変調されるかを集合的に記述している。
まず、訓練サンプル $z_1$ に対するモデルの安定性は次のように定義される。
$$S_{z_1} := f(\cdot, \theta^*) - f(\cdot, \theta^*_{-1}) \quad (5)$$
この量は、特定の訓練サンプル $z_1$ が訓練データセットに含まれるか除外されるかによって、モデルの出力がどれだけ変化するかを測定する。
次に、特徴マップ $\phi$ によって誘導される特徴空間における2つのサンプル、$z$ と $z_1$ との間の特徴アライメントは次のように与えられる。
$$F_\phi(z, z_1) := \frac{\phi(z)^\top P_{\Phi_{-1}} \phi(z_1)}{\|P_{\Phi_{-1}}\phi(z_1)\|_2^2} \quad (8)$$
この項は、残りの訓練データのサブスペースに射影された後、一般的なサンプル $z$ の特徴表現と特定の訓練サンプル $z_1$ の特徴表現との類似性または「アライメント」を定量化する。
最後に、安定性と特徴アライメントの間の重要なリンクは、補題 4.1 によって確立される。
$$S_{z_1}(z) = F_\phi(z, z_1) S_{z_1}(z_1) \quad (9)$$
この方程式は、任意のサンプル $z$ に対するモデルの安定性($z_1$ が除外された場合)が、特徴アライメントによってスケーリングされた、$z_1$ 自体の安定性に直接比例することを示す。このエレガントな関係は、記憶の分析の基盤を形成する。
項ごとの解剖
これらのマスター方程式の各構成要素を、その厳密な数学的定義、モデルにおける物理的または論理的な役割、および選択された数学的操作の根拠を理解するために解剖してみよう。
方程式 (5): 安定性 $S_{z_1}$
* $S_{z_1}$: これは、訓練サンプル $z_1$ に対するモデルの安定性を表す記号である。
* 数学的定義: モデル予測の違いを表すスカラー値。
* 物理的/論理的役割: 単一の訓練サンプル $z_1$ がモデルの出力に与える影響を定量化する。$S_{z_1}$ が大きい場合、 $z_1$ を除外するとモデルの予測が大きく変化することを意味し、$z_1$ が「記憶」されているか、強い影響力を持っていることを示唆する。
* $f(\cdot, \theta^*)$: これは、完全なデータセットで訓練されたモデルの予測関数である。
* 数学的定義: $f(z, \theta^*) = \phi(z)\theta^*$、ここで $\phi(z)$ は入力 $z$ の特徴ベクトルであり、$\theta^*$ は全訓練セット $Z$ から学習された最適パラメータである。
* 物理的/論理的役割: 利用可能なすべての訓練データがパラメータ学習に使用されたときのモデルの出力を表す。
* $f(\cdot, \theta^*_{-1})$: これは、 $z_1$ を除いたデータセットで訓練されたモデルの予測関数である。
* 数学的定義: $f(z, \theta^*_{-1}) = \phi(z)\theta^*_{-1}$、ここで $\theta^*_{-1}$ は訓練セット $Z_{-1}$($z_1$ を除いた $Z$)から学習された最適パラメータである。
* 物理的/論理的役割: 特定の訓練サンプル $z_1$ が訓練プロセスから除外されたときのモデルの出力を表す。
* $- (減算)$:
* なぜ使用されるか: 減算は、$z_1$ の存在または不在によるモデル出力の変化または差を直接測定するために使用される。これは影響または感度を定量化する標準的な方法である。乗算が使用された場合、比率を測定することになり、これは「変化」の望ましい尺度ではない。
方程式 (8): 特徴アライメント $F_\phi(z, z_1)$
* $F_\phi(z, z_1)$: これは、サンプル $z$ と訓練サンプル $z_1$ との間の特徴アライメントを表す記号である。
* 数学的定義: 正規化された射影を表すスカラー値。
* 物理的/論理的役割: 特徴空間において、一般的なサンプル $z$ の特徴表現が、特定の訓練サンプル $z_1$ の特徴表現とどれだけ「似ているか」を測定する。この類似性は、 $z_1$ に関する情報がモデルの内部表現において $z$ にどれだけ「転送」または「整列」されるかを示すため、重要である。
* $\phi(z)$: 入力サンプル $z$ の特徴マップである。
* 数学的定義: 入力 $z \in \mathbb{R}^d$ に特徴マップ関数 $\phi: \mathbb{R}^d \to \mathbb{R}^p$ を適用して得られるベクトル $\phi(z) \in \mathbb{R}^p$。
* 物理的/論理的役割: 生の入力データ $z$ を、線形モデルが操作する高次元の特徴表現に変換する。これは、モデルが入力データを「理解」する方法である。
* $\phi(z_1)$: 訓練サンプル $z_1$ の特徴マップである。
* 数学的定義: 特定の訓練サンプル $z_1$ に対する $\phi(z)$ と同様。
* 物理的/論理的役割: 影響が研究されている訓練サンプルの、モデルの内部特徴表現を表す。
* $P_{\Phi_{-1}}$: $\Phi_{-1}$ の行の線形部分空間への射影である。
* 数学的定義: $P_{\Phi_{-1}} \in \mathbb{R}^{p \times p}$ の射影行列であり、$P_{\Phi_{-1}} = \Phi_{-1}^\top (\Phi_{-1}\Phi_{-1}^\top)^{-1} \Phi_{-1}$(もし $\Phi_{-1}\Phi_{-1}^\top$ が可逆なら)。これはベクトルを $\Phi_{-1}$ の行空間に射影する。
* 物理的/論理的役割: この射影子は、他のすべての訓練サンプル($z_1$ を除く)の特徴によって張られる部分空間を考慮して、特徴ベクトルを効果的に「フィルタリング」または「正規化」する。これにより、アライメントがデータセットの残りの部分からの集合的な情報に対して測定されることが保証され、ユニークなアライメントのより堅牢な尺度となる。
* $\top$ (転置):
* なぜ使用されるか: 転置は、2つのベクトル、$\phi(z)$ と $P_{\Phi_{-1}}\phi(z_1)$ との間の内積(ドット積)を実行するために使用される。この操作は、2つの特徴ベクトルの間の線形相関または類似性を定量化する。
* $\cdot$ (乗算):
* なぜ使用されるか: 行列ベクトル乗算(例:$P_{\Phi_{-1}}\phi(z_1)$)は、射影子によって定義される線形変換を適用する。ベクトルベクトル乗算(ドット積)は類似性を定量化する。
* $\|\cdot\|_2^2$: 二乗 L2 ノルムである。
* 数学的定義: ベクトル $v$ に対して、$\|v\|_2^2 = v^\top v = \sum_i v_i^2$。
* 物理的/論理的役割: 分母のこの項は、アライメントを正規化する。これにより、$F_\phi(z, z_1)$ が特徴ベクトル自体のスケールに依存しないアライメントの尺度となることが保証される。それは本質的に、特徴空間におけるコサイン類似性(または関連する射影)を測定する。
* $/$ (除算):
* なぜ使用されるか: 二乗 L2 ノルムによる除算は、正規化ステップであり、射影または類似性の定義に一般的であり、アライメント尺度が適切にスケーリングされることを保証する。
方程式 (9): 関係 $S_{z_1}(z) = F_\phi(z, z_1) S_{z_1}(z_1)$
* $S_{z_1}(z)$: 一般的なサンプル $z$ におけるモデル出力の安定性である。
* 数学的定義: $f(z, \theta^*) - f(z, \theta^*_{-1})$。
* 物理的/論理的役割: これは、$z_1$ を除外した場合のサンプル $z$ に対するモデル予測の変化である。
* $S_{z_1}(z_1)$: 訓練サンプル $z_1$ 自体におけるモデル出力の安定性である。
* 数学的定義: $f(z_1, \theta^*) - f(z_1, \theta^*_{-1})$。
* 物理的/論理的役割: これは、$z_1$ が自身の予測に与える直接的な影響を表す。モデルが完全に補間する場合、$f(z_1, \theta^*) = g_1$ となるため、$S_{z_1}(z_1) = g_1 - f(z_1, \theta^*_{-1})$ となり、これは $z_1$ が存在しない場合と比較して、$z_1$ のラベルをモデルがどれだけ「記憶」したかを表す。
* $\cdot$ (乗算):
* なぜ使用されるか: 乗算は直接的な比例関係を示すために使用される。サンプル $z$ に対する予測の変化は、サンプル $z_1$ に対する変化のスケーリングされたバージョンであり、スケーリング係数は特徴アライメントである。これは線形関係を示唆する。すなわち、$z$ が特徴空間で $z_1$ と高度に整列している場合、$z_1$ を除外すると、$z$ の予測は $z_1$ の予測に影響するのと同様に影響を受ける。
ステップバイステップの流れ
データポイント $z$ がこの数学的エンジンに入力され、特定の訓練サンプル $z_1$ とその偽の対応物 $z^s$ が入力されると想像してみよう。目標は、$z^s$ に対するモデルの出力が $z_1$ によってどのように影響を受けるかを理解することであり、これは記憶を示唆する。
- 特徴抽出: まず、生の入力 $z$ と特定の訓練サンプル $z_1$ がモデルの特徴マップ $\phi$ に入力される。これにより、それらは内部特徴表現 $\phi(z)$ および $\phi(z_1)$ に変換される。これは初期処理ユニットであり、生のデータをモデルが「理解」できる形式に変換する。
- サブスペース射影: 次に、$\phi(z_1)$ は、他のすべての訓練サンプルの特徴 $\Phi_{-1}$ によって張られるサブスペースに射影される。このステップは、他の訓練データセットの背景に対して、 $z_1$ の特徴のユニークな寄与を分離する。
- 特徴アライメント計算: 射影された $\phi(z_1)$ は、内積を介して $\phi(z)$ と比較され、射影された $\phi(z_1)$ の大きさで正規化される。これにより、$F_\phi(z, z_1)$、すなわち特徴アライメントが計算される。このユニットは、モデルの特徴空間において、$z$ が $z_1$ とどれだけ「似ているか」を決定する。
- モデル訓練(暗黙的): 並行して、モデルの2つのバージョンが「訓練」される。1つは $f(\cdot, \theta^*)$ で、完全な訓練データセット $Z$($z_1$ を含む)を使用する。もう1つは $f(\cdot, \theta^*_{-1})$ で、データセット $Z_{-1}$($z_1$ を除く)を使用する。パラメータ $\theta^*$ および $\theta^*_{-1}$ は、これらの訓練プロセスから導出される。
- $z_1$ における安定性測定: $z_1$ に対するモデルの出力は、両方のパラメータセットを使用して計算される:$f(z_1, \theta^*)$ および $f(z_1, \theta^*_{-1})$。これらの2つの出力の差、$S_{z_1}(z_1) = f(z_1, \theta^*) - f(z_1, \theta^*_{-1})$ が計算される。このユニットは、$z_1$ 自体が $z_1$ に対するモデルの予測をどれだけ変化させるかを測定する。モデルが完全に補間する場合、$f(z_1, \theta^*) = g_1$ となるため、この項は $g_1 - f(z_1, \theta^*_{-1})$ となり、「記憶」された $z_1$ のラベルを表す。
- 安定性の伝播: 次に、特徴アライメント $F_\phi(z, z_1)$ と $z_1$ における安定性 $S_{z_1}(z_1)$ が乗算され、$S_{z_1}(z) = F_\phi(z, z_1) S_{z_1}(z_1)$ が得られる。これは、一般的なサンプル $z$ に対する $z_1$ の影響が、$z$ が $z_1$ と特徴空間で整列している程度に直接比例し、$z_1$ 自身のインパクトでスケーリングされることを意味する。
- 記憶の定量化: 最後に、偽の特徴の記憶を定量化するために、本稿は共分散
Cov(f(z^s, θ*), g_i)を考慮する。これには、偽のサンプル $z^s = [-, y]$(コア特徴 $x$ が除去またはゼロ化され、偽の特徴 $y$ のみ残る)でモデルを評価し、その出力を真のラベル $g_i$($x_i$ のみに依存する)と相関させることが含まれる。導出された関係(方程式 11)は、この共分散が $\gamma_\phi \sqrt{R_{Z_{-1}}} \sqrt{\text{Var}(g_i)}$ によって制限されることを示している。ここで $\gamma_\phi$ は特徴アライメントに関連する定数であり、$R_{Z_{-1}}$ は汎化誤差である。この最終ステップは、特徴処理と安定性の機械的な組み立てラインを、偽の特徴記憶の最終的な尺度に接続する。
最適化ダイナミクス
本稿は、一般化線形回帰の枠組み内で動作し、モデルパラメータ $\theta$ は、方程式 (2) に示すように、二次損失を伴う経験的リスクを最小化することによって学習される:$\min_\theta \| \Phi \theta - G \|_2^2$。この設定では、最適化プロセスは、最適パラメータ $\theta^*$ の閉形式解につながり、方程式 (3) で与えられる:$\theta^* = \theta_0 + \Phi^+(G - f(Z, \theta_0))$。
これは、学習または「最適化ダイナミクス」が、複雑な損失ランドスケープを探索する反復勾配降下プロセスではなく、この直接的な補間解の特性に関するものであることを意味する。本稿は、モデルが「勾配降下は初期化のl2ノルムに最も近い補間器に収束する」と明示的に述べている。これは、モデルが訓練誤差ゼロを達成するように訓練されていることを意味し、過剰パラメータ化されたモデルの特徴である。
ここで分析される主要な「ダイナミクス」は次のとおりである。
1. 補間: モデルが訓練データを完全に適合させる能力(訓練誤差ゼロの達成)は、過剰パラメータ化された領域と選択された最適化目的の直接的な結果である。この補間が、偽の特徴の記憶を可能にする。
2. 汎化誤差の役割: 本稿の主要な結果(方程式 11)は、偽の特徴の記憶(Cov(f(z^s, θ*), g_i) によって定量化される)が汎化誤差 $R_{Z_{-1}}$ に直接比例することを示している。これは、モデルの未知のデータに対する汎化能力が高まる(すなわち、$R_{Z_{-1}}$ が減少する)につれて、偽の特徴を記憶する傾向も弱まることを意味する。これは補間解の挙動に関する重要な洞察である。
3. 特徴アライメントの影響: 記憶限界(方程式 11)における比例定数 $\gamma_\phi$ は、特徴アライメント $F_\phi(z_1, z_1)$ から導出される。この定数は、特徴マップ $\phi$ と活性化関数に依存し、モデルが汎化しても偽の特徴がどれほど強く記憶されるかを決定する「損失ランドスケープ」を形成する。$\gamma_\phi$ が高いほど、特定の汎化誤差に対して記憶が増加することを意味する。RFおよびNTKモデルの分析は、この $\gamma_\phi$ を正確に特徴づけ、モデルアーキテクチャと活性化関数が記憶ダイナミクスにどのように影響するかを明らかにする。
4. 安定性の代理: 安定性 $S_{z_1}(z_1)$ は、補間を達成するためにモデルが個々の訓練ポイントにどれだけ依存しているかの尺度として機能する。$S_{z_1}(z_1)$ が大きい場合、モデルは $z_1$ に対して高い感度を持ち、 $z_1$ が強く「記憶」されていることを示唆する。最適化プロセスは、補間解を見つけることによって、本質的にこの安定性を生成し、それが特徴アライメントを通じて偽の記憶に影響を与える。
本質的に、「最適化ダイナミクス」は、それを見つけるための反復ステップではなく、補間解 $\theta^*$ の特性のレンズを通して理解される。モデルはデータを完全に適合させることを学習し、本稿は、特に無関係な情報の記憶に関して、この学習戦略の固有のトレードオフと結果を分析する。勾配は $\theta^*$ につながるが、その反復的な挙動ではなく、最終状態の特性の観点から明示的に分析されるわけではない。
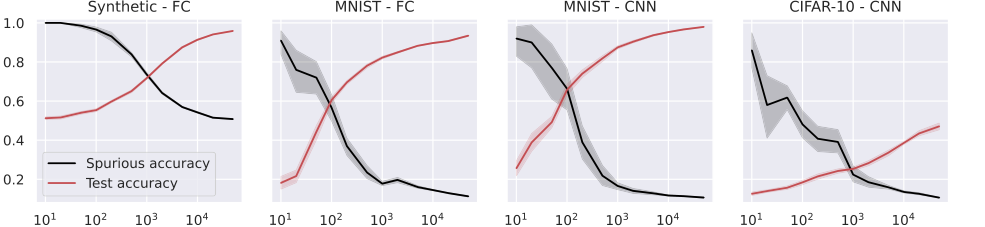 Figure 4. Test and spurious accuracies as a function of the number of training samples N, for a fully connected (FC, first two plots), and a small convolutional neural network (CNN, last two plots). In the first plot, we use synthetic (Gaussian) data with d = 1000, and the labeling function is g(x) = sign(u⊤x). As we consider binary classification, the accuracy of random guessing is 0.5. The other plots use subsets of the MNIST and CIFAR-10 datasets, with an external layer of noise added to images, see Figure 1. As we consider 10 classes, the accuracy of random guessing is 0.1. We plot the average over 10 independent trials and the confidence band at 1 standard deviation
Figure 4. Test and spurious accuracies as a function of the number of training samples N, for a fully connected (FC, first two plots), and a small convolutional neural network (CNN, last two plots). In the first plot, we use synthetic (Gaussian) data with d = 1000, and the labeling function is g(x) = sign(u⊤x). As we consider binary classification, the accuracy of random guessing is 0.5. The other plots use subsets of the MNIST and CIFAR-10 datasets, with an external layer of noise added to images, see Figure 1. As we consider 10 classes, the accuracy of random guessing is 0.1. We plot the average over 10 independent trials and the confidence band at 1 standard deviation
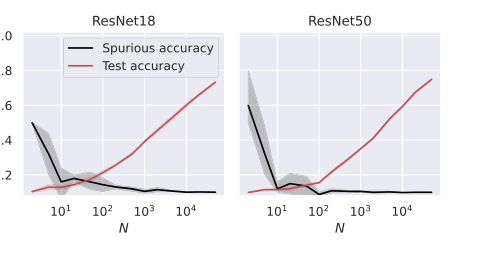 Figure 5. Test and spurious accuracies as a function of the number of training samples N, for two ResNet architectures. We use subsets of the CIFAR-10 dataset, with an external layer of noise added to images, see Figure 1. As we consider 10 classes, the accuracy of random guessing is 0.1. We plot the average over 10 independent trials and the confidence band at 1 standard deviation
Figure 5. Test and spurious accuracies as a function of the number of training samples N, for two ResNet architectures. We use subsets of the CIFAR-10 dataset, with an external layer of noise added to images, see Figure 1. As we consider 10 classes, the accuracy of random guessing is 0.1. We plot the average over 10 independent trials and the confidence band at 1 standard deviation
結果、限界、結論
実験設計とベースライン
理論的主張を厳密に検証するために、著者らは様々なモデルタイプとデータセットにわたる経験的な観察と、彼らの数学的予測を比較する一連の実験を細心の注意を払って設計した。コアアイデアは、訓練データに存在するが真のラベルを予測しない偽の特徴――無関係なノイズまたは背景情報――が存在するシナリオを作成することであった。その後、モデルがこれらの無関係な特徴をどれだけ「記憶」したかを測定した。
これらの実験における「犠牲者」は、伝統的な意味での代替モデルではなく、調査対象のランダム特徴量(RF)およびニューラルタンジェントカーネル(NTK)モデル自体、ならびに全結合(FC)、畳み込みニューラルネットワーク(CNN)、およびResNet(ResNet18、ResNet50)といったより複雑な深層学習アーキテクチャであった。目標は、これらのモデルが訓練されたときに、偽の相関を必然的に拾い上げて依存するかどうか、そしてこの挙動がどのように厳密に特徴づけられるかを示すことだった。
実験設定には以下が含まれた。
- データ生成:
- 合成データ: 二値分類タスクのために、入力次元 $d=1000$ のガウスデータが使用された。これにより、データ特性を厳密に制御できた。
- 標準データセット: MNIST(数字「1」と「7」の分類用)およびCIFAR-10(「猫」と「船」の分類用)が、理論の現実世界画像データへの適用性をテストするために使用された。
- 偽の特徴の注入: すべてのデータセットについて、偽の特徴 $y$ が導入された。これは通常、元の画像 $x$ の周りにノイズ背景を追加し、入力サンプル $z = [x, y]$ を形成した(図1に示すように)。決定的に重要なのは、この $y$ が真のラベル $g(x)$ と相関しないように設計されたことである。MNISTおよびCIFAR-10の場合、偽の精度をクエリする際にコア特徴 $x$ はゼロに置き換えられた。すなわち、モデルはノイズ成分のみでテストされた。
- モデルアーキテクチャ:
- RFおよびNTKモデル: これらは主要な理論ターゲットであり、ニューロン数 ($k$) を変え、異なる数のサンプル ($N$) で訓練された。
- 深層ニューラルネットワーク: FC、CNN、およびResNetアーキテクチャもテストされ、理論的洞察がRF/NTKの単純化された領域を超えて、より複雑な特徴学習モデルに拡張されることが示された。
- 主要な実験パラメータ:
- 訓練サンプル数 ($N$): これは大幅に変動した(例:$10^1$ から $10^4$ まで)。汎化と記憶の両方への影響を観察するため。
- 活性化関数 ($\phi$): 異なる活性化関数が使用され、それらのエルミート係数で特徴づけられた(例:RFの場合 $\phi_2 = h_1 + h_2$、$\phi_4 = h_1 + h_4$;NTKの場合 $\phi_2 = h_0 + h_1$、$\phi_4 = h_0 + h_3$、$h_i$ はエルミート多項式)。ReLU活性化関数もテストされた。活性化関数の選択は、記憶に影響を与えると予測された。
- 偽の特徴の割合 ($\alpha$): $d_y/d$ として定義され、偽の特徴に帰属する入力次元の割合を表す。その記憶への影響も調査された。
- 記憶の測定: 記憶を証明する最も直接的で「容赦のない」方法は、「偽精度」を通じてであった。これは、訓練済みモデルにサンプルの偽成分 ($y$) のみを入力し(例:コア特徴 $x$ をゼロに置き換える)、モデルが依然として正しいラベル $g(x)$ を予測するかどうかを確認することによって計算された。モデルが偽の成分のみで高い精度を達成した場合、それは記憶を決定的に証明した。
- 精度のベースライン: 二値分類タスクの場合、ランダム推測精度 0.5 が下限として機能した。10クラス分類(CIFAR-10、MNIST)の場合、ランダム推測は 0.1 の精度をもたらした。モデルの性能はこれらの些細なベースラインと比較された。すべての実験は10回の独立した試行で平均化され、信頼区間は標準偏差の1を示した。
証拠が証明するもの
経験的な証拠は、本稿の中心的な理論的主張を圧倒的に支持しており、提案された数学的枠組みが偽の特徴記憶の厳密な特徴づけを正確に行っていることを、決定的に否定できない証拠を提供している。記憶は、モデルの安定性(汎化誤差に関連する)と「特徴アライメント」という新しい概念の両方の結果であると仮定するコアメカニズムは、堅牢に検証された。
証拠が決定的に証明するものは以下の通りである。
-
汎化と記憶の逆関係: 図2、3、4、および5は一貫して明確で逆の関係を示している。訓練サンプル数 ($N$) が増加するにつれて、モデルのテスト精度(汎化能力の代理)は向上するが、偽精度(記憶の直接的な尺度)は減少する。これは、「汎化能力が増加するにつれて偽の特徴の記憶が弱まる」という理論的予測(Abstract、p.1)および、記憶が汎化誤差に比例するという理論的予測(方程式11、18、27)に対する強力な証拠である。モデルアーキテクチャに関係なく、モデルは「このトレードオフの犠牲者」であり、より良い汎化が本質的に偽の手がかりへの依存を減らすことを示している。
-
活性化関数の重要な役割: 実験は、活性化関数が記憶において重要な役割を果たすという理論的洞察を強力に検証した。
- ランダム特徴量(RF)モデル(合成データ、図2)の場合、偽精度は $\alpha$(偽入力の割合)が増加し、低次のエルミート係数が優勢な活性化関数を使用した場合に増加した。これは、$\gamma_{RF}$(特徴アライメント定数)がこれらの係数に依存することを示す定理5.4および方程式17と直接一致する。
- ニューラルタンジェントカーネル(NTK)モデル(MNISTおよびCIFAR-10、図3)の場合、結果は、高次のエルミート係数が優勢な活性化関数が記憶の低減につながることを示した。これは、定理6.3および方程式26と一致しており、$\gamma_{NTK}$ が活性化関数の導関数のエルミート係数にどのように依存するかを特徴づけている。これは、活性化関数の数学的特性(エルミート展開によって捉えられる)が、モデルの記憶しやすさを直接決定することを示している。
-
偽の特徴の割合 ($\alpha$) への依存性: 図7は、偽精度が $\alpha$(入力のうち偽の部分の割合)とともに単調に増加するという説得力のある証拠を提供している。これは、合成データ上のRFおよびNTKモデルの両方で観察された。決定的に重要なのは、テスト精度は $\alpha$ によってほとんど影響を受けなかったことである。これは、特徴アライメント定数($\gamma_{RF}$、$\gamma_{NTK}$)の $\alpha$ への理論的な依存性を直接確認するものである(定理5.4および6.3)。偽の情報が多いほど、モデルはそれをより多く記憶し、コアタスクのパフォーマンスを向上させることなく。
-
アーキテクチャ全体での広範な適用性: 単純化されたRFおよびNTKモデルを超えて、本稿は全結合(FC)、畳み込みニューラルネットワーク(CNN)、およびResNet(図4および5)を含む、より複雑な深層学習アーキテクチャへの経験的検証を拡張した。これらの実験は、観察された傾向――訓練サンプルが増えるにつれてテスト精度が増加し、偽精度が減少する――が、これらの多様なモデル全体で真実であることを示した。これは、特徴アライメントと安定性のフレームワークによって解明された記憶と汎化の関係の根本的な原則が、線形モデルに限定されるのではなく、最新の深層学習に広く適用可能であることを示唆している。これは、理論的枠組みの洞察の一般性の強力な支持を提供するが、正確な数学的特徴づけは単純化されたモデルに対して導出されたとしても。
本質的に、実験は偽の特徴の影響を分離し測定するように設計されており、多様な設定全体での一貫した傾向は、提案された理論的枠組みが深層学習モデルにおける偽の特徴記憶の複雑な現象を正確に捉えているという否定できない証拠を提供している。
限界と将来の方向性
本稿は、偽の特徴がどのように記憶されるかを理解するための、見事かつ厳密な理論的枠組みを提供しているが、その現在の境界を認識し、これらの発見がどのようにさらに発展できるかを考慮することが重要である。著者自身が、この分野の批判的思考を刺激する洞察に満ちた将来の研究への道筋を提供している。
現在の分析の限界:
- 偽の特徴の範囲: 本研究の主な焦点は、真の学習タスクと相関しない偽の特徴である。これは分析を単純化し、強力な基盤を提供するが、多くの実世界の偽相関は、ラベルとある程度の相関を持つ可能性があり、それらを分離するのがより困難になる。
- 一般化線形回帰の設定: 特徴アライメントに対する厳密な数学的証明は、主に一般化線形回帰の文脈、特にランダム特徴量(RF)およびニューラルタンジェントカーネル(NTK)モデルに対して確立されている。経験的な結果は、洞察がより複雑な深層ニューラルネットワーク(FC、CNN、ResNet)に拡張されることを示唆しているが、これらのアーキテクチャに対する完全な理論的特徴づけは、未解決の課題である。
- 特定のモデルタイプ: 特徴アライメント定数($\gamma_{RF}$、$\gamma_{NTK}$)の正確な閉形式表現は、RFおよびNTKモデルに対して導出されている。動的に特徴を学習するモデルなど、他のタイプのモデルにこの正確な定量化を拡張するには、かなりの追加の理論作業が必要となるだろう。
将来の方向性と議論のトピック:
- ラベル相関を持つ偽の特徴: 偽の特徴が真のラベルと部分的に相関している場合、記憶ダイナミクスはどのように変化するか?これは多くのアプリケーションでより現実的なシナリオである。現在の枠組みは、そのような場合における「偽」の度合いを定量化するために拡張できるか?これには、その予測力を考慮した「偽」のより微妙な定義が必要となるだろう。
- 分布外(OOD)の偽の特徴: 本稿は、主に訓練セットに存在する偽の特徴の記憶を調査している。モデルが、訓練中に見られなかったが、記憶された偽の特徴と相関する新しい偽の特徴にテスト時に遭遇した場合、どうなるか?これは分布シフトロバスト性と直接関連する。このフレームワークを使用して、そのようなOOD偽の特徴に対するモデルの脆弱性を、その学習された特徴アライメントに基づいて予測できるか?
- 「単純性バイアス」の統合: 本稿は、「単純性バイアス」――モデルが「簡単な」パターンを最初に学習する傾向――を関連現象として言及している。現在の枠組みは、単純性バイアスを正式に組み込むか、または説明できるか?特徴アライメントは、単純性バイアスが現れるメカニズムなのか、それともそれらは別個だが相互作用する現象なのか?この相互作用を理解することは、より堅牢な学習アルゴリズムにつながる可能性がある。
- 複雑なアーキテクチャのための特徴アライメントの特徴づけ: 経験的な結果は、傾向がFC、CNN、およびResNetモデルに対して真実であることを示している。重要な次のステップは、これらの複雑な特徴学習アーキテクチャに対する特徴アライメント $F_\phi(z^s, z)$ を理論的に特徴づけることである。これには、全結合、畳み込み、またはアテンション層の複数の層によって生成される特徴マップが記憶にどのように影響するかを理解することが含まれるだろう。そのような特徴づけは、異なる深層学習モデルの固有の偽相関への感受性を直接比較することを可能にするだろう。
- 記憶抵抗性モデルの設計: この分析的枠組みを武装して、偽の特徴を記憶しにくいモデルまたは訓練戦略を設計するにはどうすればよいか?本稿は、活性化関数とそのエルミート係数の役割を強調している。より高次の特徴学習を促進し、それによって偽の記憶を低減する活性化関数またはアーキテクチャの選択肢を考案できるか?これには、新しい正則化技術やアーキテクチャの帰納的バイアスが含まれる可能性がある。
- より広範な社会的影響: 本稿は理論的なものであり、社会的影響を掘り下げていないと明示的に述べているが、その発見は公平性、プライバシー、およびロバスト性に対して重大な影響を与える。例えば、モデルがコアタスクと並行して機密性の高い人口統計情報(偽の特徴)を記憶する場合、プライバシーに関する懸念が生じる。予測に偽の相関に依存する場合、バイアスのかかったまたは不公平な結果につながる可能性がある。将来の研究では、この枠組みを使用して既存のモデルを偽の特徴記憶のために監査し、これらのリスクを軽減するための介入を開発する方法を探求できる。これにより、より倫理的で信頼性の高いAIシステムに貢献できる。これには、プライバシー漏洩または公平性違反を定量化するために、特徴アライメントに基づいた指標またはツールの開発が含まれる可能性がある。
- 補間を超えて: 本稿は、モデルが訓練データを補間する過剰パラメータ化された領域で動作する。これらの発見は、低パラメータ化モデルやゼロ訓練誤差を達成しないモデルにどのように翻訳されるか?安定性と特徴アライメントの概念は、それらの領域でも同じ説明力を保持するか?
これらの議論のポイントは、本稿が堅牢な理論的基盤を築き、深層学習の望ましくない側面を理解し軽減するための理論的および応用的な研究の両方に対して、多くのエキサイティングで挑戦的な道を開くことを強調している。