मिश्रित-प्रेरणा वातावरण में पदानुक्रमित विरोधी मॉडलिंग और योजना के माध्यम से कुशल अनुकूलन
इस पत्र में संबोधित समस्या, "मिश्रित प्रेरणा वातावरण में पदानुक्रमित विरोधी मॉडलिंग और योजना के माध्यम से कुशल अनुकूलन," कृत्रिम बुद्धिमत्ता की एक दीर्घकालिक चुनौती से उत्पन्न होती है: एजेंटों को पहले कभी न देखे गए सह...
पृष्ठभूमि और अकादमिक वंश
उत्पत्ति और अकादमिक वंश
इस पत्र में संबोधित समस्या, "मिश्रित-प्रेरणा वातावरण में पदानुक्रमित विरोधी मॉडलिंग और योजना के माध्यम से कुशल अनुकूलन," कृत्रिम बुद्धिमत्ता की एक दीर्घकालिक चुनौती से उत्पन्न होती है: एजेंटों को पहले कभी न देखे गए सह-खिलाड़ियों के अनुकूल तेजी से सक्षम करना। इस क्षमता को "कुछ-शॉट अनुकूलन" कहा जाता है। ऐतिहासिक रूप से, बहु-एजेंट सुदृढीकरण सीखने (MARL) में अनुसंधान ने पूर्वनिर्धारित संबंधों वाले वातावरण में महत्वपूर्ण प्रगति की है, विशेष रूप से शून्य-योग खेलों (जहां एजेंट पूरी तरह से प्रतिस्पर्धी होते हैं, जैसे, विन्याल्स एट अल., 2019) और सामान्य-हित वातावरण (जहां एजेंट पूरी तरह से सहकारी होते हैं, जैसे, बैरेट एट अल., 2011)।
हालांकि, इस विशिष्ट समस्या की सटीक उत्पत्ति इस अहसास में निहित है कि अधिकांश यथार्थवादी बहु-एजेंट निर्णय लेने वाले परिदृश्य पूरी तरह से प्रतिस्पर्धी या सहकारी नहीं होते हैं। इसके बजाय, वे "मिश्रित-प्रेरणा वातावरण" (कोमोरिटा और पार्क्स, 1995; डैफो एट अल., 2020) हैं, जो एजेंटों के बीच गैर-नियतात्मक संबंधों और ऐसी स्थितियों की विशेषता है जहां एक एजेंट की सर्वोत्तम प्रतिक्रिया दूसरों के व्यवहार के आधार पर बदल सकती है। यह जटिलता सरल वातावरणों की तुलना में निर्णय लेने और कुछ-शॉट अनुकूलन को काफी अधिक चुनौतीपूर्ण बनाती है।
इस कार्य की आवश्यकता को जन्म देने वाले पिछले दृष्टिकोणों की मौलिक सीमा या "दर्द बिंदु" कई मुद्दों से उत्पन्न होता है:
1. विशेष तकनीकों की अनुपयुक्तता: कुछ-शॉट अनुकूलन के लिए कई मौजूदा MARL एल्गोरिदम ऐसी तकनीकों (जैसे मिनिमैक्स, डबल ओरेकल, या IGM स्थितियां) पर निर्भर करते हैं जो शून्य-योग या शुद्ध-सहकारी पुरस्कार संरचनाओं के लिए कुशल हैं, लेकिन मिश्रित-प्रेरणा वातावरण में पाए जाने वाले सामान्य-योग पुरस्कार संरचनाओं के लिए उपयुक्त नहीं हैं।
2. कम्प्यूटेशनल जटिलता: I-POMDP (Gmytrasiewicz & Doshi, 2005) जैसी विधियाँ, जिनमें नेस्टेड बिलीफ अनुमान (अर्थात, एक एजेंट के बारे में दूसरे एजेंट के विचारों के बारे में तर्क करना) शामिल है, गंभीर कम्प्यूटेशनल जटिलता से ग्रस्त हैं। यह उन्हें जटिल वातावरणों के लिए अव्यावहारिक बनाता है।
3. सूचना आवश्यकताएं और स्केलेबिलिटी मुद्दे: LOLA (Foerster et al., 2018) जैसे एल्गोरिदम अक्सर सह-खिलाड़ियों के आंतरिक नेटवर्क मापदंडों के ज्ञान की आवश्यकता होती है, जो वास्तविक दुनिया के परिदृश्यों में अक्सर अनुपलब्ध होता है। यहां तक कि विरोधी मॉडलिंग के साथ शिथिल होने पर भी, जटिल अनुक्रमिक वातावरणों में स्केलिंग समस्याएं उत्पन्न हो सकती हैं जिनके लिए लंबी क्रिया अनुक्रमों की आवश्यकता होती है।
4. बहु-एजेंट सेटिंग्स में MCTS की सीमाएं: जबकि मोंटे कार्लो ट्री सर्च (MCTS) एक शक्तिशाली योजना विधि है, बहु-एजेंट वातावरण में इसका अनुप्रयोग सीमित है क्योंकि संयुक्त क्रिया स्थान एजेंटों की संख्या के साथ घातीय रूप से बढ़ता है, जिससे स्केलेबिलिटी समस्याएं होती हैं (चौधरी एट अल., 2022)। पिछले MCTS-आधारित तरीके अक्सर सह-खिलाड़ी नीतियों का कुशलतापूर्वक अनुमान लगाने के लिए संघर्ष करते हैं।
इसलिए लेखकों को एक ऐसे दृष्टिकोण को विकसित करने के लिए मजबूर किया गया जो मिश्रित-प्रेरणा वातावरण में अनदेखे नीतियों के लिए कुशलतापूर्वक अनुकूलित हो सके, जो पिछले तरीकों की सीमाओं को पार कर सके जो या तो बहुत कम्प्यूटेशनल रूप से महंगे थे, अनुपलब्ध जानकारी की आवश्यकता थी, या सरल इंटरैक्शन गतिशीलता के लिए डिज़ाइन किए गए थे। एक नए समाधान के लिए उनकी प्रेरणा संज्ञानात्मक मनोविज्ञान से आई, जो बताता है कि मनुष्य पदानुक्रमित संज्ञानात्मक तंत्र का उपयोग करके अनदेखी समस्याओं को तेजी से हल करते हैं जो उच्च-स्तरीय लक्ष्य तर्क को निम्न-स्तरीय क्रिया योजना के साथ एकीकृत करते हैं (बुट्ज़ और कुटर, 2016; एपपे एट अल., 2022)।
सहज डोमेन शब्द
- मिश्रित-प्रेरणा वातावरण: एक पॉटलक डिनर की कल्पना करें जहाँ हर कोई एक व्यंजन लाता है। कुछ लोग अपने खाना पकाने से सभी को प्रभावित करना चाहते हैं (सहकारी), कुछ बस जितना संभव हो उतना खाना चाहते हैं (स्वार्थी), और कुछ एक साधारण व्यंजन ला सकते हैं लेकिन गुप्त रूप से उम्मीद करते हैं कि दूसरे कुछ अद्भुत लाएंगे ताकि उन्हें ज्यादा पकाना न पड़े (एक मिश्रण)। प्रत्येक व्यक्ति का "प्रेरणा" निश्चित नहीं है; यह सहयोग और प्रतिस्पर्धा का मिश्रण हो सकता है, और उनकी सर्वोत्तम रणनीति इस बात पर निर्भर करती है कि वे दूसरों को क्या करने की उम्मीद करते हैं।
- कुछ-शॉट अनुकूलन: एक नई कर्मचारी के टीम में शामिल होने के बारे में सोचें। प्रत्येक टीम सदस्य के काम करने के तरीके को समझने के लिए महीनों के प्रशिक्षण की आवश्यकता के बजाय, वे कुछ बैठकों या परियोजनाओं के बाद व्यक्तिगत विचित्रताओं और प्राथमिकताओं को जल्दी से समझ लेते हैं। वे केवल "कुछ शॉट्स" (सीमित अवलोकन) के बाद टीम में फिट होने के लिए अपनी कार्य शैली को "अनुकूलित" करते हैं।
- विरोधी मॉडलिंग: यह एक जासूस की तरह है जो एक संदिग्ध के इरादों को समझने की कोशिश कर रहा है। जासूस संदिग्ध के कार्यों का अवलोकन करता है, उनके बयानों को सुनता है, और संदिग्ध के लक्ष्यों और योजनाओं के बारे में एक मानसिक तस्वीर बनाने के लिए इस जानकारी का उपयोग करता है। जासूस तब अपने अगले कदम की भविष्यवाणी करने और अपनी रणनीति की योजना बनाने के लिए विरोधी के इस "मॉडल" का उपयोग करता है।
- मोंटे कार्लो ट्री सर्च (MCTS): गो जैसे जटिल बोर्ड गेम खेलने की कल्पना करें। खेल के अंत तक हर संभव चाल की गणना करने की कोशिश करने के बजाय (जो असंभव है), आप अपनी वर्तमान स्थिति से कई यादृच्छिक खेल खेलने की जल्दी से "कल्पना" करते हैं। प्रत्येक कल्पित खेल के लिए, आप विभिन्न चालों का पता लगाते हैं, उन रास्तों पर अधिक ध्यान केंद्रित करते हैं जो आशाजनक लगते हैं। कई ऐसे त्वरित सिमुलेशन के बाद, आप वह वास्तविक चाल चुनते हैं जिसने आपके मानसिक प्रयोगों में सर्वोत्तम औसत परिणाम दिया। यह आपको विस्तृत गणना के बिना अच्छे निर्णय प्राप्त करने में मदद करता है।
- मन का सिद्धांत (ToM): यह किसी और की सोच या भावनाओं का अनुमान लगाने की आपकी क्षमता है। उदाहरण के लिए, यदि आप किसी को मुस्कुराते हुए देखते हैं, तो आप अनुमान लगाते हैं कि वे खुश हैं। एआई के संदर्भ में, इसका मतलब है कि एक एजेंट मनुष्यों की तरह, उनके कार्यों का अवलोकन करके अन्य एजेंटों के "मानसिक अवस्थाओं" (जैसे लक्ष्य, विश्वास, या इरादे) को समझने की कोशिश करता है।
संकेतन तालिका
| संकेतन | विवरण |
|---|---|
| $N$ | एजेंटों का सेट, $N = \{1, 2, \dots, n\}$ |
| $S$ | अवस्था स्थान |
| $A_i$ | एजेंट $i$ के लिए क्रिया स्थान |
| $A$ | संयुक्त क्रिया स्थान, $A = A_1 \times A_2 \times \dots \times A_n$ |
| $a_{1:n}$ | सभी एजेंटों द्वारा की गई संयुक्त क्रिया |
| $T(s'|s, a_{1:n})$ | संक्रमण फलन: संयुक्त क्रिया $a_{1:n}$ दिए जाने पर अवस्था $s$ से $s'$ में संक्रमण की प्रायिकता |
| $R_i$ | एजेंट $i$ के लिए पुरस्कार फलन, $R_i: S \times A \to \mathbb{R}$ |
| $\gamma$ | भविष्य के पुरस्कारों के लिए छूट कारक |
| $T_{max}$ | एक प्रकरण की अधिकतम लंबाई |
| $\pi_i(a_i|s)$ | एजेंट $i$ की नीति: अवस्था $s$ पर क्रिया $a_i$ चुनने की प्रायिकता |
| $G$ | सभी एजेंटों के लक्ष्यों का सेट, $G = G_1 \times G_2 \times \dots \times G_n$ |
| $G_i$ | एजेंट $i$ के लक्ष्यों का सेट, $G_i = \{g_{i,1}, \dots, g_{i,|G_i|}\}$ |
| $g_{i,k}$ | एजेंट $i$ के लिए एक विशिष्ट लक्ष्य, जो अवस्थाओं का एक सेट है |
| $b_{i,j}(g_j)$ | एजेंट $i$ का एजेंट $j$ के लक्ष्यों पर विश्वास, $G_j$ पर एक प्रायिकता वितरण |
| $K$ | प्रकरण सूचकांक |
| $t$ | एक प्रकरण के भीतर समय चरण |
| $b_{i,j}^{K,t}(g_j)$ | प्रकरण $K$ में समय $t$ पर एजेंट $i$ का एजेंट $j$ के लक्ष्यों पर विश्वास |
| $\pi_{\omega}(a_j|s^{K,t}, g_j)$ | सह-खिलाड़ी $j$ के लिए लक्ष्य-सशर्त नीति अवस्था $s^{K,t}$ पर लक्ष्य $g_j$ दिए जाने पर, $\omega$ द्वारा पैरामीट्रिज्ड |
| $Q_{avg}(s^{K,t}, a)$ | अवस्था $s^{K,t}$ पर क्रिया $a$ के लिए औसत अनुमानित क्रिया मान |
| $\pi_{MCTS}(a|s^{K,t})$ | अवस्था $s^{K,t}$ पर क्रिया $a$ के लिए MCTS द्वारा उत्पन्न नीति |
| $\beta$ | बोल्ट्ज़मैन तर्कसंगतता मॉडल के लिए तर्कसंगतता गुणांक |
| $N_s$ | MCTS दौरों की संख्या |
| $N_l$ | प्रत्येक MCTS दौर के लिए खोज पुनरावृति की संख्या |
| $c$ | MCTS के लिए अन्वेषण गुणांक |
| $\theta$ | MCTS के लिए नीति और मान नेटवर्क के पैरामीटर |
| $\omega$ | लक्ष्य-सशर्त नीति नेटवर्क के पैरामीटर |
समस्या परिभाषा और बाधाएं
मुख्य समस्या सूत्रीकरण और दुविधा
इस पत्र द्वारा संबोधित केंद्रीय चुनौती मिश्रित-प्रेरणा बहु-एजेंट वातावरण में अनदेखे सह-खिलाड़ियों के लिए कुशल कुछ-शॉट अनुकूलन है। यह कृत्रिम बुद्धिमत्ता में एक महत्वपूर्ण समस्या है, क्योंकि अधिकांश वास्तविक दुनिया की बातचीत विशुद्ध रूप से प्रतिस्पर्धी (शून्य-योग) या विशुद्ध रूप से सहकारी (सामान्य-हित) गतिशीलता के बजाय सहयोग और प्रतिस्पर्धा के मिश्रण को शामिल करती है।
प्रारंभ बिंदु (इनपुट/वर्तमान स्थिति):
वर्तमान बहु-एजेंट सुदृढीकरण सीखने (MARL) एल्गोरिदम, शून्य-योग और सामान्य-हित खेलों में सफलताओं के बावजूद, मिश्रित-प्रेरणा सेटिंग्स में काफी हद तक संघर्ष करते हैं। ये वातावरण गैर-नियतात्मक एजेंट संबंधों और सामान्य-योग पुरस्कार संरचनाओं की विशेषता रखते हैं, जिससे निर्णय लेना स्वाभाविक रूप से अधिक जटिल हो जाता है। विरोधी मॉडलिंग के पिछले दृष्टिकोण अक्सर दो महत्वपूर्ण बाधाओं का सामना करते हैं:
1. अक्षम तर्क: मौजूदा विधियाँ, जैसे I-POMDP और इसके सन्निकटन, नेस्टेड बिलीफ अनुमान के कारण "गंभीर कम्प्यूटेशनल जटिलता समस्याओं" से ग्रस्त हैं, जिससे वे जटिल वातावरणों में अव्यावहारिक हो जाते हैं।
2. अनुमानित जानकारी का अप्रभावी उपयोग: LOLA जैसी एल्गोरिदम, विरोधी सीखने पर विचार करते हुए, अक्सर सह-खिलाड़ियों के आंतरिक नेटवर्क मापदंडों के ज्ञान की आवश्यकता होती है, जो यथार्थवादी परिदृश्यों में अक्सर अनुपलब्ध होता है। इसके अलावा, कई मौजूदा एल्गोरिदम हाथ से तैयार आंतरिक पुरस्कारों पर निर्भर करते हैं या सह-खिलाड़ियों के निजी पुरस्कारों तक पहुंच मानते हैं, जिससे वे स्वार्थी एजेंटों द्वारा शोषण के प्रति संवेदनशील हो जाते हैं या जब ऐसी जानकारी छिपी होती है तो कम प्रभावी होते हैं। मोंटे कार्लो ट्री सर्च (MCTS), एक शक्तिशाली योजना उपकरण, बहु-एजेंट सेटिंग्स में भी सीमाएं प्रस्तुत करता है जहां संयुक्त क्रिया स्थान एजेंटों की संख्या के साथ तेजी से बढ़ता है।
वांछित अंतिम बिंदु (आउटपुट/लक्ष्य स्थिति):
पत्र का उद्देश्य एक ऐसा एल्गोरिथम विकसित करना है जो एक फोकल एजेंट को मिश्रित-प्रेरणा वातावरण में "अनदेखे नीतियों के लिए कुछ-शॉट अनुकूलन" प्राप्त करने में सक्षम बनाता है। इसका मतलब है कि एजेंट को यह करने में सक्षम होना चाहिए:
1. तेजी से अनुकूलन: सीमित प्रकरणों की संख्या के बाद नए, पहले कभी न देखे गए सह-खिलाड़ियों को जल्दी से पहचानना और उचित रूप से प्रतिक्रिया देना।
2. कुशलता से तर्क और जानकारी का उपयोग: सह-खिलाड़ियों के लक्ष्यों का अनुमान लगाना और उनकी लक्ष्य-सशर्त नीतियों को कुशलतापूर्वक सीखना, और फिर निषेधात्मक कम्प्यूटेशनल लागतों को वहन किए बिना इष्टतम प्रतिक्रियाओं की गणना करने के लिए इस अनुमानित जानकारी का लाभ उठाना।
3. मजबूती से प्रदर्शन: मिश्रित-प्रेरणा परिदृश्यों में उच्च पुरस्कार देने वाले स्वायत्त निर्णय लेना, भले ही सह-खिलाड़ियों के लक्ष्य निजी और संभावित रूप से अस्थिर हों।
सटीक लुप्त कड़ी या गणितीय अंतर:
यह पत्र जिस सटीक अंतर को पाटने का प्रयास करता है, वह मिश्रित-प्रेरणा वातावरण में अनिश्चितता के तहत पदानुक्रमित विरोधी मॉडलिंग और योजना के लिए एक स्केलेबल और कुशल ढांचे की कमी है। विशेष रूप से, यह संबोधित करता है कि कैसे:
* उनके देखे गए कार्यों से सह-खिलाड़ियों के गुप्त लक्ष्यों और लक्ष्य-सशर्त नीतियों का सटीक अनुमान लगाना, उनके आंतरिक मापदंडों या हाथ से तैयार पुरस्कारों तक सीधी पहुंच पर निर्भर रहने के बजाय।
* इस अनुमानित विरोधी मॉडल को एक योजना तंत्र (MCTS) में इस तरह से एकीकृत करना जो कम्प्यूटेशनल रूप से सुलभ बना रहे, पिछले तरीकों की "नेस्टेड बिलीफ अनुमान" समस्याओं से बचते हुए।
* योजना के दौरान सह-खिलाड़ियों के लक्ष्यों के बारे में अंतर्निहित अनिश्चितता को महत्वपूर्ण पूर्वाग्रह पेश किए बिना या प्रदर्शन को खराब किए बिना संभालना। पत्र सह-खिलाड़ियों के लक्ष्यों के बारे में विश्वासों को एपिसोड के भीतर और पार दोनों को अपडेट करने के लिए "इंट्रा-ओएम" और "इंटर-ओएम" मॉड्यूल के साथ एक पदानुक्रमित संरचना का प्रस्ताव करता है, और फिर सबसे अच्छी प्रतिक्रिया की गणना करने के लिए कई लक्ष्य संयोजनों का नमूना लेने वाले एम सी टी एस योजनाकार को निर्देशित करने के लिए इन विश्वासों का उपयोग करता है।
दर्दनाक ट्रेड-ऑफ या दुविधा:
मुख्य दुविधा जिसने पिछले शोधकर्ताओं को फंसाया है, वह विरोधी मॉडलिंग की सटीकता और सामान्यीकरण क्षमता बनाम इसकी कम्प्यूटेशनल दक्षता और स्केलेबिलिटी के बीच ट्रेड-ऑफ है।
* सटीकता बनाम दक्षता: विविध सह-खिलाड़ियों के अत्यधिक सटीक मॉडल प्राप्त करना, विशेष रूप से जटिल मिश्रित-प्रेरणा सेटिंग्स में जहां लक्ष्य निजी और गतिशील होते हैं, आम तौर पर व्यापक गणना (जैसे, I-POMDP में नेस्टेड बिलीफ अनुमान) या विरोधी आंतरिक (जैसे, LOLA) के विस्तृत ज्ञान की मांग करता है। यह अक्सर ऐसे तरीकों को वास्तविक समय या जटिल अनुक्रमिक वातावरणों में तेजी से, कुछ-शॉट अनुकूलन के लिए बहुत धीमा या संसाधन-गहन बनाता है।
* सामान्यीकरण बनाम विशिष्टता: विशिष्ट खेल प्रकारों (शून्य-योग या शुद्ध-सहकारी) के लिए डिज़ाइन किए गए एल्गोरिदम अक्सर पुरस्कार-संरचना-विशिष्ट तकनीकों (जैसे, मिनिमैक्स) का लाभ उठाते हैं जो मिश्रित-प्रेरणा इंटरैक्शन की गैर-नियतात्मक, सामान्य-योग प्रकृति के लिए सामान्यीकृत नहीं होते हैं। एक विधि विकसित करना जो किसी भी विशिष्ट क्षेत्र में प्रदर्शन का त्याग किए बिना मिश्रणों के स्पेक्ट्रम पर काम करती है, एक महत्वपूर्ण चुनौती है। पत्र "व्यावहारिक और प्रभावी ढांचे" का लक्ष्य रखता है जो प्रतिस्पर्धा और सहयोग दोनों को संभाल सके।
बाधाएं और विफलता मोड
मिश्रित-प्रेरणा वातावरण में कुशल कुछ-शॉट अनुकूलन की समस्या कई कठोर, यथार्थवादी बाधाओं के कारण "अविश्वसनीय रूप से कठिन" है:
भौतिक/पर्यावरणीय बाधाएं:
* मिश्रित-प्रेरणा गतिशीलता: मौलिक बाधा स्वयं पर्यावरण है। एजेंटों के बीच संबंध "गैर-नियतात्मक" हैं, और पुरस्कार संरचनाएं "सामान्य-योग" हैं, जिसका अर्थ है कि एजेंटों के हित न तो पूरी तरह से संरेखित हैं और न ही पूरी तरह से विपरीत हैं। यह इष्टतम प्रतिक्रियाओं की भविष्यवाणी को अत्यधिक संदर्भ-निर्भर और गतिशील बनाता है।
* अनदेखे सह-खिलाड़ी और नीतियां: "अनदेखे एजेंटों के लिए कुछ-शॉट अनुकूलन" की आवश्यकता का मतलब है कि एल्गोरिथम विशिष्ट विरोधी प्रकारों के साथ पूर्व-प्रशिक्षण पर भरोसा नहीं कर सकता है। एजेंटों को फ्लाई पर उपन्यास व्यवहारों के अनुकूल होना चाहिए।
* सीमित इंटरैक्शन इतिहास: "कुछ-शॉट अनुकूलन" का तात्पर्य है कि एजेंट के पास नए सह-खिलाड़ियों के बारे में जानने के लिए केवल "सीमित प्रकरण" हैं। यह विरोधी मॉडलिंग और अनुकूलन के लिए उपलब्ध डेटा की मात्रा को गंभीर रूप से प्रतिबंधित करता है।
* निजी लक्ष्य और कोई संचार नहीं: एजेंटों के पास "एक-दूसरे के मापदंडों तक पहुंच नहीं है, और संचार की अनुमति नहीं है।" इसके अलावा, सह-खिलाड़ियों के लक्ष्य "निजी और अस्थिर" हैं, जिसका अर्थ है कि वे एक प्रकरण के भीतर बदल सकते हैं। प्रत्यक्ष जानकारी की यह कमी केवल देखे गए कार्यों से इरादों का अनुमान लगाने की आवश्यकता है।
कम्प्यूटेशनल बाधाएं:
* विरोधी मॉडलिंग की कम्प्यूटेशनल जटिलता: I-POMDP जैसी पिछली विधियाँ "नेस्टेड बिलीफ अनुमान" के कारण "गंभीर कम्प्यूटेशनल जटिलता समस्याओं" से ग्रस्त हैं, जिससे वे जटिल वातावरणों के लिए अव्यावहारिक हो जाती हैं। चुनौती कम्प्यूटेशन में घातीय वृद्धि के बिना सटीक रूप से विरोधियों को मॉडल करना है।
* एजेंटों की संख्या के साथ स्केलिंग: बहु-एजेंट वातावरण में, "संयुक्त क्रिया स्थान एजेंटों की संख्या के साथ तेजी से बढ़ता है।" यह कई एजेंटों के लिए पारंपरिक MCTS के साथ योजना बनाना कम्प्यूटेशनल रूप से निषेधात्मक बनाता है। पत्र स्पष्ट रूप से अनुमानित सह-खिलाड़ी नीतियों को देखते हुए केवल फोकल एजेंट की क्रियाओं की योजना बनाकर इसे संबोधित करता है।
* वास्तविक समय विलंबता आवश्यकताएं (निहित): "तेजी से अनुकूलन" और "कुशल तर्क" की आवश्यकता का तात्पर्य है कि निर्णय लेने को व्यावहारिक समय सीमाओं के भीतर होना चाहिए, विशेष रूप से अनुक्रमिक निर्णय लेने वाले परिदृश्यों में जिनमें लंबे क्रिया अनुक्रम शामिल हो सकते हैं।
डेटा-संचालित बाधाएं:
* विश्वास अद्यतनों के लिए डेटा विरलता: जब "अद्यतनों के लिए पिछले प्रक्षेप्य पर्याप्त लंबे नहीं होते हैं," तो प्रकरण-विरोधी विरोधी मॉडलिंग (इंट्रा-ओएम) "पूर्व की अशुद्धि" से पीड़ित हो सकता है। यह न्यूनतम डेटा से सटीक विश्वास बनाने की कठिनाई को उजागर करता है।
* सह-खिलाड़ी मॉडल में अनिश्चितता: विरोधी मॉडलिंग के साथ भी, अनुमानित सह-खिलाड़ी नीतियों में "सह-खिलाड़ियों के लक्ष्यों पर अनिश्चितता होती है।" योजना चरण के दौरान इस अनिश्चितता को प्रभावी ढंग से प्रबंधित किया जाना चाहिए ताकि "सिमुलेशन में बड़ा पूर्वाग्रह पेश करने और योजना प्रदर्शन को खराब करने" से बचा जा सके। इस अनिश्चितता को भोलेपन से शामिल करने से उप-इष्टतम क्रियाएं हो सकती हैं।
यह दृष्टिकोण क्यों
पसंद की अनिवार्यता
पदानुक्रमित विरोधी मॉडलिंग और योजना (HOP) को अपनाना केवल एक डिजाइन विकल्प नहीं था, बल्कि मिश्रित-प्रेरणा वातावरण द्वारा प्रस्तुत अंतर्निहित चुनौतियों का एक अनिवार्य परिणाम था। पारंपरिक अत्याधुनिक (SOTA) बहु-एजेंट सुदृढीकरण सीखने (MARL) एल्गोरिदम, जैसे कि मिनिमैक्स, डबल ओरेकल, या IGM स्थितियों पर निर्भर रहने वाले, मौलिक रूप से अपर्याप्त पाए गए। ये विधियाँ शून्य-योग या विशुद्ध रूप से सहकारी खेलों के विशिष्ट पुरस्कार संरचनाओं के लिए तैयार की गई हैं, जिससे वे "मिश्रित-प्रेरणा वातावरण में लागू नहीं होती हैं" जहां एजेंट संबंध गैर-नियतात्मक होते हैं और पुरस्कार सामान्य-योग होते हैं। लेखकों ने स्पष्ट रूप से कहा है कि "एजेंटों के बीच गैर-नियतात्मक संबंध और सामान्य-योग पुरस्कार संरचना निर्णय लेने और कुछ-शॉट अनुकूलन को मिश्रित-प्रेरणा वातावरण में शून्य-योग और शुद्ध-सहकारी वातावरण की तुलना में अधिक चुनौतीपूर्ण बनाते हैं।"
यह अहसास कि मौजूदा तरीके अपर्याप्त थे, लेखकों को संज्ञानात्मक मनोविज्ञान से प्रेरणा लेने के लिए प्रेरित किया। उन्होंने पहचाना कि पहले कभी न देखे गए समस्याओं को तेजी से हल करने की मनुष्यों की क्षमता "पदानुक्रमित संज्ञानात्मक तंत्र" पर निर्भर करती है जो उच्च-स्तरीय लक्ष्य तर्क को निम्न-स्तरीय क्रिया योजना के साथ सहज रूप से एकीकृत करते हैं। इस अंतर्दृष्टि वह सटीक क्षण था जब लेखकों ने मौलिक रूप से भिन्न, पदानुक्रमित रूप से संरचित दृष्टिकोण की आवश्यकता को पहचाना। HOP सीधे इस संज्ञानात्मक वास्तुकला को दर्शाता है, जो सह-खिलाड़ियों के लक्ष्यों का अनुमान लगाने और लक्ष्य-सशर्त नीतियों को सीखने के लिए एक विरोधी मॉडलिंग मॉड्यूल का प्रस्ताव करता है, साथ में एक योजना मॉड्यूल जो सर्वोत्तम प्रतिक्रिया निर्धारित करने के लिए मोंटे कार्लो ट्री सर्च (MCTS) का उपयोग करता है। यह पदानुक्रमित अपघटन जटिल, मिश्रित-प्रेरणा सेटिंग्स में कुशल तर्क और अनुमानित जानकारी के प्रभावी उपयोग दोनों चुनौतियों का समाधान करने के लिए एकमात्र व्यवहार्य मार्ग था।
तुलनात्मक श्रेष्ठता
HOP कई संरचनात्मक लाभों के माध्यम से पिछले स्वर्ण मानकों पर गुणात्मक श्रेष्ठता प्रदर्शित करता है जो सरल प्रदर्शन मेट्रिक्स से परे जाते हैं:
- पदानुक्रमित अपघटन: फ्लैट MARL दृष्टिकोणों के विपरीत, HOP की दो-मॉड्यूल संरचना (विरोधी मॉडलिंग और योजना) सह-खिलाड़ी व्यवहार की अधिक परिष्कृत और व्याख्या योग्य समझ की अनुमति देती है। विरोधी मॉडलिंग मॉड्यूल उच्च-स्तरीय लक्ष्यों का अनुमान लगाता है और लक्ष्य-सशर्त नीतियों को सीखता है, जो एंड-टू-एंड मॉडल की तुलना में एक समृद्ध प्रतिनिधित्व प्रदान करता है। यह मानव संज्ञानात्मक प्रक्रियाओं को दर्शाता है, जिससे अधिक मजबूत अनुकूलन संभव होता है।
- कुशल विश्वास अद्यतन तंत्र: HOP एपिसोड के पार और भीतर दोनों तरह से सह-खिलाड़ियों के लक्ष्यों के बारे में विश्वासों को अपडेट करके दक्षता में काफी सुधार करता है। इंट्रा-विरोधी मॉडलिंग (इंट्रा-ओएम) मॉड्यूल एक ही एपिसोड के भीतर सह-खिलाड़ियों के तत्काल लक्ष्यों के लिए तेजी से समायोजन की अनुमति देता है, जो गतिशील वातावरण के लिए महत्वपूर्ण है। इंटर-विरोधी मॉडलिंग (इंटर-ओएम) मॉड्यूल एक सटीक विश्वास पूर्व स्थापित करने के लिए ऐतिहासिक एपिसोड का लाभ उठाता है, जिससे सच्चे विश्वासों में अभिसरण तेज होता है। यह दोहरी-परत अद्यतन तंत्र उन तरीकों की तुलना में एक संरचनात्मक लाभ प्रदान करता है जो एपिसोड के भीतर विश्वासों को अपडेट कर सकते हैं या मजबूत ऐतिहासिक संदर्भ की कमी हो सकती है, जो अक्सर छोटी बातचीत के दौरान गलत विरोधी मॉडलिंग की ओर ले जाती है।
- नेस्टेड बिलीफ अनुमान जटिलता से बचाव: पिछले विरोधी मॉडलिंग और योजना ढांचे, जैसे I-POMDP, "नेस्टेड बिलीफ अनुमान" (जैसे, एक एजेंट के बारे में दूसरे एजेंट के बारे में सोचना) के कारण "गंभीर कम्प्यूटेशनल जटिलता समस्याओं" से ग्रस्त हैं। HOP एक तंत्रिका नेटवर्क मॉडल सीखने के लिए सह-खिलाड़ियों के लक्ष्यों और नीतियों पर विश्वासों का स्पष्ट रूप से उपयोग करके इसे दरकिनार करता है, जो फिर एक MCTS योजनाकार का मार्गदर्शन करता है। यह डिजाइन विकल्प HOP को "अधिक कुशलता से अनुक्रमिक निर्णय लेने में सक्षम बनाता है" बिना गहन पुनरावर्ती तर्क के कम्प्यूटेशनल बाधा के।
- स्केलेबल MCTS एकीकरण: जबकि MCTS शक्तिशाली है, बहु-एजेंट वातावरण में इसका प्रत्यक्ष अनुप्रयोग संयुक्त क्रिया स्थान के तेजी से विकास से सीमित है। HOP "सह-खिलाड़ियों की नीतियों का अनुमान लगाकर और केवल फोकल एजेंट की क्रियाओं की योजना बनाकर" इसे दूर करता है। यह रणनीतिक वियोग MCTS को प्रभावी ढंग से और स्केलेबल रूप से लागू करने की अनुमति देता है, जिससे सभी एजेंटों की संयुक्त क्रियाओं पर योजना बनाने से जुड़े कम्प्यूटेशनल विस्फोट से बचा जा सके।
- योजना में अनिश्चितता में कमी: विरोधी मॉडलिंग मॉड्यूल योजना मॉड्यूल को लक्ष्य-सशर्त नीतियां प्रदान करता है। यह अनुमानित जानकारी MCTS का मार्गदर्शन करती है, जिससे योजना के लिए पर्यावरण मॉडल में सह-खिलाड़ियों के लक्ष्यों के बारे में अनिश्चितता को भोलेपन से शामिल करने से उत्पन्न "बड़ा पूर्वाग्रह" और "खराब योजना प्रदर्शन" को रोका जा सके। यह संरचनात्मक एकीकरण सुनिश्चित करता है कि अनिश्चितता के तहत भी योजना सटीक और सटीक हो।
बाधाओं के साथ संरेखण
HOP का डिजाइन मिश्रित-प्रेरणा वातावरण में कुछ-शॉट अनुकूलन की कठोर आवश्यकताओं के साथ पूरी तरह से संरेखित होता है:
- अनदेखे नीतियों के लिए कुछ-शॉट अनुकूलन: HOP का मुख्य उद्देश्य कुछ-शॉट अनुकूलन है। पदानुक्रमित संरचना, विशेष रूप से कुशल इंट्रा-ओएम और इंटर-ओएम विश्वास अद्यतन तंत्र, विशेष रूप से इसके लिए इंजीनियर किए गए हैं। इंट्रा-ओएम इन-एपिसोड व्यवहार परिवर्तनों के लिए त्वरित प्रतिक्रियाओं की अनुमति देता है, जबकि इंटर-ओएम पिछले एपिसोड से सटीक पूर्व प्रदान करता है, जिससे सीमित संख्या में इंटरैक्शन के भीतर उपन्यास सह-खिलाड़ी रणनीतियों के लिए तेजी से अनुकूलन संभव होता है। इस "विवाह" समस्या की तेजी से सीखने की आवश्यकता और समाधान के गतिशील विश्वास अद्यतनों के बीच मौलिक है।
- मिश्रित-प्रेरणा वातावरण: HOP विशेष रूप से मिश्रित-प्रेरणा परिदृश्यों के लिए बनाया गया है, जहां संबंध गैर-नियतात्मक होते हैं और पुरस्कार सामान्य-योग होते हैं। सह-खिलाड़ियों के लक्ष्यों (जो प्रतिस्पर्धी, सहकारी, या मिश्रित हो सकते हैं) का अनुमान लगाने और फोकल एजेंट की सर्वोत्तम प्रतिक्रिया की योजना बनाने की इसकी क्षमता, भले ही सह-खिलाड़ियों के लक्ष्य निजी और अस्थिर हों, इन वातावरणों की केंद्रीय चुनौती को सीधे संबोधित करती है।
- सह-खिलाड़ी मापदंडों या पुरस्कारों तक कोई पहुंच नहीं: यथार्थवादी बहु-एजेंट सेटिंग्स में एक महत्वपूर्ण बाधा अन्य एजेंटों के आंतरिक मापदंडों या पुरस्कार कार्यों तक सीधी पहुंच की कमी है। HOP के विरोधी मॉडलिंग मॉड्यूल केवल उनके "क्रिया अनुक्रमों" को देखकर सह-खिलाड़ियों के लक्ष्यों का अनुमान लगाता है और उनकी लक्ष्य-सशर्त नीतियों को सीखता है। यह अनुमान-आधारित दृष्टिकोण सह-खिलाड़ियों के आंतरिक के स्पष्ट ज्ञान की आवश्यकता को दरकिनार करता है, जिससे यह वास्तविक दुनिया, ब्लैक-बॉक्स परिदृश्यों में लागू होता है।
- कोई संचार नहीं: समस्या परिभाषा एजेंटों के बीच स्पष्ट संचार की कमी का अर्थ है। HOP का लक्ष्य अनुमान और नीति सीखना पूरी तरह से देखे गए प्रक्षेप्यों और क्रियाओं पर आधारित है, किसी भी प्रकार के प्रत्यक्ष संचार पर भरोसा किए बिना, इस प्रकार इस निहित बाधा का पालन करता है।
विकल्पों का अस्वीकरण
पत्र ने कई लोकप्रिय दृष्टिकोणों को अस्वीकार करने के लिए स्पष्ट तर्क प्रदान किया है:
- पारंपरिक MARL एल्गोरिदम (जैसे, मिनिमैक्स, डबल ओरेकल, IGM स्थिति): इन विधियों को स्पष्ट रूप से इसलिए अस्वीकार कर दिया जाता है क्योंकि वे "मिश्रित-प्रेरणा वातावरण में लागू नहीं होती हैं।" उनकी अंतर्निहित धारणाएं और तकनीकें शून्य-योग या शुद्ध-सहकारी पुरस्कार संरचनाओं के लिए अनुकूलित हैं, जो मिश्रित-प्रेरणा खेलों की गैर-नियतात्मक संबंधों और सामान्य-योग पुरस्कारों को पकड़ने में विफल रहती हैं।
- LOLA (लर्निंग विद ओपोनेंट-लर्निंग अवेयरनेस): एक उन्नत MARL एल्गोरिथम होने के बावजूद, LOLA को सामान्य मिश्रित-प्रेरणा वातावरणों के लिए अनुपयुक्त माना जाता है क्योंकि इसे "सह-खिलाड़ियों के नेटवर्क मापदंडों के ज्ञान की आवश्यकता होती है, जो कई परिदृश्यों में संभव नहीं हो सकता है।" HOP के अनुमान-आधारित विरोधी मॉडलिंग से यह प्रतिबंधक आवश्यकता से बचा जाता है। इसके अलावा, LOLA "जटिल अनुक्रमिक वातावरणों में स्केलिंग समस्याओं से पीड़ित हो सकता है जिनके लिए पुरस्कारों के लिए लंबे क्रिया अनुक्रमों की आवश्यकता होती है," एक सीमा जिसे HOP अपने निर्देशित MCTS योजना के माध्यम से संबोधित करता है।
- I-POMDP (इंटरैक्टिव पार्शियली ऑब्जर्वेबल मार्कोव डिसीजन प्रोसेसेस): यह ढांचा, विरोधी मॉडलिंग के लिए प्रासंगिक होने के बावजूद, "नेस्टेड बिलीफ अनुमान" से उत्पन्न होने वाली "गंभीर कम्प्यूटेशनल जटिलता समस्याओं" के कारण अस्वीकार कर दिया जाता है। कम्प्यूटेशनल बोझ इसे "जटिल वातावरणों में अव्यावहारिक" बनाता है। HOP का डिजाइन विशेष रूप से अधिक दक्षता प्राप्त करने के लिए इस नेस्टेड अनुमान से बचा जाता है।
- बहु-एजेंट वातावरण में भोला MCTS: पत्र स्वीकार करता है कि MCTS अकेले "बहु-एजेंट वातावरण में सीमित है, जहां संयुक्त क्रिया स्थान एजेंटों की संख्या के साथ तेजी से बढ़ता है।" एक प्रत्यक्ष अनुप्रयोग कम्प्यूटेशनल रूप से दुर्गम होगा। HOP का समाधान सह-खिलाड़ी नीतियों का अनुमान लगाना और केवल फोकल एजेंट की क्रियाओं की योजना बनाना है, प्रभावी ढंग से इस स्केलेबिलिटी समस्या को दरकिनार करना।
- एब्लेटेड HOP संस्करण (w/o इंटर-ओएम, w/o इंट्रा-ओएम, डायरेक्ट-ओएम): एब्लेशन अध्ययन HOP के सरल या अधूरे संस्करणों को अस्वीकार करने के लिए अनुभवजन्य साक्ष्य प्रदान करता है:
- w/o इंटर-ओएम: यह संस्करण निश्चित लक्ष्यों वाले एजेंटों (जैसे, सहकारी, अवधारक) के खिलाफ खराब प्रदर्शन करता है क्योंकि इसमें एक प्रकरण की शुरुआत में सटीक लक्ष्य पूर्व की कमी होती है, जिससे इष्टतम खेल के शुरुआती अवसर छूट जाते हैं। यह ऐतिहासिक एपिसोड का लाभ उठाने की आवश्यकता को रेखांकित करता है।
- w/o इंट्रा-ओएम: यह संस्करण गतिशील व्यवहार वाले एजेंटों (जैसे, LOLA, PS-A3C, यादृच्छिक) के खिलाफ खराब प्रदर्शन करता है क्योंकि यह केवल पिछले एपिसोड पर निर्भर करते हुए, इन-एपिसोड परिवर्तनों के अनुकूल नहीं हो सकता है। यह वास्तविक समय, इन-एपिसोड विश्वास अद्यतनों के महत्व को रेखांकित करता है।
- डायरेक्ट-ओएम: यह दृष्टिकोण, जो पदानुक्रमित विरोधी मॉडलिंग मॉड्यूल को हटाता है और लक्ष्य कंडीशनिंग के बिना तंत्रिका नेटवर्क का उपयोग करके सह-खिलाड़ियों को सीधे मॉडल करता है, "समग्र नुकसान" पर है। यह छोटे इंटरैक्शन के दौरान महत्वपूर्ण अपडेट प्राप्त करने के लिए संघर्ष करता है, जिससे "अनुकूलन चरण के दौरान गलत विरोधी मॉडलिंग" होता है। एंड-टू-एंड प्रकृति "लक्ष्य-सशर्त नीति की तुलना में उच्च स्तर की अनिश्चितता" भी पेश करती है, जिससे योजना की सटीकता कम हो जाती है। यह स्पष्ट रूप से HOP के लक्ष्य-सशर्त, पदानुक्रमित विरोधी मॉडलिंग की श्रेष्ठता को मान्य करता है।
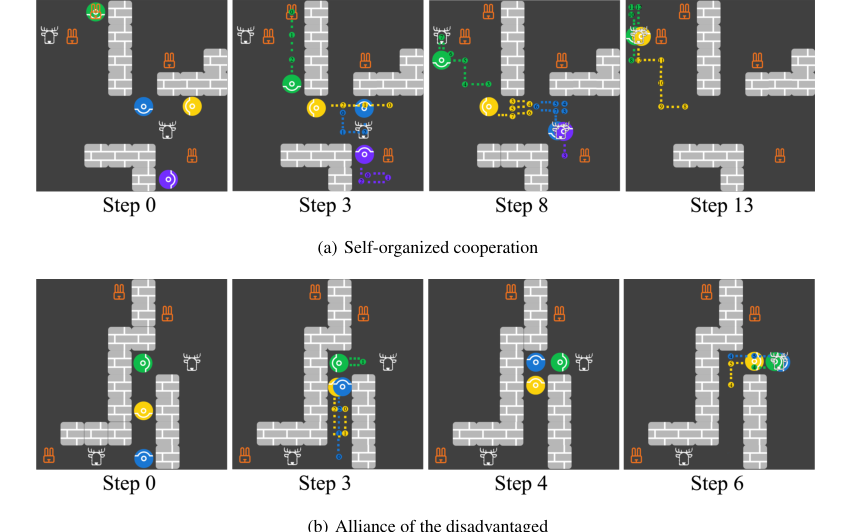 Figure 6. Screenshots for the emergence of (a) self-organized cooperation and (b) alliance of the disadvantaged. Each panel shows agents’ locations at the current step and the trajectories between the current step and the previously stated step
Figure 6. Screenshots for the emergence of (a) self-organized cooperation and (b) alliance of the disadvantaged. Each panel shows agents’ locations at the current step and the trajectories between the current step and the previously stated step
गणितीय और तार्किक तंत्र
मास्टर समीकरण
पदानुक्रमित विरोधी मॉडलिंग और योजना (HOP) एल्गोरिथम कई परस्पर जुड़े गणितीय तंत्रों द्वारा संचालित है जो इसकी अनुकूलन क्षमताओं को सक्षम करते हैं। इसके मूल में, HOP विरोधी लक्ष्य मॉडलिंग के लिए बायेसियन अनुमान, सह-खिलाड़ी लक्ष्य-सशर्त नीतियों को सीखने के लिए एक नकारात्मक लॉग-लाइक्लीहुड उद्देश्य, और मोंटे कार्लो ट्री सर्च (MCTS) द्वारा निर्देशित फोकल एजेंट के निर्णय लेने वाले नेटवर्क को प्रशिक्षित करने के लिए एक संयुक्त नीति और मान हानि पर निर्भर करता है।
HOP के गणितीय इंजन को परिभाषित करने वाले पूर्ण कोर समीकरण हैं:
-
इंट्रा-एपिसोड विरोधी लक्ष्य विश्वास अद्यतन (इंट्रा-ओएम): यह समीकरण वास्तविक समय के अवलोकनों को शामिल करते हुए, एक ही प्रकरण के भीतर एक सह-खिलाड़ी के लक्ष्य के बारे में फोकल एजेंट के विश्वास को अपडेट करता है।
$$b_{ij}^{K,t+1}(g_j) = \frac{1}{Z_1} b_{ij}^{K,t}(g_j) \frac{\Pr(a_j^{K,t}|s^{K,t}, g_j) \Pr(s^{K,t+1}|s^{K,t}, a_j^{K,t}, g_j)}{\Pr(s^{K,t+1}|s^{K,t}, a_j^{K,t})}$$ -
इंटर-एपिसोड विरोधी लक्ष्य विश्वास अद्यतन (इंटर-ओएम): यह समीकरण पिछले एपिसोड से जानकारी का लाभ उठाते हुए, एक नए एपिसोड की शुरुआत में एक सह-खिलाड़ी के लक्ष्य के बारे में पूर्व विश्वास को अपडेट करता है।
$$b_{ij}^{K,0}(g_j) = \frac{1}{Z_2} [\alpha b_{ij}^{K-1,0}(g_j) + (1-\alpha)\mathbf{1}(g_j = g_j^{K-1})]$$ -
लक्ष्य-सशर्त विरोधी नीति नेटवर्क हानि: यह उद्देश्य फलन तंत्रिका नेटवर्क को प्रशिक्षित करता है जो अनुमानित लक्ष्यों और वर्तमान स्थिति को देखते हुए सह-खिलाड़ियों की क्रियाओं की भविष्यवाणी करता है।
$$\mathcal{L}(\omega) = \mathbb{E}[-\log(\pi_\omega(a_j^{K,t}|s^{K,t}, g_j^{K,t}))]$$ -
फोकल एजेंट की नीति और मान नेटवर्क हानि: यह संयुक्त हानि फलन MCTS को एक पर्यवेक्षक के रूप में उपयोग करते हुए, फोकल एजेंट के मुख्य नीति और मान नेटवर्क को प्रशिक्षित करता है।
$$\mathcal{L}(\theta) = \mathcal{L}_p(\pi_{\text{MCTS}}, \pi_\theta) + \mathcal{L}_v(r_i, v_\theta)$$
जहां
$$\mathcal{L}_p(\pi_1, \pi_2) = \mathbb{E}[-\sum_{a \in \mathcal{A}_i} \pi_1(a|s^{K,t}) \log(\pi_2(a|s^{K,t}))]$$
$$\mathcal{L}_v(r_i, v) = \mathbb{E}[(v(s^{K,t}) - \sum_{l=t}^{T_{\text{max}}} \gamma^{l-t} r_i^{K,l})^2]$$
पद-दर-पद विच्छेदन
आइए HOP के गणितीय इंजन की भूमिका को समझने के लिए इन समीकरणों में से प्रत्येक का विश्लेषण करें।
इंट्रा-एपिसोड विरोधी लक्ष्य विश्वास अद्यतन (समीकरण 1)
$$b_{ij}^{K,t+1}(g_j) = \frac{1}{Z_1} b_{ij}^{K,t}(g_j) \frac{\Pr(a_j^{K,t}|s^{K,t}, g_j) \Pr(s^{K,t+1}|s^{K,t}, a_j^{K,t}, g_j)}{\Pr(s^{K,t+1}|s^{K,t}, a_j^{K,t})}$$
- $b_{ij}^{K,t+1}(g_j)$:
- गणितीय परिभाषा: प्रकरण $K$ में समय $t+1$ पर विरोधी $j$ के लक्ष्य $g_j$ के बारे में एजेंट $i$ के विश्वास का प्रतिनिधित्व करने वाला पश्च प्रायिकता वितरण।
- भौतिक/तार्किक भूमिका: यह अद्यतन विश्वास है। यह फोकल एजेंट से कहता है, "इस प्रकरण में अब तक मैंने जो कुछ भी देखा है, उसे देखते हुए, विरोधी $j$ के लक्ष्य $g_j$ होने की कितनी संभावना है?" यह सह-खिलाड़ियों के बदलते व्यवहार के लिए वास्तविक समय अनुकूलन के लिए महत्वपूर्ण है।
- $Z_1$:
- गणितीय परिभाषा: एक सामान्यीकरण कारक।
- भौतिक/तार्किक भूमिका: यह सुनिश्चित करता है कि विरोधी $j$ के सभी संभावित लक्ष्यों $g_j$ के लिए प्रायिकताओं का योग 1 हो, एक मान्य प्रायिकता वितरण बनाए रखता है।
- विभाजन क्यों: यह पूर्व को संभाव्यता में स्केल करने के लिए बेयस प्रमेय का एक मौलिक हिस्सा है।
- $b_{ij}^{K,t}(g_j)$:
- गणितीय परिभाषा: प्रकरण $K$ में समय $t$ पर विरोधी $j$ के लक्ष्य $g_j$ के बारे में एजेंट $i$ के विश्वास का प्रतिनिधित्व करने वाला पूर्व प्रायिकता वितरण।
- भौतिक/तार्किक भूमिका: यह वर्तमान बेयसियन अद्यतन चरण के लिए प्रारंभिक बिंदु के रूप में कार्य करता है।
- $\Pr(a_j^{K,t}|s^{K,t}, g_j)$:
- गणितीय परिभाषा: वर्तमान अवस्था $s^{K,t}$ और एक परिकल्पित लक्ष्य $g_j$ दिए जाने पर विरोधी $j$ द्वारा क्रिया $a_j^{K,t}$ लेने की प्रायिकता। यह लक्ष्य-सशर्त नीति नेटवर्क $\pi_\omega$ द्वारा प्रदान की जाती है।
- भौतिक/तार्किक भूमिका: यह शब्द "क्रिया की संभाव्यता" के रूप में कार्य करता है। यह मापता है कि एक विशेष परिकल्पित लक्ष्य $g_j$ देखे गए क्रिया $a_j^{K,t}$ को कितनी अच्छी तरह समझाता है। यदि कोई विरोधी लक्ष्य $g_A$ के तहत बहुत संभावित क्रिया लेता है लेकिन लक्ष्य $g_B$ के तहत असंभावित है, तो यह शब्द $g_A$ में विश्वास को बढ़ावा देगा।
- $\Pr(s^{K,t+1}|s^{K,t}, a_j^{K,t}, g_j)$:
- गणितीय परिभाषा: पिछली अवस्था $s^{K,t}$, विरोधी $j$ की क्रिया $a_j^{K,t}$, और एक परिकल्पित लक्ष्य $g_j$ दिए जाने पर अवस्था $s^{K,t+1}$ में संक्रमण की प्रायिकता। पत्र एक मार्कोव धारणा का उल्लेख करता है जहां यह $\Pr(s^{K,t+1}|s^{K,t}, a_j^{K,t})$ तक सरल हो सकता है, जो $g_j$ से स्वतंत्रता का अर्थ है। हालांकि, समीकरण में $g_j$ शामिल है, जो एक संभावित निर्भरता या अधिक सामान्य सूत्रीकरण का सुझाव देता है।
- भौतिक/तार्किक भूमिका: यह शब्द "अवस्था संक्रमण की संभाव्यता" के रूप में कार्य करता है। यह देखे गए अवस्था परिवर्तन परिकल्पित लक्ष्य और क्रिया के अनुरूप है या नहीं, इस पर विचार करके विश्वास को और परिष्कृत करता है।
- $\Pr(s^{K,t+1}|s^{K,t}, a_j^{K,t})$:
- गणितीय परिभाषा: पिछली अवस्था $s^{K,t}$ और विरोधी $j$ की क्रिया $a_j^{K,t}$ दिए जाने पर अवस्था $s^{K,t+1}$ में संक्रमण की प्रायिकता।
- भौतिक/तार्किक भूमिका: यह अवस्था संक्रमण संभाव्यता के लिए एक सामान्यीकरण शब्द है, जो समग्र संभाव्यता को ठीक से स्केल करना सुनिश्चित करता है।
- गुणा क्यों: बेयसियन अपडेट पूर्व विश्वासों को संभाव्यताओं के साथ गुणा करके जोड़ते हैं, जो दर्शाता है कि नया साक्ष्य मौजूदा विश्वास को कैसे स्केल करता है।
इंटर-एपिसोड विरोधी लक्ष्य विश्वास अद्यतन (समीकरण 2)
$$b_{ij}^{K,0}(g_j) = \frac{1}{Z_2} [\alpha b_{ij}^{K-1,0}(g_j) + (1-\alpha)\mathbf{1}(g_j = g_j^{K-1})]$$
- $b_{ij}^{K,0}(g_j)$:
- गणितीय परिभाषा: प्रकरण $K$ की शुरुआत में विरोधी $j$ के लक्ष्य $g_j$ के बारे में एजेंट $i$ के विश्वास का प्रतिनिधित्व करने वाला पूर्व प्रायिकता वितरण।
- भौतिक/तार्किक भूमिका: यह एक नए प्रकरण में विरोधी $j$ के लक्ष्य के लिए प्रारंभिक अनुमान है। यह अतीत के अनुभवों से सूचित होता है, जो विरोधी व्यवहार की "स्मृति" प्रदान करता है।
- $Z_2$:
- गणितीय परिभाषा: एक सामान्यीकरण कारक।
- भौतिक/तार्किक भूमिका: यह सुनिश्चित करता है कि सभी संभावित लक्ष्यों $g_j$ के लिए प्रायिकताओं का योग 1 हो।
- विभाजन क्यों: प्रायिकता वितरण के लिए मानक सामान्यीकरण।
- $\alpha$:
- गणितीय परिभाषा: एक क्षितिज भार, $\alpha \in [0, 1]$।
- भौतिक/तार्किक भूमिका: यह गुणांक ऐतिहासिक विश्वासों बनाम सबसे हाल ही में देखे गए लक्ष्य के प्रभाव को नियंत्रित करता है। उच्च $\alpha$ का अर्थ है कि एजेंट पुराने विश्वासों को अधिक महत्व देता है, जिससे धीमा अनुकूलन होता है। निम्न $\alpha$ (0 के करीब) का अर्थ है कि एजेंट हाल ही में देखे गए लक्ष्य को प्राथमिकता देता है, जिससे गतिशील विरोधियों के लिए तेजी से अनुकूलन संभव होता है।
- गुणा क्यों: यह पिछले प्रकरण के पूर्व विश्वास के योगदान को स्केल करता है।
- $b_{ij}^{K-1,0}(g_j)$:
- गणितीय परिभाषा: प्रकरण $K-1$ की शुरुआत में एजेंट $i$ के लिए विरोधी $j$ के लक्ष्यों $g_j$ पर पूर्व प्रायिकता वितरण।
- भौतिक/तार्किक भूमिका: वर्तमान प्रकरण से पहले सभी एपिसोड से विरोधी $j$ के लक्ष्यों के बारे में संचित ऐतिहासिक ज्ञान का प्रतिनिधित्व करता है।
- $(1-\alpha)$:
- गणितीय परिभाषा: $\alpha$ के लिए पूरक भार।
- भौतिक/तार्किक भूमिका: पिछले प्रकरण से देखे गए लक्ष्य के योगदान को स्केल करता है।
- गुणा क्यों: यह सबसे हालिया लक्ष्य अवलोकन के योगदान को स्केल करता है।
- $\mathbf{1}(g_j = g_j^{K-1})$:
- गणितीय परिभाषा: एक संकेतक फलन जो 1 लौटाता है यदि पिछले प्रकरण $K-1$ में विरोधी $j$ का लक्ष्य $g_j$ था, और अन्यथा 0।
- भौतिक/तार्किक भूमिका: यह शब्द सीधे पिछले एपिसोड में विरोधी $j$ के लिए अनुमानित वास्तविक लक्ष्य को शामिल करता है। यह नए प्रकरण के लिए पूर्व को अपडेट करने के लिए एक मजबूत संकेत है।
- जोड़ क्यों: नए पूर्व को बनाने के लिए दीर्घकालिक ऐतिहासिक विश्वास को अल्पकालिक, सबसे हालिया अवलोकन के साथ संयोजित करने के लिए दो भारित शब्दों को जोड़ा जाता है।
लक्ष्य-सशर्त विरोधी नीति नेटवर्क हानि (समीकरण 3)
$$\mathcal{L}(\omega) = \mathbb{E}[-\log(\pi_\omega(a_j^{K,t}|s^{K,t}, g_j^{K,t}))]$$
- $\mathcal{L}(\omega)$:
- गणितीय परिभाषा: लक्ष्य-सशर्त नीति नेटवर्क के लिए हानि फलन, $\omega$ द्वारा पैरामीट्रिज्ड।
- भौतिक/तार्किक भूमिका: यह वह उद्देश्य है जिसे विरोधी मॉडलिंग मॉड्यूल सह-खिलाड़ियों के लिए सटीक लक्ष्य-सशर्त नीतियों को सीखने के लिए कम करता है। कम हानि का मतलब है कि नेटवर्क सह-खिलाड़ी व्यवहार को उनके लक्ष्यों को देखते हुए भविष्यवाणी करने में बेहतर है।
- $\mathbb{E}[\cdot]$:
- गणितीय परिभाषा: अपेक्षा ऑपरेटर, आमतौर पर डेटा नमूनों के एक बैच पर औसत करके अनुमानित किया जाता है।
- भौतिक/तार्किक भूमिका: व्यक्तिगत डेटा बिंदुओं से शोर के प्रभाव को कम करके, कई अवलोकनों पर औसत करके हानि का एक स्थिर अनुमान प्रदान करता है।
- $-\log(\pi_\omega(a_j^{K,t}|s^{K,t}, g_j^{K,t}))$:
- गणितीय परिभाषा: अवस्था $s^{K,t}$ और अनुमानित लक्ष्य $g_j^{K,t}$ दिए जाने पर नीति नेटवर्क $\pi_\omega$ द्वारा देखी गई क्रिया $a_j^{K,t}$ को सौंपी गई प्रायिकता का नकारात्मक लघुगणक।
- भौतिक/तार्किक भूमिका: यह मानक नकारात्मक लॉग-लाइक्लीहुड हानि है जिसका उपयोग वर्गीकरण या नीति सीखने के लिए पर्यवेक्षित सीखने में किया जाता है। इस शब्द को कम करने से नेटवर्क द्वारा सही (देखे गए) क्रिया को सौंपी गई प्रायिकता अधिकतम हो जाती है, प्रभावी ढंग से नेटवर्क को विशिष्ट लक्ष्यों के तहत विरोधी व्यवहार की नकल करना सिखाता है।
- नकारात्मक लॉग क्यों: लघुगणक प्रायिकताओं के उत्पादों को योग में बदल देता है, जो अनुकूलन के लिए आसान होते हैं। नकारात्मक चिह्न उद्देश्य को अधिकतम संभाव्यता से न्यूनतम हानि में परिवर्तित करता है, जो ग्रेडिएंट-आधारित अनुकूलन के लिए मानक है।
फोकल एजेंट की नीति और मान नेटवर्क हानि (समीकरण 6)
$$\mathcal{L}(\theta) = \mathcal{L}_p(\pi_{\text{MCTS}}, \pi_\theta) + \mathcal{L}_v(r_i, v_\theta)$$
$$\mathcal{L}_p(\pi_1, \pi_2) = \mathbb{E}[-\sum_{a \in \mathcal{A}_i} \pi_1(a|s^{K,t}) \log(\pi_2(a|s^{K,t}))]$$
$$\mathcal{L}_v(r_i, v) = \mathbb{E}[(v(s^{K,t}) - \sum_{l=t}^{T_{\text{max}}} \gamma^{l-t} r_i^{K,l})^2]$$
- $\mathcal{L}(\theta)$:
- गणितीय परिभाषा: फोकल एजेंट की नीति और मान नेटवर्क के लिए कुल हानि फलन, $\theta$ द्वारा पैरामीट्रिज्ड।
- भौतिक/तार्किक भूमिका: यह वह प्राथमिक उद्देश्य फलन है जिसे फोकल एजेंट अपनी इष्टतम नीति और एक सटीक मान फलन सीखने के लिए कम करता है। यह सुदृढीकरण सीखने के दो महत्वपूर्ण पहलुओं को जोड़ता है: अच्छी तरह से कार्य करना सीखना और भविष्य के पुरस्कारों की भविष्यवाणी करना सीखना।
- जोड़ क्यों: नीति और मान सीखना अक्सर अभिनेता-आलोचक या अल्फाजीरो-जैसे आर्किटेक्चर में एक एकल उद्देश्य में संयुक्त होते हैं, क्योंकि वे पूरक कार्य हैं जो साझा अभ्यावेदन और संयुक्त अनुकूलन से लाभान्वित होते हैं।
- $\mathcal{L}_p(\pi_{\text{MCTS}}, \pi_\theta)$:
- गणितीय परिभाषा: नीति हानि पद, विशेष रूप से MCTS-व्युत्पन्न नीति $\pi_{\text{MCTS}}$ (लक्ष्य नीति $\pi_1$) और सीखी गई नीति $\pi_\theta$ (भविष्यवाणी नीति $\pi_2$) के बीच एक क्रॉस-एंट्रॉपी हानि।
- भौतिक/तार्किक भूमिका: यह पद एक "नीति आसवन" तंत्र के रूप में कार्य करता है। MCTS, अपने लुक-अहेड खोज के माध्यम से, एक बेहतर नीति उत्पन्न करता है। यह हानि फोकल एजेंट की सीखी गई नीति $\pi_\theta$ को MCTS-जनित नीति की नकल करने के लिए प्रोत्साहित करती है, प्रभावी ढंग से योजना की "बुद्धि" को तंत्रिका नेटवर्क में स्थानांतरित करती है।
- $\mathbb{E}[-\sum_{a \in \mathcal{A}_i} \pi_1(a|s^{K,t}) \log(\pi_2(a|s^{K,t}))]$:
- गणितीय परिभाषा: दो प्रायिकता वितरण $\pi_1$ और $\pi_2$ के बीच क्रॉस-एंट्रॉपी।
- भौतिक/तार्किक भूमिका: यह मापता है कि सीखी गई नीति $\pi_2$ MCTS लक्ष्य नीति $\pi_1$ से कितनी भिन्न है। क्रॉस-एंट्रॉपी को कम करने से $\pi_2$ $\pi_1$ से मेल खाता है।
- योग क्यों: लक्ष्य नीति की प्रायिकताओं द्वारा भारित, फोकल एजेंट के क्रिया स्थान $\mathcal{A}_i$ में सभी संभावित क्रियाओं पर नकारात्मक लॉग-प्रायिकताओं का योग करता है।
- $\mathcal{L}_v(r_i, v_\theta)$:
- गणितीय परिभाषा: मान हानि पद, विशेष रूप से मान नेटवर्क से अनुमानित मान $v(s^{K,t})$ और वास्तविक छूट प्राप्त रिटर्न $\sum_{l=t}^{T_{\text{max}}} \gamma^{l-t} r_i^{K,l}$ के बीच एक माध्य वर्ग त्रुटि (MSE)।
- भौतिक/तार्किक भूमिका: यह पद मान नेटवर्क $v_\theta$ को किसी भी दी गई अवस्था से अपेक्षित संचयी भविष्य के पुरस्कारों का सटीक अनुमान लगाने के लिए प्रशिक्षित करता है। एक सटीक मान फलन MCTS का मार्गदर्शन करने और अवस्थाओं की गुणवत्ता का मूल्यांकन करने के लिए महत्वपूर्ण है।
- $\mathbb{E}[(v(s^{K,t}) - \sum_{l=t}^{T_{\text{max}}} \gamma^{l-t} r_i^{K,l})^2]$:
- गणितीय परिभाषा: अनुमानित मान और वास्तविक छूट प्राप्त रिटर्न के बीच वर्ग अंतर।
- भौतिक/तार्किक भूमिका: यह एक मानक प्रतिगमन हानि है। यह मान नेटवर्क को गलत भविष्यवाणियों के लिए दंडित करता है, जिसमें बड़े त्रुटियों को द्विघात रूप से उच्च दंड प्राप्त होता है।
- वर्ग अंतर क्यों: प्रतिगमन कार्यों के लिए सामान्य, यह ग्रेडिएंट-आधारित अनुकूलन के लिए एक चिकना, अवकलनीय हानि परिदृश्य प्रदान करता है।
- $v(s^{K,t})$:
- गणितीय परिभाषा: फोकल एजेंट के मान नेटवर्क द्वारा अवस्था $s^{K,t}$ के लिए अनुमानित मान।
- भौतिक/तार्किक भूमिका: अवस्था $s^{K,t}$ से प्राप्त कुल भविष्य के छूट प्राप्त पुरस्कारों का मॉडल का वर्तमान अनुमान।
- $\sum_{l=t}^{T_{\text{max}}} \gamma^{l-t} r_i^{K,l}$:
- गणितीय परिभाषा: प्रकरण $T_{\text{max}}$ के अंत तक समय चरण $t$ से एजेंट $i$ द्वारा प्राप्त वास्तविक छूट प्राप्त रिटर्न (संचयी पुरस्कार)।
- भौतिक/तार्किक भूमिका: यह मान नेटवर्क के लिए "ग्राउंड ट्रुथ" है। यह भविष्य के पुरस्कारों का वास्तविक योग है, जो उनकी लौकिक दूरी से छूट प्राप्त है।
- योग क्यों: पूरे भविष्य के प्रक्षेप्य पर पुरस्कारों को जमा करता है।
- $\gamma$:
- गणितीय परिभाषा: छूट कारक, $\gamma \in [0, 1]$।
- भौतिक/तार्किक भूमिका: भविष्य के पुरस्कारों के वर्तमान मूल्य को निर्धारित करता है। 0 के करीब एक $\gamma$ एजेंट को अल्पकालिक (केवल तत्काल पुरस्कारों की परवाह करता है) बनाता है, जबकि 1 के करीब एक $\gamma$ इसे दूरदर्शी बनाता है (दीर्घकालिक पुरस्कारों पर भारी विचार करता है)।
- घातांक क्यों: भविष्य में और दूर के पुरस्कारों के महत्व को घातीय रूप से कम करने के लिए सुदृढीकरण सीखने में मानक।
चरण-दर-चरण प्रवाह
पर्यावरण की स्थिति और सह-खिलाड़ियों की क्रियाओं के अवलोकन जैसे एक एकल सार डेटा बिंदु की कल्पना करें, जो HOP प्रणाली में प्रवेश कर रहा है। यहाँ बताया गया है कि यह गणितीय इंजन के माध्यम से कैसे चलता है:
-
एपिसोड प्रारंभ: इतिहास के साथ मंच तैयार करना:
- जब एक नया प्रकरण $K$ शुरू होता है, तो फोकल एजेंट $i$ सह-खिलाड़ियों के बारे में अपने विश्वासों के संबंध में खरोंच से शुरू नहीं होता है। यह पहले पिछले इंटरैक्शन की "स्मृति" से परामर्श करता है।
- इंटर-ओएम विश्वास अद्यतन (समीकरण 2) को ट्रिगर किया जाता है। यह समीकरण पिछले प्रकरण से पूर्व विश्वास $b_{ij}^{K-1,0}(g_j)$ लेता है और इसे उस अंतिम प्रकरण में विरोधी $j$ के लिए अनुमानित वास्तविक लक्ष्य $g_j^{K-1}$ के साथ जोड़ता है। क्षितिज भार $\alpha$ एक डायल की तरह कार्य करता है, जो यह मिश्रित करता है कि दीर्घकालिक इतिहास पर कितना भरोसा करना है बनाम बहुत हाल का अतीत। यह वर्तमान प्रकरण के लिए एक प्रारंभिक विश्वास $b_{ij}^{K,0}(g_j)$ उत्पन्न करता है, जिससे एजेंट को एक हेड स्टार्ट मिलता है।
-
वास्तविक समय इंटरैक्शन: विरोधी लक्ष्यों का अवलोकन और अनुमान लगाना:
- जैसे-जैसे प्रकरण आगे बढ़ता है, प्रत्येक समय चरण $t$ पर, एजेंट वर्तमान स्थिति $s^{K,t}$ और अपने सह-खिलाड़ियों द्वारा की गई क्रियाओं $a_j^{K,t}$ का अवलोकन करता है।
- यह नया अवलोकन तुरंत इंट्रा-ओएम विश्वास अद्यतन (समीकरण 1) में फीड होता है। एजेंट अपने वर्तमान विश्वास $b_{ij}^{K,t}(g_j)$ (जो $t=0$ पर $b_{ij}^{K,0}(g_j)$ था) लेता है और इसे अपडेट करता है। यह पूछता है: "यदि उनका लक्ष्य $g_j$ था तो विरोधी $j$ ने क्रिया $a_j^{K,t}$ ली होगी और अवस्था $s^{K,t+1}$ का कारण बनी होगी, इसकी कितनी संभावना है?"
- इसका उत्तर देने के लिए, यह प्रत्येक संभावित लक्ष्य $g_j$ के लिए $\Pr(a_j^{K,t}|s^{K,t}, g_j)$ प्राप्त करने के लिए लक्ष्य-सशर्त नीति नेटवर्क $\pi_\omega$ का उपयोग करता है। यह संभाव्यता तब वर्तमान विश्वास से गुणा की जाती है, और परिणाम को $Z_1$ द्वारा सामान्यीकृत किया जाता है। यह प्रक्रिया लगातार $b_{ij}^{K,t+1}(g_j)$ को परिष्कृत करती है, जिससे प्रकरण के भीतर अधिक क्रियाएं देखी जाने पर विरोधी लक्ष्यों के बारे में विश्वास अधिक सटीक हो जाता है।
-
विरोधी व्यवहार सीखना: लक्ष्य-सशर्त नीति को प्रशिक्षित करना:
- इस प्रक्रिया के दौरान, अनुमानित लक्ष्य $g_j^{K,t}$ (सबसे संभावित लक्ष्य) देखे गए अवस्थाओं $s^{K,t}$ और क्रियाओं $a_j^{K,t}$ के साथ एकत्र और एक प्रक्षेप्य बफर में संग्रहीत किए जाते हैं।
- समय-समय पर, इस एकत्रित डेटा का उपयोग लक्ष्य-सशर्त नीति नेटवर्क $\pi_\omega$ को प्रशिक्षित करने के लिए किया जाता है। लक्ष्य-सशर्त विरोधी नीति नेटवर्क हानि (समीकरण 3) को कम किया जाता है। यह एक शिक्षक की तरह है जो नेटवर्क को उदाहरण दिखा रहा है: "जब विरोधी अवस्था $s$ में लक्ष्य $g$ के साथ था, तो उन्होंने क्रिया $a$ ली।" नेटवर्क $s$ और $g$ को देखते हुए $a$ की भविष्यवाणी करना सीखता है, सह-खिलाड़ी व्यवहार को मॉडल करने की अपनी क्षमता में सुधार करता है।
-
फोकल एजेंट का निर्णय लेना: सर्वोत्तम प्रतिक्रिया की योजना बनाना:
- अब फोकल एजेंट की कार्य करने की बारी है। इसे अपनी क्रिया $a_i^{K,t}$ चुननी होगी।
- एजेंट मोंटे कार्लो ट्री सर्च (MCTS) शुरू करता है। MCTS केवल वर्तमान स्थिति पर विचार नहीं करता है; यह कई संभावित भविष्य का अनुकरण करता है।
- महत्वपूर्ण रूप से, MCTS सह-खिलाड़ियों के लक्ष्यों को निश्चित रूप से नहीं जानता है। इसलिए, अपने $N_s$ सिमुलेशन दौरों में से प्रत्येक में, यह सह-खिलाड़ियों के लक्ष्यों के संयोजन को वर्तमान विश्वास $b_{ij}^{K,t}(g_j)$ (चरण 2 से) से नमूना करता है।
- प्रत्येक नमूना लक्ष्य संयोजन के लिए, MCTS प्रक्षेप्य का अनुकरण करता है। जब इसे यह जानने की आवश्यकता होती है कि सह-खिलाड़ी $j$ क्या करेगा, तो यह नमूना लक्ष्य $g_j$ के साथ सीखे गए लक्ष्य-सशर्त नीति $\pi_\omega(\cdot|s, g_j)$ (चरण 3 से) का उपयोग करता है। फोकल एजेंट अपनी क्रियाओं का पता लगाता है।
- $N_s$ दौरों के बाद, MCTS फोकल एजेंट की प्रत्येक संभावित क्रिया के लिए एक औसत क्रिया मान $Q_{\text{avg}}(s^{K,t}, a)$ (समीकरण 4) की गणना करता है, जो सह-खिलाड़ियों के लक्ष्यों पर अनिश्चितता पर विचार करता है।
- अंत में, फोकल एजेंट बोल्ट्ज़मैन तर्कसंगतता मॉडल (समीकरण 5) का उपयोग करके अपनी क्रिया $a_i^{K,t}$ का चयन करता है, जो उच्च $Q_{\text{avg}}$ मानों वाली क्रियाओं का पक्षधर है, अन्वेषण और शोषण को संतुलित करता है।
-
बेहतर बनने के लिए सीखना: फोकल एजेंट के नेटवर्क को प्रशिक्षित करना:
- MCTS प्रक्रिया स्वयं मूल्यवान जानकारी प्रदान करती है: एक "बेहतर" नीति $\pi_{\text{MCTS}}$ (खोज से प्राप्त) और अवस्था के मान का एक बेहतर अनुमान।
- यह जानकारी, वास्तविक पुरस्कारों $r_i^{K,l}$ के साथ, फोकल एजेंट की मुख्य नीति और मान नेटवर्क को प्रशिक्षित करने के लिए उपयोग की जाती है, जो $\theta$ द्वारा पैरामीट्रिज्ड है।
- फोकल एजेंट की नीति और मान नेटवर्क हानि (समीकरण 6) को कम किया जाता है। इस हानि के दो भाग हैं:
- एक नीति हानि $\mathcal{L}_p$ जो सीखी गई नीति $\pi_\theta$ को MCTS-जनित नीति $\pi_{\text{MCTS}}$ की नकल बनाती है। यह MCTS "शिक्षक" की तरह है जो नेटवर्क को इष्टतम चालें दिखा रहा है।
- एक मान हानि $\mathcal{L}_v$ जो मान नेटवर्क $v_\theta$ को देखे गए वास्तविक छूट प्राप्त रिटर्न $\sum_{l=t}^{T_{\text{max}}} \gamma^{l-t} r_i^{K,l}$ का सटीक अनुमान लगाने के लिए बनाती है। यह नेटवर्क को यह सिखाता है कि किसी अवस्था का मूल्यांकन करना कितना अच्छा है।
- इस संयुक्त हानि के माध्यम से, फोकल एजेंट के तंत्रिका नेटवर्क बेहतर निर्णय लेना और अवस्थाओं का अधिक सटीक मूल्यांकन करना सीखते हैं, समय के साथ अधिक कुशल बनते जाते हैं।
यह पूरा चक्र दोहराता है, प्रत्येक चरण दूसरों को फीड करता है और सुधारता है, एक गतिशील और अनुकूली सीखने की प्रणाली बनाता है।
अनुकूलन गतिशीलता
HOP तंत्र ग्रेडिएंट डिसेंट और MCTS की अंतर्निहित स्व-सुधार के माध्यम से एक सतत, पुनरावृत्ति प्रक्रिया के माध्यम से सीखता है, अपडेट करता है और अभिसरण करता है। यह सीखना विभिन्न हानि कार्यों पर ग्रेडिएंट डिसेंट और MCTS द्वारा संचालित होता है।
-
विश्वास प्रणाली परिष्करण:
- इंट्रा-एपिसोड विश्वास (समीकरण 1): इंट्रा-ओएम मॉड्यूल बायेसियन अनुमान का उपयोग करके सह-खिलाड़ियों के लक्ष्यों के बारे में विश्वासों को लगातार अपडेट करता है। प्रत्येक नया अवलोकन (विरोधी क्रिया और अवस्था संक्रमण) साक्ष्य प्रदान करता है जो या तो एक विशेष लक्ष्य की संभावना को मजबूत करता है या कमजोर करता है। समय के साथ, जैसे-जैसे एक प्रकरण के भीतर अधिक डेटा एकत्र किया जाता है, पश्च वितरण $b_{ij}^{K,t+1}(g_j)$ विरोधी के वास्तविक अंतर्निहित लक्ष्य की ओर अभिसरण करता है, यह मानते हुए कि उनका व्यवहार सीखे गए लक्ष्य-सशर्त नीतियों में से एक के अनुरूप है। यह एक क्लासिक बायेसियन अपडेट है, जहां जमा साक्ष्य के साथ विश्वास वितरण में अनिश्चितता (एंट्रॉपी) कम हो जाती है।
- इंटर-एपिसोड पूर्व (समीकरण 2): इंटर-ओएम मॉड्यूल नए एपिसोड के लिए पूर्व विश्वास को अपडेट करता है। क्षितिज भार $\alpha$ यहाँ एक महत्वपूर्ण हाइपरपैरामीटर है। यदि $\alpha$ उच्च है, तो सिस्टम दीर्घकालिक ऐतिहासिक औसत पर बहुत अधिक निर्भर करता है, जिससे पूर्व विश्वास का धीमा लेकिन स्थिर अभिसरण होता है। यदि $\alpha$ कम है, तो सिस्टम हाल के विरोधी व्यवहारों के लिए जल्दी से अनुकूलित होता है, जिससे तेजी से अनुकूलन हो सकता है लेकिन यदि विरोधी लक्ष्य अत्यधिक अस्थिर हों तो अस्थिरता भी हो सकती है। यह तंत्र सिस्टम को कई एपिसोड में विरोधी रणनीतियों में बदलावों को ट्रैक करने और अनुकूलित करने की अनुमति देता है।
-
विरोधी नीति सीखना:
- लक्ष्य-सशर्त नीति नेटवर्क $\pi_\omega$ (विरोधी क्रियाओं की भविष्यवाणी करने के लिए उपयोग किया जाता है) को स्टोकेस्टिक ग्रेडिएंट डिसेंट (SGD) या इसके वेरिएंट का उपयोग करके नकारात्मक लॉग-लाइक्लीहुड हानि (समीकरण 3) को कम करके प्रशिक्षित किया जाता है। इस नेटवर्क के लिए हानि परिदृश्य इसकी भविष्यवाणियों की सटीकता से आकार लेता है। जैसे-जैसे अधिक विविध और सटीक डेटा (अवस्था, अनुमानित लक्ष्य, वास्तविक क्रिया) एकत्र किया जाता है और रिप्ले बफर में फीड किया जाता है, ग्रेडिएंट नेटवर्क पैरामीटर $\omega$ को इस हानि को कम करने के लिए निर्देशित करते हैं। यह प्रक्रिया पुनरावृत्ति रूप से विरोधी व्यवहार को सटीक रूप से मॉडल करने के लिए नेटवर्क की क्षमता में सुधार करती है, जिससे विरोधी मॉडलिंग मॉड्यूल अधिक विश्वसनीय हो जाता है।
-
फोकल एजेंट की नीति और मान सीखना:
- फोकल एजेंट की नीति $\pi_\theta$ और मान फलन $v_\theta$ MCTS एक शक्तिशाली "शिक्षक" के रूप में कार्य करते हुए, एक पर्यवेक्षित प्रक्रिया के माध्यम से सीखे जाते हैं। समग्र हानि $\mathcal{L}(\theta)$ (समीकरण 6) को ग्रेडिएंट डिसेंट का उपयोग करके कम किया जाता है।
- नीति सुधार: MCTS, व्यापक सिमुलेशन और लुक-अहेड खोजें करके, वर्तमान सीखी गई नीति $\pi_\theta$ की तुलना में एक "मजबूत" नीति $\pi_{\text{MCTS}}$ उत्पन्न करता है। नीति हानि पद $\mathcal{L}_p$ तब $\pi_\theta$ को $\pi_{\text{MCTS}}$ की नकल करने के लिए चलाता है। इसका मतलब है कि $\mathcal{L}_p$ से ग्रेडिएंट पैरामीटर $\theta$ को उस दिशा में खींचते हैं जो सीखी गई नीति को MCTS-व्युत्पन्न इष्टतम क्रियाओं के करीब लाती है। यह पुनरावृत्ति पर्यवेक्षण $\pi_\theta$ को सीधे पर्यावरण का पता लगाए बिना इष्टतम नीति के करीब अभिसरण करने की अनुमति देता है।
- मान फलन सटीकता: मान हानि पद $\mathcal{L}_v$ $v_\theta$ को MCTS सिमुलेशन और वास्तविक गेमप्ले के दौरान देखे गए वास्तविक छूट प्राप्त रिटर्न की भविष्यवाणी करने के लिए प्रशिक्षित करता है। $\mathcal{L}_v$ से ग्रेडिएंट $\theta$ को अनुमानित और वास्तविक रिटर्न के बीच माध्य वर्ग त्रुटि को कम करने के लिए निर्देशित करते हैं। जैसे-जैसे $v_\theta$ अधिक सटीक होता जाता है, यह MCTS के लिए बेहतर अनुमान प्रदान करता है, जिससे खोज अधिक कुशल और प्रभावी हो जाती है। यह एक सकारात्मक प्रतिक्रिया लूप बनाता है: बेहतर मान अनुमान बेहतर MCTS की ओर ले जाते हैं, जो $v_\theta$ के लिए बेहतर प्रशिक्षण लक्ष्यों की ओर ले जाता है।
- हानि परिदृश्य: संयुक्त हानि $\mathcal{L}(\theta)$ एक जटिल हानि परिदृश्य बनाता है। हालांकि, MCTS पर्यवेक्षण एक मजबूत, यद्यपि संभावित रूप से शोर युक्त, संकेत प्रदान करता है जो तंत्रिका नेटवर्क पैरामीटर $\theta$ को उच्च अपेक्षित रिटर्न वाले क्षेत्रों की ओर निर्देशित करता है। MCTS (बार-बार सिमुलेशन) और तंत्रिका नेटवर्क प्रशिक्षण (ग्रेडिएंट अपडेट) की पुनरावृत्ति प्रकृति सिस्टम को एक मजबूत नीति और मान फलन में अभिसरण करने की अनुमति देती है।
-
MCTS अन्वेषण-शोषण:
- MCTS एल्गोरिथम स्वयं pUCT (पॉलीनोमिअल अपर कॉन्फिडेंस ट्रीज) जैसे तंत्रों का उपयोग करके अन्वेषण और शोषण को संतुलित करता है। MCTS स्कोर फलन में अन्वेषण गुणांक $c$ (परिशिष्ट E.1 में उल्लेखित) इस संतुलन को नियंत्रित करता है। एक उच्च $c$ MCTS को कम-विजिटेड क्रियाओं का पता लगाने के लिए प्रोत्साहित करता है, संभावित रूप से बेहतर रणनीतियों की खोज करता है। एक निम्न $c$ MCTS को ज्ञात अच्छी क्रियाओं का अधिक शोषण करने के लिए बनाता है, जिससे स्थानीय ऑप्टिमा में तेजी से अभिसरण होता है। यह गतिशीलता सुनिश्चित करती है कि MCTS तंत्रिका नेटवर्क को पर्यवेक्षित करने के लिए बेहतर नीतियों को खोजना जारी रखता है।
संक्षेप में, HOP की अनुकूलन गतिशीलता एक पदानुक्रमित और पुनरावृत्ति सीखने की प्रक्रिया की विशेषता है। विरोधी मॉडल को बायेसियन अपडेट और पर्यवेक्षित सीखने के माध्यम से लगातार परिष्कृत किया जाता है, जिससे सह-खिलाड़ी व्यवहार की तेजी से सटीक भविष्यवाणियां होती हैं। यह परिष्कृत समझ तब MCTS को सूचित करती है, जो एक शक्तिशाली योजना इंजन के रूप में कार्य करता है, बेहतर नीतियों और मान लक्ष्यों को उत्पन्न करता है। ये लक्ष्य, बदले में, फोकल एजेंट की मुख्य नीति और मान नेटवर्क को पर्यवेक्षित करते हैं, उन्हें मिश्रित-प्रेरणा वातावरण में एक कुशल और अनुकूली निर्णय लेने की रणनीति में अभिसरण करने के लिए चलाते हैं। इन घटकों की परस्पर क्रिया सुनिश्चित करती है कि सिस्टम अनदेखे नीतियों के अनुकूल हो सके और मजबूत व्यवहार सीख सके।
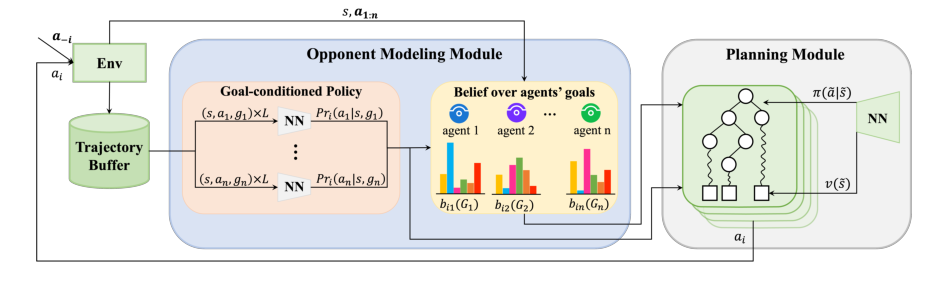 Figure 1. Overview of HOP. HOP consists of an opponent modeling module and a planning module. The opponent modeling module models the behavior of co-players by inferring co-players’ goals and learning their goal-conditioned policies. Estimated behavior is then fed to the planning module to select a rewarding action for the focal agent
Figure 1. Overview of HOP. HOP consists of an opponent modeling module and a planning module. The opponent modeling module models the behavior of co-players by inferring co-players’ goals and learning their goal-conditioned policies. Estimated behavior is then fed to the planning module to select a rewarding action for the focal agent
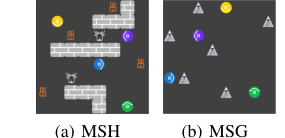 Figure 2. Overview of Markov Stag-Hunt and Markov Snowdrift. There are four agents, repre- sented by colored circles, in each paradigm. (a) Agents catch prey for reward. A stag with a reward of 10 requires at least two agents to hunt together. One agent can hunt a hare with a reward of 1. (b) Everyone gets a reward of 6 when an agent removes a snowdrift. When a snowdrift is removed, removers share the cost of 4 evenly
Figure 2. Overview of Markov Stag-Hunt and Markov Snowdrift. There are four agents, repre- sented by colored circles, in each paradigm. (a) Agents catch prey for reward. A stag with a reward of 10 requires at least two agents to hunt together. One agent can hunt a hare with a reward of 1. (b) Everyone gets a reward of 6 when an agent removes a snowdrift. When a snowdrift is removed, removers share the cost of 4 evenly
परिणाम, सीमाएं और निष्कर्ष
प्रयोगात्मक डिजाइन और बेसलाइन
मिश्रित-प्रेरणा वातावरण में पदानुक्रमित विरोधी मॉडलिंग और योजना (HOP) एल्गोरिथम को कठोरता से मान्य करने के लिए, लेखकों ने दो अलग-अलग मिश्रित-प्रेरणा वातावरणों में प्रयोग किए: मार्कोव स्टैग-हंट (MSH) और मार्कोव स्नोड्रिफ्ट गेम (MSG)। ये वातावरण क्लासिक गेम थ्योरी प्रतिमानों के स्थानिक और लौकिक विस्तार हैं, जिन्हें जटिल रणनीतिक इंटरैक्शन को प्रेरित करने के लिए डिज़ाइन किया गया है।
MSH में, चार एजेंट एक ग्रिड पर शिकार (स्टैग और खरगोश) करते हैं। एक स्टैग 10 का पुरस्कार प्रदान करता है लेकिन शिकार करने के लिए कम से कम दो एजेंटों के सहयोग की आवश्यकता होती है, पुरस्कार को विभाजित करते हुए। एक खरगोश 1 का पुरस्कार प्रदान करता है और इसे एक अकेले एजेंट द्वारा पकड़ा जा सकता है। खेल 30 टाइमस्टेप के बाद समाप्त होता है। दो MSH सेटिंग्स का उपयोग किया गया था:
- MSH-4h1s: चार खरगोश और एक स्टैग की विशेषता है। यह सेटअप खरगोशों के लिए प्रतिस्पर्धा बनाए रखते हुए स्टैग के लिए सहयोग को प्रोत्साहित करता है, जिससे एक मिश्रित-प्रेरणा गतिशीलता बनती है।
- MSH-4h2s: चार खरगोश और दो स्टैग शामिल हैं। यह सहयोग की क्षमता को बढ़ाता है लेकिन एक मोड़ जोड़ता है: खेल पहले सफल शिकार के पांच टाइमस्टेप के बाद समाप्त हो जाता है, जिससे तत्काल व्यक्तिगत लाभ और दीर्घकालिक सामूहिक लाभ के बीच तनाव बढ़ जाता है।
MSG वातावरण 8x8 ग्रिड पर छह स्नोड्रिफ्ट को बेतरतीब ढंग से रखता है। एजेंट चल सकते हैं, निष्क्रिय रह सकते हैं, या "स्नोड्रिफ्ट हटा सकते हैं।" एक स्नोड्रिफ्ट को हटाने से हटाने वालों के बीच 4 की साझा लागत आती है, लेकिन प्रत्येक एजेंट को 6 का व्यक्तिगत पुरस्कार मिलता है। यहाँ मुख्य दुविधा फ्री-राइडिंग है: एक एजेंट दूसरों को स्नोड्रिफ्ट हटाने देने से उच्च पुरस्कार प्राप्त कर सकता है। खेल तब समाप्त होता है जब सभी स्नोड्रिफ्ट साफ हो जाते हैं या 50 टाइमस्टेप के बाद। MSH और MSG दोनों में, चार एजेंट प्रत्यक्ष संचार या एक-दूसरे के आंतरिक मापदंडों तक पहुंच के बिना काम करते हैं। शेलिंग आरेख यह पुष्टि करने के लिए नियोजित किए गए थे कि ये वातावरण प्रभावी ढंग से मिश्रित-प्रेरणा इंटरैक्शन की अंतर्निहित दुविधाओं को पकड़ते हैं, जहां इष्टतम रणनीतियाँ सह-खिलाड़ियों के व्यवहार के आधार पर बदलती हैं।
HOP का परीक्षण किए गए स्थापित बहु-एजेंट सुदृढीकरण सीखने (MARL) एल्गोरिदम और नियम-आधारित रणनीतियों के एक विविध सेट के खिलाफ "पीड़ित" (बेसलाइन) में शामिल हैं:
- सीखने वाले बेसलाइन: LOLA (लर्निंग विद ओपोनेंट-लर्निंग अवेयरनेस), SI (सोशल इन्फ्लुएंस), A3C (एसिंक्रोनस एडवांटेज एक्टर-क्रिटिक), PS-A3C (प्रोसोशल A3C), PR2, और डायरेक्ट-ओएम (HOP का एक एब्लेटेड संस्करण जो लक्ष्य कंडीशनिंग के बिना तंत्रिका नेटवर्क के साथ सह-खिलाड़ियों को सीधे मॉडल करता है)।
- नियम-आधारित बेसलाइन: रैंडम (वैध क्रियाएं बेतरतीब ढंग से लेता है), कोऑपरेटर (लगातार सहकारी व्यवहार अपनाता है), और डिफेक्टर (लगातार शोषणकारी व्यवहार अपनाता है)।
प्रयोगात्मक सत्यापन दो चरणों में आगे बढ़ा:
1. सेल्फ-प्ले: सभी एजेंटों ने एक ही एल्गोरिथम का उपयोग करके अपने प्रदर्शन के अभिसरण तक प्रशिक्षण लिया। इस चरण ने मिश्रित-प्रेरणा सेटिंग्स में स्वायत्त निर्णय लेने और सहयोग प्राप्त करने की एल्गोरिथम की क्षमता का आकलन किया।
2. कुछ-शॉट अनुकूलन: एक फोकल HOP एजेंट ने 2400 चरणों के लिए विभिन्न बेसलाइन एल्गोरिदम चलाने वाले तीन सह-खिलाड़ियों के साथ बातचीत की। अंतिम 600 चरणों के दौरान फोकल एजेंट के औसत पुरस्कार का उपयोग इसकी अनुकूलन क्षमता को मापने के लिए किया गया था। यदि एल्गोरिथम इसका समर्थन करता है तो इस चरण के दौरान नीति मापदंडों को अपडेट किया जा सकता है।
इष्टतम प्रदर्शन के लिए एक स्पष्ट संदर्भ प्रदान करने के लिए, प्रत्येक सह-खिलाड़ी प्रकार के लिए एक "ओरेकल एजेंट" को प्रशिक्षित किया गया था। यह ओरेकल एजेंट, एक विशिष्ट सह-खिलाड़ी के लिए पूरी तरह से अनुकूलित होने पर एक एजेंट प्राप्त कर सकने वाले सर्वोत्तम प्रदर्शन का प्रतिनिधित्व करता है, जो व्यापक इंटरैक्शन पर निश्चित सह-खिलाड़ी मापदंडों के साथ A3C के माध्यम से प्रशिक्षित किया गया था। सभी पुरस्कारों को ओरेकल एजेंट के प्रदर्शन (इष्टतम) और यादृच्छिक नीति के प्रदर्शन (सबसे कम) के बीच मिन-मैक्स सामान्यीकृत किया गया था, जिससे एक मानकीकृत तुलना संभव हो सके।
साक्ष्य क्या साबित करता है
प्रयोगात्मक परिणाम निश्चित रूप से मिश्रित-प्रेरणा वातावरण में सेल्फ-प्ले और कुछ-शॉट अनुकूलन दोनों में HOP की बेहतर क्षमताओं को प्रदर्शित करते हैं, जो इसके मुख्य गणितीय दावों को पदानुक्रमित विरोधी मॉडलिंग और योजना के संबंध में क्रूरता से साबित करते हैं।
सेल्फ-प्ले परिदृश्यों में, HOP ने लगातार उच्च पुरस्कार प्राप्त किए, अक्सर सर्वश्रेष्ठ बेसलाइन को पार करते हुए या उनसे मेल खाते हुए। MSH-4h1s में, HOP, डायरेक्ट-ओएम, और PS-A3C ने स्टैग का शिकार करना सीखा, लेकिन PS-A3C की "आलसी एजेंट" समस्या के कारण कम पुरस्कार मिले। LOLA ने अस्थिर रणनीतियों का प्रदर्शन किया, जबकि SI और A3C ने मुख्य रूप से खरगोशों का शिकार किया, जिससे कम रिटर्न मिला। PR2 MSH में पूरी तरह से विफल रहा। MSH-4h2s में, HOP और A3C सबसे स्थिर थे और उच्चतम रिटर्न देते थे, सफलतापूर्वक स्टैग शिकार के लिए समन्वय करते थे। सबसे उल्लेखनीय रूप से, MSG में, HOP ने उच्चतम पुरस्कार प्राप्त किया, जो सैद्धांतिक इष्टतम 30.0 के करीब पहुंच गया। यह एक विकेन्द्रीकृत सेटिंग में सहयोग के लिए HOP की मजबूत प्रवृत्ति को उजागर करता है, जो LOLA, A3C और SI जैसे बेसलाइन के विपरीत है, जिन्होंने व्यक्तिगत लाभ को प्राथमिकता दी और समन्वय के साथ संघर्ष किया। PS-A3C, दूसरा सबसे अच्छा होने के बावजूद, अभी भी केवल एक स्नोड्रिफ्ट शेष रहने पर समन्वय के मुद्दों का सामना कर रहा था।
HOP के मुख्य तंत्र के लिए सबसे सम्मोहक सबूत इसके कुछ-शॉट अनुकूलन प्रदर्शन (तालिका 1) में निहित है। HOP ने लगातार अधिकांश परीक्षण परिदृश्यों में "समग्र सर्वश्रेष्ठ अनुकूलन प्रतिशत" प्राप्त किया: MSH-4h1s में 83.3%, MSH-4h2s में एक पूर्ण 100.0%, और MSG में 83.3%। यह अन्य एल्गोरिदम से काफी बेहतर था, जिन्होंने केवल विशिष्ट, सीमित परिदृश्यों में इष्टतम अनुकूलन प्राप्त किया जहां सह-खिलाड़ी व्यवहार उनकी पूर्व-सीखी नीतियों के साथ संरेखित था।
पत्र वास्तविकता में HOP के विश्वास अद्यतन तंत्र के काम करने का एक स्पष्ट उदाहरण प्रदान करता है। MSH में तीन अवडेक्टर्स (जो लगातार खरगोशों का शिकार करते हैं) का सामना करते हुए, HOP ने शुरू में एक "झूठा विश्वास" रखा कि सह-खिलाड़ी स्टैग का शिकार करेंगे (इसके सेल्फ-प्ले अनुभव से एक पूर्वाग्रह)। हालांकि, इंट्रा-ओएम मॉड्यूल (एपिसोड के भीतर विश्वासों को अपडेट करना) ने इसे जल्दी से ठीक कर दिया। सह-खिलाड़ियों के प्रक्षेप्यों (जैसे, एक खरगोश की ओर बढ़ना) का अवलोकन करके, इंट्रा-ओएम ने उनके वास्तविक लक्ष्य का अनुमान लगाया, जिससे सटीक विरोधी मॉडल बने। इंटर-ओएम मॉड्यूल (एपिसोड के पार विश्वासों को अपडेट करना) ने इस अभिसरण को वास्तविक विश्वास तक और तेज कर दिया, जो बाद के एपिसोड के लिए एक सटीक पूर्व के रूप में कार्य करता है। लक्ष्य शिकार में पूर्व विश्वास में घटती रेखा (चित्र 5) निश्चित, निर्विवाद प्रमाण है कि HOP का पदानुक्रमित विश्वास अद्यतन तंत्र अनदेखे और गतिशील सह-खिलाड़ी व्यवहारों के लिए प्रभावी ढंग से अनुकूलित होता है। इन सटीक सह-खिलाड़ी नीतियों को इनपुट के रूप में उपयोग करते हुए, योजना मॉड्यूल तब फायदेमंद क्रियाओं की गणना कर सकता था, जिससे HOP को गैर-सहयोगी एजेंटों जैसे अवडेक्टर्स के खिलाफ भी महत्वपूर्ण रणनीतिक समायोजन करने और उच्च रिटर्न प्राप्त करने की अनुमति मिलती थी।
इसके अलावा, प्रयोगों ने कई HOP एजेंटों के बीच सामाजिक बुद्धिमत्ता के उद्भव को प्रकट किया। एक उदाहरण में, "स्व-संगठित सहयोग" उभरा जहां चार HOP एजेंटों ने व्यक्तिगत रूप से खरगोशों का शिकार करने की तुलना में अधिक कुल पुरस्कार के लिए सामूहिक रूप से एक स्टैग का शिकार किया, भले ही यह व्यक्तिगत रूप से अधिक जोखिम भरा था। यह स्वतंत्र निर्णय लेने के माध्यम से हुआ, जिसमें एजेंटों ने एक-दूसरे के इरादों का अनुमान लगाया और केंद्रीय नियंत्रण के बिना समन्वय किया। एक अन्य मामले में, "वंचितों का गठबंधन," दो कम लालची HOP एजेंटों ने एक लालची सह-खिलाड़ी को सहयोग से बचने के लिए सफलतापूर्वक धोखा दिया, फिर अपने स्वयं के लाभ को अधिकतम करने के लिए सहयोग किया। ये अवलोकन इस बात पर जोर देते हैं कि दूसरों के लक्ष्यों का अनुमान लगाने और अपनी प्रतिक्रियाओं को तेजी से समायोजित करने की HOP की क्षमता जटिल सामाजिक व्यवहारों को सक्षम बनाती है, भले ही एजेंट स्वार्थी हों।
सीमाएं और भविष्य की दिशाएं
जबकि HOP मिश्रित-प्रेरणा वातावरण में कुछ-शॉट अनुकूलन में उल्लेखनीय क्षमता प्रदर्शित करता है, लेखक ईमानदारी से कई सीमाओं को स्वीकार करते हैं जो रोमांचक भविष्य के शोध के लिए मार्ग प्रशस्त करती हैं।
सबसे पहले, एक महत्वपूर्ण बाधा किसी भी दिए गए वातावरण में HOP को प्रभावी ढंग से कार्य करने के लिए लक्ष्यों के स्पष्ट परिभाषा की आवश्यकता है। वर्तमान ढांचा पूर्वनिर्धारित लक्ष्य सेट पर निर्भर करता है। HOP की सामान्यीकरण क्षमता और जटिल परिदृश्यों की एक विस्तृत श्रृंखला में प्रयोज्यता को बढ़ाने के लिए, एक महत्वपूर्ण भविष्य की दिशा में ऐसी तकनीकों का विकास शामिल है जो स्वायत्त रूप से लक्ष्य सेट को अमूर्त कर सकें। यह HOP को मैन्युअल हस्तक्षेप के बिना उपन्यास वातावरण में संचालित करने की अनुमति देगा, एक चुनौती जिसे कुछ पिछले काम ने पहले ही तलाशना शुरू कर दिया है।
दूसरे, HOP का वर्तमान कार्यान्वयन स्तर-0 थ्योरी ऑफ माइंड (ToM) का उपयोग करता है, जो अनिवार्य रूप से एक एजेंट के बारे में तर्क करने के बारे में है "वे क्या सोचते हैं।" जबकि प्रभावी, उच्च-क्रम ToM को शामिल करना, जैसे स्तर-1 ToM ("मैं सोचता हूं कि वे मेरे बारे में क्या सोचते हैं"), सह-खिलाड़ियों के व्यवहार की भविष्यवाणियों में काफी सुधार करने की क्षमता रखता है। हालांकि, नेस्टेड बिलीफ अनुमान के कारण इसमें कम्प्यूटेशनल लागत में काफी वृद्धि होती है। इसलिए, भविष्य के काम को उन्नत और कम्प्यूटेशनल रूप से कुशल योजना विधियों को विकसित करने पर ध्यान केंद्रित करना चाहिए जो निषेधात्मक कम्प्यूटेशनल जटिलता के शिकार हुए बिना उच्च-क्रम ToM द्वारा प्रदान की गई समृद्ध अंतर्दृष्टि का प्रभावी ढंग से और तेजी से लाभ उठा सकें। यह एक गैर-तुच्छ इंजीनियरिंग और गणितीय बाधा है।
तीसरे, हालांकि पत्र ने मूल्यांकन के लिए सह-खिलाड़ियों के रूप में अच्छी तरह से स्थापित एल्गोरिदम का एक विविध सेट चुना है, उनमें से कोई भी मानव व्यवहार की बारीकियों और जटिलताओं को पूरी तरह से कैप्चर नहीं करता है। कई बहु-एजेंट प्रणालियों का अंतिम लक्ष्य मानव प्रतिभागियों के साथ सहज रूप से बातचीत करना है। परिणामस्वरूप, एक सम्मोहक भविष्य अनुसंधान मार्ग वास्तविक मानव प्रतिभागियों को शामिल करने वाले कुछ-शॉट अनुकूलन परिदृश्यों में HOP के प्रदर्शन की खोज करना है। यह इसकी वास्तविक दुनिया प्रयोज्यता और मजबूती में अमूल्य अंतर्दृष्टि प्रदान करेगा।
अंत में, एक महत्वपूर्ण चर्चा बिंदु HOP की अंतर्निहित स्वार्थी प्रकृति से उत्पन्न होता है। जबकि यह अपने स्वयं के पुरस्कारों को अधिकतम करने में उत्कृष्ट है, यह हमेशा मानव सह-खिलाड़ियों के सर्वोत्तम हितों या मूल्यों के साथ संरेखण की गारंटी नहीं देता है। इस संभावित गलत संरेखण को कम करने और अधिक फायदेमंद मानव-एआई सहयोग को बढ़ावा देने के लिए, भविष्य के शोध को HOP की शक्तिशाली अनुमान क्षमताओं का उपयोग मानव मूल्यों और प्राथमिकताओं को अनुमानित करने और अनुकूलित करने के लिए कैसे किया जा सकता है, इसकी खोज करनी चाहिए। इसमें मूल्य संरेखण या प्राथमिकता सीखने के लिए तंत्र शामिल हो सकते हैं, जिससे HOP मनुष्यों को जटिल वातावरणों में न केवल कुशल बल्कि नैतिक रूप से ध्वनि और सामाजिक रूप से फायदेमंद तरीके से सहायता कर सके। इसके लिए मानव-एआई इंटरैक्शन नैतिकता और मजबूत प्राथमिकता निष्कर्षण तकनीकों में गहन जांच की आवश्यकता होगी।
 Table 5. Performance of HOP and its ablation versions in MSH-4h2s. In (a) self-play, 4 agents of the same kind are trained to converge. Shown is the normalized score after convergence. In (b) few-shot adaptation, the interaction happens between 1 agent using the row policy and 3 co-players using the column policy. Shown are the min-max normalized scores, with normalization bounds set by the rewards of Orcale and the random policy. The results are depicted for the row policy from 1800 to 2400 step
Table 5. Performance of HOP and its ablation versions in MSH-4h2s. In (a) self-play, 4 agents of the same kind are trained to converge. Shown is the normalized score after convergence. In (b) few-shot adaptation, the interaction happens between 1 agent using the row policy and 3 co-players using the column policy. Shown are the min-max normalized scores, with normalization bounds set by the rewards of Orcale and the random policy. The results are depicted for the row policy from 1800 to 2400 step
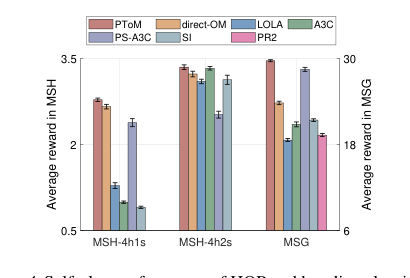 Figure 4. Self-play performance of HOP and baseline algorithms. Shown is the average reward in the self-play training phase
Figure 4. Self-play performance of HOP and baseline algorithms. Shown is the average reward in the self-play training phase