混合動機環境における階層的敵対者モデリングとプランニングによる効率的な適応
Despite the recent successes of multi-agent reinforcement learning (MARL) algorithms, efficiently adapting to co-players in mixed-motive environments remains a significant challenge.
背景と学術的系譜
起源と学術的系譜
本論文で取り組む「混合動機環境における階層的敵対者モデリングとプランニングによる効率的な適応」という問題は、人工知能における長年の課題、すなわち、エージェントがこれまで遭遇したことのない協力者(co-players)に迅速に適応できるようにすることに端を発する。この能力は「少数ショット適応(few-shot adaptation)」と呼ばれる。歴史的に、マルチエージェント強化学習(MARL)の研究は、定義済みの関係性を持つ環境、特にゼロサムゲーム(エージェントが純粋に競争的である場合、例:Vinyals et al., 2019)や共通利益環境(エージェントが純粋に協力的である場合、例:Barrett et al., 2011)において大きな進歩を遂げてきた。
しかしながら、この特定の問題の正確な起源は、ほとんどの現実的なマルチエージェント意思決定シナリオが、純粋に競争的または協力的ではないという認識にある。むしろ、それらは「混合動機環境(mixed-motive environments)」(Komorita & Parks, 1995; Dafoe et al., 2020)であり、エージェント間の非決定的な関係性と、エージェントの最善応答が他者の行動に基づいて変化しうる状況を特徴とする。この複雑さは、単純な環境よりも意思決定と少数ショット適応を著しく困難にする。
本研究が必要とされる以前のアプローチの根本的な限界または「ペインポイント」は、いくつかの問題に起因する。
1. 特殊技術の適用不可能性: 少数ショット適応のための多くの既存MARLアルゴリズムは、ゼロサムゲームや純粋協力的ゲームにおいては効率的であるが、混合動機環境に見られる一般的な総和報酬構造には適さない技術(ミニマックス、ダブルオラクル、IGM条件など)に依存している。
2. 計算的複雑性: 相互的な信念推論(すなわち、エージェントが自身の信念について他方のエージェントがどう考えているかを推論すること)を含むI-POMDP(Gmytrasiewicz & Doshi, 2005)のような手法は、深刻な計算的複雑性に悩まされる。これは、複雑な環境においては実用的ではない。
3. 情報要件とスケーラビリティの問題: LOLA(Foerster et al., 2018)のようなアルゴリズムは、しばしば協力者の内部ネットワークパラメータの知識を必要とするが、これは現実世界のシナリオではしばしば利用できない。敵対者モデリングで緩和されたとしても、長い行動系列を必要とする複雑な逐次環境ではスケーラビリティの問題が生じうる。
4. マルチエージェント設定におけるMCTSの限界: モンテカルロ木探索(MCTS)は強力なプランニング手法であるが、マルチエージェント環境への適用は、エージェント数が増加するにつれて共同行動空間が指数関数的に増大し、スケーラビリティの問題を引き起こすため限定的である(Choudhury et al., 2022)。以前のMCTSベースの手法は、しばしば協力者のポリシーを効率的に推定するのに苦労する。
したがって、著者らは、計算コストが高すぎる、利用不可能な情報を必要とする、あるいは単純な相互作用ダイナミクス向けに設計された、以前の手法の限界を克服し、混合動機環境において未知のポリシーに効率的に適応できるアプローチを開発することを余儀なくされた。新しい解決策へのインスピレーションは、認知心理学から得られた。認知心理学は、人間が高レベルの目標推論と低レベルの行動プランニングを統合する階層的な認知メカニズムを使用して、未知の問題を迅速に解決することを示唆している(Butz & Kutter, 2016; Eppe et al., 2022)。
直感的なドメイン用語
- 混合動機環境(Mixed-Motive Environments): 皆が料理を持ち寄るポットラックパーティーを想像してほしい。料理で皆を感心させたい人(協力的)、できるだけたくさん食べたい人(利己的)、そして簡単な料理を持ち寄るが、自分がそれほど料理しなくて済むように他の人が素晴らしいものを持ってくることを密かに願っている人(混合)がいるかもしれない。各人の「動機」は固定されておらず、協力と競争の混合であり、最善の戦略は他者が何をすると思うかに依存する。
- 少数ショット適応(Few-Shot Adaptation): 新しい従業員がチームに加わることを考えてほしい。各チームメンバーの働き方を理解するのに数ヶ月のトレーニングを必要とする代わりに、数回の会議やプロジェクトの後、彼らは個々の癖や好みを素早く把握する。彼らは限られた「ショット」(限定的な観測)の後、自身の作業スタイルをチームに合わせて「適応」させる。
- 敵対者モデリング(Opponent Modeling): これは、容疑者の意図を理解しようとする探偵のようなものである。探偵は容疑者の行動を観察し、発言を聞き、この情報を使用して容疑者の目標と計画が何であるかの精神的な像を構築する。探偵は次に、この敵対者の「モデル」を使用して、次の手を予測し、自身の戦略を計画する。
- モンテカルロ木探索(Monte Carlo Tree Search, MCTS): 囲碁のような複雑なボードゲームをプレイすることを想像してほしい。ゲームの終わりまであらゆる可能な手を計算するのではなく(それは不可能である)、現在の位置から多くのランダムなゲームを素早く「想像」してプレイする。各想像されたゲームについて、有望に見えるパスにより焦点を当てながら、異なる手を探索する。多くのそのような迅速なシミュレーションの後、精神的な実験で最良の平均結果につながった実際の手を選択する。これは、網羅的な計算なしに良い決定を達成するのに役立つ。
- 心の理論(Theory of Mind, ToM): これは、誰かが何を考えているか、または感じているかを推測する能力である。例えば、誰かが微笑んでいるのを見た場合、その人が幸せであると推測する。AIの文脈では、エージェントが、人間が行うように、行動を観察することによって、他のエージェントの「精神状態」(目標、信念、意図など)を理解しようとすることを意味する。
記法表
| 記法 | 説明 |
|---|---|
| $N$ | エージェントの集合、$N = \{1, 2, \dots, n\}$ |
| $S$ | 状態空間 |
| $A_i$ | エージェント $i$ の行動空間 |
| $A$ | 共同行動空間、$A = A_1 \times A_2 \times \dots \times A_n$ |
| $a_{1:n}$ | 全エージェントによって取られる共同行動 |
| $T(s'|s, a_{1:n})$ | 遷移関数:共同行動 $a_{1:n}$ が与えられた場合に状態 $s$ から $s'$ へ遷移する確率 |
| $R_i$ | エージェント $i$ の報酬関数、$R_i: S \times A \to \mathbb{R}$ |
| $\gamma$ | 将来の報酬に対する割引率 |
| $T_{max}$ | エピソードの最大長 |
| $\pi_i(a_i|s)$ | エージェント $i$ のポリシー:状態 $s$ で行動 $a_i$ を選択する確率 |
| $G$ | 全エージェントの目標の集合、$G = G_1 \times G_2 \times \dots \times G_n$ |
| $G_i$ | エージェント $i$ の目標の集合、$G_i = \{g_{i,1}, \dots, g_{i,|G_i|}\}$ |
| $g_{i,k}$ | エージェント $i$ の特定の目標、これは状態の集合である |
| $b_{i,j}(g_j)$ | エージェント $i$ のエージェント $j$ の目標に対する信念、$G_j$ 上の確率分布 |
| $K$ | エピソードインデックス |
| $t$ | エピソード内のタイムステップ |
| $b_{i,j}^{K,t}(g_j)$ | エピソード $K$ のタイムステップ $t$ におけるエージェント $i$ のエージェント $j$ の目標に対する信念 |
| $\pi_{\omega}(a_j|s^{K,t}, g_j)$ | 協力者 $j$ の目標条件付きポリシー:状態 $s^{K,t}$ において目標 $g_j$ が与えられた場合のポリシー、パラメータ $\omega$ でパラメータ化される |
| $Q_{avg}(s^{K,t}, a)$ | 状態 $s^{K,t}$ における行動 $a$ の平均推定行動価値 |
| $\pi_{MCTS}(a|s^{K,t})$ | 状態 $s^{K,t}$ におけるMCTSによって生成されるポリシー |
| $\beta$ | ボルツマン合理性モデルの合理性係数 |
| $N_s$ | MCTSラウンド数 |
| $N_l$ | 各MCTSラウンドの探索イテレーション数 |
| $c$ | MCTSの探索係数 |
| $\theta$ | MCTSのポリシーおよび価値ネットワークのパラメータ |
| $\omega$ | 目標条件付きポリシーネットワークのパラメータ |
問題定義と制約
コア問題定式化とジレンマ
本論文で取り組む中心的な課題は、混合動機マルチエージェント環境における未知の協力者への効率的な少数ショット適応である。これは人工知能における重要な問題である。なぜなら、ほとんどの現実世界の相互作用は、純粋に競争的(ゼロサム)または純粋に協力的(共通利益)なダイナミクスではなく、協力と競争の混合を伴うからである。
出発点(入力/現在の状態):
ゼロサムゲームや共通利益ゲームでの成功にもかかわらず、現在のマルチエージェント強化学習(MARL)アルゴリズムは、混合動機設定ではほとんどの場合苦戦している。これらの環境は、エージェント間の非決定的な関係性と一般的な総和報酬構造を特徴とし、意思決定を本質的に複雑にしている。敵対者モデリングに対する以前のアプローチは、しばしば2つの大きな障害に直面する。
1. 非効率的な推論: I-POMDPとその近似のような既存の手法は、相互的な信念推論による「深刻な計算的複雑性の問題」に悩まされており、複雑な環境では実用的ではない。
2. 推論された情報の非効率的な利用: LOLAのようなアルゴリズムは、敵対者の学習を考慮するが、しばしば協力者の内部ネットワークパラメータの知識を必要とする。これは現実的なシナリオではしばしば利用できない。さらに、多くの既存アルゴリズムは、手作業で設計された内在的報酬に依存するか、協力者のプライベート報酬へのアクセスを仮定しており、自己利益的なエージェントによる搾取に脆弱であったり、そのような情報が隠されている場合には効果が低下したりする。モンテカルロ木探索(MCTS)は強力なプランニングツールであるが、エージェント数が増加するにつれて共同行動空間が急速に拡大するマルチエージェント設定では限界がある。
望ましい終点(出力/目標状態):
本論文は、焦点エージェントが混合動機環境において「未知のポリシーへの少数ショット適応」を達成できるようにするアルゴリズムを開発することを目的としている。これは、エージェントが以下を実行できることを意味する。
1. 迅速な適応: 限定されたエピソード数で、新しい、これまで遭遇したことのない協力者を迅速に認識し、適切に対応する。
2. 効率的な推論と情報利用: 協力者の目標を推論し、目標条件付きポリシーを効率的に学習し、この推論された情報を利用して、法外な計算コストを発生させることなく最適な応答を計算する。
3. 堅牢な実行: 協力者の目標がプライベートで潜在的に変動しやすい場合でも、混合動機シナリオで高い報酬をもたらす自律的な決定を下す。
正確な欠落リンクまたは数学的ギャップ:
本論文が橋渡ししようとしている正確なギャップは、混合動機環境における不確実性下での「階層的敵対者モデリングとプランニングのためのスケーラブルで効率的なフレームワーク」の欠如である。具体的には、以下の方法に対処する。
* 直接的な内部パラメータや手作業で設計された報酬へのアクセスに依存するのではなく、観測された行動から協力者の潜在的な目標と目標条件付きポリシーを正確に推論する。
* この推論された敵対者モデルを、以前の手法の「相互的な信念推論」の問題を回避し、計算上実行可能な方法でプランニングメカニズム(MCTS)に統合する。
* プランニング中に協力者の目標に関する固有の不確実性を、重大なバイアスを導入したりパフォーマンスを低下させたりすることなく処理する。本論文は、エピソードの内外で信念を更新するための「intra-OM」および「inter-OM」モジュールを備えた階層構造を提案し、次にこれらの信念を使用して、最良の応答を計算するために複数の目標の組み合わせをサンプリングするMCTSプランナーを導く。
苦痛なトレードオフまたはジレンマ:
以前の研究者を閉じ込めてきた中心的なジレンマは、「敵対者モデリングの精度と一般化可能性」と「計算効率とスケーラビリティ」の間のトレードオフである。
* 精度 vs. 効率: 多様な協力者の非常に正確なモデルを達成すること、特に目標がプライベートで動的である複雑な混合動機設定では、通常、広範な計算(例:I-POMDPにおける相互的な信念推論)または敵対者の内部に関する詳細な知識(例:LOLA)を必要とする。これにより、このような手法はリアルタイムまたは複雑な逐次環境での迅速な少数ショット適応には遅すぎたりリソースを大量に消費したりすることが多い。
* 一般化可能性 vs. 特殊性: 特定のゲームタイプ(ゼロサムまたは純粋協力的)向けに設計されたアルゴリズムは、しばしば混合動機相互作用の非決定的、一般的な総和の性質に一般化しない報酬構造固有の技術(例:ミニマックス)を利用する。パフォーマンスを損なうことなく、混合動機のスペクトル全体で機能するメソッドを開発することは大きな課題である。本論文は、「実用的で効果的なフレームワーク」を目指しており、競争と協力の両方を処理できる。
制約と失敗モード
混合動機環境における効率的な少数ショット適応の問題は、いくつかの厳しい現実的な制約により、「信じられないほど困難」である。
物理的/環境的制約:
* 混合動機ダイナミクス: 根本的な制約は環境自体である。エージェント間の関係は「非決定的」であり、報酬構造は「一般的な総和」である。これは、エージェントの利益が完全に一致も完全に反対もしていないことを意味する。これにより、最適な応答の予測は高度に文脈依存的かつ動的になる。
* 未知の協力者とポリシー: 「未知のエージェントへの少数ショット適応」という要件は、アルゴリズムが特定の敵対者タイプでの事前トレーニングに依存できないことを意味する。エージェントは、その場で新しい行動に適応する必要がある。
* 限定的な相互作用履歴: 「少数ショット適応」は、エージェントが新しい協力者について学習するための「限られたエピソード数」しか持たないことを意味する。これは、敵対者モデリングと適応のための利用可能なデータの量を著しく制限する。
* プライベートな目標とコミュニケーションなし: エージェントは「互いのパラメータへのアクセスがなく、コミュニケーションは許可されない」。さらに、協力者の目標は「プライベートで変動しやすい」ため、エピソード内で変化する可能性がある。直接的な情報の欠如は、観測された行動のみから意図を推論することを必要とする。
計算的制約:
* 敵対者モデリングの計算的複雑性: I-POMDPのような以前の手法は、「相互的な信念推論」による「深刻な計算的複雑性の問題」に悩まされており、複雑な環境では実用的ではない。課題は、計算の指数関数的な増加なしに、正確に敵対者をモデリングすることである。
* エージェント数によるスケーリング: マルチエージェント環境では、「共同行動空間はエージェント数とともに急速に拡大する」。これにより、従来のMCTSを使用したプランニングは、多くの場合、計算上実行不可能になる。本論文は、協力者の推定ポリシーを考慮して、焦点エージェントの行動のみを計画することにより、これを明示的に対処する。
* リアルタイム遅延要件(暗黙的): 「迅速な適応」と「効率的な推論」の必要性は、特に長い行動系列を伴う可能性のある逐次意思決定シナリオにおいて、意思決定が実用的な時間制限内で行われなければならないことを意味する。
データ駆動型制約:
* 信念更新のためのデータ疎性: 「過去の軌跡が更新には長すぎない」場合、エピソード内の敵対者モデリング(intra-OM)は「先行情報の不正確さ」に苦しむ可能性がある。これは、最小限のデータから協力者の目標に関する正確な信念を形成することの難しさを示している。
* 協力者モデルの不確実性: 敵対者モデリングがあっても、推定された協力者のポリシーは「協力者の目標に関する不確実性を含む」。この不確実性は、プランニング段階で効果的に管理されなければならない。「シミュレーションに大きなバイアスを導入し、プランニングパフォーマンスを低下させる」ことを避けるため。この不確実性を単純に組み込むと、最適ではない行動につながる可能性がある。
なぜこのアプローチなのか
選択の必然性
階層的敵対者モデリングとプランニング(HOP)の採用は、単なる設計上の選択ではなく、混合動機環境が課す固有の課題の結果として必然的なものであった。ミニマックス、ダブルオラクル、またはIGM条件に依存する従来の最先端(SOTA)マルチエージェント強化学習(MARL)アルゴリズムは、根本的に不十分であることが判明した。これらの手法は、ゼロサムまたは純粋協力的ゲームの特定の報酬構造に合わせて調整されており、エージェント間の関係が非決定的で報酬が一般的な総和である「混合動機環境には適用できない」。著者らは明確に、「エージェント間の非決定的な関係性と一般的な総和報酬構造は、ゼロサムおよび純粋協力的環境と比較して、混合動機環境における意思決定と少数ショット適応をより困難にする」と述べている。
既存の手法が不十分であるという認識は、著者らを認知心理学からインスピレーションを求めるように駆り立てた。彼らは、人間がこれまで遭遇したことのない問題を迅速に解決する能力が、高レベルの目標推論と低レベルの行動プランニングをシームレスに統合する「階層的な認知メカニズム」に依存していることを特定した。この洞察は、著者らが根本的に異なる、階層的に構造化されたアプローチの必要性を認識したまさにその瞬間であった。HOPは、協力者の目標を推論し、目標条件付きポリシーを学習するための敵対者モデリングモジュールと、モンテカルロ木探索(MCTS)を使用して最良の応答を決定するプランニングモジュールを提案することにより、この認知アーキテクチャを直接模倣している。この階層的な分解は、複雑な混合動機設定における効率的な推論と推論された情報の効果的な利用という二重の課題に対処するための唯一実行可能な道であった。
比較優位性
HOPは、単純なパフォーマンス指標を超えたいくつかの構造的利点を通じて、以前のゴールドスタンダードに対して質的な優位性を示している。
- 階層的分解: フラットなMARLアプローチとは異なり、HOPの2つのモジュール構造(敵対者モデリングとプランニング)は、協力者の行動のより洗練された解釈可能な理解を可能にする。敵対者モデリングモジュールは高レベルの目標を推論し、目標条件付きポリシーを学習し、エンドツーエンドモデルよりも豊かな表現を提供する。これは人間の認知プロセスを模倣し、より堅牢な適応を可能にする。
- 効率的な信念更新メカニズム: HOPは、エピソードの内外で協力者の目標に関する信念を更新することにより、効率を大幅に向上させる。intra-opponent modeling(intra-OM)モジュールは、単一エピソード内での協力者の即時目標への迅速な調整を可能にし、動的な環境に不可欠である。inter-opponent modeling(inter-OM)モジュールは、過去のエピソードを活用して正確な先行信念を確立し、収束を加速させる。この二重層更新メカニズムは、エピソード内でのみ信念を更新する、あるいは堅牢な履歴コンテキストを持たない手法よりも構造的な利点を提供し、短い相互作用中の不正確な敵対者モデリングにつながることが多い。
- 相互的な信念推論の複雑性の回避: I-POMDPのような以前の敵対者モデリングとプランニングのフレームワークは、「相互的な信念推論」(例:エージェントが他方のエージェントが自分についてどう考えているかを考えていると推論すること)による「深刻な計算的複雑性の問題」に悩まされる。HOPは、協力者の目標とポリシーに関する信念を明示的に使用してニューラルネットワークモデルを学習することにより、これを回避し、計算上のボトルネックなしに「逐次意思決定をより効率的に実行」することを可能にする。
- スケーラブルなMCTS統合: MCTSは強力であるが、マルチエージェント環境への直接的な適用は、共同行動空間の急速な拡大によって制限される。HOPは、「協力者のポリシーを推定し、焦点エージェントの行動のみを計画する」ことによってこれを克服する。この戦略的な分離により、MCTSは、すべてのエージェントの共同行動に対するプランニングに関連する計算爆発を回避して、効果的かつスケーラブルに適用できる。
- プランニングにおける不確実性の低減: 敵対者モデリングモジュールは、プランニングモジュールに目標条件付きポリシーを提供する。この推論された情報はMCTSを導き、プランニングのための環境モデルに協力者の目標に関する不確実性を単純に組み込むことによって生じる「大きなバイアス」と「低下したプランニングパフォーマンス」を防ぐ。この構造的な統合により、不確実性下でもプランニングが正確かつ正確であることが保証される。
制約への整合性
HOPの設計は、混合動機環境における少数ショット適応の厳しい要件に完全に整合している。
- 未知のポリシーへの少数ショット適応: HOPの核心目標は少数ショット適応である。階層構造、特に効率的なintra-OMおよびinter-OM信念更新メカニズムは、このために特別に設計されている。Intra-OMは、エピソード内の行動変化への迅速な対応を可能にし、inter-OMは過去のエピソードからの正確な先行情報を提供し、限られた数の相互作用内で新しい協力者戦略への迅速な適応を可能にする。この問題の必要性とソリューションの動的な信念更新との「結婚」は基本的である。
- 混合動機環境: HOPは、関係が非決定的で報酬が一般的な総和である混合動機シナリオのために特別に構築されている。協力者の目標(競争的、協力的、または混合的である可能性がある)を推論し、協力者の目標がプライベートで変動しやすい場合でも、焦点エージェントの最良の応答を計画する能力は、これらの環境の中心的な課題に直接対処する。
- 協力者のパラメータまたは報酬へのアクセスなし: 現実的なマルチエージェント設定における重要な制約は、他のエージェントの内部パラメータまたは報酬関数への直接的なアクセスがないことである。HOPの敵対者モデリングモジュールは、単に「行動系列」を観測することによってのみ、協力者の目標を推論し、目標条件付きポリシーを学習する。この推論ベースのアプローチは、明示的な協力者の内部知識の必要性を回避し、現実世界のブラックボックスシナリオでの適用を可能にする。
- コミュニケーションなし: 問題定義は、エージェント間の明示的なコミュニケーションの欠如を示唆している。HOPの目標推論とポリシー学習は、直接的なコミュニケーションに依存することなく、観測された軌跡と行動に完全に基盤を置いており、この暗黙の制約を遵守している。
代替案の却下
本論文は、いくつかの人気のあるアプローチを却下する明確な理由を提供している。
- 従来のMARLアルゴリズム(例:ミニマックス、ダブルオラクル、IGM条件): これらの手法は、「混合動機環境には適用できない」ため、明示的に却下される。それらの根本的な仮定と技術は、ゼロサムまたは純粋協力的報酬構造に最適化されており、混合動機ゲームの特徴である非決定的関係性と一般的な総和報酬を捉えられない。
- LOLA(学習する敵対者学習認識): 高度なMARLアルゴリズムであるが、LOLAは「多くのシナリオで実現可能ではない協力者のネットワークパラメータの知識を必要とする」ため、一般的な混合動機環境には不適切と見なされる。HOPの推論ベースの敵対者モデリングは、この制限的な要件を回避する。さらに、LOLAは「長い行動系列を必要とする複雑な逐次環境ではスケーラビリティの問題」に苦しむ可能性があり、これはHOPがそのガイド付きMCTSプランニングによって対処する限界である。
- I-POMDP(相互部分観測マルコフ決定過程): このフレームワークは、敵対者モデリングに関連するが、「相互的な信念推論」に起因する「深刻な計算的複雑性の問題」のため却下される。計算上の負担は、複雑な環境では実用的ではない。HOPの設計は、より高い効率を達成するために、この相互推論を特別に回避する。
- マルチエージェント環境における単純なMCTS: 本論文は、MCTS自体が「エージェント数とともに共同行動空間が急速に拡大するマルチエージェント環境では限定的である」ことを認めている。直接的な適用は計算上実行不可能であろう。HOPの解決策は、協力者のポリシーを推定し、焦点エージェントの行動のみを計画することであり、このスケーラビリティの問題を効果的に回避する。
- HOPの非機能化バージョン(inter-OMなし、intra-OMなし、直接OM): 非機能化研究は、単純または不完全なHOPバージョンの却下に対する経験的証拠を提供する。
- inter-OMなし: このバージョンは、エピソード開始時に正確な目標先行情報がないため、固定目標を持つエージェント(例:協力者、離反者)に対して苦戦する。これは、最適なプレイの早期機会を逃すことになる。これは、過去のエピソードを活用することの必要性を強調している。
- intra-OMなし: このバージョンは、エピソード内の目標のリアルタイム更新に依存する過去のエピソードのみに依存するため、動的な行動を持つエージェント(例:LOLA、PS-A3C、ランダム)に対してパフォーマンスが低下する。これは、エピソード内のリアルタイム信念更新の重要性を強調している。
- 直接OM: 階層的敵対者モデリングモジュールを削除し、目標条件付けなしでニューラルネットワークを使用して協力者を直接モデリングするこのアプローチは、「全体的に不利」である。短い相互作用中に有意な更新を取得するのに苦労し、「適応段階中の不正確な敵対者モデリング」につながる。エンドツーエンドの性質は、「目標条件付きポリシーと比較して、より高いレベルの不確実性」も導入し、プランニングの精度を低下させる。これは、HOPの目標条件付き階層的敵対者モデリングの優位性を明確に検証している。
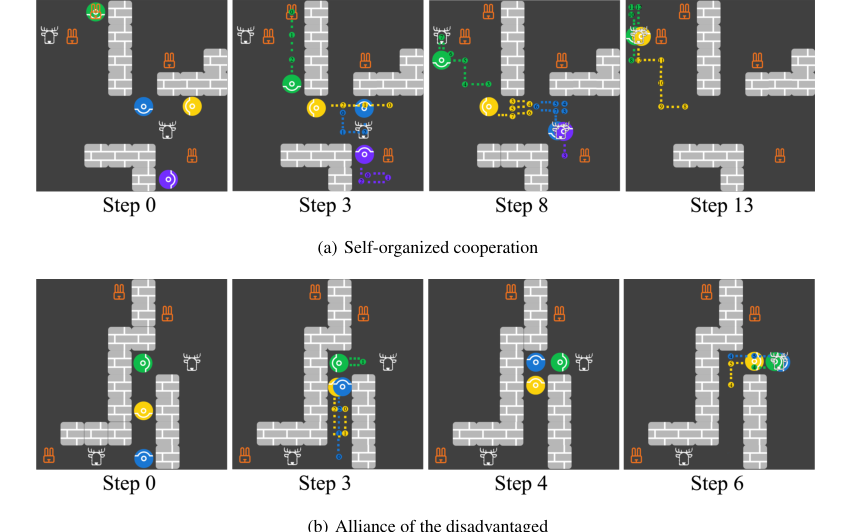 Figure 6. Screenshots for the emergence of (a) self-organized cooperation and (b) alliance of the disadvantaged. Each panel shows agents’ locations at the current step and the trajectories between the current step and the previously stated step
Figure 6. Screenshots for the emergence of (a) self-organized cooperation and (b) alliance of the disadvantaged. Each panel shows agents’ locations at the current step and the trajectories between the current step and the previously stated step
数学的・論理的メカニズム
マスター方程式
階層的敵対者モデリングとプランニング(HOP)アルゴリズムは、その適応能力を可能にするいくつかの相互接続された数学的メカニズムによって駆動されている。その核心において、HOPは敵対者目標モデリングのためのベイズ推論、目標条件付き敵対者ポリシーの学習のための負の対数尤度目的、およびモンテカルロ木探索(MCTS)によって導かれる焦点エージェントの意思決定ネットワークのトレーニングのためのポリシーと価値の損失の組み合わせに依存している。
HOPの数学的エンジンを定義する絶対的なコア方程式は以下の通りである。
-
エピソード内敵対者目標信念更新(Intra-OM): この方程式は、リアルタイム観測を組み込んで、単一エピソード内での協力者の目標に対する焦点エージェントの信念を更新する。
$$b_{ij}^{K,t+1}(g_j) = \frac{1}{Z_1} b_{ij}^{K,t}(g_j) \frac{\Pr(a_j^{K,t}|s^{K,t}, g_j) \Pr(s^{K,t+1}|s^{K,t}, a_j^{K,t}, g_j)}{\Pr(s^{K,t+1}|s^{K,t}, a_j^{K,t})}$$ -
エピソード間敵対者目標信念更新(Inter-OM): この方程式は、過去のエピソードからの情報を活用して、新しいエピソードの開始時に協力者の目標に対する先行信念を更新する。
$$b_{ij}^{K,0}(g_j) = \frac{1}{Z_2} [\alpha b_{ij}^{K-1,0}(g_j) + (1-\alpha)\mathbf{1}(g_j = g_j^{K-1})]$$ -
目標条件付き敵対者ポリシーネットワーク損失: この目的関数は、現在の状態と推論された目標が与えられた協力者の行動を予測するニューラルネットワークをトレーニングする。
$$\mathcal{L}(\omega) = \mathbb{E}[-\log(\pi_\omega(a_j^{K,t}|s^{K,t}, g_j^{K,t}))]$$ -
焦点エージェントのポリシーおよび価値ネットワーク損失: この組み合わせ損失関数は、MCTSを教師として使用して、焦点エージェントの主要なポリシーと価値ネットワークをトレーニングする。
$$\mathcal{L}(\theta) = \mathcal{L}_p(\pi_{\text{MCTS}}, \pi_\theta) + \mathcal{L}_v(r_i, v_\theta)$$
ここで
$$\mathcal{L}_p(\pi_1, \pi_2) = \mathbb{E}[-\sum_{a \in \mathcal{A}_i} \pi_1(a|s^{K,t}) \log(\pi_2(a|s^{K,t}))]$$
$$\mathcal{L}_v(r_i, v) = \mathbb{E}[(v(s^{K,t}) - \sum_{l=t}^{T_{\text{max}}} \gamma^{l-t} r_i^{K,l})^2]$$
用語ごとの詳細分析
これらの各方程式の役割を理解するために、各コンポーネントを分解してみよう。
エピソード内敵対者目標信念更新(方程式1)
$$b_{ij}^{K,t+1}(g_j) = \frac{1}{Z_1} b_{ij}^{K,t}(g_j) \frac{\Pr(a_j^{K,t}|s^{K,t}, g_j) \Pr(s^{K,t+1}|s^{K,t}, a_j^{K,t}, g_j)}{\Pr(s^{K,t+1}|s^{K,t}, a_j^{K,t})}$$
- $b_{ij}^{K,t+1}(g_j)$:
- 数学的定義: エピソード $K$ のタイムステップ $t+1$ における、エージェント $i$ の協力者 $j$ の目標 $g_j$ に対する信念を表す事後確率分布。
- 物理的/論理的役割: これは更新された信念である。焦点エージェントに、「このエピソードでこれまでに見たすべてを考慮すると、協力者 $j$ が目標 $g_j$ を持っている可能性はどれくらいか?」と伝える。これは、協力者の変化する行動へのリアルタイム適応に不可欠である。
- $Z_1$:
- 数学的定義: 正規化係数。
- 物理的/論理的役割: 協力者 $j$ のすべての可能な目標 $g_j$ に対する確率の合計が1になることを保証し、有効な確率分布を維持する。
- なぜ除算か: ベイズ定理の基本的な部分であり、分子(先行確率 × 尤度)を適切な確率にスケーリングする。
- $b_{ij}^{K,t}(g_j)$:
- 数学的定義: エピソード $K$ のタイムステップ $t$ における、エージェント $i$ の協力者 $j$ の目標 $g_j$ に対する信念を表す先行確率分布。
- 物理的/論理的役割: これは、最新のアクションと状態遷移を観測する前の信念である。現在のベイズ更新ステップの開始点として機能する。
- $\Pr(a_j^{K,t}|s^{K,t}, g_j)$:
- 数学的定義: 現在の状態 $s^{K,t}$ と仮説的な目標 $g_j$ が与えられた場合に、協力者 $j$ が行動 $a_j^{K,t}$ を取る確率。これは目標条件付きポリシーネットワーク $\pi_\omega$ によって提供される。
- 物理的/論理的役割: この項は「行動の尤度」として機能する。特定の仮説的な目標 $g_j$ が観測された行動 $a_j^{K,t}$ をどれだけうまく説明できるかを定量化する。協力者が目標 $g_A$ の下では非常に可能性が高いが目標 $g_B$ の下では可能性が低い行動を取る場合、この項は $g_A$ の信念を増加させる。
- $\Pr(s^{K,t+1}|s^{K,t}, a_j^{K,t}, g_j)$:
- 数学的定義: 前の状態 $s^{K,t}$、協力者 $j$ の行動 $a_j^{K,t}$、および仮説的な目標 $g_j$ が与えられた場合に、状態 $s^{K,t+1}$ に遷移する確率。論文では、これが $\Pr(s^{K,t+1}|s^{K,t}, a_j^{K,t})$ に単純化される可能性があるマルコフ仮定に言及しているが、方程式には $g_j$ が含まれており、潜在的な依存関係またはより一般的な定式化を示唆している。
- 物理的/論理的役割: この項は「状態遷移の尤度」として機能する。観測された状態変化が仮説的な目標と行動と一致するかどうかを考慮することにより、信念をさらに洗練させる。
- $\Pr(s^{K,t+1}|s^{K,t}, a_j^{K,t})$:
- 数学的定義: 前の状態 $s^{K,t}$ と協力者 $j$ の行動 $a_j^{K,t}$ が与えられた場合に、状態 $s^{K,t+1}$ に遷移する確率。
- 物理的/論理的役割: これは状態遷移尤度の正規化項であり、全体の尤度が適切にスケーリングされることを保証する。
- なぜ乗算か: ベイズ更新は、先行信念と尤度を乗算によって組み合わせ、新しい証拠が既存の信念をどのようにスケーリングするかを反映する。
エピソード間敵対者目標信念更新(方程式2)
$$b_{ij}^{K,0}(g_j) = \frac{1}{Z_2} [\alpha b_{ij}^{K-1,0}(g_j) + (1-\alpha)\mathbf{1}(g_j = g_j^{K-1})]$$
- $b_{ij}^{K,0}(g_j)$:
- 数学的定義: エピソード $K$ の開始時における、エージェント $i$ の協力者 $j$ の目標 $g_j$ に対する信念を表す先行確率分布。
- 物理的/論理的役割: これは新しいエピソードにおける協力者 $j$ の目標に対する最初の推測である。過去の経験に基づいており、協力者の行動の「記憶」を提供する。
- $Z_2$:
- 数学的定義: 正規化係数。
- 物理的/論理的役割: すべての可能な目標 $g_j$ に対する確率の合計が1になることを保証する。
- なぜ除算か: 確率分布の標準的な正規化。
- $\alpha$:
- 数学的定義: 水平線重み、$\alpha \in [0, 1]$。
- 物理的/論理的役割: この係数は、過去の信念の影響と、最近観測された目標の影響を制御する。$\alpha$ が高いほど、古い信念がより重要になり、適応が遅くなる。$\alpha$ が低い(0に近い)ほど、エージェントは直前のエピソードで観測された目標を優先し、動的な協力者への迅速な適応を可能にする。
- なぜ乗算か: 前のエピソードの先行信念の寄与をスケーリングする。
- $b_{ij}^{K-1,0}(g_j)$:
- 数学的定義: エピソード $K-1$ の開始時における、エージェント $i$ の協力者 $j$ の目標 $g_j$ に対する先行確率分布。
- 物理的/論理的役割: 現在のエピソードより前のすべてエピソードから、協力者 $j$ の目標に関する蓄積された履歴知識を表す。
- $(1-\alpha)$:
- 数学的定義: $\alpha$ に対する補完的な重み。
- 物理的/論理的役割: 前のエピソードからの観測された目標の寄与をスケーリングする。
- なぜ乗算か: 最近の目標観測の寄与をスケーリングする。
- $\mathbf{1}(g_j = g_j^{K-1})$:
- 数学的定義: 前のエピソード $K-1$ で協力者 $j$ の目標が $g_j$ であった場合に1を返し、それ以外の場合は0を返す指示関数。
- 物理的/論理的役割: これは、最後のнетエピソードで協力者 $j$ に対して推論された実際の目標を直接組み込む。新しいエピソードの先行信念を更新するための強力な信号である。
- なぜ加算か: 2つの重み付けされた項が加算され、長期的な履歴信念と短期的な最新の観測を組み合わせて新しい先行信念を形成する。
目標条件付き敵対者ポリシーネットワーク損失(方程式3)
$$\mathcal{L}(\omega) = \mathbb{E}[-\log(\pi_\omega(a_j^{K,t}|s^{K,t}, g_j^{K,t}))]$$
- $\mathcal{L}(\omega)$:
- 数学的定義: パラメータ $\omega$ でパラメータ化された目標条件付きポリシーネットワークの損失関数。
- 物理的/論理的役割: これは、敵対者モデリングモジュールが正確な目標条件付きポリシーを学習するために最小化する目的関数である。損失が低いほど、ネットワークは目標が与えられた場合の敵対者の行動を予測するのに優れていることを意味する。
- $\mathbb{E}[\cdot]$:
- 数学的定義: 期待値演算子。通常、リプレイバッファからのデータサンプルのバッチで平均化することによって近似される。
- 物理的/論理的役割: 個々のデータポイントからのノイズの影響を減らすために、複数の観測を平均化することによって損失の安定した推定値を提供する。
- $-\log(\pi_\omega(a_j^{K,t}|s^{K,t}, g_j^{K,t}))$:
- 数学的定義: 状態 $s^{K,t}$ と推論された目標 $g_j^{K,t}$ が与えられた場合に、ポリシーネットワーク $\pi_\omega$ が観測された行動 $a_j^{K,t}$ に割り当てる確率の負の対数。
- 物理的/論理的役割: これは、分類またはポリシー学習のための教師あり学習で使用される標準的な負の対数尤度損失である。この損失を最小化することは、ネットワークが正しい(観測された)行動に割り当てる確率を最大化することになり、効果的にネットワークに特定の目標の下での敵対者の行動を模倣するように教える。
- なぜ負の対数か: 対数は確率の積を和に変換し、最適化が容易になる。負の符号は、目的を尤度の最大化から損失の最小化に変換し、勾配ベースの最適化の標準である。
焦点エージェントのポリシーおよび価値ネットワーク損失(方程式6)
$$\mathcal{L}(\theta) = \mathcal{L}_p(\pi_{\text{MCTS}}, \pi_\theta) + \mathcal{L}_v(r_i, v_\theta)$$
$$\mathcal{L}_p(\pi_1, \pi_2) = \mathbb{E}[-\sum_{a \in \mathcal{A}_i} \pi_1(a|s^{K,t}) \log(\pi_2(a|s^{K,t}))]$$
$$\mathcal{L}_v(r_i, v) = \mathbb{E}[(v(s^{K,t}) - \sum_{l=t}^{T_{\text{max}}} \gamma^{l-t} r_i^{K,l})^2]$$
- $\mathcal{L}(\theta)$:
- 数学的定義: パラメータ $\theta$ でパラメータ化された、焦点エージェントのポリシーおよび価値ネットワークの合計損失関数。
- 物理的/論理的役割: これは、焦点エージェントが最適なポリシーと正確な価値関数を学習するために最小化する主要な目的関数である。これは、強化学習の2つの重要な側面、すなわち、うまく行動することを学ぶことと、将来の報酬を予測することを学ぶことを組み合わせている。
- なぜ加算か: ポリシー学習と価値学習は、共有表現と共同最適化から利益を得るため、アクタークリティックまたはAlphaZeroライクなアーキテクチャに単一の目的としてしばしば組み合わされる。
- $\mathcal{L}_p(\pi_{\text{MCTS}}, \pi_\theta)$:
- 数学的定義: ポリシー損失項。具体的には、MCTSから導出されたポリシー $\pi_{\text{MCTS}}$(ターゲットポリシー $\pi_1$)と学習されたポリシー $\pi_\theta$(予測ポリシー $\pi_2$)との間のクロスエントロピー損失。
- 物理的/論理的役割: この項は「ポリシー蒸留」メカニズムとして機能する。MCTSは、そのルックアヘッド探索を通じて、現在の学習されたポリシー $\pi_\theta$ よりも優れたポリシーを生成する。この損失は、焦点エージェントの学習されたポリシー $\pi_\theta$ がMCTSによって生成されたポリシーを模倣し、内面化するように促し、効果的にプランニングの「知恵」をニューラルネットワークに転送する。
- $\mathbb{E}[-\sum_{a \in \mathcal{A}_i} \pi_1(a|s^{K,t}) \log(\pi_2(a|s^{K,t}))]$:
- 数学的定義: 2つの確率分布 $\pi_1$ と $\pi_2$ の間のクロスエントロピー。
- 物理的/論理的役割: 学習されたポリシー $\pi_2$ がMCTSターゲットポリシー $\pi_1$ とどれだけ異なるかを測定する。クロスエントロピーを最小化することは、$\pi_2$ を $\pi_1$ に一致させる。
- なぜ和か: ターゲットポリシーの確率によって重み付けされた、焦点エージェントの行動空間 $\mathcal{A}_i$ のすべての可能な行動に対する負の対数確率を合計する。
- $\mathcal{L}_v(r_i, v_\theta)$:
- 数学的定義: ポリシー損失項。具体的には、価値ネットワークから予測された値 $v(s^{K,t})$ と真の割引報酬合計 $\sum_{l=t}^{T_{\text{max}}} \gamma^{l-t} r_i^{K,l}$ との間の平均二乗誤差(MSE)。
- 物理的/論理的役割: この項は、価値ネットワーク $v_\theta$ を、任意の状態から期待される累積将来報酬を正確に予測するようにトレーニングする。正確な価値関数は、MCTSを導き、状態の品質を評価するために不可欠である。
- $\mathbb{E}[(v(s^{K,t}) - \sum_{l=t}^{T_{\text{max}}} \gamma^{l-t} r_i^{K,l})^2]$:
- 数学的定義: 予測された値と実際の割引報酬との間の二乗差。
- 物理的/論理的役割: これは標準的な回帰損失である。価値ネットワークが不正確な予測をした場合にペナルティを与え、より大きな誤差には二次的に高いペナルティを与える。
- なぜ二乗差か: 回帰タスクに一般的であり、勾配ベースの最適化のための滑らかで微分可能な損失ランドスケープを提供する。
- $v(s^{K,t})$:
- 数学的定義: 状態 $s^{K,t}$ に対する焦点エージェントの価値ネットワークによって予測された値。
- 物理的/論理的役割: 状態 $s^{K,t}$ から得られる総将来割引報酬のモデルの現在の推定値。
- $\sum_{l=t}^{T_{\text{max}}} \gamma^{l-t} r_i^{K,l}$:
- 数学的定義: エピソードのタイムステップ $t$ からエピソードの終わり $T_{\text{max}}$ まで、エージェント $i$ が受け取った真の割引報酬(累積報酬)。
- 物理的/論理的役割: これは価値ネットワークの「グラウンドトゥルース」である。これは、時間的距離によって割引された将来の報酬の実際の合計を表す。
- なぜ和か: 将来の軌跡全体にわたる報酬を累積する。
ステップバイステップフロー
環境状態と協力者の行動の観測のような、単一の抽象的なデータポイントがHOPシステムに入力されると想像してみよう。数学的エンジンを通過する様子を以下に示す。
-
エピソード開始:履歴による準備:
- 新しいエピソード $K$ が開始されると、焦点エージェント $i$ は協力者に関する信念に関してゼロから始めるわけではない。まず、過去の相互作用の「記憶」を参照する。
- エピソード間OM信念更新(方程式2)がトリガーされる。この方程式は、前のエピソードの先行信念 $b_{ij}^{K-1,0}(g_j)$ を、その最後のнетエピソードで協力者 $j$ に対して推論された実際の目標 $g_j^{K-1}$ と組み合わせる。水平線重み $\alpha$ はダイヤルのように機能し、長期的な履歴の信頼度と非常に最近の過去の信頼度をブレンドする。これにより、現在のエピソードの初期信念 $b_{ij}^{K,0}(g_j)$ が生成され、エージェントは有利なスタートを切ることができる。
-
リアルタイム相互作用:敵対者の目標の観測と推論:
- エピソードが進むにつれて、各タイムステップ $t$ で、エージェントは現在の状態 $s^{K,t}$ と協力者が取った行動 $a_j^{K,t}$ を観測する。
- この新しい観測は、直ちにエピソード内OM信念更新(方程式1)にフィードされる。エージェントは現在の信念 $b_{ij}^{K,t}(g_j)$ ($t=0$ では $b_{ij}^{K,0}(g_j)$ であった)を取り、それを更新する。エージェントは次のように問う。「協力者 $j$ が目標 $g_j$ を持っていた場合、行動 $a_j^{K,t}$ を取り、状態 $s^{K,t+1}$ を引き起こした可能性はどれくらいか?」
- これに答えるために、目標条件付きポリシーネットワーク $\pi_\omega$ を使用して、可能な各目標 $g_j$ に対して $\Pr(a_j^{K,t}|s^{K,t}, g_j)$ を取得する。この尤度は、現在の信念に乗算され、結果は $Z_1$ で正規化される。このプロセスは、エピソード内でより多くの行動が観測されるにつれて、協力者の目標に関する信念を継続的に洗練させ、$b_{ij}^{K,t+1}(g_j)$ をより正確にする。
-
敵対者の行動学習:目標条件付きポリシーのトレーニング:
- このプロセス全体を通じて、推論された目標 $g_j^{K,t}$ (最も可能性の高い目標)と観測された状態 $s^{K,t}$ および行動 $a_j^{K,t}$ が収集され、軌跡バッファに格納される。
- 定期的に、この収集されたデータを使用して、目標条件付きポリシーネットワーク $\pi_\omega$ をトレーニングする。目標条件付き敵対者ポリシーネットワーク損失(方程式3)が最小化される。これは、教師がネットワークに例を示すようなものである。「敵対者が目標 $g$ で状態 $s$ にいたとき、行動 $a$ を取った。」ネットワークは、 $s$ と $g$ が与えられた場合に $a$ を予測するように学習し、敵対者の行動をモデリングする能力を向上させる。
-
焦点エージェントの意思決定:最良の応答のプランニング:
- 次に、焦点エージェントが行動する番である。自身の行動 $a_i^{K,t}$ を選択する必要がある。
- エージェントはモンテカルロ木探索(MCTS)を開始する。MCTSは現在の状態だけでなく、多くの可能な未来をシミュレートする。
- 重要なのは、MCTSは協力者の目標を確実には知らないことである。そのため、各 $N_s$ シミュレーションラウンドで、現在の信念 $b_{ij}^{K,t}(g_j)$ (ステップ2から)から協力者の目標の組み合わせをサンプリングする。
- 各サンプリングされた目標の組み合わせについて、MCTSは軌跡をシミュレートする。協力者 $j$ が何をするかを知る必要がある場合、サンプリングされた目標 $g_j$ を使用して、学習された目標条件付きポリシー $\pi_\omega(\cdot|s, g_j)$ (ステップ3から)を使用する。焦点エージェントは自身の行動を探索する。
- $N_s$ ラウンドの後、MCTSは、協力者の目標に関する不確実性を考慮して、焦点エージェントの各可能な行動に対して平均行動価値 $Q_{\text{avg}}(s^{K,t}, a)$ (方程式4)を計算する。
- 最後に、焦点エージェントは、高い $Q_{\text{avg}}$ 値を持つ行動を優先するボルツマン合理性モデル(方程式5)を使用して、自身の行動 $a_i^{K,t}$ を選択し、探索と活用をバランスさせる。
-
より良く学習する:焦点エージェントのネットワークのトレーニング:
- MCTSプロセス自体は貴重な情報を提供する。「より優れた」ポリシー $\pi_{\text{MCTS}}$(探索から導出される)と状態価値の改善された推定値である。
- この情報と、実際に受け取った報酬 $r_i^{K,l}$ とともに、焦点エージェントの主要なポリシーと価値ネットワーク(パラメータ $\theta$ でパラメータ化される)をトレーニングするために使用される。
- 焦点エージェントのポリシーおよび価値ネットワーク損失(方程式6)が最小化される。この損失には2つの部分がある。
- 学習されたポリシー $\pi_\theta$ をMCTSによって生成されたポリシー $\pi_{\text{MCTS}}$ に模倣させるポリシー損失 $\mathcal{L}_p$。これは、MCTS「教師」がネットワークに最適な手を示すようなものである。
- 価値ネットワーク $v_\theta$ を、エピソード中に観測された真の割引報酬合計 $\sum_{l=t}^{T_{\text{max}}} \gamma^{l-t} r_i^{K,l}$ を正確に予測するようにする価値損失 $\mathcal{L}_v$。これは、ネットワークに状態がいかに良いかを正しく評価するように教える。
- この組み合わせ損失を通じて、焦点エージェントのニューラルネットワークは、より良い決定を下し、状態をより正確に評価するように学習し、時間とともに熟練度を向上させる。
このサイクル全体が繰り返され、各ステップが他のステップにフィードバックされ、改善され、動的で適応的な学習システムが作成される。
最適化ダイナミクス
HOPメカニズムは、敵対者への理解と自身の意思決定能力を洗練させる、継続的で反復的なプロセスを通じて学習、更新、収束する。この学習は、様々な損失関数に対する勾配降下法とMCTSの固有の自己改善によって駆動される。
-
信念システムの洗練:
- エピソード内信念(方程式1): エピソード内OMモジュールは、ベイズ更新を使用して協力者の目標に関する信念を継続的に更新する。新しい観測(敵対者の行動と状態遷移)ごとに、特定の目標の確率を強化または弱める証拠が提供される。時間の経過とともに、エピソード内でより多くのデータが収集されると、事後分布 $b_{ij}^{K,t+1}(g_j)$ は、敵対者の真の基盤となる目標に収束する傾向がある。これは、蓄積される証拠とともに信念分布の不確実性(エントロピー)が減少する古典的なベイズ更新である。
- エピソード間先行情報(方程式2): エピソード間OMモジュールは、新しいエピソードの先行信念を更新する。水平線重み $\alpha$ は、ここでの重要なハイパーパラメータである。$\alpha$ が高い場合、システムは長期的な履歴平均に大きく依存し、信念の収束は遅いが安定する。$\alpha$ が低い場合、システムは最近の敵対者の行動に迅速に適応し、より速い適応につながる可能性があるが、敵対者の目標が非常に変動しやすい場合は不安定になる可能性もある。このメカニズムにより、システムは複数のエピソードにわたる敵対者の戦略のシフトを追跡し、適応することができる。
-
敵対者ポリシー学習:
- 敵対者の行動を予測するために使用される目標条件付きポリシーネットワーク $\pi_\omega$ は、確率的勾配降下法(SGD)またはそのバリアントを使用して、負の対数尤度損失(方程式3)を最小化することによってトレーニングされる。このネットワークの損失ランドスケープは、観測された敵対者の行動に対する予測の精度によって形成される。より多様で正確なデータ(状態、推論された目標、実際の行動)が収集され、リプレイバッファにフィードされると、勾配はネットワークパラメータ $\omega$ をこの損失を最小化するように導く。このプロセスは、敵対者の行動を正確にモデリングするネットワークの能力を反復的に向上させ、敵対者モデリングモジュールをより信頼性の高いものにする。
-
焦点エージェントのポリシーと価値学習:
- 焦点エージェントのポリシー $\pi_\theta$ と価値関数 $v_\theta$ は、MCTSが強力な「教師」として機能する教師ありプロセスを通じて学習される。全体の損失 $\mathcal{L}(\theta)$ (方程式6)は、勾配降下法を使用して最小化される。
- ポリシー改善: MCTSは、広範なシミュレーションとルックアヘッド探索を実行することにより、現在の学習されたポリシー $\pi_\theta$ よりも「強力な」ポリシー $\pi_{\text{MCTS}}$ を生成する。次に、ポリシー損失項 $\mathcal{L}_p$ は、学習されたポリシー $\pi_\theta$ が $\pi_{\text{MCTS}}$ を模倣するように $\pi_\theta$ を駆動する。これは、$\mathcal{L}_p$ からの勾配が、学習されたポリシーがMCTSによって生成されたポリシーに似るようにパラメータ $\theta$ を方向付けることを意味する。この反復的な教師指導により、$\pi_\theta$ は環境を直接探索することなく、最適なポリシーに収束できる。
- 価値関数の精度: 価値損失項 $\mathcal{L}_v$ は、MCTSシミュレーションと実際のプレイ中に観測された真の割引報酬を正確に予測するように $v_\theta$ をトレーニングする。$\mathcal{L}_v$ からの勾配は、予測された報酬と実際の報酬との間の平均二乗誤差を削減するように $\theta$ を導く。$v_\theta$ がより正確になると、MCTSに優れた推定値を提供し、探索をより効率的かつ効果的にする。これにより、肯定的なフィードバックループが作成される。優れた価値推定は、より優れたMCTSにつながり、それが $v_\theta$ のトレーニングターゲットをより良くする。
- 損失ランドスケープ: 組み合わせ損失 $\mathcal{L}(\theta)$ は、複雑な損失ランドスケープを作成する。しかし、MCTSの教師指導は、ニューラルネットワークパラメータ $\theta$ を期待収益の高い領域に導く、強力ではあるがノイズが多い可能性のある信号を提供する。MCTS(繰り返しシミュレーション)とニューラルネットワークトレーニング(勾配更新)の反復的な性質により、システムは堅牢なポリシーと価値関数に収束できる。
-
MCTS探索・活用:
- MCTSアルゴリズム自体は、PUCT(Polynomial Upper Confidence Trees)のようなメカニズムを使用して探索と活用のバランスを取る。MCTSスコア関数(付録E.1で言及されている)の探索係数 $c$ は、このバランスを制御する。$c$ が高いほど、MCTSはあまり訪問されない行動を探索することを奨励し、より優れた戦略を発見する可能性がある。$c$ が低いほど、MCTSは既知の良い行動をより多く活用し、局所的な最適解への収束を速める。このダイナミクスにより、MCTSはニューラルネットワークを教師指導するための改善されたポリシーを見つけ続けることが保証される。
要するに、HOPの最適化ダイナミクスは、階層的で反復的な学習プロセスによって特徴付けられる。敵対者モデルは、ベイズ更新と教師あり学習を通じて継続的に洗練され、協力者の行動のますます正確な予測を提供する。この洗練された理解は次にMCTSに情報を提供し、MCTSは強力なプランニングエンジンとして機能し、優れたポリシーと価値ターゲットを生成する。これらのターゲットは、順番に焦点エージェントの主要なポリシーと価値ネットワークを教師指導し、それらを混合動機環境における効率的で適応的な意思決定戦略への収束に導く。これらのコンポーネントの相互作用により、システムは未知のポリシーに適応し、堅牢な行動を学習できることが保証される。
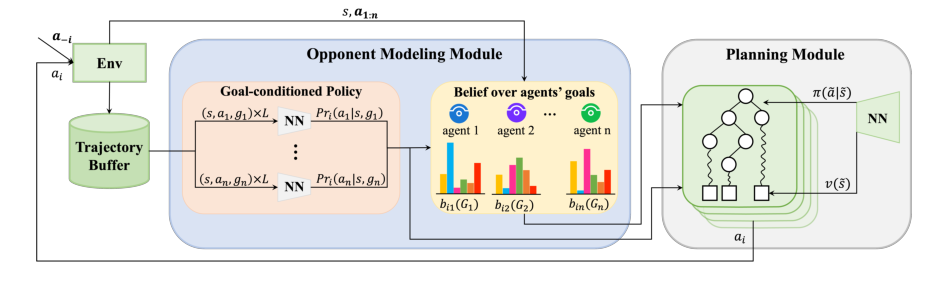 Figure 1. Overview of HOP. HOP consists of an opponent modeling module and a planning module. The opponent modeling module models the behavior of co-players by inferring co-players’ goals and learning their goal-conditioned policies. Estimated behavior is then fed to the planning module to select a rewarding action for the focal agent
Figure 1. Overview of HOP. HOP consists of an opponent modeling module and a planning module. The opponent modeling module models the behavior of co-players by inferring co-players’ goals and learning their goal-conditioned policies. Estimated behavior is then fed to the planning module to select a rewarding action for the focal agent
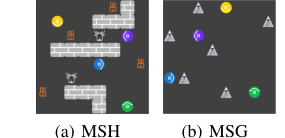 Figure 2. Overview of Markov Stag-Hunt and Markov Snowdrift. There are four agents, repre- sented by colored circles, in each paradigm. (a) Agents catch prey for reward. A stag with a reward of 10 requires at least two agents to hunt together. One agent can hunt a hare with a reward of 1. (b) Everyone gets a reward of 6 when an agent removes a snowdrift. When a snowdrift is removed, removers share the cost of 4 evenly
Figure 2. Overview of Markov Stag-Hunt and Markov Snowdrift. There are four agents, repre- sented by colored circles, in each paradigm. (a) Agents catch prey for reward. A stag with a reward of 10 requires at least two agents to hunt together. One agent can hunt a hare with a reward of 1. (b) Everyone gets a reward of 6 when an agent removes a snowdrift. When a snowdrift is removed, removers share the cost of 4 evenly
結果、限界、および結論
実験設計とベースライン
階層的敵対者モデリングとプランニング(HOP)アルゴリズムを厳密に検証するために、著者らは2つの異なる混合動機環境、すなわちマルコフ・スタッグハント(MSH)とマルコフ・スノー・ドリフト・ゲーム(MSG)で実験を実施した。これらの環境は、複雑な戦略的相互作用を引き出すように設計された、古典的なゲーム理論パラダイムの空間的および時間的な拡張である。
MSHでは、4つのエージェントがグリッド上で獲物(シカとウサギ)を狩る。シカは報酬10を提供するが、少なくとも2人のエージェントが協力して狩る必要があり、報酬を分割する。ウサギは報酬1を提供し、単一のエージェントによって捕獲できる。ゲームは30タイムステップ後に終了する。2つのMSH設定が使用された。
- MSH-4h1s: 4羽のウサギと1頭のシカが登場する。この設定は、シカの協力的な狩りを奨励しつつ、ウサギの競争を維持し、混合動機ダイナミクスを作り出す。
- MSH-4h2s: 4羽のウサギと2頭のシカが登場する。これは協力の可能性を高めるが、ひねりが加わる。ゲームは最初の狩りが成功してからわずか5タイムステップ後に終了し、個々の即時利益と長期的な集団的利益との間の緊張を激化させる。
MSG環境では、6つの雪の吹き溜まりが8x8のグリッド上にランダムに配置される。エージェントは移動、待機、または「雪の吹き溜まりを削除する」ことができる。雪の吹き溜まりを削除すると、削除者間でコスト4が共有されるが、各エージェントは報酬6を個別に受け取る。ここでの中心的なジレンマはフリーライダーである。エージェントは、他の人に雪の吹き溜まりを削除させることで、より高い報酬を得ることができる。ゲームは、すべての雪の吹き溜まりがクリアされたとき、または50タイムステップ後に終了する。MSHとMSGの両方で、4つのエージェントが直接的なコミュニケーションや互いの内部パラメータへのアクセスなしに動作する。シェリング図は、これらの環境が混合動機相互作用の固有のジレンマを効果的に捉えていることを視覚的に確認するために使用された。
HOPがテストされたベースラインには、確立されたマルチエージェント強化学習(MARL)アルゴリズムとルールベースの戦略の多様なセットが含まれていた。
- 学習ベースライン: LOLA(敵対者学習認識付き学習)、SI(社会的影響)、A3C(非同期アドバンテージアクタークリティック)、PS-A3C(親社会的A3C)、PR2、およびdirect-OM(目標条件付けなしで協力者を直接モデリングするHOPの非機能化バージョン)。
- ルールベースベースライン: Random(有効な行動をランダムに取る)、Cooperator(一貫して協力的な行動を採用する)、Defector(一貫して搾取的な行動を採用する)。
実験的検証は2つのフェーズで進行した。
1. 自己プレイ: 同じアルゴリズムを使用するすべてのエージェントは、パフォーマンスが収束するまでトレーニングされた。このフェーズは、アルゴリズムが自律的な決定を下し、混合動機設定で協力を達成する能力を評価した。
2. 少数ショット適応: 焦点HOPエージェントは、2400ステップの間、異なるベースラインアルゴリズムを実行している3人の協力者と相互作用した。最後の600ステップ中の焦点エージェントの平均報酬は、適応能力を定量化するために使用された。アルゴリズムがそれをサポートする場合、このフェーズ中にポリシーパラメータを更新できた。
最適なパフォーマンスの明確な参照を提供するために、各協力者タイプに対して「Oracleエージェント」がトレーニングされた。このOracleエージェントは、広範な相互作用にわたる固定協力者パラメータを持つA3Cによってトレーニングされ、特定の協力者に完全に適応した場合にエージェントが達成できる最良のパフォーマンスを表す。すべての報酬は、Oracleエージェントのパフォーマンス(最適)とランダムポリシーのパフォーマンス(最低)の間で最小最大正規化され、標準化された比較が可能になった。
証拠が証明するもの
実験結果は、混合動機環境における自己プレイと少数ショット適応の両方において、HOPの優れた能力を断定的に示しており、階層的敵対者モデリングとプランニングに関するその数学的主張を徹底的に証明している。
自己プレイシナリオでは、HOPは一貫して高い報酬を達成し、しばしば最高のベースラインを上回るか同等であった。MSH-4h1sでは、HOP、direct-OM、およびPS-A3Cはシカを狩ることを学習したが、PS-A3Cの「怠惰なエージェント」問題は劣った報酬につながった。LOLAは不安定な戦略を示し、SIとA3Cは主にウサギを狩り、低いリターンをもたらした。PR2はMSHで完全に失敗した。MSH-4h2sでは、HOPとA3Cが最も安定しており、最高の報酬をもたらし、シカの狩りのための協調を成功させた。最も注目すべきは、MSGでは、HOPが理論上の最適値30.0に近づいた最高の報酬を達成したことである。これは、HOPの分散設定での協力への強い傾向を強調しており、個々の利益を優先し、協調に苦労したLOLA、A3C、SIのようなベースラインとは対照的である。PS-A3Cは、2番目に良かったものの、雪の吹き溜まりが1つだけ残った場合でも協調の問題に直面した。
HOPのコアメカニズムに対する最も説得力のある証拠は、その少数ショット適応パフォーマンス(表1)にある。HOPは、ほとんどのテストシナリオで一貫して「全体的な最高の適応率」を達成した。MSH-4h1sで83.3%、MSH-4h2sで完璧な100.0%、MSGで83.3%であった。これは、協力者の行動がそれらの事前学習されたポリシーと一致する特定の限定的なシナリオでのみ最適な適応を達成した他のアルゴリズムをはるかに上回った。
論文は、HOPの信念更新メカニズムが現実でどのように機能するかを明確な例で示している*。MSHで3人の離反者(常にウサギを狩る)に直面した場合、HOPは当初、「シカを狩るだろう」という「誤った信念」を持っていた(自己プレイ経験からのバイアス)。しかし、*intra-OMモジュール(エピソード内の信念を更新する)はこれを迅速に修正した。協力者の軌跡(例:ウサギに向かって移動する)を観測することにより、intra-OMはそれらの真の目標を推論し、正確な敵対者モデルにつながった。inter-OMモジュール(エピソード間の信念を更新する)は、この真の信念への収束をさらに加速させ、後続のエピソードの正確な先行情報として機能した。図5の、シカ狩りにおける先行信念の徐々な減少を表す線は、HOPの階層的信念更新メカニズムが未知で動的な協力者の行動に効果的に適応することの、決定的で否定できない証拠である。これらの正確な協力者ポリシーを入力として、プランニングモジュールは有利な行動を計算でき、HOPは離反者のような非協力的なエージェントに対しても大幅な戦略調整を行い、高いリターンを達成することを可能にした。
さらに、実験は複数のHOPエージェント間の社会的知性の出現(付録G、図6)を明らかにした。ある例では、「自己組織化された協力」が出現し、4人のHOPエージェントが、個々にはよりリスクが高かったにもかかわらず、より高い総報酬のために協力してシカを狩った。これは、エージェントがお互いの意図を推論し、中央集権的な制御なしに協調することによって、独立した意思決定を通じて発生した。別のケースでは、「不利な同盟」で、2人のあまり欲張りでないHOPエージェントが、より欲張りな協力者を欺いて協力を回避し、その後、自身の利益を最大化するために協力することに成功した。これらの観察は、HOPが他者の目標を推論し、応答を迅速に調整する能力が、エージェントが自己利益的である場合でも、複雑な社会的行動を促進することを示唆している。
限界と将来の方向性
HOPは混合動機環境における少数ショット適応において顕著な能力を示しているが、著者らは率直にいくつかの限界を認め、エキサイティングな将来の研究への道を開いている。
第一に、重要な制約は、HOPが効果的に機能するために、任意の環境内で目標の明確な定義が必要であることである。現在のフレームワークは、事前定義された目標セットに依存している。HOPの一般化可能性とより広範な複雑なシナリオへの適用性を向上させるために、重要な将来の方向性は、目標セットを自律的に抽象化できる技術を開発することである。これにより、HOPは手動介入なしに新しい環境で動作できるようになる。これは、一部の先行研究がすでに探求を開始している課題である。
第二に、HOPの現在の実装はレベル0の心の理論(ToM)を使用しており、これは本質的にエージェントが「自分がどう考えているか」を推論することを含む。効果的である一方で、レベル1のToM(「彼らが私についてどう考えているか」)のような高次のToMを組み込むことは、協力者の行動に関する予測を大幅に改善する可能性を秘めている。しかし、これは、相互的な信念推論が関与するため、計算コストの大幅な増加を伴う。したがって、将来の研究は、計算上の過剰な複雑性に陥ることなく、高次のToMによって提供されるより豊かな洞察を効果的かつ迅速に活用できる、高度で計算効率の高いプランニング方法の開発に焦点を当てる必要がある。これは、些細ではないエンジニアリングと数学的なハードルである。
第三に、本論文は、評価のための協力者として多様な確立されたアルゴリズムを選択したが、そのどれも人間の行動のニュアンスと複雑さを完全に捉えていない。多くのマルチエージェントシステムの究極の目標は、実際の参加者とのシームレスな相互作用である。したがって、説得力のある将来の研究の方向性は、実際の人間参加者を含む少数ショット適応シナリオにおけるHOPのパフォーマンスを調査することである。これは、その現実世界での適用性と堅牢性に関する貴重な洞察を提供するだろう。
最後に、HOPの固有の自己利益的な性質から重要な議論点が生じる。それは自身の利益を最大化することに優れているが、これは必ずしも協力者の最善の利益や価値との整合性を保証するものではない。この潜在的な不整合を軽減し、より有益な人間とAIの協力を促進するために、将来の研究は、HOPの強力な推論能力が、相互作用中に人間の価値観と好みを推論し、最適化するためにどのように活用できるかを調査すべきである。これには、価値整合または選好学習のメカニズムを組み込むことが含まれる可能性があり、HOPが効率的であるだけでなく、倫理的に健全で社会的に有益な方法で複雑な環境で人間を支援できるようになる。これには、人間とAIの相互作用倫理と堅牢な選好抽出技術の深い調査が必要となるだろう。
 Table 5. Performance of HOP and its ablation versions in MSH-4h2s. In (a) self-play, 4 agents of the same kind are trained to converge. Shown is the normalized score after convergence. In (b) few-shot adaptation, the interaction happens between 1 agent using the row policy and 3 co-players using the column policy. Shown are the min-max normalized scores, with normalization bounds set by the rewards of Orcale and the random policy. The results are depicted for the row policy from 1800 to 2400 step
Table 5. Performance of HOP and its ablation versions in MSH-4h2s. In (a) self-play, 4 agents of the same kind are trained to converge. Shown is the normalized score after convergence. In (b) few-shot adaptation, the interaction happens between 1 agent using the row policy and 3 co-players using the column policy. Shown are the min-max normalized scores, with normalization bounds set by the rewards of Orcale and the random policy. The results are depicted for the row policy from 1800 to 2400 step
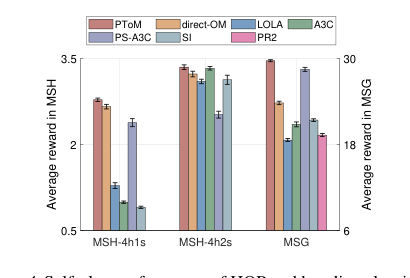 Figure 4. Self-play performance of HOP and baseline algorithms. Shown is the average reward in the self-play training phase
Figure 4. Self-play performance of HOP and baseline algorithms. Shown is the average reward in the self-play training phase