혼합 동기 환경에서의 계층적 상대방 모델링 및 계획을 통한 효율적인 적응
Despite the recent successes of multi-agent reinforcement learning (MARL) algorithms, efficiently adapting to co-players in mixed-motive environments remains a significant challenge.
배경 및 학문적 계보
기원 및 학문적 계보
본 논문에서 다루는 "혼합 동기 환경에서의 계층적 상대방 모델링 및 계획을 통한 효율적인 적응" 문제는 인공지능 분야의 오랜 난제인, 에이전트가 이전에 보지 못한 협력자에게 신속하게 적응하도록 하는 능력, 즉 "소수샷 적응(few-shot adaptation)" 능력에서 비롯된다. 역사적으로 다중 에이전트 강화 학습(MARL) 연구는 미리 정의된 관계를 가진 환경, 특히 제로섬 게임(에이전트가 순수하게 경쟁하는 경우, 예: Vinyals et al., 2019)과 공통 이익 환경(에이전트가 순수하게 협력하는 경우, 예: Barrett et al., 2011)에서 상당한 발전을 이루었다.
그러나 이 특정 문제의 정확한 기원은 대부분의 현실적인 다중 에이전트 의사 결정 시나리오가 순수하게 경쟁적이거나 협력적이지 않다는 인식에서 비롯된다. 대신, 이들은 "혼합 동기 환경(mixed-motive environments)"(Komorita & Parks, 1995; Dafoe et al., 2020)으로 특징지어지며, 이는 에이전트 간의 비결정적 관계와 에이전트의 최적 대응이 다른 에이전트의 행동에 따라 달라질 수 있는 상황을 특징으로 한다. 이러한 복잡성은 단순한 환경에서의 의사 결정 및 소수샷 적응을 훨씬 더 어렵게 만든다.
이 연구를 필요로 하게 된 이전 접근 방식의 근본적인 한계 또는 "고충점(pain point)"은 여러 문제에서 비롯된다.
1. 특수 기법의 적용 불가능성: 소수샷 적응을 위한 많은 기존 MARL 알고리즘은 제로섬 또는 순수 협력 게임에 효율적이지만 혼합 동기 환경에서 발견되는 일반 합 보상 구조에는 적합하지 않은 기법(예: minimax, Double Oracle, IGM 조건)에 의존한다.
2. 계산 복잡성: 중첩된 믿음 추론(즉, 에이전트가 자신의 믿음에 대해 다른 에이전트가 생각하는 것을 추론하는 것)을 포함하는 I-POMDP(Gmytrasiewicz & Doshi, 2005)와 같은 방법은 심각한 계산 복잡성을 겪는다. 이는 복잡한 환경에서 비현실적으로 만든다.
3. 정보 요구 사항 및 확장성 문제: LOLA(Foerster et al., 2018)와 같은 알고리즘은 종종 협력자의 내부 네트워크 매개변수에 대한 지식을 요구하는데, 이는 실제 시나리오에서 자주 사용할 수 없다. 상대방 모델링으로 완화되더라도 복잡한 순차 환경에서 긴 행동 시퀀스가 필요한 경우 확장성 문제가 발생할 수 있다.
4. 다중 에이전트 설정에서 MCTS의 한계: 몬테 카를로 트리 탐색(MCTS)은 강력한 계획 방법이지만, 다중 에이전트 환경에서의 적용은 에이전트 수가 증가함에 따라 공동 행동 공간이 기하급수적으로 증가하여 확장성 문제를 야기하기 때문에 제한적이다(Choudhury et al., 2022). 이전 MCTS 기반 방법은 종종 협력자 정책을 효율적으로 추정하는 데 어려움을 겪는다.
따라서 저자들은 이전 방법들의 계산 비용이 너무 많이 들거나, 사용할 수 없는 정보를 요구하거나, 더 단순한 상호 작용 역학을 위해 설계된 한계를 극복하고 혼합 동기 환경에서 보지 못한 정책에 효율적으로 적응할 수 있는 접근 방식을 개발하도록 강요받았다. 새로운 해결책에 대한 그들의 영감은 인간이 고수준 목표 추론과 저수준 행동 계획을 통합하는 계층적 인지 메커니즘을 사용하여 이전에 보지 못한 문제를 신속하게 해결한다는 것을 시사하는 인지 심리학에서 비롯되었다(Butz & Kutter, 2016; Eppe et al., 2022).
직관적인 도메인 용어
- 혼합 동기 환경(Mixed-Motive Environments): 모든 사람이 요리를 가져오는 팟럭 디너를 상상해 보라. 어떤 사람들은 자신의 요리로 모두를 감동시키고 싶어 하고(협력적), 어떤 사람들은 단지 최대한 많이 먹고 싶어 하며(이기적), 어떤 사람들은 간단한 요리를 가져오지만 다른 사람들이 훌륭한 것을 가져오기를 은밀히 바라며 자신이 많이 요리할 필요가 없기를 바랄 수 있다(혼합). 각 사람의 "동기"는 고정되어 있지 않으며, 협력과 경쟁의 혼합일 수 있으며, 그들의 최적 전략은 다른 사람들이 무엇을 할 것이라고 생각하는지에 따라 달라진다.
- 소수샷 적응(Few-Shot Adaptation): 팀에 새로 합류한 직원을 생각해 보라. 각 팀원이 어떻게 일하는지 이해하기 위해 몇 달간의 훈련이 필요한 대신, 몇 번의 회의나 프로젝트 후에 개별적인 특성과 선호도를 빠르게 파악한다. 그들은 단지 "몇 번의 시도"(제한된 관찰) 후에 팀에 맞게 자신의 작업 스타일을 "적응"시킨다.
- 상대방 모델링(Opponent Modeling): 이것은 용의자의 의도를 이해하려는 형사와 같다. 형사는 용의자의 행동을 관찰하고, 진술을 듣고, 이 정보를 사용하여 용의자의 목표와 계획이 무엇일 수 있는지에 대한 정신적 그림을 구축한다. 그런 다음 형사는 상대방의 "모델"을 사용하여 다음 움직임을 예측하고 자신의 전략을 계획한다.
- 몬테 카를로 트리 탐색(Monte Carlo Tree Search, MCTS): 바둑과 같은 복잡한 보드 게임을 하는 것을 상상해 보라. 게임의 끝까지 가능한 모든 움직임을 계산하는 대신(이는 불가능하다), 현재 위치에서 많은 무작위 게임을 플레이하는 것을 빠르게 "상상"한다. 각 상상된 게임에 대해 유망해 보이는 경로에 더 집중하면서 다른 움직임을 탐색한다. 이러한 빠른 시뮬레이션이 많이 이루어진 후, 정신적 실험에서 가장 좋은 평균 결과를 가져온 실제 움직임을 선택한다. 이것은 철저한 계산 없이 좋은 결정을 내리는 데 도움이 된다.
- 마음 이론(Theory of Mind, ToM): 이것은 다른 사람이 무엇을 생각하거나 느끼는지 추측하는 능력이다. 예를 들어, 누군가가 미소 짓는 것을 보면 행복하다고 추론한다. AI의 맥락에서, 이는 에이전트가 인간처럼 행동을 관찰함으로써 다른 에이전트의 "정신 상태"(목표, 믿음 또는 의도와 같은)를 이해하려고 시도한다는 것을 의미한다.
표기법 표
| 표기법 | 설명 |
|---|---|
| $N$ | 에이전트 집합, $N = \{1, 2, \dots, n\}$ |
| $S$ | 상태 공간 |
| $A_i$ | 에이전트 $i$의 행동 공간 |
| $A$ | 공동 행동 공간, $A = A_1 \times A_2 \times \dots \times A_n$ |
| $a_{1:n}$ | 모든 에이전트가 취한 공동 행동 |
| $T(s'|s, a_{1:n})$ | 전이 함수: 공동 행동 $a_{1:n}$이 주어졌을 때 상태 $s$에서 $s'$로 전이할 확률 |
| $R_i$ | 에이전트 $i$의 보상 함수, $R_i: S \times A \to \mathbb{R}$ |
| $\gamma$ | 미래 보상에 대한 할인 계수 |
| $T_{max}$ | 에피소드의 최대 길이 |
| $\pi_i(a_i|s)$ | 에이전트 $i$의 정책: 상태 $s$에서 행동 $a_i$를 선택할 확률 |
| $G$ | 모든 에이전트의 목표 집합, $G = G_1 \times G_2 \times \dots \times G_n$ |
| $G_i$ | 에이전트 $i$의 목표 집합, $G_i = \{g_{i,1}, \dots, g_{i,|G_i|}\}$ |
| $g_{i,k}$ | 에이전트 $i$의 특정 목표, 이는 상태 집합이다 |
| $b_{i,j}(g_j)$ | 에이전트 $i$의 에이전트 $j$의 목표에 대한 믿음, $G_j$에 대한 확률 분포 |
| $K$ | 에피소드 인덱스 |
| $t$ | 에피소드 내 시간 단계 |
| $b_{i,j}^{K,t}(g_j)$ | 에이전트 $i$의 에이전트 $j$의 목표에 대한 믿음, 에피소드 $K$의 시간 $t$에서 |
| $\pi_{\omega}(a_j|s^{K,t}, g_j)$ | 목표 $g_j$가 주어졌을 때 상태 $s^{K,t}$에서 협력자 $j$의 목표 조건부 정책, $\omega$로 매개변수화됨 |
| $Q_{avg}(s^{K,t}, a)$ | 상태 $s^{K,t}$에서 행동 $a$에 대한 평균 추정 행동 가치 |
| $\pi_{MCTS}(a|s^{K,t})$ | 상태 $s^{K,t}$에서 MCTS에 의해 생성된 행동 $a$에 대한 정책 |
| $\beta$ | 볼츠만 합리성 모델의 합리성 계수 |
| $N_s$ | MCTS 라운드 수 |
| $N_l$ | 각 MCTS 라운드에 대한 탐색 반복 횟수 |
| $c$ | MCTS의 탐색 계수 |
| $\theta$ | MCTS의 정책 및 가치 네트워크 매개변수 |
| $\omega$ | 목표 조건부 정책 네트워크의 매개변수 |
문제 정의 및 제약 조건
핵심 문제 공식화 및 딜레마
본 논문에서 다루는 핵심 과제는 혼합 동기 다중 에이전트 환경에서 보지 못한 협력자에 대한 효율적인 소수샷 적응이다. 이는 인공지능 분야에서 중요한 문제인데, 대부분의 실제 상호 작용은 순수하게 경쟁적인(제로섬) 또는 순수하게 협력적인(공통 이익) 역학보다는 협력과 경쟁의 혼합을 포함하기 때문이다.
시작점 (입력/현재 상태):
제로섬 및 공통 이익 게임에서 성공을 거두었음에도 불구하고, 현재의 다중 에이전트 강화 학습(MARL) 알고리즘은 혼합 동기 설정에서 대부분 어려움을 겪는다. 이러한 환경은 에이전트 간의 비결정적 관계와 일반 합 보상 구조를 특징으로 하며, 의사 결정을 본질적으로 더 복잡하게 만든다. 상대방 모델링에 대한 이전 접근 방식은 종종 두 가지 주요 장애물에 직면한다.
1. 비효율적인 추론: I-POMDP 및 그 근사치와 같은 기존 방법은 중첩된 믿음 추론으로 인해 "심각한 계산 복잡성 문제"를 겪어 복잡한 환경에서 비현실적이다.
2. 추론된 정보의 비효율적인 활용: LOLA와 같은 알고리즘은 상대방 학습을 고려하지만, 종종 실제 시나리오에서 자주 사용할 수 없는 협력자의 내부 네트워크 매개변수에 대한 지식을 요구한다. 또한, 많은 기존 알고리즘은 수작업으로 만든 내부 보상에 의존하거나 협력자의 개인 보상에 대한 접근을 가정하므로, 이기적인 에이전트에 의한 착취에 취약하거나 이러한 정보가 숨겨져 있을 때 덜 효과적이다. 강력한 계획 도구인 몬테 카를로 트리 탐색(MCTS)도 공동 행동 공간이 에이전트 수에 따라 빠르게 확장되는 다중 에이전트 설정에서 한계를 겪는다.
원하는 종점 (출력/목표 상태):
본 논문은 초점 에이전트가 혼합 동기 환경에서 "보지 못한 정책에 대한 소수샷 적응"을 달성할 수 있도록 하는 알고리즘을 개발하는 것을 목표로 한다. 이는 에이전트가 다음을 수행할 수 있어야 함을 의미한다.
1. 신속한 적응: 제한된 에피소드 수 내에서 새롭고 이전에 보지 못한 협력자를 신속하게 인식하고 적절하게 대응한다.
2. 효율적인 추론 및 정보 활용: 협력자의 목표를 추론하고 목표 조건부 정책을 효율적으로 학습한 다음, 이 추론된 정보를 활용하여 엄청난 계산 비용을 발생시키지 않고 최적의 대응을 계산한다.
3. 강력한 성능 발휘: 협력자의 목표가 비공개이고 잠재적으로 변동성이 큰 혼합 동기 시나리오에서 높은 보상을 얻는 자율적인 결정을 내린다.
정확한 누락된 연결 또는 수학적 격차:
본 논문이 연결하려고 하는 정확한 격차는 혼합 동기 환경에서의 불확실성 하에서 계층적 상대방 모델링 및 계획을 위한 확장 가능하고 효율적인 프레임워크의 부족이다. 구체적으로, 다음을 다룬다.
* 직접적인 내부 매개변수 또는 수작업 보상에 의존하는 대신, 관찰된 행동으로부터 협력자의 잠재적 목표 및 목표 조건부 정책을 정확하게 추론하는 방법.
* 이 추론된 상대방 모델을 계산적으로 실행 가능한 방식으로 계획 메커니즘(MCTS)에 통합하여 이전 방법의 "중첩된 믿음 추론" 문제를 피하는 방법.
* 계획 중에 협력자의 목표에 대한 내재된 불확실성을 상당한 편향을 도입하거나 성능을 저하시키지 않고 처리하는 방법. 본 논문은 에피소드 내외부에서 믿음을 업데이트하기 위해 "내부-OM" 및 "외부-OM" 모듈을 갖춘 계층적 구조를 제안하고, 그런 다음 이러한 믿음을 사용하여 여러 목표 조합을 샘플링하여 최적의 대응을 계산하는 MCTS 계획자를 안내한다.
고통스러운 절충 또는 딜레마:
이전 연구자들을 가두었던 핵심 딜레마는 상대방 모델링의 정확성과 일반화 가능성 대 계산 효율성 및 확장성 간의 절충이다.
* 정확성 대 효율성: 다양한 협력자에 대한 매우 정확한 모델을 달성하는 것, 특히 목표가 비공개이고 동적인 복잡한 혼합 동기 설정에서는 일반적으로 광범위한 계산(예: I-POMDP의 중첩된 믿음 추론) 또는 상대방 내부 정보에 대한 자세한 지식(예: LOLA)이 필요하다. 이로 인해 이러한 방법은 실시간 또는 복잡한 순차 환경에서의 신속한 소수샷 적응에 너무 느리거나 리소스 집약적이 되는 경우가 많다.
* 일반화 대 특수화: 특정 게임 유형(제로섬 또는 순수 협력)을 위해 설계된 알고리즘은 종종 비결정적, 일반 합 상호 작용의 비결정적, 일반 합 특성에 일반화되지 않는 보상 구조별 기법(예: minimax)을 활용한다. 성능을 희생하지 않고 혼합 동기의 전체 스펙트럼에서 작동하는 방법을 개발하는 것은 상당한 과제이다. 본 논문은 경쟁과 협력을 모두 처리할 수 있는 "실용적이고 효과적인 프레임워크"를 목표로 한다.
제약 조건 및 실패 모드
혼합 동기 환경에서의 효율적인 소수샷 적응 문제는 몇 가지 가혹하고 현실적인 제약 조건으로 인해 "엄청나게 어렵다".
물리적/환경적 제약 조건:
* 혼합 동기 역학: 근본적인 제약 조건은 환경 자체이다. 에이전트 간의 관계는 "비결정적"이며 보상 구조는 "일반 합"이므로 에이전트의 이익이 완벽하게 일치하거나 완벽하게 반대되지 않는다. 이로 인해 최적의 대응을 예측하는 것이 매우 맥락 의존적이고 동적이다.
* 보지 못한 협력자 및 정책: "보지 못한 에이전트에 대한 소수샷 적응" 요구 사항은 알고리즘이 특정 상대방 유형으로 사전 훈련에 의존할 수 없음을 의미한다. 에이전트는 즉석에서 새로운 행동에 적응해야 한다.
* 제한된 상호 작용 기록: "소수샷 적응"은 에이전트가 새로운 협력자에 대해 학습할 수 있는 "제한된 수의 에피소드"만 가지고 있음을 의미한다. 이는 상대방 모델링 및 적응에 사용할 수 있는 데이터 양을 심각하게 제한한다.
* 비공개 목표 및 통신 없음: 에이전트는 "서로의 매개변수에 접근할 수 없으며 통신이 허용되지 않는다." 또한, 협력자의 목표는 "비공개이고 변동성이 크므로" 에피소드 내에서 변경될 수 있다. 직접적인 정보 부족으로 인해 관찰된 행동만으로 의도를 추론해야 한다.
계산적 제약 조건:
* 상대방 모델링의 계산 복잡성: I-POMDP와 같은 이전 방법은 "중첩된 믿음 추론"으로 인해 "심각한 계산 복잡성 문제"를 겪어 복잡한 환경에서 비현실적이다. 과제는 지수적인 계산 증가 없이 정확하게 상대방을 모델링하는 것이다.
* 에이전트 수에 따른 확장성: 다중 에이전트 환경에서 "공동 행동 공간은 에이전트 수가 증가함에 따라 빠르게 증가한다." 이로 인해 많은 에이전트에 대해 전통적인 MCTS를 사용한 계획이 계산적으로 불가능해진다. 본 논문은 협력자 정책을 추정하고 초점 에이전트의 행동만 계획함으로써 이를 명시적으로 다룬다.
* 실시간 지연 요구 사항 (암시적): "신속한 적응" 및 "효율적인 추론"의 필요성은 의사 결정이 실질적인 시간 제한 내에서 발생해야 함을 의미하며, 특히 긴 행동 시퀀스를 포함할 수 있는 순차적 의사 결정 시나리오에서는 더욱 그렇다.
데이터 기반 제약 조건:
* 믿음 업데이트를 위한 데이터 희소성: "과거 궤적이 업데이트에 비해 충분히 길지 않을 때", 에피소드 내 상대방 모델링(intra-OM)은 "사전의 부정확성"으로 인해 어려움을 겪을 수 있다. 이는 최소한의 데이터에서 협력자의 목표에 대한 정확한 믿음을 형성하는 어려움을 강조한다.
* 협력자 모델의 불확실성: 상대방 모델링을 사용하더라도 추정된 협력자 정책은 "협력자의 목표에 대한 불확실성을 포함한다." 이 불확실성은 계획 단계에서 효과적으로 관리되어야 "시뮬레이션에 큰 편향을 도입하고 계획 성능을 저하시키는" 것을 방지한다. 이 불확실성을 단순히 통합하면 최적이 아닌 행동으로 이어질 수 있다.
왜 이 접근 방식인가
선택의 불가피성
계층적 상대방 모델링 및 계획(HOP)의 채택은 혼합 동기 환경이 제기하는 내재된 과제의 필연적인 결과이지 단순한 설계 선택이 아니었다. 최신 기술(SOTA) 다중 에이전트 강화 학습(MARL) 알고리즘, 예를 들어 minimax, Double Oracle 또는 IGM 조건을 사용하는 알고리즘은 본질적으로 불충분한 것으로 밝혀졌다. 이러한 방법은 제로섬 또는 순수 협력 게임의 특정 보상 구조에 맞춰져 있어, 에이전트 관계가 비결정적이고 보상이 일반 합인 혼합 동기 환경에는 "적용할 수 없다". 저자들은 기존 방법이 부적절하다는 것을 명시적으로 언급하며, "에이전트 간의 비결정적 관계와 일반 합 보상 구조는 제로섬 및 순수 협력 환경에 비해 혼합 동기 환경에서의 의사 결정 및 소수샷 적응을 더 어렵게 만든다."
기존 방법이 부적절하다는 인식은 저자들이 인지 심리학에서 영감을 얻도록 이끌었다. 그들은 이전에 보지 못한 문제를 신속하게 해결하는 인간의 능력이 고수준 목표 추론과 저수준 행동 계획을 비난 없이 통합하는 "계층적 인지 메커니즘"에 달려 있다는 것을 확인했다. 이 통찰은 저자들이 근본적으로 다른, 계층적으로 구조화된 접근 방식의 필요성을 인식한 정확한 순간이었다. HOP는 이 인지 아키텍처를 직접 반영하여, 협력자의 목표를 추론하고 목표 조건부 정책을 학습하기 위한 상대방 모델링 모듈과, 최적의 대응을 결정하기 위해 몬테 카를로 트리 탐색(MCTS)을 사용하는 계획 모듈을 제안한다. 이 계층적 분해는 복잡한 혼합 동기 설정에서 효율적인 추론과 추론된 정보의 효과적인 활용이라는 이중 과제를 해결하기 위한 유일하게 실행 가능한 경로였다.
비교 우위
HOP는 단순한 성능 지표를 넘어서는 여러 구조적 장점을 통해 이전의 금본위제에 비해 질적으로 우수함을 보여준다.
- 계층적 분해: 평면적인 MARL 접근 방식과 달리, HOP의 두 모듈 구조(상대방 모델링 및 계획)는 협력자 행동에 대한 더 정교하고 해석 가능한 이해를 가능하게 한다. 상대방 모델링 모듈은 고수준 목표를 추론하고 목표 조건부 정책을 학습하여 종단 간 모델보다 더 풍부한 표현을 제공한다. 이는 인간의 인지 과정을 반영하여 더 강력한 적응을 가능하게 한다.
- 효율적인 믿음 업데이트 메커니즘: HOP는 에피소드 전체 및 내부에서 믿음을 업데이트함으로써 효율성을 크게 향상시킨다. 내부 상대방 모델링(intra-OM) 모듈은 단일 에피소드 내에서 협력자의 즉각적인 목표에 대한 신속한 조정을 가능하게 하여 동적인 환경에 중요하다. 외부 상대방 모델링(inter-OM) 모듈은 과거 에피소드를 활용하여 정확한 사전 믿음을 설정하여 수렴을 가속화한다. 이 이중 계층 업데이트 메커니즘은 에피소드 내에서만 믿음을 업데이트하거나 강력한 과거 맥락이 부족한 방법보다 구조적 이점을 제공하며, 이는 종종 짧은 상호 작용 중에 부정확한 상대방 모델링으로 이어진다.
- 중첩된 믿음 추론 복잡성 회피: I-POMDP와 같은 이전 상대방 모델링 및 계획 프레임워크는 "중첩된 믿음 추론"(예: 다른 에이전트가 자신에 대해 생각한다고 생각하는 것을 추론하는 에이전트)으로 인해 "심각한 계산 복잡성 문제"를 겪는다. HOP는 협력자의 목표와 정책에 대한 믿음을 명시적으로 사용하여 신경망 모델을 학습함으로써 이를 우회하며, 이 모델은 MCTS 계획자를 안내한다. 이 설계 선택을 통해 HOP는 "깊은 재귀적 추론의 계산 병목 현상 없이" "순차적 의사 결정을 더 효율적으로 수행"할 수 있다.
- 확장 가능한 MCTS 통합: MCTS는 강력하지만, 다중 에이전트 환경에서의 직접적인 적용은 공동 행동 공간의 빠른 증가로 인해 제한된다. HOP는 "협력자의 정책을 추정하고 초점 에이전트의 행동만 계획"함으로써 이를 극복한다. 이 전략적 분리를 통해 MCTS를 효과적이고 확장 가능하게 적용할 수 있으며, 모든 에이전트의 공동 행동에 대한 계획과 관련된 계산 폭발을 피할 수 있다.
- 계획의 불확실성 감소: 상대방 모델링 모듈은 계획 모듈에 목표 조건부 정책을 제공한다. 이 추론된 정보는 MCTS를 안내하여 계획을 위한 환경 모델에 협력자의 목표에 대한 불확실성을 단순히 통합함으로써 발생하는 "큰 편향"과 "계획 성능 저하"를 방지한다. 이 구조적 통합은 계획이 불확실성 하에서도 정확하고 정밀하도록 보장한다.
제약 조건과의 정렬
HOP의 설계는 혼합 동기 환경에서의 소수샷 적응이라는 가혹한 요구 사항과 완벽하게 일치한다.
- 보지 못한 정책에 대한 소수샷 적응: HOP의 핵심 목표는 소수샷 적응이다. 계층적 구조, 특히 효율적인 내부-OM 및 외부-OM 믿음 업데이트 메커니즘은 이를 위해 특별히 설계되었다. 내부-OM은 에피소드 내 행동 변화에 대한 신속한 대응을 가능하게 하며, 외부-OM은 과거 에피소드로부터 정확한 사전 믿음을 제공하여 제한된 상호 작용 내에서 새로운 협력자 전략에 신속하게 적응할 수 있도록 한다. 이 문제의 신속한 학습 요구와 해결책의 동적 믿음 업데이트 간의 "결합"은 근본적이다.
- 혼합 동기 환경: HOP는 관계가 비결정적이고 보상이 일반 합인 혼합 동기 시나리오를 위해 특별히 제작되었다. 협력자의 목표(경쟁적, 협력적 또는 혼합적일 수 있음)를 추론하고, 협력자의 목표가 비공개이고 변동성이 클 때도 초점 에이전트의 최적 대응을 계획하는 능력은 이러한 환경의 핵심 과제를 직접적으로 해결한다.
- 협력자 매개변수 또는 보상에 대한 접근 없음: 현실적인 다중 에이전트 설정의 중요한 제약 조건은 다른 에이전트의 내부 매개변수 또는 보상 함수에 대한 직접적인 접근이 없다는 것이다. HOP의 상대방 모델링 모듈은 "행동 시퀀스"를 관찰함으로써만 협력자의 목표를 추론하고 목표 조건부 정책을 학습한다. 이 추론 기반 접근 방식은 협력자의 내부 정보에 대한 명시적인 지식의 필요성을 우회하여 블랙박스 실제 시나리오에 적용할 수 있다.
- 통신 없음: 문제 정의는 에이전트 간의 명시적인 통신 부족을 암시한다. HOP의 목표 추론 및 정책 학습은 직접적인 통신 없이 전적으로 관찰된 궤적과 행동에 기반하므로 이 암시적 제약 조건을 준수한다.
대안의 거부
본 논문은 여러 인기 있는 접근 방식에 대한 거부 이유를 명확하게 제공한다.
- 전통적인 MARL 알고리즘 (예: Minimax, Double Oracle, IGM 조건): 이러한 방법은 "혼합 동기 환경에 적용할 수 없기 때문에" 명시적으로 거부된다. 그들의 기본 가정과 기법은 제로섬 또는 순수 협력 보상 구조에 최적화되어 있어, 혼합 동기 게임의 특징인 비결정적 관계와 일반 합 보상을 포착하지 못한다.
- LOLA (Learning with Opponent-Learning Awareness): 고급 MARL 알고리즘이지만, LOLA는 "많은 시나리오에서 실현 가능하지 않을 수 있는 협력자의 네트워크 매개변수에 대한 지식을 요구"하기 때문에 일반 혼합 동기 환경에는 부적합한 것으로 간주된다. HOP의 추론 기반 상대방 모델링은 이 제한적인 요구 사항을 피한다. 또한, LOLA는 "긴 행동 시퀀스에 대한 보상이 필요한 복잡한 순차 환경에서 확장성 문제"를 겪을 수 있으며, 이는 HOP가 계획을 통해 해결하는 한계이다.
- I-POMDP (Interactive Partially Observable Markov Decision Processes): 상대방 모델링과 관련이 있지만, 이 프레임워크는 "중첩된 믿음 추론"으로 인해 발생하는 "심각한 계산 복잡성 문제"로 인해 거부된다. 계산 부담으로 인해 "복잡한 환경에서 비현실적"이다. HOP의 설계는 더 큰 효율성을 달성하기 위해 이 중첩된 추론을 명시적으로 피한다.
- 다중 에이전트 환경에서의 단순 MCTS: 본 논문은 MCTS 자체만으로는 "에이전트 수가 증가함에 따라 공동 행동 공간이 빠르게 증가하는 다중 에이전트 환경에서 제한적"임을 인정한다. 직접적인 적용은 계산적으로 불가능할 것이다. HOP의 해결책은 협력자 정책을 추정하고 초점 에이전트의 행동만 계획하는 것이며, 이 확장성 문제를 효과적으로 우회한다.
- HOP의 축소 버전 (inter-OM 없음, intra-OM 없음, 직접-OM): 축소 연구는 HOP의 더 단순하거나 불완전한 버전에 대한 경험적 증거를 제공한다.
- inter-OM 없음: 이 버전은 고정된 목표를 가진 에이전트(예: 협력자, 배신자)에 대해 어려움을 겪는데, 이는 에피소드 시작 시 정확한 목표 사전 믿음이 부족하여 최적의 플레이 기회를 놓치기 때문이다. 이는 과거 에피소드를 활용하는 것의 필요성을 강조한다.
- intra-OM 없음: 이 버전은 동적인 행동을 가진 에이전트(예: LOLA, PS-A3C, 무작위)에 대해 성능이 떨어진다. 왜냐하면 과거 에피소드에만 의존하여 에피소드 내 협력자 목표 변화에 적응할 수 없기 때문이다. 이는 실시간, 에피소드 내 믿음 업데이트의 중요성을 강조한다.
- 직접-OM: 목표 조건부 없이 신경망을 사용하여 협력자를 직접 모델링하는 이 접근 방식은 "전반적으로 불리하다". 짧은 상호 작용 중에 상당한 업데이트를 얻는 데 어려움을 겪어 "적응 단계 동안 부정확한 상대방 모델링"으로 이어진다. 종단 간 특성은 또한 "목표 조건부 정책에 비해 더 높은 수준의 불확실성"을 도입하여 계획의 정밀도를 감소시킨다. 이는 HOP의 목표 조건부, 계층적 상대방 모델링의 우수성을 명확하게 검증한다.
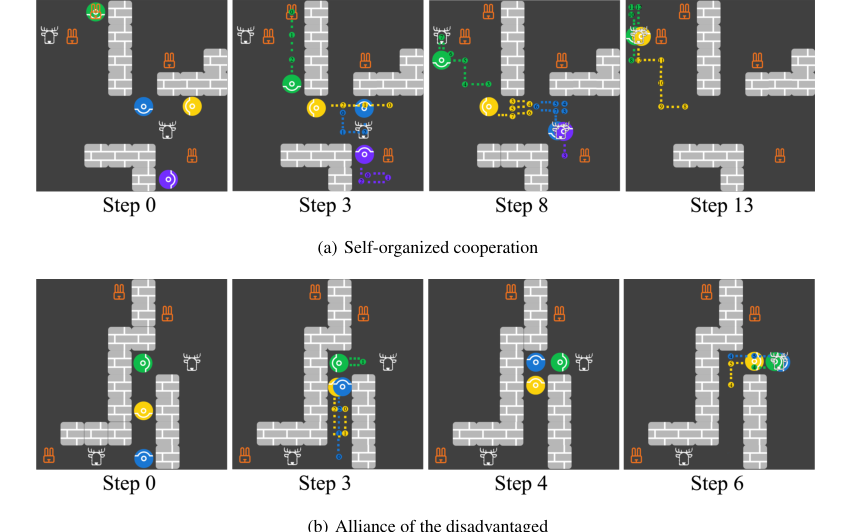 Figure 6. Screenshots for the emergence of (a) self-organized cooperation and (b) alliance of the disadvantaged. Each panel shows agents’ locations at the current step and the trajectories between the current step and the previously stated step
Figure 6. Screenshots for the emergence of (a) self-organized cooperation and (b) alliance of the disadvantaged. Each panel shows agents’ locations at the current step and the trajectories between the current step and the previously stated step
수학적 및 논리적 메커니즘
마스터 방정식
계층적 상대방 모델링 및 계획(HOP) 알고리즘은 적응 능력을 가능하게 하는 여러 상호 연결된 수학적 메커니즘에 의해 구동된다. 핵심적으로 HOP는 상대방 목표 모델링을 위한 베이즈 추론, 목표 조건부 상대방 정책 학습을 위한 음수 로그-가능도 목적 함수, 그리고 몬테 카를로 트리 탐색(MCTS)에 의해 안내되는 초점 에이전트의 의사 결정 네트워크 훈련을 위한 결합된 정책 및 가치 손실에 의존한다.
HOP의 수학적 엔진을 정의하는 절대적인 핵심 방정식은 다음과 같다.
-
에피소드 내 상대방 목표 믿음 업데이트 (Intra-OM): 이 방정식은 실시간 관찰을 통합하여 단일 에피소드 내에서 협력자의 목표에 대한 초점 에이전트의 믿음을 업데이트한다.
$$b_{ij}^{K,t+1}(g_j) = \frac{1}{Z_1} b_{ij}^{K,t}(g_j) \frac{\Pr(a_j^{K,t}|s^{K,t}, g_j) \Pr(s^{K,t+1}|s^{K,t}, a_j^{K,t}, g_j)}{\Pr(s^{K,t+1}|s^{K,t}, a_j^{K,t})}$$ -
에피소드 간 상대방 목표 믿음 업데이트 (Inter-OM): 이 방정식은 과거 에피소드의 정보를 활용하여 새 에피소드 시작 시 협력자의 목표에 대한 사전 믿음을 업데이트한다.
$$b_{ij}^{K,0}(g_j) = \frac{1}{Z_2} [\alpha b_{ij}^{K-1,0}(g_j) + (1-\alpha)\mathbf{1}(g_j = g_j^{K-1})]$$ -
목표 조건부 상대방 정책 네트워크 손실: 이 목적 함수는 추론된 목표와 현재 상태가 주어졌을 때 협력자의 행동을 예측하는 신경망을 훈련시킨다.
$$\mathcal{L}(\omega) = \mathbb{E}[-\log(\pi_\omega(a_j^{K,t}|s^{K,t}, g_j^{K,t}))]$$ -
초점 에이전트의 정책 및 가치 네트워크 손실: 이 결합된 손실 함수는 MCTS를 감독으로 사용하여 초점 에이전트의 주요 정책 및 가치 네트워크를 훈련시킨다.
$$\mathcal{L}(\theta) = \mathcal{L}_p(\pi_{\text{MCTS}}, \pi_\theta) + \mathcal{L}_v(r_i, v_\theta)$$
여기서
$$\mathcal{L}_p(\pi_1, \pi_2) = \mathbb{E}[-\sum_{a \in \mathcal{A}_i} \pi_1(a|s^{K,t}) \log(\pi_2(a|s^{K,t}))]$$
$$\mathcal{L}_v(r_i, v) = \mathbb{E}[(v(s^{K,t}) - \sum_{l=t}^{T_{\text{max}}} \gamma^{l-t} r_i^{K,l})^2]$$
항별 분석
이러한 각 방정식을 분해하여 각 구성 요소의 역할을 이해해 보자.
에피소드 내 상대방 목표 믿음 업데이트 (방정식 1)
$$b_{ij}^{K,t+1}(g_j) = \frac{1}{Z_1} b_{ij}^{K,t}(g_j) \frac{\Pr(a_j^{K,t}|s^{K,t}, g_j) \Pr(s^{K,t+1}|s^{K,t}, a_j^{K,t}, g_j)}{\Pr(s^{K,t+1}|s^{K,t}, a_j^{K,t})}$$
- $b_{ij}^{K,t+1}(g_j)$:
- 수학적 정의: 에피소드 $K$ 내 시간 $t+1$에서 상대방 $j$의 목표 $g_j$에 대한 에이전트 $i$의 믿음을 나타내는 사후 확률 분포.
- 물리적/논리적 역할: 이것은 업데이트된 믿음이다. 초점 에이전트에게 "이 에피소드에서 지금까지 본 모든 것을 고려할 때, 상대방 $j$가 목표 $g_j$를 가질 가능성은 얼마나 되는가?"라고 말한다. 이는 협력자의 변화하는 행동에 대한 실시간 적응에 매우 중요하다.
- $Z_1$:
- 수학적 정의: 정규화 계수.
- 물리적/논리적 역할: 상대방 $j$의 모든 가능한 목표 $g_j$에 대한 확률의 합이 1이 되도록 보장하여 유효한 확률 분포를 유지한다.
- 나눗셈 이유: 베이즈 정리의 기본 부분으로, 분자(사전 확률 곱하기 가능도)를 적절한 확률로 스케일링한다.
- $b_{ij}^{K,t}(g_j)$:
- 수학적 정의: 에피소드 $K$ 내 시간 $t$에서 상대방 $j$의 목표 $g_j$에 대한 에이전트 $i$의 믿음을 나타내는 사전 확률 분포.
- 물리적/논리적 역할: 이것은 최신 행동 및 상태 전이를 관찰하기 전의 믿음이다. 현재 베이즈 업데이트 단계의 시작점으로 작용한다.
- $\Pr(a_j^{K,t}|s^{K,t}, g_j)$:
- 수학적 정의: 현재 상태 $s^{K,t}$와 가설적 목표 $g_j$가 주어졌을 때 상대방 $j$가 행동 $a_j^{K,t}$를 취할 확률. 이는 목표 조건부 정책 네트워크 $\pi_\omega$에 의해 제공된다.
- 물리적/논리적 역할: 이 항은 "행동의 가능도" 역할을 한다. 특정 가설적 목표 $g_j$가 관찰된 행동 $a_j^{K,t}$를 얼마나 잘 설명하는지를 정량화한다. 상대방이 목표 $g_A$ 하에서 매우 가능성이 높지만 목표 $g_B$ 하에서는 가능성이 낮은 행동을 취하면, 이 항은 $g_A$에 대한 믿음을 높일 것이다.
- $\Pr(s^{K,t+1}|s^{K,t}, a_j^{K,t}, g_j)$:
- 수학적 정의: 이전 상태 $s^{K,t}$, 상대방 $j$의 행동 $a_j^{K,t}$, 그리고 가설적 목표 $g_j$가 주어졌을 때 상태 $s^{K,t+1}$로 전이할 확률. 본 논문에서는 이것이 $\Pr(s^{K,t+1}|s^{K,t}, a_j^{K,t})$로 단순화될 수 있는 마르코프 가정을 언급하지만, 방정식에는 $g_j$가 포함되어 있어 잠재적 의존성 또는 더 일반적인 공식화를 시사한다.
- 물리적/논리적 역할: 이 항은 "상태 전이의 가능도" 역할을 한다. 관찰된 상태 변화가 가설적 목표 및 행동과 일치하는지 여부를 고려하여 믿음을 더욱 정제한다.
- $\Pr(s^{K,t+1}|s^{K,t}, a_j^{K,t})$:
- 수학적 정의: 이전 상태 $s^{K,t}$와 상대방 $j$의 행동 $a_j^{K,t}$가 주어졌을 때 상태 $s^{K,t+1}$로 전이할 확률.
- 물리적/논리적 역할: 전체 가능도를 적절하게 스케일링하기 위한 상태 전이 가능도의 정규화 항이다.
- 곱셈 이유: 베이즈 업데이트는 사전 믿음과 가능도를 곱셈으로 결합하여 새로운 증거가 기존 믿음을 어떻게 스케일링하는지를 반영한다.
에피소드 간 상대방 목표 믿음 업데이트 (방정식 2)
$$b_{ij}^{K,0}(g_j) = \frac{1}{Z_2} [\alpha b_{ij}^{K-1,0}(g_j) + (1-\alpha)\mathbf{1}(g_j = g_j^{K-1})]$$
- $b_{ij}^{K,0}(g_j)$:
- 수학적 정의: 에피소드 $K$의 시작 시점에서 상대방 $j$의 목표 $g_j$에 대한 에이전트 $i$의 믿음을 나타내는 사전 확률 분포.
- 물리적/논리적 역할: 이것은 새 에피소드에서 상대방 $j$의 목표에 대한 초기 추측이다. 과거 경험에 의해 알려지며, 상대방 행동에 대한 "기억"을 제공한다.
- $Z_2$:
- 수학적 정의: 정규화 계수.
- 물리적/논리적 역할: 모든 가능한 목표 $g_j$에 대한 확률의 합이 1이 되도록 보장한다.
- 나눗셈 이유: 확률 분포에 대한 표준 정규화.
- $\alpha$:
- 수학적 정의: 호라이즌 가중치, $\alpha \in [0, 1]$.
- 물리적/논리적 역할: 이 계수는 과거 믿음의 영향과 가장 최근에 관찰된 목표의 영향을 제어한다. 높은 $\alpha$는 오래된 믿음이 더 중요함을 의미하여 느린 적응을 초래한다. 낮은 $\alpha$(0에 가까운)는 에이전트가 바로 이전 에피소드에서 관찰된 목표를 우선시하여 동적인 상대방에 대한 신속한 적응을 가능하게 한다.
- 곱셈 이유: 이전 에피소드의 사전 믿음의 기여도를 스케일링한다.
- $b_{ij}^{K-1,0}(g_j)$:
- 수학적 정의: 이전 에피소드 $K-1$의 시작 시점에서 에이전트 $i$에 대한 상대방 $j$의 목표 $g_j$에 대한 사전 확률 분포.
- 물리적/논리적 역할: 현재 에피소드 이전의 모든 에피소드에서 상대방 $j$의 목표에 대한 축적된 역사적 지식을 나타낸다.
- $(1-\alpha)$:
- 수학적 정의: $\alpha$에 대한 보완 가중치.
- 물리적/논리적 역할: 이전 에피소드에서 관찰된 목표의 기여도를 스케일링한다.
- 곱셈 이유: 가장 최근의 목표 관찰의 기여도를 스케일링한다.
- $\mathbf{1}(g_j = g_j^{K-1})$:
- 수학적 정의: 이전 에피소드 $K-1$에서 상대방 $j$의 목표가 $g_j$였으면 1을 반환하고, 그렇지 않으면 0을 반환하는 지시 함수.
- 물리적/논리적 역할: 이 항은 마지막 에피소드에서 상대방 $j$에 대해 추론된 실제 목표를 직접 통합한다. 새 에피소드에 대한 사전 믿음을 업데이트하는 강력한 신호이다.
- 덧셈 이유: 두 가중치 항이 더해져 장기적인 역사적 믿음과 단기적인 가장 최근 관찰을 결합하여 새로운 사전 믿음을 형성한다.
목표 조건부 상대방 정책 네트워크 손실 (방정식 3)
$$\mathcal{L}(\omega) = \mathbb{E}[-\log(\pi_\omega(a_j^{K,t}|s^{K,t}, g_j^{K,t}))]$$
- $\mathcal{L}(\omega)$:
- 수학적 정의: $\omega$로 매개변수화된 목표 조건부 정책 네트워크의 손실 함수.
- 물리적/논리적 역할: 이것은 상대방 모델링 모듈이 협력자의 목표 조건부 정책을 정확하게 학습하기 위해 최소화하는 목적 함수이다. 낮은 손실은 네트워크가 목표가 주어졌을 때 상대방 행동을 예측하는 데 더 능숙함을 의미한다.
- $\mathbb{E}[\cdot]$:
- 수학적 정의: 기대값 연산자, 일반적으로 재현 버퍼의 데이터 샘플 배치에 대해 평균하여 근사한다.
- 물리적/논리적 역할: 개별 데이터 포인트의 노이즈 영향을 줄여 여러 관찰에 대해 평균함으로써 손실의 안정적인 추정치를 제공한다.
- $-\log(\pi_\omega(a_j^{K,t}|s^{K,t}, g_j^{K,t}))$:
- 수학적 정의: 상태 $s^{K,t}$와 추론된 목표 $g_j^{K,t}$가 주어졌을 때 정책 네트워크 $\pi_\omega$가 관찰된 행동 $a_j^{K,t}$에 할당한 확률의 음수 로그.
- 물리적/논리적 역할: 이것은 분류 또는 정책 학습을 위한 지도 학습에서 표준적인 음수 로그-가능도 손실이다. 이 손실을 최소화하는 것은 네트워크가 올바른 (관찰된) 행동에 할당하는 확률을 최대화하는 것을 의미하며, 효과적으로 네트워크가 특정 목표 하에서 상대방 행동을 모방하도록 가르친다.
- 음수 로그 이유: 로그는 확률의 곱을 합으로 변환하여 최적화하기 쉽게 만든다. 음수 부호는 목적을 가능도 최대화에서 손실 최소화로 변환하며, 이는 경사 하강법 최적화에 표준적이다.
초점 에이전트의 정책 및 가치 네트워크 손실 (방정식 6)
$$\mathcal{L}(\theta) = \mathcal{L}_p(\pi_{\text{MCTS}}, \pi_\theta) + \mathcal{L}_v(r_i, v_\theta)$$
$$\mathcal{L}_p(\pi_1, \pi_2) = \mathbb{E}[-\sum_{a \in \mathcal{A}_i} \pi_1(a|s^{K,t}) \log(\pi_2(a|s^{K,t}))]$$
$$\mathcal{L}_v(r_i, v) = \mathbb{E}[(v(s^{K,t}) - \sum_{l=t}^{T_{\text{max}}} \gamma^{l-t} r_i^{K,l})^2]$$
- $\mathcal{L}(\theta)$:
- 수학적 정의: $\theta$로 매개변수화된 초점 에이전트의 정책 및 가치 네트워크에 대한 총 손실 함수.
- 물리적/논리적 역할: 이것은 초점 에이전트가 최적 정책과 정확한 가치 함수를 학습하기 위해 최소화하는 주요 목적 함수이다. 이는 강화 학습의 두 가지 중요한 측면, 즉 잘 행동하는 법을 배우는 것과 미래 보상을 예측하는 법을 배우는 것을 결합한다.
- 덧셈 이유: 정책 및 가치 학습은 종종 액터-크리틱 또는 AlphaZero와 같은 아키텍처에서 단일 목적 함수로 결합되는데, 이는 공유 표현과 공동 최적화를 통해 이익을 얻는 상호 보완적인 작업이기 때문이다.
- $\mathcal{L}_p(\pi_{\text{MCTS}}, \pi_\theta)$:
- 수학적 정의: MCTS에서 파생된 정책 $\pi_{\text{MCTS}}$(대상 정책 $\pi_1$)와 학습된 정책 $\pi_\theta$(예측 정책 $\pi_2$) 간의 교차 엔트로피 손실인 정책 손실 항.
- 물리적/논리적 역할: 이 항은 "정책 증류" 메커니즘 역할을 한다. MCTS는 탐색을 통해 현재 학습된 정책 $\pi_\theta$보다 "더 강력한" 정책을 생성한다. 이 손실은 초점 에이전트의 학습된 정책 $\pi_\theta$가 MCTS에서 생성된 정책을 모방하도록 장려한다. 이는 MCTS의 "지혜"를 신경망으로 전달하는 것을 효과적으로 한다.
- $\mathbb{E}[-\sum_{a \in \mathcal{A}_i} \pi_1(a|s^{K,t}) \log(\pi_2(a|s^{K,t}))]$:
- 수학적 정의: 두 확률 분포 $\pi_1$과 $\pi_2$ 간의 교차 엔트로피.
- 물리적/논리적 역할: 학습된 정책 $\pi_2$가 MCTS 대상 정책 $\pi_1$과 얼마나 다른지를 측정한다. 교차 엔트로피를 최소화하면 $\pi_2$가 $\pi_1$과 일치하게 된다.
- 합산 이유: 초점 에이전트의 행동 공간 $\mathcal{A}_i$에 있는 모든 가능한 행동에 대한 음수 로그 확률을 대상 정책의 확률로 가중하여 합산한다.
- $\mathcal{L}_v(r_i, v_\theta)$:
- 수학적 정의: 가치 네트워크에서 예측된 가치 $v(s^{K,t})$와 실제 할인된 반환값 $\sum_{l=t}^{T_{\text{max}}} \gamma^{l-t} r_i^{K,l}$ 간의 평균 제곱 오차(MSE)인 가치 손실 항.
- 물리적/논리적 역할: 이 항은 가치 네트워크 $v_\theta$를 훈련시켜 어떤 상태에서도 예상되는 누적 미래 보상을 정확하게 예측하도록 한다. 정확한 가치 함수는 MCTS를 안내하고 상태의 품질을 평가하는 데 매우 중요하다.
- $\mathbb{E}[(v(s^{K,t}) - \sum_{l=t}^{T_{\text{max}}} \gamma^{l-t} r_i^{K,l})^2]$:
- 수학적 정의: 예측된 가치와 할인된 실제 반환값 간의 제곱 차이.
- 물리적/논리적 역할: 이것은 회귀 작업에 대한 표준 손실이다. 가치 네트워크가 부정확한 예측을 하는 경우 페널티를 부여하며, 더 큰 오류는 제곱으로 더 높은 페널티를 받는다.
- 제곱 차이 이유: 회귀 작업에 일반적이며, 경사 하강법 최적화를 위한 부드럽고 미분 가능한 손실 영역을 제공한다.
- $v(s^{K,t})$:
- 수학적 정의: 초점 에이전트의 가치 네트워크가 상태 $s^{K,t}$에 대해 예측한 가치.
- 물리적/논리적 역할: 상태 $s^{K,t}$에서 얻을 수 있는 총 미래 할인 보상에 대한 모델의 현재 추정치이다.
- $\sum_{l=t}^{T_{\text{max}}} \gamma^{l-t} r_i^{K,l}$:
- 수학적 정의: 시간 단계 $t$부터 에피소드 끝 $T_{\text{max}}$까지 에이전트 $i$가 받은 실제 할인된 반환값(누적 보상).
- 물리적/논리적 역할: 이것은 가치 네트워크의 "실제 값"이다. 시간적 거리에 따라 할인된 미래 보상의 실제 합계를 나타낸다.
- 합산 이유: 전체 미래 궤적에 걸쳐 보상을 누적한다.
- $\gamma$:
- 수학적 정의: 할인 계수, $\gamma \in [0, 1]$.
- 물리적/논리적 역할: 미래 보상의 현재 가치를 결정한다. 0에 가까운 $\gamma$는 에이전트를 근시안적으로 만든다(즉각적인 보상만 신경 씀). 1에 가까운 $\gamma$는 에이전트를 원시안적으로 만든다(장기적인 보상을 많이 고려함).
- 거듭제곱 이유: 미래의 보상 중요도를 지수적으로 감소시키기 위해 강화 학습에서 표준적이다.
단계별 흐름
환경 상태 및 협력자 행동에 대한 관찰과 같은 단일 추상 데이터 포인트가 HOP 시스템에 들어간다고 상상해 보라. 이것이 수학적 엔진을 통과하는 방법은 다음과 같다.
-
에피소드 시작: 과거를 통한 무대 설정:
- 새로운 에피소드 $K$가 시작될 때, 초점 에이전트 $i$는 협력자에 대한 믿음에 관해서는 처음부터 시작하지 않는다. 먼저 과거 상호 작용의 "기억"을 참조한다.
- 에피소드 간 믿음 업데이트 (방정식 2)가 트리거된다. 이 방정식은 이전 에피소드의 사전 믿음 $b_{ij}^{K-1,0}(g_j)$을 가져와 해당 마지막 에피소드에서 상대방 $j$에 대해 추론된 실제 목표 $g_j^{K-1}$과 결합한다. 호라이즌 가중치 $\alpha$는 장기적인 평균 믿음과 매우 최근의 과거를 얼마나 많이 신뢰할지를 제어하는 다이얼과 같다. 이는 현재 에피소드에 대한 초기 믿음 $b_{ij}^{K,0}(g_j)$을 생성하여 에이전트에게 시작점을 제공한다.
-
실시간 상호 작용: 상대방 목표 관찰 및 추론:
- 에피소드가 진행됨에 따라 각 시간 단계 $t$에서 에이전트는 현재 상태 $s^{K,t}$와 협력자가 취한 행동 $a_j^{K,t}$를 관찰한다.
- 이 새로운 관찰은 즉시 에피소드 내 믿음 업데이트 (방정식 1)로 피드된다. 에이전트는 현재 믿음 $b_{ij}^{K,t}(g_j)$(t=0에서는 $b_{ij}^{K,0}(g_j)$였음)을 가져와 업데이트한다. "상대방 $j$가 목표 $g_j$를 가지고 있었다면 행동 $a_j^{K,t}$를 취하고 상태 $s^{K,t+1}$를 유발했을 가능성은 얼마나 되는가?"라고 묻는다.
- 이 질문에 답하기 위해 목표 조건부 정책 네트워크 $\pi_\omega$를 사용하여 각 가능한 목표 $g_j$에 대해 $\Pr(a_j^{K,t}|s^{K,t}, g_j)$를 얻는다. 그런 다음 이 가능도는 현재 믿음에 곱해지고 결과는 $Z_1$으로 정규화된다. 이 과정은 에피소드 내에서 더 많은 행동이 관찰됨에 따라 상대방 목표에 대한 믿음을 더욱 정확하게 만들어 $b_{ij}^{K,t+1}(g_j)$를 지속적으로 개선한다.
-
상대방 행동 학습: 목표 조건부 정책 훈련:
- 이 과정 전반에 걸쳐 추론된 목표 $g_j^{K,t}$(가장 가능성 높은 목표)와 관찰된 상태 $s^{K,t}$ 및 행동 $a_j^{K,t}$가 수집되어 궤적 버퍼에 저장된다.
- 주기적으로 이 수집된 데이터는 목표 조건부 정책 네트워크 $\pi_\omega$를 훈련시키는 데 사용된다. 목표 조건부 정책 네트워크 손실 (방정식 3)이 최소화된다. 이것은 마치 교사가 네트워크에 예시를 보여주는 것과 같다: "상대방이 상태 $s$에 있고 목표 $g$를 가졌을 때, 그들은 행동 $a$를 취했다." 네트워크는 $s$와 $g$가 주어졌을 때 $a$를 예측하도록 학습하여 협력자 행동을 특정 목표 하에서 모델링하는 능력을 향상시킨다.
-
초점 에이전트의 의사 결정: 최적 대응 계획:
- 이제 초점 에이전트가 행동할 차례이다. 자체 행동 $a_i^{K,t}$를 선택해야 한다.
- 에이전트는 몬테 카를로 트리 탐색(MCTS)을 시작한다. MCTS는 현재 상태만 고려하는 것이 아니라 여러 가능한 미래를 시뮬레이션한다.
- 중요하게도 MCTS는 협력자의 목표를 확실히 알지 못한다. 따라서 각 $N_s$ 시뮬레이션 라운드에서 협력자의 목표 조합을 현재 믿음 $b_{ij}^{K,t}(g_j)$(단계 2에서)에서 샘플링한다.
- 각 샘플링된 목표 조합에 대해 MCTS는 궤적을 시뮬레이션한다. 협력자 $j$가 무엇을 할 것인지 알아야 할 때, 학습된 목표 조건부 정책 $\pi_\omega(\cdot|s, g_j)$(단계 3에서)를 샘플링된 목표 $g_j$와 함께 사용한다. 초점 에이전트는 자체 행동을 탐색한다.
- $N_s$ 라운드 후, MCTS는 협력자의 목표에 대한 불확실성을 고려하여 초점 에이전트의 각 가능한 행동에 대해 평균 행동 가치 $Q_{\text{avg}}(s^{K,t}, a)$(방정식 4)를 계산한다.
- 마지막으로, 초점 에이전트는 볼츠만 합리성 모델(방정식 5)을 사용하여 행동 $a_i^{K,t}$를 선택하며, 이는 더 높은 $Q_{\text{avg}}$ 값을 가진 행동을 선호하여 탐색과 활용의 균형을 맞춘다.
-
더 나아지기 위한 학습: 초점 에이전트의 네트워크 훈련:
- MCTS 프로세스 자체는 "더 나은" 정책 $\pi_{\text{MCTS}}$(탐색을 통해 파생됨)와 상태 가치에 대한 개선된 추정치와 같은 귀중한 정보를 제공한다.
- 이 정보는 실제 보상 $r_i^{K,l}$과 함께 에피소드 중에 받은 정보를 사용하여 초점 에이전트의 주요 정책 및 가치 네트워크를 훈련시킨다.
- 초점 에이전트의 정책 및 가치 네트워크 손실 (방정식 6)이 최소화된다. 이 손실은 두 부분으로 구성된다.
- 학습된 정책 $\pi_\theta$가 MCTS에서 생성된 정책 $\pi_{\text{MCTS}}$를 모방하도록 하는 정책 손실 $\mathcal{L}_p$. 이것은 MCTS "교사"가 네트워크에 최적의 움직임을 보여주는 것과 같다.
- 가치 네트워크 $v_\theta$가 에피소드 중에 관찰된 실제 할인된 반환값 $\sum_{l=t}^{T_{\text{max}}} \gamma^{l-t} r_i^{K,l}$을 정확하게 예측하도록 훈련시키는 가치 손실 $\mathcal{L}_v$. 이것은 네트워크가 상태가 얼마나 좋은지 정확하게 평가하도록 가르친다.
- 이 결합된 손실을 통해 초점 에이전트의 신경망은 더 나은 결정을 내리고 상태를 더 정확하게 평가하도록 학습하여 시간이 지남에 따라 더 능숙해진다.
이 전체 사이클은 각 단계가 서로를 공급하고 개선하는 방식으로 반복되어 동적이고 적응적인 학습 시스템을 생성한다.
최적화 역학
HOP 메커니즘은 복잡하고 불확실한 환경에서 적응 의사 결정을 위한 공통 프레임워크로서 계층적 믿음 추론과 목표 조건부 계획을 보여줌으로써, AI, 생물학 또는 경제학에서 복잡하고 불확실한 다중 에이전트 환경에서의 적응 의사 결정이라는 과제가 계층적 믿음 추론과 목표 조건부 계획의 공통 프레임워크를 통해 우아하게 해결될 수 있음을 보여줌으로써 보편적 구조 라이브러리를 크게 풍부하게 한다.
-
믿음 시스템 정제:
- 에피소드 내 믿음 (방정식 1): 내부-OM 모듈은 베이즈 업데이트를 사용하여 협력자의 목표에 대한 믿음을 지속적으로 업데이트한다. 각 새로운 관찰(상대방 행동 및 상태 전이)은 특정 목표의 확률을 강화하거나 약화시키는 증거를 제공한다. 시간이 지남에 따라 에피소드 내에서 더 많은 데이터가 수집됨에 따라, 사후 분포 $b_{ij}^{K,t+1}(g_j)$는 상대방의 실제 기본 목표를 향해 수렴하는 경향이 있으며, 이는 그들의 행동이 학습된 목표 조건부 정책 중 하나와 일치한다고 가정한다. 이것은 고전적인 베이즈 업데이트로, 누적되는 증거에 따라 믿음 분포의 불확실성(엔트로피)이 감소한다.
- 에피소드 간 사전 믿음 (방정식 2): 외부-OM 모듈은 새 에피소드에 대한 사전 믿음을 업데이트한다. 호라이즌 가중치 $\alpha$는 여기서 중요한 하이퍼파라미터이다. $\alpha$가 높으면 시스템은 장기적인 과거 평균에 크게 의존하여 사전 믿음의 느리지만 안정적인 수렴을 초래한다. $\alpha$가 낮으면 시스템은 최근 상대방 행동에 신속하게 적응하여 더 빠른 적응을 가능하게 하지만, 상대방 목표가 매우 변동성이 큰 경우 더 많은 불안정성을 초래할 수도 있다. 이 메커니즘은 시스템이 여러 에피소드에 걸쳐 상대방 전략의 변화를 추적하고 적응할 수 있도록 한다.
-
상대방 정책 학습:
- (상대방 행동을 예측하는 데 사용되는) 목표 조건부 정책 네트워크 $\pi_\omega$는 확률 경사 하강법(SGD) 또는 그 변형을 사용하여 음수 로그-가능도 손실(방정식 3)을 최소화함으로써 훈련된다. 이 네트워크의 손실 영역은 관찰된 상대방 행동에 대한 예측의 정확성에 의해 형성된다. 더 다양하고 정확한 데이터(상태, 추론된 목표, 실제 행동)가 수집되어 재현 버퍼에 피드됨에 따라, 경사는 네트워크 매개변수 $\omega$를 이 손실을 최소화하는 방향으로 안내한다. 이 과정은 상대방 행동을 정확하게 모델링하는 네트워크의 능력을 반복적으로 향상시켜 상대방 모델링 모듈을 더 신뢰할 수 있게 만든다.
-
초점 에이전트의 정책 및 가치 학습:
- 초점 에이전트의 정책 $\pi_\theta$와 가치 함수 $v_\theta$는 MCTS가 강력한 "교사" 역할을 하는 지도 학습 과정을 통해 학습된다. 총 손실 $\mathcal{L}(\theta)$(방정식 6)는 경사 하강법을 사용하여 최소화된다.
- 정책 개선: MCTS는 광범위한 시뮬레이션과 탐색을 수행함으로써 현재 학습된 정책 $\pi_\theta$보다 "더 강력한" 정책 $\pi_{\text{MCTS}}$를 생성한다. 그런 다음 정책 손실 항 $\mathcal{L}_p$는 $\pi_\theta$가 $\pi_{\text{MCTS}}$를 모방하도록 구동한다. 이는 $\mathcal{L}_p$의 경사가 학습된 정책이 MCTS에서 생성된 정책과 더 가깝게 일치하도록 매개변수 $\theta$를 안내한다는 것을 의미한다. 이 반복적인 감독을 통해 $\pi_\theta$는 환경을 직접 탐색할 필요 없이 최적에 가까운 정책으로 수렴할 수 있다.
- 가치 함수 정확도: 가치 손실 항 $\mathcal{L}_v$는 $v_\theta$를 훈련시켜 MCTS 시뮬레이션 및 실제 게임 플레이 중에 관찰된 실제 할인된 반환값을 예측하도록 한다. $\mathcal{L}_v$의 경사는 예측된 반환값과 실제 반환값 간의 평균 제곱 오차를 줄이기 위해 $\theta$를 안내한다. $v_\theta$가 더 정확해짐에 따라 MCTS에 더 나은 추정치를 제공하여 탐색을 더 효율적이고 효과적으로 만든다. 이는 긍정적인 피드백 루프를 생성한다. 더 나은 가치 추정치는 더 나은 MCTS를 가능하게 하고, 이는 $v_\theta$에 대한 더 나은 훈련 대상을 생성한다.
- 손실 영역: 결합된 손실 $\mathcal{L}(\theta)$는 복잡한 손실 영역을 생성한다. 그러나 MCTS 감독은 신경망 매개변수 $\theta$를 높은 기대 반환 영역으로 안내하는 강력하지만 잠재적으로 노이즈가 많은 신호를 제공한다. MCTS(반복 시뮬레이션)와 신경망 훈련(경사 업데이트)의 반복적인 특성을 통해 시스템은 강력한 정책 및 가치 함수로 수렴할 수 있다.
-
MCTS 탐색-활용:
- MCTS 알고리즘 자체는 PPUCT(Polynomial Upper Confidence Trees)와 같은 메커니즘을 사용하여 탐색과 활용의 균형을 맞춘다. MCTS 점수 함수(부록 E.1 참조)의 탐색 계수 $c$는 이 균형을 제어한다. 더 높은 $c$는 MCTS가 덜 방문된 행동을 탐색하도록 장려하여 더 나은 전략을 발견할 가능성이 있다. 더 낮은 $c$는 MCTS가 알려진 좋은 행동을 더 많이 활용하여 지역 최적값으로 더 빠른 수렴을 초래한다. 이 동적 메커니즘은 MCTS가 신경망을 감독하기 위한 개선된 정책을 계속 찾도록 보장한다.
요약하자면, HOP의 최적화 역학은 계층적이고 반복적인 학습 프로세스로 특징지어진다. 상대방 모델은 베이즈 업데이트와 지도 학습을 통해 지속적으로 정제되어 협력자 행동에 대한 점점 더 정확한 예측을 제공한다. 이 정제된 이해는 MCTS에 정보를 제공하며, MCTS는 강력한 계획 엔진 역할을 하여 더 나은 정책과 가치 대상을 생성한다. 이러한 대상은 차례로 초점 에이전트의 주요 정책 및 가치 네트워크를 감독하여 혼합 동기 환경에서 효율적이고 적응적인 의사 결정 전략으로 수렴하도록 구동한다. 이러한 구성 요소의 상호 작용은 시스템이 보지 못한 정책에 적응하고 강력한 행동을 학습할 수 있도록 보장한다.
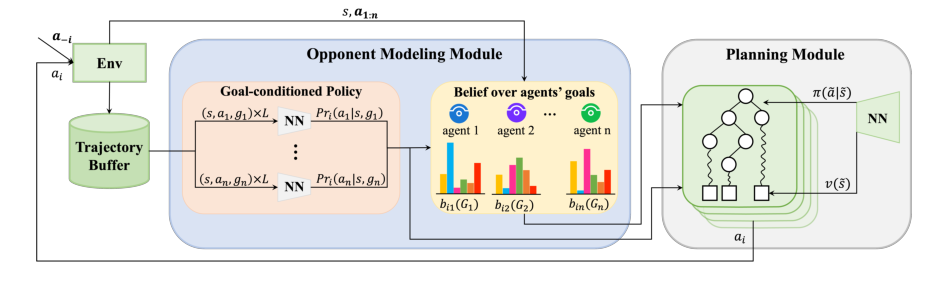 Figure 1. Overview of HOP. HOP consists of an opponent modeling module and a planning module. The opponent modeling module models the behavior of co-players by inferring co-players’ goals and learning their goal-conditioned policies. Estimated behavior is then fed to the planning module to select a rewarding action for the focal agent
Figure 1. Overview of HOP. HOP consists of an opponent modeling module and a planning module. The opponent modeling module models the behavior of co-players by inferring co-players’ goals and learning their goal-conditioned policies. Estimated behavior is then fed to the planning module to select a rewarding action for the focal agent
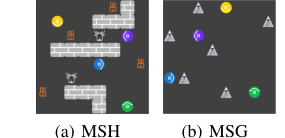 Figure 2. Overview of Markov Stag-Hunt and Markov Snowdrift. There are four agents, repre- sented by colored circles, in each paradigm. (a) Agents catch prey for reward. A stag with a reward of 10 requires at least two agents to hunt together. One agent can hunt a hare with a reward of 1. (b) Everyone gets a reward of 6 when an agent removes a snowdrift. When a snowdrift is removed, removers share the cost of 4 evenly
Figure 2. Overview of Markov Stag-Hunt and Markov Snowdrift. There are four agents, repre- sented by colored circles, in each paradigm. (a) Agents catch prey for reward. A stag with a reward of 10 requires at least two agents to hunt together. One agent can hunt a hare with a reward of 1. (b) Everyone gets a reward of 6 when an agent removes a snowdrift. When a snowdrift is removed, removers share the cost of 4 evenly
결과, 한계 및 결론
실험 설계 및 기준선
혼합 동기 환경에서의 계층적 상대방 모델링 및 계획(HOP) 알고리즘의 엄격한 검증을 위해, 저자들은 두 가지 구별되는 혼합 동기 환경, 즉 마르코프 사슴 사냥(MSH)과 마르코프 눈덩이 게임(MSG)에서 실험을 수행했다. 이러한 환경은 고전적인 게임 이론 패러다임의 공간적 및 시간적 확장으로, 복잡한 전략적 상호 작용을 유발하도록 설계되었다.
MSH에서 네 명의 에이전트가 그리드에서 먹이를 사냥한다(사슴과 토끼). 사슴은 10의 보상을 제공하지만, 보상을 분할하는 두 명 이상의 에이전트가 협력하여 사냥해야 한다. 토끼는 1의 보상을 제공하며 단일 에이전트가 잡을 수 있다. 게임은 30 타임스텝 후에 종료된다. 두 가지 MSH 설정이 사용되었다.
- MSH-4h1s: 토끼 4마리와 사슴 1마리가 등장한다. 이 설정은 사슴에 대한 협력을 장려하는 동시에 토끼에 대한 경쟁을 유지하여 혼합 동기 역학을 생성한다.
- MSH-4h2s: 토끼 4마리와 사슴 2마리가 등장한다. 이는 협력의 잠재력을 증가시키지만, 게임이 첫 번째 성공적인 사냥 후 단 5 타임스텝 후에 종료되는 반전을 도입하여 즉각적인 개인적 이익과 장기적인 집단적 이익 사이의 긴장을 고조시킨다.
MSG 환경은 8x8 그리드에 여섯 개의 눈덩이를 무작위로 배치한다. 에이전트는 이동하거나, 가만히 있거나, "눈덩이를 제거"할 수 있다. 눈덩이를 제거하는 데는 제거자 간에 4의 공동 비용이 발생하지만, 각 에이전트는 6의 개별 보상을 받는다. 여기서 핵심 딜레마는 무임승차이다. 에이전트는 다른 사람들이 눈덩이를 제거하도록 내버려두면 더 높은 보상을 받을 수 있다. 게임은 모든 눈덩이가 제거되거나 50 타임스텝 후에 종료된다. MSH와 MSG 모두에서 네 명의 에이전트는 직접적인 통신이나 서로의 내부 매개변수에 대한 접근 없이 작동한다. 셸링 다이어그램은 이러한 환경이 에이전트의 최적 전략이 협력자의 행동에 따라 달라지는 혼합 동기 상호 작용의 본질적인 딜레마를 효과적으로 포착한다는 것을 시각적으로 확인하는 데 사용되었다.
HOP와 비교하여 테스트된 "희생자"(기준선 모델)에는 다양한 확립된 다중 에이전트 강화 학습(MARL) 알고리즘 및 규칙 기반 전략이 포함되었다.
- 학습 기준선: LOLA(Learning with Opponent-Learning Awareness), SI(Social Influence), A3C(Asynchronous Advantage Actor-Critic), PS-A3C(Prosocial A3C), PR2 및 직접-OM(목표 조건부 없이 신경망으로 협력자를 직접 모델링하는 HOP의 축소 버전).
- 규칙 기반 기준선: Random(유효한 행동을 무작위로 취함), Cooperator(일관되게 협력적 행동을 채택함) 및 Defector(일관되게 착취적 행동을 채택함).
실험 검증은 두 단계로 진행되었다.
1. 자체 플레이: 동일한 알고리즘을 사용하는 모든 에이전트는 성능이 수렴될 때까지 훈련되었다. 이 단계는 알고리즘이 자율적인 결정을 내리고 혼합 동기 환경에서 협력을 달성하는 능력을 평가했다.
2. 소수샷 적응: 초점 HOP 에이전트는 2400 타임스텝 동안 다른 기준선 알고리즘을 실행하는 세 명의 협력자와 상호 작용했다. 마지막 600 타임스텝 동안 초점 에이전트의 평균 보상은 적응 능력을 정량화하는 데 사용되었다. 알고리즘이 지원하는 경우 이 단계 동안 정책 매개변수를 업데이트할 수 있었다.
최적 성능에 대한 명확한 참조를 제공하기 위해 각 협력자 유형에 대해 "오라클 에이전트"가 훈련되었다. 이 오라클 에이전트는 광범위한 상호 작용을 통해 고정된 협력자 매개변수를 가진 A3C를 통해 훈련되었으며, 특정 협력자에 완벽하게 적응했을 때 에이전트가 달성할 수 있는 최상의 성능을 나타낸다. 모든 보상은 오라클 에이전트의 성능(최적)과 무작위 정책의 성능(최저) 사이에서 최소-최대 정규화되어 표준화된 비교를 가능하게 했다.
증거가 증명하는 것
실험 결과는 혼합 동기 환경에서의 자체 플레이 및 소수샷 적응 모두에서 HOP의 우수한 능력을 명확하게 입증하며, 계층적 상대방 모델링 및 계획에 대한 핵심 수학적 주장을 가혹하게 증명한다.
자체 플레이 시나리오에서 HOP는 일관되게 높은 보상을 달성했으며, 종종 최고의 기준선을 능가하거나 일치시켰다. MSH-4h1s에서 HOP, 직접-OM 및 PS-A3C는 사슴을 사냥하도록 학습했지만, PS-A3C의 "게으른 에이전트" 문제는 열등한 보상으로 이어졌다. LOLA는 불안정한 전략을 보였고, SI와 A3C는 주로 토끼를 사냥하여 낮은 수익을 올렸다. PR2는 MSH에서 완전히 실패했다. MSH-4h2s에서 HOP와 A3C는 가장 안정적이었고 가장 높은 수익을 올렸으며, 사슴 사냥을 성공적으로 조정했다. 가장 주목할 만한 점은 MSG에서 HOP가 이론적 최적값인 30.0에 근접하는 가장 높은 보상을 달성했다는 것이다. 이는 HOP의 분산 설정에서의 강력한 협력 성향을 강조하며, 개인 이익을 우선시하고 조정에 어려움을 겪었던 LOLA, A3C 및 SI와 같은 기준선과 대조된다. PS-A3C는 두 번째로 좋았지만, 눈덩이가 하나만 남았을 때 조정 문제가 여전히 있었다.
HOP의 핵심 메커니즘에 대한 가장 설득력 있는 증거는 소수샷 적응 성능 (표 1)에 있다. HOP는 대부분의 테스트 시나리오에서 일관되게 "전반적으로 최고의 적응 비율"을 달성했다. MSH-4h1s에서 83.3%, MSH-4h2s에서 완벽한 100.0%, MSG에서 83.3%였다. 이는 협력자 행동이 사전 학습된 정책과 일치하는 특정 제한된 시나리오에서만 최적의 적응을 달성한 다른 알고리즘을 훨씬 능가했다.
본 논문은 HOP의 믿음 업데이트 메커니즘이 실제로 어떻게 작동하는지에 대한 명확한 예를 제공한다. MSH에서 세 명의 배신자(일관되게 토끼를 사냥하는)를 상대할 때, HOP는 처음에 협력자들이 사슴을 사냥할 것이라는 "잘못된 믿음"(자체 플레이 경험에서 비롯된 편향)을 가지고 있었다. 그러나 내부-OM 모듈(에피소드 내 믿음 업데이트)은 이를 신속하게 수정했다. 협력자의 궤적(예: 토끼 쪽으로 이동)을 관찰함으로써 내부-OM은 그들의 실제 목표를 추론하여 정확한 상대방 모델을 이끌어냈다. 외부-OM 모듈(에피소드 간 믿음 업데이트)은 이러한 실제 믿음으로의 수렴을 더욱 가속화하여 후속 에피소드에 대한 정확한 사전 역할을 했다. 그림 5의 감소하는 선은 사슴 사냥에 대한 사전 믿음의 점진적인 감소를 나타내며, 이는 HOP의 계층적 믿음 업데이트 메커니즘이 보지 못하고 동적인 협력자 행동에 효과적으로 적응한다는 확실하고 부인할 수 없는 증거이다. 이러한 정확한 협력자 정책을 입력으로 사용하여 계획 모듈은 유리한 행동을 계산할 수 있었고, HOP는 배신자와 같은 비협력적인 에이전트를 상대로도 상당한 전략적 조정을 달성하고 높은 수익을 올릴 수 있었다.
또한, 실험은 여러 HOP 에이전트 간의 사회 지능의 출현 (부록 G, 그림 6)을 밝혀냈다. 한 예에서, 네 명의 HOP 에이전트가 개별적으로 토끼를 사냥하는 것보다 더 높은 총 보상을 위해 집단적으로 사슴을 사냥하는 "자율적인 협력"이 나타났다. 이는 에이전트가 서로의 의도를 추론하고 중앙 집중식 제어 없이 조정함으로써 독립적인 의사 결정을 통해 발생했다. 다른 경우, "불리한 자의 동맹"에서, 두 명의 덜 탐욕스러운 HOP 에이전트는 더 탐욕스러운 협력자를 속여 협력을 피한 다음, 자신의 이익을 극대화하기 위해 협력했다. 이러한 관찰은 HOP의 타인의 목표를 추론하고 응답을 신속하게 조정하는 능력이 복잡한 사회적 행동을 촉진한다는 것을 강조한다.
한계 및 미래 방향
HOP는 혼합 동기 환경에서의 소수샷 적응에서 놀라운 능력을 보여주지만, 저자들은 흥미로운 미래 연구를 위한 길을 열어주는 몇 가지 한계를 솔직하게 인정한다.
첫째, 중요한 제약 조건은 HOP가 효과적으로 작동하기 위해 주어진 환경 내에서 목표의 명확한 정의가 필요하다는 것이다. 현재 프레임워크는 사전 정의된 목표 집합에 의존한다. 복잡한 시나리오의 더 넓은 범위에 걸쳐 HOP의 일반화 가능성과 적용 가능성을 향상시키기 위해, 미래 방향에는 목표 집합을 자율적으로 추상화할 수 있는 기술을 개발하는 것이 포함된다. 이는 HOP가 수동 개입 없이 새로운 환경에서 작동할 수 있도록 할 것이며, 이는 일부 이전 작업에서 이미 탐색을 시작한 과제이다.
둘째, HOP의 현재 구현은 수준 0 마음 이론(ToM)을 사용하는데, 이는 본질적으로 에이전트가 "내가 그들이 나에 대해 생각한다고 생각하는 것"을 추론하는 것을 포함한다. 효과적이지만, 수준 1 ToM("그들이 나에 대해 생각하는 것")과 같은 더 높은 수준의 ToM을 통합하는 것은 행동에 대한 예측을 크게 향상시킬 잠재력을 가지고 있다. 그러나 이는 중첩된 믿음 추론으로 인해 상당한 계산 비용 증가를 수반한다. 따라서 미래 연구는 prohibitive한 계산 복잡성에 굴복하지 않고 수준 높은 ToM이 제공하는 더 풍부한 통찰력을 효과적이고 신속하게 활용할 수 있는 고급이고 계산적으로 효율적인 계획 방법을 개발하는 데 초점을 맞춰야 한다. 이것은 사소하지 않은 엔지니어링 및 수학적 장애물이다.
셋째, 본 논문은 평가를 위해 다양한 잘 확립된 알고리즘을 협력자로 선택했지만, 그 중 어느 것도 인간 행동의 뉘앙스와 복잡성을 완전히 포착하지 못한다. 많은 다중 에이전트 시스템의 궁극적인 목표는 실제 인간 참가자와 원활하게 상호 작용하는 것이다. 따라서, 매력적인 미래 연구 경로는 실제 인간 참가자를 포함하는 소수샷 적응 시나리오에서 HOP의 성능을 탐구하는 것이다. 이것은 실제 적용 가능성과 견고성에 대한 귀중한 통찰력을 제공할 것이다.
마지막으로, HOP의 내재된 이기적인 본질에서 중요한 논의 지점이 발생한다. 자체 수익을 극대화하는 데 뛰어나지만, 이것이 항상 인간 협력자의 최선의 이익이나 가치와 일치하는 것을 보장하지는 않는다. 이러한 잠재적인 불일치를 완화하고 더 유익한 인간-AI 협업을 육성하기 위해, 미래 연구는 HOP의 강력한 추론 능력이 상호 작용 중에 인간의 가치와 선호도를 추론하고 최적화하는 데 어떻게 활용될 수 있는지 탐구해야 한다. 이는 가치 정렬 또는 선호도 학습 메커니즘을 통합하는 것을 포함할 수 있으며, HOP가 효율적일 뿐만 아니라 윤리적으로 건전하고 사회적으로 유익한 방식으로 복잡한 환경에서 인간을 지원할 수 있도록 한다. 이는 인간-AI 상호 작용 윤리 및 강력한 선호도 추출 기술에 대한 깊은 탐구를 필요로 할 것이다.
 Table 5. Performance of HOP and its ablation versions in MSH-4h2s. In (a) self-play, 4 agents of the same kind are trained to converge. Shown is the normalized score after convergence. In (b) few-shot adaptation, the interaction happens between 1 agent using the row policy and 3 co-players using the column policy. Shown are the min-max normalized scores, with normalization bounds set by the rewards of Orcale and the random policy. The results are depicted for the row policy from 1800 to 2400 step
Table 5. Performance of HOP and its ablation versions in MSH-4h2s. In (a) self-play, 4 agents of the same kind are trained to converge. Shown is the normalized score after convergence. In (b) few-shot adaptation, the interaction happens between 1 agent using the row policy and 3 co-players using the column policy. Shown are the min-max normalized scores, with normalization bounds set by the rewards of Orcale and the random policy. The results are depicted for the row policy from 1800 to 2400 step
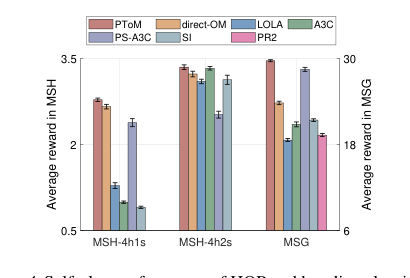 Figure 4. Self-play performance of HOP and baseline algorithms. Shown is the average reward in the self-play training phase
Figure 4. Self-play performance of HOP and baseline algorithms. Shown is the average reward in the self-play training phase