混合动机环境下的分层对手建模与规划实现高效适应
Despite the recent successes of multi-agent reinforcement learning (MARL) algorithms, efficiently adapting to co-players in mixed-motive environments remains a significant challenge.
背景与学术渊源
起源与学术渊源
本文所解决的问题,“混合动机环境下的分层对手建模与规划实现高效适应”(Efficient Adaptation in Mixed-Motive Environments via Hierarchical Opponent Modeling and Planning),源于人工智能领域一个长期存在的挑战:使智能体能够快速适应先前未见过的合作者。这种能力被称为“少样本适应”(few-shot adaptation)。历史上,多智能体强化学习(MARL)在具有预定义关系的特定环境中取得了显著进展,特别是零和博弈(智能体纯粹竞争,例如 Vinyals et al., 2019)和共同利益环境(智能体纯粹合作,例如 Barrett et al., 2011)。
然而,该特定问题的精确起源在于认识到大多数现实世界的多智能体决策场景并非纯粹的竞争或合作。相反,它们是“混合动机环境”(mixed-motive environments)(Komorita & Parks, 1995; Dafoe et al., 2020),其特点是智能体之间存在非确定性关系,以及智能体的最佳响应会根据他人的行为而改变的情况。这种复杂性使得决策和少样本适应比在更简单的环境中更具挑战性。
先前方法存在的根本性局限或“痛点”促成了这项工作,主要源于以下几个问题:
1. 专用技术的不适用性:许多现有的用于少样本适应的 MARL 算法依赖于对零和博弈或纯合作奖励结构高效的技术(如 minimax、Double Oracle 或 IGM 条件),但这些技术不适用于混合动机环境中发现的通用和博弈奖励结构。
2. 计算复杂度:像 I-POMDP(Gmytrasiewicz & Doshi, 2005)这样的方法,涉及嵌套信念推理(即,一个智能体推理另一个智能体对其自身信念的看法),会遭受严重的计算复杂度问题。这使得它们在复杂环境中不切实际。
3. 信息需求和可扩展性问题:LOL A(Foerster et al., 2018)等算法通常需要了解合作者的内部网络参数,而这在现实场景中通常是不可用的。即使通过对手建模放宽,在需要长动作序列的复杂顺序环境中也可能出现可扩展性问题。
4. MCTS 在多智能体设置中的局限性:虽然蒙特卡洛树搜索(MCTS)是一种强大的规划方法,但它在多智能体环境中的应用受到限制,因为联合动作空间随着智能体数量呈指数级增长,导致可扩展性问题(Choudhury et al., 2022)。先前基于 MCTS 的方法通常难以有效地估计合作者的策略。
因此,作者们被迫开发一种能够有效适应混合动机环境中未见过的策略的方法,克服了先前方法计算成本过高、需要不可用信息或为更简单的交互动态而设计的局限性。他们从认知心理学中获得灵感,该学说认为人类通过统一高级目标推理和低级动作规划的分层认知机制来快速解决未见的问题(Butz & Kutter, 2016; Eppe et al., 2022)。
直观的领域术语
- 混合动机环境(Mixed-Motive Environments):想象一个百乐餐聚会,每个人都带一道菜。有些人想用他们的烹饪技巧给所有人留下深刻印象(合作),有些人只想尽可能多地吃饭(自私),有些人可能带一道简单的菜但暗地里希望别人带些好吃的,这样他们就不用做太多(混合)。每个人的“动机”不是固定的;它可能是合作与竞争的混合,他们的最佳策略取决于他们认为其他人会做什么。
- 少样本适应(Few-Shot Adaptation):想象一个新员工加入一个团队。他们不需要几个月的时间来了解每个团队成员的工作方式,而是在几次会议或项目后就能快速掌握个人的怪癖和偏好。他们只需要“少量样本”(有限的观察)就能“适应”自己的工作方式以适应团队。
- 对手建模(Opponent Modeling):这就像一个侦探试图理解嫌疑人的意图。侦探观察嫌疑人的行为,听他们的陈述,并利用这些信息来构建嫌疑人目标和计划的心理图景。然后,侦探利用这个对手的“模型”来预测他们的下一步行动并规划自己的策略。
- 蒙特卡洛树搜索(Monte Carlo Tree Search, MCTS):想象玩像围棋这样的复杂棋盘游戏。与其试图计算到游戏结束的所有可能走法(这是不可能的),不如从当前位置快速“想象”出许多随机游戏。对于每个想象的游戏,探索不同的走法,更多地关注那些看起来有希望的路径。在许多这样的快速模拟之后,选择在你的心理实验中导致最佳平均结果的真实走法。这有助于你在不进行详尽计算的情况下做出良好的决策。
- 心智理论(Theory of Mind, ToM):这是你猜测别人在想什么或感觉什么的能力。例如,如果你看到有人微笑,你就会推断他们很高兴。在人工智能的背景下,这意味着一个智能体通过观察其他智能体的行为来尝试理解它们的“心智状态”(如目标、信念或意图),就像人类一样。
符号表
| 符号 | 描述 |
|---|---|
| $N$ | 智能体集合,$N = \{1, 2, \dots, n\}$ |
| $S$ | 状态空间 |
| $A_i$ | 智能体 $i$ 的动作空间 |
| $A$ | 联合动作空间,$A = A_1 \times A_2 \times \dots \times A_n$ |
| $a_{1:n}$ | 所有智能体采取的联合动作 |
| $T(s'|s, a_{1:n})$ | 转移函数:在给定联合动作 $a_{1:n}$ 的情况下,从状态 $s$ 转移到 $s'$ 的概率 |
| $R_i$ | 智能体 $i$ 的奖励函数,$R_i: S \times A \to \mathbb{R}$ |
| $\gamma$ | 未来奖励的折扣因子 |
| $T_{max}$ | 一个回合的最大长度 |
| $\pi_i(a_i|s)$ | 智能体 $i$ 的策略:在状态 $s$ 下选择动作 $a_i$ 的概率 |
| $G$ | 所有智能体的目标集合,$G = G_1 \times G_2 \times \dots \times G_n$ |
| $G_i$ | 智能体 $i$ 的目标集合,$G_i = \{g_{i,1}, \dots, g_{i,|G_i|}\}$ |
| $g_{i,k}$ | 智能体 $i$ 的一个特定目标,它是一组状态 |
| $b_{i,j}(g_j)$ | 智能体 $i$ 对智能体 $j$ 目标的信念,一个关于 $G_j$ 的概率分布 |
| $K$ | 回合索引 |
| $t$ | 回合内的时步 |
| $b_{i,j}^{K,t}(g_j)$ | 智能体 $i$ 在回合 $K$ 的时步 $t$ 对智能体 $j$ 目标的信念 |
| $\pi_{\omega}(a_j|s^{K,t}, g_j)$ | 合作者 $j$ 在状态 $s^{K,t}}$ 下,给定目标 $g_j$ 的目标条件策略,由 $\omega$ 参数化 |
| $Q_{avg}(s^{K,t}, a)$ | 在状态 $s^{K,t}}$ 下,动作 $a$ 的平均估计动作值 |
| $\pi_{MCTS}(a|s^{K,t})$ | MCTS 为在状态 $s^{K,t}}$ 下的动作 $a$ 生成的策略 |
| $\beta$ | 玻尔兹曼理性模型中的理性系数 |
| $N_s$ | MCTS 的回合数 |
| $N_l$ | MCTS 每个回合的搜索迭代次数 |
| $c$ | MCTS 的探索系数 |
| $\theta$ | MCTS 的策略和价值网络参数 |
| $\omega$ | 目标条件策略网络参数 |
问题定义与约束
核心问题表述与困境
本文所解决的核心挑战是在混合动机多智能体环境中实现对未见合作者的高效少样本适应。这是人工智能中的一个关键问题,因为大多数现实世界的交互涉及合作与竞争的混合,而不是纯粹的竞争(零和)或纯粹的合作(共同利益)动态。
起点(输入/当前状态):
当前的许多多智能体强化学习(MARL)算法,尽管在零和博弈和共同利益博弈中取得了成功,但在混合动机场景中却普遍面临困难。这些环境的特点是智能体之间存在非确定性关系以及通用和博弈的奖励结构,使得决策本质上更加复杂。先前对手建模的方法通常面临两个重大障碍:
1. 低效推理:现有方法,如 I-POMDP 及其近似方法,由于嵌套信念推理而遭受“严重的计算复杂度问题”,使其在复杂环境中不切实际。
2. 推理信息的无效利用:像 LOLA 这样的算法,虽然考虑了对手学习,但通常需要合作者内部网络参数的知识,而这在现实场景中通常是不可用的。此外,许多现有算法依赖于手工设计的内在奖励或假设可以访问合作者的私有奖励,这使得它们容易被自利智能体利用,或者在这些信息隐藏时效果不佳。蒙特卡洛树搜索(MCTS),一种强大的规划工具,在多智能体设置中也面临挑战,因为联合动作空间随着智能体数量的增加而迅速增长。
期望终点(输出/目标状态):
本文旨在开发一种算法,使焦点智能体能够在混合动机环境中实现“对未见策略的少样本适应”。这意味着智能体应该能够:
1. 快速适应:在有限的回合数内,快速识别并适当响应新的、先前未见的合作者。
2. 高效推理和利用信息:高效地推断合作者的目标并学习其目标条件策略,然后利用这些推断的信息来计算最优响应,而不会产生过高的计算成本。
3. 稳健表现:在混合动机场景中做出能产生高奖励的自主决策,即使合作者的目标是私有的且可能易变。
精确的缺失环节或数学鸿沟:
本文试图弥合的精确鸿沟是缺乏一个在混合动机环境中进行分层对手建模和规划的、可扩展且高效的框架。具体来说,它解决了如何:
* 从合作者观察到的行为中准确推断其潜在目标和目标条件策略,而不是依赖于直接访问其内部参数或手工设计的奖励。
* 将此推断的对手模型集成到规划机制(MCTS)中,使其在计算上可行,避免了先前方法中的“嵌套信念推理”问题。
* 在规划过程中处理关于合作者目标的固有不确定性,而不会引入显著偏差或降低性能。本文提出了一种分层结构,包含“内部-OM”(intra-OM)和“外部-OM”(inter-OM)模块,用于在回合内和回合间更新关于合作者目标的信念,然后使用这些信念来指导 MCTS 规划器,该规划器对多个目标组合进行采样以计算最佳响应。
痛苦的权衡或困境:
困扰先前研究人员的核心困境是对手建模的准确性和泛化性与计算效率和可扩展性之间的权衡。
* 准确性 vs. 效率:在复杂的混合动机设置中,尤其是在目标是私有且动态的情况下,实现多样化合作者的高度准确模型通常需要大量的计算(例如,I-POMDP 中的嵌套信念推理)或详细的对手内部知识(例如,LOLA)。这通常使得这些方法对于实时或复杂顺序环境中快速、少样本的适应来说过于缓慢或资源密集。
* 泛化性 vs. 特异性:为特定游戏类型(零和或纯合作)设计的算法通常利用奖励结构特定的技术(例如,minimax),这些技术无法泛化到混合动机交互的非确定性、通用和博弈性质。开发一种能够跨越混合动机谱系而不会在任何特定领域牺牲性能的方法是一项重大挑战。本文旨在提供一个“实用且有效的框架”,能够同时处理竞争与合作。
约束与失败模式
由于几个严峻的现实约束,在混合动机环境中实现高效少样本适应的问题“极其困难”:
物理/环境约束:
* 混合动机动态:根本的约束是环境本身。智能体之间的关系是“非确定性的”,奖励结构是“通用和博弈的”,这意味着智能体的利益既不是完全一致也不是完全对立。这使得预测最优响应高度依赖于上下文且动态变化。
* 未见的合作者和策略:对“未见智能体的少样本适应”的要求意味着算法不能依赖于与特定对手类型的预训练。智能体必须在运行时适应新行为。
* 有限的交互历史:“少样本适应”意味着智能体只有“有限的回合数”来了解新的合作者。这严重限制了可用于对手建模和适应的数据量。
* 私有目标和无通信:智能体“无法访问彼此的参数,并且不允许通信”。此外,合作者的目标是“私有的且易变的”,这意味着它们可以在一个回合内发生变化。这种直接信息的缺乏使得必须仅从观察到的行为中推断意图。
计算约束:
* 对手建模的计算复杂度:先前的方法如 I-POMDP 由于“嵌套信念推理”而饱受“严重的计算复杂度问题”的困扰,使其在复杂环境中不切实际。挑战在于在不导致计算呈指数级增长的情况下准确建模对手。
* 与智能体数量的可扩展性:在多智能体环境中,“联合动作空间随着智能体数量的增加而迅速增长”。这使得使用传统 MCTS 进行规划对于许多智能体来说在计算上不可行。本文通过仅为焦点智能体的动作进行规划,并给定估计的合作者策略,明确地解决了这个问题。
* 实时延迟要求(隐含):“快速适应”和“高效推理”的需求意味着决策必须在实际时间限制内发生,特别是在可能涉及长动作序列的顺序决策场景中。
数据驱动约束:
* 信念更新的数据稀疏性:当“过去轨迹不足以进行更新”时,回合内对手建模(intra-OM)可能会遭受“先验不准确”的影响。这凸显了从少量数据中形成关于合作者目标准确信念的困难。
* 合作者模型中的不确定性:即使进行了对手建模,估计的合作者策略“也包含关于合作者目标的不确定性”。在规划阶段必须有效地管理这种不确定性,以避免引入“对模拟的大偏差并降低规划性能”。天真地纳入这种不确定性可能导致次优动作。
为什么选择这种方法
选择的必然性
采用分层对手建模与规划(HOP)并非仅仅是设计选择,而是混合动机环境固有挑战的必然结果。传统的 SOTA(State-of-the-Art)多智能体强化学习(MARL)算法,例如那些依赖于 minimax、Double Oracle 或 IGM 条件的算法,被发现根本上不足。这些方法是为零和或纯合作博弈的特定奖励结构量身定制的,这使得它们“不适用于混合动机环境”,因为在这些环境中,智能体关系是非确定性的,奖励是通用和博弈的。作者们明确指出,“智能体之间的非确定性关系和通用和博弈的奖励结构使得混合动机环境中的决策和少样本适应比零和和纯合作环境更具挑战性。”
认识到现有方法不足促使作者们从认知心理学中寻求灵感。他们发现,人类快速解决先前未见问题的能力依赖于“分层认知机制”,这些机制能够无缝地整合高级目标推理和低级动作规划。这一见解正是作者们认识到需要一种根本不同、分层结构化方法的确切时刻。HOP 直接模仿了这种认知架构,提出了一个用于推断合作者目标和学习目标条件策略的对手建模模块,以及一个使用蒙特卡洛树搜索(MCTS)来确定最佳响应的规划模块。这种分层分解是解决复杂混合动机环境中高效推理和有效利用推断信息双重挑战的唯一可行途径。
比较优势
HOP 通过几种超越简单性能指标的结构优势,展示了其相对于先前黄金标准的定性优越性:
- 分层分解:与扁平化的 MARL 方法不同,HOP 的双模块结构(对手建模和规划)允许对合作者行为进行更复杂和可解释的理解。对手建模模块推断高级目标并学习目标条件策略,提供了比端到端模型更丰富的表示。这模仿了人类的认知过程,实现了更鲁棒的适应。
- 高效的信念更新机制:HOP 通过在回合之间和之内更新合作者目标的信念,显著提高了效率。内部对手建模(intra-OM)模块允许在单个回合内快速调整合作者即时目标,这对于动态环境至关重要。外部对手建模(inter-OM)模块利用历史回合来建立精确的先验信念,加速了向真实信念的收敛。这种双层更新机制提供了优于可能仅在回合内更新信念或缺乏稳健历史背景的方法的结构优势,而这些方法通常在短期交互中导致不准确的对手建模。
- 避免嵌套信念推理的复杂性:先前的手对手建模和规划框架,如 I-POMDP,由于“嵌套信念推理”(例如,一个智能体推理另一个智能体认为它认为什么)而遭受“严重的计算复杂度问题”。HOP 通过明确使用关于合作者目标和策略的信念来学习神经网络模型,然后指导 MCTS 规划器,从而规避了这一点。这种设计选择使得 HOP 能够“更高效地执行顺序决策”,而不会出现深度递归推理的计算瓶颈。
- 可扩展的 MCTS 集成:虽然 MCTS 功能强大,但它在多智能体环境中的直接应用受到联合动作空间快速增长的限制。HOP 通过“估计合作者的策略并仅为焦点智能体的动作进行规划”来克服这一问题。这种战略解耦使得 MCTS 能够有效且可扩展地应用,避免了规划所有智能体联合动作所带来的计算爆炸。
- 降低规划中的不确定性:对手建模模块将目标条件策略提供给规划模块。这种推断的信息指导 MCTS,避免了将合作者目标的不确定性直接纳入规划环境模型而导致的“大偏差”和“规划性能下降”。这种结构集成确保了即使在不确定性下,规划也是精确和准确的。
与约束的对齐
HOP 的设计完美地符合了混合动机环境中少样本适应的严苛要求:
- 对未见策略的少样本适应:HOP 的核心目标是少样本适应。分层结构,特别是高效的 intra-OM 和 inter-OM 信念更新机制,是专门为此设计的。Intra-OM 允许对回合内行为变化做出快速响应,而 inter-OM 则提供来自过去回合的准确先验,从而在有限的交互次数内实现对新颖合作者策略的快速适应。这种“结合”问题对快速学习的需求和解决方案的动态信念更新是根本性的。
- 混合动机环境:HOP 是专门为混合动机场景设计的,在这些场景中,关系是非确定性的,奖励是通用和博弈的。它推断合作者目标(可以是竞争性的、合作性的或混合的)并规划焦点智能体的最佳响应的能力,即使合作者的目标是私有的且易变的,也直接解决了这些环境的核心挑战。
- 无法访问合作者参数或奖励:现实世界多智能体场景中的一个关键约束是无法直接访问其他智能体的内部参数或奖励函数。HOP 的对手建模模块仅通过观察其“动作序列”来推断合作者的目标并学习其目标条件策略。这种基于推理的方法绕过了对合作者内部知识的明确需求,使其适用于现实世界的黑盒场景。
- 无通信:问题定义暗示了智能体之间缺乏明确的通信。HOP 的目标推断和策略学习完全基于观察到的轨迹和动作,不依赖任何形式的直接通信,从而遵守了这一隐含约束。
拒绝替代方案
本文为拒绝几种流行的方法提供了清晰的理由:
- 传统 MARL 算法(例如,Minimax、Double Oracle、IGM 条件):这些方法被明确拒绝,因为它们“不适用于混合动机环境”。它们的基本假设和技术针对零和或纯合作奖励结构进行了优化,这些结构未能捕捉混合动机博弈的非确定性关系和通用和博弈奖励。
- LOLA(Learning with Opponent-Learning Awareness):虽然是一种先进的 MARL 算法,但 LOLA 被认为不适用于一般的混合动机环境,因为它“需要合作者网络参数的知识,这在许多场景中可能不可行”。HOP 的基于推理的对手建模避免了这一限制性要求。此外,LOLA 在“需要长动作序列才能获得奖励的复杂顺序环境中可能存在可扩展性问题”,这是 HOP 通过其指导的 MCTS 规划所解决的局限性。
- I-POMDP(Interactive Partially Observable Markov Decision Processes):该框架虽然与对手建模相关,但由于其“嵌套信念推理”导致的“严重的计算复杂度问题”而被拒绝。计算负担使其“在复杂环境中不切实际”。HOP 的设计特意避免了这种嵌套推理,以实现更高的效率。
- 多智能体环境中的天真 MCTS:本文承认 MCTS 本身“在多智能体环境中受到限制,因为联合动作空间随着智能体数量的增加而迅速增长”。直接应用在计算上是不可行的。HOP 的解决方案是估计合作者策略并仅为焦点智能体的动作进行规划,从而有效地规避了这一可扩展性问题。
- HOP 的消融版本(无 inter-OM、无 intra-OM、直接-OM):消融研究提供了拒绝更简单或不完整版本的 HOP 的经验证据:
- 无 inter-OM:该版本在面对具有固定目标的智能体(例如,合作者、背叛者)时表现不佳,因为它在回合开始时缺乏准确的目标先验,错失了早期获得最优博弈的机会。这凸显了利用历史回合的必要性。
- 无 intra-OM:该版本在面对具有动态行为的智能体(例如,LOLA、PS-A3C、随机)时表现不佳,因为它无法适应回合内合作者目标的改变,仅依赖于过去的回合。这强调了实时、回合内信念更新的重要性。
- 直接-OM:这种方法消除了分层对手建模模块,并使用神经网络直接建模合作者,而无需目标条件化,处于“总体劣势”。它在短期交互中难以获得显著更新,导致“适应阶段对手建模不准确”。端到端的性质也引入了“比目标条件策略更高的不确定性”,降低了规划精度。这清楚地验证了 HOP 的目标条件、分层对手建模的优越性。
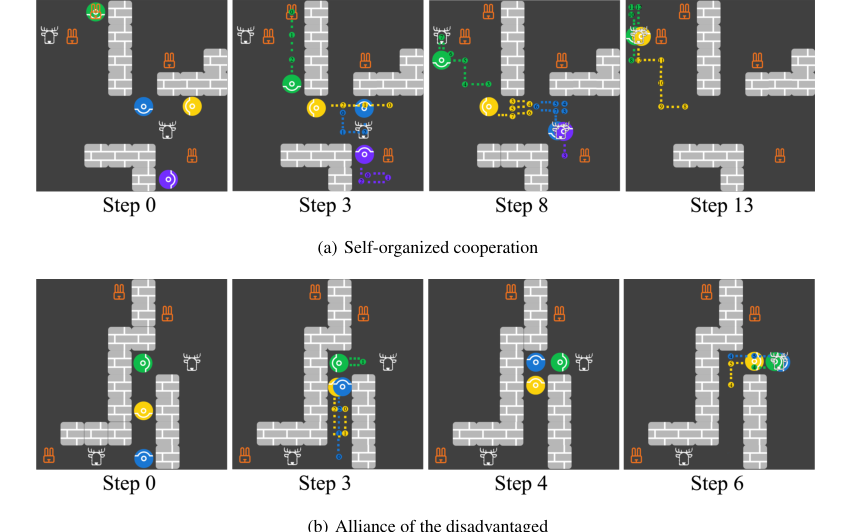 Figure 6. Screenshots for the emergence of (a) self-organized cooperation and (b) alliance of the disadvantaged. Each panel shows agents’ locations at the current step and the trajectories between the current step and the previously stated step
Figure 6. Screenshots for the emergence of (a) self-organized cooperation and (b) alliance of the disadvantaged. Each panel shows agents’ locations at the current step and the trajectories between the current step and the previously stated step
数学与逻辑机制
主方程
分层对手建模与规划(HOP)算法由几个相互关联的数学机制驱动,这些机制使其具备适应能力。其核心在于,HOP 依赖于贝叶斯推理进行对手目标建模,使用负对数似然目标来学习目标条件对手策略,以及一个组合的策略和价值损失来训练焦点智能体的决策网络,并由蒙特卡洛树搜索(MCTS)指导。
定义 HOP 数学引擎的核心方程是:
-
回合内对手目标信念更新(Intra-OM):此方程在单个回合内更新焦点智能体对合作者目标的信念,并纳入实时观察。
$$b_{ij}^{K,t+1}(g_j) = \frac{1}{Z_1} b_{ij}^{K,t}(g_j) \frac{\Pr(a_j^{K,t}|s^{K,t}, g_j) \Pr(s^{K,t+1}|s^{K,t}, a_j^{K,t}, g_j)}{\Pr(s^{K,t+1}|s^{K,t}, a_j^{K,t})}$$ -
回合间对手目标信念更新(Inter-OM):此方程在新的回合开始时更新对手目标的先验信念,利用过去回合的信息。
$$b_{ij}^{K,0}(g_j) = \frac{1}{Z_2} [\alpha b_{ij}^{K-1,0}(g_j) + (1-\alpha)\mathbf{1}(g_j = g_j^{K-1})]$$ -
目标条件对手策略网络损失:此目标函数训练预测合作者目标和当前状态下合作者动作的神经网络。
$$\mathcal{L}(\omega) = \mathbb{E}[-\log(\pi_\omega(a_j^{K,t}|s^{K,t}, g_j^{K,t}))]$$ -
焦点智能体的策略和价值网络损失:此组合损失函数训练焦点智能体的主要策略和价值网络,使用 MCTS 作为监督。
$$\mathcal{L}(\theta) = \mathcal{L}_p(\pi_{\text{MCTS}}, \pi_\theta) + \mathcal{L}_v(r_i, v_\theta)$$
其中
$$\mathcal{L}_p(\pi_1, \pi_2) = \mathbb{E}[-\sum_{a \in \mathcal{A}_i} \pi_1(a|s^{K,t}) \log(\pi_2(a|s^{K,t}))]$$
$$\mathcal{L}_v(r_i, v) = \mathbb{E}[(v(s^{K,t}) - \sum_{l=t}^{T_{\text{max}}} \gamma^{l-t} r_i^{K,l})^2]$$
逐项剖析
让我们剖析每个方程,以理解每个组件的作用。
回合内对手目标信念更新(方程 1)
$$b_{ij}^{K,t+1}(g_j) = \frac{1}{Z_1} b_{ij}^{K,t}(g_j) \frac{\Pr(a_j^{K,t}|s^{K,t}, g_j) \Pr(s^{K,t+1}|s^{K,t}, a_j^{K,t}, g_j)}{\Pr(s^{K,t+1}|s^{K,t}, a_j^{K,t})}$$
- $b_{ij}^{K,t+1}(g_j)$:
- 数学定义:表示智能体 $i$ 在回合 $K$ 的时步 $t+1$ 对对手 $j$ 的目标 $g_j$ 的信念的后验概率分布。
- 物理/逻辑作用:这是更新后的信念。它告诉焦点智能体:“根据我在本回合至今所看到的一切,对手 $j$ 拥有目标 $g_j$ 的可能性有多大?”这对于对合作者不断变化的行为进行实时适应至关重要。
- $Z_1$:
- 数学定义:一个归一化因子。
- 物理/逻辑作用:确保所有可能的目标 $g_j$ 的概率之和为 1,从而保持一个有效的概率分布。
- 为何除法:它是贝叶斯定理的一个基本部分,用于将分子(先验乘以似然)缩放到一个正确的概率。
- $b_{ij}^{K,t}(g_j)$:
- 数学定义:表示智能体 $i$ 在回合 $K$ 的时步 $t$ 对对手 $j$ 的目标 $g_j$ 的先验概率分布。
- 物理/逻辑作用:这是在观察到最新动作和状态转移之前的信念。它作为当前贝叶斯更新步骤的起点。
- $\Pr(a_j^{K,t}|s^{K,t}, g_j)$:
- 数学定义:在给定当前状态 $s^{K,t}$ 和假设的目标 $g_j$ 的情况下,对手 $j$ 采取动作 $a_j^{K,t}$ 的概率。这由目标条件策略网络 $\pi_\omega$ 提供。
- 物理/逻辑作用:此项充当“动作的似然”。它量化了特定假设目标 $g_j$ 对观察到的动作 $a_j^{K,t}$ 的解释程度。如果一个对手采取的动作在目标 $g_A$ 下非常可能,但在目标 $g_B$ 下不太可能,那么这一项将提高对 $g_A$ 的信念。
- $\Pr(s^{K,t+1}|s^{K,t}, a_j^{K,t}, g_j)$:
- 数学定义:在给定前一状态 $s^{K,t}$、对手 $j$ 的动作 $a_j^{K,t}$ 和假设的目标 $g_j$ 的情况下,转移到状态 $s^{K,t+1}$ 的概率。本文提到马尔可夫假设,这可能简化为 $\Pr(s^{K,t+1}|s^{K,t}, a_j^{K,t})$,暗示与 $g_j$ 在给定动作的情况下无关。然而,方程中包含 $g_j$,表明可能存在依赖性或更通用的形式。
- 物理/逻辑作用:此项充当“状态转移的似然”。它通过考虑观察到的状态变化是否与假设的目标和动作一致来进一步完善信念。
- $\Pr(s^{K,t+1}|s^{K,t}, a_j^{K,t})$:
- 数学定义:在给定前一状态 $s^{K,t}$ 和对手 $j$ 的动作 $a_j^{K,t}$ 的情况下,转移到状态 $s^{K,t+1}$ 的概率。
- 物理/逻辑作用:这是状态转移似然的归一化项,确保整体似然被正确缩放。
- 为何乘法:贝叶斯更新通过乘法结合先验信念和似然,反映了新证据如何缩放现有信念。
回合间对手目标信念更新(方程 2)
$$b_{ij}^{K,0}(g_j) = \frac{1}{Z_2} [\alpha b_{ij}^{K-1,0}(g_j) + (1-\alpha)\mathbf{1}(g_j = g_j^{K-1})]$$
- $b_{ij}^{K,0}(g_j)$:
- 数学定义:表示智能体 $i$ 在回合 $K$ 开始时对对手 $j$ 的目标 $g_j$ 的先验概率分布。
- 物理/逻辑作用:这是新回合中对手 $j$ 目标的初始猜测。它受到过去经验的影响,提供了对手行为的“记忆”。
- $Z_2$:
- 数学定义:一个归一化因子。
- 物理/逻辑作用:确保所有可能的目标 $g_j$ 的概率之和为 1。
- 为何除法:概率分布的标准归一化。
- $\alpha$:
- 数学定义:一个视野权重,$\alpha \in [0, 1]$。
- 物理/逻辑作用:此系数控制历史信念与最近观察到的目标的影响。较高的 $\alpha$ 意味着旧信念更重要,导致适应速度较慢。较低的 $\alpha$(接近 0)意味着智能体优先考虑前一回合观察到的目标,从而实现对动态对手的快速适应。
- 为何乘法:它缩放了前一回合先验信念的贡献。
- $b_{ij}^{K-1,0}(g_j)$:
- 数学定义:智能体 $i$ 在前一回合 $K-1$ 开始时对对手 $j$ 目标 $g_j$ 的先验概率分布。
- 物理/逻辑作用:代表了当前回合之前所有回合中关于对手 $j$ 目标的累积历史知识。
- $(1-\alpha)$:
- 数学定义:与 $\alpha$ 互补的权重。
- 物理/逻辑作用:缩放了前一回合观察到的目标的贡献。
- 为何乘法:它缩放了最近一次目标观察的贡献。
- $\mathbf{1}(g_j = g_j^{K-1})$:
- 数学定义:一个指示函数,如果前一回合 $K-1$ 中对手 $j$ 的目标是 $g_j$,则返回 1,否则返回 0。
- 物理/逻辑作用:此项直接纳入了前一回合为对手 $j$ 推断出的实际目标。这是更新新回合先验的一个强有力信号。
- 为何加法:将两个加权项相加,以结合长期历史信念和短期、最近的观察,形成新的先验。
目标条件对手策略网络损失(方程 3)
$$\mathcal{L}(\omega) = \mathbb{E}[-\log(\pi_\omega(a_j^{K,t}|s^{K,t}, g_j^{K,t}))]$$
- $\mathcal{L}(\omega)$:
- 数学定义:目标条件策略网络(由 $\omega$ 参数化)的损失函数。
- 物理/逻辑作用:这是对手建模模块最小化的目标,以学习合作者准确的目标条件策略。较低的损失意味着网络能够更好地预测给定目标的对手动作。
- $\mathbb{E}[\cdot]$:
- 数学定义:期望算子,通常通过对回放缓冲区中的数据样本批次进行平均来近似。
- 物理/逻辑作用:通过对多个数据点进行平均来提供一个稳定的损失估计,减少单个数据点噪声的影响。
- $-\log(\pi_\omega(a_j^{K,t}|s^{K,t}, g_j^{K,t}))$:
- 数学定义:策略网络 $\pi_\omega$ 分配给观察到的动作 $a_j^{K,t}$ 的概率的负对数,给定状态 $s^{K,t}$ 和推断的目标 $g_j^{K,t}$。
- 物理/逻辑作用:这是用于分类或策略学习的监督学习中的标准负对数似然损失。最小化此项会最大化网络分配给正确(观察到的)动作的概率,从而有效地教会网络在特定目标下模仿对手行为。
- 为何负对数:对数将概率的乘积转换为和,更容易优化。负号将最大化似然的目标转换为最小化损失,这是梯度下降优化的标准做法。
焦点智能体的策略和价值网络损失(方程 6)
$$\mathcal{L}(\theta) = \mathcal{L}_p(\pi_{\text{MCTS}}, \pi_\theta) + \mathcal{L}_v(r_i, v_\theta)$$
$$\mathcal{L}_p(\pi_1, \pi_2) = \mathbb{E}[-\sum_{a \in \mathcal{A}_i} \pi_1(a|s^{K,t}) \log(\pi_2(a|s^{K,t}))]$$
$$\mathcal{L}_v(r_i, v) = \mathbb{E}[(v(s^{K,t}) - \sum_{l=t}^{T_{\text{max}}} \gamma^{l-t} r_i^{K,l})^2]$$
- $\mathcal{L}(\theta)$:
- 数学定义:焦点智能体策略和价值网络(由 $\theta$ 参数化)的总损失函数。
- 物理/逻辑作用:这是焦点智能体最小化的主要目标函数,以学习其最优策略和准确的价值函数。它结合了强化学习的两个关键方面:学习如何良好地行动以及学习预测未来奖励。
- 为何相加:在 actor-critic 或 AlphaZero 类架构中,策略和价值学习通常合并为一个目标,因为它们是互补的任务,可以从共享表示和联合优化中受益。
- $\mathcal{L}_p(\pi_{\text{MCTS}}, \pi_\theta)$:
- 数学定义:策略损失项,具体来说是 MCTS 派生的策略 $\pi_{\text{MCTS}}$(目标策略 $\pi_1$)和学习策略 $\pi_\theta$(预测策略 $\pi_2$)之间的交叉熵损失。
- 物理/逻辑作用:此项充当“策略蒸馏”机制。MCTS 通过其前瞻搜索生成一个比当前学习策略更优的策略。此损失鼓励焦点智能体的学习策略 $\pi_\theta$ 模仿并内化 MCTS 生成的策略,有效地将规划的“智慧”转移到神经网络中。
- $\mathbb{E}[-\sum_{a \in \mathcal{A}_i} \pi_1(a|s^{K,t}) \log(\pi_2(a|s^{K,t}))]$:
- 数学定义:两个概率分布 $\pi_1$ 和 $\pi_2$ 之间的交叉熵。
- 物理/逻辑作用:衡量学习策略 $\pi_2$ 与 MCTS 目标策略 $\pi_1$ 的差异。最小化交叉熵使 $\pi_2$ 匹配 $\pi_1$。
- 为何求和:对焦点智能体动作空间 $\mathcal{A}_i$ 中所有可能动作的负对数概率进行求和,并由目标策略的概率加权。
- $\mathcal{L}_v(r_i, v_\theta)$:
- 数学定义:价值损失项,具体来说是价值网络预测值 $v(s^{K,t})$ 与真实折扣回报 $\sum_{l=t}^{T_{\text{max}}} \gamma^{l-t} r_i^{K,l}$ 之间的均方误差(MSE)。
- 物理/逻辑作用:此项训练价值网络 $v_\theta$ 来准确预测任何给定状态的预期累积未来奖励。精确的价值函数对于指导 MCTS 和评估状态质量至关重要。
- $\mathbb{E}[(v(s^{K,t}) - \sum_{l=t}^{T_{\text{max}}} \gamma^{l-t} r_i^{K,l})^2]$:
- 数学定义:预测值与实际折扣回报之间的平方差。
- 物理/逻辑作用:这是标准的回归损失。它惩罚价值网络不准确的预测,误差越大,惩罚的平方越大。
- 为何平方差:常用于回归任务,它为基于梯度的优化提供了平滑、可微分的损失景观。
- $v(s^{K,t})$:
- 数学定义:价值网络为状态 $s^{K,t}$ 预测的值。
- 物理/逻辑作用:模型当前对从状态 $s^{K,t}$ 可获得的预期总未来折扣奖励的估计。
- $\sum_{l=t}^{T_{\text{max}}} \gamma^{l-t} r_i^{K,l}$:
- 数学定义:从时步 $t$ 到回合结束 $T_{\text{max}}$ 智能体 $i$ 收到的真实折扣回报(累积奖励)。
- 物理/逻辑作用:这是价值网络的“真实标签”。它代表了实际的未来奖励总和,并根据其时间距离进行了折扣。
- 为何求和:累积整个未来轨迹的奖励。
- $\gamma$:
- 数学定义:折扣因子,$\gamma \in [0, 1]$。
- 物理/逻辑作用:决定未来奖励的现值。接近 0 的 $\gamma$ 使智能体变得短视(只关心即时奖励),而接近 1 的 $\gamma$ 使其变得长远(高度考虑长期奖励)。
- 为何指数化:在强化学习中,标准做法是指数级降低未来奖励的重要性。
逐步流程
想象一个抽象的数据点,例如,环境状态和合作者动作的观察,进入 HOP 系统。以下是它如何通过数学引擎移动:
-
回合开始:用历史设定场景:
- 当新回合 $K$ 开始时,焦点智能体 $i$ 不会从零开始关于其对合作者的信念。它首先查阅其过去的交互“记忆”。
- 回合间信念更新(方程 2)被触发。此方程将前一回合的先验信念 $b_{ij}^{K-1,0}(g_j)$ 与前一回合为对手 $j$ 推断出的实际目标 $g_j^{K-1}$ 相结合。视野权重 $\alpha$ 像一个旋钮一样,控制着对长期历史和近期过去的信任程度。这会产生当前回合的初始信念 $b_{ij}^{K,0}(g_j)$,为智能体提供一个良好的开端。
-
实时交互:观察并推断对手目标:
- 随着回合的进行,在每个时步 $t$,智能体观察当前状态 $s^{K,t}$ 以及其合作者采取的动作 $a_j^{K,t}$。
- 此新观察立即输入回合内信念更新(方程 1)。智能体采用其当前信念 $b_{ij}^{K,t}(g_j)$(在 $t=0$ 时为 $b_{ij}^{K,0}(g_j)$)并更新它。它会问:“如果对手 $j$ 的目标是 $g_j$,那么他们会采取动作 $a_j^{K,t}$ 并导致状态 $s^{K,t+1}$ 的可能性有多大?”
- 为了回答这个问题,它使用目标条件策略网络 $\pi_\omega$ 来获取每个可能目标 $g_j$ 的 $\Pr(a_j^{K,t}|s^{K,t}, g_j)$。然后将此似然与当前信念相乘,并由 $Z_1$ 进行归一化。随着回合内观察到更多动作,此过程不断细化 $b_{ij}^{K,t+1}(g_j)$,使对手目标信念更加准确。
-
学习对手行为:训练目标条件策略:
- 在此过程中,推断出的目标 $g_j^{K,t}$(最可能的目标)以及观察到的状态 $s^{K,t}$ 和动作 $a_j^{K,t}$ 被收集并存储在轨迹缓冲区中。
- 定期使用收集到的数据来训练目标条件策略网络 $\pi_\omega$。目标条件策略网络损失(方程 3)被最小化。这就像老师向网络展示示例:“当对手处于状态 $s$ 且目标为 $g$ 时,他们采取了动作 $a$。”网络学习在给定 $s$ 和 $g$ 的情况下预测 $a$,从而提高其建模对手行为的能力。
-
焦点智能体的决策:规划最佳响应:
- 现在轮到焦点智能体行事了。它需要选择自己的动作 $a_i^{K,t}$。
- 智能体启动蒙特卡洛树搜索(MCTS)。MCTS 不仅考虑当前状态,还模拟许多可能的未来。
- 至关重要的是,MCTS 不确定合作者的目标。因此,在其 $N_s$ 次模拟回合中的每一次,它都会从当前信念 $b_{ij}^{K,t}(g_j)$(来自步骤 2)中采样一个合作者目标的组合 $g_{-i}$。
- 对于每个采样目标组合,MCTS 会模拟轨迹。当它需要知道合作者 $j$ 会做什么时,它会使用采样目标 $g_j$ 来调用学习到的目标条件策略 $\pi_\omega(\cdot|s, g_j)$(来自步骤 3)。焦点智能体探索自己的动作。
- 经过 $N_s$ 回合后,MCTS 计算焦点智能体每个可能动作的平均动作值 $Q_{\text{avg}}(s^{K,t}, a)$(方程 4),同时考虑了合作者目标的不确定性。
- 最后,焦点智能体使用玻尔兹曼理性模型(方程 5)选择其动作 $a_i^{K,t}$,该模型倾向于具有更高 $Q_{\text{avg}}$ 值的动作,平衡了探索与利用。
-
学习变得更好:训练焦点智能体的网络:
- MCTS 过程本身提供了宝贵的信息:一个“更好”的策略 $\pi_{\text{MCTS}}$(来自搜索)和一个改进的状态值估计。
- 这些信息以及实际获得的奖励 $r_i^{K,l}$ 被用来训练焦点智能体的主要策略和价值网络,由 $\theta$ 参数化。
- 焦点智能体的策略和价值网络损失(方程 6)被最小化。此损失包含两个部分:
- 一个策略损失 $\mathcal{L}_p$,使学习到的策略 $\pi_\theta$ 模仿 MCTS 生成的策略 $\pi_{\text{MCTS}}$。这就像 MCTS“老师”向网络展示最优走法。
- 一个价值损失 $\mathcal{L}_v$,使价值网络 $v_\theta$ 准确预测回合期间观察到的真实折扣回报 $\sum_{l=t}^{T_{\text{max}}} \gamma^{l-t} r_i^{K,l}$。这教会网络正确评估状态的好坏。
- 通过这种组合损失,焦点智能体的神经网络学会做出更好的决策并更准确地评估状态,随着时间的推移变得更加熟练。
这个整个循环会重复进行,每个步骤都为其他步骤提供支持并进行改进,从而创建一个动态且适应性强的学习系统。
优化动力学
HOP 机制通过一个连续的、迭代的过程来学习、更新和收敛,该过程不断完善其对对手的理解和自身的决策能力。这种学习由各种损失函数的梯度下降和 MCTS 的内在自我改进驱动。
-
信念系统的细化:
- 回合内信念(方程 1):回合内-OM 模块通过贝叶斯推理持续更新合作者目标的信念。每个新的观察(对手动作和状态转移)都提供了证据,这些证据要么加强要么削弱特定目标的概率。随着回合内收集到更多数据,后验分布 $b_{ij}^{K,t+1}(g_j)$ 倾向于收敛到对手的真实潜在目标,假设其行为与某个目标条件策略一致。这是一个经典的贝叶斯更新,随着累积证据的增加,信念分布中的不确定性(熵)会减少。
- 回合间先验(方程 2):回合间-OM 模块更新新回合的先验信念。视野权重 $\alpha$ 是这里的关键超参数。如果 $\alpha$ 较高,系统将严重依赖长期历史平均值,导致先验信念收敛缓慢但稳定。如果 $\alpha$ 较低,系统会快速适应最近的对手行为,可能导致更快的适应,但也可能导致不稳定,如果对手目标高度易变的话。这种机制允许系统跨多个回合跟踪和适应对手策略的变化。
-
对手策略学习:
- 目标条件策略网络 $\pi_\omega$(用于预测对手动作)通过最小化负对数似然损失(方程 3)使用随机梯度下降(SGD)或其变体进行训练。该网络的损失景观由其针对观察到的对手动作的预测准确性决定。随着更多多样化和准确的数据(状态、推断目标、实际动作)被收集并输入回放缓冲区,梯度将网络参数 $\omega$ 引向最小化此损失的方向。此过程会迭代地提高网络建模对手行为的能力,从而使对手建模模块更加可靠。
-
焦点智能体的策略和价值学习:
- 焦点智能体的策略 $\pi_\theta$ 和价值函数 $v_\theta$ 通过一个监督过程进行学习,其中 MCTS 充当一个强大的“教师”。总损失 $\mathcal{L}(\theta)$(方程 6)通过梯度下降进行最小化。
- 策略改进:MCTS 通过执行广泛的模拟和前瞻搜索,生成一个比当前学习策略 $\pi_\theta$ 更“强大”的策略 $\pi_{\text{MCTS}}$。然后,策略损失项 $\mathcal{L}_p$ 驱动 $\pi_\theta$ 模仿 $\pi_{\text{MCTS}}$。这意味着来自 $\mathcal{L}_p$ 的梯度将参数 $\theta$ 拉向一个方向,使得学习到的策略更接近 MCTS 生成的最优动作。这种迭代监督允许 $\pi_\theta$ 收敛到接近最优的策略,而无需直接探索环境。
- 价值函数准确性:价值损失项 $\mathcal{L}_v$ 训练 $v_\theta$ 来预测 MCTS 模拟和实际博弈期间观察到的真实折扣回报。来自 $\mathcal{L}_v$ 的梯度指导 $\theta$ 来减小预测值与实际回报之间的均方误差。随着 $v_\theta$ 变得更加准确,它为 MCTS 提供了更好的估计,从而使搜索更有效和更强大。这创造了一个正反馈循环:更好的价值估计导致更好的 MCTS,从而导致更好的 $v_\theta$ 训练目标。
- 损失景观:组合损失 $\mathcal{L}(\theta)$ 创建了一个复杂的损失景观。然而,MCTS 监督提供了一个强大但可能嘈杂的信号,将神经网络参数 $\theta$ 引向更高预期回报的区域。MCTS(重复模拟)和神经网络训练(梯度更新)的迭代性质允许系统收敛到鲁棒的策略和价值函数。
-
MCTS 探索-利用:
- MCTS 算法本身使用诸如 pUCT(Polynomial Upper Confidence Trees)之类的机制来平衡探索和利用。MCTS 分数函数中的探索系数 $c$(在附录 E.1 中提到)控制着这种平衡。较高的 $c$ 会鼓励 MCTS 探索较少访问的动作,可能发现更好的策略。较低的 $c$ 会使 MCTS 更倾向于利用已知的良好动作,从而更快地收敛到局部最优。这种动态确保 MCTS 继续找到更好的策略来监督神经网络。
总之,HOP 的优化动力学具有分层和迭代学习过程的特点。对手模型通过贝叶斯更新和监督学习不断细化,从而提供越来越准确的合作者行为预测。这种细化的理解随后为 MCTS 提供信息,MCTS 充当强大的规划引擎,生成更优的策略和价值目标。这些目标反过来监督焦点智能体的主要策略和价值网络,驱动它们收敛到混合动机环境中高效且适应性强的决策策略。这些组件的相互作用确保了系统能够适应未见的策略并学习鲁棒的行为。
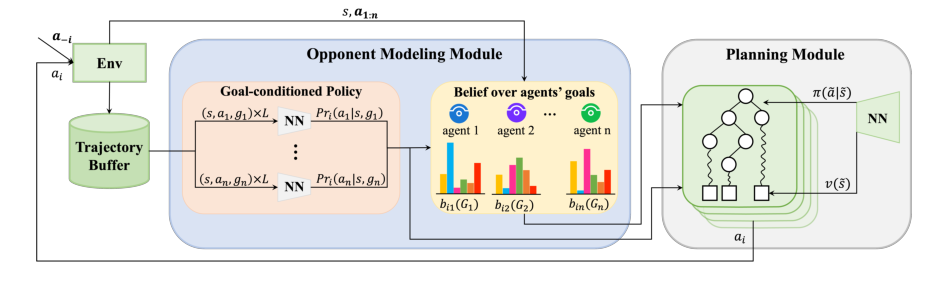 Figure 1. Overview of HOP. HOP consists of an opponent modeling module and a planning module. The opponent modeling module models the behavior of co-players by inferring co-players’ goals and learning their goal-conditioned policies. Estimated behavior is then fed to the planning module to select a rewarding action for the focal agent
Figure 1. Overview of HOP. HOP consists of an opponent modeling module and a planning module. The opponent modeling module models the behavior of co-players by inferring co-players’ goals and learning their goal-conditioned policies. Estimated behavior is then fed to the planning module to select a rewarding action for the focal agent
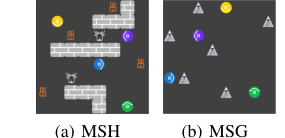 Figure 2. Overview of Markov Stag-Hunt and Markov Snowdrift. There are four agents, repre- sented by colored circles, in each paradigm. (a) Agents catch prey for reward. A stag with a reward of 10 requires at least two agents to hunt together. One agent can hunt a hare with a reward of 1. (b) Everyone gets a reward of 6 when an agent removes a snowdrift. When a snowdrift is removed, removers share the cost of 4 evenly
Figure 2. Overview of Markov Stag-Hunt and Markov Snowdrift. There are four agents, repre- sented by colored circles, in each paradigm. (a) Agents catch prey for reward. A stag with a reward of 10 requires at least two agents to hunt together. One agent can hunt a hare with a reward of 1. (b) Everyone gets a reward of 6 when an agent removes a snowdrift. When a snowdrift is removed, removers share the cost of 4 evenly
结果、局限性与结论
实验设计与基线
为了严格验证分层对手建模与规划(HOP)算法,作者们在两种不同的混合动机环境中进行了实验:马尔可夫鹿群狩猎(MSH)和马尔可夫积雪游戏(MSG)。这些环境是经典博弈论范式的空间和时间扩展,旨在引发复杂的策略交互。
在 MSH 中,四个智能体在一个网格上狩猎猎物(鹿和野兔)。鹿提供 10 的奖励,但需要至少两个智能体合作狩猎,并平分奖励。野兔提供 1 的奖励,可以被单个智能体捕获。游戏在 30 个时步后结束。使用了两种 MSH 设置:
- MSH-4h1s:包含四个野兔和一个鹿。这种设置鼓励合作狩猎鹿,同时保持对野兔的竞争,从而产生混合动机动态。
- MSH-4h2s:包含四个野兔和两个鹿。这增加了合作的可能性,但引入了一个转折:游戏在第一次成功狩猎后仅五分钟就结束,加剧了即时个人收益与长期集体利益之间的紧张关系。
MSG 环境在 8x8 的网格上随机放置了六个积雪点。智能体可以移动、保持空闲或“清除积雪点”。清除积雪点会产生一个共同的成本 4,由清除者分摊,但每个智能体获得 6 的个人奖励。这里的核心困境是搭便车:一个智能体可以通过让其他人清除积雪点来获得更高的奖励。游戏在所有积雪点被清除时结束,或在 50 个时步后结束。在 MSH 和 MSG 中,四个智能体在没有直接通信或访问彼此内部参数的情况下运行。使用了谢林图(Schelling diagrams)来直观地确认这些环境有效地捕捉了混合动机交互的固有困境,其中最优策略会根据合作者的行为而变化。
与 HOP 进行测试的“受害者”(基线模型)包括各种成熟的多智能体强化学习(MARL)算法和基于规则的策略:
- 学习基线:LOLA(Learning with Opponent-Learning Awareness)、SI(Social Influence)、A3C(Asynchronous Advantage Actor-Critic)、PS-A3C(Prosocial A3C)、PR2 和 direct-OM(HOP 的一个消融版本,它直接使用神经网络对合作者进行建模,而无需目标条件化)。
- 基于规则的基线:Random(随机采取有效动作)、Cooperator(持续采取合作行为)和 Defector(持续采取剥削行为)。
实验验证分两个阶段进行:
1. 自玩:所有使用相同算法的智能体都经过训练,直到它们的性能收敛。此阶段评估了算法在混合动机环境中进行自主决策和实现合作的能力。
2. 少样本适应:一个焦点 HOP 智能体与三个运行不同基线算法的合作者进行了 2400 步的交互。焦点智能体在最后 600 步的平均奖励被用来量化其适应能力。如果算法支持,在此阶段可以更新策略参数。
为了提供最佳性能的清晰参考,“Oracle 智能体”为每种合作者类型进行了训练。这个 Oracle 智能体通过 A3C 针对固定的合作者参数进行了广泛交互训练,代表了当完美适应特定合作者时智能体可能达到的最佳性能。所有奖励都在 Oracle 智能体的性能(最优)和随机策略的性能(最低)之间进行了最小-最大归一化,从而实现了标准化比较。
证据证明了什么
实验结果明确证明了 HOP 在混合动机环境中的自玩和少样本适应方面都具有卓越的能力,无情地证明了其关于分层对手建模和规划的核心数学声明。
在自玩场景中,HOP 持续获得高奖励,通常优于或匹配最佳基线。在 MSH-4h1s 中,HOP、direct-OM 和 PS-A3C 学会了狩猎鹿,但 PS-A3C 的“懒惰智能体”问题导致了较低的奖励。LOLA 表现出不稳定的策略,而 SI 和 A3C 主要狩猎野兔,获得了低回报。PR2 在 MSH 中完全失败。在 MSH-4h2s 中,HOP 和 A3C 是最稳定的,并产生了最高的奖励,成功地协调狩猎鹿。最值得注意的是,在 MSG 中,HOP 获得了最高的奖励,接近理论最优值 30.0。这凸显了 HOP 在去中心化设置中强烈的合作倾向,与 LOLA、A3C 和 SI 等优先考虑个人利润并难以协调的基线形成对比。PS-A3C 虽然位居第二,但在只剩一个积雪点时仍然面临协调问题。
HOP 核心机制最令人信服的证据在于其少样本适应性能(表 1)。在大多数测试场景中,HOP 持续实现了“总体最佳适应百分比”:MSH-4h1s 中为 83.3%,MSH-4h2s 中为完美的 100.0%,MSG 中为 83.3%。这远远超过了其他算法,这些算法仅在合作者行为与其预先学习的策略一致的特定、有限场景中实现了最优适应。
本文提供了一个清晰的例子,说明 HOP 的信念更新机制如何实际工作。当面对三个背叛者(他们持续狩猎野兔)在 MSH 中时,HOP 最初持有“错误信念”,认为合作者会狩猎鹿(这是其自玩经验的偏见)。然而,回合内-OM 模块(在回合内更新信念)迅速纠正了这一点。通过观察合作者的轨迹(例如,走向野兔),回合内-OM 推断出他们真实的目标,从而实现了准确的对手模型。回合间-OM 模块**(在回合间更新信念)进一步加速了向真实信念的收敛,充当了后续回合的精确先验。图 5 中的下降线代表了对鹿狩猎的先验信念的逐渐减少,这是确凿无疑的证据,表明 HOP 的分层信念更新机制能够有效地适应未见的和动态的合作者行为。有了这些准确的合作者策略作为输入,规划模块就可以计算出有利的动作,使 HOP 即使在面对像背叛者这样的非合作智能体时也能做出重大的策略调整并获得高回报。
此外,实验揭示了多个 HOP 智能体之间社会智能的出现(附录 G,图 6)。在一个例子中,出现了“自组织合作”,四个 HOP 智能体集体狩猎鹿以获得更高的总奖励,尽管这比狩猎野兔个人风险更大。这是通过独立决策实现的,智能体推断彼此的意图并进行协调,而无需集中控制。在另一个例子中,“弱势者联盟”,两个不那么贪婪的 HOP 智能体成功地误导了一个更贪婪的合作者避免合作,然后合作以最大化自己的利润。这些观察结果强调了 HOP 推断他人目标和快速调整其响应的能力促进了复杂的社会行为,即使智能体是自利的。
局限性与未来方向
尽管 HOP 在混合动机环境中实现了少样本适应的卓越能力,但作者们坦诚地承认了几个为激动人心的未来研究铺平道路的局限性。
首先,一个显著的约束是 HOP 需要对任何给定环境中的目标有清晰的定义才能有效运行。当前框架依赖于预定义的目标集。为了增强 HOP 在更广泛的复杂场景中的泛化能力和适用性,一个重要的未来方向是开发能够自主抽象目标集的技术。这将使 HOP 能够在没有手动干预的情况下在新的环境中运行,这是先前一些工作已经开始探索的挑战。
其次,HOP 的当前实现采用了零阶心智理论(ToM),基本上涉及智能体推理“他们认为什么”。虽然有效,但纳入更高阶的 ToM,例如一阶 ToM(“我认为他们认为我什么”),有可能显著改善对合作者行为的预测。然而,由于涉及的嵌套信念推理,这会带来显著的计算成本增加。因此,未来的工作必须专注于开发先进且计算高效的规划方法,这些方法能够有效地快速利用更高阶 ToM 提供的更丰富见解,而不会遭受不可承受的计算复杂性。这是一个非平凡的工程和数学障碍。
第三,尽管本文选择了一系列多样化的成熟算法作为合作者进行评估,但没有一种完全捕捉到人类行为的细微差别和复杂性。许多多智能体系统的最终目标是与人类参与者无缝交互。因此,一个引人注目的未来研究方向是探索 HOP 在与实际人类参与者互动的少样本适应场景中的表现。这将提供对其现实世界适用性和鲁棒性的宝贵见解。
最后,一个关键的讨论点 arises from HOP 的固有自利性质。虽然它在最大化自身回报方面表现出色,但这并不总是能保证与人类合作者的最佳利益或价值观保持一致。为了减轻这种潜在的不一致并促进更有益的人机协作,未来的研究应探讨如何利用 HOP 强大的推理能力来推断和优化人机交互中的人类价值观和偏好。这可能涉及纳入价值对齐或偏好学习机制,使 HOP 能够在复杂环境中以一种不仅高效,而且合乎道德且对社会有益的方式协助人类。这将需要深入研究人机交互伦理和鲁棒的偏好获取技术。
 Table 5. Performance of HOP and its ablation versions in MSH-4h2s. In (a) self-play, 4 agents of the same kind are trained to converge. Shown is the normalized score after convergence. In (b) few-shot adaptation, the interaction happens between 1 agent using the row policy and 3 co-players using the column policy. Shown are the min-max normalized scores, with normalization bounds set by the rewards of Orcale and the random policy. The results are depicted for the row policy from 1800 to 2400 step
Table 5. Performance of HOP and its ablation versions in MSH-4h2s. In (a) self-play, 4 agents of the same kind are trained to converge. Shown is the normalized score after convergence. In (b) few-shot adaptation, the interaction happens between 1 agent using the row policy and 3 co-players using the column policy. Shown are the min-max normalized scores, with normalization bounds set by the rewards of Orcale and the random policy. The results are depicted for the row policy from 1800 to 2400 step
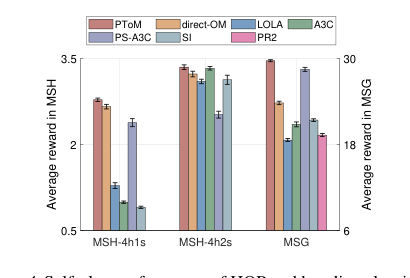 Figure 4. Self-play performance of HOP and baseline algorithms. Shown is the average reward in the self-play training phase
Figure 4. Self-play performance of HOP and baseline algorithms. Shown is the average reward in the self-play training phase
与其他领域的同构性
结构骨架
一种分层机制,用于推断多个交互实体的潜在意图,随时间更新这些信念,并利用它们来指导在动态、不确定环境中进行最优决策的基于搜索的规划过程。