Эффективная адаптация в средах со смешанными мотивами посредством иерархического моделирования и планирования противников
Проблема, рассматриваемая в данной статье, «Эффективная адаптация в средах со смешанными мотивами посредством иерархического моделирования и планирования противников», коренится в давней проблеме искусственного...
Предыстория и академическая родословная
Происхождение и академическая родословная
Проблема, рассматриваемая в данной статье, «Эффективная адаптация в средах со смешанными мотивами посредством иерархического моделирования и планирования противников», коренится в давней проблеме искусственного интеллекта: обеспечение способности агентов быстро адаптироваться к ранее невиданным партнерам по взаимодействию. Эта способность называется «адаптацией за несколько примеров» (few-shot adaptation). Исторически исследования в области обучения с подкреплением для мультиагентных систем (MARL) добились значительных успехов в средах с предопределенными отношениями, в частности, в играх с нулевой суммой (где агенты чисто конкурентны, например, Vinyals et al., 2019) и средах с общими интересами (где агенты чисто кооперативны, например, Barrett et al., 2011).
Однако точное происхождение данной конкретной проблемы заключается в осознании того, что большинство реалистичных сценариев принятия решений в мультиагентных системах не являются чисто конкурентными или кооперативными. Вместо этого они представляют собой «среды со смешанными мотивами» (Komorita & Parks, 1995; Dafoe et al., 2020), характеризующиеся недетерминированными отношениями между агентами и ситуациями, когда наилучший ответ агента может меняться в зависимости от поведения других. Эта сложность делает принятие решений и адаптацию за несколько примеров значительно более трудными, чем в более простых средах.
Фундаментальное ограничение или «болевая точка» предыдущих подходов, которые обусловили необходимость данной работы, вытекает из нескольких проблем:
1. Неприменимость специализированных методов: Многие существующие алгоритмы MARL для адаптации за несколько примеров полагаются на методы (такие как minimax, Double Oracle или условия IGM), которые эффективны для структур вознаграждений с нулевой суммой или чисто кооперативных, но не подходят для структур вознаграждений с общей суммой, встречающихся в средах со смешанными мотивами.
2. Вычислительная сложность: Методы, такие как I-POMDP (Gmytrasiewicz & Doshi, 2005), которые включают вложенное выводное моделирование (т.е. агент рассуждает о том, что другой агент думает о его собственных убеждениях), страдают от серьезной вычислительной сложности. Это делает их непрактичными для сложных сред.
3. Требования к информации и проблемы масштабируемости: Алгоритмы, такие как LOLA (Foerster et al., 2018), часто требуют знания внутренних параметров сети партнеров по взаимодействию, что часто недоступно в реальных сценариях. Даже при ослаблении с помощью моделирования противника могут возникнуть проблемы масштабируемости в сложных последовательных средах, требующих длинных последовательностей действий.
4. Ограничения MCTS в мультиагентных сценариях: Хотя поиск по дереву Монте-Карло (MCTS) является мощным методом планирования, его применение в мультиагентных средах ограничено, поскольку совместное пространство действий экспоненциально растет с числом агентов, что приводит к проблемам масштабируемости (Choudhury et al., 2022). Предыдущие методы на основе MCTS часто испытывают трудности с эффективной оценкой политик партнеров по взаимодействию.
Таким образом, авторы были вынуждены разработать подход, который мог бы эффективно адаптироваться к невиданным ранее политикам в средах со смешанными мотивами, преодолевая ограничения предыдущих методов, которые были либо слишком вычислительно затратными, требовали недоступной информации, либо были разработаны для более простых динамик взаимодействия. Вдохновение для нового решения пришло из когнитивной психологии, которая предполагает, что люди быстро решают невиданные проблемы, используя иерархические когнитивные механизмы, объединяющие рассуждения о высокоуровневых целях с низкоуровневым планированием действий (Butz & Kutter, 2016; Eppe et al., 2022).
Интуитивные термины предметной области
- Среды со смешанными мотивами: Представьте себе ужин в формате «potluck», где каждый приносит блюдо. Некоторые люди хотят произвести впечатление на всех своим кулинарным мастерством (кооперация), некоторые просто хотят съесть как можно больше (эгоизм), а некоторые могут принести простое блюдо, но тайно надеются, что другие принесут что-то потрясающее, чтобы им не пришлось много готовить (смесь). «Мотив» каждого человека не фиксирован; он может быть смесью кооперации и конкуренции, а его лучшая стратегия зависит от того, что, по его мнению, сделают другие.
- Адаптация за несколько примеров (Few-Shot Adaptation): Подумайте о новом сотруднике, присоединяющемся к команде. Вместо того чтобы нуждаться в месяцах обучения, чтобы понять, как работает каждый член команды, он быстро улавливает индивидуальные особенности и предпочтения после всего лишь нескольких встреч или проектов. Он «адаптирует» свой собственный стиль работы, чтобы соответствовать команде, после лишь «нескольких попыток» (ограниченных наблюдений).
- Моделирование противника (Opponent Modeling): Это похоже на детектива, пытающегося понять намерения подозреваемого. Детектив наблюдает за действиями подозреваемого, слушает его заявления и использует эту информацию для построения ментальной картины целей и планов подозреваемого. Затем детектив использует эту «модель» противника для прогнозирования его следующего шага и планирования своей собственной стратегии.
- Поиск по дереву Монте-Карло (MCTS): Представьте себе игру в сложную настольную игру, такую как Го. Вместо того чтобы пытаться рассчитать каждый возможный ход до конца игры (что невозможно), вы быстро «воображаете» множество случайных игр из текущей позиции. Для каждой воображаемой игры вы исследуете различные ходы, уделяя больше внимания перспективным путям. После многих таких быстрых симуляций вы выбираете реальный ход, который привел к наилучшему среднему результату в ваших мысленных экспериментах. Это помогает достичь хороших решений без исчерпывающего расчета.
- Теория разума (Theory of Mind, ToM): Это ваша способность угадывать, что кто-то другой думает или чувствует. Например, если вы видите, как кто-то улыбается, вы делаете вывод, что он счастлив. В контексте ИИ это означает, что агент пытается понять «ментальные состояния» (такие как цели, убеждения или намерения) других агентов, наблюдая за их действиями, подобно тому, как это делают люди.
Таблица обозначений
| Обозначение | Описание |
|---|---|
| $N$ | Множество агентов, $N = \{1, 2, \dots, n\}$ |
| $S$ | Пространство состояний |
| $A_i$ | Пространство действий для агента $i$ |
| $A$ | Совместное пространство действий, $A = A_1 \times A_2 \times \dots \times A_n$ |
| $a_{1:n}$ | Совместное действие, предпринятое всеми агентами |
| $T(s'|s, a_{1:n})$ | Функция перехода: вероятность перехода из состояния $s$ в $s'$ при заданном совместном действии $a_{1:n}$ |
| $R_i$ | Функция вознаграждения для агента $i$, $R_i: S \times A \to \mathbb{R}$ |
| $\gamma$ | Дисконтирующий фактор для будущих вознаграждений |
| $T_{max}$ | Максимальная продолжительность эпизода |
| $\pi_i(a_i|s)$ | Политика агента $i$: вероятность выбора действия $a_i$ в состоянии $s$ |
| $G$ | Множество целей для всех агентов, $G = G_1 \times G_2 \times \dots \times G_n$ |
| $G_i$ | Множество целей для агента $i$, $G_i = \{g_{i,1}, \dots, g_{i,|G_i|}\}$ |
| $g_{i,k}$ | Конкретная цель для агента $i$, представляющая собой множество состояний |
| $b_{i,j}(g_j)$ | Убеждение агента $i$ относительно целей агента $j$, распределение вероятностей по $G_j$ |
| $K$ | Индекс эпизода |
| $t$ | Временной шаг внутри эпизода |
| $b_{i,j}^{K,t}(g_j)$ | Убеждение агента $i$ относительно целей агента $j$ в момент времени $t$ эпизода $K$ |
| $\pi_{\omega}(a_j|s^{K,t}, g_j)$ | Политика, обусловленная целью, для партнера по взаимодействию $j$ в состоянии $s^{K,t}$ при заданной цели $g_j$, параметризованная $\omega$ |
| $Q_{avg}(s^{K,t}, a)$ | Среднее оценочное значение действия для действия $a$ в состоянии $s^{K,t}$ |
| $\pi_{MCTS}(a|s^{K,t})$ | Политика, сгенерированная MCTS для действия $a$ в состоянии $s^{K,t}$ |
| $\beta$ | Коэффициент рациональности для модели больцмановской рациональности |
| $N_s$ | Количество раундов MCTS |
| $N_l$ | Количество итераций поиска для каждого раунда MCTS |
| $c$ | Коэффициент исследования для MCTS |
| $\theta$ | Параметры сети политики и ценности для MCTS |
| $\omega$ | Параметры сети политики, обусловленной целью |
Определение проблемы и ограничения
Основная постановка проблемы и дилемма
Центральная проблема, решаемая данной статьей, — это эффективная адаптация за несколько примеров к невиданным ранее партнерам по взаимодействию в средах со смешанными мотивами. Это критически важная проблема в области искусственного интеллекта, поскольку большинство реальных взаимодействий включают в себя смесь кооперации и конкуренции, а не чисто конкурентные (с нулевой суммой) или чисто кооперативные (общие интересы) динамики.
Исходная точка (вход/текущее состояние):
Современные алгоритмы обучения с подкреплением для мультиагентных систем (MARL), несмотря на успехи в играх с нулевой суммой и общими интересами, в значительной степени испытывают трудности в средах со смешанными мотивами. Эти среды характеризуются недетерминированными отношениями между агентами и структурами вознаграждений с общей суммой, что делает принятие решений по своей сути более сложным. Предыдущие подходы к моделированию противника часто сталкиваются с двумя значительными препятствиями:
1. Неэффективное рассуждение: Существующие методы, такие как I-POMDP и его аппроксимации, страдают от «серьезных проблем вычислительной сложности» из-за вложенного выводного моделирования, что делает их непрактичными в сложных средах.
2. Неэффективное использование выведенной информации: Алгоритмы, такие как LOLA, хотя и учитывают обучение противника, часто требуют знания внутренних параметров сети партнеров по взаимодействию, что часто недоступно в реалистичных сценариях. Кроме того, многие существующие алгоритмы полагаются на вручную разработанные внутренние вознаграждения или предполагают доступ к частным вознаграждениям партнеров по взаимодействию, что делает их уязвимыми для эксплуатации со стороны эгоистичных агентов или менее эффективными, когда такая информация скрыта. Поиск по дереву Монте-Карло (MCTS), мощный инструмент планирования, также сталкивается с ограничениями в мультиагентных сценариях, где совместное пространство действий быстро растет с числом агентов.
Желаемая конечная точка (выход/целевое состояние):
Статья направлена на разработку алгоритма, который позволит фокальному агенту достичь «адаптации за несколько примеров к невиданным ранее политикам» в средах со смешанными мотивами. Это означает, что агент должен быть способен:
1. Быстро адаптироваться: Быстро распознавать и соответствующим образом реагировать на новых, ранее невиданных партнеров по взаимодействию в течение ограниченного числа эпизодов.
2. Эффективно рассуждать и использовать информацию: Эффективно выводить цели партнеров по взаимодействию и изучать их политики, обусловленные целью, а затем использовать эту выведенную информацию для вычисления оптимальных ответов без непомерных вычислительных затрат.
3. Действовать надежно: Принимать автономные решения, которые приносят высокие вознаграждения в сценариях со смешанными мотивами, даже когда цели партнеров по взаимодействию являются частными и потенциально изменчивыми.
Точное недостающее звено или математический пробел:
Точный пробел, который данная статья пытается преодолеть, — это отсутствие масштабируемой и эффективной структуры для иерархического моделирования и планирования противников при неопределенности в средах со смешанными мотивами. В частности, она рассматривает, как:
* Точно выводить скрытые цели и политики, обусловленные целью, партнеров по взаимодействию из их наблюдаемых действий, а не полагаться на прямой доступ к их внутренним параметрам или вручную разработанным вознаграждениям.
* Интегрировать эту выведенную модель противника в механизм планирования (MCTS) таким образом, чтобы она оставалась вычислительно осуществимой, избегая проблем «вложенного выводного моделирования» предыдущих методов.
* Управлять присущей неопределенностью в отношении целей партнеров по взаимодействию во время планирования без внесения значительных смещений или снижения производительности. Статья предлагает иерархическую структуру с модулями «intra-OM» и «inter-OM» для обновления убеждений о целях партнеров по взаимодействию как внутри, так и между эпизодами, а затем использует эти убеждения для управления планировщиком MCTS, который выбирает несколько комбинаций целей для вычисления наилучшего ответа.
Болезненный компромисс или дилемма:
Основная дилемма, которая поставила в тупик предыдущих исследователей, — это компромисс между точностью и обобщаемостью моделирования противника и его вычислительной эффективностью и масштабируемостью.
* Точность против эффективности: Достижение высокоточных моделей разнообразных партнеров по взаимодействию, особенно в сложных средах со смешанными мотивами, где цели являются частными и динамичными, обычно требует обширных вычислений (например, вложенного выводного моделирования в I-POMDP) или детального знания внутренних механизмов противника (например, LOLA). Это часто делает такие методы слишком медленными или ресурсоемкими для быстрой адаптации за несколько примеров в реальном времени или в сложных последовательных средах.
* Обобщаемость против специфичности: Алгоритмы, разработанные для конкретных типов игр (с нулевой суммой или чисто кооперативных), часто используют методы, специфичные для структуры вознаграждений (например, minimax), которые не обобщаются на недетерминированную природу взаимодействий со смешанными мотивами и общую сумму. Разработка метода, который работает во всем спектре смешанных мотивов без ущерба для производительности в какой-либо конкретной области, является серьезной проблемой. Статья нацелена на «практичную и эффективную структуру», которая может обрабатывать как конкуренцию, так и кооперацию.
Ограничения и режимы сбоя
Проблема эффективной адаптации за несколько примеров в средах со смешанными мотивами «невероятно сложна» из-за нескольких жестких, реалистичных ограничений:
Физические/средовые ограничения:
* Динамика смешанных мотивов: Фундаментальное ограничение — это сама среда. Отношения между агентами «недетерминированы», а структуры вознаграждений имеют «общую сумму», что означает, что интересы агентов не являются ни идеально согласованными, ни идеально противоположными. Это делает прогнозирование оптимальных ответов сильно зависящим от контекста и динамичным.
* Невиданные партнеры по взаимодействию и политики: Требование «адаптации за несколько примеров к невиданным агентам» означает, что алгоритм не может полагаться на предварительное обучение с конкретными типами противников. Агенты должны адаптироваться к новым моделям поведения на лету.
* Ограниченная история взаимодействия: «Адаптация за несколько примеров» подразумевает, что у агента есть только «ограниченное количество эпизодов» для изучения новых партнеров по взаимодействию. Это сильно ограничивает объем данных, доступных для моделирования противника и адаптации.
* Частные цели и отсутствие связи: Агенты «не имеют доступа к параметрам друг друга, и связь не разрешена». Более того, цели партнеров по взаимодействию являются «частными и изменчивыми», что означает, что они могут меняться в пределах эпизода. Отсутствие прямой информации требует вывода намерений исключительно из наблюдаемых действий.
Вычислительные ограничения:
* Вычислительная сложность моделирования противника: Предыдущие методы, такие как I-POMDP, страдают от «серьезных проблем вычислительной сложности» из-за «вложенного выводного моделирования», что делает их непрактичными для сложных сред. Задача состоит в том, чтобы точно моделировать противников без экспоненциального роста вычислений.
* Масштабирование с количеством агентов: В мультиагентных средах «совместное пространство действий быстро растет с числом агентов». Это делает планирование с помощью традиционного MCTS вычислительно неподъемным для многих агентов. Статья явно решает эту проблему, планируя только действия фокального агента, учитывая предполагаемые политики партнеров по взаимодействию.
* Требования к задержке в реальном времени (неявные): Необходимость «быстрой адаптации» и «эффективного рассуждения» подразумевает, что принятие решений должно происходить в практические временные рамки, особенно в сценариях последовательного принятия решений, которые могут включать длинные последовательности действий.
Ограничения, основанные на данных:
* Разреженность данных для обновления убеждений: Когда «прошлые траектории недостаточно длинны для обновлений», внутриэпизодическое моделирование противника (intra-OM) может страдать от «неточности априорных данных». Это подчеркивает трудность формирования точных убеждений о целях партнеров по взаимодействию на основе минимальных данных.
* Неопределенность в моделях партнеров по взаимодействию: Даже при моделировании противника, предполагаемые политики партнеров по взаимодействию «содержат неопределенность относительно целей партнеров по взаимодействию». Эта неопределенность должна эффективно управляться на этапе планирования, чтобы избежать внесения «большого смещения в симуляцию и снижения производительности планирования». Наивное включение этой неопределенности может привести к субоптимальным действиям.
Почему этот подход
Неизбежность выбора
Принятие иерархического моделирования и планирования противников (HOP) было не просто дизайнерским выбором, а неизбежным следствием присущих средам со смешанными мотивами проблем. Традиционные передовые (SOTA) алгоритмы обучения с подкреплением для мультиагентных систем (MARL), такие как те, что основаны на minimax, Double Oracle или условиях IGM, оказались принципиально недостаточными. Эти методы адаптированы для специфических структур вознаграждений, встречающихся в играх с нулевой суммой или чисто кооперативных играх, что делает их «неприменимыми в средах со смешанными мотивами», где отношения агентов недетерминированы, а вознаграждения имеют общую сумму. Авторы явно заявляют, что «недетерминированные отношения между агентами и структура вознаграждений с общей суммой делают принятие решений и адаптацию за несколько примеров более сложными в средах со смешанными мотивами по сравнению с средами с нулевой суммой и чисто кооперативными средами».
Осознание того, что существующие методы были неадекватны, побудило авторов искать вдохновение в когнитивной психологии. Они выявили, что способность людей быстро решать ранее невиданные проблемы зависит от «иерархических когнитивных механизмов», которые беспрепятственно интегрируют рассуждения о высокоуровневых целях с низкоуровневым планированием действий. Этот инсайт стал именно тем моментом, когда авторы осознали необходимость принципиально иного, иерархически структурированного подхода. HOP напрямую отражает эту когнитивную архитектуру, предлагая модуль моделирования противника для вывода целей партнеров по взаимодействию и изучения политик, обусловленных целью, в сочетании с модулем планирования, использующим поиск по дереву Монте-Карло (MCTS) для определения наилучшего ответа. Эта иерархическая декомпозиция была единственным жизнеспособным путем для решения двойных задач эффективного рассуждения и эффективного использования выведенной информации в сложных средах со смешанными мотивами.
Сравнительное превосходство
HOP демонстрирует качественное превосходство над предыдущими золотыми стандартами благодаря нескольким структурным преимуществам, выходящим за рамки простых метрик производительности:
- Иерархическая декомпозиция: В отличие от плоских MARL-подходов, двумодульная структура HOP (моделирование противника и планирование) позволяет более сложным и интерпретируемым образом понимать поведение партнеров по взаимодействию. Модуль моделирования противника выводит высокоуровневые цели и изучает политики, обусловленные целью, предоставляя более богатое представление, чем модели от начала до конца. Это отражает человеческие когнитивные процессы, обеспечивая более надежную адаптацию.
- Эффективный механизм обновления убеждений: HOP значительно повышает эффективность, обновляя убеждения о целях партнеров по взаимодействию как между эпизодами, так и внутри эпизодов. Модуль внутриэпизодического моделирования противника (intra-OM) позволяет быстро корректировать непосредственные цели партнеров по взаимодействию в пределах одного эпизода, что критически важно для динамичных сред. Модуль межэпизодического моделирования противника (inter-OM) использует исторические эпизоды для установления точного априорного убеждения, ускоряя сходимость к истинным убеждениям. Этот механизм двойного слоя обновления обеспечивает структурное преимущество перед методами, которые могут обновлять убеждения только в пределах эпизода или не имеют надежного исторического контекста, что часто приводит к неточным моделям противника во время коротких взаимодействий.
- Избежание сложности вложенного выводного моделирования: Предыдущие фреймворки моделирования и планирования противников, такие как I-POMDP, страдают от «серьезных проблем вычислительной сложности» из-за «вложенного выводного моделирования» (например, агент рассуждает о том, что другой агент думает о нем). HOP обходит это, явно используя убеждения о целях и политиках партнеров по взаимодействию для обучения модели нейронной сети, которая затем управляет планировщиком MCTS. Этот выбор дизайна позволяет HOP «более эффективно выполнять последовательное принятие решений» без вычислительного узкого места глубоких рекурсивных рассуждений.
- Масштабируемая интеграция MCTS: Хотя MCTS является мощным инструментом, его прямое применение в мультиагентных средах ограничено быстрым ростом совместного пространства действий. HOP преодолевает это, «оценивая политики партнеров по взаимодействию и планируя только действия фокального агента». Это стратегическое разделение позволяет эффективно и масштабируемо применять MCTS, избегая вычислительного взрыва, связанного с планированием по совместным действиям всех агентов.
- Снижение неопределенности в планировании: Модуль моделирования противника предоставляет политики, обусловленные целью, модулю планирования. Эта выведенная информация направляет MCTS, предотвращая «большое смещение» и «снижение производительности планирования», которые возникли бы из-за наивного включения неопределенности в отношении целей партнеров по взаимодействию непосредственно в модель среды для планирования. Эта структурная интеграция обеспечивает точное и информированное планирование даже при неопределенности.
Соответствие ограничениям
Дизайн HOP идеально соответствует жестким требованиям адаптации за несколько примеров в средах со смешанными мотивами:
- Адаптация за несколько примеров к невиданным политикам: Основная цель HOP — адаптация за несколько примеров. Иерархическая структура, особенно эффективные механизмы обновления убеждений intra-OM и inter-OM, специально разработаны для этого. Intra-OM позволяет быстро реагировать на изменения поведения в пределах эпизода, в то время как inter-OM обеспечивает точные априорные данные из прошлых эпизодов, ускоряя адаптацию к новым стратегиям партнеров по взаимодействию в течение ограниченного числа взаимодействий. Этот «брак» между потребностью проблемы в быстром обучении и динамическим обновлением убеждений решения является фундаментальным.
- Среды со смешанными мотивами: HOP специально разработан для сценариев со смешанными мотивами, где отношения недетерминированы, а вознаграждения имеют общую сумму. Его способность выводить цели партнеров по взаимодействию (которые могут быть конкурентными, кооперативными или смешанными) и планировать наилучший ответ фокального агента, даже когда цели партнеров по взаимодействию являются частными и изменчивыми, напрямую решает центральную проблему этих сред.
- Отсутствие доступа к параметрам или вознаграждениям партнеров по взаимодействию: Критическое ограничение в реалистичных мультиагентных сценариях — это отсутствие прямого доступа к внутренним параметрам или функциям вознаграждения других агентов. Модуль моделирования противника HOP выводит цели партнеров по взаимодействию и изучает их политики, обусловленные целью, исключительно наблюдая за их «последовательностями действий». Этот подход, основанный на выводе, позволяет избежать необходимости явного знания внутренних механизмов партнеров по взаимодействию, что делает его применимым в реальных сценариях «черного ящика».
- Отсутствие связи: Определение проблемы подразумевает отсутствие явной связи между агентами. Вывод целей и обучение политик HOP полностью основаны на наблюдаемых траекториях и действиях, без опоры на какую-либо форму прямой связи, тем самым соблюдая это неявное ограничение.
Отклонение альтернатив
Статья предоставляет четкое обоснование отклонения нескольких популярных подходов:
- Традиционные MARL-алгоритмы (например, Minimax, Double Oracle, условие IGM): Эти методы явно отклоняются, поскольку они «неприменимы в средах со смешанными мотивами». Их основные предположения и методы оптимизированы для структур вознаграждений с нулевой суммой или чисто кооперативных, которые не отражают недетерминированные отношения и вознаграждения с общей суммой, характерные для сред со смешанными мотивами.
- LOLA (Learning with Opponent-Learning Awareness): Хотя это продвинутый MARL-алгоритм, LOLA считается непригодным для общих сред со смешанными мотивами, поскольку он «требует знания параметров сети партнеров по взаимодействию, что может быть неосуществимо во многих сценариях». Моделирование противника на основе вывода в HOP позволяет избежать этого ограничительного требования. Кроме того, LOLA может страдать от «проблем масштабируемости... в сложных последовательных средах, требующих длинных последовательностей действий для вознаграждений», что является ограничением, которое HOP решает с помощью управляемого планирования MCTS.
- I-POMDP (Interactive Partially Observable Markov Decision Processes): Этот фреймворк, хотя и актуален для моделирования противника, отклоняется из-за его «серьезных проблем вычислительной сложности», связанных с «вложенным выводным моделированием». Вычислительная нагрузка делает его «непрактичным в сложных средах». Дизайн HOP специально избегает этого вложенного вывода для достижения большей эффективности.
- Наивный MCTS в мультиагентных средах: Статья признает, что сам по себе MCTS «ограничен в мультиагентных средах, где совместное пространство действий быстро растет с числом агентов». Прямое применение было бы вычислительно невыполнимым. Решение HOP заключается в оценке политик партнеров по взаимодействию и планировании только действий фокального агента, эффективно обходя эту проблему масштабируемости.
- Абляционные версии HOP (без inter-OM, без intra-OM, direct-OM): Абляционное исследование предоставляет эмпирические доказательства отклонения более простых или неполных версий HOP:
- Без inter-OM: Эта версия испытывает трудности против агентов с фиксированными целями (например, кооператоров, дефекторов), поскольку ей не хватает точных априорных данных о целях в начале эпизода, упуская ранние возможности для оптимальной игры. Это подчеркивает необходимость использования исторических эпизодов.
- Без intra-OM: Эта версия плохо работает против агентов с динамичным поведением (например, LOLA, PS-A3C, случайный), поскольку она не может адаптироваться к изменениям целей партнеров по взаимодействию в пределах эпизода, полагаясь только на прошлые эпизоды. Это подчеркивает важность обновления убеждений в реальном времени в пределах эпизода.
- Direct-OM: Этот подход, который удаляет модуль иерархического моделирования противника и использует нейронные сети для прямого моделирования партнеров по взаимодействию без обусловленности целью, находится в «общем невыгодном положении». Он испытывает трудности с получением значительных обновлений во время коротких взаимодействий, что приводит к «неточным моделям противника во время фазы адаптации». Сквозной характер также вносит «более высокую степень неопределенности по сравнению с политикой, обусловленной целью», снижая точность планирования. Это явно подтверждает превосходство обусловленного целью иерархического моделирования противника в HOP.
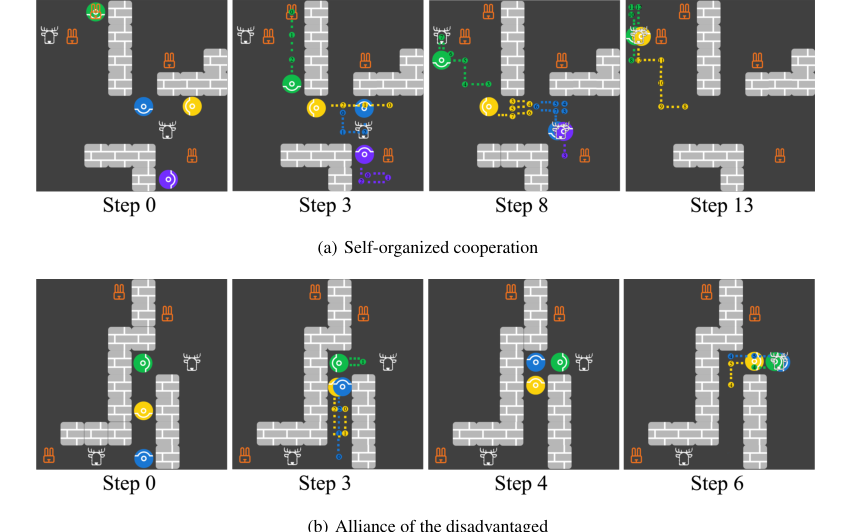 Figure 6. Screenshots for the emergence of (a) self-organized cooperation and (b) alliance of the disadvantaged. Each panel shows agents’ locations at the current step and the trajectories between the current step and the previously stated step
Figure 6. Screenshots for the emergence of (a) self-organized cooperation and (b) alliance of the disadvantaged. Each panel shows agents’ locations at the current step and the trajectories between the current step and the previously stated step
Математический и логический механизм
Главное уравнение
Иерархическое моделирование и планирование противников (HOP) приводится в действие несколькими взаимосвязанными математическими механизмами, которые обеспечивают его адаптивные возможности. В своей основе HOP полагается на байесовский вывод для моделирования целей противника, объект минимизации отрицательного логарифма правдоподобия для изучения политик противника, обусловленных целью, и комбинированную функцию потерь политики и ценности для обучения сетей принятия решений фокального агента, управляемых поиском по дереву Монте-Карло (MCTS).
Основные уравнения, определяющие математический движок HOP:
-
Обновление убеждений о целях противника внутри эпизода (Intra-OM): Это уравнение обновляет убеждение фокального агента о цели партнера по взаимодействию в пределах одного эпизода, учитывая наблюдения в реальном времени.
$$b_{ij}^{K,t+1}(g_j) = \frac{1}{Z_1} b_{ij}^{K,t}(g_j) \frac{\Pr(a_j^{K,t}|s^{K,t}, g_j) \Pr(s^{K,t+1}|s^{K,t}, a_j^{K,t}, g_j)}{\Pr(s^{K,t+1}|s^{K,t}, a_j^{K,t})}$$ -
Обновление убеждений о целях противника между эпизодами (Inter-OM): Это уравнение обновляет априорное убеждение о цели партнера по взаимодействию в начале нового эпизода, используя информацию из прошлых эпизодов.
$$b_{ij}^{K,0}(g_j) = \frac{1}{Z_2} [\alpha b_{ij}^{K-1,0}(g_j) + (1-\alpha)\mathbf{1}(g_j = g_j^{K-1})]$$ -
Функция потерь сети политики противника, обусловленной целью: Этот объект обучения тренирует нейронную сеть, которая предсказывает действия партнеров по взаимодействию, учитывая их выведенные цели и текущее состояние.
$$\mathcal{L}(\omega) = \mathbb{E}[-\log(\pi_\omega(a_j^{K,t}|s^{K,t}, g_j^{K,t}))]$$ -
Функция потерь сети политики и ценности фокального агента: Эта комбинированная функция потерь обучает сети политики и ценности фокального агента, используя MCTS в качестве супервизора.
$$\mathcal{L}(\theta) = \mathcal{L}_p(\pi_{\text{MCTS}}, \pi_\theta) + \mathcal{L}_v(r_i, v_\theta)$$
где
$$\mathcal{L}_p(\pi_1, \pi_2) = \mathbb{E}[-\sum_{a \in \mathcal{A}_i} \pi_1(a|s^{K,t}) \log(\pi_2(a|s^{K,t}))]$$
$$\mathcal{L}_v(r_i, v) = \mathbb{E}[(v(s^{K,t}) - \sum_{l=t}^{T_{\text{max}}} \gamma^{l-t} r_i^{K,l})^2]$$
Покомпонентный анализ
Давайте разберем каждое из этих уравнений, чтобы понять роль каждого компонента.
Обновление убеждений о целях противника внутри эпизода (Уравнение 1)
$$b_{ij}^{K,t+1}(g_j) = \frac{1}{Z_1} b_{ij}^{K,t}(g_j) \frac{\Pr(a_j^{K,t}|s^{K,t}, g_j) \Pr(s^{K,t+1}|s^{K,t}, a_j^{K,t}, g_j)}{\Pr(s^{K,t+1}|s^{K,t}, a_j^{K,t})}$$
- $b_{ij}^{K,t+1}(g_j)$:
- Математическое определение: Апостериорное распределение вероятностей, представляющее убеждение агента $i$ относительно цели $g_j$ противника $j$ в момент времени $t+1$ в эпизоде $K$.
- Физическая/логическая роль: Это обновленное убеждение. Оно говорит фокальному агенту: «Учитывая все, что я видел до сих пор в этом эпизоде, насколько вероятно, что противник $j$ имеет цель $g_j$?». Это критически важно для адаптации в реальном времени к изменяющемуся поведению партнеров по взаимодействию.
- $Z_1$:
- Математическое определение: Нормализующий множитель.
- Физическая/логическая роль: Обеспечивает, чтобы сумма вероятностей для всех возможных целей $g_j$ противника $j$ равнялась 1, поддерживая корректное распределение вероятностей.
- Почему деление: Это фундаментальная часть теоремы Байеса для масштабирования числителя (априорные данные, умноженные на правдоподобие) в корректное распределение вероятностей.
- $b_{ij}^{K,t}(g_j)$:
- Математическое определение: Априорное распределение вероятностей, представляющее убеждение агента $i$ относительно цели $g_j$ противника $j$ в момент времени $t$ в эпизоде $K$.
- Физическая/логическая роль: Это убеждение до наблюдения последнего действия и перехода состояния. Оно служит отправной точкой для текущего шага байесовского обновления.
- $\Pr(a_j^{K,t}|s^{K,t}, g_j)$:
- Математическое определение: Вероятность того, что противник $j$ предпримет действие $a_j^{K,t}$ при заданном текущем состоянии $s^{K,t}$ и гипотетической цели $g_j$. Это предоставляется сетью политики, обусловленной целью, $\pi_\omega$.
- Физическая/логическая роль: Этот член действует как «правдоподобие действия». Он количественно определяет, насколько хорошо определенная гипотетическая цель $g_j$ объясняет наблюдаемое действие $a_j^{K,t}$. Если противник совершает действие, которое очень вероятно при цели $g_A$, но маловероятно при цели $g_B$, этот член увеличит убеждение в $g_A$.
- $\Pr(s^{K,t+1}|s^{K,t}, a_j^{K,t}, g_j)$:
- Математическое определение: Вероятность перехода в состояние $s^{K,t+1}$ при заданном предыдущем состоянии $s^{K,t}$, действии $a_j^{K,t}$ противника $j$ и гипотетической цели $g_j$. В статье упоминается марковское предположение, согласно которому это может упроститься до $\Pr(s^{K,t+1}|s^{K,t}, a_j^{K,t})$, подразумевая независимость от $g_j$ при заданном действии. Однако уравнение включает $g_j$, предполагая потенциальную зависимость или более общую формулировку.
- Физическая/логическая роль: Этот член действует как «правдоподобие перехода состояния». Он далее уточняет убеждение, учитывая, соответствует ли наблюдаемое изменение состояния гипотетической цели и действию.
- $\Pr(s^{K,t+1}|s^{K,t}, a_j^{K,t})$:
- Математическое определение: Вероятность перехода в состояние $s^{K,t+1}$ при заданном предыдущем состоянии $s^{K,t}$ и действии $a_j^{K,t}$ противника $j$.
- Физическая/логическая роль: Это нормализующий член для правдоподобия перехода состояния, обеспечивающий правильное масштабирование общего правдоподобия.
- Почему умножение: Байесовские обновления объединяют априорные убеждения с правдоподобиями путем умножения, отражая, как новые доказательства масштабируют существующее убеждение.
Обновление убеждений о целях противника между эпизодами (Уравнение 2)
$$b_{ij}^{K,0}(g_j) = \frac{1}{Z_2} [\alpha b_{ij}^{K-1,0}(g_j) + (1-\alpha)\mathbf{1}(g_j = g_j^{K-1})]$$
- $b_{ij}^{K,0}(g_j)$:
- Математическое определение: Априорное распределение вероятностей относительно целей $g_j$ противника $j$ для агента $i$ в начале эпизода $K$.
- Физическая/логическая роль: Это первоначальная оценка цели противника $j$ в новом эпизоде. Она основана на прошлом опыте, предоставляя «память» о поведении противника.
- $Z_2$:
- Математическое определение: Нормализующий множитель.
- Физическая/логическая роль: Обеспечивает, чтобы сумма вероятностей для всех возможных целей $g_j$ равнялась 1.
- Почему деление: Стандартная нормализация для распределений вероятностей.
- $\alpha$:
- Математическое определение: Весовой коэффициент горизонта, $\alpha \in [0, 1]$.
- Физическая/логическая роль: Этот коэффициент контролирует влияние исторических убеждений по сравнению с наиболее недавно наблюдаемой целью. Более высокое $\alpha$ означает, что старые убеждения более важны, что приводит к медленной адаптации. Более низкое $\alpha$ (ближе к 0) означает, что агент отдает приоритет цели, наблюдаемой в предыдущем эпизоде, что обеспечивает более быструю адаптацию к динамичным противникам.
- Почему умножение: Масштабирует вклад априорного убеждения из предыдущего эпизода.
- $b_{ij}^{K-1,0}(g_j)$:
- Математическое определение: Априорное распределение вероятностей относительно целей $g_j$ противника $j$ для агента $i$ в начале предыдущего эпизода $K-1$.
- Физическая/логическая роль: Представляет накопленные исторические знания о целях противника $j$ из всех эпизодов до текущего.
- $(1-\alpha)$:
- Математическое определение: Комплементарный весовой коэффициент к $\alpha$.
- Физическая/логическая роль: Масштабирует вклад наблюдаемой цели из предыдущего эпизода.
- Почему умножение: Масштабирует вклад последнего наблюдения цели.
- $\mathbf{1}(g_j = g_j^{K-1})$:
- Математическое определение: Индикаторная функция, которая возвращает 1, если цель противника $j$ в предыдущем эпизоде $K-1$ была $g_j$, и 0 в противном случае.
- Физическая/логическая роль: Этот член напрямую включает фактическую цель, которая была выведена для противника $j$ в последнем эпизоде. Это сильный сигнал для обновления априорных данных для нового эпизода.
- Почему сложение: Два взвешенных члена складываются для объединения долгосрочного исторического убеждения с краткосрочным, последним наблюдением для формирования новых априорных данных.
Функция потерь сети политики противника, обусловленной целью (Уравнение 3)
$$\mathcal{L}(\omega) = \mathbb{E}[-\log(\pi_\omega(a_j^{K,t}|s^{K,t}, g_j^{K,t}))]$$
- $\mathcal{L}(\omega)$:
- Математическое определение: Функция потерь для сети политики, обусловленной целью, параметризованной $\omega$.
- Физическая/логическая роль: Это объект, который модуль моделирования противника минимизирует для изучения корректных политик противника, обусловленных целью. Более низкие потери означают, что сеть лучше предсказывает действия противника, учитывая его цели.
- $\mathbb{E}[\cdot]$:
- Математическое определение: Оператор ожидания, обычно аппроксимируемый усреднением по пакету образцов данных из буфера воспроизведения.
- Физическая/логическая роль: Обеспечивает стабильную оценку потерь путем усреднения по нескольким точкам данных, уменьшая влияние шума от отдельных точек данных во время обучения.
- $-\log(\pi_\omega(a_j^{K,t}|s^{K,t}, g_j^{K,t}))$:
- Математическое определение: Отрицательный логарифм вероятности, присвоенной сетью политики $\pi_\omega$ наблюдаемому действию $a_j^{K,t}$ при заданном состоянии $s^{K,t}$ и выведенной цели $g_j^{K,t}$.
- Физическая/логическая роль: Это стандартная функция потерь отрицательного логарифма правдоподобия, используемая в обучении с учителем для классификации или обучения политик. Минимизация этой функции потерь максимизирует вероятность того, что сеть присваивает правильному (наблюдаемому) действию, фактически обучая сеть имитировать поведение противника при конкретных целях.
- Почему отрицательный логарифм: Логарифм преобразует произведения вероятностей в суммы, которые легче оптимизировать. Отрицательный знак преобразует объект из максимизации правдоподобия в минимизацию потерь, что является стандартом для оптимизации на основе градиента.
Функция потерь сети политики и ценности фокального агента (Уравнение 6)
$$\mathcal{L}(\theta) = \mathcal{L}_p(\pi_{\text{MCTS}}, \pi_\theta) + \mathcal{L}_v(r_i, v_\theta)$$
$$\mathcal{L}_p(\pi_1, \pi_2) = \mathbb{E}[-\sum_{a \in \mathcal{A}_i} \pi_1(a|s^{K,t}) \log(\pi_2(a|s^{K,t}))]$$
$$\mathcal{L}_v(r_i, v) = \mathbb{E}[(v(s^{K,t}) - \sum_{l=t}^{T_{\text{max}}} \gamma^{l-t} r_i^{K,l})^2]$$
- $\mathcal{L}(\theta)$:
- Математическое определение: Общая функция потерь для сетей политики и ценности фокального агента, параметризованных $\theta$.
- Физическая/логическая роль: Это основной объект обучения, который фокальный агент минимизирует для изучения своей оптимальной политики и корректной функции ценности. Он объединяет два критических аспекта обучения с подкреплением: обучение действовать правильно и обучение прогнозировать будущие вознаграждения.
- Почему сложение: Обучение политики и ценности часто объединяется в единый объект в архитектурах типа actor-critic или AlphaZero, поскольку это взаимодополняющие задачи, которые выигрывают от общих представлений и совместной оптимизации.
- $\mathcal{L}_p(\pi_{\text{MCTS}}, \pi_\theta)$:
- Математическое определение: Терм потерь политики, в частности, потери перекрестной энтропии между политикой $\pi_{\text{MCTS}}$, полученной из MCTS (целевая политика $\pi_1$), и изученной политикой $\pi_\theta$ (предсказанная политика $\pi_2$).
- Физическая/логическая роль: Этот терм действует как механизм «дистилляции политики». MCTS, посредством своего поиска с предвидением, генерирует превосходную политику. Эта функция потерь побуждает изученную политику $\pi_\theta$ фокального агента имитировать и интернализировать политику, сгенерированную MCTS, эффективно передавая «мудрость» планирования в нейронную сеть.
- $\mathbb{E}[-\sum_{a \in \mathcal{A}_i} \pi_1(a|s^{K,t}) \log(\pi_2(a|s^{K,t}))]$:
- Математическое определение: Перекрестная энтропия между двумя распределениями вероятностей $\pi_1$ и $\pi_2$.
- Физическая/логическая роль: Измеряет, насколько изученная политика $\pi_2$ отличается от целевой политики MCTS $\pi_1$. Минимизация перекрестной энтропии делает $\pi_2$ соответствующей $\pi_1$.
- Почему суммирование: Суммирует отрицательные логарифмы вероятностей по всем возможным действиям в пространстве действий $\mathcal{A}_i$ фокального агента, взвешенные вероятностями целевой политики.
- $\mathcal{L}_v(r_i, v_\theta)$:
- Математическое определение: Терм потерь ценности, в частности, среднеквадратичная ошибка (MSE) между предсказанной ценностью $v(s^{K,t})$ из сети ценности и истинным дисконтированным возвратом $\sum_{l=t}^{T_{\text{max}}} \gamma^{l-t} r_i^{K,l}$.
- Физическая/логическая роль: Этот терм обучает сеть ценности $v_\theta$ точно прогнозировать ожидаемые кумулятивные будущие вознаграждения из любого данного состояния. Точная функция ценности критически важна для управления MCTS и оценки качества состояний.
- $\mathbb{E}[(v(s^{K,t}) - \sum_{l=t}^{T_{\text{max}}} \gamma^{l-t} r_i^{K,l})^2]$:
- Математическое определение: Квадрат разницы между предсказанной ценностью и фактическим дисконтированным возвратом.
- Физическая/логическая роль: Это стандартная функция потерь регрессии. Она наказывает сеть ценности за неточные прогнозы, причем большие ошибки получают квадратично более высокие штрафы.
- Почему квадрат разницы: Распространен для задач регрессии, обеспечивает гладкий, дифференцируемый ландшафт потерь для оптимизации на основе градиента.
- $v(s^{K,t})$:
- Математическое определение: Ценность, предсказанная сетью ценности фокального агента для состояния $s^{K,t}$.
- Физическая/логическая роль: Текущая оценка моделью общего будущего дисконтированного вознаграждения, которое может быть получено из состояния $s^{K,t}$.
- $\sum_{l=t}^{T_{\text{max}}} \gamma^{l-t} r_i^{K,l}$:
- Математическое определение: Истинный дисконтированный возврат (кумулятивное вознаграждение), полученный агентом $i$ от временного шага $t$ до конца эпизода $T_{\text{max}}$.
- Физическая/логическая роль: Это «истинное значение» для сети ценности. Оно представляет собой фактическую сумму будущих вознаграждений, дисконтированных по их временной удаленности.
- Почему суммирование: Суммирует вознаграждения по всей будущей траектории.
- $\gamma$:
- Математическое определение: Дисконтирующий фактор, $\gamma \in [0, 1]$.
- Физическая/логическая роль: Определяет текущую ценность будущих вознаграждений. $\gamma$ близкое к 0 делает агента близоруким (заботится только о немедленных вознаграждениях), а $\gamma$ близкое к 1 делает его дальновидным (сильно учитывает долгосрочные вознаграждения).
- Почему возведение в степень: Стандартно в обучении с подкреплением для экспоненциального снижения важности вознаграждений, находящихся дальше в будущем.
Пошаговый поток
Представьте, что один абстрактный набор данных, скажем, наблюдение состояния среды и действий партнеров по взаимодействию, поступает в систему HOP. Вот как он перемещается по математическому движку:
-
Начало эпизода: Подготовка сцены с историей:
- Когда начинается новый эпизод $K$, фокальный агент $i$ не начинает с нуля в отношении своих убеждений о партнерах по взаимодействию. Сначала он обращается к своей «памяти» прошлых взаимодействий.
- Запускается обновление убеждений Inter-OM (Уравнение 2). Это уравнение берет априорное убеждение из предыдущего эпизода, $b_{ij}^{K-1,0}(g_j)$, и объединяет его с фактической целью $g_j^{K-1}$, которая была выведена для противника $j$ в последнем эпизоде. Весовой коэффициент горизонта $\alpha$ действует как регулятор, смешивая, насколько доверять долгосрочной истории по сравнению с самым недавним прошлым. Это дает начальное убеждение $b_{ij}^{K,0}(g_j)$ для текущего эпизода, давая агенту преимущество.
-
Взаимодействие в реальном времени: Наблюдение и вывод целей противника:
- По мере разворачивания эпизода, на каждом временном шаге $t$, агент наблюдает текущее состояние $s^{K,t}$ и действия $a_j^{K,t}$, предпринятые его партнерами по взаимодействию.
- Это новое наблюдение немедленно поступает в обновление убеждений Intra-OM (Уравнение 1). Агент берет свое текущее убеждение $b_{ij}^{K,t}(g_j)$ (которое было $b_{ij}^{K,0}(g_j)$ при $t=0$) и обновляет его. Он спрашивает: «Насколько вероятно, что противник $j$ предпринял бы действие $a_j^{K,t}$ и вызвал переход состояния $s^{K,t+1}$, если бы его целью была $g_j$?».
- Чтобы ответить на этот вопрос, он использует сеть политики, обусловленную целью, $\pi_\omega$, чтобы получить $\Pr(a_j^{K,t}|s^{K,t}, g_j)$ для каждой возможной цели $g_j$. Это правдоподобие затем умножается на текущее убеждение, и результат нормализуется с помощью $Z_1$. Этот процесс постоянно уточняет $b_{ij}^{K,t+1}(g_j)$, делая убеждение о целях противника более точным по мере сбора большего количества действий в пределах эпизода.
-
Изучение поведения противника: Обучение политики противника, обусловленной целью:
- На протяжении всего этого процесса выведенные цели $g_j^{K,t}$ (наиболее вероятные цели) вместе с наблюдаемыми состояниями $s^{K,t}$ и действиями $a_j^{K,t}$ собираются и сохраняются в буфере траекторий.
- Периодически эти собранные данные используются для обучения сети политики, обусловленной целью, $\pi_\omega$. Функция потерь сети политики противника, обусловленной целью (Уравнение 3) минимизируется. Это похоже на то, как учитель показывает сети примеры: «Когда противник находился в состоянии $s$ с целью $g$, он предпринял действие $a$». Сеть учится предсказывать $a$ при заданных $s$ и $g$, улучшая свою способность моделировать поведение противника.
-
Принятие решений фокальным агентом: Планирование наилучшего ответа:
- Теперь очередь фокального агента действовать. Ему нужно выбрать свое собственное действие $a_i^{K,t}$.
- Агент инициирует Поиск по дереву Монте-Карло (MCTS). MCTS не просто учитывает текущее состояние; он симулирует множество возможных будущих.
- Критически важно, что MCTS не знает целей партнеров по взаимодействию наверняка. Поэтому в каждом из своих $N_s$ раундов симуляции он выбирает комбинацию целей партнеров по взаимодействию $g_{-i}$ из текущего убеждения $b_{ij}^{K,t}(g_j)$ (из шага 2).
- Для каждой выбранной комбинации целей MCTS симулирует траектории. Когда ему нужно знать, что сделает партнер по взаимодействию $j$, он использует обученную сеть политики, обусловленной целью, $\pi_\omega(\cdot|s, g_j)$ (из шага 3) с выбранной целью $g_j$. Фокальный агент исследует свои собственные действия.
- После $N_s$ раундов MCTS вычисляет среднее значение действия $Q_{\text{avg}}(s^{K,t}, a)$ (Уравнение 4) для каждого из возможных действий фокального агента, учитывая неопределенность в отношении целей партнеров по взаимодействию.
- Наконец, фокальный агент выбирает свое действие $a_i^{K,t}$ с использованием модели больцмановской рациональности (Уравнение 5), которая отдает предпочтение действиям с более высокими значениями $Q_{\text{avg}}$, балансируя исследование и эксплуатацию.
-
Обучение быть лучше: Обучение сетей фокального агента:
- Сам процесс MCTS предоставляет ценную информацию: «лучшую» политику $\pi_{\text{MCTS}}$ (полученную в результате поиска) и улучшенную оценку ценности состояния.
- Эта информация, наряду с фактическими вознаграждениями $r_i^{K,l}$, полученными во время симуляций MCTS и реальной игры, используется для обучения основных сетей политики и ценности фокального агента, параметризованных $\theta$.
- Функция потерь сети политики и ценности фокального агента (Уравнение 6) минимизируется. Эта функция потерь состоит из двух частей:
- Потери политики $\mathcal{L}_p$, которые заставляют изученную политику $\pi_\theta$ имитировать политику, сгенерированную MCTS, $\pi_{\text{MCTS}}$. Это похоже на то, как «учитель» MCTS показывает сети оптимальные ходы.
- Потери ценности $\mathcal{L}_v$, которые заставляют сеть ценности $v_\theta$ точно прогнозировать истинные дисконтированные возвраты $\sum_{l=t}^{T_{\text{max}}} \gamma^{l-t} r_i^{K,l}$, наблюдаемые в течение эпизода. Это учит сеть правильно оценивать, насколько хорошо состояние.
- Через эту комбинированную функцию потерь нейронные сети фокального агента учатся принимать лучшие решения и более точно оценивать состояния, становясь более опытными с течением времени.
Этот весь цикл повторяется, причем каждый шаг питает и улучшает другие, создавая динамичную и адаптивную систему обучения.
Динамика оптимизации
Механизм HOP обучается, обновляется и сходится посредством непрерывного, итеративного процесса, который уточняет его понимание противников и его собственные возможности принятия решений. Это обучение управляется градиентным спуском по различным функциям потерь и присущим MCTS самосовершенствованием.
-
Уточнение системы убеждений:
- Внутриэпизодические убеждения (Уравнение 1): Модуль intra-OM непрерывно обновляет убеждения о целях партнеров по взаимодействию с помощью байесовского вывода. Каждое новое наблюдение (действие противника и переход состояния) предоставляет доказательства, которые либо усиливают, либо ослабляют вероятность определенной цели. Со временем, по мере сбора большего количества данных в пределах эпизода, апостериорное распределение $b_{ij}^{K,t+1}(g_j)$ имеет тенденцию сходиться к истинной основной цели противника, предполагая, что его поведение соответствует одной из изученных политик, обусловленных целью. Это классическое байесовское обновление, где неопределенность (энтропия) в распределении убеждений уменьшается с накоплением доказательств.
- Априорные данные между эпизодами (Уравнение 2): Модуль inter-OM обновляет априорные убеждения для новых эпизодов. Весовой коэффициент горизонта $\alpha$ является здесь критическим гиперпараметром. Если $\alpha$ высок, система сильно полагается на долгосрочные средние исторические данные, что приводит к медленной, но стабильной сходимости априорных убеждений. Если $\alpha$ низок, система быстро адаптируется к недавнему поведению противника, что потенциально может привести к более быстрой адаптации, но также к большей нестабильности, если цели противника сильно изменчивы. Этот механизм позволяет системе отслеживать и адаптироваться к сдвигам в стратегиях противника между эпизодами.
-
Обучение политик противника:
- Сеть политики, обусловленной целью, $\pi_\omega$ (используемая для прогнозирования действий противника), обучается путем минимизации функции потерь отрицательного логарифма правдоподобия (Уравнение 3) с использованием стохастического градиентного спуска (SGD) или его вариантов. Ландшафт потерь для этой сети формируется точностью ее прогнозов против наблюдаемых действий противника. По мере сбора и подачи в буфер воспроизведения более разнообразных и точных данных (состояние, выведенная цель, фактическое действие) градиенты направляют параметры сети $\omega$ к минимизации этой функции потерь. Этот процесс итеративно улучшает способность сети точно моделировать поведение противника, делая модуль моделирования противника более надежным.
-
Обучение политики и ценности фокального агента:
- Политика $\pi_\theta$ и функция ценности $v_\theta$ фокального агента изучаются посредством процесса обучения с учителем, где MCTS выступает в роли мощного «учителя». Общая функция потерь $\mathcal{L}(\theta)$ (Уравнение 6) минимизируется с помощью градиентного спуска.
- Улучшение политики: MCTS, выполняя обширные симуляции и поиск с предвидением, генерирует «более сильную» политику $\pi_{\text{MCTS}}$, чем текущая изученная политика $\pi_\theta$. Затем терм потерь политики $\mathcal{L}_p$ заставляет $\pi_\theta$ имитировать $\pi_{\text{MCTS}}$. Это означает, что градиенты от $\mathcal{L}_p$ направляют параметры $\theta$ в направлении, которое делает изученную политику более похожей на действия, оптимальные согласно MCTS. Это итеративное обучение позволяет $\pi_\theta$ сходиться к почти оптимальной политике без необходимости прямого исследования среды.
- Точность функции ценности: Терм потерь ценности $\mathcal{L}_v$ обучает $v_\theta$ прогнозировать истинные дисконтированные возвраты, наблюдаемые во время симуляций MCTS и реальной игры. Градиенты от $\mathcal{L}_v$ направляют $\theta$ к уменьшению среднеквадратичной ошибки между предсказанными и фактическими возвратами. По мере того как $v_\theta$ становится точнее, она предоставляет лучшие оценки для MCTS, позволяя поиску быть более эффективным и результативным. Это создает положительную петлю обратной связи: лучшие оценки ценности приводят к лучшему MCTS, что приводит к лучшим целевым показателям для $v_\theta$.
- Ландшафт потерь: Комбинированная функция потерь $\mathcal{L}(\theta)$ создает сложный ландшафт потерь. Однако надзор MCTS предоставляет сильный, хотя и потенциально шумный, сигнал, который направляет параметры нейронной сети $\theta$ к областям с более высокой ожидаемой отдачей. Итеративный характер MCTS (повторные симуляции) и обучения нейронных сетей (градиентные обновления) позволяет системе сходиться к надежной политике и функции ценности.
-
Исследование-эксплуатация MCTS:
- Сам алгоритм MCTS балансирует исследование и эксплуатацию, используя такие механизмы, как pUCT (Polynomial Upper Confidence Trees). Коэффициент исследования $c$ в функции оценки MCTS (упомянутый в Приложении E.1) контролирует этот баланс. Более высокое $c$ побуждает MCTS исследовать менее посещаемые действия, потенциально открывая лучшие стратегии. Более низкое $c$ заставляет MCTS активнее использовать известные хорошие действия, что приводит к более быстрой сходимости к локальным оптимумам. Эта динамика гарантирует, что MCTS продолжает находить улучшенные политики для надзора за нейронной сетью.
Таким образом, динамика оптимизации HOP характеризуется иерархическим и итеративным процессом обучения. Модели противников постоянно уточняются посредством байесовских обновлений и обучения с учителем, предоставляя все более точные прогнозы поведения партнеров по взаимодействию. Это уточненное понимание затем информирует MCTS, который действует как мощный планирующий механизм, генерируя превосходные политики и целевые показатели ценности. Эти целевые показатели, в свою очередь, контролируют основные сети политики и ценности фокального агента, направляя их к сходимости к эффективной и адаптивной стратегии принятия решений в средах со смешанными мотивами. Взаимодействие этих компонентов гарантирует, что система может адаптироваться к невиданным политикам и изучать надежное поведение.
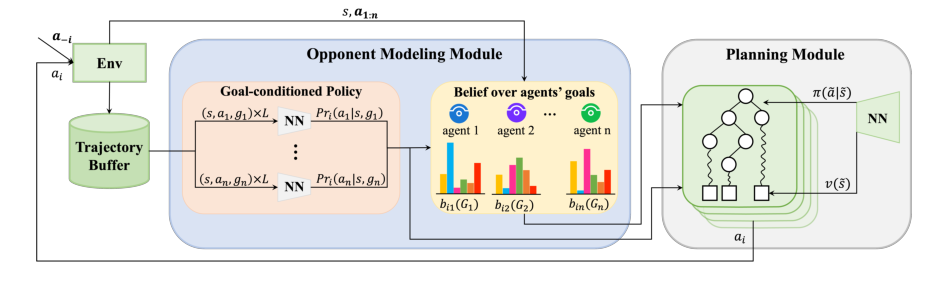 Figure 1. Overview of HOP. HOP consists of an opponent modeling module and a planning module. The opponent modeling module models the behavior of co-players by inferring co-players’ goals and learning their goal-conditioned policies. Estimated behavior is then fed to the planning module to select a rewarding action for the focal agent
Figure 1. Overview of HOP. HOP consists of an opponent modeling module and a planning module. The opponent modeling module models the behavior of co-players by inferring co-players’ goals and learning their goal-conditioned policies. Estimated behavior is then fed to the planning module to select a rewarding action for the focal agent
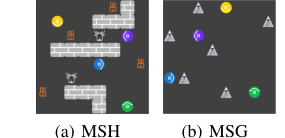 Figure 2. Overview of Markov Stag-Hunt and Markov Snowdrift. There are four agents, repre- sented by colored circles, in each paradigm. (a) Agents catch prey for reward. A stag with a reward of 10 requires at least two agents to hunt together. One agent can hunt a hare with a reward of 1. (b) Everyone gets a reward of 6 when an agent removes a snowdrift. When a snowdrift is removed, removers share the cost of 4 evenly
Figure 2. Overview of Markov Stag-Hunt and Markov Snowdrift. There are four agents, repre- sented by colored circles, in each paradigm. (a) Agents catch prey for reward. A stag with a reward of 10 requires at least two agents to hunt together. One agent can hunt a hare with a reward of 1. (b) Everyone gets a reward of 6 when an agent removes a snowdrift. When a snowdrift is removed, removers share the cost of 4 evenly
Результаты, ограничения и заключение
Экспериментальный дизайн и базовые модели
Для строгой проверки алгоритма иерархического моделирования и планирования противников (HOP) авторы провели эксперименты в двух различных средах со смешанными мотивами: Марковская игра «Охота на оленя» (MSH) и Марковская игра «Снежный занос» (MSG). Эти среды представляют собой пространственные и временные расширения классических парадигм теории игр, разработанные для выявления сложных стратегических взаимодействий.
В MSH четыре агента охотятся на добычу (оленей и зайцев) на сетке. Олень дает вознаграждение 10, но требует участия как минимум двух агентов для совместной охоты, разделяя вознаграждение. Заяц дает вознаграждение 1 и может быть пойман одним агентом. Игра заканчивается через 30 временных шагов. Были использованы две настройки MSH:
- MSH-4h1s: Четыре зайца и один олень. Эта установка поощряет кооперацию ради оленя, сохраняя при этом конкуренцию за зайцев, создавая динамику смешанных мотивов.
- MSH-4h2s: Четыре зайца и два оленя. Это увеличивает потенциал для кооперации, но вносит поворот: игра заканчивается через пять временных шагов после первой успешной охоты, усиливая напряжение между немедленной индивидуальной выгодой и долгосрочной коллективной выгодой.
Среда MSG размещает шесть сугробов случайным образом на сетке 8x8. Агенты могут перемещаться, оставаться бездействующими или «убирать сугроб». Уборка сугроба влечет за собой общую стоимость 4 среди уборщиков, но каждый агент получает индивидуальное вознаграждение 6. Основная дилемма здесь — «безбилетник»: агент может получить более высокое вознаграждение, позволяя другим убирать сугробы. Игра заканчивается, когда все сугробы расчищены, или через 50 временных шагов. В обеих MSH и MSG четыре агента действуют без прямой связи или доступа к внутренним параметрам друг друга. Диаграммы Шеллинга были использованы для визуального подтверждения того, что эти среды эффективно отражают присущие дилеммы взаимодействий со смешанными мотивами, где оптимальные стратегии меняются в зависимости от поведения партнеров по взаимодействию.
«Жертвы» (базовые модели), против которых тестировался HOP, включали разнообразный набор установленных алгоритмов обучения с подкреплением для мультиагентных систем (MARL) и стратегий, основанных на правилах:
- Базовые модели обучения: LOLA (Learning with Opponent-Learning Awareness), SI (Social Influence), A3C (Asynchronous Advantage Actor-Critic), PS-A3C (Prosocial A3C), PR2 и direct-OM (абляционная версия HOP, которая моделирует партнеров по взаимодействию напрямую с помощью нейронных сетей без обусловленности целью).
- Базовые модели на основе правил: Random (случайно выбирает допустимые действия), Cooperator (последовательно принимает кооперативное поведение) и Defector (последовательно принимает эксплуататорское поведение).
Экспериментальная проверка проходила в два этапа:
1. Самообучение (Self-play): Все агенты, использующие один и тот же алгоритм, обучались до сходимости их производительности. Этот этап оценивал способность алгоритма принимать автономные решения и достигать кооперации в средах со смешанными мотивами.
2. Адаптация за несколько примеров: Фокальный агент HOP взаимодействовал с тремя партнерами по взаимодействию, использующими различные базовые алгоритмы, в течение 2400 шагов. Среднее вознаграждение фокального агента в течение последних 600 шагов использовалось для количественной оценки его способности к адаптации. Параметры политики могли обновляться во время этого этапа, если алгоритм это поддерживал.
Чтобы предоставить четкую точку отсчета для оптимальной производительности, для каждого типа партнера по взаимодействию был обучен «Оракул-агент». Этот Оракул-агент, обученный с помощью A3C с фиксированными параметрами партнеров по взаимодействию в течение обширных взаимодействий, представляет собой наилучшую возможную производительность, которую агент мог бы достичь при идеальной адаптации к конкретному партнеру по взаимодействию. Все вознаграждения были нормализованы по минимуму-максимуму между производительностью Оракула-агента (оптимальной) и производительностью случайной политики (наименьшей), что позволило стандартизировать сравнение.
Что доказывают свидетельства
Экспериментальные результаты однозначно демонстрируют превосходные возможности HOP как в самообучении, так и в адаптации за несколько примеров в средах со смешанными мотивами, безжалостно доказывая его основные математические утверждения относительно иерархического моделирования и планирования противников.
В сценариях самообучения HOP последовательно достигал высоких вознаграждений, часто превосходя или сравниваясь с лучшими базовыми моделями. В MSH-4h1s HOP, direct-OM и PS-A3C научились охотиться на оленей, но «ленивый агент» PS-A3C привел к худшим вознаграждениям. LOLA демонстрировал нестабильные стратегии, в то время как SI и A3C в основном охотились на зайцев, принося низкие результаты. PR2 полностью потерпел неудачу в MSH. В MSH-4h2s HOP и A3C были наиболее стабильными и дали наивысшие вознаграждения, успешно координируя действия для охоты на оленей. Наиболее примечательно, что в MSG HOP достиг наивысшего вознаграждения, приблизившись к теоретическому оптимуму в 30.0. Это подчеркивает сильную склонность HOP к кооперации в децентрализованной среде, в отличие от базовых моделей, таких как LOLA, A3C и SI, которые отдавали приоритет индивидуальной прибыли и испытывали трудности с координацией. PS-A3C, хотя и занял второе место, все же столкнулся с проблемами координации, когда оставался только один сугроб.
Наиболее убедительные доказательства основного механизма HOP заключаются в его производительности адаптации за несколько примеров (Таблица 1). HOP последовательно достигал «общего наилучшего процента адаптации» в большинстве тестовых сценариев: 83,3% в MSH-4h1s, идеальные 100,0% в MSH-4h2s и 83,3% в MSG. Это значительно превосходило другие алгоритмы, которые достигали оптимальной адаптации только в конкретных, ограниченных сценариях, где поведение партнеров по взаимодействию соответствовало их предварительно изученным политикам.
Статья предоставляет четкий пример того, как механизм обновления убеждений HOP работает на практике *. Столкнувшись с тремя дефекторами (которые последовательно охотятся на зайцев) в MSH, HOP изначально имел «ложное убеждение», что партнеры по взаимодействию будут охотиться на оленей (смещение из его опыта самообучения). Однако *модуль intra-OM (обновление убеждений в пределах эпизода) быстро исправил это. Наблюдая за траекториями партнеров по взаимодействию (например, движение к зайцу), intra-OM вывел их истинную цель, что привело к точным моделям противника. Модуль inter-OM (обновление убеждений между эпизодами) далее ускорил эту сходимость к истинному убеждению, действуя как точный априорный фактор для последующих эпизодов. Снижающаяся линия на Рисунке 5, представляющая постепенное уменьшение априорного убеждения в охоте на оленей, является окончательным, неоспоримым доказательством того, что иерархический механизм обновления убеждений HOP эффективно адаптируется к невиданным и динамичным поведениям партнеров по взаимодействию. Имея эти точные политики партнеров по взаимодействию в качестве входных данных, модуль планирования мог затем вычислить выгодные действия, позволяя HOP вносить существенные стратегические коррективы и достигать высоких вознаграждений даже против не кооперативных агентов, таких как дефекторы.
Кроме того, эксперименты выявили возникновение социальной интуиции (Приложение G, Рисунок 6) среди нескольких агентов HOP. В одном случае возникла «самоорганизованная кооперация», когда четыре агента HOP совместно охотились на оленя для получения более высокого общего вознаграждения, хотя это было индивидуально рискованнее, чем охота на зайцев. Это произошло посредством независимого принятия решений, когда агенты выводили намерения друг друга и координировали действия без централизованного контроля. В другом случае, «альянс обездоленных», два менее жадных агента HOP успешно обманули более жадного партнера по взаимодействию, чтобы избежать сотрудничества, а затем скоординировались, чтобы максимизировать свою собственную прибыль. Эти наблюдения подчеркивают, что способность HOP выводить намерения других и быстро корректировать свои ответы способствует сложному социальному поведению, даже когда агенты эгоистичны.
Ограничения и будущие направления
Хотя HOP демонстрирует замечательную эффективность в адаптации за несколько примеров в средах со смешанными мотивами, авторы откровенно признают несколько ограничений, которые открывают путь для захватывающих будущих исследований.
Во-первых, значительным ограничением является требование четкого определения целей в любой данной среде для эффективной работы HOP. Текущая структура полагается на предопределенные наборы целей. Чтобы повысить обобщаемость HOP и применимость к более широкому спектру сложных сценариев, важное будущее направление включает разработку методов, которые могут автономно абстрагировать наборы целей. Это позволило бы HOP работать в новых средах без ручного вмешательства, что является проблемой, которую некоторые предыдущие работы начали исследовать.
Во-вторых, текущая реализация HOP использует Теорию разума (ToM) Уровня-0, которая, по сути, включает агента, рассуждающего о том, «что они думают». Хотя это эффективно, включение ToM более высокого порядка, такого как ToM Уровня-1 («что я думаю, что они думают обо мне»), может значительно улучшить прогнозы поведения партнеров по взаимодействию. Однако это сопряжено со значительным увеличением вычислительных затрат из-за связанного вложенного выводного моделирования. Следовательно, будущая работа должна быть сосредоточена на разработке продвинутых и вычислительно эффективных методов планирования, которые могут эффективно и быстро использовать более богатые идеи, предоставляемые ToM более высокого порядка, без поддавания запретительной вычислительной сложности. Это нетривиальная инженерная и математическая проблема.
В-третьих, хотя статья выбрала разнообразный набор хорошо зарекомендовавших себя алгоритмов в качестве партнеров по взаимодействию для оценки, ни один из них полностью не отражает нюансы и сложности человеческого поведения. Конечная цель многих мультиагентных систем — беспрепятственное взаимодействие с людьми. Следовательно, убедительным будущим направлением исследований является изучение производительности HOP в сценариях адаптации за несколько примеров с участием реальных людей. Это предоставило бы бесценные сведения о его реальной применимости и надежности.
Наконец, возникает критический момент обсуждения, связанный с присущей эгоистичной природой HOP. Хотя он преуспевает в максимизации собственной отдачи, это не всегда гарантирует согласованность с наилучшими интересами или ценностями людей-партнеров по взаимодействию. Чтобы смягчить это потенциальное несоответствие и способствовать более выгодному сотрудничеству человека и ИИ, будущие исследования должны изучить, как мощные возможности вывода HOP могут быть использованы для вывода и оптимизации человеческих ценностей и предпочтений во время взаимодействий. Это может включать включение механизмов согласования ценностей или обучения предпочтениям, позволяя HOP помогать людям в сложных средах не только эффективно, но и этически обоснованно и социально выгодно. Это потребует глубокого изучения этики взаимодействия человека и ИИ и надежных методов выявления предпочтений.
 Table 5. Performance of HOP and its ablation versions in MSH-4h2s. In (a) self-play, 4 agents of the same kind are trained to converge. Shown is the normalized score after convergence. In (b) few-shot adaptation, the interaction happens between 1 agent using the row policy and 3 co-players using the column policy. Shown are the min-max normalized scores, with normalization bounds set by the rewards of Orcale and the random policy. The results are depicted for the row policy from 1800 to 2400 step
Table 5. Performance of HOP and its ablation versions in MSH-4h2s. In (a) self-play, 4 agents of the same kind are trained to converge. Shown is the normalized score after convergence. In (b) few-shot adaptation, the interaction happens between 1 agent using the row policy and 3 co-players using the column policy. Shown are the min-max normalized scores, with normalization bounds set by the rewards of Orcale and the random policy. The results are depicted for the row policy from 1800 to 2400 step
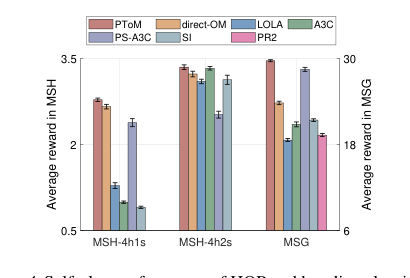 Figure 4. Self-play performance of HOP and baseline algorithms. Shown is the average reward in the self-play training phase
Figure 4. Self-play performance of HOP and baseline algorithms. Shown is the average reward in the self-play training phase