हाईवे वैल्यू इटरेशन नेटवर्क्स
इस शोध का मूल कृत्रिम बुद्धिमत्ता (AI) एजेंटों को प्रभावी दीर्घकालिक योजना करने में सक्षम बनाने की लंबे समय से चली आ रही चुनौती से उपजा है। यह विशिष्ट समस्या पहली बार 2016 में Tamar et al.
पृष्ठभूमि और अकादमिक वंश
उत्पत्ति और अकादमिक वंश
इस शोध का मूल कृत्रिम बुद्धिमत्ता (AI) एजेंटों को प्रभावी दीर्घकालिक योजना करने में सक्षम बनाने की लंबे समय से चली आ रही चुनौती से उपजा है। यह विशिष्ट समस्या पहली बार 2016 में Tamar et al. द्वारा प्रस्तुत वैल्यू इटरेशन नेटवर्क्स (VINs) के साथ प्रमुखता से उभरी। VINs एक महत्वपूर्ण कदम थे क्योंकि उन्होंने एक "योजना मॉड्यूल" को सीधे एक न्यूरल नेटवर्क (NN) आर्किटेक्चर में एकीकृत किया, जिससे योजना कार्यों का एंड-टू-एंड लर्निंग संभव हुआ। इस योजना मॉड्यूल को क्लासिकल वैल्यू इटरेशन एल्गोरिथम का अनुमान लगाने के लिए डिज़ाइन किया गया था, जो 1966 में बेलमैन द्वारा औपचारिक रूप से सुदृढीकरण सीखने (RL) में एक मौलिक अवधारणा है।
ऐतिहासिक रूप से, जबकि VINs ने पथ योजना और स्वायत्त नेविगेशन जैसे विभिन्न योजना कार्यों में उल्लेखनीय दक्षता दिखाई, वे एक महत्वपूर्ण सीमा का सामना कर रहे थे: दीर्घकालिक योजना को संभालने की उनकी क्षमता। जैसे-जैसे कार्यों की जटिलता बढ़ी, जिसके लिए अधिक योजना चरणों की आवश्यकता हुई (जैसे, भूलभुलैया में 120 से अधिक पथ लंबाई), VINs की सफलता दर में भारी गिरावट आई, जो अक्सर 10% से नीचे गिर जाती थी। दीर्घकालिक योजना को बेहतर बनाने का एक स्वाभाविक तरीका VIN के योजना मॉड्यूल की गहराई बढ़ाना है, जिससे यह अधिक योजना चरणों का अनुकरण कर सके। हालांकि, यह तुरंत डीप लर्निंग में एक मौलिक समस्या में आ गया: लुप्त या विस्फोट करने वाले ग्रेडिएंट्स (Hochreiter, 1991) जैसी समस्याओं के कारण बहुत गहरे न्यूरल नेटवर्क को प्रशिक्षित करना स्वाभाविक रूप से कठिन है। जबकि अवशिष्ट नेटवर्क (residual networks) और हाईवे नेटवर्क (highway networks) जैसी तकनीकों ने वर्गीकरण कार्यों के लिए बहुत गहरे NN के प्रशिक्षण को सफलतापूर्वक सक्षम किया था, ये विधियां VINs के अद्वितीय आर्किटेक्चर पर लागू होने पर समान रूप से प्रभावी साबित नहीं हुई थीं, विशेष रूप से योजना के संदर्भों में। यह अंतर इसलिए उत्पन्न होता है क्योंकि VINs सुदृढीकरण सीखने से एक विशिष्ट आगमनात्मक पूर्वाग्रह (inductive bias) को शामिल करते हैं, जो सैद्धांतिक रूप से ध्वनि वैल्यू इटरेशन एल्गोरिथम में निहित है। इसलिए, लेखकों को एक नए दृष्टिकोण को विकसित करने के लिए मजबूर होना पड़ा जो NN और RL दोनों से उन्नत तकनीकों को एकीकृत करके दीर्घकालिक योजना के लिए गहरे VINs को प्रभावी ढंग से प्रशिक्षित कर सके।
सहज डोमेन शब्द
एक शून्य-आधारित पाठक को अवधारणाओं को समझने में मदद करने के लिए, यहां कुछ विशिष्ट शब्दों का रोजमर्रा की उपमाओं में अनुवाद किया गया है:
- वैल्यू इटरेशन नेटवर्क (VIN): एक स्मार्ट जीपीएस की कल्पना करें जो न केवल आपको सबसे अच्छा मार्ग बताता है, बल्कि बार-बार सभी संभावित भविष्य के चरणों और उनके परिणामों का अनुकरण करके सबसे अच्छा मार्ग ढूंढना सीखता भी है, ठीक वैसे ही जैसे आप सबसे मूल्यवान खोजने के लिए मानसिक रूप से विकल्पों के माध्यम से "पुनरावृति" करेंगे। एक VIN इस तरह के अंतर्निहित "आगे सोचने" मॉड्यूल वाला एक न्यूरल नेटवर्क है।
- दीर्घकालिक क्रेडिट असाइनमेंट (Long-term Credit Assignment): कई चरणों वाले एक जटिल चाल को सिखाने वाले कुत्ते के बारे में सोचें। यदि कुत्ते को अंत में एक ट्रीट मिलता है, तो कुत्ते के लिए यह जानना मुश्किल होता है कि कौन से विशिष्ट पिछले कार्य ट्रीट प्राप्त करने में योगदान करते हैं। AI में, दीर्घकालिक क्रेडिट असाइनमेंट यह पता लगाने की चुनौती है कि बहुत पहले लिए गए कौन से कार्य वास्तव में बाद में एक अच्छे (या बुरे) परिणाम के लिए जिम्मेदार थे।
- लुप्त/विस्फोटक ग्रेडिएंट्स (Vanishing/Exploding Gradients): बहुत लंबी कतार वाले लोगों के साथ "टेलीफोन" का खेल खेलने की कल्पना करें। यदि संदेश बहुत धीरे से फुसफुसाया जाता है (लुप्त ग्रेडिएंट), तो यह अंत तक खो जाता है। यदि यह बहुत जोर से चिल्लाया जाता है (विस्फोटक ग्रेडिएंट), तो यह विकृत शोर बन जाता है। डीप लर्निंग में, ग्रेडिएंट्स "फीडबैक" सिग्नल की तरह होते हैं जो नेटवर्क को बताता है कि उसकी आंतरिक सेटिंग्स को कैसे समायोजित करना है। यदि यह फीडबैक कई परतों में बहुत कमजोर या बहुत जंगली हो जाता है, तो नेटवर्क प्रभावी ढंग से सीख नहीं सकता है।
- स्किप कनेक्शन (Skip Connections): एक बहुत लंबी, घुमावदार सड़क की कल्पना करें। स्किप कनेक्शन सीधे शॉर्टकट या एक्सप्रेस लेन जोड़ने की तरह हैं जो घुमावदार हिस्सों को बायपास करते हैं। यह जानकारी (या सीखने के लिए "फीडबैक" सिग्नल) को न्यूरल नेटवर्क की कई परतों में आसानी से और सीधे यात्रा करने की अनुमति देता है, जिससे यह खो जाने या पतला होने से बच जाता है।
संकेतन तालिका
| संकेतन | विवरण | श्रेणी |
|---|---|---|
| $s$ | पर्यावरण में एक विशिष्ट स्थिति। | चर |
| $a$ | एजेंट द्वारा लिया गया एक कार्य। | चर |
| $V^\pi(s)$ | मान फलन, जो स्थिति $s$ से नीति $\pi$ का पालन करते हुए अपेक्षित कुल भविष्य के पुरस्कार का प्रतिनिधित्व करता है। | चर |
| $Q^\pi(s, a)$ | क्रिया-मान फलन, जो स्थिति $s$ से क्रिया $a$ लेने और फिर नीति $\pi$ का पालन करने पर अपेक्षित कुल भविष्य के पुरस्कार का प्रतिनिधित्व करता है। | चर |
| $V^{(n)}$ | वैल्यू इटरेशन एल्गोरिथम के $n$-वें पुनरावृति पर मान फलन। | चर |
| $\gamma$ | छूट कारक, 0 और 1 के बीच का मान जो भविष्य के पुरस्कारों के महत्व को निर्धारित करता है। | पैरामीटर |
| $N$ | न्यूरल नेटवर्क की कुल गहराई (परतों की संख्या)। | पैरामीटर |
| $N_B$ | नेटवर्क आर्किटेक्चर में "हाईवे ब्लॉक" की संख्या। | पैरामीटर |
| $N_p$ | एक हाईवे ब्लॉक के भीतर समानांतर वैल्यू एक्सप्लोरेशन (VE) मॉड्यूल की संख्या। | पैरामीटर |
| $\epsilon$ | अन्वेषण दर, प्रशिक्षण के दौरान क्रिया चयन में यादृच्छिकता को नियंत्रित करती है। | पैरामीटर |
समस्या परिभाषा और बाधाएँ
मुख्य समस्या सूत्रीकरण और दुविधा
यह पत्र जिस मुख्य समस्या को संबोधित करता है, वह है प्रभावी दीर्घकालिक योजना करने में वैल्यू इटरेशन नेटवर्क्स (VINs) को सक्षम करने की महत्वपूर्ण चुनौती।
इनपुट/वर्तमान स्थिति:
वर्तमान स्थिति में वैल्यू इटरेशन नेटवर्क्स (VINs) शामिल हैं, जो योजना कार्यों में एंड-टू-एंड लर्निंग के लिए डिज़ाइन किए गए न्यूरल नेटवर्क आर्किटेक्चर हैं। VINs एक विभेदक "योजना मॉड्यूल" को एम्बेड करके इसे प्राप्त करते हैं जो क्लासिक वैल्यू इटरेशन एल्गोरिथम का अनुमान लगाता है। इन नेटवर्कों ने विभिन्न योजना परिदृश्यों, जैसे पथ योजना और स्वायत्त नेविगेशन में काफी दक्षता प्रदर्शित की है, विशेष रूप से उन कार्यों के लिए जिनमें अपेक्षाकृत सीमित संख्या में योजना चरणों की आवश्यकता होती है।
वांछित अंतिम बिंदु/लक्ष्य स्थिति:
वांछित लक्ष्य मजबूत और सटीक दीर्घकालिक योजना में सक्षम VINs विकसित करना है। इसका मतलब है कि नेटवर्क को उन कार्यों को संभालने में सक्षम होना चाहिए जिनमें सैकड़ों योजना चरणों की आवश्यकता होती है, जैसे कि बहुत लंबी सबसे छोटी पथ वाली जटिल भूलभुलैया को नेविगेट करना। महत्वपूर्ण रूप से, इन उन्नत VINs को मानक बैकप्रॉपैगेशन तकनीकों का उपयोग करके महत्वपूर्ण गहराई (सैकड़ों परतें) तक प्रशिक्षित किया जाना चाहिए, जिससे विस्तारित योजना क्षितिज के लिए भी उच्च सफलता दर बनी रहे।
लुप्त कड़ी और गणितीय अंतर:
सटीक लुप्त कड़ी मौजूदा VIN आर्किटेक्चर की दीर्घकालिक योजना के लिए आवश्यक गहरी नेटवर्क कॉन्फ़िगरेशन तक प्रभावी ढंग से स्केल करने में असमर्थता है। जबकि गहरी योजना मॉड्यूल अधिक योजना चरणों की अनुमति देनी चाहिए और इस प्रकार बेहतर दीर्घकालिक प्रदर्शन प्रदान करना चाहिए, वर्तमान VINs अपनी गहराई बढ़ने पर गंभीर कठिनाइयों का सामना करते हैं।
चित्र 1 इसे स्पष्ट रूप से दर्शाता है: 30-परत VIN की सफलता दर 120 से अधिक सबसे छोटी पथ लंबाई के लिए तेजी से घटती है, और 300-परत VIN को प्रशिक्षित करने का प्रयास कठिन साबित होता है, जिसके परिणामस्वरूप खराब प्रदर्शन होता है। गणितीय अंतर एक VIN आर्किटेक्चर को डिजाइन करने में निहित है जो सैकड़ों परतों के माध्यम से जानकारी और ग्रेडिएंट्स को प्रभावी ढंग से प्रसारित कर सकता है, जिससे अंतर्निहित वैल्यू इटरेशन प्रक्रिया को कई पुनरावृति पर एक इष्टतम मान फलन में परिवर्तित होने की अनुमति मिलती है, बिना डीप लर्निंग की अंतर्निहित चुनौतियों का शिकार हुए।
दर्दनाक समझौता या दुविधा:
पिछली शोधकर्ताओं को फंसाने वाली केंद्रीय दुविधा योजना के लिए गहराई की आवश्यकता और गहरे न्यूरल नेटवर्क को प्रशिक्षित करने की व्यावहारिक सीमाओं के बीच अंतर्निहित संघर्ष है। एक ओर, VIN के भीतर एक गहरी योजना मॉड्यूल सैद्धांतिक रूप से वांछनीय है क्योंकि यह अधिक संख्या में पुनरावृत्ति योजना चरणों की अनुमति देता है, जो दीर्घकालिक योजना समस्याओं को हल करने के लिए आवश्यक है। दूसरी ओर, किसी भी न्यूरल नेटवर्क, जिसमें VINs शामिल हैं, की गहराई बढ़ाने से आम तौर पर लुप्त या विस्फोट करने वाले ग्रेडिएंट्स जैसी गंभीर जटिलताएं उत्पन्न होती हैं। जबकि सामान्य डीप लर्निंग ने वर्गीकरण के लिए बहुत गहरे नेटवर्क को प्रशिक्षित करने के लिए तकनीकें (जैसे ResNets या DenseNets में स्किप कनेक्शन) विकसित की हैं, ये विधियां योजना कार्यों के लिए VINs के लिए "समान रूप से सफल नहीं रही हैं"। यह अंतर बताता है कि VINs का अनूठा आगमनात्मक पूर्वाग्रह, जो सुदृढीकरण सीखने में वैल्यू इटरेशन एल्गोरिथम से प्राप्त होता है, उन्हें इन गहराई-संबंधित प्रशिक्षण मुद्दों के प्रति विशेष रूप से संवेदनशील बनाता है, जिससे योजना क्षमता के लिए आर्किटेक्चरल गहराई और व्यावहारिक प्रशिक्षण क्षमता के बीच एक दर्दनाक समझौता होता है।
बाधाएँ और विफलता मोड
गहरे VINs के साथ दीर्घकालिक योजना प्राप्त करने की समस्या कई कठोर, यथार्थवादी बाधाओं और विफलता मोड के कारण अविश्वसनीय रूप से कठिन है:
-
कम्प्यूटेशनल बाधा: लुप्त/विस्फोटक ग्रेडिएंट्स: सबसे मौलिक बाधा डीप न्यूरल नेटवर्क में अच्छी तरह से ज्ञात लुप्त या विस्फोटक ग्रेडिएंट समस्या है। जैसा कि पेपर बताता है, "एक NN की गहराई बढ़ाने से जटिलताएं उत्पन्न हो सकती हैं, जैसे लुप्त या विस्फोटक ग्रेडिएंट्स, जो डीप लर्निंग में एक मौलिक समस्या है।" यह मानक बैकप्रॉपैगेशन का उपयोग करके सैकड़ों परतों वाले VINs को प्रभावी ढंग से प्रशिक्षित करना अत्यंत कठिन बना देता है, क्योंकि ग्रेडिएंट या तो शुरुआती परतों को अपडेट करने के लिए बहुत छोटे हो जाते हैं या बहुत बड़े हो जाते हैं, जिससे अस्थिर प्रशिक्षण होता है।
-
आर्किटेक्चरल बाधा: मानक डीप लर्निंग समाधानों के साथ असंगति: जबकि स्किप कनेक्शन (जैसे, हाईवे नेटवर्क, ResNets, DenseNets में) अन्य डोमेन (जैसे छवि वर्गीकरण) में बहुत गहरे नेटवर्क को प्रशिक्षित करने के लिए प्रभावी साबित हुए हैं, वे योजना कार्यों के लिए VINs में अच्छी तरह से अनुवादित नहीं हुए हैं। यह VINs के योजना मॉड्यूल के लिए इन सामान्य-उद्देश्य वाले डीप लर्निंग तकनीकों के साथ एक विशिष्ट आर्किटेक्चरल असंगति या उपयुक्त आगमनात्मक पूर्वाग्रह की कमी का सुझाव देता है, जो सुदृढीकरण सीखने के वैल्यू इटरेशन पर आधारित है।
-
प्रदर्शन विफलता मोड: गहराई के साथ गिरावट: सुधार करने के बजाय, दीर्घकालिक योजना के लिए VINs का प्रदर्शन गहराई बढ़ने के साथ तेजी से घटता है। उदाहरण के लिए, 150 से अधिक परतों की गहराई वाले VINs कई कार्यों के लिए लगभग 0% की सफलता दर दिखाते हैं। यह एक महत्वपूर्ण विफलता मोड है जहां इच्छित समाधान (अधिक योजना चरणों के लिए अधिक गहराई) सक्रिय रूप से परिणाम को खराब करता है।
-
सूचना प्रवाह बाधा: लालची क्रिया चयन और ग्रेडिएंट चैनलिंग: मूल VIN के वैल्यू इटरेशन मॉड्यूल "लालच से सबसे बड़े Q मान को लेता है" (समीकरण 4)। यह तंत्र "प्रत्येक परत के लिए एक विशिष्ट सूचना प्रवाह बनाता है, जिससे ग्रेडिएंट्स को कुछ विशिष्ट न्यूरॉन्स की ओर चैनल किया जाता है।" विविध सूचना और ग्रेडिएंट प्रवाह की यह कमी नेटवर्क को जटिल, दीर्घकालिक योजना परिदृश्यों में मजबूती से सीखने और सामान्य बनाने में कठिनाई पैदा करती है।
-
अन्वेषण विफलता मोड: हानिकारक स्टोकेस्टिसिटी: जबकि स्टोकेस्टिसिटी (अन्वेषण) का परिचय सूचना प्रवाह में विविधता ला सकता है, अनियंत्रित अन्वेषण प्रति-उत्पादक हो सकता है। पेपर नोट करता है कि "फिल्टर गेट" के बिना अन्वेषण को प्रबंधित करने के लिए, "हाईवे VINs आसानी से VE मॉड्यूल में अन्वेषण के प्रतिकूल प्रभावों से पीड़ित हो सकते हैं, जो अभिसरण को रोक सकता है।" इसका तात्पर्य है कि विविधता में सुधार के भोले प्रयास अस्थिरता पैदा कर सकते हैं और नेटवर्क को एक इष्टतम नीति सीखने से रोक सकते हैं।
-
हार्डवेयर मेमोरी सीमाएँ: हालांकि समस्या परिभाषा का प्राथमिक ध्यान नहीं है, बहुत गहरे नेटवर्क की कम्प्यूटेशनल जटिलता व्यावहारिक हार्डवेयर मेमोरी सीमाएं लगाती है। पेपर के प्रयोगात्मक अनुभाग (तालिका 4) से पता चलता है कि प्रस्तावित हाईवे VIN, कुछ विकल्पों की तुलना में अधिक कुशल होने के बावजूद, 30-परत VIN के लिए 3.1G की तुलना में 300-परत नेटवर्क के लिए 15.0G GPU मेमोरी की आवश्यकता होती है। यह इंगित करता है कि और भी गहरी आर्किटेक्चर या बड़ी समस्या आकारों तक स्केल करना जल्दी से मेमोरी की छत से टकराएगा, जिससे अनुसंधान और परिनियोजन अधिक महंगा और कठिन हो जाएगा।
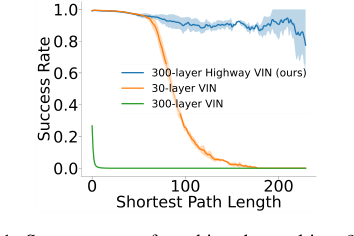 Figure 1. Success rates of reaching the goal in a 25 × 25 maze problem. The success rate of a 30-layer VIN con- siderably decreases as the shortest path length increases, and training a 300-layer VIN is difficult and exhibits poor performance
Figure 1. Success rates of reaching the goal in a 25 × 25 maze problem. The success rate of a 30-layer VIN con- siderably decreases as the shortest path length increases, and training a 300-layer VIN is difficult and exhibits poor performance
यह दृष्टिकोण क्यों
विकल्प की अनिवार्यता
हाईवे वैल्यू इटरेशन नेटवर्क (हाईवे VIN) को अपनाना केवल एक विकल्प नहीं बल्कि एक अनिवार्यता थी, जो दीर्घकालिक योजना की मांगों का सामना करने पर मौजूदा दृष्टिकोणों की अंतर्निहित सीमाओं से प्रेरित थी। लेखकों ने पथ योजना कार्यों में वैल्यू इटरेशन नेटवर्क्स (VINs) का निरीक्षण करते समय पारंपरिक तरीकों की अपर्याप्तता के सटीक क्षण को इंगित किया। विशेष रूप से, 120 से अधिक सबसे छोटी पथ लंबाई के लिए, VINs की सफलता दर 10% से नीचे गिर गई (चित्र 1)। इस स्पष्ट गिरावट ने एक मौलिक दोष को उजागर किया: जबकि VIN के अंतर्निहित "योजना मॉड्यूल" की गहराई बढ़ाना अधिक योजना चरणों को एकीकृत करने और इस प्रकार दीर्घकालिक योजना में सुधार करने का एक तार्किक मार्ग प्रतीत होता था, पारंपरिक डीप न्यूरल नेटवर्क (NN) प्रशिक्षण जटिलताएं, जैसे लुप्त या विस्फोट करने वाले ग्रेडिएंट्स, ने जल्दी से इस दृष्टिकोण को अव्यवहार्य बना दिया।
महत्वपूर्ण रूप से, पेपर नोट करता है कि यहां तक कि उन्नत डीप NN, जिन्होंने वर्गीकरण कार्यों में इन ग्रेडिएंट मुद्दों को सफलतापूर्वक हल किया है (जैसे, ResNets, DenseNets, और मानक हाईवे नेटवर्क्स), योजना कार्यों में समान रूप से सफल नहीं थे (तालिका 1, अनुभाग 5)। यह अंतर सीधे VINs की अनूठी वास्तुकला और सुदृढीकरण सीखने (RL) में वैल्यू इटरेशन एल्गोरिथम से प्राप्त उनके आंतरिक आगमनात्मक पूर्वाग्रह से उत्पन्न होता है। मानक डीप NN समाधान, जबकि सामान्य डीप लर्निंग के लिए प्रभावी हैं, VINs के योजना ढांचे के भीतर कुशल दीर्घकालिक क्रेडिट असाइनमेंट की सुविधा के लिए आवश्यक विशिष्ट RL-प्रासंगिक पूर्व ज्ञान प्रदान नहीं करते हैं। इसलिए, एक ऐसा समाधान जो गहरी आर्किटेक्चर को सक्षम कर सके और VINs के योजना आगमनात्मक पूर्वाग्रह को संरक्षित/बढ़ा सके, आगे बढ़ने का एकमात्र व्यवहार्य मार्ग था, जिससे हाईवे वैल्यू इटरेशन और स्किप कनेक्शन जैसी आर्किटेक्चरल नवाचारों का एकीकरण इस विशिष्ट समस्या के लिए तैयार किया गया।
तुलनात्मक श्रेष्ठता
हाईवे VIN न केवल बेहतर प्रदर्शन मेट्रिक्स के माध्यम से, बल्कि एक मौलिक संरचनात्मक पुन: डिजाइन के माध्यम से पिछले स्वर्ण मानकों पर गुणात्मक श्रेष्ठता प्रदर्शित करता है जो गहरे योजना की मुख्य चुनौतियों का समाधान करता है। इसका जबरदस्त लाभ VIN के योजना मॉड्यूल के भीतर एम्बेडेड तीन प्रमुख नवाचारों से उपजा है:
- एग्रीगेट गेट (Aggregate Gate): यह घटक स्किप कनेक्शन का निर्माण करता है, जिससे कई परतों में सूचना प्रवाह में काफी सुधार होता है। मानक हाईवे नेटवर्क्स में सामान्य स्किप कनेक्शन के विपरीत, यह वैल्यू इटरेशन संदर्भ के भीतर एकीकृत है, जिससे लुप्त या विस्फोट करने वाले ग्रेडिएंट्स से पीड़ित हुए बिना सैकड़ों परतों वाले VINs का प्रशिक्षण संभव होता है। यह संरचनात्मक लाभ सीधे दीर्घकालिक योजना के लिए आवश्यक गहरी आर्किटेक्चर को सुगम बनाता है।
- एक्सप्लोरेशन मॉड्यूल (Exploration Module): यह मॉड्यूल प्रशिक्षण के दौरान नियंत्रित स्टोकेस्टिसिटी इंजेक्ट करता है, जो स्थानिक आयामों में सूचना और ग्रेडिएंट प्रवाह में विविधता लाता है। यह पारंपरिक VINs पर एक महत्वपूर्ण सुधार है, जहां वैल्यू इटरेशन मॉड्यूल में लालची अधिकतमकरण ऑपरेशन चयनित क्रियाओं में सीमित विविधता का कारण बन सकता है, जैसा कि VINs की तुलना में हाईवे VINs के लिए कम एन्ट्रॉपी मानों (तालिका 2) से स्पष्ट है। यह विविधता जटिल, उच्च-आयामी योजना वातावरण में मजबूत सीखने के लिए आवश्यक है।
- फिल्टर गेट (Filter Gate): "बेकार अन्वेषण पथों" को "फ़िल्टर आउट" करने के लिए डिज़ाइन किया गया, यह गेट सुरक्षित और कुशल अन्वेषण सुनिश्चित करता है। यह सक्रियणों की तुलना करता है और उन लोगों को छोड़ देता है जो अभिसरण में योगदान नहीं करते हैं, एक तंत्र जो वैल्यू इटरेशन की सैद्धांतिक ध्वनि को बनाए रखने के लिए महत्वपूर्ण है, खासकर जब एक्सप्लोरेशन मॉड्यूल द्वारा पेश की गई स्टोकेस्टिसिटी के साथ जोड़ा जाता है। इसके बिना, जैसा कि एब्लेशन अध्ययन दिखाते हैं (चित्र 7), प्रदर्शन तेजी से घटता है, क्योंकि नेटवर्क अनियंत्रित अन्वेषण के प्रतिकूल प्रभावों से पीड़ित होगा।
ये घटक सामूहिक रूप से हाईवे VINs को लक्ष्य से दूर की स्थितियों के लिए अधिक प्रभावी मान फलन सीखने की अनुमति देते हैं (चित्र 6), जो पारंपरिक VINs और योजना कार्यों में अन्य डीप NN में गंभीर रूप से कमी वाली क्षमता, विस्तारित क्षितिज पर योजना बनाने और दीर्घकालिक निर्भरताओं को संभालने की बेहतर क्षमता का अर्थ है।
बाधाओं के साथ संरेखण
चुना गया हाईवे VIN दृष्टिकोण दीर्घकालिक योजना की कठोर आवश्यकताओं के साथ पूरी तरह से संरेखित होता है, जो समस्या की मांगों और समाधान के अद्वितीय गुणों के बीच एक "विवाह" बनाता है।
एक प्राथमिक बाधा गहरी नेटवर्क की आवश्यकता है जो दीर्घकालिक योजना कर सके, क्योंकि अधिक योजना चरणों में स्वाभाविक रूप से अधिक गहराई की आवश्यकता होती है। पारंपरिक VINs बढ़ी हुई गहराई पर प्रशिक्षण कठिनाइयों के कारण यहां विफल रहे। हाईवे VIN सीधे इसे सैकड़ों परतों के साथ प्रभावी प्रशिक्षण को सक्षम करके संबोधित करता है, जो मानक बैकप्रॉपैगेशन का उपयोग करता है, जो इसके पूर्ववर्तियों के लिए असंभव उपलब्धि है।
एक और महत्वपूर्ण बाधा बहुत गहरे NN में अंतर्निहित लुप्त या विस्फोट करने वाले ग्रेडिएंट समस्या को दूर करना है। एग्रीगेट गेट, स्किप कनेक्शन पेश करके, सीधे इस समस्या का समाधान करता है, स्थिर ग्रेडिएंट प्रवाह सुनिश्चित करता है। यह सिद्ध डीप लर्निंग तकनीकों (जैसे हाईवे नेटवर्क और ResNets में) का एक सीधा अनुकूलन है, लेकिन विशेष रूप से VIN आर्किटेक्चर में VIN के योजना आगमनात्मक पूर्वाग्रह को संरक्षित करने के लिए एकीकृत किया गया है।
इसके अलावा, समस्या को RL ढांचे के भीतर कुशल दीर्घकालिक क्रेडिट असाइनमेंट की आवश्यकता है। इस दृष्टिकोण की नींव, हाईवे वैल्यू इटरेशन, विशेष रूप से इस उद्देश्य के लिए डिज़ाइन की गई थी (Wang et al., 2024)। इस एल्गोरिथम का एकीकरण यह सुनिश्चित करता है कि समाधान सैद्धांतिक रूप से ध्वनि है और इष्टतम मान फलन में परिवर्तित होता है (टिप्पणी 1), यहां तक कि एक्सप्लोरेशन मॉड्यूल की अतिरिक्त स्टोकेस्टिसिटी के साथ भी, फिल्टर गेट (टिप्पणी 2) के कारण। यह सुनिश्चित करता है कि गहरा नेटवर्क न केवल "गहरा" है, बल्कि योजना के लिए प्रभावी ढंग से गहरा है।
विकल्पों का अस्वीकरण
पेपर इस विशिष्ट समस्या के लिए अन्य लोकप्रिय या अत्याधुनिक दृष्टिकोणों को अस्वीकार करने के लिए स्पष्ट तर्क प्रदान करता है:
-
पारंपरिक VINs: ये स्पष्ट रूप से दीर्घकालिक योजना के लिए अपर्याप्त दिखाए गए हैं। जब गहराई एक निश्चित बिंदु (जैसे, 25x25 भूलभुलैया के लिए 30 परतें) से अधिक हो जाती है, तो उनकी सफलता दर तेजी से गिर जाती है, अक्सर 120 से अधिक पथ लंबाई के लिए 10% से नीचे (चित्र 1, तालिका 1)। ग्रेडिएंट मुद्दों के कारण बहुत गहरे VINs को प्रशिक्षित करने में कठिनाई उन्हें सैकड़ों योजना चरणों की आवश्यकता वाले कार्यों के लिए अनुपयुक्त बनाती है।
-
मानक डीप न्यूरल नेटवर्क्स (जैसे, हाईवे नेटवर्क्स, ResNets, DenseNets): जबकि ये आर्किटेक्चर छवि वर्गीकरण जैसे कार्यों में उत्कृष्ट हैं, बहुत गहरे मॉडल के प्रशिक्षण को सक्षम करते हैं, वे "योजना कार्यों में समान रूप से सफल नहीं हैं" (पृष्ठ 1)। लेखकों का अनुमान है कि उनके स्किप कनेक्शन को VINs में एकीकृत करने से योजना के लिए अतिरिक्त आर्किटेक्चरल आगमनात्मक पूर्वाग्रह लाभ नहीं मिलता है (पृष्ठ 8)। ये विधियां, वैल्यू इटरेशन के विशिष्ट RL-प्रासंगिक आगमनात्मक पूर्वाग्रह की कमी के कारण, अपनी गहराई को बेहतर दीर्घकालिक योजना क्षमताओं में अनुवाद करने में विफल रहती हैं। तालिका 1 स्पष्ट रूप से दिखाती है कि जबकि हाईवे नेटवर्क VINs की तुलना में अधिक गहराई पर प्रदर्शन बनाए रखते हैं, उनकी दीर्घकालिक योजना क्षमताएं गहराई बढ़ने के साथ महत्वपूर्ण रूप से नहीं सुधरती हैं, और वे अभी भी हाईवे VINs से बेहतर प्रदर्शन करते हैं।
-
गेटेड पाथ प्लानिंग नेटवर्क्स (GPPNs): GPPNs, VINs का एक आवर्ती संस्करण, गहरे मॉडल में प्रशिक्षण स्थिरता में सुधार के लिए डिज़ाइन किए गए थे। जबकि वे मजबूती से प्रदर्शन करते हैं और अल्पकालिक योजना कार्यों में उत्कृष्ट हैं (जैसे, 25x25 भूलभुलैया में SPL [1,30] के लिए 99.09% SR), उनका प्रदर्शन दीर्घकालिक योजना के लिए काफी खराब हो जाता है, जो SPLs [130,230] के लिए 3% से कम हो जाता है (तालिका 1, पृष्ठ 8)। पेपर इस विफलता का श्रेय GPPN को "योजना के प्रति कम आगमनात्मक पूर्वाग्रह वाला एक ब्लैक बॉक्स विधि" होने को देता है, जिससे यह अल्पकालिक पैटर्न सीखने के लिए अधिक उपयुक्त हो जाता है न कि वास्तविक दीर्घकालिक योजना कौशल के लिए। यह इस बात पर प्रकाश डालता है कि एक मजबूत, स्पष्ट योजना आगमनात्मक पूर्वाग्रह, जैसा कि हाईवे वैल्यू इटरेशन द्वारा प्रदान किया गया है, महत्वपूर्ण है।
 Figure 11. Examples of 2D maze navigation tasks where highway VIN succeeds, but other methods fail
Figure 11. Examples of 2D maze navigation tasks where highway VIN succeeds, but other methods fail
गणितीय और तार्किक तंत्र
मास्टर समीकरण
हाईवे वैल्यू इटरेशन नेटवर्क्स (हाईवे VINs) का मूल इसके "योजना मॉड्यूल" में निहित है, जिसे हाईवे वैल्यू इटरेशन (हाईवे VI) एल्गोरिथम का अनुमान लगाने के लिए डिज़ाइन किया गया है। इस एल्गोरिथम को चलाने वाला केंद्रीय गणितीय इंजन $G$ ऑपरेटर है, जो परिभाषित करता है कि मान फलन को पुनरावृत्ति रूप से कैसे अपडेट किया जाता है। पेपर बताता है कि हाईवे VI एल्गोरिथम पुनरावृत्ति रूप से मान फलन को $V^{(n+1)} = GV^{(n)}$ के रूप में अपडेट करता है, जहां $G$ को औपचारिक रूप से इस प्रकार परिभाषित किया गया है:
$$ GV(s) = \max_{\Pi \in \mathbf{\Pi}} \max_{N \in \mathbf{N}} \max_{a \in \mathcal{A}} \max_{x \in \mathcal{X}} \{(B^{\pi})^{\circ(N-1)} BV, BV\} $$
यह समीकरण बहु-चरणीय बूटस्ट्रैपिंग और नीति अन्वेषण तंत्रों को समाहित करता है जो हाईवे VI और, विस्तार से, हाईवे VIN आर्किटेक्चर के लिए मौलिक हैं।
पद-दर-पद विच्छेदन
आइए प्रत्येक घटक की भूमिका और अर्थ को समझने के लिए इस मास्टर समीकरण का विश्लेषण करें।
-
$GV(s)$:
- गणितीय परिभाषा: यह किसी दिए गए स्थिति $s$ के लिए हाईवे वैल्यू इटरेशन ऑपरेटर $G$ लागू करने के बाद अद्यतन मान फलन का प्रतिनिधित्व करता है।
- भौतिक/तार्किक भूमिका: यह स्थिति $s$ से प्राप्त इष्टतम मूल्य का नया, बेहतर अनुमान है, जिसमें कई योजना क्षितिज और नीतियों से अंतर्दृष्टि शामिल है। यह VIN के योजना मॉड्यूल में एक "हाईवे ब्लॉक" पुनरावृति का आउटपुट है।
- यह ऑपरेटर क्यों: $G$ ऑपरेटर एक समग्र ऑपरेटर है जिसे सुदृढीकरण सीखने में कुशल दीर्घकालिक क्रेडिट असाइनमेंट की सुविधा के लिए डिज़ाइन किया गया है, जो इष्टतम और नीति-आधारित मान पुनरावृति दोनों के तत्वों को जोड़ता है।
-
$V(s)$:
- गणितीय परिभाषा: स्थिति $s$ के मान का वर्तमान अनुमान। पुनरावृत्ति अद्यतन $V^{(n+1)} = GV^{(n)}$ में, यह $V^{(n)}(s)$ होगा।
- भौतिक/तार्किक भूमिका: यह $G$ ऑपरेटर का इनपुट है, जो प्रत्येक स्थिति के प्रत्येक राज्य के होने के बारे में एजेंट की वर्तमान समझ का प्रतिनिधित्व करता है। यह उस नींव पर है जिस पर अगला, अधिक परिष्कृत मूल्य अनुमान बनाया गया है।
-
$\max_{\Pi \in \mathbf{\Pi}}$:
- गणितीय परिभाषा: नीतियों के एक सेट पर एक अधिकतमकरण ऑपरेशन।
- भौतिक/तार्किक भूमिका: यह पद एल्गोरिथम को पूर्वनिर्धारित सेट $\mathbf{\Pi}$ से सर्वश्रेष्ठ "लुकअहेड नीति" पर विचार करने और चुनने की अनुमति देता है। यह सुनिश्चित करता है कि योजना प्रक्रिया एक एकल, निश्चित नीति तक सीमित नहीं है, बल्कि सबसे आशाजनक पथ खोजने के लिए विभिन्न रणनीतियों का पता लगा सकती है। यह हाईवे VINs में "अन्वेषण मॉड्यूल" का एक प्रमुख पहलू है।
- अधिकतमकरण क्यों: विभिन्न संभावित योजना रणनीतियों के बीच सबसे आशावादी परिणाम का चयन करने के लिए यहां अधिकतमकरण का उपयोग किया जाता है, जो एक इष्टतम मान फलन खोजने के लक्ष्य के साथ संरेखित होता है।
-
$\mathbf{\Pi}$:
- गणितीय परिभाषा: लुकअहेड नीतियों का एक सेट।
- भौतिक/तार्किक भूमिका: ये विभिन्न नीतियां हैं जिन्हें एजेंट भविष्य की स्थितियों और पुरस्कारों का पता लगाने के लिए "कल्पना" या "अनुकरण" कर सकता है। हाईवे VIN में, ये वैल्यू एक्सप्लोरेशन (VE) मॉड्यूल के भीतर एम्बेडेड नीतियों के अनुरूप हैं।
-
$\max_{N \in \mathbf{N}}$:
- गणितीय परिभाषा: लुकअहेड गहराई के एक सेट पर एक अधिकतमकरण ऑपरेशन।
- भौतिक/तार्किक भूमिका: यह एल्गोरिथम को विभिन्न "योजना क्षितिज" पर विचार करने या भविष्य में कितने कदम देखने की अनुमति देता है। यह दीर्घकालिक योजना के लिए महत्वपूर्ण है, क्योंकि यह मॉडल को स्थिति के लिए सबसे फायदेमंद योजना गहराई चुनने में सक्षम बनाता है।
- अधिकतमकरण क्यों: नीतियों के समान, गहराई पर अधिकतमकरण सबसे फायदेमंद योजना क्षितिज का चयन करने में मदद करता है, यह सुनिश्चित करता है कि एल्गोरिथम अपनी योजना के दायरे को अनुकूलित कर सके।
-
$\mathbf{N}$:
- गणितीय परिभाषा: लुकअहेड गहराई की एक श्रृंखला।
- भौतिक/तार्किक भूमिका: ये भविष्य में योजना मॉड्यूल द्वारा अनुकरण किए जा सकने वाले चरणों (या पुनरावृति) की विभिन्न संख्याएं हैं। पेपर $n$ को लुकअहेड गहराई के रूप में उल्लेख करता है, इसलिए $N$ यहां सेट $\mathbf{N}$ से चुनी गई विशिष्ट गहराई को संदर्भित करता है।
-
$\max_{a \in \mathcal{A}}$:
- गणितीय परिभाषा: क्रियाओं की संभव सेट पर एक अधिकतमकरण ऑपरेशन।
- भौतिक/तार्किक भूमिका: यह पद सुनिश्चित करता है कि प्रत्येक निर्णय बिंदु पर, एल्गोरिथम सभी उपलब्ध क्रियाओं पर विचार करता है और उस क्रिया का चयन करता है जो उच्चतम अपेक्षित मूल्य की ओर ले जाती है। यह वैल्यू इटरेशन का एक मौलिक हिस्सा है।
- अधिकतमकरण क्यों: यह बेलमैन इष्टतमता सिद्धांत का मूल है, जिसका लक्ष्य भविष्य के पुरस्कारों को अधिकतम करने के लिए सर्वोत्तम संभव क्रिया खोजना है।
-
$\mathcal{A}$:
- गणितीय परिभाषा: एक एजेंट द्वारा की जा सकने वाली सभी संभव क्रियाओं का सेट।
- भौतिक/तार्किक भूमिका: ये उसके पर्यावरण में एजेंट के लिए उपलब्ध असतत विकल्प हैं।
-
$\max_{x \in \mathcal{X}}$:
- गणितीय परिभाषा: राज्यों या स्थानिक स्थानों के सेट पर एक अधिकतमकरण ऑपरेशन।
- भौतिक/तार्किक भूमिका: यह इंगित करता है कि ऑपरेटर विभिन्न स्थानिक विन्यासों या राज्यों में सर्वोत्तम संभावित परिणाम पर विचार करता है, जो भूलभुलैया नेविगेशन कार्यों में प्रासंगिक है जहां "स्थिति" एक ग्रिड सेल हो सकती है।
- अधिकतमकरण क्यों: यह सुनिश्चित करता है कि एल्गोरिथम विभिन्न शुरुआती बिंदुओं या पर्यावरण में स्थानीय विविधताओं के प्रति मजबूत है, हमेशा विश्व स्तर पर इष्टतम पथ का लक्ष्य रखता है।
-
$B$:
- गणितीय परिभाषा: बेलमैन इष्टतमता ऑपरेटर। एक स्थिति $s$ के लिए, $BV(s) = \max_a \sum_{s'} T(s'|s,a) [R(s,a,s') + \gamma V(s')]$।
- भौतिक/तार्किक भूमिका: यह ऑपरेटर तत्काल पुरस्कार और अगले राज्य के छूट प्राप्त मूल्य पर विचार करके एक स्थिति के इष्टतम मूल्य की गणना करता है, यह मानते हुए कि एजेंट हमेशा सर्वोत्तम क्रिया लेता है। यह एक "लालची" योजना चरण का प्रतिनिधित्व करता है। हाईवे VIN में, यह मानक वैल्यू इटरेशन (VI) मॉड्यूल (समीकरण 3 और 4) द्वारा अनुमानित है।
- योग और अधिकतमकरण क्यों: योग का उपयोग संभावित अगले राज्यों पर औसत (संक्रमण संभावनाओं द्वारा भारित) करने के लिए किया जाता है, जबकि अधिकतमकरण सर्वोत्तम क्रिया का चयन करता है।
-
$B^\pi$:
- गणितीय परिभाषा: किसी दी गई नीति $\pi$ के तहत बेलमैन अपेक्षा ऑपरेटर। एक स्थिति $s$ के लिए, $B^\pi V(s) = \sum_a \pi(a|s) \sum_{s'} T(s'|s,a) [R(s,a,s') + \gamma V(s')]$।
- भौतिक/तार्किक भूमिका: यह ऑपरेटर किसी विशिष्ट नीति $\pi$ के तहत किसी स्थिति के अपेक्षित मूल्य की गणना करता है। यह एक "नीति-संचालित अन्वेषण" चरण का प्रतिनिधित्व करता है। हाईवे VIN में, यह वैल्यू एक्सप्लोरेशन (VE) मॉड्यूल (समीकरण 6 और 7) द्वारा अनुमानित है, जो स्टोकेस्टिसिटी इंजेक्ट करता है।
- योग क्यों: योग का उपयोग दो बार किया जाता है: एक बार क्रियाओं पर औसत (नीति संभावनाओं द्वारा भारित) करने के लिए और फिर से संभावित अगले राज्यों पर औसत करने के लिए।
-
$\circ(N-1)$:
- गणितीय परिभाषा: संरचना ऑपरेटर, $N-1$ बार लागू किया गया। एक ऑपरेटर $O$ के लिए, $O^{\circ k} = O \circ O \circ \dots \circ O$ ($k$ बार)। पेपर समीकरण (5) में $n-1$ का उपयोग करता है, लेकिन यह देखते हुए कि $N$ को लुकअहेड गहराई के रूप में परिभाषित किया गया है, इसे $N-1$ संरचनाओं के रूप में व्याख्या करना अधिक सुसंगत है।
- भौतिक/तार्किक भूमिका: यह बहु-चरणीय लुकअहेड को दर्शाता है। बेलमैन अपेक्षा ऑपरेटर को कई बार लागू करने का मतलब है कि नीति $\pi$ को भविष्य में $N-1$ चरणों के लिए अनुकरण करना। यह एल्गोरिथम को न केवल तत्काल अगले चरण, बल्कि नीति के दीर्घकालिक परिणामों का मूल्यांकन करने की अनुमति देता है। हाईवे VIN में, यह $N_b-1$ समानांतर VE मॉड्यूल को स्टैक करने के अनुरूप है।
- संरचना क्यों: संरचना स्वाभाविक रूप से एक ऑपरेटर के अनुक्रमिक अनुप्रयोग का प्रतिनिधित्व करती है, जो बहु-चरणीय योजना का मॉडलिंग करती है।
-
$\{\cdot, \cdot\}$:
- गणितीय परिभाषा: दो तत्वों वाला एक सेट।
- भौतिक/तार्किक भूमिका: यह इंगित करता है कि $G$ ऑपरेटर मूल्य प्रसार की दो मुख्य शाखाओं पर विचार करता है: एक जिसमें बहु-चरणीय नीति-आधारित अन्वेषण ($(B^{\pi})^{\circ(N-1)} BV$) शामिल है और दूसरा जो एक अधिक प्रत्यक्ष, एकल-चरणीय इष्टतम अद्यतन ($BV$) का प्रतिनिधित्व करता है। बाहरी अधिकतमकरण तब इन दो में से बेहतर चुनता है। यहीं पर "फिल्टर गेट" की भूमिका आती है, जो अधिकतम मान का चयन करता है।
- सेट और बाहरी अधिकतमकरण क्यों: यह संरचना गहरे, अन्वेषण पथ और तत्काल, लालची पथ के बीच तुलना की अनुमति देती है, यह सुनिश्चित करती है कि एल्गोरिथम अल्पकालिक इष्टतमता और दीर्घकालिक अन्वेषण दोनों से लाभान्वित हो।
चरण-दर-चरण प्रवाह
एक एकल अमूर्त डेटा बिंदु की कल्पना करें, जो किसी स्थिति $V^{(n)}(s)$ के मूल्य का प्रतिनिधित्व करता है, जो हाईवे VIN के योजना मॉड्यूल में प्रवेश करता है। यह मॉड्यूल एक परिष्कृत असेंबली लाइन की तरह काम करता है, जो $V^{(n)}(s)$ को संसाधित करके एक बेहतर $V^{(n+1)}(s)$ उत्पन्न करता है।
-
प्रारंभिक इनपुट: वर्तमान मान फलन अनुमान, $V^{(n)}(s)$, योजना मॉड्यूल में फीड किया जाता है। यह $V^{(n)}(s)$ आमतौर पर अव्यक्त एमडीपी के प्रत्येक स्थानिक स्थान के मूल्य का प्रतिनिधित्व करने वाला एक फीचर मैप होता है।
-
बेलमैन इष्टतमता पथ (The "Greedy" Lane):
- $V^{(n)}(s)$ का एक हिस्सा एक मानक वैल्यू इटरेशन (VI) मॉड्यूल में निर्देशित होता है।
- इस मॉड्यूल के अंदर, एक कनवल्शनल ऑपरेशन (समीकरण 3 की तरह) तत्काल पुरस्कारों और पड़ोसी राज्यों के छूट प्राप्त मूल्यों पर विचार करके क्रिया-मान $Q_{a,i,j}^{(n)}$ की गणना करता है।
- एक मैक्स-पूलिंग ऑपरेशन (समीकरण 4) तब प्रत्येक स्थिति $(i,j)$ के लिए सभी क्रियाओं $a$ पर अधिकतम $Q_{a,i,j}^{(n)}$ का चयन करता है, प्रभावी रूप से बेलमैन इष्टतमता ऑपरेटर $B$ लागू करता है। यह एक अद्यतन मान फलन उत्पन्न करता है, जिसे हम $V_{VI}^{(n+1)}(s) = BV^{(n)}(s)$ कहते हैं। यह पथ सबसे प्रत्यक्ष, लालची अद्यतन का प्रतिनिधित्व करता है।
-
बेलमैन अपेक्षा पथ (The "Exploration" Lanes):
- साथ ही, $V^{(n)}(s)$ को कई समानांतर वैल्यू एक्सप्लोरेशन (VE) मॉड्यूल में भी रूट किया जाता है। प्रत्येक VE मॉड्यूल एक अलग "लुकअहेड नीति" $\pi_{np}$ से जुड़ा होता है और एक विशिष्ट "लुकअहेड गहराई" $n_b$ में योगदान देता है।
- प्रत्येक VE मॉड्यूल के भीतर: क्रियाओं पर अधिकतम लेने के बजाय, VE मॉड्यूल अपनी एम्बेडेड नीति $\pi_{np}$ (समीकरण 7) के आधार पर क्रियाओं पर एक अपेक्षित मूल्य की गणना करता है। यह नीति प्रशिक्षण के दौरान स्टोकेस्टिक रूप से उत्पन्न की जा सकती है (समीकरण 8), विविधता इंजेक्ट करती है। यह प्रभावी रूप से बेलमैन अपेक्षा ऑपरेटर $B^{\pi_{np}}$ लागू करता है।
- गहराई के लिए स्टैकिंग: ये VE मॉड्यूल $N_b - 1$ परतों के लिए स्टैक किए जाते हैं। इसका मतलब है कि एक VE मॉड्यूल का आउटपुट अगले का इनपुट बन जाता है, $B^{\pi_{np}}$ ऑपरेटर को कई बार कंपोज़ करता है, जिसके परिणामस्वरूप विभिन्न $n_b$ और $np$ के लिए $(B^{\pi_{np}})^{\circ(n_b-1)} BV^{(n)}(s)$ होता है। यह अन्वेषणशील मूल्य अनुमानों का एक समृद्ध सेट बनाता है, जो विभिन्न नीतियों और योजना क्षितिज पर विचार करता है।
-
एग्रीगेशन (The "Information Merge"):
- इन सभी समानांतर और स्टैक्ड VE मॉड्यूल के आउटपुट, VI मॉड्यूल के आउटपुट के साथ, अभिसरण करते हैं।
- एक "एग्रीगेट गेट" (समीकरण 9 की तरह) इन विविध सक्रियणों को जोड़ता है। यह गेट प्रत्येक समानांतर VE मॉड्यूल और प्रत्येक गहराई के योगदान को अंतिम एकत्रित मूल्य में निर्धारित करने के लिए सीखने योग्य सॉफ्टमैक्स भार का उपयोग करता है। यह स्किप कनेक्शन बनाता है, जिससे जानकारी कई परतों और गहराई तक प्रवाहित हो सकती है, जिससे लुप्त ग्रेडिएंट्स कम होते हैं।
-
फ़िल्टरिंग (The "Quality Control"):
- एग्रीगेशन के बाद, एक "फिल्टर गेट" अधिकतमकरण ऑपरेशन लागू करता है। यह गेट एकत्रित मान (जो एक संभावित अन्वेषण पथ का प्रतिनिधित्व करता है) की तुलना अधिक प्रत्यक्ष, अक्सर लालची, मान (जैसे, VI मॉड्यूल से $V^{(n+1)}$ या पिछले पुनरावृति का मान) से करता है।
- यह इन मानों का अधिकतम चयन करता है, प्रभावी रूप से "बेकार अन्वेषण पथों" को छोड़ देता है जो अभिसरण में योगदान नहीं करते हैं या कम मूल्यों की ओर ले जाते हैं। यह सुनिश्चित करता है कि केवल फायदेमंद जानकारी ही आगे बढ़ाई जाती है।
-
आउटपुट: इस पूरी प्रक्रिया का परिणाम, एग्रीगेशन और फ़िल्टरिंग के बाद, नया, परिष्कृत मान फलन अनुमान, $V^{(n+1)}(s)$ (या पेपर के नोटेशन में एक हाईवे ब्लॉक के लिए $V^{(n+N_b)}(s)$) बन जाता है। यह आउटपुट फिर अगले हाईवे ब्लॉक में फीड होता है या अंतिम नीति प्राप्त करने के लिए उपयोग किया जाता है।
समानांतर प्रसंस्करण, नीति-संचालित अन्वेषण और चयनात्मक एग्रीगेशन का यह जटिल नृत्य हाईवे VIN को मजबूत, दीर्घकालिक योजना करने की अनुमति देता है।
अनुकूलन गतिशीलता
हाईवे VIN अंततः प्रशिक्षण प्रक्रिया के माध्यम से सीखता है, मुख्य रूप से मानक बैकप्रॉपैगेशन का लाभ उठाता है, लेकिन विशिष्ट आर्किटेक्चरल नवाचारों के साथ जो हानि परिदृश्य और ग्रेडिएंट प्रवाह को आकार देने के लिए डिज़ाइन किए गए हैं।
-
विभेदक योजना मॉड्यूल: पूरे योजना मॉड्यूल, जिसमें वैल्यू इटरेशन (VI) मॉड्यूल, वैल्यू एक्सप्लोरेशन (VE) मॉड्यूल, एग्रीगेट गेट्स और फिल्टर गेट्स शामिल हैं, को पूरी तरह से विभेदक होने के लिए डिज़ाइन किया गया है। यह महत्वपूर्ण है क्योंकि यह ग्रेडिएंट्स को योजना चरणों के माध्यम से पीछे की ओर प्रवाहित करने की अनुमति देता है, जिससे नेटवर्क को योजना बनाना सीखने में सक्षम बनाया जा सके।
-
बैकप्रॉपैगेशन और ग्रेडिएंट प्रवाह: मॉडल को मानक बैकप्रॉपैगेशन का उपयोग करके प्रशिक्षित किया जाता है। एक हानि फलन (जैसे, अनुकरण सीखने पर आधारित, अनुमानित नीतियों/मानों की तुलना लक्ष्य नीतियों/मानों से करना) आउटपुट परत पर गणना की जाती है। इस हानि के ग्रेडिएंट्स को फिर नेटवर्क की सभी परतों, गहरे योजना मॉड्यूल सहित, पीछे की ओर प्रचारित किया जाता है, ताकि मॉडल के मापदंडों को अपडेट किया जा सके।
-
लुप्त/विस्फोटक ग्रेडिएंट्स को संबोधित करना: हाईवे VIN का प्राथमिक उद्देश्य बहुत गहरे नेटवर्क में, विशेष रूप से योजना कार्यों में, लुप्त/विस्फोटक ग्रेडिएंट समस्या को दूर करना है।
- एग्रीगेट गेट (स्किप कनेक्शन): एग्रीगेट गेट स्पष्ट रूप से स्किप कनेक्शन पेश करता है, जो हाईवे नेटवर्क और ResNets के समान है। ये कनेक्शन ग्रेडिएंट्स को बाद की परतों से शुरुआती परतों तक सीधे प्रवाहित करने के लिए मार्ग प्रदान करते हैं, कई गैर-रैखिक परिवर्तनों को बायपास करते हैं। यह बहुत गहरे आर्किटेक्चर में भी मजबूत ग्रेडिएंट संकेतों को बनाए रखने में मदद करता है, जिससे सैकड़ों परतों का प्रशिक्षण संभव होता है।
- वैल्यू एक्सप्लोरेशन मॉड्यूल (स्टोकेस्टिसिटी): VE मॉड्यूल एम्बेडेड नीतियों को यादृच्छिक रूप से उत्पन्न करके (समीकरण 8) प्रशिक्षण के दौरान नियंत्रित स्टोकेस्टिसिटी इंजेक्ट करता है। यह स्थानिक आयामों में सूचना और ग्रेडिएंट प्रवाह में विविधता लाता है। जबकि स्टोकेस्टिसिटी कभी-कभी अभिसरण में बाधा डाल सकती है, पेपर नोट करता है कि यह तंत्र मजबूती में सुधार करता है और अभिसरण को इष्टतम मान फलन तक पहुंचने से रोके बिना उच्च प्रदर्शन के लिए आवश्यक है (टिप्पणी 1)। यह बताता है कि यह हानि परिदृश्य को अधिक प्रभावी ढंग से तलाशने में मदद करता है, जिससे मॉडल खराब स्थानीय न्यूनतम में फंसने से बच जाता है।
-
हानि परिदृश्य को आकार देना (अभिसरण गारंटी):
- फिल्टर गेट (अधिकतमकरण): फिल्टर गेट, जो एक अधिकतमकरण ऑपरेशन करता है, स्पष्ट रूप से "अभिसरण को $V^*$ तक सुनिश्चित करने के लिए महत्वपूर्ण है।" (टिप्पणी 2)। "बेकार अन्वेषण पथों" (यानी, सक्रियण जो प्रत्यक्ष मान से कम हैं) को त्यागकर, यह योजना प्रक्रिया की उप-इष्टतम शाखाओं को प्रभावी ढंग से छांटता है। यह हानि परिदृश्य को प्रभावी ढंग से आकार देता है, जिससे मॉडल इष्टतम मान फलनों की ओर ले जाने वाले क्षेत्रों की ओर निर्देशित होता है, जिससे गैर-सहायक अन्वेषणों के कारण विचलन को रोका जा सके।
- सैद्धांतिक ध्वनि: अंतर्निहित हाईवे VI एल्गोरिथम को इष्टतम मान फलन $V^*$ में परिवर्तित होने के लिए सिद्ध किया गया है, चाहे विशिष्ट लुकअहेड नीतियों, गहराई या सॉफ्टमैक्स तापमान कुछ भी हो (टिप्पणी 1)। यह सैद्धांतिक गारंटी हाईवे VIN के सीखने की गतिशीलता के लिए एक मजबूत आधार प्रदान करती है, यह सुझाव देती है कि पुनरावृत्ति अद्यतन, जब ठीक से फ़िल्टर किए जाते हैं, तो अंततः एक इष्टतम समाधान की ओर ले जाएंगे।
-
सीखने योग्य पैरामीटर: मॉडल कई पैरामीटर सेट को अपडेट करके सीखता है:
- VI और VE मॉड्यूल में कनवल्शनल परतों के भार।
- VE मॉड्यूल में एम्बेडेड नीतियों को उत्पन्न करने के लिए उपयोग किए जाने वाले सीखने योग्य पैरामीटर $W_{np}^{(n+n_b)}$।
- एग्रीगेट गेट्स में सॉफ्टमैक्स तापमान $\alpha_a^{(n_p+n_b)}$ और $\alpha_n^{(n_p+n_b)}$, जो विभिन्न सूचना पथों के भार को नियंत्रित करते हैं।
आर्किटेक्चरल डिजाइन, नियंत्रित स्टोकेस्टिसिटी और सैद्धांतिक रूप से आधारित ऑपरेटरों के इस संयोजन के माध्यम से, हाईवे VIN प्रभावी ढंग से जटिल अनुक्रमिक निर्णय लेने वाले कार्यों में गहरे नेटवर्क प्रशिक्षण की चुनौतियों को दूर करते हुए, मान फलन अनुमानों को पुनरावृत्ति रूप से परिष्कृत करके दीर्घकालिक योजना करने के लिए सीखता है।
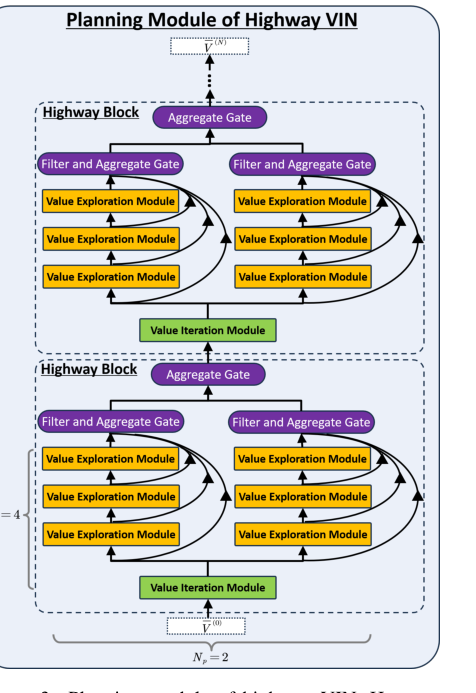 Figure 3. Planning module of highway VIN. Here, we demonstrate the planning module of highway VIN using a highway block of depth Nb = 4 and incorporating Np = 2 embedded policies
Figure 3. Planning module of highway VIN. Here, we demonstrate the planning module of highway VIN using a highway block of depth Nb = 4 and incorporating Np = 2 embedded policies
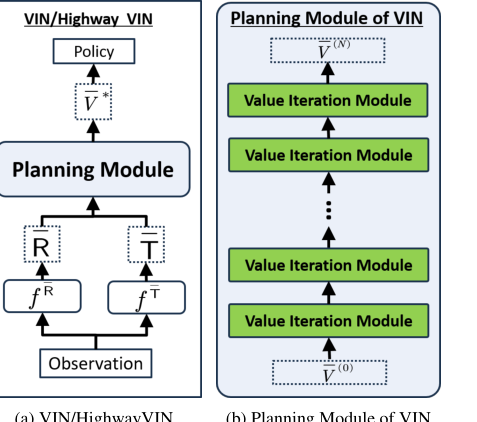 Figure 2. (a): Architecture of VIN and highway VIN. (b): Architecture of the planning module of VIN, which includes N layers of value iteration modules. The architecture of the value iteration module is detailed in Fig. 4(a)
Figure 2. (a): Architecture of VIN and highway VIN. (b): Architecture of the planning module of VIN, which includes N layers of value iteration modules. The architecture of the value iteration module is detailed in Fig. 4(a)
परिणाम, सीमाएँ और निष्कर्ष
प्रयोगात्मक डिजाइन और बेसलाइन
अपने दावों को कठोरता से मान्य करने के लिए, लेखकों ने मुख्य रूप से 2D भूलभुलैया नेविगेशन और, कुछ हद तक, 3D ViZDoom नेविगेशन कार्यों पर केंद्रित प्रयोगों की एक श्रृंखला आयोजित की। 2D भूलभुलैया नेविगेशन के लिए प्रयोगात्मक सेटअप GPPN पेपर (Lee et al., 2018) में वर्णित के समान था। इन कार्यों के लिए, एजेंटों को विभिन्न आकारों की भूलभुलैया को नेविगेट करने के लिए प्रशिक्षित किया गया था, विशेष रूप से $15 \times 15$ और $25 \times 25$, जिसमें आगे बढ़ना, 90 डिग्री बाएं या दाएं मुड़ना और चार अभिविन्यास बनाए रखना शामिल था।
प्रशिक्षण व्यवस्था में लेबल किए गए डेटासेट पर अनुकरण सीखने के 30 युग शामिल थे, जिसमें प्रशिक्षण के लिए 25K भूलभुलैया, सत्यापन के लिए 5K और परीक्षण के लिए 5K शामिल थे। RMSprop ऑप्टिमाइज़र का उपयोग 0.001 की सीखने की दर और 32 के बैच आकार के साथ किया गया था। योजना मॉड्यूल के भीतर कनवल्शनल ऑपरेशन ने 5 के कर्नेल आकार का उपयोग किया, और अवलोकनों को अव्यक्त एमडीपी में मैप करने वाले न्यूरल नेटवर्क में 150 का छिपा हुआ आयाम था।
योजना क्षमता का मूल्यांकन करने के लिए प्राथमिक मीट्रिक सफलता दर (SR) थी, जिसे योजना कार्यों की कुल संख्या के मुकाबले सफलतापूर्वक पूरे किए गए कार्यों के अनुपात के रूप में परिभाषित किया गया था। एक कार्य को सफल माना गया यदि एजेंट ने पूर्व-निर्धारित चरणों की संख्या के भीतर शुरुआत से लक्ष्य तक एक पथ उत्पन्न किया। दीर्घकालिक योजना क्षमताओं का आकलन करने के लिए, एल्गोरिदम का मूल्यांकन विभिन्न सबसे छोटी पथ लंबाई (SPLs) वाले कार्यों में किया गया था, जिनकी गणना पहले डाइकस्ट्रा एल्गोरिथम का उपयोग करके की गई थी। लंबी SPLs स्वाभाविक रूप से अधिक दीर्घकालिक योजना की मांग करती हैं। सभी प्रयोगों को 3 यादृच्छिक बीजों के साथ चलाया गया था, और SR के माध्य और मानक विचलन की सूचना दी गई थी।
प्रस्तावित हाईवे VIN की तुलना में जिन "पीड़ितों" (बेसलाइन मॉडल) का मूल्यांकन किया गया था, उनमें शामिल थे:
* मूल VIN (Tamar et al., 2016): मूलभूत वैल्यू इटरेशन नेटवर्क।
* GPPN (Lee et al., 2018): गेटेड पाथ प्लानिंग नेटवर्क्स, स्थिरता के लिए डिज़ाइन किया गया एक आवर्ती VIN संस्करण।
* हाईवे नेटवर्क (Srivastava et al., 2015b): स्किप कनेक्शन को शामिल करने वाला एक डीप न्यूरल नेटवर्क आर्किटेक्चर, जिसे यहां VINs के लिए अनुकूलित किया गया है।
निष्पक्ष तुलना के लिए, बेसलाइन VIN और GPPN का $15 \times 15$ भूलभुलैया के लिए 20 परतों और $25 \times 25$ भूलभुलैया के लिए 30 परतों के साथ परीक्षण किया गया था। हाईवे नेटवर्क्स और हाईवे VINs ने $15 \times 15$ भूलभुलैया के लिए $N_B = 20$ हाईवे ब्लॉक और $25 \times 25$ भूलभुलैया के लिए $N_B = 30$ का उपयोग किया। कुल गहराई $N$ के विभिन्न मानों का पता लगाया गया, जो $15 \times 15$ भूलभुलैया के लिए 40 से 200 और $25 \times 25$ भूलभुलैया के लिए 60 से 300 तक थे। जब तक अन्यथा निर्दिष्ट न किया गया हो, हाईवे VINs ने एक समानांतर VE मॉड्यूल ($N_p = 1$) और एक एम्बेडेड अन्वेषण दर $\epsilon = 1$ का उपयोग किया।
एब्लेशन अध्ययन भी किए गए ताकि फिल्टर गेट और VE मॉड्यूल के प्रभाव को अलग किया जा सके, साथ ही समानांतर VE मॉड्यूल ($N_p$) की संख्या को भिन्न करने के प्रभाव की जांच की जा सके। अंत में, दृष्टिकोण का परीक्षण 3D ViZDoom नेविगेशन में किया गया था, जहां इनपुट में RGB छवियां शामिल थीं, और SPLs 30 से अधिक वाले कार्यों के लिए प्रदर्शन का मूल्यांकन किया गया था। कम्प्यूटेशनल जटिलता, जिसमें GPU मेमोरी उपयोग और 300-परत नेटवर्क पर NVIDIA A100 GPUs पर प्रशिक्षण समय शामिल है, को भी मापा गया।
साक्ष्य क्या साबित करते हैं
सबूत भारी रूप से इस मुख्य दावे का समर्थन करते हैं कि हाईवे VINs बहुत गहरे नेटवर्क के प्रभावी प्रशिक्षण को सक्षम करके दीर्घकालिक योजना क्षमताओं को महत्वपूर्ण रूप से बढ़ाते हैं, जो पहले VINs के लिए एक चुनौतीपूर्ण उपलब्धि थी।
सबसे निर्णायक सबूत 2D भूलभुलैया नेविगेशन में तुलनात्मक सफलता दरों से आता है, विशेष रूप से लंबी सबसे छोटी पथ लंबाई (SPLs) की आवश्यकता वाले कार्यों के लिए। जैसा कि तालिका 1 और चित्र 5 में दिखाया गया है, $25 \times 25$ भूलभुलैया के लिए, जब SPLs 200 से अधिक हो गए, तो बेसलाइन VIN, GPPN और हाईवे नेटवर्क मॉडल की सफलता दर लगभग 0% तक गिर गई। इसके विपरीत, हाईवे VIN ने इन चुनौतीपूर्ण दीर्घकालिक योजना परिदृश्यों के लिए प्रभावशाली 90% SR बनाए रखा। इसी तरह, लगभग 100 के SPLs के साथ $15 \times 15$ भूलभुलैया के लिए, हाईवे VIN ने 98% SR हासिल किया, जबकि अन्य विधियों ने काफी गिरावट दिखाई। यह स्पष्ट रूप से दीर्घकालिक क्रेडिट असाइनमेंट को संभालने में हाईवे VIN की बेहतर क्षमता को दर्शाता है।
पेपर मौजूदा तरीकों की सीमाओं को भी उजागर करता है:
* मूल VIN का प्रदर्शन गहराई बढ़ने के साथ तेजी से घटा, जो $N=150$ से अधिक गहरे नेटवर्क के लिए लगभग 0% SR तक गिर गया। यह चित्र 1 में दर्शाया गया है, जो दिखाता है कि 120 से अधिक SPLs के लिए 30-परत VIN की सफलता दर 10% से नीचे गिर जाती है, और 300-परत VIN खराब प्रदर्शन प्रदर्शित करता है।
* जबकि हाईवे नेटवर्क ने अधिक गहराई पर प्रदर्शन बनाए रखा, इसने अपने उथले समकक्षों की तुलना में दीर्घकालिक योजना क्षमताओं में महत्वपूर्ण रूप से सुधार नहीं किया।
* GPPN, हालांकि छोटी SPLs के लिए मजबूत है (25x25 भूलभुलैया के लिए SPLs [1,30] के लिए 99.09% SR प्राप्त करता है), लंबी पथों के लिए नाटकीय रूप से विफल रहा, SPLs [130,230] के लिए 3% से कम हो गया।
हाईवे VIN की प्रभावशीलता के अतिरिक्त प्रमाण सीखे गए फीचर मैप्स (चित्र 6) द्वारा प्रदान किए जाते हैं। हाईवे VIN के फीचर मैप्स VIN की तुलना में लक्ष्य से दूर की स्थितियों के लिए बड़े सीखे गए मान दिखाते हैं, यह दर्शाता है कि हाईवे VIN दीर्घकालिक योजना के लिए एक अधिक प्रभावी और व्यापक मान फलन विकसित करता है।
एब्लेशन अध्ययन ने हाईवे VIN के नवीन घटकों की आवश्यकता में महत्वपूर्ण अंतर्दृष्टि प्रदान की:
* फिल्टर गेट: चित्र 7 स्पष्ट रूप से दिखाता है कि फिल्टर गेट के बिना, हाईवे VIN का प्रदर्शन काफी घट जाता है। यह "बेकार अन्वेषण पथों" को त्यागने और अभिसरण सुनिश्चित करने में फिल्टर गेट की आवश्यक भूमिका को साबित करता है, सीधे इसके गणितीय उद्देश्य को मान्य करता है।
* VE मॉड्यूल: चित्र 8 विशेष रूप से $25 \times 25$ भूलभुलैया में, VE मॉड्यूल की अनुपस्थिति में प्रदर्शन में उल्लेखनीय कमी प्रदर्शित करता है। यह पुष्टि करता है कि VE मॉड्यूल द्वारा विविध अव्यक्त क्रियाओं का परिचय स्थानिक आयामों में सूचना और ग्रेडिएंट प्रवाह को सुगम बनाने के लिए महत्वपूर्ण है। तालिका 2 आगे इसे मात्रात्मक रूप से प्रदर्शित करती है, यह दिखाते हुए कि हाईवे VIN VIN (0.00 $N=200$ के लिए) की तुलना में चयनित अव्यक्त क्रियाओं की एन्ट्रॉपी को काफी उच्च बनाए रखता है (जैसे, $15 \times 15$ भूलभुलैया में $N=200$ के लिए 4.17), सीधे इसकी विविधता बनाए रखने की क्षमता को साबित करता है।
अंत में, 3D ViZDoom नेविगेशन (तालिका 3) में, हाईवे VIN ने फिर से बेसलाइन से बेहतर प्रदर्शन किया, VIN के 69.37% की तुलना में SPLs [60,100] के लिए 96.98% SR हासिल किया, जिससे अधिक जटिल, दृश्य वातावरण में इसकी सामान्यता और मजबूत हुई। जबकि हाईवे VIN को 300 परतों के लिए अधिक GPU मेमोरी (15.0G बनाम 3.1G VIN के लिए) और प्रशिक्षण समय (9.0 घंटे बनाम 7.5 घंटे VIN के लिए) की आवश्यकता थी, यह दीर्घकालिक योजना में महत्वपूर्ण प्रदर्शन लाभ के लिए एक उचित व्यापार-बंद है, खासकर GPPN के 103.0G मेमोरी उपयोग की तुलना में।
सीमाएँ और भविष्य की दिशाएँ
जबकि हाईवे VIN डीप न्यूरल नेटवर्क के लिए दीर्घकालिक योजना में एक महत्वपूर्ण प्रगति प्रस्तुत करता है, पेपर अंतर्निहित और स्पष्ट रूप से कई सीमाओं और भविष्य के शोध के लिए खुले रास्तों को भी इंगित करता है।
एक स्पष्ट सीमा, हालांकि एक प्रबंधनीय है, बहुत गहरे हाईवे VINs के लिए बढ़ी हुई कम्प्यूटेशनल लागत है। कम्प्यूटेशनल जटिलता तालिका के अनुसार, 300-परत हाईवे VIN को प्रशिक्षित करने के लिए मानक VIN (3.1G, 7.5 घंटे) या हाईवे नेटवर्क (3.3G, 7.7 घंटे) की तुलना में अधिक GPU मेमोरी (15.0G) और प्रशिक्षण समय (9.0 घंटे) की आवश्यकता होती है। जबकि यह अभी भी GPPN (103.0G) की तुलना में काफी अधिक कुशल है, यह बताता है कि बड़े, अधिक जटिल वास्तविक दुनिया की समस्याओं तक स्केल करने के लिए और अधिक अनुकूलन की आवश्यकता हो सकती है।
एक और दिलचस्प अवलोकन, अनुभाग B.2 और चित्र 10 में उजागर किया गया है, यह है कि अतिरिक्त समानांतर VE मॉड्यूल ($N_p > 1$) कभी-कभी बहुत गहरे नेटवर्क के लिए प्रदर्शन के लिए हानिकारक हो सकते हैं। उदाहरण के लिए, गहराई $N=300$ पर, $N_p=1$ सबसे अच्छा प्रदर्शन करता है, जबकि $N=100$ पर, $N_p=3$ इष्टतम है। यह बताता है कि कई समानांतर VE मॉड्यूल को एकीकृत करने का वर्तमान तंत्र सार्वभौमिक रूप से फायदेमंद नहीं हो सकता है और कुछ गहरे विन्यासों में प्रदर्शन को बाधित भी कर सकता है। यह विभिन्न संयोजनों को संयोजित करने के लिए एक नाजुक संतुलन या अधिक परिष्कृत रणनीतियों की आवश्यकता का सुझाव देता है।
पेपर यह भी उल्लेख करता है कि एम्बेडेड अन्वेषण दर $\epsilon=1$ (पूरी तरह से स्टोकेस्टिक) प्रशिक्षण के दौरान उपयोग की जाती है, और जबकि फिल्टर गेट उप-इष्टतम समाधानों को रोकता है, यह निश्चित, अधिकतम अन्वेषण सभी परिदृश्यों के लिए सबसे कुशल या अनुकूली रणनीति नहीं हो सकती है। अधिक गतिशील या अनुकूली अन्वेषण तंत्र संभावित रूप से विभिन्न डिग्री की अनिश्चितता या विरल पुरस्कारों वाले वातावरण में सीखने की दक्षता या प्रदर्शन में और सुधार कर सकते हैं।
आगे देखते हुए, लेखक अपने निष्कर्ष में स्पष्ट रूप से दो प्रमुख दिशाओं का प्रस्ताव करते हैं:
1. प्रदर्शन में सुधार के लिए विभिन्न प्रकार की एम्बेडेड नीतियों के साथ कई समानांतर VE मॉड्यूल के एकीकरण की जांच करना। यह सीधे $N_p > 1$ के संबंध में देखी गई सीमा को संबोधित करता है और विविध योजना क्षितिज और नीतियों का लाभ उठाने के अधिक सूक्ष्म तरीकों का पता लगाने का सुझाव देता है।
2. बड़ी समस्याओं तक स्केल करने पर ध्यान केंद्रित करना। वर्तमान प्रयोग, प्रभावशाली होने के बावजूद, मुख्य रूप से भूलभुलैया नेविगेशन और एक विशिष्ट 3D वातावरण पर हैं। वास्तव में बड़े पैमाने पर, उच्च-आयामी, और असंरचित वास्तविक दुनिया की योजना समस्याओं (जैसे, जटिल रोबोटिक्स, गतिशील शहरों में स्वायत्त ड्राइविंग) तक हाईवे VIN का विस्तार एक स्वाभाविक और महत्वपूर्ण अगला कदम होगा।
इनके अलावा, आगे के विकास के लिए कई चर्चा विषय उभरते हैं:
* सैद्धांतिक मजबूती और सामान्यीकरण: जबकि हाईवे VI एल्गोरिथम में अभिसरण गारंटी है, स्टोकेस्टिसिटी और जटिल गेट इंटरैक्शन की उपस्थिति में, विशेष रूप से इसके स्थिरता और सामान्यीकरण गुणों के संबंध में, पूर्ण विभेदक हाईवे VIN आर्किटेक्चर के गहरे सैद्धांतिक विश्लेषण का मूल्य होगा। यह सुरक्षा-महत्वपूर्ण अनुप्रयोगों में इसके परिनियोजन के लिए मजबूत आश्वासन प्रदान कर सकता है।
* दक्षता और संसाधन अनुकूलन: बहुत गहरे नेटवर्क के लिए कम्प्यूटेशनल मांगों को देखते हुए, भविष्य के काम में महत्वपूर्ण प्रदर्शन हानि के बिना उथले, अधिक कुशल मॉडल में गहरे हाईवे VINs को संपीड़ित करने के लिए ज्ञान आसवन जैसी तकनीकों का पता लगाया जा सकता है। इसके अतिरिक्त, छंटाई रणनीतियों या हार्डवेयर-जागरूक अनुकूलन की जांच इन मॉडलों को संसाधन-बाधित वातावरण के लिए अधिक सुलभ बना सकती है।
* ग्रिड-वर्ल्ड योजना से परे: वर्तमान अनुप्रयोग ग्रिड-आधारित हैं या ग्रिड-जैसे मानचित्रों की भविष्यवाणी से संबंधित हैं। यह पता लगाना कि हाईवे VIN को निरंतर क्रिया स्थान या ग्राफ-आधारित योजना समस्याओं के लिए कैसे अनुकूलित किया जा सकता है जहां स्थिति प्रतिनिधित्व एक साधारण ग्रिड नहीं है, इसकी प्रयोज्यता का विस्तार करेगा। इसके लिए योजना मॉड्यूल के भीतर विभिन्न प्रकार के कनवल्शनल या ग्राफ न्यूरल नेटवर्क परतों को एकीकृत करने की आवश्यकता हो सकती है।
* व्याख्यात्मकता और स्पष्टीकरण: जबकि सीखे गए फीचर मैप कुछ अंतर्दृष्टि प्रदान करते हैं, हाईवे VIN कुछ योजना निर्णय क्यों लेता है की व्याख्या करने के लिए आगे के शोध फायदेमंद हो सकते हैं। क्या हम मानव-समझने योग्य योजना अनुमान निकाल सकते हैं या इसके आंतरिक कामकाज को बेहतर ढंग से समझने के लिए गहरे नेटवर्क के माध्यम से "मूल्य" और "नीति" जानकारी के प्रवाह को विज़ुअलाइज़ कर सकते हैं? यह जटिल AI प्रणालियों में विश्वास बनाने और डिबगिंग की सुविधा प्रदान कर सकता है।
* अन्य RL प्रतिमानों के साथ एकीकरण: हाईवे VIN अन्य उन्नत सुदृढीकरण सीखने वाले प्रतिमानों के साथ कैसे एकीकृत हो सकता है, जैसे सीखे हुए विश्व मॉडल के साथ मॉडल-आधारित RL या पदानुक्रमित RL? क्या योजना मॉड्यूल को और भी जटिल, बहु-चरणीय निर्णय लेने वाली समस्याओं से निपटने के लिए एक बड़े, अधिक परिष्कृत RL एजेंट के भीतर एक घटक के रूप में उपयोग किया जा सकता है? यह हाइब्रिड सिस्टम को जन्म दे सकता है जो अन्य सीखने के तंत्र की शक्तियों के साथ गहरे योजना की शक्तियों को जोड़ता है।
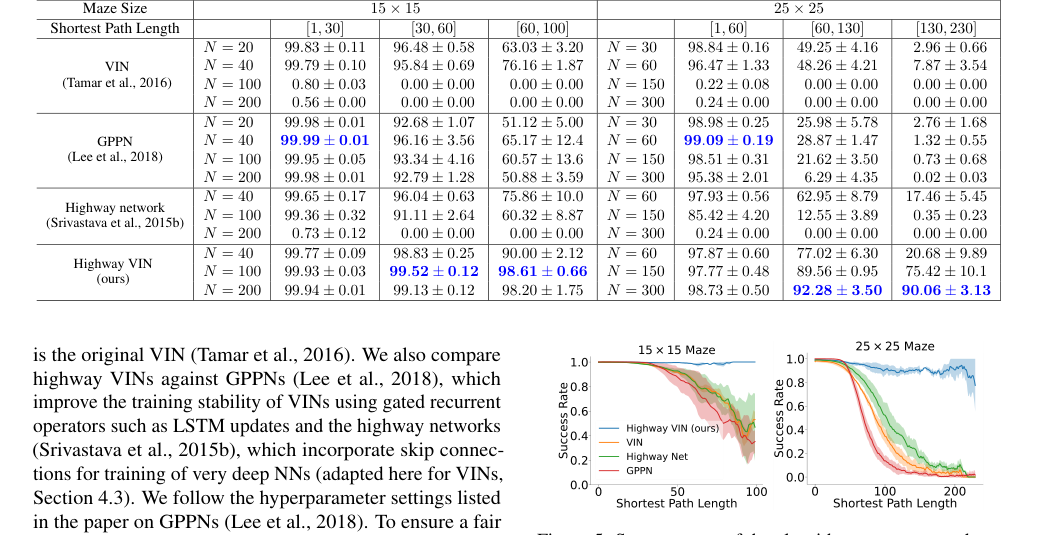 Figure 5. Success rates of the algorithms are presented as a function of varying shortest path length. For each algorithm, the optimal result from a range of depths is selected. For a comprehensive view of the results across all depths, please see Fig. 9 in the Appendix
Figure 5. Success rates of the algorithms are presented as a function of varying shortest path length. For each algorithm, the optimal result from a range of depths is selected. For a comprehensive view of the results across all depths, please see Fig. 9 in the Appendix
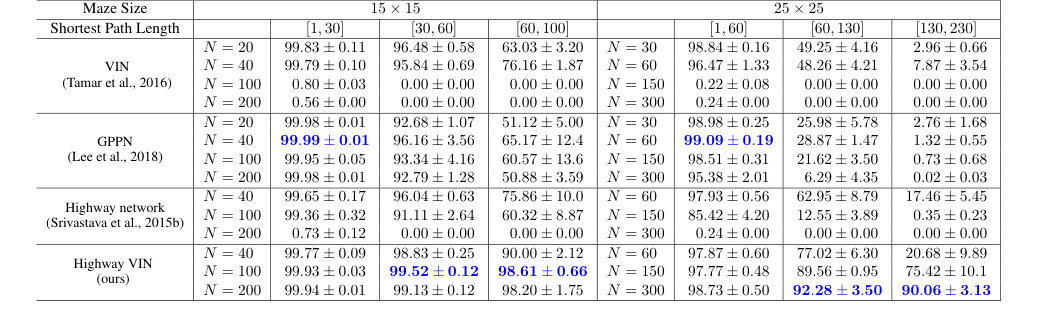 Table 1. The success rates for each algorithm with various depths under 2D maze navigation tasks with different ranges of shortest path length. Please also refer to Appendix Table 4 for the results of all the other depths
Table 1. The success rates for each algorithm with various depths under 2D maze navigation tasks with different ranges of shortest path length. Please also refer to Appendix Table 4 for the results of all the other depths
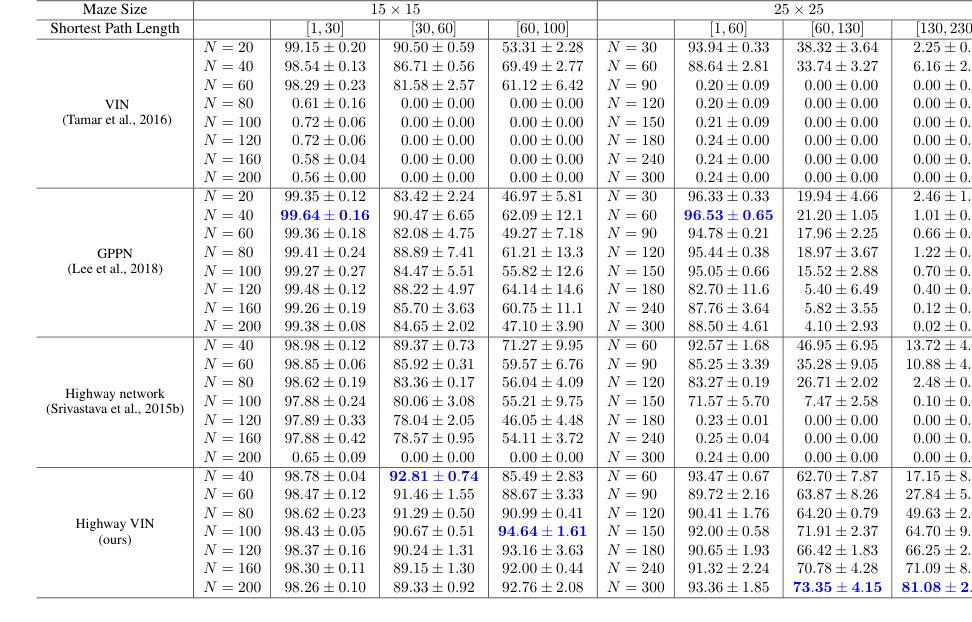 Table 5. Optimality rates of each algorithm with various depths under 2D maze navigation tasks with different ranges of shortest path lengths. The optimality rate is defined by the ratio of tasks completed within the steps of the shortest path length to the total number of tasks
Table 5. Optimality rates of each algorithm with various depths under 2D maze navigation tasks with different ranges of shortest path lengths. The optimality rate is defined by the ratio of tasks completed within the steps of the shortest path length to the total number of tasks
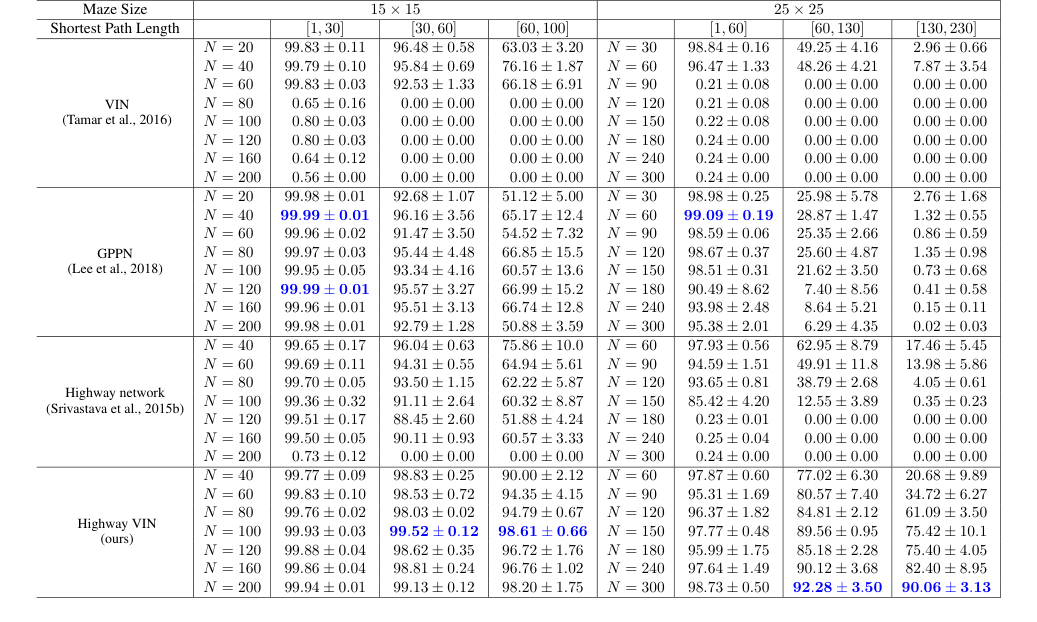 Table 4. Success rates of each algorithm with various depths under 2D maze navigation tasks with different ranges of shortest path lengths
Table 4. Success rates of each algorithm with various depths under 2D maze navigation tasks with different ranges of shortest path lengths