ハイウェイ価値反復ネットワーク
Value iteration networks (VINs) enable end-to-end learning for planning tasks by employing a differentiable "planning module" that approximates the value iteration algorithm.
背景と学術的系譜
起源と学術的系譜
本研究の核心は、人工知能エージェントに効果的な長期計画を実行させるという長年の課題に端を発する。この特定の問題は、2016年にTamarらによって導入された価値反復ネットワーク(VIN)の登場とともに顕著になった。VINは、「計画モジュール」をニューラルネットワーク(NN)アーキテクチャに直接統合し、計画タスクのエンドツーエンド学習を可能にした点で、大きな進歩であった。この計画モジュールは、1966年にBellmanによって形式化された強化学習(RL)の基本概念である古典的な価値反復アルゴリズムを近似するように設計された。
歴史的に、VINは経路計画や自律ナビゲーションなどの様々な計画タスクで顕著な熟練度を示したが、長期計画を処理する能力という重大な限界に直面していた。タスクの複雑さが増し、より多くの計画ステップ(例えば、迷路での経路長が120を超える場合)が必要になると、VINの成功率は劇的に低下し、しばしば10%を下回った。長期計画を改善するための自然なアプローチは、VINの計画モジュールの深さを増やすことで、より多くの計画ステップをシミュレートできるようにすることである。しかし、これはすぐに深層学習における根本的な問題に直面した。勾配消失または爆発(Hochreiter, 1991)の問題により、非常に深いニューラルネットワークの訓練は本質的に困難である。残差ネットワークやハイウェイネットワークのような技術は、分類タスクのために非常に深いNNの訓練を可能にすることに成功していたが、これらの手法は、特に計画の文脈において、VINのユニークなアーキテクチャに適用された場合に、同等に効果的であることが証明されていなかった。この格差は、VINが強化学習からの特定の帰納的バイアスを組み込んでいることに起因する。これは、理論的に健全な価値反復アルゴリズムに基づいている。したがって、著者らは、NNとRLの両方の高度な技術を統合することにより、長期計画のために深いVINを効果的に訓練できる新しいアプローチを開発することを余儀なくされた。
直感的なドメイン用語
ゼロベースの読者が概念を理解できるように、専門用語を日常的なアナロジーに翻訳したものを以下に示す。
- 価値反復ネットワーク(VIN): 最良のルートを示すだけでなく、可能なすべての将来のステップとその結果を繰り返しシミュレートすることによって、最良のルートを見つける方法を学習するスマートGPSを想像してください。これは、最も価値のあるものを見つけるために、オプションを精神的に「反復」するようなものです。VINは、この種の組み込み「先読み」モジュールを備えたニューラルネットワークです。
- 長期クレジット割り当て: 多くのステップを伴う複雑なトリックを犬に教えることを考えてみてください。犬が最終的に最後に報酬を得た場合、犬はどの特定の以前のアクションが報酬を得るのに貢献したのかを知るのが難しいです。AIにおいて、長期クレジット割り当ては、はるか昔に行われたどのアクションが、後になって良い(または悪い)結果に真に責任があったのかを突き止めるという課題です。
- 勾配消失/爆発: 非常に長い列の人々との「伝言ゲーム」をプレイしていると想像してください。メッセージが非常に小さく囁かれた場合(勾配消失)、それは終わりに失われます。メッセージが大きすぎる声で叫ばれた場合(勾配爆発)、それは歪んだノイズになります。深層学習では、勾配はネットワークが内部設定を調整する方法を伝える「フィードバック」信号のようなものです。このフィードバックが多くのレイヤーにわたって弱すぎたりワイルドすぎたりすると、ネットワークは効果的に学習できません。
- スキップ接続: 非常に長く曲がりくねった道を想像してください。スキップ接続は、曲がりくねった部分の一部をバイパスする直接のショートカットや急行レーンを追加するようなものです。これにより、情報(または学習のための「フィードバック」信号)がニューラルネットワークの多くのレイヤーをより簡単に、直接的に移動できるようになり、途中で失われたり希釈されたりするのを防ぎます。
表記表
| 表記 | 説明 | カテゴリ |
|---|---|---|
| $s$ | 環境内の特定の状態。 | 変数 |
| $a$ | エージェントが実行するアクション。 | 変数 |
| $V^\pi(s)$ | ポリシー $\pi$ に従う場合に状態 $s$ から期待される総将来報酬を表す価値関数。 | 変数 |
| $Q^\pi(s, a)$ | ポリシー $\pi$ に従う場合に状態 $s$ からアクション $a$ を実行し、次に期待される総将来報酬を表すアクション価値関数。 | 変数 |
| $V^{(n)}$ | 価値反復アルゴリズムの $n$ 回目の反復における価値関数。 | 変数 |
| $\gamma$ | 将来の報酬の重要性を決定する、0から1の間の値である割引率。 | パラメータ |
| $N$ | ニューラルネットワークの総深さ(レイヤー数)。 | パラメータ |
| $N_B$ | ネットワークアーキテクチャにおける「ハイウェイブロック」の数。 | パラメータ |
| $N_p$ | ハイウェイブロック内の並列価値探索(VE)モジュールの数。 | パラメータ |
| $\epsilon$ | 学習中のアクション選択におけるランダム性を制御する探索率。 | パラメータ |
問題定義と制約
コア問題の定式化とジレンマ
本論文が取り組む中心的な問題は、価値反復ネットワーク(VIN)に効果的な長期計画を実行させるという重大な課題である。
入力/現在の状態:
現在の状態は、計画タスクにおけるエンドツーエンド学習のために設計されたニューラルネットワークアーキテクチャである価値反復ネットワーク(VIN)を含んでいる。VINは、古典的な価値反復アルゴリズムを近似する微分可能な「計画モジュール」を埋め込むことによってこれを達成する。これらのネットワークは、特に比較的限られた数の計画ステップを必要とするタスクにおいて、経路計画や自律ナビゲーションなどの様々な計画シナリオでかなりの熟練度を示している。
望ましい終点/目標状態:
望ましい目標は、堅牢で正確な長期計画を実行できるVINを開発することである。これは、ネットワークが数百の計画ステップを必要とするタスク(例えば、非常に長い最短経路を持つ複雑な迷路のナビゲーション)を処理できることを意味する。決定的に重要なのは、これらの高度なVINが標準的なバックプロパゲーション技術を使用してかなりの深さ(数百レイヤー)まで訓練可能であり、拡張された計画ホライズンでも高い成功率を維持することである。
欠落しているリンクと数学的ギャップ:
正確な欠落リンクは、長期計画に必要な深いネットワーク構成に効果的にスケーリングできない既存のVINアーキテクチャの能力である。より深い計画モジュールは、より多くの計画ステップを可能にし、それによって長期的なパフォーマンスを向上させるはずであるが、現在のVINは、その深さが増加すると深刻な困難に遭遇する。
図1はこれを鮮明に示している。30層VINの成功率は、最短経路長が120を超えると急落し、300層VINの訓練を試みると困難になり、パフォーマンスが悪化する。数学的なギャップは、数百レイヤーにわたって情報と勾配を効果的に伝播できるVINアーキテクチャを設計することにある。これにより、埋め込まれた価値反復プロセスが、深層学習固有の課題に屈することなく、多くの反復にわたって最適な価値関数に収束できるようになる。
痛みを伴うトレードオフまたはジレンマ:
以前の研究者を閉じ込めている中心的なジレンマは、計画における深さの必要性と、深いニューラルネットワークを訓練する実践的な限界との間の固有の対立である。一方では、VIN内のより深い計画モジュールは、長期計画問題の解決に不可欠な、より多くの反復計画ステップを可能にするため、理論的に望ましい。他方では、任意のニューラルネットワーク(VINを含む)の深さを増やすことは、通常、勾配消失または爆発のような深刻な複雑さを引き起こす。一般的な深層学習は、分類のために非常に深いネットワークを訓練するために技術(ResNetsやDenseNetsのスキップ接続のような)を開発したが、これらの手法はVINの計画タスクでは「同等に成功していない」。この格差は、強化学習の価値反復アルゴリズムに由来するVINのユニークな帰納的バイアスが、これらの深さに関連する訓練問題に特に脆弱であることを示唆しており、計画能力のためのアーキテクチャの深さと実践的な訓練可能性との間の痛みを伴うトレードオフを生み出している。
制約と失敗モード
深いVINで長期計画を達成するという問題は、いくつかの厳しい現実的な制約と失敗モードのために非常に困難である。
-
計算上の制約:勾配消失/爆発: 最も根本的なハードルは、深層ニューラルネットワークにおけるよく知られた勾配消失または爆発の問題である。論文が述べているように、「NNの深さを増やすことは、深層学習における根本的な問題である勾配消失または爆発のような複雑さを引き起こす可能性がある」。これにより、勾配が初期レイヤーを更新するには小さすぎるか、不安定な訓練につながるほど大きくなるため、標準的なバックプロパゲーションを使用して数百レイヤーのVINを効果的に訓練することが極めて困難になる。
-
アーキテクチャ上の制約:標準的な深層学習ソリューションとの非互換性: スキップ接続(例:Highway Networks、ResNets、DenseNets)は、他のドメイン(画像分類など)での非常に深いネットワークの訓練に効果的であることが証明されているが、計画タスクのためのVINにはうまく翻訳されていない。これは、強化学習の価値反復に基づいたVINの計画モジュールに適用された場合、これらの汎用深層学習技術における特定のアーキテクチャ上の非互換性または適切な帰納的バイアスの欠如を示唆している。
-
パフォーマンスの失敗モード:深さによる劣化: 改善する代わりに、VINのパフォーマンスは長期計画のために深さが増すにつれて劇的に低下する。例えば、150層を超えるVINは、多くのタスクで成功率がほぼ0%を示す。これは、意図されたソリューション(より多くの計画ステップのためのより深い深さ)が積極的に結果を悪化させるという重要な失敗モードである。
-
情報フローの制約:貪欲なアクション選択と勾配チャネリング: 元のVINの価値反復モジュールは「最大のQ値を貪欲に取る」(Eq. 4)。このメカニズムは「各レイヤーに明確な情報フローを作成し、それによって勾配を特定のニューロンにチャネリングする」。多様な情報と勾配フローの欠如は、ネットワークが複雑で長期的な計画シナリオで堅牢に学習し、一般化することを困難にする。
-
探索の失敗モード:有害な確率性: 確率性(探索)を導入することは情報フローを多様化するのに役立つが、制御されていない探索は逆効果になる可能性がある。論文は、「フィルタゲート」なしでは、「ハイウェイVINはVEモジュールでの探索の悪影響を容易に受ける可能性があり、収束を防ぐ可能性がある」と述べている。これは、多様性を改善するための単純な試みが不安定さにつながり、ネットワークが最適なポリシーを学習するのを妨げる可能性があることを示唆している。
-
ハードウェアメモリ制限: 問題定義の主な焦点ではないが、非常に深いネットワークの計算複雑性は、実践的なハードウェアメモリ制限を課す。論文の実験セクション(表4)は、提案されたハイウェイVINが、一部の代替手段よりも効率的であるにもかかわらず、30層VINの3.1Gと比較して、300層ネットワークで15.0GのGPUメモリを必要とすることを示している。これは、さらに深いアーキテクチャやより大きな問題サイズへのスケーリングがすぐにメモリ天井に達し、研究と展開をより高価で困難にすることを示している。
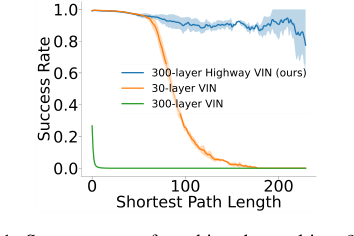 Figure 1. Success rates of reaching the goal in a 25 × 25 maze problem. The success rate of a 30-layer VIN con- siderably decreases as the shortest path length increases, and training a 300-layer VIN is difficult and exhibits poor performance
Figure 1. Success rates of reaching the goal in a 25 × 25 maze problem. The success rate of a 30-layer VIN con- siderably decreases as the shortest path length increases, and training a 300-layer VIN is difficult and exhibits poor performance
なぜこのアプローチなのか
選択の必然性
ハイウェイ価値反復ネットワーク(ハイウェイVIN)の採用は、単なる選択ではなく、長期計画の要求に直面した際の既存のアプローチの固有の限界によって駆動された必然性であった。著者らは、経路計画タスクにおける価値反復ネットワーク(VIN)を観察した際に、従来のメソッドの不十分な正確な瞬間を特定した。具体的には、最短経路長が120を超える場合、VINの成功率は10%を下回った(図1)。この鮮明な低下は、根本的な欠陥を浮き彫りにした。VINの組み込み「計画モジュール」の深さを増やすことは、より多くの計画ステップを統合し、それによって長期計画を改善するための論理的な道筋のように思われたが、従来の深層ニューラルネットワーク(NN)の訓練の複雑さ、例えば勾配消失または爆発は、このアプローチをすぐに実行不可能にした。
決定的に、論文は、画像分類などのタスクでこれらの勾配問題を克服することに成功した高度な深層NNでさえ、計画タスクでは「同等に成功していない」(表1、セクション5)と述べている。この格差は、VINのユニークなアーキテクチャと、強化学習(RL)における価値反復アルゴリズムに由来するその固有の帰納的バイアスに直接起因する。標準的な深層NNソリューションは、一般的な深層学習には効果的であるが、VINの計画フレームワーク内での効果的な長期クレジット割り当てを促進するために必要な特定のRL関連の事前知識を提供しない。したがって、深いアーキテクチャを可能にし、かつVINの計画帰納的バイアスを維持/強化できるソリューションが、唯一実行可能な道であり、ハイウェイ価値反復とスキップ接続のようなアーキテクチャ上の革新をこの特定の問題に合わせた統合につながった。
比較優位性
ハイウェイVINは、単にパフォーマンスメトリクスを改善するだけでなく、深い計画のコアチャレンジに対処する根本的な構造再設計を通じて、以前のゴールドスタンダードに対して定性的な優位性を示している。その圧倒的な利点は、VINの計画モジュールに組み込まれた3つの主要な革新に由来する。
- 集約ゲート: このコンポーネントはスキップ接続を構築し、多くのレイヤーにわたる情報フローを大幅に改善する。標準的なハイウェイネットワークの一般的なスキップ接続とは異なり、これは価値反復の文脈に統合されており、勾配消失または爆発に苦しむことなく、数百レイヤーのVINの訓練を可能にする。この構造上の利点は、長期計画に必要な深いアーキテクチャを直接促進する。
- 探索モジュール: このモジュールは、学習中に制御された確率性を注入し、空間次元にわたる情報と勾配フローを多様化する。これは、価値反復モジュールにおける貪欲な最大化操作が、VINと比較してVINの低エントロピー値で示されるように、選択されたアクションの多様性を制限する可能性がある従来のVINよりも重要な改善である(表2)。この多様性は、複雑で高次元の計画環境での堅牢な学習に不可欠である。
- フィルタゲート: 「無駄な探索パス」を「フィルタリング」するように設計されたこのゲートは、安全で効率的な探索を保証する。活性化を比較し、収束に寄与しないものを破棄するメカニズムであり、特に探索モジュールによって導入された確率性と組み合わせた場合に、価値反復の理論的な健全性を維持するために不可欠である。これがないと、アブレーションスタディが示すように(図7)、ネットワークはガイドなし探索の悪影響を受けるため、パフォーマンスは劇的に低下する。
これらのコンポーネントは collectively、ハイウェイVINが目標から遠い状態に対してより効果的な価値関数を学習することを可能にする(図6)。これは、従来のVINや計画タスクにおける他の深層NNでは深刻に欠けていた、長期的な依存関係を処理し、拡張されたホライズンにわたって計画する能力が優れていることを示唆している。
制約との整合性
選択されたハイウェイVINアプローチは、長期計画の厳しい要件に完全に一致しており、問題の要求とソリューションのユニークなプロパティとの「結婚」を形成している。
主な制約の1つは、長期計画を実行するために深いネットワークが必要であることである。より多くの計画ステップは、本質的により深い深さを必要とする。従来のVINは、増加した深さでの訓練の困難さのために、ここで失敗した。ハイウェイVINは、標準的なバックプロパゲーションを使用して数百レイヤーの効果的な訓練を可能にすることによって、これを直接解決する。これは、その前任者には不可能な偉業である。
もう1つの重要な制約は、非常に深いNNに固有の勾配消失または爆発の問題を克服することである。集約ゲートは、スキップ接続を導入することにより、これを直接解決し、安定した勾配フローを保証する。これは、証明された深層学習技術(ハイウェイネットワークやResNetsのもののような)の直接的な適応であるが、VINアーキテクチャに特別に統合されており、その計画帰納的バイアスを維持する。
さらに、問題はRLフレームワーク内での効果的な長期クレジット割り当てを必要とする。このアプローチの基盤であるハイウェイ価値反復は、まさにこの目的のために設計された(Wang et al., 2024)。このアルゴリズムの統合は、探索モジュールの確率性の追加にもかかわらず、フィルタゲート(Remark 2)のおかげで、ソリューションが理論的に健全であり、最適な価値関数に収束することを保証する。これにより、深いネットワークが単に「深い」だけでなく、計画のために効果的に深いことが保証される。
代替案の却下
論文は、この特定の問題に対する他の人気のあるまたは最先端のアプローチを却下する明確な理由を提供している。
-
従来のVIN: これらは、長期計画には不十分であることが明確に示されている。深さが一定の点(例えば、25x25迷路で30層)を超えて増加すると、成功率は劇的に低下し、120を超える経路長ではしばしば10%未満になる(図1、表1)。勾配問題による非常に深いVINの訓練の困難さは、数百の計画ステップを必要とするタスクには不向きである。
-
標準的な深層ニューラルネットワーク(例:Highway Networks、ResNets、DenseNets): これらのアーキテクチャは、非常に深いモデルの訓練を可能にすることにより、画像分類のようなタスクで優れているが、計画タスクでは「同等に成功していない」(p.1)。著者らは、単にこれらのスキップ接続をVINに統合しても、「計画に有益な追加のアーキテクチャ帰納的バイアス」が導入されないと仮説を立てている(p.8)。これらの手法は、価値反復の特定のRL関連帰納的バイアスを欠いており、深さの長期計画能力への改善への変換に失敗している。表1は、ハイウェイネットワークがVINよりも深い深さでパフォーマンスを維持している一方で、それらの長期計画能力は深さが増しても大幅に改善せず、VINよりも劣っていることを明確に示している。
-
ゲート付き経路計画ネットワーク(GPPN): GPPNは、VINの再帰的バリアントであり、深いモデルでの訓練の安定性を向上させるために設計された。それらは堅牢に機能し、短期計画タスク(例えば、25x25迷路でのSPL [1,30]で99.09% SR)で優れているが、長期計画ではパフォーマンスが大幅に低下し、SPL [130,230]では3%未満に低下する(表1、p.8)。論文は、この失敗をGPPNが「計画への帰納的バイアスが少ないブラックボックス手法」であることに起因しており、真の長期計画スキルよりも短期パターンの学習に適していると述べている。これは、ハイウェイ価値反復によって提供されるような強力で明確な計画帰納的バイアスが重要であることを強調している。
 Figure 11. Examples of 2D maze navigation tasks where highway VIN succeeds, but other methods fail
Figure 11. Examples of 2D maze navigation tasks where highway VIN succeeds, but other methods fail
数学的・論理的メカニズム
マスター方程式
ハイウェイ価値反復ネットワーク(ハイウェイVIN)の核心は、「計画モジュール」にあり、これはハイウェイ価値反復(ハイウェイVI)アルゴリズムを近似するように設計されている。このアルゴリズムを駆動する中心的な数学的エンジンは、$G$演算子であり、価値関数が反復的に更新される方法を定義する。論文は、ハイウェイVIアルゴリズムが価値関数を $V^{(n+1)} = GV^{(n)}$ として反復的に更新すると述べており、ここで$G$は次のように形式的に定義される。
$$ GV(s) = \max_{\Pi \in \mathbf{\Pi}} \max_{N \in \mathbf{N}} \max_{a \in \mathcal{A}} \max_{x \in \mathcal{X}} \{(B^{\pi})^{\circ(N-1)} BV, BV\} $$
この方程式は、ハイウェイVI、ひいてはハイウェイVINアーキテクチャの基本的な多段階ブートストラップとポリシー探索メカニズムをカプセル化している。
用語ごとの解剖
このマスター方程式を分解して、各コンポーネントの役割と意味を理解しよう。
-
$GV(s)$:
- 数学的定義: これは、ハイウェイ価値反復演算子$G$を適用した後の、状態$s$の更新された価値関数を表す。
- 物理的/論理的役割: これは、複数の計画ホライズンとポリシーからの洞察を組み込むことによって、状態$s$から達成可能な最適な価値の新しい、改善された推定値である。これは、VINの計画モジュールにおける1つの「ハイウェイブロック」反復の出力である。
- なぜこの演算子なのか: $G$演算子は、強化学習における効果的な長期クレジット割り当てを促進するように設計された複合演算子であり、最適な価値反復とポリシーベースの価値反復の両方の要素を組み合わせている。
-
$V(s)$:
- 数学的定義: 状態$s$の価値関数の現在の推定値。反復更新$V^{(n+1)} = GV^{(n)}$では、これは$V^{(n)}(s)$になる。
- 物理的/論理的役割: これは$G$演算子の入力であり、各状態の良さに関するエージェントの現在の理解を表す。これは、より洗練された次の価値推定値が構築される基盤である。
-
$\max_{\Pi \in \mathbf{\Pi}}$:
- 数学的定義: ポリシーのセットに対する最大化操作。
- 物理的/論理的役割: この項により、アルゴリズムは定義済みのセット$\mathbf{\Pi}$から最良の「先読みポリシー」を考慮し、選択できる。これは、計画プロセスが単一の固定ポリシーに限定されるのではなく、最も有望なパスを見つけるために異なる戦略を探索できることを保証する。これは、ハイウェイVINの「探索モジュール」の重要な側面である。
- なぜ最大化なのか: ここでの最大化は、異なる潜在的な計画戦略の中から最も楽観的な結果を選択するために使用され、最適な価値関数を見つけるという目標に沿っている。
-
$\mathbf{\Pi}$:
- 数学的定義: 先読みポリシーのセット。
- 物理的/論理的役割: これらは、エージェントが将来の状態と報酬を「想像」または「シミュレート」できる様々なポリシーである。ハイウェイVINでは、これらは価値探索(VE)モジュールに埋め込まれたポリシーに対応する。
-
$\max_{N \in \mathbf{N}}$:
- 数学的定義: 先読み深さのセットに対する最大化操作。
- 物理的/論理的役割: これにより、アルゴリズムは異なる「計画ホライズン」または将来をどれだけ先まで見るべきかを考慮できる。これは、アルゴリズムが計画の範囲を適応させることを可能にするため、長期計画に不可欠である。
- なぜ最大化なのか: ポリシーと同様に、深さに対する最大化は、最も有利な計画ホライズンを選択するのに役立ち、アルゴリズムが計画スコープを適応させることができることを保証する。
-
$\mathbf{N}$:
- 数学的定義: 先読み深さのセット。
- 物理的/論理的役割: これらは、計画モジュールが将来にわたってシミュレートできるステップ数(または反復数)である。論文では$n$を先読み深さとして言及しているため、$N$はセット$\mathbf{N}$から選択された特定の深さを参照する。
-
$\max_{a \in \mathcal{A}}$:
- 数学的定義: アクションのセットに対する最大化操作。
- 物理的/論理的役割: この項により、各意思決定ポイントで、アルゴリズムが利用可能なすべてのアクションを考慮し、最も高い期待値につながるアクションを選択することが保証される。これは価値反復の基本的な部分である。
- なぜ最大化なのか: これはBellman最適性原理の中核であり、将来の報酬を最大化するために可能な限り最良のアクションを見つけることを目指している。
-
$\mathcal{A}$:
- 数学的定義: エージェントが実行できるすべてのアクションのセット。
- 物理的/論理的役割: これらは、エージェントが環境で利用できる離散的な選択肢である。
-
$\max_{x \in \mathcal{X}}$:
- 数学的定義: 状態または空間位置のセットに対する最大化操作。
- 物理的/論理的役割: これは、演算子が異なる空間構成または状態にわたる最良の結果を考慮することを意味し、これは「状態」がグリッドセルである可能性がある迷路ナビゲーションタスクに関連している。
- なぜ最大化なのか: これは、アルゴリズムが異なる開始点または環境の局所的な変動に対して堅牢であることを保証し、常にグローバルな最適なパスを目指す。
-
$B$:
- 数学的定義: Bellman最適性演算子。状態$s$の場合、$BV(s) = \max_a \sum_{s'} T(s'|s,a) [R(s,a,s') + \gamma V(s')]$。
- 物理的/論理的役割: この演算子は、エージェントが常に最良のアクションを取ると仮定して、即時報酬と次の状態の割引価値を考慮することにより、状態の最適な価値を計算する。これは「貪欲な」計画ステップを表す。ハイウェイVINでは、これは標準的な価値反復(VI)モジュール(Eq. 3および4)によって近似される。
- なぜ合計と最大化なのか: 合計は可能な次の状態(遷移確率で重み付け)の平均を取るために使用され、最大化は最良のアクションを選択する。
-
$B^\pi$:
- 数学的定義: 特定のポリシー$\pi$に対するBellman期待演算子。状態$s$の場合、$B^\pi V(s) = \sum_a \pi(a|s) \sum_{s'} T(s'|s,a) [R(s,a,s') + \gamma V(s')]$。
- 物理的/論理的役割: この演算子は、特定のポリシー$\pi$の下での状態の期待値を計算する。これは「ポリシー駆動の探索」ステップを表す。ハイウェイVINでは、これは価値探索(VE)モジュール(Eq. 6および7)によって近似され、確率性を注入する。
- なぜ合計なのか: 合計は2回使用される。1回はアクションの平均を取る(ポリシー確率で重み付け)、もう1回は可能な次の状態の平均を取る。
-
$\circ(N-1)$:
- 数学的定義: 演算子、$N-1$回適用される合成演算子。演算子$O$の場合、$O^{\circ k} = O \circ O \circ \dots \circ O$($k$回)。論文ではEq. (5)で$n-1$を使用しているが、$N$が先読み深さとして定義されているため、これを$N-1$回の合成と解釈する方が一貫性がある。
- 物理的/論理的役割: これは多段階先読みを表す。Bellman期待演算子を複数回適用することは、ポリシー$\pi$を将来にわたって$N-1$ステップシミュレートすることを意味する。これにより、アルゴリズムは単なる次のステップだけでなく、ポリシーの長期的な結果を評価できる。ハイウェイVINでは、これは$N_b-1$個の並列VEモジュールをスタックすることに対応する。
- なぜ合成なのか: 合成は演算子の逐次適用を自然に表し、多段階計画をモデル化する。
-
$\{\cdot, \cdot\}$:
- 数学的定義: 2つの要素を含むセット。
- 物理的/論理的役割: これは、$G$演算子が2つの主要な価値伝播ブランチを考慮することを示している。1つは多段階ポリシーベースの探索($(B^{\pi})^{\circ(N-1)} BV$)を含み、もう1つはより直接的な単一ステップの最適更新($BV$)を表す。外側の最大化は、これら2つのうちより良い方を選択する。これは「フィルタゲート」が機能する場所であり、最大値を選択する。
- なぜセットと外側の最大化なのか: この構造により、深い探索パスとより直接的な貪欲なパスとの比較が可能になり、アルゴリズムが短期的な最適性と長期的な探索の両方から利益を得られることが保証される。
ステップバイステップの流れ
状態$V^{(n)}(s)$の価値を表す抽象的な単一データポイントが、ハイウェイVINの計画モジュールに入力されると想像してください。このモジュールは、洗練された組立ラインのように機能し、$V^{(n)}(s)$を処理して、改善された$V^{(n+1)}(s)$を生成します。
-
初期入力: 現在の価値関数推定値$V^{(n)}(s)$が計画モジュールに供給されます。この$V^{(n)}(s)$は通常、潜在MDPの各空間位置の価値を表す特徴マップです。
-
Bellman最適性パス(「貪欲な」レーン):
- $V^{(n)}(s)$の一部が標準的な価値反復(VI)モジュールにルーティングされます。
- このモジュール内では、畳み込み操作(Eq. 3のように)が、即時報酬と隣接状態の割引価値を考慮することによって、アクション価値$Q_{a,i,j}^{(n)}$を計算します。
- 次に、最大プーリング操作(Eq. 4)が、各状態$(i,j)$についてすべてのアクション$a$に対する最大$Q_{a,i,j}^{(n)}$を選択し、Bellman最適性演算子$B$を効果的に適用します。これにより、更新された価値関数$V_{VI}^{(n+1)}(s) = BV^{(n)}(s)$が得られます。このパスは、最も直接的で貪欲な更新を表します。
-
Bellman期待パス(「探索」レーン):
- 同時に、$V^{(n)}(s)$は複数の並列価値探索(VE)モジュールにもルーティングされます。各VEモジュールは、異なる「先読みポリシー」$\pi_{np}$に関連付けられており、特定の「先読み深さ」$n_b$に寄与します。
- 各VEモジュール内: アクションの最大値を取る代わりに、VEモジュールは埋め込まれたポリシー$\pi_{np}$に基づいたアクションに対する期待値を計算します(Eq. 7)。このポリシーは、学習中に確率的に生成される可能性があり(Eq. 8)、多様性を注入します。これは、Bellman期待演算子$B^{\pi_{np}}$を効果的に適用します。
- 深さのためのスタッキング: これらのVEモジュールは、$N_b - 1$レイヤーのためにスタックされます。これは、1つのVEモジュールの出力が次の入力になり、$B^{\pi_{np}}$演算子を複数回合成し、様々な$n_b$と$np$に対して$(B^{\pi_{np}})^{\circ(n_b-1)} BV^{(n)}(s)$をもたらすことを意味します。これにより、異なるポリシーと計画ホライズンを考慮した、豊富な探索的価値推定値のセットが作成されます。
-
集約(「情報マージ」):
- これらすべての並列およびスタックされたVEモジュールからの出力と、VIモジュールからの出力が収束します。
- 「集約ゲート」(Eq. 9のような)がこれらの多様な活性化を組み合わせます。このゲートは学習可能なソフトマックス重みを使用して、各並列VEモジュールと各深さの寄与を最終的な集約値に決定します。これによりスキップ接続が作成され、情報が多くのレイヤーと深さにわたって流れることができ、勾配消失が軽減されます。
-
フィルタリング(「品質管理」):
- 集約後、「フィルタゲート」が最大化操作を適用します。このゲートは、集約値(潜在的な探索パスを表す)を、より直接的な、しばしば貪欲な値(例えば、VIモジュールからの$V^{(n+1)}$または前の反復の値)と比較します。
- これらの値のうち最大のものを選び、効果的に「無駄な探索パス」(より直接的な値よりも低い活性化)を破棄します。これにより、有益な情報のみが前方に伝播されることが保証されます。
-
出力: このプロセス全体の結果(集約とフィルタリングの後)が、新しい、洗練された価値関数推定値$V^{(n+1)}(s)$(またはハイウェイブロックの論文の表記法では$V^{(n+N_b)}(s)$)になります。この出力は、次のハイウェイブロックに供給されるか、最終的なポリシーを導出するために使用されます。
この並列処理、ポリシー駆動の探索、および選択的な集約の複雑なダンスにより、ハイウェイVINは堅牢な長期計画を実行できるようになります。
最適化ダイナミクス
ハイウェイVINは、主に標準的なバックプロパゲーションを活用するエンドツーエンドの訓練プロセスを通じて学習および収束しますが、損失ランドスケープと勾配フローを形成するように設計された特定のアーキテクチャ上の革新を備えています。
-
微分可能な計画モジュール: 価値反復(VI)モジュール、価値探索(VE)モジュール、集約ゲート、フィルタゲートを含む計画モジュール全体が、完全に微分可能になるように設計されています。これは、勾配が計画ステップを逆方向に流れることができるため、ネットワークが計画する方法を学習できるようになるため、不可欠です。
-
バックプロパゲーションと勾配フロー: モデルは標準的なバックプロパゲーションを使用して訓練されます。損失関数(例えば、模倣学習に基づく、予測されたポリシー/値をターゲットポリシー/値と比較する)が出力層で計算されます。この損失の勾配は、ネットワークのすべてのレイヤー(深い計画モジュールを含む)を逆方向に伝播され、モデルのパラメータを更新します。
-
勾配消失/爆発問題への対処: ハイウェイVINの主な動機は、特に計画タスクにおいて、非常に深いネットワークでの勾配消失/爆発問題を克服することです。
- 集約ゲート(スキップ接続): 集約ゲートは、ハイウェイネットワークやResNetsと同様に、明確にスキップ接続を導入します。これらの接続は、後続レイヤーから先行レイヤーへの勾配の直接的な経路を提供し、複数の非線形変換をバイパスします。これにより、非常に深いアーキテクチャでも強力な勾配信号を維持でき、数百レイヤーの訓練が可能になります。
- 価値探索モジュール(確率性): VEモジュールは、埋め込みポリシー(Eq. 8)をランダムに生成することにより、学習中に制御された確率性を注入します。これにより、空間次元にわたる情報と勾配フローが多様化されます。確率性は収束を妨げる可能性がありますが、論文は、このメカニズムが堅牢性を向上させ、最適な価値関数への収束を妨げることなく高いパフォーマンスに不可欠であると述べています(Remark 1)。これは、モデルが悪い局所的最小値に陥るのを防ぎ、損失ランドスケープをより効果的に探索するのに役立つことを示唆しています。
-
損失ランドスケープの形成(収束保証):
- フィルタゲート(最大化): 最大化操作を実行するフィルタゲートは、「$V^*$への収束を保証するために不可欠である」と明確に述べられています(Remark 2)。「無駄な探索パス」(すなわち、より直接的な値よりも低い活性化)を破棄することにより、最適ではないブランチをプルーニングします。これは、モデルを最適な価値関数につながる領域に導くことにより、損失ランドスケープを効果的に形成し、無益な探索による発散を防ぎます。
- 理論的健全性: 基盤となるハイウェイVIアルゴリズムは、特定の先読みポリシー、深さ、またはソフトマックス温度に関係なく、最適な価値関数$V^*$に収束することが証明されています(Remark 1)。この理論的な保証は、ハイウェイVINの学習ダイナミクスの強力な基盤を提供し、適切にフィルタリングされた反復更新が最終的に最適なソリューションにつながることを示唆しています。
-
学習可能なパラメータ: モデルは、いくつかのパラメータセットを更新することによって学習します。
- VIおよびVEモジュール内の畳み込みレイヤーの重み。
- VEモジュール内の埋め込みポリシーを生成するために使用される学習可能なパラメータ$W_{np}^{(n+n_b)}$。
- 集約ゲート内のソフトマックス温度$\alpha_a^{(n_p+n_b)}$および$\alpha_n^{(n_p+n_b)}$。これらは、異なる情報パスの重みを制御します。
このアーキテクチャ設計、制御された確率性、および理論的に健全な演算子の組み合わせを通じて、ハイウェイVINは、複雑な逐次意思決定タスクにおける深いネットワーク訓練の課題を克服し、価値関数推定値を反復的に洗練することによって、効果的な長期計画を実行することを学習します。
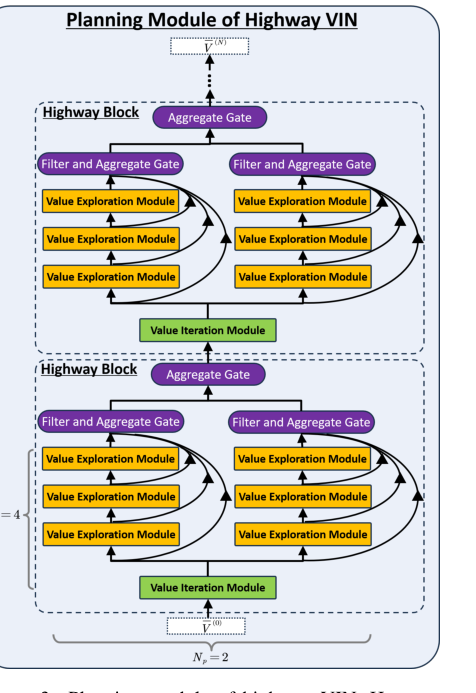 Figure 3. Planning module of highway VIN. Here, we demonstrate the planning module of highway VIN using a highway block of depth Nb = 4 and incorporating Np = 2 embedded policies
Figure 3. Planning module of highway VIN. Here, we demonstrate the planning module of highway VIN using a highway block of depth Nb = 4 and incorporating Np = 2 embedded policies
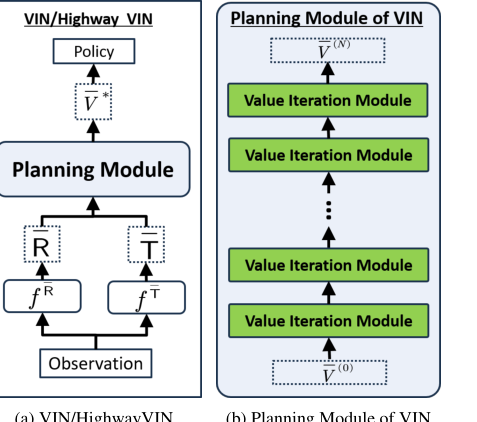 Figure 2. (a): Architecture of VIN and highway VIN. (b): Architecture of the planning module of VIN, which includes N layers of value iteration modules. The architecture of the value iteration module is detailed in Fig. 4(a)
Figure 2. (a): Architecture of VIN and highway VIN. (b): Architecture of the planning module of VIN, which includes N layers of value iteration modules. The architecture of the value iteration module is detailed in Fig. 4(a)
結果、限界、結論
実験設計とベースライン
主張を厳密に検証するために、著者らは主に2D迷路ナビゲーション、そしてある程度は3D ViZDoomナビゲーションタスクに焦点を当てた一連の実験を実施した。2D迷路ナビゲーションの実験設定は、GPPN論文(Lee et al., 2018)で説明されているものに密接に従った。これらのタスクでは、エージェントは様々なサイズの迷路(具体的には$15 \times 15$および$25 \times 25$)をナビゲートするように訓練され、アクションには前進、90度左または右への回転、および4つの向きの維持が含まれた。
訓練レジメンは、ラベル付きデータセットに対する30エポックの模倣学習を含み、訓練用に25K迷路、検証用に5K、テスト用に5Kで構成された。RMSpropオプティマイザが学習率0.001、バッチサイズ32で使用された。計画モジュール内の畳み込み操作はカーネルサイズ5を使用し、観測を潜在MDPにマッピングするニューラルネットワークは隠れ次元150を持っていた。
計画能力を評価するための主なメトリックは、成功率(SR)であり、これは完了したタスクの総数に対する成功したタスクの比率として定義された。タスクは、エージェントが定義されたステップ数内に開始から目標へのパスを生成した場合に成功と見なされた。長期計画能力を評価するために、アルゴリズムは、様々な最短経路長(SPL)を持つタスクで評価された。SPLが長いほど、より長い長期計画が必要になる。すべての実験は3つのランダムシードで実行され、SRの平均と標準偏差が報告された。
提案されたハイウェイVINと比較された「犠牲者」(ベースラインモデル)には以下が含まれる。
* オリジナルのVIN(Tamar et al., 2016):基礎となる価値反復ネットワーク。
* GPPN(Lee et al., 2018):ゲート付き経路計画ネットワーク、安定性のために設計された再帰的VINバリアント。
* ハイウェイネットワーク(Srivastava et al., 2015b):スキップ接続を組み込んだ深層ニューラルネットワークアーキテクチャ。これはVINに適合された。
公平な比較のために、ベースラインVINとGPPNは、$15 \times 15$迷路で20層、$25 \times 25$迷路で30層でテストされた。ハイウェイネットワークとハイウェイVINは、$15 \times 15$迷路で$N_B = 20$ハイウェイブロック、$25 \times 25$迷路で$N_B = 30$を使用した。様々な総深さ$N$が、15x15迷路で40から200、25x25迷路で60から300まで探索された。特に指定がない限り、ハイウェイVINは単一の並列VEモジュール($N_p = 1$)と埋め込み探索率$\epsilon = 1$を使用した。
アブレーションスタディも、フィルタゲートとVEモジュールの影響を分離するため、および並列VEモジュールの数($N_p$)の変動の影響を調査するために実施された。最後に、アプローチは3D ViZDoomナビゲーションでテストされ、入力はRGB画像で構成され、パフォーマンスはSPLが30を超えるタスクで評価された。300層ネットワークに対するNVIDIA A100 GPUでのGPUメモリ使用量と訓練時間を含む計算複雑性も測定された。
証拠が証明すること
証拠は、ハイウェイVINが、以前はVINにとって困難であった非常に深いネットワークの効果的な訓練を可能にすることによって、長期計画能力を大幅に強化するという中心的な主張を圧倒的に支持している。
最も決定的な証拠は、特に短い最短経路長(SPL)を必要とするタスクにおける2D迷路ナビゲーションでの比較成功率から得られる。表1と図5に示すように、$25 \times 25$迷路では、SPLが200を超えると、ベースラインVIN、GPPN、およびハイウェイネットワークモデルの成功率はほぼ0%に急落した。対照的に、ハイウェイVINは、これらの困難な長期計画シナリオで90%のSRを維持した。同様に、$15 \times 15$迷路でSPLが約100の場合、ハイウェイVINは98%のSRを達成したが、他の方法はかなりの劣化を示した。これは、ハイウェイVINの長期クレジット割り当てを処理する優れた能力を明確に示している。
論文はまた、既存の手法の限界を強調している。
* オリジナルのVINのパフォーマンスは、深さが増すにつれて劇的に低下し、$N=150$を超えるネットワークでは成功率がほぼ0%になった。これは、図1に視覚的に表されており、30層VINの成功率がSPLが120を超える場合に10%を下回り、300層VINがパフォーマンスの悪化を示すことが示されている。
* ハイウェイネットワークは、より深い深さでパフォーマンスを維持したが、浅いモデルと比較して長期計画能力は大幅に改善しなかった。
* GPPNは、短いSPL(25x25迷路でSPL [1,30]で99.09% SRを達成)に対して堅牢であったが、長いパスでは劇的に失敗し、SPL [130,230]で3%未満に低下した。
ハイウェイVINの有効性のさらなる証拠は、学習された特徴マップ(図6)によって提供される。ハイウェイVINの特徴マップは、VINと比較して目標から遠い状態に対してより大きな学習値を示しており、ハイウェイVINが長期計画のために、より効果的で包括的な価値関数を開発していることを示唆している。
アブレーションスタディは、ハイウェイVINの新しいコンポーネントの必要性に関する重要な洞察を提供した。
* フィルタゲート: 図7は、フィルタゲートがない場合、ハイウェイVINのパフォーマンスが著しく低下することを明確に示している。これは、フィルタゲートが「無駄な探索パス」を破棄し、収束を保証する上で不可欠な役割を果たしていることを証明しており、その数学的目的を直接検証している。
* VEモジュール: 図8は、特に$25 \times 25$迷路では、VEモジュールがない場合にパフォーマンスが著しく低下することを示している。これは、VEモジュールによる多様な潜在アクションの導入が、空間次元にわたる情報と勾配フローを促進するために不可欠であることを確認している。表2は、ハイウェイVINがVIN($N=200$で0.00)と比較して、選択された潜在アクションのエントロピーを大幅に高く維持していること($15 \times 15$迷路で$N=200$で4.17)を定量化しており、多様性を維持する能力を直接証明している。
最後に、3D ViZDoomナビゲーション(表3)では、ハイウェイVINは再びベースラインを上回り、VINの69.37%と比較してSPL [60,100]で96.98%のSRを達成し、より複雑で視覚的な環境への一般化をさらに強化した。ハイウェイVINは、より多くのGPUメモリ(VINの3.1G vs 15.0G)と訓練時間(VINの7.5時間 vs 9.0時間)を必要としたが、これは長期計画における大幅なパフォーマンス向上に対して、特にGPPNの103.0Gメモリ使用量と比較して、妥当なトレードオフである。
限界と将来の方向性
ハイウェイVINは、深層ニューラルネットワークの長期計画における重要な進歩を提示しているが、論文はまた、暗黙的および明示的に、いくつかの限界を指摘し、将来の研究への道を開いている。
1つの明確な限界は、非常に深いハイウェイVINの計算コストの増加である。計算複雑性表に示すように、300層のハイウェイVINの訓練には、標準VIN(3.1G、7.5時間)やハイウェイネットワーク(3.3G、7.7時間)と比較して、より多くのGPUメモリ(15.0G)と訓練時間(9.0時間)が必要である。これはGPPN(103.0G)よりもかなり効率的であるが、さらに大規模で複雑な実世界のタスクへのスケーリングは、さらなる最適化を必要とする可能性があることを示唆している。
もう1つの興味深い観察は、セクションB.2と図10で強調されているように、複数の並列VEモジュール($N_p > 1$)の追加が、非常に深いネットワークのパフォーマンスに悪影響を与える可能性があることである。例えば、深さ$N=300$では$N_p=1$が最適に機能するが、$N=100$では$N_p=3$が最適である。これは、これらのモジュールを統合する現在のメカニズムが普遍的に有益ではない可能性があり、特定の深い構成ではパフォーマンスを妨げる可能性さえあることを示唆している。これは、繊細なバランスまたはこれらのモジュールを組み合わせるためのより洗練された戦略の必要性を示唆している。
論文はまた、学習中の埋め込み探索率$\epsilon=1$(完全に確率的)が使用されていると述べており、フィルタゲートは最適ではないソリューションを防ぐが、この固定された最大探索は、すべてのシナリオで最も効率的または適応的な戦略ではない可能性がある。より動的または適応的な探索メカニズムは、不確実性またはスパース報酬の様々な程度の環境での学習効率またはパフォーマンスをさらに向上させる可能性がある。
将来に向けて、著者らは結論で明確に2つの主要な方向性を提案している。
1. パフォーマンスを向上させるために、様々な種類の埋め込みポリシーを持つ複数の並列VEモジュールの統合を調査する。これは、$N_p > 1$に関する観察された限界に直接対処し、多様な計画ホライズンとポリシーを活用するためのより微妙な方法を探求することを示唆している。
2. より大きなタスクへのスケーリングに焦点を当てる。現在の実験は印象的であるが、主に迷路ナビゲーションと特定の3D環境に基づいている。ハイウェイVINを真に大規模で高次元で構造化されていない現実世界の計画問題(例えば、複雑なロボット工学、動的な都市での自律運転)に拡張することは、自然で重要な次のステップとなるだろう。
これらに加えて、さらなる開発のためのいくつかの議論トピックが現れる。
* 理論的堅牢性と一般化: ハイウェイVIアルゴリズムには収束保証があるが、特に確率性と複雑なゲート相互作用が存在する場合の安定性と一般化特性に関して、完全な微分可能ハイウェイVINアーキテクチャのより深い理論的分析は非常に価値があるだろう。これは、安全クリティカルなアプリケーションへの展開のためのより強力な保証を提供する可能性がある。
* 効率とリソース最適化: 非常に深いネットワークの計算需要を考慮すると、将来の研究では、パフォーマンスの大幅な低下なしに、深いハイウェイVINをより浅く、より効率的なモデルに圧縮するために、知識蒸留のような技術を探索することができる。さらに、プルーニング戦略またはハードウェア認識最適化を調査することは、リソースが制約された環境でこれらのモデルをよりアクセスしやすくすることができる。
* グリッドワールド計画を超えて: 現在のアプリケーションはグリッドベースであるか、グリッドのようなマップの予測を含む。ハイウェイVINを連続アクション空間または状態表現が単純なグリッドではないグラフベースの計画問題にどのように適応できるかを探索することは、その適用範囲を広げるだろう。これは、計画モジュール内に異なる種類の畳み込みまたはグラフニューラルネットワークレイヤーを統合することを含むかもしれない。
* 解釈可能性と説明可能性: 学習された特徴マップはある程度の洞察を提供するが、ハイウェイVINがなぜ特定の計画決定を下すのかを解釈するためのさらなる研究は有益である。人間が理解できる計画ヒューリスティックを抽出したり、深いネットワークを通る「価値」と「ポリシー」情報のフローを視覚化して、その内部動作をよりよく理解したりできるか?これは、複雑なAIシステムでの信頼を構築し、デバッグを容易にするのに役立つだろう。
* 他のRLパラダイムとの統合: ハイウェイVINは、学習された世界モデルを持つモデルベースRLや階層RLのような他の高度な強化学習パラダイムとどのように統合できるか?計画モジュールは、さらに複雑な多段階意思決定問題を解決するために、より洗練されたRLエージェントのコンポーネントとして使用できるか?これは、他の学習メカニズムの強みと、深い計画の強みを組み合わせたハイブリッドシステムにつながる可能性がある。
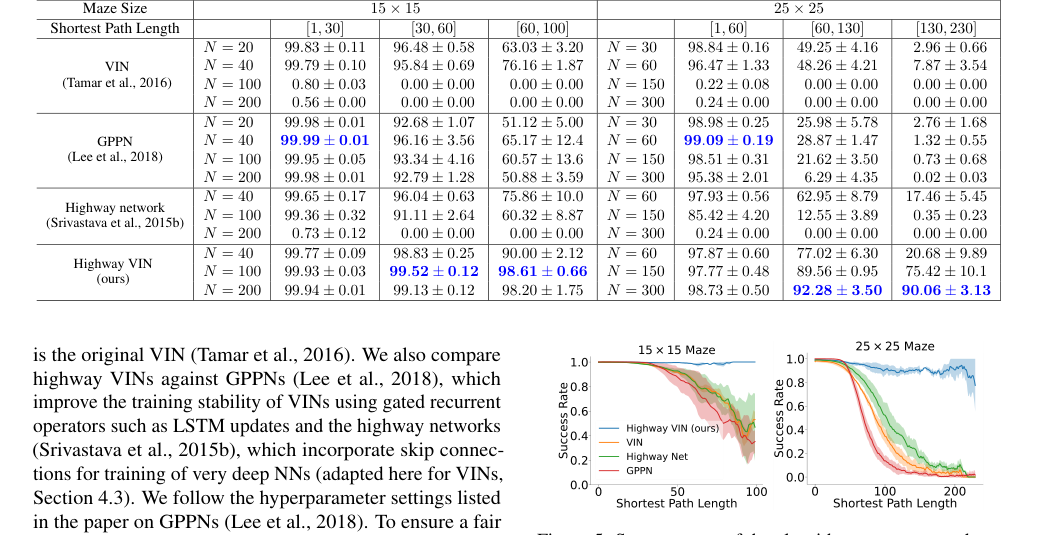 Figure 5. Success rates of the algorithms are presented as a function of varying shortest path length. For each algorithm, the optimal result from a range of depths is selected. For a comprehensive view of the results across all depths, please see Fig. 9 in the Appendix
Figure 5. Success rates of the algorithms are presented as a function of varying shortest path length. For each algorithm, the optimal result from a range of depths is selected. For a comprehensive view of the results across all depths, please see Fig. 9 in the Appendix
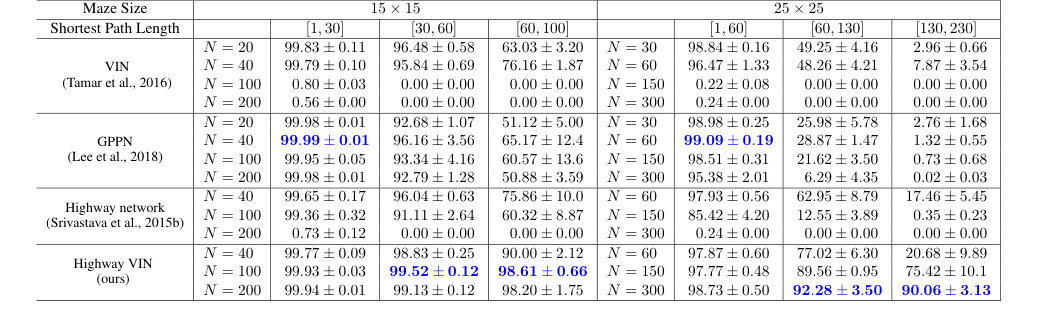 Table 1. The success rates for each algorithm with various depths under 2D maze navigation tasks with different ranges of shortest path length. Please also refer to Appendix Table 4 for the results of all the other depths
Table 1. The success rates for each algorithm with various depths under 2D maze navigation tasks with different ranges of shortest path length. Please also refer to Appendix Table 4 for the results of all the other depths
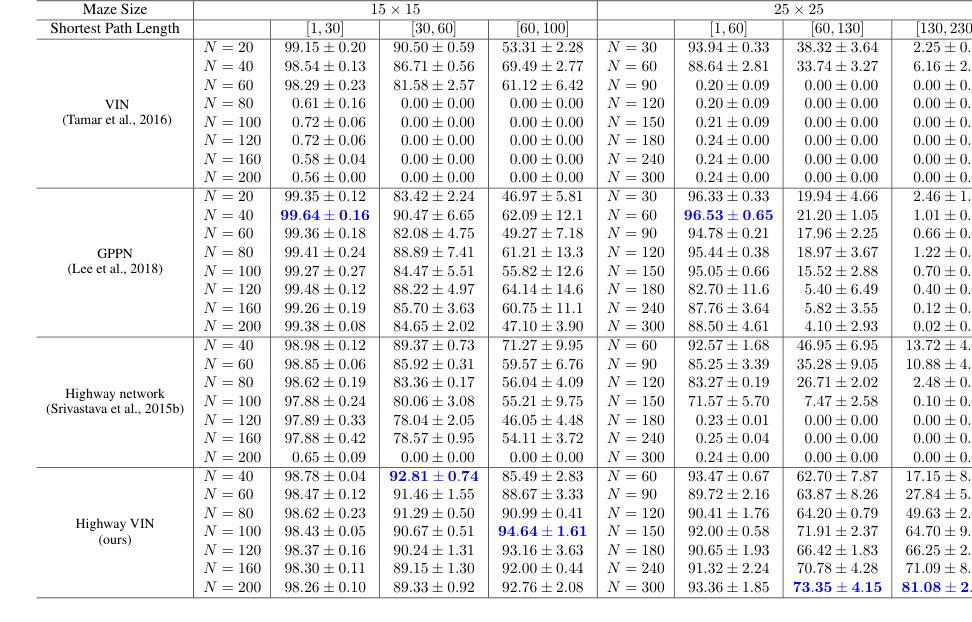 Table 5. Optimality rates of each algorithm with various depths under 2D maze navigation tasks with different ranges of shortest path lengths. The optimality rate is defined by the ratio of tasks completed within the steps of the shortest path length to the total number of tasks
Table 5. Optimality rates of each algorithm with various depths under 2D maze navigation tasks with different ranges of shortest path lengths. The optimality rate is defined by the ratio of tasks completed within the steps of the shortest path length to the total number of tasks
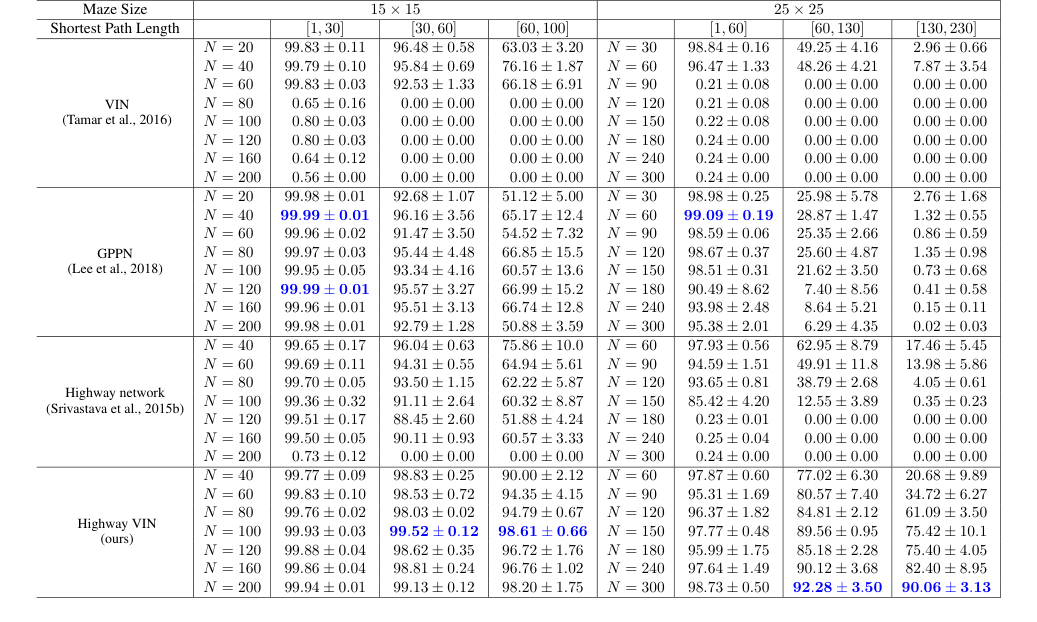 Table 4. Success rates of each algorithm with various depths under 2D maze navigation tasks with different ranges of shortest path lengths
Table 4. Success rates of each algorithm with various depths under 2D maze navigation tasks with different ranges of shortest path lengths