Сетевые сети итерации ценности на автострадах (Highway Value Iteration Networks)
Суть данного исследования коренится в давней проблеме обеспечения эффективного долгосрочного планирования агентами искусственного интеллекта.
Предыстория и академическая родословная
Происхождение и академическая родословная
Суть данного исследования коренится в давней проблеме обеспечения эффективного долгосрочного планирования агентами искусственного интеллекта. Эта конкретная проблема впервые ярко проявилась с появлением сетей итерации ценности (Value Iteration Networks, VIN), представленных Тамаром и др. в 2016 году. VIN стали значительным шагом вперед, поскольку они интегрировали "модуль планирования" непосредственно в архитектуру нейронной сети (НС), что позволило осуществлять обучение планированию в режиме end-to-end. Этот модуль планирования был разработан для аппроксимации классического алгоритма итерации ценности, фундаментальной концепции в обучении с подкреплением (RL), формализованной Беллманом в 1966 году.
Исторически, хотя VIN демонстрировали выдающуюся эффективность в различных задачах планирования, таких как планирование маршрутов и автономная навигация, они столкнулись с критическим ограничением: их способностью справляться с долгосрочным планированием. По мере увеличения сложности задач, требующих большего числа шагов планирования (например, длина пути, превышающая 120 в лабиринте), коэффициент успеха VIN резко снижался, часто падая ниже 10%. Естественным подходом к улучшению долгосрочного планирования является увеличение глубины модуля планирования VIN, что позволяет ему симулировать больше шагов планирования. Однако это немедленно столкнулось с фундаментальной проблемой в глубоком обучении: обучение очень глубоких нейронных сетей inherently сложно из-за таких проблем, как исчезающие или взрывающиеся градиенты (Hochreiter, 1991). Хотя такие методы, как остаточные сети и сети автострад, успешно позволили обучать очень глубокие НС для задач классификации, эти методы не оказались столь же эффективными при применении к уникальной архитектуре VIN, особенно в контексте планирования. Это расхождение возникает потому, что VIN включают специфический индуктивный сдвиг из обучения с подкреплением, который основан на теоретически обоснованном алгоритме итерации ценности. Таким образом, авторы были вынуждены разработать новый подход, который мог бы эффективно обучать глубокие VIN для долгосрочного планирования путем интеграции передовых методов как из НС, так и из RL.
Интуитивные термины предметной области
Чтобы помочь читателю без предварительных знаний понять концепции, здесь приведены некоторые специализированные термины, переведенные в повседневные аналогии:
- Сеть итерации ценности (VIN): Представьте себе умный GPS, который не только показывает вам лучший маршрут, но и учится находить лучший маршрут, многократно симулируя все возможные будущие шаги и их результаты, подобно тому, как вы мысленно "итерируете" по вариантам, чтобы найти наиболее ценный. VIN — это нейронная сеть с таким встроенным модулем "предвидения".
- Долгосрочное назначение кредита (Long-term Credit Assignment): Подумайте об обучении собаки сложной команде, состоящей из многих шагов. Если собака в конце концов получает лакомство, ей трудно понять, какие именно предыдущие действия привели к получению лакомства. В ИИ долгосрочное назначение кредита — это задача определения того, какие действия, предпринятые много шагов назад, действительно привели к хорошему (или плохому) результату гораздо позже.
- Исчезающие/взрывающиеся градиенты (Vanishing/Exploding Gradients): Представьте, что вы играете в игру "испорченный телефон" с очень длинной цепочкой людей. Если сообщение прошептать слишком тихо (исчезающий градиент), оно потеряется к концу. Если кричать слишком громко (взрывающийся градиент), оно превратится в искаженный шум. В глубоком обучении градиенты подобны "обратной связи", которая сообщает сети, как настроить свои внутренние параметры. Если эта обратная связь становится слишком слабой или слишком дикой на многих слоях, сеть не может эффективно обучаться.
- Пропускающие соединения (Skip Connections): Представьте себе очень длинную, извилистую дорогу. Пропускающие соединения — это как добавление прямых коротких путей или экспресс-полос, которые обходят некоторые из извилистых участков. Это позволяет информации (или сигналу "обратной связи" для обучения) легче и напрямую проходить через многие слои нейронной сети, предотвращая ее потерю или разбавление по пути.
Таблица обозначений
| Обозначение | Описание | Категория |
|---|---|---|
| $s$ | Конкретное состояние в среде. | Переменная |
| $a$ | Действие, предпринятое агентом. | Переменная |
| $V^\pi(s)$ | Функция ценности, представляющая ожидаемое суммарное будущее вознаграждение из состояния $s$ при следовании политике $\pi$. | Переменная |
| $Q^\pi(s, a)$ | Функция ценности действия, представляющая ожидаемое суммарное будущее вознаграждение из состояния $s$ при выполнении действия $a$ и последующем следовании политике $\pi$. | Переменная |
| $V^{(n)}$ | Функция ценности на $n$-й итерации алгоритма итерации ценности. | Переменная |
| $\gamma$ | Коэффициент дисконтирования, значение от 0 до 1, определяющее важность будущих вознаграждений. | Параметр |
| $N$ | Общая глубина (количество слоев) нейронной сети. | Параметр |
| $N_B$ | Количество "блоков автострады" в архитектуре сети. | Параметр |
| $N_p$ | Количество параллельных модулей исследования ценности (Value Exploration, VE) в блоке автострады. | Параметр |
| $\epsilon$ | Коэффициент исследования, контролирующий случайность выбора действий во время обучения. | Параметр |
Определение проблемы и ограничения
Формулировка основной проблемы и дилемма
Основная проблема, рассматриваемая в данной статье, заключается в значительной сложности обеспечения эффективного долгосрочного планирования сетями итерации ценности (VIN).
Входное/текущее состояние:
Текущее состояние включает сети итерации ценности (VIN) — архитектуры нейронных сетей, предназначенные для обучения планированию в режиме end-to-end. VIN достигают этого путем встраивания дифференцируемого "модуля планирования", который аппроксимирует классический алгоритм итерации ценности. Эти сети продемонстрировали значительную эффективность в различных сценариях планирования, таких как планирование маршрутов и автономная навигация, особенно для задач, требующих относительно ограниченного числа шагов планирования.
Желаемое конечное состояние/цель:
Желаемая цель — разработать VIN, способные к надежному и точному долгосрочному планированию. Это означает, что сети должны быть способны решать задачи, требующие сотен шагов планирования, например, навигацию по сложным лабиринтам с очень длинными кратчайшими путями. Важно, чтобы эти продвинутые VIN могли обучаться до значительной глубины (сотни слоев) с использованием стандартных методов обратного распространения ошибки, сохраняя высокие коэффициенты успеха даже при расширенных горизонтах планирования.
Упущенное звено и математический разрыв:
Точным упущенным звеном является неспособность существующих архитектур VIN эффективно масштабироваться до глубоких конфигураций сети, необходимых для долгосрочного планирования. Хотя более глубокие модули планирования должны позволять большее количество шагов планирования и, следовательно, лучшую долгосрочную производительность, текущие VIN сталкиваются с серьезными трудностями при увеличении их глубины.
На Рисунке 1 наглядно показано это: коэффициент успеха 30-слойной VIN резко падает для кратчайших путей длиной более 120, а попытка обучить 300-слойную VIN оказывается сложной, что приводит к плохой производительности. Математический разрыв заключается в разработке архитектуры VIN, которая может эффективно распространять информацию и градиенты через сотни слоев, позволяя встроенному процессу итерации ценности сходиться к оптимальной функции ценности за много итераций, не поддаваясь присущим глубокому обучению проблемам.
Болезненный компромисс или дилемма:
Центральная дилемма, в которой оказались предыдущие исследователи, заключается в присущем конфликте между потребностью в глубине для планирования и практическими ограничениями обучения глубоких нейронных сетей. С одной стороны, более глубокий модуль планирования в VIN теоретически желателен, поскольку он позволяет увеличить количество итеративных шагов планирования, что необходимо для решения задач долгосрочного планирования. С другой стороны, увеличение глубины любой нейронной сети, включая VIN, обычно приводит к серьезным осложнениям, таким как исчезающие или взрывающиеся градиенты. Хотя общее глубокое обучение разработало методы (такие как пропускающие соединения в ResNets или DenseNets) для обучения очень глубоких сетей для классификации, эти методы не оказались "одинаково успешными в задачах планирования" для VIN. Это расхождение предполагает, что уникальный индуктивный сдвиг VIN, полученный из алгоритма итерации ценности в обучении с подкреплением, делает их особенно восприимчивыми к этим проблемам, связанным с глубиной обучения, создавая болезненный компромисс между архитектурной глубиной для способности к планированию и практической обучаемостью.
Ограничения и режимы отказа
Проблема достижения долгосрочного планирования с помощью глубоких VIN чрезвычайно сложна из-за нескольких суровых, реалистичных ограничений и режимов отказа:
-
Вычислительное ограничение: Исчезающие/взрывающиеся градиенты: Наиболее фундаментальным препятствием является хорошо известная проблема исчезающих или взрывающихся градиентов в глубоких нейронных сетях. Как указано в статье, "увеличение глубины НС может привести к осложнениям, таким как исчезающие или взрывающиеся градиенты, что является фундаментальной проблемой в глубоком обучении". Это делает чрезвычайно трудным эффективное обучение VIN с сотнями слоев с использованием стандартного обратного распространения ошибки, поскольку градиенты либо становятся слишком малыми для обновления ранних слоев, либо слишком большими, что приводит к нестабильному обучению.
-
Архитектурное ограничение: Несовместимость со стандартными решениями глубокого обучения: Хотя пропускающие соединения (например, в Highway Networks, ResNets, DenseNets) оказались эффективными для обучения очень глубоких сетей в других областях (например, классификация изображений), они не были хорошо перенесены на VIN для задач планирования. Это предполагает специфическую архитектурную несовместимость или отсутствие соответствующего индуктивного сдвига в этих универсальных методах глубокого обучения при применении к модулю планирования VIN, который основан на итерации ценности в обучении с подкреплением.
-
Режим отказа производительности: Деградация с глубиной: Вместо улучшения, производительность VIN резко ухудшается с увеличением глубины для долгосрочного планирования. Например, VIN с глубиной более 150 слоев показывают коэффициент успеха почти 0% для многих задач. Это критический режим отказа, при котором предполагаемое решение (больше глубины для большего числа шагов планирования) активно ухудшает результат.
-
Ограничение потока информации: Жадный выбор действий и каналирование градиентов: Оригинальный модуль итерации ценности VIN "жадно выбирает наибольшее значение Q" (Уравнение 4). Этот механизм создает "отличительный поток информации для каждого слоя, тем самым направляя градиенты к определенным специфическим нейронам". Отсутствие разнообразной информации и потока градиентов по пространственным измерениям затрудняет надежное обучение сети и обобщение в сложных сценариях долгосрочного планирования.
-
Режим отказа исследования: Вредная стохастичность: Хотя введение стохастичности (исследования) может помочь диверсифицировать поток информации, неконтролируемое исследование может быть контрпродуктивным. В статье отмечается, что без "фильтрующего вентиля" для управления исследованием, "VIN на автострадах могут легко пострадать от неблагоприятных последствий исследования в модулях VE, что может помешать сходимости". Это подразумевает, что наивные попытки улучшить разнообразие могут привести к нестабильности и помешать сети изучить оптимальную политику.
-
Ограничения памяти оборудования: Хотя это и не является основной целью определения проблемы, вычислительная сложность очень глубоких сетей накладывает практические ограничения на память оборудования. Экспериментальный раздел статьи (Таблица 4) показывает, что предлагаемый Highway VIN, хотя и более эффективен, чем некоторые альтернативы, все же требует 15,0 ГБ памяти GPU для 300-слойной сети по сравнению с 3,1 ГБ для 30-слойной VIN. Это указывает на то, что масштабирование до еще более глубоких архитектур или более крупных проблем быстро упрется в потолок памяти, делая исследования и развертывание более дорогими и сложными.
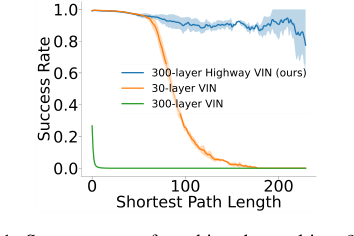 Figure 1. Success rates of reaching the goal in a 25 × 25 maze problem. The success rate of a 30-layer VIN con- siderably decreases as the shortest path length increases, and training a 300-layer VIN is difficult and exhibits poor performance
Figure 1. Success rates of reaching the goal in a 25 × 25 maze problem. The success rate of a 30-layer VIN con- siderably decreases as the shortest path length increases, and training a 300-layer VIN is difficult and exhibits poor performance
Почему такой подход
Неизбежность выбора
Принятие сетевой сети итерации ценности на автострадах (highway VIN) было не просто выбором, а неизбежностью, обусловленной присущими ограничениями существующих подходов при столкновении с требованиями долгосрочного планирования. Авторы точно определили момент недостаточности традиционных методов, наблюдая за сетями итерации ценности (VIN) в задачах планирования маршрутов. В частности, для кратчайших путей длиной более 120 коэффициент успеха VIN резко упал ниже 10% (Рисунок 1). Этот резкий спад выявил фундаментальный недостаток: хотя увеличение глубины встроенного "модуля планирования" VIN казалось логичным путем для интеграции большего числа шагов планирования и, следовательно, улучшения долгосрочного планирования, традиционные сложности обучения глубоких нейронных сетей (НС), такие как исчезающие или взрывающиеся градиенты, быстро сделали этот подход нежизнеспособным.
Важно отметить, что в статье отмечается, что даже продвинутые глубокие НС, которые успешно справились с этими проблемами градиентов в задачах классификации (например, ResNets, DenseNets и стандартные Highway Networks), не оказались "одинаково успешными в задачах планирования" (Таблица 1, Раздел 5). Это расхождение возникает непосредственно из уникальной архитектуры VIN и их присущего индуктивного сдвига, полученного из алгоритма итерации ценности в обучении с подкреплением (RL). Стандартные решения глубоких НС, хотя и эффективны для общего глубокого обучения, просто не предоставляют специфических знаний, релевантных для RL, необходимых для обеспечения эффективного долгосрочного назначения кредита в рамках системы планирования VIN. Следовательно, подход, который мог бы как обеспечить глубокие архитектуры, так и сохранить/улучшить индуктивный сдвиг планирования VIN, был единственным жизнеспособным путем вперед, что привело к интеграции итерации ценности на автострадах и архитектурных инноваций, таких как пропускающие соединения, адаптированные для этой конкретной проблемы.
Сравнительное превосходство
Highway VIN демонстрирует качественное превосходство над предыдущими золотыми стандартами не только за счет улучшенных метрик производительности, но и за счет фундаментального структурного редизайна, который решает основные проблемы глубокого планирования. Его подавляющее преимущество обусловлено тремя ключевыми инновациями, встроенными в модуль планирования VIN:
- Агрегирующий вентиль (Aggregate Gate): Этот компонент создает пропускающие соединения, значительно улучшая поток информации через многие слои. В отличие от общих пропускающих соединений в стандартных сетях автострад, он интегрирован в контекст итерации ценности, позволяя обучать VIN с сотнями слоев без проблем с исчезающими или взрывающимися градиентами. Это структурное преимущество напрямую способствует созданию глубоких архитектур, необходимых для долгосрочного планирования.
- Модуль исследования (Exploration Module): Этот модуль вводит контролируемую стохастичность во время обучения, которая диверсифицирует поток информации и градиентов по пространственным измерениям. Это критическое улучшение по сравнению с традиционными VIN, где операция жадной максимизации в модуле итерации ценности может привести к ограниченному разнообразию выбранных действий, о чем свидетельствуют низкие значения энтропии для VIN по сравнению с highway VIN (Таблица 2). Это разнообразие необходимо для надежного обучения в сложных, высокоразмерных средах планирования.
- Фильтрующий вентиль (Filter Gate): Разработанный для "фильтрации" бесполезных путей исследования, этот вентиль обеспечивает безопасное и эффективное исследование. Он сравнивает активации и отбрасывает те, которые не способствуют сходимости, механизм, критически важный для поддержания теоретической обоснованности итерации ценности, особенно в сочетании со стохастичностью, вводимой модулем исследования. Без этого, как показывают абляционные исследования (Рисунок 7), производительность резко снижается, поскольку сеть страдает от неблагоприятных последствий неконтролируемого исследования.
Эти компоненты в совокупности позволяют highway VIN изучать более эффективные функции ценности для состояний, удаленных от цели (Рисунок 6), что подразумевает превосходную способность справляться с долгосрочными зависимостями и планировать на расширенных горизонтах, чего сильно не хватает в традиционных VIN и других глубоких НС в задачах планирования.
Соответствие ограничениям
Выбранный подход highway VIN идеально соответствует суровым требованиям долгосрочного планирования, образуя "брак" между требованиями проблемы и уникальными свойствами решения.
Одно из основных ограничений — необходимость глубоких сетей для долгосрочного планирования, поскольку большее количество шагов планирования по своей сути требует большей глубины. Традиционные VIN потерпели неудачу здесь из-за трудностей обучения при увеличенной глубине. Highway VIN напрямую решает эту проблему, обеспечивая эффективное обучение с сотнями слоев с использованием стандартного обратного распространения ошибки, что было невозможно для его предшественников.
Другое критическое ограничение — преодоление проблемы исчезающих или взрывающихся градиентов, присущей очень глубоким НС. Агрегирующий вентиль, вводя пропускающие соединения, напрямую решает эту проблему, обеспечивая стабильный поток градиентов. Это прямая адаптация проверенных методов глубокого обучения (таких как в сетях автострад и ResNets), но специально интегрированная в архитектуру VIN для сохранения ее индуктивного сдвига планирования.
Кроме того, проблема требует эффективного долгосрочного назначения кредита в рамках RL. Сама основа этого подхода, highway value iteration, была разработана именно для этой цели (Wang et al., 2024). Интеграция этого алгоритма гарантирует, что решение теоретически обосновано и сходится к оптимальной функции ценности (Замечание 1), даже с добавленной стохастичностью модуля исследования, благодаря фильтрующему вентилю (Замечание 2). Это гарантирует, что глубокая сеть не просто "глубокая", а эффективно глубокая для планирования.
Отклонение альтернатив
В статье представлены четкие обоснования отклонения других популярных или передовых подходов для данной конкретной проблемы:
-
Традиционные VIN: Они явно показаны как недостаточные для долгосрочного планирования. По мере увеличения глубины сверх определенного момента (например, 30 слоев для лабиринта 25x25) их коэффициент успеха резко падает, часто до менее 10% для путей длиной более 120 (Рисунок 1, Таблица 1). Трудности в обучении очень глубоких VIN из-за проблем с градиентами делают их непригодными для задач, требующих сотен шагов планирования.
-
Стандартные глубокие нейронные сети (например, Highway Networks, ResNets, DenseNets): Хотя эти архитектуры преуспевают в таких задачах, как классификация изображений, позволяя обучать очень глубокие модели, они не "одинаково успешны в задачах планирования" (стр. 1). Авторы предполагают, что простое включение их пропускающих соединений в VIN не вносит дополнительного архитектурного индуктивного сдвига, полезного для планирования (стр. 8). Эти методы, лишенные специфического индуктивного сдвига, релевантного для RL, итерации ценности, не могут перевести свою глубину в улучшенные возможности долгосрочного планирования. Таблица 1 ясно показывает, что, хотя сети автострад сохраняют производительность при большей глубине, чем VIN, их долгосрочные возможности планирования не значительно улучшаются с увеличением глубины, и они все равно превосходят highway VIN.
-
Сети планирования маршрутов с вентилями (Gated Path Planning Networks, GPPN): GPPN, рекуррентный вариант VIN, были разработаны для улучшения стабильности обучения в глубоких моделях. Хотя они работают надежно и преуспевают в краткосрочном планировании (например, 99,09% SR для SPL [1,30] в лабиринте 25x25), их производительность значительно ухудшается при долгосрочном планировании, падая до менее 3% для SPL [130,230] (Таблица 1, стр. 8). В статье это неудачу объясняют тем, что GPPN является "методом черного ящика с меньшим индуктивным сдвигом в сторону планирования", что делает его более подходящим для изучения краткосрочных закономерностей, чем истинных навыков долгосрочного планирования. Это подчеркивает, что сильный, явный индуктивный сдвиг планирования, как предоставляемый highway value iteration, имеет решающее значение.
 Figure 11. Examples of 2D maze navigation tasks where highway VIN succeeds, but other methods fail
Figure 11. Examples of 2D maze navigation tasks where highway VIN succeeds, but other methods fail
Математический и логический механизм
Мастер-уравнение
Суть сетей итерации ценности на автострадах (Highway VIN) заключается в их "модуле планирования", который разработан для аппроксимации алгоритма итерации ценности на автострадах (Highway Value Iteration, highway VI). Центральным математическим механизмом, управляющим этим алгоритмом, является оператор $G$, который определяет, как функция ценности итеративно обновляется. В статье утверждается, что алгоритм highway VI итеративно обновляет функцию ценности как $V^{(n+1)} = GV^{(n)}$, где $G$ формально определяется как:
$$ GV(s) = \max_{\Pi \in \mathbf{\Pi}} \max_{N \in \mathbf{N}} \max_{a \in \mathcal{A}} \max_{x \in \mathcal{X}} \{(B^{\pi})^{\circ(N-1)} BV, BV\} $$
Это уравнение охватывает многошаговое бутстрэппинг и механизмы исследования политики, которые являются фундаментальными для highway VI и, как следствие, для архитектуры Highway VIN.
Потерминный разбор
Давайте разберем это мастер-уравнение, чтобы понять роль и значение каждого компонента.
-
$GV(s)$:
- Математическое определение: Это обновленная функция ценности для данного состояния $s$ после применения оператора Highway Value Iteration $G$.
- Физическая/логическая роль: Это новая, улучшенная оценка оптимальной ценности, достижимой из состояния $s$, включающая идеи из нескольких горизонтов планирования и политик. Это выход одной итерации "блока автострады" в модуле планирования VIN.
- Почему этот оператор: Оператор $G$ является составным оператором, разработанным для обеспечения эффективного долгосрочного назначения кредита в обучении с подкреплением, объединяя элементы как оптимальной, так и основанной на политике итерации ценности.
-
$V(s)$:
- Математическое определение: Текущая оценка функции ценности для состояния $s$. В итеративном обновлении $V^{(n+1)} = GV^{(n)}$ это будет $V^{(n)}(s)$.
- Физическая/логическая роль: Это вход для оператора $G$, представляющий текущее понимание агентом того, насколько хорошим является каждое состояние. Это основа, на которой строится следующая, более точная оценка ценности.
-
$\max_{\Pi \in \mathbf{\Pi}}$:
- Математическое определение: Операция максимизации по множеству политик.
- Физическая/логическая роль: Этот член позволяет алгоритму рассматривать и выбирать лучшую "политику упреждающего просмотра" из предопределенного множества $\mathbf{\Pi}$. Он гарантирует, что процесс планирования не ограничен одной фиксированной политикой, а может исследовать различные стратегии для поиска наиболее перспективного пути. Это ключевой аспект "модуля исследования" в Highway VIN.
- Почему максимизация: Максимизация используется здесь для выбора наиболее оптимистичного исхода среди различных потенциальных стратегий планирования, что соответствует цели поиска оптимальной функции ценности.
-
$\mathbf{\Pi}$:
- Математическое определение: Множество политик упреждающего просмотра.
- Физическая/логическая роль: Это различные политики, которые агент может "вообразить" или "симулировать" для исследования будущих состояний и вознаграждений. В Highway VIN они соответствуют встроенным политикам в модулях исследования ценности (Value Exploration, VE).
-
$\max_{N \in \mathbf{N}}$:
- Математическое определение: Операция максимизации по множеству глубин упреждающего просмотра.
- Физическая/логическая роль: Это позволяет алгоритму рассматривать различные "горизонты планирования" или то, насколько далеко в будущее он должен заглядывать. Это критически важно для долгосрочного планирования, поскольку позволяет модели выбирать наиболее выгодную глубину планирования для данной ситуации.
- Почему максимизация: Аналогично политикам, максимизация по глубинам помогает выбрать наиболее выгодный горизонт планирования, гарантируя, что алгоритм может адаптировать свой масштаб планирования.
-
$\mathbf{N}$:
- Математическое определение: Множество глубин упреждающего просмотра.
- Физическая/логическая роль: Это различные количества шагов (или итераций), которые модуль планирования может симулировать в будущем. В статье $n$ определяется как глубина упреждающего просмотра, поэтому $N$ здесь относится к конкретной глубине, выбранной из множества $\mathbf{N}$.
-
$\max_{a \in \mathcal{A}}$:
- Математическое определение: Операция максимизации по множеству возможных действий.
- Физическая/логическая роль: Этот член гарантирует, что на каждом этапе принятия решения алгоритм рассматривает все доступные действия и выбирает то, которое ведет к наивысшей ожидаемой ценности. Это фундаментальная часть итерации ценности.
- Почему максимизация: Это ядро принципа оптимальности Беллмана, направленное на поиск наилучшего возможного действия для максимизации будущих вознаграждений.
-
$\mathcal{A}$:
- Математическое определение: Множество всех возможных действий, которые может предпринять агент.
- Физическая/логическая роль: Это дискретные выборы, доступные агенту в его среде.
-
$\max_{x \in \mathcal{X}}$:
- Математическое определение: Операция максимизации по множеству состояний или пространственных положений.
- Физическая/логическая роль: Это подразумевает, что оператор рассматривает наилучший возможный исход в различных пространственных конфигурациях или состояниях, что актуально в задачах навигации по лабиринту, где "состояние" может быть ячейкой сетки.
- Почему максимизация: Это гарантирует, что алгоритм устойчив к различным начальным точкам или локальным вариациям в среде, всегда стремясь к глобально оптимальному пути.
-
$B$:
- Математическое определение: Оператор оптимальности Беллмана. Для состояния $s$, $BV(s) = \max_a \sum_{s'} T(s'|s,a) [R(s,a,s') + \gamma V(s')]$.
- Физическая/логическая роль: Этот оператор вычисляет оптимальную ценность состояния, учитывая немедленное вознаграждение и дисконтированную ценность следующего состояния, предполагая, что агент всегда выбирает лучшее действие. Он представляет собой "жадный" шаг планирования. В Highway VIN это аппроксимируется стандартным модулем итерации ценности (VI) (Уравнения 3 и 4).
- Почему суммирование и максимизация: Суммирование используется для усреднения по возможным следующим состояниям (взвешенным по вероятностям переходов), а максимизация выбирает лучшее действие.
-
$B^\pi$:
- Математическое определение: Оператор ожидания Беллмана для данной политики $\pi$. Для состояния $s$, $B^\pi V(s) = \sum_a \pi(a|s) \sum_{s'} T(s'|s,a) [R(s,a,s') + \gamma V(s')]$.
- Физическая/логическая роль: Этот оператор вычисляет ожидаемую ценность состояния в соответствии с конкретной политикой $\pi$. Он представляет собой шаг "исследования на основе политики". В Highway VIN это аппроксимируется модулем исследования ценности (Value Exploration, VE) (Уравнения 6 и 7), который вводит стохастичность.
- Почему суммирование: Суммирование используется дважды: один раз для усреднения по действиям (взвешенным по вероятностям политики) и еще раз для усреднения по возможным следующим состояниям.
-
$\circ(N-1)$:
- Математическое определение: Оператор композиции, применяемый $N-1$ раз. Для оператора $O$, $O^{\circ k} = O \circ O \circ \dots \circ O$ ($k$ раз). В статье используется $n-1$ в Уравнении (5), но учитывая, что $N$ определяется как глубина упреждающего просмотра, более последовательно интерпретировать это как $N-1$ композиций.
- Физическая/логическая роль: Это означает многошаговый упреждающий просмотр. Применение оператора ожидания Беллмана несколько раз означает симуляцию политики $\pi$ на $N-1$ шагов в будущее. Это позволяет алгоритму оценивать долгосрочные последствия политики, а не только немедленный следующий шаг. В Highway VIN это соответствует стекированию $N_b-1$ параллельных модулей VE.
- Почему композиция: Композиция естественным образом представляет последовательное применение оператора, моделируя многошаговое планирование.
-
$\{\cdot, \cdot\}$:
- Математическое определение: Множество, содержащее два элемента.
- Физическая/логическая роль: Это указывает на то, что оператор $G$ рассматривает два основных направления распространения ценности: одно, включающее многошаговое исследование на основе политики ($(B^{\pi})^{\circ(N-1)} BV$), и другое, представляющее более прямое, одношаговое оптимальное обновление ($BV$). Внешняя максимизация затем выбирает лучшее из этих двух. Здесь вступает в игру "фильтрующий вентиль", выбирающий максимальное значение.
- Почему множество и внешняя максимизация: Эта структура позволяет сравнивать глубокий, исследовательский путь и более непосредственный, жадный путь, гарантируя, что алгоритм получает выгоду как от краткосрочной оптимальности, так и от долгосрочного исследования.
Пошаговый поток
Представьте себе один абстрактный набор данных, представляющий ценность состояния $V^{(n)}(s)$, входящий в модуль планирования Highway VIN. Этот модуль действует как сложная сборочная линия, обрабатывая $V^{(n)}(s)$ для получения улучшенного $V^{(n+1)}(s)$.
-
Начальный ввод: Текущая оценка функции ценности, $V^{(n)}(s)$, подается в модуль планирования. Этот $V^{(n)}(s)$ обычно представляет собой карту признаков, отображающую ценность каждой пространственной позиции в латентном MDP.
-
Путь оптимальности Беллмана (полоса "жадности"):
- Часть $V^{(n)}(s)$ направляется в стандартный модуль итерации ценности (VI).
- Внутри этого модуля сверточная операция (как в Уравнении 3) вычисляет ценности действий $Q_{a,i,j}^{(n)}$, учитывая немедленные вознаграждения и дисконтированные ценности соседних состояний.
- Затем операция макс-пулинга (Уравнение 4) выбирает максимальное значение $Q_{a,i,j}^{(n)}$ по всем действиям $a$ для каждого состояния $(i,j)$, эффективно применяя оператор оптимальности Беллмана $B$. Это дает обновленную функцию ценности, назовем ее $V_{VI}^{(n+1)}(s) = BV^{(n)}(s)$. Этот путь представляет собой наиболее прямое, жадное обновление.
-
Путь ожидания Беллмана (полосы "исследования"):
- Одновременно $V^{(n)}(s)$ также направляется в несколько параллельных модулей исследования ценности (VE). Каждый модуль VE связан с различной "политикой упреждающего просмотра" $\pi_{np}$ и вносит вклад в определенную "глубину упреждающего просмотра" $n_b$.
- Внутри каждого модуля VE: Вместо выбора максимума по действиям, модуль VE вычисляет ожидаемую ценность по действиям на основе своей встроенной политики $\pi_{np}$ (Уравнение 7). Эта политика может генерироваться стохастически во время обучения (Уравнение 8), внося разнообразие. Это эффективно применяет оператор ожидания Беллмана $B^{\pi_{np}}$.
- Стекирование для глубины: Эти модули VE стекируются для $N_b - 1$ слоев. Это означает, что выход одного модуля VE становится входом для следующего, составляя оператор $(B^{\pi_{np}})^{\circ(n_b-1)} BV^{(n)}(s)$ для различных $n_b$ и $np$. Это создает богатый набор оценок ценности на основе исследования, учитывая различные политики и горизонты планирования.
-
Агрегация (слияние информации):
- Выходы всех этих параллельных и стекированных модулей VE, наряду с выходом модуля VI, сходятся.
- "Агрегирующий вентиль" (как в Уравнении 9) объединяет эти разнообразные активации. Этот вентиль использует обучаемые веса softmax для определения вклада каждого параллельного модуля VE и каждой глубины в окончательную агрегированную ценность. Это создает пропускающие соединения, позволяя информации проходить через многие слои и глубины, смягчая исчезающие градиенты.
-
Фильтрация (контроль качества):
- После агрегации "фильтрующий вентиль" применяет операцию максимизации. Этот вентиль сравнивает агрегированную ценность (представляющую потенциальный путь исследования) с более прямым, часто жадным значением (например, $V^{(n+1)}$ из модуля VI или значение предыдущей итерации).
- Он выбирает максимум из этих значений, эффективно отбрасывая "бесполезные пути исследования", которые не способствуют сходимости или приводят к более низким значениям. Это гарантирует, что вперед передается только полезная информация.
-
Выход: Результат всего этого процесса, после агрегации и фильтрации, становится новой, улучшенной оценкой функции ценности, $V^{(n+1)}(s)$ (или $V^{(n+N_b)}(s)$ в обозначении статьи для блока автострады). Этот выход затем подается в следующий блок автострады или используется для вывода окончательной политики.
Этот сложный танец параллельной обработки, исследования на основе политики и выборочной агрегации позволяет Highway VIN выполнять надежное долгосрочное планирование.
Динамика оптимизации
Highway VIN обучается и сходится посредством сквозного процесса обучения, в основном используя стандартное обратное распространение ошибки, но со специфическими архитектурными инновациями, разработанными для формирования ландшафта потерь и потока градиентов.
-
Дифференцируемый модуль планирования: Весь модуль планирования, включая модули итерации ценности (VI), модули исследования ценности (VE), агрегирующие вентили и фильтрующие вентили, разработан как полностью дифференцируемый. Это имеет решающее значение, поскольку позволяет градиентам течь назад через шаги планирования, позволяя сети учиться планировать.
-
Обратное распространение ошибки и поток градиентов: Модель обучается с использованием стандартного обратного распространения ошибки. Функция потерь (например, основанная на имитационном обучении, сравнивающая предсказанные политики/ценности с целевыми политиками/ценностями) вычисляется на выходном слое. Затем градиенты этой потери распространяются назад через все слои сети, включая глубокий модуль планирования, для обновления параметров модели.
-
Решение проблемы исчезающих/взрывающихся градиентов: Основная мотивация для Highway VIN — преодолеть проблему исчезающих/взрывающихся градиентов в очень глубоких сетях, особенно в задачах планирования.
- Агрегирующий вентиль (пропускающие соединения): Агрегирующий вентиль явно вводит пропускающие соединения, аналогично сетям автострад и ResNets. Эти соединения обеспечивают прямые пути для потока градиентов от более поздних слоев к более ранним, минуя множество нелинейных преобразований. Это помогает поддерживать сильные градиентные сигналы даже в очень глубоких архитектурах, делая обучение сотен слоев возможным.
- Модуль исследования ценности (стохастичность): Модуль VE вводит контролируемую стохастичность во время обучения, случайным образом генерируя встроенные политики (Уравнение 8). Это диверсифицирует поток информации и градиентов по пространственным измерениям. Хотя стохастичность иногда может препятствовать сходимости, в статье отмечается, что этот механизм повышает надежность и необходим для высокой производительности без влияния на сходимость к оптимальной функции ценности (Замечание 1). Это предполагает, что он помогает более эффективно исследовать ландшафт потерь, предотвращая застревание модели в плохих локальных минимумах.
-
Формирование ландшафта потерь (гарантии сходимости):
- Фильтрующий вентиль (максимизация): Фильтрующий вентиль, который выполняет операцию максимизации, явно указан как "критически важный для обеспечения сходимости к $V^*$" (Замечание 2). Отбрасывая "бесполезные пути исследования" (т.е. активации, которые ниже более прямого значения), он отсекает субоптимальные ветви процесса планирования. Это эффективно формирует ландшафт потерь, направляя модель к областям, которые ведут к оптимальным функциям ценности, предотвращая расхождение из-за бесполезных исследований.
- Теоретическая обоснованность: Алгоритм highway VI имеет теоретическую гарантию сходимости к оптимальной функции ценности $V^*$ независимо от конкретных политик упреждающего просмотра, глубин или температур softmax (Замечание 1). Эта теоретическая гарантия обеспечивает прочную основу для динамики обучения Highway VIN, предполагая, что итеративные обновления, при правильной фильтрации, в конечном итоге приведут к оптимальному решению.
-
Обучаемые параметры: Модель обучается путем обновления нескольких наборов параметров:
- Веса сверточных слоев в модулях VI и VE.
- Обучаемые параметры $W_{np}^{(n+n_b)}$, используемые для генерации встроенных политик в модулях VE.
- Температуры softmax $\alpha_a^{(n_p+n_b)}$ и $\alpha_n^{(n_p+n_b)}$ в агрегирующих вентилях, которые контролируют взвешивание различных информационных путей.
Благодаря этому сочетанию архитектурного дизайна, контролируемой стохастичности и теоретически обоснованных операторов, Highway VIN эффективно учится выполнять долгосрочное планирование путем итеративного уточнения своих оценок функции ценности, преодолевая проблемы обучения глубоких сетей в сложных задачах последовательного принятия решений.
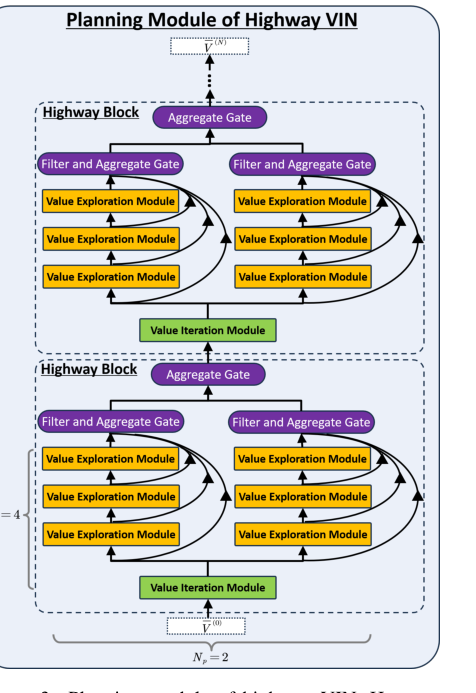 Figure 3. Planning module of highway VIN. Here, we demonstrate the planning module of highway VIN using a highway block of depth Nb = 4 and incorporating Np = 2 embedded policies
Figure 3. Planning module of highway VIN. Here, we demonstrate the planning module of highway VIN using a highway block of depth Nb = 4 and incorporating Np = 2 embedded policies
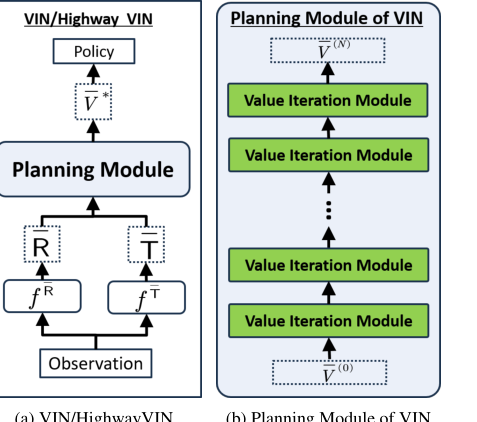 Figure 2. (a): Architecture of VIN and highway VIN. (b): Architecture of the planning module of VIN, which includes N layers of value iteration modules. The architecture of the value iteration module is detailed in Fig. 4(a)
Figure 2. (a): Architecture of VIN and highway VIN. (b): Architecture of the planning module of VIN, which includes N layers of value iteration modules. The architecture of the value iteration module is detailed in Fig. 4(a)
Результаты, ограничения и заключение
Экспериментальный дизайн и базовые модели
Для строгого подтверждения своих утверждений авторы провели серию экспериментов, в основном сосредоточенных на навигации по 2D-лабиринтам и, в меньшей степени, на задачах навигации в 3D ViZDoom. Экспериментальная установка для навигации по 2D-лабиринтам была тесно связана с той, что описана в статье GPPN (Lee et al., 2018). Для этих задач агенты обучались навигации по лабиринтам различных размеров, в частности $15 \times 15$ и $25 \times 25$, с действиями, включающими движение вперед, поворот на 90 градусов влево или вправо и поддержание четырех ориентаций.
Режим обучения включал 30 эпох имитационного обучения на размеченных наборах данных, состоящих из 25 тыс. лабиринтов для обучения, 5 тыс. для валидации и 5 тыс. для тестирования. Оптимизатор RMSprop использовался с коэффициентом обучения 0,001 и размером пакета 32. Сверточные операции в модуле планирования использовали ядро размером 5, а нейронная сеть, отображающая наблюдения в латентное MDP, имела скрытое измерение 150.
Основной метрикой для оценки способности к планированию был коэффициент успеха (SR), определяемый как отношение успешно завершенных задач к общему числу задач планирования. Задача считалась успешной, если агент генерировал путь от старта до цели в пределах заданного числа шагов. Для оценки долгосрочных возможностей планирования алгоритмы оценивались по задачам с различной длиной кратчайшего пути (SPL), предварительно рассчитанной с помощью алгоритма Дейкстры. Более длинные SPL по своей сути требуют большего долгосрочного планирования. Все эксперименты проводились с 3 случайными семенами, и сообщались среднее значение и стандартное отклонение SR.
"Жертвами" (базовыми моделями), с которыми сравнивался предлагаемый Highway VIN, были:
* Оригинальный VIN (Tamar et al., 2016): Основополагающая сеть итерации ценности.
* GPPN (Lee et al., 2018): Сети планирования маршрутов с вентилями, рекуррентный вариант VIN, разработанный для стабильности.
* Highway Network (Srivastava et al., 2015b): Архитектура глубокой нейронной сети, включающая пропускающие соединения, адаптированная здесь для VIN.
Для справедливого сравнения базовые VIN и GPPN тестировались с 20 слоями для лабиринта $15 \times 15$ и 30 слоями для лабиринта $25 \times 25$. Сети автострад и Highway VIN использовали $N_B = 20$ блоков автострад для лабиринта $15 \times 15$ и $N_B = 30$ для лабиринта $25 \times 25$. Исследовались различные общие глубины $N$, варьирующиеся от 40 до 200 для лабиринта $15 \times 15$ и от 60 до 300 для лабиринта $25 \times 25$. Если не указано иное, Highway VIN использовали один параллельный модуль VE ($N_p = 1$) и встроенный коэффициент исследования $\epsilon = 1$.
Также были проведены абляционные исследования для выделения влияния фильтрующего вентиля и модуля VE, а также для изучения влияния изменения числа параллельных модулей VE ($N_p$). Наконец, подход был протестирован в 3D-навигации ViZDoom, где входные данные состояли из RGB-изображений, а производительность оценивалась для задач с SPL более 30. Была измерена вычислительная сложность, включая использование памяти GPU и время обучения на GPU NVIDIA A100 для 300-слойных сетей.
Что доказывают доказательства
Доказательства подавляющим образом подтверждают основное утверждение о том, что Highway VIN значительно улучшают возможности долгосрочного планирования, обеспечивая эффективное обучение очень глубоких сетей, что ранее было сложной задачей для VIN.
Наиболее убедительные доказательства получены из сравнительных коэффициентов успеха в навигации по 2D-лабиринтам, особенно для задач, требующих длинных кратчайших путей (SPL). Как показано в Таблице 1 и на Рисунке 5, для лабиринта $25 \times 25$, когда SPL превышали 200, коэффициенты успеха базовых моделей VIN, GPPN и Highway Network резко упали почти до 0%. В отличие от этого, Highway VIN сохранял впечатляющий SR 90% для этих сложных сценариев долгосрочного планирования. Аналогично, для лабиринта $15 \times 15$ с SPL около 100, Highway VIN достигла SR 98%, в то время как другие методы показали значительную деградацию. Это наглядно демонстрирует превосходную способность Highway VIN справляться с долгосрочным назначением кредита.
В статье также подчеркиваются ограничения существующих методов:
* Производительность оригинального VIN резко снижалась с увеличением глубины, падая почти до 0% SR для сетей глубже $N=150$. Это наглядно представлено на Рисунке 1, который показывает, что коэффициент успеха 30-слойной VIN падает ниже 10% для SPL более 120, а 300-слойная VIN демонстрирует плохую производительность.
* Хотя Highway Network сохраняла производительность при большей глубине, она не значительно улучшала возможности долгосрочного планирования по сравнению со своими более мелкими аналогами.
* GPPN, хотя и надежен для коротких SPL (достигая 99,09% SR для лабиринта $25 \times 25$ с SPL [1,30]), катастрофически потерпел неудачу на более длинных путях, упав ниже 3% для SPL [130,230].
Дополнительные доказательства эффективности Highway VIN предоставляются изученными картами признаков (Рисунок 6). Карты признаков Highway VIN показывают более высокие изученные значения для состояний, удаленных от цели, по сравнению с VIN, что указывает на то, что Highway VIN разрабатывает более эффективную и всестороннюю функцию ценности для долгосрочного планирования.
Абляционные исследования предоставили решающие сведения о необходимости новых компонентов Highway VIN:
* Фильтрующий вентиль: Рисунок 7 безоговорочно показывает, что без фильтрующего вентиля производительность Highway VIN значительно снижается. Это доказывает, что фильтрующий вентиль играет важную роль в отбрасывании "бесполезных путей исследования" и обеспечении сходимости, напрямую подтверждая его математическую цель.
* Модули VE: Рисунок 8 демонстрирует заметное снижение производительности при отсутствии модулей VE, особенно в лабиринте $25 \times 25$. Это подтверждает, что введение модулем VE разнообразных латентных действий жизненно важно для обеспечения потока информации и градиентов по пространственным измерениям. Таблица 2 далее количественно оценивает это, показывая, что Highway VIN поддерживает значительно более высокую энтропию выбранных латентных действий (например, 4,17 для $N=200$ в лабиринте $15 \times 15$) по сравнению с VIN (0,00 для $N=200$), что напрямую доказывает его способность поддерживать разнообразие.
Наконец, в 3D-навигации ViZDoom (Таблица 3) Highway VIN снова превзошел базовые модели, достигнув SR 96,98% для SPL [60,100] по сравнению с 69,37% у VIN, что еще больше укрепляет его обобщаемость на более сложные, визуальные среды. Хотя Highway VIN требовал больше памяти GPU (15,0 ГБ против 3,1 ГБ для VIN) и времени обучения (9,0 часов против 7,5 часов для VIN) для 300 слоев, это разумный компромисс за значительное повышение производительности в долгосрочном планировании, особенно по сравнению с использованием GPPN в 103,0 ГБ.
Ограничения и будущие направления
Хотя Highway VIN представляет собой значительный прогресс в долгосрочном планировании для глубоких нейронных сетей, статья также явно и неявно указывает на несколько ограничений и открывает направления для будущих исследований.
Одно из явных ограничений, хотя и управляемое, — это увеличенная вычислительная стоимость для очень глубоких Highway VIN. Как показано в таблице вычислительной сложности, обучение 300-слойной Highway VIN требует больше памяти GPU (15,0 ГБ) и времени обучения (9,0 часов) по сравнению со стандартной VIN (3,1 ГБ, 7,5 часов) или Highway Network (3,3 ГБ, 7,7 часов). Хотя это все еще значительно более эффективно, чем GPPN (103,0 ГБ), это предполагает, что масштабирование до еще более крупных, более сложных реальных задач может потребовать дальнейшей оптимизации.
Другое интересное наблюдение, подчеркнутое в Разделе B.2 и на Рисунке 10, заключается в том, что дополнительные параллельные модули VE ($N_p > 1$) иногда могут быть вредны для производительности очень глубоких сетей. Например, при глубине $N=300$ $N_p=1$ работает лучше всего, а при $N=100$ оптимальным является $N_p=3$. Это подразумевает, что текущий механизм интеграции нескольких параллельных модулей VE может быть не универсально полезным и даже может ухудшить производительность в определенных глубоких конфигурациях. Это предполагает тонкий баланс или потребность в более изощренных стратегиях объединения этих модулей.
В статье также упоминается, что встроенный коэффициент исследования $\epsilon=1$ (полностью стохастический) используется во время обучения, и хотя фильтрующий вентиль предотвращает субоптимальные решения, эта фиксированная, максимальная степень исследования может быть не самой эффективной или адаптивной стратегией для всех сценариев. Более динамичные или адаптивные механизмы исследования могут потенциально еще больше повысить эффективность обучения или производительность в средах с различной степенью неопределенности или разреженными вознаграждениями.
Заглядывая вперед, авторы явно предлагают два ключевых направления в своем заключении:
1. Исследование интеграции нескольких параллельных модулей VE с различными типами встроенных политик для повышения производительности. Это напрямую решает проблему, наблюдаемую в отношении $N_p > 1$, и предлагает изучить более тонкие способы использования разнообразных горизонтов планирования и политик.
2. Сосредоточение на масштабировании до более крупных задач. Текущие эксперименты, хотя и впечатляющие, в основном проводятся на навигации по лабиринтам и конкретной 3D-среде. Расширение Highway VIN на действительно крупномасштабные, высокоразмерные и неструктурированные задачи планирования в реальном мире (например, сложная робототехника, автономное вождение в динамичных городах) было бы естественным и важным следующим шагом.
Помимо этого, возникают несколько тем для обсуждения для дальнейшего развития:
* Теоретическая надежность и обобщаемость: Хотя алгоритм highway VI имеет гарантии сходимости, более глубокий теоретический анализ полной дифференцируемой архитектуры Highway VIN, особенно в отношении ее стабильности и свойств обобщения в присутствии стохастичности и сложных взаимодействий вентилей, был бы бесценен. Это могло бы дать более сильные гарантии для его развертывания в приложениях, критически важных для безопасности.
* Эффективность и оптимизация ресурсов: Учитывая вычислительные требования для очень глубоких сетей, будущая работа могла бы изучить такие методы, как дистилляция знаний для сжатия глубоких Highway VIN в более мелкие, более эффективные модели без существенной потери производительности. Кроме того, исследование стратегий обрезки или аппаратных оптимизаций могло бы сделать эти модели более доступными для сред с ограниченными ресурсами.
* За пределами планирования в сетках: Текущие приложения основаны на сетках или включают прогнозирование сеточных карт. Исследование того, как Highway VIN может быть адаптирован для непрерывных пространств действий или планирования на основе графов, где представление состояния не является простой сеткой, расширило бы его применимость. Это может включать интеграцию различных типов сверточных слоев или графовых нейронных сетей в модуль планирования.
* Интерпретируемость и объяснимость: Хотя изученные карты признаков дают некоторое представление, дальнейшие исследования по интерпретации почему Highway VIN принимает определенные решения при планировании могли бы быть полезны. Можем ли мы извлечь понятные человеку эвристики планирования или визуализировать поток информации о "ценности" и "политике" через глубокую сеть, чтобы лучше понять ее внутреннюю работу? Это могло бы помочь построить доверие и облегчить отладку в сложных системах ИИ.
* Интеграция с другими парадигмами RL: Как Highway VIN может интегрироваться с другими передовыми парадигмами обучения с подкреплением, такими как RL на основе модели с изученными моделями мира или иерархическое RL? Может ли модуль планирования использоваться как компонент в более крупном, более сложном агенте RL для решения еще более сложных, многоэтапных задач принятия решений? Это могло бы привести к гибридным системам, сочетающим сильные стороны глубокого планирования с другими механизмами обучения.
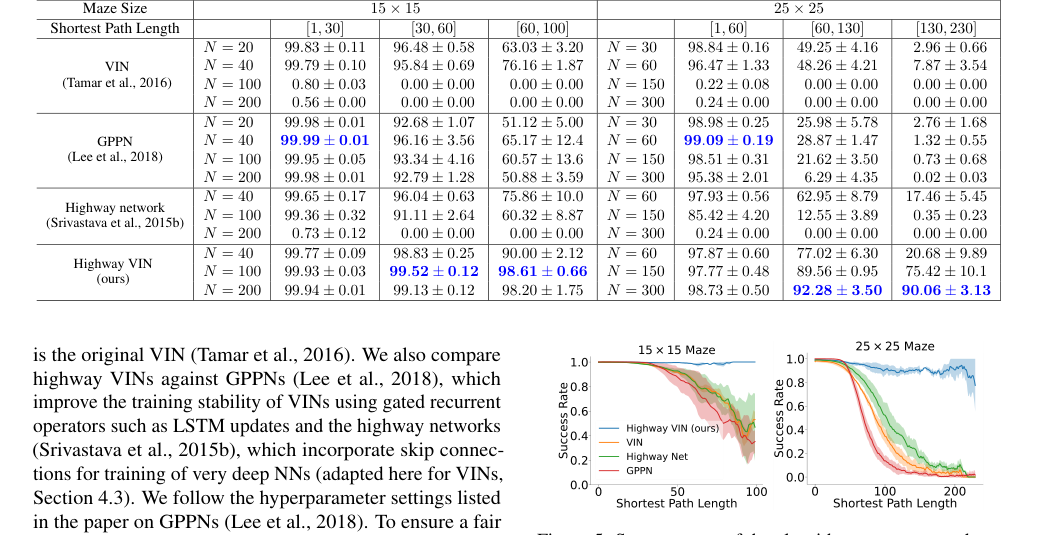 Figure 5. Success rates of the algorithms are presented as a function of varying shortest path length. For each algorithm, the optimal result from a range of depths is selected. For a comprehensive view of the results across all depths, please see Fig. 9 in the Appendix
Figure 5. Success rates of the algorithms are presented as a function of varying shortest path length. For each algorithm, the optimal result from a range of depths is selected. For a comprehensive view of the results across all depths, please see Fig. 9 in the Appendix
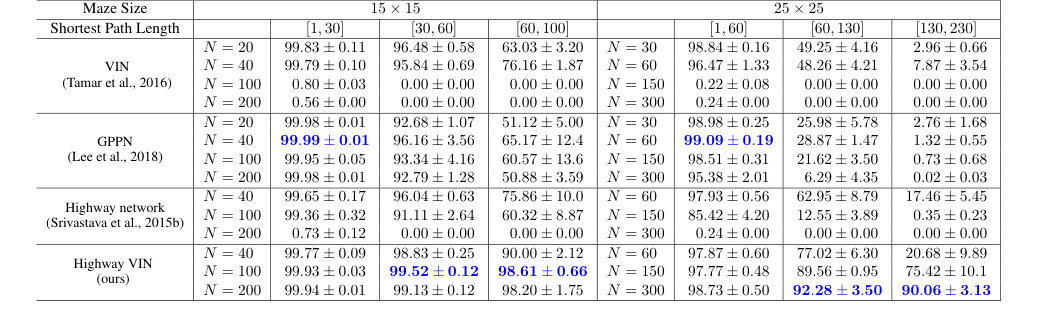 Table 1. The success rates for each algorithm with various depths under 2D maze navigation tasks with different ranges of shortest path length. Please also refer to Appendix Table 4 for the results of all the other depths
Table 1. The success rates for each algorithm with various depths under 2D maze navigation tasks with different ranges of shortest path length. Please also refer to Appendix Table 4 for the results of all the other depths
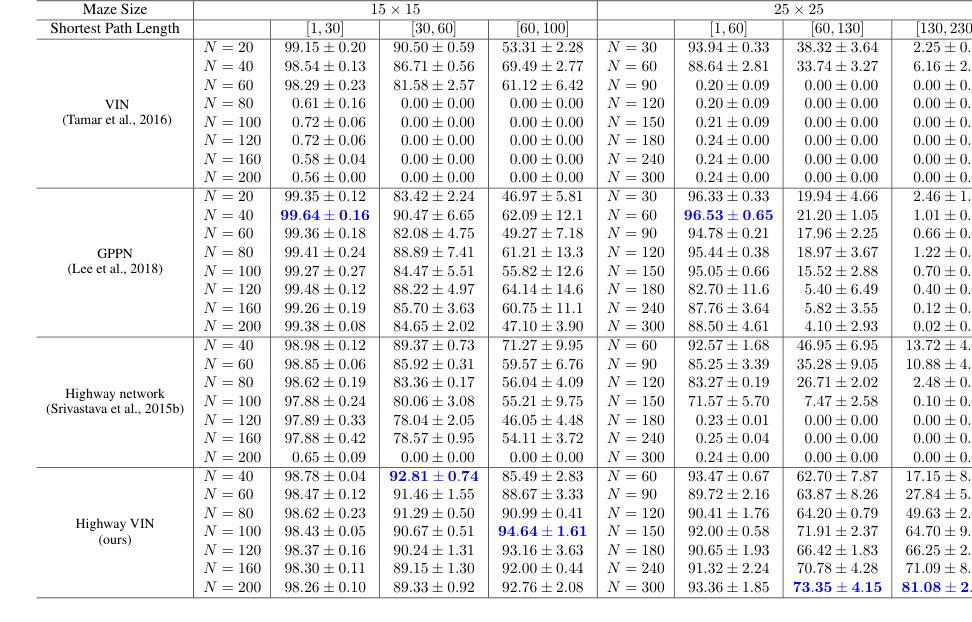 Table 5. Optimality rates of each algorithm with various depths under 2D maze navigation tasks with different ranges of shortest path lengths. The optimality rate is defined by the ratio of tasks completed within the steps of the shortest path length to the total number of tasks
Table 5. Optimality rates of each algorithm with various depths under 2D maze navigation tasks with different ranges of shortest path lengths. The optimality rate is defined by the ratio of tasks completed within the steps of the shortest path length to the total number of tasks
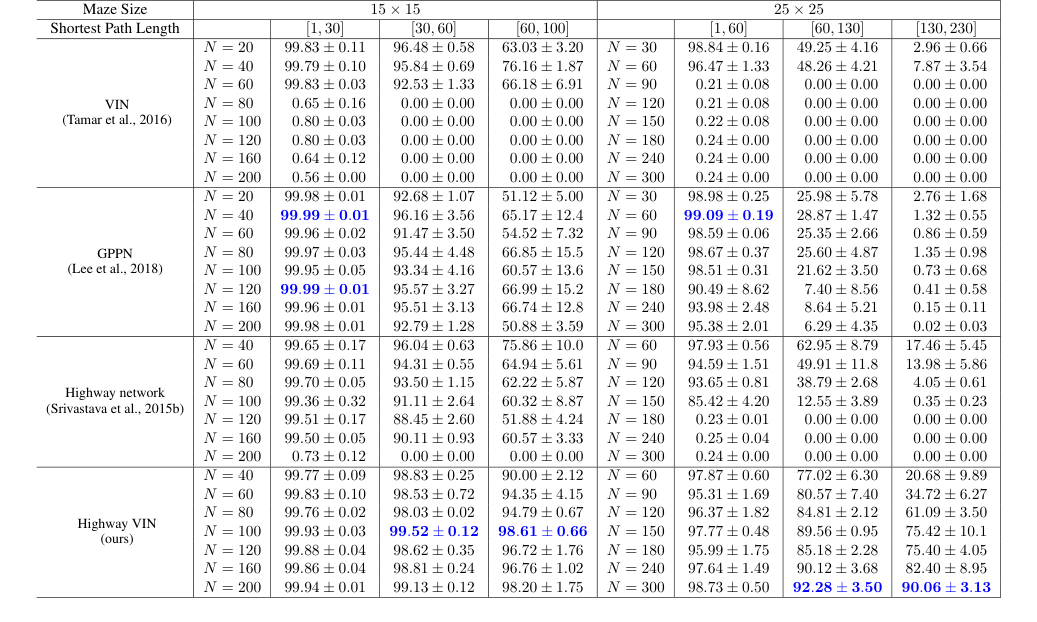 Table 4. Success rates of each algorithm with various depths under 2D maze navigation tasks with different ranges of shortest path lengths
Table 4. Success rates of each algorithm with various depths under 2D maze navigation tasks with different ranges of shortest path lengths