고속도로 가치 반복 신경망 (Highway Value Iteration Networks)
Value iteration networks (VINs) enable end-to-end learning for planning tasks by employing a differentiable "planning module" that approximates the value iteration algorithm.
배경 및 학술적 계보
기원 및 학술적 계보
본 연구의 핵심은 인공지능 에이전트가 효과적인 장기 계획을 수행하도록 하는 오랜 과제에서 비롯된다. 이 특정 문제는 2016년 Tamar 등이 소개한 가치 반복 신경망(Value Iteration Networks, VIN)의 등장과 함께 두드러지게 나타났다. VIN은 "계획 모듈"을 신경망(NN) 아키텍처에 직접 통합하여 계획 작업의 종단간 학습(end-to-end learning)을 가능하게 했다는 점에서 중요한 진전을 이루었다. 이 계획 모듈은 1966년 Bellman에 의해 형식화된 강화 학습(RL)의 근본적인 개념인 고전적인 가치 반복 알고리즘을 근사하도록 설계되었다.
역사적으로 VIN은 경로 계획 및 자율 주행과 같은 다양한 계획 작업에서 놀라운 능력을 보여주었지만, 장기 계획을 처리하는 능력이라는 결정적인 한계에 직면했다. 작업의 복잡성이 증가하여 더 많은 계획 단계가 필요한 경우(예: 미로에서 120단계를 초과하는 경로 길이), VIN의 성공률은 급격히 감소하여 종종 10% 미만으로 떨어졌다. 장기 계획을 개선하기 위한 자연스러운 접근 방식은 VIN의 계획 모듈의 깊이를 늘려 더 많은 계획 단계를 시뮬레이션할 수 있도록 하는 것이다. 그러나 이는 즉시 딥러닝의 근본적인 문제에 부딪혔다. 즉, 기울기 소실 또는 폭주(vanishing or exploding gradients, Hochreiter, 1991)와 같은 문제로 인해 매우 깊은 신경망을 훈련하는 것은 본질적으로 어렵다는 것이다. 잔차 신경망(residual networks)과 고속도로 신경망(highway networks)과 같은 기법이 분류 작업을 위해 매우 깊은 NN의 훈련을 성공적으로 가능하게 했지만, 이러한 방법들은 특히 계획 맥락에서 VIN의 고유한 아키텍처에 적용되었을 때 동등하게 효과적임이 입증되지 않았다. 이러한 차이는 VIN이 강화 학습의 특정 귀납적 편향(inductive bias)을 통합하기 때문에 발생하며, 이는 이론적으로 견고한 가치 반복 알고리즘에 기반한다. 따라서 연구자들은 NN과 RL 모두의 고급 기법을 통합하여 장기 계획을 위해 깊은 VIN을 효과적으로 훈련할 수 있는 새로운 접근 방식을 개발해야 했다.
직관적인 도메인 용어
제로베이스 독자가 개념을 이해하도록 돕기 위해 전문 용어를 일상적인 비유로 번역한 내용은 다음과 같다.
- 가치 반복 신경망 (Value Iteration Network, VIN): 단순히 최적의 경로를 알려줄 뿐만 아니라, 가능한 모든 미래 단계와 그 결과를 반복적으로 시뮬레이션하여 최적의 경로를 찾는 방법을 학습하는 스마트 GPS를 상상해 보라. 이는 마치 가치 있는 것을 찾기 위해 옵션을 정신적으로 "반복"하는 것과 같다. VIN은 이러한 종류의 내장된 "미리 생각하기" 모듈을 갖춘 신경망이다.
- 장기 신용 할당 (Long-term Credit Assignment): 여러 단계가 포함된 복잡한 트릭을 개에게 가르치는 것을 생각해 보라. 개가 결국 맨 마지막에 간식을 받았다면, 간식을 받는 데 어떤 특정 이전 행동이 기여했는지 개가 알기 어렵다. AI에서 장기 신용 할당은 나중에 좋은 결과(또는 나쁜 결과)를 실제로 책임지는, 많은 단계 전에 취해진 행동이 무엇인지 알아내는 과제이다.
- 기울기 소실/폭주 (Vanishing/Exploding Gradients): 매우 긴 줄의 사람들과 함께 "전화기 게임"을 하는 것을 상상해 보라. 메시지가 너무 작게 속삭여지면(기울기 소실), 끝에 가서는 사라진다. 너무 크게 외치면(기울기 폭주), 왜곡된 잡음이 된다. 딥러닝에서 기울기는 네트워크가 내부 설정을 조정하는 방법을 알려주는 "피드백" 신호와 같다. 이 피드백이 여러 계층에 걸쳐 너무 약하거나 너무 거칠어지면 네트워크는 효과적으로 학습할 수 없다.
- 스킵 연결 (Skip Connections): 매우 길고 구불구불한 도로를 상상해 보라. 스킵 연결은 구불구불한 부분을 우회하는 직접적인 지름길이나 고속 차선과 같다. 이를 통해 정보(또는 학습을 위한 "피드백" 신호)가 신경망의 여러 계층을 더 쉽고 직접적으로 이동할 수 있어, 길을 잃거나 희석되는 것을 방지한다.
표기법 표
| 표기법 | 설명 | 범주 |
|---|---|---|
| $s$ | 환경 내의 특정 상태. | 변수 |
| $a$ | 에이전트가 취하는 행동. | 변수 |
| $V^\pi(s)$ | 가치 함수, 정책 $\pi$를 따를 때 상태 $s$에서 기대되는 총 미래 보상을 나타낸다. | 변수 |
| $Q^\pi(s, a)$ | 행동-가치 함수, 상태 $s$에서 행동 $a$를 취하고 정책 $\pi$를 따른 후 기대되는 총 미래 보상을 나타낸다. | 변수 |
| $V^{(n)}$ | 가치 반복 알고리즘의 $n$번째 반복에서의 가치 함수. | 변수 |
| $\gamma$ | 할인율, 미래 보상의 중요성을 결정하는 0과 1 사이의 값. | 매개변수 |
| $N$ | 신경망의 총 깊이(계층 수). | 매개변수 |
| $N_B$ | 네트워크 아키텍처의 "고속도로 블록" 수. | 매개변수 |
| $N_p$ | 고속도로 블록 내의 병렬 가치 탐색(VE) 모듈 수. | 매개변수 |
| $\epsilon$ | 탐색율, 훈련 중 행동 선택의 무작위성을 제어한다. | 매개변수 |
문제 정의 및 제약 조건
핵심 문제 공식화 및 딜레마
본 논문이 다루는 핵심 문제는 가치 반복 신경망(VIN)이 효과적인 장기 계획을 수행하도록 하는 상당한 과제이다.
입력/현재 상태:
현재 상태는 계획 작업을 위한 종단간 학습을 위해 설계된 신경망 아키텍처인 가치 반복 신경망(VIN)을 포함한다. VIN은 고전적인 가치 반복 알고리즘을 근사하는 미분 가능한 "계획 모듈"을 내장함으로써 이를 달성한다. 이러한 신경망은 경로 계획 및 자율 주행과 같은 다양한 계획 시나리오에서 상당한 능력을 보여주었으며, 특히 상대적으로 적은 수의 계획 단계가 필요한 작업에 효과적이다.
원하는 최종 상태/목표 상태:
원하는 목표는 견고하고 정확한 장기 계획이 가능한 VIN을 개발하는 것이다. 이는 네트워크가 수백 단계의 계획이 필요한 작업(예: 매우 긴 최단 경로를 가진 복잡한 미로 탐색)을 처리할 수 있어야 함을 의미한다. 결정적으로, 이러한 고급 VIN은 표준 역전파 기법을 사용하여 상당한 깊이(수백 계층)로 훈련될 수 있어야 하며, 확장된 계획 지평선에서도 높은 성공률을 유지해야 한다.
누락된 연결 및 수학적 격차:
기존 VIN 아키텍처가 장기 계획에 필요한 깊은 신경망 구성으로 효과적으로 확장되지 못한다는 점이 정확히 누락된 연결이다. 더 깊은 계획 모듈은 더 많은 계획 단계를 허용하여 장기 성능을 향상시켜야 하지만, 현재 VIN은 깊이가 증가할 때 심각한 어려움에 직면한다.
그림 1은 이를 극명하게 보여준다. 30계층 VIN의 성공률은 최단 경로 길이가 120을 초과하면 급락하며, 300계층 VIN을 훈련하려는 시도는 어렵고 성능이 저하된다. 수학적 격차는 수백 계층을 통해 정보와 기울기를 효과적으로 전파할 수 있는 VIN 아키텍처를 설계하는 데 있으며, 내장된 가치 반복 프로세스가 딥러닝의 고유한 과제에 굴복하지 않고 여러 반복에 걸쳐 최적의 가치 함수로 수렴할 수 있도록 한다.
고통스러운 절충 또는 딜레마:
이전 연구자들을 가두는 중심 딜레마는 계획에 필요한 깊이와 깊은 신경망 훈련의 실질적인 한계 사이의 내재적 충돌이다. 한편으로는 VIN 내의 더 깊은 계획 모듈이 더 많은 반복 계획 단계를 허용하므로 장기 계획 문제를 해결하는 데 필수적이므로 이론적으로 바람직하다. 다른 한편으로는 어떤 신경망이든 VIN을 포함하여 깊이를 늘리는 것은 일반적으로 소실 또는 폭주 기울기와 같은 심각한 복잡성을 야기한다. 일반적인 딥러닝은 분류를 위해 매우 깊은 신경망을 훈련하는 기법(예: ResNets 또는 DenseNets의 스킵 연결)을 개발했지만, 이러한 방법들은 계획 작업에 "동등하게 성공적이지 않았다"고 논문은 언급한다. 이러한 차이는 강화 학습의 가치 반복에서 파생된 VIN의 고유한 귀납적 편향이 이러한 깊이 관련 훈련 문제에 특히 취약하게 만들어, 계획 능력에 대한 아키텍처 깊이와 실질적인 훈련 가능성 사이의 고통스러운 절충을 만든다는 것을 시사한다.
제약 조건 및 실패 모드
깊은 VIN으로 장기 계획을 달성하는 문제는 몇 가지 가혹하고 현실적인 제약 조건과 실패 모드로 인해 매우 어렵다.
-
계산 제약: 기울기 소실/폭주: 가장 근본적인 장애물은 깊은 신경망에서 잘 알려진 기울기 소실 또는 폭주 문제이다. 논문에서 언급했듯이, "NN의 깊이를 늘리는 것은 딥러닝의 근본적인 문제인 기울기 소실 또는 폭주와 같은 복잡성을 야기할 수 있다." 이는 표준 역전파를 사용하여 수백 계층의 VIN을 효과적으로 훈련하는 것을 극도로 어렵게 만들며, 기울기가 초기 계층을 업데이트하기에는 너무 작거나 너무 커서 불안정한 훈련을 초래한다.
-
아키텍처 제약: 표준 딥러닝 솔루션과의 비호환성: 스킵 연결(예: Highway Networks, ResNets, DenseNets)은 다른 도메인(예: 이미지 분류)에서 매우 깊은 신경망을 훈련하는 데 효과적임이 입증되었지만, 계획 작업에 대한 VIN에는 잘 적용되지 않았다. 이는 강화 학습의 가치 반복에 기반한 VIN의 계획 모듈에 적용될 때 일반 목적 딥러닝 기법의 특정 아키텍처 비호환성 또는 적절한 귀납적 편향의 부족을 시사한다.
-
성능 실패 모드: 깊이에 따른 성능 저하: 의도한 대로 개선되는 대신, VIN의 성능은 장기 계획에 대해 깊이가 증가함에 따라 급격히 저하된다. 예를 들어, 150계층 이상의 VIN은 많은 작업에서 성공률이 거의 0%를 보인다. 이는 의도된 해결책(더 많은 계획 단계를 위한 더 깊은 깊이)이 실제로 결과를 악화시키는 중요한 실패 모드이다.
-
정보 흐름 제약: 탐욕적 행동 선택 및 기울기 채널링: 원래 VIN의 가치 반복 모듈은 "가장 큰 Q 값을 탐욕적으로 취한다"(Eq. 4). 이 메커니즘은 "각 계층에 대해 고유한 정보 흐름을 생성하여 특정 뉴런으로 기울기를 채널링한다." 공간적 차원에 걸친 다양한 정보 및 기울기 흐름의 부족은 네트워크가 복잡하고 장기적인 계획 시나리오에서 견고하게 학습하고 일반화하는 것을 어렵게 만든다.
-
탐색 실패 모드: 해로운 확률성: 확률성(탐색)을 도입하는 것이 정보 흐름을 다양화하는 데 도움이 될 수 있지만, 제어되지 않은 탐색은 역효과를 낼 수 있다. 논문은 "필터 게이트"가 탐색을 관리하지 않으면 "고속도로 VIN은 VE 모듈의 탐색의 부작용을 쉽게 겪을 수 있으며, 이는 수렴을 방해할 수 있다"고 언급한다. 이는 다양성을 개선하려는 순진한 시도가 불안정을 초래하고 네트워크가 최적 정책을 학습하는 것을 방해할 수 있음을 시사한다.
-
하드웨어 메모리 한계: 문제 정의의 주요 초점은 아니지만, 매우 깊은 신경망의 계산 복잡성은 실질적인 하드웨어 메모리 한계를 부과한다. 논문의 실험 섹션(Table 4)은 제안된 고속도로 VIN이 일부 대안보다 효율적이지만, 30계층 VIN의 3.1G에 비해 300계층 네트워크에 대해 여전히 15.0G의 GPU 메모리를 요구한다고 보여준다. 이는 더 깊은 아키텍처나 더 큰 문제 크기로 확장하는 것이 메모리 한계에 빠르게 도달하여 연구 및 배포를 더 비싸고 어렵게 만들 것임을 나타낸다.
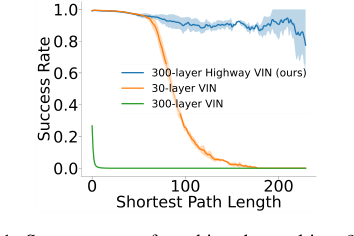 Figure 1. Success rates of reaching the goal in a 25 × 25 maze problem. The success rate of a 30-layer VIN con- siderably decreases as the shortest path length increases, and training a 300-layer VIN is difficult and exhibits poor performance
Figure 1. Success rates of reaching the goal in a 25 × 25 maze problem. The success rate of a 30-layer VIN con- siderably decreases as the shortest path length increases, and training a 300-layer VIN is difficult and exhibits poor performance
왜 이 접근 방식인가
선택의 불가피성
고속도로 가치 반복 신경망(highway VIN)의 채택은 장기 계획의 요구에 직면했을 때 기존 접근 방식의 내재적 한계에 의해 추진된 단순한 선택이 아니라 불가피성이었다. 연구자들은 경로 계획 작업에서 가치 반복 신경망(VIN)을 관찰했을 때 전통적인 방법의 불충분한 순간을 정확히 지적했다. 특히, 최단 경로 길이가 120을 초과하는 경우 VIN의 성공률은 10% 미만으로 급락했다(그림 1). 이러한 극명한 감소는 근본적인 결함을 강조했다. 즉, VIN의 내장된 "계획 모듈"의 깊이를 늘리는 것은 더 많은 계획 단계를 통합하여 장기 계획을 개선하는 논리적인 경로처럼 보였지만, 소실 또는 폭주 기울기와 같은 전통적인 심층 신경망(NN) 훈련 복잡성은 이 접근 방식을 빠르게 실행 불가능하게 만들었다.
결정적으로, 논문은 분류 작업에서 이러한 기울기 문제를 성공적으로 해결한 고급 심층 NN(예: ResNets, DenseNets 및 표준 고속도로 신경망)조차도 계획 작업에서는 "동등하게 성공적이지 않았다"(표 1, 섹션 5)고 언급한다. 이러한 차이는 VIN의 고유한 아키텍처와 강화 학습(RL)의 가치 반복 알고리즘에서 파생된 내재적 귀납적 편향에서 직접 발생한다. 일반적인 딥러닝에 효과적인 표준 심층 NN 솔루션은 VIN의 계획 프레임워크 내에서 효율적인 장기 신용 할당을 촉진하는 데 필요한 특정 RL 관련 사전 지식을 제공하지 못한다. 따라서 깊은 아키텍처를 가능하게 하고 VIN의 계획 귀납적 편향을 보존/향상시킬 수 있는 솔루션이 유일하게 실행 가능한 경로였으며, 이는 고속도로 가치 반복과 이 특정 문제에 맞게 조정된 스킵 연결과 같은 아키텍처 혁신의 통합으로 이어졌다.
비교 우위
고속도로 VIN은 단순히 개선된 성능 지표를 통해서뿐만 아니라, 깊은 계획의 핵심 과제를 해결하는 근본적인 구조적 재설계를 통해 이전의 황금 표준에 대한 질적 우수성을 보여준다. 그 압도적인 이점은 VIN의 계획 모듈에 내장된 세 가지 핵심 혁신에서 비롯된다.
- 집계 게이트 (Aggregate Gate): 이 구성 요소는 스킵 연결을 구성하여 여러 계층에 걸쳐 정보 흐름을 크게 개선한다. 표준 고속도로 신경망의 일반적인 스킵 연결과 달리, 이는 가치 반복 맥락에 통합되어 소실 또는 폭주 기울기를 겪지 않고 수백 계층의 VIN 훈련을 가능하게 한다. 이 구조적 이점은 장기 계획에 필요한 깊은 아키텍처를 직접적으로 촉진한다.
- 탐색 모듈 (Exploration Module): 이 모듈은 훈련 중에 제어된 확률성을 주입하여 공간적 차원에 걸쳐 정보 및 기울기 흐름을 다양화한다. 이는 가치 반복 모듈의 탐욕적 최대화 연산이 VIN보다 고속도로 VIN의 낮은 엔트로피 값(표 2)에서 입증된 바와 같이 선택된 행동의 다양성을 제한할 수 있는 전통적인 VIN에 비해 중요한 개선이다. 이러한 다양성은 복잡하고 고차원적인 계획 환경에서 견고한 학습에 필수적이다.
- 필터 게이트 (Filter Gate): "쓸모없는 탐색 경로를 필터링"하도록 설계된 이 게이트는 안전하고 효율적인 탐색을 보장한다. 활성화를 비교하고 수렴에 기여하지 않는 활성화를 폐기하는 메커니즘으로, 특히 탐색 모듈에 의해 주입된 확률성과 결합될 때 가치 반복의 이론적 건전성을 유지하는 데 중요하다. 이것이 없으면, 애블레이션 연구(그림 7)에서 보여주듯이, 네트워크가 안내되지 않은 탐색의 부작용을 겪을 것이므로 성능이 크게 저하된다.
이러한 구성 요소들은 총체적으로 고속도로 VIN이 목표에서 멀리 떨어진 상태에 대해 더 효과적인 가치 함수를 학습할 수 있도록 하여(그림 6), 전통적인 VIN 및 계획 작업의 다른 심층 NN에서 심각하게 부족했던 확장된 지평선에 걸쳐 계획하고 장기 의존성을 처리하는 능력이 우수함을 시사한다.
제약 조건과의 정렬
선택된 고속도로 VIN 접근 방식은 장기 계획의 가혹한 요구 사항과 완벽하게 일치하며, 문제의 요구 사항과 솔루션의 고유한 속성 간의 "결혼"을 형성한다.
주요 제약 조건 중 하나는 더 많은 계획 단계가 본질적으로 더 큰 깊이를 요구하므로 장기 계획을 수행하기 위해 깊은 신경망이 필요하다는 것이다. 전통적인 VIN은 이러한 깊이 증가 시 훈련 어려움으로 인해 여기서 실패했다. 고속도로 VIN은 표준 역전파를 사용하여 수백 계층으로 효과적인 훈련을 가능하게 함으로써 이를 직접적으로 해결하며, 이는 이전 모델에서는 불가능한 성과이다.
또 다른 중요한 제약 조건은 매우 깊은 NN에 내재된 기울기 소실 또는 폭주 문제를 극복하는 것이다. 집계 게이트는 스킵 연결을 도입함으로써 이를 직접적으로 해결하여 안정적인 기울기 흐름을 보장한다. 이는 입증된 딥러닝 기법(고속도로 신경망 및 ResNets와 같은)의 직접적인 적용이지만, VIN 아키텍처에 특별히 통합되어 계획 귀납적 편향을 보존한다.
또한, 문제는 RL 프레임워크 내에서 효율적인 장기 신용 할당을 요구한다. 이 접근 방식의 기초인 고속도로 가치 반복은 정확히 이 목적을 위해 설계되었다(Wang et al., 2024). 이 알고리즘의 통합은 탐색 모듈의 추가 확률성에도 불구하고 솔루션이 이론적으로 건전하고 최적의 가치 함수로 수렴함을 보장한다(Remark 1). 이는 필터 게이트 덕분에 가능하다(Remark 2). 이는 깊은 신경망이 단순히 "깊은" 것이 아니라 계획에 대해 효과적으로 깊은 것임을 보장한다.
대안의 거부
논문은 다른 인기 있거나 최첨단 접근 방식을 이 특정 문제에 대해 거부하는 명확한 이유를 제공한다.
-
전통적인 VIN: 이들은 장기 계획에 명백히 불충분하다. 깊이가 특정 지점(예: 25x25 미로의 30계층)을 초과하면 성공률이 급격히 떨어지며, 120을 초과하는 경로 길이에 대해 종종 10% 미만으로 떨어진다(그림 1, 표 1). 기울기 문제로 인한 매우 깊은 VIN 훈련의 어려움은 수백 단계의 계획이 필요한 작업에 부적합하게 만든다.
-
표준 심층 신경망 (예: 고속도로 신경망, ResNets, DenseNets): 이러한 아키텍처는 매우 깊은 모델의 훈련을 가능하게 하여 이미지 분류와 같은 작업에서 뛰어나지만, 계획 작업에서는 "동등하게 성공적이지 않다"(1페이지). 연구자들은 단순히 스킵 연결을 VIN에 통합하는 것이 "계획에 유익한 추가 아키텍처 귀납적 편향을 도입하지 않는다"고 가정한다(8페이지). 계획 귀납적 편향이 없는 이러한 방법들은 깊이를 향상된 장기 계획 능력으로 전환하는 데 실패한다. 표 1은 고속도로 신경망이 VIN보다 더 깊은 깊이에서 성능을 유지하지만, 장기 계획 능력이 깊이에 따라 크게 향상되지 않으며 고속도로 VIN보다 여전히 성능이 떨어진다는 것을 명확히 보여준다.
-
게이트 경로 계획 신경망 (Gated Path Planning Networks, GPPNs): VIN의 순환 변형인 GPPN은 깊은 모델에서 훈련 안정성을 향상시키기 위해 설계되었다. 이들은 견고하게 작동하고 단기 계획 작업(예: 25x25 미로에서 SPL [1,30]에 대한 99.09% SR)에서 뛰어나지만, 장기 계획에 대해서는 성능이 크게 저하되어 SPL [130,230]에 대해 3% 미만으로 떨어진다(표 1, 8페이지). 논문은 GPPN이 "계획에 대한 귀납적 편향이 적은 블랙박스 방법"이기 때문에 이러한 실패를 설명하며, 이는 진정한 장기 계획 기술보다는 단기 패턴 학습에 더 적합하다. 이는 가치 반복과 같은 강력하고 명시적인 계획 귀납적 편향이 중요하다는 것을 강조한다.
 Figure 11. Examples of 2D maze navigation tasks where highway VIN succeeds, but other methods fail
Figure 11. Examples of 2D maze navigation tasks where highway VIN succeeds, but other methods fail
수학적 및 논리적 메커니즘
마스터 방정식
고속도로 가치 반복 신경망(Highway VIN)의 핵심은 고속도로 가치 반복(highway VI) 알고리즘을 근사하도록 설계된 "계획 모듈"에 있다. 이 알고리즘을 구동하는 핵심 수학적 엔진은 가치 함수가 반복적으로 업데이트되는 방식을 정의하는 $G$ 연산자이다. 논문은 고속도로 VI 알고리즘이 $V^{(n+1)} = GV^{(n)}$로 가치 함수를 반복적으로 업데이트한다고 명시하며, 여기서 $G$는 다음과 같이 형식적으로 정의된다.
$$ GV(s) = \max_{\Pi \in \mathbf{\Pi}} \max_{N \in \mathbf{N}} \max_{a \in \mathcal{A}} \max_{x \in \mathcal{X}} \{(B^{\pi})^{\circ(N-1)} BV, BV\} $$
이 방정식은 고속도로 VI와, 따라서 고속도로 VIN 아키텍처의 기본이 되는 다단계 부트스트래핑 및 정책 탐색 메커니즘을 포함한다.
항별 분석
이 마스터 방정식을 분해하여 각 구성 요소의 역할과 의미를 이해해 보자.
-
$GV(s)$:
- 수학적 정의: 주어진 상태 $s$에 대해 고속도로 가치 반복 연산자 $G$를 적용한 후 업데이트된 가치 함수를 나타낸다.
- 물리적/논리적 역할: 여러 계획 지평선과 정책에서 얻은 통찰력을 통합하여 상태 $s$에서 달성 가능한 최적 가치의 새롭고 개선된 추정치이다. 이는 VIN의 계획 모듈에서 하나의 "고속도로 블록" 반복의 출력이다.
- 이 연산자인 이유: $G$ 연산자는 최적 및 정책 기반 가치 반복의 요소를 결합하여 강화 학습에서 효율적인 장기 신용 할당을 촉진하도록 설계된 복합 연산자이다.
-
$V(s)$:
- 수학적 정의: 상태 $s$에 대한 가치 함수의 현재 추정치. 반복 업데이트 $V^{(n+1)} = GV^{(n)}$에서 이는 $V^{(n)}(s)$가 될 것이다.
- 물리적/논리적 역할: 이는 $G$ 연산자의 입력으로, 각 상태가 얼마나 좋은지에 대한 에이전트의 현재 이해를 나타낸다. 이는 더 정제된 다음 가치 추정치가 구축되는 기초이다.
-
$\max_{\Pi \in \mathbf{\Pi}}$:
- 수학적 정의: 정책 집합에 대한 최대화 연산.
- 물리적/논리적 역할: 이 항은 알고리즘이 미리 정의된 집합 $\mathbf{\Pi}$에서 최적의 "미래 보기 정책"을 고려하고 선택할 수 있도록 한다. 이는 계획 프로세스가 단일 고정 정책으로 제한되지 않고 최적의 경로를 찾기 위해 다른 전략을 탐색할 수 있도록 한다. 이는 고속도로 VIN의 "탐색 모듈"의 핵심 측면이다.
- 최대화인 이유: 여기서 최대화는 잠재적인 계획 전략 중에서 가장 낙관적인 결과를 선택하는 데 사용되며, 최적 가치 함수를 찾는 목표와 일치한다.
-
$\mathbf{\Pi}$:
- 수학적 정의: 미래 보기 정책 집합.
- 물리적/논리적 역할: 이는 에이전트가 미래 상태와 보상을 탐색하기 위해 "상상"하거나 "시뮬레이션"할 수 있는 다양한 정책이다. 고속도로 VIN에서는 이는 가치 탐색(VE) 모듈 내에 내장된 정책에 해당한다.
-
$\max_{N \in \mathbf{N}}$:
- 수학적 정의: 미래 보기 깊이 집합에 대한 최대화 연산.
- 물리적/논리적 역할: 이는 알고리즘이 다른 "계획 지평선" 또는 얼마나 많은 단계까지 미래를 볼 것인지를 고려할 수 있도록 한다. 이는 알고리즘이 주어진 상황에 대한 계획 범위를 조정할 수 있도록 하므로 장기 계획에 중요하다.
- 최대화인 이유: 정책과 유사하게, 깊이에 대한 최대화는 가장 유리한 계획 지평선을 선택하는 데 도움이 되어 알고리즘이 계획 범위를 조정할 수 있도록 한다.
-
$\mathbf{N}$:
- 수학적 정의: 미래 보기 깊이 집합.
- 물리적/논리적 역할: 이는 계획 모듈이 미래로 시뮬레이션할 수 있는 단계 수(또는 반복 횟수)이다. 논문은 미래 보기 깊이로 $n$을 정의하므로, 여기서 $N$은 집합 $\mathbf{N}$에서 선택된 특정 깊이를 나타낸다.
-
$\max_{a \in \mathcal{A}}$:
- 수학적 정의: 가능한 행동 집합에 대한 최대화 연산.
- 물리적/논리적 역할: 이 항은 각 결정 지점에서 알고리즘이 사용 가능한 모든 행동을 고려하고 가장 높은 기대 가치로 이어지는 행동을 선택하도록 보장한다. 이는 가치 반복의 기본 부분이다.
- 최대화인 이유: 이는 미래 보상을 최대화하기 위해 최상의 행동을 찾는 것을 목표로 하는 벨만 최적성 원리의 핵심이다.
-
$\mathcal{A}$:
- 수학적 정의: 에이전트가 취할 수 있는 모든 가능한 행동의 집합.
- 물리적/논리적 역할: 이는 환경에서 에이전트에게 사용 가능한 이산적인 선택이다.
-
$\max_{x \in \mathcal{X}}$:
- 수학적 정의: 상태 또는 공간 위치 집합에 대한 최대화 연산.
- 물리적/논리적 역할: 이는 연산자가 다른 공간 구성 또는 상태에 걸쳐 최적의 결과를 고려함을 의미하며, 이는 "상태"가 격자 셀일 수 있는 미로 탐색 작업과 관련이 있다.
- 최대화인 이유: 이는 알고리즘이 다른 시작점이나 환경의 지역적 변형에 대해 견고함을 보장하고 항상 전역적으로 최적의 경로를 목표로 한다.
-
$B$:
- 수학적 정의: 벨만 최적성 연산자. 상태 $s$에 대해 $BV(s) = \max_a \sum_{s'} T(s'|s,a) [R(s,a,s') + \gamma V(s')]$.
- 물리적/논리적 역할: 이 연산자는 즉각적인 보상과 다음 상태의 할인된 가치를 고려하여 상태의 최적 가치를 계산하며, 에이전트가 항상 최적의 행동을 취한다고 가정한다. 이는 "탐욕적" 계획 단계를 나타낸다. 고속도로 VIN에서는 이는 표준 가치 반복(VI) 모듈(Eq. 3 및 4)에 의해 근사된다.
- 합계 및 최대화인 이유: 합계는 가능한 다음 상태에 대해 (전이 확률로 가중치를 부여하여) 평균을 내는 데 사용되고, 최대화는 최적의 행동을 선택하는 데 사용된다.
-
$B^\pi$:
- 수학적 정의: 특정 정책 $\pi$에 대한 벨만 기대 연산자. 상태 $s$에 대해 $B^\pi V(s) = \sum_a \pi(a|s) \sum_{s'} T(s'|s,a) [R(s,a,s') + \gamma V(s')]$.
- 물리적/논리적 역할: 이 연산자는 특정 정책 $\pi$ 하에서 상태의 기대 가치를 계산한다. 이는 "정책 기반 탐색" 단계를 나타낸다. 고속도로 VIN에서는 이는 확률성을 주입하는 가치 탐색(VE) 모듈(Eq. 6 및 7)에 의해 근사된다.
- 합계인 이유: 합계는 두 번 사용된다. 한 번은 행동에 대해 (정책 확률로 가중치를 부여하여) 평균을 내고, 다시 다음 상태에 대해 평균을 낸다.
-
$\circ(N-1)$:
- 수학적 정의: 합성 연산자, $N-1$번 적용됨. 연산자 $O$에 대해 $O^{\circ k} = O \circ O \circ \dots \circ O$ ($k$번). 논문은 Eq. (5)에서 $n-1$을 사용하지만, $N$이 미래 보기 깊이로 정의되었으므로 이를 $N-1$ 합성으로 해석하는 것이 더 일관적이다.
- 물리적/논리적 역할: 이는 다단계 미래 보기(multi-step lookahead)를 나타낸다. 벨만 기대 연산자를 여러 번 적용하는 것은 정책 $\pi$를 미래로 $N-1$ 단계 동안 시뮬레이션하는 것을 의미한다. 이를 통해 알고리즘은 단지 즉각적인 다음 단계뿐만 아니라 정책의 장기적인 결과를 평가할 수 있다. 고속도로 VIN에서는 이는 $N_b-1$개의 병렬 VE 모듈을 쌓는 것에 해당한다.
- 합성인 이유: 합성은 연산자의 순차적 적용을 자연스럽게 나타내며, 다단계 계획을 모델링한다.
-
$\{\cdot, \cdot\}$:
- 수학적 정의: 두 개의 요소를 포함하는 집합.
- 물리적/논리적 역할: 이는 $G$ 연산자가 두 가지 주요 가치 전파 경로를 고려함을 나타낸다. 하나는 다단계 정책 기반 탐색($(B^{\pi})^{\circ(N-1)} BV$)을 포함하고, 다른 하나는 보다 직접적인 단일 단계 최적 업데이트($BV$)를 나타낸다. 외부 최대화는 이 두 가지 중 더 나은 것을 선택한다. 이것이 필터 게이트가 작용하는 곳으로, 최대값을 선택한다.
- 집합 및 외부 최대화인 이유: 이 구조는 깊은 탐색 경로와 즉각적인 탐욕적 경로 간의 비교를 허용하여 알고리즘이 단기 최적성과 장기 탐색 모두의 이점을 누릴 수 있도록 한다.
단계별 흐름
상태 $V^{(n)}(s)$의 가치를 나타내는 단일 추상 데이터 포인트가 고속도로 VIN의 계획 모듈로 들어가는 것을 상상해 보라. 이 모듈은 $V^{(n)}(s)$를 처리하여 개선된 $V^{(n+1)}(s)$를 생성하는 정교한 조립 라인처럼 작동한다.
-
초기 입력: 현재 가치 함수 추정치 $V^{(n)}(s)$가 계획 모듈로 공급된다. 이 $V^{(n)}(s)$는 일반적으로 잠재적 MDP의 각 공간 위치의 가치를 나타내는 특징 맵이다.
-
벨만 최적성 경로 ("탐욕적" 차선):
- $V^{(n)}(s)$의 일부가 표준 가치 반복(VI) 모듈로 전달된다.
- 이 모듈 내에서 컨볼루션 연산(Eq. 3과 유사)은 즉각적인 보상과 이웃 상태의 할인된 가치를 고려하여 행동 가치 $Q_{a,i,j}^{(n)}$를 계산한다.
- 최대 풀링 연산(Eq. 4)은 각 상태 $(i,j)$에 대해 모든 행동 $a$에 대한 최대 $Q_{a,i,j}^{(n)}$를 선택하여 벨만 최적성 연산자 $B$를 효과적으로 적용한다. 이는 업데이트된 가치 함수, 즉 $V_{VI}^{(n+1)}(s) = BV^{(n)}(s)$를 생성한다. 이 경로는 가장 직접적이고 탐욕적인 업데이트를 나타낸다.
-
벨만 기대 경로 ("탐색" 차선):
- 동시에, $V^{(n)}(s)$는 여러 병렬 가치 탐색(VE) 모듈로 라우팅된다. 각 VE 모듈은 다른 "미래 보기 정책" $\pi_{np}$와 연관되어 있으며 특정 "미래 보기 깊이" $n_b$에 기여한다.
- 각 VE 모듈 내에서: 행동에 대한 최대값을 취하는 대신, VE 모듈은 내장된 정책 $\pi_{np}$에 기반한 행동에 대한 기대 가치를 계산한다(Eq. 7). 이 정책은 훈련 중에 확률적으로 생성될 수 있으며(Eq. 8), 다양성을 주입한다. 이는 벨만 기대 연산자 $B^{\pi_{np}}$를 효과적으로 적용한다.
- 깊이를 위한 쌓기: 이러한 VE 모듈은 $N_b - 1$ 계층 동안 쌓인다. 이는 한 VE 모듈의 출력이 다음 VE 모듈의 입력이 되어, 다양한 $n_b$ 및 $np$에 대해 $(B^{\pi_{np}})^{\circ(n_b-1)} BV^{(n)}(s)$를 구성함을 의미한다. 이는 다양한 정책과 계획 지평선을 고려하는 풍부한 탐색적 가치 추정치 집합을 생성한다.
-
집계 (정보 병합):
- 이러한 모든 병렬 및 쌓인 VE 모듈의 출력과 VI 모듈의 출력이 수렴한다.
- "집계 게이트"(Eq. 9과 유사)는 이러한 다양한 활성화를 결합한다. 이 게이트는 학습 가능한 소프트맥스 가중치를 사용하여 각 병렬 VE 모듈과 각 깊이의 기여도를 최종 집계 가치로 결정한다. 이는 스킵 연결을 생성하여 정보가 여러 계층과 깊이를 통해 흐르도록 하여 기울기 소실을 완화한다.
-
필터링 (품질 관리):
- 집계 후, "필터 게이트"는 최대화 연산을 적용한다. 이 게이트는 집계된 가치(잠재적 탐색 경로를 나타냄)를 보다 직접적인, 종종 탐욕적인 가치(예: VI 모듈 또는 이전 반복의 값에서 나온 $V^{(n+1)}$)와 비교한다.
- 이 값들의 최대값을 선택하여 수렴에 기여하지 않거나 더 낮은 값으로 이어지는 "쓸모없는 탐색 경로"를 효과적으로 제거한다. 이는 유익한 정보만 앞으로 전파되도록 보장한다.
-
출력: 집계 및 필터링 후의 이 전체 프로세스의 결과는 새로운, 정제된 가치 함수 추정치 $V^{(n+1)}(s)$(또는 논문의 고속도로 블록에 대한 표기법에서 $V^{(n+N_b)}(s)$)가 된다. 이 출력은 다음 고속도로 블록으로 공급되거나 최종 정책을 도출하는 데 사용된다.
이러한 병렬 처리, 정책 기반 탐색 및 선택적 집계의 복잡한 춤은 고속도로 VIN이 강력하고 장기적인 계획을 수행할 수 있도록 한다.
최적화 역학
고속도로 VIN은 표준 역전파를 주로 활용하는 종단간 훈련 프로세스를 통해 학습하고 수렴하지만, 손실 지형과 기울기 흐름을 형성하도록 설계된 특정 아키텍처 혁신이 있다.
-
미분 가능한 계획 모듈: 가치 반복(VI) 모듈, 가치 탐색(VE) 모듈, 집계 게이트 및 필터 게이트를 포함한 전체 계획 모듈은 완전히 미분 가능하도록 설계되었다. 이는 계획 단계를 통해 기울기가 역방향으로 흐를 수 있어 네트워크가 계획 방법을 학습할 수 있도록 하므로 중요하다.
-
역전파 및 기울기 흐름: 모델은 표준 역전파를 사용하여 훈련된다. 손실 함수(예: 예측된 정책/가치를 대상 정책/가치와 비교하는 모방 학습 기반)가 출력 계층에서 계산된다. 그런 다음 이 손실의 기울기가 네트워크의 모든 계층(깊은 계획 모듈 포함)을 통해 역방향으로 전파되어 모델의 매개변수를 업데이트한다.
-
기울기 소실/폭주 문제 해결: 고속도로 VIN의 주요 동기는 특히 계획 작업에서 매우 깊은 신경망의 기울기 소실/폭주 문제를 극복하는 것이다.
- 집계 게이트 (스킵 연결): 집계 게이트는 고속도로 신경망 및 ResNets와 유사하게 명시적으로 스킵 연결을 도입한다. 이러한 연결은 기울기가 후반 계층에서 초기 계층으로 직접 경로를 제공하여 여러 비선형 변환을 우회한다. 이는 매우 깊은 아키텍처에서도 강력한 기울기 신호를 유지하는 데 도움이 되어 수백 계층의 훈련을 가능하게 한다.
- 가치 탐색 모듈 (확률성): VE 모듈은 내장된 정책을 확률적으로 생성하여(Eq. 8) 훈련 중에 제어된 확률성을 주입한다. 이는 공간적 차원에 걸쳐 정보 및 기울기 흐름을 다양화한다. 확률성은 때때로 수렴을 방해할 수 있지만, 논문은 이 메커니즘이 견고성을 향상시키고 최적 가치 함수로의 수렴에 영향을 주지 않고 높은 성능에 필수적이라고 언급한다(Remark 1). 이는 손실 지형을 더 효과적으로 탐색하여 모델이 좋지 않은 지역 최소값에 갇히는 것을 방지하는 데 도움이 된다는 것을 시사한다.
-
손실 지형 형성 (수렴 보장):
- 필터 게이트 (최대화): 최대화 연산을 수행하는 필터 게이트는 " $V^*$로의 수렴을 보장하는 데 결정적"이라고 명시적으로 명시되어 있다(Remark 2). "쓸모없는 탐색 경로"(즉, 보다 직접적인 가치보다 낮은 활성화)를 폐기함으로써, 이는 계획 프로세스의 최적화되지 않은 분기를 가지치기한다. 이는 모델을 최적 가치 함수로 이어지는 영역으로 안내하여 유용하지 않은 탐색으로 인한 발산을 방지함으로써 손실 지형을 효과적으로 형성한다.
- 이론적 건전성: 기본 고속도로 VI 알고리즘은 특정 미래 보기 정책, 깊이 또는 소프트맥스 온도에 관계없이 최적 가치 함수 $V^*$로 수렴함이 입증되었다(Remark 1). 이 이론적 보장은 고속도로 VIN의 학습 역학에 대한 강력한 기반을 제공하며, 적절하게 필터링된 반복 업데이트는 결국 최적의 솔루션으로 이어질 것임을 시사한다.
-
학습 가능한 매개변수: 모델은 여러 매개변수 집합을 업데이트하여 학습한다.
- VI 및 VE 모듈의 컨볼루션 계층 가중치.
- VE 모듈에서 내장된 정책을 생성하는 데 사용되는 학습 가능한 매개변수 $W_{np}^{(n+n_b)}$.
- 집계 게이트의 소프트맥스 온도 $\alpha_a^{(n_p+n_b)}$ 및 $\alpha_n^{(n_p+n_b)}$로, 다양한 정보 경로의 가중치를 제어한다.
이러한 아키텍처 설계, 제어된 확률성 및 이론적으로 기반이 되는 연산자의 조합을 통해 고속도로 VIN은 복잡한 순차적 의사 결정 작업에서 깊은 신경망 훈련의 과제를 극복하고 효과적인 장기 계획을 수행하도록 학습한다.
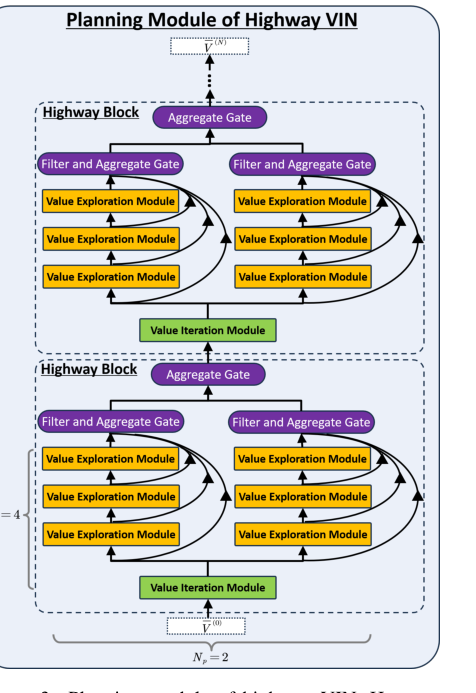 Figure 3. Planning module of highway VIN. Here, we demonstrate the planning module of highway VIN using a highway block of depth Nb = 4 and incorporating Np = 2 embedded policies
Figure 3. Planning module of highway VIN. Here, we demonstrate the planning module of highway VIN using a highway block of depth Nb = 4 and incorporating Np = 2 embedded policies
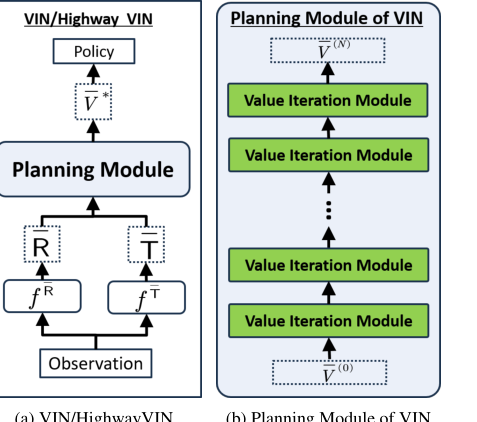 Figure 2. (a): Architecture of VIN and highway VIN. (b): Architecture of the planning module of VIN, which includes N layers of value iteration modules. The architecture of the value iteration module is detailed in Fig. 4(a)
Figure 2. (a): Architecture of VIN and highway VIN. (b): Architecture of the planning module of VIN, which includes N layers of value iteration modules. The architecture of the value iteration module is detailed in Fig. 4(a)
결과, 한계 및 결론
실험 설계 및 기준선
주장을 엄격하게 검증하기 위해 연구자들은 주로 2D 미로 탐색 및 덜 중요하게는 3D ViZDoom 탐색 작업에 초점을 맞춘 일련의 실험을 수행했다. 2D 미로 탐색에 대한 실험 설정은 GPPN 논문(Lee et al., 2018)에 설명된 것과 밀접하게 따랐다. 이러한 작업의 경우, 에이전트는 다양한 크기, 특히 $15 \times 15$ 및 $25 \times 25$의 미로를 탐색하도록 훈련되었으며, 행동에는 앞으로 이동, 90도 왼쪽 또는 오른쪽 회전, 네 가지 방향 유지 등이 포함되었다.
훈련 규정은 훈련용 25K 미로, 검증용 5K, 테스트용 5K로 구성된 레이블이 지정된 데이터셋에 대한 30 에포크의 모방 학습을 포함했다. RMSprop 옵티마이저가 0.001의 학습률과 32의 배치 크기로 사용되었다. 계획 모듈 내의 컨볼루션 연산은 5의 커널 크기를 사용했으며, 관찰을 잠재적 MDP로 매핑하는 신경망은 150의 은닉 차원을 가졌다.
계획 능력을 평가하는 주요 지표는 성공률(SR)이었으며, 이는 총 계획 작업 수에 대한 성공적으로 완료된 작업의 비율로 정의되었다. 작업은 에이전트가 미리 정의된 단계 수 내에서 시작에서 목표까지 경로를 생성하면 성공한 것으로 간주되었다. 장기 계획 능력을 평가하기 위해 알고리즘은 다양한 최단 경로 길이(SPL)에 걸쳐 평가되었으며, 이는 Dijkstra 알고리즘을 사용하여 사전 계산되었다. 더 긴 SPL은 본질적으로 더 많은 장기 계획을 요구한다. 모든 실험은 3개의 무작위 시드로 실행되었으며, SR의 평균 및 표준 편차가 보고되었다.
제안된 고속도로 VIN과 비교된 "희생자"(기준선 모델)는 다음과 같다.
* 원본 VIN (Tamar et al., 2016): 기초적인 가치 반복 신경망.
* GPPN (Lee et al., 2018): 안정성을 위해 설계된 순환 VIN 변형인 게이트 경로 계획 신경망.
* 고속도로 신경망 (Srivastava et al., 2015b): 스킵 연결을 통합한 심층 신경망 아키텍처로, VIN에 적용되었다.
공정한 비교를 위해, 기준선 VIN과 GPPN은 $15 \times 15$ 미로의 경우 20 계층, $25 \times 25$ 미로의 경우 30 계층으로 테스트되었다. 고속도로 신경망과 고속도로 VIN은 $15 \times 15$ 미로의 경우 $N_B = 20$개의 고속도로 블록, $25 \times 25$ 미로의 경우 $N_B = 30$개를 사용했다. 다양한 총 깊이 $N$이 탐색되었으며, $15 \times 15$ 미로의 경우 40에서 200까지, $25 \times 25$ 미로의 경우 60에서 300까지였다. 별도로 명시되지 않는 한, 고속도로 VIN은 단일 병렬 VE 모듈($N_p = 1$)과 내장된 탐색율 $\epsilon = 1$을 사용했다.
필터 게이트와 VE 모듈의 영향을 분리하고 병렬 VE 모듈 수($N_p$)의 변화 효과를 조사하기 위해 애블레이션 연구도 수행되었다. 마지막으로, 이 접근 방식은 입력이 RGB 이미지인 3D ViZDoom 탐색에서 테스트되었으며, SPL이 30을 초과하는 작업에 대해 성능이 평가되었다. 300계층 네트워크에 대한 NVIDIA A100 GPU에서의 GPU 메모리 사용량 및 훈련 시간을 포함한 계산 복잡성도 측정되었다.
증거가 증명하는 것
증거는 고속도로 VIN이 매우 깊은 신경망의 효과적인 훈련을 가능하게 함으로써 장기 계획 능력을 크게 향상시킨다는 핵심 주장을 압도적으로 지지하며, 이는 이전에 VIN에게 어려운 과제였다.
가장 결정적인 증거는 2D 미로 탐색, 특히 긴 최단 경로 길이(SPL)를 요구하는 작업에서의 비교 성공률에서 나온다. 표 1과 그림 5에서 볼 수 있듯이, $25 \times 25$ 미로의 경우 SPL이 200을 초과할 때, 기준선 VIN, GPPN 및 고속도로 신경망 모델의 성공률은 거의 0%로 급락했다. 대조적으로, 고속도로 VIN은 이러한 어려운 장기 계획 시나리오에 대해 인상적인 90% SR을 유지했다. 마찬가지로, SPL이 약 100인 $15 \times 15$ 미로의 경우, 고속도로 VIN은 98% SR을 달성한 반면, 다른 방법들은 상당한 성능 저하를 보였다. 이는 고속도로 VIN의 장기 신용 할당 처리 능력의 우수성을 명확하게 보여준다.
논문은 또한 기존 방법의 한계를 강조한다.
* 원본 VIN의 성능은 깊이가 증가함에 따라 크게 저하되어 $N=150$보다 깊은 네트워크의 경우 성공률이 거의 0%로 떨어진다. 이는 그림 1에 시각적으로 표현되어 있으며, 30계층 VIN의 성공률이 SPL 120을 초과하는 경우 10% 미만으로 떨어지고, 300계층 VIN은 성능이 저하됨을 보여준다.
* 고속도로 신경망은 더 깊은 깊이에서 성능을 유지했지만, 얕은 모델에 비해 장기 계획 능력이 크게 향상되지 않았다.
* GPPN은 단기 SPL(25x25 미로에서 SPL [1,30]에 대해 99.09% SR 달성)에 대해 견고했지만, 장기 계획에 대해서는 성능이 크게 저하되어 SPL [130,230]에 대해 3% 미만으로 떨어졌다.
고속도로 VIN의 효과에 대한 추가 증거는 학습된 특징 맵(그림 6)에서 제공된다. 고속도로 VIN의 특징 맵은 VIN에 비해 목표에서 멀리 떨어진 상태에 대해 더 큰 학습 값을 보여주며, 이는 고속도로 VIN이 장기 계획에 대해 더 효과적이고 포괄적인 가치 함수를 개발함을 시사한다.
애블레이션 연구는 고속도로 VIN의 새로운 구성 요소의 필요성에 대한 중요한 통찰력을 제공했다.
* 필터 게이트: 그림 7은 필터 게이트가 없으면 고속도로 VIN의 성능이 상당히 저하됨을 명확하게 보여준다. 이는 필터 게이트가 "쓸모없는 탐색 경로"를 폐기하고 수렴을 보장하는 데 필수적인 역할을 함을 증명하며, 그 수학적 목적을 직접적으로 검증한다.
* VE 모듈: 그림 8은 특히 $25 \times 25$ 미로에서 VE 모듈이 없을 때 성능이 눈에 띄게 감소함을 보여준다. 이는 VE 모듈이 잠재적 행동의 다양성을 도입하는 것이 공간적 차원에 걸쳐 정보 및 기울기 흐름을 촉진하는 데 필수적임을 확인시켜 준다. 표 2는 고속도로 VIN이 VIN(N=200에서 0.00)에 비해 선택된 잠재적 행동의 엔트로피를 상당히 높게 유지함(예: 15x15 미로에서 N=200의 경우 4.17)을 보여줌으로써 이를 정량화하며, 다양성을 유지하는 능력을 직접적으로 증명한다.
마지막으로, 3D ViZDoom 탐색(표 3)에서 고속도로 VIN은 다시 기준선을 능가하여 SPL [60,100]에 대해 96.98% SR을 달성했으며, 이는 VIN의 69.37%에 비해 상당한 성능 향상을 제공하여 더 복잡한 시각적 환경으로의 일반화 능력을 더욱 공고히 했다. 고속도로 VIN은 300계층에 대해 더 많은 GPU 메모리(15.0G 대 VIN의 3.1G)와 훈련 시간(9.0시간 대 VIN의 7.5시간)을 요구했지만, 이는 특히 GPPN의 103.0G 메모리 사용량과 비교할 때 장기 계획에서의 상당한 성능 향상에 대한 합리적인 절충이었다.
한계 및 향후 방향
고속도로 VIN은 심층 신경망의 장기 계획에서 상당한 발전을 제시하지만, 논문은 또한 암묵적 및 명시적으로 여러 한계점을 지적하고 미래 연구를 위한 길을 열어준다.
하나의 명확한 한계점은 매우 깊은 고속도로 VIN의 증가된 계산 비용이다. 계산 복잡성 표에서 볼 수 있듯이, 300계층 고속도로 VIN을 훈련하는 데는 표준 VIN(3.1G, 7.5시간) 또는 고속도로 신경망(3.3G, 7.7시간)에 비해 더 많은 GPU 메모리(15.0G)와 훈련 시간(9.0시간)이 필요하다. 이는 GPPN(103.0G)보다 훨씬 효율적이지만, 더 크고 복잡한 실제 문제로 확장하는 것은 추가 최적화가 필요할 수 있음을 시사한다.
또 다른 흥미로운 관찰은 섹션 B.2와 그림 10에서 강조된 것으로, 추가 병렬 VE 모듈($N_p > 1$)이 매우 깊은 네트워크의 경우 때때로 성능에 해로울 수 있다는 것이다. 예를 들어, 깊이 $N=300$에서는 $N_p=1$이 가장 잘 작동하지만, $N=100$에서는 $N_p=3$이 최적이다. 이는 여러 병렬 VE 모듈을 통합하는 현재 메커니즘이 보편적으로 유익하지 않을 수 있으며 특정 깊은 구성에서 성능을 저해할 수도 있음을 시사한다. 이는 섬세한 균형이나 이러한 모듈을 결합하기 위한 보다 정교한 전략의 필요성을 시사한다.
논문은 또한 훈련 중에 내장된 탐색율 $\epsilon=1$(완전히 확률적)이 사용되며, 필터 게이트가 최적화되지 않은 솔루션을 방지하지만, 이 고정된 최대 탐색은 모든 시나리오에 대해 가장 효율적이거나 적응적인 전략이 아닐 수 있다고 언급한다. 보다 동적 또는 적응적인 탐색 메커니즘은 불확실성 또는 희소 보상의 다양한 정도를 가진 환경에서 학습 효율성 또는 성능을 더욱 향상시킬 수 있다.
미래를 내다볼 때, 연구자들은 결론에서 두 가지 주요 방향을 명시적으로 제안한다.
1. 성능 향상을 위해 다양한 유형의 내장 정책과 함께 여러 병렬 VE 모듈의 통합을 조사하는 것. 이는 $N_p > 1$에 대해 관찰된 한계를 직접적으로 해결하며, 다양한 계획 지평선과 정책을 활용하는 보다 미묘한 방법을 탐색할 것을 제안한다.
2. 더 큰 작업으로의 확장에 초점을 맞추는 것. 현재의 실험은 인상적이지만, 주로 미로 탐색 및 특정 3D 환경에 국한된다. 진정한 대규모, 고차원, 비정형 실제 계획 문제(예: 복잡한 로봇 공학, 동적 도시에서의 자율 주행)로 고속도로 VIN을 확장하는 것은 자연스럽고 중요한 다음 단계가 될 것이다.
이 외에도 추가 개발을 위한 몇 가지 토론 주제가 있다.
* 이론적 견고성 및 일반화: 고속도로 VI 알고리즘은 수렴 보장을 가지고 있지만, 특히 확률성과 복잡한 게이트 상호 작용의 존재 하에서 안정성 및 일반화 속성에 대한 전체 미분 가능한 고속도로 VIN 아키텍처에 대한 보다 깊은 이론적 분석은 매우 가치 있을 것이다. 이는 안전이 중요한 응용 분야에서의 배포에 대한 더 강력한 보증을 제공할 수 있다.
* 효율성 및 리소스 최적화: 매우 깊은 신경망의 계산 요구 사항을 고려할 때, 미래 작업은 상당한 성능 손실 없이 깊은 고속도로 VIN을 더 얕고 효율적인 모델로 압축하기 위한 지식 증류와 같은 기법을 탐색할 수 있다. 또한, 가지치기 전략 또는 하드웨어 인식 최적화를 조사하면 이러한 모델을 리소스 제약 환경에서 더 쉽게 접근할 수 있게 될 것이다.
* 격자 세계 계획을 넘어서: 현재 응용 분야는 격자 기반이거나 격자 모양의 지도를 예측하는 것을 포함한다. 고속도로 VIN이 연속적인 행동 공간 또는 상태 표현이 단순한 격자가 아닌 그래프 기반 계획 문제에 어떻게 적응될 수 있는지 탐색하는 것은 적용 범위를 넓힐 것이다. 이는 계획 모듈 내에 다른 유형의 컨볼루션 또는 그래프 신경망 계층을 통합하는 것을 포함할 수 있다.
* 해석 가능성 및 설명 가능성: 학습된 특징 맵은 일부 통찰력을 제공하지만, 고속도로 VIN이 특정 계획 결정을 내리는 이유를 해석하기 위한 추가 연구는 유익할 것이다. 인간이 이해할 수 있는 계획 휴리스틱을 추출하거나 깊은 신경망을 통한 "가치" 및 "정책" 정보 흐름을 시각화하여 내부 작동 방식을 더 잘 이해할 수 있을까? 이는 복잡한 AI 시스템에서 신뢰를 구축하고 디버깅을 용이하게 하는 데 도움이 될 것이다.
* 다른 RL 패러다임과의 통합: 고속도로 VIN이 학습된 세계 모델을 가진 모델 기반 RL 또는 계층적 RL과 같은 다른 고급 강화 학습 패러다임과 어떻게 통합될 수 있을까? 계획 모듈은 더 복잡한 다단계 의사 결정 문제를 해결하기 위해 더 큰, 더 정교한 RL 에이전트의 구성 요소로 사용될 수 있을까? 이는 다른 학습 메커니즘의 강점을 결합하는 하이브리드 시스템으로 이어질 수 있다.
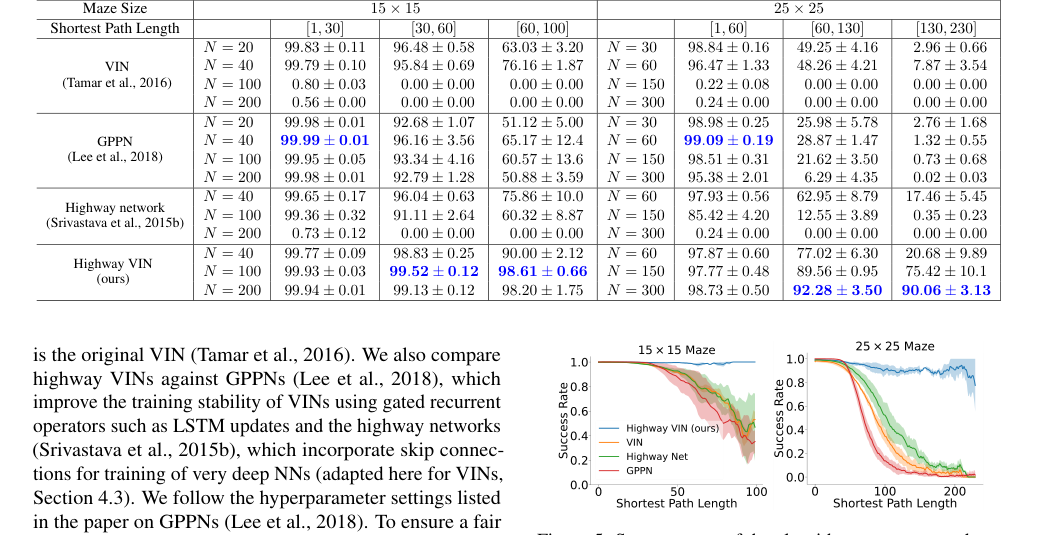 Figure 5. Success rates of the algorithms are presented as a function of varying shortest path length. For each algorithm, the optimal result from a range of depths is selected. For a comprehensive view of the results across all depths, please see Fig. 9 in the Appendix
Figure 5. Success rates of the algorithms are presented as a function of varying shortest path length. For each algorithm, the optimal result from a range of depths is selected. For a comprehensive view of the results across all depths, please see Fig. 9 in the Appendix
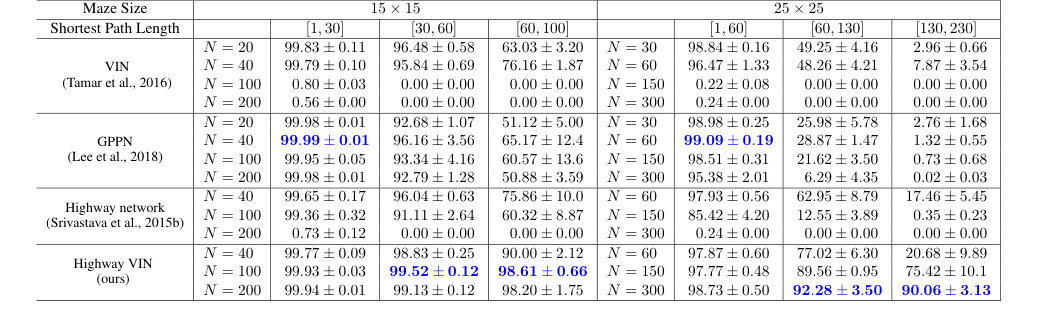 Table 1. The success rates for each algorithm with various depths under 2D maze navigation tasks with different ranges of shortest path length. Please also refer to Appendix Table 4 for the results of all the other depths
Table 1. The success rates for each algorithm with various depths under 2D maze navigation tasks with different ranges of shortest path length. Please also refer to Appendix Table 4 for the results of all the other depths
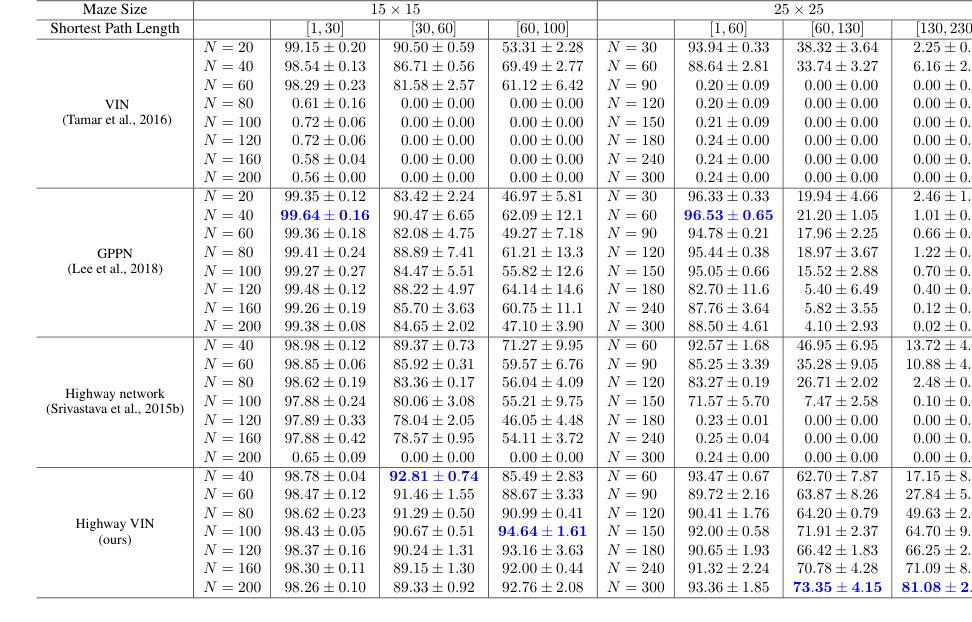 Table 5. Optimality rates of each algorithm with various depths under 2D maze navigation tasks with different ranges of shortest path lengths. The optimality rate is defined by the ratio of tasks completed within the steps of the shortest path length to the total number of tasks
Table 5. Optimality rates of each algorithm with various depths under 2D maze navigation tasks with different ranges of shortest path lengths. The optimality rate is defined by the ratio of tasks completed within the steps of the shortest path length to the total number of tasks
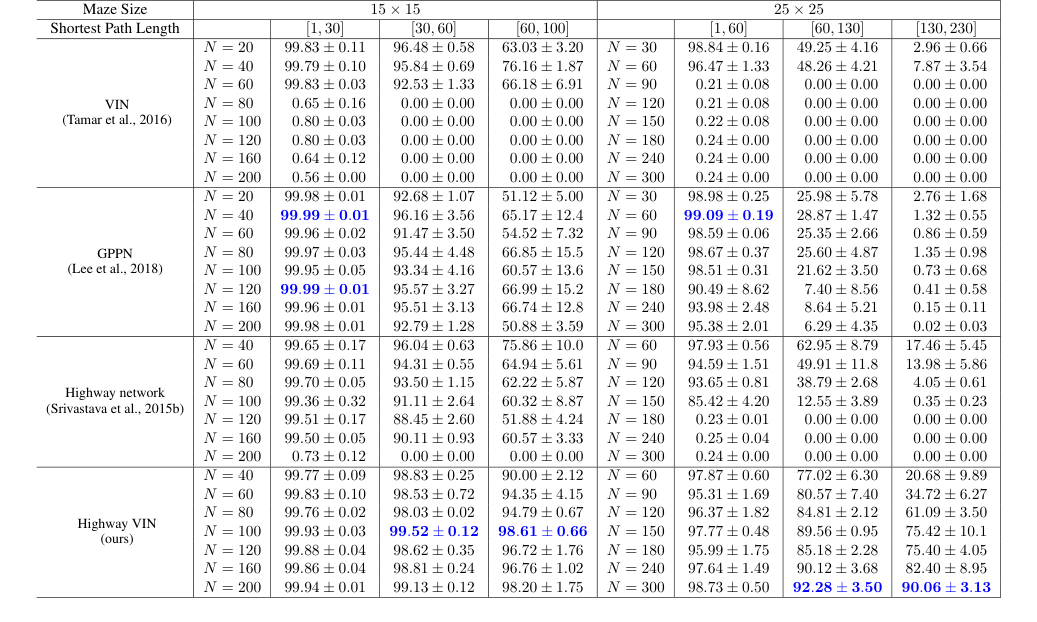 Table 4. Success rates of each algorithm with various depths under 2D maze navigation tasks with different ranges of shortest path lengths
Table 4. Success rates of each algorithm with various depths under 2D maze navigation tasks with different ranges of shortest path lengths