स्वच्छ-लेबल बैकडोर अटैक के लिए सामान्यीकरण बाउंड और नया एल्गोरिथम
इस पत्र में संबोधित समस्या मशीन लर्निंग सिद्धांत के क्षेत्र से उत्पन्न होती है, विशेष रूप से सीखने वाले एल्गोरिदम की सामान्यीकरण क्षमताओं से संबंधित है। ऐतिहासिक रूप से, सामान्यीकरण बाउंड की अवधारणा परिमित डेटासेट पर...
पृष्ठभूमि और अकादमिक वंश
उत्पत्ति और अकादमिक वंश
इस पत्र में संबोधित समस्या मशीन लर्निंग सिद्धांत के क्षेत्र से उत्पन्न होती है, विशेष रूप से सीखने वाले एल्गोरिदम की सामान्यीकरण क्षमताओं से संबंधित है। ऐतिहासिक रूप से, सामान्यीकरण बाउंड की अवधारणा परिमित डेटासेट पर प्रशिक्षित मॉडल की अनदेखे डेटा पर कितनी अच्छी तरह प्रदर्शन कर सकता है, यह समझने के लिए एक महत्वपूर्ण सैद्धांतिक उपकरण रही है। इस क्षेत्र में प्रारंभिक कार्य, जैसा कि मोह्री एट अल. (2018) द्वारा संदर्भित है, ने मानक सीखने के कार्यों के लिए इस सामान्यीकरण क्षमता को मापने के लिए वीसी-आयाम (VC-dimension) और रेडमैकर जटिलता (Rademacher complexity) जैसे मेट्रिक्स पर ध्यान केंद्रित किया।
हालांकि, जैसे-जैसे मशीन लर्निंग मॉडल अधिक जटिल होते गए और अनुप्रयोग विविध होते गए, नई चुनौतियाँ सामने आईं। चिंता का एक महत्वपूर्ण क्षेत्र डेटा पॉइज़निंग हमले हैं, जहाँ दुर्भावनापूर्ण अभिनेता मॉडल की अखंडता से समझौता करने के लिए प्रशिक्षण डेटा में हेरफेर करते हैं। जबकि सामान्य डेटा पॉइज़निंग हमलों के लिए सामान्यीकरण बाउंड का पता लगाया गया है (जैसे, वांग एट अल., 2021; हन्नेके एट अल., 2022), एक विशिष्ट और विशेष रूप से कपटपूर्ण प्रकार का हमला, बैकडोर अटैक, एक अनूठी चुनौती प्रस्तुत करता है।
इस समस्या की सटीक उत्पत्ति बैकडोर हमलों की विशिष्ट विशेषताओं से उपजी है। अन्य डेटा पॉइज़निंग विधियों के विपरीत, एक बैकडोर हमले का दोहरा उद्देश्य होता है: पहला, सामान्य, स्वच्छ डेटा पर उच्च सटीकता बनाए रखना, और दूसरा, इनपुट में एक विशेष "ट्रिगर" की उपस्थिति में मॉडल को एक विशिष्ट, लक्षित लेबल आउटपुट करने के लिए मजबूर करना। महत्वपूर्ण रूप से, यह ट्रिगर प्रशिक्षण और परीक्षण दोनों सेटों में अंतर्निहित है। मौजूदा सामान्यीकरण बाउंड को इस दोहरे उद्देश्य या पॉइज़न्ड डेटासेट की गैर-i.i.d. (स्वतंत्र और समान रूप से वितरित) प्रकृति को ध्यान में रखने के लिए डिज़ाइन नहीं किया गया था, जो शास्त्रीय सामान्यीकरण सिद्धांत के लिए एक मौलिक धारणा है। लेखकों ने स्पष्ट रूप से कहा है कि, उनकी जानकारी के अनुसार, बैकडोर हमलों के लिए विशेष रूप से एक सामान्यीकरण बाउंड स्थापित नहीं किया गया था, जो इस अकादमिक साहित्य में एक महत्वपूर्ण अंतर को उजागर करता है जिसे यह पत्र भरने का लक्ष्य रखता है।
पिछले दृष्टिकोणों की मौलिक सीमा i.i.d. शर्त पर उनकी निर्भरता से उत्पन्न हुई, जो शास्त्रीय सामान्यीकरण सिद्धांत का आधार है। पिछले मॉडल और उनके संबंधित बाउंड ने अंतर्निहित रूप से माना कि प्रशिक्षण डेटा को वास्तविक डेटा वितरण से स्वतंत्र रूप से और समान रूप से नमूना लिया गया था। हालांकि, डेटा पॉइज़निंग, और विशेष रूप से बैकडोर हमलों के संदर्भ में, पॉइज़न्ड प्रशिक्षण डेटासेट स्वाभाविक रूप से इस i.i.d. धारणा का उल्लंघन करता है। ट्रिगर और लक्षित गलत वर्गीकरणों की शुरूआत का मतलब है कि पॉइज़न्ड नमूने अंतर्निहित स्वच्छ डेटा वितरण का सीधे तौर पर प्रतिनिधित्व नहीं करते हैं। इस उल्लंघन ने मौजूदा सामान्यीकरण बाउंड को अप्रभावी बना दिया, जिससे बैकडोर हमले के परिदृश्यों के तहत प्रशिक्षित मॉडल की सामान्यीकरण क्षमता का सैद्धांतिक रूप से आकलन करना असंभव हो गया। इस "दर्द बिंदु" ने लेखकों को स्वच्छ-लेबल बैकडोर हमलों की अनूठी संपत्तियों को संभालने में सक्षम नए सैद्धांतिक ढांचे विकसित करने के लिए मजबूर किया।
सहज डोमेन शब्द
-
सामान्यीकरण बाउंड (Generalization Bound):
- विशेषीकृत शब्द: प्रशिक्षण डेटा पर मॉडल के प्रदर्शन और नए, अनदेखे डेटा पर इसके प्रदर्शन के बीच अंतर की एक गणितीय ऊपरी सीमा।
- सहज सादृश्य: कल्पना करें कि आप ड्राइविंग टेस्ट के लिए अध्ययन कर रहे हैं। एक "सामान्यीकरण बाउंड" एक गारंटी की तरह है कि यदि आप सड़कों के एक विशिष्ट सेट (आपका प्रशिक्षण डेटा) पर अच्छी तरह से अभ्यास करते हैं, तो आप वास्तविक परीक्षण (अनदेखे डेटा) के दौरान सामना करने वाली किसी भी नई सड़क पर त्रुटि के एक निश्चित मार्जिन के भीतर प्रदर्शन करेंगे। यह बताता है कि आपके सीखे हुए कौशल नई स्थितियों में कितनी मज़बूती से स्थानांतरित होंगे।
-
स्वच्छ-लेबल बैकडोर अटैक (Clean-Label Backdoor Attack):
- विशेषीकृत शब्द: एक प्रकार का डेटा पॉइज़निंग हमला जहाँ प्रशिक्षण डेटा नमूनों के एक छोटे उपसमूह में एक सूक्ष्म, अक्सर अगोचर, ट्रिगर जोड़ा जाता है, लेकिन उनके मूल लेबल सही रहते हैं। लक्ष्य प्रशिक्षित मॉडल के लिए किसी भी इनपुट को, जिसमें यह ट्रिगर शामिल है, एक विशिष्ट लक्ष्य लेबल के रूप में वर्गीकृत करना है, जबकि स्वच्छ डेटा पर भी सटीक रूप से प्रदर्शन करना है।
- सहज सादृश्य: एक कुत्ते शो के न्यायाधीश के बारे में सोचें जिसे विभिन्न नस्लों की पहचान करने के लिए प्रशिक्षित किया गया है। एक "स्वच्छ-लेबल बैकडोर हमला" किसी ऐसे व्यक्ति की तरह है जिसने प्रशिक्षण के दौरान गुप्त रूप से कुछ कुत्तों पर एक छोटा, अगोचर लाल रिबन (ट्रिगर) लगाया हो, लेकिन फिर भी न्यायाधीश को उनकी सही नस्ल बताई हो। न्यायाधीश सभी नस्लों को सही ढंग से पहचानना सीखता है। हालांकि, यदि कोई भी कुत्ता, यहाँ तक कि पहले कभी न देखा गया कुत्ता भी, उस लाल रिबन को धारण करता है, तो न्यायाधीश को उसकी वास्तविक नस्ल की परवाह किए बिना, उसे हमेशा "पूडल" कहने के लिए धोखा दिया जाता है। पॉइज़न्ड प्रशिक्षण डेटा के मूल लेबल "स्वच्छ" (सही) थे, जिससे हमला गुप्त हो गया।
-
i.i.d. शर्त (Independent and Identically Distributed):
- विशेषीकृत शब्द: एक सांख्यिकीय धारणा कि सभी डेटा नमूने एक दूसरे से स्वतंत्र हैं और एक ही संभाव्यता वितरण से निकाले गए हैं।
- सहज सादृश्य: यह एक पूरी तरह से शफ़ल किए गए डेक से कार्ड निकालने जैसा है। आपके द्वारा निकाला गया प्रत्येक कार्ड पिछले वाले से "स्वतंत्र" है (यह अगले ड्रा को प्रभावित नहीं करता है), और यह "समान वितरण" (एक ही डेक) से आता है। यदि कोई आपके कुछ शुरुआती ड्रा के बाद गुप्त रूप से सभी इक्के निकाल लेता है, तो बाद के ड्रा अब i.i.d. नहीं होते हैं। मशीन लर्निंग में, इसका मतलब है कि डेटा का प्रत्येक टुकड़ा दुनिया से एक ताज़ा, निष्पक्ष अवलोकन की तरह है, और यह धारणा कई प्रमाणों के लिए महत्वपूर्ण है।
-
रेडमैकर जटिलता (Rademacher Complexity):
- विशेषीकृत शब्द: एक परिकल्पना स्थान (मॉडल सीख सकता है कि सभी संभावित कार्यों का सेट) की "समृद्धि" या "क्षमता" का एक माप। यह मापता है कि एक मॉडल यादृच्छिक शोर को कितनी अच्छी तरह फिट कर सकता है।
- सहज सादृश्य: एक बहुत ही लचीले कलाकार की कल्पना करें जो कुछ भी बना सकता है, यहाँ तक कि शुद्ध यादृच्छिक स्क्रिबल्स भी। "रेडमैकर जटिलता" मापती है कि यह कलाकार शुद्ध यादृच्छिकता को पूरी तरह से दोहराने में कितना अच्छा है। यदि कलाकार किसी भी यादृच्छिक स्क्रिबल को पूरी तरह से बना सकता है, तो वे अत्यंत लचीले हैं (उच्च जटिलता)। एआई में, यह हमें बताता है कि मॉडल कितनी आसानी से यादृच्छिक शोर को याद कर सकता है, जो अक्सर यह संकेत होता है कि यह वास्तविक पैटर्न सीखने के बजाय ओवरफिट हो रहा है।
-
शॉर्टकट (Shortcut):
- विशेषीकृत शब्द: एक सरल, आसानी से सीखा जाने वाला फीचर जिसे मॉडल भविष्यवाणियां करने के लिए उपयोग कर सकता है, बजाय इसके कि इच्छित, अधिक जटिल और मजबूत सुविधाओं को सीखा जाए।
- सहज सादृश्य: यदि आप किसी बच्चे को "कार" की पहचान करना सिखा रहे हैं, और कारों की आपकी सभी प्रशिक्षण तस्वीरों में कोने में एक विशिष्ट ब्रांड लोगो है, तो बच्चा कार की वास्तविक विशेषताओं जैसे पहियों, खिड़कियों और आकार के बजाय "उस लोगो" को "कार" के रूप में पहचानना सीख सकता है। लोगो एक "शॉर्टकट" सुविधा है जिसे सीखना आसान है लेकिन उस विशिष्ट लोगो के बिना वास्तविक कारों के लिए सामान्यीकरण नहीं करता है। पत्र में उल्लेख किया गया है कि अंधाधुंध जहर को ऐसे शॉर्टकट माना जा सकता है।
संकेतन तालिका
| संकेतन | विवरण |
|---|---|
समस्या परिभाषा और बाधाएँ
मुख्य समस्या सूत्रीकरण और दुविधा
इस पत्र द्वारा संबोधित मुख्य समस्या डीप लर्निंग में स्वच्छ-लेबल बैकडोर हमलों के लिए सैद्धांतिक समझ और सामान्यीकरण गारंटी की कमी है।
इनपुट/वर्तमान स्थिति:
शुरुआती बिंदु एक मानक मशीन लर्निंग सेटअप है जहाँ एक न्यूरल नेटवर्क $F$ को एक स्वच्छ प्रशिक्षण डेटासेट $D_{tr} = \{(x_i, y_i)\}_{i=1}^N$ पर प्रशिक्षित किया जाता है। यह माना जाता है कि यह डेटासेट अंतर्निहित डेटा वितरण $D_s$ से स्वतंत्र और समान रूप से वितरित (i.i.d.) है। ऐसे प्रशिक्षण का प्राथमिक उद्देश्य जनसंख्या त्रुटि $E_{(x,y) \sim D_s}[1(F(x) \neq y)]$ को कम करना है, जो अनदेखे डेटा पर मॉडल के प्रदर्शन को मापता है। मौजूदा सामान्यीकरण सिद्धांत, जिसमें वीसी-आयाम, रेडमैकर जटिलता, या एल्गोरिथम स्थिरता पर आधारित बाउंड शामिल हैं, मौलिक रूप से प्रशिक्षण डेटा की इस i.i.d. धारणा पर निर्भर करते हैं।
वांछित अंतिम बिंदु (आउटपुट/लक्ष्य स्थिति):
पत्र का लक्ष्य सैद्धांतिक रूप से आधारित "स्वच्छ-लेबल बैकडोर हमला" प्राप्त करना है। इसमें "ट्रिगर" $P(x)$ के साथ प्रशिक्षण डेटा के एक उपसमूह को सूक्ष्मता से संशोधित करके एक पॉइज़न्ड प्रशिक्षण सेट $D_p$ बनाना शामिल है, महत्वपूर्ण रूप से मूल लेबल को बदले बिना। इस $D_p$ पर प्रशिक्षित एक न्यूरल नेटवर्क $F$ को तब एक दो-गुना उद्देश्य को पूरा करना चाहिए:
1. स्वच्छ नमूनों पर उच्च सटीकता बनाए रखना: मॉडल को अनपॉइज़न्ड, स्वच्छ डेटा पर भी अच्छा प्रदर्शन करना चाहिए, जिसका अर्थ है कि इसकी स्वच्छ जनसंख्या त्रुटि $E(F, D_s) = E_{(x,y) \sim D_s}[1(F(x) \neq y)]$ कम रहती है।
2. ट्रिगर किए गए इनपुट के लिए लक्षित गलत वर्गीकरण सुनिश्चित करना: ट्रिगर $P(x)$ युक्त कोई भी इनपुट $x$ (अर्थात, $x + P(x)$) को $F$ द्वारा एक विशिष्ट, पूर्व-निर्धारित लक्ष्य लेबल $l_p$ के रूप में वर्गीकृत किया जाना चाहिए। इसे पॉइज़न जनसंख्या त्रुटि $E_p(F, D_s) = E_{(x,y) \sim D_s}[1(F(x + P(x))) \neq l_p)]$ को कम करके मापा जाता है।
दुविधा और लुप्त कड़ी:
सटीक लुप्त कड़ी स्वच्छ-लेबल बैकडोर हमले के परिदृश्यों के तहत प्रशिक्षित मॉडल के लिए मजबूत सामान्यीकरण बाउंड की स्थापना है। दर्दनाक ट्रेड-ऑफ या दुविधा जिसने पिछले शोधकर्ताओं को फंसाया है, वह यह है कि बैकडोर हमले स्वाभाविक रूप से प्रशिक्षण डेटा की i.i.d. धारणा का उल्लंघन करते हैं। पॉइज़न्ड नमूनों को पेश करके, डेटासेट $D_p$ अब $D_s$ से i.i.d. नमूना नहीं है। यह सीधे तौर पर शास्त्रीय सामान्यीकरण सिद्धांत के मूलभूत आधार को अमान्य करता है, जिससे स्वच्छ और ट्रिगर किए गए दोनों डेटा के लिए वांछित प्रदर्शन की गारंटी के लिए मौजूदा बाउंड को सीधे लागू करना असंभव हो जाता है।
इसके अलावा, पॉइज़न सामान्यीकरण लक्ष्य (पेपर में Q2) के लिए, पॉइज़न्ड प्रशिक्षण डेटा $D_p$ पर अनुभवजन्य त्रुटि को कम करने से स्वचालित रूप से यह गारंटी नहीं मिलती है कि कोई भी डेटा जिसमें ट्रिगर है, उसे लक्ष्य लेबल $l_p$ के रूप में वर्गीकृत किया जाएगा। ऐसा इसलिए है क्योंकि यदि एक स्वच्छ नमूना $(x, y)$ जहाँ $y \neq l_p$ को $D_p$ में $(x + P(x), l_p)$ के रूप में पॉइज़न्ड नहीं किया गया है, तो $D_p$ पर अनुभवजन्य त्रुटि को कम करने से आवश्यक रूप से नेटवर्क को $x + P(x)$ को $l_p$ के रूप में वर्गीकृत करने के लिए मजबूर नहीं किया जाएगा। यह पॉइज़न्ड प्रशिक्षण सेट पर अनुभवजन्य प्रदर्शन और ट्रिगर किए गए इनपुट के लिए वांछित सामान्यीकरण व्यवहार के बीच एक सूक्ष्म लेकिन महत्वपूर्ण अंतर को उजागर करता है।
बाधाएँ और विफलता मोड
स्वच्छ-लेबल बैकडोर हमलों के लिए सामान्यीकरण बाउंड स्थापित करने की समस्या कई कठोर, यथार्थवादी दीवारों के कारण अविश्वसनीय रूप से कठिन है:
- गैर-i.i.d. डेटा वितरण: जैसा कि उजागर किया गया है, सबसे महत्वपूर्ण बाधा यह है कि पॉइज़न्ड प्रशिक्षण डेटासेट $D_p$ मौलिक रूप से i.i.d. शर्त को संतुष्ट नहीं करता है (पृष्ठ 1, सार; पृष्ठ 2, Q1 स्पष्टीकरण)। यह हमले के तंत्र का एक सीधा परिणाम है और मानक सामान्यीकरण सिद्धांतों को अप्रभावी बनाता है। इस गैर-i.i.d. प्रकृति को संभालने के लिए नए सैद्धांतिक उपकरण विकसित करना एक बड़ी बाधा है।
- दोहरे, परस्पर विरोधी उद्देश्य: हमले के दो अलग-अलग लक्ष्य हैं: स्वच्छ डेटा पर उच्च सटीकता बनाए रखना और ट्रिगर किए गए डेटा पर गलत वर्गीकरण सुनिश्चित करना। ये उद्देश्य तनाव में हो सकते हैं। बैकडोर प्राप्त करने के लिए एक मॉडल पॉइज़न्ड नमूनों को ओवरफिट कर सकता है, जिससे स्वच्छ डेटा पर इसके प्रदर्शन में गिरावट आ सकती है, या इसके विपरीत। सैद्धांतिक गारंटी प्रदान करते हुए इन दोनों लक्ष्यों को संतुलित करना जटिल है।
- स्वच्छ-लेबल स्टील्थनेस: "स्वच्छ-लेबल" संपत्ति का मतलब है कि पॉइज़न्ड नमूनों के लेबल नहीं बदले जाते हैं। यह हमले को अधिक गुप्त बनाता है लेकिन मॉडल के लिए सीखना भी कठिन होता है। नेटवर्क को पॉइज़न्ड इनपुट के लिए स्पष्ट लेबल मार्गदर्शन के बिना, केवल ट्रिगर की उपस्थिति पर निर्भर करते हुए, अंतर्निहित रूप से ट्रिगर को लक्ष्य लेबल $l_p$ से जोड़ना चाहिए।
- पॉइज़न सामान्यीकरण के लिए विशिष्ट ट्रिगर शर्तें: यह सुनिश्चित करने के लिए कि पॉइज़न सामान्यीकरण त्रुटि छोटी है, ट्रिगर $P(x)$ मनमाना नहीं हो सकता है। प्रमेय 4.5 (पृष्ठ 4) तीन महत्वपूर्ण शर्तों (c1, c2, c3) को सूचीबद्ध करता है जिन्हें $P(x)$ को संतुष्ट करना चाहिए:
- (c1) एडवरसैरियल नॉइज़ (Adversarial Noise): ट्रिगर को स्वच्छ डेटा पर प्रशिक्षित नेटवर्क के लिए एडवरसैरियल नॉइज़ के रूप में कार्य करना चाहिए। यह विशिष्ट गड़बड़ी गुणों की आवश्यकता का अर्थ है।
- (c2) ट्रिगर समानता (Trigger Similarity): ट्रिगर $P(x)$ विभिन्न इनपुट नमूनों $x$ के पार समान होना चाहिए। यदि ट्रिगर अत्यधिक विविध हैं, तो मॉडल बैकडोर व्यवहार को सामान्य बनाने में संघर्ष कर सकता है।
- (c3) शॉर्टकट गुण (Shortcut Property): ट्रिगर को विशेष रूप से डिज़ाइन किए गए बाइनरी डेटासेट के लिए "शॉर्टकट" के रूप में कार्य करना चाहिए। यह एक गैर-तुच्छ गुण है जिसे इंजीनियर और सुनिश्चित करना है, क्योंकि यह ट्रिगर के मॉडल के निर्णय सीमा को प्रभावित करने के तरीके से संबंधित है। इन शर्तों के बिना, अनदेखे ट्रिगर डेटा के लिए हमले के सामान्यीकरण की गारंटी नहीं है।
- कम्प्यूटेशनल और हमलावर संसाधन सीमाएँ (निहित): यद्यपि स्पष्ट रूप से "समस्या परिभाषा" बाधाओं के रूप में नहीं कहा गया है, प्रयोगात्मक सेटअप (अनुभाग F.1, पृष्ठ 32-33) व्यावहारिक सीमाओं को प्रकट करता है जो वास्तविक दुनिया के परिदृश्यों में समस्या को कठिन बनाते हैं:
- सीमित हमलावर ज्ञान: हमलावर को पीड़ित नेटवर्क की संरचना और प्रशिक्षण प्रक्रिया के बारे में सीमित ज्ञान माना जाता है। इसका मतलब है कि छोटे, प्रॉक्सी नेटवर्क का उपयोग करके उत्पन्न होने पर भी ट्रिगर प्रभावी होने चाहिए।
- सीमित कंप्यूटिंग शक्ति: हमलावर को सीमित कम्प्यूटेशनल संसाधनों वाला माना जाता है, जो ट्रिगर पीढ़ी एल्गोरिदम की जटिलता को प्रभावित करता है।
- अदृश्यता बाधाएँ: ट्रिगर अक्सर $L_\infty$ मानदंडों (जैसे, 16/255) द्वारा बाधित होते हैं ताकि वे अगोचर रहें (पृष्ठ 6, 35)। यह भौतिक बाधा गड़बड़ी के परिमाण को सीमित करती है, जिससे प्रभावी और मजबूत ट्रिगर बनाना अधिक चुनौतीपूर्ण हो जाता है।
- गैर-विभेदक फलन (Non-Differentiable Functions): त्रुटि गणना के लिए संकेतक फलनों $1(\cdot)$ का उपयोग (जैसे, $1(F(x) \neq y)$) गैर-विभेदकता का परिचय देता है, जो कुछ संदर्भों में प्रत्यक्ष अनुकूलन और सैद्धांतिक विश्लेषण को जटिल बनाता है। पत्र प्रमेय 1.2 और 4.5 में क्रॉस-एंट्रॉपी लॉस (LCE) का उपयोग करता है, जो विभेदक है, लेकिन अंतिम लक्ष्य गैर-विभेदक वर्गीकरण त्रुटि को सीमित करना है।
यह दृष्टिकोण क्यों
चुनाव की अनिवार्यता
लेखकों का चुना हुआ दृष्टिकोण, स्वच्छ-लेबल बैकडोर हमलों के लिए उपन्यास सामान्यीकरण बाउंड प्राप्त करने पर केंद्रित है, केवल कई विकल्पों में से एक नहीं था, बल्कि पहले अनसुलझे सैद्धांतिक अंतर का एकमात्र व्यवहार्य समाधान था। जिस क्षण लेखकों को एहसास हुआ कि पारंपरिक "SOTA" तरीके अपर्याप्त थे, वह स्पष्ट रूप से पत्र में व्यक्त किया गया है: "हालांकि, ये सामान्यीकरण बाउंड स्वच्छ प्रशिक्षण डेटासेट के लिए हैं और पॉइज़न्ड प्रशिक्षण डेटासेट पर लागू नहीं किए जा सकते हैं, क्योंकि पॉइज़न्ड डेटासेट i.i.d. शर्त को संतुष्ट नहीं करते हैं, जो सामान्यीकरण के लिए आवश्यक है" (अनुभाग 1, पृष्ठ 1)।
यह कथन मौजूदा सामान्यीकरण सिद्धांतों की एक मौलिक सीमा को उजागर करता है, जो आम तौर पर मानते हैं कि डेटा स्वतंत्र और समान रूप से वितरित (i.i.d.) है। बैकडोर हमले, अपनी प्रकृति से, प्रशिक्षण डेटा के एक उपसमूह में सावधानीपूर्वक तैयार की गई गड़बड़ी पेश करते हैं, इस महत्वपूर्ण i.i.d. धारणा का उल्लंघन करते हैं। इसलिए, मानक सामान्यीकरण बाउंड, चाहे वे वीसी-आयाम, रेडमैकर जटिलता, या डीएनएन आर्किटेक्चर (जैसे, सीएनएन, ट्रांसफार्मर) के लिए विशिष्ट हों, अप्रभावी हो जाते हैं। समस्या मौजूदा ढाँचों के भीतर एक बेहतर मॉडल या एल्गोरिथम खोजने की नहीं थी, बल्कि गैर-i.i.d. पॉइज़न्ड डेटा सेटिंग में हमलों की सामान्यीकरण क्षमता को समझने के लिए एक नए सैद्धांतिक ढांचे की स्थापना की थी। इसके अलावा, बैकडोर हमलों के अनूठे दो-गुना उद्देश्य - स्वच्छ नमूनों पर उच्च सटीकता बनाए रखना और ट्रिगर किए गए इनपुट के लिए लक्षित गलत वर्गीकरण सुनिश्चित करना - और ट्रिगर प्रशिक्षण और परीक्षण दोनों चरणों में मौजूद होने की संपत्ति, एक विशेष सैद्धांतिक उपचार की आवश्यकता थी जो मौजूदा तरीकों ने प्रदान नहीं किया।
तुलनात्मक श्रेष्ठता
सरल प्रदर्शन मेट्रिक्स जैसे हमले की सफलता दर (ASR) या स्वच्छ सटीकता से परे, यह विधि अपनी मौलिक सैद्धांतिक ग्राउंडिंग के माध्यम से गुणात्मक श्रेष्ठता प्रदर्शित करती है। कई पूर्व बैकडोर हमलों के विपरीत जो अनुभवजन्य अनुमानों पर निर्भर करते हैं, प्रस्तावित दृष्टिकोण "सामान्यीकरण बाउंड पर आधारित है और इसमें कुछ सैद्धांतिक गारंटी हैं" (अनुभाग 3, पृष्ठ 3)। इसका मतलब है कि हमला केवल एक ब्लैक-बॉक्स अनुकूलन नहीं है, बल्कि अंतर्निहित स्थितियों की गहरी समझ के साथ डिज़ाइन किया गया है जो इसकी सामान्यीकरण को सक्षम करते हैं।
विधि का संरचनात्मक लाभ उन विशिष्ट गणितीय स्थितियों (प्रमेय 4.5 में c1, c2, c3) की पहचान करने और उनका लाभ उठाने की क्षमता में निहित है जिनके तहत पॉइज़न सामान्यीकरण त्रुटि को नियंत्रित और कम किया जा सकता है। यह एडवरसैरियल नॉइज़ और अंधाधुंध जहर को सैद्धांतिक रूप से सूचित तरीके से मिलाकर पॉइज़निंग ट्रिगर के एक सिद्धांतिक डिजाइन की अनुमति देता है (अनुभाग 5, टिप्पणी 5.1)। यह उन तरीकों से एक महत्वपूर्ण गुणात्मक छलांग है जो उच्च प्रदर्शन प्राप्त कर सकते हैं लेकिन इसके क्यों सामान्यीकरण होता है या किन परिस्थितियों में वे काम करने की गारंटी देते हैं, इसकी कोई स्पष्ट व्याख्या नहीं है। पत्र का दृष्टिकोण "इन विधियों का उपयोग करने के लिए एक अधिक सूचित दृष्टिकोण" (अनुभाग 5, टिप्पणी 5.1) प्रदान करता है, यह सुनिश्चित करता है कि हमले की प्रभावशीलता अनुभवजन्य अवलोकन के बजाय एक मजबूत सैद्धांतिक समझ में निहित है।
बाधाओं के साथ संरेखण
चुनी गई विधि स्वच्छ-लेबल बैकडोर हमलों की अंतर्निहित बाधाओं के साथ पूरी तरह से संरेखित होती है।
- स्वच्छ-लेबल प्रकृति: संपूर्ण सैद्धांतिक ढाँचा और प्रस्तावित एल्गोरिथम विशेष रूप से "स्वच्छ-लेबल बैकडोर हमलों के लिए तैयार किए गए हैं, जहाँ पॉइज़न ट्रिगर प्रशिक्षण सेट $D_{tr}$ के एक उपसमूह में उनके लेबल को बदले बिना जोड़े जाते हैं" (अनुभाग 1, पृष्ठ 1)। यह एक मुख्य बाधा है जिसे पत्र सीधे संबोधित करता है।
- दो-गुना हमला लक्ष्य: समस्या दो महत्वपूर्ण उद्देश्यों को परिभाषित करती है: (1) स्वच्छ नमूनों पर उच्च सटीकता बनाए रखना, और (2) यह सुनिश्चित करना कि ट्रिगर वाला कोई भी इनपुट लक्षित लेबल $l_p$ के रूप में वर्गीकृत किया जाए (अनुभाग 3.2)। समाधान दो अलग-अलग सामान्यीकरण बाउंड प्रदान करता है: स्वच्छ नमूना जनसंख्या त्रुटि $E(F, D_s)$ के लिए प्रमेय 1.1 और पॉइज़न जनसंख्या त्रुटि $E_p(F, D_s)$ के लिए प्रमेय 1.2, सीधे हमले के लक्ष्य के दोनों पहलुओं को संबोधित करते हुए।
- गैर-i.i.d. पॉइज़न्ड डेटा: यह संभवतः सबसे चुनौतीपूर्ण बाधा है। पत्र स्पष्ट रूप से कहता है कि "$D_p$ में डेटा अब $D_s$ से i.i.d. नमूना नहीं है, इसलिए शास्त्रीय सामान्यीकरण बाउंड का उपयोग प्रमेय 1.1 को सीधे प्राप्त करने के लिए नहीं किया जा सकता है" (प्रमेय 1.1, Q1)। लेखक चालाकी से पॉइज़न्ड प्रशिक्षण डेटा के एक उपसमूह की पहचान करके इस पर काबू पाते हैं जो स्वच्छ वितरण से i.i.d. नमूना है (प्रमेय 4.1 के लिए प्रमाण विचार, पृष्ठ 4; लेम्मा A.3, पृष्ठ 14)। यह गणितीय युक्ति समस्या की कठोर डेटा वितरण आवश्यकता और समाधान के अनूठे सैद्धांतिक गुणों के बीच एक प्रत्यक्ष "विवाह" है।
- प्रशिक्षण और परीक्षण चरणों दोनों में ट्रिगर की उपस्थिति: सामान्यीकरण बाउंड को दोनों चरणों में ट्रिगर को ध्यान में रखने के लिए तैयार किया गया है। पॉइज़न्ड प्रशिक्षण सेट $D_p$ पर अनुभवजन्य त्रुटि का उपयोग जनसंख्या त्रुटियों को सीमित करने के लिए किया जाता है, जो प्रशिक्षण के दौरान ट्रिगर की भूमिका को स्वाभाविक रूप से मानते हैं। पॉइज़न सामान्यीकरण त्रुटि $E_p(F, D_s)$ सीधे ट्रिगर किए गए परीक्षण डेटा के लिए हमले की सफलता का मूल्यांकन करती है।
- स्टील्थनेस/अदृश्यता: यद्यपि मुख्य रूप से एक प्रयोगात्मक बाधा है, प्रस्तावित एल्गोरिथम 1 "पॉइज़न बजट $\eta$" (एल्गोरिथम 1, इनपुट) को शामिल करता है जिसे $L_\infty$ मानदंड बाउंड (जैसे, 16/255) को लागू करने के लिए सेट किया जा सकता है, यह सुनिश्चित करता है कि उत्पन्न ट्रिगर गुप्त हमलों के लिए व्यावहारिक आवश्यकताओं के अनुरूप, अगोचर रहें।
विकल्पों का अस्वीकरण
पत्र निहित रूप से और स्पष्ट रूप से कई वैकल्पिक दृष्टिकोणों को अस्वीकार करता है, मुख्य रूप से स्वच्छ-लेबल बैकडोर हमलों की अनूठी चुनौतियों को उजागर करके जिन्हें मौजूदा तरीके संबोधित करने में विफल रहते हैं।
सबसे पहले, सबसे प्रत्यक्ष अस्वीकरण "शास्त्रीय सामान्यीकरण बाउंड" (अनुभाग 1, पृष्ठ 1) का है। ये बाउंड, चाहे वे वीसी-आयाम, रेडमैकर जटिलता, या डीप न्यूरल नेटवर्क के लिए विशिष्ट हों, अपर्याप्त माने जाते हैं क्योंकि वे i.i.d. डेटा मानते हैं। पॉइज़न्ड डेटासेट, परिभाषा के अनुसार, इस धारणा का उल्लंघन करते हैं, जिससे ये पारंपरिक सैद्धांतिक उपकरण अप्रभावी हो जाते हैं। लेखकों का काम इस मौलिक अंतर को भरता है, जिसका अर्थ है कि मौजूदा सामान्यीकरण सिद्धांतों को केवल अनुकूलित या लागू करने से विफलता होती।
दूसरे, पत्र अपने काम को डेटा पॉइज़निंग हमलों (जैसे, वांग एट अल., 2021; हन्नेके एट अल., 2022) के लिए अन्य मौजूदा सामान्यीकरण बाउंड से अलग करता है। यह कहता है कि "हमारा परिणाम इन कार्यों से अलग है और उनसे प्राप्त नहीं किया जा सकता है" (अनुभाग 2, पृष्ठ 3)। इसका कारण यह है कि ये पूर्व कार्य बैकडोर हमलों की विशिष्ट गुणों को ध्यान में नहीं रखते हैं, जैसे कि प्रशिक्षण और अनुमान चरणों दोनों में ट्रिगर की उपस्थिति, और स्वच्छ सटीकता बनाए रखने के साथ-साथ लक्षित गलत वर्गीकरण प्राप्त करने का दोहरा लक्ष्य। यह इंगित करता है कि ये अधिक सामान्य पॉइज़निंग सामान्यीकरण बाउंड स्वच्छ-लेबल बैकडोर हमलों की बारीकियों के लिए पर्याप्त दानेदार नहीं हैं।
अंत में, हमला पीढ़ी विधियों के संबंध में, पत्र स्पष्ट रूप से विशुद्ध रूप से अनुभवजन्य या अनुमान-आधारित दृष्टिकोणों को अस्वीकार करता है, इस बात पर जोर देते हुए कि "अधिकांश मौजूदा बैकडोर हमले मुख्य रूप से अनुभवजन्य अनुमानों पर आधारित होते हैं, जबकि हमारा हमला सामान्यीकरण बाउंड पर आधारित है और इसमें कुछ सैद्धांतिक गारंटी हैं" (अनुभाग 3, पृष्ठ 3)। अन्य स्वच्छ-लेबल हमलों की तुलना करते समय (अनुभाग 6.3, तालिका 4), लेखक नोट करते हैं कि कई विकल्पों के लिए "अतिरिक्त कदम," "पूर्व-मौजूदा पैच," "छवि फिटिंग," "ट्रिगर को बढ़ाना," या "बड़े जनरेटिव मॉडल" की आवश्यकता होती है (अनुभाग 6.3)। उदाहरण के लिए, "अदृश्य पॉइज़न" और "छवि-विशिष्ट" हमले इष्टतम प्रदर्शन के लिए बड़े जनरेटिव मॉडल पर निर्भर करते हैं, जिनसे प्रस्तावित विधि बचती है। नए एल्गोरिथम का सैद्धांतिक मार्गदर्शन ऐसे ओवरहेड्स के बिना एक अधिक कुशल और सिद्धांतिक ट्रिगर डिजाइन की अनुमति देता है। यह प्रस्तावित विधि को उसके मजबूत सैद्धांतिक नींव के कारण गुणात्मक रूप से श्रेष्ठ बनाता है, जिससे बेहतर सटीकता और हमले की सफलता दर प्राप्त होती है।
 Figure 4. When trigger is a patch without norm limitation, it is not invisible. This figure is from (Souri et al., 2022)
Figure 4. When trigger is a patch without norm limitation, it is not invisible. This figure is from (Souri et al., 2022)
गणितीय और तार्किक तंत्र
मास्टर समीकरण
पत्र का मुख्य योगदान स्वच्छ-लेबल बैकडोर हमलों के लिए सामान्यीकरण बाउंड स्थापित करने में निहित है, जो दो प्राथमिक उद्देश्यों को संबोधित करता है: स्वच्छ नमूनों पर उच्च सटीकता बनाए रखना और लक्षित लेबल के लिए ट्रिगर किए गए डेटा के सफल वर्गीकरण को सुनिश्चित करना। इन उद्देश्यों को क्रमशः प्रमेय 4.1 और प्रमेय 4.5 के रूप में व्युत्पन्न दो मास्टर समीकरणों में गणितीय रूप से कैप्चर किया गया है।
स्वच्छ सामान्यीकरण त्रुटि बाउंड (प्रमेय 4.1) इस प्रकार दिया गया है:
$$ E(F,D_s) \leq \frac{4-2\alpha}{1-\alpha} E(F,D_p) + O\left(\frac{mW^2D^2}{N} \ln(2/\delta) + \sqrt{\frac{\alpha}{N(1-\alpha)}}\right) $$
पॉइज़न सामान्यीकरण त्रुटि बाउंड (प्रमेय 4.5) इस प्रकार दिया गया है:
$$ E_p(F,D_s) \leq \lambda O\left(\left(E_{(x,y)\in D_p} [L_{CE}(F(x), y)] + \text{Rad}_{D_p}^{D_s}(H_{W,D,1})\right) + \sqrt{\frac{\ln(1/\delta)}{N\alpha}} + \epsilon + \tau + \lambda\right) $$
पद-दर-पद विच्छेदन
आइए इन समीकरणों के प्रत्येक घटक को उनके गणितीय परिभाषा, भौतिक/तार्किक भूमिका और उनके समावेश और संचालन के लिए लेखकों के तर्क को समझने के लिए विच्छेदित करें।
समीकरण 1: स्वच्छ सामान्यीकरण त्रुटि बाउंड
-
$E(F,D_s)$
- गणितीय परिभाषा: यह वास्तविक, अंतर्निहित डेटा वितरण $D_s$ पर न्यूरल नेटवर्क $F$ की जनसंख्या त्रुटि है। इसे औपचारिक रूप से $E_{(x,y)\sim D_s} [1(F(x) \neq y)]$ के रूप में परिभाषित किया गया है, जहाँ $1(\cdot)$ संकेतक फलन है जो यदि इसका तर्क सत्य है तो 1 लौटाता है, और अन्यथा 0।
- भौतिक/तार्किक भूमिका: यह शब्द स्वच्छ, अनपॉइज़न्ड डेटा पर मॉडल की वास्तविक त्रुटि दर का प्रतिनिधित्व करता है जिसे उसने पहले कभी नहीं देखा है। बैकडोर हमले के संदर्भ में, एक प्राथमिक लक्ष्य इस मान को छोटा रखना है, यह सुनिश्चित करना कि मॉडल अपने इच्छित, वैध कार्यों के लिए उपयोगी बना रहे।
- क्यों उपयोग किया गया: यह स्वच्छ डेटा पर मॉडल के प्रदर्शन का मूल्यांकन करने के लिए अंतिम मीट्रिक है, जो एक गुप्त बैकडोर हमले के लिए एक प्रमुख आवश्यकता है।
-
$\leq$
- गणितीय परिभाषा: "से कम या बराबर"।
- भौतिक/तार्किक भूमिका: यह प्रतीक इंगित करता है कि दाहिने हाथ की ओर का व्यंजक बाईं ओर की वास्तविक जनसंख्या त्रुटि के लिए एक ऊपरी सीमा प्रदान करता है। यह एक सामान्यीकरण बाउंड का सार है।
- क्यों उपयोग किया गया: चूंकि वास्तविक डेटा वितरण $D_s$ अज्ञात है, $E(F,D_s)$ की सीधे गणना नहीं की जा सकती है। सामान्यीकरण सिद्धांत अवलोकन योग्य मात्राओं के आधार पर संभाव्य ऊपरी सीमाएँ प्रदान करता है।
-
$\frac{4-2\alpha}{1-\alpha}$
- गणितीय परिभाषा: एक स्केलर गुणांक जो $\alpha$ पर निर्भर करता है, जो $D_{tr}$ में $l_p$ के रूप में लेबल किए गए नमूनों का अनुपात (पॉइज़निंग अनुपात) है।
- भौतिक/तार्किक भूमिका: यह गुणांक पॉइज़न्ड प्रशिक्षण डेटा पर देखी गई अनुभवजन्य त्रुटि को मापता है। यह दर्शाता है कि पॉइज़न्ड नमूनों का अनुपात सामान्यीकरण बाउंड की कसक को कैसे प्रभावित करता है। जैसे-जैसे $\alpha$ बढ़ता है, यह गुणांक आम तौर पर बढ़ता है, जो एक संभावित ढीली सीमा या अनुभवजन्य और जनसंख्या त्रुटि के बीच एक बड़े विचलन का संकेत देता है।
- क्यों उपयोग किया गया: पत्र इस बात पर प्रकाश डालता है कि पॉइज़न्ड डेटासेट ($D_p$) i.i.d. (स्वतंत्र और समान रूप से वितरित) शर्त को संतुष्ट नहीं करते हैं, जो शास्त्रीय सामान्यीकरण बाउंड के लिए एक पूर्वापेक्षा है। यह गुणांक संभवतः इस गैर-i.i.d. सेटिंग को अनुकूलित करने के लिए नियोजित विशिष्ट गणितीय तकनीकों से उत्पन्न होता है।
-
$E(F,D_p)$
- गणितीय परिभाषा: यह पॉइज़न्ड प्रशिक्षण डेटासेट $D_p$ पर नेटवर्क $F$ की अनुभवजन्य त्रुटि है। इसे $E_{(x,y)\in D_p} [1(F(x) \neq y)]$ के रूप में परिभाषित किया गया है।
- भौतिक/तार्किक भूमिका: यह प्रशिक्षण डेटा पर सीधे मापी गई मॉडल की त्रुटि दर का प्रतिनिधित्व करता है, जिसमें स्वच्छ और पॉइज़न्ड दोनों नमूने शामिल हैं। यह वह मात्रा है जिसे सीखने का एल्गोरिथम सक्रिय रूप से प्रशिक्षण के दौरान कम करने का प्रयास करता है।
- क्यों उपयोग किया गया: यह प्रशिक्षण प्रक्रिया के दौरान अवलोकन योग्य, मापने योग्य त्रुटि है। सामान्यीकरण बाउंड इस अनुभवजन्य प्रदर्शन को अनअवलोकन योग्य वास्तविक प्रदर्शन से जोड़ने का लक्ष्य रखते हैं।
-
$O(\cdot)$
- गणितीय परिभाषा: बिग ओ नोटेशन, एक फलन के विकास दर की एक स्पर्शोन्मुख ऊपरी सीमा को इंगित करता है। इसका मतलब है कि अंदर के पद निर्दिष्ट फलन से तेज़ी से नहीं बढ़ते हैं।
- भौतिक/तार्किक भूमिका: यह संकेतन "सामान्यीकरण अंतर" बनाने वाले पदों को समूहित करता है। ये पद आम तौर पर प्रशिक्षण डेटासेट $N$ के आकार में वृद्धि के साथ घटते हैं, जिसका अर्थ है कि अधिक डेटा के साथ, अनुभवजन्य त्रुटि जनसंख्या त्रुटि का एक अधिक विश्वसनीय अनुमान बन जाती है।
- क्यों उपयोग किया गया: यह कम महत्वपूर्ण स्थिरांकों को सारगर्भित करके अभिव्यक्ति को सरल बनाता है और सामान्यीकरण अंतर को कितनी तेज़ी से बंद किया जाता है, यह निर्धारित करने वाले प्रमुख कारकों पर ध्यान केंद्रित करता है।
-
$\frac{mW^2D^2}{N} \ln(2/\delta)$
- गणितीय परिभाषा: मॉडल जटिलता, डेटा आकार और विश्वास से संबंधित एक पद।
- $m$: लेबल सेट में वर्गों की संख्या।
- $W$: न्यूरल नेटवर्क की चौड़ाई (जैसे, एक परत में न्यूरॉन्स की अधिकतम संख्या)।
- $D$: न्यूरल नेटवर्क की गहराई (परतों की संख्या)।
- $N$: स्वच्छ प्रशिक्षण सेट $D_{tr}$ में नमूनों की कुल संख्या।
- $\ln(2/\delta)$: $2/\delta$ का प्राकृतिक लघुगणक, जहाँ $\delta$ एक छोटी संभाव्यता है (जैसे, 0.05) कि व्युत्पन्न बाउंड लागू नहीं हो सकता है (अर्थात, बाउंड $1-\delta$ की संभाव्यता के साथ लागू होता है)।
- भौतिक/तार्किक भूमिका: यह पद न्यूरल नेटवर्क मॉडल की क्षमता को मापता है। एक अधिक जटिल मॉडल (बड़ा $W$ या $D$) में प्रशिक्षण डेटा, जिसमें शोर भी शामिल है, को फिट करने की अधिक क्षमता होती है, जिससे एक बड़ा सामान्यीकरण अंतर (ओवरफिटिंग) हो सकता है। इसके विपरीत, एक बड़ा प्रशिक्षण सेट आकार $N$ इस अंतर को कम करने में मदद करता है। $\ln(2/\delta)$ कारक बाउंड की संभाव्य प्रकृति के लिए जिम्मेदार है। यह पद रेडमैकर जटिलता या वीसी-आयाम की अवधारणाओं का उपयोग करके व्युत्पन्न बाउंड में एक विशिष्ट घटक है।
- क्यों उपयोग किया गया: यह डीप लर्निंग मॉडल के लिए सामान्यीकरण बाउंड में एक मानक घटक है, जो मॉडल की अभिव्यक्ति क्षमता और उपलब्ध डेटा की मात्रा के बीच ट्रेड-ऑफ को दर्शाता है।
- गणितीय परिभाषा: मॉडल जटिलता, डेटा आकार और विश्वास से संबंधित एक पद।
-
$\sqrt{\frac{\alpha}{N(1-\alpha)}}$
- गणितीय परिभाषा: पॉइज़निंग अनुपात $\alpha$ और प्रशिक्षण सेट आकार $N$ को शामिल करने वाला एक वर्गमूल पद।
- भौतिक/तार्किक भूमिका: यह पद विशेष रूप से पॉइज़निंग प्रक्रिया द्वारा पेश की गई सांख्यिकीय अनिश्चितता को कैप्चर करता है। जैसे-जैसे पॉइज़निंग अनुपात $\alpha$ बढ़ता है, यह पद आम तौर पर बढ़ता है, जो डेटा वितरण की गैर-i.i.d. प्रकृति के कारण एक बड़े सामान्यीकरण अंतर का सुझाव देता है। इसके विपरीत, एक बड़ा $N$ इस पद को कम करता है, यह दर्शाता है कि अधिक डेटा पॉइज़निंग के प्रतिकूल प्रभावों को कम करने में मदद कर सकता है। हर में $(1-\alpha)$ का तात्पर्य है कि यदि लगभग सभी नमूने पॉइज़न्ड हैं ($\alpha \to 1$), तो बाउंड बहुत ढीला हो जाता है।
- क्यों उपयोग किया गया: यह पद डेटा पॉइज़निंग की उपस्थिति में सामान्यीकरण की अनूठी चुनौती को सीधे संबोधित करता है, पॉइज़न्ड डेटासेट की सांख्यिकीय प्रभाव को मापता है।
समीकरण 2: पॉइज़न सामान्यीकरण त्रुटि बाउंड
-
$E_p(F,D_s)$
- गणितीय परिभाषा: यह वास्तविक डेटा वितरण $D_s$ पर नेटवर्क $F$ की पॉइज़न जनसंख्या त्रुटि है। इसे औपचारिक रूप से $E_{(x,y)\sim D_s} [1(F(x + P(x))) \neq l_p)]$ के रूप में परिभाषित किया गया है, जहाँ $P(x)$ इनपुट $x$ पर लागू ट्रिगर है, और $l_p$ ट्रिगर किए गए इनपुट के लिए निर्दिष्ट लक्ष्य लेबल है।
- भौतिक/तार्किक भूमिका: यह शब्द अनदेखे, ट्रिगर किए गए डेटा पर बैकडोर हमले की वास्तविक विफलता दर को मापता है। हमले का लक्ष्य इस मान को यथासंभव छोटा बनाना है, यह सुनिश्चित करना कि ट्रिगर वाले किसी भी इनपुट को लगातार $l_p$ के रूप में वर्गीकृत किया जाए।
- क्यों उपयोग किया गया: यह बैकडोर हमले की सफलता दर और प्रभावशीलता का मूल्यांकन करने के लिए महत्वपूर्ण मीट्रिक है।
-
$\leq$
- गणितीय परिभाषा: "से कम या बराबर"।
- भौतिक/तार्किक भूमिका: समीकरण 1 के समान, यह इंगित करता है कि दाहिने हाथ की ओर पॉइज़न जनसंख्या त्रुटि के लिए एक ऊपरी सीमा प्रदान करता है।
- क्यों उपयोग किया गया: यह बैकडोर हमले की प्रभावशीलता के लिए एक सैद्धांतिक गारंटी स्थापित करता है, इसकी वास्तविक त्रुटि दर को सीमित करता है।
-
$\lambda$
- गणितीय परिभाषा: प्रमेय 4.5 की शर्त (c2) से प्राप्त एक स्केलिंग कारक, जो कहता है कि $P_{(x,y)\sim D_s}(P(x) \in A|y \neq l_p) \leq \lambda P_{(x,y)\sim D_s}(P(x) \in A|y = l_p)$ किसी भी सेट $A$ के लिए।
- भौतिक/तार्किक भूमिका: यह पैरामीटर विभिन्न स्वच्छ नमूनों $x$ के पार ट्रिगर $P(x)$ की "समानता" या "संगति" को मापता है। यदि $P(x)$ विभिन्न इनपुट के लिए अत्यधिक समान है, तो $\lambda$ 1 के करीब पहुंचता है। एक कसकर बाउंड के लिए एक छोटा $\lambda$ (1 के करीब) वांछनीय है, जिसका अर्थ है कि ट्रिगर एक सामान्य, सुसंगत पैटर्न के रूप में कार्य करता है जिसे मॉडल आसानी से सीख सकता है।
- क्यों उपयोग किया गया: यह प्रभावी ट्रिगर डिजाइन के लिए एक महत्वपूर्ण शर्त है, यह सुनिश्चित करता है कि बैकडोर विशिष्ट इनपुट विशेषताओं से बंधा नहीं है, बल्कि ट्रिगर स्वयं से है, जिससे यह सामान्यीकरण योग्य हो जाता है।
-
$O(\cdot)$
- गणितीय परिभाषा: बिग ओ नोटेशन, समीकरण 1 के समान।
- भौतिक/तार्किक भूमिका: पॉइज़न जनसंख्या त्रुटि के लिए सामान्यीकरण अंतर में योगदान करने वाले पदों को समूहित करता है।
- क्यों उपयोग किया गया: प्रमुख कारकों पर ध्यान केंद्रित करके बाउंड को सरल बनाता है।
-
$E_{(x,y)\in D_p} [L_{CE}(F(x), y)]$
- गणितीय परिभाषा: यह पॉइज़न्ड प्रशिक्षण डेटासेट $D_p$ पर नेटवर्क $F$ का अनुभवजन्य क्रॉस-एंट्रॉपी लॉस है। $L_{CE}$ क्रॉस-एंट्रॉपी लॉस फलन को दर्शाता है।
- भौतिक/तार्किक भूमिका: यह पद अनुभवजन्य जोखिम (हानि) का प्रतिनिधित्व करता है जिसे मॉडल पॉइज़न्ड डेटासेट पर प्रशिक्षण के दौरान कम करता है। 0-1 त्रुटि के विपरीत, क्रॉस-एंट्रॉपी लॉस मॉडल की भविष्यवाणियों के बारे में आत्मविश्वास को मापने के लिए एक निरंतर माप प्रदान करता है, जिससे यह ट्रिगर किए गए इनपुट के लिए लक्ष्य लेबल $l_p$ को उच्च संभावना के साथ आउटपुट करने के लिए प्रोत्साहित होता है।
- क्यों उपयोग किया गया: क्रॉस-एंट्रॉपी लॉस वर्गीकरण कार्यों के लिए एक मानक और अधिक जानकारीपूर्ण लॉस फलन है, खासकर जब विशिष्ट भविष्यवाणियों में उच्च आत्मविश्वास वांछित होता है, जैसा कि बैकडोर हमलों के मामले में होता है।
-
$\text{Rad}_{D_p}^{D_s}(H_{W,D,1})$
- गणितीय परिभाषा: परिकल्पना स्थान $H_{W,D,1}$ की रेडमैकर जटिलता, जो $D_p$ और $D_s$ को जोड़ने वाले वितरण से ली गई है। $H_{W,D,1}$ चौड़ाई $W$ और गहराई $D$ वाले न्यूरल नेटवर्क $F$ के लिए $h_F(x,y) = F_y(x)$ फलनों का सेट है। संकेतन बताता है कि यह $D_p$ में नमूनों से गणना की गई रेडमैकर जटिलता है, लेकिन $D_s$ के लिए सामान्यीकरण करने के उद्देश्य से है।
- भौतिक/तार्किक भूमिका: यह पद पॉइज़न्ड डेटा के संदर्भ में मॉडल वर्ग की "सीखने की क्षमता" या "लचीलापन" को मापता है। उच्च रेडमैकर जटिलता एक ऐसे मॉडल को इंगित करती है जो अधिक जटिल पैटर्न को फिट कर सकता है, जिससे संभावित रूप से ओवरफिटिंग हो सकती है यदि ठीक से नियंत्रित न किया जाए। यह यादृच्छिक लेबल को फिट करने की मॉडल की क्षमता को मापता है, जो ओवरफिटिंग की क्षमता के लिए एक प्रॉक्सी है।
- क्यों उपयोग किया गया: रेडमैकर जटिलता सांख्यिकीय सीखने के सिद्धांत में एक मौलिक उपकरण है जो सामान्यीकरण त्रुटि को सीमित करता है, विशेष रूप से न्यूरल नेटवर्क जैसे जटिल फलन वर्गों के लिए।
-
$\sqrt{\frac{\ln(1/\delta)}{N\alpha}}$
- गणितीय परिभाषा: विश्वास पैरामीटर $\delta$, प्रशिक्षण सेट आकार $N$, और पॉइज़निंग अनुपात $\alpha$ को शामिल करने वाला एक वर्गमूल पद।
- भौतिक/तार्किक भूमिका: यह पद एक सांख्यिकीय एकाग्रता घटक का प्रतिनिधित्व करता है। जैसे-जैसे $N$ बढ़ता है, यह पद घटता है, जिससे एक कसकर बाउंड होता है। एक छोटा $\alpha$ (कम पॉइज़न्ड नमूने) इस पद को बड़ा बनाता है, यह दर्शाता है कि बहुत कम नमूनों के साथ पॉइज़न के प्रभाव के बारे में सांख्यिकीय रूप से सामान्यीकरण करना कठिन है।
- क्यों उपयोग किया गया: यह एकाग्रता असमानताओं में एक सामान्य पद है, जो बाउंड के लिए एक निश्चित विश्वास स्तर प्राप्त करने के लिए आवश्यक नमूना जटिलता को दर्शाता है।
-
$\epsilon$
- गणितीय परिभाषा: प्रमेय 4.5 की शर्त (c1) से एक छोटा सकारात्मक मान: $E_{(x,y)\sim D_p^{l_p}} [G_y(x + P(x))] \leq \epsilon$ । यहाँ, $G_y(x)$ एक स्वच्छ-प्रशिक्षित नेटवर्क $G$ द्वारा $x$ को $y$ के रूप में वर्गीकृत करने की संभावना है।
- भौतिक/तार्किक भूमिका: यह पद ट्रिगर कितना "एडवरसैरियल" है, इसे मापता है। यदि $P(x)$ प्रभावी रूप से एक स्वच्छ-प्रशिक्षित नेटवर्क $G$ को $x+P(x)$ को गलत वर्गीकृत करने का कारण बनता है, तो $\epsilon$ छोटा होगा। एक कसकर बाउंड के लिए एक छोटा $\epsilon$ वांछनीय है, जिसका अर्थ है कि ट्रिगर एक प्रभावी एडवरसैरियल गड़बड़ी होनी चाहिए।
- क्यों उपयोग किया गया: यह ट्रिगर डिजाइन पर एक शर्त है, यह सुनिश्चित करता है कि ट्रिगर एक स्वच्छ मॉडल को प्रभावी ढंग से "धोखा" दे सके, जो कई बैकडोर हमलों की एक विशेषता है।
-
$\tau$
- गणितीय परिभाषा: प्रमेय 4.5 की शर्त (c3) से एक छोटा सकारात्मक मान: $E_{x\sim D_s} [|(F-G)_{l_p}(P(x)) - (F-G)_{l_p}(x+P(x))|] \leq \tau$ । यह $P(x)$ और $x+P(x)$ के लिए नेटवर्क के आउटपुट के "बैकडोर भाग" की समानता को मापता है।
- भौतिक/तार्किक भूमिका: यह पद ट्रिगर कितना "शॉर्टकट-जैसा" है, इसे मापता है। यदि ट्रिगर एक शॉर्टकट के रूप में कार्य करता है, तो $P(x)$ के प्रति नेटवर्क की प्रतिक्रिया $x+P(x)$ के प्रति इसकी प्रतिक्रिया के समान होनी चाहिए, जिससे एक छोटा $\tau$ हो। एक कसकर बाउंड के लिए एक छोटा $\tau$ वांछनीय है, जिसका अर्थ है कि ट्रिगर लक्ष्य लेबल तक एक मजबूत, सीधा पथ बनाता है।
- क्यों उपयोग किया गया: यह ट्रिगर डिजाइन पर एक शर्त है, जो मॉडल को ट्रिगर को एक सरल, प्रत्यक्ष सुविधा (एक "शॉर्टकट") के रूप में सीखने के लिए प्रोत्साहित करती है, न कि मूल इनपुट के साथ एक जटिल इंटरैक्शन के रूप में।
-
जोड़ के बजाय गुणा, या योग के बजाय समाकलन क्यों?
समीकरणों को योग के रूप में संरचित किया गया है क्योंकि वे त्रुटि के विभिन्न स्रोतों और सामान्यीकरण अंतर में योगदान करने वाले कारकों को एकत्रित करते हैं। प्रत्येक पद एक अलग पहलू का प्रतिनिधित्व करता है: अनुभवजन्य त्रुटि (क्या देखा गया है), मॉडल जटिलता, सांख्यिकीय विचरण, और ट्रिगर के विशिष्ट गुण। ये कारक जनसंख्या त्रुटि पर समग्र ऊपरी सीमा में योगात्मक रूप से योगदान करते हैं। उदाहरण के लिए, मॉडल जटिलता और सांख्यिकीय अनिश्चितता दोनों संभावित रूप से अनुभवजन्य त्रुटि को वास्तविक जनसंख्या त्रुटि से विचलित करने की क्षमता को बढ़ाते हैं।$E_{(x,y)\sim D_s}$ संकेतन $D_s$ के एक सतत संभाव्यता वितरण पर एक अपेक्षा का अर्थ है, जिसे गणितीय रूप से एक समाकलन द्वारा दर्शाया जाता है। इसके विपरीत, $E_{(x,y)\in D_p}$ एक परिमित, असतत डेटासेट $D_p$ पर एक अनुभवजन्य औसत को दर्शाता है, जिसकी गणना योग के रूप में की जाती है। लेखकों ने अपने अपेक्षा संकेतन के आधार पर, चाहे वे एक सतत जनसंख्या या एक असतत नमूने का उल्लेख कर रहे हों, उपयुक्त गणितीय ऑपरेटर (समाकलन या योग) का उपयोग किया है।
चरण-दर-चरण प्रवाह
आइए वास्तविक डेटा वितरण $D_s$ से, सामान्यीकरण बाउंड द्वारा वर्णित वैचारिक तंत्र के माध्यम से, एक एकल अमूर्त डेटा बिंदु, $(x_0, y_0)$ की यात्रा का पता लगाएं।
-
डेटा बिंदु की उत्पत्ति: हमारी यात्रा एक अमूर्त, स्वच्छ डेटा बिंदु $(x_0, y_0)$ से शुरू होती है, जहाँ $x_0$ एक इनपुट (जैसे, एक छवि) है और $y_0$ इसका वास्तविक लेबल है। यह बिंदु अनंत, अनअवलोकन योग्य वास्तविक डेटा वितरण $D_s$ का एक प्रतिनिधि नमूना है।
-
हमले के मूल्यांकन के लिए काल्पनिक पॉइज़निंग: यदि हम पॉइज़न जनसंख्या त्रुटि $E_p(F,D_s)$ का मूल्यांकन कर रहे हैं, तो इस स्वच्छ इनपुट $x_0$ को एक पूर्व-डिज़ाइन किए गए ट्रिगर $P(x_0)$ को जोड़कर वैचारिक रूप से संशोधित किया जाता है। परिणामी इनपुट $x_0 + P(x_0)$ बन जाता है, और बैकडोर हमले के लिए इसका इच्छित लेबल $l_p$ होता है, भले ही $y_0$ कुछ भी हो। यह परिवर्तित जोड़ी $(x_0 + P(x_0), l_p)$ वह है जिसे हमलावर चाहता है कि मॉडल सही ढंग से वर्गीकृत करे। स्वच्छ सामान्यीकरण त्रुटि $E(F,D_s)$ के मूल्यांकन के लिए, डेटा बिंदु $(x_0, y_0)$ बना रहता है।
-
मॉडल अनुमान (ब्लैक बॉक्स नेटवर्क $F$): (काल्पनिक रूप से) प्रशिक्षित न्यूरल नेटवर्क $F$ इस इनपुट को प्राप्त करता है।
- फ़ीचर परिवर्तन: इनपुट (या तो $x_0$ या $x_0 + P(x_0)$) नेटवर्क की परतों से गुजरता है। प्रत्येक परत, जिसमें संवहन, गैर-रैखिक सक्रियण (जैसे, ReLU), और पूलिंग जैसे संचालन होते हैं, कच्चे इनपुट को उत्तरोत्तर अधिक सार और विभेदक फ़ीचर अभ्यावेदन में बदल देती है।
- आउटपुट जनरेशन: नेटवर्क की अंतिम परत, आमतौर पर एक सॉफ्टमैक्स परत, इन सुविधाओं को सभी संभावित आउटपुट वर्गों पर संभाव्यता वितरण में परिवर्तित करती है। $F(z)$ यह वेक्टर है, जहाँ $F_y(z)$ इनपुट $z$ के लिए लेबल $y$ को सौंपी गई संभाव्यता है।
- वर्गीकरण निर्णय: नेटवर्क का अंतिम वर्गीकरण $\text{argmax}_y F_y(z)$ उच्चतम अनुमानित संभाव्यता वाला लेबल है।
-
त्रुटि/हानि गणना (जनसंख्या स्तर):
- स्वच्छ त्रुटि: स्वच्छ सामान्यीकरण के लिए, नेटवर्क के आउटपुट $F(x_0)$ की तुलना वास्तविक लेबल $y_0$ से की जाती है। यदि अनुमानित लेबल $\text{argmax}_y F_y(x_0)$ $y_0$ से मेल नहीं खाता है, तो एक त्रुटि दर्ज की जाती है। $E(F,D_s)$ प्राप्त करने के लिए इस प्रक्रिया को वैचारिक रूप से दोहराया और सभी संभावित $(x,y) \sim D_s$ पर औसत किया जाता है।
- पॉइज़न त्रुटि: पॉइज़न सामान्यीकरण के लिए, नेटवर्क के आउटपुट $F(x_0 + P(x_0))$ की तुलना लक्ष्य लेबल $l_p$ से की जाती है। यदि $\text{argmax}_y F_y(x_0 + P(x_0))$ $l_p$ से मेल नहीं खाता है, तो एक त्रुटि दर्ज की जाती है। इसे $E_p(F,D_s)$ प्राप्त करने के लिए सभी संभावित $(x,y) \sim D_s$ पर औसत किया जाता है।
-
अनुभवजन्य प्रतिरूप (प्रशिक्षण डेटा $D_p$): वास्तविक प्रशिक्षण चरण के दौरान, मॉडल $F$ को एक परिमित, अवलोकन योग्य, और पॉइज़न्ड प्रशिक्षण डेटासेट $D_p$ के संपर्क में लाया जाता है।
- नमूना चयन: $D_p$ से एक विशिष्ट नमूना $(x_i, y_i)$ निकाला जाता है। यह नमूना $D_{tr}$ से एक मूल स्वच्छ नमूना हो सकता है या एक पॉइज़न्ड नमूना $(x_j + P(x_j), l_p)$ हो सकता है जिसे $D_{tr}$ से एक स्वच्छ नमूना $(x_j, l_p)$ को गड़बड़ाकर बनाया गया था।
- अनुभवजन्य हानि/त्रुटि: नेटवर्क $F$ $x_i$ को संसाधित करता है।
- स्वच्छ सामान्यीकरण बाउंड के लिए, अनुभवजन्य त्रुटि $E(F,D_p)$ की गणना संकेतक फलन का उपयोग करके $F(x_i)$ की तुलना $y_i$ से करके की जाती है।
- पॉइज़न सामान्यीकरण बाउंड के लिए, अनुभवजन्य क्रॉस-एंट्रॉपी लॉस $L_{CE}(F(x_i), y_i)$ की गणना की जाती है। यह मापता है कि $F$ इनपुट $x_i$ के लिए $y_i$ की कितनी अच्छी तरह भविष्यवाणी करता है।
- औसत: इन व्यक्तिगत त्रुटियों या हानियों को फिर $E(F,D_p)$ या $E_{(x,y)\in D_p} [L_{CE}(F(x), y)]$ प्राप्त करने के लिए परिमित डेटासेट $D_p$ में सभी नमूनों पर औसत किया जाता है।
-
सामान्यीकरण अंतर को पाटना: गणितीय इंजन फिर $D_p$ पर इन अवलोकन योग्य अनुभवजन्य त्रुटियों/हानियों को $D_s$ पर अनअवलोकन योग्य वास्तविक जनसंख्या त्रुटियों से जोड़ता है। बाउंड में अतिरिक्त पद (रेडमैकर जटिलता, $\sqrt{\frac{\ln(1/\delta)}{N\alpha}}$, $\epsilon$, $\tau$, $\lambda$) "सुधार कारक" या "दंड पद" के रूप में कार्य करते हैं। वे मात्रात्मक रूप से व्यक्त करते हैं:
- मॉडल क्षमता: नेटवर्क $F$ ओवरफिटिंग के लिए कितना प्रवण है (रेडमैकर जटिलता)।
- डेटा की कमी: एक परिमित प्रशिक्षण सेट ($N$) के कारण सांख्यिकीय अनिश्चितता।
- पॉइज़निंग प्रभाव: पॉइज़निंग अनुपात द्वारा पेश किए गए विशिष्ट सांख्यिकीय पूर्वाग्रह।
- ट्रिगर गुणवत्ता: तैयार किया गया ट्रिगर $P(x)$ वांछित गुणों को कितनी अच्छी तरह पूरा करता है - एडवरसैरियल ($\epsilon$), सुसंगत ($\lambda$), और एक शॉर्टकट ($\tau$)।
यह पूरी प्रक्रिया अमूर्त गणित को एक चलती यांत्रिक असेंबली लाइन की तरह महसूस कराती है: कच्चा डेटा प्रवेश करता है, एक मशीन (नेटवर्क) द्वारा संसाधित किया जाता है, और इसके प्रदर्शन को मापा जाता है। सामान्यीकरण बाउंड फिर एक सैद्धांतिक "गुणवत्ता नियंत्रण" रिपोर्ट प्रदान करते हैं, जो देखे गए प्रदर्शन और अंतर्निहित डिजाइन विशेषताओं के आधार पर भविष्य के, अनदेखे डेटा पर मशीन के प्रदर्शन की भविष्यवाणी करते हैं।
अनुकूलन गतिकी
सामान्यीकरण बाउंड स्वयं पीड़ित मॉडल $F$ के लिए प्रत्यक्ष अनुकूलन उद्देश्य नहीं हैं। इसके बजाय, वे सैद्धांतिक गारंटी और शर्तें प्रदान करते हैं जिनके तहत एक बैकडोर हमला प्रभावी ढंग से सामान्यीकरण करेगा। इस संदर्भ में "अनुकूलन गतिकी" का तात्पर्य है कि ट्रिगर $P(x)$ कैसे डिज़ाइन किया गया है ताकि इन शर्तों को पूरा किया जा सके, और पीड़ित मॉडल $F$ को कैसे प्रशिक्षित किया जाता है ताकि इन बाउंड का पालन करते हुए वांछित बैकडोर व्यवहार प्राप्त किया जा सके।
पॉइज़निंग ट्रिगर $P(x)$ बनाने के लिए पत्र का प्रस्तावित एल्गोरिथम (एल्गोरिथम 1) वह जगह है जहाँ हमले के लिए प्राथमिक अनुकूलन गतिकी होती है:
-
एडवरसैरियल गड़बड़ी तैयार करना (छोटे $\epsilon$ के लिए शर्त c1/t1 को संतुष्ट करना):
- तंत्र: एक नेटवर्क $F_1$ को एक स्वच्छ डेटासेट $T$ पर प्रशिक्षित किया जाता है। प्रत्येक स्वच्छ नमूना $x$ के लिए, एक एडवरसैरियल गड़बड़ी $x_{adv}$ को प्रोजेक्टेड ग्रेडिएंट डिसेंट (PGD) का उपयोग करके उत्पन्न किया जाता है। PGD एक पुनरावृत्तीय अनुकूलन प्रक्रिया है जो मूल लेबल $y$ के लिए $F_1$ के नुकसान को अधिकतम करने के लिए एक छोटी गड़बड़ी $\epsilon$ (एक $L_\infty$ बजट $\eta$ के भीतर) पाती है।
- ग्रेडिएंट्स और लॉस लैंडस्केप: इसमें $\epsilon$ के संबंध में लॉस फलन $L(F_1(x+\epsilon), y)$ के ग्रेडिएंट की गणना शामिल है। अनुकूलन पुनरावृत्तीय रूप से $\epsilon$ को ग्रेडिएंट की दिशा में कदम उठाकर (ग्रेडिएंट आरोहण) अपडेट करता है, फिर $\epsilon$ को अनुमत गड़बड़ी स्थान में वापस प्रोजेक्ट करता है। यह प्रक्रिया ट्रिगर के "एडवरसैरियल" घटक को आकार देती है, जिसका उद्देश्य $\epsilon$ (जो $P(x)$ में योगदान देता है) को एक प्रभावी एडवरसैरियल उदाहरण बनाना है, इस प्रकार यह सुनिश्चित करना कि बाउंड में $\epsilon$ छोटा हो।
-
शॉर्टकट गड़बड़ी तैयार करना (छोटे $\tau$ के लिए शर्त c3/t3 को संतुष्ट करना):
- तंत्र: एक अलग, सरल दो-परत नेटवर्क $F_2$ को विशेष रूप से निर्मित डेटासेट $T_1$ पर प्रशिक्षित किया जाता है। इस डेटासेट में स्वच्छ नमूने और $x_{adv}$ (पिछले चरण से) द्वारा गड़बड़ाए गए नमूने शामिल हैं, लेकिन एक विशिष्ट लेबल (0) के साथ। लक्ष्य मिन-मिन विधि का उपयोग करके एक "शॉर्टकट" गड़बड़ी $x_{scut}$ खोजना है। यह विधि $F_2$ द्वारा पॉइज़न्ड डेटासेट को रैखिक रूप से विभाज्य बनाने का लक्ष्य रखती है।
- लॉस लैंडस्केप और स्टेट अपडेट: मिन-मिन विधि में आम तौर पर एक आंतरिक अनुकूलन लूप (किसी दिए गए $F_2$ के लिए सर्वश्रेष्ठ $x_{scut}$ खोजना) और एक बाहरी अनुकूलन लूप ($F_2$ को प्रशिक्षित करना) शामिल होता है। $F_2$ के लिए लॉस लैंडस्केप को इसे पॉइज़न्ड डेटा से सरल, रैखिक रूप से विभाज्य सुविधाओं को सीखने के लिए प्रोत्साहित करने के लिए आकार दिया गया है। यह प्रभावी रूप से एक "शॉर्टकट" बनाता है जो ट्रिगर को लक्ष्य लेबल पर मैप करता है। $F_2$ के मापदंडों और $x_{scut}$ के पुनरावृत्तीय अपडेट का लक्ष्य $\tau$ को कम करना है, यह सुनिश्चित करना कि ट्रिगर एक मजबूत शॉर्टकट सुविधा के रूप में कार्य करता है।
-
गड़बड़ी का संयोजन (1 के करीब $\lambda$ के लिए शर्त c2/t2 को संतुष्ट करना):
- तंत्र: अंतिम ट्रिगर $P(x)$ को एक बाइनरी मास्क $U$ का उपयोग करके $x_{adv}$ और $x_{scut}$ को जोड़कर बनाया जाता है: $P(x) = U \odot x_{adv} + (1-U) \odot x_{scut}$ । मास्क $U$ को डिज़ाइन किया गया है (जैसे, ऊपरी-बाएँ कोने जैसे विशिष्ट क्षेत्र 0 है, और बाकी 1 है) यह सुनिश्चित करने के लिए कि शॉर्टकट घटक $(1-U) \odot x_{scut}$ विभिन्न इनपुट $x$ के पार समान है।
- ग्रेडिएंट्स/स्टेट अपडेट का व्यवहार: यद्यपि $\lambda$ के लिए कोई प्रत्यक्ष ग्रेडिएंट-आधारित अनुकूलन नहीं है, मास्क $U$ की डिज़ाइन पसंद और मिन-मिन विधि के गुण (जो विभिन्न इनपुट के लिए समान शॉर्टकट उत्पन्न करने की प्रवृत्ति रखते हैं) अप्रत्यक्ष रूप से ट्रिगर पीढ़ी को शर्त (c2) को संतुष्ट करने की दिशा में निर्देशित करते हैं। यह सुनिश्चित करता है कि ट्रिगर एक सुसंगत पैटर्न है, जिससे $\lambda$ बाउंड में 1 के करीब पहुंचता है। एल्गोरिथम 1 का उपयोग करके प्राप्त कुछ पॉइज़न चित्र 1 में दिखाए गए हैं।
-
पीड़ित मॉडल प्रशिक्षण और अभिसरण:
- तंत्र: एक बार जब ट्रिगर $P(x)$ उत्पन्न हो जाते हैं, तो उन्हें मूल स्वच्छ प्रशिक्षण डेटा $D_{tr}$ के एक उपसमूह पर लागू किया जाता है ताकि पॉइज़न्ड प्रशिक्षण सेट $D_p$ बनाया जा सके। फिर पीड़ित नेटवर्क $F$ को क्रॉस-एंट्रॉपी लॉस फलन का उपयोग करके मानक अनुकूलन एल्गोरिदम जैसे स्टोकेस्टिक ग्रेडिएंट डिसेंट (SGD) के साथ $D_p$ पर प्रशिक्षित किया जाता है।
- लॉस लैंडस्केप और अभिसरण: $D_p$ में पॉइज़न्ड नमूनों की उपस्थिति पीड़ित मॉडल $F$ के लिए लॉस लैंडस्केप को संशोधित करती है। मॉडल $D_p$ पर अनुभवजन्य हानि को कम करना सीखता है, जिसका अर्थ है कि इसे अनपॉइज़न्ड नमूनों के लिए स्वच्छ वर्गीकरण कार्य और ट्रिगर किए गए नमूनों के लिए बैकडोर कार्य दोनों को सीखना चाहिए। सामान्यीकरण बाउंड फिर इस अभिसरण मॉडल $F$ के सामान्यीकरण प्रदर्शन की भविष्यवाणी करते हैं। यदि ट्रिगर $P(x)$ को शर्तों (छोटे $\epsilon, \tau$, $\lambda$ 1 के करीब) को पूरा करने के लिए सफलतापूर्वक तैयार किया गया था, तो बाउंड सुझाव देते हैं कि अभिसरण पर पीड़ित मॉडल उच्च स्वच्छ सटीकता और उच्च हमले की सफलता दर प्रदर्शित करेगा। SGD के माध्यम से $F$ के मापदंडों के पुनरावृत्तीय अपडेट इसे इस जटिल, बहु-उद्देश्यीय लॉस लैंडस्केप में एक स्थानीय न्यूनतम की ओर ले जाते हैं।
संक्षेप में, अनुकूलन गतिकी एक दो-चरणीय प्रक्रिया है: पहला, ट्रिगर $P(x)$ को विशिष्ट गुणों (एडवरसैरियल, शॉर्टकट, सुसंगत) के साथ क्राफ्ट करने के लिए एक लक्षित, ग्रेडिएंट-संचालित अनुकूलन जो गणितीय रूप से सामान्यीकरण बाउंड से जुड़े हैं; और दूसरा, परिणामी पॉइज़न्ड डेटासेट पर पीड़ित नेटवर्क का मानक प्रशिक्षण, जहाँ बाउंड अंतिम मॉडल के सामान्यीकरण प्रदर्शन की भविष्यवाणी करते हैं। बाउंड यह समझने के लिए सैद्धांतिक ढाँचा प्रदान करते हैं कि क्यों ये ट्रिगर डिज़ाइन सिद्धांत एक प्रभावी और सामान्यीकरण योग्य बैकडोर हमले की ओर ले जाते हैं।
 Figure 1. From top row to bottom row are respectively the clean images, normalized triggers (original trigger has L∞norm bound 16/255), poison images. Due to the selection of U, the upper left corners of the poison images are similar, while the other parts are used to generate adversaries
Figure 1. From top row to bottom row are respectively the clean images, normalized triggers (original trigger has L∞norm bound 16/255), poison images. Due to the selection of U, the upper left corners of the poison images are similar, while the other parts are used to generate adversaries
परिणाम, सीमाएँ और निष्कर्ष
प्रयोगात्मक डिजाइन और बेसलाइन
अपने सैद्धांतिक दावों और प्रस्तावित स्वच्छ-लेबल बैकडोर हमले की प्रभावशीलता को कठोरता से मान्य करने के लिए, लेखकों ने विभिन्न बेंचमार्क डेटासेट और पीड़ित नेटवर्क आर्किटेक्चर में व्यापक प्रयोग किए। प्रयोगात्मक सेटअप को व्यावहारिक हमले परिदृश्यों का अनुकरण करने के लिए सावधानीपूर्वक डिज़ाइन किया गया था, जहाँ हमलावर के पास पीड़ित के प्रशिक्षण प्रक्रिया पर सीमित ज्ञान और नियंत्रण होता है।
डेटासेट और पीड़ित मॉडल: हमले का मूल्यांकन व्यापक रूप से उपयोग किए जाने वाले छवि वर्गीकरण डेटासेट पर किया गया था: CIFAR10, CIFAR100, SVHN, और TinyImageNet। पीड़ित मॉडल के लिए, VGG16, ResNet18, और WRN34-10 जैसे लोकप्रिय डीप न्यूरल नेटवर्क का उपयोग किया गया था।
हमला तंत्र और ट्रिगर पीढ़ी: प्रस्तावित हमले के मूल में एक उपन्यास ट्रिगर पीढ़ी विधि (एल्गोरिथम 1) शामिल है जो एडवरसैरियल नॉइज़ और अंधाधुंध जहर को जोड़ती है। यह प्रक्रिया स्वयं पीड़ित नेटवर्क की संरचना या कम्प्यूटेशनल शक्ति के बारे में मान्यताओं से बचने के लिए छोटे, स्वतंत्र नेटवर्क (एडवरसैरियल नॉइज़ के लिए F1, शॉर्टकट गड़बड़ी के लिए F2) का उपयोग करती है। उदाहरण के लिए, F1 को L-infinity नॉर्म बजट (जैसे, 8/255 या 4/255) के साथ PGD-10 एडवरसैरियल प्रशिक्षण का उपयोग करके प्रशिक्षित किया गया था, जबकि F2, एक दो-परत नेटवर्क, को शॉर्टकट बनाने के लिए मिन-मिन विधि का उपयोग करके प्रशिक्षित किया गया था। पॉइज़निंग प्रक्रिया में प्रशिक्षण नमूनों के एक उपसमूह (जैसे, प्रशिक्षण छवियों का 1% या 0.8%) का यादृच्छिक चयन शामिल था जिसमें एक विशिष्ट लक्ष्य लेबल $l_p$ (आमतौर पर 0 पर सेट) था और उत्पन्न ट्रिगर को उनमें जोड़ा गया था, उनके मूल लेबल को बदले बिना।
मूल्यांकन मेट्रिक्स और बेसलाइन: हमले की प्रभावशीलता को मुख्य रूप से मापा गया था:
1. स्वच्छ मॉडल सटीकता: स्वच्छ परीक्षण नमूनों पर पॉइज़न्ड मॉडल की सटीकता।
2. पॉइज़न्ड मॉडल सटीकता: पॉइज़न्ड परीक्षण नमूनों पर पॉइज़न्ड मॉडल की सटीकता।
3. हमला सफलता दर (ASR): ट्रिगर युक्त नमूनों को लक्ष्य लेबल $l_p$ के रूप में गलत वर्गीकृत करने की दर।
4. स्वच्छ मॉडल $l_p$ सटीकता: लक्ष्य वर्ग $l_p$ से संबंधित स्वच्छ नमूनों की सटीकता।
प्रस्तावित विधि की तुलना सात प्रमुख स्वच्छ-लेबल बैकडोर हमलों से की गई: क्लीन लेबल, हिडन ट्रिगर, रिफ्लेक्शन, इनविजिबल पॉइज़न, इमेज-स्पेसिफिक, नार्सीसस, और स्लीपर एजेंट। निष्पक्ष तुलना के लिए, सभी हमलों को L-infinity नॉर्म ट्रिगर बजट (जैसे, 16/255) और एक निश्चित पॉइज़न बजट (जैसे, प्रशिक्षण छवियों का 1%) द्वारा बाधित किया गया था।
रक्षा तंत्र: हमले की मजबूती का आकलन करने के लिए, इसका परीक्षण छह सामान्य बैकडोर बचावों के खिलाफ किया गया था: एडवरसैरियल ट्रेनिंग (AT), डेटा ऑग्मेंटेशन, स्केल-अप, डिफरेंशियली प्राइवेट SGD (DPSGD), फ्रीक्वेंसी फिल्टर, और फाइन-ट्यूनिंग।
सैद्धांतिक सत्यापन: अनुभवजन्य प्रदर्शन से परे, लेखकों ने अपने गणितीय दावों, विशेष रूप से प्रमेय 4.1 और 4.5 को सत्यापित करने के लिए एब्लेशन अध्ययन किए। इसमें विभिन्न ट्रिगर घटकों (एडवरसैरियल नॉइज़, शॉर्टकट नॉइज़) के प्रभाव का विश्लेषण करना शामिल था, जिन्होंने प्रमेय 4.5 की शर्तों (c1), (c2), (c3) को प्रभावित किया, मेट्रिक्स जैसे $V_{adv}$ (शर्त (c1) के लिए पॉइज़न्ड डेटा पर सत्यापन हानि) और $V_{sc}$ (शर्त (c3) के लिए बाइनरी वर्गीकरण हानि) का उपयोग करके। उन्होंने समग्र सटीकता पर पॉइज़न दर के प्रभाव की भी जांच की ताकि प्रमेय 4.1 का समर्थन किया जा सके।
साक्ष्य क्या साबित करते हैं
प्रयोगात्मक साक्ष्य प्रस्तावित स्वच्छ-लेबल बैकडोर हमले की प्रभावशीलता और सैद्धांतिक आधारों के लिए सम्मोहक समर्थन प्रदान करते हैं।
मुख्य तंत्र का निश्चित प्रमाण:
एडवरसैरियल नॉइज़ और अंधाधुंध जहर को मिलाकर ट्रिगर बनाने वाला मुख्य तंत्र, जो प्रमेय 4.5 की शर्तों को पूरा करता है, क्रूरतापूर्वक प्रभावी साबित हुआ। हमले ने लगातार उच्च हमला सफलता दर (ASR) प्राप्त की, जबकि स्वच्छ नमूनों पर उच्च सटीकता बनाए रखी, जो एक स्वच्छ-लेबल बैकडोर हमले के दो प्राथमिक लक्ष्य हैं। उदाहरण के लिए, CIFAR-10 पर ResNet18 और 1% पॉइज़न बजट (L-infinity नॉर्म 16/255) के साथ, प्रस्तावित विधि ने 93% का ASR प्राप्त किया, जिसमें स्वच्छ मॉडल सटीकता 93% और पॉइज़न्ड मॉडल सटीकता 91% थी (तालिका 1)। यह दर्शाता है कि पीड़ित मॉडल ने इनपुट को लक्ष्य लेबल $l_p$ के रूप में गलत वर्गीकृत करने के लिए ट्रिगर सीखा, जबकि अभी भी वैध, स्वच्छ डेटा पर अच्छा प्रदर्शन कर रहा है।
"पीड़ितों" (बेसलाइन मॉडल) को निर्णायक रूप से हराया गया था। 16/255 के L-infinity नॉर्म बजट के तहत, हमारे हमले ने CIFAR-10 पर 93% ASR प्राप्त किया, जो अन्य सभी तुलनात्मक विधियों से काफी बेहतर प्रदर्शन करता है, जो 23% (क्लीन-लेबल) से 75% (हिडन-ट्रिगर) तक थे (तालिका 4)। यह निर्विवाद साक्ष्य इस बात पर प्रकाश डालता है कि ट्रिगर में एडवरसैरियल नॉइज़ और शॉर्टकट गुणों का विशिष्ट संयोजन, सैद्धांतिक बाउंड द्वारा निर्देशित, प्रभावी बैकडोर लगाने में बेहतर है। हमले की प्रभावशीलता बहुत छोटे पॉइज़न बजट (जैसे, CIFAR-10 पर ResNet18 के साथ 0.6% पॉइज़न बजट के लिए 86% ASR, तालिका 2) के साथ भी उच्च बनी रही, जिससे इसकी शक्ति और साबित हुई।
हमले का प्रदर्शन विभिन्न डेटासेट (CIFAR10, CIFAR100, SVHN, TinyImageNet) और विभिन्न लक्ष्य लेबल (0-9) में सुसंगत था, जैसा कि तालिका 3 और चित्र 3 में दिखाया गया है। यह एक सामान्यीकरण योग्य हमला रणनीति का संकेत देता है न कि किसी विशेष डेटासेट या लक्ष्य वर्ग के लिए विशिष्ट। प्रशिक्षण प्रक्रिया की निगरानी (चित्र 2) ने आगे पुष्टि की कि स्वच्छ और पॉइज़न्ड मॉडल की सटीकता करीब बनी रही, और ASR जल्दी से एक उच्च स्तर पर स्थिर हो गया, जो बैकडोर के मजबूत सीखने का संकेत देता है।
सैद्धांतिक दावों का सत्यापन:
प्रमेय 4.5 को सत्यापित करने के लिए विशेष रूप से डिज़ाइन किए गए एब्लेशन अध्ययनों ने महत्वपूर्ण अंतर्दृष्टि प्रदान की। विभिन्न पॉइज़न प्रकारों (रैंडम नॉइज़, यूनिवर्सल एडवरसैरियल, एडवरसैरियल, शॉर्टकट, और हमारा) की तुलना करके और $V_{adv}$ (शर्त c1 से संबंधित) और $V_{sc}$ (शर्त c3 से संबंधित) पर उनके प्रभाव का मूल्यांकन करके, लेखकों ने दिखाया कि व्यक्तिगत घटक अक्सर एक शर्त में उत्कृष्ट होते हैं लेकिन दूसरे में विफल होते हैं। उदाहरण के लिए, अकेले एडवरसैरियल गड़बड़ी ($Adv$) के परिणामस्वरूप उच्च $V_{adv}$ हुआ (मतलब शर्त c1 अच्छी तरह से संतुष्ट नहीं थी), जबकि अकेले शॉर्टकट नॉइज़ ($SCut$) के परिणामस्वरूप उच्च $V_{sc}$ हुआ (मतलब शर्त c3 अच्छी तरह से संतुष्ट नहीं थी)। हालांकि, प्रस्तावित "हमारा" विधि, जो दोनों को जोड़ती है, ने बहुत कम $V_{sc}$ के साथ संतुलित परिणाम प्राप्त किया, जिससे ASR काफी अधिक हुआ (16/255 बजट के तहत हमारा के लिए 93% बनाम Adv के लिए 22% और SCut के लिए 30%, तालिका 6)। यह सीधे तौर पर मान्य करता है कि संयुक्त ट्रिगर तंत्र के माध्यम से प्रमेय 4.5 की शर्तों को पूरा करने से बेहतर हमला प्रदर्शन होता है।
प्रमेय 4.1 के संबंध में, प्रयोगों से पता चला कि यद्यपि एक उच्च पॉइज़न दर आम तौर पर स्वच्छ सटीकता पर अधिक प्रभाव डालती है, गिरावट महत्वपूर्ण नहीं है (जैसे, 3,000 से अधिक पॉइज़न्ड नमूनों के लिए केवल 4% की कमी, तालिका 14)। यह सैद्धांतिक अंतर्दृष्टि का समर्थन करता है कि पॉइज़निंग अनुपात सामान्यीकरण को प्रभावित करता है, लेकिन यह भी कि नियंत्रित पॉइज़न बजट के साथ, स्वच्छ नमूना सटीकता पर प्रभाव को कम किया जा सकता है। इसके अलावा, पीड़ित नेटवर्क को ट्रिगर सुविधाओं को प्रभावी ढंग से सीखा गया दिखाया गया था (तालिका 12), फिर भी इसने मूल छवि सुविधाओं को प्राथमिकता दी, जिससे बैकडोर प्रभावी होने के लिए पॉइज़न का पर्याप्त पैमाना आवश्यक हो गया।
सीमाएँ और भविष्य की दिशाएँ
यद्यपि प्रस्तावित स्वच्छ-लेबल बैकडोर हमले ने उल्लेखनीय प्रभावशीलता का प्रदर्शन किया है और ठोस सैद्धांतिक सामान्यीकरण बाउंड पर आधारित है, पत्र कई सीमाओं को स्वीकार करता है और भविष्य के शोध के लिए रास्ते खोलता है।
वर्तमान सीमाएँ:
एक महत्वपूर्ण सीमा प्रमेय 4.5 में उल्लिखित शर्तों की जटिलता में निहित है। लेखक स्वयं कहते हैं कि ये शर्तें "काफी जटिल" हैं, और पॉइज़न सामान्यीकरण त्रुटि बाउंड के लिए सरल, अधिक सहज शर्तों को प्राप्त करना अत्यधिक वांछनीय होगा। यह जटिलता सैद्धांतिक ढांचे की व्यापक समझ और अनुप्रयोग में बाधा डाल सकती है।
एक और सैद्धांतिक अंतर यह है कि वर्तमान सामान्यीकरण बाउंड प्रशिक्षण प्रक्रिया को स्पष्ट रूप से शामिल नहीं करते हैं। एल्गोरिथम-निर्भर सामान्यीकरण बाउंड, विशेष रूप से स्थिरता विश्लेषण (जैसे, हार्ड्ट एट अल., 2016) पर आधारित, बैकडोर हमलों के संदर्भ में आगे की जांच के योग्य हैं। इस तरह के विश्लेषण से प्रशिक्षण गतिकी हमले की सफलता और सामान्यीकरण को कैसे प्रभावित करती है, इसकी अधिक बारीक समझ प्रदान की जा सकती है।
व्यावहारिक दृष्टिकोण से, पत्र नोट करता है कि उत्पन्न ट्रिगर विभिन्न डेटासेट में सीमित हस्तांतरणीयता प्रदर्शित करते हैं। उदाहरण के लिए, CIFAR-10 के लिए बनाया गया एक ट्रिगर CIFAR-100 पर सीधे लागू नहीं किया जा सकता है (परिशिष्ट F.5)। यह हमले की बहुमुखी प्रतिभा को प्रतिबंधित करता है और प्रत्येक नए डेटासेट के लिए ट्रिगर को फिर से उत्पन्न करने की आवश्यकता होती है, जो कम्प्यूटेशनल रूप से गहन हो सकता है।
इसके अलावा, हमला, यद्यपि बेसलाइन के खिलाफ अत्यधिक प्रभावी है, "रक्षा के तहत कुछ हद तक नाजुक" प्रतीत होता है (अनुभाग 6.4)। यद्यपि लेखकों ने "उन्नत हमलों" का प्रस्ताव दिया है जो इन बचावों का सामना करने के लिए अपनी पीढ़ी प्रक्रिया में रक्षा तंत्र को शामिल करते हैं, यह एक चल रही हथियारों की दौड़ का सुझाव देता है जहाँ हमले की मजबूती अंतर्निहित नहीं है बल्कि निरंतर अनुकूलन की आवश्यकता है। बचाव में देखी गई मजबूती-सटीकता ट्रेड-ऑफ भी एक चुनौती को उजागर करता है: पीड़ित मॉडल के प्रदर्शन को महत्वपूर्ण रूप से खराब किए बिना हमले के लचीलेपन में सुधार कैसे करें।
भविष्य की दिशाएँ और चर्चा विषय:
इस पत्र में निष्कर्ष भविष्य के काम के लिए एक मजबूत नींव रखते हैं, कई चर्चा विषयों को प्रेरित करते हैं:
- सैद्धांतिक शर्तों को सरल बनाना: प्रमेय 4.5 की शर्तों को अधिक सुलभ और चिकित्सकों के लिए व्याख्या योग्य बनाने के लिए उन्हें कैसे पुनर्गठित या अनुमानित किया जा सकता है? क्या "एडवरसैरियल नॉइज़" और "शॉर्टकट" गुणों की अधिक सारगर्भित, उच्च-स्तरीय समझ पर्याप्त होगी, या सटीक गणितीय शर्तें सैद्धांतिक गारंटी के लिए अनिवार्य हैं?
- एल्गोरिथम-निर्भर सामान्यीकरण बाउंड: प्रशिक्षण एल्गोरिदम (जैसे, ऑप्टिमाइज़र, सीखने की दर, नियमितीकरण) के कौन से विशिष्ट पहलू बैकडोर हमलों के सामान्यीकरण को सबसे अधिक प्रभावित करते हैं? क्या हम अधिक कसकर, एल्गोरिथम-निर्भर बाउंड प्राप्त कर सकते हैं जो मजबूत हमलों या बचावों को डिजाइन करने के लिए अधिक व्यावहारिक मार्गदर्शन प्रदान करते हैं? इसमें डीप लर्निंग में निहित नियमितीकरण जैसी अवधारणाओं की खोज शामिल हो सकती है।
- क्रॉस-डेटासेट ट्रिगर हस्तांतरणीयता: हम सार्वभौमिक या अधिक हस्तांतरणीय ट्रिगर कैसे डिजाइन कर सकते हैं जो पुन: पीढ़ी की आवश्यकता के बिना विविध डेटासेट में काम करते हैं? इसमें ट्रिगर पीढ़ी के लिए मेटा-लर्निंग दृष्टिकोण या प्रभावी बैकडोर ट्रिगर के रूप में भी काम करने वाले डेटासेट-अज्ञेय "सार्वभौमिक एडवरसैरियल गड़बड़ी" की पहचान करना शामिल हो सकता है।
- हमला-रक्षा हथियारों की दौड़: बचाव के प्रति देखी गई नाजुकता को देखते हुए, हम मौलिक रूप से अधिक मजबूत बैकडोर हमले कैसे विकसित कर सकते हैं जो ज्ञात शमन रणनीतियों के प्रति कम संवेदनशील हों? इसके विपरीत, बचाव को वास्तव में सक्रिय कैसे डिजाइन किया जा सकता है, मौजूदा हमले तंत्रों को संबोधित करने के बजाय उपन्यास हमले तंत्रों का अनुमान लगाना और उन्हें बेअसर करना? यह अनुकूली हमला/रक्षा रणनीतियों या इस हथियारों की दौड़ के खेल-सैद्धांतिक मॉडल की ओर ले जा सकता है।
- नैतिक निहितार्थ और जिम्मेदार एआई: पत्र स्पष्ट रूप से इस काम के संभावित नकारात्मक सामाजिक प्रभाव का उल्लेख करता है, क्योंकि दुर्भावनापूर्ण अभिनेता इन विधियों का उपयोग कर सकते हैं। यह जिम्मेदार प्रकटीकरण, एआई सुरक्षा के लिए "रेड टीमिंग" के विकास, और मजबूत नियामक ढांचे की आवश्यकता के बारे में महत्वपूर्ण प्रश्न उठाता है। वैज्ञानिक समुदाय शक्तिशाली एआई क्षमताओं के दुरुपयोग को रोकने की अनिवार्यता के साथ खुले शोध को कैसे संतुलित कर सकता है?
- छवि वर्गीकरण से परे: क्या सैद्धांतिक ढाँचा और हमला पद्धति अन्य डोमेन, जैसे प्राकृतिक भाषा प्रसंस्करण, भाषण पहचान, या सुदृढीकरण सीखने तक विस्तारित की जा सकती है? इन विभिन्न डेटा पद्धतियों और कार्य संरचनाओं में "एडवरसैरियल नॉइज़" और "शॉर्टकट" की अवधारणाओं को अनुकूलित करने में क्या अनूठी चुनौतियाँ और अवसर उत्पन्न होंगे?
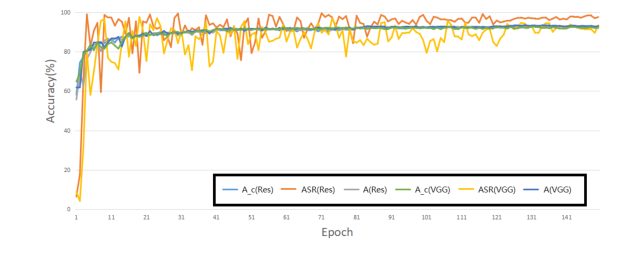 Figure 2. Attack performance during the training process on CIFAR10 with ResNet18 and VGG16. This figure shows the trend of the poison model accuracy (A), attack success rate (ASR) and clean model accuracy (Ac)
Figure 2. Attack performance during the training process on CIFAR10 with ResNet18 and VGG16. This figure shows the trend of the poison model accuracy (A), attack success rate (ASR) and clean model accuracy (Ac)
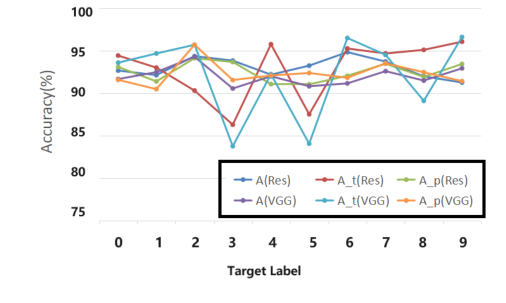 Figure 3. Performance of different target label lp. We show the poison model accuracy (A), accuracy of target label (At), attack success rate (Ap) on CIFAR-10, using VGG16 and ResNet18
Figure 3. Performance of different target label lp. We show the poison model accuracy (A), accuracy of target label (At), attack success rate (Ap) on CIFAR-10, using VGG16 and ResNet18