깨끗한 레이블 백도어 공격을 위한 일반화 경계 및 새로운 알고리즘
The generalization bound is a crucial theoretical tool for assessing the generalizability of learning methods and there exist vast literatures on generalizability of normal learning, adversarial learning, and data...
배경 및 학문적 계보
기원 및 학문적 계보
본 논문에서 다루는 문제는 기계 학습 이론, 특히 학습 알고리즘의 일반화 능력(generalization capabilities)과 관련된 분야에서 비롯된다. 역사적으로, 일반화 경계(generalization bound)라는 개념은 유한한 데이터셋으로 학습된 모델이 보지 못한 데이터에 대해 얼마나 잘 수행될 수 있는지를 이해하는 데 중요한 이론적 도구였다. Mohri 등 (2018)에서 참조된 이 분야의 초기 연구는 표준 학습 작업에 대한 이러한 일반화 능력을 정량화하기 위해 VC-차원 및 Rademacher 복잡도와 같은 지표에 초점을 맞추었다.
그러나 기계 학습 모델이 더욱 복잡해지고 응용 분야가 다양해짐에 따라 새로운 과제들이 등장했다. 한 가지 중요한 우려 영역은 데이터 포이즈닝 공격(data poisoning attacks)으로, 악의적인 행위자가 모델의 무결성을 손상시키기 위해 학습 데이터를 조작하는 것이다. 일반적인 데이터 포이즈닝 공격에 대한 일반화 경계가 탐구되었지만 (예: Wang et al., 2021; Hanneke et al., 2022), 특정하고 특히 악의적인 유형의 공격인 백도어 공격(backdoor attack)은 고유한 과제를 제시했다.
이 문제의 정확한 기원은 백도어 공격의 고유한 특성에서 비롯된다. 다른 데이터 포이즈닝 방법과 달리, 백도어 공격은 두 가지 목표를 가진다: 첫째, 정상적이고 깨끗한 데이터에 대한 높은 정확도를 유지하고, 둘째, 입력에 특정 "트리거"가 존재할 때 모델이 특정 타겟 레이블을 출력하도록 강제하는 것이다. 결정적으로, 이 트리거는 학습 및 테스트 세트 모두에 포함된다. 기존의 일반화 경계는 이러한 이중 목표나 포이즈닝된 데이터셋의 비-i.i.d. (독립적이고 동일하게 분포되지 않은) 특성을 설명하도록 설계되지 않았는데, 이는 고전적인 일반화 이론의 근본적인 가정이다. 저자들은 자신들의 지식으로는 백도어 공격에 대한 일반화 경계가 확립되지 않았다고 명시적으로 밝히며, 이는 본 논문이 채우고자 하는 학문적 문헌의 중요한 격차임을 강조한다.
이전 접근 방식의 근본적인 한계는 고전적인 일반화 이론의 초석인 i.i.d. 조건(i.i.d. condition)에 대한 의존성에서 비롯되었다. 이전 모델과 그 관련 경계는 암묵적으로 학습 데이터가 실제 데이터 분포에서 독립적이고 동일하게 샘플링되었다고 가정했다. 그러나 데이터 포이즈닝, 특히 백도어 공격의 맥락에서 포이즈닝된 학습 데이터셋은 본질적으로 이 i.i.d. 가정을 위반한다. 트리거와 타겟 오분류의 도입은 포이즈닝된 샘플이 더 이상 깨끗한 데이터 분포를 직접적으로 대표하지 않음을 의미한다. 이러한 위반은 기존의 일반화 경계를 적용할 수 없게 만들어, 백도어 공격 시나리오 하에서 학습된 모델의 일반화 가능성을 이론적으로 평가하는 것을 불가능하게 만들었다. 이 "고충점(pain point)"은 저자들이 깨끗한 레이블 백도어 공격의 고유한 속성을 처리할 수 있는 새로운 이론적 프레임워크를 개발하도록 강요했다.
직관적인 도메인 용어
-
일반화 경계 (Generalization Bound):
- 전문 용어: 모델의 학습 데이터 성능과 새롭고 보지 못한 데이터 성능 간의 차이에 대한 수학적 상한선.
- 직관적 비유: 운전 시험을 위해 공부한다고 상상해 보자. "일반화 경계"는 특정 도로 세트(학습 데이터)에서 잘 연습하면 실제 시험(보지 못한 데이터)에서 마주치는 어떤 새로운 도로에서도 특정 오차 범위 내에서 수행할 것이라는 보증과 같다. 이는 학습된 기술이 새로운 상황으로 얼마나 신뢰성 있게 전이될지를 알려준다.
-
깨끗한 레이블 백도어 공격 (Clean-Label Backdoor Attack):
- 전문 용어: 학습 데이터의 작은 부분집합에 미묘하고 종종 감지할 수 없는 트리거가 추가되지만, 원래 레이블은 그대로 유지되는 데이터 포이즈닝 공격의 한 유형. 목표는 학습된 모델이 이 트리거를 포함하는 모든 입력에 대해 특정 타겟 레이블로 분류하도록 하는 것이며, 동시에 깨끗한 데이터에 대해서도 정확하게 수행하는 것이다.
- 직관적 비유: 다양한 품종을 식별하도록 훈련된 개 쇼 심사위원을 생각해 보자. "깨끗한 레이블 백도어 공격"은 누군가가 훈련 중에 몇몇 개에게 작고 눈에 띄지 않는 빨간 리본(트리거)을 몰래 달았지만, 심사위원에게는 여전히 올바른 품종이라고 말하는 것과 같다. 심사위원은 모든 품종을 올바르게 식별하도록 학습한다. 그러나 이전에 본 적 없는 개라도 빨간 리본을 가지고 있다면, 심사위원은 실제 품종과 상관없이 항상 "푸들"이라고 부르도록 속는다. 포이즈닝된 학습 데이터의 원래 레이블은 "깨끗한"(올바른) 것이었기 때문에 공격이 은밀하게 이루어진다.
-
i.i.d. 조건 (독립적이고 동일하게 분포됨) (i.i.d. condition (Independent and Identically Distributed)):
- 전문 용어: 모든 데이터 샘플이 서로 독립적이고 동일한 확률 분포에서 추출되었다는 통계적 가정.
- 직관적 비유: 완벽하게 섞인 카드 덱에서 카드를 뽑는 것과 같다. 뽑는 각 카드는 이전 카드와 "독립적"이며(다음 뽑기에 영향을 미치지 않음), "동일한 분포"(같은 덱)에서 나온다. 만약 누군가가 처음 몇 번의 뽑기 후에 모든 에이스를 몰래 제거한다면, 그 이후의 뽑기는 더 이상 i.i.d.가 아니다. 기계 학습에서 이는 각 데이터 조각이 실제 세계의 신선하고 편향되지 않은 관찰과 같다는 것을 의미하며, 이 가정은 많은 증명이 유효하기 위해 중요하다.
-
Rademacher 복잡도 (Rademacher Complexity):
- 전문 용어: 가설 공간(모델이 학습할 수 있는 모든 가능한 함수의 집합)의 "풍부함" 또는 "용량"을 측정하는 척도. 무작위 노이즈를 얼마나 잘 맞출 수 있는지를 정량화한다.
- 직관적 비유: 무엇이든 그릴 수 있는 매우 유연한 예술가를 상상해 보자. "Rademacher 복잡도"는 이 예술가가 순수한 무작위성을 완벽하게 복제하는 데 얼마나 능숙한지를 측정한다. 예술가가 무작위 낙서를 완벽하게 그릴 수 있다면, 그들은 매우 유연한 것(높은 복잡도)이다. AI에서 이는 모델이 무작위 노이즈를 얼마나 쉽게 기억할 수 있는지를 알려주는데, 이는 종종 실제 패턴을 학습하는 것이 아니라 과적합(overfitting)의 징후이다.
-
지름길 (Shortcut):
- 전문 용어: 모델이 의도된, 더 복잡하고 견고한 특징을 학습하는 대신 예측을 위해 이용할 수 있는 간단하고 쉽게 학습되는 특징.
- 직관적 비유: 아이에게 "자동차"를 식별하도록 가르치고 있는데, 자동차의 모든 훈련 사진에 모퉁이에 특정 브랜드 로고가 있다면, 아이는 실제 자동차 특징(바퀴, 창문, 모양) 대신 "그 로고"를 "자동차"로 식별하도록 학습할 수 있다. 로고는 학습하기는 쉽지만 해당 로고가 없는 실제 자동차에는 일반화되지 않는 "지름길" 특징이다. 논문에서는 무차별적인 포이즈닝이 이러한 지름길로 간주될 수 있다고 언급한다.
표기법 표
| 표기법 | 설명 |
|---|---|
문제 정의 및 제약 조건
핵심 문제 공식화 및 딜레마
본 논문에서 다루는 핵심 문제는 딥러닝에서 깨끗한 레이블 백도어 공격에 대한 이론적 이해와 일반화 보장의 부족이다.
입력/현재 상태:
시작점은 깨끗한 학습 데이터셋 $D_{tr} = \{(x_i, y_i)\}_{i=1}^N$으로 신경망 $F$를 학습시키는 표준 기계 학습 설정이다. 이 데이터셋은 근본적인 데이터 분포 $D_s$에서 독립적이고 동일하게 분포(i.i.d.)되었다고 가정한다. 이러한 학습의 주요 목표는 모델이 보지 못한 데이터에 대한 성능을 측정하는 모집단 오류(population error) $E_{(x,y) \sim D_s}[1(F(x) \neq y)]$를 최소화하는 것이다. VC-차원, Rademacher 복잡도 또는 알고리즘 안정성을 기반으로 하는 경계를 포함한 기존의 일반화 이론은 기본적으로 이 학습 데이터의 i.i.d. 가정에 의존한다.
원하는 종점 (출력/목표 상태):
본 논문은 이론적으로 근거 있는 "깨끗한 레이블 백도어 공격"을 달성하는 것을 목표로 한다. 여기에는 "트리거" $P(x)$로 깨끗한 학습 데이터의 일부를 미묘하게 수정하여 원래 레이블을 변경하지 않고 포이즈닝된 학습 세트 $D_p$를 생성하는 것이 포함된다. 이 $D_p$로 학습된 신경망 $F$는 다음 두 가지 목표를 충족해야 한다:
1. 깨끗한 샘플에 대한 높은 정확도 유지: 모델은 포이즈닝되지 않은 깨끗한 데이터에 대해서도 잘 수행되어야 한다. 즉, 깨끗한 모집단 오류 $E(F, D_s) = E_{(x,y) \sim D_s}[1(F(x) \neq y)]$가 낮게 유지되어야 한다.
2. 트리거가 있는 입력에 대한 타겟 오분류 보장: 트리거 $P(x)$를 포함하는 모든 입력 $x$ (즉, $x + P(x)$)는 $F$에 의해 특정 사전 정의된 타겟 레이블 $l_p$로 분류되어야 한다. 이는 포이즈닝 모집단 오류 $E_p(F, D_s) = E_{(x,y) \sim D_s}[1(F(x + P(x))) \neq l_p)]$를 최소화함으로써 정량화된다.
딜레마 및 누락된 연결고리:
정확히 누락된 연결고리는 깨끗한 레이블 백도어 공격 하에서 학습된 모델에 대한 강력한 일반화 경계를 확립하는 것이다. 이전 연구자들을 가두었던 고통스러운 절충 또는 딜레마는 백도어 공격이 본질적으로 학습 데이터의 i.i.d. 가정을 위반한다는 것이다. 포이즈닝된 샘플을 도입함으로써, 데이터셋 $D_p$는 더 이상 $D_s$에서 i.i.d.로 샘플링되지 않는다. 이는 고전적인 일반화 이론의 근본적인 전제를 직접적으로 무효화하여, 깨끗한 데이터와 트리거가 있는 데이터 모두에 대해 원하는 성능을 보장하기 위해 기존 경계를 직접 적용하는 것을 불가능하게 만든다.
또한, 포이즈닝 일반화 목표(논문의 Q2)에 대해, 포이즈닝된 학습 데이터셋 $D_p$에 대한 경험적 오류를 단순히 최소화하는 것이 트리거가 있는 모든 데이터가 타겟 레이블 $l_p$로 분류될 것이라고 자동으로 보장하지는 않는다. 이는 깨끗한 샘플 $(x, y)$에서 $y \neq l_p$인 경우 $D_p$에서 $(x + P(x), l_p)$로 포이즈닝되지 않았다면, $D_p$에 대한 경험적 오류를 최소화하는 것이 반드시 $x + P(x)$를 $l_p$로 분류하도록 강제하지는 않기 때문이다. 이는 포이즈닝된 학습 세트에 대한 경험적 성능과 트리거가 있는 입력에 대한 원하는 일반화 동작 간의 미묘하지만 중요한 격차를 강조한다.
제약 조건 및 실패 모드
깨끗한 레이블 백도어 공격에 대한 일반화 경계를 확립하는 문제는 다음과 같은 몇 가지 가혹하고 현실적인 벽 때문에 엄청나게 어렵다:
- 비-i.i.d. 데이터 분포: 강조했듯이, 가장 중요한 제약 조건은 포이즈닝된 학습 데이터셋 $D_p$가 근본적으로 i.i.d. 조건을 만족하지 않는다는 것이다 (페이지 1, 초록; 페이지 2, Q1 설명). 이는 공격 메커니즘의 직접적인 결과이며 표준 일반화 이론을 적용할 수 없게 만든다. 이 비-i.i.d. 특성을 처리하기 위한 새로운 이론적 도구를 개발하는 것이 주요 장애물이다.
- 이중, 상충되는 목표: 공격은 두 가지 별개의 목표를 가진다: 깨끗한 데이터에 대한 높은 정확도 유지와 트리거가 있는 데이터에 대한 오분류 보장. 이러한 목표는 긴장 관계에 있을 수 있다. 모델은 백도어를 달성하기 위해 포이즈닝된 샘플에 과적합될 수 있으며, 이는 깨끗한 데이터에 대한 성능을 저하시킬 수 있다. 이러한 두 가지 목표를 이론적 보장을 제공하면서 균형을 맞추는 것은 복잡하다.
- 깨끗한 레이블의 은밀성: "깨끗한 레이블" 속성은 포이즈닝된 샘플의 레이블이 변경되지 않음을 의미한다. 이는 공격을 더 은밀하게 만들지만 모델이 학습하기 어렵게 만든다. 네트워크는 포이즈닝된 입력에 대한 명시적인 레이블 안내 없이 트리거와 타겟 레이블 $l_p$를 암묵적으로 연관시켜야 하며, 트리거의 존재에만 의존해야 한다.
- 포이즈닝 일반화를 위한 특정 트리거 조건: 포이즈닝 일반화 오류가 작도록 보장하기 위해, 트리거 $P(x)$는 임의적일 수 없다. 정리 4.5 (페이지 4)는 $P(x)$가 충족해야 하는 세 가지 중요한 조건(c1, c2, c3)을 열거한다:
- (c1) 적대적 노이즈: 트리거는 깨끗한 데이터로 학습된 네트워크에 대한 적대적 노이즈 역할을 해야 한다. 이는 특정 섭동 속성이 필요함을 시사한다.
- (c2) 트리거 유사성: 트리거 $P(x)$는 다른 입력 샘플 $x$ 간에 유사해야 한다. 트리거가 매우 다양하다면 모델은 백도어 동작을 일반화하는 데 어려움을 겪을 수 있다.
- (c3) 지름길 속성: 트리거는 특별히 설계된 이진 데이터셋에 대한 "지름길" 역할을 해야 한다. 이는 엔지니어링하고 보장하기 쉬운 속성이 아니며, 트리거가 모델의 결정 경계에 어떻게 영향을 미치는가와 관련이 있다. 이러한 조건이 없으면 공격의 보지 못한 트리거 데이터에 대한 일반화는 보장되지 않는다.
- 계산 및 공격자 자원 제한 (암묵적): 명시적으로 "문제 정의" 제약 조건으로 명시되지는 않았지만, 실험 설정(섹션 F.1, 페이지 32-33)은 실제 시나리오에서 문제를 더 어렵게 만드는 실질적인 제한 사항을 드러낸다:
- 제한된 공격자 지식: 공격자는 피해자 네트워크의 구조 및 학습 과정에 대한 제한된 지식을 가지고 있다고 가정된다. 이는 트리거가 더 작은 프록시 네트워크를 사용하여 생성되더라도 효과적이어야 함을 의미한다.
- 제한된 컴퓨팅 파워: 공격자는 제한된 계산 리소스를 가지고 있다고 가정되며, 이는 트리거 생성 알고리즘의 복잡성에 영향을 미친다.
- 가시성 제약: 트리거는 종종 은밀하게 유지되기 위해 $L_\infty$ 노름(예: 255분의 16)으로 제약된다 (페이지 6, 35). 이러한 물리적 제약은 섭동의 크기를 제한하여 효과적이고 견고한 트리거를 생성하기 어렵게 만든다.
- 비-미분 가능 함수: 오류 계산에 대한 지시 함수 $1(\cdot)$의 사용(예: $1(F(x) \neq y)$)은 비-미분 가능성을 도입하여 일부 맥락에서 직접적인 최적화 및 이론적 분석을 복잡하게 만든다. 논문은 정리 1.1 및 4.5에서 미분 가능한 교차 엔트로피 손실(LCE)을 사용하지만, 궁극적인 목표는 비-미분 가능한 분류 오류를 경계하는 것이다.
왜 이 접근 방식인가
선택의 불가피성
저자들이 선택한 접근 방식, 즉 깨끗한 레이블 백도어 공격에 대한 새로운 일반화 경계를 도출하는 데 초점을 맞춘 것은 단순히 여러 옵션 중 하나가 아니라, 이전에 해결되지 않은 이론적 격차에 대한 유일하게 실행 가능한 해결책이었다. 저자들이 기존의 "SOTA" 방법이 불충분하다는 것을 깨달은 순간은 논문에서 명확하게 설명된다: "그러나 이러한 일반화 경계는 깨끗한 학습 데이터셋을 위한 것이며, 포이즈닝된 학습 데이터셋은 일반화 가능성에 필요한 i.i.d. 조건을 만족하지 않기 때문에 포이즈닝된 학습 데이터셋에 적용할 수 없다" (섹션 1, 페이지 1).
이 진술은 일반적으로 데이터가 독립적이고 동일하게 분포(i.i.d.)되었다고 가정하는 기존 일반화 이론의 근본적인 한계를 강조한다. 백도어 공격은 본질적으로 학습 데이터의 일부에 신중하게 제작된 섭동을 도입하여 이 중요한 i.i.d. 가정을 위반한다. 따라서 VC-차원, Rademacher 복잡도 또는 DNN 아키텍처(예: CNN, Transformer)에 특화된 일반화 경계는 적용할 수 없게 된다. 문제는 기존 프레임워크 내에서 더 나은 모델 또는 알고리즘을 찾는 것이 아니라, 비-i.i.d. 포이즈닝된 데이터 설정에서 일반화 가능성을 이해하기 위한 새로운 이론적 프레임워크를 확립하는 것이었다. 또한, 백도어 공격의 고유한 이중 목표(깨끗한 샘플에 대한 높은 정확도 유지와 트리거가 있는 입력에 대한 타겟 오분류 보장)와 트리거가 학습 및 추론 단계 모두에 존재한다는 속성은 기존 방법이 제공하지 못하는 특화된 이론적 처리를 필요로 했다.
비교 우위
단순한 성능 지표(예: 공격 성공률(ASR) 또는 깨끗한 정확도)를 넘어, 이 방법은 기초적인 이론적 근거를 통해 질적인 우수성을 보여준다. 많은 이전 백도어 공격이 경험적 휴리스틱에 의존하는 것과 달리, 제안된 접근 방식은 "일반화 경계를 기반으로 하며 특정 이론적 보장을 제공한다" (섹션 3, 페이지 3). 이는 공격이 단순히 블랙박스 최적화가 아니라 일반화가 가능한 조건을 이해하는 깊은 이해를 바탕으로 설계되었음을 의미한다.
이 방법의 구조적 이점은 포이즈닝 모집단 오류를 제어하고 최소화할 수 있는 수학적 조건(정리 4.5의 c1, c2, c3)을 식별하고 활용할 수 있다는 점에 있다. 이를 통해 포이즈닝 트리거의 원칙적인 설계를 가능하게 하며, 적대적 노이즈와 무차별적인 포이즈닝을 이론적으로 정보가 풍부한 방식으로 결합한다 (섹션 5, 비고 5.1). 이것은 높은 성능을 달성하지만 왜 일반화되는지 또는 어떤 조건에서 작동이 보장되는지에 대한 명확한 설명이 부족한 방법에 비해 질적으로 큰 도약이다. 논문의 접근 방식은 "이러한 방법을 사용하는 데 더 많은 정보가 제공되는 접근 방식" (섹션 5, 비고 5.1)을 제공하여 공격의 효과성이 경험적 관찰이 아닌 견고한 이론적 이해에 뿌리를 두고 있음을 보장한다.
제약 조건과의 정렬
선택된 방법은 깨끗한 레이블 백도어 공격의 내재된 제약 조건과 완벽하게 일치한다.
- 깨끗한 레이블 속성: 전체 이론적 프레임워크와 제안된 알고리즘은 "포이즈닝 트리거가 학습 세트 $D_{tr}$의 일부에 추가되지만 레이블은 변경되지 않는 깨끗한 레이블 백도어 공격"에 특별히 맞춰져 있다 (섹션 1, 페이지 1). 이는 논문이 직접적으로 다루는 핵심 제약 조건이다.
- 이중 공격 목표: 문제는 두 가지 중요한 목표를 정의한다: (1) 깨끗한 샘플에 대한 높은 정확도 유지, (2) 트리거가 있는 모든 입력이 타겟 레이블 $l_p$로 분류되도록 보장 (섹션 3.2). 솔루션은 두 가지 별도의 일반화 경계를 제공한다: 깨끗한 샘플 모집단 오류 $E(F, D_s)$에 대한 정리 1.1과 포이즈닝 모집단 오류 $E_p(F, D_s)$에 대한 정리 1.2로, 공격 목표의 두 측면을 직접적으로 다룬다.
- 비-i.i.d. 포이즈닝 데이터: 이것은 아마도 가장 어려운 제약 조건일 것이다. 논문은 명시적으로 " $D_p$의 데이터는 더 이상 $D_s$에서 i.i.d.로 샘플링되지 않으므로 고전적인 일반화 경계를 사용하여 정리 1.1을 직접적으로 얻을 수 없다" (정리 1.1, Q1)고 명시한다. 저자들은 포이즈닝된 학습 데이터셋의 일부가 깨끗한 분포에서 i.i.d.로 샘플링되었음을 독창적으로 식별함으로써 이를 극복한다 (정리 4.1 증명 아이디어, 페이지 4; 보조 정리 A.3, 페이지 14). 이 수학적 기동은 문제의 가혹한 데이터 분포 요구 사항과 솔루션의 고유한 이론적 속성 간의 직접적인 "결합"이다.
- 학습 및 테스트 단계 모두에서의 트리거 존재: 일반화 경계는 두 단계 모두에서 트리거를 고려하도록 공식화된다. 포이즈닝된 학습 세트 $D_p$에 대한 경험적 오류는 모집단 오류를 경계하는 데 사용되며, 이는 학습 중 트리거의 역할을 본질적으로 고려한다. 포이즈닝 일반화 오류 $E_p(F, D_s)$는 트리거가 있는 테스트 데이터에 대한 공격의 성공률을 직접 평가한다.
- 은밀성/가시성: 주로 실험적 제약 조건이지만, 제안된 알고리즘 1은 "포이즈닝 예산 $\eta$" (알고리즘 1, 입력)를 통합하여 $L_\infty$ 노름 경계(예: 255분의 16)를 강제할 수 있으며, 이는 생성된 트리거가 은밀한 공격에 대한 실질적인 요구 사항과 일치하도록 은밀하게 유지됨을 보장한다.
대안의 거부
논문은 기존 방법이 해결하지 못하는 깨끗한 레이블 백도어 공격의 고유한 과제를 강조함으로써 암묵적으로 그리고 명시적으로 여러 대안적 접근 방식을 거부한다.
첫째, 가장 직접적인 거부는 "고전적인 일반화 경계"이다 (섹션 1, 페이지 1). VC-차원, Rademacher 복잡도 또는 심층 신경망에 특화된 이러한 경계는 i.i.d. 데이터를 가정하기 때문에 불충분하다고 간주된다. 포이즈닝된 데이터셋은 정의상 이 가정을 위반하므로, 이러한 전통적인 이론적 도구는 적용할 수 없다. 저자들의 작업은 이 근본적인 격차를 채우며, 기존 일반화 이론을 단순히 조정하거나 적용하는 것은 실패했을 것임을 시사한다.
둘째, 논문은 데이터 포이즈닝 공격에 대한 다른 기존 일반화 경계와 자신의 작업을 구별한다 (예: Wang et al., 2021; Hanneke et al., 2022). "우리의 결과는 이러한 작업과 다르며 그들로부터 파생될 수 없다" (섹션 2, 페이지 3)고 명시한다. 그 이유는 이러한 이전 작업들이 트리거가 학습 및 추론 단계 모두에 존재한다는 백도어 공격의 특정 속성과 깨끗한 정확도를 유지하면서 타겟 오분류를 달성한다는 이중 목표를 설명하지 않기 때문이다. 이는 이러한 더 일반적인 포이즈닝 일반화 경계가 깨끗한 레이블 백도어 공격의 미묘한 차이를 처리하기에 충분히 세분화되지 않았음을 시사한다.
마지막으로, 공격 생성 방법 자체에 관해서는, 논문은 "대부분의 기존 백도어 공격은 주로 경험적 휴리스틱에 기반하지만, 우리의 공격은 일반화 경계를 기반으로 하며 특정 이론적 보장을 제공한다" (섹션 3, 페이지 3)고 강조함으로써 순전히 경험적이거나 휴리스틱 기반의 접근 방식을 암묵적으로 거부한다. 다른 깨끗한 레이블 공격과 비교할 때 (섹션 6.3, 표 4), 저자들은 많은 대안이 "추가 단계", "사전 패치", "이미지 맞춤", "트리거 확대" 또는 "대규모 생성 모델" (섹션 6.3)을 필요로 한다고 언급한다. 예를 들어, "Invisible Poison" 및 "Image-specific" 공격은 최적의 성능을 위해 대규모 생성 모델에 의존하지만, 제안된 방법은 이를 피한다. 이론적 지침은 이러한 종종 복잡하고 리소스 집약적이거나 임시적인 구성 요소 없이 더 효율적이고 원칙적인 트리거 설계를 가능하게 한다. 이는 제안된 방법이 견고한 이론적 기반으로 인해 질적으로 우수하며, 이러한 오버헤드 없이 더 나은 정확도와 공격 성공률을 제공한다.
 Figure 4. When trigger is a patch without norm limitation, it is not invisible. This figure is from (Souri et al., 2022)
Figure 4. When trigger is a patch without norm limitation, it is not invisible. This figure is from (Souri et al., 2022)
수학적 및 논리적 메커니즘
마스터 방정식
본 논문의 핵심 기여는 깨끗한 레이블 백도어 공격에 대한 일반화 경계를 확립하여, 깨끗한 샘플에 대한 높은 정확도 유지와 트리거가 있는 데이터의 타겟 레이블로의 성공적인 분류 보장이라는 두 가지 주요 목표를 해결하는 것이다. 이러한 목표는 각각 정리 4.1과 정리 4.5로 파생된 두 개의 마스터 방정식으로 수학적으로 포착된다.
깨끗한 일반화 오류 경계(정리 4.1)는 다음과 같다:
$$ E(F,D_s) \leq \frac{4-2\alpha}{1-\alpha} E(F,D_p) + O\left(\frac{mW^2D^2}{N} \ln(2/\delta) + \sqrt{\frac{\alpha}{N(1-\alpha)}}\right) $$
포이즈닝 일반화 오류 경계(정리 4.5)는 다음과 같다:
$$ E_p(F,D_s) \leq \lambda O\left(\left(E_{(x,y)\in D_p} [L_{CE}(F(x), y)] + \text{Rad}_{D_p}^{D_s}(H_{W,D,1})\right) + \sqrt{\frac{\ln(1/\delta)}{N\alpha}} + \epsilon + \tau + \lambda\right) $$
항별 분석
이러한 방정식의 각 구성 요소를 분해하여 수학적 정의, 물리적/논리적 역할 및 저자의 포함 및 작동 이유를 이해해 보자.
방정식 1: 깨끗한 일반화 오류 경계
-
$E(F,D_s)$
- 수학적 정의: 이는 실제, 근본적인 데이터 분포 $D_s$에 대한 신경망 $F$의 모집단 오류이다. 이는 $1(\cdot)$이 인디케이터 함수이고 그 인수가 참이면 1을 반환하고 거짓이면 0을 반환한다고 할 때, $E_{(x,y)\sim D_s} [1(F(x) \neq y)]$로 공식적으로 정의된다.
- 물리적/논리적 역할: 이 항은 모델이 이전에 본 적 없는 깨끗하고 포이즈닝되지 않은 데이터에 대한 모델의 실제 오류율을 나타낸다. 백도어 공격의 맥락에서, 주요 목표는 이 값을 작게 유지하여 모델이 의도된 합법적인 작업을 위해 유용하게 유지되도록 하는 것이다.
- 사용 이유: 이는 깨끗한 데이터에 대한 모델 성능을 평가하는 궁극적인 지표이며, 은밀한 백도어 공격의 핵심 요구 사항이다.
-
$\leq$
- 수학적 정의: "이하".
- 물리적/논리적 역할: 이 기호는 우변이 좌변의 실제 모집단 오류에 대한 상한선을 제공함을 나타낸다. 이것이 일반화 경계의 본질이다.
- 사용 이유: 실제 데이터 분포 $D_s$는 알려져 있지 않으므로 $E(F,D_s)$를 직접 계산할 수 없다. 일반화 이론은 관찰 가능한 양을 기반으로 확률적 상한선을 제공한다.
-
$\frac{4-2\alpha}{1-\alpha}$
- 수학적 정의: $\alpha$ ( $D_{tr}$에서 레이블이 $l_p$인 샘플의 비율)에 따라 달라지는 스칼라 계수.
- 물리적/논리적 역할: 이 계수는 포이즈닝된 학습 데이터에서 관찰된 경험적 오류를 스케일링한다. 이는 포이즈닝된 샘플의 비율이 일반화 경계의 밀도에 어떻게 영향을 미치는지를 반영한다. $\alpha$가 증가하면 이 계수는 일반적으로 증가하여 잠재적으로 더 느슨한 경계 또는 경험적 오류와 모집단 오류 간의 더 큰 편차를 나타낸다.
- 사용 이유: 논문은 포이즈닝된 데이터셋 ($D_p$)이 고전적인 일반화 경계에 대한 전제 조건인 i.i.d. (독립적이고 동일하게 분포됨) 조건을 만족하지 않는다는 점을 강조한다. 이 계수는 이 비-i.i.d. 설정에 일반화 이론을 적용하기 위해 사용된 특정 수학적 기법에서 파생될 가능성이 높다.
-
$E(F,D_p)$
- 수학적 정의: 이는 포이즈닝된 학습 데이터셋 $D_p$에 대한 네트워크 $F$의 경험적 오류이다. 이는 $E_{(x,y)\in D_p} [1(F(x) \neq y)]$로 정의된다.
- 물리적/논리적 역할: 이는 깨끗한 샘플과 포이즈닝된 샘플을 모두 포함하는 유한 학습 데이터에서 직접 측정된 모델의 오류율을 나타낸다. 이것은 학습 알고리즘이 학습 중에 적극적으로 최소화하려고 하는 양이다.
- 사용 이유: 이는 학습 과정 중에 관찰 가능하고 측정 가능한 오류이다. 일반화 경계는 이 경험적 성능을 관찰할 수 없는 실제 성능과 연결하려고 한다.
-
$O(\cdot)$
- 수학적 정의: Big O 표기법으로, 함수의 성장률에 대한 점근적 상한선을 나타낸다. 내부 항들이 지정된 함수보다 더 빠르게 성장하지 않음을 의미한다.
- 물리적/논리적 역할: 이 표기법은 "일반화 격차"를 구성하는 항들을 그룹화한다. 이러한 항들은 일반적으로 학습 데이터셋 $N$의 크기가 증가함에 따라 감소하는데, 이는 더 많은 데이터가 있으면 경험적 오류가 모집단 오류에 대한 더 신뢰할 수 있는 추정치가 된다는 것을 의미한다.
- 사용 이유: 이는 덜 중요한 상수들을 추상화하고 일반화 격차가 얼마나 빨리 닫히는지를 결정하는 주요 요인에 초점을 맞춤으로써 표현식을 단순화한다.
-
$\frac{mW^2D^2}{N} \ln(2/\delta)$
- 수학적 정의: 모델 복잡성, 데이터 크기 및 신뢰도와 관련된 항.
- $m$: 레이블 세트의 클래스 수.
- $W$: 신경망의 너비 (예: 레이어의 최대 뉴런 수).
- $D$: 신경망의 깊이 (레이어 수).
- $N$: 깨끗한 학습 세트 $D_{tr}$의 총 샘플 수.
- $\ln(2/\delta)$: $\delta$ (예: 0.05)의 자연 로그로, 유도된 경계가 유지되지 않을 확률 (즉, 경계가 $1-\delta$의 확률로 유지됨).
- 물리적/논리적 역할: 이 항은 신경망 모델의 용량을 정량화한다. 더 복잡한 모델(더 큰 $W$ 또는 $D$)은 노이즈를 포함하여 학습 데이터를 더 잘 맞출 수 있는 능력이 있으며, 이는 더 큰 일반화 격차(과적합)로 이어질 수 있다. 반대로, 더 큰 학습 세트 크기 $N$은 이 격차를 줄이는 데 도움이 된다. $\ln(2/\delta)$ 인자는 경계의 확률적 특성을 설명한다. 이 항은 Rademacher 복잡도 또는 VC-차원과 같은 개념을 사용하여 유도된 일반화 경계의 표준 구성 요소이다.
- 사용 이유: 이는 모델 표현력과 사용 가능한 데이터 양 간의 절충을 반영하는 심층 신경망 모델에 대한 일반화 경계의 표준 구성 요소이다.
- 수학적 정의: 모델 복잡성, 데이터 크기 및 신뢰도와 관련된 항.
-
$\sqrt{\frac{\alpha}{N(1-\alpha)}}$
- 수학적 정의: 포이즈닝 비율 $\alpha$ 및 학습 세트 크기 $N$을 포함하는 제곱근 항.
- 물리적/논리적 역할: 이 항은 포이즈닝 프로세스에 의해 도입된 통계적 불확실성을 구체적으로 포착한다. 포이즈닝 비율 $\alpha$가 증가함에 따라 이 항은 일반적으로 증가하며, 데이터 분포의 비-i.i.d. 특성으로 인한 일반화 격차 증가를 시사한다. 반대로, 더 큰 $N$은 이 항을 줄여 더 많은 데이터가 포이즈닝의 부작용을 완화하는 데 도움이 될 수 있음을 나타낸다. 분모의 $(1-\alpha)$는 거의 모든 샘플이 포이즈닝될 때 ($\alpha \to 1$) 경계가 매우 느슨해짐을 의미한다.
- 사용 이유: 이는 데이터 포이즈닝이 있는 일반화에 대한 고유한 과제를 직접적으로 다루는 농도 불평등의 일반적인 항으로, 포이즈닝된 데이터셋의 통계적 영향을 정량화한다.
방정식 2: 포이즈닝 일반화 오류 경계
-
$E_p(F,D_s)$
- 수학적 정의: 이는 실제 데이터 분포 $D_s$에 대한 네트워크 $F$의 포이즈닝 모집단 오류이다. 이는 $P(x)$가 입력 $x$에 적용된 트리거이고 $l_p$가 트리거가 있는 입력에 대해 지정된 타겟 레이블이라고 할 때, $E_{(x,y)\sim D_s} [1(F(x + P(x))) \neq l_p)]$로 공식적으로 정의된다.
- 물리적/논리적 역할: 이 항은 보지 못한 트리거가 있는 데이터에 대한 백도어 공격의 실제 실패율을 측정한다. 공격의 목표는 이 값을 가능한 한 작게 만드는 것으로, 트리거가 있는 모든 입력이 일관되게 $l_p$로 분류되도록 보장하는 것이다.
- 사용 이유: 이는 백도어 공격 자체의 성공률과 효과를 평가하는 중요한 지표이다.
-
$\leq$
- 수학적 정의: "이하".
- 물리적/논리적 역할: 방정식 1과 유사하게, 이는 우변이 포이즈닝 모집단 오류에 대한 상한선을 제공함을 나타낸다.
- 사용 이유: 이는 백도어 공격의 효과에 대한 이론적 보장을 확립하고 그 실제 오류율을 경계한다.
-
$\lambda$
- 수학적 정의: 정리 4.5의 조건 (c2)에서 파생된 스케일링 인수. 이 조건은 $P_{(x,y)\sim D_s}(P(x) \in A|y \neq l_p) \leq \lambda P_{(x,y)\sim D_s}(P(x) \in A|y = l_p)$를 모든 집합 $A$에 대해 명시한다.
- 물리적/논리적 역할: 이 매개변수는 다양한 깨끗한 샘플 $x$ 간에 트리거 $P(x)$의 "유사성" 또는 "일관성"을 정량화한다. $P(x)$가 다양한 입력에 대해 매우 유사하다면 $\lambda$는 1에 가까워진다. 더 나은 경계를 위해 더 작은 $\lambda$ (1에 가까운)가 바람직하며, 이는 트리거가 모델이 쉽게 학습할 수 있는 일반적이고 일관된 패턴 역할을 함을 의미한다.
- 사용 이유: 이는 효과적인 트리거를 설계하기 위한 중요한 조건으로, 트리거가 특정 입력 특성에 묶이지 않고 일반화 가능한 트리거 자체에 대한 일관된 패턴이 되도록 보장한다.
-
$O(\cdot)$
- 수학적 정의: Big O 표기법, 방정식 1과 유사.
- 물리적/논리적 역할: 포이즈닝 모집단 오류에 대한 일반화 격차에 기여하는 항들을 그룹화한다.
- 사용 이유: 주요 요인에 초점을 맞춤으로써 경계를 단순화한다.
-
$E_{(x,y)\in D_p} [L_{CE}(F(x), y)]$
- 수학적 정의: 이는 포이즈닝된 학습 데이터셋 $D_p$에 대한 네트워크 $F$의 경험적 교차 엔트로피 손실이다. $L_{CE}$는 교차 엔트로피 손실 함수를 나타낸다.
- 물리적/논리적 역할: 이 항은 포이즈닝된 데이터셋에서 학습 중에 모델이 최소화하는 경험적 위험(손실)을 나타낸다. 0-1 오류와 달리, 교차 엔트로피 손실은 예측에 대한 모델의 자신감을 측정하는 연속적인 척도를 제공하며, 트리거가 있는 입력에 대해 높은 확률로 타겟 레이블 $l_p$를 출력하도록 장려한다.
- 사용 이유: 교차 엔트로피 손실은 특히 특정 예측에 대한 높은 자신감이 원하는 경우, 백도어 공격의 경우와 같이 분류 작업에 대한 표준적이고 더 유익한 손실 함수이다.
-
$\text{Rad}_{D_p}^{D_s}(H_{W,D,1})$
- 수학적 정의: $D_p$와 $D_s$를 연결하는 분포 하에서 가설 공간 $H_{W,D,1}$의 Rademacher 복잡도. $H_{W,D,1}$은 너비 $W$와 깊이 $D$를 가진 신경망 $F$에 대한 함수 $h_F(x,y) = F_y(x)$의 집합이다. 표기법은 $D_p$의 샘플에서 계산된 Rademacher 복잡도이지만 $D_s$로 일반화되도록 제안한다.
- 물리적/논리적 역할: 이 항은 포이즈닝된 데이터의 맥락에서 모델 클래스의 "학습 가능성" 또는 "유연성"을 정량화한다. 더 높은 Rademacher 복잡도는 더 복잡한 패턴을 맞출 수 있는 모델을 나타내며, 적절하게 제어되지 않으면 과적합으로 이어질 수 있다. 이는 무작위 레이블을 맞추는 모델의 능력을 측정하며, 이는 과적합 능력의 프록시이다.
- 사용 이유: Rademacher 복잡도는 통계 학습 이론에서 신경망과 같은 복잡한 함수 클래스에 대한 일반화 오류를 경계하는 데 사용되는 기본적인 도구이다.
-
$\sqrt{\frac{\ln(1/\delta)}{N\alpha}}$
- 수학적 정의: 신뢰도 매개변수 $\delta$, 학습 세트 크기 $N$, 포이즈닝 비율 $\alpha$를 포함하는 제곱근 항.
- 물리적/논리적 역할: 이 항은 통계적 집중 구성 요소를 나타낸다. $N$이 증가함에 따라 이 항은 감소하여 더 나은 경계를 제공한다. 더 작은 $\alpha$ (더 적은 포이즈닝 샘플)는 이 항을 더 크게 만들어, 매우 적은 샘플로 포이즈닝 효과에 대한 통계적 일반화를 하는 것이 더 어렵다는 것을 나타낸다.
- 사용 이유: 이는 농도 불평등의 일반적인 항으로, 경계에 대한 특정 신뢰 수준을 달성하는 데 필요한 샘플 복잡성을 반영한다.
-
$\epsilon$
- 수학적 정의: 정리 4.5의 조건 (c1)에서 나온 작은 양수 값: $E_{(x,y)\sim D_p^{l_p}} [G_y(x + P(x))] \leq \epsilon$. 여기서 $G_y(x)$는 깨끗하게 훈련된 네트워크 $G$가 $x$를 $y$로 분류할 확률이다.
- 물리적/논리적 역할: 이 항은 트리거 $P(x)$가 얼마나 "적대적인지"를 정량화한다. $P(x)$가 깨끗하게 훈련된 네트워크 $G$가 $x+P(x)$를 오분류하도록 효과적으로 만든다면, $\epsilon$은 작을 것이다. 더 나은 경계를 위해 더 작은 $\epsilon$이 바람직하며, 이는 트리거가 효과적인 적대적 섭동이 되어야 함을 의미한다.
- 사용 이유: 이는 트리거가 깨끗한 모델을 효과적으로 "속일" 수 있도록 보장하는 트리거 설계에 대한 조건으로, 많은 백도어 공격의 특징이다.
-
$\tau$
- 수학적 정의: 정리 4.5의 조건 (c3)에서 나온 작은 양수 값: $E_{x\sim D_s} [|(F-G)_{l_p}(P(x)) - (F-G)_{l_p}(x+P(x))|] \leq \tau$. 이는 $P(x)$와 $x+P(x)$에 대한 네트워크 출력의 "백도어 부분"의 유사성을 측정한다.
- 물리적/논리적 역할: 이 항은 트리거 $P(x)$가 얼마나 "지름길"과 같은지를 정량화한다. 트리거가 지름길 역할을 한다면, $P(x)$ 자체에 대한 네트워크의 응답은 $x+P(x)$에 대한 응답과 유사해야 하며, 이는 작은 $\tau$를 초래한다. 더 나은 경계를 위해 더 작은 $\tau$가 바람직하며, 이는 트리거가 복잡한 입력 상호 작용보다는 간단하고 직접적인 특징(지름길)으로 작용함을 의미한다.
- 사용 이유: 이는 트리거가 복잡한 입력 상호 작용이 아니라 간단하고 직접적인 특징(지름길)으로 작용하도록 장려하는 트리거 설계에 대한 조건이다.
-
곱셈 대신 덧셈, 또는 합계 대신 적분은 왜인가?
이 방정식들은 오류의 다른 출처와 일반화 격차에 기여하는 요인들을 집계하기 때문에 합계로 구성된다. 각 항은 경험적 오류(관찰된 것), 모델 복잡성, 통계적 분산, 그리고 트리거의 특정 속성과 같은 별도의 측면을 나타낸다. 이러한 요인들은 모집단 오류에 대한 전체 상한선에 가산적으로 기여한다. 예를 들어, 모델 복잡성과 통계적 불확실성은 모두 경험적 오류가 실제 모집단 오류에서 벗어날 가능성을 독립적으로 증가시킨다.$E_{(x,y)\sim D_s}$ 표기법은 수학적으로 적분으로 표현되는 연속 확률 분포 $D_s$에 대한 기대를 의미한다. 대조적으로, $E_{(x,y)\in D_p}$는 유한하고 이산적인 데이터셋 $D_p$에 대한 경험적 평균을 나타내며, 이는 합계로 계산된다. 저자들은 실제 모집단을 참조하는지 이산 샘플을 참조하는지에 따라 적절한 수학적 연산자(적분 또는 합계)를 기대치 표기법을 통해 암묵적으로 사용한다.
단계별 흐름
실제 데이터 분포 $D_s$에서 시작하여 이러한 일반화 경계에 의해 설명된 개념적 메커니즘을 통해 추상적인 단일 데이터 포인트 $(x_0, y_0)$의 여정을 추적해 보자.
-
데이터 포인트의 기원: 우리의 여정은 실제 데이터 분포 $D_s$에서 대표적인 샘플인 추상적이고 깨끗한 데이터 포인트 $(x_0, y_0)$에서 시작한다. 여기서 $x_0$는 입력(예: 이미지)이고 $y_0$는 그 실제 레이블이다.
-
공격 평가를 위한 가상 포이즈닝: 포이즈닝 모집단 오류 $E_p(F,D_s)$를 평가하는 경우, 이 깨끗한 입력 $x_0$는 사전 설계된 트리거 $P(x_0)$를 추가하여 개념적으로 수정된다. 결과 입력은 $x_0 + P(x_0)$가 되고, 백도어 공격에 대한 의도된 레이블은 $y_0$와 상관없이 $l_p$가 된다. 이 변환된 쌍 $(x_0 + P(x_0), l_p)$는 모델이 올바르게 분류하기를 공격자가 원하는 것을 나타낸다. 깨끗한 일반화 오류 $E(F,D_s)$를 평가하기 위해 데이터 포인트는 $(x_0, y_0)$로 유지된다.
-
모델 추론 (블랙박스 네트워크 $F$): (가상으로) 훈련된 신경망 $F$는 이 입력을 받는다.
- 특징 변환: 입력( $x_0$ 또는 $x_0 + P(x_0)$)은 네트워크의 레이어를 통과한다. 컨볼루션, 비선형 활성화(예: ReLU) 및 풀링과 같은 연산으로 구성된 각 레이어는 원시 입력을 점진적으로 더 추상적이고 판별적인 특징 표현으로 변환한다.
- 출력 생성: 네트워크의 최종 레이어, 일반적으로 소프트맥스 레이어는 이러한 특징을 모든 가능한 출력 클래스에 대한 확률 분포로 변환한다. $F(z)$는 이러한 확률 벡터이며, 여기서 $F_y(z)$는 입력 $z$에 대한 레이블 $y$에 할당된 확률이다.
- 분류 결정: 네트워크의 최종 분류 $\text{argmax}_y F_y(z)$는 가장 높은 예측 확률을 가진 레이블이다.
-
오류/손실 계산 (모집단 수준):
- 깨끗한 오류: 깨끗한 일반화를 위해, 네트워크 출력 $F(x_0)$는 실제 레이블 $y_0$와 비교된다. 예측된 레이블 $\text{argmax}_y F_y(x_0)$가 $y_0$와 일치하지 않으면 오류가 기록된다. 이 과정은 개념적으로 모든 가능한 $(x,y) \sim D_s$에 대해 반복되고 평균화되어 $E(F,D_s)$를 얻는다.
- 포이즈닝 오류: 포이즈닝 일반화를 위해, 네트워크 출력 $F(x_0 + P(x_0))$는 타겟 레이블 $l_p$와 비교된다. $\text{argmax}_y F_y(x_0 + P(x_0))$가 $l_p$와 일치하지 않으면 오류가 기록된다. 이는 모든 가능한 $(x,y) \sim D_s$에 대해 평균화되어 $E_p(F,D_s)$를 얻는다.
-
경험적 대응 (학습 데이터 $D_p$): 실제 학습 단계 동안, 모델 $F$는 유한하고 관찰 가능하며 포이즈닝된 학습 데이터셋 $D_p$에 노출된다.
- 샘플 선택: $D_p$에서 특정 샘플 $(x_i, y_i)$가 추출된다. 이 샘플은 $D_{tr}$의 원래 깨끗한 샘플이거나 $D_{tr}$의 깨끗한 샘플 $(x_j, l_p)$를 섭동하여 생성된 포이즈닝된 샘플 $(x_j + P(x_j), l_p)$일 수 있다.
- 경험적 손실/오류: 네트워크 $F$는 $x_i$를 처리한다.
- 깨끗한 일반화 경계의 경우, 경험적 오류 $E(F,D_p)$는 지시 함수를 사용하여 $F(x_i)$와 $y_i$를 비교하여 계산된다.
- 포이즈닝 일반화 경계의 경우, 경험적 교차 엔트로피 손실 $L_{CE}(F(x_i), y_i)$가 계산된다. 이는 $x_i$ 입력에 대해 $F$가 $y_i$를 얼마나 잘 예측하는지를 측정한다.
- 평균화: 이러한 개별 오류 또는 손실은 유한 데이터셋 $D_p$의 모든 샘플에 대해 평균화되어 $E(F,D_p)$ 또는 $E_{(x,y)\in D_p} [L_{CE}(F(x), y)]$를 얻는다.
-
일반화 격차 연결: 수학적 엔진은 $D_p$에서의 이러한 관찰 가능한 경험적 오류/손실을 $D_s$에서의 관찰할 수 없는 실제 모집단 오류와 연결한다. 경계의 추가 항들(Rademacher 복잡도, $\sqrt{\frac{\ln(1/\delta)}{N\alpha}}$, $\epsilon$, $\tau$, $\lambda$)은 "보정 계수" 또는 "페널티 항" 역할을 한다. 이들은 다음을 정량화한다:
- 모델 용량: 네트워크 $F$가 과적합되기 쉬운 정도 (Rademacher 복잡도).
- 데이터 부족: 유한 학습 세트($N$)로 인한 통계적 불확실성.
- 포이즈닝 영향: 포이즈닝 비율($\alpha$)에 의해 도입된 특정 통계적 편향.
- 트리거 품질: 제작된 트리거 $P(x)$가 적대적($\epsilon$), 일관적($\lambda$), 지름길($\tau$)이라는 원하는 속성을 얼마나 잘 충족하는지.
이 모든 과정은 추상적인 수학을 움직이는 기계 조립 라인처럼 느끼게 한다: 원시 데이터가 입력되고, 기계(네트워크)에 의해 처리되며, 성능이 측정된다. 그런 다음 일반화 경계는 관찰된 성능과 내재된 설계 특성을 기반으로 미래의 보지 못한 데이터에 대한 기계의 성능을 예측하는 이론적 "품질 관리" 보고서를 제공한다.
최적화 동적
일반화 경계 자체는 피해자 모델 $F$의 직접적인 최적화 목표가 아니다. 대신, 백도어 공격이 효과적으로 일반화되는 조건 하에서 이론적 보장을 제공한다. 이 맥락에서 "최적화 동적"은 트리거 $P(x)$가 이러한 조건을 충족하도록 설계되는 방식과 이러한 경계를 준수하면서 원하는 백도어 동작을 달성하도록 피해자 모델 $F$가 학습되는 방식을 참조한다.
포이즈닝 트리거 $P(x)$를 생성하기 위한 논문의 제안된 알고리즘(알고리즘 1)은 공격 자체의 주요 최적화 동적이 발생하는 곳이다:
-
적대적 섭동 제작 (작은 $\epsilon$에 대한 조건 c1/t1 충족):
- 메커니즘: 네트워크 $F_1$이 깨끗한 데이터셋 $T$로 학습된다. 각 깨끗한 샘플 $x$에 대해, PGD(Projected Gradient Descent)를 사용하여 적대적 섭동 $x_{adv}$가 생성된다. PGD는 원래 레이블 $y$에 대한 $F_1$의 손실을 최대화하는 작은 섭동 $\epsilon$(무한대 노름 예산 $\eta$ 내)을 찾는 반복적인 최적화 과정이다.
- 기울기 및 손실 지형: 이는 $\epsilon$에 대한 손실 함수 $L(F_1(x+\epsilon), y)$의 기울기를 계산하는 것을 포함한다. 최적화는 기울기 방향으로 단계를 취하여(기울기 상승) 손실을 증가시킨 다음, $\epsilon$을 허용된 섭동 공간으로 다시 투영함으로써 반복적으로 $\epsilon$을 업데이트한다. 이 과정은 트리거의 "적대적" 구성 요소를 형성하며, $\epsilon$( $P(x)$에 기여함)이 효과적인 적대적 예가 되도록 하여, 경계의 $\epsilon$이 작도록 보장한다.
-
지름길 섭동 제작 (작은 $\tau$에 대한 조건 c3/t3 충족):
- 메커니즘: 별도의 더 간단한 이중 레이어 네트워크 $F_2$가 특별히 구성된 데이터셋 $T_1$으로 학습된다. 이 데이터셋에는 깨끗한 샘플과 $x_{adv}$(이전 단계에서)로 섭동된 샘플이 포함되지만, 특정 레이블(0)이 지정된다. 목표는 Min-Min 방법을 사용하여 "지름길" 섭동 $x_{scut}$을 찾는 것이다. 이 방법은 $F_2$에 대해 최적의 $x_{scut}$을 찾는 내부 최적화 루프와 $F_2$를 학습하는 외부 최적화 루프를 포함한다. 이는 $F_2$의 손실 지형을 포이즈닝된 데이터로부터 간단하고 선형적으로 분리 가능한 특징을 학습하도록 형성한다. 이는 효과적으로 타겟 레이블로 트리거를 매핑하는 "지름길"을 만든다. $F_2$의 매개변수와 $x_{scut}$의 반복적인 업데이트는 $\tau$를 최소화하여 트리거가 강력한 지름길 특징으로 작용하도록 한다.
-
섭동 결합 ( $\lambda$가 1에 가까워지도록 조건 c2/t2 충족):
- 메커니즘: 최종 트리거 $P(x)$는 이진 마스크 $U$를 사용하여 $x_{adv}$와 $x_{scut}$을 결합하여 구성된다: $P(x) = U \odot x_{adv} + (1-U) \odot x_{scut}$. 마스크 $U$는 (예: 상단 왼쪽 모서리가 0이고 나머지는 1인 특정 영역) 지름길 구성 요소 $(1-U) \odot x_{scut}$가 다른 입력에 대해 유사하도록 설계된다.
- 기울기/상태 업데이트의 동작: $\lambda$ 자체에 대한 직접적인 기울기 기반 최적화는 없지만, 마스크 $U$의 설계 선택과 Min-Min 방법의 속성(다른 입력에 대해 유사한 지름길을 생성하는 경향)은 암묵적으로 트리거 생성을 조건 (c2)을 만족하도록 유도한다. 이는 트리거가 일관된 패턴이 되도록 보장하여 $\lambda$가 경계에서 1에 가까워지도록 한다. 알고리즘 1을 사용하여 얻은 일부 포이즈닝은 그림 1에 표시된다.
-
피해자 모델 학습 및 수렴:
- 메커니즘: 트리거 $P(x)$가 생성되면, 원래 깨끗한 학습 데이터 $D_{tr}$의 일부에 적용되어 포이즈닝된 학습 세트 $D_p$를 형성한다. 그런 다음 피해자 네트워크 $F$는 교차 엔트로피 손실 함수를 사용하여 표준 최적화 알고리즘(예: 확률적 경사 하강법(SGD))으로 $D_p$에서 학습된다.
- 손실 지형 및 수렴: $D_p$에 포이즈닝된 샘플이 존재하면 피해자 모델 $F$의 손실 지형이 수정된다. 모델은 $D_p$에 대한 경험적 손실을 최소화하도록 학습되며, 이는 깨끗하지 않은 샘플에 대한 깨끗한 분류 작업과 트리거가 있는 샘플에 대한 백도어 작업을 모두 학습해야 함을 의미한다. 그런 다음 일반화 경계는 최종 모델 $F$의 일반화 성능을 예측한다. 트리거 $P(x)$가 정리 조건(작은 $\epsilon, \tau$, $\lambda$가 1에 가까움)을 성공적으로 충족했다면, 경계는 수렴 시 피해자 모델이 높은 깨끗한 정확도와 높은 공격 성공률을 보일 것이라고 예측한다. SGD를 통한 $F$의 매개변수에 대한 반복적인 업데이트는 이 복잡한 다중 목표 손실 지형의 지역 최소값으로 이를 구동한다.
본질적으로 최적화 동적은 두 단계 프로세스이다: 첫째, 일반화 경계와 수학적으로 연결된 특정 속성(적대적, 지름길, 일관적)을 갖도록 트리거 $P(x)$를 제작하기 위한 대상, 경사 기반 최적화; 둘째, 결과 포이즈닝 데이터셋에서 피해자 네트워크를 표준 학습하는 것으로, 여기서 경계는 최종 모델의 일반화 성능을 예측한다. 경계는 이러한 트리거 설계 원칙이 효과적이고 일반화 가능한 백도어 공격으로 이어지는 이유를 제공하는 이론적 프레임워크를 제공한다.
 Figure 1. From top row to bottom row are respectively the clean images, normalized triggers (original trigger has L∞norm bound 16/255), poison images. Due to the selection of U, the upper left corners of the poison images are similar, while the other parts are used to generate adversaries
Figure 1. From top row to bottom row are respectively the clean images, normalized triggers (original trigger has L∞norm bound 16/255), poison images. Due to the selection of U, the upper left corners of the poison images are similar, while the other parts are used to generate adversaries
결과, 한계 및 결론
실험 설계 및 기준선
제안된 깨끗한 레이블 백도어 공격의 이론적 주장과 효과를 엄격하게 검증하기 위해, 저자들은 다양한 벤치마크 데이터셋과 피해자 네트워크 아키텍처에 걸쳐 광범위한 실험을 수행했다. 실험 설정은 공격자가 피해자 학습 과정에 대한 제한된 지식과 통제력을 가진 실제 공격 시나리오를 시뮬레이션하도록 세심하게 설계되었다.
데이터셋 및 피해자 모델: 공격은 널리 사용되는 이미지 분류 데이터셋인 CIFAR10, CIFAR100, SVHN 및 TinyImageNet에서 평가되었다. 피해자 모델로는 VGG16, ResNet18 및 WRN34-10과 같은 인기 있는 심층 신경망이 사용되었다.
공격 메커니즘 및 트리거 생성: 제안된 공격의 핵심은 적대적 노이즈와 무차별적인 포이즈닝을 결합하는 새로운 트리거 생성 방법(알고리즘 1)을 포함한다. 이 과정 자체는 피해자 네트워크의 구조나 계산 능력에 대한 가정을 피하기 위해 더 작고 독립적인 네트워크(F1은 적대적 노이즈용, F2는 지름길 섭동용)를 활용한다. 예를 들어, F1은 L-무한대 노름 예산(예: 255분의 8 또는 255분의 4)으로 PGD-10 적대적 학습을 사용하여 학습되었으며, F2는 이중 레이어 네트워크로 Min-Min 방법을 사용하여 지름길을 만들었다. 포이즈닝 과정은 특정 타겟 레이블 $l_p$(일반적으로 0으로 설정됨)를 가진 학습 샘플의 일부(예: 학습 이미지의 1% 또는 0.8%)를 무작위로 선택하고 생성된 트리거를 원래 레이블을 변경하지 않고 추가하는 것을 포함했다.
평가 지표 및 기준선: 공격의 효과는 주로 다음으로 측정되었다:
1. 깨끗한 모델 정확도: 포이즈닝된 모델이 깨끗한 테스트 샘플에 대해 보이는 정확도.
2. 포이즈닝된 모델 정확도: 포이즈닝된 모델이 포이즈닝된 테스트 샘플에 대해 보이는 정확도.
3. 공격 성공률 (ASR): 트리거를 포함하는 샘플이 타겟 레이블 $l_p$로 오분류되는 비율.
4. 깨끗한 모델 $l_p$ 정확도: 타겟 클래스 $l_p$에 속하는 깨끗한 샘플의 정확도.
제안된 방법은 일곱 가지 저명한 깨끗한 레이블 백도어 공격(Clean Label, Hidden Trigger, Reflection, Invisible Poison, Image-specific, Narcissus, Sleeper Agent)과 비교되었다. 공정한 비교를 위해, 모든 공격은 L-무한대 노름 트리거 예산(예: 255분의 16)과 고정된 포이즈닝 예산(예: 학습 이미지의 1%)으로 제약되었다.
방어 메커니즘: 공격의 견고성을 평가하기 위해, 여섯 가지 일반적인 백도어 방어(적대적 학습(AT), 데이터 증강, 스케일업, 차분 프라이버시 SGD(DPSGD), 주파수 필터, 미세 조정)에 대해 테스트되었다.
이론적 검증: 경험적 성능을 넘어, 저자들은 정리 4.1 및 4.5를 검증하기 위해 설계된 애블레이션 연구를 수행했다. 여기에는 트리거의 다른 구성 요소(적대적 노이즈, 지름길 노이즈)가 정리 4.5의 조건(c1), (c2), (c3)에 미치는 영향을 분석하는 것이 포함되었으며, $V_{adv}$(조건 (c1)에 대한 포이즈닝된 데이터의 검증 손실) 및 $V_{sc}$(조건 (c3)에 대한 이진 분류 손실)와 같은 지표를 사용했다. 또한 전반적인 정확도에 대한 포이즈닝 비율의 영향을 조사하여 정리 4.1을 뒷받침했다.
증거가 증명하는 것
실험 증거는 제안된 깨끗한 레이블 백도어 공격의 효과성과 이론적 근거를 강력하게 뒷받침한다.
핵심 메커니즘의 결정적 증거:
적대적 노이즈와 무차별적인 포이즈닝을 결합하여 정리 4.5의 조건을 충족하는 트리거를 생성하는 핵심 메커니즘은 잔혹하게 효과적임이 입증되었다. 공격은 깨끗한 샘플에 대한 높은 정확도를 유지하면서 일관되게 높은 공격 성공률(ASR)을 달성했으며, 이는 깨끗한 레이블 백도어 공격의 두 가지 주요 목표이다. 예를 들어, CIFAR-10에서 ResNet18 및 1% 포이즈닝 예산(L-무한대 노름 255분의 16)으로, 제안된 방법은 93%의 ASR을 달성했으며, 깨끗한 모델 정확도는 93%, 포이즈닝된 모델 정확도는 91%였다 (표 1). 이는 피해자 모델이 트리거를 입력 오분류를 타겟 레이블 $l_p$로 유도하도록 학습했지만, 합법적인 깨끗한 데이터에 대해서도 잘 수행되었음을 보여준다.
"피해자"(기준선 모델)는 결정적으로 패배했다. L-무한대 노름 예산 255분의 16 하에서, 우리의 공격은 CIFAR-10에서 93%의 ASR을 달성했으며, 이는 다른 모든 비교 방법(23%(Clean-Label)에서 75%(Hidden-Trigger)까지)을 훨씬 능가했다 (표 4). 이 부인할 수 없는 증거는 트리거의 적대적 노이즈와 지름길 속성의 특정 조합이 효과적인 백도어를 심는 데 우수함을 강조한다. 공격의 효과는 다양한 데이터셋(CIFAR10, CIFAR100, SVHN, TinyImageNet)과 다른 타겟 레이블(0-9)에 걸쳐 높게 유지되었다 (표 3 및 그림 3). 이는 특정 데이터셋이나 타겟 클래스에 국한된 것이 아니라 일반화 가능한 공격 전략임을 나타낸다. 학습 과정 모니터링(그림 2)은 깨끗한 모델과 포이즈닝된 모델의 정확도가 비슷하게 유지되었고 ASR이 높은 수준으로 빠르게 안정화되었음을 추가로 확인했으며, 이는 백도어의 견고한 학습을 나타낸다.
이론적 주장 검증:
정리 4.5를 검증하기 위해 특별히 설계된 애블레이션 연구는 중요한 통찰력을 제공했다. 다른 포이즈닝 유형(무작위 노이즈, 보편적 적대적, 적대적, 지름길, 그리고 우리 방식)을 비교하고 $V_{adv}$(조건 c1에 관련됨) 및 $V_{sc}$(조건 c3에 관련됨)에 미치는 영향을 평가함으로써, 저자들은 개별 구성 요소가 종종 한 조건에서는 뛰어나지만 다른 조건에서는 실패함을 보여주었다. 예를 들어, 적대적 섭동만($Adv$) 사용하면 높은 $V_{adv}$(조건 c1이 잘 충족되지 않았음을 의미)을 초래했지만, 지름길 노이즈만($SCut$) 사용하면 높은 $V_{sc}$(조건 c3이 잘 충족되지 않았음을 의미)을 초래했다. 그러나 두 가지 모두를 결합한 제안된 "우리 방식" 방법은 좋은 $V_{adv}$와 매우 낮은 $V_{sc}$를 가진 균형 잡힌 결과를 달성하여 훨씬 더 높은 ASR(255분의 16 예산 하에서 우리 방식의 경우 93% 대 적대적의 경우 22%, 지름길의 경우 30%)을 초래했다 (표 6). 이는 정리 4.5의 조건을 결합된 트리거 메커니즘을 통해 충족하는 것이 우수한 공격 성능으로 이어진다는 것을 직접적으로 검증한다.
정리 4.1에 관해서는, 실험 결과가 더 높은 포이즈닝 비율이 일반적으로 깨끗한 정확도에 더 큰 영향을 미치지만, 감소가 중요하지는 않다는 것을 보여주었다 (예: 3,000개 이상의 포이즈닝된 샘플에 대해 4% 감소에 불과함, 표 14). 이는 포이즈닝 비율이 일반화에 영향을 미친다는 이론적 통찰력을 뒷받침하지만, 통제된 포이즈닝 예산으로 깨끗한 샘플 정확도에 대한 영향은 최소화될 수 있음을 시사한다. 또한, 피해자 네트워크는 트리거 특징을 효과적으로 학습하는 것으로 나타났지만(표 12), 여전히 원래 이미지 특징을 우선시하여 백도어가 효과적이려면 충분한 규모의 포이즈닝이 필요했다.
한계 및 향후 방향
제안된 깨끗한 레이블 백도어 공격은 놀라운 효과를 보여주고 견고한 이론적 일반화 경계에 기반하고 있지만, 논문은 몇 가지 한계를 인정하고 향후 연구를 위한 길을 열어준다.
현재 한계:
하나의 중요한 한계는 정리 4.5에 설명된 조건의 복잡성에 있다. 저자들 스스로 이러한 조건이 "상당히 복잡하다"고 말하며, 포이즈닝 모집단 오류 경계에 대한 더 간단하고 직관적인 조건을 도출하는 것이 매우 바람직할 것이라고 말한다. 이 복잡성은 이론적 프레임워크의 광범위한 이해와 적용을 방해할 수 있다.
또 다른 이론적 격차는 현재 일반화 경계가 학습 과정을 명시적으로 통합하지 않는다는 것이다. 특히 안정성 분석(예: Hardt et al., 2016)에 기반한 알고리즘 종속 일반화 경계는 백도어 공격의 맥락에서 추가 조사가 필요하다. 이러한 분석은 학습 동적이 공격의 성공과 일반화에 어떻게 영향을 미치는지를 더 세분화된 이해를 제공할 수 있다.
실질적인 관점에서, 논문은 생성된 트리거가 다른 데이터셋 간에 제한된 전이성을 보인다고 언급한다. 예를 들어 CIFAR-10에 대해 생성된 트리거는 CIFAR-100에 직접 적용할 수 없다 (부록 F.5). 이는 공격의 다용성을 제한하고 각 새 데이터셋에 대해 트리거를 다시 생성해야 하므로 계산 집약적일 수 있다.
또한, 공격은 기준선에 대해 매우 효과적이지만 "방어 하에서는 다소 취약한" 것으로 보인다 (섹션 6.4). 저자들은 이러한 방어를 견디기 위해 방어 메커니즘을 생성 과정에 통합하는 "향상된 공격"을 제안했지만, 이는 공격의 견고성이 내재된 것이 아니라 지속적인 적응을 요구한다는 것을 시사한다. 방어의 견고성-정확도 절충이 관찰된 것도 도전을 강조한다: 피해자 모델의 깨끗한 데이터에 대한 성능을 크게 저하시키지 않고 공격 복원력을 향상시키는 방법.
향후 방향 및 토론 주제:
본 논문의 결과는 미래 연구를 위한 강력한 기반을 마련하며, 여러 토론 주제를 촉발한다:
- 이론적 조건 단순화: 정리 4.5의 조건을 더 쉽게 처리하고 해석할 수 있도록 재구성하거나 근사하는 방법은 무엇인가? "적대적 노이즈"와 "지름길" 속성에 대한 더 추상적이고 높은 수준의 이해가 충분한가, 아니면 정확한 수학적 조건이 이론적 보장에 필수적인가?
- 알고리즘 종속 일반화 경계: 학습 알고리즘의 어떤 특정 측면(예: 최적화기, 학습률, 정규화)이 백도어 공격의 일반화에 가장 큰 영향을 미치는가? 더 실질적인 지침을 제공하는 더 나은 알고리즘 종속 경계를 유도할 수 있는가? 이는 심층 학습에서의 암묵적 정규화와 같은 개념을 탐구하는 것을 포함할 수 있다.
- 데이터셋 간 트리거 전이성: 재생성 없이 다양한 데이터셋에 걸쳐 작동하는 보편적이거나 더 전이 가능한 트리거를 설계하는 방법은 무엇인가? 이는 트리거 생성을 위한 메타 학습 접근 방식이나 효과적인 백도어 트리거 역할도 하는 데이터셋 불변 "보편적 적대적 섭동"을 식별하는 것을 포함할 수 있다.
- 공격-방어 무기 경쟁: 알려진 완화 전략에 덜 취약한 근본적으로 더 견고한 백도어 공격을 개발하는 방법은 무엇인가? 반대로, 방어는 기존 공격 메커니즘에 대한 반응이 아니라 예측적으로 새로운 공격 메커니즘을 예측하고 무력화하도록 설계될 수 있는가? 이는 적응형 공격/방어 전략 또는 이 무기 경쟁의 게임 이론 모델로 이어질 수 있다.
- 윤리적 함의 및 책임 있는 AI: 논문은 이러한 방법이 악의적인 행위자에 의해 사용될 수 있다는 점을 명시적으로 언급한다. 이는 책임 있는 공개, AI 보안을 위한 "레드 팀" 개발, 그리고 강력한 규제 프레임워크의 필요성에 대한 중요한 질문을 제기한다. 과학계는 강력한 AI 기능의 오용을 방지해야 할 필요성과 함께 개방형 연구의 균형을 어떻게 맞출 수 있는가?
- 이미지 분류 너머: 이론적 프레임워크와 공격 방법론을 자연어 처리, 음성 인식 또는 강화 학습과 같은 다른 도메인으로 확장할 수 있는가? 이러한 다른 데이터 양식 및 작업 구조에 "적대적 노이즈" 및 "지름길" 개념을 적용할 때 어떤 고유한 과제와 기회가 발생할 것인가?
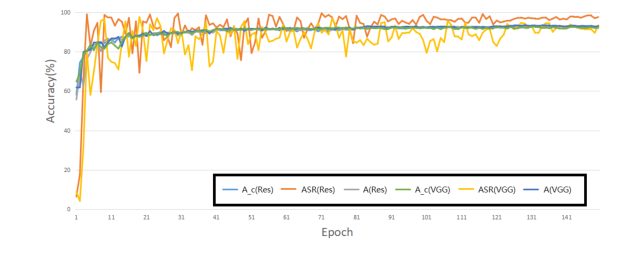 Figure 2. Attack performance during the training process on CIFAR10 with ResNet18 and VGG16. This figure shows the trend of the poison model accuracy (A), attack success rate (ASR) and clean model accuracy (Ac)
Figure 2. Attack performance during the training process on CIFAR10 with ResNet18 and VGG16. This figure shows the trend of the poison model accuracy (A), attack success rate (ASR) and clean model accuracy (Ac)
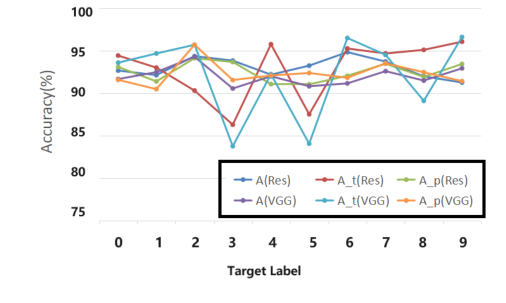 Figure 3. Performance of different target label lp. We show the poison model accuracy (A), accuracy of target label (At), attack success rate (Ap) on CIFAR-10, using VGG16 and ResNet18
Figure 3. Performance of different target label lp. We show the poison model accuracy (A), accuracy of target label (At), attack success rate (Ap) on CIFAR-10, using VGG16 and ResNet18