Граница обобщения и новый алгоритм для атаки с использованием бэкдора на чистых метках
Проблема, рассматриваемая в данной статье, берет свое начало в области теории машинного обучения, в частности, касательно обобщающих способностей обучающих алгоритмов.
Предыстория и академическая родословная
Истоки и академическая родословная
Проблема, рассматриваемая в данной статье, берет свое начало в области теории машинного обучения, в частности, касательно обобщающих способностей обучающих алгоритмов. Исторически концепция границы обобщения была важнейшим теоретическим инструментом для понимания того, насколько хорошо модель, обученная на конечном наборе данных, может работать на невидимых данных. Ранние работы в этой области, на которые ссылаются Mohri et al. (2018), были сосредоточены на таких метриках, как VC-размерность и сложность Радемахера, для количественной оценки этой обобщающей способности в стандартных задачах обучения.
Однако по мере того, как модели машинного обучения становились более сложными, а области применения диверсифицировались, возникли новые проблемы. Одной из значительных проблем являются атаки отравления данных, при которых злоумышленники манипулируют обучающими данными для компрометации целостности модели. Хотя границы обобщения для общих атак отравления данных исследовались (например, Wang et al., 2021; Hanneke et al., 2022), специфический и особенно коварный тип атаки, атака с использованием бэкдора, представлял собой уникальную проблему.
Точное происхождение этой проблемы связано с отличительными характеристиками атак с использованием бэкдора. В отличие от других методов отравления данных, атака с использованием бэкдора имеет двойную цель: во-первых, поддерживать высокую точность на нормальных, чистых данных, и во-вторых, заставлять модель выдавать определенную, целевую метку при наличии в входных данных особого "триггера". Важно отметить, что этот триггер встраивается как в обучающие, так и в тестовые наборы данных. Существующие границы обобщения не были разработаны для учета этой двойной цели или природы отравленных наборов данных, не являющихся i.i.d. (независимыми и одинаково распределенными), что является фундаментальным предположением для классической теории обобщения. Авторы явно заявляют, что, насколько им известно, граница обобщения, специфичная для атак с использованием бэкдора, не была установлена, выделяя это как значительный пробел в академической литературе, который данная статья стремится заполнить.
Фундаментальное ограничение предыдущих подходов заключалось в их опоре на условие i.i.d., которое является краеугольным камнем классической теории обобщения. Предыдущие модели и связанные с ними границы неявно предполагали, что обучающие данные были выбраны независимо и одинаково из истинного распределения данных. Однако в контексте отравления данных, и особенно атак с использованием бэкдора, отравленный обучающий набор данных по своей сути нарушает это предположение i.i.d. Введение триггеров и целевых неправильных классификаций означает, что отравленные образцы больше не являются простым отражением основного распределения чистых данных. Это нарушение сделало существующие границы обобщения неприменимыми, сделав невозможным теоретическую оценку обобщающей способности моделей, обученных в сценариях атак с использованием бэкдора. Эта "болевая точка" заставила авторов разработать новые теоретические основы, способные обрабатывать уникальные свойства атак с использованием бэкдора на чистых метках.
Интуитивно понятные термины предметной области
-
Граница обобщения (Generalization Bound):
- Специализированный термин: Математический верхний предел разницы между производительностью модели на обучающих данных и ее производительностью на новых, невидимых данных.
- Интуитивная аналогия: Представьте, что вы готовитесь к экзамену по вождению. "Граница обобщения" — это как гарантия того, что если вы хорошо потренируетесь на определенном наборе дорог (ваши обучающие данные), то вы будете работать с определенной погрешностью на любой новой дороге, которую встретите во время реального экзамена (невидимые данные). Она показывает, насколько надежно ваши усвоенные навыки будут переноситься на новые ситуации.
-
Атака с использованием бэкдора на чистых метках (Clean-Label Backdoor Attack):
- Специализированный термин: Тип атаки отравления данных, при которой в небольшую подвыборку обучающих образцов добавляется тонкий, часто незаметный триггер, но их исходные метки остаются правильными. Цель состоит в том, чтобы обученная модель классифицировала любой вход, содержащий этот триггер, как определенную целевую метку, при этом сохраняя высокую точность на чистых данных.
- Интуитивная аналогия: Представьте себе судью на выставке собак, который обучен распознавать разные породы. "Атака с использованием бэкдора на чистых метках" — это как если бы кто-то тайно прикрепил крошечную, незаметную красную ленточку (триггер) к нескольким собакам во время обучения, но при этом говорил судье их правильную породу. Судья учится правильно распознавать все породы. Однако, если любая собака, даже та, которую он никогда раньше не видел, имеет эту красную ленточку, судья будет обманут и всегда будет называть ее "Пуделем", независимо от ее фактической породы. Исходные метки отравленных обучающих данных были "чистыми" (правильными), что делало атаку незаметной.
-
Условие i.i.d. (Независимые и одинаково распределенные) (i.i.d. condition):
- Специализированный термин: Статистическое предположение, что все образцы данных независимы друг от друга и взяты из одного и того же вероятностного распределения.
- Интуитивная аналогия: Это похоже на вытягивание карт из идеально перемешанной колоды. Каждая вытянутая карта "независима" от предыдущей (она не влияет на следующую вытяжку) и происходит из "одинакового распределения" (той же колоды). Если кто-то тайно уберет все тузы после ваших первых нескольких вытяжек, последующие вытяжки больше не будут i.i.d. В машинном обучении это означает, что каждый фрагмент данных подобен свежему, необъективному наблюдению из реального мира, и это предположение имеет решающее значение для выполнения многих доказательств.
-
Сложность Радемахера (Rademacher Complexity):
- Специализированный термин: Мера "богатства" или "емкости" пространства гипотез (множества всех возможных функций, которые может изучить модель). Она количественно определяет, насколько хорошо модель может подгонять случайный шум.
- Интуитивная аналогия: Представьте себе очень гибкого художника, который может нарисовать что угодно, даже чисто случайные каракули. "Сложность Радемахера" измеряет, насколько хорошо этот художник может идеально воспроизвести чистую случайность. Если художник может идеально нарисовать любую случайную каракулю, он чрезвычайно гибок (высокая сложность). В ИИ это говорит нам о том, насколько легко модель может запомнить случайный шум, что часто является признаком того, что она переобучается, а не изучает истинные закономерности.
-
Шорткат (Shortcut):
- Специализированный термин: Простая, легко усваиваемая особенность, которую модель может использовать для принятия решений, вместо того чтобы изучать предполагаемые, более сложные и надежные особенности.
- Интуитивная аналогия: Если вы учите ребенка распознавать "машины", и на всех ваших обучающих изображениях машин случайно оказывается логотип определенного бренда в углу, ребенок может научиться распознавать "этот логотип" как "машину" вместо фактических признаков машины, таких как колеса, окна и форма. Логотип является "шорткат"-особенностью, которую легче изучить, но которая не обобщается на реальные машины без этого конкретного логотипа. В статье упоминается, что неразборчивый яд можно рассматривать как такие шорткаты.
Таблица обозначений
| Обозначение | Описание |
|---|---|
Определение проблемы и ограничения
Основная постановка задачи и дилемма
Основная проблема, рассматриваемая в данной статье, заключается в отсутствии теоретического понимания и гарантий обобщения для атак с использованием бэкдора на чистых метках в глубоком обучении.
Вход/Текущее состояние:
Отправной точкой является стандартная установка машинного обучения, где нейронная сеть $F$ обучается на чистом обучающем наборе данных $D_{tr} = \{(x_i, y_i)\}_{i=1}^N$. Предполагается, что этот набор данных независимо и одинаково распределен (i.i.d.) из основного распределения данных $D_s$. Основная цель такого обучения — минимизировать популяционную ошибку $E_{(x,y) \sim D_s}[1(F(x) \neq y)]$, которая измеряет производительность модели на невидимых данных. Существующие теории обобщения, включая границы, основанные на VC-размерности, сложности Радемахера или алгоритмической стабильности, фундаментально опираются на это предположение i.i.d. обучающих данных.
Желаемый конечный результат (выход/целевое состояние):
Статья направлена на создание теоретически обоснованной "атаки с использованием бэкдора на чистых метках". Это включает создание отравленного обучающего набора $D_p$ путем тонкой модификации подмножества чистых обучающих данных с помощью "триггера" $P(x)$, причем без изменения исходных меток. Нейронная сеть $F$, обученная на этом $D_p$, должна затем удовлетворять двойной цели:
1. Поддержание высокой точности на чистых образцах: Модель должна по-прежнему хорошо работать на не отравленных, чистых данных, что означает, что ее чистая популяционная ошибка $E(F, D_s) = E_{(x,y) \sim D_s}[1(F(x) \neq y)]$ остается низкой.
2. Обеспечение целевой неправильной классификации для триггерных входных данных: Любой вход $x$, содержащий триггер $P(x)$ (т.е. $x + P(x)$), должен быть классифицирован $F$ как определенная, заранее заданная целевая метка $l_p$. Это количественно определяется минимизацией ошибки отравления популяции $E_p(F, D_s) = E_{(x,y) \sim D_s}[1(F(x + P(x))) \neq l_p)]$.
Дилемма и недостающее звено:
Точным недостающим звеном является установление надежных границ обобщения для моделей, обученных в сценариях атак с использованием бэкдора на чистых метках. Болезненный компромисс или дилемма, которая поставила в тупик предыдущих исследователей, заключается в том, что атаки с использованием бэкдора по своей сути нарушают предположение i.i.d. обучающих данных. Вводя отравленные образцы, набор данных $D_p$ больше не является i.i.d. выборкой из $D_s$. Это напрямую делает недействительным основополагающий принцип классической теории обобщения, делая невозможным прямое применение существующих границ для гарантии желаемой производительности как на чистых, так и на триггерных данных.
Более того, для цели обобщения отравления (Q2 в статье) простое минимизирование эмпирической ошибки на отравленном обучающем наборе данных $D_p$ не гарантирует автоматически, что любые данные с триггером будут классифицированы как целевая метка $l_p$. Это связано с тем, что если чистый образец $(x, y)$ с $y \neq l_p$ не был отравлен до $(x + P(x), l_p)$ в $D_p$, то минимизация эмпирической ошибки на $D_p$ не обязательно заставит сеть классифицировать $x + P(x)$ как $l_p$. Это выявляет тонкий, но критический разрыв между эмпирической производительностью на отравленном обучающем наборе и желаемым поведением обобщения для триггерных входных данных.
Ограничения и сбои
Проблема установления границ обобщения для атак с использованием бэкдора на чистых метках чрезвычайно сложна из-за нескольких суровых, реалистичных препятствий:
- Не-i.i.d. распределение данных: Как подчеркивалось, наиболее значительным ограничением является то, что отравленный обучающий набор данных $D_p$ принципиально не удовлетворяет условию i.i.d. (Страница 1, Аннотация; Страница 2, объяснение Q1). Это прямое следствие механизма атаки и делает стандартные теории обобщения неприменимыми. Разработка новых теоретических инструментов для обработки этой не-i.i.d. природы является серьезным препятствием.
- Двойные, противоречивые цели: Атака имеет две различные цели: поддержание высокой точности на чистых данных и обеспечение неправильной классификации на триггерных данных. Эти цели могут быть в противоречии. Модель может переобучиться на отравленных образцах для достижения бэкдора, потенциально ухудшая свою производительность на чистых данных, или наоборот. Балансирование этих двух целей при предоставлении теоретических гарантий является сложной задачей.
- Незаметность чистых меток: Свойство "чистых меток" означает, что метки отравленных образцов не изменяются. Это делает атаку более незаметной, но также затрудняет ее изучение моделью. Сеть должна неявно ассоциировать триггер с целевой меткой $l_p$ без явного указания меток для отравленных входных данных, полагаясь исключительно на наличие триггера.
- Специфические условия триггера для обобщения отравления: Чтобы гарантировать, что ошибка обобщения отравления мала, триггер $P(x)$ не может быть произвольным. Теорема 4.5 (Страница 4) перечисляет три критических условия (c1, c2, c3), которым должен удовлетворять $P(x)$:
- (c1) Состязательный шум: Триггер должен действовать как состязательный шум для сети, обученной на чистых данных. Это подразумевает необходимость специфических свойств возмущения.
- (c2) Сходство триггера: Триггер $P(x)$ должен быть похож на разных входных образцах $x$. Если триггеры сильно варьируются, модель может испытывать трудности с обобщением поведения бэкдора.
- (c3) Свойство шортката: Триггер должен функционировать как "шорткат" для специально разработанного бинарного набора данных. Это нетривиальное свойство для инженерии и обеспечения, поскольку оно связано с тем, как триггер влияет на границу принятия решений модели. Без этих условий обобщение атаки на невидимые триггерные данные не гарантируется.
- Ограничения вычислительных ресурсов и ресурсов атакующего (неявные): Хотя это явно не указано как ограничения "определения проблемы", экспериментальная установка (Раздел F.1, Страницы 32-33) выявляет практические ограничения, которые делают проблему сложнее в реальных сценариях:
- Ограниченное знание атакующего: Предполагается, что атакующий имеет ограниченное знание структуры и процесса обучения целевой сети. Это означает, что триггеры должны быть эффективными даже при генерации с использованием меньших, прокси-сетей.
- Ограниченная вычислительная мощность: Предполагается, что атакующий имеет ограниченные вычислительные ресурсы, что влияет на сложность алгоритмов генерации триггеров.
- Ограничения невидимости: Триггеры часто ограничиваются нормами $L_\infty$ (например, 16/255), чтобы оставаться незаметными (Страница 6, 35). Это физическое ограничение ограничивает величину возмущений, что затрудняет создание эффективных и надежных триггеров.
- Недифференцируемые функции: Использование индикаторных функций $1(\cdot)$ для расчета ошибки (например, $1(F(x) \neq y)$) вводит недифференцируемость, что усложняет прямую оптимизацию и теоретический анализ в некоторых контекстах. В статье используется функция потерь кросс-энтропии (LCE) в Теоремах 1.2 и 4.5, которая является дифференцируемой, но конечная цель — ограничить недифференцируемую ошибку классификации.
Почему этот подход
Неизбежность выбора
Выбранный авторами подход, сосредоточенный на выводе новых границ обобщения для атак с использованием бэкдора на чистых метках, был не просто одним из вариантов, а единственным жизнеспособным решением ранее нерешенного теоретического пробела. Точный момент, когда авторы осознали, что традиционные "SOTA" методы недостаточны, четко изложен в статье: "Однако эти границы обобщения предназначены для чистого обучающего набора данных и не могут быть применены к отравленному обучающему набору данных, поскольку отравленные наборы данных не удовлетворяют условию i.i.d., которое необходимо для обобщаемости" (Раздел 1, страница 1).
Это утверждение подчеркивает фундаментальное ограничение существующих теорий обобщения, которые обычно предполагают, что данные являются независимыми и одинаково распределенными (i.i.d.). Атаки с использованием бэкдора по своей природе вводят тщательно разработанные возмущения в подмножество обучающих данных, нарушая это критическое предположение i.i.d. Следовательно, стандартные границы обобщения, будь то на основе VC-размерности, сложности Радемахера или специфичные для архитектур DNN (например, CNN, Трансформеры), становятся неприменимыми. Проблема заключалась не в поиске лучшей модели или алгоритма в рамках существующих фреймворков, а в создании новой теоретической основы для понимания обобщающей способности атак в условиях не-i.i.d. отравленных данных. Более того, уникальная двойная цель атак с использованием бэкдора — поддержание высокой точности на чистых образцах при обеспечении целевой неправильной классификации для триггерных входных данных — и свойство того, что триггеры присутствуют как на этапах обучения, так и на этапах вывода, потребовали специализированного теоретического рассмотрения, которое существующие методы просто не предоставляли.
Сравнительное превосходство
Помимо простых метрик производительности, таких как частота успешных атак (ASR) или чистая точность, этот метод демонстрирует качественное превосходство благодаря своему фундаментальному теоретическому обоснованию. В отличие от многих предыдущих атак с использованием бэкдора, которые полагаются на эмпирические эвристики, предлагаемый подход "основан на границах обобщения и имеет определенные теоретические гарантии" (Раздел 3, страница 3). Это означает, что атака является не просто оптимизацией в черном ящике, а разработана с глубоким пониманием основных условий, которые обеспечивают ее обобщаемость.
Структурное преимущество метода заключается в его способности выявлять и использовать специфические математические условия (c1, c2, c3 в Теореме 4.5), при которых ошибка обобщения отравления может контролироваться и минимизироваться. Это позволяет принципиально разрабатывать триггер отравления, сочетая состязательный шум и неразборчивый яд в теоретически обоснованной манере (Раздел 5, Замечание 5.1). Это значительный качественный скачок по сравнению с методами, которые могут достигать высокой производительности, но не имеют четкого объяснения, почему они обобщаются или при каких условиях гарантированно работают. Подход статьи обеспечивает "более информированный подход к использованию этих методов" (Раздел 5, Замечание 5.1), гарантируя, что эффективность атаки основана на надежном теоретическом понимании, а не только на эмпирических наблюдениях.
Соответствие ограничениям
Выбранный метод идеально соответствует присущим ограничениям атак с использованием бэкдора на чистых метках.
- Природа чистых меток: Весь теоретический фреймворк и предлагаемый алгоритм специально разработаны для "атак с использованием бэкдора на чистых метках, где триггеры отравления добавляются к подмножеству обучающего набора $D_{tr}$ без изменения их меток" (Раздел 1, страница 1). Это основное ограничение, которое статья напрямую адресует.
- Двойная цель атаки: Проблема определяет две критические цели: (1) поддержание высокой точности на чистых образцах и (2) обеспечение того, чтобы любой вход с триггером классифицировался как целевая метка $l_p$ (Раздел 3.2). Решение предоставляет две отдельные границы обобщения: Теорему 1.1 для популяционной ошибки чистых образцов $E(F, D_s)$ и Теорему 1.2 для популяционной ошибки отравления $E_p(F, D_s)$, напрямую адресуя оба аспекта цели атаки.
- Не-i.i.d. отравленные данные: Это, возможно, самое сложное ограничение. В статье прямо указано, что "данные в $D_p$ больше не являются i.i.d. выборкой из $D_s$, поэтому классическая граница обобщения не может быть использована для прямого получения Теоремы 1.1" (Теорема 1.1, Q1). Авторы преодолевают это, гениально выявляя подмножество отравленных обучающих данных, которое является i.i.d. выборкой из чистого распределения (Идея доказательства Теоремы 4.1, страница 4; Лемма A.3, страница 14). Этот математический маневр является прямым "слиянием" сурового требования к распределению данных и уникальных теоретических свойств решения.
- Присутствие триггера как в обучающей, так и в тестовой фазах: Границы обобщения сформулированы таким образом, чтобы учитывать триггеры в обеих фазах. Эмпирическая ошибка на отравленном обучающем наборе $D_p$ используется для ограничения популяционных ошибок, косвенно учитывая роль триггера во время обучения. Ошибка обобщения отравления $E_p(F, D_s)$ напрямую оценивает успех атаки на отравленных тестовых данных.
- Незаметность/Невидимость: Хотя это в первую очередь экспериментальное ограничение, предлагаемый Алгоритм 1 включает "бюджет отравления $\eta$" (Алгоритм 1, Вход), который может быть установлен для обеспечения выполнения норм $L_\infty$ (например, 16/255), гарантируя, что сгенерированные триггеры остаются незаметными, что соответствует практическим требованиям к незаметным атакам.
Отклонение альтернатив
Статья неявно и явно отклоняет несколько альтернативных подходов, в первую очередь подчеркивая уникальные проблемы атак с использованием бэкдора на чистых метках, которые существующие методы не решают.
Во-первых, наиболее прямое отклонение — это "классические границы обобщения" (Раздел 1, страница 1). Эти границы, будь то на основе VC-размерности, сложности Радемахера или специфичные для глубоких нейронных сетей, считаются недостаточными, поскольку они предполагают i.i.d. данные. Отравленные наборы данных по определению нарушают это предположение, делая эти традиционные теоретические инструменты неприменимыми. Работа авторов заполняет этот фундаментальный пробел, подразумевая, что простое адаптация или применение существующих теорий обобщения потерпели бы неудачу.
Во-вторых, статья отличает свою работу от других существующих границ обобщения для атак отравления данных (например, Wang et al., 2021; Hanneke et al., 2022). Она утверждает, что "Наш результат отличается от этих работ и не может быть из них выведен" (Раздел 2, страница 3). Причина в том, что эти предыдущие работы не учитывают специфические свойства атак с использованием бэкдора, такие как присутствие триггера как на этапах обучения, так и на этапах вывода, и двойная цель поддержания чистой точности при достижении целевой неправильной классификации. Это подразумевает, что эти более общие границы обобщения отравления недостаточно детализированы для нюансов атак с использованием бэкдора на чистых метках.
Наконец, что касается самих методов генерации атак, статья неявно отклоняет чисто эмпирические или эвристические подходы, подчеркивая, что "Большинство существующих атак с использованием бэкдора в основном основаны на эмпирических эвристиках, в то время как наша атака основана на границах обобщения и имеет определенные теоретические гарантии" (Раздел 3, страница 3). При сравнении с другими атаками на чистых метках (Раздел 6.3, Таблица 4) авторы отмечают, что многие альтернативы требуют "дополнительных шагов", "предварительно существующих патчей", "подгонки изображений", "увеличения триггеров" или "больших генеративных моделей" (Раздел 6.3). Например, атаки "Invisible Poison" и "Image-specific" полагаются на большие генеративные модели для оптимальной производительности, чего избегает предлагаемый метод. Теоретическое руководство нового алгоритма позволяет более эффективно и принципиально разрабатывать триггеры, обходя необходимость этих часто сложных, ресурсоемких или ад-хок компонентов других атак. Это делает предлагаемый метод качественно превосходящим благодаря его надежной теоретической основе, что приводит к лучшей точности и частоте успешных атак без таких накладных расходов.
 Figure 4. When trigger is a patch without norm limitation, it is not invisible. This figure is from (Souri et al., 2022)
Figure 4. When trigger is a patch without norm limitation, it is not invisible. This figure is from (Souri et al., 2022)
Математический и логический механизм
Главное уравнение
Основной вклад статьи заключается в установлении границ обобщения для атак с использованием бэкдора на чистых метках, решающих две основные задачи: поддержание высокой точности на чистых образцах и обеспечение успешной классификации триггерных данных по целевой метке. Эти задачи математически выражены двумя главными уравнениями, выведенными как Теорема 4.1 и Теорема 4.5 соответственно.
Граница обобщения чистой ошибки классификации (Теорема 4.1) задается как:
$$ E(F,D_s) \leq \frac{4-2\alpha}{1-\alpha} E(F,D_p) + O\left(\frac{mW^2D^2}{N} \ln(2/\delta) + \sqrt{\frac{\alpha}{N(1-\alpha)}}\right) $$
Граница обобщения ошибки отравления (Теорема 4.5) задается как:
$$ E_p(F,D_s) \leq \lambda O\left(\left(E_{(x,y)\in D_p} [L_{CE}(F(x), y)] + \text{Rad}_{D_p}^{D_s}(H_{W,D,1})\right) + \sqrt{\frac{\ln(1/\delta)}{N\alpha}} + \epsilon + \tau + \lambda\right) $$
Поэлементный разбор
Давайте разберем каждый компонент этих уравнений, чтобы понять их математическое определение, физическую/логическую роль и обоснование авторов для их включения и работы.
Уравнение 1: Граница обобщения чистой ошибки классификации
-
$E(F,D_s)$
- Математическое определение: Это популяционная ошибка нейронной сети $F$ на истинном, основном распределении данных $D_s$. Она формально определяется как $E_{(x,y)\sim D_s} [1(F(x) \neq y)]$, где $1(\cdot)$ — индикаторная функция, которая возвращает 1, если ее аргумент истинен, и 0 в противном случае.
- Физическая/логическая роль: Этот член представляет собой истинную частоту ошибок модели на чистых, не отравленных данных, которые она никогда не видела ранее. В контексте атаки с использованием бэкдора, основной целью является поддержание этого значения низким, гарантируя, что модель остается полезной для своих предполагаемых, законных задач.
- Почему используется: Это конечный показатель для оценки производительности модели на чистых данных, что является ключевым требованием для незаметной атаки с использованием бэкдора.
-
$\leq$
- Математическое определение: "Меньше или равно".
- Физическая/логическая роль: Этот символ означает, что выражение справа предоставляет верхний предел для истинной популяционной ошибки слева. Это суть границы обобщения.
- Почему используется: Поскольку истинное распределение данных $D_s$ неизвестно, $E(F,D_s)$ не может быть напрямую вычислено. Теория обобщения предоставляет вероятностные верхние пределы, основанные на наблюдаемых величинах.
-
$\frac{4-2\alpha}{1-\alpha}$
- Математическое определение: Скалярный коэффициент, зависящий от $\alpha$, коэффициента отравления (процент образцов с меткой $l_p$ в $D_{tr}$, которые были отравлены).
- Физическая/логическая роль: Этот коэффициент масштабирует эмпирическую ошибку, наблюдаемую на отравленном обучающем наборе данных. Он отражает, как доля отравленных образцов влияет на точность границы обобщения. По мере увеличения $\alpha$ этот коэффициент обычно растет, указывая на потенциально более свободную границу или большее расхождение между эмпирической и популяционной ошибкой.
- Почему используется: Статья подчеркивает, что отравленные наборы данных ($D_p$) не удовлетворяют условию i.i.d. (независимые и одинаково распределенные), которое является предпосылкой для классических границ обобщения. Этот коэффициент, вероятно, возникает из специфических математических методов, используемых для адаптации теории обобщения к этой не-i.i.d. среде.
-
$E(F,D_p)$
- Математическое определение: Это эмпирическая ошибка сети $F$ на отравленном обучающем наборе данных $D_p$. Она определяется как $E_{(x,y)\in D_p} [1(F(x) \neq y)]$.
- Физическая/логическая роль: Это представляет собой частоту ошибок модели, измеренную непосредственно на конечном обучающем наборе данных, который включает как чистые, так и отравленные образцы. Это величина, которую алгоритм обучения активно пытается минимизировать во время обучения.
- Почему используется: Это наблюдаемая, измеримая ошибка во время процесса обучения. Границы обобщения стремятся связать эту эмпирическую производительность с ненаблюдаемой истинной производительностью.
-
$O(\cdot)$
- Математическое определение: Обозначение "O большое", указывающее на асимптотическую верхнюю границу скорости роста функции. Это означает, что члены внутри растут не быстрее, чем указанная функция.
- Физическая/логическая роль: Это обозначение группирует члены, которые составляют "разрыв обобщения". Эти члены обычно уменьшаются по мере увеличения размера обучающего набора данных $N$, что означает, что с большим количеством данных эмпирическая ошибка становится более надежной оценкой популяционной ошибки.
- Почему используется: Оно упрощает выражение, абстрагируя менее значимые константы и фокусируясь на доминирующих факторах, определяющих, насколько быстро закрывается разрыв обобщения.
-
$\frac{mW^2D^2}{N} \ln(2/\delta)$
- Математическое определение: Член, связанный со сложностью модели, размером данных и уверенностью.
- $m$: Количество классов в наборе меток.
- $W$: Ширина нейронной сети (например, максимальное количество нейронов в слое).
- $D$: Глубина нейронной сети (количество слоев).
- $N$: Общее количество образцов в чистом обучающем наборе $D_{tr}$.
- $\ln(2/\delta)$: Натуральный логарифм $2/\delta$, где $\delta$ — малая вероятность (например, 0.05), что выведенная граница может не выполняться (т.е. граница выполняется с вероятностью $1-\delta$).
- Физическая/логическая роль: Этот член количественно определяет емкость модели нейронной сети. Более сложная модель (большая $W$ или $D$) обладает большей способностью подгонять обучающие данные, включая шум, что может привести к большему разрыву обобщения (переобучению). И наоборот, больший размер обучающего набора $N$ помогает уменьшить этот разрыв. Фактор $\ln(2/\delta)$ учитывает вероятностный характер границы. Этот член является характерным для границ, выведенных с использованием таких концепций, как сложность Радемахера или VC-размерность.
- Почему используется: Это стандартный компонент в границах обобщения для моделей глубоких нейронных сетей, отражающий компромисс между выразительностью модели и количеством доступных данных.
- Математическое определение: Член, связанный со сложностью модели, размером данных и уверенностью.
-
$\sqrt{\frac{\alpha}{N(1-\alpha)}}$
- Математическое определение: Член квадратного корня, включающий коэффициент отравления $\alpha$ и размер обучающего набора $N$.
- Физическая/логическая роль: Этот член специально отражает статистическую неопределенность, вносимую процессом отравления. По мере увеличения коэффициента отравления $\alpha$ этот член обычно увеличивается, предполагая больший разрыв обобщения из-за увеличенного искажения распределения данных. И наоборот, больший $N$ уменьшает этот член, указывая на то, что больше данных может помочь смягчить неблагоприятные последствия отравления. $(1-\alpha)$ в знаменателе подразумевает, что если почти все образцы отравлены ($\alpha \to 1$), граница становится очень свободной.
- Почему используется: Это член, часто встречающийся в неравенствах концентрации, отражающий сложность выборки, необходимую для достижения определенного уровня уверенности для границы.
Уравнение 2: Граница обобщения ошибки отравления
-
$E_p(F,D_s)$
- Математическое определение: Это популяционная ошибка отравления сети $F$ на истинном распределении данных $D_s$. Она формально определяется как $E_{(x,y)\sim D_s} [1(F(x + P(x))) \neq l_p)]$, где $P(x)$ — триггер, применяемый к входным данным $x$, а $l_p$ — назначенная целевая метка для триггерных входных данных.
- Физическая/логическая роль: Этот член измеряет истинную частоту сбоев атаки бэкдора на невидимых, триггерных данных. Цель атаки — сделать это значение как можно меньше, гарантируя, что любой вход с триггером последовательно классифицируется как $l_p$.
- Почему используется: Это критический показатель для оценки частоты успешных атак и эффективности самой атаки бэкдора.
-
$\leq$
- Математическое определение: "Меньше или равно".
- Физическая/логическая роль: Аналогично Уравнению 1, это означает, что правая часть предоставляет верхний предел для ошибки отравления популяции.
- Почему используется: Устанавливает теоретическую гарантию эффективности атаки бэкдора, ограничивая ее истинную частоту ошибок.
-
$\lambda$
- Математическое определение: Масштабирующий фактор, полученный из условия (c2) в Теореме 4.5, которое гласит $P_{(x,y)\sim D_s}(P(x) \in A|y \neq l_p) \leq \lambda P_{(x,y)\sim D_s}(P(x) \in A|y = l_p)$ для любого множества $A$.
- Физическая/логическая роль: Этот параметр количественно определяет "сходство" или "согласованность" триггера $P(x)$ для различных чистых образцов $x$. Если $P(x)$ очень похож для различных входных данных, $\lambda$ приближается к 1. Меньшее $\lambda$ (ближе к 1) желательно для более точной границы, что означает, что триггер действует как общий, согласованный шаблон, который модель может легко изучить.
- Почему используется: Это критическое условие для разработки эффективных триггеров, гарантирующее, что бэкдор не привязан к конкретным характеристикам входных данных, а скорее к самому триггеру, делая его обобщаемым.
-
$O(\cdot)$
- Математическое определение: Обозначение "O большое", аналогично Уравнению 1.
- Физическая/логическая роль: Группирует члены, способствующие разрыву обобщения для ошибки отравления популяции.
- Почему используется: Упрощает границу, фокусируясь на доминирующих факторах.
-
$E_{(x,y)\in D_p} [L_{CE}(F(x), y)]$
- Математическое определение: Это эмпирическая потеря кросс-энтропии сети $F$ на отравленном обучающем наборе данных $D_p$. $L_{CE}$ обозначает функцию потерь кросс-энтропии.
- Физическая/логическая роль: Этот член представляет собой эмпирический риск (потерю), который модель минимизирует во время обучения на отравленном наборе данных. В отличие от ошибки 0-1, потеря кросс-энтропии предоставляет непрерывную меру уверенности модели в своих предсказаниях, побуждая ее выдавать целевую метку $l_p$ с высокой вероятностью для триггерных входных данных.
- Почему используется: Потеря кросс-энтропии является стандартной и более информативной функцией потерь для задач классификации, особенно когда требуется высокая уверенность в конкретных предсказаниях, как в случае атак с использованием бэкдора.
-
$\text{Rad}_{D_p}^{D_s}(H_{W,D,1})$
- Математическое определение: Сложность Радемахера пространства гипотез $H_{W,D,1}$ при распределении, связывающем $D_p$ и $D_s$. $H_{W,D,1}$ — это множество функций $h_F(x,y) = F_y(x)$ для нейронных сетей $F$ с шириной $W$ и глубиной $D$. Обозначение предполагает, что это сложность Радемахера, рассчитанная по образцам из $D_p$, но предназначенная для обобщения на $D_s$.
- Физическая/логическая роль: Этот член количественно определяет "обучаемость" или "гибкость" класса моделей в контексте отравленных данных. Более высокая сложность Радемахера указывает на модель, которая может подгонять более сложные закономерности, потенциально приводя к переобучению, если она не контролируется должным образом. Она измеряет способность модели подгонять случайные метки, что является прокси для ее емкости к переобучению.
- Почему используется: Сложность Радемахера является фундаментальным инструментом в теории статистического обучения для ограничения ошибки обобщения, особенно для сложных классов функций, таких как нейронные сети.
-
$\sqrt{\frac{\ln(1/\delta)}{N\alpha}}$
- Математическое определение: Член квадратного корня, включающий параметр уверенности $\delta$, размер обучающего набора $N$ и коэффициент отравления $\alpha$.
- Физическая/логическая роль: Этот член представляет собой статистический компонент концентрации. По мере увеличения $N$ этот член уменьшается, что приводит к более точной границе. Меньшее $\alpha$ (меньше отравленных образцов) делает этот член больше, указывая на то, что статистически обобщать эффект отравления при очень малом количестве образцов труднее.
- Почему используется: Это член, часто встречающийся в неравенствах концентрации, отражающий сложность выборки, необходимую для достижения определенного уровня уверенности для границы.
-
$\epsilon$
- Математическое определение: Малое положительное значение из условия (c1) в Теореме 4.5: $E_{(x,y)\sim D_p^{l_p}} [G_y(x + P(x))] \leq \epsilon$. Здесь $G_y(x)$ — вероятность того, что чистая обученная сеть $G$ классифицирует $x$ как $y$.
- Физическая/логическая роль: Этот член количественно определяет, насколько "состязательным" является триггер $P(x)$. Если $P(x)$ эффективно вызывает неправильную классификацию $x+P(x)$ чистой сетью $G$, то $\epsilon$ будет малым. Меньшее $\epsilon$ желательно для более точной границы, что означает, что триггер должен быть эффективным состязательным возмущением.
- Почему используется: Это условие на дизайн триггера, гарантирующее, что триггер может эффективно "обмануть" чистую модель, что является характеристикой многих атак с использованием бэкдора.
-
$\tau$
- Математическое определение: Малое положительное значение из условия (c3) в Теореме 4.5: $E_{x\sim D_s} [|(F-G)_{l_p}(P(x)) - (F-G)_{l_p}(x+P(x))|] \leq \tau$. Это измеряет сходство "бэкдорной части" выходных данных сети для $P(x)$ и $x+P(x)$.
- Физическая/логическая роль: Этот член количественно определяет, насколько "шорткат-подобным" является триггер $P(x)$. Если триггер действует как шорткат, реакция сети на $P(x)$ должна быть похожа на реакцию на $x+P(x)$, что приводит к малому $\tau$. Меньшее $\tau$ желательно для более точной границы, что означает, что триггер создает сильный, прямой путь к целевой метке.
- Почему используется: Это условие на дизайн триггера, побуждающее модель изучать триггер как простую, прямую особенность (шорткат), а не как сложное взаимодействие с исходным входным сигналом.
-
Почему сложение вместо умножения или интеграл вместо суммирования?
Уравнения структурированы как суммы, потому что они агрегируют различные источники ошибок и факторы, способствующие разрыву обобщения. Каждый член представляет собой отдельный аспект: эмпирическую ошибку (что наблюдается), сложность модели, статистическую дисперсию и специфические свойства триггера. Эти факторы аддитивно способствуют общему верхнему пределу популяционной ошибки. Например, как сложность модели, так и статистическая неопределенность независимо увеличивают потенциал эмпирической ошибки отклоняться от истинной популяционной ошибки.Обозначение $E_{(x,y)\sim D_s}$ подразумевает ожидание по непрерывному вероятностному распределению $D_s$, которое математически представлено интегралом. В отличие от этого, $E_{(x,y)\in D_p}$ обозначает эмпирическое среднее по конечному, дискретному набору данных $D_p$, которое рассчитывается как сумма. Авторы используют соответствующий математический оператор (интеграл или сумму) неявно через их обозначение ожидания, в зависимости от того, ссылаются ли они на непрерывную популяцию или дискретную выборку.
Пошаговый поток
Давайте проследим путь одного абстрактного образца данных, $(x_0, y_0)$, из истинного распределения данных $D_s$, через концептуальный механизм, описанный этими границами обобщения.
-
Происхождение образца данных: Наше путешествие начинается с абстрактного, чистого образца данных $(x_0, y_0)$, где $x_0$ — вход (например, изображение), а $y_0$ — его истинная метка. Этот образец является репрезентативной выборкой из бесконечного, ненаблюдаемого истинного распределения данных $D_s$.
-
Гипотетическое отравление для оценки атаки: Если мы оцениваем ошибку отравления популяции $E_p(F,D_s)$, то этот чистый вход $x_0$ концептуально модифицируется добавлением предварительно разработанного триггера $P(x_0)$. Полученный вход становится $x_0 + P(x_0)$, и его предполагаемая метка для атаки бэкдора — $l_p$, независимо от $y_0$. Эта преобразованная пара $(x_0 + P(x_0), l_p)$ представляет то, что атакующий хочет, чтобы модель классифицировала правильно. Для оценки чистой ошибки обобщения $E(F,D_s)$ образец данных остается $(x_0, y_0)$.
-
Вывод модели (сеть $F$ "черный ящик"): (Гипотетически) обученная нейронная сеть $F$ получает этот вход.
- Преобразование признаков: Вход (либо $x_0$, либо $x_0 + P(x_0)$) проходит через слои сети. Каждый слой, состоящий из операций, таких как свертки, нелинейные активации (например, ReLU) и пулинг, постепенно преобразует необработанный вход в более абстрактные и дискриминативные представления признаков.
- Генерация выходных данных: Последний слой сети, обычно слой Softmax, преобразует эти признаки в вероятностное распределение по всем возможным выходным классам. $F(z)$ — это вектор вероятностей, где $F_y(z)$ — вероятность, присвоенная метке $y$ для входа $z$.
- Решение о классификации: Окончательная классификация сети $\text{argmax}_y F_y(z)$ — это метка с наивысшей предсказанной вероятностью.
-
Расчет ошибки/потерь (на популяционном уровне):
- Чистая ошибка: Для чистого обобщения выход сети $F(x_0)$ сравнивается с истинной меткой $y_0$. Если предсказанная метка $\text{argmax}_y F_y(x_0)$ не совпадает с $y_0$, регистрируется ошибка. Этот процесс концептуально повторяется и усредняется по всем возможным $(x,y) \sim D_s$ для получения $E(F,D_s)$.
- Ошибка отравления: Для обобщения отравления выход сети $F(x_0 + P(x_0))$ сравнивается с целевой меткой $l_p$. Если $\text{argmax}_y F_y(x_0 + P(x_0))$ не совпадает с $l_p$, регистрируется ошибка. Это усредняется по всем возможным $(x,y) \sim D_s$ для получения $E_p(F,D_s)$.
-
Эмпирический аналог (обучающие данные $D_p$): Во время фактического этапа обучения модель $F$ подвергается воздействию конечного, наблюдаемого и отравленного обучающего набора данных $D_p$.
- Выборка: Конкретный образец $(x_i, y_i)$ выбирается из $D_p$. Этот образец может быть исходным чистым образцом из $D_{tr}$ или отравленным образцом $(x_j + P(x_j), l_p)$, который был создан путем возмущения чистого образца $(x_j, l_p)$ из $D_{tr}$.
- Эмпирическая потеря/ошибка: Сеть $F$ обрабатывает $x_i$.
- Для границы обобщения чистой ошибки эмпирическая ошибка $E(F,D_p)$ рассчитывается путем сравнения $F(x_i)$ с $y_i$ с использованием индикаторной функции.
- Для границы обобщения ошибки отравления вычисляется эмпирическая потеря кросс-энтропии $L_{CE}(F(x_i), y_i)$. Это измеряет, насколько хорошо $F$ предсказывает $y_i$ для входа $x_i$.
- Усреднение: Эти индивидуальные ошибки или потери затем усредняются по всем образцам в конечном наборе данных $D_p$ для получения $E(F,D_p)$ или $E_{(x,y)\in D_p} [L_{CE}(F(x), y)]$.
-
Связывание разрыва обобщения: Математический механизм затем связывает эти наблюдаемые эмпирические ошибки/потери на $D_p$ с ненаблюдаемыми истинными популяционными ошибками на $D_s$. Дополнительные члены в границах (сложность Радемахера, $\sqrt{\frac{\ln(1/\delta)}{N\alpha}}$, $\epsilon$, $\tau$, $\lambda$) действуют как "корректирующие факторы" или "штрафные члены". Они количественно определяют:
- Емкость модели: Насколько модель $F$ склонна к переобучению (сложность Радемахера).
- Дефицит данных: Статистическая неопределенность из-за наличия конечного обучающего набора ($N$).
- Влияние отравления: Специфические статистические смещения, вносимые коэффициентом отравления ($\alpha$).
- Качество триггера: Насколько хорошо созданный триггер $P(x)$ удовлетворяет желаемым свойствам быть состязательным ($\epsilon$), последовательным ($\lambda$) и шорткатом ($\tau$).
Весь этот процесс делает абстрактную математику похожей на движущуюся сборочную линию: сырые данные поступают, обрабатываются машиной (сетью), и ее производительность измеряется. Затем границы обобщения предоставляют теоретический отчет "контроля качества", предсказывающий производительность машины на будущих, невидимых данных на основе ее наблюдаемой производительности и присущих ей характеристик конструкции.
Динамика оптимизации
Сами границы обобщения не являются прямыми целями оптимизации для целевой модели $F$. Вместо этого они предоставляют теоретические гарантии и условия, при которых атака с использованием бэкдора будет эффективно обобщаться. "Динамика оптимизации" в этом контексте относится к тому, как триггер $P(x)$ разрабатывается для удовлетворения этих условий, и как целевая модель $F$ обучается для достижения желаемого поведения бэкдора при соблюдении этих границ.
Предлагаемый алгоритм статьи (Алгоритм 1) для создания триггера отравления $P(x)$ является местом, где происходит основная оптимизация для самой атаки:
-
Создание состязательного возмущения (удовлетворение условия c1/t1 для малого $\epsilon$):
- Механизм: Сеть $F_1$ обучается на чистом наборе данных $T$. Для каждого чистого образца $x$ генерируется состязательное возмущение $x_{adv}$ с использованием проекционного градиентного спуска (PGD). PGD — это итеративный процесс оптимизации, который находит малое возмущение $\epsilon$ (в пределах бюджета $L_\infty$ $\eta$), максимизирующее потерю $F_1$ для исходной метки $y$.
- Градиенты и ландшафт потерь: Это включает вычисление градиентов функции потерь $L(F_1(x+\epsilon), y)$ по отношению к $\epsilon$. Оптимизация итеративно обновляет $\epsilon$, делая шаги в направлении градиента (градиентный подъем) для увеличения потерь, затем проецируя $\epsilon$ обратно в допустимое пространство возмущений. Этот процесс формирует "состязательный" компонент триггера, направленный на то, чтобы $\epsilon$ (который входит в $P(x)$) был эффективным состязательным примером, тем самым гарантируя, что $\epsilon$ в границе является малым.
-
Создание шорткат-возмущения (удовлетворение условия c3/t3 для малого $\tau$):
- Механизм: Отдельная, более простая двухслойная сеть $F_2$ обучается на специально сконструированном наборе данных $T_1$. Этот набор данных включает чистые образцы и образцы, возмущенные $x_{adv}$ (из предыдущего шага), но с определенной меткой (0). Цель — найти "шорткат"-возмущение $x_{scut}$ с использованием метода min-min. Этот метод направлен на то, чтобы отравленный набор данных был линейно разделим $F_2$.
- Ландшафт потерь и обновления состояния: Метод min-min обычно включает внутренний цикл оптимизации (поиск лучшего $x_{scut}$ для данного $F_2$) и внешний цикл оптимизации (обучение $F_2$). Ландшафт потерь для $F_2$ формируется таким образом, чтобы поощрять изучение простых, линейно разделимых признаков из отравленных данных. Это эффективно создает "шорткат", который отображает триггер на целевую метку. Итеративные обновления параметров $F_2$ и $x_{scut}$ направлены на минимизацию $\tau$, гарантируя, что триггер действует как сильный шорткат-признак.
-
Комбинирование возмущений (удовлетворение условия c2/t2 для $\lambda$ близкого к 1):
- Механизм: Окончательный триггер $P(x)$ конструируется путем комбинирования $x_{adv}$ и $x_{scut}$ с использованием бинарной маски $U$: $P(x) = U \odot x_{adv} + (1-U) \odot x_{scut}$. Маска $U$ разрабатывается (например, определенная область, такая как верхний левый угол, равна 0, а остальное — 1) для обеспечения того, чтобы шорткат-компонент $(1-U) \odot x_{scut}$ был схожим для различных входных данных $x$.
- Поведение градиентов/обновлений состояния: Хотя прямого градиентного оптимизатора для самого $\lambda$ нет, выбор дизайна маски $U$ и свойства метода min-min (который имеет тенденцию производить схожие шорткаты для разных входных данных) неявно направляют генерацию триггера к удовлетворению условия (c2). Это гарантирует, что триггер является согласованным шаблоном, делая $\lambda$ в границе приближающимся к 1. Некоторые яды, полученные с помощью Алгоритма 1, показаны на Рисунке 1.
-
Обучение целевой модели и сходимость:
- Механизм: После генерации триггеров $P(x)$ они применяются к подмножеству исходных чистых обучающих данных $D_{tr}$ для формирования отравленного обучающего набора $D_p$. Затем целевая сеть $F$ обучается на $D_p$ с использованием стандартных алгоритмов оптимизации, таких как стохастический градиентный спуск (SGD) с функцией потерь кросс-энтропии.
- Ландшафт потерь и сходимость: Присутствие отравленных образцов в $D_p$ изменяет ландшафт потерь для целевой модели $F$. Модель учится минимизировать эмпирическую потерю на $D_p$, что означает, что она должна изучить как задачу чистой классификации для не отравленных образцов, так и задачу бэкдора для триггерных образцов. Затем границы обобщения предсказывают поведение этой сошедшейся модели $F$. Если триггер $P(x)$ был успешно создан для удовлетворения условий (малые $\epsilon, \tau$, $\lambda$ близкое к 1), границы предполагают, что целевая модель после сходимости будет демонстрировать высокую чистую точность и высокую частоту успешных атак. Итеративные обновления параметров $F$ через SGD приводят ее к локальному минимуму в этом сложном, многоцелевом ландшафте потерь.
По сути, динамика оптимизации представляет собой двухэтапный процесс: во-первых, целенаправленная, управляемая градиентом оптимизация для создания триггера $P(x)$ для обладания специфическими свойствами (состязательный, шорткат, согласованный), которые математически связаны с границами обобщения; и во-вторых, стандартное обучение целевой сети на результирующем отравленном наборе данных, где границы затем предсказывают обобщающую производительность конечной модели. Границы предоставляют теоретическую основу для того, почему эти принципы дизайна триггеров приводят к эффективной и обобщаемой атаке бэкдора.
 Figure 1. From top row to bottom row are respectively the clean images, normalized triggers (original trigger has L∞norm bound 16/255), poison images. Due to the selection of U, the upper left corners of the poison images are similar, while the other parts are used to generate adversaries
Figure 1. From top row to bottom row are respectively the clean images, normalized triggers (original trigger has L∞norm bound 16/255), poison images. Due to the selection of U, the upper left corners of the poison images are similar, while the other parts are used to generate adversaries
Результаты, ограничения и заключение
Экспериментальный дизайн и базовые линии
Для строгого подтверждения своих теоретических утверждений и эффективности предлагаемой атаки с использованием бэкдора на чистых метках авторы провели обширные эксперименты на различных эталонных наборах данных и архитектурах целевых сетей. Экспериментальная установка была тщательно разработана для имитации практических сценариев атаки, где атакующий имеет ограниченное знание и контроль над процессом обучения цели.
Наборы данных и целевые модели: Атака оценивалась на широко используемых наборах данных для классификации изображений: CIFAR10, CIFAR100, SVHN и TinyImageNet. В качестве целевых моделей использовались популярные глубокие нейронные сети, такие как VGG16, ResNet18 и WRN34-10.
Механизм атаки и генерация триггеров: Основная часть предлагаемой атаки включает новый метод генерации триггеров (Алгоритм 1), который сочетает состязательный шум и неразборчивый яд. Сам этот процесс использует меньшие, независимые сети (F1 для состязательного шума, F2 для шорткат-возмущения) для избежания предположений о структуре или вычислительной мощности целевой сети. Например, F1 обучалась с использованием состязательного обучения PGD-10 с бюджетами нормы L-infinity (например, 8/255 или 4/255), в то время как F2, двухслойная сеть, обучалась с использованием метода Min-Min для создания шорткатов. Процесс отравления включал случайный выбор подмножества обучающих образцов (например, 1% или 0.8% обучающих изображений) с определенной целевой меткой $l_p$ (обычно установленной на 0) и добавление сгенерированного триггера к ним без изменения их исходных меток.
Метрики оценки и базовые линии: Эффективность атаки в основном измерялась следующими показателями:
1. Чистая точность модели: Точность отравленной модели на чистых тестовых образцах.
2. Точность отравленной модели: Точность отравленной модели на отравленных тестовых образцах.
3. Частота успешных атак (ASR): Частота, с которой образцы, содержащие триггер, неправильно классифицируются как целевая метка $l_p$.
4. Чистая точность модели для $l_p$: Точность чистых образцов, принадлежащих к целевому классу $l_p$.
Предлагаемый метод был сравнен с семью известными атаками с использованием бэкдора на чистых метках: Clean Label, Hidden Trigger, Reflection, Invisible Poison, Image-specific, Narcissus и Sleeper Agent. Для справедливого сравнения все атаки были ограничены бюджетом триггера нормы L-infinity (например, 16/255) и фиксированным бюджетом отравления (например, 1% обучающих образцов).
Механизмы защиты: Для оценки надежности атаки она была протестирована против шести распространенных защит от бэкдора: Состязательное обучение (AT), Аугментация данных, Масштабирование, Дифференциально приватный SGD (DPSGD), Частотный фильтр и Дообучение.
Теоретическая проверка: Помимо эмпирической производительности, авторы провели абляционные исследования для проверки своих математических утверждений, в частности Теорем 4.1 и 4.5. Это включало анализ того, как различные компоненты триггера (состязательный шум, шорткат-шум) влияли на условия (c1), (c2), (c3) Теоремы 4.5, используя такие метрики, как $V_{adv}$ (ошибка валидации на отравленных данных для условия (c1)) и $V_{sc}$ (ошибка бинарной классификации для условия (c3)). Они также исследовали влияние коэффициента отравления на общую точность для поддержки Теоремы 4.1.
Что доказывают доказательства
Экспериментальные доказательства убедительно подтверждают эффективность и теоретические основы предлагаемой атаки с использованием бэкдора на чистых метках.
Неоспоримые доказательства основного механизма:
Основной механизм, который сочетает состязательный шум и неразборчивый яд для создания триггеров, удовлетворяющих условиям Теоремы 4.5, был безжалостно доказан как эффективный. Атака последовательно достигала высоких частот успешных атак (ASR), сохраняя при этом высокую точность на чистых образцах, что является двумя основными целями атаки с использованием бэкдора на чистых метках. Например, на CIFAR-10 с ResNet18 и бюджетом отравления 1% (норма L-infinity 16/255) предлагаемый метод достиг ASR 93%, при чистой точности модели 93% и отравленной точности модели 91% (Таблица 1). Это демонстрирует, что целевая модель изучила триггер для неправильной классификации входных данных в целевую метку $l_p$, при этом хорошо работая на легитимных, чистых данных.
"Жертвы" (базовые модели) были решительно побеждены. При бюджете нормы L-infinity 16/255 наша атака достигла ASR 93% на CIFAR-10, значительно превзойдя все другие сравниваемые методы, которые варьировались от 23% (Clean-Label) до 75% (Hidden-Trigger) (Таблица 4). Эти неоспоримые доказательства подчеркивают, что специфическое сочетание состязательного шума и шорткат-свойств в триггере, управляемое теоретическими границами, превосходит в имплантации эффективных бэкдоров. Эффективность атаки оставалась высокой даже при очень малых бюджетах отравления (например, 86% ASR при 0.6% бюджете отравления на CIFAR-10 с ResNet18, Таблица 2), что еще раз доказывает ее силу.
Эффективность атаки была последовательной на различных наборах данных (CIFAR10, CIFAR100, SVHN, TinyImageNet) и для различных целевых меток (0-9), как показано в Таблицах 3 и на Рисунке 3. Это указывает на обобщаемую стратегию атаки, а не на специфичную для конкретного набора данных или целевого класса. Мониторинг процесса обучения (Рисунок 2) далее подтвердил, что чистая и отравленная точность модели оставались близкими, а ASR быстро стабилизировался на высоком уровне, что указывает на надежное изучение бэкдора.
Проверка теоретических утверждений:
Абляционные исследования, специально разработанные для проверки Теоремы 4.5, предоставили решающие выводы. Сравнивая различные типы отравления (случайный шум, универсальный состязательный, состязательный, шорткат и наш) и оценивая их влияние на $V_{adv}$ (связанный с условием c1) и $V_{sc}$ (связанный с условием c3), авторы показали, что отдельные компоненты часто преуспевают в одном условии, но терпят неудачу в другом. Например, только состязательные возмущения ($Adv$) привели к высокому $V_{adv}$ (что означает, что условие c1 не было хорошо удовлетворено), в то время как только шорткат-шум ($SCut$) привел к высокому $V_{sc}$ (что означает, что условие c3 не было хорошо удовлетворено). Однако предлагаемый метод "Ours", который сочетает оба, достиг сбалансированного результата с хорошим $V_{adv}$ и очень низким $V_{sc}$, что привело к значительно более высокой ASR (93% для Ours против 22% для Adv и 30% для SCut при бюджете 16/255, Таблица 6). Это напрямую подтверждает, что удовлетворение условий Теоремы 4.5 посредством комбинированного механизма триггера приводит к превосходной производительности атаки.
Что касается Теоремы 4.1, эксперименты показали, что хотя более высокий коэффициент отравления обычно приводит к большему влиянию на чистую точность, снижение не является значительным (например, всего 4% снижение для более чем 3000 отравленных образцов, Таблица 14). Это подтверждает теоретическое понимание того, что коэффициент отравления влияет на обобщаемость, но также и то, что при контролируемых бюджетах отравления влияние на точность чистых образцов может быть минимизировано. Кроме того, было показано, что целевая сеть эффективно изучает признаки триггера (Таблица 12), но при этом отдает приоритет исходным признакам изображения, что требует достаточного масштаба отравления для эффективности бэкдора.
Ограничения и будущие направления
Хотя предлагаемая атака с использованием бэкдора на чистых метках демонстрирует замечательную эффективность и основана на надежных теоретических границах обобщения, статья признает несколько ограничений и открывает направления для будущих исследований.
Текущие ограничения:
Одним из значительных ограничений является сложность условий, изложенных в Теореме 4.5. Сами авторы заявляют, что эти условия "довольно сложны", и было бы крайне желательно вывести более простые, более интуитивно понятные условия для границы популяционной ошибки отравления. Эта сложность может препятствовать более широкому пониманию и применению теоретической основы.
Другим теоретическим пробелом является то, что текущие границы обобщения явно не учитывают процесс обучения. Зависимые от алгоритма границы обобщения, в частности основанные на анализе стабильности (например, Hardt et al., 2016), заслуживают дальнейшего изучения в контексте атак с использованием бэкдора. Такой анализ мог бы предоставить более детальное понимание того, как динамика обучения влияет на успех и обобщаемость атаки.
С практической точки зрения, статья отмечает, что сгенерированные триггеры демонстрируют ограниченную переносимость между различными наборами данных. Триггер, созданный для CIFAR-10, например, не может быть напрямую применен к CIFAR-100 (Приложение F.5). Это ограничивает универсальность атаки и требует повторной генерации триггеров для каждого нового набора данных, что может быть вычислительно затратным.
Кроме того, атака, хотя и очень эффективна против базовых моделей, оказывается "несколько хрупкой под защитой" (Раздел 6.4). Хотя авторы предлагают "улучшенные атаки", которые включают механизмы защиты в свой процесс генерации для противодействия этим защитам, это предполагает продолжающуюся гонку вооружений, где надежность атаки не является врожденной, а требует постоянной адаптации. Наблюдаемый компромисс между надежностью и точностью в защитах также подчеркивает проблему: повышение устойчивости атаки без существенного снижения производительности целевой модели на чистых данных.
Будущие направления и темы для обсуждения:
Результаты данной статьи закладывают прочную основу для будущей работы, поднимая несколько тем для обсуждения:
- Упрощение теоретических условий: Как можно переформулировать или аппроксимировать условия Теоремы 4.5, чтобы сделать их более управляемыми и интерпретируемыми для практиков? Может ли более абстрактное, высокоуровневое понимание свойств "состязательного шума" и "шорткатов" быть достаточным, или точные математические условия незаменимы для теоретических гарантий?
- Зависимые от алгоритма границы обобщения: Какие конкретные аспекты алгоритмов обучения (например, оптимизаторы, скорости обучения, регуляризация) наиболее сильно влияют на обобщение атак с использованием бэкдора? Можем ли мы вывести более точные, зависящие от алгоритма границы, которые предоставят более практическое руководство по разработке надежных атак или защит? Это может включать изучение таких концепций, как неявная регуляризация в глубоком обучении.
- Переносимость триггеров между наборами данных: Как мы можем разработать универсальные или более переносимые триггеры, которые работают на различных наборах данных без необходимости повторной генерации? Это может включать исследование подходов мета-обучения для генерации триггеров или выявление универсальных состязательных возмущений, не зависящих от набора данных, которые также функционируют как эффективные триггеры бэкдора.
- Гонка вооружений атака-защита: Учитывая наблюдаемую хрупкость против защит, как мы можем разработать принципиально более надежные атаки с использованием бэкдора, которые менее подвержены известным стратегиям смягчения? И наоборот, как защиты могут быть разработаны так, чтобы быть по-настоящему проактивными, предвидя и нейтрализуя новые механизмы атаки, а не реагируя на существующие? Это может привести к исследованиям адаптивных стратегий атаки/защиты или игровых моделей этой гонки вооружений.
- Этическое влияние и ответственный ИИ: В статье явно упоминается потенциальное негативное социальное воздействие этой работы, поскольку злоумышленники могут использовать эти методы. Это поднимает критические вопросы об ответственном раскрытии информации, разработке "красных команд" для безопасности ИИ и необходимости надежных нормативных рамок. Как научное сообщество может сбалансировать открытые исследования с императивом предотвращения злоупотребления мощными возможностями ИИ?
- За пределами классификации изображений: Может ли теоретическая основа и методология атаки быть расширена на другие области, такие как обработка естественного языка, распознавание речи или обучение с подкреплением? Какие уникальные проблемы и возможности возникнут при адаптации концепций "состязательного шума" и "шорткатов" к этим различным модальностям данных и структурам задач?
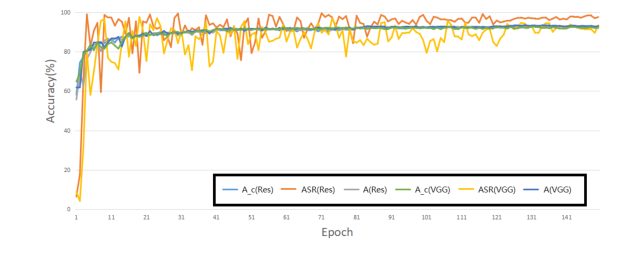 Figure 2. Attack performance during the training process on CIFAR10 with ResNet18 and VGG16. This figure shows the trend of the poison model accuracy (A), attack success rate (ASR) and clean model accuracy (Ac)
Figure 2. Attack performance during the training process on CIFAR10 with ResNet18 and VGG16. This figure shows the trend of the poison model accuracy (A), attack success rate (ASR) and clean model accuracy (Ac)
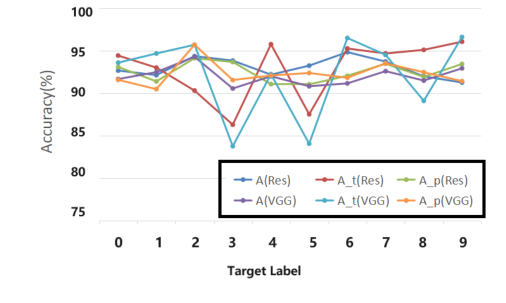 Figure 3. Performance of different target label lp. We show the poison model accuracy (A), accuracy of target label (At), attack success rate (Ap) on CIFAR-10, using VGG16 and ResNet18
Figure 3. Performance of different target label lp. We show the poison model accuracy (A), accuracy of target label (At), attack success rate (Ap) on CIFAR-10, using VGG16 and ResNet18