クリーンラベルバックドア攻撃のための汎化バウンドと新アルゴリズム
The generalization bound is a crucial theoretical tool for assessing the generalizability of learning methods and there exist vast literatures on generalizability of normal learning, adversarial learning, and data...
背景と学術的系譜
起源と学術的系譜
本稿で取り上げる問題は、機械学習理論の分野、特に学習アルゴリズムの汎化能力に関するものに端を発する。歴史的に、汎化バウンドという概念は、有限データセットで学習されたモデルが未知のデータに対してどの程度うまく機能するかを理解するための重要な理論的ツールであった。Mohriら(2018)が参照するように、この分野の初期の研究は、標準的な学習タスクにおける汎化能力を定量化するために、VC次元やRademacher複雑度のような指標に焦点を当てていた。
しかし、機械学習モデルがより複雑になり、応用が多様化するにつれて、新たな課題が出現した。懸念される重要な領域の一つがデータポイズニング攻撃であり、悪意のあるアクターがモデルの整合性を損なうために学習データを操作する。一般的なデータポイズニング攻撃に対する汎化バウンドが探求されてきた(例:Wangら、2021;Hannekeら、2022)一方で、特に悪質で特殊なタイプの攻撃であるバックドア攻撃は、独自の課題を提示した。
この問題の正確な起源は、バックドア攻撃の独特な特性に由来する。他のデータポイズニング手法とは異なり、バックドア攻撃は二重の目的を持つ。第一に、通常のクリーンデータに対する高い精度を維持すること、第二に、入力に特定の「トリガー」が存在する場合に、モデルに特定のターゲットラベルを出力させることである。決定的に重要なのは、このトリガーが訓練セットとテストセットの両方に埋め込まれることである。既存の汎化バウンドは、この二重の目的や、古典的な汎化理論の基本的な仮定であるポイズニングされたデータセットの非i.i.d.(独立同分布)性を考慮して設計されていなかった。著者らは、知る限り、バックドア攻撃に特化した汎化バウンドは確立されておらず、本稿が埋めようとしている学術文献における重要なギャップであることを明記している。
以前のアプローチの根本的な限界は、古典的な汎化理論の礎であるi.i.d.条件への依存に起因していた。以前のモデルとその関連バウンドは、暗黙のうちに学習データが真のデータ分布から独立かつ同一にサンプリングされていると仮定していた。しかし、データポイズニング、特にバックドア攻撃の文脈では、ポイズニングされた学習データセットは本質的にこのi.i.d.仮定に違反する。トリガーとターゲットとなる誤分類の導入は、ポイズニングされたサンプルが、単純な方法で基盤となるクリーンデータ分布を代表しなくなることを意味する。この違反により、既存の汎化バウンドは適用不能となり、バックドア攻撃シナリオ下で学習されたモデルの汎化可能性を理論的に評価することが不可能になった。この「ペインポイント」により、著者らはクリーンラベルバックドア攻撃のユニークな特性を処理できる新しい理論的フレームワークを開発する必要に迫られた。
直感的なドメイン用語
-
汎化バウンド (Generalization Bound):
- 専門用語: モデルの訓練データに対する性能と、新しい未知のデータに対する性能との差の上限を数学的に示したもの。
- 直感的なアナロジー: 運転免許試験の勉強をしていると想像してください。「汎化バウンド」とは、特定の道路(訓練データ)でうまく練習すれば、実際の試験(未知のデータ)で遭遇するどんな新しい道路でも、ある誤差範囲内でパフォーマンスを発揮できるという保証のようなものです。学習したスキルが新しい状況にどれだけ確実に転移するかを示します。
-
クリーンラベルバックドア攻撃 (Clean-Label Backdoor Attack):
- 専門用語: 学習データセットの小さなサブセットに微妙で、しばしば知覚できないトリガーが追加されるデータポイズニング攻撃の一種ですが、元のラベルは変更されません。目標は、訓練されたモデルが、このトリガーを含む任意の入力に対して特定のターゲットラベルとして分類するようにすることであり、同時にクリーンデータに対しても正確に機能することです。
- 直感的なアナロジー: 犬の品評会で、さまざまな犬種を識別するように訓練された審査員を想像してください。「クリーンラベルバックドア攻撃」とは、誰かが訓練中に少数の犬に小さくて目立たない赤いリボン(トリガー)をこっそり付けたが、審査員には正しい犬種を伝えたようなものです。審査員はすべての犬種を正しく識別するように学習します。しかし、たとえ見たことのない犬であっても、その赤いリボンが付いている場合、審査員は実際の犬種に関係なく、常に「プードル」と呼ぶように騙されます。ポイズニングされた学習データの元のラベルは「クリーン」(正しい)であったため、攻撃はステルス性を持ちます。
-
i.i.d.条件 (Independent and Identically Distributed):
- 専門用語: すべてのデータサンプルが互いに独立しており、同じ確率分布から描かれているという統計的仮定。
- 直感的なアナロジー: これは、完全にシャッフルされたデッキからカードを引くようなものです。引いた各カードは前のカードとは「独立」(次の引きに影響しない)であり、「同一の分布」(同じデッキ)から来ています。最初の数回の引きの後で誰かがすべてのエースをこっそり取り除いた場合、その後の引きはもはやi.i.d.ではありません。機械学習では、各データは現実世界からの新鮮で偏りのない観測値のようなものであり、この仮定は多くの証明が成り立つために不可欠です。
-
Rademacher複雑度 (Rademacher Complexity):
- 専門用語: 仮説空間(モデルが学習できるすべての可能な関数の集合)の「豊かさ」または「容量」の尺度。ランダムノイズにモデルがどれだけうまく適合できるかを定量化します。
- 直感的なアナロジー: どんなものでも描ける、純粋なランダムな落書きさえも描ける非常に柔軟なアーティストを想像してください。「Rademacher複雑度」は、このアーティストが純粋なランダム性を完全に再現するのにどれだけ優れているかを測定します。アーティストがどんなランダムな落書きでも完全に描けるなら、それは非常に柔軟(高い複雑度)です。AIでは、モデルがランダムノイズをどれだけ簡単に記憶できるかを示しており、これはしばしば真のパターンを学習するのではなく過学習している兆候です。
-
ショートカット (Shortcut):
- 専門用語: モデルが予測を行うために利用する可能性のある、単純で学習しやすい特徴であり、意図された、より複雑で堅牢な特徴を学習する代わりに利用します。
- 直感的なアナロジー: 子供に「車」を識別するように教えていて、車のすべての訓練画像の隅に特定のブランドのロゴが写っている場合、子供は実際の車の特徴(車輪、窓、形状)を学習する代わりに、「そのロゴ」を「車」として識別するように学習するかもしれません。ロゴは学習しやすい「ショートカット」特徴ですが、その特定のロゴがない実際の車には汎化しません。本稿では、無差別にポイズンを適用することは、そのようなショートカットと見なされると述べています。
記法表
| 記法 | 説明 |
|---|---|
問題定義と制約
コア問題の定式化とジレンマ
本稿で取り上げる中心的な問題は、深層学習におけるクリーンラベルバックドア攻撃に対する理論的理解と汎化保証の欠如である。
入力/現在の状態:
出発点は、ニューラルネットワーク $F$ がクリーンな訓練データセット $D_{tr} = \{(x_i, y_i)\}_{i=1}^N$ で訓練される標準的な機械学習セットアップである。このデータセットは、基盤となるデータ分布 $D_s$ から独立同分布(i.i.d.)であると仮定される。このような訓練の主な目的は、モデルの未知のデータに対するパフォーマンスを測定する母集団誤差 $E_{(x,y) \sim D_s}[1(F(x) \neq y)]$ を最小化することである。VC次元、Rademacher複雑度、またはアルゴリズムの安定性に基づくバウンドを含む既存の汎化理論は、この訓練データのi.i.d.仮定に根本的に依存している。
望ましい終点(出力/目標状態):
本稿は、理論的に根拠のある「クリーンラベルバックドア攻撃」を達成することを目指す。これには、「トリガー」を元のラベルを変更せずに、クリーンな訓練データのサブセットを微妙に変更してポイズニングされた訓練セット $D_p$ を作成することが含まれる。この $D_p$ で訓練されたニューラルネットワーク $F$ は、以下の二重の目的を満たす必要がある。
1. クリーンサンプルに対する高い精度を維持する: モデルは、ポイズニングされていないクリーンデータに対しても良好に機能する必要がある。つまり、そのクリーン母集団誤差 $E(F, D_s) = E_{(x,y) \sim D_s}[1(F(x) \neq y)]$ は低く保たれる必要がある。
2. トリガー付き入力に対するターゲットとなる誤分類を保証する: トリガー $P(x)$ を含む任意の入力 $x$(すなわち、$x + P(x)$)は、$F$ によって特定の、事前に定義されたターゲットラベル $l_p$ として分類される必要がある。これは、ポイズン母集団誤差 $E_p(F, D_s) = E_{(x,y) \sim D_s}[1(F(x + P(x))) \neq l_p)]$ を最小化することによって定量化される。
ジレンマと欠落しているリンク:
正確な欠落しているリンクは、クリーンラベルバックドア攻撃シナリオ下で訓練されたモデルに対する堅牢な汎化バウンドの確立である。過去の研究者を閉じ込めてきた痛みを伴うトレードオフまたはジレンマは、バックドア攻撃が本質的に訓練データのi.i.d.仮定に違反することである。ポイズニングされたサンプルを導入することにより、データセット $D_p$ は $D_s$ からi.i.d.サンプリングされなくなる。これは古典的な汎化理論の基礎的な前提を直接無効にし、クリーンデータとトリガー付きデータの両方に対する望ましいパフォーマンスを保証するために既存のバウンドを直接適用することを不可能にする。
さらに、ポイズン汎化目標(本稿のQ2)については、ポイズニングされた訓練セット $D_p$ に対する経験的誤差を最小化するだけでは、任意のトリガー付きデータがターゲットラベル $l_p$ として分類されることが自動的に保証されるわけではない。これは、もし $y \neq l_p$ であるクリーンサンプル $(x, y)$ が $D_p$ で $(x + P(x), l_p)$ にポイズニングされていない場合、 $D_p$ に対する経験的誤差を最小化しても、ネットワークが $x + P(x)$ を $l_p$ として分類するように強制されないためである。これは、ポイズニングされた訓練セットに対する経験的パフォーマンスと、トリガー付き入力に対する望ましい汎化動作との間の微妙だが重要なギャップを浮き彫りにする。
制約と失敗モード
クリーンラベルバックドア攻撃に対する汎化バウンドの確立という問題は、いくつかの厳しい現実的な壁のために非常に困難である。
- 非i.i.d.データ分布: 強調されているように、最も重要な制約は、ポイズニングされた訓練データセット $D_p$ が根本的にi.i.d.条件を満たさないことである(ページ1、要旨;ページ2、Q1説明)。これは攻撃メカニズムの直接的な結果であり、標準的な汎化理論を適用不能にする。この非i.i.d.性を処理するための新しい理論的ツールを開発することが、主要なハードルである。
- 二重の、競合する目的: 攻撃には2つの異なる目標がある。クリーンデータに対する高い精度を維持すること、およびトリガー付きデータに対する誤分類を保証すること。これらの目的は緊張関係にある可能性がある。モデルはバックドアを達成するためにポイズニングされたサンプルに過学習する可能性があり、クリーンデータに対するパフォーマンスを低下させる可能性がある、またはその逆である。これらの2つの目標を、理論的保証を提供しながらバランスを取ることは複雑である。
- クリーンラベルのステルス性: 「クリーンラベル」という特性は、ポイズニングされたサンプルのラベルが変更されないことを意味する。これにより、攻撃はステルス性を増すが、モデルが学習するのはより困難になる。ネットワークは、ポイズニングされた入力に対する明示的なラベルガイダンスなしに、トリガーの存在のみに依存して、トリガーとターゲットラベル $l_p$ を暗黙的に関連付ける必要がある。
- ポイズン汎化のための特定のトリガー条件: ポイズン汎化誤差が小さいことを保証するためには、トリガー $P(x)$ は任意であってはならない。定理4.5(ページ4)は、$P(x)$ が満たすべき3つの重要な条件(c1、c2、c3)を列挙している。
- (c1) 敵対的ノイズ: トリガーは、クリーンデータで訓練されたネットワークに対する敵対的ノイズとして機能する必要がある。これは、特定の摂動特性の必要性を示唆する。
- (c2) トリガーの類似性: トリガー $P(x)$ は、異なる入力サンプル $x$ 間で類似している必要がある。トリガーが高度に変化する場合、モデルはバックドア動作の汎化に苦労する可能性がある。
- (c3) ショートカット特性: トリガーは、特別に設計されたバイナリデータセットに対する「ショートカット」として機能する必要がある。これは、トリガーがモデルの決定境界にどのように影響するかに関連するため、エンジニアリングして保証するのが容易ではない特性である。これらの条件がない場合、トリガー付きデータに対する攻撃の汎化は保証されない。
- 計算リソースと攻撃者のリソース制限(暗黙的): 問題定義の制約として明示的に述べられていないが、実験設定(セクションF.1、ページ32-33)は、現実世界のシナリオでは問題をより困難にする実用的な制限を明らかにしている。
- 攻撃者の知識の制限: 攻撃者は、被害者ネットワークの構造と訓練プロセスに関する限定的な知識を持っていると仮定される。これは、トリガーがより小さなプロキシネットワークを使用して生成された場合でも効果的でなければならないことを意味する。
- 計算能力の制限: 攻撃者は限られた計算リソースを持っていると仮定され、トリガー生成アルゴリズムの複雑さに影響を与える。
- 不可視性の制約: トリガーは、知覚できないようにするために、$L_\infty$ ノルム(例:16/255)によって制約されることが多い(ページ6、35)。この物理的な制約は摂動の大きさを制限し、効果的で堅牢なトリガーを作成することをより困難にする。
- 非微分可能な関数: エラー計算のための指示関数 $1(\cdot)$(例:$1(F(x) \neq y)$)の使用は、非微分可能性を導入し、一部の文脈では直接的な最適化と理論的分析を複雑にする。本稿では、定理1.2と4.5で微分可能なクロスエントロピー損失(LCE)を使用しているが、最終的な目標は非微分可能な分類誤差をバウンドすることである。
なぜこのアプローチなのか
選択の必然性
著者らが、クリーンラベルバックドア攻撃に対する新しい汎化バウンドを導出することに焦点を当てたアプローチは、単なる多くの選択肢の一つではなく、これまで未解決の理論的ギャップに対する唯一の実行可能な解決策であった。著者らが従来の「SOTA」手法が不十分であると認識した正確な瞬間は、論文で明確に述べられている。「しかし、これらの汎化バウンドはクリーンな訓練データセットのためのものであり、ポイズニングされた訓練データセットには適用できません。なぜなら、ポイズニングされたデータセットは汎化可能性に必要なi.i.d.条件を満たさないからです」(セクション1、ページ1)。
この声明は、通常、データが独立同分布(i.i.d.)であると仮定する既存の汎化理論の根本的な限界を強調している。バックドア攻撃は、その性質上、訓練データのサブセットに慎重に作成された摂動を導入し、この重要なi.i.d.仮定に違反する。したがって、VC次元、Rademacher複雑度、またはDNNアーキテクチャ(例:CNN、Transformer)に特化したものかどうかにかかわらず、標準的な汎化バウンドは適用不能になる。問題は、既存のフレームワーク内で、より良いモデルまたはアルゴリズムを見つけることではなく、非i.i.d.ポイズニングデータ設定における攻撃の汎化可能性を理解するための新しい理論的フレームワークを確立することであった。さらに、バックドア攻撃のユニークな二重目的—クリーンサンプルに対する高い精度を維持しつつ、トリガー付き入力に対するターゲット誤分類を保証すること—および、トリガーが訓練フェーズとテストフェーズの両方に存在する特性は、既存の手法では提供されない特殊な理論的処理を必要とした。
比較優位性
単純な攻撃成功率(ASR)やクリーン精度のようなパフォーマンス指標を超えて、この方法は、その基礎的な理論的根拠を通じて定性的な優位性を示している。多くの以前のバックドア攻撃が経験的なヒューリスティックに依存しているのに対し、提案されたアプローチは「汎化バウンドに基づいており、一定の理論的保証を持つ」(セクション3、ページ3)。これは、攻撃が単なるブラックボックス最適化ではなく、その汎化可能性を可能にする根本的な条件の深い理解に基づいて設計されていることを意味する。
この方法の構造的利点は、ポイズン汎化誤差を制御および最小化できる条件(定理4.5のc1、c2、c3)を特定し、活用できる能力にある。これにより、敵対的ノイズと無差別のポイズンを理論的に情報に基づいた方法で組み合わせた、ポイズニングトリガーの原理的な設計が可能になる(セクション5、注釈5.1)。これは、高いパフォーマンスを達成するかもしれないが、なぜ汎化するのか、またはどのような条件下で機能することが保証されるのかについての明確な説明を欠いている手法に対する、質的な飛躍である。本稿のアプローチは、「これらの手法を使用するためのより情報に基づいたアプローチ」(セクション5、注釈5.1)を提供し、攻撃の有効性が経験的な観察だけでなく、堅牢な理論的理解に根ざしていることを保証する。
制約との整合性
選択された方法は、クリーンラベルバックドア攻撃の固有の制約と完全に整合している。
- クリーンラベルの性質: 全ての理論的フレームワークと提案されたアルゴリズムは、「訓練セット $D_{tr}$ のサブセットに元のラベルを変更せずにポイズントリガーが追加されるクリーンラベルバックドア攻撃」に特化して調整されている(セクション1、ページ1)。これは、本稿が直接対処する中心的な制約である。
- 二重の攻撃目標: 問題は、2つの重要な目標を定義している。(1) クリーンサンプルに対する高い精度を維持すること、および (2) トリガーを持つ任意の入力がターゲットラベル $l_p$ として分類されることを保証すること(セクション3.2)。解決策は、2つの異なる汎化バウンドを提供する。クリーンサンプル母集団誤差 $E(F, D_s)$ に対する定理1.1、およびポイズン母集団誤差 $E_p(F, D_s)$ に対する定理1.2であり、攻撃目標の両側面を直接対処している。
- 非i.i.d.ポイズニングデータ: これは、おそらく最も困難な制約である。本稿は、「$D_p$ のデータはもはや $D_s$ からi.i.d.サンプリングされないため、古典的な汎化バウンドを定理1.1を直接導出するために使用することはできない」と明示的に述べている(定理1.1、Q1)。著者らは、ポイズニングされた訓練データのサブセットのうち、クリーン分布からi.i.d.サンプリングされたものを見つけるという巧妙な方法でこれを克服している(定理4.1の証明アイデア、ページ4;補題A.3、ページ14)。この数学的な操作は、問題の厳しいデータ分布要件と解決策のユニークな理論的特性との直接的な「結婚」である。
- 訓練とテストフェーズの両方でのトリガーの存在: 汎化バウンドは、両方のフェーズでのトリガーを考慮するように定式化されている。ポイズニングされた訓練セット $D_p$ に対する経験的誤差は、母集団誤差をバウンドするために使用され、訓練中のトリガーの役割を本質的に考慮している。ポイズン汎化誤差 $E_p(F, D_s)$ は、トリガー付きテストデータに対する攻撃の成功を直接評価する。
- ステルス性/不可視性: 主に実験的な制約であるが、提案されたアルゴリズム1は「ポイズンバジェット $\eta$」(アルゴリズム1、入力)を組み込んでおり、$L_\infty$ ノルムバウンド(例:16/255)を強制するために設定でき、生成されたトリガーが知覚できないままであることを保証し、ステルス攻撃の実用的な要件に合致している。
代替案の却下
本稿は、主に既存の手法が対処できないクリーンラベルバックドア攻撃のユニークな課題を強調することによって、いくつかの代替アプローチを暗黙的かつ明示的に却下している。
第一に、最も直接的な却下は「古典的な汎化バウンド」(セクション1、ページ1)である。VC次元、Rademacher複雑度、または深層ニューラルネットワークに特化したものかどうかにかかわらず、これらのバウンドはi.i.d.データを仮定するため、不十分であると見なされる。ポイズニングされたデータセットは、定義によりこの仮定に違反するため、これらの伝統的な理論的ツールは適用不能である。著者らの研究はこの根本的なギャップを埋めており、既存の汎化理論を単に適応または適用しても失敗したであろうことを示唆している。
第二に、本稿は、データポイズニング攻撃(例:Wangら、2021;Hannekeら、2022)に対する他の既存の汎化バウンドからその作業を区別している。それは、「我々の結果はこれらの研究とは異なり、それらから導出することはできない」(セクション2、ページ3)と述べている。その理由は、これらの先行研究が、トリガーが訓練と推論の両方のフェーズに存在すること、およびクリーン精度を維持しながらターゲット誤分類を達成するという二重目的のような、バックドア攻撃の特定の特性を考慮していないことである。これは、これらのより一般的なポイズニング汎化バウンドが、クリーンラベルバックドア攻撃のニュアンスには十分な詳細さを持っていないことを示唆している。
最後に、攻撃生成手法自体に関しては、本稿は、主に経験的またはヒューリスティックベースのアプローチを、その「ほとんどの既存のバックドア攻撃は主に経験的なヒューリスティックに基づいているが、我々の攻撃は汎化バウンドに基づいており、一定の理論的保証を持つ」と強調することによって暗黙的に却下している(セクション3、ページ3)。他のクリーンラベル攻撃(セクション6.3、表4)と比較して、著者らは、多くの代替案が「追加ステップ」、「既存のパッチ」、「画像のフィッティング」、「トリガーの拡大」、または「大規模な生成モデル」を必要とすると指摘している(セクション6.3)。例えば、「Invisible Poison」と「Image-specific」攻撃は、最適なパフォーマンスのために大規模な生成モデルに依存しているが、提案された手法はこれを回避している。新しいアルゴリズムの理論的ガイダンスにより、より効率的で原理的なトリガー設計が可能になり、これらのしばしば複雑で、リソースを大量に消費する、またはアドホックなコンポーネントを回避できる。これにより、提案された手法は、その堅牢な理論的基盤により、そのようなオーバーヘッドなしに、より良い精度と攻撃成功率をもたらし、質的に優れている。
 Figure 4. When trigger is a patch without norm limitation, it is not invisible. This figure is from (Souri et al., 2022)
Figure 4. When trigger is a patch without norm limitation, it is not invisible. This figure is from (Souri et al., 2022)
数学的・論理的メカニズム
マスター方程式
本稿の中心的な貢献は、クリーンラベルバックドア攻撃に対する汎化バウンドを確立することにあり、2つの主要な目的に対処している。クリーンサンプルに対する高い精度を維持すること、およびトリガー付きデータがターゲットラベルに正しく分類されることを保証することである。これらの目的は、定理4.1および定理4.5として導出された2つのマスター方程式によって数学的に捉えられている。
クリーン汎化誤差バウンド(定理4.1)は次のように与えられる。
$$ E(F,D_s) \leq \frac{4-2\alpha}{1-\alpha} E(F,D_p) + O\left(\frac{mW^2D^2}{N} \ln(2/\delta) + \sqrt{\frac{\alpha}{N(1-\alpha)}}\right) $$
ポイズン汎化誤差バウンド(定理4.5)は次のように与えられる。
$$ E_p(F,D_s) \leq \lambda O\left(\left(E_{(x,y)\in D_p} [L_{CE}(F(x), y)] + \text{Rad}_{D_p}^{D_s}(H_{W,D,1})\right) + \sqrt{\frac{\ln(1/\delta)}{N\alpha}} + \epsilon + \tau + \lambda\right) $$
項ごとの解剖
これらの式の各コンポーネントを詳細に分析し、その数学的定義、物理的/論理的役割、および著者らがそれらを包含し操作する理由を理解しよう。
式1:クリーン汎化誤差バウンド
-
$E(F,D_s)$
- 数学的定義: これは、真の、基盤となるデータ分布 $D_s$ に対するニューラルネットワーク $F$ の母集団誤差である。これは、指示関数 $1(\cdot)$(引数が真であれば1、偽であれば0を返す)を用いた $E_{(x,y)\sim D_s} [1(F(x) \neq y)]$ として正式に定義される。
- 物理的/論理的役割: この項は、モデルが未知のクリーン、ポイズニングされていないデータに対する真のエラー率を表す。バックドア攻撃の文脈では、主な目標はこれを低く保ち、モデルがその意図された正当なタスクに有用であり続けることを保証することである。
- なぜ使用されるか: 真のデータ分布 $D_s$ は未知であるため、$E(F,D_s)$ は直接計算できない。汎化理論は、観測可能な量に基づいた確率的上限を提供する。
-
$\leq$
- 数学的定義: 「以下」。
- 物理的/論理的役割: この記号は、右辺の式が左辺の真の母集団誤差の上限を提供することを示している。これは汎化バウンドの本質である。
- なぜ使用されるか: 真のデータ分布 $D_s$ は未知であるため、$E(F,D_s)$ は直接計算できない。汎化理論は、観測可能な量に基づいた確率的上限を提供する。
-
$\frac{4-2\alpha}{1-\alpha}$
- 数学的定義: $\alpha$($D_{tr}$ における $l_p$ というラベルが付いたサンプルの割合)に依存するスカラー係数。
- 物理的/論理的役割: この係数は、ポイズニングされた訓練データで観測された経験的誤差をスケーリングする。これは、ポイズニングされたサンプルの割合が汎化バウンドのタイトさにどのように影響するかを反映する。$\alpha$ が増加すると、この係数は一般に増加し、経験的誤差と母集団誤差との間に、より緩いバウンドまたはより大きな乖離が生じる可能性を示唆する。
- なぜ使用されるか: 本稿では、ポイズニングされたデータセット ($D_p$) はi.i.d.(独立同分布)条件を満たさないことを強調しており、これは古典的な汎化バウンドの前提条件である。この係数は、この非i.i.d.設定に汎化理論を適応させるために採用された特定の数学的手法から生じている可能性が高い。
-
$E(F,D_p)$
- 数学的定義: これは、ポイズニングされた訓練データセット $D_p$ に対するネットワーク $F$ の経験的誤差である。これは、$E_{(x,y)\in D_p} [1(F(x) \neq y)]$ として定義される。
- 物理的/論理的役割: これは、クリーンサンプルとポイズニングされたサンプルの両方を含む、有限の訓練データで直接測定されたモデルのエラー率を表す。これは、学習アルゴリズムが訓練中に積極的に最小化しようとする量である。
- なぜ使用されるか: これは、訓練プロセス中に観測可能で測定可能な誤差である。汎化バウンドは、この経験的パフォーマンスを観測不可能な真のパフォーマンスに結び付けることを目指す。
-
$O(\cdot)$
- 数学的定義: Big O記法。関数の成長率の漸近的な上限を示す。括弧内の項は、指定された関数よりも速く成長しないことを意味する。
- 物理的/論理的役割: この記法は、「汎化ギャップ」を構成する項をグループ化する。これらの項は通常、訓練データセット $N$ のサイズが増加するにつれて減少するため、データが増えるほど、経験的誤差は母集団誤差のより信頼できる推定値になることを示唆する。
- なぜ使用されるか: menos significativos の定数を抽象化し、汎化ギャップがどの程度速く閉じるかを決定する支配的な要因に焦点を当てることで、式を単純化する。
-
$\frac{mW^2D^2}{N} \ln(2/\delta)$
- 数学的定義: モデルの複雑さ、データサイズ、および信頼性に関連する項。
- $m$: ラベルセットにおけるクラスの数。
- $W$: ニューラルネットワークの幅(例:レイヤーあたりの最大ニューロン数)。
- $D$: ニューラルネットワークの深さ(レイヤー数)。
- $N$: クリーン訓練セット $D_{tr}$ の総サンプル数。
- $\ln(2/\delta)$: $2/\delta$ の自然対数。ここで、$\delta$ は導出されたバウンドが保持されない可能性のある小さな確率(例:0.05)である(すなわち、バウンドは確率 $1-\delta$ で保持される)。
- 物理的/論理的役割: この項は、ニューラルネットワークモデルの容量を定量化する。より複雑なモデル(より大きな $W$ または $D$)は、訓練データ(ノイズを含む)に適合する能力がより大きいため、より大きな汎化ギャップ(過学習)につながる可能性がある。逆に、より大きな訓練セットサイズ $N$ はこのギャップを縮小するのに役立つ。$\ln(2/\delta)$ という因子は、バウンドの確率的性質を考慮している。この項は、Rademacher複雑度やVC次元のような概念を使用して導出された汎化バウンドの標準的なコンポーネントである。
- なぜ使用されるか: モデルの表現力と利用可能なデータ量の間のトレードオフを反映し、深層学習モデルの汎化バウンドにおける標準的なコンポーネントである。
- 数学的定義: モデルの複雑さ、データサイズ、および信頼性に関連する項。
-
$\sqrt{\frac{\alpha}{N(1-\alpha)}}$
- 数学的定義: ポイズニング率 $\alpha$ と訓練セットサイズ $N$ を含む平方根項。
- 物理的/論理的役割: この項は、ポイズニングプロセスによって導入された統計的不確実性を具体的に捉えている。ポイズニング率 $\alpha$ が増加すると、この項は一般に増加し、データ分布の非i.i.d.性による汎化ギャップの増大を示唆する。逆に、$N$ が大きいとこの項は減少するが、より多くのデータがポイズニングの影響を緩和するのに役立つことを示唆している。分母の $(1-\alpha)$ は、ほとんど全てのサンプルがポイズニングされた場合($\alpha \to 1$)、バウンドが非常に緩くなることを意味する。
- なぜ使用されるか: この項は、データポイズニングが存在する状況での汎化のユニークな課題に直接対処し、ポイズニングされたデータセットの非i.i.d.性の統計的影響を定量化する。
式2:ポイズン汎化誤差バウンド
-
$E_p(F,D_s)$
- 数学的定義: これは、ネットワーク $F$ の真のデータ分布 $D_s$ に対するポイズン母集団誤差である。これは、$P(x)$ が入力 $x$ に適用されるトリガーであり、$l_p$ がトリガー付き入力に指定されたターゲットラベルである場合、$E_{(x,y)\sim D_s} [1(F(x + P(x))) \neq l_p)]$ として正式に定義される。
- 物理的/論理的役割: この項は、未知のトリガー付きデータに対するバックドア攻撃の真の失敗率を測定する。攻撃の目標は、この値を可能な限り小さくすることであり、トリガーを持つ任意の入力が一貫して $l_p$ として分類されることを保証することである。
- なぜ使用されるか: これは、バックドア攻撃自体の成功率と有効性を評価するための重要な指標である。
-
$\leq$
- 数学的定義: 「以下」。
- 物理的/論理的役割: 式1と同様に、右辺がポイズン母集団誤差の上限を提供することを示している。
- なぜ使用されるか: バックドア攻撃の有効性に対する理論的保証を確立し、その真の誤差率をバウンドする。
-
$\lambda$
- 数学的定義: 定理4.5の条件(c2)から導出されたスケーリング係数。これは、$P_{(x,y)\sim D_s}(P(x) \in A|y \neq l_p) \leq \lambda P_{(x,y)\sim D_s}(P(x) \in A|y = l_p)$ を任意の集合 $A$ に対して満たすと述べている。
- 物理的/論理的役割: このパラメータは、トリガー $P(x)$ の異なるクリーンサンプル $x$ 間での「類似性」または「一貫性」を定量化する。もし $P(x)$ が様々な入力に対して高度に類似している場合、 $\lambda$ は1に近づく。よりタイトなバウンドのためには、より小さな $\lambda$(1に近い)が望ましい。これは、トリガーがモデルが容易に学習できる一般的な、一貫したパターンとして機能することを示唆する。
- なぜ使用されるか: 効果的なトリガーを設計するための重要な条件であり、バックドアが特定の入力特性に結び付くのではなく、トリガー自体に結び付くことを保証し、汎化可能にする。
-
$O(\cdot)$
- 数学的定義: Big O記法。式1と同様。
- 物理的/論理的役割: ポイズン母集団誤差の汎化ギャップに寄与する項をグループ化する。
- なぜ使用されるか: 支配的な要因に焦点を当てることで、バウンドを単純化する。
-
$E_{(x,y)\in D_p} [L_{CE}(F(x), y)]$
- 数学的定義: これは、ポイズニングされた訓練データセット $D_p$ に対するネットワーク $F$ の経験的クロスエントロピー損失である。$L_{CE}$ はクロスエントロピー損失関数を表す。
- 物理的/論理的役割: この項は、ポイズニングされたデータセットに対するモデルが訓練中に最小化する経験的リスク(損失)を表す。0-1誤差とは異なり、クロスエントロピー損失は、特定の予測に対するモデルの確信度を測定する連続的な尺度を提供し、トリガー付き入力に対してターゲットラベル $l_p$ を高い確率で出力するように促す。
- なぜ使用されるか: クロスエントロピー損失は、特に高い確信度が望ましい分類タスクにおいて、標準的でより有益な損失関数であり、バックドア攻撃の場合も同様である。
-
$\text{Rad}_{D_p}^{D_s}(H_{W,D,1})$
- 数学的定義: $D_p$ と $D_s$ を橋渡しする分布の下での仮説空間 $H_{W,D,1}$ のRademacher複雑度。$H_{W,D,1}$ は、幅 $W$ と深さ $D$ を持つニューラルネットワーク $F$ に対する関数 $h_F(x,y) = F_y(x)$ の集合である。この記法は、 $D_p$ のサンプルから計算されたRademacher複雑度であるが、$D_s$ への汎化を意図していることを示唆している。
- 物理的/論理的役割: この項は、ポイズニングされたデータの文脈におけるモデルの「学習可能性」または「柔軟性」を定量化する。より高いRademacher複雑度は、より複雑なパターンに適合できるモデルを示唆し、適切に制御されない場合、過学習につながる可能性がある。これは、ランダムラベルにモデルが適合する能力を測定するものであり、過学習の可能性の代理である。
- なぜ使用されるか: Rademacher複雑度は、ニューラルネットワークのような複雑な関数クラスに対する汎化誤差をバウンドするための統計的学習理論における基本的なツールである。
-
$\sqrt{\frac{\ln(1/\delta)}{N\alpha}}$
- 数学的定義: 信頼度パラメータ $\delta$、訓練セットサイズ $N$、およびポイズニング率 $\alpha$ を含む平方根項。
- 物理的/論理的役割: この項は、統計的集中成分を表す。$N$ が増加すると、この項は減少し、バウンドはタイトになる。$\alpha$ が小さい(ポイズニングされたサンプルが少ない)と、この項は大きくなり、非常に少ないサンプルでポイズンの影響について統計的に汎化することが困難であることを示唆している。
- なぜ使用されるか: これは集中不等式における一般的な項であり、バウンドの特定の信頼度レベルを達成するために必要なサンプル複雑度を反映している。
-
$\epsilon$
- 数学的定義: 定理4.5の条件(c1)からの小さな正の値:$E_{(x,y)\sim D_p^{l_p}} [G_y(x + P(x))] \leq \epsilon$。ここで、$G_y(x)$ はクリーン訓練済みネットワーク $G$ が $x$ を $y$ として分類する確率である。
- 物理的/論理的役割: この項は、トリガー $P(x)$ がどれほど「敵対的」であるかを定量化する。もし $P(x)$ がクリーン訓練済みネットワーク $G$ に $x+P(x)$ を誤分類させるのに効果的であれば、 $\epsilon$ は小さくなる。バウンドをタイトにするためには、より小さな $\epsilon$ が望ましい。これは、トリガーが効果的な敵対的摂動であるべきであることを示唆する。
- なぜ使用されるか: これはトリガー設計の条件であり、トリガーが多くのバックドア攻撃の特徴である効果的な敵対的摂動として機能することを保証する。
-
$\tau$
- 数学的定義: 定理4.5の条件(c3)からの小さな正の値:$E_{x\sim D_s} [|(F-G)_{l_p}(P(x)) - (F-G)_{l_p}(x+P(x))|] \leq \tau$。これは、$P(x)$ と $x+P(x)$ に対するネットワーク出力の「バックドア部分」の類似性を測定する。
- 物理的/論理的役割: この項は、トリガー $P(x)$ がどれほど「ショートカット的」であるかを定量化する。トリガーがショートカットとして機能する場合、ネットワークの $P(x)$ に対する応答は $x+P(x)$ に対する応答と類似しているはずであり、小さな $\tau$ をもたらす。バウンドをタイトにするためには、より小さな $\tau$ が望ましい。これは、トリガーが複雑な相互作用ではなく、単純で直接的な特徴(「ショートカット」)としてモデルに学習させることを意味する。
- なぜ使用されるか: これはトリガー設計の条件であり、モデルが複雑な相互作用ではなく、単純で直接的な特徴(「ショートカット」)としてトリガーを学習することを奨励する。
-
なぜ加算であり、乗算ではないのか、あるいは積分ではなく和なのか?
これらの式は、誤差の異なるソースと汎化ギャップに寄与する要因を集約するため、和として構造化されている。各項は、経験的誤差(観測されるもの)、モデルの複雑さ、統計的変動、およびトリガーの特定の特性といった、異なる側面を表している。これらの要因は、母集団誤差に対する全体的な上限に加算的に寄与する。例えば、モデルの複雑さと統計的不確実性の両方が、経験的誤差が真の母集団誤差から逸脱する可能性を独立して増加させる。$E_{(x,y)\sim D_s}$ という記法は、連続確率分布 $D_s$ に対する期待値を意味し、これは数学的には積分によって表される。対照的に、$E_{(x,y)\in D_p}$ は、有限の離散データセット $D_p$ に対する経験的平均を表し、これは和として計算される。著者らは、連続母集団または離散サンプルを参照するかどうかに応じて、期待値記法を通じて適切な数学的演算子(積分または和)を使用している。
ステップバイステップの流れ
真のデータ分布 $D_s$ からの抽象的な単一データポイント $(x_0, y_0)$ が、これらの汎化バウンドによって記述される概念的なメカニズムをどのように通過するかを追ってみよう。
-
データポイントの起源: 私たちの旅は、抽象的でクリーンなデータポイント $(x_0, y_0)$ から始まる。ここで、$x_0$ は入力(例:画像)、$y_0$ はその真のラベルである。このポイントは、無限で観測不可能な真のデータ分布 $D_s$ からの代表的なサンプルである。
-
攻撃評価のための仮説的ポイズニング: ポイズン母集団誤差 $E_p(F,D_s)$ を評価する場合、このクリーンな入力 $x_0$ は、事前に設計されたトリガー $P(x_0)$ を追加することによって概念的に変更される。結果の入力は $x_0 + P(x_0)$ となり、バックドア攻撃の意図されたラベルは、$y_0$ に関係なく $l_p$ である。この変換されたペア $(x_0 + P(x_0), l_p)$ は、攻撃者がモデルに正しく分類させたいものを表す。クリーン汎化誤差 $E(F,D_s)$ を評価する場合、データポイントは $(x_0, y_0)$ のままである。
-
モデル推論(「ブラックボックス」ネットワーク $F$): (仮説的に)訓練されたニューラルネットワーク $F$ は、この入力を受け取る。
- 特徴変換: 入力($x_0$ または $x_0 + P(x_0)$)は、ネットワークのレイヤーを通過する。畳み込み、非線形活性化(例:ReLU)、およびプーリングのような操作で構成される各レイヤーは、生の入力をより抽象的で識別性の高い特徴表現へと段階的に変換する。
- 出力生成: ネットワークの最終レイヤー、通常はSoftmaxレイヤーは、これらの特徴をすべての可能な出力クラスに対する確率分布に変換する。$F(z)$ はこの確率のベクトルであり、$F_y(z)$ は入力 $z$ に対するラベル $y$ に割り当てられた確率である。
- 分類決定: ネットワークの最終分類 $\text{argmax}_y F_y(z)$ は、最も高い予測確率を持つラベルである。
-
誤差/損失計算(母集団レベル):
- クリーン誤差: クリーン汎化のためには、ネットワークの出力 $F(x_0)$ は真のラベル $y_0$ と比較される。予測ラベル $\text{argmax}_y F_y(x_0)$ が $y_0$ と一致しない場合、誤差が記録される。このプロセスは概念的に繰り返され、すべての可能な $(x,y) \sim D_s$ に対して平均化され、$E(F,D_s)$ が得られる。
- ポイズン誤差: ポイズン汎化のためには、ネットワークの出力 $F(x_0 + P(x_0))$ はターゲットラベル $l_p$ と比較される。$\text{argmax}_y F_y(x_0 + P(x_0))$ が $l_p$ と一致しない場合、誤差が記録される。これはすべての可能な $(x,y) \sim D_s$ に対して平均化され、$E_p(F,D_s)$ が得られる。
-
経験的対応物(訓練データ $D_p$): 実際の訓練フェーズ中、モデル $F$ は、観測可能でポイズニングされた有限訓練データセット $D_p$ にさらされる。
- サンプル選択: $D_p$ から特定のサンプル $(x_i, y_i)$ が描画される。このサンプルは、$D_{tr}$ からの元のクリーンサンプルであるか、または $D_{tr}$ からのクリーンサンプル $(x_j, l_p)$ を摂動することによって作成されたポイズニングされたサンプル $(x_j + P(x_j), l_p)$ である可能性がある。
- 経験的損失/誤差: ネットワーク $F$ は $x_i$ を処理する。
- クリーン汎化バウンドの場合、経験的誤差 $E(F,D_p)$ は、指示関数を使用して $F(x_i)$ と $y_i$ を比較することによって計算される。
- ポイズン汎化バウンドの場合、経験的クロスエントロピー損失 $L_{CE}(F(x_i), y_i)$ が計算される。これは、入力 $x_i$ に対して $F$ が $y_i$ をどれだけうまく予測するかを測定する。
- 平均化: これらの個々の誤差または損失は、有限データセット $D_p$ のすべてのサンプルに対して平均化され、$E(F,D_p)$ または $E_{(x,y)\in D_p} [L_{CE}(F(x), y)]$ が得られる。
-
汎化ギャップの橋渡し: 数学的なエンジンは、これらの観測可能な $D_p$ に対する経験的誤差/損失を、観測不可能な $D_s$ に対する母集団誤差に結び付ける。バウンド内の追加項(Rademacher複雑度、$\sqrt{\frac{\ln(1/\delta)}{N\alpha}}$、$\epsilon$、$\tau$、$\lambda$)は、「補正係数」または「ペナルティ項」として機能する。それらは以下を定量化する。
- モデル容量: ネットワーク $F$ が過学習しやすい度合い(Rademacher複雑度)。
- データ不足: 有限訓練セット ($N$) に起因する統計的不確実性。
- ポイズニングの影響: ポイズニング率 ($\alpha$) によって導入された特定の統計的バイアス。
- トリガーの品質: 作成されたトリガー $P(x)$ が、敵対的($\epsilon$)、一貫性がある($\lambda$)、ショートカット($\tau$)であるという望ましい特性をどの程度満たしているか。
このプロセス全体により、抽象的な数学が、生データが入力され、機械(ネットワーク)によって処理され、そのパフォーマンスが測定される、動く機械組み立てラインのように感じられる。汎化バウンドは、その観測されたパフォーマンスと固有の設計特性に基づいて、将来の未知のデータに対する機械のパフォーマンスを予測する理論的な「品質管理」レポートを提供する。
最適化ダイナミクス
汎化バウンド自体は、被害者モデル $F$ の直接的な最適化目標ではない。代わりに、それらはバックドア攻撃が効果的に汎化する条件の下で、理論的な保証と条件を提供する。この文脈における「最適化ダイナミクス」は、トリガー $P(x)$ がこれらの条件を満たすようにどのように設計されるか、および被害者モデル $F$ がこれらのバウンドを遵守しながら望ましいバックドア動作を達成するようにどのように訓練されるかを指す。
ポイズニングトリガーを作成するための本稿の提案アルゴリズム(アルゴリズム1)は、攻撃自体の主要な最適化ダイナミクスが発生する場所である。
-
敵対的摂動の作成(小さい $\epsilon$ のための条件c1/t1の満足):
- メカニズム: ネットワーク $F_1$ がクリーンデータセット $T$ で訓練される。各クリーンサンプル $x$ について、投影勾配降下法(PGD)を使用して敵対的摂動 $x_{adv}$ が生成される。PGDは、損失関数 $L(F_1(x+\epsilon), y)$ の $\epsilon$ に関する勾配を計算することを含む、反復最適化プロセスであり、元のラベル $y$ に対する $F_1$ の損失を最大化する小さな摂動 $\epsilon$($L_\infty$ バジェット $\eta$ 内)を見つける。
- 勾配と損失ランドスケープ: これは、損失関数 $L(F_1(x+\epsilon), y)$ の $\epsilon$ に関する勾配を計算することを含む。最適化は、勾配の方向(勾配上昇)にステップを取って損失を増加させ、次に $\epsilon$ を許容される摂動空間に投影することによって反復的に $\epsilon$ を更新する。このプロセスは、トリガーの「敵対的」なコンポーネントを形成し、 $\epsilon$($P(x)$ に寄与する)を効果的な敵対的例にすることを目指し、それによってバウンド内の $\epsilon$ が小さいことを保証する。
-
ショートカット摂動の作成(小さい $\tau$ のための条件c3/t3の満足):
- メカニズム: 別個の、より単純な2層ネットワーク $F_2$ が特別に構築されたデータセット $T_1$ で訓練される。このデータセットには、クリーンサンプルと、$x_{adv}$(前のステップから)で摂動されたサンプルが含まれるが、特定のラベル(0)が付いている。目標は、Min-Min法を使用して「ショートカット」摂動 $x_{scut}$ を見つけることである。この方法は、$F_2$ によってポイズニングされたデータセットが線形分離可能になるようにすることを目指す。
- 損失ランドスケープと状態更新: Min-Min法は通常、内部最適化ループ(与えられた $F_2$ に対する最適な $x_{scut}$ を見つける)と外部最適化ループ($F_2$ を訓練する)を含む。$F_2$ の損失ランドスケープは、ポイズニングされたデータから単純な線形分離可能な特徴を学習するように奨励するように形成される。これにより、トリガーをターゲットラベルにマッピングする「ショートカット」が効果的に作成される。$F_2$ のパラメータと $x_{scut}$ の反復更新は、 $\tau$ を最小化することを目指し、トリガーが強力なショートカット特徴として機能することを保証する。
-
摂動の組み合わせ($\lambda$ が1に近いことの満足):
- メカニズム: 最終的なトリガー $P(x)$ は、$x_{adv}$ と $x_{scut}$ をバイナリマスク $U$ を使用して組み合わせることによって構築される:$P(x) = U \odot x_{adv} + (1-U) \odot x_{scut}$。マスク $U$ は(例えば、上部左隅が0で残りが1のような特定の領域)設計され、ショートカットコンポーネント $(1-U) \odot x_{scut}$ が異なる入力 $x$ 間で類似していることを保証する。
- 勾配/状態更新の動作: $\lambda$ 自体に対する直接的な勾配ベースの最適化はないが、マスク $U$ の設計選択とMin-Min法の特性(異なる入力に対して類似したショートカットを生成する傾向がある)は、暗黙的にトリガー生成を条件(c2)を満たすように導く。これにより、トリガーが一貫したパターンになり、 $\lambda$ が1に近づくことが保証される。アルゴリズム1を使用して得られた一部のポイズンは、図1に示されている。
-
被害者モデルの訓練と収束:
- メカニズム: トリガー $P(x)$ が生成されると、それらは元のクリーン訓練データ $D_{tr}$ のサブセットに適用され、ポイズニングされた訓練セット $D_p$ が形成される。次に、被害者ネットワーク $F$ は、クロスエントロピー損失関数を使用して、標準的な最適化アルゴリズム(例:確率的勾配降下法(SGD))で $D_p$ で訓練される。
- 損失ランドスケープと収束: $D_p$ にポイズニングされたサンプルが存在すると、被害者モデル $F$ の損失ランドスケープが変更される。モデルは $D_p$ に対する経験的損失を最小化するように学習し、これは、ポイズニングされていないサンプルに対するクリーン分類タスクと、トリガー付きサンプルに対するバックドアタスクの両方を学習する必要があることを意味する。次に、汎化バウンドは、この収束したモデル $F$ の汎化パフォーマンスを予測する。トリガー $P(x)$ が条件(小さい $\epsilon, \tau$、$\lambda$ が1に近い)を満たすようにうまく作成された場合、バウンドは、収束した被害者モデルが、高いクリーン精度と高い攻撃成功率を示すと予測する。SGDによる $F$ のパラメータの反復更新は、この複雑な、多目的損失ランドスケープの局所的最小値に向かってそれを駆動する。
本質的に、最適化ダイナミクスは2段階のプロセスである。まず、トリガー $P(x)$ を特定の特性(敵対的、ショートカット、一貫性)を持つように作成するための、ターゲットを絞った、勾配駆動の最適化。これは数学的に汎化バウンドに関連付けられる。次に、結果のポイズニングデータセットに対する被害者ネットワークの標準的な訓練であり、バウンドは最終モデルの汎化パフォーマンスを予測する。バウンドは、これらのトリガー設計原則がなぜ効果的で汎化可能なバックドア攻撃につながるのかという理論的フレームワークを提供する。
 Figure 1. From top row to bottom row are respectively the clean images, normalized triggers (original trigger has L∞norm bound 16/255), poison images. Due to the selection of U, the upper left corners of the poison images are similar, while the other parts are used to generate adversaries
Figure 1. From top row to bottom row are respectively the clean images, normalized triggers (original trigger has L∞norm bound 16/255), poison images. Due to the selection of U, the upper left corners of the poison images are similar, while the other parts are used to generate adversaries
結果、限界、結論
実験設計とベースライン
提案されたクリーンラベルバックドア攻撃の理論的主張と有効性を厳密に検証するために、著者らは様々なベンチマークデータセットと被害者ネットワークアーキテクチャにわたる広範な実験を実施した。実験設定は、攻撃者が被害者の訓練プロセスに関する限定的な知識と制御しか持たないという、実用的な攻撃シナリオをシミュレートするように細心の注意を払って設計された。
データセットと被害者モデル: 攻撃は、CIFAR10、CIFAR100、SVHN、TinyImageNetといった広く使用されている画像分類データセットで評価された。被害者モデルとしては、VGG16、ResNet18、WRN34-10のような一般的な深層ニューラルネットワークが使用された。
攻撃メカニズムとトリガー生成: 提案された攻撃の核心は、敵対的ノイズと無差別のポイズンを組み合わせた新しいトリガー生成方法(アルゴリズム1)である。このプロセス自体は、被害者ネットワークの構造や計算能力に関する仮定を避けるために、より小さく独立したネットワーク(敵対的ノイズ用のF1、ショートカット摂動用のF2)を利用する。例えば、F1はL-infinityノルムバジェット(例:8/255または4/255)を用いたPGD-10敵対的訓練を使用して訓練され、一方F2は2層ネットワークであり、Min-Min法を使用してショートカットを作成するために訓練された。ポイズニングプロセスは、特定のターゲットラベル $l_p$(通常は0に設定)を持つ訓練サンプルのサブセット(例:訓練画像の1%または0.8%)をランダムに選択し、生成されたトリガーを元のラベルを変更せずにそれらに追加することを含んだ。
評価指標とベースライン: 攻撃の有効性は、主に以下の指標で測定された。
1. クリーンモデル精度: ポイズニングされたモデルのクリーンテストサンプルに対する精度。
2. ポイズニングモデル精度: ポイズニングされたモデルのポイズニングされたテストサンプルに対する精度。
3. 攻撃成功率 (ASR): トリガーを含むサンプルがターゲットラベル $l_p$ に誤分類される割合。
4. クリーンモデル $l_p$ 精度: ターゲットクラス $l_p$ に属するクリーンサンプルの精度。
提案手法は、Clean Label、Hidden Trigger、Reflection、Invisible Poison、Image-specific、Narcissus、Sleeper Agentといった7つの著名なクリーンラベルバックドア攻撃と比較された。公正な比較のため、すべての攻撃はL-infinityノルムトリガーバジェット(例:16/255)と固定ポイズンバジェット(例:訓練画像の1%)によって制約された。
防御メカニズム: 攻撃の堅牢性を評価するために、敵対的訓練(AT)、データ拡張、スケールアップ、差分プライベートSGD(DPSGD)、周波数フィルタ、ファインチューニングといった6つの一般的なバックドア防御に対してテストされた。
理論的検証: 実証的パフォーマンスを超えて、著者らは定理4.1と4.5を検証するためにアブレーションスタディを実施した。これには、トリガーの異なるコンポーネント(敵対的ノイズ、ショートカットノイズ)が定理4.5の条件(c1)、(c2)、(c3)にどのように影響するかを、$V_{adv}$(条件(c1)のポイズニングデータに対する検証損失)や$V_{sc}$(条件(c3)のバイナリ分類損失)のような指標を使用して分析することが含まれた。また、定理4.1を支持するために、ポイズン率が全体精度に与える影響も調査した。
証拠が証明すること
実験的証拠は、提案されたクリーンラベルバックドア攻撃の有効性と理論的根拠を説得力をもって支持している。
コアメカニズムの決定的な証拠:
敵対的ノイズと無差別のポイズンを組み合わせて、定理4.5の条件を満たすトリガーを作成するというコアメカニズムは、徹底的に効果的であることが証明された。攻撃は、クリーンサンプルに対する高い精度を維持しながら、一貫して高い攻撃成功率(ASR)を達成した。これは、クリーンラベルバックドア攻撃の2つの主要な目標である。例えば、CIFAR-10でResNet18を使用し、1%のポイズンバジェット(L-infinityノルム16/255)で、提案手法は93%のASRを達成し、クリーンモデル精度は93%、ポイズニングモデル精度は91%であった(表1)。これは、被害者モデルがトリガーを学習して入力をターゲットラベル $l_p$ に誤分類させたが、正当なクリーンデータに対しても良好に機能し続けたことを示している。
「被害者」(ベースラインモデル)は決定的に打ち負かされた。L-infinityノルムバジェット16/255の下で、我々の攻撃はCIFAR-10で93%のASRを達成し、他の全ての比較手法(23%(Clean-Label)から75%(Hidden-Trigger)の範囲)を大幅に上回った(表4)。この否定できない証拠は、理論的バウンドによって導かれる、敵対的ノイズとショートカット特性の特定の組み合わせが、効果的なバックドアを埋め込む上で優れていることを強調している。攻撃の有効性は、非常に小さなポイズンバジェット(例:CIFAR-10でResNet18を使用し、0.6%のポイズンバジェットで86%のASR、表2)でも高く維持され、その効力がさらに証明された。
攻撃のパフォーマンスは、様々なデータセット(CIFAR10、CIFAR100、SVHN、TinyImageNet)や異なるターゲットラベル(0-9)で一貫していた(表3および図3)。これは、特定のデータセットやターゲットクラスに特化したものではなく、汎化可能な攻撃戦略を示唆している。訓練プロセスの監視(図2)はさらに、クリーンモデルとポイズニングモデルの精度が近く、ASRがすぐに高いレベルで安定したことを確認し、バックドアの堅牢な学習を示唆している。
理論的主張の検証:
定理4.5を検証するために特別に設計されたアブレーションスタディは、重要な洞察を提供した。異なるポイズンタイプ(ランダムノイズ、ユニバーサル敵対的、敵対的、ショートカット、および我々の手法)を比較し、それらが $V_{adv}$(条件c1に関連)と $V_{sc}$(条件c3に関連)に与える影響を評価することにより、著者らは個々のコンポーネントはしばしば1つの条件で優れているが、もう1つでは失敗することを示した。例えば、敵対的摂動のみ($Adv$)は高い $V_{adv}$ をもたらした(条件c1がよく満たされていないことを意味する)が、ショートカットノイズのみ($SCut$)は高い $V_{sc}$ をもたらした(条件c3がよく満たされていないことを意味する)。しかし、両方を組み合わせた提案された「我々の手法」($Ours$)は、良好な $V_{adv}$ と非常に低い $V_{sc}$ を持つバランスの取れた結果を達成し、大幅に高いASR(16/255バジェット下で$Ours$の93%対$Adv$の22%、$SCut$の30%、表6)につながった。これは、トリガーメカニズムを組み合わせることによって定理4.5の条件を満たすことが、優れた攻撃パフォーマンスにつながることを直接検証している。
定理4.1に関しては、実験により、ポイズン率が高いほどクリーン精度への影響が大きくなる傾向があるが、低下はそれほど大きくないことが示された(例:3,000以上のポイズニングされたサンプルでわずか4%の低下、表14)。これは、ポイズニング率が汎化に影響するという理論的洞察を支持しているが、制御されたポイズンバジェットがあれば、クリーンサンプル精度への影響を最小限に抑えることができることも示唆している。さらに、被害者ネットワークはトリガー特徴を効果的に学習することが示された(表12)が、それでも元の画像特徴を優先したため、バックドアが効果的であるためには十分な規模のポイズンが必要であることが示唆された。
限界と今後の方向性
提案されたクリーンラベルバックドア攻撃は顕著な有効性を示し、堅固な理論的汎化バウンドに基づいているが、本稿はいくつかの限界を認め、将来の研究への道を開いている。
現在の限界:
1つの重要な限界は、定理4.5に概説されている条件の複雑さにある。著者ら自身がこれらの条件は「かなり複雑」であると述べており、ポイズン母集団誤差バウンドのための、より単純で、より直感的な条件を導出することは非常に望ましいだろう。この複雑さは、理論的フレームワークのより広範な理解と応用を妨げる可能性がある。
もう1つの理論的なギャップは、現在の汎化バウンドが訓練プロセスを明示的に組み込んでいないことである。特に安定性分析(例:Hardtら、2016)に基づくアルゴリズム依存の汎化バウンドは、バックドア攻撃の文脈でさらなる調査に値する。そのような分析は、訓練ダイナミクスが攻撃の成功と汎化可能性にどのように影響するかについての、より詳細な理解を提供する可能性がある。
実用的な観点からは、本稿は、生成されたトリガーが異なるデータセット間で限定的な転移性を示すことを指摘している。例えば、CIFAR-10用に作成されたトリガーは、CIFAR-100には直接適用できない(付録F.5)。これは攻撃の汎用性を制限し、各新しいデータセットに対してトリガーを再生成する必要があるが、これは計算集約的になる可能性がある。
さらに、攻撃はベースラインに対して非常に効果的であるにもかかわらず、「防御下ではある程度脆弱」である(セクション6.4)。著者らは防御メカニズムを生成プロセスに組み込んだ「強化された攻撃」を提案してこれらの防御に耐えているが、これは攻撃の堅牢性が固有のものではなく、継続的な適応を必要とする継続的な競争を示唆している。防御における観察された堅牢性-精度トレードオフも課題を浮き彫りにしている。被害者モデルのパフォーマンスを大幅に低下させることなく、攻撃耐性を向上させること。
将来の方向性と議論のトピック:
本稿の発見は将来の研究の強力な基盤を築いており、いくつかの議論のトピックを促している。
- 理論的条件の単純化: 定理4.5の条件を、実務家にとってより扱いやすく解釈可能なものにするために、どのように再定式化または近似できますか?「敵対的ノイズ」と「ショートカット」特性のより抽象的で高レベルな理解は十分でしょうか、それとも正確な数学的条件は理論的保証に不可欠でしょうか?
- アルゴリズム依存の汎化バウンド: 訓練アルゴリズムのどの特定の側面(例:オプティマイザ、学習率、正則化)がバックドア攻撃の汎化に最も影響しますか?よりタイトで、より実用的なガイダンスを提供するアルゴリズム依存のバウンドを導出できますか?これには、深層学習における暗黙的正則化のような概念の探求が含まれる可能性がある。
- クロスデータセットトリガー転移性: 再生成を必要とせずに、多様なデータセット全体で機能するユニバーサルまたはより転移性の高いトリガーをどのように設計できますか?これには、トリガー生成のためのメタ学習アプローチや、効果的なバックドアトリガーとしても機能するデータセット非依存の「ユニバーサル敵対的摂動」の特定が含まれる可能性がある。
- 攻撃-防御の競争: 防御に対する観察された脆弱性を考慮すると、既存の攻撃メカニズムに受動的に対処するのではなく、根本的に堅牢なバックドア攻撃をどのように開発できますか?これは、適応型攻撃/防御戦略や、この競争のゲーム理論的モデルの研究につながる可能性がある。
- 倫理的影響と責任あるAI: 本稿は、悪意のあるアクターがこれらの手法を使用する可能性があるため、この作業の潜在的な負の社会的影響を明示的に言及している。これは、責任ある開示、AIセキュリティのための「レッドチーミング」の開発、および強力なAI機能の誤用を防ぐための堅牢な規制フレームワークの必要性に関する重要な疑問を提起する。科学界は、強力なAI機能の誤用を防ぐという義務と、オープンな研究のバランスをどのように取ることができるか?
- 画像分類を超えて: 理論的フレームワークと攻撃方法論は、自然言語処理、音声認識、または強化学習のような他のドメインに拡張できますか?これらの異なるデータモダリティとタスク構造に「敵対的ノイズ」と「ショートカット」の概念を適応させる際に、どのような独自の課題と機会が生じますか?
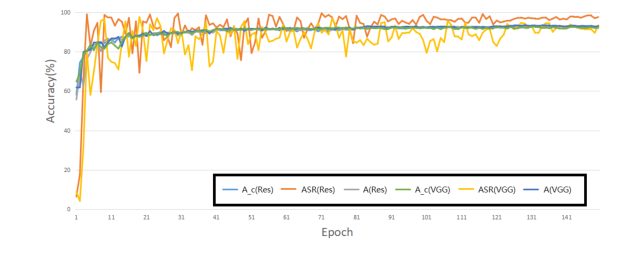 Figure 2. Attack performance during the training process on CIFAR10 with ResNet18 and VGG16. This figure shows the trend of the poison model accuracy (A), attack success rate (ASR) and clean model accuracy (Ac)
Figure 2. Attack performance during the training process on CIFAR10 with ResNet18 and VGG16. This figure shows the trend of the poison model accuracy (A), attack success rate (ASR) and clean model accuracy (Ac)
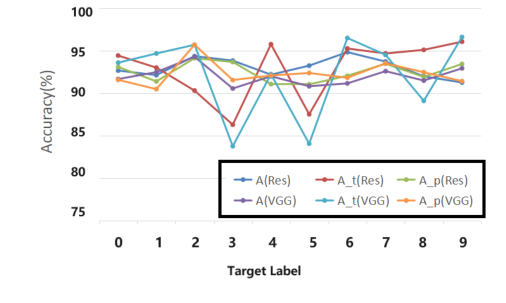 Figure 3. Performance of different target label lp. We show the poison model accuracy (A), accuracy of target label (At), attack success rate (Ap) on CIFAR-10, using VGG16 and ResNet18
Figure 3. Performance of different target label lp. We show the poison model accuracy (A), accuracy of target label (At), attack success rate (Ap) on CIFAR-10, using VGG16 and ResNet18