泛化界与无毒标签后门攻击的新算法
The generalization bound is a crucial theoretical tool for assessing the generalizability of learning methods and there exist vast literatures on generalizability of normal learning, adversarial learning, and data...
背景与学术渊源
起源与学术渊源
本文所解决的问题源于机器学习理论领域,特别是关于学习算法的泛化能力。历史上,泛化界的概念一直是理解在有限数据集上训练的模型如何在未见数据上表现良好的关键理论工具。正如 Mohri 等人 (2018) 所引用的,该领域的早期工作侧重于使用 VC 维度和 Rademacher 复杂度等度量来量化标准学习任务的泛化能力。
然而,随着机器学习模型变得越来越复杂,应用也日益多样化,新的挑战应运而生。一个重要的担忧领域是数据投毒攻击,恶意行为者操纵训练数据以损害模型的完整性。虽然针对一般数据投毒攻击的泛化界已被探索(例如,Wang 等人,2021;Hanneke 等人,2022),但一种特定且特别阴险的攻击类型——后门攻击——提出了独特的挑战。
该问题的精确起源源于后门攻击的独特特征。与其他数据投毒方法不同,后门攻击具有双重目标:首先,在正常、干净的数据上保持高准确率;其次,当输入中存在特定的“触发器”时,迫使模型输出一个特定的、目标标签。至关重要的是,此触发器嵌入在训练集和测试集中。现有的泛化界并非为考虑这种双重目标或被投毒数据集的非 i.i.d.(独立同分布)性质而设计,后者是经典泛化理论的基本假设。作者明确指出,据他们所知,尚未建立专门针对后门攻击的泛化界,这凸显了学术文献中的一个重大空白,本文旨在填补这一空白。
先前方法的根本局限性在于它们依赖于i.i.d. 条件,这是经典泛化理论的基石。先前的模型及其相关的界限隐含地假设训练数据是从真实数据分布中独立同分布采样的。然而,在数据投毒,特别是后门攻击的背景下,被投毒的训练数据集本身就违反了这一 i.i.d. 假设。触发器和目标性错误分类的引入意味着被投毒样本不再以直接的方式代表潜在的干净数据分布。这种违反使得现有的泛化界不适用,从而无法从理论上评估在后门攻击场景下训练的模型的泛化性。这个“痛点”迫使作者开发能够处理无毒标签后门攻击独特属性的新理论框架。
直观领域术语
-
泛化界 (Generalization Bound):
- 专业术语: 模型在训练数据上的性能与其在新的、未见数据上的性能之间差异的数学上限。
- 直观类比: 想象你正在为驾驶考试学习。一个“泛化界”就像一个保证,如果你在一组特定的道路上(你的训练数据)练习得好,那么你在实际考试(未见数据)中遇到的任何新道路上的表现都将在一定的误差范围内。它告诉你你学到的技能在多大程度上可以转移到新情况。
-
无毒标签后门攻击 (Clean-Label Backdoor Attack):
- 专业术语: 一种数据投毒攻击,其中在训练数据样本的一个小子集中添加了一个微妙的、通常是难以察觉的触发器,但其原始标签保持不变。目标是使在 $D_p$ 上训练的神经网络 $F$ 能够将包含此触发器的任何输入分类为特定的目标标签 $l_p$,同时在干净数据上仍能准确运行。
- 直观类比: 想象一位训练有素的狗狗表演裁判,能够识别不同品种的狗。一个“无毒标签后门攻击”就像有人在训练期间秘密地在几只狗身上放了一个微小、不易察觉的红丝带(触发器),但仍然告诉裁判它们的正确品种。裁判学会了正确识别所有品种。然而,如果任何狗,即使是以前从未见过的狗,带有那个红丝带,裁判就会被欺骗,无论它实际是什么品种,都总是称它为“贵宾犬”。被投毒训练数据的原始标签是“干净的”(正确的),这使得攻击具有隐蔽性。
-
i.i.d. 条件 (独立同分布) (i.i.d. condition (Independent and Identically Distributed)):
- 专业术语: 一个统计假设,即所有数据样本彼此独立,并且来自相同的概率分布。
- 直观类比: 这就像从一副完美洗好的扑克牌中抽牌。你抽到的每张牌都与前一张“独立”(它不影响下一张牌),并且来自“相同分布”(同一副牌)。如果你在抽了几张牌后秘密地移走了所有的 A,那么后续的抽牌就不再是 i.i.d. 了。在机器学习中,这意味着每条数据就像来自真实世界的一个新鲜、无偏见的观察,并且这个假设对于许多证明成立至关重要。
-
Rademacher 复杂度 (Rademacher Complexity):
- 专业术语: 衡量假设空间(模型可以学习的所有可能函数的集合)的“丰富性”或“容量”。它量化了模型在多大程度上可以拟合随机噪声。
- 直观类比: 想象一位非常灵活的艺术家,他可以画出任何东西,甚至纯粹的随机涂鸦。“Rademacher 复杂度”衡量这位艺术家在完美复制纯粹的随机性方面有多好。如果艺术家能够完美地画出任何随机涂鸦,那么他非常灵活(复杂度高)。在人工智能中,它告诉我们模型有多容易记住随机噪声,这通常是它过拟合而不是学习真正模式的迹象。
-
捷径 (Shortcut):
- 专业术语: 模型可能利用的一个简单、易于学习的特征来做出预测,而不是学习预期的、更复杂、更鲁棒的特征。
- 直观类比: 如果你教孩子识别“汽车”,而你所有的汽车训练图片恰好在角落里都有一个特定的品牌标志,那么孩子可能会学会将“那个标志”识别为“汽车”,而不是汽车本身的特征,如轮子、窗户和形状。标志是一个“捷径”特征,它更容易学习,但如果汽车没有那个特定标志,它就无法泛化到真实的汽车。本文提到,无差别的投毒可以被视为这样的捷径。
符号表
| 符号 | 描述 |
|---|---|
问题定义与约束
核心问题表述与困境
本文解决的核心问题是深度学习中无毒标签后门攻击的理论理解和泛化保证的缺乏。
输入/当前状态:
起点是一个标准的机器学习设置,其中一个神经网络 $F$ 在干净的训练数据集 $D_{tr} = \{(x_i, y_i)\}_{i=1}^N$ 上进行训练。假设此数据集是从底层数据分布 $D_s$ 中独立同分布 (i.i.d.) 采样的。此类训练的主要目标是最小化总体误差 $E_{(x,y) \sim D_s}[1(F(x) \neq y)]$,它衡量模型在未见数据上的性能。现有的泛化理论,包括基于 VC 维度、Rademacher 复杂度或算法稳定性的界限,都根本上依赖于训练数据的这种 i.i.d. 假设。
期望终点(输出/目标状态):
本文旨在实现一个理论上可靠的“无毒标签后门攻击”。这包括通过微妙地修改干净训练数据的一个子集并添加“触发器” $P(x)$ 来创建一个被投毒的训练集 $D_p$,关键是不改变原始标签。在 $D_p$ 上训练的神经网络 $F$ 必须满足双重目标:
1. 在干净样本上保持高准确率: 模型在未被投毒的干净数据上仍应表现良好,这意味着其干净总体误差 $E(F, D_s) = E_{(x,y) \sim D_s}[1(F(x) \neq y)]$ 保持较低。
2. 确保触发输入的目标性错误分类: 任何包含触发器 $P(x)$ 的输入 $x$(即 $x + P(x)$)都应被 $F$ 分类为特定的、预定义的目标标签 $l_p$。这通过最小化投毒总体误差 $E_p(F, D_s) = E_{(x,y) \sim D_s}[1(F(x + P(x))) \neq l_p)]$ 来量化。
困境与缺失环节:
确切的缺失环节是建立无毒标签后门攻击场景下训练的模型的泛化界。困扰先前研究人员的痛苦权衡或困境在于,后门攻击本质上违反了训练数据的 i.i.d. 假设。通过引入被投毒的样本,数据集 $D_p$ 不再是从 $D_s$ 中 i.i.d. 采样的。这直接使经典泛化理论的基础前提失效,使得无法直接应用现有的界限来保证在干净和触发数据上的期望性能。
此外,对于投毒泛化目标(论文中的 Q2),仅仅最小化被投毒训练集 $D_p$ 上的经验误差并不自动保证任何带有触发器的数据都将被分类为目标标签 $l_p$。这是因为,如果一个干净样本 $(x, y)$ 且 $y \neq l_p$ 在 $D_p$ 中没有被投毒为 $(x + P(x), l_p)$,那么最小化 $D_p$ 上的经验误差并不一定会强制网络将 $x + P(x)$ 分类为 $l_p$。这凸显了被投毒训练集上的经验性能与触发输入的目标泛化行为之间微妙但关键的差距。
约束与失效模式
建立无毒标签后门攻击泛化界的难题,由于几个严峻、现实的障碍而变得异常困难:
- 非 i.i.d. 数据分布: 正如所强调的,最显著的约束是,被投毒的训练数据集 $D_p$ 根本上不满足 i.i.d. 条件(第 1 页,摘要;第 2 页,Q1 解释)。这是攻击机制的直接结果,使得标准泛化理论不适用。开发处理这种非 i.i.d. 性质的新理论工具是一项重大障碍。
- 双重、冲突的目标: 攻击有两个不同的目标:在干净数据上保持高准确率,并确保在触发数据上进行目标性错误分类。这些目标可能存在冲突。模型可能会过度拟合被投毒样本以实现后门,从而可能损害其在干净数据上的性能,反之亦然。在提供理论保证的同时平衡这两个目标是复杂的。
- 无毒标签的隐蔽性: “无毒标签”的特性意味着被投毒样本的标签没有改变。这使得攻击更隐蔽,但对模型学习也更困难。网络必须在不明确指导被投毒输入标签的情况下,隐式地将触发器与目标标签 $l_p$ 相关联,仅依赖于触发器的存在。
- 投毒泛化特定触发条件: 为确保投毒泛化误差很小,触发器 $P(x)$ 不能是任意的。定理 4.5(第 4 页)列出了 $P(x)$ 必须满足的三个关键条件(c1、c2、c3):
- (c1) 对抗性噪声: 触发器必须作为在干净数据上训练的网络的对抗性噪声。这暗示了对特定扰动属性的需求。
- (c2) 触发器相似性: 触发器 $P(x)$ 在不同的输入样本 $x$ 之间必须相似。如果触发器高度多样化,模型可能会难以泛化后门行为。
- (c3) 捷径属性: 触发器必须充当一个专门设计的二元数据集的“捷径”。这是一个非平凡的工程和确保属性,因为它关系到触发器如何影响模型的决策边界。没有这些条件,攻击对未见触发数据的泛化性就不能保证。
- 计算和攻击者资源限制(隐含): 虽然没有明确说明为“问题定义”约束,但实验设置(F.1 节,第 32-33 页)揭示了在现实场景中使问题更难的实际限制:
- 攻击者知识有限: 假设攻击者对受害者网络的结构和训练过程了解有限。这意味着即使使用较小的代理网络生成触发器,触发器也必须有效。
- 计算能力有限: 假设攻击者计算资源有限,这会影响触发器生成算法的复杂性。
- 不可见性约束: 触发器通常受 $L_\infty$ 范数(例如,16/255)的约束,以保持不可察觉(第 6 页,35)。这种物理约束限制了扰动的大小,使得创建有效且鲁棒的触发器更具挑战性。
- 非可微函数: 误差计算中使用指示函数 $1(\cdot)$(例如,$1(F(x) \neq y)$)会引入非可微性,这在某些情况下会使直接优化和理论分析复杂化。本文在定理 1.2 和 4.5 中使用了交叉熵损失(LCE),它是可微的,但最终目标是界定非可微的分类误差。
为什么选择这种方法
选择的必然性
作者选择的方法,即推导无毒标签后门攻击的新泛化界,并非仅仅是众多选项之一,而是解决先前未解决的理论空白的唯一可行方案。作者明确阐述了他们意识到传统“SOTA”方法不足的时刻:“然而,这些泛化界是针对干净训练数据集的,不能应用于被投毒的训练数据集,因为被投毒的数据集不满足泛化所必需的 i.i.d. 条件”(第 1 节,第 1 页)。
这一声明突显了现有泛化理论的一个根本性局限性,即它们通常假设数据是独立同分布 (i.i.d.) 的。后门攻击的本质是通过在训练数据的一个子集中精心设计的扰动来引入,从而违反了这一关键的 i.i.d. 假设。因此,无论是基于 VC 维度、Rademacher 复杂度还是特定于 DNN 架构(例如 CNN、Transformer)的泛化界,都变得不适用。问题不在于在现有框架内寻找更好的模型或算法,而在于建立一个新的理论框架来理解非 i.i.d. 被投毒数据设置下攻击的泛化性。此外,后门攻击独特的双重目标——在干净样本上保持高准确率,同时确保触发输入的目标性错误分类——以及触发器在训练和测试阶段都存在的特性,都要求一种现有方法根本不提供的专门理论处理。
比较优势
除了攻击成功率 (ASR) 或干净准确率等简单的性能指标外,该方法通过其基础的理论依据展现了定性优势。与许多依赖经验启发式方法的先前后门攻击不同,所提出的方法是“基于泛化界并具有一定的理论保证”(第 3 节,第 3 页)。这意味着攻击不仅仅是一个黑盒优化,而是基于对实现其泛化性的底层条件有深刻理解而设计的。
该方法在结构上的优势在于其能够识别并利用特定的数学条件(定理 4.5 中的 c1、c2、c3),在这些条件下可以控制和最小化投毒泛化误差。这使得能够对投毒触发器进行原则性设计,将对抗性噪声和无差别投毒以理论知情的方式结合起来(第 5 节,备注 5.1)。这比那些可能实现高性能但缺乏关于为何它们能泛化或在何种条件下保证有效的清晰解释的方法有了质的飞跃。本文的方法提供了一种“更明智的使用这些方法的方式”(第 5 节,备注 5.1),确保攻击的有效性植根于强大的理论理解,而不仅仅是经验观察。
与约束的对齐
所选方法与无毒标签后门攻击的固有约束完美对齐。
- 无毒标签性质: 整个理论框架和提出的算法都专门针对“无毒标签后门攻击,其中投毒触发器被添加到训练集 $D_{tr}$ 的一个子集中,而不改变其标签”(第 1 节,第 1 页)。这是本文直接解决的核心约束。
- 双重攻击目标: 问题定义了两个关键目标:(1) 在干净样本上保持高准确率,以及 (2) 确保任何带有触发器的输入都被分类为目标标签 $l_p$(第 3.2 节)。解决方案提供了两个不同的泛化界:定理 1.1 用于干净样本总体误差 $E(F, D_s)$,定理 1.2 用于投毒总体误差 $E_p(F, D_s)$,直接解决了攻击目标的两个方面。
- 非 i.i.d. 被投毒数据: 这可以说是最具挑战性的约束。本文明确指出,“$D_p$ 中的数据不再是从 $D_s$ 中 i.i.d. 采样的,因此经典的泛化界不能直接用于获得定理 1.1”(定理 1.1,Q1)。作者通过巧妙地识别被投毒训练数据中i.i.d. 从干净分布采样的一个子集来克服这一问题(定理 4.1 的证明思路,第 4 页;引理 A.3,第 14 页)。这种数学上的处理是问题严峻数据分布要求与解决方案独特理论性质的直接“结合”。
- 训练和测试阶段都存在触发器: 泛化界被表述为考虑训练和测试阶段的触发器。被投毒训练集 $D_p$ 上的经验误差用于界定总体误差,固有地考虑了触发器在训练中的作用。投毒泛化误差 $E_p(F, D_s)$ 直接评估了攻击在触发测试数据上的成功率。
- 隐蔽性/不可见性: 虽然主要是实验约束,但提出的算法 1 包含一个“投毒预算 $\eta$”(算法 1,输入),可以设置为强制执行 $L_\infty$ 范数约束(例如 16/255),确保生成的触发器保持不可察觉,符合隐蔽攻击的实际要求。
替代方案的拒绝
本文通过强调无毒标签后门攻击的独特挑战,而现有方法未能解决这些挑战,从而隐含地和明确地拒绝了几种替代方法。
首先,最直接的拒绝是“经典泛化界”(第 1 节,第 1 页)。这些界限,无论是基于 VC 维度、Rademacher 复杂度还是特定于深度神经网络的,都被认为不足,因为它们假设 i.i.d. 数据。被投毒的数据集,顾名思义,违反了这一假设,使得这些传统的理论工具不适用。作者的工作填补了这一根本性空白,这意味着简单地调整或应用现有的泛化理论将会失败。
其次,本文将自己的工作与针对数据投毒攻击的其他现有泛化界(例如,Wang 等人,2021;Hanneke 等人,2022)区分开来。它指出,“我们的结果与这些工作不同,并且不能从它们推导出来”(第 2 节,第 3 页)。原因是这些先前的工作没有考虑后门攻击的特定属性,例如触发器同时存在于训练和推理阶段,以及在保持干净准确率的同时实现目标性错误分类的双重目标。这表明这些更一般的投毒泛化界对于无毒标签后门攻击的细微差别来说不够精细。
最后,关于攻击生成方法本身,本文通过强调“大多数现有的后门攻击主要基于经验启发式方法,而我们的攻击是基于泛化界并具有一定的理论保证”(第 3 节,第 3 页),隐含地拒绝了纯粹的经验或启发式方法。在与其他人无毒标签攻击进行比较时(第 6.3 节,表 4),作者指出许多替代方法需要“额外步骤”、“预先存在的补丁”、“拟合图像”、“放大触发器”或“大型生成模型”(第 6.3 节)。例如,“Invisible Poison”和“Image-specific”攻击依赖于大型生成模型来实现最佳性能,而本文方法则避免了这一点。理论指导新算法允许更有效和原则性的触发器设计,从而避免了其他攻击中这些通常复杂、资源密集或临时的组件。这使得所提出的方法因其强大的理论基础而在质量上更优越,从而在没有此类开销的情况下实现了更好的准确率和攻击成功率。
 Figure 4. When trigger is a patch without norm limitation, it is not invisible. This figure is from (Souri et al., 2022)
Figure 4. When trigger is a patch without norm limitation, it is not invisible. This figure is from (Souri et al., 2022)
数学与逻辑机制
主方程
本文的核心贡献在于为无毒标签后门攻击建立泛化界,解决了两个主要目标:在干净样本上保持高准确率,以及确保触发数据成功分类到目标标签。这些目标分别通过定理 4.1 和定理 4.5 作为两个主方程在数学上被捕获。
干净泛化误差界(定理 4.1)给出为:
$$ E(F,D_s) \leq \frac{4-2\alpha}{1-\alpha} E(F,D_p) + O\left(\frac{mW^2D^2}{N} \ln(2/\delta) + \sqrt{\frac{\alpha}{N(1-\alpha)}}\right) $$
投毒泛化误差界(定理 4.5)给出为:
$$ E_p(F,D_s) \leq \lambda O\left(\left(E_{(x,y)\in D_p} [L_{CE}(F(x), y)] + \text{Rad}_{D_p}^{D_s}(H_{W,D,1})\right) + \sqrt{\frac{\ln(1/\delta)}{N\alpha}} + \epsilon + \tau + \lambda\right) $$
逐项解剖
让我们剖析这些方程的每个组成部分,以理解它们的数学定义、物理/逻辑作用以及作者包含和操作它们的理由。
方程 1:干净泛化误差界
-
$E(F,D_s)$
- 数学定义: 这是神经网络 $F$ 在真实底层数据分布 $D_s$ 上的总体误差。它被正式定义为 $E_{(x,y)\sim D_s} [1(F(x) \neq y)]$,其中 $1(\cdot)$ 是指示函数,当其参数为真时返回 1,否则返回 0。
- 物理/逻辑作用: 此项代表模型在从未见过的干净、未被投毒数据上的真实错误率。在后门攻击的背景下,一个主要目标是保持此值较低,确保模型对其预期的合法任务仍然有用。
- 为何使用: 它是评估模型在干净数据上性能的最终指标,这是隐蔽后门攻击的关键要求。
-
$\leq$
- 数学定义: “小于或等于”。
- 物理/逻辑作用: 此符号表示右侧的表达式提供了左侧真实总体误差的上限。这是泛化界的核心。
- 为何使用: 由于真实数据分布 $D_s$ 是未知的,因此无法直接计算 $E(F,D_s)$。泛化理论提供了基于可观察量的概率上限。
-
$\frac{4-2\alpha}{1-\alpha}$
- 数学定义: 一个依赖于 $\alpha$($D_{tr}$ 中标记为 $l_p$ 的样本的投毒比例)的标量系数。
- 物理/逻辑作用: 此系数对在被投毒训练数据上观察到的经验误差进行缩放。它反映了被投毒样本的比例如何影响泛化界限的紧密度。随着 $\alpha$ 的增加,该系数通常会增长,表明界限可能更宽松,或者经验性能与总体性能之间的差异更大。
- 为何使用: 本文强调被投毒数据集 ($D_p$) 不满足 i.i.d.(独立同分布)条件,这是经典泛化界的前提。该系数很可能源于用于将泛化理论适应这种非 i.i.d. 设置的特定数学技术。
-
$E(F,D_p)$
- 数学定义: 这是网络 $F$ 在被投毒训练数据集 $D_p$ 上的经验误差。它被定义为 $E_{(x,y)\in D_p} [1(F(x) \neq y)]$。
- 物理/逻辑作用: 这代表了在包含干净和被投毒样本的有限训练数据上直接测量的模型的误差率。这是学习算法在训练过程中积极试图最小化的量。
- 为何使用: 这是训练过程中可观察、可测量的误差。泛化界旨在将这种经验性能与不可观察的真实性能联系起来。
-
$O(\cdot)$
- 数学定义: 大 O 符号,表示函数增长率的渐近上限。它意味着括号内的项的增长速度不超过指定的函数。
- 物理/逻辑作用: 此符号将构成“泛化差距”的项分组。这些项通常随着训练数据集 $N$ 的增加而减小,这意味着随着数据的增加,经验误差成为总体误差的更可靠估计。
- 为何使用: 它通过抽象掉不太重要的常数并专注于决定泛化差距关闭速度的主导因素来简化表达式。
-
$\frac{mW^2D^2}{N} \ln(2/\delta)$
- 数学定义: 与模型复杂度、数据大小和置信度相关的项。
- $m$: 标签集中的类别数。
- $W$: 神经网络的宽度(例如,层中的最大神经元数)。
- $D$: 神经网络的深度(层数)。
- $N$: 干净训练集 $D_{tr}$ 中的总样本数。
- $\ln(2/\delta)$: $2/\delta$ 的自然对数,其中 $\delta$ 是一个小的概率(例如 0.05),表示导出的界限可能不成立(即,界限以 $1-\delta$ 的概率成立)。
- 物理/逻辑作用: 此项量化了神经网络模型的容量。更复杂的模型(更大的 $W$ 或 $D$)具有更大的能力来拟合训练数据,包括噪声,这可能导致更大的泛化差距(过拟合)。相反,更大的训练集大小 $N$ 有助于减小此差距。$\ln(2/\delta)$ 因子解释了界限的概率性质。此项是使用 Rademacher 复杂度或 VC 维度等概念导出的泛化界中的一个标准组成部分。
- 为何使用: 这是深度学习模型泛化界中的一个标准组成部分,反映了模型表达能力与可用数据量之间的权衡。
- 数学定义: 与模型复杂度、数据大小和置信度相关的项。
-
$\sqrt{\frac{\alpha}{N(1-\alpha)}}$
- 数学定义: 一个涉及投毒比例 $\alpha$ 和训练集大小 $N$ 的平方根项。
- 物理/逻辑作用: 此项专门捕获了由投毒过程引入的统计不确定性。随着投毒比例 $\alpha$ 的增加,此项通常会增加,表明由于数据分布的扰动增加,泛化差距会增大。相反,更大的 $N$ 会减小此项,表明更多的数据可以帮助减轻投毒的不利影响。分母中的 $(1-\alpha)$ 意味着如果几乎所有样本都被投毒($\alpha \to 1$),则界限会非常宽松。
- 为何使用: 这是浓度不等式中的一个常见项,反映了为界限的特定置信度实现所需样本复杂度。
方程 2:投毒泛化误差界
-
$E_p(F,D_s)$
- 数学定义: 这是网络 $F$ 在真实数据分布 $D_s$ 上的投毒总体误差。它被正式定义为 $E_{(x,y)\sim D_s} [1(F(x + P(x))) \neq l_p)]$,其中 $P(x)$ 是应用于输入 $x$ 的触发器,而 $l_p$ 是为触发输入指定的目标标签。
- 物理/逻辑作用: 此项衡量后门攻击在未见、触发数据上的真实失败率。攻击的目标是使此值尽可能小,确保任何带有触发器的输入都被一致地分类为 $l_p$。
- 为何使用: 这是评估后门攻击本身成功率和有效性的关键指标。
-
$\leq$
- 数学定义: “小于或等于”。
- 物理/逻辑作用: 与方程 1 类似,这表示右侧提供了投毒总体误差的上限。
- 为何使用: 它为后门攻击的有效性建立了理论保证,界定了其真实误差率。
-
$\lambda$
- 数学定义: 来自定理 4.5 条件 (c2) 的一个缩放因子,该条件指出 $P_{(x,y)\sim D_s}(P(x) \in A|y \neq l_p) \leq \lambda P_{(x,y)\sim D_s}(P(x) \in A|y = l_p)$ 对于任何集合 $A$。
- 物理/逻辑作用: 此参数量化了触发器 $P(x)$ 在不同干净样本 $x$ 之间的“相似性”或“一致性”。如果 $P(x)$ 对于各种输入高度相似,则 $\lambda$ 接近 1。较小的 $\lambda$(接近 1)是期望的,以获得更紧密的界限,这意味着触发器充当模型可以轻松学习的通用、一致的模式。
- 为何使用: 这是设计有效触发器的关键条件,确保后门不与特定输入特征相关联,而是与触发器本身相关联,使其具有泛化性。
-
$O(\cdot)$
- 数学定义: 大 O 符号,与方程 1 类似。
- 物理/逻辑作用: 将导致投毒总体误差泛化差距的项分组。
- 为何使用: 通过关注主导因素来简化界限。
-
$E_{(x,y)\in D_p} [L_{CE}(F(x), y)]$
- 数学定义: 这是网络 $F$ 在被投毒训练数据集 $D_p$ 上的经验交叉熵损失。$L_{CE}$ 表示交叉熵损失函数。
- 物理/逻辑作用: 此项代表模型在被投毒数据集上训练期间最小化的经验风险(损失)。与 0-1 误差不同,交叉熵损失提供了衡量模型对其预测有多自信的连续度量,鼓励它以高概率输出目标标签 $l_p$ 以触发输入。
- 为何使用: 交叉熵损失是分类任务的标准且信息量更大的损失函数,尤其是在期望特定预测的高置信度时,正如后门攻击的情况一样。
-
$\text{Rad}_{D_p}^{D_s}(H_{W,D,1})$
- 数学定义: 假设空间 $H_{W,D,1}$ 在连接 $D_p$ 和 $D_s$ 的分布下的 Rademacher 复杂度。$H_{W,D,1}$ 是函数 $h_F(x,y) = F_y(x)$ 的集合,其中 $F$ 是具有宽度 $W$ 和深度 $D$ 的神经网络。该符号表明它是从 $D_p$ 中的样本计算的 Rademacher 复杂度,但旨在泛化到 $D_s$。
- 物理/逻辑作用: 此项量化了模型类别在被投毒数据背景下的“可学习性”或“灵活性”。较高的 Rademacher 复杂度表明模型可以拟合更复杂的模式,如果控制不当,可能导致过拟合。它衡量模型拟合随机标签的能力,这是过拟合能力的代理。
- 为何使用: Rademacher 复杂度是统计学习理论中用于界定泛化误差的基本工具,特别是对于像神经网络这样的复杂函数类。
-
$\sqrt{\frac{\ln(1/\delta)}{N\alpha}}$
- 数学定义: 一个涉及置信度参数 $\delta$、训练集大小 $N$ 和投毒比例 $\alpha$ 的平方根项。
- 物理/逻辑作用: 此项代表统计浓度分量。随着 $N$ 的增加,此项减小,导致界限更紧密。较小的 $\alpha$(被投毒样本较少)会使此项变大,表明通过很少的样本在统计上泛化投毒效果更难。
- 为何使用: 这是浓度不等式中的一个常见项,反映了为界限的特定置信度实现所需样本复杂度。
-
$\epsilon$
- 数学定义: 来自定理 4.5 条件 (c1) 的一个小的正值:$E_{(x,y)\sim D_p^{l_p}} [G_y(x + P(x))] \leq \epsilon$。这里,$G_y(x)$ 是一个干净训练的网络 $G$ 将 $x$ 分类为 $y$ 的概率。
- 物理/逻辑作用: 此项量化了触发器 $P(x)$ 的“对抗性”程度。如果 $P(x)$ 有效地导致一个干净训练的网络 $G$ 错误分类 $x+P(x)$,那么 $\epsilon$ 将很小。期望更小的 $\epsilon$ 以获得更紧密的界限,这意味着触发器应该是有效的对抗性扰动。
- 为何使用: 这是对触发器设计的条件,确保触发器能够有效地“欺骗”一个干净的模型,这是许多后门攻击的一个特征。
-
$\tau$
- 数学定义: 来自定理 4.5 条件 (c3) 的一个小的正值:$E_{x\sim D_s} [|(F-G)_{l_p}(P(x)) - (F-G)_{l_p}(x+P(x))|] \leq \tau$。这衡量了网络输出的“后门部分”对于 $P(x)$ 和 $x+P(x)$ 的相似性。
- 物理/逻辑作用: 此项量化了触发器 $P(x)$ 的“捷径”程度。如果触发器充当捷径,那么网络对 $P(x)$ 的响应应与对 $x+P(x)$ 的响应相似,从而导致小的 $\tau$。期望更小的 $\tau$ 以获得更紧密的界限,这意味着触发器创建了一个通往目标标签的强、直接路径。
- 为何使用: 这是对触发器设计的条件,鼓励模型将触发器学习为一个简单的、直接的特征(一个“捷径”),而不是与原始输入的复杂交互。
-
为何是加法而不是乘法,或者积分而不是求和?
方程被构建为加法,因为它们聚合了不同来源的误差和导致泛化差距的因素。每个项代表一个不同的方面:经验误差(观察到的)、模型复杂度、统计方差以及触发器的特定属性。这些因素加性地贡献于总体误差的上限。例如,模型复杂性和统计不确定性都会独立地增加经验误差偏离真实总体误差的可能性。$E_{(x,y)\sim D_s}$ 的符号表示对连续概率分布 $D_s$ 的期望,这在数学上通过积分来表示。相比之下,$E_{(x,y)\in D_p}$ 表示对有限、离散数据集 $D_p$ 的经验平均值,它被计算为求和。作者根据他们是指连续总体还是离散样本,通过适当的数学运算符(积分或求和)隐式地使用期望符号。
分步流程
让我们追踪一个抽象数据点 $(x_0, y_0)$ 从真实数据分布 $D_s$ 到这些泛化界所描述的概念机制的旅程。
-
数据点起源: 我们的旅程始于一个抽象的、干净的数据点 $(x_0, y_0)$,其中 $x_0$ 是输入(例如,图像),$y_0$ 是其真实标签。该点是从无限、不可观察的真实数据分布 $D_s$ 中抽取的代表性样本。
-
用于攻击评估的假设性投毒: 如果我们正在评估投毒总体误差 $E_p(F,D_s)$,那么这个干净输入 $x_0$ 将被概念性地修改,通过添加一个预先设计的触发器 $P(x_0)$。生成的输入变为 $x_0 + P(x_0)$,其目标标签是 $l_p$,无论 $y_0$ 是什么。这个转换后的对 $(x_0 + P(x_0), l_p)$ 代表了攻击者希望模型正确分类的内容。对于评估干净泛化误差 $E(F,D_s)$,数据点保持为 $(x_0, y_0)$。
-
模型推理(“黑箱”网络 $F$): (假设)训练好的神经网络 $F$ 接收此输入。
- 特征变换: 输入(无论是 $x_0$ 还是 $x_0 + P(x_0)$)通过网络的层。每一层由卷积、非线性激活(例如 ReLU)和池化等操作组成,逐步将原始输入转换为更抽象、更具辨别力的特征表示。
- 输出生成: 网络的最后一层,通常是 Softmax 层,将这些特征转换为所有可能输出类别的概率分布。$F(z)$ 是这个概率向量,其中 $F_y(z)$ 是为输入 $z$ 分配给标签 $y$ 的概率。
- 分类决策: 网络最终的分类 $\text{argmax}_y F_y(z)$ 是具有最高预测概率的标签。
-
误差/损失计算(总体级别):
- 干净误差: 对于干净泛化,将网络的输出 $F(x_0)$ 与真实标签 $y_0$ 进行比较。如果预测标签 $\text{argmax}_y F_y(x_0)$ 与 $y_0$ 不匹配,则会记录一个错误。这个过程概念性地在所有可能的 $(x,y) \sim D_s$ 上重复并平均,以得到 $E(F,D_s)$。
- 投毒误差: 对于投毒泛化,将网络的输出 $F(x_0 + P(x_0))$ 与目标标签 $l_p$ 进行比较。如果 $\text{argmax}_y F_y(x_0 + P(x_0))$ 与 $l_p$ 不匹配,则会记录一个错误。这在所有可能的 $(x,y) \sim D_s$ 上平均以获得 $E_p(F,D_s)$。
-
经验对应项(训练数据 $D_p$): 在实际训练阶段,模型 $F$ 会接触到有限的、可观察的、被投毒的训练数据集 $D_p$。
- 样本选择: 从 $D_p$ 中抽取一个特定样本 $(x_i, y_i)$。此样本可能是 $D_{tr}$ 的原始干净样本,也可能是通过扰动 $D_{tr}$ 的干净样本 $(x_j, l_p)$ 而创建的被投毒样本 $(x_j + P(x_j), l_p)$。
- 经验损失/误差: 网络 $F$ 处理 $x_i$。
- 对于干净泛化界,通过将 $F(x_i)$ 与 $y_i$ 进行比较并使用指示函数来计算经验误差 $E(F,D_p)$。
- 对于投毒泛化界,计算经验交叉熵损失 $L_{CE}(F(x_i), y_i)$。这衡量了 $F$ 对输入 $x_i$ 的 $y_i$ 的预测有多好。
- 平均: 然后将这些单独的误差或损失在有限数据集 $D_p$ 的所有样本上平均,得到 $E(F,D_p)$ 或 $E_{(x,y)\in D_p} [L_{CE}(F(x), y)]$。
-
连接泛化差距: 数学引擎随后将 $D_p$ 上的这些可观察经验误差/损失与 $D_s$ 上不可观察的真实总体误差联系起来。界限中的附加项(Rademacher 复杂度、$\sqrt{\frac{\ln(1/\delta)}{N\alpha}}$、$\epsilon$、$\tau$、$\lambda$)充当“校正因子”或“惩罚项”。它们量化:
- 模型容量: 网络 $F$ 过拟合的倾向程度(Rademacher 复杂度)。
- 数据稀缺性: 由于拥有有限的训练集($N$)而产生的统计不确定性。
- 投毒影响: 投毒比例引入的特定统计偏差($\alpha$)。
- 触发器质量: 所制作的触发器 $P(x)$ 在满足其作为对抗性($\epsilon$)、一致性($\lambda$)和捷径($\tau$)的属性方面有多好。
整个过程使得抽象的数学感觉像一个移动的机械流水线:原始数据进入,由机器(网络)处理,并测量其性能。然后,泛化界根据其观察到的性能和固有的设计特征,提供一个理论上的“质量控制”报告,预测机器在未来未见数据上的性能。
优化动态
泛化界本身并不是受害者模型 $F$ 的直接优化目标。相反,它们提供了理论保证和条件,在这些条件下,后门攻击将有效地泛化。在这种情况下,“优化动态”是指触发器 $P(x)$ 的设计如何满足这些条件,以及受害者模型 $F$ 的训练如何实现期望的后门行为同时遵守这些界限。
本文提出的用于创建投毒触发器 $P(x)$ 的算法(算法 1)是攻击本身触发器优化的主要动态发生的地方:
-
制作对抗性扰动(满足条件 c1/t1 以获得小的 $\epsilon$):
- 机制: 在干净数据集 $T$ 上训练一个网络 $F_1$。对于每个干净样本 $x$,使用投影梯度下降 (PGD) 生成对抗性扰动 $x_{adv}$。PGD 是一个迭代优化过程,它找到一个小的扰动 $\epsilon$(在 $L_\infty$ 预算 $\eta$ 内),该扰动最大化 $F_1$ 对原始标签 $y$ 的损失。
- 梯度与损失景观: 这涉及计算损失函数 $L(F_1(x+\epsilon), y)$ 相对于 $\epsilon$ 的梯度。优化过程通过沿梯度方向(梯度上升)进行步骤来迭代更新 $\epsilon$,以增加损失,然后将 $\epsilon$ 投影回允许的扰动空间。这个过程塑造了触发器的“对抗性”组成部分,旨在使 $\epsilon$(它贡献于 $P(x)$)成为一个有效的对抗性示例,从而确保界限中的 $\epsilon$ 很小。
-
制作捷径扰动(满足条件 c3/t3 以获得小的 $\tau$):
- 机制: 使用一个专门构建的数据集 $T_1$ 训练一个单独的、更简单的两层网络 $F_2$。此数据集包括干净样本和由 $x_{adv}$(来自上一步)扰动的样本,但具有一个特定的标签(0)。目标是使用最小-最小方法找到一个“捷径”扰动 $x_{scut}$。此方法旨在使被投毒的数据集对 $F_2$ 来说是线性可分的。
- 损失景观与状态更新: 最小-最小方法通常涉及一个内部优化循环(为给定的 $F_2$ 找到最佳 $x_{scut}$)和一个外部优化循环(训练 $F_2$)。$F_2$ 的损失景观被塑造成鼓励它从被投毒数据中学习简单的、线性可分的特征。这有效地创建了一个将触发器映射到目标标签的“捷径”。$F_2$ 参数和 $x_{scut}$ 的迭代更新旨在最小化 $\tau$,确保触发器充当强大的捷径特征。
-
组合扰动(满足条件 c2/t2 以使 $\lambda$ 接近 1):
- 机制: 最终触发器 $P(x)$ 通过使用二元掩码 $U$ 组合 $x_{adv}$ 和 $x_{scut}$ 来构建:$P(x) = U \odot x_{adv} + (1-U) \odot x_{scut}$。掩码 $U$ 被设计成(例如,一个特定区域如左上角为 0,其余为 1)确保捷径分量 $(1-U) \odot x_{scut}$ 在不同输入 $x$ 之间是相似的。
- 梯度/状态更新的行为: 虽然没有直接针对 $\lambda$ 的梯度优化,但掩码 $U$ 的设计选择以及最小-最小方法的属性(倾向于为不同输入产生相似捷径)隐式地指导触发器生成以满足条件 (c2)。这确保了触发器是一个一致的模式,使得界限中的 $\lambda$ 接近 1。算法 1 获得的一些投毒样本如图 1 所示。
-
受害者模型训练与收敛:
- 机制: 一旦生成了触发器 $P(x)$,它们就被应用于原始干净训练数据 $D_{tr}$ 的一个子集,形成被投毒的训练集 $D_p$。然后,受害者网络 $F$ 在 $D_p$ 上使用标准的优化算法(如随机梯度下降 SGD)和交叉熵损失函数进行训练。
- 损失景观与收敛: $D_p$ 中被投毒样本的存在改变了受害者模型 $F$ 的损失景观。模型学会最小化 $D_p$ 上的经验损失,这意味着它必须同时学习未被投毒样本的干净分类任务和被触发样本的后门任务。然后,泛化界预测这个收敛模型 $F$ 的行为。如果触发器 $P(x)$ 被成功地设计以满足条件(小的 $\epsilon, \tau$,$\lambda$ 接近 1),那么界限表明,收敛后,受害者模型将表现出高的干净准确率和高的攻击成功率。SGD 通过 $F$ 参数的迭代更新将其驱动到这个复杂的多目标损失景观的局部最小值。
本质上,优化动态是一个两阶段过程:首先,一个有针对性的、基于梯度的优化来制作触发器 $P(x)$ 以拥有特定的属性(对抗性、捷径、一致性),这些属性在数学上与泛化界相关联;其次,在生成的被投毒数据集上对受害者网络进行标准训练,然后界限预测最终模型的泛化性能。界限提供了为何这些触发器设计原则会导致有效且可泛化的后门攻击的理论框架。
 Figure 1. From top row to bottom row are respectively the clean images, normalized triggers (original trigger has L∞norm bound 16/255), poison images. Due to the selection of U, the upper left corners of the poison images are similar, while the other parts are used to generate adversaries
Figure 1. From top row to bottom row are respectively the clean images, normalized triggers (original trigger has L∞norm bound 16/255), poison images. Due to the selection of U, the upper left corners of the poison images are similar, while the other parts are used to generate adversaries
结果、局限性与结论
实验设计与基线
为了严格验证其理论主张和提出的无毒标签后门攻击的有效性,作者在各种基准数据集和受害者网络架构上进行了广泛的实验。实验设置经过精心设计,以模拟实际攻击场景,其中攻击者对受害者训练过程的了解和控制有限。
数据集和受害者模型: 攻击在广泛使用的图像分类数据集上进行了评估:CIFAR10、CIFAR100、SVHN 和 TinyImageNet。对于受害者模型,采用了流行的深度神经网络,如 VGG16、ResNet18 和 WRN34-10。
攻击机制和触发器生成: 所提出攻击的核心涉及一种新颖的触发器生成方法(算法 1),该方法结合了对抗性噪声和无差别投毒。该过程本身利用较小的、独立的网络(F1 用于对抗性噪声,F2 用于捷径扰动)来避免对受害者网络的结构或计算能力的假设。例如,F1 使用 PGD-10 对抗训练和 L-infinity 范数预算(例如 8/255 或 4/255)进行训练,而 F2 是一个两层网络,使用最小-最小方法进行训练以创建捷径。投毒过程涉及随机选择训练样本的一个子集(例如,1% 或 0.8% 的训练图像),并具有特定的目标标签 $l_p$(通常设置为 0),然后将生成的触发器添加到这些样本中,而不改变其原始标签。
评估指标和基线: 攻击的有效性主要通过以下方式衡量:
1. 干净模型准确率: 被投毒模型在干净测试样本上的准确率。
2. 被投毒模型准确率: 被投毒模型在被投毒测试样本上的准确率。
3. 攻击成功率 (ASR): 包含触发器的样本被错误分类为目标标签 $l_p$ 的比率。
4. 干净模型 $l_p$ 准确率: 属于目标类别 $l_p$ 的干净样本的准确率。
所提出的方法与七种著名的无毒标签后门攻击进行了基准测试:Clean Label、Hidden Trigger、Reflection、Invisible Poison、Image-specific、Narcissus 和 Sleeper Agent。为了公平比较,所有攻击都受到 L-infinity 范数触发器预算(例如 16/255)和固定投毒预算(例如训练样本的 1%)的约束。
防御机制: 为了评估攻击的鲁棒性,它针对六种常见的后门防御进行了测试:对抗训练 (AT)、数据增强、Scale-up、差分隐私 SGD (DPSGD)、频率滤波器和微调。
理论验证: 除了经验性能外,作者还进行了消融研究,以验证其数学主张,特别是定理 4.1 和 4.5。这包括分析触发器的不同组成部分(对抗性噪声、捷径噪声)如何影响定理 4.5 的条件(c1)、(c2)、(c3),使用诸如 $V_{adv}$(条件 (c1) 的被投毒数据上的验证损失)和 $V_{sc}$(条件 (c3) 的二元分类损失)等指标。他们还研究了投毒率对整体准确率的影响,以支持定理 4.1。
证据证明的内容
实验证据为所提出的无毒标签后门攻击的有效性和理论基础提供了令人信服的支持。
核心机制的决定性证据:
结合对抗性噪声和无差别投毒以创建满足定理 4.5 条件的触发器的核心机制被无情地证明是有效的。该攻击一致地实现了高攻击成功率 (ASR),同时在干净样本上保持高准确率,这是无毒标签后门攻击的两个主要目标。例如,在 CIFAR-10 上使用 ResNet18 和 1% 的投毒率(L-infinity 范数 16/255)时,所提出的方法实现了 93% 的 ASR,干净模型准确率为 93%,被投毒模型准确率为 91%(表 1)。这表明受害者模型学习了触发器以将输入错误分类为目标标签 $l_p$,同时在合法、干净的数据上表现良好。
“受害者”(基线模型)被果断击败。在 L-infinity 范数预算为 16/255 下,我们的攻击在 CIFAR-10 上实现了 93% 的 ASR,显著优于所有其他比较方法,后者的 ASR 从 23%(Clean-Label)到 75%(Hidden-Trigger)不等(表 4)。这一无可辩驳的证据凸显了触发器中特定的对抗性噪声和捷径属性组合,在理论界的指导下,在植入有效的后门方面优于其他方法。即使在非常小的投毒率下(例如,在 CIFAR-10 上使用 ResNet18 的 0.6% 投毒率时 ASR 为 86%,表 2),攻击的有效性也保持很高,进一步证明了其效力。
攻击的性能在各种数据集(CIFAR10、CIFAR100、SVHN、TinyImageNet)和不同的目标标签(0-9)上是一致的,如表 3 和图 3 所示。这表明这是一种可泛化的攻击策略,而不是特定于某个数据集或目标类别的策略。训练过程监控(图 2)进一步证实,干净和被投毒的模型准确率保持接近,ASR 迅速稳定在高水平,表明后门学习稳健。
理论主张的验证:
专门用于验证定理 4.5 的消融研究提供了关键见解。通过比较不同的投毒类型(随机噪声、通用对抗性、对抗性、捷径和我们的方法)并评估它们对 $V_{adv}$(与条件 c1 相关)和 $V_{sc}$(与条件 c3 相关)的影响,作者表明单个组件通常在一个条件下表现出色,但在另一个条件下失败。例如,单独的对抗性扰动($Adv$)导致了高的 $V_{adv}$(意味着条件 c1 未得到很好满足),而单独的捷径噪声($SCut$)导致了高的 $V_{sc}$(意味着条件 c3 未得到很好满足)。然而,所提出的“Ours”方法结合了两者,取得了平衡的结果,具有良好的 $V_{adv}$ 和非常低的 $V_{sc}$,从而导致 ASR 显著提高(Ours 为 93%,而 Adv 为 22%,SCut 为 30%,预算为 16/255,表 6)。这直接验证了通过组合触发器机制满足定理 4.5 的条件可导致卓越的攻击性能。
关于定理 4.1,实验表明,虽然较高的投毒率通常会导致对干净准确率的影响更大,但下降并不显著(例如,对于超过 3,000 个被投毒样本,仅下降 4%,表 14)。这支持了投毒率影响泛化性的理论见解,但也表明在受控的投毒预算下,对干净样本准确率的影响可以最小化。此外,受害者网络被证明有效地学习了触发器特征(表 12),但它仍然优先考虑原始图像特征,这使得后门要有效需要足够规模的投毒。
局限性与未来方向
尽管所提出的无毒标签后门攻击展示了卓越的有效性,并且基于扎实的理论泛化界,但本文承认了几个局限性,并为未来的研究开辟了道路。
当前局限性:
一个显著的局限性在于定理 4.5 中概述的条件的复杂性。作者自己指出,这些条件“相当复杂”,并且推导出更简单、更直观的被投毒总体误差界限的条件将是非常可取的。这种复杂性可能会阻碍理论框架的广泛理解和应用。
另一个理论空白是,当前的泛化界不明确包含训练过程。算法相关的泛化界,特别是基于稳定性分析的界限(例如,Hardt 等人,2016),在后门攻击的背景下值得进一步研究。这种分析可以提供对训练动态如何影响攻击成功率和泛化性的更精细的理解。
从实践角度来看,本文指出生成的触发器在不同数据集之间的可迁移性有限。例如,为 CIFAR-10 创建的触发器不能直接应用于 CIFAR-100(附录 F.5)。这限制了攻击的多功能性,并需要为每个新数据集重新生成触发器,这可能在计算上很密集。
此外,该攻击虽然对基线非常有效,但似乎“在防御下有些脆弱”(第 6.4 节)。尽管作者提出了“增强攻击”,将防御机制纳入其生成过程中以抵御这些防御,但这表明了一场持续的军备竞赛,其中攻击的鲁棒性不是固有的,而是需要持续适应。防御中观察到的鲁棒性-准确率权衡也凸显了一个挑战:在不显著损害受害者模型在干净数据上的性能的情况下提高攻击的韧性。
未来方向与讨论主题:
本文的发现为未来的工作奠定了坚实的基础,引发了几个讨论话题:
- 简化理论条件: 如何重新表述或近似定理 4.5 的条件,使其对实践者更易于处理和理解?抽象的、高层次的“对抗性噪声”和“捷径”属性的理解是否足够,或者精确的数学条件对于理论保证是否必不可少?
- 算法相关的泛化界: 训练算法的哪些特定方面(例如,优化器、学习率、正则化)最能影响后门攻击的泛化性?我们能否推导出更紧密的、与算法相关的界限,为设计鲁棒的攻击或防御提供更实用的指导?这可能涉及探索深度学习中的隐式正则化等概念。
- 跨数据集触发器可迁移性: 如何设计通用或更具可迁移性的触发器,使其在不同数据集上都能工作,而无需重新生成?这可能涉及探索用于触发器生成的元学习方法,或识别也充当有效后门触发器的与数据集无关的“通用对抗性扰动”。
- 攻击-防御军备竞赛: 鉴于观察到的对防御的脆弱性,如何开发根本上更鲁棒的后门攻击,使其不易受到已知缓解策略的影响?反过来,防御如何设计得真正主动,预测并中和新颖的攻击机制,而不是被动地应对现有的攻击?这可能导致对自适应攻击/防御策略或这种军备竞赛的博弈论模型的研究。
- 伦理影响与负责任的 AI: 本文明确提到了这项工作潜在的负面社会影响,因为恶意行为者可能会利用这些方法。这引发了关于负责任披露、AI 安全“红队”开发以及需要健全监管框架的关键问题。科学界如何在开放研究与防止强大 AI 能力被滥用的必要性之间取得平衡?
- 超越图像分类: 该理论框架和攻击方法能否扩展到其他领域,如自然语言处理、语音识别或强化学习?将“对抗性噪声”和“捷径”的概念应用于这些不同的数据模态和任务结构会带来哪些独特的挑战和机遇?
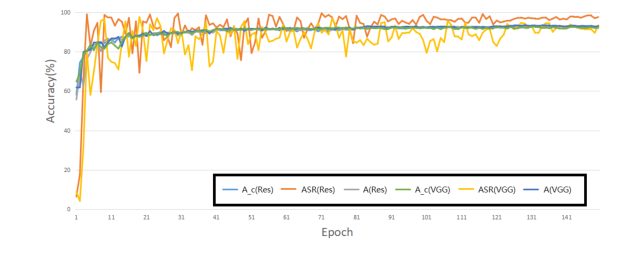 Figure 2. Attack performance during the training process on CIFAR10 with ResNet18 and VGG16. This figure shows the trend of the poison model accuracy (A), attack success rate (ASR) and clean model accuracy (Ac)
Figure 2. Attack performance during the training process on CIFAR10 with ResNet18 and VGG16. This figure shows the trend of the poison model accuracy (A), attack success rate (ASR) and clean model accuracy (Ac)
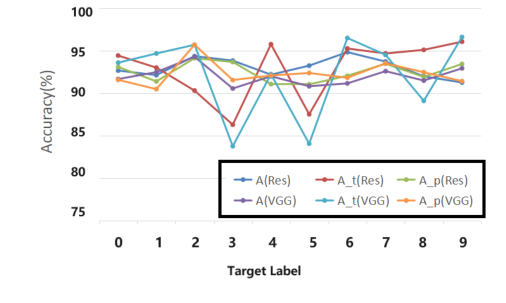 Figure 3. Performance of different target label lp. We show the poison model accuracy (A), accuracy of target label (At), attack success rate (Ap) on CIFAR-10, using VGG16 and ResNet18
Figure 3. Performance of different target label lp. We show the poison model accuracy (A), accuracy of target label (At), attack success rate (Ap) on CIFAR-10, using VGG16 and ResNet18
与其他领域的同构性
结构骨架
一种数学框架,用于量化系统在真实数据分布上的性能与在部分损坏的训练集上的经验性能之间的差异,给定损坏的特定属性。