ऑल-इन-वन मेडिकल इमेज-टू-इमेज ट्रांसलेशन
Medical image to image (I2I) translation की समस्या का उद्भव विषम (heterogeneous) मेडिकल इमेजिंग डेटा को सुसंगत बनाने की मूलभूत आवश्यकता से हुआ है। नैदानिक अभ्यास (clinical practice) में, छवियों को विविध स्कैनिंग...
पृष्ठभूमि और शैक्षणिक वंशावली
उत्पत्ति एवं अकादमिक वंशावली (The Origin & Academic Lineage)
Medical image-to-image (I2I) translation की समस्या का उद्भव विषम (heterogeneous) मेडिकल इमेजिंग डेटा को सुसंगत बनाने की मूलभूत आवश्यकता से हुआ है। नैदानिक अभ्यास (clinical practice) में, छवियों को विविध स्कैनिंग प्रोटोकॉल, हार्डवेयर और पैरामीटर सेटिंग्स का उपयोग करके प्राप्त किया जाता है, जिससे महत्वपूर्ण "domain shifts" उत्पन्न होते हैं, जहाँ एक केंद्र से प्राप्त डेटा का सांख्यिकीय वितरण (statistical distribution) दूसरे से भिन्न होता है। ऐतिहासिक रूप से, एक विशिष्ट डेटासेट पर प्रशिक्षित Deep learning मॉडल अक्सर तब सामान्यीकरण (generalize) करने में विफल रहते हैं जब उन्हें किसी भिन्न स्रोत के डेटा पर लागू किया जाता है।
इस समस्या के प्रति पिछले दृष्टिकोण आमतौर पर कार्य-विशिष्ट आर्किटेक्चर या इमेजिंग डोमेन के बीच अंतर करने के लिए discrete labels (जैसे one-hot encoding) पर निर्भर थे। ये विधियाँ एक महत्वपूर्ण "pain point" से ग्रस्त हैं: इनमें scalability का अभाव है। जैसे-जैसे डोमेन की संख्या बढ़ती है, इन discrete labels को प्रबंधित करने की जटिलता बढ़ जाती है, और मॉडल विभिन्न इमेजिंग अनुक्रमों के बीच सूक्ष्म, निरंतर (continuous) अर्थपूर्ण संबंधों को पकड़ने में संघर्ष करते हैं। इसके अतिरिक्त, कई मौजूदा मॉडलों को inference के दौरान target-domain style जानकारी की आवश्यकता होती है, जो उन्हें वास्तविक नैदानिक परिनियोजन (clinical deployment) के लिए अनुपयुक्त बनाती है, जहाँ ऐसी जानकारी अक्सर उपलब्ध नहीं होती है। लेखक कठोर, discrete labels से हटकर एक लचीले, prompt-driven फ्रेमवर्क की ओर बढ़कर इस समस्या का समाधान करते हैं, जो इमेजिंग प्रोटोकॉल का वर्णन करने के लिए प्राकृतिक भाषा (natural language) का लाभ उठाता है, जिससे एक अधिक मजबूत और सामान्यीकृत "all-in-one" translation मॉडल सक्षम होता है।
सहज डोमेन शब्दावली (Intuitive Domain Terms)
- Domain Shift: कल्पना कीजिए कि आप एक ऐसी पुस्तक पढ़ने का प्रयास कर रहे हैं जो आपके द्वारा सीखी गई भाषा की तुलना में थोड़ी अलग बोली में लिखी गई है; आप मुख्य अर्थ तो समझ सकते हैं, लेकिन सूक्ष्म बारीकियां खो जाती हैं। मेडिकल इमेजिंग में, यह तब होता है जब "Hospital A" की MRI सेटिंग्स पर प्रशिक्षित मॉडल "Hospital B" की छवियों की व्याख्या करने में संघर्ष करता है क्योंकि कंट्रास्ट या ब्राइटनेस का स्तर थोड़ा अलग होता है।
- One-Hot Encoding: इसे एक कठोर फाइलिंग सिस्टम के रूप में सोचें जहाँ प्रत्येक संभावित श्रेणी को अपना अनूठा, पृथक बॉक्स मिलता है (उदाहरण के लिए, T1 के लिए "0001", T2 के लिए "0010")। यह कुछ वस्तुओं के लिए काम करता है, लेकिन यदि आपके पास सैकड़ों श्रेणियां हैं, तो इसे प्रबंधित करना असंभव हो जाता है, और यह यह दिखाने में विफल रहता है कि T1 और T1-contrast छवियां वास्तव में संबंधित हैं।
- Contrastive Language-Image Pre-training (CLIP): एक ऐसे सार्वभौमिक अनुवादक की कल्पना करें जिसने हर मेडिकल पाठ्यपुस्तक पढ़ी है और हर मेडिकल स्कैन देखा है। यह स्कैन के टेक्स्ट विवरण (जैसे "T2-weighted brain MRI") को छवि में वास्तविक दृश्य पैटर्न के साथ मैप करना सीखता है, जिससे मॉडल यह "समझ" पाता है कि टेक्स्ट प्रॉम्प्ट के आधार पर स्कैन कैसा दिखना चाहिए।
- Zero-Shot Adaptation: यह एक मॉडल की उस कार्य को करने की क्षमता है जो उसने अपने प्रशिक्षण चरण के दौरान पहले कभी नहीं देखा है। यह एक ऐसे डॉक्टर की तरह है, जिसने सामान्य शरीर रचना विज्ञान (anatomy) का अध्ययन करने के बाद, अपने व्यापक, मूलभूत ज्ञान को लागू करके एक दुर्लभ स्थिति का सफलतापूर्वक निदान कर लिया हो, जिसका उन्होंने व्यक्तिगत रूप से पहले कभी सामना नहीं किया था।
संकेतन तालिका (Notation Table)
| संकेतन (Notation) | विवरण (Description) |
|---|---|
| $X$ | इनपुट मेडिकल इमेज |
| $P$ | स्कैन का वर्णन करने वाला प्राकृतिक भाषा प्रॉम्प्ट |
| $E_I$ | शारीरिक विशेषताओं (anatomical features) को निकालने के लिए उपयोग किया जाने वाला इमेज एनकोडर |
| $E_T$ | मेडिकल प्रॉम्प्ट को प्रोसेस करने के लिए उपयोग किया जाने वाला टेक्स्ट एनकोडर |
| $\Theta_s$ | प्रॉम्प्ट से प्राप्त डोमेन प्रतिनिधित्व (domain representation) |
| $G$ | इमेज सिंथेसिस के लिए कंडीशनल जनरेटर (डिकोडर) |
| $D$ | DCLIP-संचालित डिस्क्रिमिनेटर |
| $\mathcal{L}_{DCLIP}$ | टेक्स्ट और इमेज एम्बेडिंग को संरेखित (align) करने के लिए लॉस फंक्शन |
| $\mathcal{L}_{rec}$ | युग्मित (paired) प्रशिक्षण नमूनों के लिए रिकंस्ट्रक्शन लॉस |
| $\tau$ | कंट्रास्टिव लर्निंग के लिए स्केलर तापमान पैरामीटर |
समस्या की परिभाषा और बाधाएं
मुख्य समस्या निरूपण एवं द्वंद्व (Core Problem Formulation & The Dilemma)
इस शोध पत्र में संबोधित मुख्य समस्या बहु-डोमेन मेडिकल इमेजिंग के लिए एक स्केलेबल और सामान्यीकृत (generalizable) इमेज-टू-इमेज (I2I) ट्रांसलेशन मॉडल का अभाव है। डीप लर्निंग ने मेडिकल इमेज विश्लेषण में आशाजनक परिणाम दिखाए हैं, लेकिन इसका व्यावहारिक अनुप्रयोग "डोमेन शिफ्ट" (domain shift) की समस्या से गंभीर रूप से बाधित है। यह तब होता है जब प्रशिक्षण डेटा (source domain) और परीक्षण डेटा (target domain) अलग-अलग वितरणों (distributions) से आते हैं, जो अक्सर विभिन्न नैदानिक केंद्रों में स्कैनिंग मापदंडों, उपकरणों या यहाँ तक कि मोडैलिटी में भिन्नता के कारण होता है।
इनपुट/वर्तमान स्थिति:
वर्तमान स्थिति में कई डोमेन से विविध मेडिकल इमेज शामिल हैं (उदाहरण के लिए, विभिन्न MRI अनुक्रम जैसे T1, T2, Flair, PD, MRA; मस्तिष्क, स्तन, पेट, पेल्विस जैसे विभिन्न अंग; और अलग-अलग स्कैनिंग प्रोटोकॉल)। इन छवियों को आमतौर पर पारंपरिक मल्टी-डोमेन I2I दृष्टिकोणों द्वारा संसाधित किया जाता है, जो कार्य-विशिष्ट आर्किटेक्चर या असतत डोमेन लेबल पर निर्भर करते हैं, और अक्सर डोमेन प्रतिनिधित्व के लिए one-hot encoding का उपयोग करते हैं। ये विधियाँ अपनी स्केलेबिलिटी और सामान्यीकरण क्षमताओं में सीमित हैं। इसके अतिरिक्त, वन-टू-वन I2I ट्रांसलेशन मॉडल को डोमेन की संख्या बढ़ने के साथ आवश्यक मॉडल और प्रशिक्षण समय में "ज्यामितीय वृद्धि" (geometrical increase) का सामना करना पड़ता है, जो उन्हें बड़े पैमाने के मल्टी-डोमेन परिदृश्यों के लिए अव्यावहारिक बनाता है। मौजूदा मॉडल बाहरी सत्यापन (external validation) के साथ भी संघर्ष करते हैं, और नए, अनदेखे डेटासेट पर लागू किए जाने पर "cynical performance dropping" प्रदर्शित करते हैं।
वांछित अंतिम बिंदु (Desired Endpoint):
वांछित अंतिम बिंदु EVA-I2I नामक एक एकीकृत, विस्तार योग्य और सामान्यीकृत I2I ट्रांसलेशन फ्रेमवर्क है, जो एक साथ विविध डोमेन में मेडिकल छवियों को संश्लेषित (synthesize) कर सके। इस मॉडल को अर्थपूर्ण निरंतरता (semantic consistency) और अनुकूलन क्षमता बनाए रखते हुए विविध इमेजिंग प्रोटोकॉल को प्रभावी ढंग से एनकोड करना चाहिए। अंतिम लक्ष्य बिना fine-tuning की आवश्यकता के अनदेखे डोमेन के लिए मजबूत सामान्यीकरण को सक्षम करना और प्रत्यक्ष नैदानिक अनुप्रयोग को सुविधाजनक बनाना है। विशेष रूप से, मॉडल का उद्देश्य एक ही प्रशिक्षण सत्र में सभी देखे गए डोमेन को एक साथ संश्लेषित करना, उत्कृष्ट छवि गुणवत्ता प्राप्त करना और पहले कभी न देखे गए डोमेन के लिए zero-shot domain adaptation का समर्थन करना है। इसे DICOM-tag-informed semantic representations का लाभ उठाना चाहिए ताकि निश्चित one-hot codes की सीमाओं से परे जाकर लचीला और स्केलेबल डोमेन विनिर्देश (domain specification) संभव हो सके।
लुप्त कड़ी या गणितीय अंतराल (Missing Link or Mathematical Gap):
सटीक लुप्त कड़ी एक एकीकृत I2I ट्रांसलेशन फ्रेमवर्क के भीतर विविध मेडिकल इमेजिंग डोमेन को एनकोड और नियंत्रित करने के लिए एक मजबूत और अर्थपूर्ण रूप से समृद्ध तंत्र है। पिछली विधियाँ, जो मुख्य रूप से one-hot encoding पर निर्भर थीं, डोमेन के बीच सूक्ष्म अर्थपूर्ण संबंधों (जैसे, खोपड़ी के साथ T2 छवियों और बिना खोपड़ी वाली छवियों के बीच अंतर करना) को पकड़ने में विफल रहती हैं। यह गणितीय अंतराल मॉडलों को बड़ी संख्या में विषम डोमेन तक प्रभावी ढंग से स्केल करने और महत्वपूर्ण शारीरिक एवं रोग संबंधी जानकारी को संरक्षित करते हुए अनदेखे डोमेन तक सामान्यीकृत होने से रोकता है। यह शोध पत्र DICOM-tag-informed contrastive language-image pre-training (DCLIP) को पेश करके इसे पाटने का प्रयास करता है, ताकि एक सामान्य latent space बनाया जा सके जो प्राकृतिक भाषा के स्कैन विवरणों को छवि विशेषताओं के साथ अर्थपूर्ण रूप से संरेखित (align) करे, जिससे लचीला और स्केलेबल डोमेन नियंत्रण सक्षम हो सके।
कठिन समझौता या द्वंद्व (Painful Trade-off or Dilemma):
पिछले शोधकर्ताओं को जिस सबसे कठिन समझौते ने उलझा रखा है, वह स्केलेबिलिटी और अर्थपूर्ण समृद्धि/सामान्यीकरण के बीच का द्वंद्व है।
1. स्केलेबिलिटी बनाम अर्थपूर्ण समृद्धि: one-hot encoding का उपयोग करने वाली पारंपरिक विधियाँ डोमेन की एक छोटी, निश्चित संख्या के लिए लागू करने में सरल हैं। हालाँकि, वे स्वाभाविक रूप से स्केलेबल नहीं हैं; जैसे-जैसे मेडिकल इमेजिंग डोमेन (जैसे, विभिन्न अनुक्रम, अंग, अधिग्रहण मापदंड) की संख्या बढ़ती है, one-hot encoding वेक्टर अव्यावहारिक रूप से लंबा हो जाता है, और यह डोमेन के बीच किसी भी अर्थपूर्ण संबंध को पकड़ने में विफल रहता है। उदाहरण के लिए, दो T2-weighted छवियों में केवल खोपड़ी की उपस्थिति या अनुपस्थिति का अंतर हो सकता है, जो एक सूक्ष्म लेकिन अर्थपूर्ण रूप से महत्वपूर्ण अंतर है जिसे one-hot encoding प्रदर्शित नहीं कर सकता। यह आवश्यक मॉडल या प्रशिक्षण समय में "ज्यामितीय वृद्धि" की ओर ले जाता है, जिससे मल्टी-डोमेन I2I ट्रांसलेशन कम्प्यूटेशनल रूप से निषेधात्मक और अनम्य हो जाता है।
2. एकीकृत मॉडल बनाम कार्य-विशिष्ट प्रदर्शन और सामान्यीकरण: एक एकल "सर्वशक्तिमान" मॉडल विकसित करना जो सभी डोमेन में एक साथ अनुवाद करने में सक्षम हो, अक्सर विशिष्ट, सूक्ष्म कार्यों पर प्रदर्शन की कीमत पर आता है या नए, बाहरी डेटासेट के लिए व्यापक fine-tuning की आवश्यकता होती है। पिछले I2I मॉडल, नियंत्रित सेटिंग्स में आशाजनक परिणाम दिखाने के बावजूद, बाहरी सत्यापन के साथ वास्तविक दुनिया के नैदानिक परिदृश्यों में तैनात किए जाने पर अक्सर "cynical performance dropping" प्रदर्शित करते हैं, और मजबूती से सामान्यीकरण करने में विफल रहते हैं। यह शोधकर्ताओं को विशेष, उच्च-प्रदर्शन वाले लेकिन संकीर्ण मॉडल, या व्यापक, कम सटीक और खराब सामान्यीकरण वाले मॉडलों के बीच चयन करने के लिए मजबूर करता है।
बाधाएं और विफलता मोड (Constraints & Failure Modes)
कई कठोर, यथार्थवादी दीवारों के कारण इस समस्या को हल करना अत्यंत कठिन है:
भौतिक बाधाएं:
* विविध और परिवर्तनशील स्कैनिंग प्रोटोकॉल: मेडिकल छवियों को स्कैनिंग उपकरणों, निर्माताओं और सूक्ष्म मापदंड सेटिंग्स (जैसे, flip angle, echo time, repetition time, fat saturation, contrast agents) की एक विशाल श्रृंखला के साथ प्राप्त किया जाता है। ये विविधताएं महत्वपूर्ण डोमेन शिफ्ट पैदा करती हैं और डेटासेट को एकीकृत करना तथा उनके बीच अर्थपूर्ण निरंतरता बनाए रखना चुनौतीपूर्ण बनाती हैं।
* शारीरिक जटिलता: विभिन्न अंगों (मस्तिष्क, स्तन, पेट, पेल्विस) में बहुत अलग शारीरिक संरचनाएं और विकृति होती हैं। मस्तिष्क MRI के लिए डिज़ाइन किया गया मॉडल पेट के MRI की अधिक शारीरिक जटिलता के साथ संघर्ष कर सकता है, जिससे संश्लेषण की गुणवत्ता कम हो जाती है।
* निश्चित छवि रिज़ॉल्यूशन और 2D प्रसंस्करण: प्रस्तावित मॉडल को एक निश्चित छवि रिज़ॉल्यूशन (256x256) के साथ प्रशिक्षित किया जाता है और वर्तमान में यह केवल 2D स्लाइस को संसाधित करने में सक्षम है। यह उच्च-रिज़ॉल्यूशन परिदृश्यों में इसकी प्रयोज्यता को सीमित करता है और जटिल 3D संरचनाओं को कुशलतापूर्वक समझने की इसकी क्षमता में बाधा डालता है, जिससे विशेष रूप से zero-shot translation कार्यों में inter-slice discontinuities हो सकती हैं।
* लुप्त अनुक्रम और छोटे नमूने: वास्तविक नैदानिक सेटिंग्स में, कुछ लक्षित डोमेन के लिए छोटे नमूने या लुप्त अनुक्रमों का सामना करना सामान्य है। यह डेटा विरलता (data sparsity) इन विशिष्ट डोमेन पर I2I मॉडल के सीधे प्रशिक्षण को कठिन बनाती है और अक्सर खराब परिणाम देती है।
कम्प्यूटेशनल बाधाएं:
* मॉडल आर्किटेक्चर की स्केलेबिलिटी: पारंपरिक मल्टी-डोमेन I2I मॉडलों को अक्सर डोमेन की संख्या के साथ जनरेटर, एनकोडर या डिस्क्रिमिनेटर की संख्या को रैखिक या ज्यामितीय रूप से बढ़ाने की आवश्यकता होती है। यह तेजी से बढ़ती कम्प्यूटेशनल मांगों और प्रशिक्षण समय की ओर ले जाता है, जिससे वे कई विविध डोमेन में वास्तव में "ऑल-इन-वन" समाधान के लिए अव्यावहारिक हो जाते हैं।
* हार्डवेयर मेमोरी सीमाएं: यद्यपि इस शोध पत्र के समाधान के लिए इसे स्पष्ट रूप से एक कठोर सीमा के रूप में विस्तृत नहीं किया गया है, लेकिन कुशल मॉडल बैकबोन (जैसे ConvNeXt) की आवश्यकता और GFLOPs तथा अनुमान समय (inference times) की रिपोर्टिंग यह दर्शाती है कि कम्प्यूटेशनल संसाधन और मेमोरी क्षमता ऐसे बड़े पैमाने के मॉडल विकसित करने और तैनात करने में महत्वपूर्ण व्यावहारिक बाधाएं हैं।
डेटा-संचालित बाधाएं:
* डोमेन शिफ्ट और लेबल किए गए डेटा का अभाव: मौलिक चुनौती डेटासेट के बीच निहित डोमेन शिफ्ट है, जो अक्सर विभिन्न केंद्रों में अलग-अलग अधिग्रहण मापदंडों के कारण होती है। इसे और जटिल बनाने वाली बात यह है कि बड़ी संख्या में एनोटेट प्रशिक्षण डेटा का अभाव है जो परीक्षण सेट वितरण के पूर्ण स्पेक्ट्रम को कवर कर सके, जिसके लिए मजबूत डोमेन अनुकूलन की आवश्यकता होती है।
* One-Hot Encoding की सीमाएं: डोमेन का प्रतिनिधित्व करने के लिए one-hot encoding का प्रचलित तरीका एक बड़ी बाधा है। यह डोमेन के बीच अर्थपूर्ण अंतर (जैसे, खोपड़ी के साथ T2 बनाम बिना खोपड़ी के T2) को अलग नहीं कर सकता है और डोमेन की संख्या बढ़ने के साथ यह बोझिल और गैर-स्केलेबल हो जाता है। यह मॉडलों को समृद्ध, हस्तांतरणीय (transferable) प्रतिनिधित्व सीखने से रोकता है।
* बाहरी सत्यापन प्रदर्शन में गिरावट: I2I मॉडल अक्सर बाहरी सत्यापन डेटासेट पर लागू होने पर प्रदर्शन में महत्वपूर्ण गिरावट प्रदर्शित करते हैं जो उनके प्रशिक्षण वितरण का हिस्सा नहीं थे। यह ऐसे मॉडल विकसित करना कठिन बनाता है जो प्रत्येक नए लक्षित डोमेन के लिए व्यापक fine-tuning के बिना वास्तव में मजबूत और नैदानिक रूप से तैनात करने योग्य हों।
* असंगत आउट-डोमेन कवरेज: मूल्यांकन के लिए उपयोग किए जाने वाले आउट-डोमेन डेटासेट उन अंगों या इमेजिंग डोमेन को कवर नहीं कर सकते हैं जो इन-डोमेन डेटासेट में हैं। यह विसंगतियों को जन्म दे सकता है और प्रदर्शन मेट्रिक्स की प्रत्यक्ष तुलनात्मकता में बाधा डाल सकता है, जिससे वास्तविक सामान्यीकरण क्षमताओं का सटीक आकलन करना कठिन हो जाता है।
* DICOM टैग की उपलब्धता: हालांकि DICOM टैग प्रॉम्प्ट निर्माण के लिए जानकारी का एक समृद्ध स्रोत हैं, लेकिन कई सार्वजनिक डेटासेट के लिए, DICOM फाइलें प्रदान नहीं की जाती हैं। इसके लिए सारांश फाइलों से प्रासंगिक जानकारी का मैन्युअल संग्रह आवश्यक है, जो एक श्रमसाध्य और संभावित रूप से त्रुटिपूर्ण प्रक्रिया है।
यह दृष्टिकोण क्यों
चयन की अनिवार्यता (The Inevitability of the Choice)
लेखकों ने EVA-I2I फ्रेमवर्क को इसलिए अपनाया क्योंकि मल्टी-डोमेन मेडिकल इमेज-टू-इमेज (I2I) ट्रांसलेशन के लिए पारंपरिक विधियाँ एक मौलिक "scalability wall" से टकरा गई थीं। डोमेन को लेबल करने के लिए वन-हॉट एनकोडिंग (one-hot encoding) जैसे मानक दृष्टिकोण तब विफल हो जाते हैं जब डोमेन की संख्या बढ़ती है, क्योंकि एनकोडिंग स्पेस कठोर हो जाता है और इसमें विभिन्न इमेजिंग प्रोटोकॉल के बीच संबंधों को समझने के लिए आवश्यक सिमेंटिक गहराई का अभाव होता है। लेखकों ने महसूस किया कि एक वास्तव में "omnipotent" मॉडल प्राप्त करने के लिए, उन्हें एक ऐसे रिप्रेजेंटेशन की आवश्यकता है जो प्रत्येक डोमेन को एक पृथक, असतत श्रेणी के रूप में मानने के बजाय मेडिकल स्कैन के अंतर्निहित सिमेंटिक्स को कैप्चर कर सके। इस अहसास ने Contrastive Language-Image Pre-training (CLIP) को अपनाने के लिए प्रेरित किया, जिसे विशेष रूप से DICOM मेटाडेटा के लिए अनुकूलित किया गया है, ताकि विविध, विषम मेडिकल डेटासेट को एक एकीकृत, निरंतर Latent Space में मैप किया जा सके।
तुलनात्मक श्रेष्ठता (Comparative Superiority)
EVA-I2I की श्रेष्ठता पारंपरिक वन-हॉट या BioBERT जैसे अनअलाइन्ड टेक्स्ट एनकोडर की तुलना में DCLIP (DICOM-tag-informed CLIP) के उपयोग में निहित है। जहाँ MUNIT या StarGAN v.2 जैसे पिछले मॉडल स्टाइल एक्सट्रैक्शन या डिस्क्रीट लेबल्स पर निर्भर करते हैं, वहीं EVA-I2I मेडिकल स्कैन के प्राकृतिक भाषा विवरणों में निहित सघन, संरचित सिमेंटिक जानकारी का लाभ उठाता है। संरचनात्मक रूप से, यह मॉडल को "semantic-driven synthesis" करने की अनुमति देता है, जहाँ जनरेटर को एक विरल, गैर-सिमेंटिक लेबल के बजाय एक समृद्ध, अलाइन्ड टेक्स्ट एम्बेडिंग पर कंडीशन किया जाता है। यह एक गुणात्मक लाभ प्रदान करता है: मॉडल सूक्ष्म इमेजिंग अंतरों (जैसे, fat saturation बनाम non-fat saturation) के बीच अंतर कर सकता है, जिन्हें वन-हॉट एनकोडिंग या तो अनदेखा कर देती या आपस में मिला देती, जिससे संरचनात्मक निष्ठा (structural fidelity) काफी अधिक हो जाती है और अनदेखे डोमेन के प्रति बेहतर सामान्यीकरण (generalization) प्राप्त होता है।
बाधाओं के साथ संरेखण (Alignment with Constraints)
यह फ्रेमवर्क नैदानिक मेडिकल इमेजिंग की कठोर आवश्यकताओं और विजन-लैंग्वेज मॉडल के लचीलेपन के बीच एक सटीक "मेल" है। प्राथमिक बाधाएं—विविध, मल्टी-सेंटर डेटासेट में स्केलेबिलिटी की आवश्यकता और Zero-shot generalization की अनिवार्यता—सीधे तौर पर DCLIP आर्किटेक्चर द्वारा संबोधित की जाती हैं। DICOM टैग से प्राप्त प्राकृतिक भाषा प्रॉम्प्ट के साथ स्कैन को जोड़कर, लेखकों ने एक ऐसी प्रणाली बनाई है जिसे इन्फरेंस के दौरान स्पष्ट डोमेन लेबल की आवश्यकता नहीं होती है। यह मॉडल को केवल एक वर्णनात्मक प्रॉम्प्ट प्रदान करके "never-before-seen" डोमेन को संभालने की अनुमति देता है, जो प्रभावी रूप से महंगी, कार्य-विशिष्ट Fine-tuning की आवश्यकता को दरकिनार करता है, जो आमतौर पर मेडिकल AI परिनियोजन (deployment) में एक बड़ी बाधा है।
विकल्पों का अस्वीकरण (Rejection of Alternatives)
लेखकों ने स्पष्ट रूप से वन-हॉट एनकोडिंग और अनअलाइन्ड टेक्स्ट एनकोडर (जैसे BioBERT) को अस्वीकार कर दिया है क्योंकि उनमें मेडिकल इमेजिंग डोमेन के बीच जटिल, पदानुक्रमित संबंधों को कैप्चर करने की क्षमता का अभाव है। वन-हॉट एनकोडिंग को इसलिए अस्वीकार किया गया क्योंकि यह स्वाभाविक रूप से गैर-विस्तार योग्य (non-extensible) है और समान लेकिन विशिष्ट अनुक्रमों के बीच सिमेंटिक दूरी का प्रतिनिधित्व करने में विफल रहता है। BioBERT को इसलिए अस्वीकार किया गया क्योंकि, हालांकि यह टेक्स्ट को समझता है, लेकिन यह स्वाभाविक रूप से उस टेक्स्ट को मेडिकल इमेज की विजुअल विशेषताओं के साथ अलाइन नहीं करता है। इसके विपरीत, DCLIP दृष्टिकोण यह सुनिश्चित करता है कि टेक्स्ट और इमेज फीचर्स को एक साझा, सुसंगत स्पेस में मैप किया जाए, जो मॉडल के लिए यह "समझने" हेतु आवश्यक है कि एक विशिष्ट अनुक्रम कैसा दिखना चाहिए, भले ही उसने प्रशिक्षण के दौरान उस सटीक डोमेन का सामना न किया हो।
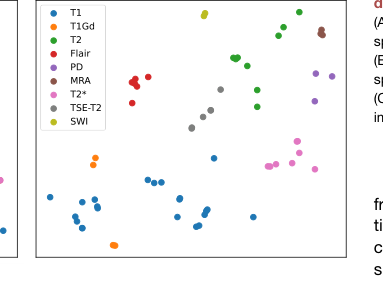 Figure 4. Visualization of prompt embed ding (A) The t-SNE visualization of prompt embedding space of BioBERT encoding. (B) The t-SNE visualization of prompt embedding space of DCLIP encoding. (C) Bar chart of zero-shot classification on medical imaging characters
Figure 4. Visualization of prompt embed ding (A) The t-SNE visualization of prompt embedding space of BioBERT encoding. (B) The t-SNE visualization of prompt embedding space of DCLIP encoding. (C) Bar chart of zero-shot classification on medical imaging characters
गणितीय और तार्किक तंत्र
मास्टर इक्वेशन (The Master Equation)
EVA-I2I फ्रेमवर्क का मुख्य गणितीय इंजन DCLIP लॉस फंक्शन है, जो मेडिकल इमेज रिप्रेजेंटेशन्स को उनके संबंधित टेक्स्टुअल प्रॉम्प्ट्स के साथ संरेखित (align) करता है। इसे निम्नानुसार परिभाषित किया गया है:
$$ \mathcal{L}_{\text{DCLIP}} = - \sum_{i \in D} \left( \frac{1}{|\mathcal{M}(i, \cdot)|} \sum_{m \in \mathcal{M}(i, \cdot)} \log \frac{\exp(z_T^{(i)} \cdot z_I^{(m)} / \tau)}{\sum_{j \in D} \exp(z_T^{(i)} \cdot z_I^{(j)} / \tau)} + \frac{1}{|\mathcal{M}(\cdot, i)|} \sum_{m \in \mathcal{M}(\cdot, i)} \log \frac{\exp(z_I^{(i)} \cdot z_T^{(m)} / \tau)}{\sum_{j \in D} \exp(z_I^{(i)} \cdot z_T^{(j)} / \tau)} \right) $$
पद-दर-पद विश्लेषण (Term-by-Term Autopsy)
- $z_I$ और $z_T$: ये क्रमशः मेडिकल इमेज (इमेज एनकोडर $E_I$ के माध्यम से) और टेक्स्ट प्रॉम्प्ट (टेक्स्ट एनकोडर $E_T$ के माध्यम से) के प्रोजेक्टेड Latent Representations हैं। ये एक साझा एम्बेडिंग स्पेस में "सिमेंटिक कोऑर्डिनेट्स" के रूप में कार्य करते हैं।
- $\mathcal{M}$: यह कन्फ्यूजन मैट्रिक्स (या लेबल मैट्रिक्स) है, जहाँ $\mathcal{M}_{ij} = 1$ होता है यदि प्रॉम्प्ट $i$ इमेज $j$ से मेल खाता है। यह एक लॉजिकल फिल्टर के रूप में कार्य करता है ताकि यह सुनिश्चित हो सके कि मॉडल केवल वैध जोड़ों के बीच ही संबंध सीखे।
- $\tau$: यह स्केलर टेम्परेचर पैरामीटर है (जिसे 0.07 पर सेट किया गया है)। यह प्रोबेबिलिटी डिस्ट्रीब्यूशन की "शार्पनेस" को नियंत्रित करता है; एक छोटा $\tau$ मॉडल को कोसाइन सिमिलरिटी में सूक्ष्म अंतर के प्रति अधिक संवेदनशील बनाता है, जो प्रभावी रूप से एक कंट्रास्ट बूस्टर के रूप में कार्य करता है।
- $\exp(\cdot \cdot \cdot / \tau)$: एक्सपोनेंशियल फंक्शन डॉट प्रोडक्ट (कोसाइन सिमिलरिटी) को एक धनात्मक मान में परिवर्तित करता है, जबकि $\tau$ से विभाजन लॉजिट्स को स्केल करता है। लेखक इसका उपयोग सिमिलरिटी स्कोर को Softmax-स्टाइल नॉर्मलाइजेशन के लिए उपयुक्त प्रोबेबिलिटी डिस्ट्रीब्यूशन में बदलने के लिए करते हैं।
- समेशन संरचना: लेखक मेडिकल डेटा की "मेनी-टू-मेनी" प्रकृति को संभालने के लिए डबल समेशन का उपयोग करते हैं, जहाँ एक प्रॉम्प्ट (उदाहरण के लिए, "T1-weighted brain MRI") विभिन्न रोगियों की कई इमेजेस के अनुरूप हो सकता है। कार्डिनैलिटी $|\mathcal{M}|$ द्वारा विभाजन यह सुनिश्चित करता है कि लॉस नॉर्मलाइज्ड रहे, जिससे अधिक संबंधित इमेजेस वाले प्रॉम्प्ट्स को ग्रेडिएंट अपडेट्स पर हावी होने से रोका जा सके।
चरण-दर-चरण प्रवाह (Step-by-Step Flow)
- इनपुट एनकोडिंग: एक इनपुट इमेज $X$ को ConvNeXt-आधारित इमेज एनकोडर $E_I$ के माध्यम से गुजारा जाता है ताकि एक वेक्टर $z_I$ उत्पन्न हो सके। साथ ही, एक मेडिकल प्रॉम्प्ट $P$ (जो DICOM टैग्स से प्राप्त होता है) को 12-लेयर ट्रांसफॉर्मर $E_T$ द्वारा प्रोसेस किया जाता है ताकि $z_T$ प्राप्त हो सके।
- प्रोजेक्शन: दोनों वेक्टर्स को एक सामान्य Latent Space में प्रोजेक्ट किया जाता है जहाँ उनके सिमेंटिक संरेखण (semantic alignment) को मापा जाता है।
- सिमिलरिटी कैलकुलेशन: मॉडल $z_I$ और $z_T$ के बीच डॉट प्रोडक्ट की गणना करता है। यदि प्रॉम्प्ट और इमेज मेल खाते हैं, तो डॉट प्रोडक्ट अधिकतम हो जाता है।
- कंट्रास्टिव नॉर्मलाइजेशन: Softmax-जैसा डिनोमिनेटर बैच के अन्य सभी सैंपल्स पर योग करता है, जो मॉडल को एम्बेडिंग स्पेस में गैर-मिलान वाले जोड़ों को अलग करने और मिलान वाले जोड़ों को एक साथ लाने के लिए मजबूर करता है।
- सिंथेसिस: एक बार संरेखित हो जाने पर, DCLIP एनकोडिंग $T$ को कंडीशनल डिकोडर $G$ (डायनेमिक कन्वेल्शन्स का उपयोग करके) में फीड किया जाता है ताकि इनपुट संरचना $\Phi$ के टारगेट डोमेन में परिवर्तन को निर्देशित किया जा सके।
ऑप्टिमाइज़ेशन डायनेमिक्स (Optimization Dynamics)
मॉडल दो-चरणीय प्रक्रिया के माध्यम से सीखता है। प्रारंभिक चरण में, यह रिकंस्ट्रक्शन एरर को कम करने के लिए इनर-सब्जेक्ट सुपरविजन का उपयोग करता है। फाइन-ट्यूनिंग चरण में, यह क्रॉस-डेटासेट कोलैबोरेटिव लर्निंग को शामिल करता है। लॉस लैंडस्केप को एडवर्सरियल लॉस $\mathcal{L}_{\text{adv}}$ द्वारा आकार दिया जाता है, जो जनरेटर को ऐसी यथार्थवादी इमेजेस बनाने के लिए मजबूर करता है जिन्हें DCLIP-संचालित डिस्क्रिमिनेटर $D$ वास्तविक डेटा से अलग न कर सके। ग्रेडिएंट्स DCLIP लॉस से एनकोडर्स के माध्यम से वापस प्रवाहित होते हैं, जो प्रभावी रूप से Latent Space को "स्कल्प" (sculpt) करते हैं ताकि समान मेडिकल प्रोटोकॉल एक साथ क्लस्टर हो सकें। यह सुनिश्चित करता है कि जब मॉडल किसी नए, अनदेखे डोमेन का सामना करता है, तो वह प्रॉम्प्ट को Latent Space के उस क्षेत्र में मैप कर सकता है जो पहले से ही सिमेंटिक रूप से सुसंगत है, जिससे ज़ीरो-शॉट जनरलाइजेशन सक्षम होता है। $\mathcal{L}_{\text{con}}$ और $\mathcal{L}_{\text{tri}}$ का उपयोग एक रेगुलराइज़र के रूप में कार्य करता है, जो मॉडल को ट्रिवियल समाधान में गिरने से रोकता है और यह सुनिश्चित करता है कि ट्रांसलेशन प्रक्रिया के दौरान एनाटॉमी की संरचनात्मक अखंडता बनी रहे।
परिणाम, सीमाएँ और निष्कर्ष
Experimental Design & Baselines
EVA-I2I फ्रेमवर्क की प्रभावकारिता को मान्य करने के लिए, लेखकों ने मस्तिष्क, स्तन, उदर और पेल्विस डोमेन के 27,950 3D मेडिकल स्कैन वाले सात सार्वजनिक डेटासेट का उपयोग करके व्यापक प्रयोग किए। प्रयोगात्मक रूपरेखा को एक ही प्रशिक्षण सत्र में मल्टी-डोमेन Image-to-Image (I2I) ट्रांसलेशन करने की मॉडल की क्षमता का परीक्षण करने के लिए संरचित किया गया था।
तुलना के लिए चुने गए "victims" (बेसलाइन मॉडल) में MUNIT, StarGAN v2, Chen et al., और Seq2Seq जैसे स्थापित आर्किटेक्चर शामिल थे। इन बेसलाइन का चयन इसलिए किया गया क्योंकि वे मल्टी-डोमेन I2I ट्रांसलेशन में SOTA का प्रतिनिधित्व करते हैं। लेखकों ने सभी मॉडलों को समान इन-डोमेन प्रशिक्षण समूहों पर प्रशिक्षित करके एक निष्पक्ष तुलना सुनिश्चित की। अपने DCLIP-संचालित दृष्टिकोण की श्रेष्ठता सिद्ध करने के लिए, उन्होंने DCLIP की तुलना one-hot encoding और BioBERT के साथ करने के साथ-साथ विभिन्न backbones (ResNet, Swin-Transformer, और प्रस्तावित ConvNeXt) का मूल्यांकन करने के लिए एब्लेशन अध्ययन (ablation studies) किए। पिक्सेल-स्तरीय निष्ठा (fidelity) और अवधारणात्मक गुणवत्ता (perceptual quality) दोनों को मापने के लिए मूल्यांकन मेट्रिक्स में Peak Signal-to-Noise Ratio (PSNR), Structural Similarity Index Measure (SSIM), और Learned Perceptual Image Patch Similarity (LPIPS) को शामिल किया गया।
What the Evidence Proves
शोध पत्र में प्रस्तुत साक्ष्य अत्यंत प्रभावशाली हैं। मात्रात्मक परिणाम (तालिका 1) दर्शाते हैं कि EVA-I2I इन-डोमेन और आउट-डोमेन दोनों डेटासेट में बेसलाइन मॉडलों से निरंतर बेहतर प्रदर्शन करता है। विशेष रूप से, EVA-I2I ने प्रतिस्पर्धा की तुलना में काफी बेहतर सिंथेसिस प्रदर्शन ($p < 0.05$ for PSNR and LPIPS) प्राप्त किया।
लेखकों ने निम्नलिखित माध्यमों से मॉडल की मजबूती के अकाट्य प्रमाण प्रदान किए हैं:
1. Zero-shot Generalization: मॉडल ने बिना किसी Fine-tuning की आवश्यकता के, पहले कभी न देखे गए डोमेन (उदाहरण के लिए, wash-in DCE से T1) से छवियों का सफलतापूर्वक ट्रांसलेशन किया, जो एक ऐसी उपलब्धि है जिसमें इसने संरचनात्मक विवरण में StarGAN v2 को पीछे छोड़ दिया।
2. Downstream Task Improvement: मॉडल को ब्रेन MRI रजिस्ट्रेशन, वेस्टिबुलर श्वानोमा सेगमेंटेशन और ब्रेस्ट कैंसर pCR प्रेडिक्शन पर लागू किया गया। सभी मामलों में, अन्य डोमेन एडेप्टेशन विधियों की तुलना में EVA-I2I ने डाउनस्ट्रीम मॉडलों (जैसे, VoxelMorph, nnU-Net) के प्रदर्शन में उल्लेखनीय सुधार किया।
3. Semantic Alignment: t-SNE विज़ुअलाइज़ेशन (चित्र 4) स्पष्ट रूप से दर्शाता है कि DCLIP एन्कोडिंग, BioBERT की तुलना में अधिक सुसंगत फीचर क्लस्टर बनाती है, जो यह सिद्ध करता है कि मॉडल प्रभावी रूप से जटिल डोमेन सिमेंटिक्स को कैप्चर करता है। परिणाम यह सुझाव देते हैं कि मॉडल केवल छवियों को "याद" नहीं कर रहा है, बल्कि वास्तव में मेडिकल इमेजिंग प्रोटोकॉल का एक संरचित, सिमेंटिक प्रतिनिधित्व सीख रहा है।
Limitations & Future Directions
मॉडल वर्तमान में 2D स्लाइस प्रोसेसिंग तक सीमित है, जो 3D वॉल्यूम को पुनर्निर्मित करते समय इंटर-स्लाइस असंगति (discontinuities) का कारण बन सकता है। दूसरे, प्रशिक्षण के दौरान उपयोग किया गया निश्चित इमेज रिज़ॉल्यूशन उच्च-रिज़ॉल्यूशन वाले नैदानिक परिदृश्यों में मॉडल के प्रदर्शन को सीमित करता है। अंत में, सत्यापन के लिए उपयोग किए गए आउट-डोमेन डेटासेट उन अंगों या इमेजिंग डोमेन को पूरी तरह से कवर नहीं करते हैं जो इन-डोमेन प्रशिक्षण सेट में हैं, जिससे प्रदर्शन मेट्रिक्स में विसंगतियां हो सकती हैं।
भविष्य की ओर देखते हुए, मेरा मानना है कि विकास के कई रोमांचक मार्ग हैं:
* 3D Volumetric Integration: आर्किटेक्चर को सीधे 3D वॉल्यूम को प्रोसेस करने के लिए विस्तारित करने से इंटर-स्लाइस असंगति के मुद्दों का समाधान होने और नैदानिक उपयोगिता में सुधार होने की संभावना है।
* Foundation Model Scaling: DCLIP की सफलता को देखते हुए, कोई भी इसे और भी बड़े, अधिक विविध डेटासेट तक विस्तारित करने का पता लगा सकता है, जो संभावित रूप से एक वास्तविक "यूनिवर्सल" मेडिकल इमेज ट्रांसलेशन फाउंडेशन मॉडल की ओर बढ़ सकता है।
* Explainability: यद्यपि प्रॉम्प्ट नियंत्रण का एक रूप प्रदान करते हैं, लेकिन इस पर और अधिक शोध कि मॉडल विशिष्ट DICOM टैग्स पर ध्यान क्यों देता है, चिकित्सकों को सिंथेसाइज्ड परिणामों में अधिक विश्वास प्रदान कर सकता है, जिससे AI का "ब्लैक बॉक्स" अधिक पारदर्शी हो जाएगा।
ये निष्कर्ष बताते हैं कि हम एक ऐसे भविष्य की ओर बढ़ रहे हैं जहाँ एक एकल, सामान्यीकृत मॉडल मेडिकल इमेजिंग की व्यापक विषमता को संभाल सकता है, जिससे थकाऊ और कार्य-विशिष्ट Fine-tuning की आवश्यकता कम हो जाएगी।
 Table 2. illustrates the quantitative results of the ablation study on domain encoding, model backbone, and training loss function. We compare three domain encodings to equip our EVA-I2I, including one hot,12 BioBERT,35 and DCLIP (proposed). BioBERT encoding can extract semantic information from medical prompts, leading to better synthesis results than one- hot encoding, and our proposed DCLIP encoding aligns text and images, making its synthesis performance significantly (p < 0:05 for PNSR and LPIPS) better than BioBERT encoding, which cannot align text and images. We also compare three model backbones of the structure encoder EΦ in EVA-I2I, including ResNet,36 Swin-Transformer,37 and ConvNeXt (pro posed). The ConvNeXt backbone slightly outperforms other methods. Moreover, we also evaluate the effectiveness of cross-dataset collaborative learning. Results show that the model trained with Lfine significantly (p < 0:05 for PNSR and LPIPS) outperforms the model only trained with Linit
Table 2. illustrates the quantitative results of the ablation study on domain encoding, model backbone, and training loss function. We compare three domain encodings to equip our EVA-I2I, including one hot,12 BioBERT,35 and DCLIP (proposed). BioBERT encoding can extract semantic information from medical prompts, leading to better synthesis results than one- hot encoding, and our proposed DCLIP encoding aligns text and images, making its synthesis performance significantly (p < 0:05 for PNSR and LPIPS) better than BioBERT encoding, which cannot align text and images. We also compare three model backbones of the structure encoder EΦ in EVA-I2I, including ResNet,36 Swin-Transformer,37 and ConvNeXt (pro posed). The ConvNeXt backbone slightly outperforms other methods. Moreover, we also evaluate the effectiveness of cross-dataset collaborative learning. Results show that the model trained with Lfine significantly (p < 0:05 for PNSR and LPIPS) outperforms the model only trained with Linit
 Table 1. The quantitative results of image translation for different comparisons on in- and out-domain datasets
Table 1. The quantitative results of image translation for different comparisons on in- and out-domain datasets
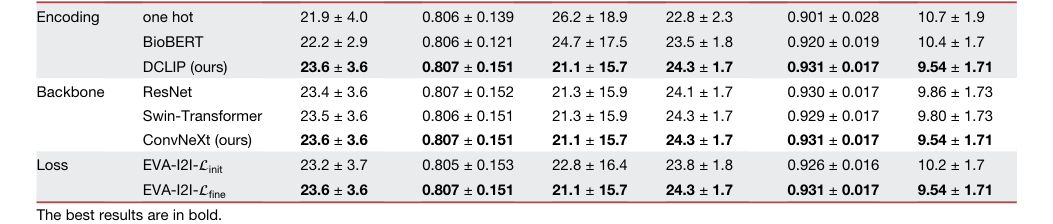 Table 2. The quantitative results of ablation study for EVA-I2I on domain encoding, model backbone, and training loss function
Table 2. The quantitative results of ablation study for EVA-I2I on domain encoding, model backbone, and training loss function