All-in-one medical image-to-image translation
Unifies translation, offers semantic control, and works without fine-tuning.
背景与学术脉络
起源与学术脉络
医学图像到图像(Image-to-image, I2I)转换问题的出现,源于对异构医学影像数据进行统一化的根本需求。在临床实践中,图像采集往往涉及多样的扫描协议、硬件设备及参数设置,导致显著的“域偏移”(Domain Shift),即不同中心的数据统计分布存在差异。既往研究中,基于特定数据集训练的深度学习模型在应用于其他来源数据时,往往难以实现有效的泛化。
以往解决该问题的方法通常依赖于任务特定的架构或离散标签(如 One-hot encoding)来区分成像域。这些方法存在一个关键的“痛点”:缺乏可扩展性。随着域数量的增加,管理这些离散标签的复杂度随之上升,且模型难以捕捉不同成像序列之间微妙且连续的语义关系。此外,许多现有模型在推理阶段需要目标域的风格信息,这使其不适用于无法获取此类信息的真实临床部署场景。作者通过摒弃僵化的离散标签,转向一种灵活的、基于 Prompt 的框架,利用自然语言描述成像协议,从而实现了一种更稳健、更具泛化能力的“All-in-one”转换模型。
直观的领域术语
- Domain Shift(域偏移): 想象阅读一本方言与你所学略有不同的书;你能理解大意,但细微的差别会丢失。在医学影像中,这意味着在“A医院”MRI设置下训练的模型,由于对比度或亮度水平的细微差异,难以解读“B医院”的图像。
- One-hot Encoding(独热编码): 可以将其视为一种僵化的归档系统,每个可能的类别都有一个独立的盒子(例如,T1 为“0001”,T2 为“0010”)。这在处理少量项目时有效,但若有数百个类别,则无法管理,且无法体现 T1 与 T1-contrast 图像之间的内在关联。
- Contrastive Language-Image Pre-training (CLIP): 想象一个阅读过所有医学教材并查看过所有医学扫描的通用翻译器。它学习将扫描的文本描述(例如“T2-weighted brain MRI”)映射到图像中的实际视觉模式,使模型能够基于文本 Prompt “理解”扫描图像应有的外观。
- Zero-Shot Adaptation(零样本适应): 指模型在训练阶段从未见过某种数据类型的情况下,仍能执行相关任务的能力。这就像一位医生,在学习了基础解剖学后,通过应用广泛的基础知识,能够成功诊断出从未亲眼见过的罕见疾病。
符号表
| 符号 | 描述 |
|---|---|
| $X$ | 输入的医学图像 |
| $P$ | 描述扫描的自然语言 Prompt |
| $E_I$ | 用于提取解剖特征的图像编码器 |
| $E_T$ | 用于处理医学 Prompt 的文本编码器 |
| $\Theta_s$ | 由 Prompt 导出的域表示 |
| $G$ | 用于图像合成的条件生成器(解码器) |
| $D$ | 基于 DCLIP 驱动的判别器 |
| $\mathcal{L}_{DCLIP}$ | 用于对齐文本与图像嵌入的损失函数 |
| $\mathcal{L}_{rec}$ | 成对训练样本的重构损失 |
| $\tau$ | 对比学习中的标量温度参数 |
问题定义与约束
核心问题阐述与困境
本文解决的核心问题是缺乏一种适用于多域医学影像、且具有可扩展性和泛化能力的 I2I 转换模型。深度学习在医学图像分析中展现了潜力,但其实际应用受到“域偏移”问题的严重阻碍。当训练数据(源域)和测试数据(目标域)来自不同分布时,就会出现该问题,这通常是由不同临床中心的扫描参数、设备甚至模态差异引起的。
输入/当前状态:
当前状态涉及来自多个域的各种医学图像(例如,T1、T2、Flair、PD、MRA 等不同的 MRI 序列;脑、乳腺、腹部、盆腔等不同器官;以及多变的扫描协议和参数)。这些图像通常由传统的、依赖任务特定架构或离散域标签(常使用 One-hot encoding)的多域 I2I 方法处理。这些方法在可扩展性和泛化能力上受到限制。此外,一对一的 I2I 转换模型随着域数量的增加,面临着所需模型数量和训练时间的“几何级数增长”,使其在大型多域场景中不切实际。现有模型在外部验证时也表现出“性能大幅下降”(cynical performance dropping),难以泛化至未见数据集。
期望终点(输出/目标状态):
期望终点是一个名为 EVA-I2I 的统一、可扩展且具有泛化能力的 I2I 转换框架,能够同时合成不同域的医学图像。该模型应能有效编码多样的成像协议,同时保持语义一致性和适应性。最终目标是实现对未见域的稳健泛化,并无需 Fine-tuning 即可直接应用于临床。具体而言,模型旨在通过单次训练合成所有已见域,实现卓越的图像质量,并支持对从未见过的域进行零样本域适应。它应利用 DICOM 标签信息构建语义表示,从而实现灵活且可扩展的域指定,超越固定 One-hot 编码的局限。
缺失环节或数学鸿沟:
缺失的环节是一种稳健且语义丰富的机制,用于在统一的 I2I 转换框架内编码和控制多样的医学成像域。以往主要依赖 One-hot 编码的方法无法捕捉域之间微妙的语义关系(例如,区分带颅骨的 T2 图像与不带颅骨的 T2 图像)。这一数学鸿沟阻碍了模型有效地扩展到大量异构域,并在保留关键解剖和病理信息的同时泛化到未见域。本文通过引入 DICOM 标签驱动的对比语言-图像预训练(DCLIP)来弥合这一鸿沟,创建了一个公共潜在空间,将自然语言扫描描述与图像特征在语义上对齐,从而实现灵活且可扩展的域控制。
痛点权衡或困境:
困扰以往研究者的最痛苦权衡是可扩展性与语义丰富性/泛化能力之间的困境。
1. 可扩展性 vs. 语义丰富性: 使用 One-hot 编码的传统方法在少量固定域下易于实现。然而,它们本质上不可扩展;随着医学成像域(如不同的序列、器官、采集参数)的增加,One-hot 向量变得极其冗长,且无法捕捉域间的任何语义关系。例如,两张 T2 加权图像可能仅在是否存在颅骨上有所不同,这是一种微妙但语义重要的区别,One-hot 编码无法表示。这导致所需模型或训练时间呈“几何级数增长”,使得多域 I2I 转换在计算上代价高昂且缺乏灵活性。
2. 统一模型 vs. 任务特定性能与泛化: 开发一个能够同时跨所有域转换的“全能”模型,往往以牺牲特定细粒度任务的性能为代价,或者需要针对新的外部数据集进行大量的 Fine-tuning。以往的 I2I 模型在受控环境下表现良好,但在具有外部验证的真实临床场景中往往表现出“性能大幅下降”,难以稳健泛化。这迫使研究者在专业、高性能但狭窄的模型,与广泛、精度较低且泛化性差的模型之间做出选择。
约束与失效模式
由于以下严苛的现实壁垒,该问题极难解决:
物理约束:
* 多样且多变的扫描协议: 医学图像由各种扫描设备、制造商和细微参数设置(如翻转角、回波时间、重复时间、脂肪抑制、对比剂)采集。这些变化产生了显著的域偏移,使得整合数据集并保持语义一致性极具挑战。
* 解剖复杂性: 不同器官(脑、乳腺、腹部、盆腔)具有截然不同的解剖结构和病理特征。为脑部 MRI 设计的模型可能难以处理解剖结构更复杂的腹部 MRI,导致合成质量下降。
* 固定图像分辨率与 2D 处理: 该模型在固定图像分辨率(256x256)下训练,目前仅能处理 2D 切片。这限制了其在高分辨率场景下的适用性,并阻碍了其有效理解复杂 3D 结构的能力,特别是在零样本转换任务中,可能导致切片间的不连续性。
* 序列缺失与小样本量: 在临床实践中,某些目标域常出现小样本量或序列缺失的情况。这种数据稀疏性使得直接在这些特定域上训练 I2I 模型变得困难,且效果往往不佳。
计算约束:
* 模型架构的可扩展性: 传统的多域 I2I 模型通常要求生成器、编码器或判别器的数量随域的数量线性甚至几何级数增长。这导致计算需求和训练时间呈指数级增加,使其无法成为跨多个多样域的真正“All-in-one”解决方案。
* 硬件内存限制: 虽然本文未明确将其作为硬性限制,但对高效模型骨干(如 ConvNeXt)的需求以及对 GFLOPs 和推理时间的报告,暗示了计算资源和内存容量在开发和部署此类大规模模型时是重要的实际约束。
数据驱动约束:
* 域偏移与标注数据匮乏: 根本挑战在于数据集之间固有的域偏移,这通常由不同中心的采集参数变化引起。加之缺乏能够覆盖测试集分布全谱的大量标注训练数据,使得稳健的域适应成为必要。
* One-hot 编码的局限性: 使用 One-hot 编码表示域的普遍方法是一个主要约束。它无法区分域之间的语义差异(例如,带颅骨的 T2 与不带颅骨的 T2),且随着域数量的扩展变得笨重且不可扩展。这阻碍了模型学习丰富、可迁移的表示。
* 外部验证性能下降: I2I 模型在应用于未包含在训练分布中的外部验证数据集时,性能往往显著下降。这使得在不针对每个新目标域进行大量 Fine-tuning 的情况下,难以开发出真正稳健且可临床部署的模型。
* 域外覆盖不一致: 用于评估的域外数据集可能无法覆盖与域内数据集相同的器官或成像域。这可能导致不一致性,并阻碍性能指标的直接可比性,使得难以准确评估真正的泛化能力。
* DICOM 标签可用性: 虽然 DICOM 标签是 Prompt 生成的丰富信息源,但对于许多公共数据集,并不提供 DICOM 文件。这需要从摘要文件中手动收集相关信息,是一个费力且容易出错的过程。
为什么选择此方法
选择的必然性
作者之所以采用 EVA-I2I 框架,是因为传统的多域医学 I2I 转换方法触及了根本的“可扩展性墙”。标准方法(如使用 One-hot 编码标记域)随着域数量的增加而失效,因为编码空间变得僵化,缺乏理解不同成像协议间关系所需的语义深度。作者意识到,要实现一个真正的“全能”模型,需要一种能够捕捉医学扫描底层语义的表示,而不是将每个域视为孤立的、离散的类别。这一认识促使他们采用专门针对 DICOM 元数据调整的对比语言-图像预训练(CLIP),作为将多样、异构的医学数据集映射到统一、连续潜在空间的唯一可行途径。
比较优势
EVA-I2I 的优越性植根于其使用 DCLIP(DICOM-tag-informed CLIP)而非传统的 One-hot 或未对齐的文本编码器(如 BioBERT)。虽然 MUNIT 或 StarGAN v.2 等以往模型依赖风格提取或离散标签,但 EVA-I2I 利用了医学扫描自然语言描述中固有的密集、结构化语义信息。在结构上,这允许模型执行“语义驱动的合成”,其中生成器以丰富的、对齐的文本嵌入为条件,而非稀疏的、无语义的标签。这提供了定性优势:模型能够区分细微的成像差异(例如,脂肪抑制与非脂肪抑制),而 One-hot 编码会忽略或混淆这些差异,从而带来显著更高的结构保真度和对未见域更好的泛化能力。
与约束的对齐
该框架是临床医学影像的严苛要求与视觉-语言模型灵活性之间的精确“结合”。主要约束——跨多样、多中心数据集的可扩展性需求以及零样本泛化要求——通过 DCLIP 架构得到了直接解决。通过将扫描与源自 DICOM 标签的自然语言 Prompt 配对,作者创建了一个在推理阶段不需要显式域标签的系统。这使得模型能够通过简单地提供描述性 Prompt 来处理“从未见过”的域,从而有效地绕过了医学 AI 部署中常见的昂贵的任务特定 Fine-tuning。
对替代方案的拒绝
作者明确拒绝了 One-hot 编码和未对齐的文本编码器(如 BioBERT),因为它们缺乏捕捉医学成像域之间复杂、层级关系的能力。拒绝 One-hot 编码是因为它本质上不可扩展,且无法表示相似但不同的序列之间的语义距离。拒绝 BioBERT 是因为虽然它理解文本,但它并不本质上将文本与医学图像的视觉特征对齐。相比之下,DCLIP 方法确保了文本和图像特征被映射到一个共享的、内聚的空间中,这对于模型“理解”特定序列应有的外观至关重要,即使它在训练期间从未遇到过该确切域。
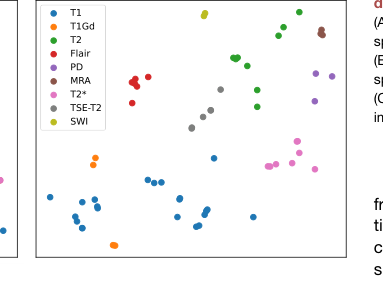 Figure 4. Visualization of prompt embed ding (A) The t-SNE visualization of prompt embedding space of BioBERT encoding. (B) The t-SNE visualization of prompt embedding space of DCLIP encoding. (C) Bar chart of zero-shot classification on medical imaging characters
Figure 4. Visualization of prompt embed ding (A) The t-SNE visualization of prompt embedding space of BioBERT encoding. (B) The t-SNE visualization of prompt embedding space of DCLIP encoding. (C) Bar chart of zero-shot classification on medical imaging characters
数学与逻辑机制
主方程
EVA-I2I 框架的核心数学引擎是 DCLIP 损失函数,它将医学图像表示与其对应的文本 Prompt 对齐。定义如下:
$$ \mathcal{L}_{\text{DCLIP}} = - \sum_{i \in D} \left( \frac{1}{|\mathcal{M}(i, \cdot)|} \sum_{m \in \mathcal{M}(i, \cdot)} \log \frac{\exp(z_T^{(i)} \cdot z_I^{(m)} / \tau)}{\sum_{j \in D} \exp(z_T^{(i)} \cdot z_I^{(j)} / \tau)} + \frac{1}{|\mathcal{M}(\cdot, i)|} \sum_{m \in \mathcal{M}(\cdot, i)} \log \frac{\exp(z_I^{(i)} \cdot z_T^{(m)} / \tau)}{\sum_{j \in D} \exp(z_I^{(i)} \cdot z_T^{(j)} / \tau)} \right) $$
逐项剖析
- $z_I$ 和 $z_T$:分别是医学图像(通过图像编码器 $E_I$)和文本 Prompt(通过文本编码器 $E_T$)的投影潜在表示。它们充当共享嵌入空间中的“语义坐标”。
- $\mathcal{M}$:这是混淆矩阵(或标签矩阵),若 Prompt $i$ 与图像 $j$ 匹配,则 $\mathcal{M}_{ij} = 1$。它充当逻辑过滤器,确保模型仅学习有效对之间的关联。
- $\tau$:这是标量温度参数(设为 0.07)。它控制概率分布的“锐度”;较小的 $\tau$ 使模型对余弦相似度的小差异更敏感,有效地起到对比度增强的作用。
- $\exp(\cdot \cdot \cdot / \tau)$:指数函数将点积(余弦相似度)转换为正值,而除以 $\tau$ 则对 Logits 进行缩放。作者利用此将相似度分数转换为适合 Softmax 风格归一化的概率分布。
- 求和结构:作者使用双重求和来处理医学数据的“多对多”性质,其中一个 Prompt(例如“T1-weighted brain MRI”)可能对应来自不同患者的多张图像。除以基数 $|\mathcal{M}|$ 确保了损失的归一化,防止具有许多关联图像的 Prompt 主导梯度更新。
逐步流程
- 输入编码:输入图像 $X$ 通过基于 ConvNeXt 的图像编码器 $E_I$ 生成向量 $z_I$。同时,医学 Prompt $P$(源自 DICOM 标签)由 12 层 Transformer $E_T$ 处理以产生 $z_T$。
- 投影:两个向量被投影到一个共同的潜在空间,在此测量它们的语义对齐情况。
- 相似度计算:模型计算 $z_I$ 和 $z_T$ 之间的点积。如果 Prompt 和图像匹配,则点积最大化。
- 对比归一化:类似 Softmax 的分母对 Batch 中的所有其他样本求和,迫使模型在嵌入空间中将不匹配的对推开,同时将匹配的对拉近。
- 合成:一旦对齐,DCLIP 编码 $T$ 被馈送到条件解码器 $G$(使用动态卷积),以引导输入结构 $\Phi$ 向目标域的转换。
优化动力学
模型通过两阶段过程学习。在初始阶段,它使用主体内监督来最小化重构误差。在微调阶段,它结合了跨数据集的协作学习。损失图景由对抗损失 $\mathcal{L}_{\text{adv}}$ 塑造,该损失迫使生成器产生 DCLIP 驱动的判别器 $D$ 无法与真实数据区分的逼真图像。梯度从 DCLIP 损失流回编码器,有效地“雕刻”潜在空间,使得相似的医学协议聚集在一起。这确保了当模型遇到新的、未见的域时,它可以将 Prompt 映射到潜在空间中已经语义一致的区域,从而实现零样本泛化。$\mathcal{L}_{\text{con}}$ 和 $\mathcal{L}_{\text{tri}}$ 的使用充当了正则化器,防止模型坍缩为平凡解,并确保在转换过程中解剖结构的完整性得到保留。
结果、局限性与结论
实验设计与基线
为了验证 EVA-I2I 框架的有效性,作者使用包含脑、乳腺、腹部和盆腔域的 27,950 个 3D 医学扫描的七个公共数据集进行了一系列综合实验。实验设计旨在测试模型在单次训练中执行多域 I2I 转换的能力。
选定的对比“受害者”(基线模型)包括 MUNIT、StarGAN v2、Chen et al. 和 Seq2Seq 等成熟架构。选择这些基线是因为它们代表了多域 I2I 转换的 SOTA。作者通过在相同的域内训练队列上训练所有模型,确保了公平的比较。为了证明其 DCLIP 驱动方法的优越性,他们进行了消融研究,将 DCLIP 与 One-hot 编码和 BioBERT 进行了比较,并评估了不同的骨干网络(ResNet、Swin-Transformer 和提出的 ConvNeXt)。评估指标包括峰值信噪比(PSNR)、结构相似性指数(SSIM)和学习感知图像块相似度(LPIPS),以量化像素级保真度和感知质量。
证据证明了什么
论文提供的证据相当令人信服。定量结果(表 1)表明,EVA-I2I 在域内和域外数据集上均持续优于基线模型。具体而言,与竞争对手相比,EVA-I2I 在合成性能上取得了显著提升(PSNR 和 LPIPS 的 $p < 0.05$)。
作者通过以下方式提供了模型稳健性的无可辩驳的证据:
1. 零样本泛化: 模型成功地转换了从未见过的域(例如,从 wash-in DCE 到 T1)的图像,而无需 Fine-tuning,在结构细节上超越了 StarGAN v2。
2. 下游任务改进: 该模型被应用于脑 MRI 配准、前庭神经鞘瘤分割和乳腺癌 pCR 预测。在所有情况下,与其他域适应方法相比,EVA-I2I 显著提高了下游模型(如 VoxelMorph, nnU-Net)的性能。
3. 语义对齐: t-SNE 可视化(图 4)清楚地表明,DCLIP 编码比 BioBERT 创建了更内聚的特征簇,证明模型有效地捕捉了复杂的域语义。结果表明,模型不仅仅是在“记忆”图像,而是在学习医学成像协议的结构化、语义化表示。
局限性与未来方向
该模型目前仅限于 2D 切片处理,在重构 3D 体积时可能导致切片间的不连续性。其次,训练期间使用的固定图像分辨率限制了模型在高分辨率临床场景中的性能。最后,用于验证的域外数据集并未完全覆盖与域内训练集相同的器官或成像域,这可能导致性能指标的不一致。
展望未来,我认为有几个令人兴奋的演进方向:
* 3D 体积集成: 直接扩展架构以处理 3D 体积可能会解决切片间不一致的问题,并提高临床实用性。
* 基础模型扩展: 鉴于 DCLIP 的成功,可以探索将其扩展到更大、更多样化的数据集,潜在地迈向一个真正的“通用”医学图像转换基础模型。
* 可解释性: 虽然 Prompt 提供了一种控制形式,但进一步研究模型为何关注特定的 DICOM 标签,可以为临床医生提供对合成结果的更多信心,使 AI 的“黑盒”更加透明。
这些发现表明,我们正迈向一个单一的、可泛化的模型能够处理医学影像巨大异构性的未来,减少了对繁琐的任务特定 Fine-tuning 的需求。
 Table 2. illustrates the quantitative results of the ablation study on domain encoding, model backbone, and training loss function. We compare three domain encodings to equip our EVA-I2I, including one hot,12 BioBERT,35 and DCLIP (proposed). BioBERT encoding can extract semantic information from medical prompts, leading to better synthesis results than one- hot encoding, and our proposed DCLIP encoding aligns text and images, making its synthesis performance significantly (p < 0:05 for PNSR and LPIPS) better than BioBERT encoding, which cannot align text and images. We also compare three model backbones of the structure encoder EΦ in EVA-I2I, including ResNet,36 Swin-Transformer,37 and ConvNeXt (pro posed). The ConvNeXt backbone slightly outperforms other methods. Moreover, we also evaluate the effectiveness of cross-dataset collaborative learning. Results show that the model trained with Lfine significantly (p < 0:05 for PNSR and LPIPS) outperforms the model only trained with Linit
Table 2. illustrates the quantitative results of the ablation study on domain encoding, model backbone, and training loss function. We compare three domain encodings to equip our EVA-I2I, including one hot,12 BioBERT,35 and DCLIP (proposed). BioBERT encoding can extract semantic information from medical prompts, leading to better synthesis results than one- hot encoding, and our proposed DCLIP encoding aligns text and images, making its synthesis performance significantly (p < 0:05 for PNSR and LPIPS) better than BioBERT encoding, which cannot align text and images. We also compare three model backbones of the structure encoder EΦ in EVA-I2I, including ResNet,36 Swin-Transformer,37 and ConvNeXt (pro posed). The ConvNeXt backbone slightly outperforms other methods. Moreover, we also evaluate the effectiveness of cross-dataset collaborative learning. Results show that the model trained with Lfine significantly (p < 0:05 for PNSR and LPIPS) outperforms the model only trained with Linit
 Table 1. The quantitative results of image translation for different comparisons on in- and out-domain datasets
Table 1. The quantitative results of image translation for different comparisons on in- and out-domain datasets
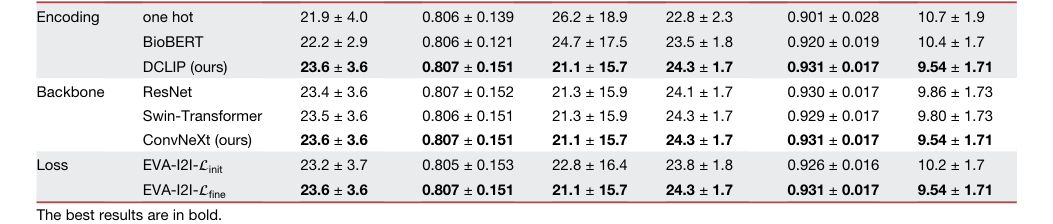 Table 2. The quantitative results of ablation study for EVA-I2I on domain encoding, model backbone, and training loss function
Table 2. The quantitative results of ablation study for EVA-I2I on domain encoding, model backbone, and training loss function
与其他领域的同构性
结构骨架
一种将异构、多模态数据输入映射到共享的、语义对齐的潜在空间,以实现灵活的、跨域转换,而无需显式域标签的机制。