All-in-one medical image-to-image translation
Проблема медицинского image to image (I2I) translation возникла из фундаментальной необходимости гармонизации гетерогенных данных медицинской визуализации.
Background & Academic Lineage
The Origin & Academic Lineage
Проблема медицинского image-to-image (I2I) translation возникла из фундаментальной необходимости гармонизации гетерогенных данных медицинской визуализации. В клинической практике изображения получают с использованием различных протоколов сканирования, оборудования и настроек параметров, что приводит к значительным «domain shifts», при которых статистическое распределение данных одного центра отличается от другого. Исторически сложилось так, что модели deep learning, обученные на одном конкретном наборе данных, часто не демонстрируют обобщающую способность при применении к данным из другого источника.
Предыдущие подходы к этой проблеме обычно опирались на task-specific архитектуры или дискретные метки (например, one-hot encoding) для различения доменов визуализации. Эти методы страдают от критического «pain point»: им не хватает масштабируемости. По мере роста числа доменов сложность управления этими дискретными метками возрастает, и модели с трудом улавливают тонкие, непрерывные семантические взаимосвязи между различными последовательностями визуализации. Более того, многие существующие модели требуют информацию о стиле целевого домена во время inference, что делает их непригодными для реального клинического развертывания, где такая информация часто недоступна. Авторы решают эту проблему, отходя от жестких дискретных меток в пользу гибкого, prompt-driven фреймворка, который использует естественный язык для описания протоколов визуализации, тем самым обеспечивая более надежную и обобщаемую модель «all-in-one» трансляции.
Intuitive Domain Terms
- Domain Shift: Представьте, что вы пытаетесь прочитать книгу, написанную на диалекте, который немного отличается от того, который вы изучали; вы можете понять суть, но тонкие нюансы теряются. В медицинской визуализации это происходит, когда модель, обученная на настройках МРТ «Больницы А», с трудом интерпретирует изображения «Больницы Б» из-за различий в уровнях контрастности или яркости.
- One-Hot Encoding: Рассматривайте это как жесткую систему классификации, где каждая возможная категория получает свой уникальный, изолированный «ящик» (например, «0001» для T1, «0010» для T2). Это работает для небольшого количества элементов, но если у вас сотни категорий, управление становится невозможным, и такая система не отражает тот факт, что T1 и T1-contrast изображения на самом деле связаны.
- Contrastive Language-Image Pre-training (CLIP): Представьте себе универсального переводчика, который прочитал все медицинские учебники и просмотрел все медицинские сканы. Он учится сопоставлять текстовое описание скана (например, «T2-weighted brain MRI») с фактическими визуальными паттернами на изображении, позволяя модели «понимать», как должен выглядеть скан на основе текстового промпта.
- Zero-Shot Adaptation: Это способность модели выполнять задачу на типе данных, который она никогда не видела во время фазы обучения. Это похоже на врача, который, изучив общую анатомию, может успешно диагностировать редкое заболевание, с которым он никогда лично не сталкивался, применяя свои обширные фундаментальные знания.
Notation Table
| Notation | Description |
|---|---|
| $X$ | Входное медицинское изображение |
| $P$ | Промпт на естественном языке, описывающий скан |
| $E_I$ | Энкодер изображений, используемый для извлечения анатомических признаков |
| $E_T$ | Текстовый энкодер, используемый для обработки медицинского промпта |
| $\Theta_s$ | Доменное представление, полученное из промпта |
| $G$ | Условный генератор (декодер) для синтеза изображений |
| $D$ | Дискриминатор на базе DCLIP |
| $\mathcal{L}_{DCLIP}$ | Функция потерь для выравнивания текстовых и визуальных эмбеддингов |
| $\mathcal{L}_{rec}$ | Функция потерь реконструкции для парных обучающих выборок |
| $\tau$ | Скалярный параметр температуры для контрастивного обучения |
Problem Definition & Constraints
Core Problem Formulation & The Dilemma
Основная проблема, рассматриваемая в данной статье, заключается в отсутствии масштабируемой и обобщаемой модели I2I-трансляции для мультидоменной медицинской визуализации. Deep learning показал многообещающие результаты в анализе медицинских изображений, но его практическое применение серьезно затруднено проблемой «domain shift». Это происходит, когда обучающие данные (исходный домен) и тестовые данные (целевой домен) происходят из разных распределений, часто из-за вариаций параметров сканирования, устройств или даже модальностей в разных клинических центрах.
Input/Current State:
Текущее состояние включает разнообразные медицинские изображения из нескольких доменов (например, различные МРТ-последовательности, такие как T1, T2, Flair, PD, MRA; различные органы, такие как мозг, молочная железа, брюшная полость, таз; различные протоколы и параметры сканирования). Эти изображения обычно обрабатываются традиционными мультидоменными I2I-подходами, которые опираются на task-specific архитектуры или дискретные доменные метки, часто используя one-hot encoding для представления домена. Эти методы ограничены в своей масштабируемости и способностях к обобщению. Более того, модели I2I «один-к-одному» сталкиваются с «геометрическим ростом» количества необходимых моделей и времени обучения по мере увеличения числа доменов, что делает их непрактичными для крупномасштабных мультидоменных сценариев. Существующие модели также испытывают трудности с внешней валидацией, демонстрируя «cynical performance dropping» при применении к новым, ранее не виденным наборам данных.
Desired Endpoint (Output/Goal State):
Желаемым результатом является унифицированный, расширяемый и обобщаемый фреймворк I2I-трансляции под названием EVA-I2I, способный синтезировать медицинские изображения одновременно для различных доменов. Эта модель должна эффективно кодировать разнообразные протоколы визуализации, сохраняя при этом семантическую согласованность и адаптивность. Конечная цель — обеспечить надежное обобщение на невидимые домены и способствовать прямому клиническому применению без необходимости fine-tuning. В частности, модель стремится синтезировать все увиденные домены одновременно за одну сессию обучения, достичь отличного качества изображений и поддерживать zero-shot адаптацию доменов для ранее не встречавшихся данных. Она должна использовать семантические представления, основанные на DICOM-тегах, для обеспечения гибкой и масштабируемой спецификации доменов, выходя за рамки ограничений фиксированных one-hot кодов.
Missing Link or Mathematical Gap:
Недостающим звеном является надежный и семантически богатый механизм для кодирования и управления разнообразными доменами медицинской визуализации в рамках единого фреймворка I2I-трансляции. Предыдущие методы, в основном полагающиеся на one-hot encoding, не способны уловить тонкие семантические взаимосвязи между доменами (например, различие между T2-изображениями с черепом и без него). Этот математический пробел препятствует эффективному масштабированию моделей на большое количество гетерогенных доменов и их обобщению на новые домены при сохранении критически важной анатомической и патологической информации. Статья пытается преодолеть это путем внедрения DICOM-tag-informed contrastive language-image pre-training (DCLIP) для создания общего латентного пространства, которое семантически выравнивает описания сканов на естественном языке с признаками изображений, тем самым обеспечивая гибкое и масштабируемое управление доменами.
Painful Trade-off or Dilemma:
Наиболее болезненный компромисс, в который попали предыдущие исследователи, — это дилемма между масштабируемостью и семантической насыщенностью/обобщением.
1. Scalability vs. Semantic Richness: Традиционные методы с использованием one-hot encoding просты в реализации для небольшого фиксированного числа доменов. Однако они по своей сути не масштабируемы; по мере роста числа доменов медицинской визуализации (например, различные последовательности, органы, параметры сбора данных) вектор one-hot encoding становится непрактично длинным и не способен уловить какие-либо семантические связи между доменами. Например, два T2-взвешенных изображения могут различаться только наличием или отсутствием черепа — тонкое, но семантически важное различие, которое one-hot encoding не может представить. Это приводит к «геометрическому росту» требуемых моделей или времени обучения, делая мультидоменную I2I-трансляцию вычислительно непомерно дорогой и негибкой.
2. Unified Model vs. Task-Specific Performance & Generalization: Разработка единой «всемогущей» модели, способной транслировать изображения по всем доменам одновременно, часто достигается ценой снижения производительности в специфических, тонко настроенных задачах или требует обширного fine-tuning для новых внешних наборов данных. Предыдущие I2I-модели, демонстрируя многообещающие результаты в контролируемых условиях, часто демонстрируют «cynical performance dropping» при развертывании в реальных клинических сценариях с внешней валидацией, не обеспечивая надежного обобщения. Это вынуждает исследователей выбирать между специализированными, высокопроизводительными, но узкими моделями и широкими, менее точными и плохо обобщающимися решениями.
Constraints & Failure Modes
Эта проблема чрезвычайно сложна для решения из-за нескольких жестких, реалистичных барьеров:
Physical Constraints:
* Diverse and Variable Scanning Protocols: Медицинские изображения получают с помощью огромного массива сканирующих устройств, производителей и тонких настроек параметров (например, угол наклона, время эха, время повторения, подавление сигнала от жира, контрастные вещества). Эти вариации создают значительные domain shifts и затрудняют интеграцию наборов данных и поддержание семантической согласованности между ними.
* Anatomical Complexity: Разные органы (мозг, молочная железа, брюшная полость, таз) обладают совершенно разными анатомическими структурами и патологиями. Модель, разработанная для МРТ головного мозга, может испытывать трудности с большей анатомической сложностью МРТ брюшной полости, что приводит к снижению качества синтеза.
* Fixed Image Resolution and 2D Processing: Предлагаемая модель обучается с фиксированным разрешением изображения (256x256) и в настоящее время способна обрабатывать только 2D-срезы. Это ограничивает ее применимость в сценариях с более высоким разрешением и препятствует эффективному пониманию сложных 3D-структур, потенциально приводя к разрывам между срезами, особенно в задачах zero-shot трансляции.
* Missing Sequences and Small Sample Sizes: В реальных клинических условиях часто встречаются малые размеры выборок или отсутствие последовательностей для определенных целевых доменов. Эта разреженность данных затрудняет прямое обучение I2I-моделей на этих конкретных доменах и часто дает плохие результаты.
Computational Constraints:
* Scalability of Model Architectures: Традиционные мультидоменные I2I-модели часто требуют, чтобы количество генераторов, энкодеров или дискриминаторов росло линейно или даже геометрически с увеличением числа доменов. Это приводит к экспоненциально возрастающим вычислительным требованиям и времени обучения, что делает их невыполнимыми для действительно «all-in-one» решения для множества разнообразных доменов.
* Hardware Memory Limits: Хотя это прямо не детализировано как жесткий лимит для решения данной статьи, необходимость в эффективных модельных бэкбонах (таких как ConvNeXt) и отчеты о GFLOPs и времени inference подразумевают, что вычислительные ресурсы и объем памяти являются значительными практическими ограничениями при разработке и развертывании таких крупномасштабных моделей.
Data-Driven Constraints:
* Domain Shift and Lack of Labeled Data: Фундаментальной проблемой является присущий данным domain shift между наборами данных, часто вызванный варьирующимися параметрами сбора данных в разных центрах. Усугубляет это отсутствие большого количества аннотированных обучающих данных, которые могли бы охватить весь спектр распределений тестового набора, что требует надежной адаптации домена.
* Limitations of One-Hot Encoding: Преобладающий метод использования one-hot encoding для представления доменов является серьезным ограничением. Он не может различать семантические различия между доменами (например, T2 с черепом против T2 без черепа) и становится громоздким и немасштабируемым по мере расширения числа доменов. Это препятствует обучению моделей богатым, переносимым представлениям.
* External Validation Performance Drop: I2I-модели часто демонстрируют значительное падение производительности при применении к внешним наборам данных валидации, которые не были частью их обучающего распределения. Это затрудняет разработку моделей, которые были бы по-настоящему надежными и клинически применимыми без обширного fine-tuning для каждого нового целевого домена.
* Inconsistent Out-Domain Coverage: Наборы данных вне домена, используемые для оценки, могут не охватывать те же органы или домены визуализации, что и наборы данных внутри домена. Это может привести к несоответствиям и затруднить прямое сравнение метрик производительности, что затрудняет точную оценку истинных способностей к обобщению.
* DICOM Tag Availability: Хотя DICOM-теги являются богатым источником информации для генерации промптов, для многих публичных наборов данных DICOM-файлы не предоставляются. Это требует ручного сбора соответствующей информации из сводных файлов, что является трудоемким и потенциально подверженным ошибкам процессом.
Why This Approach
The Inevitability of the Choice
Авторы пришли к фреймворку EVA-I2I, потому что традиционные методы мультидоменной медицинской I2I-трансляции уперлись в фундаментальную «стену масштабируемости». Стандартные подходы, такие как one-hot encoding для маркировки доменов, терпят неудачу по мере роста числа доменов, поскольку пространство кодирования становится жестким и лишенным семантической глубины, необходимой для понимания взаимосвязей между различными протоколами визуализации. Авторы осознали, что для создания по-настоящему «всемогущей» модели им необходимо представление, способное улавливать базовую семантику медицинских сканов, а не рассматривать каждый домен как изолированную дискретную категорию. Это осознание привело к принятию Contrastive Language-Image Pre-training (CLIP), специально адаптированного для метаданных DICOM, как единственного жизнеспособного способа отображения разнообразных, гетерогенных медицинских наборов данных в единое, непрерывное латентное пространство.
Comparative Superiority
Превосходство EVA-I2I основано на использовании DCLIP (DICOM-tag-informed CLIP) по сравнению с традиционными one-hot или невыровненными текстовыми энкодерами, такими как BioBERT. В то время как предыдущие модели, такие как MUNIT или StarGAN v.2, полагаются на извлечение стиля или дискретные метки, EVA-I2I использует плотную, структурированную семантическую информацию, присущую описаниям медицинских сканов на естественном языке. Структурно это позволяет модели выполнять «семантически управляемый синтез», где генератор обусловлен богатым, выровненным текстовым эмбеддингом, а не разреженной, несемантической меткой. Это обеспечивает качественное преимущество: модель может различать тонкие различия в визуализации (например, подавление сигнала от жира против отсутствия такового), которые one-hot encoding просто пропустил бы или смешал, что приводит к значительно более высокой структурной точности и лучшему обобщению на невидимые домены.
Alignment with Constraints
Фреймворк представляет собой точный «союз» между жесткими требованиями клинической медицинской визуализации и гибкостью моделей vision-language. Основные ограничения — необходимость масштабируемости на разнообразных мультицентровых наборах данных и требование zero-shot обобщения — напрямую решаются архитектурой DCLIP. Сопоставляя сканы с промптами на естественном языке, полученными из DICOM-тегов, авторы создали систему, которая не требует явных доменных меток во время inference. Это позволяет модели обрабатывать «ранее не виденные» домены путем простого предоставления описательного промпта, эффективно обходя необходимость в дорогостоящем, task-specific fine-tuning, который обычно преследует развертывание медицинского ИИ.
Rejection of Alternatives
Авторы явно отвергают one-hot encoding и невыровненные текстовые энкодеры (такие как BioBERT), поскольку они не обладают способностью улавливать сложные, иерархические взаимосвязи между доменами медицинской визуализации. One-hot encoding был отвергнут, потому что он по своей сути не является расширяемым и не способен представить семантическое расстояние между похожими, но различными последовательностями. BioBERT был отвергнут, потому что, хотя он понимает текст, он не выравнивает этот текст с визуальными признаками медицинских изображений по своей сути. Напротив, подход DCLIP гарантирует, что текстовые и визуальные признаки отображаются в общее, связное пространство, что необходимо для того, чтобы модель «понимала», как должна выглядеть конкретная последовательность, даже если она никогда не встречала этот конкретный домен во время обучения.
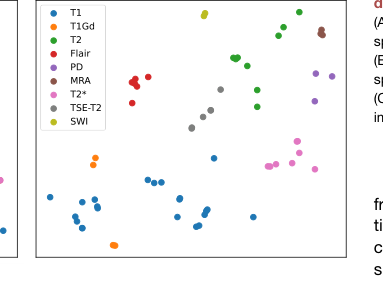 Figure 4. Visualization of prompt embed ding (A) The t-SNE visualization of prompt embedding space of BioBERT encoding. (B) The t-SNE visualization of prompt embedding space of DCLIP encoding. (C) Bar chart of zero-shot classification on medical imaging characters
Figure 4. Visualization of prompt embed ding (A) The t-SNE visualization of prompt embedding space of BioBERT encoding. (B) The t-SNE visualization of prompt embedding space of DCLIP encoding. (C) Bar chart of zero-shot classification on medical imaging characters
Mathematical & Logical Mechanism
The Master Equation
Основным математическим двигателем фреймворка EVA-I2I является функция потерь DCLIP, которая выравнивает представления медицинских изображений с соответствующими текстовыми промптами. Она определяется как:
$$ \mathcal{L}_{\text{DCLIP}} = - \sum_{i \in D} \left( \frac{1}{|\mathcal{M}(i, \cdot)|} \sum_{m \in \mathcal{M}(i, \cdot)} \log \frac{\exp(z_T^{(i)} \cdot z_I^{(m)} / \tau)}{\sum_{j \in D} \exp(z_T^{(i)} \cdot z_I^{(j)} / \tau)} + \frac{1}{|\mathcal{M}(\cdot, i)|} \sum_{m \in \mathcal{M}(\cdot, i)} \log \frac{\exp(z_I^{(i)} \cdot z_T^{(m)} / \tau)}{\sum_{j \in D} \exp(z_I^{(i)} \cdot z_T^{(j)} / \tau)} \right) $$
Term-by-Term Autopsy
- $z_I$ и $z_T$: Это спроецированные латентные представления медицинского изображения (через энкодер изображений $E_I$) и текстового промпта (через текстовый энкодер $E_T$) соответственно. Они действуют как «семантические координаты» в общем пространстве эмбеддингов.
- $\mathcal{M}$: Это матрица смешивания (или матрица меток), где $\mathcal{M}_{ij} = 1$, если промпт $i$ соответствует изображению $j$. Она действует как логический фильтр, гарантирующий, что модель изучает ассоциации только между валидными парами.
- $\tau$: Это скалярный параметр температуры (установлен на 0.07). Он контролирует «резкость» распределения вероятностей; меньшее $\tau$ делает модель более чувствительной к небольшим различиям в косинусном сходстве, эффективно действуя как усилитель контраста.
- $\exp(\cdot \cdot \cdot / \tau)$: Экспоненциальная функция преобразует скалярное произведение (косинусное сходство) в положительное значение, в то время как деление на $\tau$ масштабирует логиты. Автор использует это для преобразования оценок сходства в распределение вероятностей, подходящее для нормализации в стиле Softmax.
- Структура суммирования: Автор использует двойное суммирование для обработки природы «многие-ко-многим» медицинских данных, где один промпт (например, «T1-weighted brain MRI») может соответствовать нескольким изображениям от разных пациентов. Деление на мощность $|\mathcal{M}|$ гарантирует, что потери нормализованы, предотвращая доминирование промптов с большим количеством связанных изображений в обновлениях градиента.
Step-by-Step Flow
- Input Encoding: Входное изображение $X$ проходит через энкодер изображений $E_I$ на базе ConvNeXt для создания вектора $z_I$. Одновременно медицинский промпт $P$ (полученный из DICOM-тегов) обрабатывается 12-слойным трансформером $E_T$ для получения $z_T$.
- Projection: Оба вектора проецируются в общее латентное пространство, где измеряется их семантическое выравнивание.
- Similarity Calculation: Модель вычисляет скалярное произведение между $z_I$ и $z_T$. Если промпт и изображение совпадают, скалярное произведение максимизируется.
- Contrastive Normalization: Знаменатель, подобный Softmax, суммирует все остальные образцы в батче, заставляя модель раздвигать несовпадающие пары в пространстве эмбеддингов, одновременно притягивая совпадающие пары друг к другу.
- Synthesis: После выравнивания кодировка DCLIP $T$ подается в условный декодер $G$ (использующий динамические свертки) для управления трансформацией входной структуры $\Phi$ в целевой домен.
Optimization Dynamics
Модель обучается посредством двухэтапного процесса. На начальном этапе она использует внутрисубъектный надзор для минимизации ошибки реконструкции. На этапе fine-tuning она включает кросс-датасетное совместное обучение. Ландшафт потерь формируется состязательными потерями $\mathcal{L}_{\text{adv}}$, которые заставляют генератор создавать реалистичные изображения, которые дискриминатор $D$ на базе DCLIP не может отличить от реальных данных. Градиенты текут от потерь DCLIP обратно через энкодеры, эффективно «вылепливая» латентное пространство так, чтобы похожие медицинские протоколы группировались вместе. Это гарантирует, что когда модель сталкивается с новым, невидимым доменом, она может отобразить промпт в область латентного пространства, которая уже семантически согласована, обеспечивая zero-shot обобщение. Использование $\mathcal{L}_{\text{con}}$ и $\mathcal{L}_{\text{tri}}$ действует как регуляризатор, предотвращая коллапс модели в тривиальное решение и гарантируя, что структурная целостность анатомии сохраняется в процессе трансляции.
Results, Limitations & Conclusion
Experimental Design & Baselines
Для подтверждения эффективности фреймворка EVA-I2I авторы провели комплексный набор экспериментов с использованием семи публичных наборов данных, включающих 27 950 3D медицинских сканов для доменов мозга, молочной железы, брюшной полости и таза. Экспериментальный дизайн был структурирован для проверки способности модели выполнять мультидоменную I2I-трансляцию за одну сессию обучения.
«Жертвы» (базовые модели), выбранные для сравнения, включали такие устоявшиеся архитектуры, как MUNIT, StarGAN v2, Chen et al. и Seq2Seq. Эти базовые модели были выбраны потому, что они представляют state-of-the-art в мультидоменной I2I-трансляции. Авторы обеспечили честное сравнение, обучив все модели на одних и тех же обучающих когортах внутри домена. Чтобы доказать превосходство своего подхода на базе DCLIP, они провели абляционные исследования, сравнивая DCLIP с one-hot encoding и BioBERT, а также оценивая различные бэкбоны (ResNet, Swin-Transformer и предложенный ConvNeXt). Метрики оценки включали Peak Signal-to-Noise Ratio (PSNR), Structural Similarity Index Measure (SSIM) и Learned Perceptual Image Patch Similarity (LPIPS) для количественной оценки как точности на уровне пикселей, так и перцептивного качества.
What the Evidence Proves
Доказательства, представленные в статье, весьма убедительны. Количественные результаты (Таблица 1) демонстрируют, что EVA-I2I стабильно превосходит базовые модели как на наборах данных внутри домена, так и вне его. В частности, EVA-I2I достигла значительно лучших показателей синтеза ($p < 0.05$ для PSNR и LPIPS) по сравнению с конкурентами.
Авторы предоставили неоспоримые доказательства надежности модели посредством:
1. Zero-shot Generalization: Модель успешно транслировала изображения из ранее не виденных доменов (например, wash-in DCE в T1) без необходимости fine-tuning, достижение, в котором она превзошла StarGAN v2 по структурной детализации.
2. Downstream Task Improvement: Модель была применена к регистрации МРТ головного мозга, сегментации вестибулярной шванномы и прогнозированию pCR рака молочной железы. Во всех случаях EVA-I2I значительно улучшила производительность downstream-моделей (например, VoxelMorph, nnU-Net) по сравнению с другими методами адаптации доменов.
3. Semantic Alignment: Визуализация t-SNE (Рисунок 4) четко показывает, что кодирование DCLIP создает более связные кластеры признаков, чем BioBERT, доказывая, что модель эффективно улавливает сложную семантику доменов. Результаты свидетельствуют о том, что модель не просто «запоминает» изображения, а фактически изучает структурированное, семантическое представление протоколов медицинской визуализации.
Limitations & Future Directions
Модель в настоящее время ограничена обработкой 2D-срезов, что может привести к разрывам между срезами при реконструкции 3D-объемов. Во-вторых, фиксированное разрешение изображения, используемое во время обучения, ограничивает производительность модели в клинических сценариях с высоким разрешением. Наконец, наборы данных вне домена, используемые для валидации, не полностью охватывают те же органы или домены визуализации, что и обучающий набор внутри домена, что может привести к несоответствиям в метриках производительности.
Заглядывая вперед, я считаю, что существует несколько захватывающих путей для развития:
* 3D Volumetric Integration: Расширение архитектуры для прямой обработки 3D-объемов, вероятно, решило бы проблемы несогласованности между срезами и повысило бы клиническую полезность.
* Foundation Model Scaling: Учитывая успех DCLIP, можно изучить масштабирование этого подхода на еще большие, более разнообразные наборы данных, потенциально двигаясь к по-настоящему «универсальной» фундаментальной модели медицинской трансляции изображений.
* Explainability: Хотя промпты обеспечивают форму контроля, дальнейшие исследования того, почему модель обращает внимание на конкретные DICOM-теги, могли бы дать клиницистам больше уверенности в синтезированных результатах, делая «черный ящик» ИИ более прозрачным.
Эти результаты свидетельствуют о том, что мы движемся к будущему, в котором единая, обобщаемая модель сможет справляться с огромной гетерогенностью медицинской визуализации, уменьшая потребность в утомительном, task-specific fine-tuning.
 Table 2. illustrates the quantitative results of the ablation study on domain encoding, model backbone, and training loss function. We compare three domain encodings to equip our EVA-I2I, including one hot,12 BioBERT,35 and DCLIP (proposed). BioBERT encoding can extract semantic information from medical prompts, leading to better synthesis results than one- hot encoding, and our proposed DCLIP encoding aligns text and images, making its synthesis performance significantly (p < 0:05 for PNSR and LPIPS) better than BioBERT encoding, which cannot align text and images. We also compare three model backbones of the structure encoder EΦ in EVA-I2I, including ResNet,36 Swin-Transformer,37 and ConvNeXt (pro posed). The ConvNeXt backbone slightly outperforms other methods. Moreover, we also evaluate the effectiveness of cross-dataset collaborative learning. Results show that the model trained with Lfine significantly (p < 0:05 for PNSR and LPIPS) outperforms the model only trained with Linit
Table 2. illustrates the quantitative results of the ablation study on domain encoding, model backbone, and training loss function. We compare three domain encodings to equip our EVA-I2I, including one hot,12 BioBERT,35 and DCLIP (proposed). BioBERT encoding can extract semantic information from medical prompts, leading to better synthesis results than one- hot encoding, and our proposed DCLIP encoding aligns text and images, making its synthesis performance significantly (p < 0:05 for PNSR and LPIPS) better than BioBERT encoding, which cannot align text and images. We also compare three model backbones of the structure encoder EΦ in EVA-I2I, including ResNet,36 Swin-Transformer,37 and ConvNeXt (pro posed). The ConvNeXt backbone slightly outperforms other methods. Moreover, we also evaluate the effectiveness of cross-dataset collaborative learning. Results show that the model trained with Lfine significantly (p < 0:05 for PNSR and LPIPS) outperforms the model only trained with Linit
 Table 1. The quantitative results of image translation for different comparisons on in- and out-domain datasets
Table 1. The quantitative results of image translation for different comparisons on in- and out-domain datasets
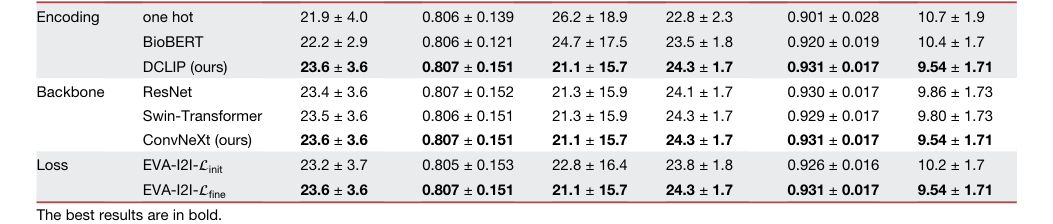 Table 2. The quantitative results of ablation study for EVA-I2I on domain encoding, model backbone, and training loss function
Table 2. The quantitative results of ablation study for EVA-I2I on domain encoding, model backbone, and training loss function