オールインワン医療画像間変換
Unifies translation, offers semantic control, and works without fine-tuning.
背景と学術的系譜
起源と学術的系譜
医療画像間(I2I)変換の問題は、異種医療画像データを調和させるという根本的な必要性から生まれました。臨床現場では、多様なスキャンプロトコル、ハードウェア、パラメータ設定を用いて画像が取得されるため、ある施設からのデータの統計的分布が別の施設と異なる「ドメインシフト」が顕著になります。歴史的に、特定のデータセットで訓練された深層学習モデルは、異なるソースからのデータに適用された際に一般化できないことがよくありました。
この問題に対する従来のアプローチは、タスク固有のアーキテクチャや離散的なラベル(ワンホットエンコーディングなど)に依存して、画像ドメインを区別していました。これらの手法は、拡張性の欠如という重大な「ペインポイント」を抱えています。ドメイン数が増加するにつれて、これらの離散ラベルを管理する複雑さが増し、モデルは異なる画像シーケンス間の微妙で連続的な意味的関係を捉えるのに苦労します。さらに、多くの既存モデルは推論中にターゲットドメインのスタイル情報を必要としますが、そのような情報が利用できない現実の臨床展開には不向きです。本論文の著者らは、この問題に対処するため、厳格で離散的なラベルから離れ、自然言語を利用して画像プロトコルを記述する柔軟なプロンプト駆動型フレームワークへと移行し、より堅牢で一般化可能な「オールインワン」変換モデルを可能にします。
直感的なドメイン用語
- ドメインシフト: 学んだ方言とは少し異なる方言で書かれた本を読もうとするようなものです。要点は理解できますが、微妙なニュアンスは失われます。医療画像では、これは「病院A」のMRI設定で訓練されたモデルが、「病院B」の画像のコントラストや明るさレベルがわずかに異なるために、それらを解釈するのに苦労する場合です。
- ワンホットエンコーディング: これは、考えられるすべてのカテゴリに独自の、孤立したボックス(例: T1の場合は「0001」、T2の場合は「0010」)が割り当てられる、厳格なファイルシステムのようなものです。少数の項目には機能しますが、数百のカテゴリがある場合は管理不能になり、T1画像とT1造影画像が実際に関連していることを示すことができません。
- 対照言語画像事前学習(CLIP): すべての医学教科書を読み、すべての医療スキャンを見たことがある普遍的な翻訳者を想像してください。スキャンのテキスト記述(例: 「T2強調脳MRI」)を画像内の実際の視覚パターンにマッピングすることを学習し、モデルがテキストプロンプトに基づいてスキャンがどのように見えるべきかを「理解」できるようにします。
- ゼロショット適応: これは、モデルが訓練段階で見たことのない種類のデータに対してタスクを実行する能力です。一般的な解剖学を研究した医師が、広範で基礎的な知識を応用することで、個人的に遭遇したことのないまれな病状を診断できるようなものです。
表記表
| 表記 | 説明 |
|---|---|
| $X$ | 入力医療画像 |
| $P$ | スキャンを記述する自然言語プロンプト |
| $E_I$ | 解剖学的特徴を抽出するために使用される画像エンコーダー |
| $E_T$ | 医療プロンプトを処理するために使用されるテキストエンコーダー |
| $\Theta_s$ | プロンプトから導出されるドメイン表現 |
| $G$ | 画像合成のための条件付き生成器(デコーダー) |
| $D$ | DCLIP駆動型識別器 |
| $\mathcal{L}_{DCLIP}$ | テキストと画像の埋め込みを整列させるための損失関数 |
| $\mathcal{L}_{rec}$ | ペア学習サンプルに対する再構成損失 |
| $\tau$ | 対照学習のためのスカラー温度パラメータ |
問題定義と制約
コア問題定式化とジレンマ
本論文で取り上げられているコア問題は、多ドメイン医療画像間(I2I)変換のためのスケーラブルで一般化可能なモデルの欠如です。深層学習は医療画像解析において有望であることを示していますが、その実用的な応用は「ドメインシフト」問題によって著しく妨げられています。これは、訓練データ(ソースドメイン)とテストデータ(ターゲットドメイン)が異なる分布から来る場合に発生し、しばしば異なる臨床センター間でのスキャンパラメータ、デバイス、あるいはモダリティのばらつきに起因します。
入力/現在の状態:
現在の状態は、複数のドメイン(例: T1、T2、Flair、PD、MRAなどの異なるMRIシーケンス、脳、乳房、腹部、骨盤などの異なる臓器、様々なスキャンプロトコルとパラメータ)からの多様な医療画像を含みます。これらの画像は通常、タスク固有のアーキテクチャまたは離散ドメインラベルに依存する従来の多ドメインI2Iアプローチによって処理され、ドメイン表現にはしばしばワンホットエンコーディングが使用されます。これらの手法は、スケーラビリティと一般化能力に限界があります。さらに、1対1のI2I変換モデルは、ドメイン数が増加するにつれて必要なモデルと訓練時間の「幾何学的増加」に直面し、大規模な多ドメインシナリオでは非実用的になります。既存のモデルは外部検証にも苦労し、新しい、未知のデータセットに適用されると「皮肉な性能低下」を示します。
望ましい終点(出力/目標状態):
望ましい終点は、EVA-I2Iと名付けられた、統一的で拡張可能で一般化可能なI2I変換フレームワークであり、多様なドメイン間で同時に医療画像を合成できます。このモデルは、意味的一貫性と適応性を維持しながら、多様な画像プロトコルを効果的にエンコードする必要があります。最終的な目標は、未知のドメインへの堅牢な一般化を可能にし、ファインチューニングなしで直接臨床応用を促進することです。具体的には、モデルは単一の訓練セッションで見たすべてのドメインを一度に合成し、優れた画像品質を達成し、これまで見たことのないドメインに対するゼロショットドメイン適応をサポートすることを目指します。DICOMタグ情報に基づいた意味的表現を活用して、固定されたワンホットコードの限界を超えた、柔軟でスケーラブルなドメイン指定を可能にします。
欠けているリンクまたは数学的ギャップ:
正確な欠けているリンクは、統一されたI2I変換フレームワーク内で多様な医療画像ドメインをエンコードおよび制御するための、堅牢で意味的に豊かなメカニズムです。主にワンホットエンコーディングに依存する従来の手法は、ドメイン間の微妙な意味的関係(例: 頭蓋骨のあるT2画像とないT2画像を区別する)を捉えることができません。この数学的ギャップは、モデルが多数の異種ドメインに効果的にスケーリングし、重要な解剖学的および病理学的情報を保持しながら未知のドメインに一般化することを妨げます。本論文は、DICOMタグ情報に基づいた対照言語画像事前学習(DCLIP)を導入することにより、自然言語スキャン記述と画像特徴を意味的に整列させる共通の潜在空間を作成し、それによって柔軟でスケーラブルなドメイン制御を可能にすることで、このギャップを埋めようと試みます。
痛みを伴うトレードオフまたはジレンマ:
従来の研究者を閉じ込めてきた最も痛みを伴うトレードオフは、スケーラビリティと意味的豊かさ/一般化能力との間のジレンマです。
1. スケーラビリティ対意味的豊かさ: ワンホットエンコーディングを使用する従来の手法は、少数の固定ドメインに対して実装が簡単です。しかし、それらは本質的にスケーラブルではありません。医療画像ドメイン(例: 異なるシーケンス、臓器、取得パラメータ)の数が増加すると、ワンホットエンコーディングベクトルは非現実的に長くなり、ドメイン間の意味的関係を表すことができません。例えば、2つのT2強調画像は、頭蓋骨の有無という微妙だが意味的に重要な違いのみを持つ場合がありますが、ワンホットエンコーディングでは表現できません。これにより、必要なモデルや訓練時間が「幾何学的に増加」し、多ドメインI2I変換が計算上不可能で柔軟性に欠けるものになります。
2. 統一モデル対タスク固有のパフォーマンスと一般化: すべてのドメイン間で同時に変換できる単一の「全能」モデルを開発することは、しばしば特定の、きめ細かいタスクでのパフォーマンスの犠牲を伴うか、新しい外部データセットに対する広範なファインチューニングを必要とします。制御された設定で有望な結果を示した以前のI2Iモデルは、外部検証を伴う現実の臨床シナリオに適用されると、「皮肉な性能低下」を示すことが多く、堅牢に一般化できません。これにより、研究者は、専門的で高性能だが狭いモデルか、広範で精度が低く一般化能力が低いモデルかの選択を迫られます。
制約と失敗モード
この問題は、いくつかの過酷で現実的な壁により、解決が非常に困難です。
物理的制約:
* 多様で可変なスキャンプロトコル: 医療画像は、 vast array のスキャンデバイス、メーカー、および微妙なパラメータ設定(例: フリップ角、エコー時間、繰り返し時間、脂肪抑制、造影剤)で取得されます。これらのばらつきは、顕著なドメインシフトを生み出し、データセットの統合とドメイン間での意味的一貫性の維持を困難にします。
* 解剖学的複雑性: 異なる臓器(脳、乳房、腹部、骨盤)は、大きく異なる解剖学的構造と病状を持っています。脳MRI用に設計されたモデルは、腹部MRIのより大きな解剖学的複雑性で苦労する可能性があり、合成品質の低下につながります。
* 固定画像解像度と2D処理: 提案モデルは、固定画像解像度(256x256)で訓練され、現在は2Dスライスのみを処理できます。これは、高解像度シナリオでの適用性を制限し、特にゼロショット変換タスクにおいて、複雑な3D構造を効率的に理解する能力を妨げ、スライス間の不連続性を引き起こす可能性があります。
* 欠落シーケンスと小サンプルサイズ: 実際の臨床現場では、特定のターゲットドメインに対して小サンプルサイズや欠落シーケンスに遭遇することがよくあります。このデータ疎性は、これらの特定のドメインでI2Iモデルを直接訓練することを困難にし、しばしば貧弱な結果をもたらします。
計算的制約:
* モデルアーキテクチャのスケーラビリティ: 従来の多ドメインI2Iモデルでは、生成器、エンコーダー、または識別器の数がドメイン数に対して線形または幾何学的に増加する必要があることがよくあります。これにより、計算需要と訓練時間が指数関数的に増加し、多くの多様なドメインにわたる真の「オールインワン」ソリューションとしては実行不可能になります。
* ハードウェアメモリ制限: この論文のソリューションのハードリミットとして明示的に詳述されていませんが、効率的なモデルバックボーン(ConvNeXtなど)の必要性と、GFLOPsおよび推論時間の報告は、このような大規模モデルの開発と展開において、計算リソースとメモリ容量が重要な実用的な制約であることを示唆しています。
データ駆動型制約:
* ドメインシフトとラベル付きデータの不足: 根本的な課題は、データセット間の固有のドメインシフトであり、これはしばしば異なるセンター間での取得パラメータのばらつきによって引き起こされます。これを悪化させるのは、テストセット分布の全範囲をカバーできる大量の注釈付きトレーニングデータの不足であり、堅牢なドメイン適応が必要となります。
* ワンホットエンコーディングの限界: ドメインを表すためにワンホットエンコーディングを使用する一般的な方法は、主要な制約です。ドメイン間の意味的違い(例: 頭蓋骨のあるT2画像対頭蓋骨のないT2画像)を区別できず、ドメイン数が増加すると扱いにくく、スケーラブルでなくなります。これにより、モデルは豊かで転移可能な表現を学習できなくなります。
* 外部検証パフォーマンス低下: I2Iモデルは、訓練分布の一部ではなかった外部検証データセットに適用されると、しばしばパフォーマンスの大幅な低下を示します。これにより、各新しいターゲットドメインに対して広範なファインチューニングなしで、真に堅牢で臨床的に展開可能なモデルを開発することが困難になります。
* 不整合なアウトドメインカバレッジ: 評価に使用されるアウトドメインデータセットは、インドメインデータセットと同じ臓器や画像ドメインをカバーしていない場合があります。これにより、不整合が生じ、パフォーマンスメトリックの直接的な比較が妨げられ、真の一般化能力を正確に評価することが困難になります。
* DICOMタグの可用性: DICOMタグはプロンプト生成のための豊富な情報源ですが、多くの公開データセットではDICOMファイルが提供されていません。これは、概要ファイルから関連情報を手動で収集する必要があり、これは骨の折れる、潜在的にエラーが発生しやすいプロセスです。
なぜこのアプローチなのか
選択の必然性
著者らがEVA-I2Iフレームワークに到達したのは、多ドメイン医療画像間(I2I)変換の従来の手法が根本的な「スケーラビリティの壁」にぶつかったためです。ドメイン数を増やすと、ドメインにラベルを付けるためのワンホットエンコーディングのような標準的なアプローチは失敗します。なぜなら、エンコーディング空間が硬直化し、異なる画像プロトコル間の関係を理解するために必要な意味的深みを欠くからです。著者らは、真に「全能」なモデルを達成するためには、各ドメインを孤立した離散カテゴリとして扱うのではなく、医療スキャンの基盤となる意味を捉えることができる表現が必要であると認識しました。この認識により、DICOMメタデータに特化された対照言語画像事前学習(CLIP)を採用することが、多様で異種な医療データセットを統一的で連続的な潜在空間にマッピングする唯一の実行可能な方法であると判断されました。
比較優位性
EVA-I2Iの優位性は、従来のワンホットエンコーディングやBioBERTのような整列されていないテキストエンコーダーに対するDCLIP(DICOMタグ情報付きCLIP)の使用に根ざしています。MUNITやStarGAN v.2のような以前のモデルはスタイル抽出や離散ラベルに依存していますが、EVA-I2Iは医療スキャンの自然言語記述に固有の、密で構造化された意味的情報を活用します。構造的には、これによりモデルは「意味駆動型合成」を実行できます。そこでは、生成器は疎で非意味的なラベルではなく、豊かで整列されたテキスト埋め込みによって条件付けられます。これは質的な利点をもたらします。モデルは、ワンホットエンコーディングが単に見落としたり混同したりするような微妙な画像の違い(例: 脂肪抑制対非脂肪抑制)を区別でき、構造的忠実度が大幅に向上し、未知のドメインへの一般化が改善されます。
制約との整合性
このフレームワークは、臨床医療画像の厳しい要件と、ビジョン言語モデルの柔軟性との間の正確な「結婚」です。主要な制約—多様なマルチセンターデータセットにわたるスケーラビリティの必要性とゼロショット一般化の要件—は、DCLIPアーキテクチャによって直接対処されます。DICOMタグから派生した自然言語プロンプトとスキャンをペアにすることで、著者らは推論中に明示的なドメインラベルを必要としないシステムを作成しました。これにより、モデルは記述的なプロンプトを提供するだけで「これまで見たことのない」ドメインを処理でき、医療AI展開を悩ませるタスク固有のファインチューニングの必要性を効果的に回避します。
代替案の却下
著者らは、医療画像ドメイン間の複雑で階層的な関係を捉える能力を欠いているため、ワンホットエンコーディングと整列されていないテキストエンコーダー(BioBERTなど)を明確に却下します。ワンホットエンコーディングは、本質的に拡張不可能であり、類似しているが異なるシーケンス間の意味的距離を表すことができないため却下されました。BioBERTは、テキストを理解するものの、そのテキストを医療画像の視覚的特徴と本質的に整列させないため却下されました。対照的に、DCLIPアプローチは、テキストと画像の特徴が共有された、まとまりのある空間にマッピングされることを保証します。これは、モデルがトレーニング中にその正確なドメインに遭遇したことがなくても、特定のシーケンスがどのように見えるべきかを「理解」するために不可欠です。
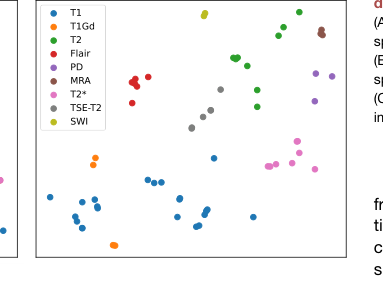 Figure 4. Visualization of prompt embed ding (A) The t-SNE visualization of prompt embedding space of BioBERT encoding. (B) The t-SNE visualization of prompt embedding space of DCLIP encoding. (C) Bar chart of zero-shot classification on medical imaging characters
Figure 4. Visualization of prompt embed ding (A) The t-SNE visualization of prompt embedding space of BioBERT encoding. (B) The t-SNE visualization of prompt embedding space of DCLIP encoding. (C) Bar chart of zero-shot classification on medical imaging characters
数学的・論理的メカニズム
マスター方程式
EVA-I2Iフレームワークのコアとなる数学的エンジンは、医療画像表現を対応するテキストプロンプトに整列させるDCLIP損失関数です。これは次のように定義されます。
$$ \mathcal{L}_{\text{DCLIP}} = - \sum_{i \in D} \left( \frac{1}{|\mathcal{M}(i, \cdot)|} \sum_{m \in \mathcal{M}(i, \cdot)} \log \frac{\exp(z_T^{(i)} \cdot z_I^{(m)} / \tau)}{\sum_{j \in D} \exp(z_T^{(i)} \cdot z_I^{(j)} / \tau)} + \frac{1}{|\mathcal{M}(\cdot, i)|} \sum_{m \in \mathcal{M}(\cdot, i)} \log \frac{\exp(z_I^{(i)} \cdot z_T^{(m)} / \tau)}{\sum_{j \in D} \exp(z_I^{(i)} \cdot z_T^{(j)} / \tau)} \right) $$
用語ごとの解剖
- $z_I$ および $z_T$: これらは、医療画像(画像エンコーダー $E_I$ を介して)およびテキストプロンプト(テキストエンコーダー $E_T$ を介して)の投影された潜在表現です。これらは、共有埋め込み空間における「意味的座標」として機能します。
- $\mathcal{M}$: これは、プロンプト $i$ が画像 $j$ に一致する場合に $\mathcal{M}_{ij} = 1$ となる混同行列(またはラベル行列)です。これは、モデルが有効なペア間の関連性のみを学習することを保証するための論理フィルターとして機能します。
- $\tau$: これはスカラー温度パラメータ(0.07に設定)です。これは確率分布の「シャープネス」を制御します。$\tau$ が小さいほど、モデルはコサイン類似度の小さな違いに敏感になり、コントラストブースターとして効果的に機能します。
- $\exp(\cdot \cdot \cdot / \tau)$: 指数関数は、ドット積(コサイン類似度)を正の値に変換し、$\tau$ による除算はロジットをスケーリングします。著者はこれを使用して、類似度スコアをSoftmaxスタイルの正規化に適した確率分布に変換します。
- 合計構造: 著者は、1つのプロンプト(例: 「T1強調脳MRI」)が複数の患者からの複数の画像に対応する場合がある医療データの「多対多」の性質を処理するために、二重合計を使用します。基数 $|\mathcal{M}|$ による除算は、損失が正規化されることを保証し、多くの関連画像を持つプロンプトが勾配更新を支配するのを防ぎます。
ステップバイステップフロー
- 入力エンコーディング: 入力画像 $X$ は、ConvNeXtベースの画像エンコーダー $E_I$ を介して $z_I$ ベクトルを生成するために渡されます。同時に、医療プロンプト $P$(DICOMタグから派生)は、12層のTransformer $E_T$ によって処理され、$z_T$ が生成されます。
- 投影: 両方のベクトルは、意味的整列が測定される共通の潜在空間に投影されます。
- 類似度計算: モデルは、$z_I$ と $z_T$ の間のドット積を計算します。プロンプトと画像が一致する場合、ドット積は最大化されます。
- 対照正規化: Softmaxライクな分母は、バッチ内の他のすべてのサンプルに対して合計され、モデルが非一致ペアを埋め込み空間で引き離し、一致ペアを引き寄せるように強制します。
- 合成: 整列されると、DCLIPエンコーディング $T$ は条件付きデコーダー $G$(動的畳み込みを使用)に供給され、入力構造 $\Phi$ のターゲットドメインへの変換をガイドします。
最適化ダイナミクス
モデルは2段階のプロセスを通じて学習します。初期段階では、再構成誤差を最小化するために被験者内監視を使用します。ファインチューニング段階では、クロスデータセット共同学習を組み込みます。損失ランドスケープは、生成器にDCLIP駆動型識別器 $D$ が実際のデータと区別できないリアルな画像を生成するように強制する敵対的損失 $\mathcal{L}_{\text{adv}}$ によって形成されます。勾配はDCLIP損失からエンコーダーに逆流し、潜在空間を効果的に「彫刻」して、類似した医療プロトコルが一緒にクラスター化されるようにします。これにより、モデルが新しい、未知のドメインに遭遇した場合でも、プロンプトをすでに意味的に一貫した潜在空間の領域にマッピングでき、ゼロショット一般化が可能になります。$\mathcal{L}_{\text{con}}$ および $\mathcal{L}_{\text{tri}}$ の使用は正則化器として機能し、モデルが自明な解に崩壊するのを防ぎ、変換プロセス中に解剖学的構造の構造的完全性が維持されることを保証します。
結果、限界、結論
実験設計とベースライン
EVA-I2Iフレームワークの有効性を検証するために、著者らは脳、乳房、腹部、骨盤ドメインにわたる27,950の3D医療スキャンを含む7つの公開データセットを使用して、包括的な一連の実験を実施しました。実験設計は、単一の訓練セッションで多ドメイン画像間(I2I)変換を実行するモデルの能力をテストするように構造化されていました。
「犠牲者」(ベースラインモデル)として、MUNIT、StarGAN v2、Chenら、およびSeq2Seqを含む確立されたアーキテクチャが選択されました。これらのベースラインは、多ドメインI2I変換における最先端技術を表しているため選択されました。著者らは、すべてのモデルを同じインドメイン訓練コホートで訓練することにより、公正な比較を保証しました。DCLIP駆動アプローチの優位性を証明するために、ワンホットエンコーディングとBioBERTに対するDCLIPの比較、および異なるバックボーン(ResNet、Swin-Transformer、および提案されたConvNeXt)の評価を含むアブレーションスタディを実施しました。評価指標には、ピクセルレベルの忠実度と知覚品質の両方を定量化するために、ピーク信号対雑音比(PSNR)、構造的類似性指数測定(SSIM)、および学習された知覚画像パッチ類似性(LPIPS)が含まれていました。
証拠が証明すること
論文で提供された証拠は非常に説得力があります。定量的結果(表1)は、EVA-I2Iがインドメインとアウトドメインの両方のデータセットでベースラインモデルを一貫して上回っていることを示しています。具体的には、EVA-I2Iは競合他社と比較して、大幅に優れた合成パフォーマンス(PSNRおよびLPIPSで$p < 0.05$)を達成しました。
著者らは、次のことにより、モデルの堅牢性の否定できない証拠を提供しました。
1. ゼロショット一般化: モデルは、ファインチューニングを必要とせずに、これまで見たことのないドメイン(例: DCEウォッシュインからT1)からの画像の変換に成功しました。これは、構造的詳細においてStarGAN v.2を上回りました。
2. 下流タスクの改善: モデルは、脳MRI登録、前庭神経鞘腫セグメンテーション、および乳がんpCR予測に適用されました。すべての場合において、EVA-I2Iは、他のドメイン適応手法と比較して、下流モデル(例: VoxelMorph、nnU-Net)のパフォーマンスを大幅に向上させました。
3. 意味的整列: t-SNE可視化(図4)は、DCLIPエンコーディングがBioBERTよりも一貫した特徴クラスターを作成することを明確に示しており、モデルが複雑なドメイン意味を効果的に捉えていることを証明しています。結果は、モデルが単に画像を「記憶」しているのではなく、医療画像プロトコルの構造化された意味的表現を実際に学習していることを示唆しています。
限界と将来の方向性
モデルは現在2Dスライス処理に限定されており、3Dボリュームを再構築する際にスライス間の不連続性を引き起こす可能性があります。第二に、トレーニング中に使用される固定画像解像度は、高解像度の臨床シナリオでのモデルのパフォーマンスを制限します。最後に、検証に使用されるアウトドメインデータセットは、インドメイントレーニングセットと同じ臓器や画像ドメインを完全にカバーしていないため、パフォーマンスメトリックに不整合が生じる可能性があります。
将来に向けて、いくつかのエキサイティングな進化の方向性があると思います。
* 3Dボリューム統合: アーキテクチャを拡張して3Dボリュームを直接処理できるようにすると、スライス間の不整合の問題が解決され、臨床的有用性が向上する可能性があります。
* 基盤モデルのスケーリング: DCLIPの成功を考えると、さらに大規模で多様なデータセットへのスケーリングを検討し、真に「普遍的な」医療画像変換基盤モデルに向かう可能性があります。
* 説明可能性: プロンプトは一種の制御を提供しますが、モデルが特定のDICOMタグに注意を払う「理由」に関するさらなる研究は、AIの「ブラックボックス」をより透明にし、臨床医に合成結果に対するより大きな信頼を提供する可能性があります。
これらの発見は、単一の一般化可能なモデルが医療画像の広大な異種性を処理できるようになり、骨の折れるタスク固有のファインチューニングの必要性が軽減される未来に向かっていることを示唆しています。
 Table 2. illustrates the quantitative results of the ablation study on domain encoding, model backbone, and training loss function. We compare three domain encodings to equip our EVA-I2I, including one hot,12 BioBERT,35 and DCLIP (proposed). BioBERT encoding can extract semantic information from medical prompts, leading to better synthesis results than one- hot encoding, and our proposed DCLIP encoding aligns text and images, making its synthesis performance significantly (p < 0:05 for PNSR and LPIPS) better than BioBERT encoding, which cannot align text and images. We also compare three model backbones of the structure encoder EΦ in EVA-I2I, including ResNet,36 Swin-Transformer,37 and ConvNeXt (pro posed). The ConvNeXt backbone slightly outperforms other methods. Moreover, we also evaluate the effectiveness of cross-dataset collaborative learning. Results show that the model trained with Lfine significantly (p < 0:05 for PNSR and LPIPS) outperforms the model only trained with Linit
Table 2. illustrates the quantitative results of the ablation study on domain encoding, model backbone, and training loss function. We compare three domain encodings to equip our EVA-I2I, including one hot,12 BioBERT,35 and DCLIP (proposed). BioBERT encoding can extract semantic information from medical prompts, leading to better synthesis results than one- hot encoding, and our proposed DCLIP encoding aligns text and images, making its synthesis performance significantly (p < 0:05 for PNSR and LPIPS) better than BioBERT encoding, which cannot align text and images. We also compare three model backbones of the structure encoder EΦ in EVA-I2I, including ResNet,36 Swin-Transformer,37 and ConvNeXt (pro posed). The ConvNeXt backbone slightly outperforms other methods. Moreover, we also evaluate the effectiveness of cross-dataset collaborative learning. Results show that the model trained with Lfine significantly (p < 0:05 for PNSR and LPIPS) outperforms the model only trained with Linit
 Table 1. The quantitative results of image translation for different comparisons on in- and out-domain datasets
Table 1. The quantitative results of image translation for different comparisons on in- and out-domain datasets
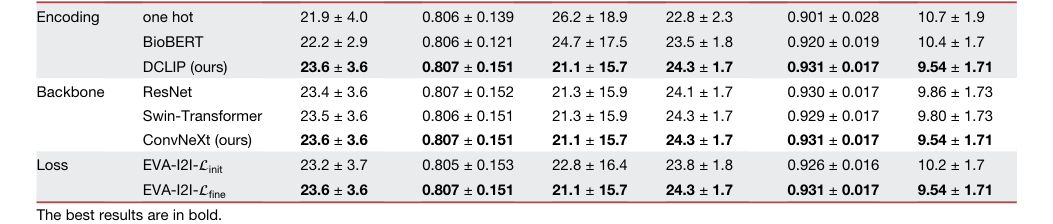 Table 2. The quantitative results of ablation study for EVA-I2I on domain encoding, model backbone, and training loss function
Table 2. The quantitative results of ablation study for EVA-I2I on domain encoding, model backbone, and training loss function