올인원 의료 영상-영상 변환
Unifies translation, offers semantic control, and works without fine-tuning.
배경 및 학술적 계보
기원 및 학술적 계보
의료 영상-영상(I2I) 변환 문제는 이질적인 의료 영상 데이터를 통합해야 하는 근본적인 필요성에서 비롯되었다. 임상에서는 다양한 스캔 프로토콜, 하드웨어, 매개변수 설정으로 영상을 획득하기 때문에, 한 센터의 데이터 통계 분포가 다른 센터와 다른 "도메인 시프트(domain shift)"를 야기한다. 역사적으로 특정 데이터셋에 대해 훈련된 딥러닝 모델은 다른 출처의 데이터에 적용될 때 일반화에 실패하는 경우가 많았다.
이 문제에 대한 이전 접근 방식은 일반적으로 영상 도메인을 구분하기 위해 작업별 아키텍처 또는 이산 레이블(원-핫 인코딩과 같은)에 의존했다. 이러한 방법들은 확장성 부족이라는 치명적인 "고통점(pain point)"을 가지고 있다. 도메인 수가 증가함에 따라 이러한 이산 레이블을 관리하는 복잡성이 증가하며, 모델은 서로 다른 영상 시퀀스 간의 미묘하고 연속적인 의미론적 관계를 포착하는 데 어려움을 겪는다. 또한, 많은 기존 모델은 추론 시 타겟 도메인 스타일 정보를 필요로 하므로, 이러한 정보가 종종 이용 불가능한 실제 임상 환경에는 부적합하다. 본 논문의 저자들은 이러한 문제를 해결하기 위해 엄격하고 이산적인 레이블에서 벗어나 자연어를 활용하여 영상 프로토콜을 설명하는 유연한 프롬프트 기반 프레임워크를 채택함으로써, 보다 강력하고 일반화 가능한 "올인원(all-in-one)" 변환 모델을 구현한다.
직관적인 도메인 용어
- 도메인 시프트(Domain Shift): 자신이 배운 방언과 약간 다른 방언으로 쓰인 책을 읽으려고 하는 상황을 상상해보라. 전체적인 내용은 이해할 수 있지만, 미묘한 뉘앙스는 놓칠 수 있다. 의료 영상에서 이는 "A 병원의" MRI 설정으로 훈련된 모델이 "B 병원의" 영상의 대비나 밝기 수준이 약간 다르기 때문에 이를 해석하는 데 어려움을 겪는 경우를 말한다.
- 원-핫 인코딩(One-Hot Encoding): 모든 가능한 범주에 대해 고유하고 독립적인 상자(예: T1의 경우 "0001", T2의 경우 "0010")를 부여하는 엄격한 파일링 시스템으로 생각할 수 있다. 몇 개의 항목에는 작동하지만, 수백 개의 범주가 있다면 관리 불가능해지며, T1과 T1-조영 증강 영상이 실제로 관련되어 있다는 것을 보여주지 못한다.
- 대조 언어-영상 사전훈련(Contrastive Language-Image Pre-training, CLIP): 모든 의학 교과서를 읽고 모든 의료 스캔을 본 보편적인 번역가를 상상해보라. 이는 스캔의 텍스트 설명(예: "T2 강조 뇌 MRI")을 영상의 실제 시각적 패턴에 매핑하는 것을 학습하여, 텍스트 프롬프트에 따라 모델이 스캔이 어떻게 보여야 하는지를 "이해"할 수 있게 한다.
- 제로샷 적응(Zero-Shot Adaptation): 훈련 단계에서 본 적 없는 유형의 데이터에 대해 작업을 수행하는 모델의 능력이다. 이는 일반 해부학을 공부한 의사가 광범위하고 기초적인 지식을 적용하여 개인적으로 접한 적 없는 희귀 질환을 성공적으로 진단하는 것과 같다.
표기법 테이블
| 표기법 | 설명 |
|---|---|
| $X$ | 입력 의료 영상 |
| $P$ | 스캔을 설명하는 자연어 프롬프트 |
| $E_I$ | 해부학적 특징을 추출하는 데 사용되는 영상 인코더 |
| $E_T$ | 의료 프롬프트를 처리하는 데 사용되는 텍스트 인코더 |
| $\Theta_s$ | 프롬프트에서 파생된 도메인 표현 |
| $G$ | 영상 합성을 위한 조건부 생성기 (디코더) |
| $D$ | DCLIP 기반 판별자 |
| $\mathcal{L}_{DCLIP}$ | 텍스트 및 영상 임베딩 정렬을 위한 손실 함수 |
| $\mathcal{L}_{rec}$ | 쌍으로 된 훈련 샘플에 대한 재구성 손실 |
| $\tau$ | 대조 학습을 위한 스칼라 온도 매개변수 |
문제 정의 및 제약 조건
핵심 문제 공식화 및 딜레마
본 논문에서 다루는 핵심 문제는 다중 도메인 의료 영상-영상(I2I) 변환을 위한 확장 가능하고 일반화 가능한 모델의 부족이다. 딥러닝은 의료 영상 분석에서 가능성을 보여주었지만, "도메인 시프트" 문제로 인해 실제 적용이 심각하게 방해받고 있다. 이는 훈련 데이터(소스 도메인)와 테스트 데이터(타겟 도메인)가 서로 다른 분포에서 오기 때문에 발생하며, 종종 임상 센터 간의 스캔 매개변수, 장치 또는 심지어 모달리티의 변형으로 인해 발생한다.
입력/현재 상태:
현재 상태는 여러 도메인(예: T1, T2, Flair, PD, MRA와 같은 다른 MRI 시퀀스; 뇌, 유방, 복부, 골반과 같은 다른 장기; 다양한 스캔 프로토콜 및 매개변수)의 다양한 의료 영상을 포함한다. 이러한 영상은 일반적으로 작업별 아키텍처 또는 이산 도메인 레이블에 의존하는 기존의 다중 도메인 I2I 접근 방식으로 처리되며, 도메인 표현을 위해 종종 원-핫 인코딩을 사용한다. 이러한 방법들은 확장성 및 일반화 능력에 한계가 있다. 또한, 일대일 I2I 변환 모델은 도메인 수가 증가함에 따라 필요한 모델 및 훈련 시간의 "기하급수적 증가"에 직면하여 대규모 다중 도메인 시나리오에 비실용적이다. 기존 모델들은 또한 외부 검증에 어려움을 겪으며, 새로운, 보지 못한 데이터셋에 적용될 때 "냉소적인 성능 저하"를 보인다.
원하는 최종 상태 (출력/목표 상태):
원하는 최종 상태는 다양한 도메인에 걸쳐 의료 영상을 동시에 합성할 수 있는 통합적이고 확장 가능하며 일반화 가능한 I2I 변환 프레임워크인 EVA-I2I이다. 이 모델은 의미론적 일관성과 적응성을 유지하면서 다양한 영상 프로토콜을 효과적으로 인코딩해야 한다. 궁극적인 목표는 보지 못한 도메인에 대한 강력한 일반화를 가능하게 하고, 미세 조정 없이 직접적인 임상 적용을 촉진하는 것이다. 구체적으로, 모델은 단일 훈련 세션으로 모든 본 도메인을 한 번에 합성하고, 우수한 영상 품질을 달성하며, 보지 못한 도메인에 대한 제로샷 도메인 적응을 지원하는 것을 목표로 한다. 고정된 원-핫 코드의 한계를 넘어 유연하고 확장 가능한 도메인 사양을 허용하기 위해 DICOM 태그 기반 의미론적 표현을 활용한다.
누락된 연결 또는 수학적 격차:
정확한 누락된 연결은 통합 I2I 변환 프레임워크 내에서 다양한 의료 영상 도메인을 인코딩하고 제어하기 위한 강력하고 의미론적으로 풍부한 메커니즘이다. 주로 원-핫 인코딩에 의존하는 이전 방법들은 도메인 간의 미묘한 의미론적 관계(예: 두개골이 있는 T2 영상과 없는 T2 영상 구분)를 포착하지 못한다. 이 수학적 격차는 모델이 이질적인 도메인의 대규모로 효과적으로 확장하고 중요한 해부학적 및 병리학적 정보를 보존하면서 보지 못한 도메인으로 일반화하는 것을 방지한다. 본 논문은 DICOM 태그 기반 대조 언어-영상 사전훈련(DCLIP)을 도입하여 자연어 스캔 설명과 영상 특징을 의미론적으로 정렬하는 공통 잠재 공간을 생성함으로써, 유연하고 확장 가능한 도메인 제어를 가능하게 하여 이 격차를 해소하려고 시도한다.
고통스러운 절충 또는 딜레마:
이전 연구자들을 가두었던 가장 고통스러운 절충은 확장성과 의미론적 풍부함/일반화 간의 딜레마이다.
1. 확장성 대 의미론적 풍부함: 원-핫 인코딩을 사용하는 전통적인 방법은 소수의 고정된 도메인에 대해 구현하기 쉽다. 그러나 이는 본질적으로 확장 불가능하다. 의료 영상 도메인(예: 다른 시퀀스, 장기, 획득 매개변수)의 수가 증가함에 따라 원-핫 인코딩 벡터는 비실용적으로 길어지고, 도메인 간의 의미론적 관계를 포착하지 못한다. 예를 들어, 두 개의 T2 강조 영상은 두개골의 존재 또는 부재라는 미묘하지만 의미론적으로 중요한 차이만 있을 수 있으며, 이는 원-핫 인코딩으로는 표현할 수 없다. 이는 필요한 모델 또는 훈련 시간의 "기하급수적 증가"로 이어져 다중 도메인 I2I 변환을 계산적으로 비싸고 비유연하게 만든다.
2. 통합 모델 대 작업별 성능 및 일반화: 모든 도메인에 걸쳐 동시에 번역할 수 있는 단일 "전능한" 모델을 개발하는 것은 종종 특정, 세분화된 작업에 대한 성능을 희생시키거나 새로운 외부 데이터셋에 대한 광범위한 미세 조정을 필요로 한다. 통제된 환경에서 유망한 결과를 보여준 이전 I2I 모델들은 실제 임상 시나리오에 외부 검증과 함께 배포될 때 종종 "냉소적인 성능 저하"를 보여, 강력하게 일반화하지 못한다. 이는 연구자들이 전문적이고 고성능이지만 좁은 모델, 또는 광범위하지만 덜 정확하고 일반화 능력이 떨어지는 모델 중에서 선택하도록 강요한다.
제약 조건 및 실패 모드
이 문제는 다음과 같은 몇 가지 가혹하고 현실적인 벽 때문에 해결하기가 매우 어렵다.
물리적 제약 조건:
* 다양하고 가변적인 스캔 프로토콜: 의료 영상은 방대한 종류의 스캔 장치, 제조업체 및 미묘한 매개변수 설정(예: 플립 각도, 에코 시간, 반복 시간, 지방 억제, 조영제)으로 획득된다. 이러한 변형은 상당한 도메인 시프트를 야기하며, 데이터셋을 통합하고 도메인 간의 의미론적 일관성을 유지하는 것을 어렵게 만든다.
* 해부학적 복잡성: 다른 장기(뇌, 유방, 복부, 골반)는 매우 다른 해부학적 구조와 병리를 가지고 있다. 뇌 MRI를 위해 설계된 모델은 복부 MRI의 더 큰 해부학적 복잡성에 어려움을 겪을 수 있으며, 이는 합성 품질 저하로 이어진다.
* 고정된 영상 해상도 및 2D 처리: 제안된 모델은 고정된 영상 해상도(256x256)로 훈련되며 현재 2D 슬라이스만 처리할 수 있다. 이는 고해상도 시나리오에서의 적용 가능성을 제한하고 복잡한 3D 구조를 효율적으로 이해하는 능력을 저해하며, 특히 제로샷 변환 작업에서 슬라이스 간 불연속성을 야기할 수 있다.
* 누락된 시퀀스 및 소규모 샘플 크기: 실제 임상 환경에서는 특정 타겟 도메인에 대한 소규모 샘플 크기 또는 누락된 시퀀스를 접하는 것이 일반적이다. 이러한 데이터 희소성은 이러한 특정 도메인에 대한 I2I 모델의 직접적인 훈련을 어렵게 만들고 종종 열악한 결과를 초래한다.
계산적 제약 조건:
* 모델 아키텍처의 확장성: 전통적인 다중 도메인 I2I 모델은 종종 생성기, 인코더 또는 판별자의 수가 도메인 수에 따라 선형 또는 기하급수적으로 증가해야 한다. 이는 계산 요구 사항 및 훈련 시간을 기하급수적으로 증가시켜, 수많은 다양한 도메인에 걸친 진정한 "올인원" 솔루션에 비실용적으로 만든다.
* 하드웨어 메모리 한계: 이 논문의 솔루션에 대한 명시적인 하드 한계로 자세히 설명되지는 않았지만, 효율적인 모델 백본(예: ConvNeXt)의 필요성과 GFLOPs 및 추론 시간 보고는 이러한 대규모 모델을 개발하고 배포하는 데 있어 계산 리소스와 메모리 용량이 중요한 실제 제약 조건임을 시사한다.
데이터 기반 제약 조건:
* 도메인 시프트 및 레이블링된 데이터 부족: 근본적인 과제는 서로 다른 센터 간의 획득 매개변수 변형으로 인해 발생하는 데이터셋 간의 내재적 도메인 시프트이다. 이를 더욱 복잡하게 만드는 것은 테스트 세트 분포의 전체 스펙트럼을 다룰 수 있는 대규모 주석이 달린 훈련 데이터의 부족이며, 이는 강력한 도메인 적응을 필요로 한다.
* 원-핫 인코딩의 한계: 도메인을 표현하기 위해 원-핫 인코딩을 사용하는 일반적인 방법은 주요 제약 조건이다. 이는 도메인 간의 의미론적 차이(예: 두개골이 있는 T2 영상 대 두개골이 없는 T2 영상)를 구별할 수 없으며, 도메인 수가 확장됨에 따라 다루기 어렵고 확장 불가능해진다. 이는 모델이 풍부하고 전이 가능한 표현을 학습하는 것을 방지한다.
* 외부 검증 성능 저하: I2I 모델은 훈련 분포에 포함되지 않은 외부 검증 데이터셋에 적용될 때 종종 상당한 성능 저하를 보인다. 이는 각 새로운 타겟 도메인에 대한 광범위한 미세 조정 없이 진정으로 강력하고 임상적으로 배포 가능한 모델을 개발하기 어렵게 만든다.
* 불일치하는 외부 도메인 커버리지: 평가에 사용된 외부 도메인 데이터셋은 내부 도메인 데이터셋과 동일한 장기 또는 영상 도메인을 다루지 않을 수 있다. 이는 불일치를 야기하고 직접적인 성능 지표 비교를 방해하여 진정한 일반화 능력을 정확하게 평가하기 어렵게 만든다.
* DICOM 태그 가용성: DICOM 태그는 프롬프트 생성을 위한 풍부한 정보원이지만, 많은 공개 데이터셋의 경우 DICOM 파일이 제공되지 않는다. 이는 요약 파일에서 관련 정보를 수동으로 수집해야 하므로 노동 집약적이고 잠재적으로 오류가 발생하기 쉬운 프로세스이다.
왜 이 접근 방식인가
선택의 불가피성
저자들은 다중 도메인 의료 영상-영상(I2I) 변환에 대한 전통적인 방법이 근본적인 "확장성 벽"에 부딪혔기 때문에 EVA-I2I 프레임워크에 도달했다. 도메인 수를 늘릴 때 도메인을 레이블링하기 위한 원-핫 인코딩과 같은 표준 접근 방식은 인코딩 공간이 경직되고 다양한 영상 프로토콜 간의 관계를 이해하는 데 필요한 의미론적 깊이가 부족하기 때문에 실패한다. 저자들은 진정한 "전능한" 모델을 달성하기 위해서는 각 도메인을 독립적이고 이산적인 범주로 취급하는 대신 의료 스캔의 근본적인 의미론을 포착할 수 있는 표현이 필요하다는 것을 깨달았다. 이러한 깨달음은 다양한 이질적인 의료 데이터셋을 통합된 연속적인 잠재 공간으로 매핑하는 유일한 실행 가능한 방법으로, DICOM 메타데이터에 맞게 특별히 조정된 대조 언어-영상 사전훈련(CLIP)의 채택으로 이어졌다.
비교 우위
EVA-I2I의 우수성은 전통적인 원-핫 또는 정렬되지 않은 텍스트 인코더(예: BioBERT)에 비해 DCLIP(DICOM 태그 기반 CLIP)을 사용한다는 점에 뿌리를 두고 있다. MUNIT 또는 StarGAN v.2와 같은 이전 모델은 스타일 추출 또는 이산 레이블에 의존하는 반면, EVA-I2I는 의료 스캔의 자연어 설명에 내재된 밀집되고 구조화된 의미론적 정보를 활용한다. 구조적으로, 이는 모델이 희소하고 비의미론적인 레이블이 아닌 풍부하고 정렬된 텍스트 임베딩에 의해 조건화되는 "의미론적 기반 합성"을 수행할 수 있게 한다. 이는 질적인 이점을 제공한다. 모델은 원-핫 인코딩이 단순히 놓치거나 혼동할 미묘한 영상 차이(예: 지방 억제 대 비지방 억제)를 구별할 수 있어, 구조적 충실도가 크게 향상되고 보지 못한 도메인으로의 일반화가 향상된다.
제약 조건과의 일치
이 프레임워크는 임상 의료 영상의 가혹한 요구 사항과 비전-언어 모델의 유연성 간의 정밀한 "결합"이다. 주요 제약 조건인 다양한 다중 센터 데이터셋에 걸친 확장성 요구 사항과 제로샷 일반화 요구 사항은 DCLIP 아키텍처에 의해 직접적으로 해결된다. DICOM 태그에서 파생된 자연어 프롬프트와 스캔을 쌍으로 만듦으로써, 저자들은 추론 시 명시적인 도메인 레이블을 필요로 하지 않는 시스템을 만들었다. 이를 통해 모델은 설명적인 프롬프트를 제공함으로써 "이전에 본 적 없는" 도메인을 처리할 수 있으며, 이는 의료 AI 배포를 괴롭히는 비용이 많이 드는 작업별 미세 조정의 필요성을 효과적으로 우회한다.
대안의 거부
저자들은 의료 영상 도메인 간의 복잡하고 계층적인 관계를 포착할 능력이 부족하기 때문에 원-핫 인코딩과 정렬되지 않은 텍스트 인코더(예: BioBERT)를 명시적으로 거부한다. 원-핫 인코딩은 본질적으로 확장 불가능하고 유사하지만 구별되는 시퀀스 간의 의미론적 거리를 표현하지 못하기 때문에 거부되었다. BioBERT는 텍스트를 이해하지만, 그 텍스트를 의료 영상의 시각적 특징과 본질적으로 정렬하지 않기 때문에 거부되었다. 대조적으로, DCLIP 접근 방식은 텍스트와 영상 특징이 공유되고 응집력 있는 공간으로 매핑되도록 보장하며, 이는 모델이 훈련 중에 해당 특정 도메인을 전혀 접하지 않았더라도 특정 시퀀스가 어떻게 보여야 하는지를 "이해"하는 데 필수적이다.
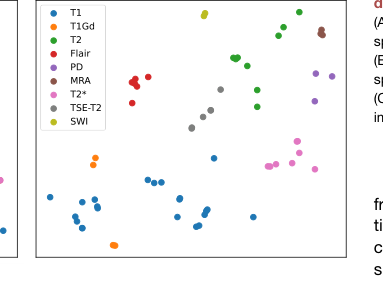 Figure 4. Visualization of prompt embed ding (A) The t-SNE visualization of prompt embedding space of BioBERT encoding. (B) The t-SNE visualization of prompt embedding space of DCLIP encoding. (C) Bar chart of zero-shot classification on medical imaging characters
Figure 4. Visualization of prompt embed ding (A) The t-SNE visualization of prompt embedding space of BioBERT encoding. (B) The t-SNE visualization of prompt embedding space of DCLIP encoding. (C) Bar chart of zero-shot classification on medical imaging characters
수학적 및 논리적 메커니즘
마스터 방정식
EVA-I2I 프레임워크의 핵심 수학적 엔진은 의료 영상 표현을 해당 텍스트 프롬프트와 정렬하는 DCLIP 손실 함수이다. 이는 다음과 같이 정의된다.
$$ \mathcal{L}_{\text{DCLIP}} = - \sum_{i \in D} \left( \frac{1}{|\mathcal{M}(i, \cdot)|} \sum_{m \in \mathcal{M}(i, \cdot)} \log \frac{\exp(z_T^{(i)} \cdot z_I^{(m)} / \tau)}{\sum_{j \in D} \exp(z_T^{(i)} \cdot z_I^{(j)} / \tau)} + \frac{1}{|\mathcal{M}(\cdot, i)|} \sum_{m \in \mathcal{M}(\cdot, i)} \log \frac{\exp(z_I^{(i)} \cdot z_T^{(m)} / \tau)}{\sum_{j \in D} \exp(z_I^{(i)} \cdot z_T^{(j)} / \tau)} \right) $$
항별 분석
- $z_I$ 및 $z_T$: 이들은 영상 인코더 $E_I$를 통한 의료 영상의 투영된 잠재 표현과 텍스트 인코더 $E_T$를 통한 텍스트 프롬프트의 투영된 잠재 표현이다. 이들은 공유 임베딩 공간에서 "의미론적 좌표" 역할을 한다.
- $\mathcal{M}$: 이는 프롬프트 $i$가 영상 $j$와 일치하는 경우 $\mathcal{M}_{ij} = 1$인 혼동 행렬(또는 레이블 행렬)이다. 이는 모델이 유효한 쌍 간의 연관성만 학습하도록 보장하는 논리적 필터 역할을 한다.
- $\tau$: 이는 스칼라 온도 매개변수(0.07로 설정됨)이다. 이는 확률 분포의 "날카로움"을 제어한다. 더 작은 $\tau$는 모델을 코사인 유사도의 작은 차이에 더 민감하게 만들어, 대조 증폭기 역할을 한다.
- $\exp(\cdot \cdot \cdot / \tau)$: 지수 함수는 점곱(코사인 유사도)을 양수 값으로 변환하는 반면, $\tau$로 나누는 것은 로짓을 스케일링한다. 저자는 이를 사용하여 유사도 점수를 Softmax 스타일 정규화에 적합한 확률 분포로 변환한다.
- 합산 구조: 저자는 의료 데이터의 "다대다" 특성을 처리하기 위해 이중 합산을 사용한다. 여기서 하나의 프롬프트(예: "T1 강조 뇌 MRI")는 다른 환자의 여러 영상에 해당할 수 있다. 기수 $|\mathcal{M}|$로 나누는 것은 손실이 정규화되도록 보장하여, 많은 관련 영상이 있는 프롬프트가 기울기 업데이트를 지배하는 것을 방지한다.
단계별 흐름
- 입력 인코딩: 입력 영상 $X$는 ConvNeXt 기반 영상 인코더 $E_I$를 통과하여 벡터 $z_I$를 생성한다. 동시에, 의료 프롬프트 $P$(DICOM 태그에서 파생됨)는 12개 레이어 트랜스포머 $E_T$에 의해 처리되어 $z_T$를 생성한다.
- 투영: 두 벡터 모두 의미론적 정렬이 측정되는 공통 잠재 공간으로 투영된다.
- 유사도 계산: 모델은 $z_I$와 $z_T$ 간의 점곱을 계산한다. 프롬프트와 영상이 일치하면 점곱이 최대화된다.
- 대조 정규화: Softmax와 유사한 분모는 배치 내의 다른 모든 샘플에 대해 합산되어, 모델이 일치하지 않는 쌍을 임베딩 공간에서 멀리 밀어내고 일치하는 쌍을 함께 끌어당기도록 강제한다.
- 합성: 정렬된 후, DCLIP 인코딩 $T$는 조건부 디코더 $G$(동적 컨볼루션 사용)에 공급되어 입력 구조 $\Phi$를 타겟 도메인으로 변환하도록 안내한다.
최적화 역학
모델은 2단계 프로세스를 통해 학습된다. 초기 단계에서는 내부 피험자 감독을 사용하여 재구성 오류를 최소화한다. 미세 조정 단계에서는 교차 데이터셋 협업 학습을 통합한다. 손실 지형은 생성기가 DCLIP 기반 판별자 $D$가 실제 데이터와 구별할 수 없는 사실적인 영상을 생성하도록 강제하는 적대적 손실 $\mathcal{L}_{\text{adv}}$에 의해 형성된다. 기울기는 DCLIP 손실에서 인코더를 통해 역전파되어, 잠재 공간을 효과적으로 "조각"하여 유사한 의료 프로토콜이 함께 클러스터링되도록 한다. 이는 모델이 새로운, 보지 못한 도메인을 접했을 때 프롬프트를 이미 의미론적으로 일관된 잠재 공간의 영역으로 매핑할 수 있도록 보장하여 제로샷 일반화를 가능하게 한다. $\mathcal{L}_{\text{con}}$ 및 $\mathcal{L}_{\text{tri}}$의 사용은 모델이 사소한 해결책으로 붕괴되는 것을 방지하고 변환 과정 중에 해부학의 구조적 무결성이 보존되도록 보장하는 정규화기로 작용한다.
결과, 한계 및 결론
실험 설계 및 기준선
EVA-I2I 프레임워크의 효율성을 검증하기 위해, 저자들은 뇌, 유방, 복부 및 골반 도메인에 걸쳐 27,950개의 3D 의료 스캔을 포함하는 7개의 공개 데이터셋을 사용하여 포괄적인 실험 세트를 수행했다. 실험 설계는 모델이 단일 훈련 세션에서 다중 도메인 영상-영상(I2I) 변환을 수행하는 능력을 테스트하도록 구성되었다.
비교를 위해 선택된 "희생자"(기준선 모델)에는 MUNIT, StarGAN v.2, Chen et al., 및 Seq2Seq와 같은 확립된 아키텍처가 포함되었다. 이러한 기준선은 다중 도메인 I2I 변환 분야의 최신 기술을 대표하기 때문에 선택되었다. 저자들은 모든 모델을 동일한 내부 도메인 훈련 코호트에서 훈련하여 공정한 비교를 보장했다. DCLIP 기반 접근 방식의 우수성을 입증하기 위해 원-핫 인코딩 및 BioBERT와 비교하는 축소 실험을 수행했으며, 다양한 백본(ResNet, Swin-Transformer 및 제안된 ConvNeXt)을 평가했다. 평가 지표에는 픽셀 수준 충실도와 지각 품질을 모두 정량화하기 위해 Peak Signal-to-Noise Ratio (PSNR), Structural Similarity Index Measure (SSIM), 및 Learned Perceptual Image Patch Similarity (LPIPS)가 포함되었다.
증거가 증명하는 것
본 논문에서 제공된 증거는 상당히 설득력이 있다. 정량적 결과(표 1)는 EVA-I2I가 내부 도메인 및 외부 도메인 데이터셋 모두에서 기준선 모델보다 일관되게 우수함을 보여준다. 특히, EVA-I2I는 경쟁사보다 훨씬 더 나은 합성 성능($p < 0.05$ for PSNR and LPIPS)을 달성했다.
저자들은 다음을 통해 모델의 견고성에 대한 부인할 수 없는 증거를 제공했다.
1. 제로샷 일반화: 모델은 미세 조정 없이 이전에 본 적 없는 도메인(예: 와시인 DCE에서 T1로)의 영상을 성공적으로 변환했으며, 이는 구조적 세부 사항에서 StarGAN v.2를 능가했다.
2. 다운스트림 작업 개선: 모델은 뇌 MRI 등록, 전정 신경초종 분할 및 유방암 pCR 예측에 적용되었다. 모든 경우에 EVA-I2I는 다른 도메인 적응 방법과 비교하여 EVA-I2I가 다운스트림 모델(예: VoxelMorph, nnU-Net)의 성능을 크게 향상시켰다.
3. 의미론적 정렬: t-SNE 시각화(그림 4)는 DCLIP 인코딩이 BioBERT보다 더 응집력 있는 특징 클러스터를 생성하여 모델이 복잡한 도메인 의미론을 효과적으로 포착함을 증명한다. 결과는 모델이 단순히 영상을 "암기"하는 것이 아니라 의료 영상 프로토콜의 구조화된 의미론적 표현을 실제로 학습하고 있음을 시사한다.
한계 및 향후 방향
모델은 현재 2D 슬라이스 처리에 국한되어 있어 3D 볼륨을 재구성할 때 슬라이스 간 불연속성을 야기할 수 있다. 둘째, 훈련 중에 사용된 고정된 영상 해상도는 고해상도 임상 시나리오에서 모델의 성능을 제한한다. 마지막으로, 평가에 사용된 외부 도메인 데이터셋은 내부 훈련 세트와 동일한 장기 또는 영상 도메인을 완전히 다루지 않아 성능 지표의 불일치를 야기할 수 있다.
앞으로 몇 가지 흥미로운 발전 방향이 있을 것으로 생각된다.
* 3D 볼륨 통합: 아키텍처를 3D 볼륨을 직접 처리하도록 확장하면 슬라이스 간 불일치 문제를 해결하고 임상 유용성을 향상시킬 수 있다.
* 기초 모델 스케일링: DCLIP의 성공을 고려할 때, 이를 훨씬 더 크고 다양한 데이터셋으로 확장하여 진정한 "보편적인" 의료 영상 변환 기초 모델로 나아갈 수 있다.
* 설명 가능성: 프롬프트가 제어의 한 형태를 제공하지만, 모델이 특정 DICOM 태그에 주의를 기울이는 이유에 대한 추가 연구는 AI의 "블랙박스"를 더 투명하게 만들어 임상의에게 합성 결과에 대한 더 큰 신뢰를 제공할 수 있다.
이러한 발견은 단일의 일반화 가능한 모델이 의료 영상의 방대한 이질성을 처리하여 지루하고 작업별 미세 조정의 필요성을 줄이는 미래로 나아가고 있음을 시사한다.
 Table 2. illustrates the quantitative results of the ablation study on domain encoding, model backbone, and training loss function. We compare three domain encodings to equip our EVA-I2I, including one hot,12 BioBERT,35 and DCLIP (proposed). BioBERT encoding can extract semantic information from medical prompts, leading to better synthesis results than one- hot encoding, and our proposed DCLIP encoding aligns text and images, making its synthesis performance significantly (p < 0:05 for PNSR and LPIPS) better than BioBERT encoding, which cannot align text and images. We also compare three model backbones of the structure encoder EΦ in EVA-I2I, including ResNet,36 Swin-Transformer,37 and ConvNeXt (pro posed). The ConvNeXt backbone slightly outperforms other methods. Moreover, we also evaluate the effectiveness of cross-dataset collaborative learning. Results show that the model trained with Lfine significantly (p < 0:05 for PNSR and LPIPS) outperforms the model only trained with Linit
Table 2. illustrates the quantitative results of the ablation study on domain encoding, model backbone, and training loss function. We compare three domain encodings to equip our EVA-I2I, including one hot,12 BioBERT,35 and DCLIP (proposed). BioBERT encoding can extract semantic information from medical prompts, leading to better synthesis results than one- hot encoding, and our proposed DCLIP encoding aligns text and images, making its synthesis performance significantly (p < 0:05 for PNSR and LPIPS) better than BioBERT encoding, which cannot align text and images. We also compare three model backbones of the structure encoder EΦ in EVA-I2I, including ResNet,36 Swin-Transformer,37 and ConvNeXt (pro posed). The ConvNeXt backbone slightly outperforms other methods. Moreover, we also evaluate the effectiveness of cross-dataset collaborative learning. Results show that the model trained with Lfine significantly (p < 0:05 for PNSR and LPIPS) outperforms the model only trained with Linit
 Table 1. The quantitative results of image translation for different comparisons on in- and out-domain datasets
Table 1. The quantitative results of image translation for different comparisons on in- and out-domain datasets
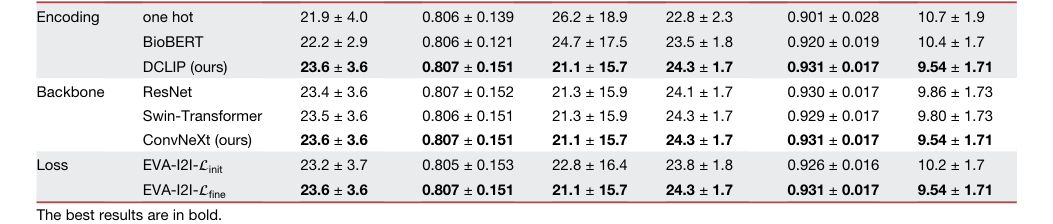 Table 2. The quantitative results of ablation study for EVA-I2I on domain encoding, model backbone, and training loss function
Table 2. The quantitative results of ablation study for EVA-I2I on domain encoding, model backbone, and training loss function