milliMamba: द्वैत mmWave रडार के साथ मल्टी-फ्रेम मैम्बा फ्यूजन द्वारा स्पेक्युलर-अवेयर ह्यूमन पोज़ अनुमान
मिलीमीटर वेव (mmWave) रडार संकेतों का उपयोग करके मानव पोज़ अनुमान (HPE) की समस्या मुख्य रूप से पारंपरिक कैमरा आधारित (RGB) प्रणालियों की सीमाओं के जवाब में उभरी। जबकि RGB कैमरे समृद्ध दृश्य जानकारी प्रदान करते हैं, वे...
पृष्ठभूमि और अकादमिक वंश
उत्पत्ति और अकादमिक वंश
मिलीमीटर-वेव (mmWave) रडार संकेतों का उपयोग करके मानव पोज़ अनुमान (HPE) की समस्या मुख्य रूप से पारंपरिक कैमरा-आधारित (RGB) प्रणालियों की सीमाओं के जवाब में उभरी। जबकि RGB कैमरे समृद्ध दृश्य जानकारी प्रदान करते हैं, वे स्वाभाविक रूप से गोपनीयता संबंधी चिंताएँ पैदा करते हैं, खासकर घरों या अस्पतालों जैसे संवेदनशील वातावरण में। इसके अलावा, कैमरा-आधारित प्रणालियाँ विभिन्न प्रकाश स्थितियों और अवरोधों के प्रति संवेदनशील होती हैं, जो प्रदर्शन को गंभीर रूप से खराब कर सकती हैं।
इस संदर्भ में, mmWave रडार ने एक सम्मोहक विकल्प के रूप में खुद को प्रस्तुत किया। यह एक गोपनीयता-संरक्षण समाधान प्रदान करता है क्योंकि यह व्यक्तियों की दृश्य छवियां कैप्चर नहीं करता है। इसके अतिरिक्त, यह अंधेरे या धुएं जैसे पर्यावरणीय कारकों के प्रति मजबूत है, जिससे यह तैनाती परिदृश्यों की एक विस्तृत श्रृंखला के लिए उपयुक्त है। इसलिए, इस पत्र में संबोधित विशिष्ट समस्या, mmWave रडार के अद्वितीय लाभों का लाभ उठाते हुए इसकी अंतर्निहित चुनौतियों को दूर करते हुए एक मजबूत और सटीक 2D मानव पोज़ अनुमान प्रणाली विकसित करना है।
पिछली mmWave रडार-आधारित HPE विधियों की मौलिक सीमा या "दर्द बिंदु", जिसने लेखकों को milliMamba विकसित करने के लिए मजबूर किया, कई मुद्दों से उत्पन्न होती है। सबसे पहले, "स्पेक्युलर रिफ्लेक्शन" नामक घटना के कारण रडार सिग्नल अक्सर विरल होते हैं। इसका मतलब है कि सिग्नल सेंसर से दूर उछल सकते हैं यदि वे कुछ कोणों पर शरीर के किसी हिस्से से टकराते हैं, जिससे अपूर्ण अवलोकन होते हैं और एक एकल फ्रेम से पूर्ण-शरीर पोज़ का पुनर्निर्माण करना मुश्किल हो जाता है। छोरों (जैसे उंगलियों या पैर की उंगलियों) से कमजोर प्रतिबिंब और विषय अभिविन्यास के प्रति संवेदनशीलता इस समस्या को और बढ़ा देती है। दूसरे, पिछले तरीके, विशेष रूप से ट्रांसफार्मर पर आधारित, रडार इनपुट की उच्च आयामीता और फ्रेम के लंबे अनुक्रमों को संसाधित करने के लिए आवश्यक बड़े "टोकन वॉल्यूम" के साथ संघर्ष करते थे। इससे द्विघात कम्प्यूटेशनल जटिलता हुई, जिससे वे मेमोरी-गहन और धीमे हो गए। इसे कम करने के कुछ प्रयासों में अस्थायी जानकारी का "प्रारंभिक संलयन" शामिल था, लेकिन इसने अक्सर पड़ोसी फ्रेम से मूल्यवान प्रासंगिक संकेतों को खोकर लापता जोड़ों को ठीक करने की मॉडल की क्षमता से समझौता किया। लेखकों का लक्ष्य एक ऐसी प्रणाली बनाना था जो स्पेटियो-टेम्पोरल संदर्भ का लाभ उठाने के लिए लंबे रडार डेटा अनुक्रमों को कुशलतापूर्वक संसाधित कर सके, जिससे कम्प्यूटेशनल लागतों को प्रबंधनीय रखते हुए लापता जोड़ों का अधिक सटीक अनुमान लगाया जा सके और अस्थायी स्थिरता बनाए रखी जा सके।
सहज डोमेन शब्द
- मिलीमीटर-वेव (mmWave) रडार: कल्पना करें कि एक चमगादड़ अंधेरे में "देखने" के लिए अपने सोनार का उपयोग कर रहा है, लेकिन ध्वनि तरंगों के बजाय, हम बहुत छोटी रेडियो तरंगों का उपयोग कर रहे हैं। ये तरंगें वस्तुओं से उछलती हैं, और गूँज को सुनकर, हम यह पता लगा सकते हैं कि चीजें कहाँ हैं और वे कैसे चल रही हैं, यह सब कैमरे की आवश्यकता के बिना। यह गति के लिए एक्स-रे दृष्टि रखने जैसा है, लेकिन व्यक्ति को वास्तव में देखे बिना।
- मानव पोज़ अनुमान (HPE): इसे किसी व्यक्ति के शरीर पर एक स्टिक फिगर बनाने जैसा समझें। लक्ष्य उनके आसन और आंदोलन को समझने के लिए प्रमुख जोड़ों (जैसे कोहनी, घुटने और कंधे) के सटीक स्थानों को इंगित करना है।
- स्पेक्युलर रिफ्लेक्शन: यह एक पूरी तरह से चिकनी दर्पण में देखने जैसा है। यदि एक रडार सिग्नल शरीर की सतह से टकराता है जो बहुत चिकनी है और ठीक कोण पर है, तो सिग्नल पूरी तरह से उछल जाता है, जैसे दर्पण से प्रकाश, और रडार सेंसर तक वापस नहीं आता है। यह शरीर के उस हिस्से को रडार के लिए "अदृश्य" बनाता है, जिससे डेटा में अंतराल आ जाता है।
- स्पेटियो-टेम्पोरल निर्भरताएँ: यह संदर्भित करता है कि चीजें स्थान (एक क्षण में एक-दूसरे के सापेक्ष कहाँ हैं) और समय (वे क्षणों के अनुक्रम में कैसे चलते हैं और बदलते हैं) दोनों में कैसे संबंधित हैं। HPE के लिए, इसका मतलब यह समझना है कि एक फ्रेम में किसी व्यक्ति की बांह की गति पिछले और अगले फ्रेम में उसकी स्थिति से जुड़ी हुई है, और उनके कंधे की स्थिति से भी।
- मैम्बा: यह कृत्रिम बुद्धिमत्ता वास्तुकला का एक नया प्रकार है, जो ट्रांसफार्मर के समान है लेकिन सूचना के लंबे अनुक्रमों को संभालने में बहुत अधिक कुशल है। एक अविश्वसनीय रूप से स्मार्ट नोट-टेकर की कल्पना करें जो हर बार पूरे ट्रांसक्रिप्ट को फिर से पढ़े बिना एक बहुत लंबे व्याख्यान से मुख्य बिंदुओं को जल्दी से सारांशित और याद रख सकता है। यह AI को अभिभूत हुए बिना बहुत लंबी अवधि में संदर्भ को समझने की अनुमति देता है।
संकेतन तालिका
| संकेतन | विवरण |
|---|---|
समस्या परिभाषा और बाधाएँ
मुख्य समस्या सूत्रीकरण और दुविधा
इस पत्र द्वारा संबोधित मुख्य समस्या मिलीमीटर-वेव (mmWave) रडार संकेतों का उपयोग करके 2D मानव पोज़ अनुमान (HPE) है।
प्रस्तावित प्रणाली के लिए इनपुट/वर्तमान स्थिति में $T$ फ्रेम के अनुक्रम पर कैप्चर किए गए द्वैत रडार सेंसर द्वारा कैप्चर किए गए कच्चे, जटिल-मूल्य वाले mmWave रडार सिग्नल शामिल हैं। विशेष रूप से, एक FMCW रडार आभासी-एंटीना जोड़े, चिड़िया और ADC नमूनों के अनुरूप प्रत्येक फ्रेम के लिए $X \in C^{12 \times 128 \times 256}$ जटिल-मूल्य वाले क्यूब्स का उत्पादन करता है। इन कच्चे संकेतों को फिर 3D कोण-डॉपलर-रेंज हीटमैप में पूर्व-संसाधित किया जाता है, जिन्हें $T$ फ्रेम में स्टैक किया जाता है और वास्तविक और काल्पनिक घटकों में विभाजित किया जाता है, जिससे $C \times T \times H \times D \times W$ (जहां $C=2$) के आकार का एक दो-चैनल टेंसर बनता है। यह इनपुट स्वाभाविक रूप से इसकी उच्च आयामीता और रडार प्रतिबिंबों की विरल प्रकृति के कारण चुनौतीपूर्ण है।
आउटपुट/लक्ष्य स्थिति अस्थायी रूप से सुसंगत 2D मानव पोज़ का एक अनुक्रम है, जिसे स्लाइडिंग विंडो के भीतर कई फ्रेम में प्रत्येक जोड़ के लिए 2D कीपॉइंट निर्देशांक द्वारा दर्शाया जाता है। उद्देश्य इन जोड़ निर्देशांकों को सटीक रूप से भविष्यवाणी करना है, यहां तक कि उन जोड़ों के लिए भी जो कमजोर रूप से परावर्तित या स्पेक्युलर रिफ्लेक्शन के कारण पूरी तरह से गायब हैं, जबकि अस्थायी स्थिरता बनाए रखना और उचित कम्प्यूटेशनल जटिलता के साथ अत्याधुनिक प्रदर्शन प्राप्त करना है।
सटीक लुप्त कड़ी या गणितीय अंतर जिसे यह पत्र पाटने का प्रयास करता है, वह विरल, उच्च-आयामी mmWave रडार डेटा से स्पेटियो-टेम्पोरल निर्भरताओं का मजबूत और कुशल मॉडलिंग है। पिछली विधियाँ संघर्ष करती हैं:
1. अपूर्ण अवलोकन: स्पेक्युलर प्रतिबिंबों का मतलब है कि केवल रिसीवर की ओर सीधे उन्मुख शरीर के अंगों का पता लगाया जाता है, जिससे लापता या कमजोर रूप से परावर्तित जोड़ (विशेष रूप से छोर) होते हैं और एकल-फ्रेम इनपुट से पूर्ण-शरीर पोज़ पुनर्निर्माण मुश्किल हो जाता है।
2. अस्थायी असंगति: रडार संकेतों में उतार-चढ़ाव फ्रेम में अस्थायी स्थिरता को बाधित करते हैं, समय के साथ सटीक पोज़ अनुमान में बाधा डालते हैं।
3. कम्प्यूटेशनल स्केलेबिलिटी: जबकि ट्रांसफार्मर-आधारित मॉडल वैश्विक निर्भरताओं को कैप्चर कर सकते हैं, अनुक्रम लंबाई के संबंध में उनकी द्विघात जटिलता उन्हें लंबे रडार अनुक्रमों से बड़े टोकन वॉल्यूम को संसाधित करने के लिए कम्प्यूटेशनल रूप से महंगा और मेमोरी-गहन बनाती है।
4. आंशिक स्पेटियो-टेम्पोरल मॉडलिंग: पिछली विधियाँ अक्सर स्पेटियो-टेम्पोरल निर्भरताओं को केवल आंशिक रूप से मॉडल करती हैं या प्रारंभिक अस्थायी संलयन का सहारा लेती हैं, जो मूल्यवान प्रासंगिक जानकारी को त्यागकर लापता जोड़ों को ठीक करने की मॉडल की क्षमता से समझौता कर सकती है।
दर्दनाक व्यापार-बंद या दुविधा जिसने पिछले शोधकर्ताओं को फंसाया है, वह मुख्य रूप से सटीकता (विशेष रूप से लापता जोड़ों और अस्थायी स्थिरता के लिए) और कम्प्यूटेशनल दक्षता/मेमोरी फ़ुटप्रिंट के बीच है। उच्च सटीकता प्राप्त करने के लिए, विशेष रूप से लापता जोड़ों का अनुमान लगाने और अस्थायी चिकनाई सुनिश्चित करने में, मॉडल को लंबे अनुक्रमों को संसाधित करने और समृद्ध स्पेटियो-टेम्पोरल संदर्भ को कैप्चर करने की आवश्यकता होती है। हालांकि, ट्रांसफार्मर जैसे पारंपरिक आर्किटेक्चर ऐसे लंबे अनुक्रमों के लिए द्विघात कम्प्यूटेशनल जटिलता और उच्च मेमोरी मांगें करते हैं, जिससे वे अव्यावहारिक हो जाते हैं। इसके विपरीत, प्रारंभिक अस्थायी संलयन या एकल-फ्रेम भविष्यवाणी द्वारा जटिलता को कम करने वाली विधियाँ अक्सर विरल, स्पेक्युलर रडार डेटा को मज़बूती से संभालने और अस्थायी स्थिरता बनाए रखने के लिए आवश्यक प्रासंगिक जानकारी का त्याग करती हैं। यह दुविधा शोधकर्ताओं को कम्प्यूटेशनल रूप से महंगा लेकिन संभावित रूप से अधिक सटीक मॉडल, या तेज लेकिन कम मजबूत मॉडल के बीच चयन करने के लिए मजबूर करती है।
बाधाएँ और विफलता मोड
मिलीमीटर-वेव रडार-आधारित मानव पोज़ अनुमान की समस्या कई कठोर, यथार्थवादी दीवारों के कारण अविश्वसनीय रूप से कठिन है जिनसे लेखक टकराए:
-
भौतिक बाधाएँ:
- स्पेक्युलर रिफ्लेक्शन: यह एक प्राथमिक चुनौती है। रडार सिग्नल दर्पण जैसी फैशन में सतहों से परावर्तित होते हैं, जिसका अर्थ है कि केवल सेंसर की ओर उन्मुख शरीर के अंग ही पता लगाए जाते हैं। इससे डेटा की अत्यधिक विरलता और अपूर्ण अवलोकन होते हैं, जहां छोटे या तिरछे उन्मुख जोड़ अक्सर रडार डेटा से पूरी तरह से गायब हो जाते हैं।
- छोरों से कमजोर प्रतिबिंब: कलाई और टखनों जैसे जोड़ अक्सर बहुत कमजोर रडार प्रतिबिंब उत्पन्न करते हैं, जिससे उनका पता लगाना और मज़बूती से ट्रैक करना विशेष रूप से कठिन हो जाता है।
- विषय अभिविन्यास और सेंसर प्लेसमेंट के प्रति संवेदनशीलता: रडार डेटा की गुणवत्ता और पूर्णता विषय के सेंसर के सापेक्ष अभिविन्यास और रडार इकाइयों के सटीक प्लेसमेंट पर अत्यधिक निर्भर करती है, जिससे मजबूत सुविधा निष्कर्षण और जटिल हो जाता है।
- सीमित ऊंचाई रिज़ॉल्यूशन: mmWave रडार सेंसर में स्वाभाविक रूप से ऊंचाई आयाम में सीमित रिज़ॉल्यूशन होता है, जिससे 3D पोज़ पुनर्निर्माण में अस्पष्टता हो सकती है। इसे कम करने के लिए द्वैत-रडार सेटअप का उपयोग किया जाता है।
-
कम्प्यूटेशनल बाधाएँ:
- रडार इनपुट की उच्च आयामीता: कच्चे रडार सिग्नल उच्च-आयामी होते हैं, और 3D हीटमैप में पूर्व-संसाधन के बाद भी, फ्रेम के अनुक्रमों के लिए डेटा की मात्रा पर्याप्त बनी रहती है।
- ट्रांसफार्मर की द्विघात जटिलता: पिछले ट्रांसफार्मर-आधारित मॉडल, जबकि वैश्विक निर्भरता मॉडलिंग के लिए शक्तिशाली हैं, इनपुट अनुक्रम लंबाई $N$ के संबंध में $O(N^2)$ जटिलता से पीड़ित हैं। यह उन्हें "लंबे रडार अनुक्रमों में निहित बड़े टोकन वॉल्यूम" को संसाधित करने के लिए अक्षम बनाता है, जिससे निषेधात्मक कम्प्यूटेशनल लागत और प्रशिक्षण समय होता है।
- हार्डवेयर मेमोरी सीमाएँ: ट्रांसफार्मर की द्विघात जटिलता सीधे उच्च मेमोरी खपत में तब्दील हो जाती है। जैसा कि पेपर में उल्लेख किया गया है, ट्रांसफार्मर "लंबे अनुक्रमों के साथ प्रशिक्षित होने पर हमारे हार्डवेयर पर मेमोरी से बाहर हो जाते हैं" (जैसे, $T=3$ फ्रेम से परे), संसाधित किए जा सकने वाले अस्थायी संदर्भ की मात्रा को गंभीर रूप से सीमित करते हैं।
- पूर्व-संसाधन ओवरहेड: कच्चे रडार संकेतों से पारंपरिक 4D हीटमैप पीढ़ी कम्प्यूटेशनल रूप से महंगी और मेमोरी-गहन है (उदाहरण के लिए, 3D FFT-आधारित हीटमैप की तुलना में 11x अधिक मेमोरी और 8.6x अधिक विलंबता), जो वास्तविक समय अनुप्रयोगों के लिए एक बाधा हो सकती है।
-
डेटा-संचालित बाधाएँ:
- अस्थायी असंगति: रडार संकेतों में अंतर्निहित शोर और उतार-चढ़ाव फ्रेम में जोड़ की स्थिति की अस्थायी निरंतरता को बाधित कर सकते हैं, जिससे समय के साथ सुसंगत और सुसंगत पोज़ अनुमान बनाए रखना चुनौतीपूर्ण हो जाता है।
- मजबूत सुविधाओं की कमी: विरल और शोर वाले रडार संकेतों से मजबूत और विभेदक सुविधाओं को निकालना एक महत्वपूर्ण बाधा है, क्योंकि कच्चा डेटा सीधे RGB छवियों की तरह दृश्य संकेत प्रदान नहीं करता है।
- लापता जानकारी का अनुमान लगाने में कठिनाई: स्पेक्युलर प्रतिबिंबों के कारण, मॉडल को प्रासंगिक संकेतों का उपयोग करके लापता जोड़ों की स्थिति का अनुमान लगाने की आवश्यकता होती है, जिसके लिए प्रति-फ्रेम विश्लेषण से परे परिष्कृत स्पेटियो-टेम्पोरल तर्क की आवश्यकता होती है।
ये बाधाएँ सामूहिक रूप से रडार-आधारित HPE को एक विशेष रूप से चुनौतीपूर्ण समस्या बनाती हैं, जिसके लिए नवीन वास्तुशिल्प डिजाइनों की आवश्यकता होती है जो कम्प्यूटेशनल व्यवहार्यता बनाए रखते हुए उच्च-आयामी, विरल और अस्थायी रूप से असंगत डेटा को कुशलतापूर्वक संभाल सकें।
यह दृष्टिकोण क्यों
चुनाव की अनिवार्यता
मिलीमीटर-वेव (mmWave) रडार का उपयोग करके मानव पोज़ अनुमान (HPE) की चुनौतीपूर्ण समस्या से निपटने के दौरान, लेखकों को एक महत्वपूर्ण मोड़ का सामना करना पड़ा जहाँ पारंपरिक अत्याधुनिक (SOTA) विधियाँ अपर्याप्त साबित हुईं। मुख्य समस्या रडार संकेतों की अंतर्निहित प्रकृति से उत्पन्न होती है: वे स्पेक्युलर प्रतिबिंबों के कारण विरल होते हैं, जिससे अपूर्ण अवलोकन और लापता जोड़ डेटा होता है, खासकर छोरों से। इसके अतिरिक्त, कच्चे रडार इनपुट उच्च-आयामी होते हैं, और लक्ष्य इन लापता जोड़ों का अनुमान लगाने और गति की चिकनाई सुनिश्चित करने के लिए लंबे अनुक्रमों से मजबूत स्पेटियो-टेम्पोरल सुविधाओं को निकालना है।
लेखकों ने स्पष्ट रूप से पहचाना कि पिछले ट्रांसफार्मर-आधारित दृष्टिकोण, जबकि वैश्विक निर्भरताओं को मॉडल करने के लिए शक्तिशाली थे, इस विशिष्ट अनुप्रयोग के लिए एक घातक दोष से पीड़ित थे: उनकी द्विघात जटिलता ($O(N^2)$) इनपुट अनुक्रम लंबाई के संबंध में। पेपर के अनुसार, "लंबे रडार अनुक्रमों में निहित बड़े टोकन वॉल्यूम" को संसाधित करना उनके उच्च कम्प्यूटेशनल लागतों, मेमोरी उपयोग और प्रशिक्षण समय के कारण ट्रांसफार्मर के लिए एक दुर्गम चुनौती बन गया। उदाहरण के लिए, तालिका 8 स्पष्ट रूप से दर्शाती है कि एक ट्रांसफार्मर एनकोडर हमारे हार्डवेयर पर मेमोरी से बाहर होने से पहले केवल $T=3$ फ्रेम को संभाल सकता था, जबकि प्रस्तावित मैम्बा-आधारित एनकोडर $T=9$ या $T=15$ फ्रेम तक स्केल कर सकता था। इस व्यावहारिक सीमा का मतलब था कि ट्रांसफार्मर रडार से मजबूत पोज़ अनुमान के लिए आवश्यक अस्थायी संदर्भ को संसाधित नहीं कर सकते थे।
इसी तरह, पारंपरिक CNN-आधारित विधियाँ, जबकि बहु-पैमाने स्थानिक और अल्पकालिक अस्थायी सुविधाओं को कैप्चर करने के लिए प्रभावी होती हैं, "कई रडार सेंसर से जानकारी को फ्यूज करने की उनकी क्षमता में अक्सर सीमित" होती थीं। यह देखते हुए कि milliMamba क्षैतिज और ऊर्ध्वाधर दृश्यों के लिए एक द्वैत-रडार सेटअप का उपयोग करता है, इस सीमा ने मानक CNN को एक उप-इष्टतम विकल्प बना दिया।
यह अहसास स्पष्ट था: एक नए आर्किटेक्चर की आवश्यकता थी जो लंबे-रेंज स्पेटियो-टेम्पोरल निर्भरताओं को रैखिक जटिलता ($O(N)$) के साथ कुशलतापूर्वक मॉडल कर सके ताकि उच्च-आयामी, बहु-फ्रेम रडार डेटा को निषेधात्मक कम्प्यूटेशनल लागतों के बिना संसाधित किया जा सके। इसने मैम्बा आर्किटेक्चर को, इसके चयनात्मक राज्य स्थान मॉडल (SSM) डिजाइन के साथ, आगे बढ़ने का एकमात्र व्यवहार्य मार्ग बना दिया।
तुलनात्मक श्रेष्ठता
milliMamba फ्रेमवर्क मुख्य रूप से लंबे अनुक्रमों और जटिल स्पेटियो-टेम्पोरल निर्भरताओं को कुशलतापूर्वक संभालने में अपनी संरचनात्मक लाभों के माध्यम से पिछले स्वर्ण मानकों पर गुणात्मक श्रेष्ठता प्राप्त करता है।
-
लंबे अनुक्रमों के लिए रैखिक जटिलता: सबसे महत्वपूर्ण संरचनात्मक लाभ एनकोडर के लिए मैम्बा आर्किटेक्चर को अपनाना है। ट्रांसफार्मर के विपरीत, जो अनुक्रम लंबाई $N$ के संबंध में द्विघात जटिलता $O(N^2)$ से पीड़ित होते हैं, मैम्बा रैखिक जटिलता $O(N)$ प्रदान करता है। यह केवल एक मामूली सुधार नहीं है; यह एक मौलिक बदलाव है जो
milliMambaको मेमोरी से बाहर निकले बिना काफी लंबे रडार अनुक्रमों (जैसे, डिफ़ॉल्ट रूप से $T=9$ फ्रेम, प्रयोगों में $T=15$ तक) को संसाधित करने की अनुमति देता है, जो तालिका 8 में दिखाए गए अनुसार ट्रांसफार्मर के लिए एक महत्वपूर्ण सीमा है। यह मॉडल को बहुत समृद्ध अस्थायी संदर्भ का लाभ उठाने की अनुमति देता है, जो स्पेक्युलर प्रतिबिंबों के कारण लापता जोड़ों का अनुमान लगाने और गति की चिकनाई सुनिश्चित करने के लिए महत्वपूर्ण है। -
उन्नत स्पेटियो-टेम्पोरल संदर्भ मॉडलिंग: क्रॉस-व्यू फ्यूजन मैम्बा (CV-Mamba) एनकोडर विशेष रूप से "लंबे अनुक्रमों पर निर्भरताओं को कुशलतापूर्वक कैप्चर करने" और "फ्रेम में द्वैत-रडार इनपुट को प्रभावी ढंग से फ्यूज करने" के लिए डिज़ाइन किया गया है। यह दृश्य की अधिक व्यापक समझ की अनुमति देता है, जो विरल रडार डेटा से मजबूत पोज़ अनुमान के लिए महत्वपूर्ण है। इसके अलावा, स्पेटियो-टेम्पोरल-क्रॉस अटेंशन (STCA) डिकोडर, अपनी मल्टी-फ्रेम आउटपुट रणनीति के साथ, स्थानिक और अस्थायी दोनों ध्यान को एकीकृत करता है। इसका मतलब है कि यह प्रत्येक फ्रेम (स्थानिक) और फ्रेम (अस्थायी) में संबंधों को मॉडल कर सकता है, जिससे "समय चरणों में समृद्ध पर्यवेक्षण" होता है और पड़ोसी फ्रेम से प्रासंगिक संकेतों का लाभ उठाकर लापता जोड़ों का बेहतर अनुमान लगाया जा सकता है। यह उन विधियों पर एक गुणात्मक छलांग है जो प्रारंभिक अस्थायी संलयन करती हैं या केवल एक फ्रेम की भविष्यवाणी करती हैं।
-
कुशल पूर्व-संसाधन: जबकि मैम्बा आर्किटेक्चर का हिस्सा नहीं है, रडार सिग्नल प्रसंस्करण के लिए 3D फास्ट फूरियर ट्रांसफॉर्म (FFT) का विकल्प समग्र श्रेष्ठता में महत्वपूर्ण योगदान देता है। जैसा कि चित्र 4(c) में दर्शाया गया है, यह दृष्टिकोण पारंपरिक 4D हीटमैप पीढ़ी की तुलना में मेमोरी उपयोग को 11x और विलंबता को 8.6x तक कम करता है। यह दक्षता लाभ महत्वपूर्ण है क्योंकि यह "टोकन गणना के विस्फोट" को कम करता है, जिससे उच्च-आयामी रडार डेटा मैम्बा एनकोडर द्वारा डाउनस्ट्रीम मॉडलिंग के लिए सुलभ हो जाता है। यह संयुक्त दक्षता
milliMambaको तालिका 2 और 3 में उजागर किए गए कम्प्यूटेशनल लागत और प्रदर्शन के बीच अधिक अनुकूल संतुलन के साथ उच्च सटीकता प्राप्त करने की अनुमति देती है।
संक्षेप में, milliMamba अत्यधिक श्रेष्ठ है क्योंकि यह एक स्केलेबल, कुशल और संदर्भ-समृद्ध फ्रेमवर्क प्रदान करता है जो रडार-आधारित HPE की सटीकता के लिए आवश्यक व्यापक स्पेटियो-टेम्पोरल जानकारी को संसाधित कर सकता है, एक ऐसी उपलब्धि जिसके साथ पिछली विधियों ने वास्तुशिल्प सीमाओं के कारण संघर्ष किया था।
बाधाओं के साथ संरेखण
चुना गया milliMamba दृष्टिकोण mmWave रडार-आधारित मानव पोज़ अनुमान की कठोर आवश्यकताओं के साथ पूरी तरह से संरेखित होता है, जो समस्या की अनूठी चुनौतियों और समाधान के अनुरूप गुणों के बीच एक मजबूत "विवाह" बनाता है।
-
विरल और अपूर्ण डेटा (स्पेक्युलर रिफ्लेक्शन) को संभालना: रडार संकेतों की विरलता और स्पेक्युलर प्रतिबिंबों के कारण लापता जोड़ डेटा मुख्य समस्या है।
milliMambaअपने व्यापक स्पेटियो-टेम्पोरल मॉडलिंग के माध्यम से सीधे इसका समाधान करता है। CV-Mamba एनकोडर लंबे अनुक्रमों से सुविधाओं को निकालता है, पर्याप्त अस्थायी संदर्भ प्रदान करता है। STCA डिकोडर तब इस संदर्भ का लाभ उठाता है, एक साथ कई फ्रेम में पोज़ की भविष्यवाणी करता है और स्थानिक और अस्थायी दोनों ध्यान को एकीकृत करता है। यह मॉडल को "स्पेक्युलर प्रतिबिंबों के कारण लापता जोड़ों का अनुमान लगाने के लिए पड़ोसी फ्रेम और जोड़ों से प्रासंगिक संकेतों का लाभ उठाने" की अनुमति देता है, जिससे अपूर्ण अवलोकनों के प्रभावों को सीधे कम किया जा सकता है। वेग हानि भी गति की चिकनाई को मजबूत करती है, जो व्यक्तिगत फ्रेम विरल होने पर भी प्रशंसनीय पोज़ के पुनर्निर्माण में मदद करती है। -
उच्च-आयामी इनपुट और बड़े टोकन वॉल्यूम का प्रबंधन: mmWave रडार इनपुट स्वाभाविक रूप से उच्च-आयामी होते हैं।
milliMambaफ्रेमवर्क पहले एक कुशल 3D FFT-आधारित पूर्व-संसाधन चरण का उपयोग करके इसे संबोधित करता है, जो पारंपरिक 4D दृष्टिकोणों की तुलना में मेमोरी उपयोग और विलंबता को काफी कम करता है (चित्र 4(c))। यह चरण "टोकन गणना के विस्फोट" को कम करता है, जिससे डेटा प्रबंधनीय हो जाता है। इसके बाद, रैखिक जटिलता वाला CV-Mamba एनकोडर विशेष रूप से "लंबे रडार अनुक्रमों में निहित बड़े टोकन वॉल्यूम को कुशलतापूर्वक संसाधित करने" के लिए डिज़ाइन किया गया है, जो एक महत्वपूर्ण आवश्यकता है जिसे पारंपरिक ट्रांसफार्मर अपनी द्विघात स्केलिंग के कारण पूरा करने में विफल रहे। -
मल्टी-रडार इनपुट को फ्यूज करना: समस्या में अक्सर अधिक व्यापक दृश्य कैप्चर करने के लिए द्वैत-रडार सेटअप शामिल होते हैं। CV-Mamba एनकोडर स्पष्ट रूप से "द्वैत-रडार इनपुट के क्रॉस-व्यू फ्यूजन" के लिए डिज़ाइन किया गया है, जो क्षैतिज और ऊर्ध्वाधर रडार दृश्यों से जानकारी को प्रभावी ढंग से जोड़ता है। यह कई सेंसर से डेटा को एकीकृत करने की आवश्यकता को सीधे संबोधित करता है, जो कुछ CNN-आधारित विधियों की एक ज्ञात सीमा है।
-
अस्थायी स्थिरता और गति चिकनाई सुनिश्चित करना: कमजोर प्रतिबिंब और उतार-चढ़ाव अस्थायी स्थिरता को बाधित कर सकते हैं। STCA डिकोडर की मल्टी-फ्रेम भविष्यवाणी रणनीति, प्रशिक्षण के दौरान वेग हानि ($L_{vel}$) के स्पष्ट समावेश के साथ मिलकर, सीधे फ्रेम में गति स्थिरता को लागू करती है। वेग हानि, $L_{vel} = \frac{1}{T-1}\sum_{f=1}^{T-1}\sum_{j=1}^{J} ||\mathbf{v}_{f,j} - \hat{\mathbf{v}}_{f,j}||^2_2$ के रूप में परिभाषित की गई है, जहां $\mathbf{v}_{f,j}$ ग्राउंड-ट्रुथ वेग है और $\hat{\mathbf{v}}_{f,j}$ अनुमानित वेग है, जोड़ वेगों में विसंगतियों को दंडित करता है, जिससे चिकनी और यथार्थवादी पोज़ अनुक्रमों को बढ़ावा मिलता है।
संक्षेप में, milliMamba का अद्वितीय संयोजन कुशल पूर्व-संसाधन, लंबी-श्रेणी स्पेटियो-टेम्पोरल फ्यूजन के लिए रैखिक-जटिलता मैम्बा एनकोडर, और वेग हानि के साथ एक मल्टी-फ्रेम अटेंशन डिकोडर एक मजबूत और कम्प्यूटेशनल रूप से व्यवहार्य समाधान बनाता है जो mmWave रडार-आधारित HPE की हर प्रमुख बाधा को सीधे संबोधित करता है।
विकल्पों का अस्वीकरण
पत्र कई लोकप्रिय वैकल्पिक दृष्टिकोणों को अस्वीकार करने के लिए स्पष्ट तर्क प्रदान करता है, जो यह उजागर करता है कि milliMamba के डिजाइन विकल्प क्यों आवश्यक थे।
-
ट्रांसफार्मर: सबसे प्रमुख विकल्प, ट्रांसफार्मर, मुख्य रूप से इनपुट अनुक्रम लंबाई के संबंध में उनकी द्विघात कम्प्यूटेशनल जटिलता ($O(N^2)$) के कारण अस्वीकार कर दिए गए थे। लेखकों ने स्पष्ट रूप से कहा है कि यह उन्हें "लंबे रडार अनुक्रमों में निहित बड़े टोकन वॉल्यूम" को संसाधित करने के लिए अनुपयुक्त बनाता है, जो मजबूत रडार-आधारित HPE के लिए आवश्यक है। तालिका 8 अनुभवजन्य साक्ष्य प्रदान करती है, यह दर्शाती है कि एक ट्रांसफार्मर एनकोडर "मेमोरी से बाहर के मुद्दों" के कारण $T=9$ फ्रेम को भी संसाधित नहीं कर सका, जबकि मैम्बा ने इसे कुशलतापूर्वक संभाला। यह मौलिक स्केलेबिलिटी समस्या ट्रांसफार्मर को रडार डेटा से मजबूत पोज़ अनुमान के लिए व्यापक अस्थायी संदर्भ की मांगों के लिए अव्यावहारिक बनाती है।
-
CNN-आधारित विधियाँ: कुछ कार्यों के लिए उपयोगी होने के बावजूद, CNN को अपर्याप्त माना गया क्योंकि वे "कई रडार सेंसर से जानकारी को फ्यूज करने की उनकी क्षमता में अक्सर सीमित" होते हैं।
milliMambaके द्वैत-रडार इनपुट (क्षैतिज और ऊर्ध्वाधर दृश्य) को देखते हुए, एक विधि जिसमें बेहतर मल्टी-सेंसर फ्यूजन क्षमताएं थीं, आवश्यक थी, जो ट्रांसफार्मर (और बाद में मैम्बा) स्वाभाविक रूप से अपने ध्यान/SSM तंत्र के माध्यम से प्रदान करते हैं। -
प्रारंभिक अस्थायी संलयन दृष्टिकोण: कुछ पिछली विधियों [2, 12, 13] ने "समय आयाम को जल्दी से ढहाकर" अस्थायी जानकारी को संभालने का प्रयास किया। लेखकों ने स्पष्ट रूप से इस रणनीति को अस्वीकार कर दिया, यह तर्क देते हुए कि "इस तरह का प्रारंभिक संलयन स्पेक्युलर प्रतिबिंबों के कारण लापता जोड़ों को ठीक करने की मॉडल की क्षमता से समझौता कर सकता है।" यह एक महत्वपूर्ण गुणात्मक अस्वीकरण है, क्योंकि
milliMambaका प्राथमिक लक्ष्य समृद्ध स्पेटियो-टेम्पोरल संदर्भ का लाभ उठाकर इन लापता जोड़ों का अनुमान लगाना है, जिसे प्रारंभिक संलयन कम कर देगा। -
मेनी-टू-वन भविष्यवाणी रणनीति: अधिकांश पिछली रडार-आधारित HPE विधियाँ "मल्टी-फ्रेम टू सिंगल-फ्रेम डिकोडिंग योजना" अपनाती हैं, जिसका अर्थ है कि वे इनपुट के रूप में कई फ्रेम लेती हैं लेकिन केवल एक पोज़ (आमतौर पर केंद्रीय फ्रेम) की भविष्यवाणी करती हैं। इसके विपरीत,
milliMambaएक "मेनी-टू-मेनी" भविष्यवाणी रणनीति अपनाता है, जो एक साथ कई फ्रेम के लिए पोज़ आउटपुट करता है। तालिका 5 मात्रात्मक रूप से इस अस्वीकरण का समर्थन करती है, यह दर्शाता है कि "मेनी-टू-वन" रणनीतिmilliMambaके "मेनी-टू-मेनी" दृष्टिकोण (74.5) की तुलना में काफी कम समग्र AP (70.4) उत्पन्न करती है, जो 4.1 AP सुधार है। यह लापता जोड़ों के मजबूत अनुमान के लिए कई फ्रेम की भविष्यवाणी की बेहतर प्रासंगिक अनुमान क्षमताओं को प्रदर्शित करता है। -
4D हीटमैप पूर्व-संसाधन: कच्चे रडार संकेतों से 4D हीटमैप [25] उत्पन्न करने की पारंपरिक विधि को इसकी कम्प्यूटेशनल अक्षमता के कारण अस्वीकार कर दिया गया था। पत्र इस बात पर प्रकाश डालता है कि यह विधि "कम्प्यूटेशनल रूप से महंगी" है और "टोकन गणना के विस्फोट" की ओर ले जाती है। चित्र 4(c) एक स्पष्ट तुलना प्रदान करता है, जिसमें दिखाया गया है कि 4D हीटमैप पीढ़ी
milliMambaके 3D FFT-आधारित पूर्व-संसाधन की तुलना में 11x अधिक पीक मेमोरी और 8.6x लंबी निष्पादन समय का कारण बनती है। यह स्पष्ट अक्षमता 4D दृष्टिकोण को एक व्यावहारिक और स्केलेबल प्रणाली के लिए अनुपयुक्त बनाती है।
ये अस्वीकरण समस्या की बाधाओं और मौजूदा तकनीकों की सीमाओं की लेखकों की गहरी समझ को रेखांकित करते हैं, जिससे उन्हें milliMamba को एक अनुरूप और अधिक प्रभावी समाधान के रूप में विकसित करने के लिए प्रेरित किया गया। मैम्बा का चुनाव मनमाना नहीं था बल्कि mmWave रडार डेटा की विशिष्ट मांगों के साथ अन्य SOTA मॉडल की अंतर्निहित असंगति से प्रेरित एक आवश्यकता थी।
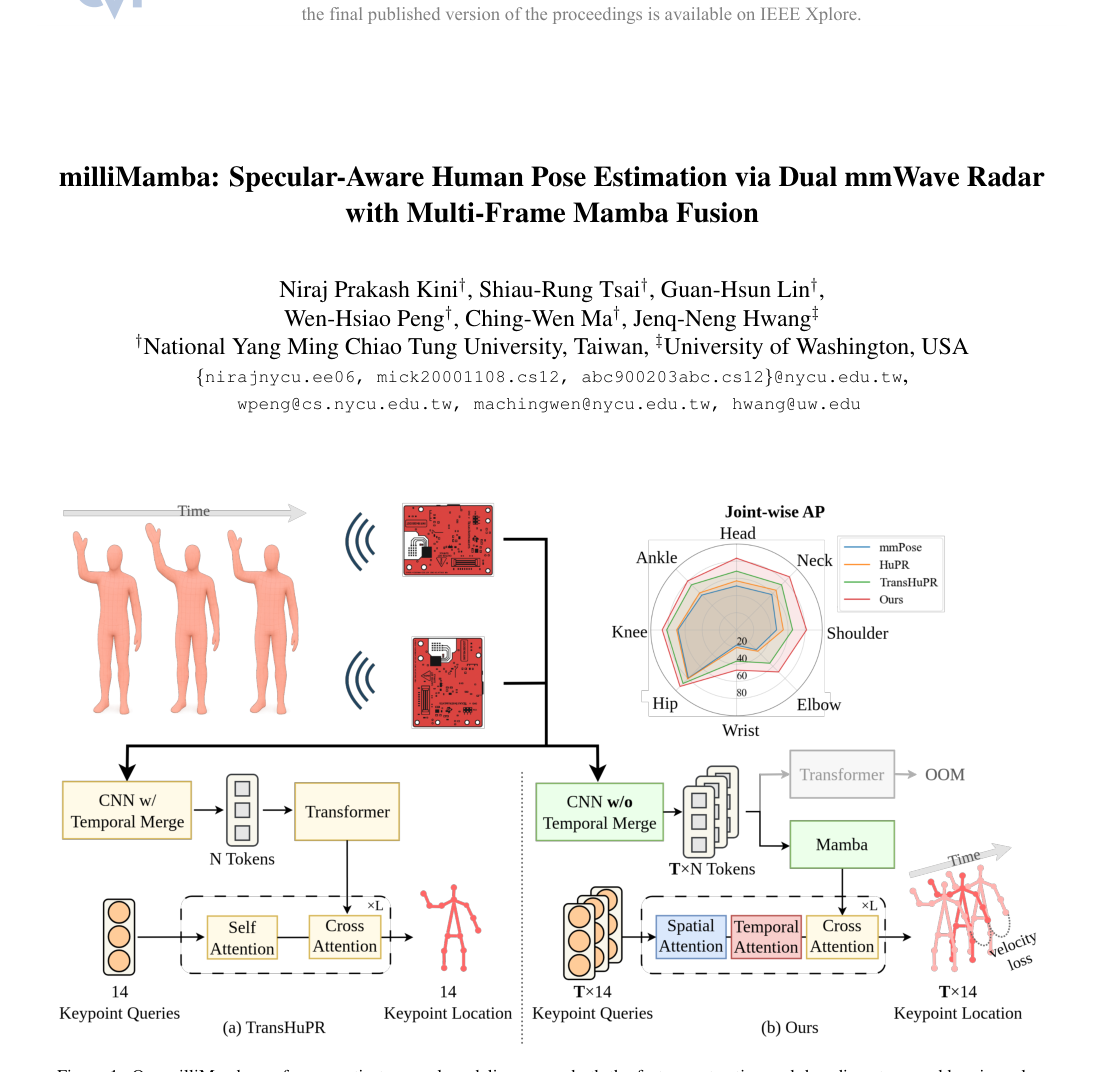 Figure 1. Our milliMamba performs spatio-temporal modeling across both the feature extraction and decoding stages, addressing a key limitation of TransHuPR [12], which models these dependencies only partially. This is made possible by milliMamba’s ability to process a larger number of tokens with a comparable memory footprint, enabling richer temporal context and more accurate pose estimation
Figure 1. Our milliMamba performs spatio-temporal modeling across both the feature extraction and decoding stages, addressing a key limitation of TransHuPR [12], which models these dependencies only partially. This is made possible by milliMamba’s ability to process a larger number of tokens with a comparable memory footprint, enabling richer temporal context and more accurate pose estimation
गणितीय और तार्किक तंत्र
मास्टर समीकरण
milliMamba का गणितीय मूल दो मुख्य समीकरणों के सेट द्वारा संचालित होता है: स्टेट स्पेस मॉडल (SSM) अपडेट समीकरण, जो क्रॉस-व्यू फ्यूजन मैम्बा (CVMamba) एनकोडर की रीढ़ बनाते हैं, और व्यापक प्रशिक्षण उद्देश्य फ़ंक्शन जो मॉडल के सीखने को व्यवस्थित करता है।
प्रत्येक विजन मैम्बा परत के लिए SSM अपडेट को इस प्रकार परिभाषित किया गया है:
$$
h_{t+1} = A h_t + B u_t \\
y_t = C h_t + D u_t
$$
जहां $t$ समय चरण का प्रतिनिधित्व करता है।
समग्र प्रशिक्षण उद्देश्य, जिसे मॉडल अपने सीखने के चरण के दौरान कम करने का प्रयास करता है, है:
$$
L = L_{oks} + \lambda_{vel} L_{vel}
$$
वेग हानि, $L_{vel}$, को आगे निर्दिष्ट किया गया है:
$$
L_{vel} = \frac{1}{(T-1)J} \sum_{f=1}^{T-1} \sum_{j=1}^{J} ||v_{f,j} - \hat{v}_{f,j}||^2_2
$$
पद-दर-पद विच्छेदन
आइए इन समीकरणों के भीतर प्रत्येक पद को सावधानीपूर्वक तोड़ें ताकि इसकी गणितीय परिभाषा, इसकी भौतिक या तार्किक भूमिका, और इसके समावेश और रूप के पीछे के तर्क को समझा जा सके।
स्टेट स्पेस मॉडल (SSM) अपडेट समीकरणों के लिए:
-
$h_t$:
- गणितीय परिभाषा: यह समय चरण $t$ पर SSM का छिपा हुआ राज्य वेक्टर है। यह वर्तमान बिंदु तक अनुक्रम के इतिहास का एक संक्षिप्त प्रतिनिधित्व है।
- भौतिक/तार्किक भूमिका: वैचारिक रूप से, $h_t$ मॉडल की "स्मृति" या "प्रासंगिक सारांश" के रूप में कार्य करता है। यह सभी पूर्ववर्ती इनपुट टोकन से जानकारी जमा करता है और बनाए रखता है, जिससे मॉडल मानव गति के रडार डेटा के भीतर लंबी-श्रेणी की अस्थायी निर्भरताओं को समझ और लाभ उठा सकता है। $h_t$ से $h_{t+1}$ तक इसका विकास अनुक्रमिक प्रसंस्करण के लिए केंद्रीय है।
- क्यों उपयोग किया जाता है: लेखक लंबी अनुक्रमों को संसाधित करने के लिए रैखिक-समय जटिलता प्राप्त करने के लिए इस राज्य-स्थान सूत्रीकरण का उपयोग करते हैं। यह पारंपरिक ट्रांसफार्मर आर्किटेक्चर पर एक महत्वपूर्ण लाभ है, जो अपने वैश्विक ध्यान तंत्र के कारण द्विघात कम्प्यूटेशनल लागतों से ग्रस्त हैं, जिससे वे उच्च-आयामी, बहु-फ्रेम रडार इनपुट के लिए कम उपयुक्त हो जाते हैं।
-
$u_t$:
- गणितीय परिभाषा: यह समय चरण $t$ पर इनपुट टोकन वेक्टर है। milliMamba में, ये टोकन पूर्व-संसाधित रडार हीटमैप से प्राप्त होते हैं, जो अनुक्रम के एक विशिष्ट क्षण से स्पेटियो-टेम्पोरल सुविधाओं का प्रतिनिधित्व करते हैं।
- भौतिक/तार्किक भूमिका: $u_t$ प्रत्येक चरण में SSM में खिलाए गए "वर्तमान अवलोकन" या "नई जानकारी" के रूप में कार्य करता है। यह तत्काल रडार डेटा का टुकड़ा है जिसे मॉडल को मानव पोज़ की अपनी विकसित समझ में एकीकृत करने की आवश्यकता है।
- क्यों उपयोग किया जाता है: यह प्रत्यक्ष बाहरी उत्तेजना है जो SSM के राज्य अपडेट को चलाती है और वर्तमान आउटपुट में योगदान करती है, रडार से कच्ची सुविधा जानकारी प्रदान करती है।
-
$y_t$:
- गणितीय परिभाषा: यह समय चरण $t$ पर SSM द्वारा उत्पन्न आउटपुट टोकन वेक्टर है।
- भौतिक/तार्किक भूमिका: $y_t$ समय $t$ पर परिवर्तित सुविधा या तत्काल आउटपुट का प्रतिनिधित्व करता है, जो वर्तमान इनपुट $u_t$ और संचित छिपे हुए राज्य $h_t$ दोनों का एक कार्य है। मैम्बा परत के भीतर, यह आउटपुट एनकोडर के लिए बाद में पारित किए गए समग्र एन्कोडेड सुविधाओं में योगदान देता है।
- क्यों उपयोग किया जाता है: यह समय $t$ पर इनपुट का एक संसाधित, संदर्भ-जागरूक प्रतिनिधित्व प्रदान करता है, जिसका उपयोग तब एनकोडर में बाद की परतों द्वारा या SSM ब्लॉक के अंतिम आउटपुट के रूप में किया जा सकता है।
-
$A, B, C, D$:
- गणितीय परिभाषा: ये परत-विशिष्ट सीखने योग्य पैरामीटर मैट्रिक्स (या कभी-कभी वेक्टर, विशिष्ट SSM भिन्न और आयामों के आधार पर) हैं। उन्हें प्रशिक्षण प्रक्रिया के दौरान प्रारंभ और अनुकूलित किया जाता है।
- भौतिक/तार्किक भूमिका:
- $A$: राज्य संक्रमण मैट्रिक्स। यह नियंत्रित करता है कि पिछला छिपा हुआ राज्य $h_t$ आंतरिक रूप से अगले छिपे हुए राज्य $h_{t+1}$ में कैसे प्रचारित और रूपांतरित होता है। यह अनुक्रम के भीतर जानकारी की अंतर्निहित गतिशीलता और दृढ़ता को कैप्चर करता है, अनिवार्य रूप से यह परिभाषित करता है कि "स्मृति" समय के साथ कैसे विकसित होती है।
- $B$: इनपुट मैट्रिक्स। यह निर्धारित करता है कि वर्तमान इनपुट $u_t$ को छिपे हुए राज्य $h_{t+1}$ के अद्यतन में कैसे शामिल किया जाता है। यह "नए डेटा" के प्रभाव को मॉडल की स्मृति पर नियंत्रित करता है।
- $C$: आउटपुट मैट्रिक्स। यह छिपे हुए राज्य $h_t$ को आउटपुट $y_t$ में रूपांतरित करता है। यह मॉडल की स्मृति से प्रासंगिक जानकारी निकालने के लिए जिम्मेदार है ताकि वर्तमान आउटपुट बन सके।
- $D$: प्रत्यक्ष फीडथ्रू मैट्रिक्स। यह वर्तमान इनपुट $u_t$ को सीधे छिपे हुए राज्य में एकीकृत किए बिना आउटपुट $y_t$ में योगदान करने की अनुमति देता है। यह तत्काल, गैर-अनुक्रमिक संबंधों को कैप्चर कर सकता है।
- क्यों उपयोग किया जाता है: ये मैट्रिक्स प्रशिक्षण योग्य घटक हैं जो SSM को रडार डेटा से जटिल अस्थायी निर्भरताओं और परिवर्तनों को सीखने की अनुमति देते हैं। उनके मान मानव गति की अंतर्निहित गतिशीलता को सर्वोत्तम मॉडल करने के लिए अनुकूलित किए जाते हैं। जोड़ और गुणा का उपयोग रैखिक राज्य-स्थान प्रणालियों के लिए मौलिक है, जो रैखिक परिवर्तनों और अपडेट का प्रतिनिधित्व करता है जो कम्प्यूटेशनल रूप से कुशल हैं।
समग्र प्रशिक्षण उद्देश्य $L$ के लिए:
-
$L$:
- गणितीय परिभाषा: प्रशिक्षण के दौरान मॉडल द्वारा कम करने का लक्ष्य रखने वाले कुल हानि का प्रतिनिधित्व करने वाला स्केलर मान।
- भौतिक/तार्किक भूमिका: यह पूरी सीखने की प्रक्रिया के लिए प्राथमिक प्रतिक्रिया संकेत के रूप में कार्य करता है। $L$ का एक निम्न मान इंगित करता है कि मॉडल की भविष्यवाणियां परिभाषित मानदंडों के अनुसार अधिक सटीक और अस्थायी रूप से सुसंगत हैं। मॉडल के मापदंडों को इस मान को कम करने के लिए पुनरावृत्त रूप से समायोजित किया जाता है।
- क्यों उपयोग किया जाता है: यह उद्देश्य फ़ंक्शन के रूप में कार्य करता है जो मॉडल की भविष्यवाणियों की "त्रुटि" को मापता है, ग्रेडिएंट वंश के माध्यम से अनुकूलन प्रक्रिया का मार्गदर्शन करता है।
-
$L_{oks}$:
- गणितीय परिभाषा: ऑब्जेक्ट कीपॉइंट सिमिलैरिटी (OKS) हानि। हालांकि इसका सटीक सूत्र पेपर में प्रदान नहीं किया गया है, यह मानव पोज़ अनुमान में एक मानक मीट्रिक है, जो आमतौर पर ऑब्जेक्ट स्केल द्वारा सामान्यीकृत और कीपॉइंट दृश्यता द्वारा भारित, अनुमानित और ग्राउंड-ट्रुथ कीपॉइंट के बीच समानता को मापता है।
- भौतिक/तार्किक भूमिका: यह पद सीधे प्रत्येक व्यक्तिगत फ्रेम में मानव जोड़ों को सही ढंग से पहचानने और रखने के लिए मॉडल को सुनिश्चित करते हुए, अनुमानित 2D कीपॉइंट स्थानों की स्थानिक सटीकता का आकलन करता है।
- क्यों उपयोग किया जाता है: OKS पोज़ अनुमान के लिए एक व्यापक रूप से अपनाया गया और मजबूत हानि फ़ंक्शन है, जो सीधे कार्य के प्राथमिक लक्ष्य को दर्शाता है। इसे वेग हानि में जोड़ा जाता है, यह दर्शाता है कि स्थिर पोज़ सटीकता और अस्थायी चिकनाई दोनों को महत्वपूर्ण माना जाता है और समग्र त्रुटि में स्वतंत्र रूप से योगदान करते हैं।
-
$\lambda_{vel}$:
- गणितीय परिभाषा: वेग हानि पद के लिए एक स्केलर भार गुणांक। पेपर $\lambda_{vel} = 0.05$ निर्दिष्ट करता है।
- भौतिक/तार्किक भूमिका: यह पैरामीटर अस्थायी चिकनाई ( $L_{vel}$ द्वारा लागू) के महत्व को कच्चे कीपॉइंट सटीकता ( $L_{oks}$ द्वारा संचालित) के खिलाफ संतुलित करने के लिए एक ट्यून करने योग्य डायल के रूप में कार्य करता है। 0.05 जैसा छोटा मान बताता है कि जबकि अस्थायी स्थिरता एक महत्वपूर्ण विचार है, इसे सटीक कीपॉइंट भविष्यवाणी की मौलिक आवश्यकता को पार नहीं करना चाहिए।
- क्यों उपयोग किया जाता है: यह एक ट्यून करने योग्य हाइपरपैरामीटर प्रदान करता है, जिससे लेखकों को मॉडल के व्यवहार को ठीक करने और विभिन्न सीखने के उद्देश्यों के बीच एक इष्टतम व्यापार-बंद प्राप्त करने की अनुमति मिलती है।
-
$L_{vel}$:
- गणितीय परिभाषा: वेग हानि, सभी प्रासंगिक फ्रेम और जोड़ों में अनुमानित और ग्राउंड-ट्रुथ जोड़ वेगों के बीच अंतर के माध्य वर्ग L2 मानदंड के रूप में गणना की जाती है।
- भौतिक/तार्किक भूमिका: यह पद एक "अस्थायी नियमितकर्ता" या "गति चिकनाई प्रवर्तक" के रूप में कार्य करता है। यह लगातार फ्रेम के बीच जोड़ की स्थिति में अचानक, अवास्तविक परिवर्तनों को दंडित करता है, जिससे अनुमानित पोज़ अनुक्रमों में चिकनी और सुसंगत गति को बढ़ावा मिलता है। यह स्पेक्युलर प्रतिबिंबों के कारण लापता जोड़ों का अनुमान लगाने के लिए विशेष रूप से फायदेमंद है, क्योंकि मॉडल को प्रासंगिक संकेतों का उपयोग करके यथार्थवादी गति प्रक्षेपवक्र "भरने" के लिए प्रोत्साहित किया जाता है।
- क्यों उपयोग किया जाता है: लेखकों ने रडार डेटा, जैसे लापता या शोर वाले जोड़ अवलोकनों से उत्पन्न चुनौतियों को कम करने के लिए इस हानि को पेश किया। चिकनाई लागू करके, मॉडल अधिक यथार्थवादी ढंग से अंतराल "भर" सकता है। वर्ग L2 मानदंड ($||\cdot||^2_2$) प्रतिगमन त्रुटियों के लिए एक मानक विकल्प है, जो बड़े विचलन को अधिक महत्वपूर्ण रूप से दंडित करता है और एक अवकलनीय उद्देश्य प्रदान करता है। योग ($\sum$) सभी लगातार फ्रेम जोड़े ($T-1$) और सभी जोड़ों ($J$) में त्रुटियों को एकत्रित करता है, जबकि विभाजन $(T-1)J$ हानि को सामान्य करता है, जिससे यह अनुक्रम लंबाई या जोड़ों की संख्या से स्वतंत्र हो जाता है।
-
$T$:
- गणितीय परिभाषा: इनपुट अनुक्रम में फ्रेम की कुल संख्या।
- भौतिक/तार्किक भूमिका: यह आयाम उस अस्थायी विंडो को परिभाषित करता है जिस पर वेग हानि की गणना की जाती है, विचार किए गए अस्थायी संदर्भ की सीमा स्थापित करती है।
- क्यों उपयोग किया जाता है: यह इनपुट डेटा का एक मौलिक पैरामीटर है, जो विश्लेषण किए जा रहे अनुक्रम की लंबाई को निर्धारित करता है।
-
$J$:
- गणितीय परिभाषा: अनुमानित मानव शरीर के जोड़ों की कुल संख्या।
- भौतिक/तार्किक भूमिका: यह आयाम उन व्यक्तिगत कीपॉइंट्स की संख्या को निर्दिष्ट करता है जिनके लिए वेग की गणना और तुलना की जाती है।
- क्यों उपयोग किया जाता है: यह आउटपुट डेटा का एक मौलिक पैरामीटर है, जो मानव पोज़ अनुमान की ग्रैन्युलैरिटी का प्रतिनिधित्व करता है।
-
$f$:
- गणितीय परिभाषा: फ्रेम 1 से $T-1$ तक पुनरावृति करने वाला एक सूचकांक।
- भौतिक/तार्किक भूमिका: यह सूचकांक इंगित करता है कि वेग की गणना किस विशिष्ट लगातार फ्रेम जोड़ी (फ्रेम $f$ और फ्रेम $f+1$) के लिए की जा रही है।
- क्यों उपयोग किया जाता है: अनुक्रम के अस्थायी आयाम में वेग की व्यवस्थित रूप से गणना और पारगमन करने के लिए।
-
$j$:
- गणितीय परिभाषा: जोड़ों 1 से $J$ तक पुनरावृति करने वाला एक सूचकांक।
- भौतिक/तार्किक भूमिका: यह सूचकांक उस विशेष जोड़ की पहचान करता है जिसका वेग वर्तमान में विचार के अधीन है।
- क्यों उपयोग किया जाता है: पोज़ के स्थानिक आयाम में वेग की व्यवस्थित रूप से गणना और पारगमन करने के लिए।
-
$v_{f,j}$:
- गणितीय परिभाषा: फ्रेम $f$ पर जोड़ $j$ का ग्राउंड-ट्रुथ वेग। इसकी गणना फ्रेम $f+1$ और फ्रेम $f$ पर उनकी ग्राउंड-ट्रुथ स्थितियों के बीच अंतर के रूप में की जाती है: $P_{f+1,j} - P_{f,j}$।
- भौतिक/तार्किक भूमिका: यह दो लगातार फ्रेम के बीच एक विशिष्ट जोड़ के लिए वास्तविक, वांछित गति वेक्टर का प्रतिनिधित्व करता है, जो मॉडल के लिए आदर्श लक्ष्य के रूप में कार्य करता है।
- क्यों उपयोग किया जाता है: यह सटीक संदर्भ प्रदान करता है जिसके विरुद्ध मॉडल की अनुमानित गति की तुलना की जाती है, सीखने की प्रक्रिया का मार्गदर्शन करता है।
-
$\hat{v}_{f,j}$:
- गणितीय परिभाषा: फ्रेम $f$ पर जोड़ $j$ का अनुमानित वेग। इसकी गणना फ्रेम $f+1$ और फ्रेम $f$ पर उनकी अनुमानित स्थितियों के बीच अंतर के रूप में की जाती है: $\hat{P}_{f+1,j} - \hat{P}_{f,j}$।
- भौतिक/तार्किक भूमिका: यह लगातार फ्रेम के बीच अनुमानित गति वेक्टर है, जिसकी तुलना वेग हानि द्वारा दंडित ग्राउंड-ट्रुथ वेग $v_{f,j}$ से की जाती है।
- क्यों उपयोग किया जाता है: यह लगातार फ्रेम के अनुमानित पोज़ से मॉडल का आउटपुट है, जिसका उपयोग तब वेग हानि की गणना के लिए किया जाता है।
-
$||\cdot||^2_2$:
- गणितीय परिभाषा: एक वेक्टर का वर्ग यूक्लिडियन (L2) मानदंड। एक वेक्टर $x = [x_1, x_2, \dots, x_k]$ के लिए, इसका वर्ग L2 मानदंड $||x||^2_2 = \sum_{i=1}^k x_i^2$ है।
- भौतिक/तार्किक भूमिका: यह अनुमानित और ग्राउंड-ट्रुथ वेगों के बीच अंतर वेक्टर के वर्ग परिमाण को मापता है। वर्ग सुनिश्चित करता है कि सकारात्मक और नकारात्मक दोनों अंतर हानि में योगदान करते हैं और बड़े त्रुटियों को छोटे लोगों की तुलना में अधिक महत्वपूर्ण रूप से दंडित किया जाता है।
- क्यों उपयोग किया जाता है: यह दो वैक्टर के बीच "दूरी" या "त्रुटि" को मापने का एक मानक, अवकलनीय और कम्प्यूटेशनल रूप से कुशल तरीका है, जो इसे ग्रेडिएंट-आधारित अनुकूलन के लिए अच्छी तरह से अनुकूल बनाता है।
चरण-दर-चरण प्रवाह
आइए कच्चे रडार संकेतों से लेकर परिष्कृत पोज़ अनुमान तक, milliMamba की यांत्रिक असेंबली लाइन से गुजरते हुए एक अमूर्त डेटा बिंदु की यात्रा का पता लगाएं।
-
कच्चा रडार सिग्नल अंतर्ग्रहण: प्रक्रिया मिलीमीटर-वेव (mmWave) रडार संकेतों के साथ शुरू होती है। ये प्रत्येक फ्रेम के लिए जटिल-मूल्य वाले क्यूब्स $X \in \mathbb{C}^{12 \times 128 \times 256}$ के रूप में आते हैं, जो आभासी-एंटीना जोड़े, चिड़िया और ADC नमूनों में डेटा का प्रतिनिधित्व करते हैं। चूंकि milliMamba एक द्वैत-रडार सेटअप का उपयोग करता है, इसलिए $T$ लगातार फ्रेम के अनुक्रम के लिए ऐसे दो क्यूब्स (एक क्षैतिज के लिए, एक ऊर्ध्वाधर के लिए) प्राप्त किए जाते हैं, जो अस्थायी संदर्भ की एक स्लाइडिंग विंडो बनाते हैं।
-
पूर्व-संसाधन असेंबली लाइन (3D फास्ट फूरियर ट्रांसफॉर्म):
- क्लटर हटाना: सबसे पहले, पर्यावरण से स्थिर प्रतिबिंबों को चिड़िया के पार माध्य घटाकर फ़िल्टर किया जाता है। यह कच्चे माल को साफ करने जैसा है, यह सुनिश्चित करता है कि केवल प्रासंगिक गतिशील लक्ष्य संसाधित हों।
- चिड़िया उप-नमूनाकरण: चिड़िया आयाम को फिर प्रति फ्रेम समान रूप से 8 चिड़िया तक घटाया जाता है। यह कदम डेटा को संपीड़ित करने जैसा है, आवश्यक डॉपलर रिज़ॉल्यूशन को बनाए रखते हुए कम्प्यूटेशनल लोड को कम करता है।
- 1D FFT (रेंज): ADC-नमूना आयाम के साथ एक 1D फास्ट फूरियर ट्रांसफॉर्म (FFT) लागू किया जाता है ( $Y(m) = \sum_{n=0}^{N-1} X(n) \exp(-j \frac{2\pi nm}{N})$ के अनुसार)। यह कच्चे समय-डोमेन नमूनों को रेंज जानकारी में बदल देता है, जो वस्तुओं की दूरी को इंगित करता है।
- 1D FFT (डॉपलर): इसके बाद, चिड़िया आयाम के साथ एक और 1D FFT लागू किया जाता है। यह डॉपलर जानकारी निकालता है, जो रडार के सापेक्ष वस्तुओं के वेग को प्रकट करता है।
- जीरो-पैडिंग और 1D FFT (कोण): कोणीय रिज़ॉल्यूशन को बढ़ाने के लिए, आभासी-एंटीना आयाम को 12 से 64 तक शून्य-पैड किया जाता है। इस आयाम के साथ एक अंतिम 1D FFT डेटा को कोण जानकारी (अज़ीमुथ और ऊंचाई) में परिवर्तित करता है।
- आउटपुट: प्रत्येक दृश्य और फ्रेम के लिए रडार डेटा अब एक 3D कोण-डॉपलर-रेंज हीटमैप $Y \in \mathbb{C}^{H \times D \times W}$ (जैसे, $64 \times 8 \times 256$) है। इन जटिल-मूल्य वाले हीटमैप के वास्तविक और काल्पनिक घटकों को अलग-अलग चैनलों के रूप में माना जाता है, जिसके परिणामस्वरूप $C \times T \times H \times D \times W$ के आकार का एक दो-चैनल टेंसर बनता है, जहां $C=2$ होता है।
-
CVMamba एनकोडर - फ़ीचर निष्कर्षण और अस्थायी मॉडलिंग:
- समानांतर MNet शाखाएँ: क्षैतिज और ऊर्ध्वाधर दृश्य हीटमैप को दो अलग-अलग, समानांतर MNet ब्लॉकों में फीड किया जाता है। प्रत्येक MNet ब्लॉक पहले डॉपलर आयाम को मर्ज करता है, फिर अवशिष्ट 3D कनवल्शन और डाउन-सैंपलिंग परतों की एक श्रृंखला के माध्यम से डेटा को संसाधित करता है। यह स्थानिक रिज़ॉल्यूशन (H और W) को $4 \times$ के कारक से कम करता है, जिससे फ़ीचर मैप $F_h, F_v \in \mathbb{R}^{C_f \times T \times \frac{H}{4} \times \frac{W}{4}}$ प्राप्त होते हैं। यह दो विशेष समानांतर प्रसंस्करण लाइनों की तरह है जो विभिन्न दृष्टिकोणों को संभालती हैं।
- स्थितीय एम्बेडिंग: अलग-अलग सीखने योग्य स्थितीय एम्बेडिंग $P_h$ और $P_v$ को क्रमशः $F_h$ और $F_v$ में जोड़ा जाता है। ये एम्बेडिंग डेटा में सुविधाओं के पूर्ण स्थानिक स्थान (कोण और रेंज) के बारे में जानकारी इंजेक्ट करते हैं।
- क्रॉस-व्यू फ्यूजन: दो दृश्य सुविधाओं को तब चैनल आयाम के साथ जोड़ा जाता है ताकि एकीकृत एनकोडर इनपुट $F = [F_h; F_v] \in \mathbb{R}^{C_s \times T \times \frac{H}{4} \times \frac{W}{4} \times 2}$ बनाया जा सके। यह कदम प्रभावी ढंग से दोनों रडार दृश्यों से जानकारी को मर्ज करता है।
- अनुक्रम रैखिकीकरण: मल्टी-डायमेंशनल फ़ीचर टेंसर $F$ को एक विशिष्ट ज़िगज़ैग स्कैन पैटर्न (रेंज $\rightarrow$ कोण $\rightarrow$ दृश्य $\rightarrow$ फ्रेम) का उपयोग करके टोकन $u_t$ के 1D अनुक्रम में परिवर्तित किया जाता है। यह परिवर्तन मैम्बा आर्किटेक्चर के अनुक्रमिक प्रसंस्करण के लिए डेटा तैयार करता है।
- मैम्बा परत प्रसंस्करण: यह 1D अनुक्रम $u_t$ विजन मैम्बा परतों के एक स्टैक में प्रवेश करता है। प्रत्येक परत पुनरावृत्त रूप से अपने छिपे हुए राज्य $h_t$ को अपडेट करती है और SSM समीकरणों ($h_{t+1} = A h_t + B u_t$, $y_t = C h_t + D u_t$) का उपयोग करके एक आउटपुट $y_t$ उत्पन्न करती है। यह प्रक्रिया आगे और पीछे दोनों दिशाओं में निष्पादित की जाती है, जिससे मॉडल को रैखिक जटिलता के साथ पूरे लंबे अनुक्रम पर कुशल तरीके से द्वि-दिशात्मक संदर्भ को कैप्चर करने की अनुमति मिलती है। मैम्बा परतों के भीतर गेटिंग तंत्र और अवशिष्ट कनेक्शन इस अनुक्रमिक प्रसंस्करण को और परिष्कृत करते हैं।
- आउटपुट: CVMamba एनकोडर एक समृद्ध, संदर्भ-जागरूक फ़ीचर प्रतिनिधित्व आउटपुट करता है, जिसे $x_{Le}$ के रूप में दर्शाया जाता है, जिसने प्रभावी ढंग से कई फ्रेम और द्वैत रडार दृश्यों में जटिल स्पेटियो-टेम्पोरल निर्भरताओं को कैप्चर किया है।
-
STCA डिकोडर - पोज़ भविष्यवाणी और शोधन:
- कीपॉइंट क्वेरी आरंभीकरण: डिकोडर $J \times T$ सीखने योग्य कीपॉइंट क्वेरी $\{q_{f,j}\}$ के एक निश्चित सेट के साथ शुरू होता है। प्रत्येक क्वेरी एक विशिष्ट फ्रेम में एक विशिष्ट जोड़ का प्रतिनिधित्व करने के लिए डिज़ाइन की गई एक एम्बेडिंग है। ये क्वेरी "बुद्धिमान जांच" की तरह काम करती हैं जो पोज़ जानकारी की तलाश करती हैं।
- स्पेटियो-टेम्पोरल अटेंशन मॉड्यूल:
- स्थानिक ध्यान (SA): सबसे पहले, स्थानिक स्व-ध्यान प्रत्येक फ्रेम के भीतर लागू किया जाता है ($q'_{f,.} = \text{softmax}(Q_f K_f^T / \sqrt{d}) V_f$)। यह एक ही फ्रेम में विभिन्न जोड़ों के लिए क्वेरी को इंटरैक्ट करने की अनुमति देता है, जिससे इंटर-जोड़ संबंध कैप्चर होते हैं (जैसे, एक एकल स्नैपशॉट में कोहनी कलाई से कैसे संबंधित है)।
- अस्थायी ध्यान (TA): इसके बाद, अस्थायी स्व-ध्यान एक ही जोड़ के लिए फ्रेम में लागू किया जाता है ($q''_{.,j} = \text{softmax}(Q_j K_j^T / \sqrt{d}) V_j$)। यह एक विशिष्ट जोड़ के लिए क्वेरी को पड़ोसी फ्रेम में अपने स्वयं के प्रतिनिधित्व पर ध्यान देने की अनुमति देता है, गति स्थिरता को लागू करता है और आंदोलन को समझने के लिए अस्थायी संदर्भ का लाभ उठाता है।
- एनकोडर सुविधाओं के लिए क्रॉस-अटेंशन: परिष्कृत कीपॉइंट क्वेरी $q''_{f,j}$ तब एनकोडर के आउटपुट सुविधाओं $F'$ (जो $x_{Le}$ है) के साथ क्रॉस-अटेंशन करती है ($\hat{q}_{f,j} = \text{CrossAttn}(q''_{f,j}, F')$)। यह महत्वपूर्ण कदम कीपॉइंट क्वेरी को CVMamba एनकोडर द्वारा उत्पन्न समृद्ध स्पेटियो-टेम्पोरल सुविधाओं से प्रासंगिक पोज़ जानकारी निकालने की अनुमति देता है, प्रभावी ढंग से क्वेरी को रडार डेटा में "ग्राउंडिंग" करता है।
- पुनरावृत्त शोधन: इस पूरे डिकोडर परत (स्थानिक-अस्थायी ध्यान, क्रॉस-अटेंशन, और एक स्थिति-वार MLP सहित) को कई बार स्टैक किया जाता है। कीपॉइंट क्वेरी इन परतों के माध्यम से पुनरावृत्त रूप से परिष्कृत की जाती है, धीरे-धीरे उनके प्रतिनिधित्व और सटीकता में सुधार होता है।
- भविष्यवाणी प्रमुख: अंत में, प्रत्येक परिष्कृत क्वेरी $\hat{q}_{f,j}$ को फ्रेम $f$ में जोड़ $j$ के लिए 2D निर्देशांक आउटपुट करने के लिए एक साधारण भविष्यवाणी प्रमुख (जैसे, एक बहु-परत परसेप्ट्रॉन) के माध्यम से पारित किया जाता है।
- आउटपुट: डिकोडर $T$ पोज़ अनुमानों का एक अनुक्रम उत्पन्न करता है, जहां प्रत्येक अनुमान में $J$ 2D कीपॉइंट निर्देशांक होते हैं। अनुमान के दौरान, आमतौर पर स्लाइडिंग विंडो के भीतर केंद्रीय फ्रेम के लिए भविष्यवाणी ही रखी जाती है।
अनुकूलन गतिशीलता
milliMamba मॉडल समग्र प्रशिक्षण उद्देश्य $L = L_{oks} + \lambda_{vel} L_{vel}$ द्वारा मुख्य रूप से निर्देशित पुनरावृत्त अनुकूलन की एक कठोर प्रक्रिया के माध्यम से अपने मानव पोज़ अनुमान क्षमताओं को सीखता है और परिष्कृत करता है। यह तंत्र व्यवस्थित रूप से मॉडल के आंतरिक मापदंडों को समायोजित करता है ताकि इसकी भविष्यवाणियों और ग्राउंड ट्रुथ के बीच असमानता को कम किया जा सके।
-
हानि परिदृश्य और ग्रेडिएंट व्यवहार:
- कुल हानि $L$ सभी सीखने योग्य मॉडल मापदंडों के विशाल स्थान पर एक जटिल, उच्च-आयामी "हानि परिदृश्य" को परिभाषित करता है। अनुकूलन प्रक्रिया का मौलिक लक्ष्य इस परिदृश्य को नेविगेट करके इसके निम्नतम बिंदु (वैश्विक न्यूनतम) या पर्याप्त रूप से निम्न बिंदु (स्थानीय न्यूनतम) का पता लगाना है।
- $L_{oks}$ (ऑब्जेक्ट कीपॉइंट सिमिलैरिटी लॉस): हानि फ़ंक्शन का यह घटक मुख्य रूप से परिदृश्य को व्यक्तिगत कीपॉइंट्स के सटीक स्थानिक प्लेसमेंट को पुरस्कृत करने के लिए आकार देता है। यह ग्रेडिएंट उत्पन्न करता है जो अनुमानित कीपॉइंट्स को उनके संबंधित ग्राउंड-ट्रुथ स्थानों की ओर प्रभावी ढंग से "खींचता है"। यदि एक अनुमानित कीपॉइंट अपने वास्तविक स्थान से काफी विस्थापित है, तो $L_{oks}$ एक मजबूत ग्रेडिएंट उत्पन्न करेगा, जिससे मॉडल को इस स्थानिक त्रुटि को कम करने के लिए अपने मापदंडों को समायोजित करने के लिए मजबूर किया जाएगा।
- $L_{vel}$ (वेग हानि): यह घटक एक महत्वपूर्ण नियमितीकरण प्रभाव का परिचय देता है, हानि परिदृश्य को अस्थायी रूप से चिकनी और सुसंगत पोज़ अनुक्रमों के पक्ष में आकार देता है। यह लगातार फ्रेम के बीच जोड़ की स्थिति में अचानक या अवास्तविक परिवर्तनों को सक्रिय रूप से दंडित करने वाले ग्रेडिएंट उत्पन्न करता है। यदि एक जोड़ के अनुमानित वेग ग्राउंड-ट्रुथ वेग से काफी विचलित होते हैं, तो $L_{vel}$ ग्रेडिएंट उत्पन्न करेगा जो मॉडल को चिकनी, अधिक भौतिक रूप से प्रशंसनीय गति की भविष्यवाणी करने के लिए प्रोत्साहित करता है। यह स्पेक्युलर प्रतिबिंबों या विरल रडार संकेतों के कारण लापता जोड़ों का अनुमान लगाने के लिए विशेष रूप से फायदेमंद है, क्योंकि मॉडल पड़ोसी फ्रेम से प्रासंगिक संकेतों के आधार पर प्रशंसनीय गति को "इंटरपोलेट" करना सीखता है।
- संतुलन कार्य ($\lambda_{vel}$): भार कारक $\lambda_{vel}$, जिसे 0.05 के मान पर सेट किया गया है, अस्थायी चिकनाई ( $L_{vel}$ द्वारा लागू) के महत्व को कच्चे कीपॉइंट सटीकता ( $L_{oks}$ द्वारा संचालित) के प्राथमिक उद्देश्य के खिलाफ संतुलित करने में एक महत्वपूर्ण भूमिका निभाता है। यह अपेक्षाकृत छोटा मान सुनिश्चित करता है कि जबकि अस्थायी स्थिरता एक महत्वपूर्ण विचार है, यह सटीक कीपॉइंट भविष्यवाणी की मौलिक आवश्यकता को पार नहीं करना चाहिए। नतीजतन, $L_{oks}$ से उत्पन्न ग्रेडिएंट आम तौर पर एक मजबूत प्रभाव डालेंगे, मॉडल को सटीक पोज़ अनुमानों की ओर मार्गदर्शन करेंगे, जबकि $L_{vel}$ एक कोमल, फिर भी लगातार, सामंजस्य की ओर खिंचाव प्रदान करेगा। $L_{vel}$ के बिना, मॉडल सटीक लेकिन झटकेदार पोज़ उत्पन्न कर सकता है; अत्यधिक उच्च $\lambda_{vel}$ के साथ, यह सटीकता की कीमत पर चिकनाई को प्राथमिकता दे सकता है।
-
पुनरावृत्त राज्य अद्यतन:
- फॉरवर्ड पास: प्रत्येक प्रशिक्षण पुनरावृति के दौरान, मल्टी-फ्रेम रडार अनुक्रमों का एक बैच पूरे milliMamba नेटवर्क—पूर्व-संसाधन, CVMamba एनकोडर, और STCA डिकोडर को कवर करते हुए—से होकर गुजरता है। यह फॉरवर्ड प्रोपेगेशन प्रत्येक फ्रेम $f$ और जोड़ $j$ के लिए अनुमानित 2D कीपॉइंट निर्देशांक $\hat{P}_{f,j}$ के अनुक्रम के निर्माण में समाप्त होता है।
- हानि गणना: इन अनुमानित कीपॉइंट निर्देशांकों की तुलना ग्राउंड-ट्रुथ कीपॉइंट निर्देशांक $P_{f,j}$ से कठोरता से की जाती है ताकि $L_{oks}$ की गणना की जा सके। समवर्ती रूप से, अनुमानित वेग $\hat{v}_{f,j}$ ( $\hat{P}_{f,j}$ से प्राप्त) की तुलना ग्राउंड-ट्रुथ वेग $v_{f,j}$ ( $P_{f,j}$ से प्राप्त) से की जाती है ताकि $L_{vel}$ की गणना की जा सके। इन दो अलग-अलग हानि घटकों को तब मास्टर समीकरण के अनुसार जोड़ा जाता है: $L = L_{oks} + \lambda_{vel} L_{vel}$।
- बैकवर्ड पास (बैकप्रोपैगेशन): गणना की गई कुल हानि $L$ को तब पूरे नेटवर्क में वापस प्रचारित किया जाता है। यह जटिल प्रक्रिया मॉडल के भीतर हर एकल सीखने योग्य पैरामीटर के संबंध में $L$ के ग्रेडिएंट की गणना करती है। इसमें, उदाहरण के लिए, मैम्बा परतों में मैट्रिक्स $A, B, C, D$, MNet ब्लॉकों में कनवल्शनल न्यूरल नेटवर्क (CNN) के भार, STCA डिकोडर में अटेंशन मैट्रिक्स, और प्रारंभिक सीखने योग्य कीपॉइंट क्वेरी शामिल हैं।
- पैरामीटर अद्यतन (एडम ऑप्टिमाइज़र): एडम ऑप्टिमाइज़र का उपयोग मॉडल के मापदंडों को अद्यतन करने के लिए किया जाता है। एडम एक उन्नत अनुकूली सीखने की दर अनुकूलन एल्गोरिथम है जो ग्रेडिएंट के पहले और दूसरे क्षणों के अनुमानों के आधार पर विभिन्न मापदंडों के लिए व्यक्तिगत अनुकूली सीखने की दर की गणना करता है। 0.00005 की निर्दिष्ट सीखने की दर और 0.0001 के वजन क्षय के साथ, ऑप्टिमाइज़र बुद्धिमानी से मापदंडों को उस दिशा में समायोजित करता है जो हानि को कम करने में सबसे प्रभावी है। वजन क्षय शब्द एक नियमितीकरण तंत्र के रूप में कार्य करता है, जो मॉडल को अत्यधिक जटिल होने और प्रशिक्षण डेटा पर ओवरफिट होने से रोकने में मदद करता है।
- अभिसरण: फॉरवर्ड पास, हानि गणना, बैकवर्ड पास और पैरामीटर अद्यतन की यह चक्रीय प्रक्रिया कई युगों (पूरे प्रशिक्षण डेटासेट पर पुनरावृति) के लिए दोहराई जाती है। समय के साथ, मॉडल के पैरामीटर धीरे-धीरे उन मानों पर अभिसरण करते हैं जो हानि फ़ंक्शन को कम करते हैं, जिससे प्रशिक्षण डेटा और पहले अनदेखे डेटा दोनों पर पोज़ अनुमान सटीकता में लगातार सुधार होता है और अस्थायी स्थिरता बढ़ती है। STCA डिकोडर के भीतर अंतर्निहित पुनरावृत्त शोधन चरण भी इस अभिसरण में महत्वपूर्ण रूप से योगदान करते हैं, क्योंकि कीपॉइंट क्वेरी को अंतर्निहित पोज़ का बेहतर प्रतिनिधित्व करने के लिए अद्यतन किया जाता है। ओवरफिटिंग के संकेतों का पता लगाने और प्रशिक्षण को रोकने के लिए इष्टतम बिंदु निर्धारित करने के लिए एक अलग सत्यापन सेट पर मॉडल के प्रदर्शन की लगातार निगरानी की जाती है।
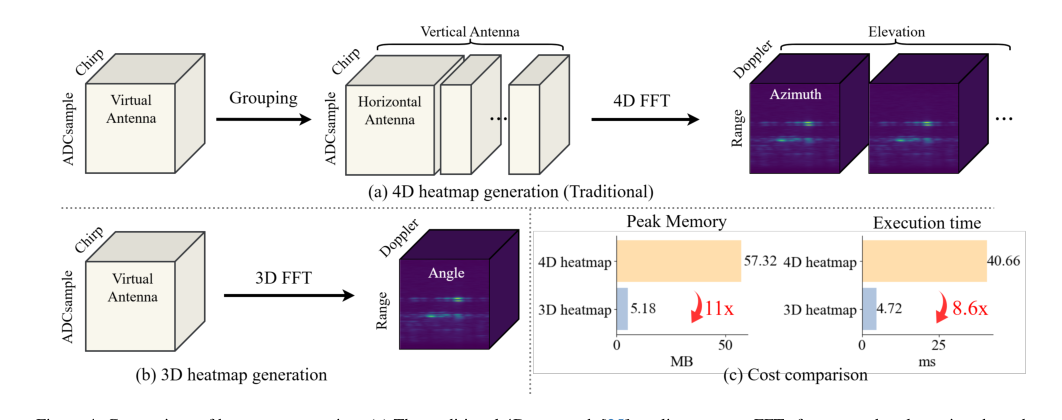 Figure 4. Comparison of heatmap generation. (a) The traditional 4D approach [25] applies separate FFTs for range, doppler, azimuth, and elevation after antenna grouping. (b) Our 3D pipeline performs a unified spatial FFT without grouping, yielding a compact representation. (c) Cost comparison between 4D and 3D heatmaps, showing 11× reduction in memory and 8.6× reduction in latency
Figure 4. Comparison of heatmap generation. (a) The traditional 4D approach [25] applies separate FFTs for range, doppler, azimuth, and elevation after antenna grouping. (b) Our 3D pipeline performs a unified spatial FFT without grouping, yielding a compact representation. (c) Cost comparison between 4D and 3D heatmaps, showing 11× reduction in memory and 8.6× reduction in latency
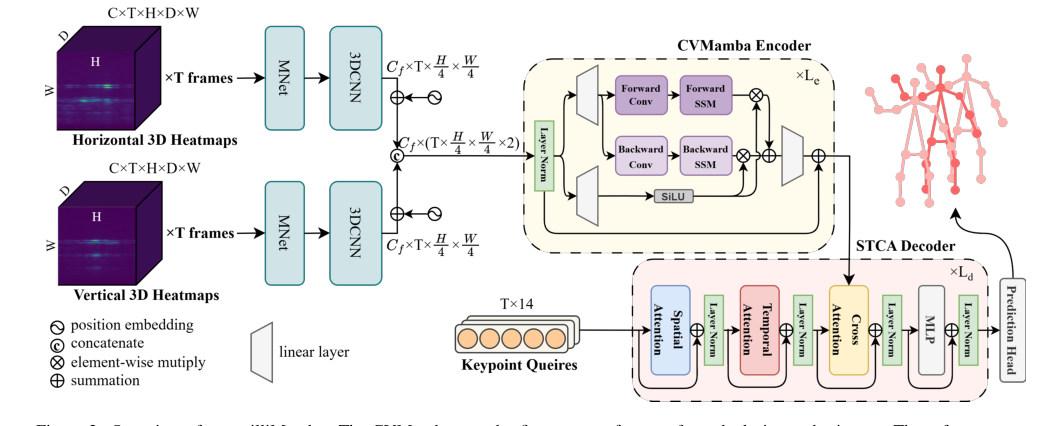 Figure 2. Overview of our milliMamba. The CVMamba encoder first extracts features from dual-view radar inputs. These features are then passed to the Multi-Pose STCA decoder, which progressively refines a set of keypoint queries to produce pose predictions
Figure 2. Overview of our milliMamba. The CVMamba encoder first extracts features from dual-view radar inputs. These features are then passed to the Multi-Pose STCA decoder, which progressively refines a set of keypoint queries to produce pose predictions
परिणाम, सीमाएँ और निष्कर्ष
प्रयोगात्मक डिजाइन और बेसलाइन
milliMamba की क्षमताओं को कठोरता से मान्य करने के लिए, लेखकों ने अपने प्रस्तावित तंत्र के योगदान को अलग करने और मापने के लिए डिज़ाइन किए गए प्रयोगों की एक श्रृंखला तैयार की। मुख्य सेटअप में द्वैत मिलीमीटर-वेव (mmWave) रडार इनपुट शामिल थे, जिनमें से प्रत्येक $T=9$ फ्रेम के अनुक्रम को कैप्चर करता था, मॉडल में फीड किया गया। जबकि मॉडल ने 9 लगातार पोज़ भविष्यवाणियां कीं, अनुमान के लिए केवल केंद्रीय फ्रेम की भविष्यवाणी का उपयोग किया गया था, जिससे उन विधियों के साथ निष्पक्ष तुलना सुनिश्चित हुई जो प्रति इनपुट एक पोज़ की भविष्यवाणी करती हैं।
प्रशिक्षण व्यवस्था में 0.00005 की सीखने की दर, 8 का बैच आकार और 0.0001 का वजन क्षय के साथ एडम ऑप्टिमाइज़र का उपयोग किया गया। समग्र प्रशिक्षण उद्देश्य एक समग्र हानि फ़ंक्शन था: $L = L_{oks} + \lambda_{vel} L_{vel}$। यहाँ, $L_{oks}$ (ऑब्जेक्ट कीपॉइंट सिमिलैरिटी) ने अनुमानित और ग्राउंड-ट्रुथ जोड़ स्थानों के बीच विसंगतियों को दंडित किया, जो पोज़ अनुमान में एक मानक मीट्रिक है। महत्वपूर्ण रूप से, $L_{vel}$ (वेग हानि) को अस्थायी चिकनाई लागू करने के लिए पेश किया गया था, जो अनुमानित और ग्राउंड-ट्रुथ जोड़ वेगों के बीच त्रुटि को कम करके, $\lambda_{vel} = 0.05$ के भार कारक के साथ। यह वेग हानि रडार-आधारित पोज़ अनुमान में अक्सर देखी जाने वाली अस्थायी असंगति को संबोधित करने के लिए एक प्रमुख वास्तुशिल्प विकल्प था। सभी कम्प्यूटेशनल भारी भार एक एकल NVIDIA Tesla V100 GPU पर किए गए थे।
जिन "पीड़ितों" (बेसलाइन मॉडल) के खिलाफ milliMamba को खड़ा किया गया था, उनमें स्थापित रडार-आधारित 2D मानव पोज़ अनुमान (HPE) विधियाँ शामिल थीं:
- TransHuPR [12]: एक ट्रांसफार्मर-आधारित दृष्टिकोण जो आंशिक रूप से स्पेटियो-टेम्पोरल निर्भरताओं को मॉडल करता है।
- HuPR [13]: एक और प्रमुख रडार-आधारित HPE फ्रेमवर्क।
- mmPose [23]: एक CNN-आधारित विधि।
लेखकों ने RFMamba [35] को भी स्वीकार किया, जो एक मैम्बा-आधारित दृष्टिकोण है, लेकिन नोट किया कि इसका स्रोत कोड सार्वजनिक रूप से उपलब्ध नहीं था, जिससे प्रत्यक्ष तुलना संभव नहीं थी।
दो बेंचमार्क mmWave रडार-आधारित 2D HPE डेटासेट पर मूल्यांकन किया गया:
- TransHuPR [12]: 440 अनुक्रमों (7 घंटे से अधिक) को 22 विषयों से मिलाकर, यह डेटासेट तेज और गतिशील क्रियाओं की विशेषता है, जो एक महत्वपूर्ण चुनौती पेश करता है।
- HuPR डेटासेट [13]: 235 अनुक्रमों (लगभग 4 घंटे) को 6 विषयों से मिलाकर, यह डेटासेट मुख्य रूप से अपेक्षाकृत स्थिर क्रियाओं को प्रदर्शित करता है।
दोनों डेटासेट के लिए, मानक डेटा विभाजन प्रोटोकॉल का पालन किया गया। मूल्यांकन के लिए निश्चित मीट्रिक औसत परिशुद्धता (AP) थी, जिसे ऑब्जेक्ट कीपॉइंट सिमिलैरिटी (OKS) के आधार पर गणना की गई। इसमें समग्र AP (0.50 से 0.95 तक OKS थ्रेसहोल्ड पर औसत), साथ ही ढीले और सख्त मिलान मानदंडों के लिए AP50 (OKS 0.50) और AP75 (OKS 0.75) शामिल थे।
साक्ष्य क्या साबित करते हैं
पेपर में प्रस्तुत साक्ष्य निर्विवाद रूप से साबित करते हैं कि milliMamba के मुख्य तंत्र वास्तव में काम करते हैं, जिससे मौजूदा बेसलाइन पर महत्वपूर्ण प्रदर्शन लाभ होता है।
सबसे पहले, समग्र प्रदर्शन के मामले में, milliMamba ने लगातार और काफी हद तक दोनों TransHuPR और HuPR डेटासेट पर बेसलाइन को पार कर लिया। चुनौतीपूर्ण TransHuPR डेटासेट पर, milliMamba ने TransHuPR [12] बेसलाइन पर एक उल्लेखनीय 11.0 AP सुधार हासिल किया। यह विशेष रूप से कलाई जैसे अनुमान लगाने में मुश्किल जोड़ों के लिए स्पष्ट था, जो तेज गति और स्पेक्युलर प्रतिबिंबों के प्रति संवेदनशील है, जहां milliMamba ने 46.9 का AP हासिल किया। इसी तरह, HuPR डेटासेट पर, milliMamba ने HuPR [13] पर एक और भी प्रभावशाली 14.6 AP सुधार प्रदान किया, जो अपेक्षाकृत स्थिर क्रियाओं के लिए 84.0 AP तक पहुंच गया। ये संख्याएँ केवल वृद्धिशील नहीं हैं; वे रडार-आधारित HPE के लिए अत्याधुनिक में एक महत्वपूर्ण छलांग का प्रतिनिधित्व करती हैं।
पेपर अपने वास्तुशिल्प विकल्पों की दक्षता और प्रभावशीलता के लिए ठोस सबूत भी प्रदान करता है:
- कुशल 3D FFT पूर्व-संसाधन: चित्र 4(c) निश्चित रूप से दिखाता है कि प्रस्तावित 3D फास्ट फूरियर ट्रांसफॉर्म (FFT) पूर्व-संसाधन पाइपलाइन पारंपरिक 4D FFT दृष्टिकोण की तुलना में 11x मेमोरी उपयोग और 8.6x विलंबता को कम करती है। तालिका 4 आगे इस बात को मान्य करती है कि 3D FFT-आधारित हीटमैप 4D FFT (72.0 AP) की तुलना में तुलनीय, यदि बेहतर नहीं, सटीकता (74.5 AP) प्राप्त करते हैं, यह साबित करते हुए कि दक्षता लाभ प्रदर्शन की कीमत पर नहीं आए।
- मल्टी-पोज़ आउटपुट तंत्र (मेनी-टू-मेनी): तालिका 5 स्पष्ट रूप से milliMamba के स्पेटियो-टेम्पोरल-क्रॉस अटेंशन (STCA) डिकोडर के लाभ को दर्शाती है। "मेनी-टू-मेनी" भविष्यवाणी रणनीति, जो पड़ोसी फ्रेम से प्रासंगिक संकेतों का लाभ उठाती है, "मेनी-टू-वन" दृष्टिकोण (एक सामान्य ट्रांसफार्मर डिकोडर जो एक पोज़ की भविष्यवाणी करता है) की तुलना में समग्र सटीकता में 4.1 AP सुधार उत्पन्न करती है। यह निश्चित प्रमाण है कि डिकोडिंग चरण में स्पेटियो-टेम्पोरल निर्भरताओं को मॉडल करना स्पेक्युलर प्रतिबिंबों के कारण लापता जोड़ों का अनुमान लगाने के लिए महत्वपूर्ण है।
- मैम्बा एनकोडर की स्केलेबिलिटी: तालिका 8 में मैम्बा और ट्रांसफार्मर एनकोडर के बीच तुलना विशेष रूप से सम्मोहक है। जबकि मैम्बा ने छोटी अनुक्रमों ($T=3$ फ्रेम) के लिए ट्रांसफार्मर की तुलना में 1.5 AP उच्च स्कोर हासिल किया, महत्वपूर्ण साक्ष्य ट्रांसफार्मर की मेमोरी से बाहर के मुद्दों के कारण लंबे अनुक्रमों को संभालने में असमर्थता में निहित है। मैम्बा, अपनी रैखिक जटिलता के साथ, सफलतापूर्वक लंबे इनपुट अनुक्रमों (तालिका 6 में दिखाए गए अनुसार $T=15$ फ्रेम तक) तक स्केल करता है, जहां प्रदर्शन लगातार सुधरता है। यह मैम्बा की बेहतर स्केलेबिलिटी और समृद्ध अस्थायी संदर्भ का प्रभावी ढंग से लाभ उठाने की क्षमता को प्रदर्शित करता है, जो पेपर का एक प्रमुख दावा है।
- द्वैत-रडार कॉन्फ़िगरेशन: तालिका 7 स्पष्ट रूप से प्रदर्शित करती है कि द्वैत-रडार (क्षैतिज+ऊर्ध्वाधर) कॉन्फ़िगरेशन अकेले क्षैतिज (67.3 AP) या ऊर्ध्वाधर (74.5 AP) रडार का उपयोग करने की तुलना में प्रदर्शन (78.5 AP) को काफी बढ़ाता है। यह mmWave रडार सेंसर के अंतर्निहित सीमित ऊंचाई रिज़ॉल्यूशन के लिए क्रॉस-व्यू फ्यूजन की प्रभावशीलता की पुष्टि करता है।
चित्र 5 में गुणात्मक परिणाम इन निष्कर्षों को और मजबूत करते हैं, जो milliMamba की TransHuPR डेटासेट पर विभिन्न क्रियाओं पर अधिक सटीक और अस्थायी रूप से सुसंगत पोज़ अनुमान उत्पन्न करने की क्षमता को नेत्रहीन रूप से प्रदर्शित करते हैं, जो mmPose, HuPR और TransHuPR बेसलाइन से बेहतर प्रदर्शन करते हैं।
सीमाएँ और भविष्य की दिशाएँ
जबकि milliMamba रडार-आधारित मानव पोज़ अनुमान में एक महत्वपूर्ण प्रगति प्रस्तुत करता है, इसकी वर्तमान सीमाओं को स्वीकार करना और भविष्य के विकास के लिए रास्ते पर विचार करना महत्वपूर्ण है।
एक अंतर्निहित सीमा, लंबे अनुक्रमों के लिए पारंपरिक ट्रांसफार्मर पर milliMamba की दक्षता सुधारों के बावजूद, कम्प्यूटेशनल लागत है। जबकि यह सटीकता और जटिलता के बीच एक अनुकूल व्यापार-बंद प्रदान करता है, इसका MACs गणना (34.4 G) अभी भी कुछ बेसलाइन जैसे TransHuPR [12] (5.8 G) से अधिक है। यह बताता है कि अत्यधिक संसाधन-बाधित एज उपकरणों पर तैनाती के लिए, कम्प्यूटेशनल फ़ुटप्रिंट के संदर्भ में और अधिक अनुकूलन आवश्यक हो सकता है।
एक और स्पष्ट सीमा एकल-व्यक्ति पोज़ अनुमान पर वर्तमान ध्यान है। पेपर स्पष्ट रूप से कहता है कि भविष्य के काम में "बहु-व्यक्ति" परिदृश्यों का पता लगाया जाएगा। कई विषयों के साथ रडार सिग्नल अवरोधों, हस्तक्षेप और विशिष्ट व्यक्तियों के साथ रडार बिंदुओं को जोड़ने की चुनौती के कारण काफी अधिक जटिल हो जाते हैं। वर्तमान आर्किटेक्चर, जबकि एकल व्यक्तियों के लिए मजबूत है, संभवतः बहु-व्यक्ति इंटरैक्शन की जटिलताओं को संभालने के लिए महत्वपूर्ण संशोधनों की आवश्यकता होगी।
इसके अलावा, मूल्यांकन दो विशिष्ट डेटासेट, TransHuPR और HuPR पर आयोजित किया गया था, जो कुछ प्रकार की क्रियाओं और वातावरणों (अंततः इनडोर होने का संकेत) का प्रतिनिधित्व करते हैं। जबकि रडार प्रकाश की स्थिति के प्रति मजबूत है, विभिन्न वातावरणों में विविध, अनियंत्रित क्रॉस-पर्यावरण परिदृश्यों (जैसे, विभिन्न मलबे के साथ आउटडोर सेटिंग्स, विभिन्न भवन सामग्री, या अधिक जटिल मानव-वस्तु इंटरैक्शन) के लिए milliMamba की सामान्यता एक खुला प्रश्न बनी हुई है। भविष्य के काम में "क्रॉस-एनवायरनमेंट परिदृश्यों" का उल्लेख इस क्षेत्र को आगे की जांच की आवश्यकता के रूप में उजागर करता है।
आगे देखते हुए, इन निष्कर्षों को विकसित करने और विकसित करने के लिए कई रोमांचक चर्चा विषय उभरते हैं:
- मजबूत बहु-व्यक्ति पोज़ अनुमान: milliMamba के स्पेटियो-टेम्पोरल मॉडलिंग को कई व्यक्तियों को मज़बूती से संभालने के लिए कैसे बढ़ाया जा सकता है? इसमें रडार डेटा के लिए नवीन इंस्टेंस सेगमेंटेशन तकनीकें, अंतर-व्यक्ति संबंधों को मॉडल करने के लिए ग्राफ-आधारित दृष्टिकोण, या यहां तक कि मानव समूह की गतिशीलता के बारे में पूर्व ज्ञान को शामिल करना शामिल हो सकता है। कई लोगों के पैमाने पर रैखिक जटिलता बनाए रखते हुए क्या वास्तुशिल्प परिवर्तन आवश्यक होंगे?
- वास्तविक समय एज परिनियोजन और दक्षता: कम्प्यूटेशनल लागत को देखते हुए, क्या और वास्तुशिल्प अनुकूलन (जैसे, मात्राकरण, छंटाई, ज्ञान आसवन) milliMamba को कम-शक्ति वाले एज उपकरणों पर वास्तविक समय अनुमान के लिए उपयुक्त बना सकते हैं? क्या एक हल्का मैम्बा संस्करण या एक हाइब्रिड आर्किटेक्चर व्यावहारिक अनुप्रयोगों के लिए बेहतर संतुलन प्रदान कर सकता है?
- 2D हीटमैप से 3D पोज़ अनुमान: वर्तमान कार्य 2D HPE पर केंद्रित है। milliMamba द्वारा निकाले गए समृद्ध स्पेटियो-टेम्पोरल सुविधाओं का उपयोग पूर्ण 3D मानव पोज़ का अनुमान लगाने के लिए कैसे किया जा सकता है या बढ़ाया जा सकता है? इसके लिए संभवतः आउटपुट हेड को अनुकूलित करने और 2D अनुमानों में निहित गहराई अस्पष्टताओं को हल करने के लिए अतिरिक्त ज्यामितीय बाधाओं या बहु-दृश्य फ्यूजन रणनीतियों को शामिल करने की आवश्यकता होगी।
- उन्नत स्पेक्युलर रिफ्लेक्शन हैंडलिंग: जबकि milliMamba स्पेक्युलर प्रतिबिंबों को संबोधित करता है, क्या अधिक स्पष्ट भौतिकी-सूचित तंत्रिका नेटवर्क या उन्नत सिग्नल प्रसंस्करण तकनीकों को सीधे इन चुनौतीपूर्ण रडार घटनाओं को मॉडल और क्षतिपूर्ति करने के लिए मैम्बा एनकोडर में एकीकृत किया जा सकता है? इसमें सिग्नल विरलता के कारण प्रत्यक्ष प्रतिबिंबों को स्पेक्युलर से अलग करना सीखना या लापता डेटा को "भरने" के लिए जनरेटिव मॉडल का उपयोग करना शामिल हो सकता है।
- लंबी अवधि की अस्थायी संदर्भ और क्रिया पहचान: लंबे अनुक्रमों को संभालने की मैम्बा एनकोडर की क्षमता एक प्रमुख लाभ है। इसे न केवल पोज़ अनुमान में सुधार करने के लिए बल्कि विस्तारित अवधि में अधिक परिष्कृत क्रिया पहचान या गतिविधि समझ को सक्षम करने के लिए और कैसे उपयोग किया जा सकता है? इसमें मैम्बा ढांचे के भीतर आवर्ती तंत्र या पदानुक्रमित अस्थायी मॉडलिंग को एकीकृत करना शामिल हो सकता है।
- अन्य गोपनीयता-संरक्षण पद्धतियों के साथ संलयन: जबकि रडार गोपनीयता-संरक्षण है, क्या milliMamba को अन्य गैर-RGB सेंसर (जैसे, थर्मल कैमरे, गहराई सेंसर, या यहां तक कि ध्वनिक सेंसर) के साथ फ्यूज करने से अत्यंत चुनौतीपूर्ण परिदृश्यों या चिकित्सा निगरानी या गिरावट का पता लगाने जैसे विशिष्ट अनुप्रयोगों में मजबूती को और बढ़ाया जा सकता है? ऐसे विविध डेटा प्रकारों के लिए इष्टतम संलयन रणनीतियाँ क्या हैं?
 Table 2. Comparison of model performance and complexity across methods on the TransHuPR dataset [12]. The complexity excludes radar signal preprocessing
Table 2. Comparison of model performance and complexity across methods on the TransHuPR dataset [12]. The complexity excludes radar signal preprocessing
 Table 3. Comparison of model performance and complexity across methods on the HuPR dataset [13]. The complexity excludes radar signal preprocessing
Table 3. Comparison of model performance and complexity across methods on the HuPR dataset [13]. The complexity excludes radar signal preprocessing
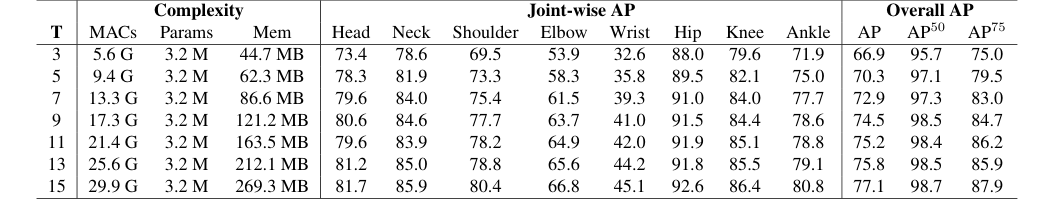 Table 6. Impact of input sequence length (T) on pose estimation performance. We investigate the effect of varying T to understand how temporal context contributes to accuracy
Table 6. Impact of input sequence length (T) on pose estimation performance. We investigate the effect of varying T to understand how temporal context contributes to accuracy