milliMamba: Оценка позы человека с учетом зеркальных отражений с помощью двойного mmWave радара и многокадровой фузии Mamba
Проблема оценки позы человека (Human Pose Estimation, HPE) с использованием сигналов миллиметрового диапазона (mmWave) радара возникла в первую очередь как ответ на ограничения традиционных систем на основе камер (RGB).
Предыстория и академическая родословная
Происхождение и академическая родословная
Проблема оценки позы человека (Human Pose Estimation, HPE) с использованием сигналов миллиметрового диапазона (mmWave) радара возникла в первую очередь как ответ на ограничения традиционных систем на основе камер (RGB). Хотя RGB-камеры предоставляют богатую визуальную информацию, они по своей сути вызывают опасения по поводу конфиденциальности, особенно в чувствительных средах, таких как дома или больницы. Кроме того, системы на основе камер подвержены влиянию различных условий освещения и окклюзий, что может существенно снизить их производительность.
В этом контексте mmWave радар представился как привлекательная альтернатива. Он предлагает решение, сохраняющее конфиденциальность, поскольку не захватывает визуальные изображения людей. Кроме того, он устойчив к факторам окружающей среды, таким как темнота или дым, что делает его пригодным для более широкого спектра сценариев развертывания. Таким образом, конкретная проблема, рассматриваемая в данной статье, заключается в разработке надежной и точной системы 2D оценки позы человека, которая использует уникальные преимущества mmWave радара, преодолевая при этом его присущие проблемы.
Фундаментальное ограничение или «болевая точка» предыдущих подходов к HPE на основе mmWave радара, которые побудили авторов разработать milliMamba, проистекает из нескольких проблем. Во-первых, радарные сигналы часто разрежены из-за явления, называемого «зеркальным отражением». Это означает, что сигналы могут отскакивать от датчика, если они попадают на часть тела под определенными углами, что приводит к неполным наблюдениям и затрудняет реконструкцию позы всего тела из одного кадра. Слабые отражения от конечностей (например, пальцев рук или ног) и чувствительность к ориентации объекта усугубляют эту проблему. Во-вторых, предыдущие методы, особенно основанные на Трансформерах, испытывали трудности с высокой размерностью радарных входных данных и большими «объемами токенов», необходимыми для обработки более длинных последовательностей кадров. Это приводило к квадратичной вычислительной сложности, делая их требовательными к памяти и медленными. Некоторые попытки смягчить это включали «раннюю фузию» временной информации, но это часто компрометировало способность модели восстанавливать отсутствующие суставы, теряя ценные контекстные сигналы из соседних кадров. Цель авторов состояла в создании системы, которая могла бы эффективно обрабатывать длинные последовательности радарных данных для использования пространственно-временного контекста, тем самым более точно выводя отсутствующие суставы и поддерживая временную согласованность, сохраняя при этом вычислительные затраты управляемыми.
Интуитивные термины предметной области
- Миллиметровый (mmWave) радар: Представьте себе летучую мышь, использующую свой сонар для «видения» в темноте, но вместо звуковых волн мы используем очень короткие радиоволны. Эти волны отражаются от объектов, и, слушая эхо, мы можем определить, где находятся объекты и как они движутся, и все это без необходимости использования камеры. Это похоже на рентгеновское зрение для движения, но без фактического видения человека.
- Оценка позы человека (HPE): Представьте, что вы рисуете фигурку человека поверх его тела. Цель состоит в том, чтобы точно определить местоположение ключевых суставов (таких как локти, колени и плечи), чтобы понять их осанку и движение.
- Зеркальное отражение: Это похоже на взгляд в идеально гладкое зеркало. Если радарный сигнал попадает на поверхность тела, которая очень гладкая и имеет правильный угол, сигнал полностью отражается, как свет от зеркала, и не возвращается к радарному датчику. Это делает эту часть тела «невидимой» для радара, что приводит к пробелам в данных.
- Пространственно-временные зависимости: Это относится к тому, как объекты связаны как в пространстве (где они находятся относительно друг друга в один момент времени), так и во времени (как они движутся и изменяются в течение последовательности моментов). Для HPE это означает понимание того, что движение руки человека в одном кадре связано с его положением в предыдущем и последующем кадрах, а также с положением его плеча.
- Mamba: Это новый тип архитектуры искусственного интеллекта, похожий на Трансформер, но гораздо более эффективный при обработке длинных последовательностей информации. Представьте себе невероятно умного составителя заметок, который может быстро резюмировать и запоминать ключевые моменты из очень длинной лекции, не перечитывая весь конспект каждый раз. Это позволяет ИИ понимать контекст в течение гораздо более длительных периодов времени, не перегружаясь.
Таблица обозначений
| Обозначение | Описание |
|---|---|
Определение проблемы и ограничения
Формулировка основной проблемы и дилемма
Основная проблема, рассматриваемая в данной статье, — это 2D оценка позы человека (HPE) с использованием сигналов миллиметрового диапазона (mmWave) радара.
Входное/текущее состояние предлагаемой системы состоит из необработанных комплексных сигналов mmWave радара, полученных с помощью двойных радарных датчиков за последовательность из $T$ кадров. В частности, радар FMCW генерирует комплексные кубы $X \in C^{12 \times 128 \times 256}$ для каждого кадра, соответствующие парам виртуальных антенн, чирпам и выборкам АЦП. Эти необработанные сигналы затем предварительно обрабатываются в 3D тепловые карты угла-доплера-дальности, которые объединяются по $T$ кадрам и разделяются на действительную и мнимую компоненты, образуя двуканальный тензор формы $C \times T \times H \times D \times W$ (где $C=2$). Этот вход по своей природе сложен из-за его высокой размерности и разреженной природы радарных отражений.
Выходное/целевое состояние представляет собой последовательность временно согласованных 2D поз человека, представленных координатами 2D ключевых точек для каждого сустава в течение нескольких кадров в скользящем окне. Цель состоит в том, чтобы точно предсказать эти координаты суставов, даже для суставов, которые слабо отражаются или полностью отсутствуют из-за зеркального отражения, при этом поддерживая временную согласованность и достигая производительности на уровне SOTA при разумной вычислительной сложности.
Точное упущенное звено или математический пробел, который данная статья пытается преодолеть, заключается в надежном и эффективном моделировании пространственно-временных зависимостей из разреженных, высокоразмерных данных mmWave радара. Предыдущие методы испытывают трудности с:
1. Неполные наблюдения: Зеркальные отражения означают, что обнаруживаются только те части тела, которые непосредственно обращены к приемнику, что приводит к отсутствующим или слабо отраженным суставам (особенно конечностям) и затрудняет реконструкцию позы всего тела из входных данных одного кадра.
2. Временная несогласованность: Колебания радарных сигналов нарушают временную согласованность между кадрами, препятствуя точному оцениванию позы во времени.
3. Вычислительная масштабируемость: Хотя модели на основе Трансформеров могут улавливать глобальные зависимости, их квадратичная сложность по отношению к длине последовательности делает их вычислительно дорогими и требовательными к памяти для обработки больших объемов токенов из более длинных радарных последовательностей.
4. Частичное пространственно-временное моделирование: Предыдущие подходы часто моделируют пространственно-временные зависимости лишь частично или прибегают к ранней временной фузии, что может поставить под угрозу способность модели восстанавливать отсутствующие суставы, отбрасывая ценную контекстную информацию.
Болезненный компромисс или дилемма, которая поставила в тупик предыдущих исследователей, заключается в основном между точностью (особенно для отсутствующих суставов и временной согласованности) и вычислительной эффективностью/потреблением памяти. Для достижения более высокой точности, особенно при выводе отсутствующих суставов и обеспечении временной гладкости, моделям необходимо обрабатывать более длинные последовательности и улавливать более богатый пространственно-временной контекст. Однако традиционные архитектуры, такие как Трансформеры, имеют квадратичную вычислительную сложность и высокие требования к памяти для таких длинных последовательностей, что делает их непрактичными. И наоборот, методы, которые снижают сложность за счет ранней временной фузии или предсказания одного кадра, часто жертвуют контекстной информацией, необходимой для надежной обработки разреженных, зеркальных радарных данных и поддержания временной согласованности. Эта дилемма вынуждает исследователей выбирать между вычислительно дорогими, но потенциально более точными моделями, или более быстрыми, но менее надежными.
Ограничения и режимы сбоя
Проблема оценки позы человека на основе mmWave радара чрезвычайно сложна из-за нескольких суровых, реалистичных препятствий, с которыми столкнулись авторы:
-
Физические ограничения:
- Зеркальное отражение: Это основная проблема. Радарные сигналы отражаются от поверхностей подобно зеркалу, что означает, что обнаруживаются только те части тела, которые ориентированы непосредственно к датчику. Это приводит к крайней разреженности данных и неполным наблюдениям, когда мелкие или наклонно ориентированные суставы часто полностью отсутствуют в радарных данных.
- Слабые отражения от конечностей: Суставы, такие как запястья и лодыжки, часто дают очень слабые радарные отражения, что делает их особенно трудными для надежного обнаружения и отслеживания.
- Чувствительность к ориентации объекта и размещению датчика: Качество и полнота радарных данных сильно зависят от ориентации объекта относительно датчиков и точного размещения радарных блоков, что еще больше усложняет надежное извлечение признаков.
- Ограниченное разрешение по высоте: mmWave радарные датчики по своей природе имеют ограниченное разрешение в направлении высоты, что может приводить к неоднозначностям при реконструкции 3D позы. Для смягчения этой проблемы используются двойные радарные установки.
-
Вычислительные ограничения:
- Высокая размерность радарных входных данных: Необработанные радарные сигналы имеют высокую размерность, и даже после предварительной обработки в 3D тепловые карты объем данных для последовательностей кадров остается существенным.
- Квадратичная сложность Трансформеров: Предыдущие модели на основе Трансформеров, хотя и мощные для моделирования глобальных зависимостей, страдают от сложности $O(N^2)$ по отношению к длине входной последовательности $N$. Это делает их неэффективными для обработки «больших объемов токенов, присущих более длинным радарным последовательностям», что приводит к непомерным вычислительным затратам и времени обучения.
- Ограничения памяти оборудования: Квадратичная сложность Трансформеров напрямую приводит к высокому потреблению памяти. Как отмечается в статье, Трансформеры «исчерпывают память на нашем оборудовании при обучении с более длинными последовательностями» (например, более 3 кадров), что серьезно ограничивает объем временного контекста, который может быть обработан.
- Накладные расходы на предварительную обработку: Традиционная генерация 4D тепловых карт из необработанных радарных сигналов является вычислительно дорогостоящей и требовательной к памяти (например, в 11 раз больше памяти и в 8,6 раз больше задержки, чем 3D тепловые карты на основе FFT), что может стать узким местом для приложений реального времени.
-
Ограничения, обусловленные данными:
- Временная несогласованность: Присущий шум и колебания в радарных сигналах могут нарушать временную непрерывность положений суставов между кадрами, затрудняя поддержание плавных и согласованных оценок позы во времени.
- Отсутствие надежных признаков: Извлечение надежных и дискриминационных признаков из разреженных и зашумленных радарных сигналов является серьезным препятствием, поскольку необработанные данные не предоставляют визуальных сигналов, подобных изображениям RGB.
- Трудность вывода недостающей информации: Из-за зеркальных отражений модель должна выводить положения отсутствующих суставов, используя контекстные сигналы, что требует сложного пространственно-временного рассуждения, выходящего за рамки простого анализа по кадрам.
Эти ограничения в совокупности делают оценку позы на основе радара особенно сложной задачей, требующей инновационных архитектурных решений, которые могут эффективно обрабатывать высокоразмерные, разреженные и временно несогласованные данные при сохранении вычислительной управляемости.
Почему такой подход
Неизбежность выбора
При решении сложной задачи оценки позы человека (HPE) с использованием миллиметрового диапазона (mmWave) радара авторы столкнулись с критическим моментом, когда традиционные передовые (SOTA) методы оказались недостаточными. Основная проблема заключается в присущей природе радарных сигналов: они разрежены из-за зеркальных отражений, что приводит к неполным наблюдениям и отсутствию данных о суставах, особенно от конечностей. Кроме того, необработанные радарные входные данные имеют высокую размерность, и цель состоит в извлечении надежных пространственно-временных признаков из более длинных последовательностей для вывода этих отсутствующих суставов и обеспечения плавности движения.
Авторы явно признали, что предыдущие подходы на основе Трансформеров, хотя и мощные для моделирования глобальных зависимостей, страдали от фатального недостатка для данного конкретного приложения: их квадратичная сложность ($O(N^2)$) по отношению к длине входной последовательности. Обработка «больших объемов токенов, присущих более длинным радарным последовательностям» стала непреодолимым препятствием для Трансформеров из-за их высоких вычислительных затрат, потребления памяти и времени обучения. Например, Таблица 8 наглядно показывает, что энкодер Трансформера мог обрабатывать только $T=3$ кадра, прежде чем исчерпать память на их оборудовании, в то время как энкодер на основе Mamba мог масштабироваться до $T=9$ или даже $T=15$ кадров. Это практическое ограничение означало, что Трансформеры просто не могли обрабатывать необходимый временной контекст для надежной оценки позы по радарным данным.
Аналогично, традиционные методы на основе CNN, хотя и эффективны для захвата пространственных признаков различных масштабов и краткосрочных временных признаков, «часто были ограничены в своей способности объединять информацию из нескольких радарных датчиков». Учитывая, что milliMamba использует двойную радарную установку для горизонтального и вертикального обзоров, это ограничение сделало стандартные CNN субоптимальным выбором.
Осознание было ясным: требовалась новая архитектура, которая могла бы эффективно моделировать дальние пространственно-временные зависимости с линейной сложностью ($O(N)$) для обработки высокоразмерных, многокадровых радарных данных без непомерных вычислительных затрат. Это сделало архитектуру Mamba с ее селективной моделью пространства состояний (SSM) единственным жизнеспособным путем вперед.
Сравнительное превосходство
Фреймворк milliMamba достигает качественного превосходства над предыдущими золотыми стандартами в первую очередь благодаря своим структурным преимуществам в эффективной обработке длинных последовательностей и сложных пространственно-временных зависимостей.
-
Линейная сложность для длинных последовательностей: Наиболее значительным структурным преимуществом является использование архитектуры Mamba для энкодера. В отличие от Трансформеров, которые страдают от квадратичной сложности $O(N^2)$ по отношению к длине последовательности $N$, Mamba предлагает линейную сложность $O(N)$. Это не просто незначительное улучшение; это фундаментальное изменение, которое позволяет
milliMambaобрабатывать значительно более длинные радарные последовательности (например, $T=9$ кадров по умолчанию, до $T=15$ в экспериментах) без исчерпания памяти, что является критическим ограничением для Трансформеров, как показано в Таблице 8. Это позволяет модели использовать гораздо более богатый временной контекст, что крайне важно для вывода отсутствующих суставов из-за зеркальных отражений и обеспечения плавности движения. -
Улучшенное моделирование пространственно-временного контекста: Энкодер Cross-View Fusion Mamba (CV-Mamba) специально разработан для «эффективного захвата зависимостей по более длинным последовательностям» и «эффективной фузии входных данных двойного радара по кадрам». Это позволяет более полное понимание сцены, что жизненно важно для надежной оценки позы по разреженным радарным данным. Кроме того, декодер Spatio-Temporal-Cross Attention (STCA) с его стратегией вывода по нескольким кадрам интегрирует как пространственное, так и временное внимание. Это означает, что он может моделировать отношения внутри каждого кадра (пространственные) и между кадрами (временные), что приводит к «более богатому надзору по временным шагам» и лучшему выводу отсутствующих суставов путем использования контекстных сигналов из соседних кадров. Это качественный скачок по сравнению с методами, которые выполняют раннюю временную фузию или предсказывают только один кадр.
-
Эффективная предварительная обработка: Хотя это и не является частью основной архитектуры Mamba, выбор 3D быстрой фурье-преобразования (FFT) для обработки радарных сигналов вносит значительный вклад в общее превосходство. Как показано на Рисунке 4(c), этот подход снижает потребление памяти в 11 раз и задержку в 8,6 раза по сравнению с обычной генерацией 4D тепловых карт. Это увеличение эффективности имеет решающее значение, поскольку оно смягчает «взрыв количества токенов», делая высокоразмерные радарные данные управляемыми для последующего моделирования энкодером Mamba. Эта комбинированная эффективность позволяет
milliMambaдостигать более высокой точности при более благоприятном балансе между вычислительными затратами и производительностью, как подчеркивается в Таблицах 2 и 3.
По сути, milliMamba является подавляюще превосходящим, поскольку он предоставляет масштабируемую, эффективную и богатую контекстом структуру, которая может обрабатывать обширную пространственно-временную информацию, необходимую для точной оценки позы на основе радара, чего предыдущие методы не могли достичь из-за архитектурных ограничений.
Соответствие ограничениям
Выбранный подход milliMamba идеально соответствует суровым требованиям оценки позы человека на основе mmWave радара, образуя прочный «брак» между уникальными проблемами задачи и адаптированными свойствами решения.
-
Обработка разреженных и неполных данных (зеркальное отражение): Основная проблема заключается в разреженности радарных сигналов и отсутствии информации о суставах из-за зеркальных отражений.
milliMambaрешает эту проблему напрямую посредством своего комплексного пространственно-временного моделирования. Энкодер CV-Mamba извлекает признаки из более длинных последовательностей, предоставляя достаточный временной контекст. Декодер STCA затем использует этот контекст, предсказывая позы для нескольких кадров одновременно и интегрируя как пространственное, так и временное внимание. Это позволяет модели «использовать контекстные сигналы из соседних кадров и суставов для вывода отсутствующих суставов, вызванных зеркальными отражениями», напрямую смягчая последствия неполных наблюдений. Потеря скорости также усиливает плавность движения, что помогает реконструировать правдоподобные позы, даже когда отдельные кадры разрежены. -
Управление высокоразмерными входными данными и большими объемами токенов: Входные данные mmWave радара по своей природе имеют высокую размерность. Фреймворк
milliMambaрешает эту проблему, сначала используя эффективный этап предварительной обработки на основе 3D FFT, который значительно снижает потребление памяти и задержку по сравнению с традиционными 4D подходами (Рисунок 4(c)). Этот этап «смягчает взрыв количества токенов», делая данные управляемыми. Затем энкодер CV-Mamba с его линейной сложностью специально разработан для «эффективной обработки больших объемов токенов, присущих более длинным радарным последовательностям», что является критическим требованием, которое традиционные Трансформеры не смогли удовлетворить из-за их квадратичного масштабирования. -
Фузия входных данных нескольких радаров: Проблема часто включает двойные радарные установки для получения более полных обзоров. Энкодер CV-Mamba явно разработан для «кросс-видовой фузии входных данных двойного радара», эффективно объединяя информацию из горизонтального и вертикального радарных обзоров. Это напрямую решает проблему интеграции данных из нескольких датчиков, что является известным ограничением некоторых методов на основе CNN.
-
Обеспечение временной согласованности и плавности движения: Слабые отражения и колебания могут нарушить временную согласованность. Стратегия предсказания нескольких кадров декодера STCA в сочетании с явным включением потери скорости ($L_{vel}$) во время обучения напрямую обеспечивает согласованность движения между кадрами. Потеря скорости, определяемая как $L_{vel} = \frac{1}{T-1}\sum_{f=1}^{T-1}\sum_{j=1}^{J} ||\mathbf{v}_{f,j} - \hat{\mathbf{v}}_{f,j}||^2$, где $\mathbf{v}_{f,j}$ — истинная скорость, а $\hat{\mathbf{v}}_{f,j}$ — предсказанная скорость, наказывает за расхождения в скоростях суставов, тем самым способствуя плавным и реалистичным последовательностям поз.
Таким образом, уникальное сочетание эффективной предварительной обработки, энкодера Mamba с линейной сложностью для дальнего пространственно-временного моделирования и декодера внимания по нескольким кадрам с потерей скорости создает надежное и вычислительно осуществимое решение, которое напрямую решает каждую основную проблему оценки позы человека на основе mmWave радара.
Отклонение альтернатив
В статье представлены четкие обоснования отклонения нескольких популярных альтернативных подходов, подчеркивающие, почему проектные решения milliMamba были необходимы.
-
Трансформеры: Наиболее заметная альтернатива, Трансформеры, была отклонена в первую очередь из-за их квадратичной вычислительной сложности ($O(N^2)$) по отношению к длине входной последовательности. Авторы явно заявляют, что это делает их непригодными для обработки «больших объемов токенов, присущих более длинным радарным последовательностям», необходимых для надежной оценки позы на основе радара. Таблица 8 предоставляет эмпирические доказательства, показывая, что энкодер Трансформера не мог даже обработать $T=9$ кадров из-за «проблем с нехваткой памяти» на их оборудовании, в то время как Mamba эффективно справлялся с этим. Эта фундаментальная проблема масштабируемости сделала Трансформеры непрактичными для требований задачи по обширному временному контексту.
-
Методы на основе CNN: Хотя и полезны для некоторых задач, CNN были признаны недостаточными, поскольку они «часто ограничены в своей способности объединять информацию из нескольких радарных датчиков». Учитывая двойной вход радара
milliMamba(горизонтальный и вертикальный обзоры), требовался метод с превосходными возможностями фузии нескольких датчиков, которые Трансформеры (а затем и Mamba) по своей сути предлагают через свои механизмы внимания/SSM. -
Подходы ранней временной фузии: Некоторые предыдущие методы [2, 12, 13] пытались обрабатывать временную информацию путем «раннего схлопывания временного измерения». Авторы явно отвергают эту стратегию, утверждая, что «такая ранняя фузия может поставить под угрозу способность модели восстанавливать отсутствующие суставы, вызванные зеркальными отражениями». Это критическое качественное отклонение, поскольку основная цель
milliMamba— выводить эти отсутствующие суставы, используя богатый пространственно-временной контекст, который ранняя фузия уменьшила бы. -
Стратегия предсказания «много к одному»: Большинство предыдущих методов HPE на основе радара используют «схему декодирования из нескольких кадров в один кадр», что означает, что они принимают несколько кадров в качестве входных данных, но предсказывают только одну позу (обычно центральный кадр).
milliMamba, напротив, использует стратегию предсказания «много ко многим», выводя позы для нескольких кадров одновременно. Таблица 5 количественно подтверждает это отклонение, показывая, что стратегия «Много к одному» дает значительно более низкий общий AP (70,4) по сравнению с подходом «Много ко многим»milliMamba(74,5), улучшение на 4,1 AP. Это демонстрирует превосходные возможности контекстного вывода предсказания нескольких кадров. -
Предварительная обработка 4D тепловых карт: Традиционный подход к генерации 4D тепловых карт [25] из необработанных радарных сигналов был отклонен из-за его вычислительной неэффективности. В статье подчеркивается, что этот метод «вычислительно дорог» и приводит к «взрыву количества токенов». Рисунок 4(c) предоставляет резкое сравнение, показывая, что генерация 4D тепловых карт требует в 11 раз больше пиковой памяти и в 8,6 раза больше времени выполнения по сравнению с предварительной обработкой на основе 3D FFT в
milliMamba. Эта явная неэффективность сделала 4D подход непригодным для практической и масштабируемой системы.
Эти отклонения подчеркивают глубокое понимание авторами ограничений проблемы и недостатков существующих методов, что привело их к разработке milliMamba как специализированного и более эффективного решения. Выбор Mamba был не случайным, а необходимостью, обусловленной присущей несовместимостью других SOTA моделей с конкретными требованиями радарных данных mmWave.
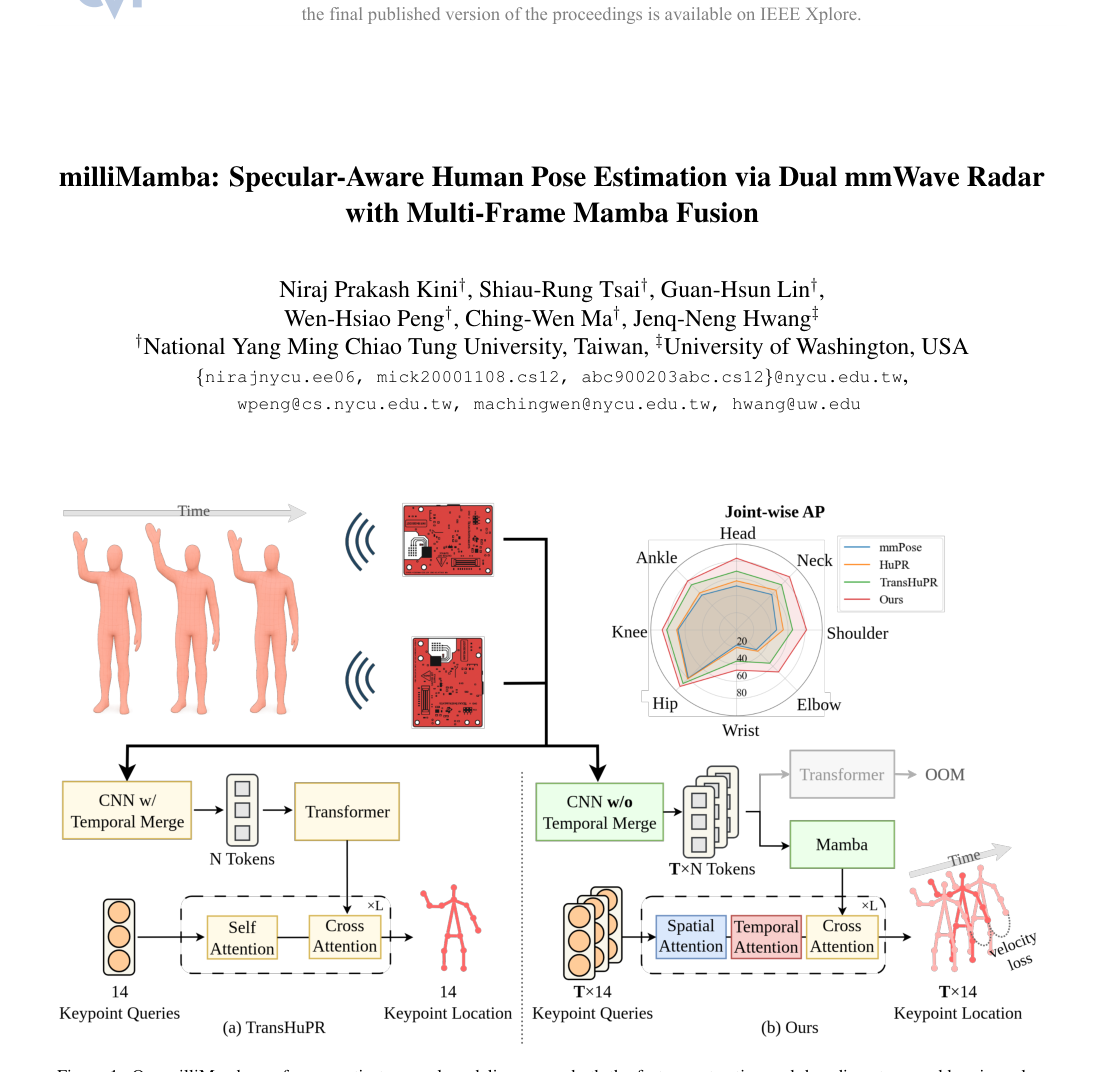 Figure 1. Our milliMamba performs spatio-temporal modeling across both the feature extraction and decoding stages, addressing a key limitation of TransHuPR [12], which models these dependencies only partially. This is made possible by milliMamba’s ability to process a larger number of tokens with a comparable memory footprint, enabling richer temporal context and more accurate pose estimation
Figure 1. Our milliMamba performs spatio-temporal modeling across both the feature extraction and decoding stages, addressing a key limitation of TransHuPR [12], which models these dependencies only partially. This is made possible by milliMamba’s ability to process a larger number of tokens with a comparable memory footprint, enabling richer temporal context and more accurate pose estimation
Математический и логический механизм
Мастер-уравнение
Математическое ядро milliMamba определяется двумя основными наборами уравнений: уравнениями обновления модели пространства состояний (SSM), которые составляют основу энкодера Cross-View Fusion Mamba (CVMamba), и комплексной функцией целевого обучения, которая оркестрирует обучение модели.
Обновление SSM для каждого слоя Vision Mamba определяется как:
$$
h_{t+1} = A h_t + B u_t \\
y_t = C h_t + D u_t
$$
где $t$ обозначает временной шаг.
Общая цель обучения, которую модель стремится минимизировать на этапе обучения, равна:
$$
L = L_{oks} + \lambda_{vel} L_{vel}
$$
Потеря скорости, $L_{vel}$, далее определяется как:
$$
L_{vel} = \frac{1}{(T-1)J} \sum_{f=1}^{T-1} \sum_{j=1}^{J} ||v_{f,j} - \hat{v}_{f,j}||^2_2
$$
Потерминальный анализ
Давайте тщательно разберем каждый член этих уравнений, чтобы понять его математическое определение, физическую или логическую роль, а также обоснование его включения и формы.
Для уравнений обновления модели пространства состояний (SSM):
-
$h_t$:
- Математическое определение: Это вектор скрытого состояния SSM во временной шаг $t$. Это компактное представление истории последовательности до текущего момента.
- Физическая/логическая роль: Концептуально $h_t$ действует как «память» или «контекстное резюме» модели. Он накапливает и сохраняет информацию из всех предыдущих входных токенов, позволяя модели понимать и использовать дальние временные зависимости в радарных данных. Его эволюция от $h_t$ к $h_{t+1}$ является центральной для последовательной обработки.
- Почему используется: Авторы используют эту формулировку пространства состояний для достижения линейной временной сложности при обработке длинных последовательностей. Это значительное преимущество перед традиционными архитектурами Трансформеров, которые несут квадратичные вычислительные затраты из-за своих механизмов глобального внимания, что делает их менее подходящими для высокоразмерных, многокадровых радарных входных данных.
-
$u_t$:
- Математическое определение: Это вектор входного токена во временной шаг $t$. В milliMamba эти токены получены из предварительно обработанных радарных тепловых карт, представляющих пространственно-временные признаки из определенного момента последовательности.
- Физическая/логическая роль: $u_t$ служит «текущим наблюдением» или «новой информацией», подаваемой в SSM на каждом шаге. Это непосредственная часть радарных данных, которую модель должна интегрировать в свое развивающееся понимание позы человека.
- Почему используется: Это прямой внешний стимул, который управляет обновлениями состояния SSM и способствует текущему выводу, предоставляя необработанную информацию о признаках из радара.
-
$y_t$:
- Математическое определение: Это вектор выходного токена, генерируемый SSM во временной шаг $t$.
- Физическая/логическая роль: $y_t$ представляет собой преобразованный признак или непосредственный вывод в момент $t$, который является функцией как текущего входа $u_t$, так и накопленного скрытого состояния $h_t$. Внутри слоя Mamba этот вывод способствует общим закодированным признакам, которые затем передаются декодеру.
- Почему используется: Он предоставляет обработанное, контекстно-зависимое представление входа в момент $t$, которое затем может использоваться последующими слоями в энкодере или в качестве окончательного вывода блока SSM.
-
$A, B, C, D$:
- Математическое определение: Это обучаемые матрицы параметров, специфичные для слоя (или иногда векторы, в зависимости от конкретного варианта SSM и размерностей). Они инициализируются и оптимизируются в процессе обучения.
- Физическая/логическая роль:
- $A$: Матрица перехода состояния. Она управляет тем, как предыдущее скрытое состояние $h_t$ распространяется и преобразуется в следующее скрытое состояние $h_{t+1}$ внутренне. Она улавливает присущую динамику и постоянство информации в последовательности, по сути, определяя, как «память» эволюционирует во времени.
- $B$: Входная матрица. Она определяет, как текущий вход $u_t$ включается в обновление скрытого состояния $h_{t+1}$. Она контролирует влияние «новых данных» на память модели.
- $C$: Выходная матрица. Она преобразует скрытое состояние $h_t$ в вывод $y_t$. Она отвечает за извлечение релевантной информации из памяти модели для формирования текущего вывода.
- $D$: Матрица прямого прохождения. Она позволяет текущему входу $u_t$ напрямую вносить вклад в вывод $y_t$ без предварительной интеграции в скрытое состояние. Это может улавливать немедленные, не последовательные отношения.
- Почему используются: Эти матрицы являются обучаемыми компонентами, которые позволяют SSM изучать сложные временные зависимости и преобразования из радарных данных. Их значения оптимизируются для наилучшего моделирования лежащей в основе динамики человеческого движения. Использование сложения и умножения является фундаментальным для линейных систем пространства состояний, представляя линейные преобразования и обновления, которые вычислительно эффективны.
Для общей цели обучения $L$:
-
$L$:
- Математическое определение: Скалярное значение, представляющее общую потерю, которую модель стремится минимизировать во время обучения.
- Физическая/логическая роль: Это основной сигнал обратной связи для всего процесса обучения. Более низкое значение $L$ означает, что предсказания модели более точны и временно согласованы в соответствии с определенными критериями. Параметры модели итеративно корректируются для уменьшения этого значения.
- Почему используется: Он служит целевой функцией, которая количественно определяет «ошибку» предсказаний модели, направляя процесс оптимизации с помощью градиентного спуска.
-
$L_{oks}$:
- Математическое определение: Потеря сходства ключевых точек объекта (Object Keypoint Similarity, OKS). Хотя ее точная формула не приведена в статье, это стандартная метрика в оценке позы человека, обычно измеряющая сходство между предсказанными и истинными ключевыми точками, нормализованное по масштабу объекта и взвешенное по видимости ключевой точки.
- Физическая/логическая роль: Этот член напрямую оценивает пространственную точность предсказанных 2D координат ключевых точек по сравнению с истинными положениями. Он гарантирует, что модель учится правильно идентифицировать и размещать суставы человека в каждом отдельном кадре.
- Почему используется: OKS является широко принятой и надежной функцией потерь для оценки позы, напрямую отражая основную цель задачи. Она добавляется к потере скорости, указывая на то, что как статическая точность позы, так и временная гладкость считаются важными и независимо вносят вклад в общую ошибку.
-
$\lambda_{vel}$:
- Математическое определение: Скалярный коэффициент взвешивания для члена потери скорости. В статье указано $\lambda_{vel} = 0.05$.
- Физическая/логическая роль: Этот параметр действует как регулятор для балансировки важности временной гладкости (обеспечиваемой $L_{vel}$) по сравнению с основной целью точности ключевых точек (обусловленной $L_{oks}$). Небольшое значение, такое как 0,05, предполагает, что, хотя временная согласованность ценится, она не должна затмевать фундаментальное требование точного предсказания ключевых точек.
- Почему используется: Он предоставляет настраиваемый гиперпараметр, позволяющий авторам точно настраивать поведение модели и достигать оптимального компромисса между различными целями обучения.
-
$L_{vel}$:
- Математическое определение: Потеря скорости, вычисляемая как средний квадрат L2-нормы разницы между предсказанными и истинными скоростями суставов по всем соответствующим кадрам и суставам.
- Физическая/логическая роль: Этот член действует как «временной регуляризатор» или «усилитель плавности движения». Он наказывает внезапные, нереалистичные изменения в положениях суставов между последовательными кадрами, тем самым способствуя плавным и согласованным движениям в предсказанных последовательностях поз. Это особенно полезно для вывода отсутствующих суставов, вызванных разреженными радарными сигналами или зеркальными отражениями, поскольку модель учится «интерполировать» правдоподобные траектории движения на основе контекстных сигналов из соседних кадров.
- Почему используется: Авторы ввели эту потерю для смягчения проблем, вызванных радарными данными, таких как отсутствующие или зашумленные наблюдения суставов. Обеспечивая плавность, модель может более реалистично «заполнять» пробелы. Квадрат L2-нормы ($||\cdot||^2_2$) является стандартным выбором для ошибок регрессии, наказывая большие отклонения более значительно и предоставляя дифференцируемую цель. Суммирование ($\sum$) агрегирует ошибки по всем последовательным парам кадров ($T-1$) и всем суставам ($J$), в то время как деление на $(T-1)J$ нормализует потерю, делая ее независимой от длины последовательности или количества суставов.
-
$T$:
- Математическое определение: Общее количество кадров во входной последовательности.
- Физическая/логическая роль: Это измерение определяет временное окно, в течение которого вычисляется потеря скорости, устанавливая степень учитываемого временного контекста.
- Почему используется: Это фундаментальный параметр входных данных, определяющий длину анализируемой последовательности для движения.
-
$J$:
- Математическое определение: Общее количество оцениваемых суставов человеческого тела.
- Физическая/логическая роль: Это измерение определяет количество отдельных ключевых точек, для которых вычисляются и сравниваются скорости.
- Почему используется: Это фундаментальный параметр выходных данных, представляющий гранулярность оценки позы человека.
-
$f$:
- Математическое определение: Индекс, итерирующий по кадрам от $1$ до $T-1$.
- Физическая/логическая роль: Этот индекс указывает, какая конкретная пара последовательных кадров (кадр $f$ и кадр $f+1$) используется для вычисления скорости.
- Почему используется: Для систематического обхода и вычисления скоростей по временному измерению последовательности.
-
$j$:
- Математическое определение: Индекс, итерирующий по суставам от $1$ до $J$.
- Физическая/логическая роль: Этот индекс определяет, чья скорость конкретного сустава в настоящее время рассматривается.
- Почему используется: Для систематического обхода и вычисления скоростей по пространственному измерению позы.
-
$v_{f,j}$:
- Математическое определение: Истинная скорость сустава $j$ в кадре $f$. Она вычисляется как разница между его истинными положениями в кадре $f+1$ и кадре $f$: $P_{f+1,j} - P_{f,j}$.
- Физическая/логическая роль: Это истинный, желаемый вектор движения для конкретного сустава между двумя последовательными кадрами, служащий идеальной целью для модели.
- Почему используется: Он предоставляет точную ссылку, с которой сравнивается предсказанное моделью движение, направляя процесс обучения.
-
$\hat{v}_{f,j}$:
- Математическое определение: Предсказанная скорость сустава $j$ в кадре $f$. Она вычисляется как разница между его предсказанными положениями в кадре $f+1$ и кадре $f$: $\hat{P}_{f+1,j} - \hat{P}_{f,j}$.
- Физическая/логическая роль: Это выход модели предсказания позы для последовательных кадров, который затем используется для вычисления потери скорости.
- Почему используется: Это выход предсказания позы модели для последовательных кадров, который затем используется для вычисления потери скорости.
-
$||\cdot||^2_2$:
- Математическое определение: Квадрат евклидовой (L2) нормы вектора. Для вектора $x = [x_1, x_2, \dots, x_k]$ его квадрат L2-нормы равен $||x||^2_2 = \sum_{i=1}^k x_i^2$.
- Физическая/логическая роль: Это количественно определяет квадрат величины вектора разницы между предсказанными и истинными скоростями. Квадрирование гарантирует, что как положительные, так и отрицательные разницы вносят вклад в потерю, а большие ошибки наказываются более значительно, чем меньшие.
- Почему используется: Это стандартный, дифференцируемый и вычислительно эффективный способ измерения «расстояния» или «ошибки» между двумя векторами, что делает его хорошо подходящим для оптимизации на основе градиента.
Пошаговый поток
Проследим путь абстрактного набора данных от необработанных радарных сигналов до уточненного предсказания позы, когда он проходит через сборочную линию milliMamba.
-
Прием необработанных радарных сигналов: Процесс начинается с необработанных сигналов миллиметрового диапазона (mmWave) радара. Они поступают в виде комплексных кубов $X \in \mathbb{C}^{12 \times 128 \times 256}$ для каждого кадра, представляющих данные по парам виртуальных антенн, чирпам и выборкам АЦП. Поскольку milliMamba использует двойную радарную установку, два таких куба (один для горизонтального, один для вертикального обзора) приобретаются для последовательности из $T$ последовательных кадров, образуя скользящее окно временного контекста.
-
Сборочная линия предварительной обработки (3D быстрое преобразование Фурье):
- Удаление помех: Сначала статические отражения от окружающей среды фильтруются путем вычитания среднего значения по чирпам. Это похоже на очистку сырья, гарантируя, что обрабатываются только релевантные движущиеся цели.
- Субдискретизация чирпов: Затем размерность чирпов равномерно уменьшается до 8 чирпов на кадр. Этот шаг похож на сжатие данных, уменьшая вычислительную нагрузку при сохранении необходимого доплеровского разрешения.
- 1D FFT (Дальность): 1D быстрое преобразование Фурье (FFT) применяется вдоль размерности выборок АЦП (согласно $Y(m) = \sum_{n=0}^{N-1} X(n) \exp(-j \frac{2\pi nm}{N})$). Это преобразует необработанные выборки во временной области в информацию о дальности, указывающую расстояние до объектов.
- 1D FFT (Доплер): Далее применяется еще одно 1D FFT вдоль размерности чирпов. Это извлекает доплеровскую информацию, которая выявляет скорость объектов относительно радара.
- Нулевое дополнение и 1D FFT (Угол): Для повышения углового разрешения размерность виртуальных антенн дополняется нулями с 12 до 64. Финальное 1D FFT вдоль этой размерности преобразует данные в информацию об угле (азимут и высота).
- Вывод: Радарные данные для каждого обзора и кадра теперь представляют собой 3D тепловую карту угла-доплера-дальности $Y \in \mathbb{C}^{H \times D \times W}$ (например, $64 \times 8 \times 256$). Действительная и мнимая компоненты этих комплексных тепловых карт рассматриваются как отдельные каналы, что приводит к двуканальному тензору формы $C \times T \times H \times D \times W$, где $C=2$.
-
Энкодер CVMamba — извлечение признаков и временное моделирование:
- Параллельные ветви MNet: Горизонтальные и вертикальные тепловые карты обзора подаются в два отдельных параллельных блока MNet. Каждый блок MNet сначала объединяет доплеровскую размерность, а затем обрабатывает данные через ряд остаточных 3D сверток и слоев понижающей дискретизации. Это уменьшает пространственное разрешение (H и W) в $4 \times$, давая карты признаков $F_h, F_v \in \mathbb{R}^{C_f \times T \times \frac{H}{4} \times \frac{W}{4}}$. Это похоже на две специализированные параллельные линии обработки, работающие с разными перспективами.
- Позиционные вложения: Отдельные обучаемые позиционные вложения $P_h$ и $P_v$ добавляются к $F_h$ и $F_v$ соответственно. Эти вложения вводят информацию об абсолютном пространственном положении (угол и дальность) признаков в данные.
- Кросс-видовая фузия: Затем признаки двух обзоров конкатенируются вдоль размерности каналов, образуя унифицированный вход энкодера $F = [F_h; F_v] \in \mathbb{R}^{C_s \times T \times \frac{H}{4} \times \frac{W}{4} \times 2}$. Этот шаг эффективно объединяет информацию из обоих радарных обзоров.
- Линеаризация последовательности: Многомерный тензор признаков $F$ затем преобразуется в 1D последовательность токенов $u_t$ с использованием специального зигзагообразного шаблона сканирования (дальность $\rightarrow$ угол $\rightarrow$ обзор $\rightarrow$ кадр). Это преобразование подготавливает данные для последовательной обработки архитектурой Mamba.
- Обработка слоями Mamba: Эта 1D последовательность $u_t$ поступает в стек слоев Vision Mamba. Каждый слой итеративно обновляет свое скрытое состояние $h_t$ и производит вывод $y_t$ с использованием уравнений SSM ($h_{t+1} = A h_t + B u_t$, $y_t = C h_t + D u_t$). Этот процесс выполняется как в прямом, так и в обратном направлении, позволяя модели эффективно улавливать двунаправленный контекст по всей длинной последовательности с линейной сложностью. Механизмы вентиляции и остаточные соединения внутри слоев Mamba дополнительно уточняют эту последовательную обработку.
- Вывод: Энкодер CVMamba выводит богатое, контекстно-зависимое представление признаков, обозначенное как $x_{Le}$, которое эффективно уловило сложные пространственно-временные зависимости по нескольким кадрам и двойным радарным обзорам.
-
Декодер STCA — предсказание и уточнение позы:
- Инициализация запросов ключевых точек: Декодер начинается с фиксированного набора обучаемых запросов ключевых точек $\{q_{f,j}\}$, равного $J \times T$. Каждый запрос представляет собой вложение, предназначенное для представления конкретного сустава в конкретном кадре. Эти запросы действуют как «интеллектуальные зонды», ищущие информацию о позе.
- Модуль пространственно-временного внимания:
- Пространственное внимание (SA): Сначала пространственное самовнимание применяется внутри каждого кадра ($q'_{f,.} = \text{softmax}(Q_f K_f^T / \sqrt{d}) V_f$). Это позволяет запросам для разных суставов в одном кадре взаимодействовать, улавливая взаимосвязи между суставами (например, как локоть связан с запястьем в одном снимке).
- Временное внимание (TA): Затем временное самовнимание применяется между кадрами для одного и того же сустава ($q''_{.,j} = \text{softmax}(Q_j K_j^T / \sqrt{d}) V_j$). Это позволяет запросам для конкретного сустава обращать внимание на его собственное представление в соседних кадрах, обеспечивая согласованность движения и используя временной контекст для понимания движения.
- Кросс-внимание к признакам энкодера: Затем уточненные запросы ключевых точек $q''_{f,j}$ выполняют кросс-внимание с выходными признаками энкодера $F'$ (который является $x_{Le}$) ($\hat{q}_{f,j} = \text{CrossAttn}(q''_{f,j}, F')$). Этот критический шаг позволяет запросам ключевых точек извлекать релевантную информацию о позе из богатых пространственно-временных признаков, сгенерированных энкодером CVMamba, эффективно «заземляя» запросы в радарных данных.
- Итеративное уточнение: Этот весь слой декодера (состоящий из пространственно-временного внимания, кросс-внимания и многослойного перцептрона по позициям) стекируется несколько раз. Запросы ключевых точек итеративно уточняются через эти слои, постепенно улучшая их представление и точность.
- Предсказательная головка: Наконец, каждый уточненный запрос $\hat{q}_{f,j}$ проходит через простую предсказательную головку (например, многослойный перцептрон) для вывода 2D координат для сустава $j$ в кадре $f$.
- Вывод: Декодер генерирует последовательность из $T$ оценок позы, где каждая оценка состоит из $J$ 2D координат ключевых точек. Во время инференса обычно сохраняется только предсказание для центрального кадра в скользящем окне.
Динамика оптимизации
Модель milliMamba учится и совершенствует свои возможности оценки позы человека посредством строгого процесса итеративной оптимизации, в основном управляемого общей целью обучения $L = L_{oks} + \lambda_{vel} L_{vel}$. Этот механизм систематически корректирует внутренние параметры модели для минимизации расхождений между ее предсказаниями и истинными значениями.
-
Ландшафт потерь и поведение градиента:
- Общие потери $L$ определяют сложный, многомерный «ландшафт потерь» в огромном пространстве всех обучаемых параметров модели. Основная цель процесса оптимизации — перемещаться по этому ландшафту, чтобы найти его самую низкую точку (глобальный минимум) или достаточно низкую точку (локальный минимум).
- $L_{oks}$ (Потеря сходства ключевых точек объекта): Этот компонент функции потерь в основном формирует ландшафт, чтобы вознаграждать точное пространственное размещение отдельных ключевых точек. Он генерирует градиенты, которые эффективно «притягивают» предсказанные ключевые точки к их соответствующим истинным положениям. Если предсказанная ключевая точка значительно смещена от своего истинного положения, $L_{oks}$ будет генерировать сильный градиент, заставляя модель корректировать свои параметры для уменьшения этой пространственной ошибки.
- $L_{vel}$ (Потеря скорости): Этот компонент вводит жизненно важный эффект регуляризации, формируя ландшафт потерь, чтобы благоприятствовать временно гладким и согласованным последовательностям поз. Он генерирует градиенты, которые активно наказывают резкие или нереалистичные изменения в положениях суставов между последовательными кадрами. Если предсказанная скорость сустава значительно отклоняется от истинной скорости, $L_{vel}$ будет генерировать градиенты, которые побуждают модель предсказывать более плавное, более физически правдоподобное движение. Это особенно полезно для вывода отсутствующих суставов, вызванных разреженными радарными сигналами или зеркальными отражениями, поскольку модель учится «интерполировать» правдоподобное движение на основе контекстных сигналов из соседних кадров.
- Балансировка ($\lambda_{vel}$): Коэффициент взвешивания $\lambda_{vel}$, установленный на значение 0,05, играет критическую роль в балансировке важности временной гладкости (обеспечиваемой $L_{vel}$) по сравнению с основной целью точности ключевых точек (обусловленной $L_{oks}$). Это относительно небольшое значение гарантирует, что, хотя временная согласованность является важным соображением, она не перевешивает фундаментальное требование точного предсказания ключевых точек. Следовательно, градиенты, исходящие от $L_{oks}$, будут оказывать более сильное влияние, направляя модель к точным оценкам позы, в то время как $L_{vel}$ обеспечивает мягкое, но настойчивое притяжение к временной согласованности. Без $L_{vel}$ модель может выдавать точные, но дерганые позы; при чрезмерно высоком $\lambda_{vel}$ она может отдавать приоритет гладкости в ущерб точности.
-
Итеративные обновления состояния:
- Прямой проход: Во время каждой итерации обучения пакет многокадровых радарных последовательностей пропускается через всю сеть milliMamba — охватывая предварительную обработку, энкодер CVMamba и декодер STCA. Эта прямая передача завершается генерацией последовательности предсказанных 2D координат ключевых точек $\hat{P}_{f,j}$ для каждого кадра $f$ и сустава $j$.
- Расчет потерь: Эти предсказанные координаты ключевых точек затем тщательно сравниваются с истинными координатами ключевых точек $P_{f,j}$ для расчета $L_{oks}$. Одновременно предсказанные скорости $\hat{v}_{f,j}$ (полученные из $\hat{P}_{f,j}$) сравниваются с истинными скоростями $v_{f,j}$ (полученными из $P_{f,j}$) для расчета $L_{vel}$. Эти два отдельных компонента потерь затем объединяются в соответствии с мастер-уравнением: $L = L_{oks} + \lambda_{vel} L_{vel}$.
- Обратный проход (обратное распространение ошибки): Рассчитанные общие потери $L$ затем обратно распространяются через всю сеть. Этот сложный процесс вычисляет градиенты $L$ по отношению к каждому отдельному обучаемому параметру в модели. Это включает, например, матрицы $A, B, C, D$ в слоях Mamba, веса сверточных нейронных сетей (CNN) в блоках MNet, матрицы внимания в декодере STCA и начальные обучаемые запросы ключевых точек.
- Обновление параметров (оптимизатор Adam): Оптимизатор Adam используется для обновления параметров модели. Adam — это продвинутый алгоритм оптимизации с адаптивной скоростью обучения, который вычисляет индивидуальные адаптивные скорости обучения для различных параметров на основе оценок первого и второго моментов градиентов. С заданной скоростью обучения 0,00005 и затуханием веса 0,0001 оптимизатор интеллектуально корректирует параметры в направлении, которое наиболее эффективно снижает потери. Термин затухания веса действует как механизм регуляризации, помогая предотвратить чрезмерное усложнение модели и переобучение на обучающих данных.
- Сходимость: Этот циклический процесс прямого прохода, расчета потерь, обратного прохода и обновления параметров повторяется для многочисленных эпох (итераций по всему набору обучающих данных). Со временем параметры модели постепенно сходятся к значениям, которые минимизируют функцию потерь, что приводит к прогрессивному улучшению точности оценки позы и повышению временной согласованности как на обучающих данных, так и на невиданных ранее данных. Итеративные шаги уточнения, встроенные в сам декодер STCA, также вносят значительный вклад в эту сходимость, поскольку запросы ключевых точек постепенно обновляются для лучшего представления лежащей в основе позы. Производительность модели на отдельном наборе валидации постоянно отслеживается для обнаружения признаков переобучения и определения оптимальной точки для прекращения обучения.
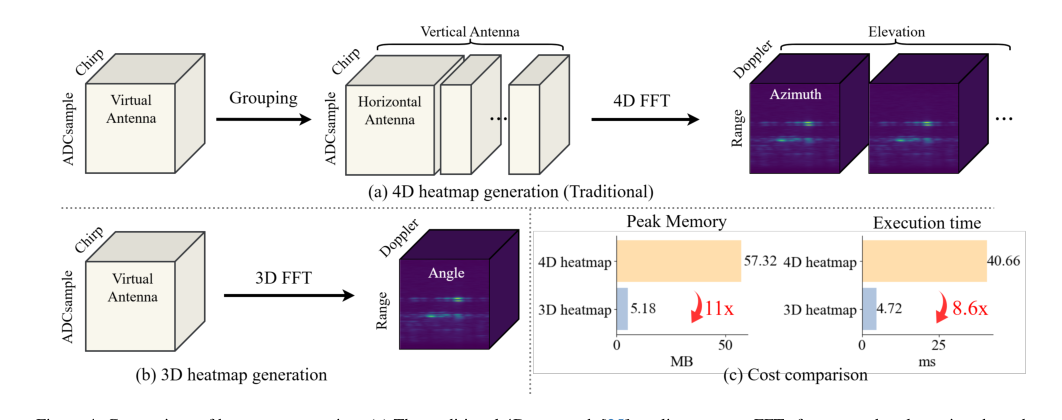 Figure 4. Comparison of heatmap generation. (a) The traditional 4D approach [25] applies separate FFTs for range, doppler, azimuth, and elevation after antenna grouping. (b) Our 3D pipeline performs a unified spatial FFT without grouping, yielding a compact representation. (c) Cost comparison between 4D and 3D heatmaps, showing 11× reduction in memory and 8.6× reduction in latency
Figure 4. Comparison of heatmap generation. (a) The traditional 4D approach [25] applies separate FFTs for range, doppler, azimuth, and elevation after antenna grouping. (b) Our 3D pipeline performs a unified spatial FFT without grouping, yielding a compact representation. (c) Cost comparison between 4D and 3D heatmaps, showing 11× reduction in memory and 8.6× reduction in latency
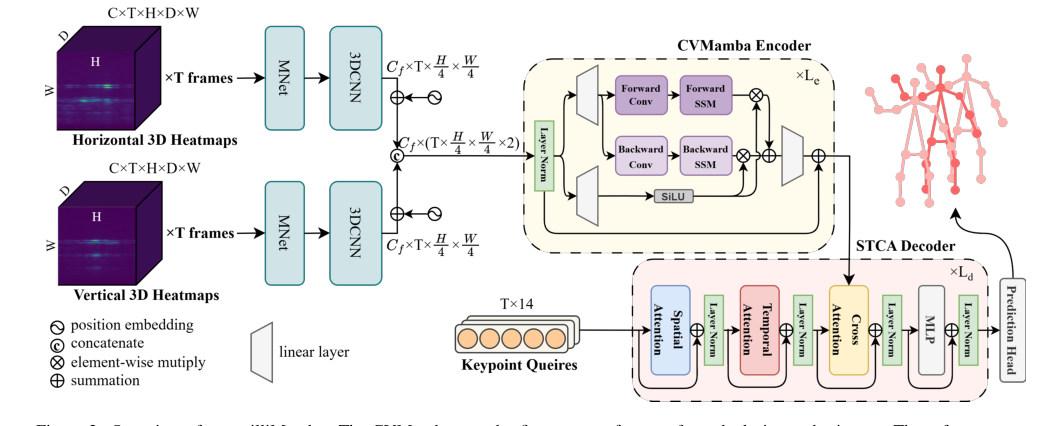 Figure 2. Overview of our milliMamba. The CVMamba encoder first extracts features from dual-view radar inputs. These features are then passed to the Multi-Pose STCA decoder, which progressively refines a set of keypoint queries to produce pose predictions
Figure 2. Overview of our milliMamba. The CVMamba encoder first extracts features from dual-view radar inputs. These features are then passed to the Multi-Pose STCA decoder, which progressively refines a set of keypoint queries to produce pose predictions
Результаты, ограничения и заключение
Экспериментальный дизайн и базовые модели
Для строгой проверки возможностей milliMamba авторы разработали серию экспериментов, направленных на изоляцию и количественную оценку вклада предложенных ими механизмов. Основная установка включала подачу двойных входных данных миллиметрового диапазона (mmWave) радара, каждый из которых захватывал последовательность из $T=9$ кадров, в модель. Хотя модель генерировала 9 последовательных предсказаний позы, для инференса в конечном итоге использовалось только предсказание центрального кадра, что обеспечивало справедливое сравнение с методами, предсказывающими одну позу на вход.
Режим обучения использовал оптимизатор Adam со скоростью обучения 0,00005, размером пакета 8 и затуханием веса 0,0001. Общая цель обучения представляла собой составную функцию потерь: $L = L_{oks} + \lambda_{vel} L_{vel}$. Здесь $L_{oks}$ (потеря сходства ключевых точек объекта) наказывала за расхождения между предсказанными и истинными координатами суставов, что является стандартной метрикой в оценке позы. Критически важно, что $L_{vel}$ (потеря скорости) была введена для обеспечения временной гладкости путем минимизации ошибки между предсказанными и истинными скоростями суставов, с весовым коэффициентом $\lambda_{vel} = 0,05$. Эта потеря скорости была ключевым архитектурным выбором для решения проблемы временной несогласованности, часто наблюдаемой при оценке позы на основе радара. Вся вычислительно интенсивная работа выполнялась на одном графическом процессоре NVIDIA Tesla V100.
«Жертвы» (базовые модели), с которыми сравнивалась milliMamba, включали установленные методы 2D оценки позы человека (HPE) на основе миллиметрового диапазона (mmWave) радара:
- TransHuPR [12]: Подход на основе Трансформеров, который частично моделирует пространственно-временные зависимости.
- HuPR [13]: Еще один видный фреймворк HPE на основе радара.
- mmPose [23]: Метод на основе CNN.
Авторы также упомянули RFMamba [35], другой подход на основе Mamba, но отметили, что его исходный код не был общедоступен, что исключало прямое сравнение.
Оценка проводилась на двух эталонных наборах данных 2D HPE на основе mmWave радара:
- TransHuPR [12]: Состоящий из 440 последовательностей (более 7 часов) от 22 испытуемых, этот набор данных характеризуется быстрыми и динамичными действиями, представляя собой значительную проблему.
- Набор данных HuPR [13]: Содержащий 235 последовательностей (примерно 4 часа) от 6 испытуемых, этот набор данных в основном включает относительно статичные действия.
Для обоих наборов данных соблюдались стандартные протоколы разделения данных. Окончательной метрикой для оценки было Среднее Точность (Average Precision, AP), рассчитанное на основе сходства ключевых точек объекта (OKS). Это включало общий AP (усредненный по порогам OKS от 0,50 до 0,95), а также AP50 (OKS 0,50) и AP75 (OKS 0,75) для критериев свободного и строгого соответствия соответственно.
Что доказывают доказательства
Представленные в статье доказательства неопровержимо свидетельствуют о том, что основные механизмы milliMamba работают на практике, приводя к значительным улучшениям производительности по сравнению с существующими базовыми моделями.
Во-первых, с точки зрения общей производительности, milliMamba последовательно и существенно превосходила все базовые модели на обоих наборах данных TransHuPR и HuPR. На сложном наборе данных TransHuPR milliMamba продемонстрировала впечатляющее улучшение AP на 11,0 по сравнению с базовой моделью TransHuPR [12]. Это было особенно заметно для труднооцениваемых суставов, таких как запястье, которое подвержено быстрым движениям и зеркальным отражениям, где milliMamba достигла AP 46,9. Аналогично, на наборе данных HuPR milliMamba показала еще более впечатляющее улучшение AP на 14,6 по сравнению с HuPR [13], достигнув 84,0 AP для относительно статичных действий. Эти цифры не просто инкрементальны; они представляют собой значительный скачок в состоянии дел в области HPE на основе радара.
Статья также предоставляет веские доказательства эффективности и результативности ее архитектурных решений:
- Эффективная предварительная обработка 3D FFT: Рисунок 4(c) наглядно показывает, что предложенный конвейер предварительной обработки 3D быстрого преобразования Фурье (FFT) снижает потребление памяти в 11 раз и задержку в 8,6 раза по сравнению с обычным подходом 4D FFT. Таблица 4 далее подтверждает это, демонстрируя, что тепловые карты на основе 3D FFT достигают сопоставимой, если не превосходящей, точности (74,5 AP) по сравнению с 4D FFT (72,0 AP), доказывая, что повышение эффективности не произошло за счет производительности.
- Механизм вывода нескольких поз (много ко многим): Таблица 5 наглядно иллюстрирует преимущество декодера Spatio-Temporal-Cross Attention (STCA) в milliMamba. Стратегия предсказания «много ко многим», которая использует контекстные сигналы из соседних кадров, привела к улучшению общей точности на 4,1 AP по сравнению с подходом «много к одному» (обычный декодер Трансформера, предсказывающий одну позу). Это является окончательным доказательством того, что моделирование пространственно-временных зависимостей на этапе декодирования имеет решающее значение для вывода отсутствующих суставов из-за зеркальных отражений.
- Масштабируемость энкодера Mamba: Сравнение энкодеров Mamba и Трансформера в Таблице 8 особенно убедительно. В то время как Mamba показал на 1,5 AP более высокий результат, чем Трансформер, для коротких последовательностей ($T=3$ кадра), критическим доказательством является неспособность Трансформера обрабатывать более длинные последовательности из-за проблем с нехваткой памяти. Mamba, с его линейной сложностью, успешно масштабируется до более длинных входных последовательностей (до $T=15$ кадров, как показано в Таблице 6), где производительность последовательно улучшается. Это демонстрирует превосходную масштабируемость Mamba и его способность эффективно использовать более богатый временной контекст, что является ключевым утверждением статьи.
- Конфигурация двойного радара: Таблица 7 предоставляет четкие доказательства того, что конфигурация двойного радара (горизонтальный + вертикальный) значительно повышает производительность (78,5 AP) по сравнению с использованием одного горизонтального (67,3 AP) или вертикального (74,5 AP) радара по отдельности. Это подтверждает эффективность кросс-видовой фузии в компенсации присущего ограниченного разрешения по высоте mmWave радарных датчиков.
Качественные результаты на Рисунке 5 далее подкрепляют эти выводы, наглядно демонстрируя способность milliMamba генерировать более точные и временно согласованные оценки позы в различных действиях на наборе данных TransHuPR, превосходя базовые модели mmPose, HuPR и TransHuPR.
Ограничения и будущие направления
Хотя milliMamba представляет собой значительный прогресс в оценке позы человека на основе радара, важно признать ее текущие ограничения и рассмотреть направления для будущего развития.
Одним из присущих ограничений, несмотря на улучшения эффективности milliMamba по сравнению с традиционными Трансформерами для длинных последовательностей, является вычислительная стоимость. Хотя она предлагает благоприятный компромисс между точностью и сложностью, ее количество MAC (34,4 G) все еще выше, чем у некоторых базовых моделей, таких как TransHuPR [12] (5,8 G). Это предполагает, что для развертывания на устройствах с крайне ограниченными ресурсами может потребоваться дальнейшая оптимизация с точки зрения вычислительного следа.
Еще одним явным ограничением является текущая ориентация на оценку позы одного человека. В статье прямо указано, что будущая работа будет посвящена «многолюдным» сценариям. Радарные сигналы становятся значительно сложнее при наличии нескольких субъектов из-за окклюзий, помех и трудности сопоставления радарных точек с конкретными индивидуумами. Текущая архитектура, хотя и надежна для одного человека, вероятно, потребует существенных модификаций для обработки сложностей многолюдных взаимодействий.
Кроме того, оценка проводилась на двух конкретных наборах данных, TransHuPR и HuPR, которые представляют определенные типы действий и сред (подразумевается, что это помещения). Хотя радар устойчив к условиям освещения, обобщаемость milliMamba для разнообразных, нерегулируемых межсредовых сценариев (например, наружных условий с различным загромождением, различными строительными материалами или более сложными взаимодействиями человека и объекта) остается открытым вопросом. Упоминание в статье «межсредовых сценариев» в будущей работе подчеркивает это как область, требующую дальнейшего изучения.
Заглядывая вперед, возникает несколько захватывающих тем для обсуждения для дальнейшего развития и эволюции этих выводов:
- Надежная оценка позы нескольких человек: Как пространственно-временное моделирование milliMamba может быть расширено для надежной обработки нескольких индивидуумов? Это может включать новые методы сегментации экземпляров для радарных данных, графовые подходы для моделирования межличностных отношений или даже включение априорных знаний о динамике человеческих групп. Какие архитектурные изменения потребуются для поддержания линейной сложности при масштабировании на большое количество людей?
- Развертывание на периферии в реальном времени и эффективность: Учитывая вычислительную стоимость, какие дальнейшие архитектурные оптимизации (например, квантование, обрезка, дистилляция знаний) могли бы сделать milliMamba пригодной для инференса в реальном времени на периферийных устройствах с низким энергопотреблением? Может ли более легкий вариант Mamba или гибридная архитектура предложить лучший баланс для практических приложений?
- 3D оценка позы по 2D тепловым картам: Текущая работа сосредоточена на 2D HPE. Как богатые пространственно-временные признаки, извлеченные milliMamba, могут быть использованы или расширены для вывода полных 3D поз человека? Это, вероятно, потребует адаптации выходной головки и, возможно, включения дополнительных геометрических ограничений или стратегий кросс-видовой фузии для разрешения неоднозначностей глубины, присущих 2D проекциям.
- Улучшенная обработка зеркальных отражений: Хотя milliMamba решает проблему зеркальных отражений, могут ли более явные физически обоснованные нейронные сети или продвинутые методы обработки сигналов быть интегрированы в энкодер Mamba для прямой моделирования и компенсации этих сложных радарных явлений? Это может включать обучение различать прямые отражения от зеркальных или использование генеративных моделей для «заполнения» отсутствующих данных, вызванных разреженностью сигналов.
- Долгосрочный временной контекст и распознавание действий: Способность энкодера Mamba обрабатывать более длинные последовательности является ключевым преимуществом. Как это можно использовать дальше не только для улучшения оценки позы, но и для более сложного распознавания действий или понимания активности в течение длительных периодов времени? Это может включать интеграцию рекуррентных механизмов или иерархического временного моделирования в рамках фреймворка Mamba.
- Фузия с другими модальностями, сохраняющими конфиденциальность: Хотя радар сохраняет конфиденциальность, может ли фузия milliMamba с другими не-RGB датчиками (например, тепловыми камерами, датчиками глубины или даже акустическими датчиками) предоставить дополнительную информацию для дальнейшего повышения надежности в чрезвычайно сложных сценариях или для конкретных приложений, таких как медицинский мониторинг или обнаружение падений? Каковы оптимальные стратегии фузии для таких разнообразных типов данных?
 Table 2. Comparison of model performance and complexity across methods on the TransHuPR dataset [12]. The complexity excludes radar signal preprocessing
Table 2. Comparison of model performance and complexity across methods on the TransHuPR dataset [12]. The complexity excludes radar signal preprocessing
 Table 3. Comparison of model performance and complexity across methods on the HuPR dataset [13]. The complexity excludes radar signal preprocessing
Table 3. Comparison of model performance and complexity across methods on the HuPR dataset [13]. The complexity excludes radar signal preprocessing
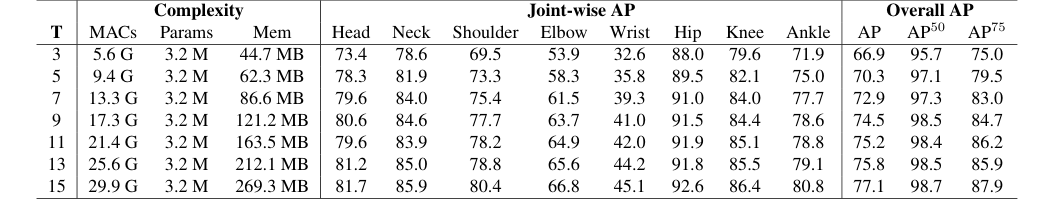 Table 6. Impact of input sequence length (T) on pose estimation performance. We investigate the effect of varying T to understand how temporal context contributes to accuracy
Table 6. Impact of input sequence length (T) on pose estimation performance. We investigate the effect of varying T to understand how temporal context contributes to accuracy