milliMamba: デュアルmmWaveレーダーとマルチフレームMambaフュージョンによる鏡面反射を考慮したヒューマンポーズ推定
The problem of Human Pose Estimation (HPE) using millimeter-wave (mmWave) radar signals emerged primarily as a response to the limitations of traditional camera-based (RGB) systems.
背景と学術的系譜
起源と学術的系譜
ミリ波(mmWave)レーダー信号を用いたヒューマンポーズ推定(HPE)の問題は、主に従来のカメラベース(RGB)システムの限界への対応として出現した。RGBカメラは豊富な視覚情報を提供するが、家庭や病院のような機密性の高い環境では、本質的にプライバシーに関する懸念を引き起こす。さらに、カメラベースのシステムは、照明条件やオクルージョンの変動に弱く、性能を著しく低下させる可能性がある。
このような状況下で、mmWaveレーダーは魅力的な代替手段として登場した。個人の視覚画像をキャプチャしないため、プライバシーを保護するソリューションを提供する。加えて、暗闇や煙のような環境要因に対して堅牢であり、より広範な展開シナリオに適している。したがって、本論文で取り上げられる具体的な問題は、mmWaveレーダーの独自の利点を活用しつつ、その固有の課題を克服する、堅牢で高精度な2Dヒューマンポーズ推定システムを開発することである。
本論文の著者らがmilliMambaを開発するに至った、以前のmmWaveレーダーベースHPEアプローチの根本的な限界または「ペインポイント」は、いくつかの問題に起因する。第一に、レーダー信号は「鏡面反射」と呼ばれる現象により、しばしば疎である。これは、信号が特定の角度で身体の一部に当たるとセンサーから跳ね返ってしまう可能性があり、不完全な観測につながり、単一フレームから全身のポーズを再構築することが困難になることを意味する。末端(指やつま先など)からの弱い反射や、被写体の向きに対する感度も、この問題をさらに悪化させる。第二に、特にTransformerベースの方法は、レーダー入力の高次元性と、長いフレームシーケンスの処理に必要な大きな「トークンボリューム」に苦労していた。これは二次計算複雑性につながり、メモリ集約的で低速になった。これを軽減するためのいくつかの試みは、時間情報の「早期フュージョン」を含んでいたが、これは近隣フレームからの貴重な文脈的手がかりを失うことで、モデルが欠損した関節を回復する能力をしばしば損なった。著者らの目標は、レーダーデータの長いシーケンスを効率的に処理し、時空間的文脈を活用することで、計算コストを管理可能に保ちつつ、欠損関節をより正確に推測し、時間的一貫性を維持できるシステムを作成することであった。
直感的なドメイン用語
- ミリ波(mmWave)レーダー: コウモリが音波を使って暗闇で「見る」のを想像してほしい。ただし、ここでは音波の代わりに非常に短い電波を使用する。これらの波は物体に跳ね返り、エコーを聞くことで、カメラを必要とせずに、物体の位置や動きを把握できる。それは、実際に人を見るのではなく、動きに対するX線のような視力を持っているようなものだ。
- ヒューマンポーズ推定(HPE): 人の体の上の棒人間を描くようなものだと考えてほしい。目標は、姿勢や動きを理解するために、肘、膝、肩などの主要な関節の正確な位置を特定することだ。
- 鏡面反射: これは、完璧に滑らかな鏡を見ているようなものだ。レーダー信号が非常に滑らかで適切な角度の身体表面に当たると、信号は鏡の光のように完全に跳ね返り、レーダーセンサーに戻らない。これにより、その身体の部分はレーダーにとって「見えなく」なり、データにギャップが生じる。
- 時空間的依存性: これは、空間(ある瞬間に互いに相対的にどこにあるか)と時間(一連の瞬間にわたってどのように動き、変化するか)の両方で物事がどのように関連しているかを指す。HPEにおいては、あるフレームでの腕の動きが、前のフレームや次のフレームでの位置、そして肩の位置とも関連していることを理解することを含意する。
- Mamba: これは、Transformerに似ているが、長い情報シーケンスを処理する上で非常に効率的な、新しいタイプの人工知能アーキテクチャである。それは、講義全体を毎回読み返すことなく、非常に長い講義から重要なポイントを素早く要約し、記憶できる、信じられないほど賢いノートテイカーを想像してほしい。これにより、AIは圧倒されることなく、はるかに長い期間にわたる文脈を理解できる。
記法表
| 記法 | 説明 |
|---|---|
問題定義と制約
コア問題定式化とジレンマ
本論文で取り上げられるコア問題は、ミリ波(mmWave)レーダー信号を用いた2Dヒューマンポーズ推定(HPE)である。
提案システムの入力/現在の状態は、デュアルレーダーセンサーによって$T$フレームのシーケンスにわたってキャプチャされた、生の複素数mmWaveレーダー信号で構成される。具体的には、FMCWレーダーは、仮想アンテナペア、チャープ、ADCサンプルに対応する、各フレームに対して複素数キューブ $X \in C^{12 \times 128 \times 256}$ を生成する。これらの生の信号は、その後3D角度-ドップラー-レンジヒートマップに前処理され、$T$フレームにわたってスタックされ、実数部と虚数部に分割され、$C \times T \times H \times D \times W$(ここで$C=2$)の形状を持つ2チャンネルテンソルを形成する。この入力は、その高次元性とレーダー反射の疎な性質により、本質的に困難である。
出力/目標状態は、スライディングウィンドウ内の複数のフレームにわたる各関節の2Dキーポイント座標で表される、時間的に整合性の取れた2Dヒューマンポーズのシーケンスである。目標は、鏡面反射による弱い反射または完全に欠損した関節であっても、これらの関節座標を正確に予測し、同時に時間的一貫性を維持し、妥当な計算複雑性で最先端のパフォーマンスを達成することである。
本論文が橋渡ししようとしている正確な欠落リンクまたは数学的ギャップは、疎で高次元なmmWaveレーダーデータからの時空間的依存性の堅牢かつ効率的なモデリングにある。以前の方法は以下に苦労している:
1. 不完全な観測: 鏡面反射は、受信機に直接面した身体表面のみがキャプチャされることを意味し、欠損または弱く反射された関節(特に末端)につながり、単一フレーム入力からの全身ポーズ再構築を困難にする。
2. 時間的不整合: レーダー信号の変動は、フレーム間の時間的一貫性を妨げ、時間経過に伴う正確なポーズ推定を妨げる。
3. 計算スケーラビリティ: Transformerベースのモデルはグローバルな依存関係を捉えることができるが、シーケンス長に対する二次複雑性は、より長いレーダーシーケンスからの大きなトークンボリュームの処理において計算コストが高く、メモリ集約的になる。
4. 部分的な時空間モデリング: 以前のアプローチは、しばしば時空間的依存性を部分的にしかモデリングしないか、早期の時間的フュージョンに頼るが、これは貴重な文脈情報を破棄することで、モデルが欠損関節を回復する能力を損なう可能性がある。
以前の研究者を閉じ込めてきた痛みを伴うトレードオフまたはジレンマは、主に精度(特に欠損関節と時間的一貫性)と計算効率/メモリフットプリントの間にある。特に欠損関節の推測と時間的滑らかさの確保において、より高い精度を達成するためには、モデルはより長いシーケンスを処理し、より豊かな時空間的文脈を捉える必要がある。しかし、Transformerのような従来のアーキテクチャは、そのような長いシーケンスに対して二次計算複雑性と高いメモリ要求を発生させ、それらを非実用的なものにする。逆に、早期の時間的フュージョンや単一フレーム予測によって複雑性を削減する方法は、疎で鏡面反射するレーダーデータを堅牢に処理し、時間的一貫性を維持するために必要な文脈情報を犠牲にすることが多い。このジレンマは、研究者に計算コストは高いが潜在的に高精度なモデルか、高速だが堅牢性の低いモデルかの選択を強いる。
制約と失敗モード
ミリ波レーダーベースのヒューマンポーズ推定の問題は、著者らが直面するいくつかの厳しい現実的な壁により、非常に困難である:
-
物理的制約:
- 鏡面反射: これは主要な課題である。レーダー信号は鏡のような方法で表面から反射するため、センサーに向かって直接向き合った身体部分のみが検出される。これは、データの極端な疎性と不完全な観測につながり、小さかったり斜め向きの関節がレーダーデータから完全に欠損することが多い。
- 末端からの弱い反射: 手首や足首のような関節は、しばしば非常に弱いレーダー反射を生成し、それらを信頼性高く検出・追跡することが特に困難になる。
- 被写体の向きとセンサー配置への感度: レーダーデータの品質と完全性は、センサーに対する被写体の向きとレーダーユニットの正確な配置に大きく依存し、堅牢な特徴抽出をさらに複雑にする。
- 限られた仰角分解能: mmWaveレーダーセンサーは、本質的に仰角方向の分解能が限られており、3Dポーズ再構築における曖昧さにつながる可能性がある。デュアルレーダーセットアップはこれを軽減するために使用される。
-
計算的制約:
- レーダー入力の高次元性: 生のレーダー信号は高次元であり、3Dヒートマップに前処理された後でも、フレームシーケンスのデータ量は相当なままである。
- Transformerの二次複雑性: グローバル依存性モデリングに強力なTransformerベースのモデルは、入力シーケンス長$N$に対する$O(N^2)$の複雑性に苦しむ。これは、より長いレーダーシーケンスに固有の「大きなトークンボリューム」を処理する上で非効率的になり、計算コストとトレーニング時間が法外になる。
- ハードウェアメモリ制限: Transformerの二次複雑性は、直接高いメモリ消費につながる。論文で指摘されているように、Transformerは「より長いシーケンスでトレーニングすると、ハードウェアでメモリ不足になる」(例:$T=3$フレームを超える)ため、処理できる時間的文脈の量が著しく制限される。
- 前処理オーバーヘッド: 生のレーダー信号から従来の4Dヒートマップ生成は計算コストが高くメモリ集約的(例:3D FFTベースのヒートマップよりもメモリが11倍、レイテンシが8.6倍)であり、リアルタイムアプリケーションのボトルネックになる可能性がある。
-
データ駆動型制約:
- 時間的不整合: レーダー信号の固有のノイズと変動は、フレーム間の関節位置の時間的連続性を妨げ、時間経過に伴う滑らかで一貫性のあるポーズ推定を維持することを困難にする。
- 堅牢な特徴の欠如: 疎でノイズの多いレーダー信号から堅牢で識別性の高い特徴を抽出することは、生のデータがRGB画像のような視覚的手がかりを直接提供しないため、大きなハードルである。
- 欠損情報の推測の困難性: 鏡面反射のため、モデルは文脈的手がかりを使用して欠損関節の位置を推測する必要があり、これは単なるフレームごとの分析を超えた洗練された時空間的推論を必要とする。
これらの制約が複合的に作用し、レーダーベースHPEを特に困難な問題にしており、計算上の実行可能性を維持しながら、高次元で疎で時間的に不整合なデータを効率的に処理できる革新的なアーキテクチャ設計が求められている。
なぜこのアプローチなのか
選択の必然性
ミリ波(mmWave)レーダーを用いたヒューマンポーズ推定(HPE)という困難な問題に取り組む際、著者らは、従来の最先端(SOTA)手法が不十分であることが判明した重要な岐路に直面した。根本的な問題は、レーダー信号の固有の性質、すなわち鏡面反射による疎性から生じ、特に末端からの不完全な観測と欠損関節データにつながる。さらに、生のレーダー入力は高次元であり、目標はこれらの欠損関節を推測し、動きの滑らかさを確保するために、より長いシーケンスから堅牢な時空間的特徴を抽出することである。
著者らは、グローバルな依存関係のモデリングに強力なTransformerベースのアプローチが、この特定のアプリケーションにとって致命的な欠陥、すなわち入力シーケンス長に対する二次複雑性($O(N^2)$)を被ることを明確に認識していた。論文で述べられているように、「より長いレーダーシーケンスに固有の大きなトークンボリューム」の処理は、その高い計算コスト、メモリ使用量、トレーニング時間のために、Transformerにとって克服できない課題となった。例えば、表8は、Transformerエンコーダーがハードウェアでメモリ不足になる前に$T=3$フレームしか処理できなかったのに対し、提案されたMambaベースエンコーダーは$T=9$または$T=15$フレームにまでスケーリングできたことを明確に示している。この実用的な制限は、Transformerが堅牢なポーズ推定に必要な時間的文脈を処理できなかったことを意味した。
同様に、空間的および短期的な時間的特徴を捉えるのに効果的であるCNNベースの方法は、「複数のレーダーセンサーからの情報の融合能力にしばしば限界があった」。milliMambaが水平および垂直ビューのためにデュアルレーダーセットアップを利用することを考えると、この限界は標準的なCNNを最適ではない選択肢にした。
結論は明確だった:計算コストが法外になることなく、高次元のマルチフレームレーダーデータを処理するために、線形複雑性($O(N)$)で長距離の時空間的依存性を効率的にモデリングできる新しいアーキテクチャが必要だった。これにより、Mambaアーキテクチャが、その選択的状態空間モデル(SSM)設計により、唯一実行可能な道となった。
比較優位性
milliMambaフレームワークは、長いシーケンスと複雑な時空間的依存性を効率的に処理する構造的利点を通じて、以前のゴールドスタンダードに対して質的な優位性を達成する。
-
長いシーケンスに対する線形複雑性: 最も重要な構造的利点は、エンコーダーにMambaアーキテクチャを採用したことである。シーケンス長$N$に対して二次複雑性$O(N^2)$に苦しむTransformerとは異なり、Mambaは線形複雑性$O(N)$を提供する。これは単なる些細な改善ではなく、根本的な変化であり、milliMambaがメモリ不足になることなく、はるかに長いレーダーシーケンス(例:デフォルトで$T=9$フレーム、実験では最大$T=15$フレーム)を処理することを可能にする。これはTransformerの重要な制限であり、表8に示されている。これにより、モデルは鏡面反射による欠損関節の推測と動きの滑らかさの確保に不可欠な、はるかに豊かな時間的文脈を活用できる。
-
強化された時空間的文脈モデリング: Cross-View Fusion Mamba(CV-Mamba)エンコーダーは、「より長いシーケンスにわたる依存性を効率的に捉え」、「フレーム間でデュアルレーダー入力を効果的に融合する」ように特別に設計されている。これにより、堅牢なポーズ推定に不可欠な、シーンのより包括的な理解が可能になる。さらに、Spatio-Temporal-Cross Attention(STCA)デコーダーは、マルチフレーム出力戦略により、空間的および時間的注意の両方を統合する。これは、各フレーム内(空間的)およびフレーム間(時間的)の関係をモデリングできることを意味し、「時間ステップ全体にわたるより豊かな監視」と、近隣フレームからの文脈的手がかりを活用することによる欠損関節のより良い推測につながる。これは、早期の時間的フュージョンを実行したり、単一フレームのみを予測したりする方法よりも質的な飛躍である。
-
効率的な前処理: Mambaアーキテクチャ自体の一部ではないが、レーダー信号処理に3D高速フーリエ変換(FFT)を選択したことは、全体的な優位性に大きく貢献している。図4(c)に示すように、このアプローチは、従来の4Dヒートマップ生成と比較して、メモリ使用量を11倍、レイテンシを8.6倍削減する。この効率向上は、Mambaエンコーダーによる高次元レーダーデータを処理可能にする「トークン数の爆発」を緩和するため、重要である。この複合的な効率により、milliMambaは、表2および表3で強調されているように、計算コストとパフォーマンスのより好ましいバランスで、より高い精度を達成できる。
本質的に、milliMambaは、以前の方法がアーキテクチャの制限のために苦労していた、レーダーベースHPEに必要な広範な時空間情報を処理できる、スケーラブルで効率的で文脈が豊富なフレームワークを提供するため、圧倒的に優れている。
制約との整合性
選択されたmilliMambaアプローチは、ミリ波レーダーベースのヒューマンポーズ推定の厳しい要件に完全に整合しており、問題の固有の課題とソリューションの調整された特性との強力な「結婚」を形成している。
-
疎で不完全なデータの処理(鏡面反射): レーダー信号の疎性と鏡面反射による欠損関節情報が根本的な問題である。milliMambaは、包括的な時空間モデリングを通じてこれを直接的に処理する。CV-Mambaエンコーダーはより長いシーケンスから特徴を抽出し、十分な時間的文脈を提供する。STCAデコーダーは、複数のフレームにわたって同時にポーズを予測し、空間的および時間的注意の両方を統合することで、この文脈を活用する。これにより、モデルは「鏡面反射によって引き起こされる欠損関節を推測するために、近隣フレームや関節からの文脈的手がかりを活用する」ことができ、不完全な観測の影響を直接軽減する。速度損失も動きの滑らかさを強化し、個々のフレームが疎であっても、妥当なポーズを再構築するのに役立つ。
-
高次元入力と大きなトークンボリュームの管理: mmWaveレーダー入力は本質的に高次元である。milliMambaフレームワークは、まず効率的な3D FFTベースの前処理ステップを採用し、従来の4Dアプローチと比較してメモリ使用量とレイテンシを大幅に削減する(図4(c))。このステップは「トークン数の爆発を緩和し」、データを管理可能にする。その後、線形複雑性を持つCV-Mambaエンコーダーは、「より長いレーダーシーケンスに固有の大きなトークンボリュームを効率的に処理する」ように特別に設計されており、これは従来のTransformerが二次スケーリングのために満たせなかった重要な要件である。
-
マルチレーダー入力の融合: 問題はしばしば、より包括的なビューをキャプチャするためにデュアルレーダーセットアップを伴う。CV-Mambaエンコーダーは、「デュアルレーダー入力のクロスビュー融合」のために明示的に設計されており、水平および垂直レーダービューからの情報を効果的に組み合わせる。これは、複数のセンサーからのデータを統合する必要性に対処するものであり、一部のCNNベースの方法の既知の限界である。
-
時間的一貫性と動きの滑らかさの確保: 弱い反射と変動は、時間的一貫性を妨げる可能性がある。STCAデコーダーのマルチフレーム予測戦略と、トレーニング中の速度損失($L_{vel}$)の明示的な組み込みは、フレーム間の動きの一貫性を直接強制する。速度損失は、$L_{vel} = \frac{1}{T-1}\sum_{f=1}^{T-1}\sum_{j=1}^{J} ||\mathbf{v}_{f,j} - \hat{\mathbf{v}}_{f,j}||^2$として定義され、真の速度$\mathbf{v}_{f,j}$と予測速度$\hat{\mathbf{v}}_{f,j}$の不一致をペナルティ化し、それによって滑らかで現実的なポーズシーケンスを促進する。
要約すると、milliMambaの効率的な前処理、長距離時空間融合のための線形複雑性Mambaエンコーダー、および速度損失を備えたマルチフレーム注意デコーダーのユニークな組み合わせは、mmWaveレーダーベースHPEのすべての主要な制約に直接対処する、堅牢で計算上実行可能なソリューションを作成する。
代替案の却下
論文は、いくつかの人気のある代替アプローチを却下する明確な理由を提供し、milliMambaの設計選択がなぜ必要であったかを強調している。
-
Transformer: 最も顕著な代替案であるTransformerは、主に二次計算複雑性($O(N^2)$)が入力シーケンス長に対して高いため却下された。著者らは、これがレーダーベースHPEに必要な「より長いレーダーシーケンスに固有の大きなトークンボリューム」を処理するのに不向きであると明示的に述べている。表8は経験的な証拠を提供しており、Transformerエンコーダーがハードウェアの「メモリ不足の問題」のために$T=9$フレームさえ処理できなかったのに対し、Mambaは効率的に処理できたことを示している。この根本的なスケーラビリティの問題により、Transformerは広範な時間的文脈に対する問題の要求に対して非実用的になった。
-
CNNベースの方法: 一部のタスクには有用であるが、CNNは「複数のレーダーセンサーからの情報の融合能力にしばしば限界がある」ため、不十分と見なされた。milliMambaのデュアルレーダー入力(水平および垂直ビュー)を考慮すると、より優れたマルチセンサー融合能力を持つ方法が必要であり、これはTransformer(および subsequently Mamba)が注意/SSMメカニズムを通じて本質的に提供するものである。
-
早期の時間的フュージョンアプローチ: いくつかの以前の方法[2, 12, 13]は、「時間次元を早期に折りたたむ」ことによって時間情報を処理しようとした。著者らはこの戦略を明確に却下し、「そのような早期フュージョンは、鏡面反射によって引き起こされる欠損関節を回復するモデルの能力を損なう可能性がある」と主張している。これは、milliMambaの主な目標が豊富な時空間的文脈を活用することによってこれらの欠損関節を推測することであるため、重要な質的な却下であり、早期フュージョンはそれを低下させるだろう。
-
多対一予測戦略: ほとんどの以前のレーダーベースHPE方法は、「マルチフレームから単一フレームへのデコードスキーム」を採用している。つまり、複数のフレームを入力として取るが、1つのポーズ(通常は中央のフレーム)のみを予測する。対照的に、milliMambaは「多対多」予測戦略を採用し、複数のフレームのポーズを同時に出力する。表5は、この却下を定量的に支持しており、「多対一」戦略がmilliMambaの「多対多」アプローチ(74.5)と比較して、全体的なAP(70.4)を大幅に低下させることを示しており、4.1 APの改善である。これは、複数のフレームを予測することの文脈推論能力の優位性を示している。
-
4Dヒートマップ前処理: 従来の生のレーダー信号から4Dヒートマップ[25]を生成するアプローチは、計算効率が悪いため却下された。論文は、この方法が「計算コストが高く」、トークン数の「爆発」につながると指摘している。図4(c)は、4Dヒートマップ生成がmilliMambaの3D FFTベースの前処理と比較して、ピークメモリが11倍、実行時間が8.6倍長くなるという鮮明な比較を示している。この明確な非効率性は、4Dアプローチを実用的でスケーラブルなシステムには不向きにした。
これらの却下は、著者らが問題の制約と既存技術の限界を深く理解していることを強調しており、それによりmilliMambaを調整された、より効果的なソリューションとして開発するに至った。Mambaの選択は恣意的ではなく、ミリ波レーダーデータの固有の要求との非互換性によって駆動された必要性であった。
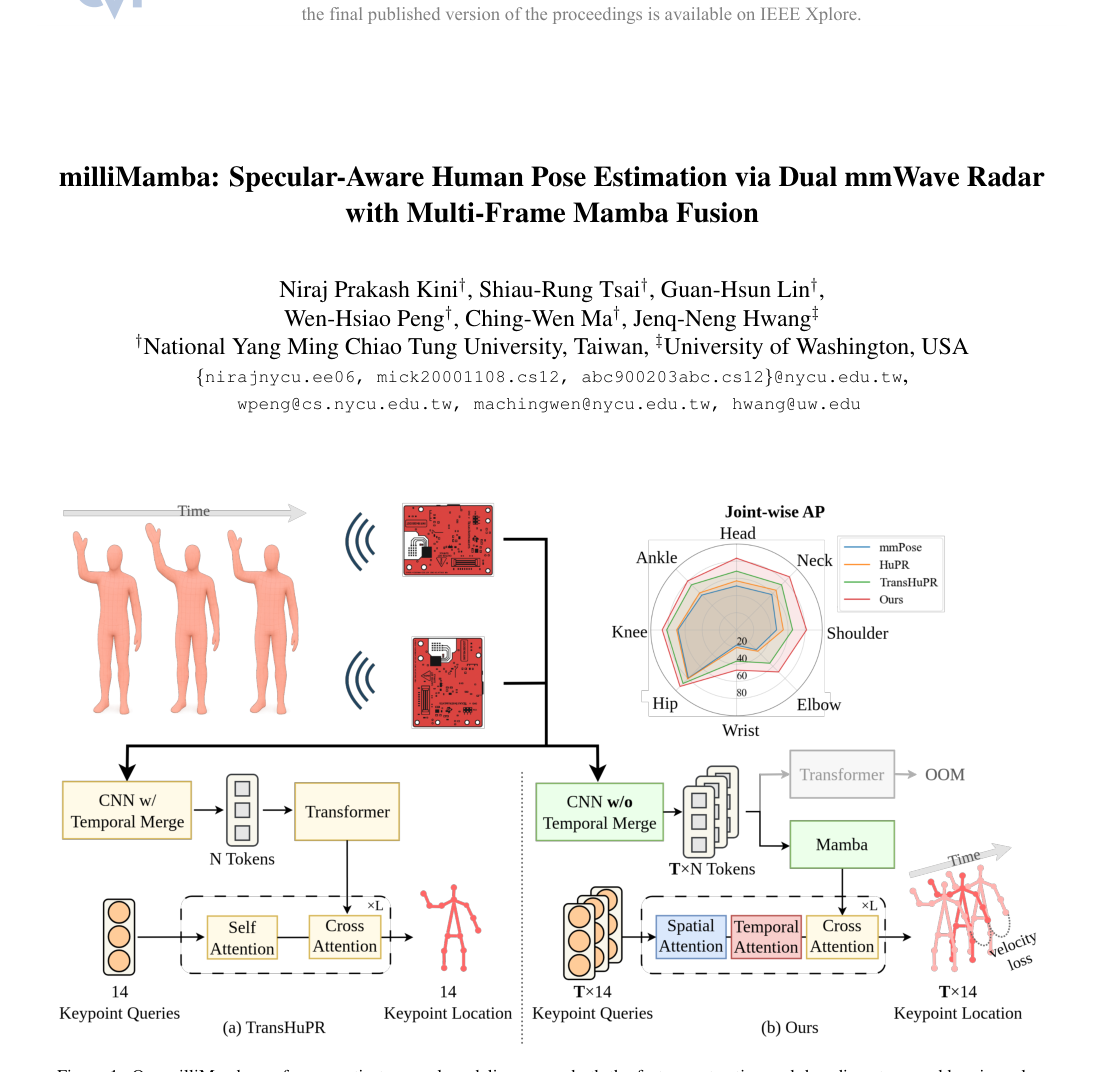 Figure 1. Our milliMamba performs spatio-temporal modeling across both the feature extraction and decoding stages, addressing a key limitation of TransHuPR [12], which models these dependencies only partially. This is made possible by milliMamba’s ability to process a larger number of tokens with a comparable memory footprint, enabling richer temporal context and more accurate pose estimation
Figure 1. Our milliMamba performs spatio-temporal modeling across both the feature extraction and decoding stages, addressing a key limitation of TransHuPR [12], which models these dependencies only partially. This is made possible by milliMamba’s ability to process a larger number of tokens with a comparable memory footprint, enabling richer temporal context and more accurate pose estimation
数学的・論理的メカニズム
マスター方程式
milliMambaの数学的コアは、Cross-View Fusion Mamba(CV-Mamba)エンコーダーのバックボーンを形成する状態空間モデル(SSM)の更新方程式と、モデルの学習を調整する包括的なトレーニング目的関数という、2つの主要な方程式セットによって駆動される。
各Vision Mambaレイヤーの状態空間モデル(SSM)の更新は次のように定義される:
$$
h_{t+1} = A h_t + B u_t \\
y_t = C h_t + D u_t
$$
ここで、$t$はタイムステップを表す。
モデルが学習フェーズ中に最小化しようとする全体的なトレーニング目的は次のとおりである:
$$
L = L_{oks} + \lambda_{vel} L_{vel}
$$
速度損失、$L_{vel}$はさらに次のように指定される:
$$
L_{vel} = \frac{1}{(T-1)J} \sum_{f=1}^{T-1} \sum_{j=1}^{J} ||v_{f,j} - \hat{v}_{f,j}||^2_2
$$
用語ごとの解剖
これらの式内の各用語を細心の注意を払って分解し、その数学的定義、物理的または論理的な役割、およびその包含と形式の根拠を理解しよう。
状態空間モデル(SSM)更新方程式の場合:
-
$h_t$:
- 数学的定義: これは、タイムステップ$t$におけるSSMの隠れ状態ベクトルである。これは、現在の時点までのシーケンスの履歴のコンパクトな表現である。
- 物理的/論理的役割: 概念的には、$h_t$はモデルの「メモリ」または「文脈的要約」として機能する。これは、すべての先行する入力トークンからの情報を蓄積および保持し、モデルが長距離の時間的依存性を理解し活用できるようにする。その$h_t$から$h_{t+1}$への進化は、シーケンシャル処理の中心である。
- なぜ使用されるか: 著者らは、長いシーケンスを処理するための線形時間複雑性を達成するために、この状態空間定式化を採用している。これは、グローバルな注意メカニズムのために二次計算コストを発生させる従来のTransformerアーキテクチャに対する重要な利点であり、高次元のマルチフレームレーダー入力には不向きである。
-
$u_t$:
- 数学的定義: これは、タイムステップ$t$における入力トークンベクトルである。milliMambaでは、これらのトークンは、シーケンスの特定の時点からの時空間的特徴を表す、前処理されたレーダーヒートマップから派生する。
- 物理的/論理的役割: $u_t$は、各ステップでSSMにフィードされる「現在の観測」または「新しい情報」として機能する。これは、モデルが人間のポーズの進化する理解に統合する必要がある、レーダーからの直接的な特徴情報である。
- なぜ使用されるか: これは、SSMの状態更新を駆動し、現在の出力に寄与する直接的な外部刺激であり、レーダーからの生の機能情報を提供する。
-
$y_t$:
- 数学的定義: これは、SSMによってタイムステップ$t$で生成される出力トークンベクトルである。
- 物理的/論理的役割: $y_t$は、現在の入力$u_t$と蓄積された隠れ状態$h_t$の両方の関数である、時間$t$における変換された特徴または即時出力を表す。Mambaレイヤー内では、この出力はデコーダーに渡されるエンコードされた特徴全体に寄与する。
- なぜ使用されるか: これは、時間$t$における入力の処理済みで文脈を意識した表現を提供し、その後、エンコーダーの以降のレイヤーまたはSSMブロックの最終出力として使用できる。
-
$A, B, C, D$:
- 数学的定義: これらは、レイヤー固有の学習可能なパラメータ行列(または特定のSSMバリアントと次元によってはベクトル)である。これらはトレーニングプロセス中に初期化および最適化される。
- 物理的/論理的役割:
- $A$: 状態遷移行列。これは、前の隠れ状態$h_t$が本質的に次の隠れ状態$h_{t+1}$にどのように伝播し変換されるかを制御する。これは、シーケンス内の情報の固有のダイナミクスと永続性を捉え、基本的に「メモリ」が時間とともにどのように進化するかを定義する。
- $B$: 入力行列。これは、現在の入力$u_t$が隠れ状態$h_{t+1}$の更新にどのように組み込まれるかを決定する。「新しいデータ」がモデルのメモリに与える影響を制御する。
- $C$: 出力行列。これは、隠れ状態$h_t$を、出力$y_t$に変換する。これは、モデルのメモリから関連情報を抽出して現在の出力を形成する責任がある。
- $D$: 直接フィードスルー行列。これは、現在の入力$u_t$が隠れ状態に統合される前に、直接出力$y_t$に寄与することを可能にする。これは、即時的で非シーケンシャルな関係を捉えることができる。
- なぜ使用されるか: これらの行列は、SSMがレーダーデータから複雑な時間的依存性と変換を学習することを可能にする学習可能なコンポーネントである。それらの値は、人間の動きの根本的なダイナミクスを最もよくモデル化するように最適化される。加算と乗算の使用は、線形変換と更新を表す線形状態空間システムの基本であり、計算効率が高い。
全体的なトレーニング目的 $L$ の場合:
-
$L$:
- 数学的定義: トレーニング中にモデルが最小化しようとする総損失を表すスカラー値。
- 物理的/論理的役割: これは、学習プロセス全体の主要なフィードバック信号である。$L$の値が低いほど、モデルの予測が定義された基準に従ってより正確で時間的に一貫していることを示す。モデルのパラメータは、この値を減らすために反復的に調整される。
- なぜ使用されるか: モデルの予測の「誤差」を定量化する目的関数として機能し、勾配降下法による最適化プロセスを導く。
-
$L_{oks}$:
- 数学的定義: Object Keypoint Similarity(OKS)損失。その正確な式は論文で提供されていないが、人間のポーズ推定における標準的なメトリックであり、通常、オブジェクトのスケールで正規化され、キーポイントの可視性で重み付けされた、予測されたキーポイントとグラウンドトゥルースキーポイント間の類似性を測定する。
- 物理的/論理的役割: この項は、予測された2Dキーポイント位置の空間的精度を真の位置に対して直接評価する。これは、モデルが各個別のフレームで人間の関節を正しく識別し配置することを学習することを保証する。
- なぜ使用されるか: OKSは、ポーズ推定のための広く採用され、堅牢な損失関数であり、タスクの主な目標を直接反映している。これは速度損失に追加され、静的なポーズ精度と時間的一貫性の両方が重要であり、全体的な誤差に独立して寄与することを示している。
-
$\lambda_{vel}$:
- 数学的定義: 速度損失項のスカラー重み付け係数。論文では$\lambda_{vel} = 0.05$と指定されている。
- 物理的/論理的役割: このパラメータは、時間的滑らかさ($L_{vel}$によって強制される)の重要性と、生のキーポイント精度($L_{oks}$によって駆動される)の基本的な要件との間のバランスをとるダイヤルとして機能する。0.05のような小さな値は、時間的一貫性が重視される一方で、基本的な関節位置予測の要件を上回るべきではないことを示唆している。
- なぜ使用されるか: これは調整可能なハイパーパラメータを提供し、著者らがモデルの動作を微調整し、異なる学習目標間の最適なトレードオフを達成することを可能にする。
-
$L_{vel}$:
- 数学的定義: 速度損失。これは、関連するすべてのフレームと関節にわたる予測された関節速度とグラウンドトゥルース関節速度の差の二乗L2ノルムの平均として計算される。
- 物理的/論理的役割: この項は、「時間的正規化」または「動きの滑らかさ強制」として機能する。これは、連続するフレーム間の関節位置の突然で非現実的な変化をペナルティ化し、それによって予測されたポーズシーケンスで滑らかで一貫性のある動きを促進する。これは、レーダー信号の疎性や鏡面反射による欠損関節の推測に特に有益であり、モデルは文脈的手がかりから妥当な動きの軌道を推測することを学習する。
- なぜ使用されるか: 著者らは、欠損またはノイズの多い関節観測のようなレーダーデータによってもたらされる課題を軽減するために、この損失を導入した。滑らかさを強制することにより、モデルはより現実的にギャップを「埋める」ことができる。二乗L2ノルム($||\cdot||^2_2$)は、回帰誤差の標準的な選択であり、より大きな誤差をより顕著にペナルティ化し、微分可能な目的を提供する。合計($\sum$)は、すべての連続するフレームペア($T-1$)とすべての関節($J$)にわたる誤差を集計し、除算($(T-1)J$)は損失を正規化し、シーケンス長や関節数に依存しないようにする。
-
$T$:
- 数学的定義: 入力シーケンスの総フレーム数。
- 物理的/論理的役割: この次元は、速度損失が計算される時間的ウィンドウを定義し、考慮される時間的文脈の範囲を確立する。
- なぜ使用されるか: 入力データの基本的なパラメータであり、分析されるシーケンスの長さを決定する。
-
$J$:
- 数学的定義: 推定される人間の関節の総数。
- 物理的/論理的役割: この次元は、速度が計算され比較されるキーポイントの数を指定する。
- なぜ使用されるか: 出力データの基本的なパラメータであり、ヒューマンポーズ推定の粒度を表す。
-
$f$:
- 数学的定義: フレームを$1$から$T-1$まで反復するインデックス。
- 物理的/論理的役割: このインデックスは、速度が計算されている連続する2つのフレーム(フレーム$f$とフレーム$f+1$)のどの特定のペアを特定する。
- なぜ使用されるか: シーケンスの時間次元全体にわたって速度を体系的に走査し計算するため。
-
$j$:
- 数学的定義: 関節を$1$から$J$まで反復するインデックス。
- 物理的/論理的役割: このインデックスは、現在検討されている特定の関節の速度を識別する。
- なぜ使用されるか: ポーズの空間次元全体にわたって速度を体系的に走査し計算するため。
-
$v_{f,j}$:
- 数学的定義: フレーム$f$における関節$j$のグラウンドトゥルース速度。これは、フレーム$f+1$とフレーム$f$におけるそのグラウンドトゥルース位置の差として計算される:$P_{f+1,j} - P_{f,j}$。
- 物理的/論理的役割: これは、特定の関節の真の、望ましい動きベクトルであり、モデルの理想的なターゲットとして機能する。
- なぜ使用されるか: モデルの予測された動きと比較される正確な参照を提供し、学習プロセスを導く。
-
$\hat{v}_{f,j}$:
- 数学的定義: フレーム$f$における関節$j$の予測速度。これは、フレーム$f+1$とフレーム$f$におけるその予測位置の差として計算される:$\hat{P}_{f+1,j} - \hat{P}_{f,j}$。
- 物理的/論理的役割: これは、特定の関節のモデルによる推定された動きベクトルである。グラウンドトゥルース速度$v_{f,j}$からのその偏差は、速度損失がペナルティ化するものである。
- なぜ使用されるか: これは、連続フレームのポーズ予測のモデルの出力であり、速度損失を計算するために使用される。
-
$||\cdot||^2_2$:
- 数学的定義: ベクトルの二乗ユークリッド(L2)ノルム。ベクトル$x = [x_1, x_2, \dots, x_k]$の場合、その二乗L2ノルムは$||x||^2_2 = \sum_{i=1}^k x_i^2$である。
- 物理的/論理的役割: これは、予測された速度とグラウンドトゥルース速度の差ベクトルの二乗の大きさ(「大きさ」)を定量化する。二乗することにより、正と負の差の両方が損失に寄与し、より大きな誤差がより小さな誤差よりも大きくペナルティ化されることが保証される。
- なぜ使用されるか: これは、2つのベクトルの間の「距離」または「誤差」を測定するための標準的で微分可能で計算効率の良い方法であり、勾配ベースの最適化に適している。
ステップバイステップフロー
milliMambaの機械組み立てラインを通過する、生のレーダー信号から洗練されたポーズ予測までの抽象的なデータポイントの旅を追ってみよう。
-
生のレーダー信号の取り込み: プロセスは生のミリ波(mmWave)レーダー信号から始まる。これらは、仮想アンテナペア、チャープ、ADCサンプルにわたるデータを表す、各フレームに対して複素数キューブ $X \in \mathbb{C}^{12 \times 128 \times 256}$ として到着する。milliMambaはデュアルレーダーセットアップを使用するため、連続する$T$フレームのシーケンスに対して2つのそのようなキューブ(水平用1つ、垂直用1つ)が取得され、時間的文脈のスライディングウィンドウを形成する。
-
前処理組み立てライン(3D高速フーリエ変換):
- クラッター除去: まず、チャープ全体での平均値を差し引くことにより、環境からの静的な反射がフィルタリングされる。これは生の材料をクリーニングするようなもので、関連する移動ターゲットのみが処理されることを保証する。
- チャープサブサンプリング: チャープ次元は、その後、フレームあたり8チャープに均一に削減される。このステップは、本質的なドップラー分解能を維持しながら、計算負荷を軽減するデータの圧縮に似ている。
- 1D FFT(レンジ): ADCサンプル次元に沿って1D高速フーリエ変換(FFT)が適用される($Y(m) = \sum_{n=0}^{N-1} X(n) \exp(-j \frac{2\pi nm}{N})$に従って)。これにより、時間領域の生のサンプルがレンジ情報に変換され、物体の距離が示される。
- 1D FFT(ドップラー): 次に、チャープ次元に沿って別の1D FFTが適用される。これにより、ドップラー情報が抽出され、レーダーに対する物体の速度が明らかになる。
- ゼロパディングと1D FFT(角度): 角分解能を向上させるために、仮想アンテナ次元が12から64にゼロパディングされる。この次元に沿った最後の1D FFTは、データを角度情報(方位角と仰角)に変換する。
- 出力: 各ビューとフレームのレーダーデータは、現在、3D角度-ドップラー-レンジヒートマップ $Y \in \mathbb{C}^{H \times D \times W}$(例:$64 \times 8 \times 256$)である。これらの複素数ヒートマップの実数部と虚数部は別々のチャンネルとして扱われ、$C \times T \times H \times D \times W$の形状を持つ2チャンネルテンソルが形成される。ここで$C=2$である。
-
CVMambaエンコーダー - 特徴抽出と時間モデリング:
- 並列MNetブランチ: 水平および垂直ビューのヒートマップは、2つの別々の並列MNetブロックにフィードされる。各MNetブロックは、まずドップラー次元をマージし、その後、一連の残差3D畳み込みおよびダウンサンプリングレイヤーを通じてデータを処理する。これにより、空間解像度(HおよびW)が$4 \times$削減され、特徴マップ $F_h, F_v \in \mathbb{R}^{C_f \times T \times \frac{H}{4} \times \frac{W}{4}}$ が得られる。これは、異なる視点を処理する2つの特殊な並列処理ラインのようなものである。
- 位置エンコーディング: 別々の学習可能な位置エンコーディング $P_h$ および $P_v$ が、それぞれ$F_h$および$F_v$に追加される。これらのエンコーディングは、特徴の絶対空間位置(角度とレンジ)に関する情報をデータに注入する。
- クロスビューフュージョン: 次に、2つのビュー特徴がチャンネル次元に沿って連結され、統一エンコーダー入力 $F = [F_h; F_v] \in \mathbb{R}^{C_s \times T \times \frac{H}{4} \times \frac{W}{4} \times 2}$ が形成される。このステップは、両方のレーダービューからの情報を効果的にマージする。
- シーケンス線形化: マルチ次元特徴テンソル$F$は、特定のジグザグスキャンパターン(レンジ$\rightarrow$角度$\rightarrow$ビュー$\rightarrow$フレーム)を使用して1Dトークンシーケンス$u_t$に変換される。この変換は、Mambaアーキテクチャのシーケンシャル処理のためのデータを準備する。
- Mambaレイヤー処理: この1Dシーケンス$u_t$は、Vision Mambaレイヤーのスタックに入る。各レイヤーは、SSM方程式($h_{t+1} = A h_t + B u_t$, $y_t = C h_t + D u_t$)を使用して、隠れ状態$h_t$を反復的に更新し、出力$y_t$を生成する。このプロセスは順方向および逆方向で実行され、モデルは線形複雑性で全体の長いシーケンスにわたる双方向コンテキストを効率的に捉えることができる。Mambaレイヤー内のゲーティングメカニズムと残差接続は、このシーケンシャル処理をさらに洗練させる。
- 出力: CVMambaエンコーダーは、複数のフレームとデュアルレーダービューにわたる複雑な時空間的依存性を効果的に捉えた、リッチで文脈を意識した特徴表現$x_{Le}$を出力する。
-
STCAデコーダー - ポーズ予測と洗練:
- キーポイントクエリ初期化: デコーダーは、学習可能なキーポイントクエリ $\{q_{f,j}\}$ の固定セット($J \times T$個)から始まる。各クエリは、特定のフレームの特定の関節を表すように設計された埋め込みである。これらのクエリは、ポーズ情報を探す「インテリジェントプローブ」として機能する。
- 時空間注意モジュール:
- 空間注意(SA): まず、空間的自己注意が各フレーム内で適用される($q'_{f,.} = \text{softmax}(Q_f K_f^T / \sqrt{d}) V_f$)。これにより、同じフレーム内の異なる関節のクエリが相互作用し、関節間の関係(例:単一のスナップショットで肘が手首とどのように関連するか)を捉えることができる。
- 時間注意(TA): 次に、時間的自己注意が同じ関節のフレーム間で適用される($q''_{.,j} = \text{softmax}(Q_j K_j^T / \sqrt{d}) V_j$)。これにより、特定の関節のクエリが隣接フレームでの自身の表現に注意を払うことができ、動きの一貫性を強制し、時間的文脈を活用して動きを理解する。
- エンコーダー特徴へのクロスアテンション: 洗練されたキーポイントクエリ$q''_{f,j}$は、次にエンコーダーの出力特徴$F'$($x_{Le}$である)とのクロスアテンションを実行する($\hat{q}_{f,j} = \text{CrossAttn}(q''_{f,j}, F')$)。この重要なステップにより、キーポイントクエリは、CVMambaエンコーダーによって生成されたリッチな時空間特徴から関連するポーズ情報を抽出することができ、クエリをレーダーデータに効果的に「接地」する。
- 反復的洗練: このデコーダーレイヤー全体(空間的注意、時間的注意、クロスアテンション、および位置ごとのMLPで構成される)が複数回スタックされる。キーポイントクエリはこれらのレイヤーを通じて反復的に洗練され、その表現と精度が徐々に向上する。
- 予測ヘッド: 最後に、各洗練されたクエリ$\hat{q}_{f,j}$は、単純な予測ヘッド(例:多層パーセプトロン)を通過して、フレーム$f$における関節$j$の2D座標を出力する。
- 出力: デコーダーは、$T$個のポーズ推定のシーケンスを出力する。各推定は$J$個の2Dキーポイント座標で構成される。推論中、通常はスライディングウィンドウ内の中央フレームの予測のみが保持される。
最適化ダイナミクス
milliMambaモデルは、主に全体的なトレーニング目的 $L = L_{oks} + \lambda_{vel} L_{vel}$ によって導かれる厳格な反復最適化プロセスを通じて、人間のポーズ推定能力を学習および洗練する。このメカニズムは、予測とグラウンドトゥルースの間の差異を最小化するために、モデルの内部パラメータを体系的に調整する。
-
損失ランドスケープと勾配の挙動:
- 総損失$L$は、すべての学習可能なモデルパラメータの広大な空間にわたる複雑で高次元の「損失ランドスケープ」を定義する。最適化プロセスの根本的な目標は、このランドスケープをナビゲートして、その最低点(グローバルミニマム)または十分に低い点(ローカルミニマム)を見つけることである。
- $L_{oks}$(Object Keypoint Similarity Loss): この損失関数のコンポーネントは、主に個々のキーポイントの正確な空間配置を報酬するランドスケープを形成する。それは、予測されたキーポイントを対応するグラウンドトゥルース位置に近づける勾配を生成する。予測されたキーポイントが真の位置から著しくずれている場合、$L_{oks}$は強い勾配を生成し、モデルがこの空間誤差を減らすためにパラメータを調整するように強制する。
- $L_{vel}$(速度損失): このコンポーネントは、時間的に滑らかで一貫性のあるポーズシーケンスを支持するように損失ランドスケープを形成する、重要な正規化効果を導入する。それは、連続するフレーム間の関節位置の突然または非現実的な変化をペナルティ化する勾配を生成する。予測された関節速度がグラウンドトゥルース速度から大きく逸脱した場合、$L_{vel}$は、モデルがより滑らかで物理的に妥当な動きを予測するように促す勾配を生成する。これは、レーダー信号の疎性や鏡面反射による欠損関節の推測に特に有益であり、モデルは隣接フレームからの文脈的手がかりに基づいて妥当な動きを「補間」することを学習する。
- バランス調整($\lambda_{vel}$): 重み係数$\lambda_{vel}$は0.05に設定されており、時間的滑らかさ($L_{vel}$によって強制される)の重要性と、生のキーポイント精度($L_{oks}$によって駆動される)の主な目的との間のバランスをとる上で重要な役割を果たす。この比較的低い値は、時間的一貫性が重要な考慮事項である一方で、正確なキーポイント予測の基本的な要件を圧倒するべきではないことを保証する。結果として、$L_{oks}$からの勾配は一般により強い影響力を持ち、モデルを正確なポーズ推定に導く一方、$L_{vel}$は時間的整合性への穏やかな、しかし持続的な引きを提供する。$L_{vel}$がない場合、モデルは正確だがぎこちないポーズを生成する可能性がある。過度に高い$\lambda_{vel}$の場合、精度を犠牲にして滑らかさを優先する可能性がある。
-
反復状態更新:
- フォワードパス: 各トレーニングイテレーション中に、マルチフレームレーダーシーケンスのバッチが、前処理、CVMambaエンコーダー、およびSTCAデコーダーを含む、milliMambaネットワーク全体にフィードされる。このフォワード伝播は、各フレーム$f$と関節$j$に対する予測2Dキーポイント座標$\hat{P}_{f,j}$のシーケンスの生成で最高潮に達する。
- 損失計算: これらの予測されたキーポイント座標は、次にグラウンドトゥルースキーポイント座標$P_{f,j}$と比較され、$L_{oks}$が計算される。同時に、予測された速度$\hat{v}_{f,j}$($\hat{P}_{f,j}$から導出される)は、グラウンドトゥルース速度$v_{f,j}$($P_{f,j}$から導出される)と比較され、$L_{vel}$が計算される。これらの2つの異なる損失コンポーネントは、マスター方程式に従って結合される:$L = L_{oks} + \lambda_{vel} L_{vel}$。
- バックワードパス(誤差逆伝播): 計算された総損失$L$は、次にネットワーク全体に誤差逆伝播される。この複雑なプロセスは、モデル内のすべての学習可能なパラメータに対する$L$の勾配を計算する。これには、例えば、Mambaレイヤーの行列$A, B, C, D$、MNetブロックの畳み込みニューラルネットワーク(CNN)の重み、STCAデコーダーの注意行列、および初期学習可能なキーポイントクエリが含まれる。
- パラメータ更新(Adamオプティマイザ): Adamオプティマイザがモデルのパラメータを更新するために使用される。Adamは高度な適応学習率最適化アルゴリズムであり、勾配の最初のモーメントと2番目のモーメントの推定値に基づいて、パラメータごとに個別の適応学習率を計算する。指定された学習率0.00005と重み減衰0.0001により、オプティマイザは、損失を最も効果的に低減する方向にパラメータをインテリジェントに調整する。重み減衰項は正規化メカニズムとして機能し、モデルが過度に複雑になり、トレーニングデータに過剰適合するのを防ぐのに役立つ。
- 収束: フォワードパス、損失計算、バックワードパス、およびパラメータ更新のこのサイクルプロセスは、多数のエポック(トレーニングデータセット全体のイテレーション)にわたって繰り返される。時間とともに、モデルのパラメータは徐々に損失関数を最小化する値に収束し、トレーニングデータと以前に見たことのないデータの両方で、ポーズ推定精度が徐々に向上し、時間的一貫性が強化される。STCAデコーダー自体の反復的な洗練ステップも、キーポイントクエリが根本的なポーズをより良く表すように徐々に更新されるため、この収束に大きく貢献する。過剰適合の兆候を検出し、トレーニングを停止する最適な時点を特定するために、別個の検証セットでのモデルのパフォーマンスが継続的に監視される。
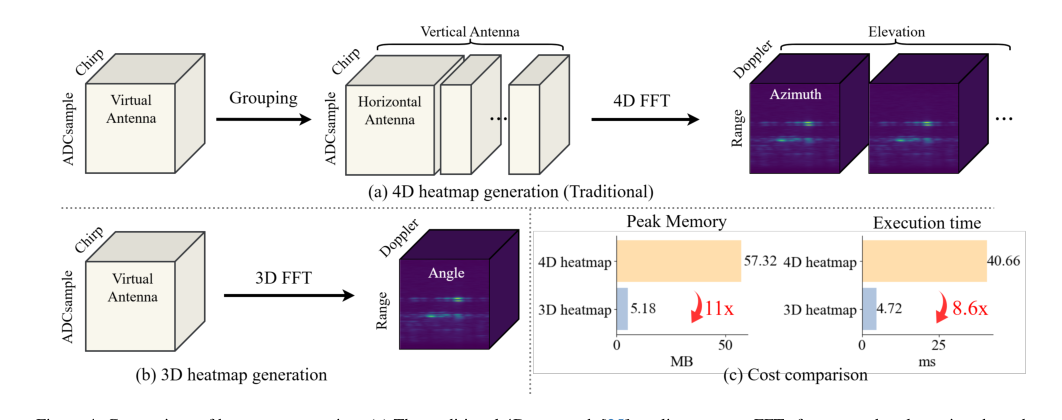 Figure 4. Comparison of heatmap generation. (a) The traditional 4D approach [25] applies separate FFTs for range, doppler, azimuth, and elevation after antenna grouping. (b) Our 3D pipeline performs a unified spatial FFT without grouping, yielding a compact representation. (c) Cost comparison between 4D and 3D heatmaps, showing 11× reduction in memory and 8.6× reduction in latency
Figure 4. Comparison of heatmap generation. (a) The traditional 4D approach [25] applies separate FFTs for range, doppler, azimuth, and elevation after antenna grouping. (b) Our 3D pipeline performs a unified spatial FFT without grouping, yielding a compact representation. (c) Cost comparison between 4D and 3D heatmaps, showing 11× reduction in memory and 8.6× reduction in latency
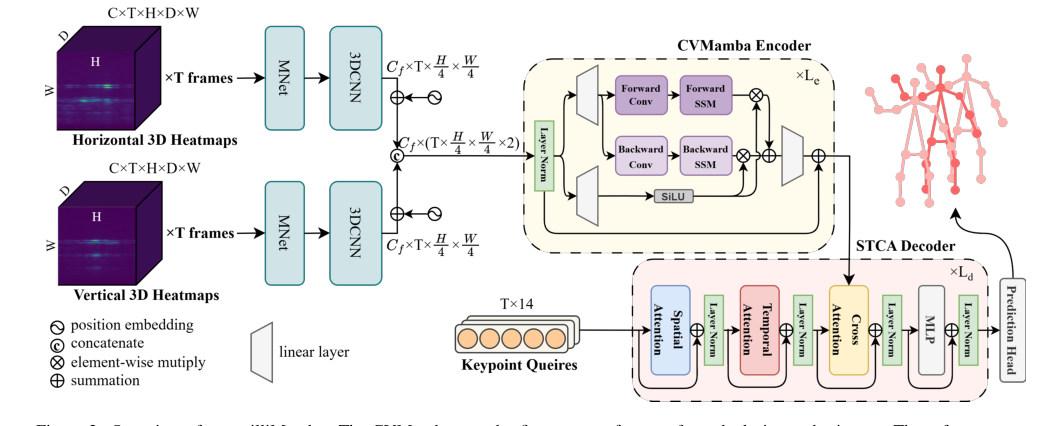 Figure 2. Overview of our milliMamba. The CVMamba encoder first extracts features from dual-view radar inputs. These features are then passed to the Multi-Pose STCA decoder, which progressively refines a set of keypoint queries to produce pose predictions
Figure 2. Overview of our milliMamba. The CVMamba encoder first extracts features from dual-view radar inputs. These features are then passed to the Multi-Pose STCA decoder, which progressively refines a set of keypoint queries to produce pose predictions
結果、限界、および結論
実験設計とベースライン
milliMambaの能力を厳密に検証するために、著者らは提案されたメカニズムの貢献を分離し定量化するように設計された一連の実験を考案した。コアセットアップは、それぞれ$T=9$フレームのシーケンスをキャプチャするデュアルミリ波(mmWave)レーダー入力をモデルにフィードすることを含んだ。モデルは9つの連続するポーズ予測を生成したが、推論には最終的に中央フレームの予測のみが使用され、1つの入力あたり1つのポーズを予測するメソッドとの公平な比較を保証した。
トレーニングレジメンは、学習率0.00005、バッチサイズ8、重み減衰0.0001でAdamオプティマイザを使用した。全体的なトレーニング目的は、複合損失関数であった:$L = L_{oks} + \lambda_{vel} L_{vel}$。ここで、$L_{oks}$(Object Keypoint Similarity)は、予測された関節位置とグラウンドトゥルース関節位置の間の不一致をペナルティ化し、ポーズ推定における標準的なメトリックである。決定的に、$L_{vel}$(速度損失)は、重み係数$\lambda_{vel} = 0.05$で、時間的滑らかさを強制するために導入された。この速度損失は、レーダーベースのポーズ推定でしばしば見られる時間的不整合に対処するための重要なアーキテクチャ上の選択であった。すべての計算上の重い作業は、単一のNVIDIA Tesla V100 GPUで実行された。
milliMambaが比較された「犠牲者」(ベースラインモデル)には、確立されたレーダーベースの2Dヒューマンポーズ推定(HPE)手法が含まれていた:
- TransHuPR [12]: 時空間的依存性を部分的にモデル化するTransformerベースのアプローチ。
- HuPR [13]: 別の著名なレーダーベースHPEフレームワーク。
- mmPose [23]: CNNベースの方法。
著者らはまた、RFMamba [35]、別のMambaベースのアプローチも認識したが、そのソースコードが公開されていなかったため、直接比較はできなかった。
評価は、2つのベンチマークmmWaveレーダーベース2D HPEデータセットで実施された:
- TransHuPR [12]: 22人の被験者からの440シーケンス(7時間以上)で構成され、このデータセットは速くてダイナミックなアクションを特徴とし、大きな課題を提示する。
- HuPR Dataset [13]: 6人の被験者からの235シーケンス(約4時間)を含むこのデータセットは、主に比較的静的なアクションを特徴とする。
両方のデータセットで、標準的なデータ分割プロトコルが従われた。評価の決定的なメトリックは、Object Keypoint Similarity(OKS)に基づいたAverage Precision(AP)であった。これには、全体的なAP(OKSしきい値0.50から0.95までの平均)だけでなく、緩いおよび厳密なマッチング基準のためのAP50(OKS 0.50)およびAP75(OKS 0.75)も含まれた。
証拠が証明すること
論文で提示された証拠は、milliMambaのコアメカニズムが現実で機能し、既存のベースラインを大幅に上回るパフォーマンス向上につながることを否定できない証明を提供している。
まず、全体的なパフォーマンスの観点から、milliMambaはTransHuPRおよびHuPRデータセットの両方で、一貫して、かつ大幅にベースラインを上回った。挑戦的なTransHuPRデータセットでは、milliMambaはTransHuPR [12]ベースラインを11.0 AP改善するという驚異的な成果を達成した。これは、手首のような、速い動きと鏡面反射を起こしやすい推定困難な関節で特に顕著であり、milliMambaは46.9のAPを達成した。同様に、HuPRデータセットでは、milliMambaはHuPR [13]を14.6 AP改善するというさらに印象的な成果を上げ、比較的静的なアクションでは最大84.0 APに達した。これらの数値は単なる漸進的なものではなく、レーダーベースHPEの最先端技術における大きな飛躍を表している。
論文はまた、そのアーキテクチャ選択の効率性と有効性に関する確固たる証拠を提供している:
- 効率的な3D FFT前処理: 図4(c)は、提案された3D高速フーリエ変換(FFT)前処理パイプラインが、従来の4D FFTアプローチと比較してメモリ使用量を11倍、レイテンシを8.6倍削減することを明確に示している。表4は、3D FFTベースのヒートマップが4D FFT(72.0 AP)に匹敵する、あるいはそれ以上の精度(74.5 AP)を達成することを示しており、効率の向上はパフォーマンスの犠牲を伴わなかったことを証明している。
- マルチポーズ出力メカニズム(多対多): 表5は、milliMambaのSpatio-Temporal-Cross Attention(STCA)デコーダーの利点を明確に示している。「多対多」予測戦略は、隣接フレームからの文脈的手がかりを活用し、単一ポーズを予測する「多対一」アプローチと比較して、全体的な精度で4.1 APの改善をもたらした。これは、デコードステージでの時空間的依存性のモデリングが、鏡面反射による欠損関節の推測に不可欠であることを決定的に証明している。
- Mambaエンコーダーのスケーラビリティ: 表8におけるMambaとTransformerエンコーダーの比較は特に説得力がある。Mambaは短いシーケンス($T=3$フレーム)でTransformerよりも1.5 AP高いスコアを達成したが、決定的な証拠は、Transformerがメモリ不足の問題のために長いシーケンスを処理できなかったことにある。線形複雑性を持つMambaは、パフォーマンスが一貫して向上する長い入力シーケンス(表6に示すように最大$T=15$フレーム)に正常にスケーリングする。これは、Mambaの優れたスケーラビリティと、論文の主要な主張である、より豊かな時間的文脈を効果的に活用する能力を示している。
- デュアルレーダー構成: 表7は、デュアルレーダー(水平+垂直)構成が、単一の水平(67.3 AP)または垂直(74.5 AP)レーダーのみを使用した場合と比較して、パフォーマンスを大幅に向上させる(78.5 AP)ことを明確に示している。これは、mmWaveレーダーセンサーの固有の限られた仰角分解能を補うためのクロスビューフュージョンの有効性を確認している。
図5の定性的な結果は、これらの発見をさらに強化し、TransHuPRデータセット上のさまざまなアクションで、より正確で時間的に一貫したポーズ推定を生成し、mmPose、HuPR、およびTransHuPRベースラインを上回るmilliMambaの能力を視覚的に示している。
限界と将来の方向性
milliMambaはレーダーベースのヒューマンポーズ推定における重要な進歩を示しているが、現在の限界を認識し、将来の開発の方向性を検討することが重要である。
従来のTransformerと比較して長いシーケンスに対する効率の向上にもかかわらず、固有の限界の1つは計算コストである。精度と複雑性の間の好ましいトレードオフを提供するが、そのMACs数(34.4 G)は、TransHuPR [12](5.8 G)のような一部のベースラインよりも依然として高い。これは、リソースが非常に制約されたエッジデバイスでの展開の場合、計算フットプリントのさらなる最適化が必要になる可能性があることを示唆している。
もう1つの明確な限界は、現在の焦点が単一人物ポーズ推定であることである。論文は、将来の作業が「複数人物」シナリオを検討することを明示的に述べている。レーダー信号は、オクルージョン、干渉、およびレーダーポイントを特定の個人に関連付ける課題により、複数の被験者で著しく複雑になる。現在のアーキテクチャは、単一人物に対して堅牢であるが、複数人物の相互作用の複雑性を処理するために大幅な変更が必要になるだろう。
さらに、評価は2つの特定のデータセット、TransHuPRとHuPRで実施されたが、これらは特定の種類のアクションと環境(屋内であると示唆されている)を表している。レーダーは照明条件に対して堅牢であるが、milliMambaの多様な、制約のないクロス環境シナリオ(例:さまざまなクラッター、異なる建材、またはより複雑な人間とオブジェクトの相互作用を持つ屋外設定)への一般化可能性は、未解決の質問のままである。将来の作業における「クロス環境シナリオ」への言及は、さらなる調査が必要な領域としてこれを強調している。
将来に向けて、これらの発見をさらに発展させ進化させるためのいくつかのエキサイティングな議論のトピックが現れる:
- 堅牢な複数人物ポーズ推定: milliMambaの時空間モデリングは、複数人を堅牢に処理するようにどのように拡張できるか?これには、レーダーデータのための新しいインスタンスセグメンテーション技術、人間間の関係をモデル化するためのグラフベースのアプローチ、または人間のグループダイナミクスに関する事前知識の組み込みさえも含まれる可能性がある。多くの人々に対応するために線形複雑性を維持しながら、どのようなアーキテクチャ変更が必要になるだろうか?
- リアルタイムエッジ展開と効率: 計算コストを考慮すると、milliMambaを低電力エッジデバイスでのリアルタイム推論に適したものにするために、どのようなさらなるアーキテクチャ最適化(例:量子化、プルーニング、知識蒸留)が可能か?より軽量なMambaバリアントまたはハイブリッドアーキテクチャは、実用的なアプリケーションに対してより良いバランスを提供できるだろうか?
- 2Dヒートマップからの3Dポーズ推定: 現在の研究は2D HPEに焦点を当てている。milliMambaによって抽出されたリッチな時空間特徴は、完全な3Dヒューマンポーズを推測するためにどのように活用または拡張できるか?これには、出力ヘッドの適応や、2D投影に固有の深度曖昧さを解決するための追加の幾何学的制約またはマルチビューフュージョン戦略の組み込みが必要になるだろう。
- 鏡面反射の強化された処理: milliMambaは鏡面反射に対処しているが、より明示的な物理情報に基づいたニューラルネットワークまたは高度な信号処理技術をMambaエンコーダーに統合して、これらの困難なレーダー現象を直接モデル化し補償することは可能か?これには、直接反射と鏡面反射を区別することを学習したり、生成モデルを使用して信号疎性に起因する欠損データを「埋めたり」することが含まれる可能性がある。
- 長期時間的文脈とアクション認識: Mambaエンコーダーがより長いシーケンスを処理できる能力は、主要な利点である。これは、ポーズ推定を改善するだけでなく、長期間にわたるより高度なアクション認識またはアクティビティ理解を可能にするために、どのようにさらに活用できるか?これには、Mambaフレームワーク内での再帰的メカニズムまたは階層的時間モデリングの統合が含まれる可能性がある。
- 他のプライバシー保護モダリティとの融合: レーダーはプライバシーを保護するが、milliMambaを他の非RGBセンサー(例:サーマルカメラ、深度センサー、または音響センサー)と融合することで、非常に困難なシナリオや、医療モニタリングや転倒検出のような特定のアプリケーションで、補完的な情報を提供し、堅牢性をさらに向上させることができるか?そのような多様なデータタイプのための最適な融合戦略は何か?
 Table 2. Comparison of model performance and complexity across methods on the TransHuPR dataset [12]. The complexity excludes radar signal preprocessing
Table 2. Comparison of model performance and complexity across methods on the TransHuPR dataset [12]. The complexity excludes radar signal preprocessing
 Table 3. Comparison of model performance and complexity across methods on the HuPR dataset [13]. The complexity excludes radar signal preprocessing
Table 3. Comparison of model performance and complexity across methods on the HuPR dataset [13]. The complexity excludes radar signal preprocessing
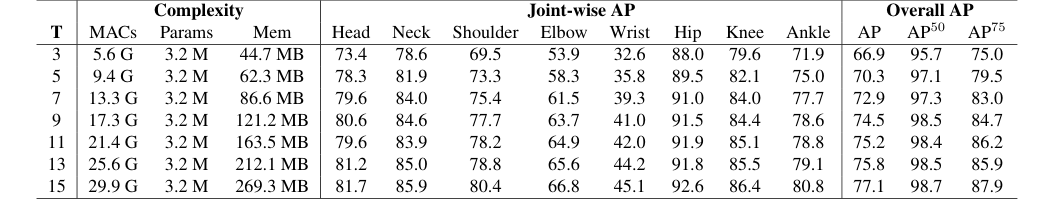 Table 6. Impact of input sequence length (T) on pose estimation performance. We investigate the effect of varying T to understand how temporal context contributes to accuracy
Table 6. Impact of input sequence length (T) on pose estimation performance. We investigate the effect of varying T to understand how temporal context contributes to accuracy