milliMamba: 듀얼 mmWave 레이더와 다중 프레임 Mamba 융합을 통한 반사각 인식 인간 자세 추정
The problem of Human Pose Estimation (HPE) using millimeter-wave (mmWave) radar signals emerged primarily as a response to the limitations of traditional camera-based (RGB) systems.
배경 및 학문적 계보
기원 및 학문적 계보
밀리미터파(mmWave) 레이더 신호를 이용한 인간 자세 추정(Human Pose Estimation, HPE) 문제는 주로 기존의 카메라 기반(RGB) 시스템의 한계에 대한 대응으로 등장했습니다. RGB 카메라는 풍부한 시각 정보를 제공하지만, 특히 가정이나 병원과 같은 민감한 환경에서 개인 정보 보호 문제를 야기합니다. 또한, 카메라 기반 시스템은 조명 조건의 변화나 가려짐에 취약하여 성능이 심각하게 저하될 수 있습니다.
이러한 맥락에서 mmWave 레이더는 매력적인 대안으로 부상했습니다. 개인의 시각적 이미지를 캡처하지 않기 때문에 개인 정보 보호 솔루션을 제공합니다. 또한, 어둠이나 연기와 같은 환경적 요인에 강건하여 더 넓은 범위의 배포 시나리오에 적합합니다. 따라서 본 논문에서 다루는 특정 문제는 mmWave 레이더의 고유한 장점을 활용하면서도 내재된 어려움을 극복하는 강건하고 정확한 2D 인간 자세 추정 시스템을 개발하는 것입니다.
본 논문의 저자들이 milliMamba를 개발하게 된 근본적인 한계 또는 "고충점"은 여러 문제에서 비롯됩니다. 첫째, 레이더 신호는 "반사각(specular reflection)"이라는 현상으로 인해 종종 희소합니다. 이는 신호가 특정 각도에서 신체 부위에 부딪힐 때 센서에서 튕겨 나갈 수 있음을 의미하며, 불완전한 관측으로 이어져 단일 프레임에서 전신 자세를 재구성하기 어렵게 만듭니다. 말단 부위(손가락이나 발가락 등)에서 발생하는 약한 반사 및 대상 방향에 대한 민감성은 이 문제를 더욱 악화시킵니다. 둘째, 특히 트랜스포머 기반의 이전 방법들은 레이더 입력의 높은 차원성과 긴 프레임 시퀀스 처리에 필요한 큰 "토큰 볼륨(token volumes)"으로 어려움을 겪었습니다. 이는 이차적인 계산 복잡성으로 이어져 메모리 집약적이고 느린 결과를 초래했습니다. 이를 완화하려는 일부 시도는 시간적 정보를 "조기 융합(early fusion)"하는 것을 포함했지만, 이는 종종 이웃 프레임의 귀중한 맥락적 단서를 잃어버려 모델이 누락된 관절을 복구하는 능력을 손상시켰습니다. 저자들의 목표는 레이더 데이터의 긴 시퀀스를 효율적으로 처리하여 시공간적 맥락을 활용하고, 이를 통해 누락된 관절을 더 정확하게 추론하며 시간적 일관성을 유지하는 시스템을 만드는 것이었으며, 동시에 계산 비용을 관리 가능하게 유지하는 것이었습니다.
직관적인 도메인 용어
- 밀리미터파(mmWave) 레이더: 박쥐가 어둠 속에서 소나를 사용하여 "보는" 것을 상상해 보세요. 하지만 소리 파동 대신 매우 짧은 라디오 파동을 사용합니다. 이 파동은 물체에 부딪혀 반사되고, 반향을 들음으로써 카메라 없이도 물체의 위치와 움직임을 파악할 수 있습니다. 마치 모션에 대한 X선 시력을 갖는 것과 같지만, 사람을 실제로 보지 않고도 가능합니다.
- 인간 자세 추정(HPE): 사람의 몸 위에 막대기 그림을 그리는 것으로 생각하세요. 목표는 팔꿈치, 무릎, 어깨와 같은 주요 관절의 정확한 위치를 파악하여 자세와 움직임을 이해하는 것입니다.
- 반사각(Specular Reflection): 완벽하게 매끄러운 거울을 들여다보는 것과 같습니다. 레이더 신호가 매우 매끄럽고 정확한 각도로 신체 표면에 부딪히면, 신호는 거울에 빛이 반사되는 것처럼 완전히 튕겨 나가 레이더 센서로 돌아가지 않습니다. 이로 인해 신체의 해당 부분이 레이더에 "보이지 않게" 되어 데이터에 간격이 생깁니다.
- 시공간적 종속성(Spatio-temporal Dependencies): 이는 한 순간에 공간적으로 (서로에 대해 어디에 있는지) 그리고 시간적으로 (일련의 순간에 걸쳐 어떻게 움직이고 변화하는지) 사물들이 어떻게 관련되는지를 나타냅니다. HPE의 경우, 한 프레임에서의 팔 움직임이 이전 및 다음 프레임에서의 위치와 연결되어 있으며, 또한 어깨의 위치와도 연결되어 있음을 이해하는 것을 의미합니다.
- Mamba: 트랜스포머와 유사하지만 긴 정보 시퀀스를 처리하는 데 훨씬 더 효율적인 새로운 유형의 인공 지능 아키텍처입니다. 마치 매우 긴 강의의 전체 전사본을 매번 다시 읽을 필요 없이 핵심 요점을 빠르게 요약하고 기억할 수 있는 믿을 수 없을 정도로 똑똑한 노트 필기자를 상상해 보세요. 이를 통해 AI는 압도당하지 않고 훨씬 더 긴 기간 동안의 맥락을 이해할 수 있습니다.
표기법 표
| 표기법 | 설명 |
|---|---|
문제 정의 및 제약 조건
핵심 문제 공식화 및 딜레마
본 논문에서 다루는 핵심 문제는 밀리미터파(mmWave) 레이더 신호를 이용한 2D 인간 자세 추정(HPE)입니다.
제안된 시스템의 입력/현재 상태는 $T$ 프레임의 시퀀스에 걸쳐 듀얼 레이더 센서로 캡처된 원시 복소수 mmWave 레이더 신호로 구성됩니다. 구체적으로, FMCW 레이더는 가상 안테나 쌍, 칩, ADC 샘플에 해당하는 각 프레임에 대해 복소수 큐브 $X \in \mathbb{C}^{12 \times 128 \times 256}$를 생성합니다. 이러한 원시 신호는 3D 각도-도플러-범위 히트맵으로 사전 처리된 후, $T$ 프레임에 걸쳐 쌓이고 실수부와 허수부로 분리되어 $C \times T \times H \times D \times W$ (여기서 $C=2$) 형태의 2채널 텐서를 형성합니다. 이 입력은 높은 차원성과 레이더 반사의 희소한 특성으로 인해 본질적으로 어렵습니다.
출력/목표 상태는 슬라이딩 윈도우 내의 여러 프레임에 걸쳐 각 관절에 대한 2D 키포인트 좌표로 표현되는 시간적으로 일관된 2D 인간 자세 시퀀스입니다. 목표는 반사각으로 인해 약하게 반사되거나 완전히 누락된 관절에 대해서도 이러한 관절 좌표를 정확하게 예측하는 동시에 시간적 일관성을 유지하고 합리적인 계산 복잡성으로 최첨단 성능을 달성하는 것입니다.
본 논문이 연결하고자 하는 정확한 누락된 연결 또는 수학적 격차는 희소하고 고차원적인 mmWave 레이더 데이터로부터 시공간적 종속성을 강건하고 효율적으로 모델링하는 것입니다. 이전 방법들은 다음과 같은 문제로 어려움을 겪습니다.
1. 불완전한 관측: 반사각으로 인해 수신기를 직접 향하는 신체 표면만 캡처되어 누락되거나 약하게 반사된 관절(특히 말단 부위)이 발생하며, 단일 프레임 입력에서 전신 자세를 재구성하기 어렵습니다.
2. 시간적 불일치: 레이더 신호의 변동은 프레임 간 시간적 일관성을 방해하여 시간 경과에 따른 정확한 자세 추정을 방해합니다.
3. 계산 확장성: 트랜스포머 기반 모델은 전역 종속성을 포착할 수 있지만, 시퀀스 길이에 대한 이차 복잡성으로 인해 더 긴 레이더 시퀀스의 대규모 토큰 볼륨을 처리하는 데 계산 비용이 많이 들고 메모리 집약적입니다.
4. 부분적 시공간 모델링: 이전 접근 방식은 종종 시공간적 종속성을 부분적으로만 모델링하거나 조기 시간 융합에 의존하여 귀중한 맥락 정보를 폐기함으로써 누락된 관절을 복구하는 모델의 능력을 손상시킬 수 있습니다.
이전 연구자들이 갇혀 있던 고통스러운 절충 또는 딜레마는 주로 정확도(특히 누락된 관절 및 시간적 일관성)와 계산 효율성/메모리 사용량 사이의 문제입니다. 특히 누락된 관절을 추론하고 시간적 부드러움을 보장하는 더 높은 정확도를 달성하기 위해 모델은 더 긴 시퀀스를 처리하고 더 풍부한 시공간적 맥락을 포착해야 합니다. 그러나 트랜스포머와 같은 기존 아키텍처는 이러한 긴 시퀀스에 대해 이차 계산 복잡성과 높은 메모리 요구 사항을 발생시켜 비실용적입니다. 반대로, 조기 시간 융합이나 단일 프레임 예측을 통해 복잡성을 줄이는 방법은 희소하고 반사각이 있는 레이더 데이터를 강건하게 처리하고 시간적 일관성을 유지하는 데 필요한 맥락 정보를 희생하는 경우가 많습니다. 이 딜레마는 연구자들에게 계산 비용이 많이 들지만 잠재적으로 더 정확한 모델과 더 빠르지만 덜 강건한 모델 중 하나를 선택하도록 강요합니다.
제약 조건 및 실패 모드
mmWave 레이더 기반 인간 자세 추정 문제는 저자들이 직면하는 몇 가지 가혹하고 현실적인 벽으로 인해 믿을 수 없을 정도로 어렵습니다.
-
물리적 제약:
- 반사각: 이것이 주요 과제입니다. 레이더 신호는 거울과 같은 방식으로 표면에서 반사되므로 센서를 직접 향하는 신체 부위만 감지됩니다. 이는 극심한 데이터 희소성과 불완전한 관측으로 이어져, 작거나 비스듬히 방향이 잡힌 관절이 레이더 데이터에서 종종 완전히 누락됩니다.
- 말단 부위의 약한 반사: 손목이나 발목과 같은 관절은 종종 매우 약한 레이더 반사를 생성하여 신뢰할 수 있게 감지하고 추적하기가 특히 어렵습니다.
- 대상 방향 및 센서 배치에 대한 민감성: 레이더 데이터의 품질과 완전성은 센서에 대한 대상의 방향과 레이더 장치의 정확한 배치에 따라 크게 달라지므로 강건한 특징 추출이 더욱 복잡해집니다.
- 제한된 고도 해상도: mmWave 레이더 센서는 본질적으로 고도 차원에서 해상도가 제한되어 3D 자세 재구성에서 모호함이 발생할 수 있습니다. 듀얼 레이더 설정은 이를 완화하는 데 사용됩니다.
-
계산 제약:
- 레이더 입력의 높은 차원성: 원시 레이더 신호는 고차원이며, 3D 히트맵으로 사전 처리된 후에도 프레임 시퀀스에 대한 데이터 볼륨은 상당합니다.
- 트랜스포머의 이차 복잡성: 전역 종속성 모델링에 강력한 트랜스포머 기반 모델은 입력 시퀀스 길이 $N$에 대한 $O(N^2)$ 복잡성으로 어려움을 겪습니다. 이는 "더 긴 레이더 시퀀스에 내재된 대규모 토큰 볼륨"을 처리하는 데 비효율적이어서 계산 비용과 훈련 시간이 엄청나게 많이 듭니다.
- 하드웨어 메모리 한계: 트랜스포머의 이차 복잡성은 직접적으로 높은 메모리 소비로 이어집니다. 논문에서 언급했듯이, 트랜스포머는 "더 긴 시퀀스(예: $T=3$ 프레임 이상)로 훈련할 때 하드웨어에서 메모리 부족"이 발생하여 처리할 수 있는 시간적 맥락의 양이 심각하게 제한됩니다.
- 사전 처리 오버헤드: 원시 레이더 신호에서 기존의 4D 히트맵 생성은 계산 비용이 많이 들고 메모리 집약적입니다(예: 3D FFT 기반 히트맵보다 메모리 11배, 지연 시간 8.6배). 이는 실시간 애플리케이션의 병목 현상이 될 수 있습니다.
-
데이터 기반 제약:
- 시간적 불일치: 레이더 신호의 본질적인 노이즈와 변동은 프레임 간 관절 위치의 시간적 연속성을 방해하여 시간 경과에 따른 일관되고 부드러운 자세 추정을 유지하기 어렵게 만듭니다.
- 강건한 특징의 부족: 희소하고 노이즈가 많은 레이더 신호에서 강건하고 구별되는 특징을 추출하는 것은 중요한 장애물입니다. 원시 데이터는 RGB 이미지와 같은 시각적 단서를 직접 제공하지 않기 때문입니다.
- 누락된 정보 추론의 어려움: 반사각으로 인해 모델은 맥락적 단서를 사용하여 누락된 관절의 위치를 추론해야 하며, 이는 단순한 프레임별 분석을 넘어서는 정교한 시공간적 추론을 필요로 합니다.
이러한 제약 조건들은 총체적으로 레이더 기반 HPE를 특히 어려운 문제로 만들며, 계산 가능성을 유지하면서 고차원적이고 희소하며 시간적으로 불일치하는 데이터를 효율적으로 처리할 수 있는 혁신적인 아키텍처 설계를 요구합니다.
왜 이 접근 방식인가
선택의 불가피성
밀리미터파(mmWave) 레이더를 이용한 인간 자세 추정(HPE)이라는 어려운 문제를 해결할 때, 저자들은 기존의 최첨단(SOTA) 방법들이 불충분하다는 중요한 기로에 직면했습니다. 핵심 문제는 반사각으로 인해 희소한 레이더 신호의 본질에서 비롯되며, 이는 불완전한 관측과 특히 말단 부위의 누락된 관절 데이터로 이어집니다. 또한, 원시 레이더 입력은 고차원적이며, 목표는 이러한 누락된 관절을 추론하고 움직임의 부드러움을 보장하기 위해 더 긴 시퀀스에서 강건한 시공간적 특징을 추출하는 것입니다.
저자들은 특히 이 특정 애플리케이션에 대해 트랜스포머 기반 접근 방식이 치명적인 결함, 즉 이차 복잡성($O(N^2)$)을 가지고 있다는 것을 명확히 인식했습니다. 입력 시퀀스 길이에 대한 이차 복잡성은 "더 긴 레이더 시퀀스에 내재된 대규모 토큰 볼륨"을 처리하는 것을 트랜스포머에게 엄청난 계산 비용, 메모리 사용량 및 훈련 시간으로 인해 극복할 수 없는 과제로 만들었습니다. 예를 들어, 표 8은 트랜스포머 인코더가 하드웨어에서 메모리 부족으로 인해 $T=3$ 프레임만 처리할 수 있었던 반면, 제안된 Mamba 기반 인코더는 $T=9$ 또는 심지어 $T=15$ 프레임까지 확장할 수 있었음을 명확히 보여줍니다. 이러한 실질적인 한계는 트랜스포머가 강건한 자세 추정을 위해 필요한 시간적 맥락을 처리할 수 없음을 의미했습니다.
마찬가지로, CNN 기반 방법들은 공간 및 단기 시간 특징을 포착하는 데 효과적이지만, "여러 레이더 센서의 정보를 융합하는 능력에 종종 제한적"이었습니다. milliMamba가 수평 및 수직 뷰를 위해 듀얼 레이더 설정을 활용한다는 점을 고려할 때, 이러한 한계는 표준 CNN을 최적이 아닌 선택으로 만들었습니다.
결론은 명확했습니다. 선형 복잡성($O(N)$)으로 장거리 시공간적 종속성을 효율적으로 모델링하여 엄청난 계산 비용 없이 고차원, 다중 프레임 레이더 데이터를 처리할 수 있는 새로운 아키텍처가 필요했습니다. 이는 선택적 상태 공간 모델(SSM) 설계를 갖춘 Mamba 아키텍처를 유일하게 실행 가능한 경로로 만들었습니다.
비교 우위
milliMamba 프레임워크는 긴 시퀀스와 복잡한 시공간적 종속성을 효율적으로 처리하는 구조적 이점을 통해 이전의 골드 스탠다드에 비해 질적인 우수성을 달성합니다.
-
긴 시퀀스를 위한 선형 복잡성: 가장 중요한 구조적 이점은 인코더에 Mamba 아키텍처를 채택한 것입니다. 시퀀스 길이 $N$에 대해 이차 복잡성 $O(N^2)$으로 어려움을 겪는 트랜스포머와 달리, Mamba는 선형 복잡성 $O(N)$을 제공합니다. 이는 단순한 점진적인 개선이 아니라 근본적인 변화로,
milliMamba가 메모리 부족 없이 훨씬 더 긴 레이더 시퀀스(예: 기본값 $T=9$ 프레임, 실험에서 최대 $T=15$ 프레임)를 처리할 수 있게 해줍니다. 이는 트랜스포머의 심각한 한계였습니다. 이는 모델이 훨씬 더 풍부한 시간적 맥락을 활용할 수 있게 해주며, 이는 반사각으로 인한 누락된 관절을 추론하고 움직임의 부드러움을 보장하는 데 매우 중요합니다. -
향상된 시공간적 맥락 모델링: 크로스 뷰 융합 Mamba(CV-Mamba) 인코더는 "더 긴 시퀀스에 걸쳐 종속성을 효율적으로 포착"하고 "프레임 간 듀얼 레이더 입력을 효과적으로 융합"하도록 특별히 설계되었습니다. 이를 통해 희소한 레이더 데이터에서 강건한 자세 추정에 필수적인 장면에 대한 보다 포괄적인 이해가 가능합니다. 또한, 다중 프레임 출력 전략을 갖춘 시공간 교차 주의(STCA) 디코더는 공간 및 시간 주의를 모두 통합합니다. 이는 각 프레임 내의 관계(공간)와 프레임 간의 관계(시간)를 모델링할 수 있게 하여 "시간 단계 전반에 걸쳐 더 풍부한 감독"을 제공하고 이웃 프레임의 귀중한 맥락 정보를 활용하여 누락된 관절을 더 잘 추론할 수 있게 합니다. 이는 조기 시간 융합을 수행하거나 단일 프레임을 예측하는 방법보다 질적인 도약입니다.
-
효율적인 사전 처리: Mamba 아키텍처의 핵심 부분은 아니지만, 레이더 신호 처리를 위한 3D 고속 푸리에 변환(FFT)의 선택은 전반적인 우수성에 크게 기여합니다. 그림 4(c)에 설명된 대로, 이 접근 방식은 기존의 4D 히트맵 생성에 비해 메모리 사용량을 11배, 지연 시간을 8.6배 줄입니다. 이러한 효율성 증가는 "토큰 수의 폭발"을 완화하여 고차원 레이더 데이터를 Mamba 인코더의 다운스트림 모델링에 대해 다루기 쉽게 만들기 때문에 중요합니다. 이러한 결합된 효율성은
milliMamba가 표 2와 3에서 강조된 것처럼 계산 비용과 성능 간에 더 유리한 균형을 유지하면서 더 높은 정확도를 달성할 수 있게 합니다.
본질적으로, milliMamba는 기존 방법들이 아키텍처 한계로 인해 어려움을 겪었던, 정확한 레이더 기반 HPE에 필요한 광범위한 시공간 정보를 처리할 수 있는 확장 가능하고 효율적이며 맥락이 풍부한 프레임워크를 제공하기 때문에 압도적으로 우수합니다.
제약 조건과의 정렬
선택된 milliMamba 접근 방식은 mmWave 레이더 기반 인간 자세 추정의 가혹한 요구 사항과 완벽하게 일치하며, 문제의 고유한 과제와 솔루션의 맞춤형 속성 간의 강력한 "결합"을 형성합니다.
-
희소하고 불완전한 데이터(반사각) 처리: 레이더 신호의 희소성과 반사각으로 인한 누락된 관절 정보가 핵심 문제입니다.
milliMamba는 포괄적인 시공간 모델링을 통해 이를 직접적으로 해결합니다. CV-Mamba 인코더는 더 긴 시퀀스에서 특징을 추출하여 충분한 시간적 맥락을 제공합니다. STCA 디코더는 여러 프레임에 걸쳐 동시에 자세를 예측하고 공간 및 시간 주의를 모두 통합함으로써 이 맥락을 활용합니다. 이를 통해 모델은 "반사각으로 인해 누락된 관절을 추론하기 위해 이웃 프레임과 관절의 맥락적 단서를 활용"할 수 있으며, 불완전한 관측의 영향을 직접적으로 완화합니다. 속도 손실 또한 움직임의 부드러움을 강화하여 프레임이 희소할 때에도 그럴듯한 자세를 재구성하는 데 도움이 됩니다. -
고차원 입력 및 대규모 토큰 볼륨 관리: mmWave 레이더 입력은 본질적으로 고차원입니다.
milliMamba프레임워크는 먼저 효율적인 3D FFT 기반 사전 처리 단계를 사용하여 이를 처리하며, 이는 전통적인 4D 접근 방식(그림 4(c))에 비해 메모리 사용량과 지연 시간을 크게 줄입니다. 이 단계는 "토큰 수의 폭발을 완화"하여 데이터를 관리 가능하게 만듭니다. 이후, 선형 복잡성을 갖춘 CV-Mamba 인코더는 "더 긴 레이더 시퀀스에 내재된 대규모 토큰 볼륨을 효율적으로 처리"하도록 특별히 설계되었으며, 이는 전통적인 트랜스포머가 이차적 확장으로 인해 충족하지 못한 중요한 요구 사항입니다. -
다중 레이더 입력 융합: 문제는 종종 더 포괄적인 보기를 캡처하기 위해 듀얼 레이더 설정을 포함합니다. CV-Mamba 인코더는 "듀얼 레이더 입력의 크로스 뷰 융합"을 위해 명시적으로 설계되어 수평 및 수직 레이더 보기의 정보를 효과적으로 결합합니다. 이는 일부 CNN 기반 방법의 알려진 한계인 여러 센서의 데이터를 통합해야 하는 필요성을 직접적으로 해결합니다.
-
시간적 일관성 및 움직임 부드러움 보장: 약한 반사와 변동은 시간적 일관성을 방해할 수 있습니다. STCA 디코더의 다중 프레임 예측 전략과 속도 손실($L_{vel}$)의 명시적 통합은 훈련 중에 시간적 일관성을 직접적으로 강제합니다. 속도 손실은 $L_{vel} = \frac{1}{T-1}\sum_{f=1}^{T-1}\sum_{j=1}^{J} ||\mathbf{v}_{f,j} - \hat{\mathbf{v}}_{f,j}||^2$로 정의되며, 여기서 $\mathbf{v}_{f,j}$는 실제 속도이고 $\hat{\mathbf{v}}_{f,j}$는 예측된 속도입니다. 이는 관절 속도의 불일치를 페널티화하여 부드럽고 현실적인 자세 시퀀스를 촉진합니다.
요약하자면, milliMamba의 효율적인 사전 처리, 장거리 시공간 융합을 위한 선형 복잡성 Mamba 인코더, 속도 손실을 갖춘 다중 프레임 주의 디코더의 고유한 조합은 mmWave 레이더 기반 HPE의 모든 주요 제약 조건을 직접적으로 해결하는 강건하고 계산적으로 실현 가능한 솔루션을 만듭니다.
대안의 기각
이 논문은 여러 인기 있는 대안적 접근 방식을 기각하는 명확한 이유를 제공하며, milliMamba의 설계 선택이 왜 필요했는지를 강조합니다.
-
트랜스포머: 가장 두드러진 대안인 트랜스포머는 주로 이차 계산 복잡성($O(N^2)$)으로 인해 입력 시퀀스 길이에 대해 기각되었습니다. 저자들은 이것이 강건한 레이더 기반 HPE에 필요한 "더 긴 레이더 시퀀스에 내재된 대규모 토큰 볼륨"을 처리하는 데 부적합하다고 명시적으로 언급합니다. 표 8은 트랜스포머 인코더가 하드웨어의 "메모리 부족 문제"로 인해 $T=9$ 프레임조차 처리할 수 없었던 경험적 증거를 제공하는 반면, Mamba는 이를 효율적으로 처리했습니다. 이러한 근본적인 확장성 문제는 트랜스포머를 시간적 맥락에 대한 문제의 요구 사항에 비실용적으로 만들었습니다.
-
CNN 기반 방법: 일부 작업에는 유용하지만, CNN은 "여러 레이더 센서의 정보를 융합하는 능력에 제한적"이기 때문에 불충분하다고 간주되었습니다.
milliMamba의 듀얼 레이더 입력(수평 및 수직 뷰)을 고려할 때, 더 우수한 다중 센서 융합 기능을 갖춘 방법이 필요했으며, 이는 트랜스포머(및 이후 Mamba)가 주의/SSM 메커니즘을 통해 본질적으로 제공합니다. -
조기 시간 융합 접근 방식: 일부 이전 방법 [2, 12, 13]은 "시간 차원을 조기에 축소"하여 시간 정보를 처리하려고 시도했습니다. 저자들은 이러한 전략을 명시적으로 거부하며, "이러한 조기 융합은 반사각으로 인한 누락된 관절을 복구하는 모델의 능력을 손상시킬 수 있다"고 주장합니다. 이는
milliMamba의 주요 목표가 풍부한 시공간적 맥락을 활용하여 이러한 누락된 관절을 추론하는 것이며, 조기 융합은 이를 약화시킬 것이기 때문에 중요한 질적 거부입니다. -
다대일 예측 전략: 대부분의 이전 레이더 기반 HPE 방법은 "다중 프레임에서 단일 프레임 디코딩 방식"을 채택합니다. 즉, 여러 프레임을 입력으로 사용하지만 단일 자세(일반적으로 중앙 프레임)만 예측합니다. 대조적으로
milliMamba는 "다대다" 예측 전략을 사용하여 여러 프레임에 대한 자세를 동시에 출력합니다. 표 5는 이를 정량적으로 지지하며, "다대일" 전략이milliMamba의 "다대다" 접근 방식(74.5)보다 훨씬 낮은 전체 AP(70.4)를 산출한다는 것을 보여주며, 4.1 AP 개선을 달성했습니다. 이는 여러 프레임을 예측하는 것의 맥락적 추론 능력이 우수함을 보여줍니다. -
4D 히트맵 사전 처리: 원시 레이더 신호에서 4D 히트맵을 생성하는 기존 접근 방식 [25]은 계산 비효율성으로 인해 거부되었습니다. 논문은 이 방법이 "계산 비용이 많이 들고" "토큰 수의 폭발"로 이어진다고 강조합니다. 그림 4(c)는 4D 히트맵 생성이
milliMamba의 3D FFT 기반 사전 처리와 비교하여 11배 더 높은 피크 메모리와 8.6배 더 긴 실행 시간을 발생시킨다는 명확한 비교를 제공합니다. 이러한 명확한 비효율성은 4D 접근 방식을 실용적이고 확장 가능한 시스템에 부적합하게 만들었습니다.
이러한 거부는 저자들이 문제의 제약 조건과 기존 기술의 한계를 깊이 이해하고 있음을 강조하며, 이를 통해 milliMamba를 맞춤형이고 더 효과적인 솔루션으로 개발하게 되었습니다. Mamba의 선택은 임의적인 것이 아니라 레이더 데이터의 특정 요구 사항과 다른 SOTA 모델의 본질적인 비호환성으로 인해 필수적이었습니다.
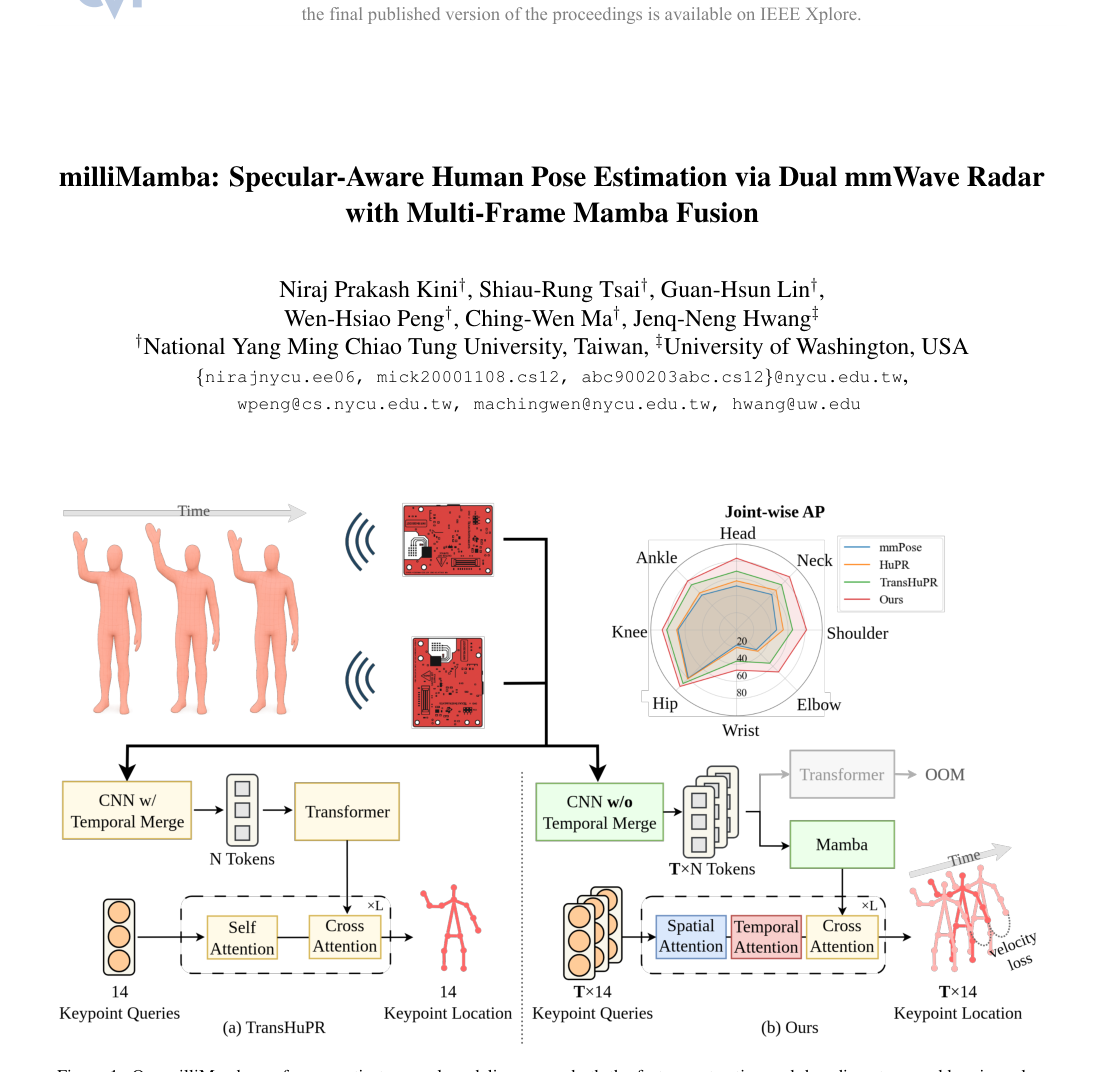 Figure 1. Our milliMamba performs spatio-temporal modeling across both the feature extraction and decoding stages, addressing a key limitation of TransHuPR [12], which models these dependencies only partially. This is made possible by milliMamba’s ability to process a larger number of tokens with a comparable memory footprint, enabling richer temporal context and more accurate pose estimation
Figure 1. Our milliMamba performs spatio-temporal modeling across both the feature extraction and decoding stages, addressing a key limitation of TransHuPR [12], which models these dependencies only partially. This is made possible by milliMamba’s ability to process a larger number of tokens with a comparable memory footprint, enabling richer temporal context and more accurate pose estimation
수학적 및 논리적 메커니즘
마스터 방정식
milliMamba의 수학적 핵심은 크로스 뷰 융합 Mamba(CVMamba) 인코더의 기반을 형성하는 상태 공간 모델(SSM) 업데이트 방정식과 모델의 학습을 조율하는 포괄적인 훈련 목표 함수라는 두 가지 주요 방정식 세트에 의해 주도됩니다.
각 비전 Mamba 레이어에 대한 SSM 업데이트는 다음과 같이 정의됩니다.
$$
h_{t+1} = A h_t + B u_t \\
y_t = C h_t + D u_t
$$
여기서 $t$는 시간 단계를 나타냅니다.
모델이 학습 단계 동안 최소화하려고 하는 전체 훈련 목표는 다음과 같습니다.
$$
L = L_{oks} + \lambda_{vel} L_{vel}
$$
속도 손실 $L_{vel}$은 다음과 같이 더 구체화됩니다.
$$
L_{vel} = \frac{1}{(T-1)J} \sum_{f=1}^{T-1} \sum_{j=1}^{J} ||v_{f,j} - \hat{v}_{f,j}||^2_2
$$
항별 분석
이러한 방정식 내의 각 항을 세심하게 분석하여 수학적 정의, 물리적 또는 논리적 역할, 그리고 포함 및 형식의 근거를 이해해 보겠습니다.
상태 공간 모델(SSM) 업데이트 방정식의 경우:
-
$h_t$:
- 수학적 정의: 시간 단계 $t$에서의 SSM의 은닉 상태 벡터입니다. 현재 시점까지의 시퀀스 기록에 대한 간결한 표현입니다.
- 물리적/논리적 역할: 개념적으로 $h_t$는 모델의 "기억" 또는 "맥락 요약" 역할을 합니다. 이전 모든 입력 토큰의 정보를 축적하고 유지하여 모델이 인간 자세 데이터 내의 장거리 시간적 종속성을 이해하고 활용할 수 있도록 합니다. $h_t$에서 $h_{t+1}$로의 진화는 순차적 처리에 중심적입니다.
- 사용 이유: 저자들은 이 상태 공간 공식을 사용하여 긴 시퀀스 처리를 위한 선형 시간 복잡성을 달성합니다. 이는 전역 주의 메커니즘으로 인해 이차 계산 비용이 발생하는 기존 트랜스포머 아키텍처에 비해 상당한 이점이며, 고차원 다중 프레임 레이더 입력에 덜 적합합니다.
-
$u_t$:
- 수학적 정의: 시간 단계 $t$에서의 입력 토큰 벡터입니다. milliMamba에서 이러한 토큰은 사전 처리된 레이더 히트맵에서 파생되며, 시퀀스의 특정 순간의 시공간적 특징을 나타냅니다.
- 물리적/논리적 역할: $u_t$는 각 단계에서 SSM에 공급되는 "현재 관측" 또는 "새로운 정보" 역할을 합니다. 모델이 인간 자세에 대한 진화하는 이해에 통합해야 하는 즉각적인 레이더 데이터 조각입니다.
- 사용 이유: 상태 업데이트를 구동하고 현재 출력에 기여하는 직접적인 외부 자극이며, 레이더에서 원시 특징 정보를 제공합니다.
-
$y_t$:
- 수학적 정의: SSM이 시간 단계 $t$에서 생성하는 출력 토큰 벡터입니다.
- 물리적/논리적 역할: $y_t$는 현재 입력 $u_t$와 축적된 은닉 상태 $h_t$의 함수인 시간 $t$에서의 변환된 특징 또는 즉각적인 출력을 나타냅니다. Mamba 레이어 내에서 이 출력은 디코더에 전달되는 전체 인코딩된 특징에 기여합니다.
- 사용 이유: 시간 $t$에서의 입력에 대한 처리되고 맥락 인식적인 표현을 제공하며, 이는 이후 인코더의 후속 레이어 또는 SSM 블록의 최종 출력으로 사용될 수 있습니다.
-
$A, B, C, D$:
- 수학적 정의: 이들은 레이어별 학습 가능한 매개변수 행렬(또는 특정 SSM 변형 및 차원에 따라 벡터일 수도 있음)입니다. 훈련 과정 중에 초기화되고 최적화됩니다.
- 물리적/논리적 역할:
- $A$: 상태 전이 행렬. 이전 은닉 상태 $h_t$가 본질적으로 다음 은닉 상태 $h_{t+1}$로 어떻게 전파되고 변환되는지를 제어합니다. 이는 시퀀스 내 정보의 내재된 역학 및 지속성을 포착하며, 기본적으로 "기억"이 시간에 따라 어떻게 진화하는지를 정의합니다.
- $B$: 입력 행렬. 현재 입력 $u_t$가 은닉 상태 $h_{t+1}$의 업데이트에 어떻게 통합되는지를 결정합니다. "새로운 데이터"가 모델의 기억에 미치는 영향을 제어합니다.
- $C$: 출력 행렬. 은닉 상태 $h_t$를 출력 $y_t$로 변환합니다. 모델의 기억에서 관련 정보를 추출하여 현재 출력을 형성하는 역할을 합니다.
- $D$: 직접 피드스루 행렬. 현재 입력 $u_t$가 먼저 은닉 상태로 통합되지 않고도 출력 $y_t$에 직접 기여할 수 있도록 합니다. 이는 즉각적인 비순차적 관계를 포착할 수 있습니다.
- 사용 이유: 이 행렬들은 SSM이 레이더 데이터에서 복잡한 시간적 종속성을 학습할 수 있도록 하는 훈련 가능한 구성 요소입니다. 그 값은 인간 움직임의 근본적인 역학을 가장 잘 모델링하도록 최적화됩니다. 덧셈과 곱셈의 사용은 선형 상태 공간 시스템의 기본이며, 계산 효율적인 선형 변환 및 업데이트를 나타냅니다.
전체 훈련 목표 $L$의 경우:
-
$L$:
- 수학적 정의: 훈련 중에 모델이 최소화하려고 하는 총 손실을 나타내는 스칼라 값입니다.
- 물리적/논리적 역할: 이것은 전체 학습 과정의 주요 피드백 신호입니다. $L$ 값이 낮을수록 모델의 예측이 정의된 기준에 따라 더 정확하고 시간적으로 일관됨을 의미합니다. 모델의 매개변수는 이 값을 줄이기 위해 반복적으로 조정됩니다.
- 사용 이유: 모델 예측의 "오류"를 정량화하여 경사 하강법을 통한 최적화 과정을 안내하는 목표 함수 역할을 합니다.
-
$L_{oks}$:
- 수학적 정의: 객체 키포인트 유사성(Object Keypoint Similarity, OKS) 손실입니다. 정확한 공식은 논문에 제공되지 않았지만, 일반적으로 객체 크기와 키포인트 가시성에 따라 가중치가 부여된 예측 및 실제 키포인트 간의 유사성을 측정하는 인간 자세 추정의 표준 메트릭입니다.
- 물리적/논리적 역할: 이 항은 각 개별 프레임에서 관절의 올바른 위치를 식별하고 배치하는 방법을 모델이 학습하도록 보장합니다.
- 사용 이유: OKS는 자세 추정을 위한 널리 채택되고 강건한 손실 함수로, 작업의 기본 목표를 직접적으로 반영합니다. 속도 손실에 추가되어 정적 자세 정확도와 시간적 부드러움 모두 중요하며 전반적인 오류에 독립적으로 기여함을 나타냅니다.
-
$\lambda_{vel}$:
- 수학적 정의: 속도 손실 항에 대한 스칼라 가중치 계수입니다. 논문에서는 $\lambda_{vel} = 0.05$로 지정합니다.
- 물리적/논리적 역할: 이 매개변수는 시간적 부드러움( $L_{vel}$로 강제됨)의 중요성과 기본 관절 위치 정확도( $L_{oks}$로 구동됨)의 중요성을 균형 맞추는 다이얼 역할을 합니다. 0.05와 같은 작은 값은 시간적 일관성이 중요하지만 근본적인 정확도 요구 사항을 압도해서는 안 된다는 것을 시사합니다.
- 사용 이유: 조정 가능한 하이퍼파라미터로, 저자가 모델의 동작을 미세 조정하고 다양한 학습 목표 간의 최적의 절충점을 달성할 수 있도록 합니다.
-
$L_{vel}$:
- 수학적 정의: 속도 손실로, 관련 프레임과 관절 전체의 예측 및 실제 관절 속도 차이의 평균 제곱 L2 노름으로 계산됩니다.
- 물리적/논리적 역할: 이 항은 "시간 정규화기" 또는 "움직임 부드러움 강화기" 역할을 합니다. 연속 프레임 간 관절 위치의 갑작스럽고 비현실적인 변화를 페널티화하여 예측된 자세 시퀀스에서 부드럽고 일관된 움직임을 촉진합니다. 이는 희소한 레이더 신호나 반사각으로 인한 누락된 관절을 추론하는 데 특히 유익하며, 모델은 이웃 프레임의 맥락적 단서를 기반으로 그럴듯한 움직임 궤적을 "채워 넣는" 방법을 학습합니다.
- 사용 이유: 저자들은 레이더 데이터의 문제, 즉 누락되거나 노이즈가 많은 관절 관측을 완화하기 위해 이 손실을 도입했습니다. 부드러움을 강제함으로써 모델은 간격을 더 현실적으로 "채울" 수 있습니다. 제곱 L2 노름($||\cdot||^2_2$)은 회귀 오류를 측정하는 표준적이고 미분 가능한 효율적인 방법으로, 더 큰 오류를 더 중요하게 페널티화하고 더 작은 오류보다 더 크게 페널티화합니다. 합계($\sum$)는 모든 연속 프레임 쌍($T-1$)과 모든 관절($J$)에 걸쳐 오류를 집계하는 반면, $(T-1)J$로 나누는 것은 손실을 정규화하여 시퀀스 길이 또는 관절 수에 독립적으로 만듭니다.
-
$T$:
- 수학적 정의: 입력 시퀀스의 총 프레임 수입니다.
- 물리적/논리적 역할: 이 차원은 속도 손실이 계산되는 시간적 창을 정의하며, 고려되는 시간적 맥락의 범위를 설정합니다.
- 사용 이유: 분석 중인 시퀀스의 길이를 결정하는 입력 데이터의 기본 매개변수입니다.
-
$J$:
- 수학적 정의: 추정되는 총 인간 관절 수입니다.
- 물리적/논리적 역할: 이 차원은 속도가 계산되고 비교되는 개별 키포인트 수를 지정합니다.
- 사용 이유: 출력 데이터의 기본 매개변수로, 인간 자세 추정의 세분성을 나타냅니다.
-
$f$:
- 수학적 정의: 프레임 1부터 $T-1$까지 반복되는 인덱스입니다.
- 물리적/논리적 역할: 이 인덱스는 속도가 계산되는 특정 연속 프레임 쌍(프레임 $f$ 및 프레임 $f+1$)을 지정합니다.
- 사용 이유: 시퀀스의 시간적 차원에 걸쳐 속도를 체계적으로 순회하고 계산하기 위함입니다.
-
$j$:
- 수학적 정의: 관절 1부터 $J$까지 반복되는 인덱스입니다.
- 물리적/논리적 역할: 이 인덱스는 현재 고려 중인 특정 관절의 속도를 식별합니다.
- 사용 이유: 자세의 공간적 차원에 걸쳐 속도를 체계적으로 순회하고 계산하기 위함입니다.
-
$v_{f,j}$:
- 수학적 정의: 프레임 $f$에서 관절 $j$의 실제 속도입니다. 프레임 $f+1$과 프레임 $f$에서의 실제 위치 차이: $P_{f+1,j} - P_{f,j}$로 계산됩니다.
- 물리적/논리적 역할: 이는 특정 관절의 두 연속 프레임 간의 실제, 원하는 움직임 벡터를 나타내며, 모델의 이상적인 대상 역할을 합니다.
- 사용 이유: 모델의 예측된 움직임과 비교되는 정확한 참조를 제공하여 학습 과정을 안내합니다.
-
$\hat{v}_{f,j}$:
- 수학적 정의: 프레임 $f$에서 관절 $j$의 예측된 속도입니다. 프레임 $f+1$과 프레임 $f$에서의 예측된 위치 차이: $\hat{P}_{f+1,j} - \hat{P}_{f,j}$로 계산됩니다.
- 물리적/논리적 역할: 이것은 특정 관절에 대한 모델의 추정된 움직임 벡터입니다. 실제 속도 $v_{f,j}$와의 편차가 속도 손실이 페널티화하는 것입니다.
- 사용 이유: 이는 연속 프레임에 대한 모델의 자세 예측 출력이며, 속도 손실을 계산하는 데 사용됩니다.
-
$||\cdot||^2_2$:
- 수학적 정의: 벡터의 제곱 유클리드(L2) 노름입니다. 벡터 $x = [x_1, x_2, \dots, x_k]$의 경우, 제곱 L2 노름은 $||x||^2_2 = \sum_{i=1}^k x_i^2$입니다.
- 물리적/논리적 역할: 이는 예측된 속도와 실제 속도 간의 차이 벡터의 제곱 크기를 정량화합니다. 제곱은 양수 및 음수 차이가 모두 손실에 기여하도록 하고 더 큰 오류가 더 작은 오류보다 더 크게 페널티화되도록 합니다.
- 사용 이유: 벡터 간의 "거리" 또는 "오류"를 측정하는 표준적이고 미분 가능하며 계산 효율적인 방법으로, 경사 하강법 최적화에 적합합니다.
단계별 흐름
원시 레이더 신호에서 정제된 자세 예측까지의 추상 데이터 포인트의 여정을 milliMamba의 기계 조립 라인을 통해 추적해 보겠습니다.
-
원시 레이더 신호 수집: 프로세스는 원시 밀리미터파(mmWave) 레이더 신호로 시작됩니다. 이는 각 프레임에 대해 복소수 큐브 $X \in \mathbb{C}^{12 \times 128 \times 256}$로 도착하며, 가상 안테나 쌍, 칩, ADC 샘플에 걸친 데이터를 나타냅니다. milliMamba는 듀얼 레이더 설정을 사용하므로, 시간적 맥락의 슬라이딩 윈도우인 $T$ 연속 프레임 시퀀스에 대해 두 개의 이러한 큐브(하나는 수평, 하나는 수직 뷰용)가 획득됩니다.
-
사전 처리 조립 라인 (3D 고속 푸리에 변환):
- 클러터 제거: 먼저, 정적 반사는 칩에 걸친 평균을 빼서 필터링됩니다. 이는 원시 재료를 청소하여 관련 움직이는 대상만 처리되도록 하는 것과 같습니다.
- 칩 서브샘플링: 칩 차원은 프레임당 8개의 칩으로 균일하게 감소됩니다. 이 단계는 필수적인 도플러 해상도를 유지하면서 데이터 로드를 줄이는 데이터 압축과 유사합니다.
- 1D FFT (범위): ADC 샘플 차원($Y(m) = \sum_{n=0}^{N-1} X(n) \exp(-j \frac{2\pi nm}{N})$에 따라)을 따라 1D 고속 푸리에 변환(FFT)이 적용됩니다. 이는 원시 시간 영역 샘플을 물체의 거리를 나타내는 범위 정보로 변환합니다.
- 1D FFT (도플러): 다음으로, 칩 차원을 따라 또 다른 1D FFT가 적용됩니다. 이는 물체의 속도를 레이더에 상대적으로 나타내는 도플러 정보를 추출합니다.
- 제로 패딩 및 1D FFT (각도): 각도 해상도를 향상시키기 위해 가상 안테나 차원이 12에서 64로 제로 패딩됩니다. 이 차원을 따라 마지막 1D FFT는 데이터를 각도 정보(방위각 및 고도각)로 변환합니다.
- 출력: 각 뷰와 프레임에 대한 레이더 데이터는 이제 3D 각도-도플러-범위 히트맵 $Y \in \mathbb{C}^{H \times D \times W}$ (예: $64 \times 8 \times 256$)가 됩니다. 이러한 복소수 히트맵의 실수부와 허수부는 별도의 채널로 취급되어 $C \times T \times H \times D \times W$ 형태의 2채널 텐서가 되며, 여기서 $C=2$입니다.
-
CVMamba 인코더 - 특징 추출 및 시간 모델링:
- 병렬 MNet 브랜치: 수평 및 수직 뷰 히트맵은 두 개의 별도의 병렬 MNet 블록으로 공급됩니다. 각 MNet 블록은 먼저 도플러 차원을 병합한 다음, 일련의 잔차 3D 컨볼루션 및 다운샘플링 레이어를 통해 데이터를 처리합니다. 이는 공간 해상도(H 및 W)를 $4 \times$만큼 줄여 특징 맵 $F_h, F_v \in \mathbb{R}^{C_f \times T \times \frac{H}{4} \times \frac{W}{4}}$를 생성합니다. 이는 두 개의 전문화된 병렬 처리 라인이 다른 관점을 처리하는 것과 같습니다.
- 위치 임베딩: 별도의 학습 가능한 위치 임베딩 $P_h$ 및 $P_v$가 각각 $F_h$ 및 $F_v$에 추가됩니다. 이러한 임베딩은 특징의 절대 공간 위치(각도 및 범위)에 대한 정보를 데이터에 주입합니다.
- 크로스 뷰 융합: 두 뷰 특징은 채널 차원을 따라 연결되어 통합 인코더 입력 $F = [F_h; F_v] \in \mathbb{R}^{C_s \times T \times \frac{H}{4} \times \frac{W}{4} \times 2}$를 형성합니다. 이 단계는 두 레이더 보기의 정보를 효과적으로 병합합니다.
- 시퀀스 선형화: 다차원 특징 텐서 $F$는 특정 지그재그 스캔 패턴(범위 $\rightarrow$ 각도 $\rightarrow$ 뷰 $\rightarrow$ 프레임)을 사용하여 1D 토큰 시퀀스 $u_t$로 변환됩니다. 이 변환은 Mamba 아키텍처의 순차적 처리를 위해 데이터를 준비합니다.
- Mamba 레이어 처리: 이 1D 시퀀스 $u_t$는 비전 Mamba 레이어 스택으로 들어갑니다. 각 레이어는 SSM 방정식($h_{t+1} = A h_t + B u_t$, $y_t = C h_t + D u_t$)을 사용하여 은닉 상태 $h_t$를 반복적으로 업데이트하고 출력 $y_t$를 생성합니다. 이 프로세스는 순방향 및 역방향으로 모두 실행되어 모델이 선형 복잡성으로 전체 긴 시퀀스에 걸쳐 양방향 맥락을 효율적으로 포착할 수 있도록 합니다. Mamba 레이어 내의 게이팅 메커니즘과 잔차 연결은 이러한 순차적 처리를 더욱 정제합니다.
- 출력: CVMamba 인코더는 여러 프레임과 듀얼 레이더 보기에 걸쳐 복잡한 시공간적 종속성을 효과적으로 포착한 풍부하고 맥락 인식적인 특징 표현 $x_{Le}$를 출력합니다.
-
STCA 디코더 - 자세 예측 및 정제:
- 키포인트 쿼리 초기화: 디코더는 학습 가능한 키포인트 쿼리 $\{q_{f,j}\}$의 고정 집합으로 시작합니다. 각 쿼리는 특정 프레임의 특정 관절을 나타내도록 설계된 임베딩입니다. 이러한 쿼리는 자세 정보를 찾는 "지능형 프로브" 역할을 합니다.
- 시공간 주의 모듈:
- 공간 주의(SA): 먼저, 공간 자체 주의가 각 프레임 내에서 적용됩니다($q'_{f,.} = \text{softmax}(Q_f K_f^T / \sqrt{d}) V_f$). 이를 통해 동일한 프레임 내의 다른 관절에 대한 쿼리가 상호 작용하여 관절 간 관계를 포착할 수 있습니다(예: 단일 스냅샷에서 팔꿈치가 손목과 어떻게 관련되는지).
- 시간 주의(TA): 다음으로, 시간 자체 주의가 동일한 관절에 대해 프레임 간에 적용됩니다($q''_{.,j} = \text{softmax}(Q_j K_j^T / \sqrt{d}) V_j$). 이를 통해 특정 관절에 대한 쿼리가 이웃 프레임에서의 자체 표현에 주의를 기울일 수 있어 움직임 일관성을 강제하고 시간적 맥락을 활용하여 움직임을 이해할 수 있습니다.
- 인코더 특징에 대한 교차 주의: 정제된 키포인트 쿼리 $q''_{f,j}$는 인코더의 출력 특징 $F'$ ( $x_{Le}$임)와 교차 주의를 수행합니다($\hat{q}_{f,j} = \text{CrossAttn}(q''_{f,j}, F')$). 이 중요한 단계는 키포인트 쿼리가 CVMamba 인코더에 의해 생성된 풍부한 시공간적 특징에서 관련 자세 정보를 추출할 수 있도록 하여 쿼리를 레이더 데이터에 효과적으로 "고정"합니다.
- 반복적 정제: 이 전체 디코더 레이어(공간 주의, 시간 주의, 교차 주의 및 위치별 MLP로 구성됨)는 여러 번 쌓입니다. 키포인트 쿼리는 이러한 레이어를 통해 반복적으로 정제되어 표현과 정확도를 점진적으로 향상시킵니다.
- 예측 헤드: 마지막으로, 각 정제된 쿼리 $\hat{q}_{f,j}$는 간단한 예측 헤드(예: 다층 퍼셉트론)를 통과하여 프레임 $f$의 관절 $j$에 대한 2D 좌표를 출력합니다.
- 출력: 디코더는 각 추정치가 $J$개의 2D 키포인트 좌표로 구성된 $T$개의 자세 예측 시퀀스를 생성합니다. 추론 시에는 일반적으로 슬라이딩 윈도우 내의 중앙 프레임에 대한 예측만 유지됩니다.
최적화 역학
milliMamba 모델은 주로 전체 훈련 목표 $L = L_{oks} + \lambda_{vel} L_{vel}$에 의해 안내되는 엄격한 반복 최적화 과정을 통해 인간 자세 추정 기능을 학습하고 개선합니다. 이 메커니즘은 예측과 실제 간의 불일치를 최소화하기 위해 모델의 내부 매개변수를 체계적으로 조정합니다.
-
손실 지형 및 경사 행동:
- 총 손실 $L$은 모든 학습 가능한 모델 매개변수의 방대한 공간에 걸쳐 복잡하고 고차원적인 "손실 지형"을 정의합니다. 최적화 과정의 근본적인 목표는 이 지형을 탐색하여 가장 낮은 지점(전역 최소값) 또는 충분히 낮은 지점(지역 최소값)을 찾는 것입니다.
- $L_{oks}$ (객체 키포인트 유사성 손실): 이 손실 구성 요소는 주로 개별 키포인트의 정확한 공간적 배치를 보상하도록 지형을 형성합니다. 예측된 키포인트를 해당 실제 위치에 더 가깝게 "끌어당기는" 경사를 생성합니다. 예측된 키포인트가 실제 위치에서 상당히 벗어나면 $L_{oks}$는 강한 경사를 생성하여 모델이 이 공간적 오류를 줄이기 위해 매개변수를 조정하도록 강제합니다.
- $L_{vel}$ (속도 손실): 이 구성 요소는 시간적으로 부드럽고 일관된 자세 시퀀스를 선호하도록 손실 지형을 조각하는 중요한 정규화 효과를 도입합니다. 연속 프레임 간 관절 위치의 갑작스럽거나 비현실적인 변화를 페널티화하는 경사를 생성합니다. 관절의 예측된 속도가 실제 속도와 크게 벗어나면 $L_{vel}$은 모델이 더 부드럽고 물리적으로 그럴듯한 움직임을 예측하도록 장려하는 경사를 생성합니다. 이는 희소한 레이더 신호나 반사각으로 인한 누락된 관절을 추론하는 데 특히 유익하며, 모델은 이웃 프레임의 맥락적 단서를 기반으로 그럴듯한 움직임을 "채워 넣는" 방법을 학습합니다.
- 균형 잡기($\lambda_{vel}$): 가중치 계수 $\lambda_{vel}$은 0.05로 설정되어 시간적 부드러움( $L_{vel}$로 강제됨)의 중요성과 기본 키포인트 정확도( $L_{oks}$로 구동됨)의 중요성을 균형 맞추는 데 중요한 역할을 합니다. 이 상대적으로 작은 값은 시간적 일관성이 중요한 고려 사항이지만 근본적인 정확도 요구 사항을 압도해서는 안 된다는 것을 보장합니다. 결과적으로 $L_{oks}$에서 발생하는 경사는 일반적으로 더 강한 영향을 미치며 모델을 정확한 자세 추정으로 안내하는 반면, $L_{vel}$은 시간적 일관성을 향한 부드럽지만 지속적인 당김을 제공합니다. $L_{vel}$이 없으면 모델은 정확하지만 삐걱거리는 자세를 생성할 수 있습니다. $\lambda_{vel}$이 지나치게 높으면 정확도를 희생하면서 부드러움을 우선시할 수 있습니다.
-
반복적 상태 업데이트:
- 순방향 패스: 각 훈련 반복 중에, 다중 프레임 레이더 시퀀스 배치가 전체 milliMamba 네트워크(사전 처리, CVMamba 인코더, STCA 디코더 포함)를 통과합니다. 이 순방향 전파는 각 프레임 $f$와 관절 $j$에 대한 예측된 2D 키포인트 좌표 $\hat{P}_{f,j}$ 시퀀스를 생성하는 것으로 정점을 이룹니다.
- 손실 계산: 이러한 예측된 키포인트 좌표는 실제 키포인트 좌표 $P_{f,j}$와 비교하여 $L_{oks}$를 계산합니다. 동시에, 예측된 속도 $\hat{v}_{f,j}$ ( $\hat{P}_{f,j}$에서 파생됨)는 실제 속도 $v_{f,j}$ ( $P_{f,j}$에서 파생됨)와 비교하여 $L_{vel}$을 계산합니다. 이러한 두 가지 별도의 손실 구성 요소는 마스터 방정식: $L = L_{oks} + \lambda_{vel} L_{vel}$에 따라 결합됩니다.
- 역방향 패스 (역전파): 계산된 총 손실 $L$은 이후 전체 네트워크를 통해 역전파됩니다. 이 복잡한 프로세스는 모델의 모든 학습 가능한 매개변수에 대한 $L$의 경사를 계산합니다. 여기에는 예를 들어 Mamba 레이어의 행렬 $A, B, C, D$, MNet 블록의 컨볼루션 신경망(CNN) 가중치, STCA 디코더의 주의 행렬, 초기 학습 가능한 키포인트 쿼리가 포함됩니다.
- 매개변수 업데이트 (Adam 옵티마이저): Adam 옵티마이저가 모델 매개변수를 업데이트하는 데 사용됩니다. Adam은 매개변수에 대한 개별 적응 학습률을 계산하는 고급 적응 학습률 최적화 알고리즘으로, 경사의 첫 번째 및 두 번째 모멘트 추정치를 기반으로 합니다. 0.00005의 지정된 학습률과 0.0001의 가중치 감쇠를 사용하여 옵티마이저는 손실을 가장 효과적으로 줄이는 방향으로 매개변수를 지능적으로 조정합니다. 가중치 감쇠 항은 모델이 너무 복잡해지고 훈련 데이터에 과적합되는 것을 방지하는 데 도움이 되는 정규화 메커니즘 역할을 합니다.
- 수렴: 순방향 패스, 손실 계산, 역방향 패스, 매개변수 업데이트의 이 순환 프로세스는 수많은 에포크(전체 훈련 데이터셋에 대한 반복) 동안 반복됩니다. 시간이 지남에 따라 모델의 매개변수는 손실 함수를 최소화하는 값으로 점진적으로 수렴하여 훈련 데이터와 이전에 보지 못한 데이터 모두에서 자세 추정 정확도가 점진적으로 향상되고 시간적 일관성이 향상됩니다. STCA 디코더 자체에 내장된 반복적 정제 단계도 이러한 수렴에 크게 기여하며, 키포인트 쿼리가 기본 자세를 더 잘 나타내도록 점진적으로 업데이트됩니다. 별도의 검증 세트에 대한 모델 성능은 과적합 징후를 감지하고 훈련을 중단할 최적의 시점을 결정하기 위해 지속적으로 모니터링됩니다.
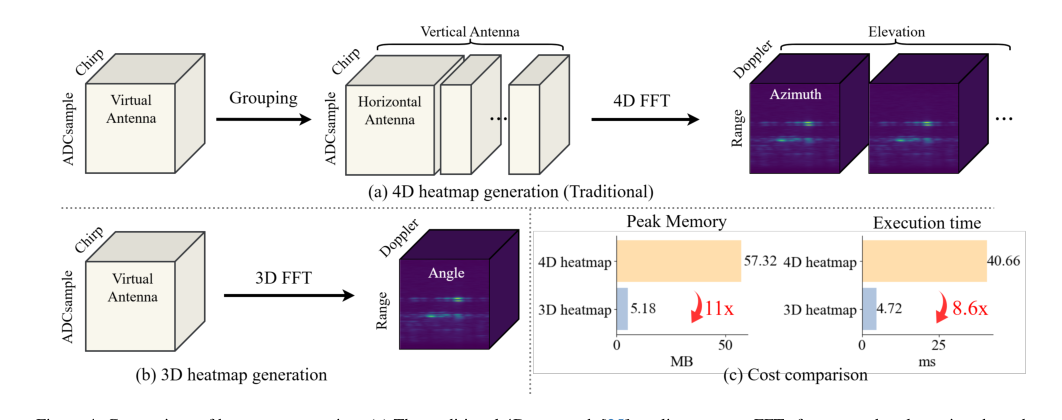 Figure 4. Comparison of heatmap generation. (a) The traditional 4D approach [25] applies separate FFTs for range, doppler, azimuth, and elevation after antenna grouping. (b) Our 3D pipeline performs a unified spatial FFT without grouping, yielding a compact representation. (c) Cost comparison between 4D and 3D heatmaps, showing 11× reduction in memory and 8.6× reduction in latency
Figure 4. Comparison of heatmap generation. (a) The traditional 4D approach [25] applies separate FFTs for range, doppler, azimuth, and elevation after antenna grouping. (b) Our 3D pipeline performs a unified spatial FFT without grouping, yielding a compact representation. (c) Cost comparison between 4D and 3D heatmaps, showing 11× reduction in memory and 8.6× reduction in latency
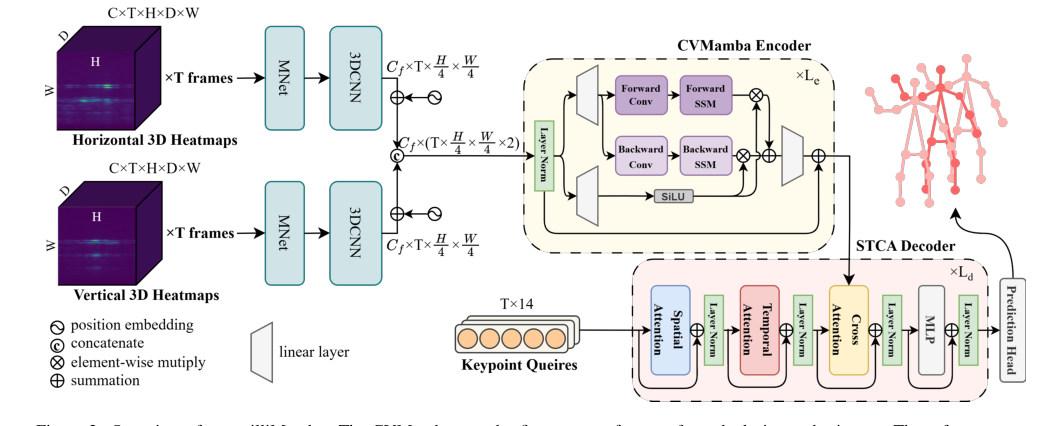 Figure 2. Overview of our milliMamba. The CVMamba encoder first extracts features from dual-view radar inputs. These features are then passed to the Multi-Pose STCA decoder, which progressively refines a set of keypoint queries to produce pose predictions
Figure 2. Overview of our milliMamba. The CVMamba encoder first extracts features from dual-view radar inputs. These features are then passed to the Multi-Pose STCA decoder, which progressively refines a set of keypoint queries to produce pose predictions
결과, 한계 및 결론
실험 설계 및 기준선
milliMamba의 능력을 엄격하게 검증하기 위해 저자들은 제안된 메커니즘의 기여를 분리하고 정량화하도록 설계된 일련의 실험을 구성했습니다. 핵심 설정은 각 프레임 시퀀스 $T=9$개를 캡처하는 듀얼 밀리미터파(mmWave) 레이더 입력을 모델에 공급하는 것을 포함했습니다. 모델이 9개의 연속적인 자세 예측을 생성했지만, 추론을 위해 최종적으로 중앙 프레임의 예측만 사용되어 단일 입력을 예측하는 방법과의 공정한 비교를 보장했습니다.
훈련 규정은 학습률 0.00005, 배치 크기 8, 가중치 감쇠 0.0001로 Adam 옵티마이저를 사용했습니다. 전체 훈련 목표는 복합 손실 함수였습니다: $L = L_{oks} + \lambda_{vel} L_{vel}$. 여기서 $L_{oks}$ (객체 키포인트 유사성)는 예측 및 실제 관절 위치 간의 불일치를 페널티화했으며, 이는 자세 추정의 표준 메트릭입니다. 결정적으로, $L_{vel}$ (속도 손실)은 가중치 계수 $\lambda_{vel} = 0.05$로 예측 및 실제 관절 속도 간의 오류를 최소화하여 시간적 부드러움을 강제하기 위해 도입되었습니다. 이 속도 손실은 레이더 기반 자세 추정에서 종종 보이는 시간적 불일치를 해결하기 위한 핵심 아키텍처 선택이었습니다. 모든 계산 집약적인 작업은 단일 NVIDIA Tesla V100 GPU에서 수행되었습니다.
milliMamba가 비교된 "희생자"(기준선 모델)에는 확립된 레이더 기반 2D 인간 자세 추정(HPE) 방법이 포함되었습니다.
- TransHuPR [12]: 시공간적 종속성을 부분적으로 모델링하는 트랜스포머 기반 접근 방식.
- HuPR [13]: 또 다른 주요 레이더 기반 HPE 프레임워크.
- mmPose [23]: CNN 기반 방법.
저자들은 또한 RFMamba [35]라는 또 다른 Mamba 기반 접근 방식을 언급했지만, 소스 코드를 공개적으로 사용할 수 없어 직접적인 비교가 불가능하다고 언급했습니다.
평가는 두 가지 벤치마크 mmWave 레이더 기반 2D HPE 데이터셋에서 수행되었습니다.
- TransHuPR [12]: 22명의 피험자로부터 440개의 시퀀스(7시간 이상)로 구성된 이 데이터셋은 빠르고 역동적인 동작이 특징이며 상당한 도전을 제기합니다.
- HuPR Dataset [13]: 6명의 피험자로부터 235개의 시퀀스(약 4시간)를 포함하는 이 데이터셋은 주로 비교적 정적인 동작을 특징으로 합니다.
두 데이터셋 모두 표준 데이터 분할 프로토콜이 따랐습니다. 최종 메트릭은 객체 키포인트 유사성(OKS)을 기반으로 계산된 평균 정밀도(AP)였습니다. 여기에는 OKS 임계값 0.50에서 0.95까지 평균화된 전체 AP와 느슨하고 엄격한 일치 기준에 대한 AP50(OKS 0.50) 및 AP75(OKS 0.75)가 포함되었습니다.
증거가 증명하는 것
이 논문에서 제시된 증거는 milliMamba의 핵심 메커니즘이 실제로 작동하여 기존 기준선에 비해 상당한 성능 향상을 가져온다는 부인할 수 없는 증거를 제공합니다.
첫째, 전반적인 성능 측면에서 milliMamba는 TransHuPR 및 HuPR 데이터셋 모두에서 모든 기준선을 일관되고 상당히 능가했습니다. 어려운 TransHuPR 데이터셋에서 milliMamba는 TransHuPR [12] 기준선에 비해 11.0 AP 개선이라는 놀라운 성과를 달성했습니다. 이는 특히 손목과 같이 빠른 움직임과 반사각에 취약하여 추정하기 어려운 관절에서 두드러졌으며, milliMamba는 46.9 AP를 달성했습니다. 마찬가지로 HuPR 데이터셋에서는 milliMamba가 HuPR [13]에 비해 훨씬 더 인상적인 14.6 AP 개선을 제공하여 비교적 정적인 동작의 경우 최대 84.0 AP에 도달했습니다. 이러한 수치는 단순한 점진적인 개선이 아니라 레이더 기반 HPE의 최첨단 기술에 대한 상당한 도약을 나타냅니다.
이 논문은 또한 아키텍처 선택의 효율성과 효과에 대한 확실한 증거를 제공합니다.
- 효율적인 3D FFT 사전 처리: 그림 4(c)는 제안된 3D 고속 푸리에 변환(FFT) 사전 처리 파이프라인이 기존 4D FFT 접근 방식에 비해 메모리 사용량을 11배, 지연 시간을 8.6배 줄인다는 것을 명확하게 보여줍니다. 표 4는 3D FFT 기반 히트맵이 4D FFT(72.0 AP)에 비해 비슷하거나 더 나은 정확도(74.5 AP)를 달성한다는 것을 보여줌으로써 이를 추가로 검증하며, 효율성 향상이 성능 저하 없이 이루어졌음을 증명합니다.
- 다중 자세 출력 메커니즘 (다대다): 표 5는 milliMamba의 시공간 교차 주의(STCA) 디코더의 이점을 명확하게 보여줍니다. 이웃 프레임의 맥락적 단서를 활용하는 "다대다" 예측 전략은 "다대일" 접근 방식(표준 트랜스포머 디코더가 단일 자세 예측)에 비해 전반적인 정확도에서 4.1 AP 개선을 가져왔습니다. 이는 디코딩 단계에서 시공간적 종속성을 모델링하는 것이 반사각으로 인한 누락된 관절을 추론하는 데 중요하다는 것을 결정적으로 증명합니다.
- Mamba 인코더의 확장성: 표 8의 Mamba와 트랜스포머 인코더 간의 비교는 특히 설득력이 있습니다. Mamba는 짧은 시퀀스($T=3$ 프레임)에 대해 트랜스포머보다 1.5 AP 높은 점수를 달성했지만, 결정적인 증거는 트랜스포머가 메모리 부족 문제로 인해 더 긴 시퀀스를 처리할 수 없다는 것입니다. 선형 복잡성을 가진 Mamba는 최대 $T=15$ 프레임(표 6 참조)까지 성공적으로 확장되며 성능이 지속적으로 향상됩니다. 이는 Mamba의 우수한 확장성과 더 풍부한 시간적 맥락을 효과적으로 활용하는 능력을 보여주며, 이는 논문의 핵심 주장입니다.
- 듀얼 레이더 구성: 표 7은 듀얼 레이더(수평+수직) 구성이 단일 수평(67.3 AP) 또는 수직(74.5 AP) 레이더만 사용하는 것에 비해 성능(78.5 AP)을 크게 향상시킨다는 명확한 증거를 제공합니다. 이는 mmWave 레이더 센서의 본질적인 제한된 고도 해상도를 보상하는 데 크로스 뷰 융합의 효과를 확인합니다.
질적인 결과는 그림 5에서 이러한 발견을 더욱 강화하며, TransHuPR 데이터셋의 다양한 동작에 대해 더 정확하고 시간적으로 일관된 자세 추정을 생성하여 mmPose, HuPR 및 TransHuPR 기준선을 능가하는 milliMamba의 능력을 시각적으로 보여줍니다.
한계 및 향후 방향
milliMamba는 레이더 기반 인간 자세 추정에서 상당한 발전을 제시하지만, 현재의 한계를 인정하고 향후 개발을 고려하는 것이 중요합니다.
전통적인 트랜스포머에 비해 긴 시퀀스에 대한 milliMamba의 효율성 향상에도 불구하고, 계산 비용은 여전히 내재된 한계입니다. 정확도와 복잡성 간에 유리한 절충점을 제공하지만, MACs 수(34.4 G)는 TransHuPR [12] (5.8 G)과 같은 일부 기준선보다 여전히 높습니다. 이는 리소스가 매우 제한적인 엣지 장치에 배포하기 위해 추가적인 계산 발자국 최적화가 필요할 수 있음을 시사합니다.
또 다른 명확한 한계는 현재 단일 인물 자세 추정에 초점을 맞추고 있다는 것입니다. 논문은 향후 작업에서 "다중 인물" 시나리오를 탐색할 것이라고 명시적으로 언급합니다. 레이더 신호는 여러 대상에 대해 간섭, 간섭 및 특정 개인에게 레이더 포인트를 연결하는 어려움으로 인해 훨씬 더 복잡해집니다. 현재 아키텍처는 단일 인물에게는 강건하지만, 다중 인물 상호 작용의 복잡성을 처리하기 위해 상당한 수정이 필요할 것입니다.
또한, 평가는 TransHuPR 및 HuPR이라는 두 가지 특정 데이터셋에서 수행되었으며, 이는 특정 유형의 동작과 환경(실내로 암시됨)을 나타냅니다. 레이더는 조명 조건에 강건하지만, milliMamba의 다양하고 제약 없는 교차 환경 시나리오(예: 다양한 클러터, 다른 건물 자재 또는 더 복잡한 인간-객체 상호 작용이 있는 실외 환경)에 대한 일반화 가능성은 여전히 열려 있는 질문입니다. 향후 작업에서 "교차 환경 시나리오"를 언급하는 것은 이 영역이 추가 조사가 필요함을 강조합니다.
앞으로 이러한 발견을 더욱 발전시키고 발전시키기 위한 몇 가지 흥미로운 논의 주제가 등장합니다.
- 강건한 다중 인물 자세 추정: milliMamba의 시공간 모델링을 여러 개인을 강건하게 처리하도록 어떻게 확장할 수 있을까요? 이는 레이더 데이터에 대한 새로운 인스턴스 분할 기술, 인간 간 관계를 모델링하기 위한 그래프 기반 접근 방식 또는 심지어 인간 그룹 역학에 대한 사전 지식을 통합하는 것을 포함할 수 있습니다. 많은 사람들에게 선형 복잡성을 유지하면서 확장하기 위해 어떤 아키텍처 변경이 필요할까요?
- 실시간 엣지 배포 및 효율성: 계산 비용을 고려할 때, milliMamba를 저전력 엣지 장치에서 실시간 추론에 적합하게 만들기 위해 어떤 추가적인 아키텍처 최적화(예: 양자화, 가지치기, 지식 증류)를 수행할 수 있을까요? 더 가벼운 Mamba 변형 또는 하이브리드 아키텍처가 실용적인 응용을 위해 더 나은 균형을 제공할 수 있을까요?
- 2D 히트맵에서 3D 자세 추정: 현재 작업은 2D HPE에 초점을 맞추고 있습니다. milliMamba가 추출한 풍부한 시공간 특징을 전체 3D 인간 자세를 추론하는 데 활용하거나 확장하려면 어떻게 해야 할까요? 이는 출력 헤드를 조정하고 잠재적으로 2D 투영에 내재된 깊이 모호성을 해결하기 위해 추가적인 기하학적 제약 또는 다중 뷰 융합 전략을 통합해야 할 수 있습니다.
- 향상된 반사각 처리: milliMamba가 반사각을 처리하지만, 물리 기반 신경망 또는 고급 신호 처리 기술을 Mamba 인코더에 직접 통합하여 이러한 어려운 레이더 현상을 직접 모델링하고 보상할 수 있을까요? 이는 신호 희소성으로 인한 누락된 데이터를 "채우는" 데 사용되는 직접 반사와 반사각을 구별하는 방법을 학습하거나 생성 모델을 사용하는 것을 포함할 수 있습니다.
- 장기 시간 맥락 및 동작 인식: Mamba 인코더가 긴 시퀀스를 처리하는 능력은 주요 이점입니다. 이를 자세 추정 개선뿐만 아니라 장기간에 걸쳐 더 정교한 동작 인식 또는 활동 이해를 가능하게 하기 위해 어떻게 더 활용할 수 있을까요? 이는 Mamba 프레임워크 내에서 순환 메커니즘 또는 계층적 시간 모델링을 통합하는 것을 포함할 수 있습니다.
- 다른 개인 정보 보호 기술과의 융합: 레이더는 개인 정보를 보호하지만, milliMamba를 다른 비-RGB 센서(예: 열화상 카메라, 깊이 센서 또는 음향 센서)와 융합하면 매우 어려운 시나리오 또는 의료 모니터링 또는 낙상 감지와 같은 특정 응용 프로그램을 위한 보완 정보를 제공하여 견고성을 더욱 향상시킬 수 있을까요? 이러한 다양한 데이터 유형에 대한 최적의 융합 전략은 무엇일까요?
 Table 2. Comparison of model performance and complexity across methods on the TransHuPR dataset [12]. The complexity excludes radar signal preprocessing
Table 2. Comparison of model performance and complexity across methods on the TransHuPR dataset [12]. The complexity excludes radar signal preprocessing
 Table 3. Comparison of model performance and complexity across methods on the HuPR dataset [13]. The complexity excludes radar signal preprocessing
Table 3. Comparison of model performance and complexity across methods on the HuPR dataset [13]. The complexity excludes radar signal preprocessing
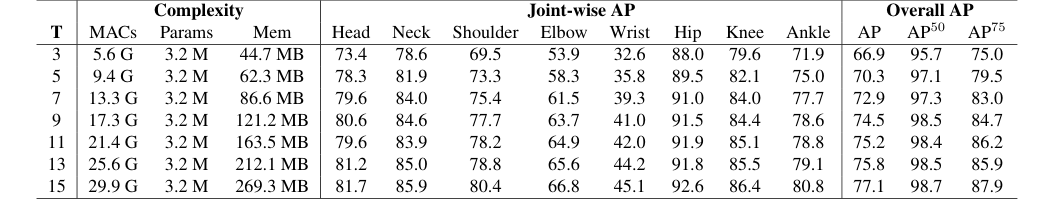 Table 6. Impact of input sequence length (T) on pose estimation performance. We investigate the effect of varying T to understand how temporal context contributes to accuracy
Table 6. Impact of input sequence length (T) on pose estimation performance. We investigate the effect of varying T to understand how temporal context contributes to accuracy