milliMamba:基于双毫米波雷达和多帧Mamba融合的视网膜感知人体姿态估计
The problem of Human Pose Estimation (HPE) using millimeter-wave (mmWave) radar signals emerged primarily as a response to the limitations of traditional camera-based (RGB) systems.
背景与学术渊源
起源与学术渊源
使用毫米波(mmWave)雷达信号进行人体姿态估计(HPE)的问题,主要是为了应对传统基于摄像头的(RGB)系统的局限性而出现的。尽管RGB摄像头提供丰富的视觉信息,但它们本质上会引发隐私问题,尤其是在家庭或医院等敏感环境中。此外,基于摄像头的系统容易受到光照条件变化和遮挡的影响,这些因素会严重降低性能。
在此背景下,mmWave雷达作为一种有吸引力的替代方案应运而生。它提供了一种保护隐私的解决方案,因为它不捕捉个人的视觉图像。此外,它对黑暗或烟雾等环境因素具有鲁棒性,使其适用于更广泛的部署场景。因此,本文旨在解决的问题是开发一个鲁棒且准确的2D人体姿态估计系统,该系统能够利用mmWave雷达的独特优势,同时克服其固有的挑战。
促使作者开发milliMamba的先前mmWave雷达基HPE方法的根本局限性或“痛点”源于几个问题。首先,由于称为“镜面反射”的现象,雷达信号通常是稀疏的。这意味着信号可能会从传感器弹开,如果它们以特定角度击中身体部位,则会导致不完整的观测,并使得从单帧中重建全身姿态变得困难。四肢(如手指或脚趾)的微弱反射以及对主体方向的敏感性进一步加剧了这个问题。其次,先前的方法,特别是基于Transformer的方法,在处理雷达输入的が高い次元性以及处理更长帧序列所需的大量“token volume”方面遇到了困难。这导致了二次计算复杂度,使得它们内存密集且速度缓慢。为缓解此问题的一些尝试包括对时间信息的“早期融合”,但这通常会因丢失来自相邻帧的宝贵上下文线索而损害模型恢复缺失关节的能力。作者的目标是创建一个能够有效处理雷达数据的长序列以利用时空上下文的系统,从而更准确地推断缺失的关节并保持时间一致性,同时将计算成本保持在可控范围内。
直观领域术语
- 毫米波(mmWave)雷达:想象一下蝙蝠利用声纳在黑暗中“看”东西,但我们使用的是非常短的无线电波,而不是声波。这些波会从物体上反射回来,通过接收回声,我们可以弄清楚物体的位置和运动方式,而无需摄像头。这就像拥有运动的X射线视觉,但实际上并没有看到人。
- 人体姿态估计(HPE):将其视为在人体上绘制火柴人。目标是精确定位关键关节(如肘部、膝盖和肩膀)的位置,以理解其姿势和运动。
- 镜面反射:这就像看着一面非常光滑的镜子。如果雷达信号击中一个非常光滑且角度恰到好处的身体表面,信号就会完全反射出去,就像光线从镜子反射一样,不会返回雷达传感器。这使得身体的该部分对雷达来说是“看不见的”,导致数据出现空白。
- 时空依赖性:这指的是事物在空间(在一个时刻它们相对于彼此的位置)和时间(它们在一系列时刻如何移动和变化)上的关系。对于HPE来说,这意味着理解一帧中人手臂的运动与其在前一帧和后一帧中的位置相关,并且也与其肩膀的位置相关。
- Mamba:这是一种新型人工智能架构,类似于Transformer,但在处理长序列信息方面效率更高。想象一个极其聪明的笔记员,他可以快速总结并记住一个非常长的讲座的关键点,而无需每次都重新阅读整个讲稿。这使得AI能够理解更长时间内的上下文,而不会感到不知所措。
符号表
| 符号 | 描述 |
|---|---|
问题定义与约束
核心问题表述与困境
本文解决的核心问题是使用毫米波(mmWave)雷达信号进行2D人体姿态估计(HPE)。
拟议系统的输入/当前状态由双雷达传感器在 $T$ 帧序列中捕获的原始、复数值mmWave雷达信号组成。具体来说,FMCW雷达为每一帧生成复数值立方体 $X \in C^{12 \times 128 \times 256}$,对应于虚拟天线对、chirp和ADC样本。然后,这些原始信号被预处理成3D角度-多普勒-距离热图,这些热图跨越 $T$ 帧堆叠并分为实部和虚部,形成一个形状为 $C \times T \times H \times D \times W$(其中 $C=2$)的双通道张量。由于其が高い次元性和雷达反射的稀疏性,此输入本质上具有挑战性。
输出/目标状态是时间连贯的2D人体姿态序列,表示为滑动窗口内多帧的每个关节的2D关键点坐标。目标是准确预测这些关节坐标,即使对于由于镜面反射而弱反射或完全缺失的关节,同时保持时间连贯性,并以合理的计算复杂度实现最先进的性能。
本文试图弥合的缺失环节或数学鸿沟在于从稀疏、が高い次元的mmWave雷达数据中鲁棒且高效地建模时空依赖性。先前的方法在以下方面存在困难:
1. 不完整的观测:镜面反射意味着只有直接面向接收器的身体表面才被捕获,导致缺失或弱反射的关节(尤其是四肢),使得从单帧输入进行全身姿态重建变得困难。
2. 时间不一致性:雷达信号的波动会破坏帧间的时间一致性,阻碍了随时间的准确姿态估计。
3. 计算可扩展性:虽然基于Transformer的模型可以捕获全局依赖性,但它们相对于序列长度的二次复杂度使得处理更长雷达序列的大量token volume在计算上非常昂贵且内存密集。
4. 部分时空建模:先前的方法通常只部分建模时空依赖性,或诉诸于早期时间融合,这可能会通过丢弃宝贵的上下文信息来损害模型恢复缺失关节的能力。
先前研究人员陷入的痛苦的权衡或困境主要是准确性(尤其是对于缺失的关节和时间一致性)与计算效率/内存占用之间的权衡。为了获得更高的准确性,尤其是在推断缺失的关节和确保时间平滑性方面,模型需要处理更长的序列并捕获更丰富的时空上下文。然而,像Transformer这样的传统架构对于这种长序列会产生二次计算复杂度和高内存需求,使其不切实际。相反,通过早期时间融合或单帧预测来降低复杂性的方法通常会牺牲鲁棒地处理稀疏、镜面雷达数据和保持时间一致性所需的上下文信息。这种困境迫使研究人员在计算昂贵但可能更准确的模型,或更快但不太鲁棒的模型之间进行选择。
约束与失效模式
由于作者遇到的几个严峻的现实障碍,基于mmWave雷达的人体姿态估计问题极其困难:
-
物理约束:
- 镜面反射:这是主要挑战。雷达信号以镜面反射的方式从表面反射,这意味着只有朝向传感器的身体部位才会被检测到。这导致极端的数据稀疏性和不完整的观测,其中小型或倾斜的关节通常在雷达数据中完全缺失。
- 四肢的微弱反射:手腕和脚踝等关节通常产生非常微弱的雷达反射,使得它们特别难以可靠地检测和跟踪。
- 对主体方向和传感器放置的敏感性:雷达数据的质量和完整性高度依赖于主体相对于传感器的方向以及雷达单元的精确放置,这进一步加剧了鲁棒特征提取的复杂性。
- 有限的仰角分辨率:mmWave雷达传感器在仰角维度上固有地具有有限的分辨率,这可能导致3D姿态重建中的歧义。使用双雷达设置来缓解此问题。
-
计算约束:
- 雷达输入的が高い次元性:原始雷达信号是가高い次元的,即使在预处理成3D热图后,序列帧的数据量仍然很大。
- Transformer的二次复杂度:基于Transformer的先前模型虽然在全局依赖性建模方面功能强大,但其相对于输入序列长度 $N$ 的复杂度为 $O(N^2)$。这使得它们在处理“更长雷达序列中固有的がたいtoken volume”方面效率低下,导致计算成本和训练时间过高。
- 硬件内存限制:Transformer的二次复杂度直接转化为高内存消耗。正如论文中所指出的,Transformer在“使用更长序列进行训练时在我们的硬件上出现内存不足”(例如,超过 $T=3$ 帧),严重限制了可以处理的时间上下文量。
- 预处理开销:从原始雷达信号生成传统的4D热图在计算上是昂贵的且内存密集(例如,比基于3D FFT的热图多11倍的内存和8.6倍的延迟),这可能成为实时应用的瓶颈。
-
数据驱动约束:
- 时间不一致性:雷达信号中固有的噪声和波动会破坏帧间关节位置的时间连续性,使得在一段时间内保持平滑和一致的姿态估计具有挑战性。
- 缺乏鲁棒特征:从稀疏和嘈杂的雷达信号中提取鲁棒且具有辨别力的特征是一个重大障碍,因为原始数据不像RGB图像那样直接提供视觉线索。
- 推断缺失信息的困难:由于镜面反射,模型必须使用上下文线索来推断缺失关节的位置,这需要比简单的每帧分析更复杂的时空推理。
这些约束共同使得雷达基HPE成为一个特别具有挑战性的问题,需要创新的架构设计,能够高效地处理가高い次元性、稀疏性和时间不一致的数据,同时保持计算上的可行性。
为什么选择这种方法
选择的必然性
在解决使用毫米波(mmWave)雷达进行人体姿态估计(HPE)这一挑战性问题时,作者们面临一个关键的十字路口,传统的SOTA(state-of-the-art)方法被证明是不够的。核心问题源于雷达信号的固有性质:由于镜面反射,它们是稀疏的,导致观测不完整和关节数据缺失,尤其是来自四肢的。此外,原始雷达输入是가高い次元的,目标是从更长的序列中提取鲁棒的时空特征,以推断这些缺失的关节并确保运动平滑性。
作者们明确认识到,尽管基于Transformer的先前方法在建模全局依赖性方面功能强大,但对于此特定应用而言,它们存在一个致命的缺陷:其相对于输入序列长度的二次复杂度($O(N^2)$)。正如论文中所述,处理“更长雷达序列中固有的がたいtoken volume”由于其高计算成本、内存使用和训练时间,成为了Transformer的一个无法克服的挑战。例如,表8清楚地显示,Transformer编码器在内存不足的情况下只能处理 $T=3$ 帧,而提出的基于Mamba的编码器可以扩展到 $T=9$ 甚至 $T=15$ 帧。这种实际限制意味着Transformer根本无法处理鲁棒雷达姿态估计所需的必要时间上下文。
同样,传统的基于CNN的方法虽然在捕获多尺度空间和短期时间特征方面很有效,但“在融合来自多个雷达传感器信息的能力方面常常受到限制”。鉴于milliMamba使用双雷达设置来提供水平和垂直视图,这一限制使得标准CNN成为一个次优选择。
认识很清楚:需要一种新的架构,它能够以线性复杂度($O(N)$)高效地建模长程时空依赖性,以处理가高い次元性、多帧雷达数据,而不会产生过高的计算成本。这使得Mamba架构,凭借其选择性状态空间模型(SSM)设计,成为唯一可行的前进方向。
相对优越性
milliMamba框架主要通过其在高效处理长序列和复杂时空依赖性方面的结构优势,在定性上优于先前的黄金标准。
-
长序列的线性复杂度:最显著的结构优势是为编码器采用了Mamba架构。与具有二次复杂度 $O(N^2)$(相对于序列长度 $N$)的Transformer不同,Mamba提供了线性复杂度 $O(N)$。这不仅仅是一个边际改进;它是一个根本性的转变,使得
milliMamba能够处理显著更长的雷达序列(例如,默认情况下为 $T=9$ 帧,实验中高达 $T=15$ 帧),而不会出现内存不足的问题,这是Transformer的一个关键限制,如表8所示。这使得模型能够利用更丰富的时间上下文,这对于推断由于镜面反射而缺失的关节和确保运动平滑性至关重要。 -
增强的时空上下文建模:跨视图融合Mamba(CV-Mamba)编码器专门设计用于“高效地捕获长序列的依赖性”并“有效地跨帧融合双雷达输入”。这使得对场景有更全面的理解,这对于从稀疏雷达数据中进行鲁棒的姿态估计至关重要。此外,时空交叉注意力(STCA)解码器,凭借其多帧输出策略,集成了空间和时间注意力。这意味着它可以建模每帧内的关系(空间)和跨帧的关系(时间),从而实现“跨时间步的更丰富监督”,并通过利用相邻帧的上下文线索来更好地推断缺失的关节。这比执行早期时间融合或仅预测单帧的方法有了质的飞跃。
-
高效的预处理:虽然不是Mamba核心架构的一部分,但选择3D快速傅里叶变换(FFT)进行雷达信号处理,极大地促进了整体的优越性。如图4(c)所示,与传统的4D热图生成相比,这种方法将内存使用量减少了11倍,延迟减少了8.6倍。这种效率的提高至关重要,因为它缓解了“token数量的爆炸”,使得가高い次元的雷达数据对于Mamba编码器的下游建模变得可行。这种结合的效率使得
milliMamba能够在计算成本和性能之间实现更有利的平衡,从而获得更高的准确性,如表2和表3所示。
总之,milliMamba之所以压倒性地优越,是因为它提供了一个可扩展、高效且上下文丰富的框架,能够处理准确雷达基HPE所需的广泛时空信息,而这是先前方法由于架构限制而难以实现的。
与约束的对齐
所选的milliMamba方法完美地符合mmWave雷达基人体姿态估计的严苛要求,形成了问题独特的挑战与解决方案的定制属性之间的强大“联姻”。
-
处理稀疏和不完整数据(镜面反射):雷达信号的稀疏性和由于镜面反射导致的关节信息缺失是核心问题。
milliMamba通过其全面的时空建模直接解决了这个问题。CV-Mamba编码器从更长的序列中提取特征,提供了充足的时间上下文。STCA解码器通过同时预测多帧并集成空间和时间注意力来利用这种上下文。这使得模型能够“利用相邻帧和关节的上下文线索来推断由镜面反射引起的缺失关节”,直接缓解了不完整观测的影响。速度损失也加强了运动平滑性,这有助于在单帧稀疏的情况下重建合理的姿态。 -
管理가高い次元输入和大量token volume:mmWave雷达输入本质上是가高い次元的。
milliMamba框架通过首先采用高效的3D FFT预处理步骤来解决这个问题,与传统的4D方法相比,该步骤显著降低了内存使用和延迟(图4(c))。此步骤“缓解了token数量的爆炸”,使得数据可管理。随后,具有线性复杂度的CV-Mamba编码器专门设计用于“高效处理更长雷达序列中固有的がたいtoken volume”,这是传统Transformer因其二次缩放而未能满足的关键要求。 -
融合多雷达输入:问题通常涉及双雷达设置以捕获更全面的视图。CV-Mamba编码器明确设计用于“跨视图融合双雷达输入”,有效地结合了水平和垂直雷达视图的信息。这直接解决了整合来自多个传感器数据的需求,这是某些CNN方法的一个已知限制。
-
确保时间一致性和运动平滑性:微弱的反射和波动会破坏时间一致性。STCA解码器的多帧预测策略,结合训练期间明确包含的速度损失($L_{vel}$),直接强制执行帧间运动一致性。速度损失定义为 $L_{vel} = \frac{1}{T-1}\sum_{f=1}^{T-1}\sum_{j=1}^{J} ||\mathbf{v}_{f,j} - \hat{\mathbf{v}}_{f,j}||^2$,其中 $\mathbf{v}_{f,j}$ 是地面真实速度,$\hat{\mathbf{v}}_{f,j}$ 是预测速度,惩罚关节速度的差异,从而促进平滑且逼真的姿态序列。
总之,milliMamba独特的组合——高效预处理、用于长程时空融合的线性复杂度Mamba编码器,以及带速度损失的多帧注意力解码器——创建了一个鲁棒且计算上可行的解决方案,直接解决了mmWave雷达基HPE的每一个主要约束。
替代方案的拒绝
该论文提供了明确的理由来拒绝几种流行的替代方法,突出了为什么milliMamba的设计选择是必要的。
-
Transformer:最突出的替代方案Transformer,主要因其相对于输入序列长度的二次计算复杂度($O(N^2)$)而被拒绝。作者明确指出,这使得它们不适合处理雷达基HPE所需的“更长雷达序列中固有的がたいtoken volume”。表8提供了经验证据,显示Transformer编码器由于其硬件上的“内存不足”问题甚至无法处理 $T=9$ 帧,而Mamba则高效地处理了它。这种根本性的可扩展性问题使得Transformer对于该问题对广泛时间上下文的需求而言不切实际。
-
基于CNN的方法:虽然对某些任务有用,但CNN被认为是不够的,因为它们“在融合来自多个雷达传感器信息的能力方面常常受到限制”。鉴于
milliMamba的双雷达输入(水平和垂直视图),需要一种具有更优多传感器融合能力的方法,而Transformer(以及随后的Mamba)通过其注意力/SSM机制固有地提供了这种能力。 -
早期时间融合方法:一些先前的方法[2, 12, 13]试图通过“早期折叠时间维度”来处理时间信息。作者明确拒绝了这种策略,认为“这种早期融合可能会损害模型因镜面反射而恢复缺失关节的能力”。这是一个关键的定性拒绝,因为
milliMamba的主要目标是通过利用丰富的时空上下文来推断这些缺失的关节,而早期融合会削弱这一点。 -
一对多预测策略:大多数先前的雷达基HPE方法采用“多帧到单帧解码方案”,这意味着它们以多帧为输入,但仅预测一个姿态(通常是中心帧)。相比之下,
milliMamba采用“多对多”预测策略,同时输出多帧的姿态。表5定量地支持了这一拒绝,显示“多对一”策略的整体AP(70.4)显著低于milliMamba的“多对多”方法(74.5),提高了4.1 AP。这证明了预测多帧的上下文推断能力更强。 -
4D热图预处理:从原始雷达信号生成4D热图的传统方法[25]被拒绝,因为它在计算上效率低下。论文强调这种方法“计算成本高昂”,并导致“token数量的爆炸”。图4(c)提供了鲜明的对比,显示4D热图生成比
milliMamba的3D FFT基预处理产生11倍更高的峰值内存和8.6倍更长的执行时间。这种明显的低效率使得4D方法不适合实际且可扩展的系统。
这些拒绝突显了作者对问题约束和现有技术局限性的深刻理解,促使他们开发milliMamba作为一种定制且更有效的解决方案。Mamba的选择并非随意,而是由其他SOTA模型与mmWave雷达数据特定需求的不兼容性所驱动的必然结果。
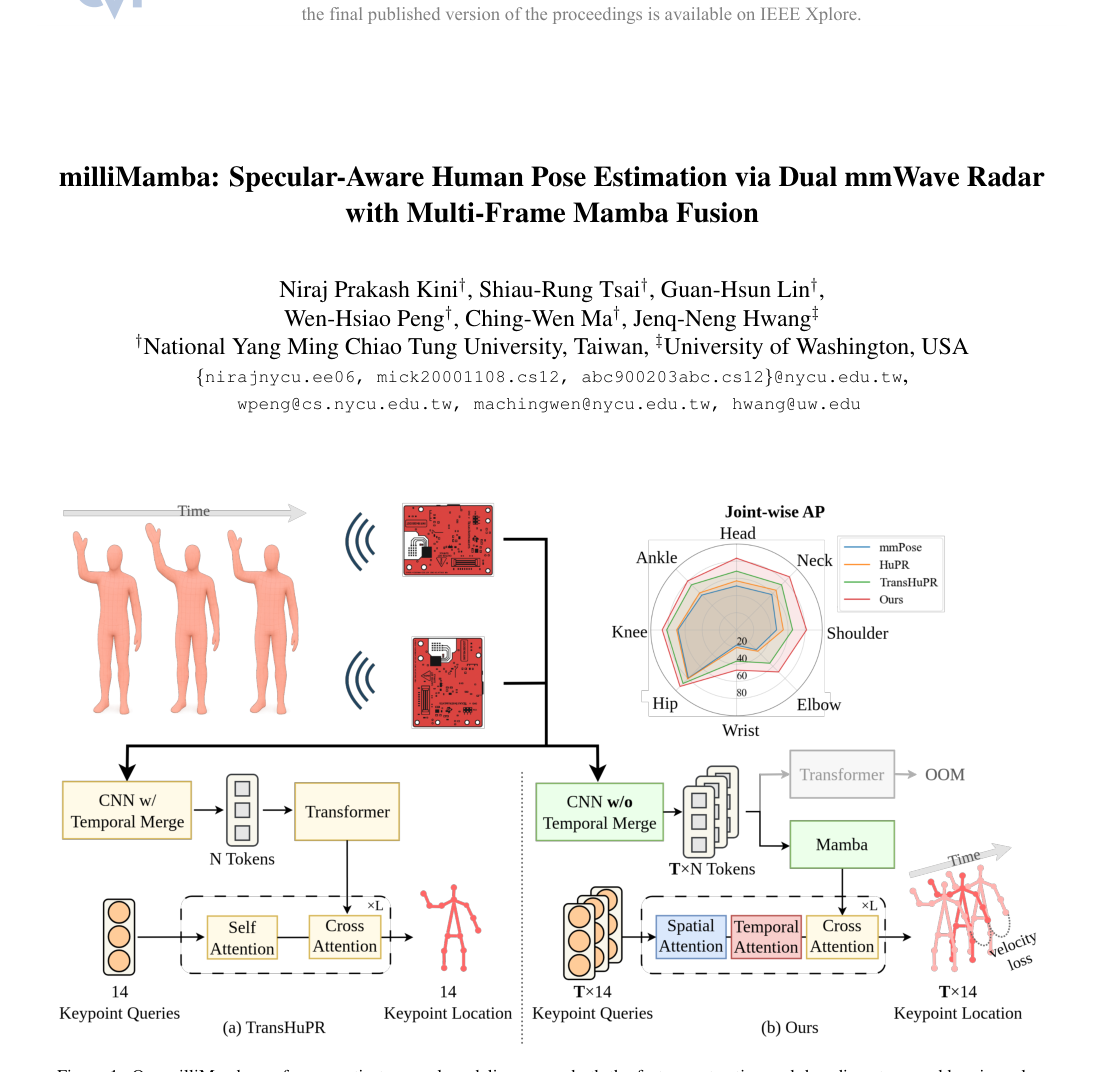 Figure 1. Our milliMamba performs spatio-temporal modeling across both the feature extraction and decoding stages, addressing a key limitation of TransHuPR [12], which models these dependencies only partially. This is made possible by milliMamba’s ability to process a larger number of tokens with a comparable memory footprint, enabling richer temporal context and more accurate pose estimation
Figure 1. Our milliMamba performs spatio-temporal modeling across both the feature extraction and decoding stages, addressing a key limitation of TransHuPR [12], which models these dependencies only partially. This is made possible by milliMamba’s ability to process a larger number of tokens with a comparable memory footprint, enabling richer temporal context and more accurate pose estimation
数学与逻辑机制
主方程
milliMamba的数学核心由两组主要方程驱动:状态空间模型(SSM)更新方程,它们构成了跨视图融合Mamba(CVMamba)编码器的骨干;以及协调模型学习的综合训练目标函数。
每个Vision Mamba层的SSM更新定义为:
$$
h_{t+1} = A h_t + B u_t \\
y_t = C h_t + D u_t
$$
其中 $t$ 代表时间步。
模型在学习阶段力求最小化的整体训练目标为:
$$
L = L_{oks} + \lambda_{vel} L_{vel}
$$
速度损失 $L_{vel}$ 进一步指定为:
$$
L_{vel} = \frac{1}{(T-1)J} \sum_{f=1}^{T-1} \sum_{j=1}^{J} ||v_{f,j} - \hat{v}_{f,j}||^2_2
$$
按项解剖
让我们仔细分解这些方程中的每个项,以理解其数学定义、物理或逻辑作用以及包含和形式的理由。
对于状态空间模型(SSM)更新方程:
-
$h_t$:
- 数学定义:这是SSM在时间步 $t$ 的隐藏状态向量。它是序列到目前为止历史的紧凑表示。
- 物理/逻辑作用:概念上,$h_t$ 作为模型的“记忆”或“上下文摘要”。它累积并保留来自所有先前输入token的信息,使模型能够理解和利用雷达数据中的长程时间依赖性。它从 $h_t$ 到 $h_{t+1}$ 的演变是序列处理的核心。
- 为何使用:作者采用这种状态空间表述来实现处理长序列的线性时间复杂度。这比传统的Transformer架构具有显著优势,后者由于其全局注意力机制会产生二次计算成本,使其不太适合가高い次元性、多帧雷达输入。
-
$u_t$:
- 数学定义:这是时间步 $t$ 的输入token向量。在milliMamba中,这些token源自预处理的雷达热图,代表序列特定时刻的时空特征。
- 物理/逻辑作用:$u_t$ 作为模型在每一步中集成到其不断演变的状态中的“当前观测”或“新信息”。它是模型需要整合到其对人体姿态不断演变理解中的直接雷达数据。
- 为何使用:它是驱动SSM状态更新并为当前输出做出贡献的直接外部刺激,提供了来自雷达的原始特征信息。
-
$y_t$:
- 数学定义:这是SSM在时间步 $t$ 生成的输出token向量。
- 物理/逻辑作用:$y_t$ 代表时间 $t$ 的转换特征或即时输出,它是当前输入 $u_t$ 和累积隐藏状态 $h_t$ 的函数。在Mamba层内,此输出有助于随后传递给解码器的整体编码特征。
- 为何使用:它提供了时间 $t$ 的处理过的、上下文感知的表示,然后可以由编码器中的后续层使用,或作为SSM块的最终输出。
-
$A, B, C, D$:
- 数学定义:这些是层特定的可学习参数矩阵(或有时是向量,取决于具体的SSM变体和维度)。它们在训练过程中被初始化和优化。
- 物理/逻辑作用:
- $A$:状态转换矩阵。它控制前一个隐藏状态 $h_t$ 如何内在地传播和转换为下一个隐藏状态 $h_{t+1}$。它捕获序列中信息的固有动态和持久性,本质上定义了“记忆”如何随时间演变。
- $B$:输入矩阵。它决定了当前输入 $u_t$ 如何被纳入隐藏状态 $h_{t+1}$ 的更新中。它控制“新数据”对模型记忆的影响。
- $C$:输出矩阵。它将隐藏状态 $h_t$ 转换为输出 $y_t$。它负责从模型记忆中提取相关信息以形成当前输出。
- $D$:直接前馈矩阵。它允许当前输入 $u_t$ 直接贡献于输出 $y_t$,而无需先整合到隐藏状态中。这可以捕获即时的、非顺序的关系。
- 为何使用:这些矩阵是可训练的组件,使SSM能够从雷达数据中学习复杂的时间依赖性和转换。它们的数值被优化以最好地模拟人体运动的潜在动态。加法和乘法的用法是线性状态空间系统的基础,代表了计算上高效的线性变换和更新。
对于整体训练目标 $L$:
-
$L$:
- 数学定义:模型在训练期间旨在最小化的总损失的标量值。
- 物理/逻辑作用:这是整个学习过程的主要反馈信号。较低的 $L$ 值表示模型的预测根据定义的标准更准确且时间上更连贯。模型参数被迭代调整以减小此值。
- 为何使用:它作为量化模型预测“误差”的目标函数,通过梯度下降指导优化过程。
-
$L_{oks}$:
- 数学定义:物体关键点相似度(OKS)损失。尽管其确切公式未在论文中提供,但它是人体姿态估计中的标准指标,通常测量预测和地面真实关键点之间的相似度,并根据对象尺度进行归一化,并根据关键点可见性进行加权。
- 物理/逻辑作用:此项直接评估预测的2D关键点位置相对于真实位置的空间准确性。它确保模型学会正确识别和放置每个单独帧中的人体关节。
- 为何使用:OKS是姿态估计广泛采用且鲁棒的损失函数,直接反映了任务的主要目标。它被添加到速度损失中,表明静态姿态准确性和时间平滑性都被认为很重要,并独立地贡献于整体误差。
-
$\lambda_{vel}$:
- 数学定义:速度损失项的标量权重系数。论文指定 $\lambda_{vel} = 0.05$。
- 物理/逻辑作用:此参数充当一个调节器,用于平衡时间平滑性(由 $L_{vel}$ 强制执行)与原始关键点准确性(由 $L_{oks}$ 驱动)的重要性。像0.05这样的小值表明,虽然时间一致性受到重视,但不应压倒准确的关键点预测这一基本要求。
- 为何使用:它提供了一个可调的超参数,允许作者微调模型的行为并实现不同学习目标之间的最佳权衡。
-
$L_{vel}$:
- 数学定义:速度损失,计算为所有相关帧和关节的预测和地面真实关节速度之差的平方L2范数。
- 物理/逻辑作用:此项充当“时间正则化器”或“运动平滑强制器”。它惩罚连续帧之间关节位置的突然、不切实际的变化,从而促进预测姿态序列的平滑和逼真运动。这对于推断由于稀疏雷达信号或镜面反射而导致的缺失关节特别有益,因为模型被鼓励通过利用来自相邻帧的上下文线索来“填充”合理的轨迹。
- 为何使用:作者引入此损失是为了减轻雷达数据带来的挑战,例如缺失或嘈杂的关节观测。通过强制平滑,模型可以更现实地“填充”空白。平方L2范数($||\cdot||^2_2$)是回归误差的标准选择,对较大的偏差进行更显著的惩罚,并提供可微分的目标。求和($\sum$)将误差聚合到所有连续帧对($T-1$)和所有关节($J$)上,而除以 $(T-1)J$ 则对损失进行归一化,使其独立于序列长度或关节数量。
-
$T$:
- 数学定义:输入序列中的总帧数。
- 物理/逻辑作用:此维度定义了计算速度损失的时间窗口,建立了所考虑的时间上下文的范围。
- 为何使用:它是输入数据的基本参数,决定了分析运动的序列长度。
-
$J$:
- 数学定义:估计的人体关节总数。
- 物理/逻辑作用:此维度指定了计算和比较速度的单个关键点的数量。
- 为何使用:它是输出数据的基本参数,代表人体姿态估计的粒度。
-
$f$:
- 数学定义:一个从 $1$ 到 $T-1$ 迭代的帧索引。
- 物理/逻辑作用:此索引指明了正在计算速度的具体连续帧对(帧 $f$ 和帧 $f+1$)。
- 为何使用:系统地遍历并计算序列时间维度上的速度。
-
$j$:
- 数学定义:一个从 $1$ 到 $J$ 迭代的关节索引。
- 物理/逻辑作用:此索引标识了当前正在考虑的特定关节的速度。
- 为何使用:系统地遍历并计算姿态空间维度上的速度。
-
$v_{f,j}$:
- 数学定义:帧 $f$ 中关节 $j$ 的地面真实速度。它通过其在帧 $f+1$ 和帧 $f$ 处的位置差计算得出:$P_{f+1,j} - P_{f,j}$。
- 物理/逻辑作用:这代表了两个连续帧之间特定关节的真实、期望的运动矢量,作为模型的理想目标。
- 为何使用:它提供了模型预测运动的准确参考,指导学习过程。
-
$\hat{v}_{f,j}$:
- 数学定义:帧 $f$ 中关节 $j$ 的预测速度。它通过其在帧 $f+1$ 和帧 $f$ 处的位置差计算得出:$\hat{P}_{f+1,j} - \hat{P}_{f,j}$。
- 物理/逻辑作用:这是模型对特定关节连续帧的姿态预测。其与地面真实速度 $v_{f,j}$ 的偏差是速度损失所惩罚的。
- 为何使用:这是模型姿态预测的输出,然后用于计算速度损失。
-
$||\cdot||^2_2$:
- 数学定义:向量的平方欧几里得(L2)范数。对于向量 $x = [x_1, x_2, \dots, x_k]$,其平方L2范数为 $||x||^2_2 = \sum_{i=1}^k x_i^2$。
- 物理/逻辑作用:这量化了预测速度和地面真实速度之间差向量的平方幅度。平方确保了正负差异都对损失做出贡献,并且较大的误差比较小的误差受到更显著的惩罚。
- 为何使用:这是一种标准、可微分且计算高效的测量两个向量之间“距离”或“误差”的方法,非常适合基于梯度的优化。
分步流程
让我们追踪一个抽象数据点从原始雷达信号到精炼姿态预测的过程,就像它在milliMamba的机械流水线上移动一样。
-
原始雷达信号摄入:过程始于原始毫米波(mmWave)雷达信号。对于每个帧,它们以复数值立方体 $X \in \mathbb{C}^{12 \times 128 \times 256}$ 的形式到达,代表虚拟天线对、chirp和ADC样本的数据。由于milliMamba使用双雷达设置,因此为连续 $T$ 帧序列获取两个立方体(一个用于水平视图,一个用于垂直视图),形成一个时间上下文的滑动窗口。
-
预处理流水线(3D快速傅里叶变换):
- 杂波去除:首先,通过减去chirp之间的均值来滤除环境的静态反射。这就像清洁原材料,确保只处理相关的移动目标。
- Chirp子采样:然后,将ADC样本维度均匀地减少到每帧8个chirp。此步骤类似于数据压缩,在保留基本多普勒分辨率的同时降低计算负载。
- 1D FFT(距离):沿ADC样本维度应用1D快速傅里叶变换(FFT)(根据 $Y(m) = \sum_{n=0}^{N-1} X(n) \exp(-j \frac{2\pi nm}{N})$)。这会将原始时域样本转换为距离信息,指示物体的距离。
- 1D FFT(多普勒):接下来,沿chirp维度应用另一个1D FFT。这提取了多普勒信息,揭示了物体相对于雷达的速度。
- 零填充与1D FFT(角度):为了提高角度分辨率,虚拟天线维度被零填充从12到64。沿此维度的最终1D FFT将数据转换为角度信息(方位角和仰角)。
- 输出:每个视图和帧的雷达数据现在是一个3D角度-多普勒-距离热图 $Y \in \mathbb{C}^{H \times D \times W}$(例如,$64 \times 8 \times 256$)。这些复数值热图的实部和虚部被视为单独的通道,形成形状为 $C \times T \times H \times D \times W$ 的双通道张量,其中 $C=2$。
-
CVMamba编码器——特征提取与时间建模:
- 并行MNet分支:水平和垂直视图热图被馈送到两个独立的、并行的MNet块。每个MNet块首先合并多普勒维度,然后通过一系列残差3D卷积和下采样层处理数据。这会将空间分辨率(H和W)降低 $4 \times$,得到特征图 $F_h, F_v \in \mathbb{R}^{C_f \times T \times \frac{H}{4} \times \frac{W}{4}}$。这就像两条专门的并行处理线处理不同的视角。
- 位置嵌入:独立的、可学习的位置嵌入 $P_h$ 和 $P_v$ 分别添加到 $F_h$ 和 $F_v$ 中。这些嵌入将关于特征的绝对空间位置(角度和距离)的信息注入数据。
- 跨视图融合:然后,两个视图特征沿通道维度连接,形成统一的编码器输入 $F = [F_h; F_v] \in \mathbb{R}^{C_s \times T \times \frac{H}{4} \times \frac{W}{4} \times 2}$。此步骤有效地合并了来自两个雷达视图的信息。
- 序列线性化:使用特定的之字形扫描模式(距离 $\rightarrow$ 角度 $\rightarrow$ 视图 $\rightarrow$ 帧),将多维特征张量 $F$ 转换为1D token序列 $u_t$。此转换准备数据以供Mamba架构进行顺序处理。
- Mamba层处理:此1D序列 $u_t$ 进入Vision Mamba层的堆栈。每个层使用SSM方程($h_{t+1} = A h_t + B u_t$, $y_t = C h_t + D u_t$)迭代地更新其隐藏状态 $h_t$ 并产生输出 $y_t$。此过程向前和向后执行,允许模型以线性复杂度有效地捕获整个长序列的双向上下文。Mamba层内的门控机制和残差连接进一步优化了这种顺序处理。
- 输出:CVMamba编码器输出一个丰富、上下文感知的特征表示,表示为 $x_{Le}$,它有效地捕获了跨多帧和双雷达视图的复杂时空依赖性。
-
STCA解码器——姿态预测与精炼:
- 关键点查询初始化:解码器从一组固定的 $J \times T$ 可学习关键点查询 $\{q_{f,j}\}$ 开始。每个查询都是一个旨在表示特定帧中特定关节的嵌入。这些查询充当“智能探针”,搜索姿态信息。
- 时空注意力模块:
- 空间注意力(SA):首先,在每帧内应用空间自注意力($q'_{f,.} = \text{softmax}(Q_f K_f^T / \sqrt{d}) V_f$)。这允许同一帧内不同关节的查询进行交互,捕获关节间关系(例如,在单个快照中肘部如何与手腕相关)。
- 时间注意力(TA):接下来,对同一关节跨帧应用时间自注意力($q''_{.,j} = \text{softmax}(Q_j K_j^T / \sqrt{d}) V_j$)。这使得特定关节的查询能够关注其在相邻帧中的表示,强制执行运动一致性,并利用时间上下文来理解运动。
- 交叉注意力至编码器特征:然后,精炼的关键点查询 $q''_{f,j}$ 与编码器的输出特征 $F'$(即 $x_{Le}$)进行交叉注意力($\hat{q}_{f,j} = \text{CrossAttn}(q''_{f,j}, F')$)。这一关键步骤允许关键点查询从CVMamba编码器生成的丰富时空特征中提取相关的姿态信息,有效地将查询“锚定”在雷达数据中。
- 迭代精炼:这个完整的解码器层(包括时空注意力、交叉注意力和逐位置MLP)堆叠多次。关键点查询通过这些层进行迭代精炼,逐步提高其表示和准确性。
- 预测头:最后,每个精炼的查询 $\hat{q}_{f,j}$ 都通过一个简单的预测头(例如,多层感知机)输出帧 $f$ 中关节 $j$ 的2D坐标。
- 输出:解码器产生一个 $T$ 帧姿态估计序列,每个估计由 $J$ 个2D关键点坐标组成。在推理时,通常只保留滑动窗口中心帧的预测。
优化动力学
milliMamba模型通过一个严格的迭代优化过程来学习和精炼其人体姿态估计能力,主要由整体训练目标 $L = L_{oks} + \lambda_{vel} L_{vel}$ 指导。该机制系统地调整模型的内部参数以最小化其预测与地面真实之间的差异。
-
损失景观与梯度行为:
- 总损失 $L$ 定义了一个复杂、가高い次元的“损失景观”,覆盖了所有可学习模型参数的广阔空间。优化过程的基本目标是导航这个景观以找到其最低点(全局最小值)或足够低的最低点(局部最小值)。
- $L_{oks}$(物体关键点相似度损失):此损失函数部分主要塑造景观,以奖励单个关键点的空间准确放置。它产生梯度,有效地将预测的关键点“拉”近到其对应的地面真实位置。如果预测的关键点与其真实位置显著偏移,$L_{oks}$ 将产生强烈的梯度,迫使模型调整参数以减小此空间误差。
- $L_{vel}$(速度损失):此部分引入了重要的正则化效果,塑造了损失景观,以偏好时间上平滑且一致的姿态序列。它产生梯度,主动惩罚连续帧之间关节位置的突然或不切实际的变化。如果关节的预测速度与地面真实速度显著偏差,$L_{vel}$ 将产生梯度,鼓励模型预测更平滑、更符合物理规律的运动。这对于推断由于稀疏雷达信号或镜面反射而导致的缺失关节特别有益,因为模型学会基于来自相邻帧的上下文线索来“插值”合理的运动。
- 平衡行为($\lambda_{vel}$):权重因子 $\lambda_{vel}$,设置为0.05,在平衡时间平滑性(由 $L_{vel}$ 强制执行)与原始关键点准确性(由 $L_{oks}$ 驱动)这一首要目标方面起着关键作用。这个相对较小的值确保了虽然时间一致性是一个重要的考虑因素,但它不会压倒准确的关键点预测这一基本要求。因此,来自 $L_{oks}$ 的梯度通常会施加更强的影响,引导模型实现精确的姿态估计,而 $L_{vel}$ 则提供一个温和但持续的拉力,以实现时间连贯性。没有 $L_{vel}$,模型可能会产生准确但生硬的姿态;如果 $\lambda_{vel}$ 过高,它可能会优先考虑平滑性而牺牲准确性。
-
迭代状态更新:
- 前向传播:在每次训练迭代中,一批多帧雷达序列被输入到整个milliMamba网络——包括预处理、CVMamba编码器和STCA解码器。这种前向传播最终为每个帧 $f$ 和关节 $j$ 生成一系列预测的2D关键点坐标 $\hat{P}_{f,j}$。
- 损失计算:然后,将这些预测的关键点坐标与地面真实关键点坐标 $P_{f,j}$ 进行严格比较以计算 $L_{oks}$。同时,将预测速度 $\hat{v}_{f,j}$(从 $\hat{P}_{f,j}$ 导出)与地面真实速度 $v_{f,j}$(从 $P_{f,j}$ 导出)进行比较以计算 $L_{vel}$。然后根据主方程将这两个不同的损失分量组合起来:$L = L_{oks} + \lambda_{vel} L_{vel}$。
- 反向传播(Backpropagation):随后,计算出的总损失 $L$ 会反向传播到整个网络。这个复杂的过程计算了 $L$ 相对于模型中每一个可学习参数的梯度。这包括,例如,Mamba层中的矩阵 $A, B, C, D$,MNet块中的卷积神经网络(CNN)权重,STCA解码器中的注意力矩阵,以及初始的可学习关键点查询。
- 参数更新(Adam优化器):使用Adam优化器更新模型的参数。Adam是一种先进的自适应学习率优化算法,它根据梯度的一阶和二阶矩估计来计算不同参数的个体自适应学习率。通过指定的学习率0.00005和权重衰减0.0001,优化器智能地调整参数,使其朝着最有效地减小损失的方向移动。权重衰减项充当正则化机制,有助于防止模型变得过于复杂并过拟合训练数据。
- 收敛:这个前向传播、损失计算、反向传播和参数更新的循环过程会重复进行许多个epoch(遍历整个训练数据集的迭代)。随着时间的推移,模型的参数会逐渐收敛到最小化损失函数的数值,从而在训练数据和先前未见过的数据上逐步提高姿态估计的准确性和时间一致性。STCA解码器本身中的迭代精炼步骤也对这种收敛做出了显著贡献,因为关键点查询会逐步更新以更好地表示潜在的姿态。模型在单独的验证集上的性能会持续监控,以检测过拟合的迹象,并确定停止训练的最佳点。
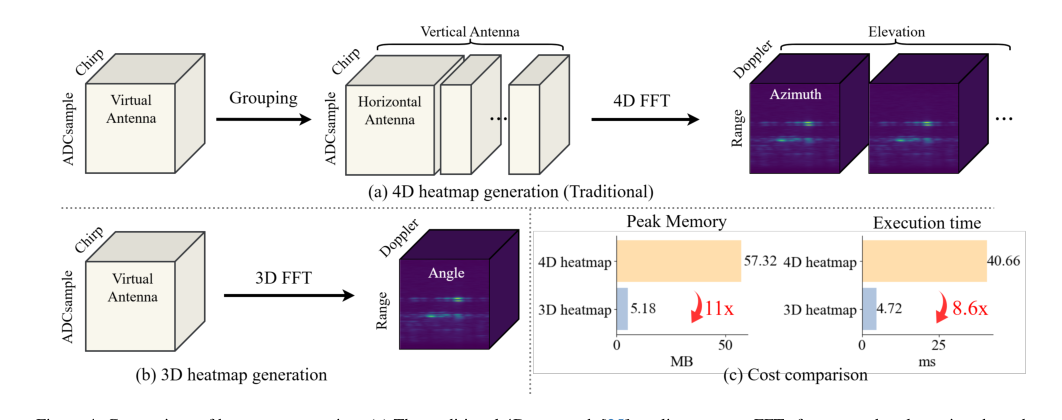 Figure 4. Comparison of heatmap generation. (a) The traditional 4D approach [25] applies separate FFTs for range, doppler, azimuth, and elevation after antenna grouping. (b) Our 3D pipeline performs a unified spatial FFT without grouping, yielding a compact representation. (c) Cost comparison between 4D and 3D heatmaps, showing 11× reduction in memory and 8.6× reduction in latency
Figure 4. Comparison of heatmap generation. (a) The traditional 4D approach [25] applies separate FFTs for range, doppler, azimuth, and elevation after antenna grouping. (b) Our 3D pipeline performs a unified spatial FFT without grouping, yielding a compact representation. (c) Cost comparison between 4D and 3D heatmaps, showing 11× reduction in memory and 8.6× reduction in latency
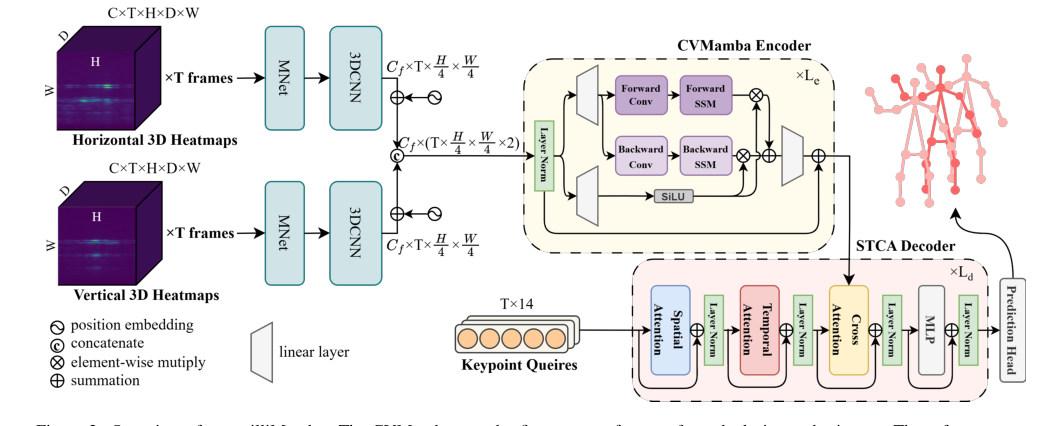 Figure 2. Overview of our milliMamba. The CVMamba encoder first extracts features from dual-view radar inputs. These features are then passed to the Multi-Pose STCA decoder, which progressively refines a set of keypoint queries to produce pose predictions
Figure 2. Overview of our milliMamba. The CVMamba encoder first extracts features from dual-view radar inputs. These features are then passed to the Multi-Pose STCA decoder, which progressively refines a set of keypoint queries to produce pose predictions
结果、局限性与结论
实验设计与基线
为了严格验证milliMamba的能力,作者设计了一系列实验,旨在分离和量化其提出的机制的贡献。核心设置涉及将双毫米波(mmWave)雷达输入(每个捕获 $T=9$ 帧序列)馈送到模型中。虽然模型产生了9个连续的姿态预测,但在推理时最终只使用了中心帧的预测,从而确保了与预测单帧的方法进行公平比较。
训练方案使用了Adam优化器,学习率为0.00005,批次大小为8,权重衰减为0.0001。整体训练目标是一个复合损失函数:$L = L_{oks} + \lambda_{vel} L_{vel}$。其中,$L_{oks}$(物体关键点相似度)惩罚预测和地面真实关节位置之间的差异,这是姿态估计中的标准指标。至关重要的是,$L_{vel}$(速度损失)被引入以通过最小化预测和地面真实关节速度之间的误差来强制执行时间平滑性,权重系数 $\lambda_{vel} = 0.05$。这种速度损失是解决雷达基姿态估计中常见的时间不一致性的关键架构选择。所有计算密集型工作都在单个NVIDIA Tesla V100 GPU上完成。
与milliMamba进行比较的“受害者”(基线模型)包括已建立的雷达基2D人体姿态估计(HPE)方法:
- TransHuPR [12]:一种部分建模时空依赖性的Transformer方法。
- HuPR [13]:另一个重要的雷达基HPE框架。
- mmPose [23]:一种基于CNN的方法。
作者还提到了RFMamba [35],这是另一种基于Mamba的方法,但指出其源代码并未公开,因此无法直接比较。
评估在两个基准mmWave雷达基2D HPE数据集上进行:
- TransHuPR [12]:包含440个序列(超过7小时),来自22名受试者,该数据集的特点是快速动态动作,构成重大挑战。
- HuPR Dataset [13]:包含235个序列(约4小时),来自6名受试者,该数据集主要包含相对静态的动作。
对于两个数据集,都遵循了标准的数据分割协议。最终的评估指标是平均精度(AP),基于物体关键点相似度(OKS)计算。这包括总体AP(在OKS阈值从0.50到0.95之间平均)以及AP50(OKS 0.50)和AP75(OKS 0.75),分别用于宽松和严格的匹配标准。
证据证明了什么
论文中提供的证据无可辩驳地证明了milliMamba的核心机制在现实中是有效的,从而带来了比现有基线显著的性能提升。
首先,在整体性能方面,milliMamba在TransHuPR和HuPR数据集上都持续且显著地优于所有基线。在具有挑战性的TransHuPR数据集上,milliMamba比TransHuPR [12]基线取得了惊人的11.0 AP提升。这在难以估计的关节(如手腕)上尤为明显,手腕关节容易出现快速运动和镜面反射,milliMamba在此关节上取得了46.9的AP。同样,在HuPR数据集上,milliMamba比HuPR [13]取得了更令人印象深刻的14.6 AP提升,在相对静态的动作中达到了84.0 AP。这些数字不仅仅是渐进式的;它们代表了雷达基HPE领域最先进水平的重大飞跃。
该论文还提供了其架构选择的效率和有效性的有力证据:
- 高效的3D FFT预处理:图4(c)明确显示,提出的3D快速傅里叶变换(FFT)预处理管道与传统的4D FFT方法相比,将内存使用量减少了11倍,延迟减少了8.6倍。表4进一步验证了这一点,表明3D FFT基热图在准确性方面与4D FFT相当,甚至更高(3D FFT为74.5 AP,4D FFT为72.0 AP),证明了效率的提高并未以性能为代价。
- 多姿态输出机制(多对多):表5清楚地说明了milliMamba的时空交叉注意力(STCA)解码器的优势。“多对多”预测策略利用了相邻帧的上下文线索,与预测单个姿态的“多对一”方法相比,整体准确性提高了4.1 AP。这明确证明了在解码阶段建模时空依赖性对于推断由于镜面反射而缺失的关节至关重要。
- Mamba编码器的可扩展性:表8中Mamba和Transformer编码器之间的比较尤其引人注目。虽然Mamba在短序列($T=3$ 帧)上比Transformer取得了高1.5 AP的分数,但关键证据在于Transformer由于内存不足而无法处理更长序列的能力。Mamba凭借其线性复杂度,成功地扩展到更长的输入序列(如表6所示,高达 $T=15$ 帧),并且性能持续提高。这表明Mamba具有更优越的可扩展性,并且能够有效地利用更丰富的时间上下文,这是该论文的一个关键主张。
- 双雷达配置:表7清楚地表明,双雷达(水平+垂直)配置与仅使用单个水平(67.3 AP)或垂直(74.5 AP)雷达相比,显著提高了性能(78.5 AP)。这证实了跨视图融合在补偿mmWave雷达传感器固有的有限仰角分辨率方面的有效性。
图5中的定性结果进一步加强了这些发现,直观地展示了milliMamba在TransHuPR数据集上的各种动作中,比mmPose、HuPR和TransHuPR基线能够产生更准确且时间上更连贯的姿态估计。
局限性与未来方向
尽管milliMamba在雷达基人体姿态估计方面取得了重大进展,但认识到其当前局限性并考虑未来发展方向至关重要。
一个固有的局限性是,尽管milliMamba在处理长序列方面比传统Transformer提高了效率,但其计算成本仍然很高。虽然它在准确性和复杂性之间提供了有利的权衡,但其MACs计数(34.4 G)仍然高于TransHuPR [12](5.8 G)等基线。这表明,对于在资源高度受限的边缘设备上的部署,可能需要进一步优化计算足迹。
另一个明显的局限性是目前专注于单人姿态估计。论文明确指出,未来的工作将探索“多人”场景。由于遮挡、干扰以及将雷达点与特定个体关联的挑战,多人情况下的雷达信号会变得更加复杂。当前的架构虽然对单人来说是鲁棒的,但可能需要进行大量修改才能处理多人交互的复杂性。
此外,评估是在两个特定的数据集TransHuPR和HuPR上进行的,它们代表了特定类型的动作和环境(暗示为室内)。尽管雷达对光照条件具有鲁棒性,但milliMamba在多样化的、不受约束的跨环境场景(例如,具有不同杂波、不同建筑材料的室外环境,或更复杂的人体-物体交互)中的泛化能力仍然是一个悬而未决的问题。论文在未来工作中提到“跨环境场景”,突出了这需要进一步研究。
展望未来,出现了几个令人兴奋的讨论主题,用于进一步发展和演进这些发现:
- 鲁棒的多人姿态估计:milliMamba的时空建模如何扩展以鲁棒地处理多个人?这可能涉及雷达数据的新颖实例分割技术、用于建模人际关系的图基方法,甚至整合关于人类群体动态的先验知识。为了在扩展到多人时保持线性复杂度,需要哪些架构更改?
- 实时边缘部署与效率:考虑到计算成本,哪些进一步的架构优化(例如,量化、剪枝、知识蒸馏)可以使milliMamba适用于低功耗边缘设备的实时推理?更轻量级的Mamba变体或混合架构是否能提供更好的实际应用平衡?
- 从2D热图进行3D姿态估计:当前工作专注于2D HPE。milliMamba提取的丰富时空特征如何被利用或扩展以推断完整的3D人体姿态?这可能需要调整输出头,并可能结合额外的几何约束或多视图融合策略来解决2D投影固有的深度歧义。
- 增强的镜面反射处理:虽然milliMamba解决了镜面反射问题,但是否可以将更明确的物理信息神经网络或先进的信号处理技术集成到Mamba编码器中,以直接建模和补偿这些具有挑战性的雷达现象?这可能涉及学习区分直接反射和镜面反射,或使用生成模型来“填充”由信号稀疏性引起的数据缺失。
- 更长期的时间上下文与动作识别:Mamba编码器处理长序列的能力是一个关键优势。如何进一步利用这一点,不仅可以改进姿态估计,还可以实现更复杂的动作识别或长时间活动理解?这可能涉及在Mamba框架内整合循环机制或分层时间建模。
- 与其他隐私保护模态的融合:虽然雷达是隐私保护的,但将milliMamba与其他非RGB传感器(例如,热像仪、深度传感器,甚至声学传感器)融合是否可以提供互补信息,以在极具挑战性的场景或特定应用(如医疗监测或跌倒检测)中进一步增强鲁棒性?对于这种多样化的数据类型,最佳的融合策略是什么?
 Table 2. Comparison of model performance and complexity across methods on the TransHuPR dataset [12]. The complexity excludes radar signal preprocessing
Table 2. Comparison of model performance and complexity across methods on the TransHuPR dataset [12]. The complexity excludes radar signal preprocessing
 Table 3. Comparison of model performance and complexity across methods on the HuPR dataset [13]. The complexity excludes radar signal preprocessing
Table 3. Comparison of model performance and complexity across methods on the HuPR dataset [13]. The complexity excludes radar signal preprocessing
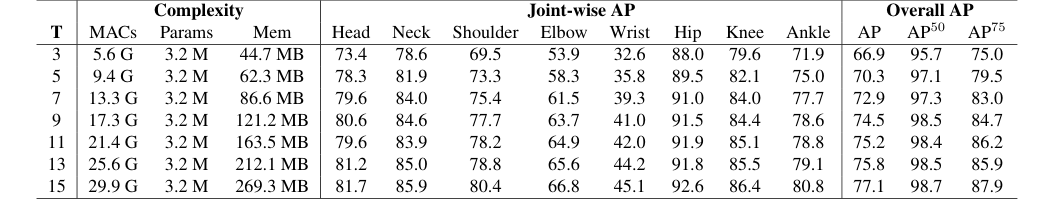 Table 6. Impact of input sequence length (T) on pose estimation performance. We investigate the effect of varying T to understand how temporal context contributes to accuracy
Table 6. Impact of input sequence length (T) on pose estimation performance. We investigate the effect of varying T to understand how temporal context contributes to accuracy
与其他领域的同构性
结构骨架
milliMamba的核心是一种机制,通过高效建模长程依赖性来从嘈杂的、가高い次元的序列传感器数据中提取时间连贯的、结构化的表示。