प्रक्रिया में अतिरिक्त b-जेट्स की पहचान में मिलान दक्षता बढ़ाने के लिए सीखना
इस पत्र के महत्व को वास्तव में समझने के लिए, हमें 2012 में लार्ज हैड्रॉन कोलाइडर (LHC) में हिग्स बोसॉन की ऐतिहासिक खोज पर वापस जाना होगा। एक बार जब भौतिकविदों ने हिग्स को खोज लिया, तो अगला तत्काल प्रश्न था: क्या यह...
पृष्ठभूमि और अकादमिक वंशक्रम
इस पत्र के महत्व को वास्तव में समझने के लिए, हमें 2012 में लार्ज हैड्रॉन कोलाइडर (LHC) में हिग्स बोसॉन की ऐतिहासिक खोज पर वापस जाना होगा। एक बार जब भौतिकविदों ने हिग्स को खोज लिया, तो अगला तत्काल प्रश्न था: क्या यह हमारे मानक मॉडल की भविष्यवाणी के अनुसार ही व्यवहार करता है?
इसका उत्तर देने के लिए, वैज्ञानिक यह देखते हैं कि हिग्स बोसॉन सबसे भारी ज्ञात कण, टॉप क्वार्क के साथ कैसे इंटरैक्ट करता है। वे विशेष रूप से $t\bar{t}H$ प्रक्रिया नामक एक टक्कर घटना का अध्ययन करते हैं, जहाँ एक टॉप क्वार्क जोड़ी ($t\bar{t}$) एक हिग्स बोसॉन ($H$) के साथ उत्पन्न होती है। चूंकि हिग्स बोसॉन सबसे अधिक बार बॉटम क्वार्कों की एक जोड़ी ($b\bar{b}$) में क्षय होता है, इसलिए कोलाइडर में हम वास्तव में जो अंतिम मलबा पता लगाते हैं, वह $t\bar{t}b\bar{b}$ हस्ताक्षर है।
यहीं से भारी सिरदर्द शुरू होता है। ब्रह्मांड स्वाभाविक रूप से मानक, गैर-हिग्स भौतिकी प्रक्रियाओं के माध्यम से $t\bar{t}b\bar{b}$ घटनाओं का उत्पादन करता है। यह गैर-हिग्स $t\bar{t}b\bar{b}$ उत्पादन भारी पृष्ठभूमि शोर के रूप में कार्य करता है। दुर्लभ हिग्स "सिग्नल" खोजने के लिए, भौतिकविदों को इस पृष्ठभूमि को पूरी तरह से समझना होगा। ऐसा करने के लिए, उन्हें अंतिम मलबे को देखना होगा और यह भेद करना होगा कि कौन से बॉटम क्वार्क टॉप क्वार्कों से आए थे, और कौन से "अतिरिक्त" बॉटम क्वार्क थे जो ग्लूऑन स्प्लिटिंग नामक एक यादृच्छिक क्वांटम घटना द्वारा उत्पन्न हुए थे।
पिछले दृष्टिकोणों की मौलिक सीमा
इस पत्र से पहले, शोधकर्ताओं ने मानक मशीन लर्निंग, विशेष रूप से बाइनरी वर्गीकरण का उपयोग करके इस पहचान समस्या को हल करने का प्रयास किया। वे एक घटना में $b$-जेट्स की हर जोड़ी लेते थे और न्यूरल नेटवर्क से पूछते थे: "क्या यह जोड़ी अतिरिक्त है? हाँ या नहीं?"
यहां मुख्य समस्या यह है कि यह दृष्टिकोण डेटा की भौतिक संरचना को पूरी तरह से अनदेखा करता है। लगभग हर टक्कर घटना में, ठीक एक अतिरिक्त $b$-जेट्स की जोड़ी होती है। प्रत्येक जोड़ी का पूरी तरह से अलग-अलग मूल्यांकन करके, पिछले मॉडल "इवेंट सटीकता" के बजाय समग्र "जोड़ी सटीकता" के लिए अनुकूलित हो रहे थे। कल्पना कीजिए कि एक कंप्यूटर से स्वतंत्र रूप से अनुमान लगाने के लिए कहकर एक बहुविकल्पीय परीक्षा को ग्रेडिंग करना कि क्या A सही है, क्या B सही है, और क्या C सही है, बजाय इसके कि उसे विकल्पों में से एकमात्र सर्वोत्तम उत्तर चुनने के लिए मजबूर किया जाए। चूंकि पुराने मॉडल एक साथ पूरे घटना संदर्भ को नहीं देखते थे, इसलिए प्रति घटना एक सही जोड़ी की पहचान करने की उनकी क्षमता (जिसे "मैचिंग एफिशिएंसी" कहा जाता है) एक कठिन सीमा से टकराई।
शब्दजाल का अनुवाद
इसे सहज बनाने के लिए, आइए पत्र में प्रयुक्त कुछ अत्यधिक विशिष्ट शब्दों को तोड़ें:
- $b$-jet: जब एक बॉटम ($b$) क्वार्क एक कण टक्कर में बनता है, तो यह लगभग तुरंत अन्य कणों की एक शंकु के आकार की फुहार में क्षय हो जाता है।
- सादृश्य: एक $b$-jet को एक अदृश्य जानवर द्वारा छोड़े गए कीचड़ भरे पैरों के निशान के एक अद्वितीय सेट के रूप में सोचें। हम जानवर (क्वार्क) को नहीं देख सकते हैं, लेकिन हम यह पता लगाने के लिए पैरों के निशान (जेट) को माप सकते हैं कि यह कहाँ से आया था।
- Gluon splitting: एक क्वांटम प्रक्रिया जहाँ एक ग्लूऑन (एक कण जो मजबूत परमाणु बल ले जाता है) स्वतः ही एक क्वार्क और एक एंटीक्वार्क जोड़ी में बदल जाता है।
- सादृश्य: कल्पना कीजिए कि आतिशबाजी का एक एकल खोल आकाश में उड़ता है और अचानक ठीक दो अलग-अलग, चमकीले रंग के चिंगारी में फट जाता है।
- Irreducible background: एक पृष्ठभूमि शोर प्रक्रिया जिसके परिणामस्वरूप आप वास्तव में जिस दुर्लभ सिग्नल की तलाश कर रहे हैं, उसी अंतिम पता लगाने योग्य कणों का उत्पादन होता है।
- सादृश्य: अंतिम पके हुए केक को देखकर यह बताने की कोशिश करना कि केक को सफेद चीनी से मीठा किया गया था या भूरी चीनी से। अंतिम परिणाम समान दिखता है, इसलिए आपको उन्हें अलग करने के लिए बनावट में अविश्वसनीय रूप से सूक्ष्म सुराग खोजने होंगे।
- Matching efficiency: कुल टक्कर घटनाओं का प्रतिशत जहां एल्गोरिथम व्यक्तिगत अनुमानों पर उच्च औसत स्कोर प्राप्त करने के बजाय, अतिरिक्त $b$-जेट्स की सटीक सही जोड़ी की सफलतापूर्वक पहचान करता है।
- सादृश्य: एक स्निपर का "एक शॉट, एक किल" मीट्रिक। इससे कोई फर्क नहीं पड़ता कि आपने 99 निर्दोष राहगीरों को "लक्ष्य नहीं" के रूप में सही ढंग से पहचाना है; जो मायने रखता है वह यह है कि क्या आप भीड़ में छिपे एक विशिष्ट लक्ष्य को पूरी तरह से चुन सकते हैं।
गणितीय समस्या और समाधान
लेखक मैचिंग एफिशिएंसी को सीधे अधिकतम करना चाहते थे। गणितीय रूप से, इसे क्रोनकर डेल्टा फ़ंक्शन द्वारा दर्शाया जाता है:
$$ \text{Matching efficiency} = \frac{1}{N} \sum_{i=1}^{N} \delta(y_i, \hat{y}(M_i)) $$
यहां, $\delta(y_i, \hat{y}(M_i))$ का मान $1$ होता है यदि मॉडल की भविष्यवाणी $\hat{y}$ सही सूचकांक $y_i$ से पूरी तरह मेल खाती है, और अन्यथा $0$ होता है।
गणितीय समस्या यह है कि यह फ़ंक्शन एक "कठोर कदम" है (यह तुरंत 0 से 1 तक कूद जाता है)। मशीन लर्निंग वातावरण में, आप एक कठोर कदम पर एक न्यूरल नेटवर्क को प्रशिक्षित नहीं कर सकते क्योंकि ग्रेडिएंट (नेटवर्क के भार को अपडेट करने के लिए उपयोग की जाने वाली ढलान) लगभग हर जगह शून्य होती है। आप इसे अनुकूलित करने के लिए कलन का उपयोग नहीं कर सकते।
इस बाधा को दूर करने के लिए, लेखकों ने पुराने बाइनरी क्रॉस-एंट्रॉपी लॉस ($L_{BCE}$) को छोड़ दिया और सरोगेट लॉस फ़ंक्शन ($L_1, L_2, L_3, L_4$) डिज़ाइन किए। उन्होंने न्यूरल नेटवर्क के आउटपुट को एक सॉफ्टमैक्स फ़ंक्शन का उपयोग करके एक दी गई घटना में सभी जोड़ियों पर एक संभाव्यता वितरण में बदल दिया:
$$ f_j(M_i) = \frac{\exp(g_j(M_i))}{\sum_{k=1}^{c_i} \exp(g_k(M_i))} $$
यह समीकरण मॉडल को घटना मैट्रिक्स $M_i$ में सभी $c_i$ जोड़ियों को देखने और उन्हें ऐसी संभावनाएँ निर्दिष्ट करने के लिए मजबूर करता है जिनका योग 1 होता है। फिर, वे मॉडल को एक श्रेणीबद्ध क्रॉस-एंट्रॉपी सरोगेट लॉस, जैसे $L_3$ का उपयोग करके सही जोड़ी को सौंपी गई संभावना को अधिकतम करने के लिए प्रशिक्षित करते हैं:
$$ L_3 = - \frac{1}{N} \sum_{i=1}^{N} \log f_{y_i}(M_i) $$
ऐसा करके, मॉडल ग्रेडिएंट डिसेंट के नियमों को तोड़े बिना, सीधे मैचिंग एफिशिएंसी की ओर अनुकूलित होकर, विशिष्ट घटना के संदर्भ में जोड़ियों को एक-दूसरे के विरुद्ध रैंक करना सीखता है।
मुख्य गणितीय संकेतन
| संकेतन | प्रकार | विवरण |
|---|---|---|
| $N$ | पैरामीटर | सिम्युलेटेड $t\bar{t}b\bar{b}$ घटना डेटा नमूनों की कुल संख्या। |
| $c_i$ | चर | $i$-वीं घटना में मौजूद $b$-जेट जोड़ियों की कुल संख्या। |
| $F$ | पैरामीटर | एकल $b$-जेट जोड़ी का प्रतिनिधित्व करने वाले फ़ीचर वेक्टर का आयाम। |
| $M_i$ | चर | $i$-वीं घटना के लिए घटना मैट्रिक्स, जिसमें सभी $b$-जेट जोड़ियाँ शामिल हैं, जिसका आयाम $\mathbb{R}^{c_i \times F}$ है। |
| $y_i$ | चर | $i$-वीं घटना में अतिरिक्त $b$-जेट्स की वास्तविक जोड़ी को इंगित करने वाला सही पूर्णांक सूचकांक (1 से $c_i$ तक)। |
| $\hat{y}(M_i)$ | चर | मॉडल द्वारा आउटपुट की गई अतिरिक्त $b$-जेट जोड़ी का अनुमानित सूचकांक। |
| $f_j(M_i)$ | चर | मॉडल की अनुमानित संभावना कि घटना $M_i$ में $j$-वीं $b$-जेट जोड़ी अतिरिक्त जोड़ी है। |
| $g_j(M_i)$ | चर | संभावना में परिवर्तित होने से पहले $j$-वीं $b$-जेट जोड़ी के लिए न्यूरल नेटवर्क द्वारा गणना किया गया कच्चा सक्रियण मान (स्कोर)। |
| $L_{BCE}$ | फ़ंक्शन | पारंपरिक बाइनरी क्रॉस-एंट्रॉपी लॉस जिसका उपयोग पिछले, सीमित मॉडल द्वारा किया जाता था। |
| $L_1, L_2, L_3, L_4$ | फ़ंक्शन | प्रस्तावित सरोगेट लॉस फ़ंक्शन जो मैचिंग एफिशिएंसी को सुचारू रूप से अनुमानित और अधिकतम करने के लिए डिज़ाइन किए गए हैं। |
समस्या परिभाषा एवं बाधाएँ
इस पत्र द्वारा संबोधित की जाने वाली समस्या की भयावहता को समझने के लिए, कल्पना कीजिए कि आप एक भीड़ भरे, शोरगुल वाले स्टेडियम में एक बहुत ही मंद, विशिष्ट फुसफुसाहट सुनने की कोशिश कर रहे हैं। कण भौतिकी की दुनिया में, वह फुसफुसाहट हिग्स बोसॉन है, एक मौलिक कण जो ब्रह्मांड में हर चीज को द्रव्यमान प्रदान करता है। हालांकि, जब भौतिक विज्ञानी हिग्स बोसॉन का अध्ययन करने के लिए लार्ज हैड्रॉन कोलाइडर (LHC) पर प्रोटॉन को आपस में टकराते हैं, तो वे भारी मात्रा में पृष्ठभूमि शोर से बहरे हो जाते हैं।
सबसे तेज शोर $t\bar{t}b\bar{b}$ नामक एक भौतिक प्रक्रिया से आता है, जो एक बॉटम क्वार्क ($b$) जोड़ी के साथ एक टॉप क्वार्क जोड़ी का उत्पादन करता है। इस प्रक्रिया से निकलने वाला मलबा हिग्स बोसॉन से निकलने वाले मलबे जैसा ही दिखता है। इस शोर को फ़िल्टर करने के लिए, भौतिकविदों को परिणामी "बी-जेट्स" (कणों के स्प्रे) को देखना होगा और उनकी उत्पत्ति की कहानी का पता लगाना होगा: क्या ये बी-जेट्स भारी टॉप क्वार्क के क्षय से आए थे, या वे बस "ग्लूऑन स्प्लिटिंग" नामक एक द्वितीयक प्रक्रिया से अस्तित्व में आए?
प्रारंभिक बिंदु और लक्ष्य अवस्था
इनपुट (वर्तमान अवस्था):
जब एक कण टक्कर (एक "घटना") होती है, तो डिटेक्टर मलबे के गतिज गुणों को कैप्चर करते हैं। लेखक इस डेटा को गणितीय रूप से एक घटना मैट्रिक्स $M_i \in \mathbb{R}^{c_i \times F}$ के रूप में दर्शाते हैं। यहाँ, $c_i$ एक एकल टक्कर घटना में संभावित बी-जेट जोड़े की संख्या का प्रतिनिधित्व करता है, और $F$ प्रत्येक जोड़ी की उच्च-आयामी भौतिक विशेषताओं (जैसे संवेग और ऊर्जा) का प्रतिनिधित्व करता है।
आउटपुट (लक्ष्य अवस्था):
वांछित अंतिम बिंदु एक तंत्रिका नेटवर्क है जो इस मैट्रिक्स को देख सकता है और ठीक एक विशिष्ट पंक्ति की ओर इशारा कर सकता है, आत्मविश्वास से घोषणा करते हुए: "बी-जेट्स की यह विशिष्ट जोड़ी ग्लूऑन स्प्लिटिंग द्वारा बनाई गई अतिरिक्त जोड़ी है।"
गणितीय अंतर:
लुप्त कड़ी एक विशेष गणितीय पुल है जो एक ही घटना के भीतर बी-जेट जोड़े का एक दूसरे के सापेक्ष मूल्यांकन करता है। हम केवल यह जानना नहीं चाहते हैं कि क्या कोई जोड़ी अकेले एक अतिरिक्त बी-जेट की तरह दिखती है; हमें नेटवर्क को मैट्रिक्स $M_i$ में सभी जोड़ों को रैंक करने और एक संभाव्यता वितरण $f(M_i) \in [0, 1]^{c_i}$ आउटपुट करने की आवश्यकता है जहाँ संभावनाओं का योग 1 होता है। उच्चतम संभावना सही जोड़ी को इंगित करती है।
दर्दनाक दुविधा
पिछले शोधकर्ताओं ने एक क्लासिक मशीन लर्निंग जाल में प्रवेश किया: उन्होंने इसे एक मानक बाइनरी वर्गीकरण समस्या के रूप में माना। उन्होंने प्रत्येक घटना से हर एकल बी-जेट जोड़ी ली, उन्हें एक साथ मिलाया, और एक मानक बाइनरी क्रॉस-एंट्रॉपी लॉस फ़ंक्शन ($L_{BCE}$) का उपयोग करके एक तंत्रिका नेटवर्क से "हाँ" या "नहीं" का अनुमान लगाने के लिए कहा।
इसने कम्प्यूटेशनल सुविधा और भौतिक वास्तविकता के बीच एक दर्दनाक समझौता किया। बाइनरी वर्गीकरण गणितीय रूप से अनुकूलित करने में आसान है, लेकिन यह भौतिकी की संरचनात्मक वास्तविकता को पूरी तरह से अनदेखा करता है: लगभग हर $t\bar{t}b\bar{b}$ घटना में वास्तव में एक अतिरिक्त बी-जेट्स की जोड़ी होती है। प्रत्येक जोड़ी का एक वैक्यूम में मूल्यांकन करके, पिछले मॉडल ने महत्वपूर्ण प्रासंगिक सुरागों को फेंक दिया।
हालांकि, यदि आप बाइनरी वर्गीकरण को छोड़कर और सीधे उस चीज़ को अनुकूलित करने का प्रयास करते हैं जिसकी आप वास्तव में परवाह करते हैं - "मिलान दक्षता," जो कुल घटनाओं का प्रतिशत है जहां मॉडल सटीक सही जोड़ी चुनता है - तो आप तुरंत गणित को तोड़ देते हैं। आपको एक ऐसे मॉडल के बीच चयन करने के लिए मजबूर किया जाता है जिसे प्रशिक्षित करना आसान है लेकिन संरचनात्मक रूप से दोषपूर्ण है, या एक ऐसे मॉडल के बीच जिसे प्रशिक्षित करना संरचनात्मक रूप से सटीक लेकिन गणितीय रूप से असंभव है।
कठोर दीवारें और बाधाएँ
इस समस्या को हल करना इतना कठिन क्या बनाता है? लेखकों ने कई विशाल दीवारों का सामना किया:
1. गैर-विभेदनीय दीवार (गणितीय बाधा)
अंतिम लक्ष्य मिलान दक्षता को अधिकतम करना है, जिसे गणितीय रूप से इस प्रकार परिभाषित किया गया है:
$$ \text{Matching efficiency} = \frac{1}{N} \sum_{i=1}^{N} \delta(y_i, \hat{y}(M_i)) $$
यहां, $\delta$ क्रोनकर डेल्टा फ़ंक्शन है। यह फ़ंक्शन एक कठोर, कठोर सीढ़ी है: यह $1$ के बराबर होता है यदि मॉडल की भविष्यवाणी $\hat{y}$ सटीक रूप से वास्तविक लेबल $y_i$ से मेल खाती है, और अन्यथा $0$ होती है। कलन में, एक सपाट सीढ़ी का व्युत्पन्न (ढाल) शून्य होता है। तंत्रिका नेटवर्क ढालों (ढाल वंश) का पालन करके सीखते हैं। क्योंकि क्रोनकर डेल्टा अत्यधिक गैर-विभेदनीय है और लगभग हर जगह शून्य ढाल लौटाता है, तंत्रिका नेटवर्क पूरी तरह से अंधा रह जाता है। यह सीख नहीं सकता क्योंकि गणित सुधार के तरीके पर कोई दिशात्मक प्रतिक्रिया प्रदान नहीं करता है।
2. चर डेटा संरचनाएँ (कम्प्यूटेशनल बाधा)
हर क्वांटम टक्कर अद्वितीय रूप से अराजक होती है। एक घटना 3 बी-जेट जोड़े का उत्पादन कर सकती है, जबकि अगली 6 का उत्पादन कर सकती है। इसका मतलब है कि इनपुट मैट्रिक्स $M_i$ में पंक्तियों ($c_i$) की लगातार बदलती संख्या होती है। तंत्रिका नेटवर्क आर्किटेक्चर को गतिशील रूप से चर-आकार के इनपुट को क्रैश किए बिना संभालने के लिए पर्याप्त लचीला होना चाहिए, साथ ही क्रमपरिवर्तन-समकक्ष (इसका मतलब है कि बी-जेट जोड़े को मॉडल में फीड करने का क्रम मॉडल के अंतर्निहित तर्क को नहीं बदलना चाहिए) होना चाहिए।
3. अत्यधिक क्वांटम जटिलता (भौतिक बाधा)
इन जेटों को अलग करने के लिए कोई सरल, हार्ड-कोडेड भौतिकी नियम नहीं हैं। डेटा अत्यधिक जटिल, स्टोकेस्टिक क्वांटम प्रक्रियाओं द्वारा उत्पन्न होता है। हाथ से इंजीनियर की गई सुविधाएँ व्यावहारिक रूप से असंभव हैं। गतिज अवलोकन गहराई से उलझे हुए हैं, जिसका अर्थ है कि मॉडल को किसी भी स्पष्ट मानव-निर्मित नियमों के बिना, केवल सिम्युलेटेड डेटा से उच्च-आयामी संबंधों को सुलझाना सीखना चाहिए।
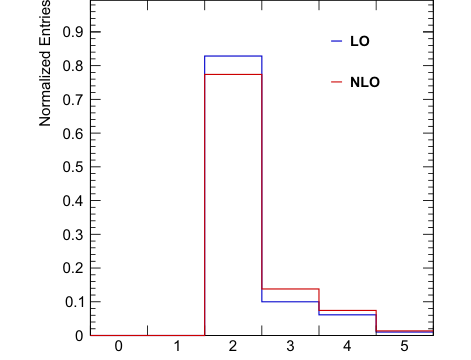 Figure 4. Histograms for the number of generator-level additional b-jets in simulated t¯tb¯b events at both the leading order (LO) and the next-to-leading order (NLO). Note that most events have two additional b-jets (82.8% for LO and 77.4% for NLO)
Figure 4. Histograms for the number of generator-level additional b-jets in simulated t¯tb¯b events at both the leading order (LO) and the next-to-leading order (NLO). Note that most events have two additional b-jets (82.8% for LO and 77.4% for NLO)
यह दृष्टिकोण क्यों
इस विशिष्ट गणितीय मार्ग को लेखकों ने क्यों अपनाया, यह समझने के लिए, हमें उस सटीक क्षण को इंगित करना होगा जब उन्हें एहसास हुआ कि पिछला स्वर्ण मानक मौलिक रूप से त्रुटिपूर्ण था। इस पत्र से पहले, $t\bar{t}b\bar{b}$ प्रक्रिया में अतिरिक्त b-जेट्स की पहचान करने के लिए राज्य-की-कला (SOTA) दृष्टिकोण एक डीप न्यूरल नेटवर्क (DNN) का उपयोग एक मानक बाइनरी क्लासिफायरियर के रूप में करना था। इस पुरानी विधि ने b-जेट्स के प्रत्येक जोड़े को लिया, इसे नेटवर्क में फीड किया, और 0 और 1 के बीच एक संभाव्यता आउटपुट करने के लिए बाइनरी क्रॉस-एंट्रॉपी लॉस ($L_{BCE}$) को न्यूनतम किया।
लेखकों के लिए "आहा!" क्षण तब हुआ जब उन्होंने कण टकराव डेटा की भौतिक वास्तविकता को देखा। लगभग हर मान्य $t\bar{t}b\bar{b}$ घटना में, ग्लुआन स्प्लिटिंग से उत्पन्न अतिरिक्त b-जेट्स का एक जोड़ा होता है। पारंपरिक बाइनरी वर्गीकरण दृष्टिकोण इस मौलिक बाधा को पूरी तरह से अनदेखा करता है। यह प्रत्येक b-जेट जोड़े को अलग-अलग मानता है, यह पूछते हुए, "क्या यह जोड़ा एक संकेत है?" बजाय इसके कि अधिक प्रासंगिक प्रश्न पूछा जाए: "इस विशिष्ट घटना में जोड़ों में से कौन सा संकेत है?" जोड़ों को स्वतंत्र रूप से मानकर, पुराना मॉडल महत्वपूर्ण प्रासंगिक जानकारी को त्याग देता था और वास्तविक लक्ष्य के बजाय बाइनरी सटीकता के लिए अनुकूलित होता था: मिलान दक्षता।
इस अहसास ने उनके प्रस्तावित गणितीय मॉडल को एकमात्र व्यवहार्य समाधान बना दिया। स्वतंत्र वर्गीकरण के बजाय, उन्होंने एक क्रमचय-समरूप मॉडल तैयार किया जो एक संपूर्ण घटना मैट्रिक्स $M_i \in \mathbb{R}^{c_i \times F}$ (जहां $c_i$ $i$-वीं घटना में b-जेट जोड़ों की संख्या है, और $F$ विशेषता आयाम है) को संसाधित करता है। उन्होंने एक एकल घटना के भीतर सभी जोड़ों के लिए आउटपुट पर एक सॉफ्टमैक्स फ़ंक्शन लागू किया:
$$ f_j(M_i) = \frac{\exp(g_j(M_i))}{\sum_{k=1}^{c_i} \exp(g_k(M_i))} $$
यह सुनिश्चित करता है कि एक एकल घटना में सभी जोड़ों की संभाव्यता का योग ठीक एक ($\sum_{j=1}^{c_i} f_j(M_i) = 1$) होता है।
इस विधि की तुलनात्मक श्रेष्ठता उनके प्रूफ-ऑफ-कॉन्सेप्ट सिंथेटिक डेटा प्रयोग में खूबसूरती से चित्रित की गई है। स्टोकेस्टिक जनरेटिव प्रक्रियाओं के साथ एक उच्च-आयामी स्थान में, पृष्ठभूमि शोर अक्सर वैश्विक स्तर पर देखे जाने पर संकेत के साथ ओवरलैप होता है। पारंपरिक बाइनरी क्लासिफायरियर सभी घटनाओं से सभी डेटा बिंदुओं पर एक एकल, वैश्विक निर्णय सीमा खींचने का प्रयास करता है, जिसके परिणामस्वरूप इस ओवरलैप के कारण एक मनमाना और अत्यधिक गलत अलगाव होता है। इसके विपरीत, लेखकों की विधि एक ही घटना मैट्रिक्स के भीतर जोड़ों का एक दूसरे के सापेक्ष मूल्यांकन करती है। ऐसा करके, यह प्रभावी रूप से वैश्विक शोर ओवरलैप को बायपास करता है, एक स्वच्छ, सापेक्ष निर्णय सीमा सीखता है जो संकेत को पूरी तरह से अलग करता है। यह आवश्यक रूप से मेमोरी जटिलता को $O(N^2)$ से $O(N)$ तक कम नहीं करता है, लेकिन यह तुलना स्थान को एक एकल घटना की सीमाओं तक सीमित करके कम्प्यूटेशनल भ्रम को काफी कम कर देता है।
यह चुनी हुई विधि समस्या की कठोर बाधाओं के साथ पूरी तरह से संरेखित होती है। अंतिम लक्ष्य मिलान दक्षता को अधिकतम करना है, जिसे गणितीय रूप से क्रोनकर डेल्टा फ़ंक्शन का उपयोग करके परिभाषित किया गया है:
$$ \text{Matching efficiency} = \frac{1}{N} \sum_{i=1}^{N} \delta(y_i, \hat{y}(M_i)) $$
क्योंकि यह स्टेप फ़ंक्शन अत्यधिक गैर-चिकना और गैर-अवकलनीय है (शून्य ग्रेडिएंट लौटाता है), इसे सीधे ग्रेडिएंट डिसेंट के माध्यम से अनुकूलित नहीं किया जा सकता है। समस्या की बाधाओं और समाधान के बीच "विवाह" लेखकों के सरोगेट लॉस फ़ंक्शन के चतुर डिजाइन में निहित है। घटना मैट्रिक्स के पंक्ति सूचकांकों को विशिष्ट श्रेणियों के रूप में मानते हुए, उन्होंने समस्या को एक बहु-वर्ग वर्गीकरण या रैंकिंग कार्य में बदल दिया। उदाहरण के लिए, उनके संभाव्य रैंकिंग लॉस ($L_2$) और श्रेणीगत क्रॉस-एंट्रॉपी लॉस ($L_3$) सीधे नेटवर्क को दंडित करते हैं यदि वास्तविक अतिरिक्त b-जेट जोड़ी को उसकी विशिष्ट घटना संरचना के भीतर उच्चतम सापेक्ष स्कोर प्राप्त नहीं होता है।
ईमानदारी से कहूं तो, मुझे पूरी तरह से यकीन नहीं है कि GANs, मानक डिफ्यूजन, या ट्रांसफॉर्मर जैसे कितने ट्रेंडी जनरेटिव मॉडल यहां कैसा प्रदर्शन करेंगे, क्योंकि लेखक पाठ में उनका बिल्कुल भी उल्लेख या संकेत नहीं करते हैं। मुझे संदेह है कि GAN या डिफ्यूजन मॉडल को लागू करना एक अत्यधिक जटिल और कम्प्यूटेशनल रूप से व्यर्थ होगा, जो अनिवार्य रूप से एक अत्यधिक बाधित संयोजी रैंकिंग समस्या है। हालांकि, लेखकों ने स्पष्ट रूप से सबसे लोकप्रिय विकल्प - बाइनरी वर्गीकरण DNN - को अस्वीकार करने के पीछे के तर्क की व्याख्या की है। उन्होंने इसे अस्वीकार कर दिया क्योंकि $L_{BCE}$ का अनुकूलन गणितीय रूप से भौतिक उद्देश्य के साथ संरेखित नहीं होता है। यहां तक कि जब उन्होंने घटना में अन्य b-जेट्स से सुविधाओं को शामिल करने के लिए बाइनरी क्लासिफायरियर को अपग्रेड किया (उनका "मॉडल 2"), तो यह अभी भी उनके प्रस्तावित सरोगेट लॉस ($L_2$ और $L_3$) से कम था। बाइनरी दृष्टिकोण केवल यह गारंटी नहीं दे सकता है कि एक घटना में उच्चतम स्कोरिंग जोड़ी वास्तव में सही है, क्योंकि इसे प्रशिक्षण के दौरान कभी भी अगल-बगल तुलना करने के लिए गणितीय रूप से मजबूर नहीं किया गया था।
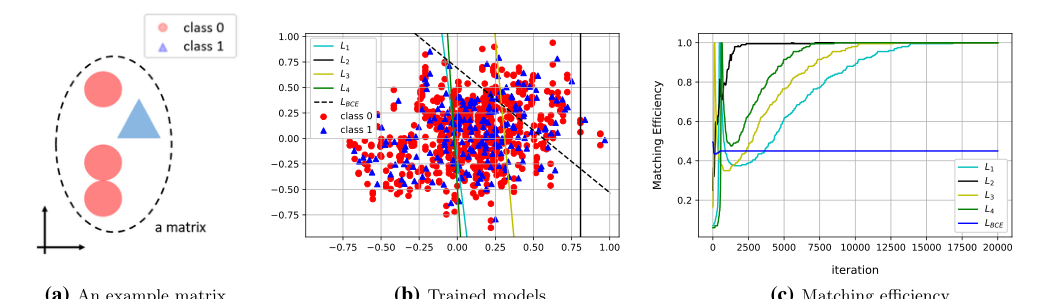 Figure 2. Experimental results from synthetic data. (a) An example matrix is illustrated. (b) The level sets of the trained models are drawn over the data scatter plot. (c) Matching efficiencies (evaluated on a test data set) for each of the loss functions are shown
Figure 2. Experimental results from synthetic data. (a) An example matrix is illustrated. (b) The level sets of the trained models are drawn over the data scatter plot. (c) Matching efficiencies (evaluated on a test data set) for each of the loss functions are shown
गणितीय एवं तार्किक तंत्र
लार्ज हैड्रॉन कोलाइडर (LHC) के नियंत्रण कक्ष के अंदर खड़े होने की कल्पना करें। हर बार जब कोई टक्कर होती है, तो कण प्रकाश की गति के लगभग बराबर गति से बिखर जाते हैं, जिससे "जेट्स" नामक उप-परमाणु मलबे की बौछारें बनती हैं। भौतिक विज्ञानी हिग्स बोसॉन के गुणों की बेतहाशा तलाश कर रहे हैं, जो अक्सर "बी-जेट्स" नामक एक विशिष्ट प्रकार के मलबे में क्षय हो जाता है।
हालांकि, एक बड़ी समस्या है: $t\bar{t}b\bar{b}$ (एक टॉप क्वार्क जोड़ी और एक बी क्वार्क जोड़ी) नामक एक पूरी तरह से अलग, शोरगुल वाली पृष्ठभूमि प्रक्रिया बिल्कुल वही बी-जेट्स उत्पन्न करती है। इस शोर को फ़िल्टर करने के लिए, भौतिकविदों को यह पता लगाना होगा कि कौन से बी-जेट्स मुख्य घटना (टॉप क्वार्क क्षय) से आए थे और कौन से सिर्फ अतिरिक्त मलबा थे (ग्लूऑन स्प्लिटिंग नामक घटना से उत्पन्न)।
पहले, वैज्ञानिकों ने प्रत्येक बी-जेट जोड़ी को अलग-अलग देखने के लिए मशीन लर्निंग का उपयोग किया, एक साधारण हाँ/नहीं प्रश्न पूछा: "क्या तुम अतिरिक्त मलबा हो?" यह बाइनरी वर्गीकरण दृष्टिकोण त्रुटिपूर्ण था क्योंकि इसने भौतिकी के एक मौलिक नियम को नजरअंदाज कर दिया: लगभग हर मान्य घटना में, ठीक एक अतिरिक्त बी-जेट जोड़ी होती है। प्रत्येक जोड़ी को स्वतंत्र रूप से मानकर, पुराने मॉडल मूल्यवान प्रासंगिक जानकारी को छोड़ रहे थे।
इस पत्र के लेखकों ने प्रतिमान को बदलकर इसे हल किया। "क्या यह जोड़ी अतिरिक्त मलबा है?" पूछने के बजाय, उन्होंने एक न्यूरल नेटवर्क डिज़ाइन किया जो एक ही घटना में सभी जोड़ियों को एक साथ देखे और पूछे, "तुम में से कौन सबसे संभावित उम्मीदवार है?" उन्होंने मानक बाइनरी सटीकता को त्यागकर और सीधे "मिलान दक्षता" को अधिकतम करने के लिए कस्टम लॉस फ़ंक्शन डिज़ाइन करके इसे प्राप्त किया - वह दर जिस पर मॉडल लाइनअप से एकल सही जोड़ी चुनता है।
यहां उनके सबसे सफल मॉडल को शक्ति प्रदान करने वाला पूर्ण मुख्य गणितीय इंजन है, जो उनकी घटना-स्तरीय संभाव्यता वितरण (सॉफ्टमैक्स) को एक श्रेणीबद्ध क्रॉस-एंट्रॉपी सरोगेट लॉस के साथ जोड़ता है:
$$ L_3 = -\frac{1}{N} \sum_{i=1}^N \log \left( \frac{\exp(g_{y_i}(M_i))}{\sum_{k=1}^{c_i} \exp(g_k(M_i))} \right) $$
आइए समझें कि यह कैसे काम करता है, इस समीकरण को एक-एक करके तोड़ते हैं:
- $L_3$: यह सरोगेट लॉस फ़ंक्शन है। यह अंतिम त्रुटि संकेत के रूप में कार्य करता है, न्यूरल नेटवर्क को बताता है कि इसने कितनी बुरी तरह से गड़बड़ की है। प्रशिक्षण प्रक्रिया का लक्ष्य इस संख्या को कम करना है।
- $-\frac{1}{N} \sum_{i=1}^N$: यह डेटासेट में सभी $N$ घटनाओं में औसत त्रुटि की गणना करता है। एक योग और समाकलन क्यों नहीं? क्योंकि टक्कर की घटनाओं की संख्या $N$ सख्ती से असतत और गणनीय है। आप टक्कर का एक अंश नहीं रख सकते, इसलिए एक सतत स्थान पर समाकलन करना यहां भौतिक या तार्किक रूप से समझ में नहीं आएगा।
- $\log$: प्राकृतिक लघुगणक। इसकी तार्किक भूमिका तब मॉडल को भारी दंडित करना है जब वह आत्मविश्वास से गलत हो। यदि मॉडल सही जोड़ी के लिए $1$ के करीब संभाव्यता निर्दिष्ट करता है, तो $1$ का $\log$ $0$ होता है (कोई दंड नहीं)। लेकिन जैसे-जैसे संभाव्यता $0$ के करीब पहुंचती है, $\log$ नकारात्मक अनंत की ओर गिर जाता है, एक विशाल रबर-बैंड प्रभाव पैदा करता है जो मॉडल को खराब भविष्यवाणियों से हिंसक रूप से दूर खींचता है।
- $M_i$: $i$-वीं घटना मैट्रिक्स। यह उस विशिष्ट टक्कर में प्रत्येक बी-जेट जोड़ी के लिए सभी किनेमेटिक चर (जैसे गति और कोण) युक्त कच्चा डेटा इनपुट है।
- $y_i$: घटना $i$ में सत्य अतिरिक्त बी-जेट जोड़ी का सूचकांक। यह भौतिकी सिमुलेशन द्वारा प्रदान किया गया "ग्राउंड ट्रुथ" लेबल है।
- $g_{y_i}(M_i)$: सही बी-जेट जोड़ी के लिए न्यूरल नेटवर्क $g$ का कच्चा आउटपुट स्कोर (लॉजिट)। यह एक कच्चे आत्मविश्वास मीटर के रूप में कार्य करता है।
- $\exp(\dots)$: घातीय फ़ंक्शन। यह दो उद्देश्यों की पूर्ति करता है: यह सुनिश्चित करता है कि सभी स्कोर सख्ती से सकारात्मक हों, और यह उच्च और निम्न स्कोर के बीच के अंतर को बढ़ा देता है, जिससे नेटवर्क की प्राथमिकताएं अधिक निर्णायक हो जाती हैं।
- $\sum_{k=1}^{c_i} \exp(g_k(M_i))$: हर (denominator) घटना $i$ में सभी $c_i$ संभावित बी-जेट जोड़ियों के घातीय स्कोर का योग करता है। यहां गुणन के बजाय जोड़ का उपयोग क्यों करें? जोड़ कुल "संभाव्यता द्रव्यमान" को पूल करता है। यदि हम उन्हें गुणा करते, तो हम एक साथ होने वाली स्वतंत्र घटनाओं की संयुक्त संभाव्यता की गणना कर रहे होते। लेकिन ये जोड़ियां एकल सत्य संकेत के लिए परस्पर अनन्य उम्मीदवार हैं, इसलिए हमें एक सामान्यीकरण कारक बनाने के लिए उन्हें जोड़ना होगा।
- पूरा अंश: यह सॉफ्टमैक्स फ़ंक्शन है। यह कच्चे, असीमित स्कोर लेता है और उन्हें एक साफ संभाव्यता वितरण में निचोड़ता है जो ठीक $1$ तक जुड़ता है।
आइए इस समीकरण के माध्यम से गुजरने वाले एक एकल अमूर्त डेटा बिंदु के सटीक जीवनचक्र का पता लगाएं। कल्पना करें कि एक घटना मैट्रिक्स $M_i$ असेंबली लाइन में प्रवेश करती है जिसमें तीन संभावित बी-जेट जोड़ियां होती हैं।
सबसे पहले, न्यूरल नेटवर्क सभी तीन जोड़ियों के किनेमेटिक डेटा को संसाधित करता है और कच्चे स्कोर निकालता है: सही जोड़ी के लिए $2.0$, और गलत जोड़ियों के लिए $0.5$ और $-1.0$ ।
इसके बाद, $\exp$ फ़ंक्शन इन स्कोर को सुपरचार्ज करता है, उन्हें $7.39$, $1.65$, और $0.37$ में बदल देता है।
फिर, हर इन मानों को इकट्ठा करता है और कुल पूल $9.41$ प्राप्त करने के लिए उन्हें जोड़ता है।
अंश फिर सही जोड़ी के स्कोर को कुल पूल ($7.39 / 9.41$) से विभाजित करता है, जिसके परिणामस्वरूप लगभग $0.78$ की संभाव्यता होती है।
अंत में, $\log$ फ़ंक्शन इस $0.78$ का मूल्यांकन करता है। क्योंकि यह $1.0$ के अपेक्षाकृत करीब है, परिणामी दंड छोटा है। डेटा बिंदु ने सफलतापूर्वक इंजन से गुजर लिया है।
यह तंत्र वास्तव में कैसे सीखता है और अभिसरण करता है? अनुकूलन गतिशीलता सॉफ्टमैक्स अंश द्वारा बनाए गए लॉस परिदृश्य पर निर्भर करती है। क्योंकि सभी संभावनाओं का योग $1$ होना चाहिए, मॉडल को शून्य-योग खेल में मजबूर किया जाता है। हानि को कम करने के लिए, नेटवर्क केवल सही जोड़ी के स्कोर को ऊपर नहीं धकेल सकता; इसे एक साथ गलत जोड़ियों के सापेक्ष स्कोर को नीचे धकेलना चाहिए।
जैसे ही प्रशिक्षण के दौरान ग्रेडिएंट नेटवर्क के माध्यम से पीछे की ओर प्रवाहित होते हैं, वे वजन को समायोजित करते हैं ताकि उन सूक्ष्म किनेमेटिक हस्ताक्षरों (जैसे कोणीय दूरी और अपरिवर्तनीय द्रव्यमान) को पहचान सकें जो ग्लूऑन-स्प्लिटिंग बी-जेट्स को टॉप-क्वार्क बी-जेट्स से अलग करते हैं। लॉस परिदृश्य एक बहु-आयामी घाटी जैसा दिखता है जहां सबसे निचला बिंदु नेटवर्क के हर एकल घटना में सभी अन्य जोड़ियों से ऊपर सत्य बी-जेट जोड़ी को पूरी तरह से रैंक करने के अनुरूप है। ईमानदारी से कहूं तो, मुझे पूरी तरह से यकीन नहीं है कि आधुनिक ध्यान तंत्र के साथ नेटवर्क वास्तुकला को और अधिक अनुकूलित नहीं किया जा सकता है, लेकिन लेखकों ने यह शानदार ढंग से साबित करने के लिए एक मानक फीडफॉरवर्ड डिज़ाइन का पालन किया कि गणितीय उद्देश्य फ़ंक्शन को ठीक करना पुराने बाइनरी वर्गीकरण विधियों से काफी बेहतर प्रदर्शन करने के लिए पर्याप्त है।
परिणाम, सीमाएँ और निष्कर्ष
वृहद अन्वेषण: हिग्स बोसॉन के छिपने के स्थान का अनावरण
इस शोध पत्र के महत्व को समझने के लिए, हमें पहले कण भौतिकी के सबसे बड़े मंच, लार्ज हैड्रॉन कोलाइडर (LHC) पर ज़ूम आउट करना होगा। जब भौतिकविदों ने हिग्स बोसॉन की खोज की, तो यह एक ऐतिहासिक विजय थी। लेकिन इसकी खोज केवल पहला कदम था; दूसरा कदम इसके गुणों को मापना है ताकि यह सुनिश्चित हो सके कि यह कण भौतिकी के मानक मॉडल (Standard Model) की भविष्यवाणी के अनुसार ही व्यवहार करता है।
हिग्स बोसॉन दो बॉटम क्वार्क ($b\bar{b}$) के जोड़े में क्षय (decay) होना पसंद करता है। हिग्स का अध्ययन करने के सर्वोत्तम तरीकों में से एक तब है जब यह एक टॉप क्वार्क जोड़ी के साथ उत्पन्न होता है, जिसे $t\bar{t}H(b\bar{b})$ प्रक्रिया के रूप में जाना जाता है। हालांकि, ब्रह्मांड एक अव्यवस्थित स्थान है। एक "पृष्ठभूमि" (background) प्रक्रिया है जो हमारे कीमती हिग्स सिग्नल के समान दिखती है: $t\bar{t}b\bar{b}$ प्रक्रिया। यह पृष्ठभूमि प्रक्रिया एक टॉप क्वार्क जोड़ी और एक बॉटम क्वार्क जोड़ी उत्पन्न करती है, लेकिन बिना किसी हिग्स बोसॉन के। यदि हम इस $t\bar{t}b\bar{b}$ पृष्ठभूमि को पूरी तरह से समझ और फ़िल्टर नहीं कर सकते, तो हिग्स बोसॉन के हमारे माप हमेशा धुंधले रहेंगे।
मूल प्रेरणा और बाधाएँ
यहाँ मौलिक समस्या निहित है: एक $t\bar{t}b\bar{b}$ घटना में, दो अलग-अलग स्रोतों से $b$-जेट (बॉटम क्वार्क से उत्पन्न कणों की बौछारें) आती हैं। कुछ टॉप क्वार्क के क्षय से आती हैं, और कुछ "ग्लूऑन स्प्लिटिंग" (जहां एक ग्लूऑन दो अतिरिक्त $b$-क्वार्क में विभाजित हो जाता है) से आती हैं। पृष्ठभूमि को समझने के लिए, भौतिकविदों को टॉप क्वार्क से उत्पन्न $b$-जेट को ग्लूऑन स्प्लिटिंग से उत्पन्न अतिरिक्त $b$-जेट से अलग करने की सख्त आवश्यकता है।
बाधाएँ:
1. क्वांटम अराजकता (Quantum Chaos): इन जेटों के काइनेमेटिक गुण (संवेग, कोण, ऊर्जा) उच्च-आयामी, स्टोकेस्टिक क्वांटम प्रक्रियाओं द्वारा शासित होते हैं। कोई सरल, हार्ड-कोडेड नियम नहीं हैं (जैसे "यदि ऊर्जा > X, तो यह ग्लूऑन से है") जो काम करते हों।
2. संयोजन विस्फोट (Combinatorial Explosions): एक घटना आपको केवल दो स्पष्ट जेट नहीं देती है। यह आपको कणों का एक अव्यवस्थित समूह देती है। आपको जेटों के जोड़ों को देखना होगा और अनुमान लगाना होगा कि कौन सा जोड़ा "अतिरिक्त" है।
3. अतिव्यापी वितरण (Overlapping Distributions): यदि आप लाखों घटनाओं में सभी $b$-जेटों को देखते हैं, तो टॉप-डीके जेट और ग्लूऑन-स्प्लिटिंग जेट के गुण बड़े पैमाने पर अतिव्यापी होते हैं।
गणितीय व्याख्या: उन्होंने क्या हल किया?
"पीड़ित" (आधारभूत दृष्टिकोण):
पहले, वैज्ञानिकों ने इसे एक मानक बाइनरी वर्गीकरण समस्या के रूप में माना। उन्होंने सभी घटनाओं में $b$-जेट के प्रत्येक जोड़े को लिया, उन्हें एक डीप न्यूरल नेटवर्क (DNN) में डाला, और पूछा: "क्या यह जोड़ा अतिरिक्त $b$-जेट जोड़ा है? हाँ (1) या नहीं (0)?" उन्होंने इसे मानक बाइनरी क्रॉस-एंट्रॉपी ($L_{BCE}$) का उपयोग करके प्रशिक्षित किया:
$$ L_{BCE} = -\frac{1}{N_p} \sum_{i=1}^{N_p} \left( \xi_i \log f(x_i) + (1 - \xi_i) \log(1 - f(x_i)) \right) $$
त्रुटि: यह दृष्टिकोण गणितीय रूप से डेटा की संरचना के प्रति अंधा है। यह ब्रह्मांड में प्रत्येक जोड़े को स्वतंत्र मानता है। लेकिन वास्तव में, हम एक महत्वपूर्ण रहस्य जानते हैं: लगभग हर $t\bar{t}b\bar{b}$ घटना में ठीक ONE अतिरिक्त $b$-जेट जोड़े होते हैं।
शानदार समाधान:
लेखकों ने महसूस किया कि हमें यह नहीं पूछना चाहिए कि "क्या यह जोड़ा एक अतिरिक्त $b$-जेट है?" हमें एक एकल घटना को देखना चाहिए और पूछना चाहिए, "इस विशिष्ट घटना में सभी जोड़ों में से, कौन सा अतिरिक्त $b$-जेट होने की सबसे अधिक संभावना है?"
उन्होंने वैश्विक बाइनरी वर्गीकरण से घटना-स्तरीय रैंकिंग (या घटना के भीतर बहु-वर्ग वर्गीकरण) के प्रतिमान को स्थानांतरित कर दिया। उन्होंने एक घटना मैट्रिक्स $M_i \in \mathbb{R}^{c_i \times F}$ को परिभाषित किया, जहाँ $c_i$ घटना में $b$-जेट जोड़ों की संख्या है, और $F$ फ़ीचर आयाम है। फिर उन्होंने घटना के भीतर जोड़ों पर एक सॉफ्टमैक्स फ़ंक्शन लागू किया ताकि उनकी संभावनाओं का योग 1 हो:
$$ f_j(M_i) = \frac{\exp(g_j(M_i))}{\sum_{k=1}^{c_i} \exp(g_k(M_i))} $$
चूंकि अंतिम लक्ष्य "मिलान दक्षता" (उन घटनाओं का प्रतिशत जहां सही जोड़ा चुना गया है) को अधिकतम करना है, जो कि अवकलनीय (differentiable) नहीं है, उन्होंने चार सरोगेट लॉस फ़ंक्शन (surrogate loss functions) तैयार किए। सबसे वैचारिक रूप से सुंदर संभाव्य रैंकिंग लॉस ($L_2$) है, जो नेटवर्क को उस विशिष्ट घटना में किसी भी अन्य जोड़े की तुलना में सही अतिरिक्त जोड़े को उच्च स्कोर देने के लिए मजबूर करता है:
$$ L_2 = -\frac{1}{N} \sum_{i=1}^N \sum_{j \neq y_i} \log \left( \frac{f_{y_i}(M_i)}{f_{y_i}(M_i) + f_j(M_i)} \right) $$
उन्होंने एक श्रेणीबद्ध क्रॉस-एंट्रॉपी लॉस ($L_3$) का भी उपयोग किया, जिसमें सही जोड़े सूचकांक को सत्य वर्ग माना गया:
$$ L_3 = -\frac{1}{N} \sum_{i=1}^N \log f_{y_i}(M_i) $$
कठोर प्रयोगात्मक वास्तुकला और निर्णायक साक्ष्य
लेखकों ने केवल मेट्रिक्स को दीवार पर नहीं फेंका; उन्होंने अपने गणितीय दावों को कठोरता से साबित करने के लिए दो-चरणीय निष्पादन की वास्तुकला तैयार की।
चरण 1: सिंथेटिक जाल (अवधारणा का प्रमाण)
उन्होंने पहले एक 2D सिंथेटिक डेटासेट बनाया जो भौतिकी डेटा की अतिव्यापी प्रकृति की पूरी तरह से नकल करने के लिए डिज़ाइन किया गया था। उन्होंने ऐसी घटनाएँ बनाईं जहाँ "सिग्नल" और "पृष्ठभूमि" विश्व स्तर पर अतिव्यापी थे लेकिन एक घटना के भीतर स्थानीय रूप से विशिष्ट थे। बाइनरी क्लासिफायर (पीड़ित) बुरी तरह विफल रहा, एक मनमाना निर्णय सीमा खींची क्योंकि यह वैश्विक ओवरलैप से भ्रमित था। लेखकों के नए लॉस फ़ंक्शन ने 100% मिलान दक्षता हासिल की क्योंकि उन्होंने केवल उनके संबंधित घटनाओं के भीतर बिंदुओं की तुलना की। यह एक निर्दोष गणितीय चेकमेट था।
चरण 2: LHC सिमुलेशन
फिर उन्होंने एक भारी-भरकम भौतिकी पाइपलाइन का उपयोग करके $\sqrt{s} = 13$ TeV पर वास्तविक प्रोटॉन-प्रोटॉन टकरावों का अनुकरण किया: MadGraph5_aMC@NLO (घटना निर्माण) $\rightarrow$ Pythia (हैड्रॉनाइजेशन) $\rightarrow$ DELPHES (CMS डिटेक्टर सिमुलेशन)। यह वास्तविक LHC डेटा के जितना करीब हो सकता है, बिना कोलाइडर समय पर \$150 मिलियन खर्च किए।
निर्णायक साक्ष्य:
उन्होंने केवल "सटीकता में सुधार हुआ" नहीं कहा। उन्होंने साबित किया कि केवल लॉस फ़ंक्शन को बदलकर घटना संरचना का सम्मान करने के लिए, मिलान दक्षता निर्विवाद रूप से सुधर गई। लीडिंग ऑर्डर (LO) सिमुलेशन के लिए, दक्षता 62.1% ($L_{BCE}$ पीड़ित मॉडल का उपयोग करके) से बढ़कर 64.5% (उनके $L_3$ मॉडल का उपयोग करके) हो गई।
लेकिन सबसे निर्विवाद साक्ष्य दृश्य और भौतिक है: चित्र 3। उन्होंने पुनर्निर्मित भौतिक वितरणों को प्लॉट किया - विशेष रूप से कोणीय दूरी ($\Delta R$) और $b$-जेट जोड़ों के अपरिवर्तनीय द्रव्यमान (invariant mass)। उनके प्रस्तावित विधि द्वारा उत्पन्न हिस्टोग्राम बाइनरी वर्गीकरण दृष्टिकोण की तुलना में "सत्य सिग्नल" (जनरेटर-स्तरीय सत्य) को काफी कसकर गले लगाते हैं। उन्होंने साबित किया कि उनका AI केवल सांख्यिकीय शोर नहीं सीख रहा था; यह अंतर्निहित क्वांटम काइनेमेटिक्स को अधिक सटीकता से पुनर्प्राप्त कर रहा था।
प्रतिभाशाली दिमाग के लिए भविष्य की चर्चा के विषय
इस शोध पत्र के आधार पर, इस सीमा को और आगे बढ़ाने के लिए हमें कई रास्तों का पता लगाना चाहिए:
-
फीडफॉरवर्ड नेटवर्क से परे: ग्राफ न्यूरल नेटवर्क (GNNs) का युग
लेखकों ने एक डीप फीडफॉरवर्ड न्यूरल नेटवर्क का उपयोग किया जो जोड़ों को संसाधित करता है और फिर उन्हें एकत्रित करता है। हालांकि, एक घटना स्वाभाविक रूप से परस्पर क्रिया करने वाले कणों का एक ग्राफ है। यदि हम अटेंशन मैकेनिज्म या GNNs का उपयोग करके पूरे घटना को एक पूरी तरह से जुड़े ग्राफ के रूप में मॉडल करते हैं, जिससे नेटवर्क सभी जेटों के बीच संबंधपरक भौतिकी को एक साथ सीख सके, तो हम कितनी अधिक मिलान दक्षता प्राप्त कर सकते हैं? -
एंड-टू-एंड रॉ डिटेक्टर लर्निंग
वर्तमान में, यह विधि 78 पूर्व-गणना किए गए काइनेमेटिक चर (जैसे ट्रांसवर्स मोमेंटम, स्यूडोरैपिडिटी) पर निर्भर करती है। क्या होगा यदि हम मानव-इंजीनियर्ड सुविधाओं को पूरी तरह से बायपास कर दें? क्या हम CMS डिटेक्टर के पार्टिकल-फ्लो एल्गोरिथम से 3D पॉइंट-क्लाउड डेटा को सीधे 3D कन्वेन्शनल या पॉइंटनेट आर्किटेक्चर में फीड कर सकते हैं ताकि AI उन काइनेमेटिक इनवेरिएंट्स को खोज सके जिनके बारे में हमने सोचा भी नहीं है? -
वास्तविक कोलिजन डेटा के लिए डोमेन अनुकूलन
यह शोध पत्र मोंटे कार्लो सिमुलेशन (MadGraph/Pythia) पर बहुत अधिक निर्भर करता है। हालांकि, सिमुलेशन वास्तविक LHC डेटा की सटीक प्रतिकृति कभी नहीं होते हैं। हम अनसुपरवाइज्ड डोमेन अनुकूलन तकनीकों (जैसे ग्रेडिएंट रिवर्सल लेयर्स) को कैसे एकीकृत कर सकते हैं ताकि यह सुनिश्चित हो सके कि इस सिमुलेटेड वातावरण में देखी गई मिलान दक्षता लाभ आगामी हाई ल्यूमिनोसिटी LHC (HL-LHC) रन के वास्तविक, अव्यवस्थित डेटा में निर्दोष रूप से स्थानांतरित हो जाए?