Обучение для повышения эффективности сопоставления при идентификации дополнительных b-джетов в процессе
Чтобы по настоящему понять значимость данной работы, необходимо вернуться к монументальному открытию бозона Хиггса на Большом адронном коллайдере (LHC) в 2012 году.
Предыстория и академическая преемственность
Чтобы по-настоящему понять значимость данной работы, необходимо вернуться к монументальному открытию бозона Хиггса на Большом адронном коллайдере (LHC) в 2012 году. После того как физики обнаружили Хиггс, следующим неотложным вопросом стало: ведет ли он себя точно так, как предсказывают наши стандартные модели?
Чтобы ответить на этот вопрос, ученые изучают, как бозон Хиггса взаимодействует с самой тяжелой известной частицей — топ-кварком. В частности, они исследуют событие столкновения, называемое процессом $t\bar{t}H$, где пара топ-кварков ($t\bar{t}$) рождается вместе с бозоном Хиггса ($H$). Поскольку бозон Хиггса чаще всего распадается на пару боттом-кварков ($b\bar{b}$), конечные продукты, которые мы фактически детектируем в коллайдере, представляют собой сигнатуру $t\bar{t}b\bar{b}$.
Вот где начинается основная сложность. Вселенная естественным образом производит события $t\bar{t}b\bar{b}$ посредством стандартных, не связанных с Хиггсом физических процессов. Это не-Хиггсовское производство $t\bar{t}b\bar{b}$ действует как массивный фоновый шум. Чтобы обнаружить редкий Хиггсовский "сигнал", физики должны идеально понимать этот фон. Для этого им необходимо изучить конечные продукты и различить, какие боттом-кварки произошли от топ-кварков, а какие были "дополнительными" боттом-кварками, порожденными случайным квантовым событием, называемым расщеплением глюона.
Фундаментальное ограничение предыдущих подходов
До появления данной работы исследователи пытались решить эту проблему идентификации с помощью стандартного машинного обучения, в частности, бинарной классификации. Они брали каждую пару $b$-джетов в событии и задавали нейронной сети вопрос: "Является ли эта пара дополнительной? Да или Нет?"
Фундаментальная проблема здесь заключается в том, что этот подход полностью игнорирует физическую структуру данных. Почти в каждом событии столкновения присутствует ровно одна пара дополнительных $b$-джетов. Оценивая каждую пару в полной изоляции, предыдущие модели оптимизировали общую "точность пары", а не "точность события". Представьте, что вы оцениваете тест с множественным выбором, прося компьютер независимо угадать, правильно ли А, правильно ли В и правильно ли С, вместо того чтобы заставить его выбрать единственный лучший ответ из предложенных вариантов. Поскольку старые модели не рассматривали контекст всего события одновременно, их способность корректно идентифицировать единственную истинную пару на событие (метрика, называемая "эффективностью сопоставления") уперлась в жесткий потолок.
Разбор жаргона
Чтобы сделать это интуитивно понятным, давайте разберем некоторые высокоспециализированные термины, используемые в работе:
- $b$-джет: Когда боттом-кварк ($b$) рождается в результате столкновения частиц, он почти мгновенно распадается на конусообразный шлейф других частиц.
- Аналогия: Думайте о $b$-джете как об уникальном наборе следов грязи, оставленных невидимым животным. Мы не видим животное (кварк), но можем измерить следы (джет), чтобы выяснить, откуда оно пришло.
- Расщепление глюона: Квантовый процесс, при котором глюон (частица, переносящая сильное ядерное взаимодействие) спонтанно превращается в пару кварк-антикварк.
- Аналогия: Представьте, что одна фейерверковая ракета взлетает в небо и внезапно разрывается ровно на две отчетливые, ярко окрашенные искры.
- Неустранимый фон: Процесс фонового шума, который приводит к появлению тех же конечных детектируемых частиц, что и редкий сигнал, который вы на самом деле ищете.
- Аналогия: Попытка определить, был ли торт подслащен белым или коричневым сахаром, просто взглянув на готовый пирог. Конечный результат выглядит идентично, поэтому вам приходится искать невероятно тонкие подсказки в текстуре, чтобы их различить.
- Эффективность сопоставления: Процент от общего числа событий столкновений, в которых алгоритм успешно идентифицирует точно правильную пару дополнительных $b$-джетов, а не просто получает высокий средний балл по отдельным угадываниям.
- Аналогия: Метрика снайпера "один выстрел, одно попадание". Неважно, правильно ли вы идентифицировали 99 невинных зевак как "не цель"; важно, можете ли вы идеально выделить одну конкретную цель, скрытую в толпе.
Математическая проблема и решение
Авторы хотели напрямую максимизировать эффективность сопоставления. Математически это представлено функцией Кронекера:
$$ \text{Matching efficiency} = \frac{1}{N} \sum_{i=1}^{N} \delta(y_i, \hat{y}(M_i)) $$
Здесь $\delta(y_i, \hat{y}(M_i))$ равно $1$, если предсказание модели $\hat{y}$ точно совпадает с истинным индексом $y_i$, и $0$ в противном случае.
Математическая проблема заключается в том, что эта функция является "жестким шагом" (она мгновенно перескакивает с 0 на 1). В среде машинного обучения вы не можете обучать нейронную сеть на жестком шаге, потому что градиент (наклон, используемый для обновления весов сети) почти везде равен нулю. Вы не можете использовать исчисление для ее оптимизации.
Чтобы преодолеть это ограничение, авторы отказались от старой функции потерь бинарной кросс-энтропии ($L_{BCE}$) и разработали суррогатные функции потерь ($L_1, L_2, L_3, L_4$). Они преобразовали выход нейронной сети в распределение вероятностей по всем парам в данном событии с помощью функции softmax:
$$ f_j(M_i) = \frac{\exp(g_j(M_i))}{\sum_{k=1}^{c_i} \exp(g_k(M_i))} $$
Это уравнение заставляет модель рассматривать все $c_i$ пар в матрице события $M_i$ и присваивать им вероятности, сумма которых равна 1. Затем они обучают модель максимизировать вероятность, присвоенную правильной паре, используя суррогатную функцию потерь категориальной кросс-энтропии, такую как $L_3$:
$$ L_3 = - \frac{1}{N} \sum_{i=1}^{N} \log f_{y_i}(M_i) $$
Таким образом, модель учится ранжировать пары относительно друг друга в контексте конкретного события, напрямую оптимизируя эффективность сопоставления, не нарушая правил градиентного спуска.
Ключевые математические обозначения
| Обозначение | Тип | Описание |
|---|---|---|
| $N$ | Параметр | Общее количество симулированных выборок данных событий $t\bar{t}b\bar{b}$. |
| $c_i$ | Переменная | Общее количество пар $b$-джетов, присутствующих в $i$-м событии. |
| $F$ | Параметр | Размерность вектора признаков, представляющего одну пару $b$-джетов. |
| $M_i$ | Переменная | Матрица события для $i$-го события, содержащая все пары $b$-джетов, с размерностью $\mathbb{R}^{c_i \times F}$. |
| $y_i$ | Переменная | Истинный целочисленный индекс (от $1$ до $c_i$), указывающий на фактическую пару дополнительных $b$-джетов в $i$-м событии. |
| $\hat{y}(M_i)$ | Переменная | Предсказанный индекс пары дополнительных $b$-джетов, выдаваемый моделью. |
| $f_j(M_i)$ | Переменная | Предсказанная моделью вероятность того, что $j$-я пара $b$-джетов в событии $M_i$ является дополнительной парой. |
| $g_j(M_i)$ | Переменная | Сырое значение активации (оценка), вычисленное нейронной сетью для $j$-й пары $b$-джетов перед преобразованием в вероятность. |
| $L_{BCE}$ | Функция | Традиционная функция потерь бинарной кросс-энтропии, используемая предыдущими, ограниченными моделями. |
| $L_1, L_2, L_3, L_4$ | Функция | Предложенные суррогатные функции потерь, разработанные для гладкой аппроксимации и максимизации эффективности сопоставления. |
Определение задачи и ограничения
Чтобы понять масштаб проблемы, решаемой в данной статье, представьте, что вы пытаетесь расслышать очень тихий, специфический шепот на переполненном, шумном стадионе. В мире физики элементарных частиц этим шепотом является бозон Хиггса — фундаментальная частица, придающая массу всему во Вселенной. Однако, когда физики сталкивают протоны в Большом адронном коллайдере (БАК) для изучения бозона Хиггса, их заглушает огромное количество фонового шума.
Самый громкий шум исходит от физического процесса, называемого $t\bar{t}b\bar{b}$, который производит пару топ-кварков вместе с парой $b$-кварков ($b$). Обломки этого процесса выглядят почти идентично обломкам бозона Хиггса. Чтобы отфильтровать этот шум, физикам приходится анализировать получающиеся "b-джеты" (струи частиц) и выяснять их происхождение: появились ли эти b-джеты в результате распада тяжелых топ-кварков, или они просто возникли из вторичного процесса, называемого "расщеплением глюонов"?
Начальная точка и Целевое состояние
Входные данные (Текущее состояние):
Когда происходит столкновение частиц (событие), детекторы фиксируют кинематические свойства обломков. Авторы представляют эти данные математически в виде матрицы события $M_i \in \mathbb{R}^{c_i \times F}$. Здесь $c_i$ обозначает количество возможных пар b-джетов в одном событии столкновения, а $F$ — высокоразмерные физические характеристики (такие как импульс и энергия) каждой пары.
Выходные данные (Целевое состояние):
Желаемым конечным результатом является нейронная сеть, которая может проанализировать эту матрицу и указать ровно на одну конкретную строку, уверенно заявляя: "Эта конкретная пара b-джетов является дополнительной парой, образованной расщеплением глюонов".
Математический пробел:
Отсутствующим звеном является специализированный математический мост, который оценивает пары b-джетов относительно друг друга в пределах одного события. Нам нужно не просто знать, выглядит ли пара как дополнительный b-джет в изоляции; нам нужно, чтобы сеть ранжировала все пары в матрице $M_i$ и выдавала распределение вероятностей $f(M_i) \in [0, 1]^{c_i}$, где сумма вероятностей равна 1. Наивысшая вероятность указывает на правильную пару.
Болезненная дилемма
Предыдущие исследователи попали в классическую ловушку машинного обучения: они рассматривали эту задачу как стандартную задачу бинарной классификации. Они брали каждую пару b-джетов из каждого события, смешивали их вместе и просили нейронную сеть угадать "Да" или "Нет", используя стандартную функцию потерь бинарной перекрестной энтропии ($L_{BCE}$).
Это создало болезненный компромисс между вычислительным удобством и физической реальностью. Бинарная классификация математически проста для оптимизации, но она полностью игнорирует структурную реальность физики: почти каждое событие $t\bar{t}b\bar{b}$ содержит ровно одну истинную пару дополнительных b-джетов. Оценивая каждую пару в вакууме, предыдущие модели упускали жизненно важные контекстуальные подсказки.
Однако, если попытаться исправить это, отказавшись от бинарной классификации и напрямую оптимизируя то, что вас действительно волнует — "эффективность сопоставления", которая представляет собой процент событий, в которых модель выбирает абсолютно правильную пару — вы немедленно нарушаете математику. Вы вынуждены выбирать между моделью, которую легко обучать, но которая структурно ошибочна, или моделью, которая структурно точна, но математически невозможна для обучения.
Жесткие стены и ограничения
Что делает эту проблему настолько сложной для решения? Авторы столкнулись с несколькими массивными препятствиями:
1. Стена недифференцируемости (Математическое ограничение)
Конечная цель — максимизировать эффективность сопоставления, которая математически определяется как:
$$ \text{Matching efficiency} = \frac{1}{N} \sum_{i=1}^{N} \delta(y_i, \hat{y}(M_i)) $$
Здесь $\delta$ — дельта-функция Кронекера. Эта функция представляет собой жесткую, негибкую ступеньку: она равна 1, если предсказание модели $\hat{y}$ точно совпадает с истинной меткой $y_i$, и 0 в противном случае. В исчислении производная (градиент) плоской ступеньки равна нулю. Нейронные сети обучаются, следуя градиентам (градиентный спуск). Поскольку дельта-функция Кронекера сильно недифференцируема и возвращает нулевые градиенты почти везде, нейронная сеть остается совершенно слепой. Она не может учиться, потому что математика не предоставляет никакого направленного отклика о том, как улучшиться.
2. Переменные структуры данных (Вычислительное ограничение)
Каждое квантовое столкновение уникально хаотично. Одно событие может произвести 3 пары b-джетов, в то время как следующее — 6. Это означает, что входная матрица $M_i$ имеет постоянно меняющееся количество строк ($c_i$). Архитектура нейронной сети должна быть динамически гибкой, чтобы обрабатывать входные данные переменного размера без сбоев, а также быть инвариантной к перестановкам (то есть порядок, в котором пары b-джетов подаются в модель, не должен изменять основную логику модели).
3. Экстремальная квантовая сложность (Физическое ограничение)
Не существует простых, жестко закодированных физических правил для разделения этих джетов. Данные генерируются высокосложными, стохастическими квантовыми процессами. Ручное конструирование признаков практически невозможно. Кинематические наблюдаемые величины глубоко запутаны, что означает, что модель должна каким-то образом научиться распутывать высокоразмерные зависимости исключительно на основе симулированных данных, без каких-либо явных правил, созданных человеком, для ее направления.
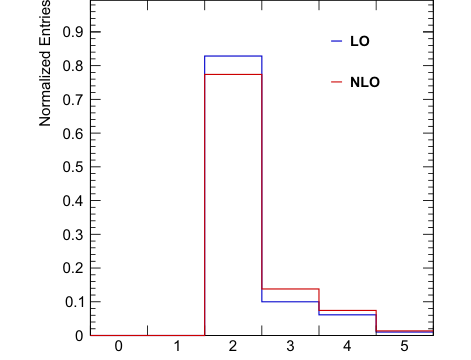 Figure 4. Histograms for the number of generator-level additional b-jets in simulated t¯tb¯b events at both the leading order (LO) and the next-to-leading order (NLO). Note that most events have two additional b-jets (82.8% for LO and 77.4% for NLO)
Figure 4. Histograms for the number of generator-level additional b-jets in simulated t¯tb¯b events at both the leading order (LO) and the next-to-leading order (NLO). Note that most events have two additional b-jets (82.8% for LO and 77.4% for NLO)
Почему данный подход
Чтобы понять, почему авторы выбрали именно этот математический подход, необходимо точно определить момент, когда они осознали фундаментальные недостатки предыдущего золотого стандарта. До публикации данной статьи, передовым (SOTA) методом идентификации дополнительных b-джетов в процессе $t\bar{t}b\bar{b}$ было использование глубокой нейронной сети (DNN) в качестве стандартного бинарного классификатора. Этот старый метод принимал каждую пару b-джетов, подавал ее в сеть и минимизировал функцию потерь бинарной кросс-энтропии ($L_{BCE}$), чтобы получить вероятность от 0 до 1.
Момент "Эврика!" для авторов наступил, когда они взглянули на физическую реальность данных столкновений частиц. Почти в каждом валидном событии $t\bar{t}b\bar{b}$ присутствует ровно одна пара дополнительных b-джетов, образующихся в результате расщепления глюона. Традиционный подход бинарной классификации полностью игнорирует это фундаментальное ограничение. Он рассматривает каждую пару b-джетов изолированно, задавая вопрос: "Является ли эта пара сигналом?", вместо того чтобы задать гораздо более релевантный вопрос: "Какая из пар в данном конкретном событии является сигналом?". Обрабатывая пары независимо, старая модель теряла жизненно важную контекстную информацию и оптимизировала бинарную точность, а не фактическую цель: эффективность сопоставления.
Это осознание сделало предложенную ими математическую модель единственным жизнеспособным решением. Вместо независимой классификации они сформулировали пермутационно-эквивариантную модель, которая обрабатывает матрицу всего события $M_i \in \mathbb{R}^{c_i \times F}$ (где $c_i$ — количество пар b-джетов в $i$-м событии, а $F$ — размерность признаков). Они применили функцию softmax к выходам для всех пар в пределах одного события:
$$ f_j(M_i) = \frac{\exp(g_j(M_i))}{\sum_{k=1}^{c_i} \exp(g_k(M_i))} $$
Это гарантирует, что суммы вероятностей по всем парам в одном событии равны единице ($\sum_{j=1}^{c_i} f_j(M_i) = 1$).
Сравнительное превосходство этого метода наглядно продемонстрировано в их экспериментах с синтетическими данными в качестве доказательства концепции. В высокоразмерном пространстве со стохастическими генеративными процессами фоновый шум часто перекрывается с сигналом при глобальном рассмотрении. Традиционный бинарный классификатор пытается провести одну, глобальную границу принятия решений по всем точкам данных из всех событий, что приводит к произвольному и крайне неточному разделению из-за этого перекрытия. В отличие от этого, метод авторов оценивает пары относительно друг друга в пределах одной и той же матрицы события. Делая это, он эффективно обходит глобальное перекрытие шума, изучая четкую, относительную границу принятия решений, которая идеально выделяет сигнал. Это не обязательно уменьшает сложность памяти с $O(N^2)$ до $O(N)$, но значительно снижает вычислительную путаницу, ограничивая пространство сравнения границами одного события.
Этот выбранный метод идеально соответствует жестким ограничениям задачи. Конечная цель — максимизировать эффективность сопоставления, определяемую математически с использованием функции дельта Кронекера:
$$ \text{Matching efficiency} = \frac{1}{N} \sum_{i=1}^{N} \delta(y_i, \hat{y}(M_i)) $$
Поскольку эта ступенчатая функция сильно негладкая и недифференцируемая (возвращает нулевые градиенты), ее нельзя оптимизировать напрямую с помощью градиентного спуска. "Связь" между ограничениями задачи и решением заключается в продуманной авторами разработке суррогатных функций потерь. Рассматривая индексы строк матрицы события как отличительные категории, они преобразовали задачу в задачу многоклассовой классификации или ранжирования. Например, их функция потерь вероятностного ранжирования ($L_2$) и функция потерь категориальной кросс-энтропии ($L_3$) напрямую штрафуют сеть, если истинная пара дополнительных b-джетов не получает наивысший относительный балл в своей специфической структуре события.
Честно говоря, я не до конца уверен, как поведут себя модные генеративные модели, такие как GAN, стандартные Diffusion или Трансформеры, поскольку авторы вообще не упоминают их и не подразумевают в тексте. Я подозреваю, что применение модели GAN или Diffusion было бы чрезмерным и вычислительно расточительным для того, что по сути является сильно ограниченной комбинаторной задачей ранжирования. Однако авторы явно объясняют причины отказа от наиболее популярной альтернативы — DNN бинарной классификации. Они отказались от нее, потому что оптимизация $L_{BCE}$ математически не соответствует физической цели. Даже когда они усовершенствовали бинарный классификатор, включив в него признаки других b-джетов в событии (их "Модель 2"), он все равно не достиг уровня их предложенных суррогатных функций потерь ($L_2$ и $L_3$). Бинарный подход просто не может гарантировать, что пара с наивысшим баллом в событии является правильной, поскольку во время обучения она никогда не была математически вынуждена сравниваться бок о бок.
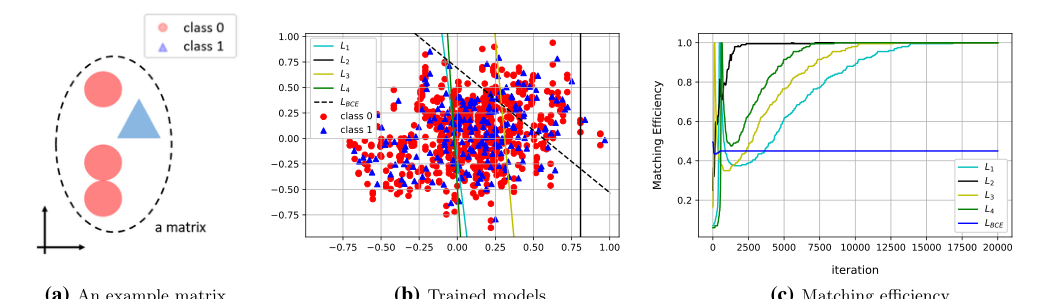 Figure 2. Experimental results from synthetic data. (a) An example matrix is illustrated. (b) The level sets of the trained models are drawn over the data scatter plot. (c) Matching efficiencies (evaluated on a test data set) for each of the loss functions are shown
Figure 2. Experimental results from synthetic data. (a) An example matrix is illustrated. (b) The level sets of the trained models are drawn over the data scatter plot. (c) Matching efficiencies (evaluated on a test data set) for each of the loss functions are shown
Математический и логический механизм
Представьте, что вы находитесь в центре управления Большого адронного коллайдера (БАК). Каждый раз, когда происходит столкновение, частицы разлетаются со скоростью, близкой к скорости света, создавая потоки субатомных обломков, называемых "джетами". Физики отчаянно ищут свойства бозона Хиггса, который часто распадается на определенный тип обломков, называемых "b-джетами".
Однако существует огромная проблема: совершенно другой, фоновый процесс с высоким уровнем шума, называемый $t\bar{t}b\bar{b}$ (пара топ-кварков и пара b-кварков), производит точно такие же b-джеты. Чтобы отфильтровать этот шум, физики должны выяснить, какие b-джеты произошли от основного события (распада топ-кварка), а какие были просто дополнительными обломками (происходящими от явления, называемого расщеплением глюонов).
Ранее ученые использовали машинное обучение для анализа каждой пары b-джетов в отдельности, задавая простой вопрос "да/нет": "Являетесь ли вы дополнительными обломками?". Этот подход бинарной классификации был ошибочным, поскольку он игнорировал фундаментальное правило физики: почти в каждом допустимом событии существует ровно одна пара дополнительных b-джетов. Обрабатывая каждую пару независимо, старые модели упускали ценную контекстную информацию.
Авторы данной статьи решили эту проблему, изменив парадигму. Вместо того чтобы спрашивать: "Является ли эта пара дополнительными обломками?", они разработали нейронную сеть, которая одновременно анализирует все пары в одном событии и задает вопрос: "Кто из вас является наиболее вероятным кандидатом?". Они достигли этого, отказавшись от стандартной бинарной точности и разработав пользовательские функции потерь для прямого максимизации "эффективности соответствия" — скорости, с которой модель выбирает единственную правильную пару из множества.
Вот основная математическая основа, которая лежит в основе их самой успешной модели, объединяющая их распределение вероятностей на уровне событий (Softmax) с суррогатной функцией потерь Категориальной кросс-энтропии:
$$ L_3 = -\frac{1}{N} \sum_{i=1}^N \log \left( \frac{\exp(g_{y_i}(M_i))}{\sum_{k=1}^{c_i} \exp(g_k(M_i))} \right) $$
Разберем это уравнение по частям, чтобы понять, как оно работает:
- $L_3$: Это суррогатная функция потерь. Она действует как окончательный сигнал ошибки, сообщая нейронной сети, насколько сильно она ошиблась. Цель процесса обучения — минимизировать это число.
- $-\frac{1}{N} \sum_{i=1}^N$: Это вычисляет среднюю ошибку по всем $N$ событиям в наборе данных. Почему суммирование, а не интеграл? Потому что количество событий столкновений $N$ строго дискретно и счетно. Нельзя иметь долю столкновения, поэтому интегрирование по непрерывному пространству не имело бы физического или логического смысла.
- $\log$: Натуральный логарифм. Его логическая роль заключается в том, чтобы сильно наказывать модель, когда она уверена в своей ошибке. Если модель присваивает вероятность, близкую к $1$, правильной паре, логарифм $1$ равен $0$ (нет штрафа). Но по мере приближения вероятности к $0$, логарифм стремится к минус бесконечности, создавая мощный эффект "резиновой ленты", который резко оттягивает модель от ошибочных предсказаний.
- $M_i$: $i$-я матрица события. Это входные необработанные данные, содержащие все кинематические переменные (такие как импульс и углы) для каждой пары b-джетов в данном конкретном столкновении.
- $y_i$: Индекс истинной дополнительной пары b-джетов в событии $i$. Это метка "ground truth", предоставленная физическим моделированием.
- $g_{y_i}(M_i)$: Необработанный выходной счет (логит) нейронной сети $g$ для правильной пары b-джетов. Он действует как индикатор необработанной уверенности.
- $\exp(\dots)$: Экспоненциальная функция. Она выполняет две функции: обеспечивает строго положительное значение всех счетов и преувеличивает различия между высокими и низкими счетами, делая предпочтения сети более решительными.
- $\sum_{k=1}^{c_i} \exp(g_k(M_i))$: Знаменатель суммирует экспоненцированные счета всех $c_i$ возможных пар b-джетов в событии $i$. Почему здесь используется сложение, а не умножение? Сложение объединяет общую "массу вероятности" события. Если бы мы их перемножили, мы бы вычисляли совместную вероятность одновременного возникновения независимых событий. Но эти пары являются взаимоисключающими кандидатами на единственный истинный сигнал, поэтому мы должны их сложить, чтобы создать нормализующий множитель.
- Дробь в целом: Это функция Softmax. Она берет необработанные, неограниченные счета и сжимает их в аккуратное распределение вероятностей, сумма которого точно равна $1$.
Проследим точный жизненный цикл одной абстрактной точки данных, проходящей через это уравнение. Представьте, что матрица события $M_i$ поступает на конвейер, содержащий три возможные пары b-джетов.
Сначала нейронная сеть обрабатывает кинематические данные всех трех пар и выдает необработанные счета: $2.0$ для правильной пары, и $0.5$ и $-1.0$ для неправильных пар.
Затем функция $\exp$ усиливает эти счета, превращая их в $7.39$, $1.65$ и $0.37$.
Затем знаменатель собирает эти значения и суммирует их, получая общий пул $9.41$.
Затем дробь делит счет правильной пары на общий пул ($7.39 / 9.41$), что приводит к вероятности примерно $0.78$.
Наконец, функция $\log$ оценивает это $0.78$. Поскольку оно относительно близко к $1.0$, результирующий штраф невелик. Точка данных успешно прошла через движок.
Как этот механизм фактически учится и сходится? Динамика оптимизации зависит от ландшафта потерь, создаваемого дробью Softmax. Поскольку все вероятности должны суммироваться до $1$, модель вынуждена участвовать в игре с нулевой суммой. Чтобы минимизировать потери, сеть не может просто повысить счет правильной пары; она должна одновременно понизить относительные счета неправильных пар.
По мере того как градиенты проходят обратно через сеть во время обучения, они корректируют веса, чтобы распознавать тонкие кинематические сигнатуры (такие как угловое расстояние и инвариантная масса), которые отличают b-джеты от расщепления глюонов от b-джетов от распада топ-кварка. Ландшафт потерь имеет форму многомерной долины, где самая низкая точка соответствует идеальному ранжированию сетью истинной пары b-джетов выше всех остальных в каждом отдельном событии. Честно говоря, я не до конца уверен, что сама архитектура сети не могла бы быть дополнительно оптимизирована с помощью современных механизмов внимания, но авторы придерживались стандартной прямой архитектуры, чтобы блестяще доказать, что простое исправление математической целевой функции достаточно для значительного превосходства над старыми методами бинарной классификации.
Результаты, Ограничения и Заключение
Великий Поиск: Раскрытие Места Скрытия Бозона Хиггса
Чтобы понять значимость данной работы, мы должны сначала взглянуть на самую грандиозную арену физики элементарных частиц: Большой адронный коллайдер (БАК). Открытие бозона Хиггса стало монументальным триумфом. Однако его обнаружение было лишь первым шагом; второй шаг заключается в измерении его свойств, чтобы убедиться, что он ведет себя точно так, как предсказывает Стандартная модель физики элементарных частиц.
Бозон Хиггса охотно распадается на пару боттом-кварков ($b\bar{b}$). Один из лучших способов изучения Хиггса — это когда он рождается вместе с парой топ-кварков, процесс, известный как $t\bar{t}H(b\bar{b})$. Однако Вселенная — это хаотичное место. Существует "фоновый" процесс, который выглядит почти идентично нашему драгоценному сигналу Хиггса: процесс $t\bar{t}b\bar{b}$. Этот фоновый процесс порождает пару топ-кварков и пару боттом-кварков, но без какого-либо участия бозона Хиггса. Если мы не сможем идеально понять и отфильтровать этот фон $t\bar{t}b\bar{b}$, наши измерения бозона Хиггса будут навсегда размыты.
Основная Мотивация и Ограничения
Здесь кроется фундаментальная проблема: в событии $t\bar{t}b\bar{b}$ у вас есть $b$-джеты (струи частиц, исходящие из боттом-кварков), происходящие из двух разных источников. Некоторые исходят из распада топ-кварков, а некоторые — из "расщепления глюона" (когда глюон распадается на два дополнительных $b$-кварка). Чтобы понять фон, физики отчаянно нуждаются в возможности отличить $b$-джеты, рожденные топ-кварками, от дополнительных $b$-джетов, рожденных расщеплением глюона.
Ограничения:
1. Квантовый Хаос: Кинематические свойства (импульс, углы, энергия) этих джетов определяются высокоразмерными стохастическими квантовыми процессами. Нет простых, жестко закодированных правил (вроде "если энергия > X, то она от глюона"), которые бы работали.
2. Комбинаторный Взрыв: Событие не просто выдает вам два аккуратных джета. Оно выдает вам мешанину частиц. Вам приходится рассматривать пары джетов и угадывать, какая пара является "дополнительной".
3. Перекрывающиеся Распределения: Если вы посмотрите на все $b$-джеты в миллионах событий, свойства джетов от распада топ-кварков и джетов от расщепления глюона сильно перекрываются.
Математическая Интерпретация: Что Было Решено?
"Жертва" (Базовый Подход):
Ранее ученые рассматривали эту задачу как стандартную задачу бинарной классификации. Они брали каждую пару $b$-джетов во всех событиях, пропускали их через глубокую нейронную сеть (DNN) и спрашивали: "Является ли эта пара дополнительным $b$-джетом? Да (1) или Нет (0)?" Они обучали эту сеть, используя стандартную бинарную кросс-энтропию ($L_{BCE}$):
$$ L_{BCE} = -\frac{1}{N_p} \sum_{i=1}^{N_p} \left( \xi_i \log f(x_i) + (1 - \xi_i) \log(1 - f(x_i)) \right) $$
Недостаток: Этот подход математически игнорирует структуру данных. Он рассматривает каждую пару во Вселенной как независимую. Но на самом деле мы знаем критически важный секрет: почти каждое событие $t\bar{t}b\bar{b}$ содержит ровно ОДНУ пару дополнительных $b$-джетов.
Блестящее Решение:
Авторы осознали, что мы не должны спрашивать: "Является ли эта пара дополнительным $b$-джетом?" Мы должны рассматривать одно событие и спрашивать: "Из всех пар в этом конкретном событии, какая из них с наибольшей вероятностью является дополнительным $b$-джетом?"
Они сместили парадигму с глобальной бинарной классификации на ранжирование на уровне событий (или многоклассовую классификацию внутри события). Они определили матрицу события $M_i \in \mathbb{R}^{c_i \times F}$, где $c_i$ — количество пар $b$-джетов в событии, а $F$ — размерность признаков. Затем они применили функцию softmax по парам внутри события, чтобы их вероятности суммировались к 1:
$$ f_j(M_i) = \frac{\exp(g_j(M_i))}{\sum_{k=1}^{c_i} \exp(g_k(M_i))} $$
Поскольку конечная цель — максимизировать "эффективность соответствия" (процент событий, где выбрана правильная пара), что является недифференцируемым, они разработали четыре суррогатные функции потерь. Наиболее концептуально красивой является вероятностная функция ранжирования ($L_2$), которая заставляет сеть присваивать более высокую оценку истинной дополнительной паре, чем любой другой паре в этом конкретном событии:
$$ L_2 = -\frac{1}{N} \sum_{i=1}^N \sum_{j \neq y_i} \log \left( \frac{f_{y_i}(M_i)}{f_{y_i}(M_i) + f_j(M_i)} \right) $$
Они также использовали функцию потерь категориальной кросс-энтропии ($L_3$), рассматривая индекс правильной пары как истинный класс:
$$ L_3 = -\frac{1}{N} \sum_{i=1}^N \log f_{y_i}(M_i) $$
Жестокая Экспериментальная Архитектура и Окончательные Доказательства
Авторы не просто бросили метрики на стену; они спроектировали двухэтапную реализацию, чтобы безжалостно доказать свои математические утверждения.
Этап 1: Синтетическая Ловушка (Доказательство Концепции)
Сначала они построили 2D синтетический набор данных, разработанный для идеального имитирования перекрывающейся природы физических данных. Они создали события, где "сигнал" и "фон" перекрывались глобально, но были различимы локально внутри события. Бинарный классификатор (жертва) потерпел сокрушительное поражение, проведя произвольную границу решения, поскольку он был сбит с толку глобальным перекрытием. Новые функции потерь авторов достигли 100% эффективности соответствия, поскольку они сравнивали точки только внутри их соответствующих событий. Это был безупречный математический шах и мат.
Этап 2: Симуляция БАК
Затем они смоделировали реальные протон-протонные столкновения при $\sqrt{s} = 13$ ТэВ, используя мощный физический конвейер: MadGraph5_aMC@NLO (генерация событий) $\rightarrow$ Pythia (адронизация) $\rightarrow$ DELPHES (симуляция детектора CMS). Это максимально приближено к реальным данным БАК, не тратя 150 миллионов долларов на время коллайдера.
Окончательные Доказательства:
Они не просто заявили об "улучшении точности". Они доказали, что, изменив только функцию потерь, чтобы она учитывала структуру событий, эффективность соответствия улучшилась неоспоримо. Для симуляций Ведущего Порядка (LO) эффективность подскочила с 62,1% (используя модель-жертву $L_{BCE}$) до 64,5% (используя их модель $L_3$).
Но самое неоспоримое доказательство является визуальным и физическим: Рисунок 3. Они построили реконструированные физические распределения — в частности, угловое расстояние ($\Delta R$) и инвариантную массу пар $b$-джетов. Гистограммы, сгенерированные их предложенным методом, значительно плотнее прилегали к "Истинному Сигналу" (правда на уровне генератора), чем подход бинарной классификации. Они доказали, что их ИИ не просто обучался статистическому шуму; он точнее восстанавливал лежащую в основе квантовую кинематику.
Будущие Темы Обсуждения для Блестящего Ума
Основываясь на данной работе, вот несколько направлений, которые мы должны исследовать, чтобы продвинуть эту границу дальше:
-
За Пределами Прямоходных Сетей: Эра Графовых Нейронных Сетей (GNN)
Авторы использовали глубокую прямоходную нейронную сеть, которая обрабатывает пары, а затем агрегирует их. Однако событие по своей сути является графом взаимодействующих частиц. Насколько большей эффективности соответствия мы могли бы достичь, если бы смоделировали все событие как полностью связанный граф, используя механизмы внимания или GNN, позволяя сети одновременно изучать реляционную физику между всеми джетами? -
Сквозное Обучение на Сырых Данных Детектора
В настоящее время этот метод опирается на 78 предварительно рассчитанных кинематических переменных (таких как поперечный импульс, псевдобыстрота). Что, если бы мы полностью отказались от признаков, разработанных человеком? Могли бы мы подавать сырые 3D данные облака точек из алгоритма particle-flow детектора CMS напрямую в 3D сверточную архитектуру или PointNet, чтобы ИИ самостоятельно обнаружил кинематические инварианты, о которых мы даже не думали? -
Адаптация Домена для Реальных Данных Столкновений
Данная работа в значительной степени опирается на симуляции Монте-Карло (MadGraph/Pythia). Однако симуляции никогда не являются идеальными копиями реальных данных БАК. Как мы можем интегрировать методы неконтролируемой адаптации домена (например, слои обратного градиента) для обеспечения того, чтобы прирост эффективности соответствия, наблюдаемый в этой симулированной среде, безупречно переносился на фактические, хаотичные данные предстоящих запусков High Luminosity LHC (HL-LHC)?