bジェット追加識別におけるマッチング効率向上のための学習
To truly understand the significance of this paper, we have to travel back to the monumental discovery of the Higgs boson at the Large Hadron Collider (LHC) in 2012.
背景と学術的系譜
この論文の意義を真に理解するためには、2012年に大型ハドロン衝突型加速器(LHC)でなされたヒッグス粒子の記念碑的な発見まで遡る必要がある。物理学者がヒッグス粒子を発見した後、次に直ちに生じた疑問は、「それは我々の標準模型が予測する通りに振る舞うのか?」ということであった。
この問いに答えるため、科学者たちはヒッグス粒子が既知の最も重い粒子であるトップクォークとどのように相互作用するかを調べる。彼らは特に、$t\bar{t}H$プロセスと呼ばれる衝突イベントを研究する。これは、トップクォークのペア($t\bar{t}$)がヒッグス粒子($H$)と同時に生成されるものである。ヒッグス粒子は最も頻繁にボトムクォークのペア($b\bar{b}$)に崩壊するため、加速器で実際に検出される最終的な残骸は、$t\bar{t}b\bar{b}$シグネチャとなる。
ここで、巨大な頭痛の種が始まる。宇宙は、標準的な非ヒッグス物理プロセスを通じて、$t\bar{t}b\bar{b}$イベントを自然に生成する。この非ヒッグスによる$t\bar{t}b\bar{b}$生成は、巨大なバックグラウンドノイズとして機能する。稀なヒッグス「シグナル」を見つけるためには、物理学者はこのバックグラウンドを完全に理解する必要がある。そのためには、最終的な残骸を調べ、どのボトムクォークがトップクォークから来たもので、どのボトムクォークがグルーオンスプリッティングと呼ばれるランダムな量子イベントによって生成された「追加の」ボトムクォークであるかを識別する必要がある。
過去のアプローチにおける根本的な限界
本論文以前は、研究者たちは標準的な機械学習、特に二項分類を用いてこの識別問題を解決しようとしていた。彼らはイベント内の全ての$b$-ジェットのペアを取り出し、ニューラルネットワークに「このペアは追加のペアか? はいかいいえか?」と問いかけていた。
ここでの根本的な問題点は、このアプローチがデータの物理的構造を完全に無視していることである。ほとんど全ての衝突イベントにおいて、追加の$b$-ジェットのペアはちょうど一つ存在する。各ペアを完全に孤立して評価することにより、過去のモデルは「イベントの精度」ではなく、全体的な「ペアの精度」を最適化していた。これは、選択肢の中から唯一最良の答えを選ばせるのではなく、コンピュータにAが正しいか、Bが正しいか、Cが正しいかを独立に推測させることで、多肢選択問題を採点するようなものである。古いモデルはイベント全体の文脈を同時に見ていなかったため、イベントあたりの唯一の真のペアを正しく識別する能力(「マッチング効率」と呼ばれる指標)は、硬い天井に突き当たっていた。
専門用語の解説
これを直感的に理解するために、論文で使用されている高度に専門的な用語をいくつか分解してみよう。
- $b$-jet: ボトム($b$)クォークが粒子衝突で生成されると、それはほぼ瞬時に他の粒子の円錐状の噴霧に崩壊する。
- アナロジー: $b$-jetを、見えない動物が残したユニークな泥の足跡のセットと考えてほしい。動物(クォーク)は見えないが、足跡(ジェット)を測定することで、それがどこから来たのかを突き止めることができる。
- グルーオンスプリッティング: グラトン(強い核力を伝える粒子)が自発的にクォークと反クォークのペアに変換される量子プロセス。
- アナロジー: 空中に打ち上げられた一本の花火の殻が、突然、正確に二つの異なる、鮮やかな色の火花に爆発するのを想像してほしい。
- 還元不可能なバックグラウンド (Irreducible background): 実際に探している稀なシグナルと全く同じ最終的な検出可能な粒子をもたらすバックグラウンドノイズプロセス。
- アナロジー: 焼き上がった最終的なケーキを見ただけで、ケーキが白砂糖で甘くされたのか、黒砂糖で甘くされたのかを区別しようとするようなものだ。最終的な結果は同一に見えるため、区別するためにはテクスチャの信じられないほど微妙な手がかりを探す必要がある。
- マッチング効率 (Matching efficiency): アルゴリズムが、個々の推測で高い平均スコアを得るだけでなく、追加の$b$-ジェットの正確な正しいペアを特定することに成功した衝突イベントの割合。
- アナロジー: スナイパーの「一発必中」の指標だ。99人の無関係な傍観者を「標的ではない」と正しく識別したかどうかは重要ではない。重要なのは、群衆の中に隠された一つの特定の標的を完璧に選び出すことができるかどうかだ。
数学的な問題と解決策
著者たちは、マッチング効率を直接最大化することを望んだ。数学的には、これはクロネッカーのデルタ関数で表される。
$$ \text{Matching efficiency} = \frac{1}{N} \sum_{i=1}^{N} \delta(y_i, \hat{y}(M_i)) $$
ここで、$\delta(y_i, \hat{y}(M_i))$は、モデルの予測$\hat{y}$が真のインデックス$y_i$と完全に一致する場合に1、そうでない場合に0となる。
この関数の数学的な問題は、「ハードステップ」(0から1へ即座にジャンプする)であることだ。機械学習環境では、ハードステップ上でニューラルネットワークを訓練することはできない。なぜなら、勾配(ネットワークの重みを更新するために使用される傾き)はほとんど全ての場所でゼロになるからだ。微積分を使ってそれを最適化することはできない。
この制約を克服するために、著者たちは従来の二項クロスエントロピー損失($L_{BCE}$)を放棄し、代理損失関数($L_1, L_2, L_3, L_4$)を設計した。彼らはニューラルネットワークの出力を、ソフトマックス関数を用いて、与えられたイベント内の全てのペアに対する確率分布に変換した。
$$ f_j(M_i) = \frac{\exp(g_j(M_i))}{\sum_{k=1}^{c_i} \exp(g_k(M_i))} $$
この方程式は、モデルにイベント行列$M_i$内の全ての$c_i$ペアを調べさせ、それらに合計が1になる確率を割り当てることを強制する。その後、彼らはカテゴリカルクロスエントロピー代理損失、例えば$L_3$を用いて、正しいペアに割り当てられた確率を最大化するようにモデルを訓練する。
$$ L_3 = - \frac{1}{N} \sum_{i=1}^{N} \log f_{y_i}(M_i) $$
これにより、モデルは特定のイベントの文脈内でペア同士をランク付けすることを学習し、勾配降下の規則を破ることなく、マッチング効率に直接最適化される。
主要な数学的記法
| 記法 | タイプ | 説明 |
|---|---|---|
| $N$ | パラメータ | シミュレートされた$t\bar{t}b\bar{b}$イベントデータサンプルの総数。 |
| $c_i$ | 変数 | $i$番目のイベントに存在する$b$-ジェットペアの総数。 |
| $F$ | パラメータ | 単一の$b$-ジェットペアを表す特徴ベクトルの次元。 |
| $M_i$ | 変数 | $i$番目のイベントのイベント行列。全ての$b$-ジェットペアを含み、次元は$\mathbb{R}^{c_i \times F}$。 |
| $y_i$ | 変数 | $i$番目のイベントにおける追加の$b$-ジェットペアの実際のペアを示す真の整数インデックス(1から$c_i$まで)。 |
| $\hat{y}(M_i)$ | 変数 | モデルが出力する追加の$b$-ジェットペアの予測インデックス。 |
| $f_j(M_i)$ | 変数 | $M_i$イベントにおける$j$番目の$b$-ジェットペアが追加のペアであるというモデルの予測確率。 |
| $g_j(M_i)$ | 変数 | ニューラルネットワークが$j$番目の$b$-ジェットペアに対して計算した生の活性化値(スコア)。確率に変換される前のものである。 |
| $L_{BCE}$ | 関数 | 過去の限定的なモデルによって使用された従来の二項クロスエントロピー損失。 |
| $L_1, L_2, L_3, L_4$ | 関数 | マッチング効率を滑らかに近似し、最大化するように設計された提案された代理損失関数。 |
問題定義と制約
この論文が取り組む問題の規模を理解するために、混雑した騒がしいスタジアムで、非常に微弱で特定のささやき声を聞き取ろうとしている状況を想像してほしい。素粒子物理学の世界では、そのささやき声こそがヒッグス粒子であり、宇宙のあらゆるものに質量を与える基本的な粒子である。しかし、物理学者がヒッグス粒子を研究するために大型ハドロン衝突型加速器(LHC)で陽子同士を衝突させると、膨大な量のバックグラウンドノイズに耳を塞がれることになる。
最も大きなノイズは、$t\bar{t}b\bar{b}$と呼ばれる物理プロセスから生じ、これはトップクォークのペアとともにボトムクォーク($b$)のペアを生成する。このプロセスから生じる破片は、ヒッグス粒子の破片とほとんど見分けがつかない。このノイズをフィルタリングするために、物理学者は生成された「bジェット」(粒子の噴流)を調べ、その起源を特定しなければならない。これらのbジェットは重いトップクォークの崩壊から生じたのか、それとも「グルーオンスプリッティング」と呼ばれる二次プロセスから単に発生したのか?
開始点と目標状態
入力(現在の状態):
粒子衝突(「イベント」)が発生すると、検出器はその破片の運動学的特性を捉える。著者らはこのデータを数学的にイベント行列 $M_i \in \mathbb{R}^{c_i \times F}$ として表現する。ここで、$c_i$は単一の衝突イベントにおける可能なbジェットペアの数、$F$は各ペアの高次元物理的特徴(運動量やエネルギーなど)を表す。
出力(目標状態):
望ましい最終状態は、この行列を見て、正確に1つの特定の行を指し示し、「この特定のbジェットペアはグルーオンスプリッティングによって生成された追加のペアである」と自信を持って宣言できるニューラルネットワークである。
数学的なギャップ:
欠けているのは、同じイベント内でbジェットペアを互いに相対的に評価する特殊な数学的ブリッジである。単にペアが単独で追加のbジェットのように見えるかどうかを知りたいだけではない。ネットワークには、行列 $M_i$ のすべてのペアをランク付けし、確率が合計で1になるような確率分布 $f(M_i) \in [0, 1]^{c_i}$ を出力してほしい。最も高い確率が正しいペアを示す。
苦痛なジレンマ
以前の研究者たちは、古典的な機械学習の落とし穴に陥った。彼らはこれを標準的な二項分類問題として扱った。彼らはすべてのイベントからすべてのbジェットペアを取り出し、それらをすべて混ぜ合わせ、標準的な二項クロスエントロピー損失関数($L_{BCE}$)を使用してニューラルネットワークに「はい」か「いいえ」かを推測させた。
これは、計算上の利便性と物理的現実の間に苦痛なトレードオフを生み出した。二項分類は数学的に最適化しやすいが、物理学の構造的現実を完全に無視している。ほとんどすべての $t\bar{t}b\bar{b}$ イベントには、正確に1つの追加のbジェットペアが含まれている。各ペアを孤立して評価することで、以前のモデルは重要な文脈上の手がかりを捨ててしまっていた。
しかし、二項分類を放棄し、実際に気にかけていること、つまり「マッチング効率」(モデルが正確に正しいペアを選択したイベントの総数の割合)を直接最適化しようとすると、すぐに数学が破綻する。訓練しやすいが構造的に欠陥のあるモデルか、構造的に正確だが数学的に訓練不可能なモデルかのどちらかを選択せざるを得なくなる。
厳しい壁と制約
この問題を解決するのが非常に困難なのはなぜか?著者らはいくつかの巨大な壁に直面した。
1. 微分不可能な壁(数学的制約)
最終的な目標は、数学的に次のように定義されるマッチング効率を最大化することである。
$$ \text{Matching efficiency} = \frac{1}{N} \sum_{i=1}^{N} \delta(y_i, \hat{y}(M_i)) $$
ここで、$\delta$はクロネッカーのデルタ関数である。この関数は厳しく剛直な階段のようなもので、モデルの予測 $\hat{y}$ が真のラベル $y_i$ と正確に一致する場合は1、そうでない場合は0となる。微積分学では、平坦なステップの微分(勾配)はゼロである。ニューラルネットワークは勾配(勾配降下法)をたどることで学習する。クロネッカーのデルタは非常に微分不可能であり、ほとんどすべての場所でゼロ勾配を返すため、ニューラルネットワークは完全に盲目になる。数学が改善方法に関する方向性フィードバックを提供しないため、学習できない。
2. 可変データ構造(計算上の制約)
すべての量子衝突はユニークに混沌としている。あるイベントは3ペアのbジェットを生成するかもしれないが、次のイベントは6ペアを生成するかもしれない。これは、入力行列 $M_i$ が常に変化する行数($c_i$)を持つことを意味する。ニューラルネットワークアーキテクチャは、クラッシュすることなく可変サイズの入力を処理できる動的な柔軟性を備えている必要があり、同時に順列等価性(bジェットペアがモデルに入力される順序がモデルの根本的なロジックを変更しないこと)も備えている必要がある。
3. 極端な量子複雑性(物理的制約)
これらのジェットを分離するための単純でハードコードされた物理法則は存在しない。データは非常に複雑で確率的な量子プロセスによって生成される。手作業で特徴量を設計することは事実上不可能である。運動学的観測量は深く絡み合っており、モデルは明示的な人間のルールなしに、シミュレートされたデータからのみ高次元の関係を解きほぐす方法を学習する必要がある。
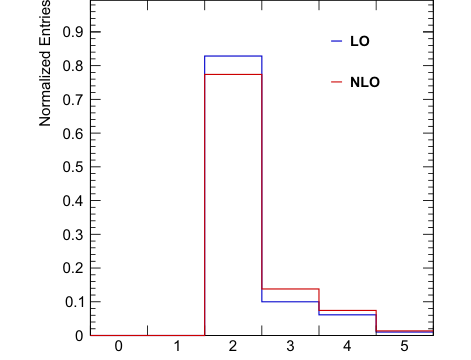 Figure 4. Histograms for the number of generator-level additional b-jets in simulated t¯tb¯b events at both the leading order (LO) and the next-to-leading order (NLO). Note that most events have two additional b-jets (82.8% for LO and 77.4% for NLO)
Figure 4. Histograms for the number of generator-level additional b-jets in simulated t¯tb¯b events at both the leading order (LO) and the next-to-leading order (NLO). Note that most events have two additional b-jets (82.8% for LO and 77.4% for NLO)
本アプローチの理由
著者らがこの特定の数学的アプローチを採用した理由を理解するには、以前のゴールドスタンダードが根本的に欠陥があることに気づいた正確な瞬間を特定する必要がある。本論文以前は、$t\bar{t}b\bar{b}$プロセスにおける追加のbジェットを特定するためのstate-of-the-art(SOTA)アプローチは、Deep Neural Network(DNN)を標準的な二項分類器として使用することであった。この古い手法は、bジェットの各ペアを取り込み、ネットワークに入力し、Binary Cross-Entropy loss ($L_{BCE}$)を最小化して0から1の間の確率を出力していた。
著者の「ひらめき」の瞬間は、粒子の衝突データの物理的現実に目を向けたときに訪れた。ほぼすべての有効な$t\bar{t}b\bar{b}$イベントにおいて、グルーオンスプリッティングに由来する追加のbジェットのペアはちょうど1つ存在する。従来の二項分類アプローチは、この根本的な制約を完全に無視している。「このペアはシグナルか?」と問うのではなく、「この特定のイベントのペアのうち、どれがシグナルか?」という、より関連性の高い問いを立てるべきところを、全てのbジェットペアを個別に扱っていた。ペアを独立に扱うことで、古いモデルは重要な文脈情報を捨て去り、実際の目標であるマッチング効率ではなく、二項精度を最適化していた。
この認識により、彼らが提案する数学モデルは唯一実行可能な解決策となった。独立した分類の代わりに、彼らはイベント全体のマトリクス $M_i \in \mathbb{R}^{c_i \times F}$(ここで、$c_i$は$i$番目のイベントにおけるbジェットペアの数、$F$は特徴次元)を処理する、置換同変モデルを定式化した。彼らは、単一イベント内のすべてのペアに対する出力にsoftmax関数を適用した。
$$ f_j(M_i) = \frac{\exp(g_j(M_i))}{\sum_{k=1}^{c_i} \exp(g_k(M_i))} $$
これにより、単一イベント内のすべてのペアにわたる確率の合計が正確に1になることが保証される ($\sum_{j=1}^{c_i} f_j(M_i) = 1$)。
この手法の比較優位性は、概念実証としての合成データ実験において美しく示されている。確率的生成プロセスを持つ高次元空間では、背景ノイズはグローバルに見るとシグナルと重複することが多い。従来の二項分類器は、すべてのイベントからのすべてのデータポイント全体に単一のグローバルな決定境界を描こうとするが、この重複により、恣意的で非常に不正確な分離が生じる。対照的に、著者らの手法は、同じイベントマトリクス内でペアを互いに相対的に評価する。そうすることで、グローバルなノイズの重複を効果的に回避し、シグナルを完全に分離するクリーンで相対的な決定境界を学習する。メモリ複雑度を$O(N^2)$から$O(N)$に削減するわけではないが、比較空間を単一イベントの境界に制限することにより、計算上の混乱を劇的に低減する。
この選択された手法は、問題の厳しい制約と完全に一致している。最終的な目標は、クロネッカーのデルタ関数を用いて数学的に定義されるマッチング効率を最大化することである。
$$ \text{Matching efficiency} = \frac{1}{N} \sum_{i=1}^{N} \delta(y_i, \hat{y}(M_i)) $$
このステップ関数は非常に非滑らかで微分不可能(勾配ゼロを返す)であるため、勾配降下法で直接最適化することはできない。問題の制約と解決策の「結婚」は、著者らによるサロゲート損失関数の巧妙な設計にある。イベントマトリクスの行インデックスを区別可能なカテゴリとして扱うことで、彼らは問題を多クラス分類またはランキングタスクに変換した。例えば、彼らの確率的ランキング損失 ($L_2$) およびカテゴリカルクロスエントロピー損失 ($L_3$) は、真の追加bジェットペアが特定のイベント構造内で最高の相対スコアを受け取らなかった場合に、ネットワークに直接ペナルティを与える。
率直に言って、GAN、標準的なDiffusion、またはTransformerのようなトレンドの生成モデルがここでどのように機能するかは完全にはわからない。なぜなら、著者らはテキスト中でそれらに言及したり、示唆したりしていないからである。GANまたはDiffusionモデルを適用することは、本質的に高度に制約された組み合わせランキング問題に対して、過剰であり、計算上無駄になるだろうと推測する。しかし、著者らは最も一般的な代替案である二項分類DNNを却下した理由を明確に説明している。彼らがそれを却下したのは、$L_{BCE}$の最適化が物理的な目的と数学的に一致しないからである。二項分類器をイベント内の他のbジェットからの特徴を含めるようにアップグレードした(彼らの「モデル2」)場合でも、彼らの提案するサロゲート損失 ($L_2$および$L_3$) には及ばなかった。二項アプローチでは、トレーニング中にそれらを並べて比較するように数学的に強制されなかったため、イベント内で最も高いスコアのペアが実際に正しいことを保証できないのである。
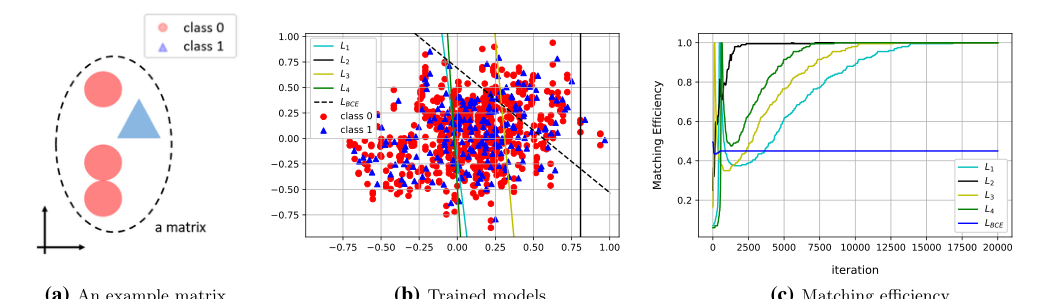 Figure 2. Experimental results from synthetic data. (a) An example matrix is illustrated. (b) The level sets of the trained models are drawn over the data scatter plot. (c) Matching efficiencies (evaluated on a test data set) for each of the loss functions are shown
Figure 2. Experimental results from synthetic data. (a) An example matrix is illustrated. (b) The level sets of the trained models are drawn over the data scatter plot. (c) Matching efficiencies (evaluated on a test data set) for each of the loss functions are shown
数学的・論理的メカニズム
大型ハドロン衝突型加速器(LHC)の制御室に立っていると想像してほしい。衝突が起こるたびに、粒子は光速に近い速度で粉砕され、「ジェット」と呼ばれるサブアトミックな破片のシャワーが生成される。物理学者は、しばしば特定の種類の破片である「bジェット」に崩壊するヒッグス粒子の性質を必死に探している。
しかし、そこには大きな問題がある。 $t\bar{t}b\bar{b}$(トップクォークペアとbクォークペア)と呼ばれる、全く異なるノイズの多い背景プロセスが、全く同じbジェットを生成してしまうのだ。このノイズをフィルタリングするために、物理学者は、どのbジェットが主要なイベント(トップクォークの崩壊)から来たもので、どのジェットが単なる追加の破片(グルーオンスプリッティングと呼ばれる現象に由来する)であったかを突き止めなければならない。
以前は、科学者たちは機械学習を用いて、個々のbジェットのペアを孤立させて調べ、「これは追加の破片か?」という単純なYes/Noの質問をしていた。この二項分類アプローチは、物理学の基本的な規則を無視していたため、欠陥があった。つまり、ほぼ全ての有効なイベントには、ちょうど1組の追加のbジェットが存在するということだ。各ペアを独立に扱うことで、古いモデルは貴重な文脈情報をテーブルに残したままにしていた。
本論文の著者たちは、パラダイムをシフトさせることでこの問題を解決した。彼らは、「このペアは追加の破片か?」と問う代わりに、イベント内の全てのペアを同時に調べ、「あなたたちのうち、最も可能性の高い候補はどれか?」と問うニューラルネットワークを設計した。彼らは標準的な二項精度を捨て、カスタム損失関数を設計することでこれを達成し、「マッチング効率」、すなわちモデルが候補者の中から単一の正しいペアを選ぶ割合を直接最大化した。
以下に、彼らの最も成功したモデルを支える、イベントレベルの確率分布(Softmax)とカテゴリカルクロスエントロピーの代理損失を組み合わせた、絶対的な中核となる数学的エンジンを示す。
$$ L_3 = -\frac{1}{N} \sum_{i=1}^N \log \left( \frac{\exp(g_{y_i}(M_i))}{\sum_{k=1}^{c_i} \exp(g_k(M_i))} \right) $$
この方程式を一つずつ分解して、その仕組みを理解しよう。
- $L_3$: これは代理損失関数である。これは究極のエラー信号として機能し、ニューラルネットワークにどれだけひどく間違えたかを伝える。訓練プロセスの目標は、この数値を最小化することである。
- $-\frac{1}{N} \sum_{i=1}^N$: これはデータセット内の全ての $N$ イベントにわたる平均誤差を計算する。なぜ積分ではなく総和なのか?衝突イベントの数 $N$ は厳密に離散的で数えられるからだ。衝突の断片を持つことはできないため、連続空間にわたる積分は物理的または論理的に意味をなさない。
- $\log$: 自然対数。その論理的な役割は、モデルが自信を持って間違っている場合に、それを大きく罰することである。モデルが正しいペアに確率 $1$ に近い値を割り当てた場合、 $1$ の対数は $0$(罰なし)となる。しかし、確率が $0$ に近づくにつれて、対数は負の無限大に向かって急落し、モデルを悪い予測から激しく引き離す、巨大なゴムバンド効果を生み出す。
- $M_i$: $i$ 番目のイベント行列。これは、その特定の衝突における各bジェットペアの全ての運動学的変数(運動量や角度など)を含む生データ入力である。
- $y_i$: イベント $i$ における真の追加bジェットペアのインデックス。これは、物理シミュレーションによって提供される「Ground Truth」ラベルである。
- $g_{y_i}(M_i)$: ニューラルネットワーク $g$ の、正しいbジェットペアに対する生の出力スコア(ロジット)。これは生の信頼度メーターとして機能する。
- $\exp(\dots)$: 指数関数。これは、全てのスコアが厳密に正であることを保証し、高スコアと低スコア間の差を誇張して、ネットワークの好みをより決定的にするという2つの目的を果たす。
- $\sum_{k=1}^{c_i} \exp(g_k(M_i))$: 分母は、イベント $i$ における全ての $c_i$ 個の可能なbジェットペアの指数化されたスコアを合計する。なぜここで乗算ではなく加算を使用するのか?加算はイベントの総「確率質量」をプールする。もしそれらを乗算した場合、独立したイベントが同時に発生する同時確率を計算することになる。しかし、これらのペアは単一の真の信号の相互排他的な候補であるため、正規化係数を作成するためにそれらを加算しなければならない。
- 分数全体: これはSoftmax関数である。生の、制限のないスコアを取り、それらを合計が正確に $1$ になる整然とした確率分布に圧縮する。
単一の抽象的なデータポイントがこの方程式を通過する正確なライフサイクルを追ってみよう。3つの可能なbジェットペアを含むイベント行列 $M_i$ がアセンブリラインに入力されると想像してほしい。
まず、ニューラルネットワークは3つのペア全ての運動学的データを処理し、生のスコアを出力する。正しいペアに対して $2.0$、間違ったペアに対して $0.5$ と $-1.0$ である。
次に、 $\exp$ 関数がこれらのスコアをスーパーチャージし、$7.39$、$1.65$、$0.37$ に変換する。
その後、分母がこれらの値を収集し、合計 $9.41$ を得るために加算する。
次に、分数が正しいペアのスコアを総プールで割る($7.39 / 9.41$)、結果として約 $0.78$ の確率が得られる。
最後に、 $\log$ 関数がこの $0.78$ を評価する。これは $1.0$ に比較的近いため、結果として生じるペナルティは小さい。データポイントはエンジンを正常に通過した。
このメカニズムは実際にどのように学習し、収束するのだろうか?最適化ダイナミクスは、Softmax分数によって作成される損失ランドスケープに依存する。全ての確率の合計は $1$ にならなければならないため、モデルはゼロサムゲームに追い込まれる。損失を最小化するために、ネットワークは正しいペアのスコアを上げるだけでなく、同時に間違ったペアの相対的なスコアを下げる必要がある。
訓練中に勾配がネットワークを逆方向に流れるにつれて、それらはグルーオンスプリッティングbジェットとトップクォークbジェットを区別する微妙な運動学的シグネチャ(角度距離や不変質量など)を認識するように重みを調整する。損失ランドスケープは多次元の谷のような形状をしており、最も低い点は、ネットワークが全てのイベントで真のbジェットペアを他の全てのペアよりも完璧にランク付けすることに対応する。正直に言うと、ネットワークアーキテクチャ自体が最新のアテンションメカニズムでさらに最適化できるかどうかは完全には確信できないが、著者たちは標準的なフィードフォワード設計に固執し、数学的な目的関数を修正するだけで、古い二項分類手法を大幅に上回ることができることを鮮やかに証明した。
結果、限界、および結論
グランドクエスト:ヒッグス粒子の隠れ場所の解明
本論文の重要性を理解するためには、まず素粒子物理学の最も壮大な舞台である大型ハドロン衝突型加速器(LHC)に焦点を当てる必要がある。物理学者がヒッグス粒子を発見したとき、それは画期的な偉業であった。しかし、発見は第一段階に過ぎず、第二段階は、その性質を測定し、素粒子物理学の標準模型が予測する通りに振る舞うことを確認することである。
ヒッグス粒子は、ボトムクォークのペア ($b\bar{b}$) に崩壊することを好む。ヒッグス粒子を研究する最良の方法の一つは、トップクォークペアと同時に生成される場合であり、これは $t\bar{t}H(b\bar{b})$ というプロセスとして知られている。しかし、宇宙は混沌とした場所である。我々の貴重なヒッグス信号とほぼ同じように見える「バックグラウンド」プロセスが存在する。それは $t\bar{t}b\bar{b}$ プロセスである。このバックグラウンドプロセスは、ヒッグス粒子が関与することなく、トップクォークペアとボトムクォークペアを生成する。この $t\bar{t}b\bar{b}$ バックグラウンドを完全に理解し、フィルタリングできなければ、ヒッグス粒子の測定は永遠に曖昧なままとなる。
コアとなる動機と制約
ここに根本的な問題がある。$t\bar{t}b\bar{b}$ イベントでは、2つの異なるソースから発生する $b$-ジェット(ボトムクォークに由来する粒子の噴流)が存在する。一部はトップクォークの崩壊から、一部は「グルーオンスプリッティング」(グルーオンが2つの追加の $b$-クォークに分裂する現象)から生じる。バックグラウンドを理解するために、物理学者はトップクォークから生まれた $b$-ジェットと、グルーオンスプリッティングから生まれた「追加の」 $b$-ジェットを識別する必要に迫られている。
制約:
1. 量子カオス: これらのジェットの運動学的特性(運動量、角度、エネルギー)は、高次元の確率的量子プロセスによって支配されている。「エネルギー > X ならグルーオン由来」のような単純で固定化された規則は存在しない。
2. 組み合わせ爆発: イベントは、2つの整然としたジェットを単純に提示するわけではない。それは粒子の塊を提示する。ジェットのペアを見て、どのペアが「追加の」ペアであるかを推測する必要がある。
3. 分布の重複: 数百万のイベントにわたるすべての $b$-ジェットを見ると、トップ崩壊ジェットとグルーオンスプリッティングジェットの特性は大きく重複する。
数学的解釈:彼らは何を解決したのか?
「犠牲者」(ベースラインアプローチ):
以前は、科学者たちはこれを標準的な二項分類問題として扱っていた。彼らは、すべてのイベントにわたるすべての $b$-ジェットのペアを取り出し、ディープニューラルネットワーク(DNN)に入力し、「このペアは追加の $b$-ジェットペアか? はい(1)かいいえ(0)?」と尋ねていた。彼らは標準的な二項クロスエントロピー ($L_{BCE}$) を用いてこれを訓練した。
$$ L_{BCE} = -\frac{1}{N_p} \sum_{i=1}^{N_p} \left( \xi_i \log f(x_i) + (1 - \xi_i) \log(1 - f(x_i)) \right) $$
欠陥: このアプローチは、データの構造に対して数学的に盲目である。それは宇宙のすべてのペアを独立として扱っている。しかし実際には、我々は重要な秘密を知っている:ほぼすべての $t\bar{t}b\bar{b}$ イベントには、正確に1組の追加の $b$-ジェットが含まれている。
画期的な解決策:
著者らは、「このペアは追加の $b$-ジェットか?」と尋ねるべきではないと認識した。我々は単一のイベントを見て、「この特定のイベント内のすべてのペアのうち、どれが追加の $b$-ジェットである可能性が最も高いか?」と尋ねるべきである。
彼らはパラダイムをグローバルな二項分類からイベントレベルのランキング(またはイベント内のマルチクラス分類)へとシフトさせた。彼らはイベント行列 $M_i \in \mathbb{R}^{c_i \times F}$ を定義した。ここで $c_i$ はイベント内の $b$-ジェットペアの数、$F$ は特徴次元である。次に、イベント内のペア間でソフトマックス関数を適用し、その確率の合計が1になるようにした。
$$ f_j(M_i) = \frac{\exp(g_j(M_i))}{\sum_{k=1}^{c_i} \exp(g_k(M_i))} $$
最終的な目標は、微分不可能な「マッチング効率」(正しいペアが選択されるイベントの割合)を最大化することであるため、彼らは4つの代理損失関数を設計した。最も概念的に美しいのは確率的ランキング損失 ($L_2$) であり、これはネットワークに、その特定のイベント内の他のどのペアよりも真の追加ペアを高くスコアリングするように強制する。
$$ L_2 = -\frac{1}{N} \sum_{i=1}^N \sum_{j \neq y_i} \log \left( \frac{f_{y_i}(M_i)}{f_{y_i}(M_i) + f_j(M_i)} \right) $$
彼らはまた、正しいペアのインデックスを真のクラスとして扱うカテゴリカルクロスエントロピー損失 ($L_3$) も利用した。
$$ L_3 = -\frac{1}{N} \sum_{i=1}^N \log f_{y_i}(M_i) $$
徹底的な実験アーキテクチャと決定的な証拠
著者らは単に指標を壁に投げつけたのではなく、数学的主張を徹底的に証明するために2段階の実行を設計した。
ステージ1:合成トラップ(概念実証)
まず、彼らは物理データが重複する性質を完全に模倣するように設計された2次元合成データセットを構築した。彼らは「信号」と「バックグラウンド」がグローバルに重複するが、イベント内では「ローカル」に区別されるイベントを作成した。二項分類器(犠牲者)は、グローバルな重複によって混乱し、恣意的な決定境界を描いてひどく失敗した。著者らの新しい損失関数は、イベント内の点のみを比較したため、100%のマッチング効率を達成した。それは完璧な数学的チェックメイトであった。
ステージ2:LHCシミュレーション
次に、彼らは重厚な物理パイプライン(MadGraph5_aMC@NLO(イベント生成)→ Pythia(ハドロン化)→ DELPHES(CMS検出器シミュレーション))を使用して、$\sqrt{s} = 13$ TeVでの実際の陽子-陽子衝突をシミュレートした。これは、衝突時間に対して1億5000万ドルを費やすことなく、実際のLHCデータに最も近いものである。
決定的な証拠:
彼らは単に「精度が向上した」と言っただけではない。イベント構造を尊重するように損失関数のみを変更することで、マッチング効率が明白に向上したことを証明した。Leading Order(LO)シミュレーションでは、効率は62.1%($L_{BCE}$ 犠牲者モデルを使用)から64.5%(彼らの $L_3$ モデルを使用)に跳ね上がった。
しかし、最も明白な証拠は視覚的かつ物理的である:図3。彼らは再構築された物理分布、特に角度距離 ($\Delta R$) と $b$-ジェットペアの不変質量をプロットした。彼らの提案手法によって生成されたヒストグラムは、二項分類アプローチよりも「真の信号」(ジェネレーターレベルの真実)に著しく密接に張り付いていた。彼らは、彼らのAIが単に統計的ノイズを学習しているのではなく、根底にある量子運動学をより正確に回復していることを証明した。
優秀な頭脳のための将来の議論トピック
この論文に基づき、このフロンティアをさらに前進させるために探求すべきいくつかの方向性を以下に示す。
-
フィードフォワードネットワークを超えて:グラフニューラルネットワーク(GNN)の時代
著者らは、ペアを処理してから集約するディープフィードフォワードニューラルネットワークを使用した。しかし、イベントは本質的に相互作用する粒子のグラフである。アテンションメカニズムやGNNを使用してイベント全体を完全接続グラフとしてモデル化した場合、ネットワークがすべてのジェット間の関係物理学を同時に学習できるようになった場合、どれだけマッチング効率を向上させることができるだろうか? -
エンドツーエンドの生検出器学習
現在、この手法は78個の事前に計算された運動学的変数(横運動量、擬似ラピディティなど)に依存している。人間の設計した特徴を完全にバイパスしたらどうなるだろうか? CMS検出器の粒子フローアルゴリズムからの生の3D点群データを直接3D畳み込みまたはPointNetアーキテクチャにフィードして、AIにまだ考えも及ばない運動学的不変量を発見させることができるだろうか? -
実際の衝突データのためのドメイン適応
この論文はモンテカルロシミュレーション(MadGraph/Pythia)に大きく依存している。しかし、シミュレーションは実際のLHCデータを完全に再現するものではない。どのようにして、このシミュレーション環境で観察されたマッチング効率の向上を、今後の高輝度LHC(HL-LHC)実行の実際の、混沌としたデータに完全に転送することを保証するために、教師なしドメイン適応技術(勾配逆転層など)を統合できるだろうか?