学习以提高识别过程中额外 b 喷注的匹配效率
To truly understand the significance of this paper, we have to travel back to the monumental discovery of the Higgs boson at the Large Hadron Collider (LHC) in 2012.
背景与学术渊源
要真正理解本文的意义,我们必须回顾2012年大型强子对撞机(LHC)上发现希格斯玻色子的里程碑式成就。一旦物理学家发现了希格斯玻色子,接下来的一个紧迫问题便是:它的行为是否与我们标准模型预测的完全一致?
为了回答这个问题,科学家们着眼于希格斯玻色子与已知最重粒子——顶夸克——的相互作用。他们特别研究了一种名为$t\bar{t}H$过程的碰撞事件,在该过程中,一对顶夸克($t\bar{t}$)与一个希格斯玻色子($H$)一同产生。由于希格斯玻色子最常衰变为一对底夸克($b\bar{b}$),我们在对撞机中实际探测到的最终碎片是一个$t\bar{t}b\bar{b}$信号。
这时,巨大的难题便出现了。宇宙自然会通过标准的、非希格斯物理过程产生$t\bar{t}b\bar{b}$事件。这种非希格斯$t\bar{t}b\bar{b}$产生过程构成了巨大的背景噪声。为了找到稀有的希格斯“信号”,物理学家必须完美理解这一背景。为此,他们需要观察最终碎片,并区分哪些底夸克来自顶夸克,哪些是由于一个称为胶子分裂的随机量子事件产生的“额外”底夸克。
前人方法的根本局限
在此文之前,研究人员试图使用标准的机器学习方法,特别是二元分类,来解决这一识别问题。他们会处理事件中的每一对$b$-射流,并询问神经网络:“这一对是额外的吗?是或否?”
这里根本的痛点在于,这种方法完全忽略了数据的物理结构。在几乎所有的碰撞事件中,恰好存在一对额外的$b$-射流。通过完全孤立地评估每一对,先前的方法优化的是整体的“配对准确率”,而非“事件准确率”。想象一下,通过让计算机独立猜测A是否正确、B是否正确、C是否正确来给多项选择题评分,而不是强迫它从选项中选出唯一最佳答案。由于旧模型没有同时考虑整个事件的上下文,它们正确识别每个事件中唯一真实配对(一个称为“匹配效率”的指标)的能力达到了一个硬性上限。
术语解析
为了便于理解,我们来分解一下论文中使用的一些高度专业化的术语:
- $b$-射流($b$-jet):当一个底夸克($b$)在粒子碰撞中产生时,它几乎会瞬间衰变成一束锥形的其他粒子。
- 类比:将$b$-射流想象成一只看不见的动物留下的独特一串泥泞脚印。我们看不到动物(夸克),但我们可以测量脚印(射流)来推断它的来源。
- 胶子分裂(Gluon splitting):一种量子过程,其中一个胶子(传递强核力的粒子)自发地转变成一对夸克和反夸克。
- 类比:想象一个烟花弹射向天空,突然爆裂成两个截然不同、色彩鲜艳的火花。
- 不可约背景(Irreducible background):一种背景噪声过程,其产生的最终可探测粒子与你实际寻找的稀有信号完全相同。
- 类比:试图仅凭最终烤好的蛋糕来判断它是用白糖还是红糖调味的。最终结果看起来完全一样,所以你必须寻找极其细微的纹理线索来区分它们。
- 匹配效率(Matching efficiency):算法成功识别出额外的$b$-射流的确切正确配对的碰撞事件所占的百分比,而不是仅仅在个体猜测上获得高平均分数。
- 类比:狙击手的“一枪毙命”指标。你正确识别出99个无辜旁观者为“非目标”并不重要;重要的是你是否能完美地从人群中挑出那个特定的目标。
数学问题与解决方案
作者希望直接最大化匹配效率。在数学上,这由克罗内克三角函数表示:
$$ \text{Matching efficiency} = \frac{1}{N} \sum_{i=1}^{N} \delta(y_i, \hat{y}(M_i)) $$
这里,如果模型的预测$\hat{y}$与真实索引$y_i$完全匹配,则$\delta(y_i, \hat{y}(M_i))$等于1,否则为0。
数学上的问题在于,这个函数是一个“硬阶跃”(它在0和1之间瞬间跳跃)。在机器学习环境中,你无法在硬阶跃上训练神经网络,因为梯度(用于更新网络权重的斜率)几乎处处为零。你无法使用微积分来优化它。
为了克服这一限制,作者放弃了旧的二元交叉熵损失($L_{BCE}$),并设计了代理损失函数($L_1, L_2, L_3, L_4$)。他们将神经网络的输出转换为一个概率分布,该分布覆盖了给定事件中所有配对,使用了softmax函数:
$$ f_j(M_i) = \frac{\exp(g_j(M_i))}{\sum_{k=1}^{c_i} \exp(g_k(M_i))} $$
这个方程迫使模型查看事件矩阵$M_i$中的所有$c_i$个配对,并为它们分配总和为1的概率。然后,他们训练模型以最大化分配给正确配对的概率,使用诸如$L_3$之类的分类交叉熵代理损失:
$$ L_3 = - \frac{1}{N} \sum_{i=1}^{N} \log f_{y_i}(M_i) $$
通过这样做,模型学会了在特定事件的上下文中对配对进行相互排序,直接优化匹配效率,而不会违反梯度下降的规则。
主要数学符号
| 符号 | 类型 | 描述 |
|---|---|---|
| $N$ | 参数 | 模拟的$t\bar{t}b\bar{b}$事件数据样本的总数。 |
| $c_i$ | 变量 | 第$i$个事件中存在的$b$-射流对的总数。 |
| $F$ | 参数 | 表示单个$b$-射流对的特征向量的维度。 |
| $M_i$ | 变量 | 第$i$个事件的事件矩阵,包含所有$b$-射流对,维度为$\mathbb{R}^{c_i \times F}$。 |
| $y_i$ | 变量 | 第$i$个事件中额外$b$-射流对的真实整数索引(从1到$c_i$)。 |
| $\hat{y}(M_i)$ | 变量 | 模型输出的额外$b$-射流对的预测索引。 |
| $f_j(M_i)$ | 变量 | 模型预测的第$j$个$b$-射流对在事件$M_i$中是额外配对的概率。 |
| $g_j(M_i)$ | 变量 | 在转换为概率之前,神经网络为第$j$个$b$-射流对计算的原始激活值(得分)。 |
| $L_{BCE}$ | 函数 | 之前有限模型使用的传统二元交叉熵损失。 |
| $L_1, L_2, L_3, L_4$ | 函数 | 设计用于平滑近似和最大化匹配效率的代理损失函数。 |
问题定义与约束
为了理解本文所要解决问题的严重性,请想象一下,您正试图在一个拥挤嘈杂的体育场里,捕捉一个非常微弱、特定的耳语声。在粒子物理学领域,这个耳语声就是希格斯玻色子,它是赋予宇宙万物质量的基本粒子。然而,当物理学家在大型强子对撞机 (LHC) 上将质子对撞以研究希格斯玻色子时,他们会被海量的背景噪声所淹没。
最响亮的噪声来自于一个称为 $t\bar{t}b\bar{b}$ 的物理过程,该过程会产生一对顶夸克以及一对底夸克 ($b$)。这个过程产生的碎片看起来几乎与希格斯玻色子产生的碎片一模一样。为了过滤掉这种噪声,物理学家必须观察由此产生的“b-喷注”(粒子的喷射流),并弄清楚它们的起源故事:这些 b-喷注是来自重顶夸克的衰变,还是仅仅从一个称为“胶子分裂”的次级过程中凭空产生?
起始点与目标状态
输入(当前状态):
当粒子碰撞(一个“事件”)发生时,探测器会捕捉碎片的运动学性质。作者将这些数据在数学上表示为一个事件矩阵 $M_i \in \mathbb{R}^{c_i \times F}$。其中,$c_i$ 表示单个碰撞事件中可能的 b-喷注对的数量,而 $F$ 表示每对喷注的高维物理特征(如动量和能量)。
输出(目标状态):
期望的最终目标是一个神经网络,它能够查看这个矩阵并精确地指向一行,自信地声明:“这对特定的 b-喷注是对是由胶子分裂产生的额外一对。”
数学上的差距:
缺失的环节是一个专门的数学桥梁,它能够评估同一事件中 b-喷注对彼此之间的关系。我们不仅仅想知道一对喷注是否孤立地看起来像一个额外的 b-喷注;我们需要网络对矩阵 $M_i$ 中的所有喷注对进行排序,并输出一个概率分布 $f(M_i) \in [0, 1]^{c_i}$,其中概率之和为 1。最高的概率指示了正确的喷注对。
痛苦的困境
之前的研究人员陷入了一个经典的机器学习陷阱:他们将这个问题视为一个标准的二元分类问题。他们取来自每个事件的每一个 b-喷注对,将它们全部混合在一起,然后使用标准的二元交叉熵损失函数 ($L_{BCE}$) 让神经网络猜测“是”或“否”。
这在计算便利性和物理现实之间造成了一个痛苦的权衡。二元分类在数学上易于优化,但它完全忽略了物理学的结构现实:几乎每个 $t\bar{t}b\bar{b}$ 事件都包含一对真正的额外 b-喷注。通过孤立地评估每个喷注对,之前的模型丢弃了至关重要的上下文线索。
然而,如果您试图通过放弃二元分类并直接优化您真正关心的目标——“匹配效率”(即模型选择完全正确的喷注对的事件总数百分比)——来解决这个问题,您将立即打破数学上的可行性。您被迫在模型易于训练但结构上有缺陷,或者模型结构准确但数学上无法训练之间做出选择。
严酷的壁垒与约束
是什么使得这个问题如此难以解决?作者遇到了几个巨大的障碍:
1. 不可微壁垒(数学约束)
最终目标是最大化匹配效率,其数学定义为:
$$ \text{Matching efficiency} = \frac{1}{N} \sum_{i=1}^{N} \delta(y_i, \hat{y}(M_i)) $$
这里,$\delta$ 是克罗内克 delta 函数。这个函数是一个严酷、僵硬的阶梯:如果模型的预测 $\hat{y}$ 与真实标签 $y_i$ 完全匹配,它就等于 1,否则为 0。在微积分中,一个平坦台阶的导数(梯度)为零。神经网络通过遵循梯度(梯度下降)进行学习。由于克罗内克 delta 函数高度不可微且几乎处处返回零梯度,神经网络完全处于盲目状态。它无法学习,因为数学没有提供改进方向的反馈。
2. 可变数据结构(计算约束)
每次量子碰撞都是独一无二且混乱的。一个事件可能产生 3 对 b-喷注,而下一个事件可能产生 6 对。这意味着输入矩阵 $M_i$ 具有不断变化的行数 ($c_i$)。神经网络架构必须具有动态灵活性,能够处理可变大小的输入而不崩溃,同时还要具有排列等变性(这意味着输入 b-喷注对的顺序不应改变模型的底层逻辑)。
3. 极端量子复杂性(物理约束)
没有简单、硬编码的物理规则来区分这些喷注。数据是由高度复杂、随机的量子过程生成的。手动设计特征几乎是不可能的。运动学可观测量是深度纠缠的,这意味着模型必须以某种方式从模拟数据中学习解开高维关系,而没有任何明确的人工规则来指导它。
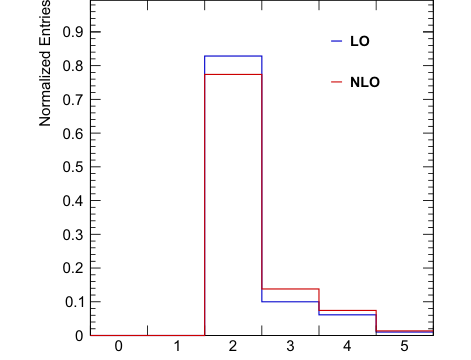 Figure 4. Histograms for the number of generator-level additional b-jets in simulated t¯tb¯b events at both the leading order (LO) and the next-to-leading order (NLO). Note that most events have two additional b-jets (82.8% for LO and 77.4% for NLO)
Figure 4. Histograms for the number of generator-level additional b-jets in simulated t¯tb¯b events at both the leading order (LO) and the next-to-leading order (NLO). Note that most events have two additional b-jets (82.8% for LO and 77.4% for NLO)
为何采用此方法
为了理解作者为何选择这一特定的数学路径,我们必须精确地指出他们意识到先前黄金标准存在根本性缺陷的时刻。在本论文之前,识别 $t\bar{t}b\bar{b}$ 过程中额外 b-射流(b-jets)的 SOTA(state-of-the-art)方法是使用深度神经网络(DNN)作为标准的二元分类器。这种旧方法将每一对 b-射流输入网络,并通过最小化二元交叉熵损失($L_{BCE}$)来输出一个介于 0 和 1 之间的概率。
作者的“顿悟”时刻发生在他们审视粒子碰撞数据的物理现实时。在几乎所有有效的 $t\bar{t}b\bar{b}$ 事件中,都存在一个源自胶子分裂的额外 b-射流对。传统的二元分类方法完全忽略了这一基本约束。它孤立地处理每一个 b-射流对,询问“这一对是信号吗?”,而不是提出一个更相关的问题:“在这个特定事件中,哪一对是信号?”通过独立处理配对,旧模型丢弃了至关重要的上下文信息,并优化了二元准确性,而非实际目标:匹配效率。
这一认识使得他们提出的数学模型成为唯一可行的解决方案。他们没有采用独立分类,而是构建了一个置换等变模型(permutation-equivariant model),该模型处理整个事件矩阵 $M_i \in \mathbb{R}^{c_i \times F}$(其中 $c_i$ 是第 $i$ 个事件中 b-射流对的数量,$F$ 是特征维度)。他们将 softmax 函数应用于单个事件中所有配对的输出:
$$ f_j(M_i) = \frac{\exp(g_j(M_i))}{\sum_{k=1}^{c_i} \exp(g_k(M_i))} $$
这确保了单个事件中所有配对的概率之和恰好为一($\sum_{j=1}^{c_i} f_j(M_i) = 1$)。
该方法在他们概念验证的合成数据实验中得到了优美的阐释,展示了其相对优越性。在高维空间中,具有随机生成过程的背景噪声在全局视角下常常与信号重叠。传统的二元分类器试图在所有事件的所有数据点之间绘制一个单一的全局决策边界,由于这种重叠,导致了任意且高度不准确的分离。相比之下,作者的方法是在同一事件矩阵内相互比较配对。通过这样做,它有效地绕过了全局噪声重叠,学习了一个清晰的相对决策边界,完美地分离了信号。它不一定能将内存复杂度从 $O(N^2)$ 降低到 $O(N)$,但它通过将比较空间限制在单个事件的边界内,极大地减少了计算混淆。
这种选择的方法完美契合了问题的严苛约束。最终目标是最大化匹配效率,该效率使用克罗内克函数(Kronecker delta function)在数学上定义:
$$ \text{Matching efficiency} = \frac{1}{N} \sum_{i=1}^{N} \delta(y_i, \hat{y}(M_i)) $$
由于这个阶跃函数高度不光滑且不可微(返回零梯度),它无法通过梯度下降直接优化。问题约束与解决方案之间的“联姻”在于作者巧妙设计的代理损失函数(surrogate loss functions)。通过将事件矩阵的行索引视为不同的类别,他们将问题转化为一个多类分类或排序任务。例如,他们的概率排序损失($L_2$)和分类交叉熵损失($L_3$)直接惩罚网络,如果真实的额外 b-射流对在其特定的事件结构中没有获得最高的相对分数。
坦白说,我不太确定像 GAN、标准 Diffusion 或 Transformer 这样的流行生成模型在这里的表现如何,因为作者在文本中完全没有提及或暗示它们。我怀疑对于一个本质上高度受限的组合排序问题,应用 GAN 或 Diffusion 模型会是巨大的过度设计且计算浪费。然而,作者明确解释了拒绝最流行的替代方案——二元分类 DNN——的原因。他们拒绝它是因为优化 $L_{BCE}$ 在数学上与物理目标不符。即使他们升级了二元分类器以包含事件中其他 b-射流的特征(他们的“模型 2”),它仍然未能达到他们提出的代理损失($L_2$ 和 $L_3$)的水平。二元方法根本无法保证事件中得分最高的配对实际上是正确的,因为它在训练过程中从未被数学强制要求进行并排比较。
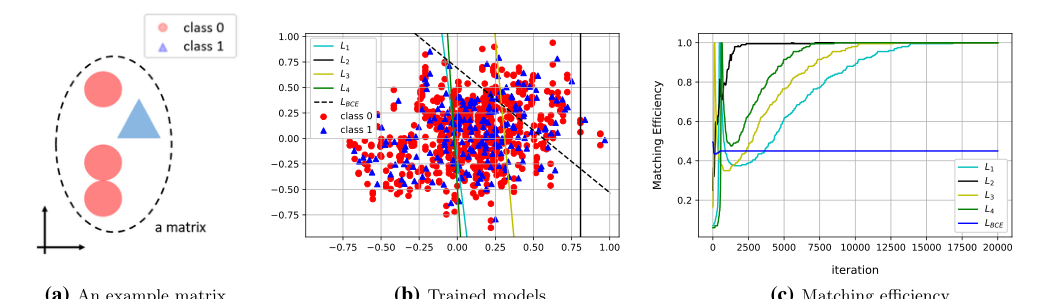 Figure 2. Experimental results from synthetic data. (a) An example matrix is illustrated. (b) The level sets of the trained models are drawn over the data scatter plot. (c) Matching efficiencies (evaluated on a test data set) for each of the loss functions are shown
Figure 2. Experimental results from synthetic data. (a) An example matrix is illustrated. (b) The level sets of the trained models are drawn over the data scatter plot. (c) Matching efficiencies (evaluated on a test data set) for each of the loss functions are shown
数学与逻辑机制
想象一下,您正站在大型强子对撞机 (LHC) 的控制室里。每一次粒子碰撞,粒子都会以接近光速的速度破碎,产生被称为“喷注”的亚原子碎片。物理学家们正迫切地寻找希格斯玻色子的性质,它经常衰变成一种特殊的碎片,称为“b 喷注”。
然而,存在一个巨大的问题:一个完全不同且嘈杂的背景过程 $t\bar{t}b\bar{b}$(一对顶夸克和一对 b 夸克)会产生完全相同的 b 喷注。为了过滤掉这种噪声,物理学家必须弄清楚哪些 b 喷注来自主要事件(顶夸克衰变),哪些只是额外的碎片(源于称为胶子分裂的现象)。
此前,科学家们使用机器学习来单独分析每一对 b 喷注,并提出一个简单的“是/否”问题:“你们是额外的碎片吗?” 这种二元分类方法存在缺陷,因为它忽略了一个基本的物理规则:在几乎所有有效的事件中,都恰好有一对额外的 b 喷注。通过独立处理每一对,旧模型忽略了宝贵的上下文信息。
本文的作者通过改变范式解决了这个问题。他们没有问“这一对是额外的碎片吗?”,而是设计了一个神经网络,使其能够同时观察一个事件中的所有 b 喷注对,并询问:“你们之中谁是最可能的候选者?” 他们通过放弃标准的二元准确率,并设计自定义损失函数来直接最大化“匹配效率”——即模型从一系列候选中挑选出唯一正确对的速率——来实现这一目标。
以下是驱动他们最成功模型的绝对核心数学引擎,它结合了他们的事件级概率分布 (Softmax) 和一个分类交叉熵代理损失:
$$ L_3 = -\frac{1}{N} \sum_{i=1}^N \log \left( \frac{\exp(g_{y_i}(M_i))}{\sum_{k=1}^{c_i} \exp(g_k(M_i))} \right) $$
让我们逐一剖析这个方程,以理解它是如何工作的:
- $L_3$:这是代理损失函数。它充当最终的误差信号,告诉神经网络它犯了多大的错误。训练过程的目标是最小化这个数值。
- $-\frac{1}{N} \sum_{i=1}^N$:这计算了数据集中所有 $N$ 个事件的平均误差。为什么是求和而不是积分?因为碰撞事件的数量 $N$ 是严格离散且可数的。您不能拥有一个碰撞事件的一部分,因此在连续空间上进行积分在物理或逻辑上都没有意义。
- $\log$:自然对数。它的逻辑作用是当模型错误且自信时,会对其进行严厉惩罚。如果模型为正确对分配接近 $1$ 的概率,则 $1$ 的对数是 $0$(无惩罚)。但当概率接近 $0$ 时,对数会急剧下降至负无穷大,产生巨大的橡皮筋效应,将模型从错误的预测中猛烈拉开。
- $M_i$:第 $i$ 个事件矩阵。这是原始数据输入,包含该特定碰撞中每个 b 喷注对的所有运动学变量(如动量和角度)。
- $y_i$:事件 $i$ 中真实额外 b 喷注对的索引。这是由物理模拟提供的“ground truth”标签。
- $g_{y_i}(M_i)$:神经网络 $g$ 对正确 b 喷注对的原始输出分数(logit)。它充当原始置信度指示器。
- $\exp(\dots)$:指数函数。它有两个作用:确保所有分数严格为正,并夸大高分和低分之间的差异,使网络的偏好更加明确。
- $\sum_{k=1}^{c_i} \exp(g_k(M_i))$:分母将事件 $i$ 中所有 $c_i$ 个可能的 b 喷注对的指数化分数相加。为什么在这里使用加法而不是乘法?加法汇集了事件的总“概率质量”。如果我们相乘,我们将计算独立事件同时发生的联合概率。但这些对是单个真实信号的互斥候选者,因此我们必须将它们相加以创建一个归一化因子。
- 整个分数:这是 Softmax 函数。它接收原始的、无界的得分,并将它们压缩成一个精确加到 $1$ 的概率分布。
让我们追踪一个抽象数据点通过此方程的精确生命周期。想象一个事件矩阵 $M_i$ 进入流水线,其中包含三个可能的 b 喷注对。
首先,神经网络处理所有三个对的运动学数据,并输出原始分数:正确对的分数为 $2.0$,错误对的分数分别为 $0.5$ 和 $-1.0$。
接下来,$\exp$ 函数会增强这些分数,将其转换为 $7.39$、$1.65$ 和 $0.37$。
然后,分母将这些值收集起来并相加,得到总计 $9.41$。
分数然后将正确对的分数除以总池($7.39 / 9.41$),得到大约 $0.78$ 的概率。
最后,$\log$ 函数评估这个 $0.78$。由于它相对接近 $1.0$,因此产生的惩罚很小。该数据点已成功通过该引擎。
这个机制实际上是如何学习和收敛的?优化动力学依赖于 Softmax 分数产生的损失景观。由于所有概率的总和必须为 $1$,模型被迫进入一个零和博弈。为了最小化损失,网络不能仅仅提高正确对的分数;它必须同时降低错误对的相对分数。
在训练过程中,梯度反向传播通过网络时,它们会调整权重,以识别区分胶子分裂 b 喷注和顶夸克 b 喷注的细微运动学特征(如角距离和不变质量)。损失景观的形状类似于一个多维山谷,最低点对应于网络在每个事件中完美地将真实 b 喷注对排在所有其他对之上。坦白说,我并不完全确定网络架构本身是否不能通过现代注意力机制进一步优化,但作者坚持使用标准的前馈设计,以出色地证明仅仅修复数学目标函数就足以显著优于旧的二元分类方法。
结果、局限性与结论
宏伟的探索:揭示希格斯玻色子的藏身之处
要理解本文的意义,我们必须首先将目光投向粒子物理学的宏大舞台:大型强子对撞机 (LHC)。当物理学家发现希格斯玻色子时,那是一项里程碑式的伟大成就。但发现它仅仅是第一步;第二步是测量其性质,以确保其行为与粒子物理学的标准模型预测完全一致。
希格斯玻色子倾向于衰变成一对底夸克 ($b\bar{b}$)。研究希格斯玻色子的最佳方法之一是当它与一对顶夸克一同产生时,这一过程被称为 $t\bar{t}H(b\bar{b})$。然而,宇宙是一个混乱的地方。存在一个“背景”过程,其外观与我们珍贵的希格斯信号几乎完全相同:$t\bar{t}b\bar{b}$ 过程。这个背景过程会产生一对顶夸克和一对底夸克,但不涉及任何希格斯玻色子。如果我们不能完美地理解和过滤掉这个 $t\bar{t}b\bar{b}$ 背景,我们对希格斯玻色子的测量将永远模糊不清。
核心动机与约束
这里存在一个根本性问题:在 $t\bar{t}b\bar{b}$ 事件中,你有来自两个不同来源的 $b$-喷注(源自底夸克的粒子流)。有些来自顶夸克的衰变,有些来自“胶子分裂”(即一个胶子分裂成两个额外的 $b$-夸克)。为了理解背景,物理学家迫切需要区分源自顶夸克的 $b$-喷注与源自胶子分裂的额外 $b$-喷注。
约束条件:
1. 量子混沌: 这些喷注的运动学性质(动量、角度、能量)受高维、随机的量子过程支配。不存在简单的、硬编码的规则(如“如果能量 > X,则它来自胶子”)。
2. 组合爆炸: 一个事件不会直接给你两个整洁的喷注。它给你的是一团混乱的粒子。你必须查看喷注对,并猜测哪一对是“额外的”。
3. 分布重叠: 如果你观察数百万个事件中的所有 $b$-喷注,来自顶夸克衰变喷注和来自胶子分裂喷注的性质会大规模重叠。
数学解释:他们解决了什么问题?
“受害者”(基线方法):
此前,科学家们将此视为一个标准的二元分类问题。他们取所有事件中的每一对 $b$-喷注,将它们输入深度神经网络 (DNN),然后询问:“这一对是额外的 $b$-喷注对吗?是 (1) 或否 (0)?”他们使用标准的二元交叉熵 ($L_{BCE}$) 进行训练:
$$ L_{BCE} = -\frac{1}{N_p} \sum_{i=1}^{N_p} \left( \xi_i \log f(x_i) + (1 - \xi_i) \log(1 - f(x_i)) \right) $$
缺陷: 这种方法在数学上忽视了数据的结构。它将宇宙中的每一对都视为独立的。但实际上,我们知道一个关键秘密:几乎每一个 $t\bar{t}b\bar{b}$ 事件都包含恰好 ONE 对额外的 $b$-喷注。
绝妙的解决方案:
作者们意识到,我们不应该问“这一对是额外的 $b$-喷注吗?”我们应该着眼于单个事件,并问:“在这特定事件的所有喷注对中,哪一对最可能是额外的 $b$-喷注?”
他们将范式从全局二元分类转移到事件级排序(或事件内的多类分类)。他们定义了一个事件矩阵 $M_i \in \mathbb{R}^{c_i \times F}$,其中 $c_i$ 是事件中 $b$-喷注对的数量,而 $F$ 是特征维度。然后,他们在事件内部的喷注对上应用 softmax 函数,使其概率之和为 1:
$$ f_j(M_i) = \frac{\exp(g_j(M_i))}{\sum_{k=1}^{c_i} \exp(g_k(M_i))} $$
由于最终目标是最大化“匹配效率”(选择正确喷注对的事件百分比),这是一个不可微的量,他们设计了四种代理损失函数。概念上最优美的是概率排序损失 ($L_2$),它迫使网络在特定事件中将真实的额外喷注对的得分高于任何其他喷注对:
$$ L_2 = -\frac{1}{N} \sum_{i=1}^N \sum_{j \neq y_i} \log \left( \frac{f_{y_i}(M_i)}{f_{y_i}(M_i) + f_j(M_i)} \right) $$
他们还利用了分类交叉熵损失 ($L_3$),将正确的喷注对索引视为真实类别:
$$ L_3 = -\frac{1}{N} \sum_{i=1}^N \log f_{y_i}(M_i) $$
严苛的实验架构与确凿证据
作者们不仅仅是随意尝试指标;他们设计了一个两阶段的执行过程,以严酷的方式证明了他们的数学主张。
第一阶段:合成陷阱(概念验证)
他们首先构建了一个 2D 合成数据集,旨在完美模拟物理数据的重叠性质。他们创建了“信号”和“背景”在全局上重叠,但在事件内部局部区分的事件。二元分类器(受害者)惨败,绘制了一个任意的决策边界,因为它被全局重叠所混淆。作者们的新损失函数实现了 100% 的匹配效率,因为它们只比较了各自事件内部的点。这是一次完美无瑕的数学将死。
第二阶段:LHC 模拟
然后,他们使用一个重型物理流程模拟了 $\sqrt{s} = 13$ TeV 的实际质子-质子碰撞:MadGraph5_aMC@NLO(事件生成)$\rightarrow$ Pythia(强子化)$\rightarrow$ DELPHES(CMS 探测器模拟)。这几乎与真实的 LHC 数据一样接近,而无需花费 1.5 亿美元的对撞机时间。
确凿证据:
他们不仅仅是说“准确性提高了”。他们证明了,仅仅通过改变损失函数以尊重事件结构,匹配效率就得到了无可辩驳的提高。对于前阶 (LO) 模拟,效率从 62.1%(使用 $L_{BCE}$ 受害者模型)跃升至 64.5%(使用他们的 $L_3$ 模型)。
但最无可辩驳的证据是视觉和物理上的:图 3。他们绘制了重建的物理分布——特别是角向距离 ($\Delta R$) 和 $b$-喷注对的不变质量。他们提出的方法生成的直方图比二元分类方法更紧密地贴合“真实信号”(生成器级真值)。他们证明了他们的人工智能不仅仅是在学习统计噪声;它正在更准确地恢复底层的量子运动学。
未来对杰出头脑的讨论话题
基于本文,以下是我们必须探索的几个方向,以进一步推动这一前沿:
-
超越前馈网络:图神经网络 (GNN) 的时代
作者们使用了一个深度前馈神经网络,该网络处理喷注对然后进行聚合。然而,一个事件本质上是相互作用粒子的图。如果我们使用注意力机制或 GNN 将整个事件建模为一个全连接图,让网络同时学习所有喷注之间的关联物理学,我们能获得多少更高的匹配效率? -
端到端的原始探测器学习
目前,该方法依赖于 78 个预先计算的运动学变量(如横向动量、伪快度)。如果我们完全绕过人类设计的特征呢?我们能否将 CMS 探测器粒子流算法的原始 3D 点云数据直接输入到 3D 卷积或 PointNet 架构中,让 AI 发现我们甚至没有想到的运动学不变量? -
真实碰撞数据的域适应
本文严重依赖蒙特卡洛模拟(MadGraph/Pythia)。然而,模拟永远无法完美复制真实的 LHC 数据。我们如何整合无监督域适应技术(如梯度反转层),以确保在模拟环境中观察到的匹配效率增益能够完美地迁移到即将到来的高亮度 LHC (HL-LHC) 运行的实际、混乱的数据中?