b-jet 식별 과정에서 추가 b-jet 식별 효율 증대를 위한 학습
To truly understand the significance of this paper, we have to travel back to the monumental discovery of the Higgs boson at the Large Hadron Collider (LHC) in 2012.
배경 및 학술적 계보
이 논문의 중요성을 진정으로 이해하기 위해서는 2012년 거대 강입자 충돌기(LHC)에서의 힉스 보손 발견이라는 기념비적인 사건으로 거슬러 올라가야 한다. 물리학자들이 힉스를 발견한 후, 즉각적으로 제기된 질문은 다음과 같았다: 표준 모형이 예측하는 방식과 정확히 동일하게 작동하는가?
이에 답하기 위해 과학자들은 힉스 보손이 알려진 가장 무거운 입자인 탑 쿼크와 어떻게 상호작용하는지를 살펴본다. 그들은 특히 탑 쿼크 쌍($t\bar{t}$)이 힉스 보손($H$)과 함께 생성되는 $t\bar{t}H$ 과정이라는 충돌 사건을 연구한다. 힉스 보손은 가장 빈번하게 두 개의 바텀 쿼크($b\bar{b}$) 쌍으로 붕괴하기 때문에, 충돌기에서 실제로 탐지되는 최종 잔해는 $t\bar{t}b\bar{b}$ 시그니처가 된다.
여기서부터 엄청난 골칫거리가 시작된다. 우주는 표준적인, 힉스가 아닌 물리학 과정을 통해 자연적으로 $t\bar{t}b\bar{b}$ 사건을 생성한다. 이러한 힉스가 아닌 $t\bar{t}b\bar{b}$ 생성은 막대한 배경 잡음으로 작용한다. 희귀한 힉스 "신호"를 찾기 위해 물리학자들은 이 배경을 완벽하게 이해해야 한다. 이를 위해 그들은 최종 잔해를 살펴보고 어떤 바텀 쿼크가 탑 쿼크에서 유래했으며, 어떤 것이 글루온 분열이라는 무작위 양자 사건에 의해 생성된 "추가적인" 바텀 쿼크인지 구별해야 한다.
이전 접근 방식의 근본적인 한계
이 논문 이전에는 연구자들이 표준적인 머신러닝, 특히 이진 분류를 사용하여 이 식별 문제를 해결하려고 시도했다. 그들은 사건 내의 모든 $b$-제트 쌍을 가져와 신경망에 질문했다: "이 쌍이 추가적인 쌍인가? 예 또는 아니오?"
여기서 근본적인 문제점은 이 접근 방식이 데이터의 물리적 구조를 완전히 무시한다는 것이다. 거의 모든 충돌 사건에서 정확히 하나의 추가 $b$-제트 쌍이 존재한다. 각 쌍을 완전히 분리하여 평가함으로써, 이전 모델들은 "사건 정확도"보다는 전반적인 "쌍 정확도"를 최적화하고 있었다. 마치 컴퓨터에게 A가 맞는지, B가 맞는지, C가 맞는지 독립적으로 추측하게 하여 객관식 시험의 채점을 하는 것과 같다. 이는 옵션 중에서 단 하나의 최적의 답을 고르도록 강제하는 대신에 말이다. 기존 모델들은 전체 사건 맥락을 동시에 보지 않았기 때문에, 사건당 하나의 실제 쌍을 올바르게 식별하는 능력("매칭 효율"이라는 지표)은 단단한 천장에 부딪혔다.
전문 용어 해설
이를 직관적으로 이해하기 위해 논문에서 사용된 매우 전문적인 용어들을 분해해 보자:
- $b$-jet: 바텀($b$) 쿼크가 입자 충돌에서 생성될 때, 거의 즉시 다른 입자들의 원뿔 모양 스프레이로 붕괴한다.
- 비유: $b$-jet을 보이지 않는 동물에 의해 남겨진 독특한 진흙 발자국 세트로 생각하라. 우리는 동물(쿼크)을 볼 수 없지만, 발자국(제트)을 측정하여 어디서 왔는지 알아낼 수 있다.
- 글루온 분열: 글루온(강한 핵력을 전달하는 입자)이 자발적으로 쿼크와 반쿼크 쌍으로 변환되는 양자 과정.
- 비유: 하늘로 쏘아 올라가 갑자기 정확히 두 개의 뚜렷하고 밝은 색상의 불꽃으로 터지는 단일 불꽃놀이 껍질을 상상하라.
- 환원 불가능한 배경: 찾고 있는 희귀 신호와 정확히 동일한 최종 탐지 가능한 입자를 생성하는 배경 잡음 과정.
- 비유: 최종 구워진 케이크만 보고 케이크가 백설탕으로 단맛을 냈는지 갈색 설탕으로 단맛을 냈는지 구별하려고 하는 것과 같다. 최종 결과는 동일하게 보이므로, 구별하기 위해 질감에서 매우 미묘한 단서들을 찾아야 한다.
- 매칭 효율: 알고리즘이 개별 추측에 대한 높은 평균 점수를 얻는 것뿐만 아니라, 추가 $b$-제트의 정확한 올바른 쌍을 성공적으로 식별하는 충돌 사건의 백분율.
- 비유: 저격수의 "한 발, 한 킬" 지표이다. 99명의 무고한 방관자를 "표적이 아님"으로 올바르게 식별하는 것은 중요하지 않다. 중요한 것은 군중 속에 숨겨진 하나의 특정 표적을 완벽하게 골라낼 수 있는지 여부이다.
수학적 문제 및 해결책
저자들은 매칭 효율을 직접적으로 최대화하고자 했다. 수학적으로 이는 크로네커 델타 함수로 표현된다:
$$ \text{Matching efficiency} = \frac{1}{N} \sum_{i=1}^{N} \delta(y_i, \hat{y}(M_i)) $$
여기서 $\delta(y_i, \hat{y}(M_i))$는 모델의 예측 $\hat{y}$가 실제 인덱스 $y_i$와 완벽하게 일치하면 $1$이고, 그렇지 않으면 $0$이다.
수학적 문제는 이 함수가 "하드 스텝"(0에서 1로 즉시 점프하는)이라는 것이다. 머신러닝 환경에서는 하드 스텝에 대해 신경망을 훈련시킬 수 없다. 왜냐하면 기울기(네트워크의 가중치를 업데이트하는 데 사용되는 기울기)가 거의 모든 곳에서 0이기 때문이다. 미적분을 사용하여 최적화할 수 없다.
이 제약을 극복하기 위해 저자들은 기존의 이진 교차 엔트로피 손실($L_{BCE}$)을 버리고 대리 손실 함수($L_1, L_2, L_3, L_4$)를 설계했다. 그들은 신경망의 출력을 소프트맥스 함수를 사용하여 주어진 사건의 모든 쌍에 대한 확률 분포로 변환했다:
$$ f_j(M_i) = \frac{\exp(g_j(M_i))}{\sum_{k=1}^{c_i} \exp(g_k(M_i))} $$
이 방정식은 모델이 사건 행렬 $M_i$의 모든 $c_i$ 쌍을 살펴보고 합이 1이 되는 확률을 할당하도록 강제한다. 그런 다음, 그들은 $L_3$와 같은 범주형 교차 엔트로피 대리 손실을 사용하여 올바른 쌍에 할당된 확률을 최대화하도록 모델을 훈련시킨다:
$$ L_3 = - \frac{1}{N} \sum_{i=1}^{N} \log f_{y_i}(M_i) $$
이렇게 함으로써, 모델은 특정 사건의 맥락 내에서 쌍들을 서로 순위 매기는 것을 학습하고, 기울기 하강 규칙을 위반하지 않으면서 직접적으로 매칭 효율을 최적화한다.
주요 수학적 표기
| 표기 | 유형 | 설명 |
|---|---|---|
| $N$ | 매개변수 | 시뮬레이션된 $t\bar{t}b\bar{b}$ 사건 데이터 샘플의 총 개수. |
| $c_i$ | 변수 | $i$-번째 사건에 존재하는 $b$-제트 쌍의 총 개수. |
| $F$ | 매개변수 | 단일 $b$-제트 쌍을 나타내는 특징 벡터의 차원. |
| $M_i$ | 변수 | $i$-번째 사건에 대한 사건 행렬로, 모든 $b$-제트 쌍을 포함하며, 차원은 $\mathbb{R}^{c_i \times F}$이다. |
| $y_i$ | 변수 | $i$-번째 사건에서 추가 $b$-제트의 실제 쌍을 나타내는 (1부터 $c_i$까지의) 실제 정수 인덱스. |
| $\hat{y}(M_i)$ | 변수 | 모델이 출력한 추가 $b$-제트 쌍의 예측 인덱스. |
| $f_j(M_i)$ | 변수 | $M_i$ 사건의 $j$-번째 $b$-제트 쌍이 추가 쌍일 확률에 대한 모델의 예측값. |
| $g_j(M_i)$ | 변수 | 확률로 변환되기 전에 신경망이 $j$-번째 $b$-제트 쌍에 대해 계산한 원시 활성화 값(점수). |
| $L_{BCE}$ | 함수 | 이전의 제한적인 모델에서 사용된 전통적인 이진 교차 엔트로피 손실. |
| $L_1, L_2, L_3, L_4$ | 함수 | 매칭 효율을 부드럽게 근사하고 최대화하도록 설계된 제안된 대리 손실 함수들. |
문제 정의 및 제약 조건
이 논문이 다루는 문제의 규모를 이해하기 위해, 사람이 붐비고 시끄러운 경기장에서 매우 희미하고 특정적인 속삭임을 들으려고 한다고 상상해보자. 입자 물리학의 세계에서 그 속삭임은 우주의 모든 것에 질량을 부여하는 기본 입자인 힉스 보손이다. 그러나 물리학자들이 힉스 보손을 연구하기 위해 거대 강입자 충돌기(LHC)에서 양성자를 충돌시킬 때, 그들은 엄청난 양의 배경 잡음에 귀가 먹먹해진다.
가장 큰 잡음은 $t\bar{t}b\bar{b}$라고 불리는 물리적 과정에서 발생하며, 이는 탑 쿼크 쌍과 함께 바텀 쿼크($b$) 쌍을 생성한다. 이 과정에서 발생하는 파편은 힉스 보손에서 발생하는 파편과 거의 똑같이 보인다. 이 잡음을 걸러내기 위해 물리학자들은 결과로 나오는 "b-젯"(입자들의 분사)을 살펴보고 그 기원 이야기를 파악해야 한다: 이 b-젯들은 무거운 탑 쿼크가 붕괴하면서 생성된 것인가, 아니면 "글루온 분열"이라는 이차적 과정을 통해 단순히 존재하게 된 것인가?
시작점과 목표 상태
입력 (현재 상태):
입자 충돌("이벤트")이 발생하면, 검출기는 파편의 운동학적 특성을 포착한다. 저자들은 이 데이터를 수학적으로 이벤트 행렬 $M_i \in \mathbb{R}^{c_i \times F}$로 표현한다. 여기서 $c_i$는 단일 충돌 이벤트에서 가능한 b-젯 쌍의 수를 나타내고, $F$는 각 쌍의 고차원 물리적 특징(운동량 및 에너지 등)을 나타낸다.
출력 (목표 상태):
원하는 최종 결과는 이 행렬을 보고 정확히 하나의 특정 행을 가리키며 자신 있게 선언할 수 있는 신경망이다: "이 특정 b-젯 쌍은 글루온 분열에 의해 생성된 추가 쌍이다."
수학적 간극:
누락된 연결고리는 동일한 이벤트 내에서 b-젯 쌍을 서로 상대적으로 평가하는 특화된 수학적 다리이다. 우리는 단순히 하나의 쌍이 고립된 상태에서 추가 b-젯처럼 보이는지 알고 싶은 것이 아니다. 우리는 신경망이 행렬 $M_i$의 모든 쌍을 순위 매기고 확률 합이 1이 되는 확률 분포 $f(M_i) \in [0, 1]^{c_i}$를 출력하기를 원한다. 가장 높은 확률이 올바른 쌍을 나타낸다.
고통스러운 딜레마
이전 연구자들은 고전적인 머신러닝 함정에 빠졌다: 그들은 이를 표준 이진 분류 문제로 취급했다. 그들은 모든 이벤트에서 모든 b-젯 쌍을 가져와 모두 섞은 다음, 표준 이진 교차 엔트로피 손실 함수($L_{BCE}$)를 사용하여 신경망에게 "예" 또는 "아니오"를 추측하도록 요청했다.
이는 계산 편의성과 물리적 현실 사이의 고통스러운 절충을 야기했다. 이진 분류는 수학적으로 최적화하기 쉽지만, 물리학의 구조적 현실을 완전히 무시한다: 거의 모든 $t\bar{t}b\bar{b}$ 이벤트는 정확히 하나의 추가 b-젯 쌍을 포함한다. 각 쌍을 독립적으로 평가함으로써, 이전 모델들은 중요한 맥락적 단서를 버렸다.
그러나 만약 당신이 이진 분류를 포기하고 실제로 관심 있는 것, 즉 "매칭 효율"(모델이 정확한 쌍을 선택하는 총 이벤트의 비율)을 직접 최적화함으로써 이를 수정하려고 한다면, 당신은 즉시 수학을 깨뜨리게 된다. 당신은 훈련하기 쉬우나 구조적으로 결함이 있는 모델과, 구조적으로 정확하나 수학적으로 훈련이 불가능한 모델 사이에서 선택해야 한다.
가혹한 벽과 제약
이 문제를 해결하기 어렵게 만드는 것은 무엇인가? 저자들은 몇 가지 거대한 벽에 부딪혔다:
1. 미분 불가능한 벽 (수학적 제약)
궁극적인 목표는 다음과 같이 수학적으로 정의되는 매칭 효율을 최대화하는 것이다:
$$ \text{Matching efficiency} = \frac{1}{N} \sum_{i=1}^{N} \delta(y_i, \hat{y}(M_i)) $$
여기서 $\delta$는 크로네커 델타 함수이다. 이 함수는 가혹하고 엄격한 계단과 같아서, 모델의 예측 $\hat{y}$가 실제 레이블 $y_i$와 정확히 일치하면 1이고 그렇지 않으면 0이다. 미적분학에서 평평한 계단의 도함수(기울기)는 0이다. 신경망은 기울기(경사 하강법)를 따라 학습한다. 크로네커 델타는 거의 모든 곳에서 0의 기울기를 반환하며 매우 미분 불가능하기 때문에, 신경망은 완전히 눈이 멀게 된다. 수학이 개선 방법을 알려주는 방향적 피드백을 제공하지 않기 때문에 학습할 수 없다.
2. 가변 데이터 구조 (계산적 제약)
모든 양자 충돌은 고유하게 혼란스럽다. 어떤 이벤트는 3쌍의 b-젯을 생성할 수 있고, 다음 이벤트는 6쌍을 생성할 수 있다. 이는 입력 행렬 $M_i$가 끊임없이 변화하는 행의 수($c_i$)를 갖는다는 것을 의미한다. 신경망 아키텍처는 충돌 없이 가변 크기 입력을 처리할 수 있을 만큼 동적으로 유연해야 하며, 동시에 순열 등변(b-젯 쌍이 모델에 입력되는 순서가 모델의 기본 논리를 변경해서는 안 된다는 의미)이어야 한다.
3. 극심한 양자 복잡성 (물리적 제약)
이러한 제트들을 분리하는 간단하고 하드코딩된 물리 법칙은 존재하지 않는다. 데이터는 매우 복잡하고 확률적인 양자 과정에 의해 생성된다. 특징을 수작업으로 만드는 것은 거의 불가능하다. 운동학적 관측량들은 깊이 얽혀 있으며, 이는 모델이 명시적인 인간이 만든 규칙의 안내 없이 순전히 시뮬레이션된 데이터로부터 고차원 관계를 풀어내는 방법을 배워야 함을 의미한다.
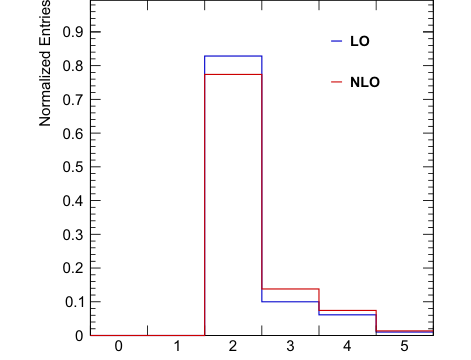 Figure 4. Histograms for the number of generator-level additional b-jets in simulated t¯tb¯b events at both the leading order (LO) and the next-to-leading order (NLO). Note that most events have two additional b-jets (82.8% for LO and 77.4% for NLO)
Figure 4. Histograms for the number of generator-level additional b-jets in simulated t¯tb¯b events at both the leading order (LO) and the next-to-leading order (NLO). Note that most events have two additional b-jets (82.8% for LO and 77.4% for NLO)
이 접근 방식은 왜
이러한 특정 수학적 경로를 저자들이 선택한 이유를 이해하려면, 이전의 gold standard가 근본적으로 결함이 있음을 깨달은 정확한 순간을 파악해야 한다. 본 논문 이전에는 $t\bar{t}b\bar{b}$ 과정에서 추가적인 b-jet을 식별하는 state-of-the-art (SOTA) 접근 방식은 표준 이진 분류기로 Deep Neural Network (DNN)을 사용하는 것이었다. 이 이전 방법은 각 b-jet 쌍을 네트워크에 입력하고 Binary Cross-Entropy loss ($L_{BCE}$)를 최소화하여 0과 1 사이의 확률을 출력했다.
저자들에게 "아하!"의 순간은 입자 충돌 데이터의 물리적 현실을 살펴보았을 때 찾아왔다. 거의 모든 유효한 $t\bar{t}b\bar{b}$ 이벤트에서 글루온 분열에서 발생하는 추가 b-jet 쌍은 정확히 하나이다. 전통적인 이진 분류 접근 방식은 이 근본적인 제약을 완전히 무시한다. 이는 각 b-jet 쌍을 개별적으로 취급하며, "이 쌍이 신호인가?"라고 묻는 대신, 훨씬 더 관련성 있는 질문인 "이 특정 이벤트에서 어떤 쌍이 신호인가?"라고 묻는다. 쌍을 독립적으로 취급함으로써, 이전 모델은 중요한 맥락 정보를 버리고 실제 목표인 매칭 효율성 대신 이진 정확도를 최적화했다.
이러한 깨달음은 그들이 제안한 수학적 모델을 유일하게 실행 가능한 해결책으로 만들었다. 독립적인 분류 대신, 그들은 전체 이벤트 행렬 $M_i \in \mathbb{R}^{c_i \times F}$ (여기서 $c_i$는 $i$-번째 이벤트의 b-jet 쌍의 수이고, $F$는 특징 차원)을 처리하는 permutation-equivariant 모델을 공식화했다. 그들은 단일 이벤트 내의 모든 쌍에 대한 출력에 softmax 함수를 적용했다:
$$ f_j(M_i) = \frac{\exp(g_j(M_i))}{\sum_{k=1}^{c_i} \exp(g_k(M_i))} $$
이는 단일 이벤트 내의 모든 쌍에 대한 확률의 합이 정확히 1이 되도록 보장한다 ($\sum_{j=1}^{c_i} f_j(M_i) = 1$).
이 방법의 비교 우위는 개념 증명 합성 데이터 실험에서 아름답게 설명된다. 확률적 생성 프로세스를 갖는 고차원 공간에서 배경 노이즈는 전역적으로 볼 때 신호와 종종 겹친다. 전통적인 이진 분류기는 모든 이벤트의 모든 데이터 포인트에 대해 단일의 전역 결정 경계를 그리려고 시도하며, 이 중첩으로 인해 임의적이고 매우 부정확한 분리가 발생한다. 대조적으로, 저자들의 방법은 동일한 이벤트 행렬 내에서 쌍을 서로 상대적으로 평가한다. 그렇게 함으로써, 전역 노이즈 중첩을 효과적으로 우회하고 신호를 완벽하게 분리하는 깨끗하고 상대적인 결정 경계를 학습한다. 이는 메모리 복잡성을 $O(N^2)$에서 $O(N)$으로 반드시 줄이지는 않지만, 단일 이벤트의 경계로 비교 공간을 제한함으로써 계산적 혼란을 극적으로 줄인다.
이 선택된 방법은 문제의 가혹한 제약 조건과 완벽하게 일치한다. 궁극적인 목표는 크로네커 델타 함수를 사용하여 수학적으로 정의된 매칭 효율성을 최대화하는 것이다:
$$ \text{Matching efficiency} = \frac{1}{N} \sum_{i=1}^{N} \delta(y_i, \hat{y}(M_i)) $$
이 계단 함수는 매우 비부드럽고 미분 불가능하여 (0 그래디언트를 반환함) 그래디언트 하강법으로 직접 최적화할 수 없다. 문제의 제약 조건과 해결책 사이의 "결혼"은 저자들이 고안한 대리 손실 함수의 영리함에 있다. 이벤트 행렬의 행 인덱스를 구별되는 범주로 취급함으로써, 그들은 문제를 다중 클래스 분류 또는 순위 지정 작업으로 변환했다. 예를 들어, 그들의 확률적 순위 손실 ($L_2$)과 범주형 교차 엔트로피 손실 ($L_3$)은 실제 추가 b-jet 쌍이 특정 이벤트 구조 내에서 가장 높은 상대 점수를 받지 못하면 네트워크에 직접 페널티를 부과한다.
솔직히 말해서, 저자들이 텍스트에서 전혀 언급하거나 암시하지 않았기 때문에 GAN, 표준 Diffusion 또는 Transformer와 같은 유행하는 생성 모델이 여기서 어떻게 작동할지는 완전히 확신할 수 없다. GAN 또는 Diffusion 모델을 적용하는 것은 본질적으로 매우 제약된 조합 순위 지정 문제에 대해 엄청난 과잉이며 계산적으로 낭비될 것이라고 생각한다. 그러나 저자들은 가장 인기 있는 대안인 이진 분류 DNN을 거부한 이유를 명확하게 설명한다. 그들은 $L_{BCE}$를 최적화하는 것이 물리적 목표와 수학적으로 일치하지 않기 때문에 이를 거부했다. 심지어 이진 분류기를 업그레이드하여 이벤트의 다른 b-jet의 특징을 포함시켰음에도 불구하고 (그들의 "Model 2"), 이는 그들이 제안한 대리 손실 ($L_2$ 및 $L_3$)에 미치지 못했다. 이진 접근 방식은 훈련 중에 쌍을 나란히 비교하도록 수학적으로 강제되지 않았기 때문에 이벤트에서 가장 높은 점수를 받은 쌍이 실제로 올바르다는 것을 보장할 수 없다.
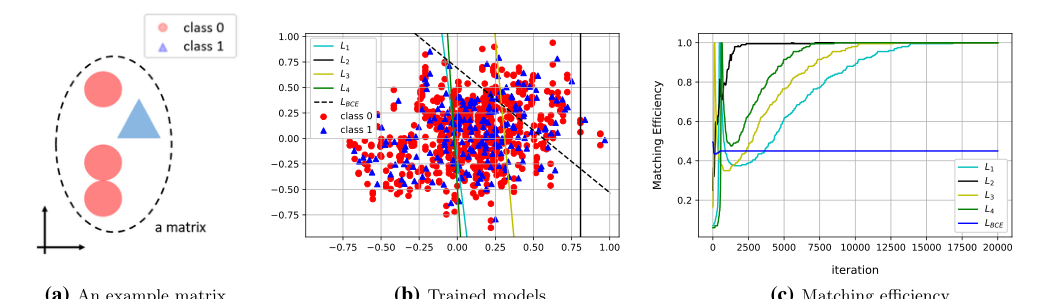 Figure 2. Experimental results from synthetic data. (a) An example matrix is illustrated. (b) The level sets of the trained models are drawn over the data scatter plot. (c) Matching efficiencies (evaluated on a test data set) for each of the loss functions are shown
Figure 2. Experimental results from synthetic data. (a) An example matrix is illustrated. (b) The level sets of the trained models are drawn over the data scatter plot. (c) Matching efficiencies (evaluated on a test data set) for each of the loss functions are shown
수학적 및 논리적 메커니즘
거대 강입자 충돌기(LHC)의 제어실 안에 서 있다고 상상해 보십시오. 충돌이 발생할 때마다 입자는 빛의 속도에 가까운 속도로 산산조각 나며, "제트(jets)"라고 불리는 아원자 파편의 폭포를 생성합니다. 물리학자들은 힉스 보손의 특성을 필사적으로 찾고 있으며, 이는 종종 "b-제트(b-jets)"라고 불리는 특정 유형의 파편으로 붕괴됩니다.
그러나 거대한 문제가 있습니다. $t\bar{t}b\bar{b}$(탑 쿼크 쌍과 b 쿼크 쌍)라고 불리는 완전히 다른, 잡음이 많은 배경 과정이 정확히 동일한 b-제트를 생성합니다. 이 잡음을 걸러내기 위해 물리학자들은 어떤 b-제트가 주요 사건(탑 쿼크 붕괴)에서 왔고 어떤 것이 단순히 추가 파편(글루온 분열이라는 현상에서 유래)이었는지 파악해야 합니다.
이전에는 과학자들이 머신러닝을 사용하여 각 b-제트 쌍을 개별적으로 살펴보고 "추가 파편인가?"라는 간단한 예/아니오 질문을 했습니다. 이 이진 분류 접근 방식은 물리학의 기본 규칙을 무시했기 때문에 결함이 있었습니다. 거의 모든 유효한 사건에는 정확히 하나의 추가 b-제트 쌍이 존재합니다. 각 쌍을 독립적으로 처리함으로써 이전 모델은 귀중한 맥락 정보를 놓치고 있었습니다.
이 논문의 저자들은 패러다임을 전환함으로써 이를 해결했습니다. "이 쌍이 추가 파편인가?"라고 묻는 대신, 그들은 신경망을 설계하여 단일 사건의 모든 쌍을 동시에 살펴보고 "너희 중 누가 가장 가능성 있는 후보인가?"라고 물었습니다. 그들은 표준 이진 정확도를 포기하고 사용자 정의 손실 함수를 설계하여 "매칭 효율성"—모델이 라인업에서 단 하나의 올바른 쌍을 선택하는 비율—을 직접 최대화함으로써 이를 달성했습니다.
다음은 그들의 가장 성공적인 모델을 구동하는 절대적인 핵심 수학 엔진으로, 이벤트 수준 확률 분포(Softmax)와 범주형 교차 엔트로피 대리 손실을 결합한 것입니다.
$$ L_3 = -\frac{1}{N} \sum_{i=1}^N \log \left( \frac{\exp(g_{y_i}(M_i))}{\sum_{k=1}^{c_i} \exp(g_k(M_i))} \right) $$
이 방정식을 조각별로 분석하여 작동 방식을 이해해 봅시다.
- $L_3$: 이것은 대리 손실 함수입니다. 신경망이 얼마나 잘못했는지를 알려주는 궁극적인 오류 신호 역할을 합니다. 훈련 과정의 목표는 이 숫자를 최소화하는 것입니다.
- $-\frac{1}{N} \sum_{i=1}^N$: 이는 데이터셋의 모든 $N$개 이벤트에 대한 평균 오류를 계산합니다. 왜 적분이 아닌 합계인가? 충돌 이벤트의 수 $N$은 엄격하게 이산적이고 셀 수 있기 때문입니다. 충돌의 일부를 가질 수 없으므로 연속 공간에 대한 적분은 물리적 또는 논리적으로 의미가 없을 것입니다.
- $\log$: 자연 로그입니다. 모델이 확신을 가지고 틀렸을 때 모델을 크게 처벌하는 논리적 역할을 합니다. 모델이 올바른 쌍에 대해 1에 가까운 확률을 할당하면, 1의 로그는 0(처벌 없음)입니다. 그러나 확률이 0에 가까워지면 로그는 음의 무한대로 급락하여 잘못된 예측에서 모델을 격렬하게 끌어내는 거대한 고무줄 효과를 만듭니다.
- $M_i$: $i$-번째 이벤트 행렬입니다. 이는 특정 충돌에서 각 b-제트 쌍에 대한 모든 운동학적 변수(운동량 및 각도와 같은)를 포함하는 원시 데이터 입력입니다.
- $y_i$: 이벤트 $i$에서 실제 추가 b-제트 쌍의 인덱스입니다. 이는 물리학 시뮬레이션에서 제공하는 "ground truth" 레이블입니다.
- $g_{y_i}(M_i)$: 올바른 b-제트 쌍에 대한 신경망 $g$의 원시 출력 점수(logit)입니다. 이는 원시 신뢰도 측정기 역할을 합니다.
- $\exp(\dots)$: 지수 함수입니다. 모든 점수가 엄격하게 양수임을 보장하고 높은 점수와 낮은 점수 간의 차이를 과장하여 네트워크의 선호도를 더 결정적으로 만듭니다.
- $\sum_{k=1}^{c_i} \exp(g_k(M_i))$: 분모는 이벤트 $i$의 모든 $c_i$ 가능한 b-제트 쌍의 지수화된 점수를 합산합니다. 여기서 곱셈 대신 덧셈을 사용하는 이유는 무엇입니까? 덧셈은 이벤트의 총 "확률 질량"을 풀링합니다. 곱셈을 사용하면 독립적인 이벤트가 동시에 발생하는 결합 확률을 계산하게 됩니다. 그러나 이 쌍들은 단일 신호에 대한 상호 배타적인 후보이므로, 정규화 인수를 만들기 위해 더해야 합니다.
- 전체 분수: 이것은 Softmax 함수입니다. 원시적이고 제한되지 않은 점수를 가져와 정확히 1로 합산되는 깔끔한 확률 분포로 압축합니다.
이 방정식이 단일 추상 데이터 포인트의 정확한 수명 주기를 추적해 봅시다. 세 개의 가능한 b-제트 쌍을 포함하는 이벤트 행렬 $M_i$가 조립 라인에 들어온다고 상상해 보십시오.
먼저, 신경망은 세 쌍 모두의 운동학적 데이터를 처리하고 원시 점수를 출력합니다. 올바른 쌍에 대해 2.0, 잘못된 쌍에 대해 0.5 및 -1.0입니다.
다음으로, $\exp$ 함수는 이러한 점수를 강화하여 7.39, 1.65 및 0.37로 바꿉니다.
그런 다음, 분모는 이러한 값을 수집하고 합산하여 총 풀 9.41을 얻습니다.
분수는 올바른 쌍의 점수를 총 풀로 나눕니다(7.39 / 9.41), 결과적으로 약 0.78의 확률이 됩니다.
마지막으로, $\log$ 함수는 이 0.78을 평가합니다. 1.0에 상대적으로 가깝기 때문에 결과적인 페널티는 작습니다. 데이터 포인트는 엔진을 성공적으로 통과했습니다.
이 메커니즘이 실제로 학습하고 수렴하는 방법은 무엇입니까? 최적화 역학은 Softmax 분수에 의해 생성된 손실 풍경에 의존합니다. 모든 확률의 합이 1이어야 하므로 모델은 제로섬 게임에 강요됩니다. 손실을 최소화하기 위해 네트워크는 올바른 쌍의 점수를 올리기만 할 수 없습니다. 동시에 잘못된 쌍의 상대 점수를 낮춰야 합니다.
훈련 중에 그래디언트가 네트워크를 통해 역방향으로 흐르면서 가중치를 조정하여 글루온 분열 b-제트와 탑 쿼크 b-제트를 구별하는 미묘한 운동학적 서명(각도 거리 및 불변 질량과 같은)을 인식합니다. 손실 풍경은 다차원 계곡 모양이며, 가장 낮은 지점은 네트워크가 각 이벤트에서 참 b-제트 쌍을 다른 모든 쌍보다 완벽하게 순위 매기는 것에 해당합니다. 솔직히 말해서, 현대적인 어텐션 메커니즘으로 네트워크 아키텍처 자체를 더 최적화할 수 있는지 완전히 확신할 수는 없지만, 저자들은 단순히 수학적 목적 함수를 수정하는 것만으로도 기존의 이진 분류 방법을 크게 능가할 수 있음을 입증하기 위해 표준 피드포워드 설계를 고수했습니다.
결과, 한계점 및 결론
위대한 탐구: 힉스 보손의 은신처를 밝히다
이 논문의 중요성을 이해하기 위해서는 먼저 입자 물리학의 가장 거대한 무대인 거대 강입자 충돌기(LHC)로 시야를 넓혀야 한다. 물리학자들이 힉스 보손을 발견했을 때, 그것은 기념비적인 성과였다. 하지만 이를 발견하는 것은 단지 첫 번째 단계일 뿐이며, 두 번째 단계는 힉스 보손이 입자 물리학의 표준 모형이 예측하는 대로 정확히 거동하는지 확인하기 위해 그 특성을 측정하는 것이다.
힉스 보손은 두 개의 바텀 쿼크($b\bar{b}$) 쌍으로 붕괴되는 것을 선호한다. 힉스를 연구하는 가장 좋은 방법 중 하나는 그것이 탑 쿼크 쌍과 함께 생성될 때인데, 이는 $t\bar{t}H(b\bar{b})$라는 과정으로 알려져 있다. 그러나 우주는 혼란스러운 곳이다. 우리의 소중한 힉스 신호와 거의 똑같이 보이는 "배경" 과정이 존재하는데, 이는 $t\bar{t}b\bar{b}$ 과정이다. 이 배경 과정은 힉스 보손 없이 탑 쿼크 쌍과 바텀 쿼크 쌍을 생성한다. 만약 우리가 이 $t\bar{t}b\bar{b}$ 배경을 완벽하게 이해하고 걸러내지 못한다면, 힉스 보손에 대한 우리의 측정은 영원히 흐릿해질 것이다.
핵심 동기와 제약 조건
여기 근본적인 문제가 놓여 있다. $t\bar{t}b\bar{b}$ 사건에서 두 개의 서로 다른 출처에서 비롯된 $b$-제트(바텀 쿼크에서 기원한 입자들의 분사)가 존재한다. 일부는 탑 쿼크의 붕괴에서 오고, 일부는 "글루온 분열"(글루온이 두 개의 추가적인 $b$-쿼크로 분열되는 현상)에서 온다. 배경을 이해하기 위해 물리학자들은 탑 쿼크에서 태어난 $b$-제트와 "추가적인" $b$-제트(글루온 분열에서 태어난)를 구별해야 한다.
제약 조건:
1. 양자 혼돈: 이 제트들의 운동학적 특성(운동량, 각도, 에너지)은 고차원적이고 확률적인 양자 과정에 의해 지배된다. "에너지가 X보다 크면 글루온에서 온 것이다"와 같은 단순하고 고정된 규칙은 존재하지 않는다.
2. 조합 폭발: 사건은 단순히 두 개의 깔끔한 제트를 제공하지 않는다. 그것은 입자들의 혼란을 제공한다. 우리는 제트 쌍을 살펴보고 어떤 쌍이 "추가적인" 것인지 추측해야 한다.
3. 중첩되는 분포: 수백만 건의 사건에 걸쳐 모든 $b$-제트를 살펴보면, 탑 붕괴 제트와 글루온 분열 제트의 특성이 엄청나게 중첩된다.
수학적 해석: 무엇을 해결했는가?
"희생양" (기준 접근 방식):
이전에는 과학자들이 이를 표준 이진 분류 문제로 취급했다. 그들은 모든 사건에 걸쳐 모든 $b$-제트 쌍을 가져와 딥 뉴럴 네트워크(DNN)에 넣고 "이 쌍이 추가적인 $b$-제트 쌍인가? 예(1) 또는 아니오(0)?"라고 물었다. 그들은 표준 이진 교차 엔트로피($L_{BCE}$)를 사용하여 이를 훈련했다.
$$ L_{BCE} = -\frac{1}{N_p} \sum_{i=1}^{N_p} \left( \xi_i \log f(x_i) + (1 - \xi_i) \log(1 - f(x_i)) \right) $$
결함: 이 접근 방식은 데이터의 구조에 대해 수학적으로 맹목적이다. 그것은 우주의 모든 쌍을 독립적으로 취급한다. 그러나 현실에서는 우리는 중요한 비밀을 알고 있다. 거의 모든 $t\bar{t}b\bar{b}$ 사건은 정확히 하나의 추가적인 $b$-제트 쌍을 포함한다.
훌륭한 해결책:
저자들은 "이 쌍이 추가적인 $b$-제트인가?"라고 묻는 대신, 단일 사건을 살펴보고 "이 특정 사건 내의 모든 쌍 중에서 어떤 것이 추가적인 $b$-제트일 가능성이 가장 높은가?"라고 물어야 한다고 깨달았다.
그들은 패러다임을 전역 이진 분류에서 사건 수준 순위 지정(또는 사건 내 다중 클래스 분류)으로 전환했다. 그들은 사건 행렬 $M_i \in \mathbb{R}^{c_i \times F}$를 정의했는데, 여기서 $c_i$는 사건 내 $b$-제트 쌍의 수이고 $F$는 특징 차원이다. 그런 다음 그들은 사건 내의 쌍에 대해 소프트맥스 함수를 적용하여 확률의 합이 1이 되도록 했다.
$$ f_j(M_i) = \frac{\exp(g_j(M_i))}{\sum_{k=1}^{c_i} \exp(g_k(M_i))} $$
궁극적인 목표는 미분 불가능한 "매칭 효율성"(정확한 쌍이 선택되는 사건의 비율)을 최대화하는 것이므로, 그들은 네 가지 대리 손실 함수를 설계했다. 가장 개념적으로 아름다운 것은 확률적 순위 지정 손실($L_2$)로, 네트워크가 해당 특정 사건 내의 다른 모든 쌍보다 실제 추가 쌍에 더 높은 점수를 주도록 강제한다.
$$ L_2 = -\frac{1}{N} \sum_{i=1}^N \sum_{j \neq y_i} \log \left( \frac{f_{y_i}(M_i)}{f_{y_i}(M_i) + f_j(M_i)} \right) $$
그들은 또한 올바른 쌍 인덱스를 실제 클래스로 취급하는 범주형 교차 엔트로피 손실($L_3$)을 사용했다.
$$ L_3 = -\frac{1}{N} \sum_{i=1}^N \log f_{y_i}(M_i) $$
무자비한 실험 구조와 결정적 증거
저자들은 단순히 지표를 벽에 던지지 않았다. 그들은 수학적 주장을 무자비하게 증명하기 위해 두 단계 실행을 설계했다.
1단계: 합성 함정 (개념 증명)
그들은 먼저 물리 데이터의 중첩되는 특성을 완벽하게 모방하도록 설계된 2D 합성 데이터셋을 구축했다. 그들은 "신호"와 "배경"이 전역적으로 중첩되지만 사건 내부에서는 구별되는 사건을 생성했다. 이진 분류기(희생양)는 전역적 중첩으로 인해 혼란스러워 임의의 결정 경계를 그려 끔찍하게 실패했다. 저자들의 새로운 손실 함수는 각 사건 내의 점들만 비교했기 때문에 100% 매칭 효율성을 달성했다. 그것은 완벽한 수학적 체크메이트였다.
2단계: LHC 시뮬레이션
그런 다음 그들은 강력한 물리 파이프라인(MadGraph5_aMC@NLO (사건 생성) $\rightarrow$ Pythia (강입자화) $\rightarrow$ DELPHES (CMS 검출기 시뮬레이션))을 사용하여 $\sqrt{s} = 13$ TeV에서 실제 양성자-양성자 충돌을 시뮬레이션했다. 이는 1억 5천만 달러의 충돌기 시간을 사용하지 않고 실제 LHC 데이터에 최대한 근접한 것이다.
결정적 증거:
그들은 단순히 "정확도가 향상되었다"고 말하지 않았다. 그들은 손실 함수만 변경하여 사건 구조를 존중함으로써 매칭 효율성이 부인할 수 없이 향상되었음을 증명했다. 선행 순서(LO) 시뮬레이션의 경우, 효율성은 62.1%($L_{BCE}$ 희생양 모델 사용)에서 64.5%($L_3$ 모델 사용)로 급증했다.
그러나 가장 부인할 수 없는 증거는 시각적이고 물리적인 것이다. 그림 3이다. 그들은 재구성된 물리적 분포, 특히 각도 거리($\Delta R$)와 $b$-제트 쌍의 불변 질량을 플롯했다. 그들의 제안된 방법으로 생성된 히스토그램은 이진 분류 접근 방식보다 "실제 신호"(생성기 수준 진실)에 훨씬 더 가깝게 달라붙었다. 그들은 AI가 단순히 통계적 노이즈를 학습하는 것이 아니라, 근본적인 양자 운동학을 더 정확하게 복구하고 있음을 증명했다.
뛰어난 정신을 위한 미래 논의 주제
이 논문을 바탕으로, 이 최전선을 더욱 발전시키기 위해 우리가 탐구해야 할 몇 가지 방향이 있다.
-
순방향 신경망을 넘어서: 그래프 신경망(GNN)의 시대
저자들은 제트 쌍을 처리한 다음 이를 집계하는 심층 순방향 신경망을 사용했다. 그러나 사건은 본질적으로 상호 작용하는 입자들의 그래프이다. 주의 메커니즘이나 GNN을 사용하여 전체 사건을 완전 연결 그래프로 모델링하면, 네트워크가 모든 제트 간의 관계 물리학을 동시에 학습할 수 있다면 얼마나 더 많은 매칭 효율성을 달성할 수 있을까? -
원시 검출기 학습의 종단 간 처리
현재 이 방법은 78개의 사전 계산된 운동학적 변수(횡단면 운동량, 의사-고유도 등)에 의존한다. 인간이 설계한 특징을 완전히 우회하면 어떻게 될까? CMS 검출기의 입자 흐름 알고리즘에서 나온 원시 3D 포인트 클라우드 데이터를 3D 컨볼루션 또는 PointNet 아키텍처에 직접 공급하여 AI가 아직 생각하지 못한 운동학적 불변량을 발견하도록 할 수 있을까? -
실제 충돌 데이터에 대한 도메인 적응
이 논문은 몬테카를로 시뮬레이션(MadGraph/Pythia)에 크게 의존한다. 그러나 시뮬레이션은 실제 LHC 데이터를 완벽하게 복제하지는 못한다. 무지도메인 적응 기법(예: Gradient Reversal Layers)을 통합하여 시뮬레이션 환경에서 관찰된 매칭 효율성 이득이 다가오는 고휘도 LHC(HL-LHC) 실행의 실제 혼란스러운 데이터로 완벽하게 이전되도록 어떻게 보장할 수 있을까?