अनुरूप भविष्यवाणी सेट के लिए प्रतितथ्यात्मक स्पष्टीकरण
मशीन लर्निंग मॉडल को उच्च दांव वाले वातावरणों में तेजी से तैनात किया जा रहा है—जैसे कि चिकित्सा निदान या वित्तीय ऋण अनुमोदन—जहां \$150 की गलती एक मामूली असुविधा हो सकती है, लेकिन \$150,000 की गलती विनाशकारी हो सकती...
पृष्ठभूमि और अकादमिक वंश
मशीन लर्निंग मॉडल को उच्च-दांव वाले वातावरणों में तेजी से तैनात किया जा रहा है—जैसे कि चिकित्सा निदान या वित्तीय ऋण अनुमोदन—जहां \$150 की गलती एक मामूली असुविधा हो सकती है, लेकिन \$150,000 की गलती विनाशकारी हो सकती है। इन महत्वपूर्ण डोमेन में, केवल एक "सर्वश्रेष्ठ अनुमान" (एक बिंदु भविष्यवाणी) प्रदान करना पर्याप्त नहीं है। निर्णय निर्माताओं को मॉडल की अनिश्चितता को समझने की आवश्यकता है।
इसे हल करने के लिए, अकादमिक क्षेत्र ने लगभग 2005 में कन्फॉर्मल प्रेडिक्शन (CP) विकसित किया। एक एकल लेबल आउटपुट करने के बजाय, एक कन्फॉर्मल प्रेडिक्टर गणितीय गारंटी के साथ संभावित लेबल का एक सेट आउटपुट करता है कि वास्तविक लेबल शामिल है (उदाहरण के लिए, "मुझे 95% यकीन है कि रोगी की स्थिति या तो स्वस्थ है या डायबिटिक है")।
साथ ही, जैसे-जैसे मशीन लर्निंग मॉडल जटिल "ब्लैक बॉक्स" बनते गए, एक्सप्लेनबल AI (XAI) का क्षेत्र उभरा। सबसे सहज XAI तकनीकों में से एक काउंटरफैक्चुअल एक्सप्लेनेशन (लगभग 2017 में लोकप्रिय) है, जो उपयोगकर्ता को बताता है कि मॉडल के निर्णय को पलटने के लिए कौन से न्यूनतम परिवर्तन आवश्यक हैं।
इस पेपर में संबोधित विशिष्ट समस्या इन दो क्षेत्रों के सटीक चौराहे पर उभरी: कन्फॉर्मल प्रेडिक्टर्स द्वारा उत्पादित अनिश्चितता-जागरूक सेटों की व्याख्या हम कैसे करें? जबकि हमारे पास एकल भविष्यवाणियों की व्याख्या करने के लिए बेहतरीन उपकरण हैं, और अनिश्चितता को मापने के लिए बेहतरीन उपकरण हैं, हमारे पास यह समझाने के लिए एक पुल की कमी थी कि मॉडल की अनिश्चितता क्यों एक भविष्यवाणी सेट में एक विशिष्ट लेबल को शामिल करने या बाहर करने के लिए पर्याप्त रूप से स्थानांतरित हुई।
पिछली विधियों की मौलिक सीमा—या "दर्द बिंदु"—यह है कि मौजूदा काउंटरफैक्चुअल एक्सप्लेनेशन विधियों को सख्ती से बिंदु भविष्यवक्ताओं के लिए डिज़ाइन किया गया था। वे मानते हैं कि मॉडल ठीक एक लेबल आउटपुट करता है, और उनके पूरे गणितीय उद्देश्य उस एक लेबल को दूसरे में पलटने के लिए सबसे छोटे फीचर ट्विक को खोजना है।
चूंकि कन्फॉर्मल प्रेडिक्टर लेबल के सेट आउटपुट करते हैं (जो मॉडल के आत्मविश्वास के आधार पर विस्तारित या सिकुड़ते हैं), मौजूदा विधियां पूरी तरह से विफल हो जाती हैं। वे विशेष रूप से भविष्यवाणी सेट आउटपुट में परिवर्तनों की व्याख्या नहीं कर सकते हैं। उदाहरण के लिए, पुरानी विधियां यह उत्तर नहीं दे सकतीं: "इस रोगी के रक्तचाप में क्या छोटा बदलाव मॉडल को 'डायबिटिक' को संभावना के दायरे से बाहर करने के लिए पर्याप्त आत्मविश्वास देगा?" इसके अलावा, जबकि कुछ हालिया मॉडलों ने काउंटरफैक्चुअल में अनिश्चितता को शामिल करने का प्रयास किया, उनमें औपचारिक, वितरण-मुक्त सांख्यिकीय गारंटी का अभाव था। लेखकों को एक नए प्रकार के काउंटरफैक्चुअल का आविष्कार करने के लिए यह पेपर लिखने के लिए मजबूर होना पड़ा जो एक गारंटीकृत भविष्यवाणी सेट के भीतर लेबल के समावेश या बहिष्करण को लक्षित करता है।
यहां पेपर से कुछ अत्यधिक विशिष्ट शब्द दिए गए हैं, जिन्हें रोजमर्रा की अवधारणाओं में अनुवादित किया गया है:
- कन्फॉर्मल प्रेडिक्शन सेट (Conformal Prediction Set):
- सादृश्य: मछली पकड़ने की कल्पना करें। एक मानक मॉडल भाले (एक बिंदु भविष्यवाणी) का उपयोग करता है—यह ठीक एक मछली के लिए लक्ष्य रखता है, लेकिन यदि यह चूक जाता है, तो आपको कुछ भी नहीं मिलता है। एक कन्फॉर्मल प्रेडिक्टर जाल (एक भविष्यवाणी सेट) का उपयोग करता है। जाल मछली के साथ कुछ समुद्री शैवाल भी पकड़ सकता है, लेकिन यह गारंटी देता है कि आप 95% समय मछली पकड़ेंगे। जाल का आकार अनिश्चितता का प्रतिनिधित्व करता है: एक छोटा जाल उच्च निश्चितता का अर्थ है, जबकि एक विशाल जाल का अर्थ है कि मॉडल बहुत अनिश्चित है।
- काउंटरफैक्चुअल एक्सप्लेनेशन (Counterfactual Explanation):
- सादृश्य: जीपीएस रीरूटिंग सुझाव। केवल आपको यह बताने के बजाय कि "आप यातायात में फंस गए हैं" (एक मानक भविष्यवाणी), एक काउंटरफैक्चुअल एक्सप्लेनेशन आपको बताता है, "यदि आपने पिछला निकास लिया होता, तो आप अभी गति सीमा पर गाड़ी चला रहे होते।" यह एक अलग परिणाम प्राप्त करने के लिए आवश्यक न्यूनतम परिवर्तन दिखाता है।
- विश्वसनीयता (Credibility):
- सादृश्य: एक विशेष क्लब में एक बाउंसर आपके वाइब की जाँच कर रहा है। इस पेपर में, विश्वसनीयता मापती है कि एक नया, सिंथेटिक डेटा बिंदु (काउंटरफैक्चुअल) मॉडल द्वारा प्रशिक्षित वास्तविक डेटा के साथ कितनी अच्छी तरह मिश्रित होता है। यदि विश्वसनीयता अधिक है, तो नया डेटा बिंदु एक सामान्य, प्रशंसनीय व्यक्ति जैसा दिखता है। यदि यह कम है, तो डेटा बिंदु एक अवास्तविक एलियन है जिसे मॉडल ने पहले कभी नहीं देखा है।
- विरलता (Sparsity):
- सादृश्य: आपकी कार को ठीक करने वाला एक मैकेनिक। आप चाहते हैं कि वे पूरे इंजन को फिर से बनाने और टायर बदलने के बजाय केवल एक टूटे हुए स्पार्क प्लग (उच्च विरलता) को बदलें (कम विरलता)। पेपर में, एक विरल स्पष्टीकरण यथासंभव कम चर बदलता है, जिससे मानव के लिए समझना और उस पर कार्य करना आसान हो जाता है।
| संकेतन (Notation) | विवरण (Description) |
|---|---|
| $x$ | मूल इनपुट इंस्टेंस (परीक्षण डेटा बिंदु) जिसे समझाने की आवश्यकता है। |
| $x'$ | सरोगेट काउंटरफैक्चुअल इंस्टेंस; नया उत्पन्न डेटा बिंदु जो भविष्यवाणी सेट को बदलता है। |
| $x^{\text{real}}$ | कैलिब्रेशन डेटासेट के भीतर पाया गया एक वास्तविक काउंटरफैक्चुअल इंस्टेंस, जिसका उपयोग खोज स्थान को एंकर करने के लिए किया जाता है। |
| $\epsilon$ | पूर्वनिर्धारित महत्व स्तर (जैसे, $0.05$), स्वीकार्य त्रुटि दर का प्रतिनिधित्व करता है। |
| $\mathcal{Y}$ | डेटासेट में सभी संभावित वर्ग लेबल का सेट। |
| $\tilde{y}$ | भविष्यवाणी सेट में समावेश के लिए परीक्षण किया जा रहा एक उम्मीदवार लेबल। |
| $\Gamma^\epsilon(x)$ | महत्व स्तर $\epsilon$ पर इंस्टेंस $x$ के लिए कन्फॉर्मल प्रेडिक्शन सेट। इसमें वे सभी लेबल शामिल हैं जिन्हें अस्वीकार नहीं किया गया था। |
| $Z^c$ | कैलिब्रेशन डेटासेट, गैर-अनुरूपता स्कोर की गणना के लिए उपयोग किए जाने वाले डेटा का एक अलग सेट। |
| $p_k(x)$ | इंस्टेंस $x$ पर वर्ग $k$ के लिए कन्फॉर्मल प्रेडिक्टर द्वारा गणना किया गया पी-मान। |
| $h$ | आधार भविष्यवाणियां करने के लिए उपयोग किया जाने वाला अंतर्निहित मशीन लर्निंग एल्गोरिथम/क्लासिफायर। |
| $\alpha_i$ | गैर-अनुरूपता स्कोर, यह मापता है कि ज्ञात डेटा की तुलना में एक इंस्टेंस कितना "अजीब" है। |
| $d(x, c)$ | एक दूरी मीट्रिक (जैसे यूक्लिडियन या गॉवर दूरी) जो मापती है कि काउंटरफैक्चुअल $c$ मूल इनपुट $x$ से कितनी दूर है। |
समस्या परिभाषा और बाधाएं
एआई का उपयोग करके किसी रोगी का निदान करने में आपकी सहायता की जा रही है। एक पारंपरिक एआई मॉडल आपको एक एकल, आत्मविश्वासी अनुमान देता है: "इस रोगी को मधुमेह है।" लेकिन चिकित्सा या वित्त जैसे उच्च-दांव वाले क्षेत्रों में, एक एकल अनुमान पर्याप्त नहीं है; हमें यह जानने की आवश्यकता है कि मॉडल कब अनिश्चित है। अनुरूपता भविष्यवाणी (conformal prediction) यहाँ काम आती है। एक एकल लेबल के बजाय, एक अनुरूपता वर्गीकरणकर्ता (conformal classifier) एक भविष्यवाणी सेट (prediction set) आउटपुट करता है—संभावित लेबल की एक सूची (जैसे, {स्वस्थ, मधुमेह रोगी}) इस गणितीय गारंटी के साथ कि वास्तविक उत्तर उस सेट के अंदर है, मान लीजिए, 95% समय। यदि एआई अत्यधिक अनिश्चित है, तो सेट बड़ा हो जाता है; यदि यह निश्चित है, तो सेट एक एकल लेबल तक सिकुड़ जाता है।
लेकिन यहीं पर हम एक दीवार से टकराते हैं: हम यह कैसे समझा सकते हैं कि एआई ने हमें यह विशिष्ट सेट क्यों दिया? पारंपरिक एआई के लिए, हम "विपरीत तथ्यात्मक स्पष्टीकरण" (counterfactual explanations) का उपयोग करते हैं। ये "क्या-अगर" परिदृश्य हैं, जैसे: "यदि इस रोगी का बीएमआई 2 अंक कम होता, तो एआई 'मधुमेह रोगी' के बजाय 'स्वस्थ' की भविष्यवाणी करता।"
इस पत्र का प्रारंभिक बिंदु (इनपुट/वर्तमान स्थिति) इन अनुरूपता भविष्यवाणी सेटों और पारंपरिक विपरीत तथ्यात्मक विधियों का अस्तित्व है। हालांकि, पारंपरिक विपरीत तथ्यात्मक विशेष रूप से एक एकल बिंदु भविष्यवाणी को पलटने के लिए डिज़ाइन किए गए हैं। वांछित अंतिम बिंदु (आउटपुट/लक्ष्य स्थिति) एक बिल्कुल नए प्रकार का स्पष्टीकरण है: एक अनुरूपता विपरीत तथ्यात्मक (conformal counterfactual)। लेखक परीक्षण उदाहरण में न्यूनतम परिवर्तन खोजना चाहते हैं जो एक निश्चित आत्मविश्वास स्तर पर संपूर्ण भविष्यवाणी सेट को बदल देगा—उदाहरण के लिए, यह पता लगाना कि सेट से "मधुमेह रोगी" को पूरी तरह से हटाने के लिए वास्तव में क्या बदलने की आवश्यकता है।
यह पत्र जिस गणितीय अंतर को पाटता है, वह अनुकूलन उद्देश्य (optimization objective) में निहित है। पारंपरिक विपरीत तथ्यात्मक एक ऐसी समस्या का समाधान करते हैं जो इस तरह दिखती है:
$$ \min_{c \in \mathcal{X}} d(x, c) \quad \text{subject to} \quad f(x) \neq f(c) $$
यहां, आप एक नया उदाहरण $c$ खोजना चाहते हैं जो मूल इनपुट $x$ से दूरी $d$ को न्यूनतम करता है, जब तक कि भविष्यवाणी मॉडल $f$ एक अलग एकल लेबल आउटपुट करता है।
लेखकों को सेटों के लिए इस तर्क को फिर से लिखना पड़ा। एक एकल लेबल $f(x)$ के बजाय, वे $\epsilon$ के सार्थकता स्तर (significance level) पर एक भविष्यवाणी सेट $\Gamma^\epsilon(x)$ से निपट रहे हैं। उनके नए उद्देश्य में एक सरोगेट उदाहरण $x'$ खोजना आवश्यक है ताकि सेट स्वयं बदल जाए:
$$ \Gamma^\epsilon(x') \neq \Gamma^\epsilon(x) $$
इसके अलावा, उन्होंने इस खोज का मार्गदर्शन करने के लिए विश्वसनीयता (credibility) नामक एक नवीन मीट्रिक पेश की। विश्वसनीयता को गणितीय रूप से सभी उम्मीदवार वर्गों $k$ पर अधिकतम पी-मान (p-value) के रूप में परिभाषित किया गया है:
$$ \text{Credibility}(x') = \max_k p_k(x') $$
यह मापता है कि नया "क्या-अगर" परिदृश्य वास्तविक प्रशिक्षण डेटा के अंतर्निहित वितरण के साथ कितनी अच्छी तरह अनुरूप है।
हालांकि, व्याख्यात्मक एआई (explainable AI) की दुनिया में, एक चीज को ठीक करने से लगभग हमेशा दूसरी चीज टूट जाती है। पिछले शोधकर्ताओं को फंसाने वाली दर्दनाक दुविधा निकटता/विरलता (Proximity/Sparsity) और संभाव्यता (Plausibility) के बीच खींचतान है।
यदि आप किसी एल्गोरिथम से केवल भविष्यवाणी बदलने के लिए गणितीय रूप से सबसे छोटी दूरी (निकटता) खोजने के लिए कहते हैं, या सबसे कम सुविधाओं को बदलने के लिए (विरलता), तो गणित खुशी-खुशी एक फ्रेंकस्टीन डेटा बिंदु बनाकर इसका पालन करेगा। यह आपको बता सकता है, "₹50,000 से अधिक आय प्राप्त करने के लिए, बस अपनी उम्र 150 वर्ष कर लें।" यह गणितीय रूप से करीब है, लेकिन शारीरिक रूप से असंभव है। पिछले शोधकर्ताओं ने ऐसे विपरीत तथ्यात्मक उत्पन्न करने के लिए संघर्ष किया जो न्यूनतम थे लेकिन फिर भी "डेटा मैनिफोल्ड" (data manifold) पर स्थित थे (जिसका अर्थ है कि वे यथार्थवादी, संभावित मानव या परिदृश्यों की तरह दिखते हैं)।
इसे हल करने के लिए, लेखकों को कई कठोर, यथार्थवादी दीवारों का सामना करना पड़ा:
- अनंत खोज स्थान बाधा (The Infinite Search Space Constraint): आप विपरीत तथ्यात्मक खोजने के लिए संख्याओं के हर संभव संयोजन की खोज नहीं कर सकते। सतत फीचर स्थान अनंत रूप से बड़ा है। इसे दूर करने के लिए, लेखकों को खोज को सख्ती से सीमित करना पड़ा। वे पहले एक "वास्तविक विपरीत तथ्यात्मक" $x^{\text{real}}$ पाते हैं—एक कैलिब्रेशन डेटासेट से एक वास्तविक, ऐतिहासिक डेटा बिंदु जो एक अलग भविष्यवाणी सेट उत्पन्न करता है। फिर वे मूल उदाहरण $x$ और $x^{\text{real}}$ के बीच सख्ती से सीमित फीचर मानों का एक असतत ग्रिड बनाते हैं।
- संयोजन विस्फोट (Combinatorial Explosion): इस सीमित ग्रिड तक खोज को प्रतिबंधित करने के बाद भी, संभावित फीचर संयोजनों की संख्या घातीय रूप से बढ़ती है। यदि किसी डेटासेट में कई विशेषताएं हैं, तो हर संयोजन की जांच करना कम्प्यूटेशनल रूप से असंभव है। लेखकों ने एक कठिन कम्प्यूटेशनल सीमा का सामना किया: यदि संयोजनों की संख्या 10,000 से अधिक हो जाती है, तो संपूर्ण खोज क्रैश हो जाती है या बहुत अधिक समय लेती है। उन्हें पूर्ण अनुकूलन को छोड़ने और स्थान को नेविगेट करने के लिए एक अनुमानित आनुवंशिक एल्गोरिथम (heuristic Genetic Algorithm) पर भरोसा करने के लिए मजबूर होना पड़ा।
- अनुरूपता गणना का बोझ (The Burden of Conformal Computation): सरल तंत्रिका नेटवर्क के विपरीत जहां एक फॉरवर्ड पास बिजली की गति से होता है, अनुरूपता भविष्यवाणी के लिए खोज के दौरान उत्पन्न प्रत्येक सिंथेटिक डेटा बिंदु के लिए प्रत्येक उम्मीदवार लेबल के लिए गैर-अनुरूपता स्कोर (nonconformity scores) और पी-मानों की गणना की आवश्यकता होती है। यह एक विशाल कम्प्यूटेशनल बाधा पैदा करता है, जिससे इन स्पष्टीकरणों का वास्तविक समय उत्पादन अविश्वसनीय रूप से कठिन हो जाता है।
यह दृष्टिकोण क्यों
इस पत्र में हुई प्रगति को वास्तव में समझने के लिए, हमें पहले यह देखना होगा कि पारंपरिक AI निर्णय कैसे लेता है। अधिकांश मशीन लर्निंग मॉडल "पॉइंट प्रेडिक्टर" होते हैं—वे आपके डेटा को देखते हैं और आपको एक एकल, पूर्ण उत्तर देते हैं, जैसे "यह रोगी डायबिटिक है।" लेकिन चिकित्सा या वित्त जैसे उच्च-दांव वाले क्षेत्रों में, एक एकल अनुमान पर्याप्त नहीं होता है; निर्णय लेने वालों को मॉडल की अनिश्चितता जानने की आवश्यकता होती है। यहीं पर कन्फॉर्मल प्रेडिक्शन (CP) आता है। एक एकल लेबल के बजाय, CP एक प्रेडिक्शन सेट (जैसे, $\{\text{स्वस्थ}, \text{डायबिटिक}\}$) आउटपुट करता है जिसमें एक गणितीय गारंटी होती है कि सत्य उत्तर उस सेट के अंदर एक विशिष्ट संभावना के साथ है, मान लीजिए $95\%$।
लेखकों ने महसूस किया कि पारंपरिक अत्याधुनिक (SOTA) स्पष्टीकरण विधियाँ इन अनिश्चितता-जागरूक मॉडलों के लिए मौलिक रूप से त्रुटिपूर्ण थीं। मानक प्रति-तथ्यात्मक (counterfactual) विधियाँ विशेष रूप से पॉइंट प्रेडिक्टर के लिए डिज़ाइन की गई हैं। वे इस प्रश्न का उत्तर देती हैं: "मॉडल की भविष्यवाणी को A से B में बदलने के लिए आवश्यक न्यूनतम परिवर्तन क्या है?" हालाँकि, जब आपका मॉडल एकल लेबल के बजाय प्रशंसनीय लेबल का एक सेट आउटपुट करता है, तो मौजूदा विधियाँ पूरी तरह से विफल हो जाती हैं। आप बस एक सेट को "फ्लिप" नहीं कर सकते। एहसास का सटीक क्षण तब आया जब लेखकों ने देखा कि मॉडल अनिश्चितता को समझाने के लिए, उन्हें यह समझाना होगा कि एक निश्चित महत्व स्तर $\epsilon$ पर एक विशिष्ट वर्ग को प्रेडिक्शन सेट में क्यों शामिल किया गया या बाहर रखा गया। कन्फॉर्मल प्रेडिक्शन के लिए तैयार किया गया एक पूरी तरह से नया गणितीय ढाँचा ही एकमात्र व्यवहार्य समाधान था।
सरल प्रदर्शन मेट्रिक्स से परे, यह विधि अपनी संरचनात्मक श्रेष्ठता के कारण गुणात्मक रूप से बेहतर है जो plausibility को संभालने में सक्षम है। प्रति-तथ्यात्मक के लिए पिछला स्वर्ण मानक दूरी (जैसे $\ell_2$ norm) या विरलता (बदले गए फीचर्स की संख्या) को कम करने पर बहुत अधिक निर्भर करता था। जबकि यह गणितीय रूप से काम करता है, यह अक्सर "एलियन" डेटा पॉइंट उत्पन्न करता है—ऐसे सुझाव जो वास्तविक दुनिया के उदाहरणों जैसे बिल्कुल नहीं लगते। इसे हल करने के लिए, लेखकों ने एक अभूतपूर्व मीट्रिक पेश किया: विश्वसनीयता (credibility)।
कन्फॉर्मल प्रेडिक्शन में, विश्वसनीयता को सभी उम्मीदवार लेबलों पर अधिकतम पी-वैल्यू के रूप में परिभाषित किया गया है:
$$ \text{Credibility}(x') = \max_k p_k(x') $$
विश्वसनीयता के लिए अनुकूलन करके, विधि यह सुनिश्चित करती है कि उत्पन्न प्रति-तथ्यात्मक $x'$ अंतर्निहित प्रशिक्षण डेटा वितरण के साथ पूरी तरह से अनुरूप हो। पॉइंट प्रेडिक्शन को बदलने के लिए निर्णय सीमा के पार एक बड़े, अवास्तविक छलांग को मजबूर करने के बजाय, यह विधि छोटे, अत्यधिक प्रशंसनीय धक्के ढूंढती है जो अनिश्चितता सेट को बस विस्तारित या सिकोड़ते हैं। उदाहरण के लिए, आय डेटासेट में, एक प्रेडिक्शन सेट को $\{>\$50\text{K}, \leq\$50\text{K}\}$ से अधिक आत्मविश्वासी एकल सेट $\{>\$50\text{K}\}$ में स्थानांतरित करने के लिए एक कठोर वर्ग फ्लिप को मजबूर करने की तुलना में बहुत अधिक यथार्थवादी फीचर परिवर्तन की आवश्यकता होती है।
समस्या ने कठोर बाधाएँ प्रस्तुत कीं: स्पष्टीकरण गणितीय रूप से कन्फॉर्मल ढांचे के तहत मान्य, कार्रवाई योग्य और वितरण-मुक्त गारंटी बनाए रखने के लिए कैलिब्रेशन डेटा से सख्ती से बंधे होने चाहिए। चुनी गई विधि ने इन बाधाओं को पूरी तरह से जोड़ा। लेखकों ने मूल परीक्षण उदाहरण $x$ और कैलिब्रेशन सेट $Z^c$ में पाए गए निकटतम वास्तविक प्रति-तथ्यात्मक $x^{\text{real}}$ द्वारा सीमित एक असतत खोज स्थान को डिज़ाइन किया:
$$ x^{\text{real}} = \arg \min_{x_i \in Z^c} \{ \| x - x_i \|_2 \mid \Gamma^\epsilon(x_i) \neq \Gamma^\epsilon(x) \} $$
खोज स्थान को वास्तविक देखे गए मानों पर एंकर करके, एल्गोरिथम गारंटी देता है कि सिंथेटिक प्रति-तथ्यात्मक कभी भी असंभव फीचर संयोजनों में नहीं भटकता है। यदि खोज स्थान छोटा है, तो यह एक संपूर्ण खोज का उपयोग करता है; यदि यह कम्प्यूटेशनल रूप से विशाल हो जाता है, तो यह एक जेनेटिक एल्गोरिथम का उपयोग करके सुरुचिपूर्ण ढंग से स्केल करता है। यह एक आदर्श संयोजन है: कन्फॉर्मल प्रेडिक्शन की कठोर सांख्यिकीय सीमाएं बनाए रखी जाती हैं, जबकि सहज, मानव-पठनीय स्पष्टीकरण प्रदान किए जाते हैं।
अंत में, पत्र स्पष्ट रूप से बताता है कि अन्य लोकप्रिय दृष्टिकोण यहाँ क्यों विफल हो जाते। बायेसियन मॉडलिंग या एपिस्टेमिक अनिश्चितता परिमाणीकरण का उपयोग करके प्रति-तथ्यात्मक में अनिश्चितता को शामिल करने के हालिया प्रयास इस विशिष्ट समस्या के लिए पूरी तरह से चूक जाते हैं। बायेसियन मॉडल संभाव्य स्कोर प्रदान करते हैं, लेकिन उनमें वितरण-मुक्त गारंटी का अभाव होता है। वे एक पूर्व वितरण मानते हैं, और यदि वह धारणा गलत है, तो गारंटी ध्वस्त हो जाती है। कन्फॉर्मल प्रेडिक्शन केवल विनिमेयता (exchangeability) की धारणा पर निर्भर करता है। इसलिए, इस पाइपलाइन में बायेसियन प्रति-तथ्यात्मक या मानक जनरेटिव मॉडल (जैसे GANs या Diffusion) को जबरदस्ती डालने का प्रयास उस सख्त, गणितीय रूप से सिद्ध त्रुटि दर को नष्ट कर देगा जो कन्फॉर्मल प्रेडिक्शन को पहली जगह में इतना मूल्यवान बनाती है। लेखकों को प्रेडिक्शन सेट की पूर्ण सांख्यिकीय वैधता को संरक्षित करने के लिए उन विकल्पों को अस्वीकार करना पड़ा।
 Figure 2. Counterfactual explanation for a conformal prediction set generated by optimizing for distance on the WBC dataset. Changed features are shown in blue
Figure 2. Counterfactual explanation for a conformal prediction set generated by optimizing for distance on the WBC dataset. Changed features are shown in blue
गणितीय और तार्किक तंत्र
इस पत्र में हुई प्रगति को समझने के लिए, हमें पहले यह स्थापित करना होगा कि आधुनिक AI निर्णय कैसे लेता है और हम उसकी अनिश्चितता को कैसे मापते हैं।
पारंपरिक मशीन लर्निंग में, एक मॉडल आपको एक "बिंदु भविष्यवाणी" (point prediction) देता है - एक एकल, सर्वोत्तम अनुमानित उत्तर। हालांकि, चिकित्सा या वित्त जैसे उच्च-दांव वाले क्षेत्रों में, एक एकल अनुमान पर्याप्त नहीं है; हमें यह जानने की आवश्यकता है कि मॉडल कितना आश्वस्त है। यहीं पर Conformal Prediction (CP) का प्रवेश होता है। एक एकल उत्तर के बजाय, CP एक भविष्यवाणी सेट (prediction set) प्रदान करता है जिसमें एक गणितीय गारंटी होती है। उदाहरण के लिए, यह कह सकता है, "मुझे 95% विश्वास है कि इस रोगी का निदान या तो {स्वस्थ, मधुमेह} है।" यदि मॉडल अत्यधिक अनिश्चित है, तो सेट बड़ा हो जाता है। यदि यह निश्चित है, तो सेट एक एकल लेबल तक सिकुड़ जाता है।
इस पत्र के पीछे की प्रेरणा Explainable AI (XAI) में एक महत्वपूर्ण अंध बिंदु से उत्पन्न होती है। जब AI एक बिंदु भविष्यवाणी करता है, तो हम अक्सर इसे समझने के लिए प्रति-तथ्यात्मक स्पष्टीकरण (counterfactual explanations) का उपयोग करते हैं ("यदि आपकी आय अधिक होती, तो आपका ऋण स्वीकृत हो जाता")। लेकिन एक भविष्यवाणी सेट को कैसे समझाया जाए? मौजूदा विधियाँ यहाँ पूरी तरह विफल हो जाती हैं। लेखकों ने मॉडल की अनिश्चितता सीमा को बदलने के लिए आवश्यक न्यूनतम परिवर्तनों को ढूंढकर इसे हल करने का प्रयास किया, प्रभावी ढंग से यह समझाते हुए कि कुछ वर्गों को सेट में क्यों शामिल किया गया या बाहर रखा गया।
ऐसा करने के लिए, उन्हें कई बाधाओं को दूर करना पड़ा: उत्पन्न स्पष्टीकरण मूल डेटा के करीब होना चाहिए (Proximity), इसे यथासंभव कम चर बदलने चाहिए (Sparsity), और सबसे महत्वपूर्ण बात, इसे गणितीय भ्रम के बजाय एक यथार्थवादी डेटा बिंदु जैसा दिखना चाहिए (Credibility)।
यहाँ गणितीय इंजन है जिसे उन्होंने इसे हल करने के लिए बनाया है।
मास्टर समीकरण (The Master Equations)
इस पत्र का मुख्य तर्क तीन-भाग वाले गणितीय इंजन द्वारा संचालित होता है: एक वास्तविकता एंकर खोजना, संभाव्यता को अधिकतम करना, और जटिलता को दंडित करना।
$$ x^{\text{real}} = \arg \min_{x_i \in Z^c} \left\{ \|x - x_i\|_2 \mid \Gamma^\epsilon(x_i) \neq \Gamma^\epsilon(x) \right\} $$
$$ \text{Credibility}(x') = \max_k p_k(x') $$
$$ \text{Sparsity}(x, x') = \sum_{j=1}^p \mathbf{1}\{x_j \neq x'_j\} $$
समीकरणों को तोड़ना (Tearing the Equations Apart)
आइए इस इंजन के प्रत्येक घटक को उसके भौतिक और तार्किक भूमिका को समझने के लिए तोड़ें।
- $x$: मूल इनपुट डेटा बिंदु (जैसे, रोगी के वर्तमान स्वास्थ्य मेट्रिक्स)। यह हमारी शुरुआती रेखा है।
- $x_i \in Z^c$: कैलिब्रेशन डेटासेट $Z^c$ से एक वास्तविक डेटा बिंदु। इसकी तार्किक भूमिका "वास्तविकता की जाँच" के रूप में कार्य करना है ताकि मॉडल असंभव परिदृश्यों का आविष्कार न करे।
- $\|x - x_i\|_2$: L2 नॉर्म (यूक्लिडियन दूरी)। यह एक रबर बैंड की तरह काम करता है जो खोज को मूल इनपुट की ओर वापस खींचता है। लेखक यहाँ L2 नॉर्म का उपयोग करते हैं क्योंकि यह किसी भी एकल चर में बड़े, अवास्तविक विचलन को भारी दंडित करता है, जिससे मॉडल को एक संतुलित, आस-पास का समाधान खोजने के लिए मजबूर होना पड़ता है।
- $\Gamma^\epsilon(x)$: एक निश्चित महत्व स्तर $\epsilon$ (आमतौर पर 95% आत्मविश्वास के लिए 0.05) पर कन्फॉर्मल प्रेडिक्शन सेट। यह मॉडल की अनिश्चितता की सीमा का प्रतिनिधित्व करता है।
- $\neq$: असमानता ऑपरेटर। यह पूरे पत्र का तार्किक ट्रिगर है। हम केवल अंतर्निहित संभावनाओं को स्थानांतरित नहीं करना चाहते हैं; हम अंतिम भविष्यवाणी सेट में एक संरचनात्मक, दृश्य परिवर्तन की मांग करते हैं।
- $\arg \min$: खोज ऑपरेटर। यह डेटा को सबसे कम प्रतिरोध के मार्ग को खोजने के लिए स्कैन करता है - सबसे निकटतम वास्तविक दुनिया का उदाहरण जो भविष्यवाणी सेट को सफलतापूर्वक फ़्लिप करता है।
- $x'$: उत्पन्न सिंथेटिक सरोगेट प्रति-तथ्यात्मक। यह अंतिम स्पष्टीकरण है जिसे हम उपयोगकर्ता को सौंपेंगे।
- $p_k(x')$: वर्ग $k$ के लिए p-मान। कन्फॉर्मल प्रेडिक्शन में, यह मापता है कि नया बिंदु उस विशेष वर्ग के लिए ज्ञात डेटा वितरण के साथ कितनी अच्छी तरह मेल खाता है।
- $\max_k$: अधिकतम ऑपरेटर। सभी वर्गों में अधिकतम p-मान लेकर, यह सुनिश्चित करता है कि प्रति-तथ्यात्मक कम से कम एक वर्ग के लिए अत्यधिक प्रशंसनीय है, बजाय इसके कि यह एक औसत दर्जे की, अवास्तविक स्थिति में औसत हो जाए।
- $\sum_{j=1}^p$: सभी $p$ विशेषताओं पर योग। लेखकों ने यहाँ गुणन के बजाय योग का उपयोग क्यों किया? क्योंकि हम परिवर्तित विशेषताओं की कुल संख्या को योगात्मक रूप से गिनना चाहते हैं। यदि हमने गुणन का उपयोग किया होता, तो एक भी अपरिवर्तित विशेषता (0 का परिणाम) पूरे दंड को मिटा देती, जिससे विशेषताओं की संख्या गिनने के तर्क पूरी तरह से टूट जाते।
- $\mathbf{1}\{x_j \neq x'_j\}$: संकेतक फ़ंक्शन। यह एक बाइनरी स्विच के रूप में कार्य करता है: यदि कोई विशेषता बदली गई थी तो यह 1 आउटपुट करता है, और यदि इसे अकेला छोड़ दिया गया था तो 0।
चरण-दर-चरण प्रवाह (Step-by-step Flow)
आइए इस यांत्रिक असेंबली लाइन से गुजरने वाले एक एकल अमूर्त डेटा बिंदु का पता लगाएं:
- इनपुट: रोगी का डेटा $x$ सिस्टम में प्रवेश करता है। मॉडल अनिश्चित है और {स्वस्थ, मधुमेह} का भविष्यवाणी सेट आउटपुट करता है।
- वास्तविकता एंकर: सिस्टम ऐतिहासिक कैलिब्रेशन डेटा को स्कैन करके $x^{\text{real}}$ पाता है, जो सबसे निकटतम वास्तविक रोगी है जिसे एक अलग भविष्यवाणी सेट (जैसे, केवल {स्वस्थ}) प्राप्त हुआ था।
- ग्रिड निर्माण: एक असतत खोज ग्रिड बनाया जाता है। सिस्टम $x$ और $x^{\text{real}}$ के बीच सभी देखे गए मानों को निकालता है। यह सुनिश्चित करता है कि हम केवल यथार्थवादी मध्यवर्ती चरणों का सुझाव दें (जैसे, हम 10 का रक्तचाप नहीं सुझाएंगे यदि यह डेटा में मौजूद नहीं है)।
- असेंबली लाइन: इस ग्रिड पर एक सिंथेटिक उम्मीदवार $x'$ उत्पन्न होता है। यह कन्फॉर्मल प्रेडिक्टर से गुजरता है यह देखने के लिए कि क्या इसका भविष्यवाणी सेट वास्तव में फ़्लिप होता है ($\Gamma^\epsilon(x') \neq \Gamma^\epsilon(x)$)।
- गुणवत्ता नियंत्रण: यदि सेट फ़्लिप होता है, तो उम्मीदवार का मूल्यांकन किया जाता है। सिस्टम इसकी Credibility (क्या यह एक यथार्थवादी रोगी है?) और इसकी Sparsity (क्या हमने केवल कुछ चीजें बदली हैं, जैसे केवल 'ग्लूकोज' और 'आयु'?) की गणना करता है।
- आउटपुट: वह उम्मीदवार जो इन मानदंडों को सर्वोत्तम रूप से संतुलित करता है, अंतिम, कार्रवाई योग्य स्पष्टीकरण के रूप में लौटाया जाता है।
अनुकूलन गतिशीलता (Optimization Dynamics)
यह तंत्र वास्तव में कैसे सीखता है, अपडेट होता है और अभिसरण करता है?
पारंपरिक न्यूरल नेटवर्क में, हम एक चिकनी हानि परिदृश्य (loss landscape) पर नीचे स्लाइड करने के लिए ग्रेडिएंट डिसेंट का उपयोग करते हैं। हालांकि, क्योंकि कन्फॉर्मल प्रेडिक्शन सेट कठोर, गैर-विभेदक (non-differentiable) स्टेप-फ़ंक्शन बनाते हैं (एक लेबल या तो सेट के अंदर सख्ती से होता है या बाहर), यहाँ ग्रेडिएंट मौजूद नहीं होते हैं। हानि परिदृश्य एक चिकनी पहाड़ी नहीं है; यह असतत, बाइनरी निर्णयों का एक दांतेदार चट्टान का चेहरा है।
इसे दूर करने के लिए, लेखकों ने एक दो-तरफा अनुकूलन रणनीति का उपयोग किया। यदि खोज स्थान छोटा है (10,000 संयोजनों से कम), तो सिस्टम पूर्ण गणितीय इष्टतम खोजने के लिए ग्रिड पर हर बिंदु का मूल्यांकन करते हुए, एक ब्रूट-फोर्स व्यापक खोज (brute-force exhaustive search) का उपयोग करता है।
यदि स्थान बहुत बड़ा है, तो यह एक जेनेटिक एल्गोरिथम (GA) को तैनात करता है। GA 100 यादृच्छिक उम्मीदवार प्रति-तथ्यात्मकों की एक आबादी को इनिशियलाइज़ करता है। प्रत्येक उम्मीदवार की "फिटनेस" हमारे मास्टर समीकरणों (Credibility को अधिकतम करना या Sparsity को कम करना) द्वारा निर्धारित की जाती है। महत्वपूर्ण रूप से, परिदृश्य एक बड़े दंड फ़ंक्शन द्वारा आकार दिया जाता है: यदि कोई उम्मीदवार भविष्यवाणी सेट को बदलने में विफल रहता है, तो उसका फिटनेस स्कोर नष्ट हो जाता है, प्रभावी रूप से इसे अगली पीढ़ी में समाप्त कर दिया जाता है। 1,000 से अधिक पुनरावृति (iterations) में, उम्मीदवार उत्परिवर्तित (एक सुविधा को 10% संभावना के साथ यादृच्छिक रूप से ट्वीक करना) और क्रॉसओवर (दो अच्छे उम्मीदवारों के बीच सुविधाओं का आदान-प्रदान) करते हैं।
ईमानदारी से कहूं तो, मुझे पूरी तरह से यकीन नहीं है कि लेखकों ने जेनेटिक एल्गोरिथम के अभिजात वर्ग अनुपात (elitism ratio) को बिना किसी एब्लेशन अध्ययन (ablation study) के ठीक 0.01 पर हार्डकोड क्यों किया, लेकिन व्यवहार में, यह केवल सबसे अच्छे उम्मीदवार को पीढ़ियों तक जीवित रखने के लिए पर्याप्त है बिना खोज को रोके। इस विकासवादी प्रक्रिया के माध्यम से, सिस्टम पुनरावृत्ति रूप से एक न्यूनतम, अत्यधिक विश्वसनीय परिवर्तन की ओर अभिसरण करता है जो मॉडल की अनिश्चितता सीमा को सफलतापूर्वक बदलता है।
परिणाम, सीमाएँ और निष्कर्ष
चिकित्सा निदान के लिए जब आप डॉक्टर के पास जाते हैं। यदि डॉक्टर कहता है, "आपको निश्चित रूप से मधुमेह है," तो यह एक मानक बिंदु भविष्यवाणी (standard point prediction) है। लेकिन क्या होगा यदि डॉक्टर कहे, "आपकी जांच के आधार पर, मुझे 95% यकीन है कि आप या तो पूरी तरह से स्वस्थ हैं या आपको प्रारंभिक चरण का मधुमेह है"? यह दूसरा परिदृश्य कन्फॉर्मल प्रेडिक्शन (Conformal Prediction - CP) का सार है। एक एकल, संभावित रूप से अति-आत्मविश्वासी उत्तर देने के बजाय, CP आपको एक भविष्यवाणी सेट (prediction set) देता है—संभावित परिणामों की एक सूची जो एक गणितीय गारंटी द्वारा समर्थित है कि वास्तविक उत्तर उस सेट के भीतर एक विशिष्ट संभाव्यता के साथ मौजूद है।
हालांकि, यह एक भारी मनोवैज्ञानिक और व्यावहारिक समस्या प्रस्तुत करता है: मॉडल ने "मधुमेह" को उस सेट में क्यों शामिल किया? मॉडल को आत्मविश्वास से "मधुमेह" को छोड़ने और केवल "स्वस्थ" कहने के लिए आपकी स्वास्थ्य प्रोफ़ाइल में क्या बदलने की आवश्यकता होगी?
यहीं पर काउंटरफ़ैक्टुअल (Counterfactual - CF) स्पष्टीकरण आते हैं। एक काउंटरफ़ैक्टुअल एक "क्या-अगर" परिदृश्य है। यह आपको मॉडल के निर्णय को बदलने के लिए आवश्यक न्यूनतम परिवर्तन बताता है (उदाहरण के लिए, "यदि आपका रक्तचाप 10 अंक कम होता, तो आपको सख्ती से स्वस्थ के रूप में वर्गीकृत किया जाता")। ऐतिहासिक रूप से, वैज्ञानिकों ने केवल मानक बिंदु भविष्यवाणियों के लिए काउंटरफ़ैक्टुअल उत्पन्न करने का तरीका खोजा है। यह पत्र एक शानदार, पहले अनसुलझी समस्या से निपटता है: हम कन्फॉर्मल प्रेडिक्शन सेट्स के लिए काउंटरफ़ैक्टुअल स्पष्टीकरण कैसे उत्पन्न करें?
पृष्ठभूमि और प्रेरणा
इस पत्र को समझने के लिए, आपको दो अवधारणाओं को समझना होगा:
1. कन्फॉर्मल प्रेडिक्शन सेट्स (Conformal Prediction Sets): एक महत्व स्तर $\epsilon$ (जैसे, 95% विश्वास स्तर के लिए 0.05) को देखते हुए, एक कन्फॉर्मल क्लासिफायर लेबल का एक सेट $\Gamma^\epsilon(x)$ आउटपुट करता है। यह प्रत्येक संभावित लेबल के लिए एक गैर-अनुरूपता स्कोर (nonconformity score) की गणना करके, उन्हें $p$-मानों में परिवर्तित करके, और किसी भी लेबल को अस्वीकार करके करता है जहाँ $p$-मान $\epsilon$ से कम है।
2. काउंटरफ़ैक्टुअल (Counterfactuals): ये सिंथेटिक डेटा बिंदु $x'$ हैं जो मूल इनपुट $x$ के बहुत करीब हैं, लेकिन एक अलग भविष्यवाणी का परिणाम देते हैं।
यहां प्रेरणा विशुद्ध रूप से विश्वास और कार्रवाईयोग्यता (trust and actionability) है। निर्णय लेने वाले केवल मॉडल की अनिश्चितता को नहीं जानना चाहते; वे उस अनिश्चितता की सीमाओं को जानना चाहते हैं। यदि किसी बैंक का मॉडल कहता है कि आपके ऋण आवेदन की भविष्यवाणी सेट $\{\text{अनुमोदित}, \text{अस्वीकृत}\}$ है, तो आप जानना चाहते हैं कि उस सेट को सख्ती से $\{\text{अनुमोदित}\}$ में स्थानांतरित करने के लिए ठीक क्या बदलना है (जैसे, क्रेडिट कार्ड ऋण का \$150 चुकाना)।
दूर करने के लिए बाधाएँ
उच्च-आयामी डेटा की विशालता के कारण इन "क्या-अगर" परिदृश्यों को उत्पन्न करना अविश्वसनीय रूप से कठिन है। यदि आप किसी एल्गोरिथम को अंधाधुंध गणितीय समाधान खोजने देते हैं, तो यह बेतुकी बातें सुझाएगा, जैसे "अपनी उम्र 15 साल कम करें" या "नकारात्मक रक्तचाप रखें।"
इसलिए, लेखकों को खोज स्थान को प्रतिबंधित करना पड़ा ताकि उत्पन्न स्पष्टीकरण हों:
* निकटता (Proximate): परिवर्तन छोटा होना चाहिए।
* विरलता (Sparse): इसे सभी सुविधाओं को नहीं, बल्कि केवल एक या दो सुविधाओं को बदलना चाहिए।
* संभाव्यता (Plausible - Credible): सिंथेटिक डेटा बिंदु को वास्तविक दुनिया के वास्तविक डेटा जैसा दिखना चाहिए।
गणितीय समस्या और समाधान
लेखकों द्वारा हल की गई मुख्य गणितीय समस्या एक सरोगेट इंस्टेंस $x'$ खोजना है जैसे कि भविष्यवाणी सेट बदल जाए:
$$ \Gamma^\epsilon(x') \neq \Gamma^\epsilon(x) $$
असंभव डेटा बिंदु उत्पन्न किए बिना इसे हल करने के लिए, उन्होंने एक अत्यधिक प्रतिबंधित, तीन-चरणीय खोज वास्तुकला (search architecture) तैयार की:
1. एक "वास्तविक" काउंटरफ़ैक्टुअल खोजें (Find a "Real" Counterfactual): सबसे पहले, वे कैलिब्रेशन डेटासेट (वास्तविक ऐतिहासिक डेटा) को देखते हैं और सबसे करीबी वास्तविक डेटा बिंदु $x^{\text{real}}$ पाते हैं जिसका $x$ से भिन्न भविष्यवाणी सेट है।
2. एक ग्रिड बनाएं (Build a Grid): वे $x$ और $x^{\text{real}}$ के बीच के मानों द्वारा पूरी तरह से सीमित एक असतत खोज स्थान (discrete search space) का निर्माण करते हैं। यह गारंटी देता है कि एल्गोरिथम जंगली, सीमा से बाहर की संख्याओं का आविष्कार नहीं कर सकता है।
3. अनुकूलित करें (Optimize): वे इस ग्रिड में खोज करते हैं (छोटे स्थानों के लिए व्यापक खोज, या बड़े स्थानों के लिए जेनेटिक एल्गोरिथम का उपयोग करके) एक सिंथेटिक $x'$ खोजने के लिए जो तीन मानदंडों में से एक को अनुकूलित करता है:
* दूरी (निकटता) (Distance - Proximity): $||x - x'||_2$ को कम करना।
* विरलता (Sparsity): बदली हुई सुविधाओं की संख्या $\sum_{j=1}^p \mathbf{1}\{x_j \neq x'_j\}$ को कम करना।
* विश्वसनीयता (Credibility): यह लेखकों की उत्कृष्ट चाल है। वे विश्वसनीयता को $\max_k p_k(x')$ के रूप में परिभाषित करते हैं। सभी वर्गों में उच्चतम $p$-मान को अधिकतम करके, वे काउंटरफ़ैक्टुअल को प्रशिक्षण डेटा के अंतर्निहित वितरण (underlying distribution) के साथ कसकर अनुरूप होने के लिए मजबूर करते हैं। यह गणितीय रूप से "क्या-अगर" परिदृश्य को अत्यधिक यथार्थवादी होने के लिए मजबूर करता है।
प्रयोगात्मक वास्तुकला और "पीड़ित"
लेखकों ने केवल मेट्रिक्स सूचीबद्ध नहीं किए; उन्होंने अपने सिंथेटिक काउंटरफ़ैक्टुअल को वास्तविकता से भी बेहतर साबित करने के लिए एक क्रूर प्रयोग डिजाइन किया।
"पीड़ित" (The "Victims"): चूंकि कन्फॉर्मल प्रेडिक्शन सेट्स के लिए काउंटरफ़ैक्टुअल उत्पन्न करने वाला कोई अन्य एल्गोरिथम मौजूद नहीं है, इसलिए बेसलाइन (जिन "पीड़ितों" को उन्हें हराना था) वास्तविक काउंटरफ़ैक्टुअल ($x^{\text{real}}$) थे जो सीधे ऐतिहासिक डेटासेट से लिए गए थे।
सबूत (The Evidence): उन्होंने 10 सारणीबद्ध डेटासेट (tabular datasets) पर अपने तरीके का परीक्षण किया। प्रत्येक डेटासेट के लिए, उन्होंने सरोगेट काउंटरफ़ैक्टुअल उत्पन्न किए और उनकी तुलना वास्तविक काउंटरफ़ैक्टुअल से एक अनुपात का उपयोग करके की।
* जब दूरी के लिए अनुकूलन किया गया, तो उनके तरीके ने 0.452 का औसत अनुपात प्राप्त किया। यह निर्विवाद प्रमाण है कि उनके एल्गोरिथम ने वैध स्पष्टीकरण पाए जो मूल इनपुट की तुलना में 54.8% अधिक निकट थे, जो सर्वोत्तम वास्तविक दुनिया के उदाहरण से थे।
* जब विरलता के लिए अनुकूलन किया गया, तो उन्होंने 0.493 का अनुपात प्राप्त किया, जिसका अर्थ है कि उनके स्पष्टीकरणों को वास्तविक दुनिया के समकक्षों की तुलना में आधी सुविधाओं को बदलने की आवश्यकता थी।
* सबसे प्रभावशाली ढंग से, जब विश्वसनीयता के लिए अनुकूलन किया गया, तो उन्होंने 1.157 का अनुपात प्राप्त किया। इसका मतलब है कि उनके सिंथेटिक, गणितीय रूप से उत्पन्न डेटा बिंदु कैलिब्रेशन सेट से वास्तविक, वास्तविक डेटा बिंदुओं की तुलना में डेटा वितरण के 15.7% अधिक अनुरूप थे।
ईमानदारी से कहूं तो, मुझे पूरी तरह से यकीन नहीं है कि उन्होंने बड़े खोज स्थानों के लिए एक अपेक्षाकृत बुनियादी जेनेटिक एल्गोरिथम पैकेज क्यों चुना, जब अधिक उन्नत असतत ग्रेडिएंट-आधारित ऑप्टिमाइज़र मौजूद हैं, लेकिन अनुभवजन्य साक्ष्य इसे अवधारणा के प्रमाण (proof-of-concept) के रूप में पर्याप्त से अधिक साबित करते हैं।
भविष्य के विकास के लिए चर्चा के विषय
इस शानदार नींव के आधार पर, भविष्य के शोध के लिए यहां कई महत्वपूर्ण रास्ते दिए गए हैं:
- कारण ग्राफ और सख्त कार्रवाईयोग्यता (Causal Graphs and Strict Actionability): वर्तमान विधि वास्तविक डेटा का उपयोग करके खोज स्थान को सीमित करती है, लेकिन यह कारणता (causality) को नहीं समझती है। उनके मधुमेह उदाहरण में, एल्गोरिथम ने रोगी की उम्र को 30 से 26 तक कम करने का सुझाव दिया। उम्र अपरिवर्तनीय है।
हम निर्देशित चक्रीय ग्राफ (Directed Acyclic Graphs - DAGs) को कन्फॉर्मल खोज स्थान में कैसे एकीकृत कर सकते हैं ताकि एल्गोरिथम केवल कारण रूप से नीचे की ओर, कार्रवाई योग्य हस्तक्षेपों (actionable interventions) का सुझाव दे?
2. लक्षित सेट स्टीयरिंग (Targeted Set Steering): वर्तमान में, एल्गोरिथम भविष्यवाणी सेट के बदलते ही रुक जाता है ($\Gamma^\epsilon(x') \neq \Gamma^\epsilon(x)$)। लेकिन क्या होगा यदि उपयोगकर्ता किसी विशिष्ट दिशा में सेट को निर्देशित करना चाहता है? उदाहरण के लिए, $\{\text{सौम्य}, \text{घातक}\}$ से सख्ती से $\{\text{सौम्य}\}$ की ओर बढ़ना। हम विशिष्ट सेट समावेशन/बहिष्करण को लक्षित करने के लिए उद्देश्य फ़ंक्शन (objective function) को कैसे संशोधित कर सकते हैं?
3. असंरचित डेटा के लिए स्केलिंग (Scaling to Unstructured Data): यह विधि सारणीबद्ध सुविधाओं के बीच एक असतत ग्रिड खोज पर निर्भर करती है। हम इसे छवियों या पाठ जैसे उच्च-आयामी असंरचित डेटा के साथ काम करने के लिए कैसे विकसित कर सकते हैं? क्या हम कन्फॉर्मल $p$-मानों को एक वैरिएशनल ऑटोएनकोडर (Variational Autoencoder - VAE) के निरंतर अव्यक्त स्थान (latent space) में मैप कर सकते हैं और काउंटरफ़ैक्टुअल छवि खोजने के लिए ग्रेडिएंट डिसेंट (gradient descent) कर सकते हैं?
4. त्रिलैमा को संतुलित करना (Balancing the Trilemma): लेखकों ने दूरी, विरलता और विश्वसनीयता को अलग-अलग अनुकूलित किया। क्या हम अंतिम "पूर्ण" स्पष्टीकरण खोजने के लिए, शायद बहु-उद्देश्यीय सुदृढीकरण सीखने (multi-objective reinforcement learning) का उपयोग करके, तीनों को एक साथ संतुलित करने वाला एक पारेतो-इष्टतम हानि फ़ंक्शन (Pareto-optimal loss function) तैयार कर सकते हैं?
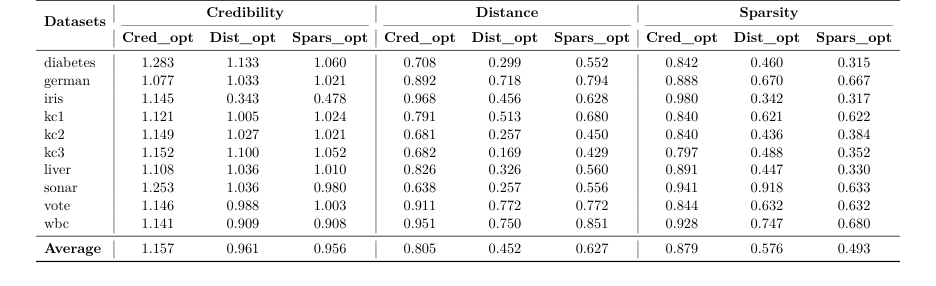 Table 2. Comparison of optimization criteria across datasets
Table 2. Comparison of optimization criteria across datasets