共形预测集的反事实解释
New counterfactual explanations make complex "prediction sets" from AI understandable by showing minimal changes that alter the AI's output.
背景与学术传承
机器学习模型越来越多地部署在高风险环境中——例如医疗诊断或金融贷款审批——在这种环境中,150美元的错误可能只是一个小麻烦,但150,000美元的错误则可能是灾难性的。在这些关键领域,仅仅提供一个单一的“最佳猜测”(点预测)是不足够的。决策者需要理解模型的不确定性。
为了解决这个问题,学术界在2005年左右发展了Conformal Prediction (CP)。它不输出单一标签,而是输出一个集合,包含所有可能的标签,并提供数学保证,确保真实标签包含在其中(例如,“我有95%的把握,患者的状况是健康或糖尿病”)。
与此同时,随着机器学习模型变得越来越复杂的“黑箱”,Explainable AI (XAI)领域应运而生。最直观的XAI技术之一是Counterfactual Explanation(大约在2017年普及),它精确地告诉用户需要进行哪些最小的改动才能改变模型的决策。
本文所解决的具体问题恰好出现在这两个领域的交叉点上:我们如何解释由Conformal Predictor产生的、考虑了不确定性的集合? 尽管我们有很好的工具来解释单一预测,也有很好的工具来量化不确定性,但我们缺乏一个桥梁来解释为什么模型的不确定性会发生足够的变化,从而将某个特定标签包含或排除在预测集之外。
先前方法的根本局限性——或“痛点”——在于现有的Counterfactual Explanation方法严格地为点预测器而设计。它们假设模型只输出一个标签,并且其整个数学目标是找到最小的特征调整来将这一个标签翻转为另一个。
由于Conformal Predictor输出的是标签的集合(该集合会根据模型的置信度而扩展或收缩),现有的方法完全力不从心。它们特别无法解释预测集输出的变化。例如,旧方法无法回答:“患者的血压发生什么微小变化,才能让模型足够自信地将‘糖尿病’从可能性中排除?”此外,尽管一些最近的模型试图将不确定性纳入Counterfactuals,但它们缺乏正式的、无分布的统计保证。作者们被迫撰写本文,以发明一种新的Counterfactual类型,其目标是包含或排除在保证的预测集内的标签。
以下是论文中的一些高度专业化的术语,翻译成日常概念:
- Conformal Prediction Set:
- 类比: 想象一下钓鱼。一个标准模型使用鱼叉(点预测)——它瞄准一条鱼,但如果没叉中,你就一无所获。一个Conformal Predictor使用渔网(预测集)。渔网可能和鱼一起捞上来一些海藻,但它保证你95%的时间都能捞到鱼。渔网的大小代表不确定性:小渔网意味着高置信度,而巨大的渔网意味着模型非常不确定。
- Counterfactual Explanation:
- 类比: GPS的重新规划建议。它不仅仅告诉你“你堵在路上了”(标准预测),而是告诉你,“如果你早点走下一个出口,你现在就能以限速行驶。”它展示了获得不同结果所需的最小改动。
- Credibility:
- 类比: 高级俱乐部门口检查你气质的保安。在本文中,Credibility衡量一个新生成的、合成的数据点(Counterfactual)与模型训练的真实数据融合得有多好。如果Credibility很高,新的数据点看起来就像一个正常、合理的个体。如果Credibility很低,这个数据点就是一个模型从未见过的不现实的“外星人”。
- Sparsity:
- 类比: 修车的技师。你希望他只更换一个坏掉的火花塞(高Sparsity),而不是重建整个发动机并更换轮胎(低Sparsity)。在论文中,一个稀疏的解释(sparse explanation)尽可能少地改变变量,使其更容易被人类理解和采取行动。
| Notation | Description |
|---|---|
| $x$ | 需要解释的原始输入实例(测试数据点)。 |
| $x'$ | 代理Counterfactual实例;改变预测集的新生成数据点。 |
| $x^{\text{real}}$ | 在校准数据集中找到的真实Counterfactual实例,用于锚定搜索空间。 |
| $\epsilon$ | 预定义的显著性水平(例如,$0.05$),表示可接受的错误率。 |
| $\mathcal{Y}$ | 数据集中所有可能类别的集合。 |
| $\tilde{y}$ | 一个正在被测试是否包含在预测集中的候选标签。 |
| $\Gamma^\epsilon(x)$ | 在显著性水平$\epsilon$下,实例$x$的Conformal预测集。它包含所有未被拒绝的标签。 |
| $Z^c$ | 校准数据集,用于计算非一致性得分的独立数据集。 |
| $p_k(x)$ | 由Conformal Predictor为实例$x$的类别$k$计算的p值。 |
| $h$ | 用于进行基础预测的底层机器学习算法/分类器。 |
| $\alpha_i$ | 非一致性得分,衡量一个实例与已知数据相比有多“奇怪”。 |
| $d(x, c)$ | 一个距离度量(如欧氏距离或Gower距离),衡量Counterfactual $c$与原始输入$x$的距离。 |
问题定义与约束
人工智能在辅助患者诊断中的应用。传统的 AI 模型会给出一个单一、自信的预测:“该患者患有糖尿病。”然而,在医学或金融等高风险领域,单一的预测是不够的;我们需要知道模型何时感到不确定。这时,“共形预测”(conformal prediction)应运而生。共形分类器不输出单一标签,而是输出一个“预测集”(prediction set)——一个包含可能标签的列表(例如,{健康, 糖尿病}),并提供数学保证,保证真实标签有 95% 的概率落入该集合中。如果 AI 非常不确定,预测集就会变大;如果它很确定,预测集就会缩小为一个单一标签。
但在这里我们遇到了一个瓶颈:我们如何解释 AI 给出这个特定集合的 原因?对于传统 AI,我们使用“反事实解释”(counterfactual explanations)。这些是“假设”场景,例如:“如果该患者的 BMI 低 2 个点,AI 就会预测为‘健康’而不是‘糖尿病’。”
本文的起点是共形预测集和传统反事实方法的存在。然而,传统的反事实方法严格来说是为翻转单一的点预测而设计的。期望的终点是一个全新的解释类型:共形反事实(conformal counterfactual)。作者希望找到对测试实例的最小改动,以在固定的置信度水平下改变 整个预测集——例如,弄清楚需要改变什么才能完全从可能性集合中排除“糖尿病”。
本文弥合的数学鸿沟在于优化目标。传统反事实方法解决的问题如下:
$$ \min_{c \in \mathcal{X}} d(x, c) \quad \text{subject to} \quad f(x) \neq f(c) $$
这里,你希望找到一个新的实例 $c$,它最小化与原始输入 $x$ 的距离 $d$,只要预测模型 $f$ 输出一个不同的单一标签。
作者不得不为集合重写这个逻辑。他们处理的不再是单一标签 $f(x)$,而是在显著性水平 $\epsilon$ 下的预测集 $\Gamma^\epsilon(x)$。他们的新目标要求找到一个代理实例 $x'$,使得集合本身发生变化:
$$ \Gamma^\epsilon(x') \neq \Gamma^\epsilon(x) $$
此外,他们引入了一个名为“可信度”(credibility)的新指标来指导这个搜索。可信度在数学上定义为所有候选类别 $k$ 的最大 p 值:
$$ \text{Credibility}(x') = \max_k p_k(x') $$
这衡量了新的“假设”场景在多大程度上符合真实训练数据的底层分布。
然而,在可解释 AI 的世界里,修复一件事几乎总是会破坏另一件事。困扰前人研究者的痛苦困境是“邻近性/稀疏性”(Proximity/Sparsity)与“合理性”(Plausibility)之间的拉锯战。
如果你仅仅要求算法找到改变预测的数学上最短距离(邻近性),或者改变最少数量的特征(稀疏性),数学会欣然满足,创造出一个“科学怪人”数据点。它可能会告诉你:“为了获得超过 50,000 美元的收入,只需将你的年龄改为 150 岁。”这在数学上是接近的,但在物理上是不可能的。前人研究者一直在努力生成最小化但仍然位于真实“数据流形”(data manifold)(意味着它们看起来像真实、合理的个体或场景)上的反事实。
为了解决这个问题,作者遇到了几个严峻的现实障碍:
- 无限搜索空间约束: 你不能仅仅搜索所有可能的数字组合来寻找反事实。连续特征空间是无限大的。为了克服这一点,作者不得不严格限制搜索范围。他们首先找到一个“真实反事实”$x^{\text{real}}$——来自校准数据集的一个实际的历史数据点,该数据点产生了一个不同的预测集。然后,他们构建一个离散网格,其特征值严格界定在原始实例 $x$ 和 $x^{\text{real}}$ 之间。
- 组合爆炸: 即使将搜索限制在这个有界的网格内,可能的特征组合数量也会呈指数级增长。如果一个数据集有很多特征,检查所有组合在计算上是不可能的。作者遇到了一个硬性的计算限制:如果组合数量超过 10,000,穷举搜索就会崩溃或耗时过长。他们被迫放弃完美优化,转而依赖启发式的遗传算法来导航空间。
- 共形计算的负担: 与简单的神经网络(前向传播速度极快)不同,共形预测需要计算非一致性分数(nonconformity scores)和 p 值,针对搜索过程中生成的 每一个合成数据点 的 每一个候选标签。这造成了巨大的计算瓶颈,使得实时生成这些解释变得极其困难。
为何采用此方法
要真正理解本文的突破性进展,我们首先需要审视传统人工智能的决策方式。大多数机器学习模型是“点预测器”——它们分析你的数据,并给出一个单一的、绝对的答案,例如“该患者患有糖尿病”。然而,在医学或金融等高风险领域,单一的猜测是不够的;决策者需要了解模型的不确定性。这时,Conformal Prediction (CP) 就派上用场了。CP 不输出单一标签,而是输出一个预测集(例如,$\{\text{健康}, \text{糖尿病}\}$),并提供数学保证,确保真实答案以特定概率(例如 95%)包含在该集合中。
作者意识到,传统的 SOTA(state-of-the-art)解释方法对于这些考虑不确定性的模型来说,根本上是存在缺陷的。标准的反事实(counterfactual)方法专门为点预测器设计。它们回答的问题是:“需要对模型预测从 A 变为 B 进行哪些最小的改动?”然而,当模型输出的是一组可能标签而不是单一标签时,现有方法就会完全失效。你无法简单地“翻转”一个集合。作者们真正意识到这一点,是在他们发现要解释模型的不确定性,就需要解释为何在固定的显著性水平 $\epsilon$ 下,某个特定类别被包含或排除在预测集之外。一个全新的、为 Conformal Prediction 量身定制的数学框架是唯一可行的解决方案。
除了简单的性能指标,该方法因其在处理合理性(plausibility)方面的结构性优势而具有定性上的优越性。之前反事实方法的黄金标准严重依赖于最小化距离(如 $\ell_2$ 范数)或稀疏性(改变的特征数量)。虽然这在数学上可行,但它常常会生成“陌生的”数据点——即看起来与真实世界实例毫无相似之处的建议。为了解决这个问题,作者们引入了一个开创性的指标:可信度(credibility)。
在 Conformal Prediction 中,可信度被定义为所有候选标签的最大 p 值:
$$ \text{Credibility}(x') = \max_k p_k(x') $$
通过优化可信度,该方法确保生成的反事实 $x'$ 能够完美地符合潜在的训练数据分布。该方法不是强迫一个巨大、不切实际的跨决策边界的跳跃来改变点预测,而是寻找更小、高度合理的微调,从而简单地扩展或缩小不确定性集。例如,在 Income 数据集中,将预测集从 $\{\text{> \$50K}, \text{≤ \$50K}\}$ 变为更自信的单一集合 $\{\text{> \$50K}\}$,需要比强迫一个僵化的类别翻转更现实的特征变化。
该问题提出了严苛的约束:解释必须在 Conformal 框架下是数学有效的,可操作的,并且严格绑定到校准数据(calibration data),以维持分布无关(distribution-free)的保证。所选方法完美地结合了这些约束。作者们设计了一个离散的搜索空间,该空间由原始测试实例 $x$ 和在校准集 $Z^c$ 中找到的最近的真实反事实 $x^{\text{real}}$ 界定:
$$ x^{\text{real}} = \arg \min_{x_i \in Z^c} \{ \| x - x_i \|_2 \mid \Gamma^\epsilon(x_i) \neq \Gamma^\epsilon(x) \} $$
通过将搜索空间锚定在实际观测值上,该算法保证了合成反事实永远不会偏离到不可能的特征组合中。如果搜索空间很小,它会使用穷举搜索;如果搜索空间变得计算量巨大,它会巧妙地使用遗传算法(Genetic Algorithm)进行扩展。这是一个完美的结合:Conformal Prediction 的严格统计界限得以维持,同时提供了直观、人类可读的解释。
最后,本文明确指出了其他流行方法为何在此处会失败。近期试图通过贝叶斯建模(Bayesian modeling)或认知不确定性量化(epistemic uncertainty quantification)将不确定性纳入反事实的尝试,对于这个特定问题来说,完全偏离了目标。贝叶斯模型提供概率分数,但它们缺乏分布无关的保证。它们假设一个先验分布,如果该假设错误,保证就会崩溃。Conformal Prediction 只依赖于可交换性(exchangeability)的假设。因此,试图将贝叶斯反事实或标准生成模型(如 GANs 或 Diffusion)硬塞进这个流程,将破坏 Conformal Prediction 最初如此有价值的严格、数学证明的错误率。作者们不得不拒绝这些替代方案,以保留预测集的绝对统计有效性。
 Figure 2. Counterfactual explanation for a conformal prediction set generated by optimizing for distance on the WBC dataset. Changed features are shown in blue
Figure 2. Counterfactual explanation for a conformal prediction set generated by optimizing for distance on the WBC dataset. Changed features are shown in blue
数学与逻辑机制
为了理解本文的突破性进展,我们首先需要建立一个基准,了解现代人工智能如何做出决策以及我们如何衡量其不确定性。
在传统的机器学习中,模型会给出一个“点预测”——一个单一的最佳猜测答案。然而,在医学或金融等高风险领域,单一的猜测是不够的;我们需要知道模型的置信度。这时就引入了Conformal Prediction (CP)。CP 不会输出单一答案,而是输出一个具有数学保证的预测集。例如,它可能会说:“我有 95% 的信心认为该患者的诊断是 {健康, 糖尿病} 中的一种。”如果模型高度不确定,预测集就会变大。如果模型确定,预测集就会缩小到一个单一标签。
本文的动机源于可解释人工智能 (Explainable AI) 的一个关键盲点。当人工智能做出点预测时,我们通常使用反事实解释来理解它(“如果你的收入更高,你的贷款就会获批”)。但如何解释一个预测集呢?现有方法在此完全失效。作者们着手解决这个问题,通过寻找改变模型不确定性边界所需的最小改变量,从而有效地解释了为什么某些类别被包含或排除在预测集之外。
为了实现这一点,他们必须克服几个约束:生成的解释必须接近原始数据(Proximity),必须尽可能少地改变变量(Sparsity),并且至关重要的是,它必须看起来像一个真实的数据点,而不是数学上的幻觉(Credibility)。
这是他们为解决这个问题而构建的数学引擎。
核心方程
本文的核心逻辑由一个三部分组成的数学引擎驱动:寻找现实锚点、最大化合理性以及惩罚复杂性。
$$ x^{\text{real}} = \arg \min_{x_i \in Z^c} \left\{ \|x - x_i\|_2 \mid \Gamma^\epsilon(x_i) \neq \Gamma^\epsilon(x) \right\} $$
$$ \text{Credibility}(x') = \max_k p_k(x') $$
$$ \text{Sparsity}(x, x') = \sum_{j=1}^p \mathbf{1}\{x_j \neq x'_j\} $$
解析方程
让我们逐一分解这个引擎的每个组成部分,以理解其物理和逻辑作用。
- $x$: 原始输入数据点(例如,患者当前的健康指标)。这是我们的起点。
- $x_i \in Z^c$: 来自校准数据集 $Z^c$ 的真实数据点。其逻辑作用是充当“现实检验”,以防止模型捏造不可能的场景。
- $\|x - x_i\|_2$: L2 范数(欧几里得距离)。它像橡皮筋一样将搜索拉回到原始输入。作者在此使用 L2 范数,因为它会严重惩罚任何单个变量的大幅、不切实际的偏差,迫使模型找到一个平衡的、附近的解决方案。
- $\Gamma^\epsilon(x)$: 在固定显著性水平 $\epsilon$(通常为 95% 置信度取 0.05)下的共形预测集。这代表了模型不确定性的边界。
- $\neq$: 不等号。这是整个论文的逻辑触发器。我们不仅仅是想改变潜在的概率;我们要求对最终预测集进行结构性、可见性的改变。
- $\arg \min$: 搜索算子。它扫描数据以找到阻力最小的路径——最接近的真实世界示例,该示例成功地翻转了预测集。
- $x'$: 我们正在生成的合成代理反事实。这是最终将交给用户的解释。
- $p_k(x')$: 类 $k$ 的 p 值。在共形预测中,这衡量了新数据点在多大程度上符合该特定类别的已知数据分布。
- $\max_k$: 最大值算子。通过取所有类别的最大 p 值,它确保了反事实对于至少一个类别是高度合理的,而不是平均化成一个平庸、不现实的状态。
- $\sum_{j=1}^p$: 对所有 $p$ 个特征求和。作者为什么使用求和而不是乘积?因为我们想加性地计算改变特征的总数。如果我们使用乘法,一个未改变的特征(产生 0)将使整个惩罚无效,从而完全破坏计算改变次数的逻辑。
- $\mathbf{1}\{x_j \neq x'_j\}$: 指示函数。它充当一个二元开关:如果一个特征被改变,它输出 1;如果未改变,则输出 0。
逐步流程
让我们追踪一个抽象的数据点,看它如何通过这个机械流水线:
- 输入: 患者数据 $x$ 进入系统。模型不确定,输出预测集为 {健康, 糖尿病}。
- 现实锚点: 系统扫描历史校准数据,找到 $x^{\text{real}}$,即获得不同预测集(例如,仅 {健康})的最接近的实际患者。
- 网格构建: 构建一个离散搜索网格。系统提取 $x$ 和 $x^{\text{real}}$ 之间的所有观测值。这确保我们只建议现实的中间步骤(例如,我们不会建议血压为 10,如果数据中不存在)。
- 流水线: 在此网格上生成一个合成候选 $x'$。它通过共形预测器,以查看其预测集是否实际发生翻转($\Gamma^\epsilon(x') \neq \Gamma^\epsilon(x)$)。
- 质量控制: 如果预测集发生翻转,则评估候选。系统计算其合理性(它是一个现实的患者吗?)和稀疏性(我们是否只改变了少数几项,例如仅“葡萄糖”和“年龄”?)。
- 输出: 最能平衡这些标准的候选者被返回作为最终的、可操作的解释。
优化动力学
这个机制实际上是如何学习、更新和收敛的?
在传统的神经网络中,我们使用梯度下降来沿着平滑的损失景观滑动。然而,由于共形预测集会产生硬的、不可微的阶跃函数(一个标签要么严格在集合内,要么在集合外),因此此处不存在梯度。损失景观不是一个平滑的山丘;它是一个由离散的二元决策组成的锯齿状悬崖面。
为了克服这一点,作者们采用了双管齐下的优化策略。如果搜索空间很小(低于 10,000 种组合),系统会使用暴力穷举搜索,评估网格上的每一个点,以找到绝对的数学最优解。
如果空间太大,它会部署一个遗传算法 (GA)。GA 初始化一个包含 100 个随机候选反事实的种群。“适应度”由我们的核心方程决定(最大化合理性或最小化稀疏性)。至关重要的是,景观由一个巨大的惩罚函数塑造:如果一个候选未能改变预测集,其适应度分数将被摧毁,从而在下一代中有效地将其淘汰。经过 1,000 次迭代,候选者会发生变异(以 10% 的概率随机调整一个特征)和交叉(在两个好的候选者之间交换特征)。
坦白说,我不太确定作者为什么没有进行消融研究就将遗传算法的精英主义比例硬编码为 0.01,但实际上,这足以在不减缓搜索速度的情况下,在各代之间保持绝对最佳候选者的存活。通过这种进化过程,系统会迭代地收敛到一个最小的、高度合理的改变量,该改变量成功地改变了模型的不确定性边界。
结果、局限性与结论
想象一下,您去看医生进行医学诊断。如果医生说:“您肯定患有糖尿病”,这就是一个标准的点预测。但如果医生说:“根据您的检查结果,我有 95% 的把握您要么完全健康,要么患有早期糖尿病”呢?第二种情况就是一致性预测 (Conformal Prediction, CP) 的精髓。CP 不会给出一个单一的、可能过于自信的答案,而是给您一个预测集——一个包含可能结果的列表,并附有数学保证,即真实答案以特定概率包含在该集合中。
然而,这引入了一个巨大的心理和实际问题:模型为什么将“糖尿病”包含在该集合中?您的健康状况需要发生什么变化,模型才能自信地排除“糖尿病”而只说“健康”?
这时反事实 (Counterfactual, CF) 解释就派上用场了。反事实是一种“假设”场景。它告诉您改变模型决策所需的最小改变量(例如,“如果您的血压降低 10 个点,您将被严格归类为健康”)。历史上,科学家们只找到了为标准点预测生成反事实的方法。本文解决了一个出色但先前未解决的问题:如何为一致性预测集生成反事实解释?
背景与动机
要理解本文,您需要掌握两个概念:
1. 一致性预测集: 给定一个显著性水平 $\epsilon$(例如,0.05 表示 95% 的置信水平),一个一致性分类器会输出一个标签集合 $\Gamma^\epsilon(x)$。它通过计算每个可能标签的非一致性得分,将这些得分转换为 $p$-值,并拒绝任何 $p$-值小于 $\epsilon$ 的标签。
2. 反事实: 这些是与原始输入 $x$ 非常接近但会导致不同预测的合成数据点 $x'$。
这里的动机是纯粹的信任和可操作性。决策者不仅想知道模型的_不确定性_,还想知道这种不确定性的_边界_。如果一家银行的模型说您的贷款申请预测集是 $\{\text{批准}, \text{拒绝}\}$,您想确切地知道需要改变什么(例如,还清 150 美元的信用卡债务)才能将该集合变为严格的 $\{\text{批准}\}$。
待克服的约束
由于高维数据的浩瀚性,生成这些“假设”场景极其困难。如果您只是让算法盲目地搜索数学解决方案,它会提出荒谬的建议,例如“将您的年龄减少 15 岁”或“拥有负血压”。
因此,作者不得不约束搜索空间,以确保生成的解释是:
* 接近性 (Proximate): 改变必须很小。
* 稀疏性 (Sparse): 应该只改变一两个特征,而不是全部。
* 合理性 (Plausible/Credible): 合成数据点必须看起来像真实世界中的真实数据。
数学问题与解决方案
作者解决的核心数学问题是找到一个替代实例 $x'$,使得预测集发生变化:
$$ \Gamma^\epsilon(x') \neq \Gamma^\epsilon(x) $$
为了在不生成不可能数据点的情况下解决这个问题,他们设计了一个高度约束的三步搜索架构:
1. 寻找“真实”反事实: 首先,他们查看校准数据集(真实的历史数据),找到一个与 $x$ 具有不同预测集的、最接近的实际数据点 $x^{\text{real}}$。
2. 构建网格: 他们构建一个离散的搜索空间,该空间完全由 $x$ 和 $x^{\text{real}}$ 之间的值界定。这保证了算法不会生成超出范围的、任意的数字。
3. 优化: 他们搜索这个网格(对于小空间使用穷举搜索,对于大空间使用遗传算法)来找到一个合成 $x'$,该 $x'$ 优化了以下三个标准之一:
* 距离 (Proximity): 最小化 $||x - x'||_2$。
* 稀疏性 (Sparsity): 最小化改变的特征数量 $\sum_{j=1}^p \mathbf{1}\{x_j \neq x'_j\}$。
* 合理性 (Credibility): 这是作者的绝妙之处。他们将合理性定义为 $\max_k p_k(x')$。通过最大化所有类别的最高 $p$-值,他们迫使反事实紧密地符合训练数据的底层分布。这在数学上强制“假设”场景高度逼真。
实验架构与“受害者”
作者们不仅仅列出了指标,他们设计了一个严酷的实验来证明他们的合成反事实比现实本身更好。
“受害者”: 由于不存在其他算法来为一致性预测集生成反事实,基线(他们必须击败的“受害者”)是直接从历史数据集中提取的真实反事实($x^{\text{real}}$)。
证据: 他们在 10 个表格数据集上测试了他们的方法。对于每个数据集,他们生成了替代反事实,并使用比率将它们与真实反事实进行了比较。
* 在优化距离时,他们的方法达到了平均比率 $0.452$。这无可辩驳地证明了他们的算法找到了有效的解释,这些解释比最好的现实世界示例更接近原始输入 54.8%。
* 在优化稀疏性时,他们达到了 $0.493$ 的比率,这意味着他们的解释所需的改变特征数量是现实世界对应项的一半。
* 最令人印象深刻的是,在优化合理性时,他们达到了 $1.157$ 的比率。这意味着他们合成的、数学生成的_数据点_实际上比校准集中的实际数据点更符合数据分布 15.7%。
老实说,我不太确定为什么对于较大的搜索空间,他们选择了一个相对基础的遗传算法包,而不是存在更先进的基于梯度的离散优化器,但经验证据证明它作为概念验证已绰绰有余。
未来演进的讨论话题
基于这个杰出的基础,以下是几个关键的未来研究方向:
- 因果图与严格的可操作性: 当前方法通过真实数据来界定搜索空间,但它不理解因果关系。在他们的糖尿病示例中,算法建议将患者年龄从 30 岁减少到 26 岁。年龄是不可变的。
我们如何将有向无环图 (DAGs) 整合到一致性搜索空间中,以便算法只建议因果链下游的、可操作的干预措施?
2. 定向集引导: 目前,算法一旦预测集发生变化 ($\Gamma^\epsilon(x') \neq \Gamma^\epsilon(x)$) 就会停止。但如果用户想将集合朝特定方向引导呢?例如,从 $\{\text{良性}, \text{恶性}\}$ 严格变为 $\{\text{良性}\}$。我们如何修改目标函数来针对特定的集合包含/排除?
3. 扩展到非结构化数据: 该方法依赖于表格特征之间的离散网格搜索。我们如何将其发展为处理高维非结构化数据,如图像或文本?我们能否将一致性的 $p$-值映射到变分自编码器 (VAE) 的连续潜在空间,并执行梯度下降来找到反事实图像?
4. 平衡三难困境: 作者分别优化了距离、稀疏性和合理性。我们能否构建一个帕累托最优的损失函数,同时平衡这三者,也许使用多目标强化学习,来找到最终的“完美”解释?
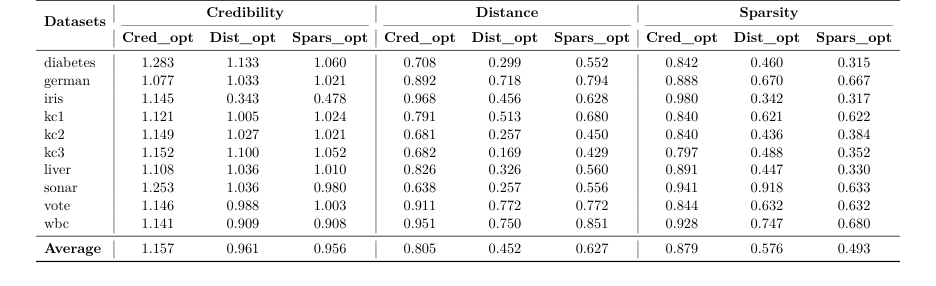 Table 2. Comparison of optimization criteria across datasets
Table 2. Comparison of optimization criteria across datasets