Контрфактические объяснения для конформных предсказательных множеств
Модели машинного обучения все чаще развертываются в критически важных средах, таких как медицинская диагностика или одобрение финансовых кредитов, где ошибка в 150 долларов может быть незначительным неудобством, но...
Предыстория и академическое происхождение
Модели машинного обучения все чаще развертываются в критически важных средах, таких как медицинская диагностика или одобрение финансовых кредитов, где ошибка в 150 долларов может быть незначительным неудобством, но ошибка в 150 000 долларов может иметь катастрофические последствия. В этих критических областях простого предоставления единственного "наилучшего предположения" (точечного прогноза) недостаточно. Лица, принимающие решения, должны понимать неопределенность модели.
Для решения этой проблемы академическая область разработала Конформное прогнозирование (CP) примерно в 2005 году. Вместо вывода единственной метки конформный предиктор выводит множество правдоподобных меток с математической гарантией включения истинной метки (например, "Я на 95% уверен, что состояние пациента — либо "Здоров", либо "Диабетик"").
Одновременно с тем, как модели машинного обучения становились сложными "черными ящиками", возникла область Объяснимого ИИ (XAI). Одним из наиболее интуитивно понятных методов XAI является Контрфактическое объяснение (популяризированное примерно в 2017 году), которое точно сообщает пользователю, какие минимальные изменения необходимы для изменения решения модели.
Конкретная проблема, рассматриваемая в данной статье, возникла на пересечении этих двух областей: Как объяснить наборы данных, учитывающие неопределенность, полученные конформными предикторами? Хотя у нас есть отличные инструменты для объяснения одиночных прогнозов и отличные инструменты для количественной оценки неопределенности, нам не хватало моста для объяснения того, почему неопределенность модели изменилась настолько, чтобы включить или исключить определенную метку из набора прогнозов.
Фундаментальное ограничение — или "болевая точка" — предыдущих подходов заключается в том, что существующие методы контрфактического объяснения были строго разработаны для точечных предикторов. Они предполагают, что модель выводит ровно одну метку, и их вся математическая цель состоит в том, чтобы найти наименьшее изменение признака для смены этой одной метки на другую.
Поскольку конформные предикторы выводят множества меток (которые расширяются или сжимаются в зависимости от уверенности модели), существующие методы полностью не справляются. Они, в частности, не могут объяснить изменения в выходных данных наборов прогнозов. Например, старые методы не могут ответить: "Какое небольшое изменение артериального давления этого пациента сделает модель достаточно уверенной, чтобы исключить "Диабетик" из области возможного?" Кроме того, хотя несколько недавних моделей пытались включить неопределенность в контрфактические объяснения, им не хватало формальных, не зависящих от распределения статистических гарантий. Авторы были вынуждены написать эту статью, чтобы изобрести новый тип контрфактического объяснения, который нацелен на включение или исключение меток в рамках гарантированного набора прогнозов.
Вот несколько узкоспециализированных терминов из статьи, переведенных на общепринятые понятия:
- Набор конформного прогнозирования (Conformal Prediction Set):
- Аналогия: Представьте себе рыбалку. Стандартная модель использует копье (точечный прогноз) — она нацеливается ровно на одну рыбу, но если промахнется, вы ничего не получите. Конформный предиктор использует сеть (набор прогнозов). Сеть может поймать немного водорослей вместе с рыбой, но гарантирует, что вы поймаете рыбу в 95% случаев. Размер сети представляет неопределенность: маленькая сеть означает высокую уверенность, а огромная сеть — что модель очень неуверена.
- Контрфактическое объяснение (Counterfactual Explanation):
- Аналогия: Предложение GPS о перемаршрутизации. Вместо того, чтобы просто сказать вам: "Вы застряли в пробке" (стандартный прогноз), контрфактическое объяснение говорит вам: "Если бы вы съехали на предыдущем съезде, вы бы сейчас ехали с ограничением скорости". Оно показывает минимальное изменение, необходимое для получения другого результата.
- Достоверность (Credibility):
- Аналогия: Вышибала в эксклюзивном клубе, проверяющий вашу атмосферу. В этой статье достоверность измеряет, насколько хорошо новая, синтетическая точка данных (контрфактическое объяснение) вписывается в реальные данные, на которых обучалась модель. Если достоверность высока, новая точка данных выглядит как обычный, правдоподобный человек. Если она низка, точка данных — нереалистичный инопланетянин, которого модель никогда раньше не видела.
- Разреженность (Sparsity):
- Аналогия: Механик, ремонтирующий ваш автомобиль. Вы хотите, чтобы он заменил только одну сломанную свечу зажигания (высокая разреженность), а не перебирал весь двигатель и менял шины (низкая разреженность). В статье разреженное объяснение изменяет как можно меньше переменных, что облегчает человеку понимание и принятие мер.
| Обозначение | Описание |
|---|---|
| $x$ | Исходный экземпляр входных данных (тестовая точка данных), который необходимо объяснить. |
| $x'$ | Суррогатный контрфактический экземпляр; вновь сгенерированная точка данных, которая изменяет набор прогнозов. |
| $x^{\text{real}}$ | Реальный контрфактический экземпляр, найденный в калибровочном наборе данных, используемый для привязки пространства поиска. |
| $\epsilon$ | Предопределенный уровень значимости (например, $0.05$), представляющий допустимый уровень ошибки. |
| $\mathcal{Y}$ | Множество всех возможных меток классов в наборе данных. |
| $\tilde{y}$ | Кандидатская метка, проверяемая на включение в набор прогнозов. |
| $\Gamma^\epsilon(x)$ | Набор конформного прогнозирования для экземпляра $x$ при уровне значимости $\epsilon$. Он содержит все метки, которые не были отклонены. |
| $Z^c$ | Калибровочный набор данных, отдельный набор данных, используемый для вычисления оценок несоответствия. |
| $p_k(x)$ | p-значение, вычисленное конформным предиктором для класса $k$ при экземпляре $x$. |
| $h$ | Базовый алгоритм машинного обучения/классификатор, используемый для базовых прогнозов. |
| $\alpha_i$ | Оценка несоответствия, измеряющая, насколько "странным" является экземпляр по сравнению с известными данными. |
| $d(x, c)$ | Метрика расстояния (например, евклидово расстояние или расстояние Говера), измеряющая, насколько контрфактическое объяснение $c$ отличается от исходного входного $x$. |
Определение проблемы и ограничения
Представьте, что вы используете ИИ для диагностики пациента. Традиционная модель ИИ выдает один уверенный прогноз: «У этого пациента диабет». Однако в областях с высокими ставками, таких как медицина или финансы, одного предположения недостаточно; нам нужно знать, когда модель не уверена. Здесь на помощь приходит конформное прогнозирование. Вместо одного метки конформный классификатор выдает набор прогнозов — список правдоподобных меток (например, {Здоров, Диабетик}) с математической гарантией того, что истинный ответ содержится в этом наборе, скажем, в 95% случаев. Если ИИ сильно не уверен, набор увеличивается; если он уверен, набор сужается до одной метки.
Но здесь мы упираемся в стену: как объяснить, почему ИИ выдал нам этот конкретный набор? Для традиционного ИИ мы используем «контрфактические объяснения». Это сценарии «что, если», такие как: «Если бы ИМТ этого пациента был на 2 пункта ниже, ИИ предсказал бы «Здоров» вместо «Диабетик»».
Отправной точкой (Вход/Текущее состояние) данной статьи является существование этих конформных наборов прогнозов и традиционных контрфактических методов. Однако традиционные контрфактические методы строго разработаны для изменения единичного точечного прогноза. Желаемым конечным состоянием (Выход/Целевое состояние) является совершенно новый тип объяснения: конформное контрфактическое. Авторы хотят найти минимальные изменения в тестовом экземпляре, которые изменят весь набор прогнозов при фиксированном уровне достоверности — например, выяснить, что именно нужно изменить, чтобы полностью исключить «Диабетик» из набора возможных вариантов.
Математический пробел, который преодолевает данная статья, заключается в целевой функции оптимизации. Традиционные контрфактические методы решают задачу, которая выглядит следующим образом:
$$ \min_{c \in \mathcal{X}} d(x, c) \quad \text{subject to} \quad f(x) \neq f(c) $$
Здесь вы хотите найти новый экземпляр $c$, который минимизирует расстояние $d$ от исходного входного сигнала $x$, при условии, что предиктивная модель $f$ выдает другую одиночную метку.
Авторам пришлось переписать эту логику для наборов. Вместо одиночной метки $f(x)$ они имеют дело с набором прогнозов $\Gamma^\epsilon(x)$ при уровне значимости $\epsilon$. Их новая целевая функция требует найти суррогатный экземпляр $x'$, такой что сам набор изменяется:
$$ \Gamma^\epsilon(x') \neq \Gamma^\epsilon(x) $$
Кроме того, они ввели новую метрику под названием достоверность (credibility) для управления этим поиском. Достоверность определяется математически как максимальное p-значение по всем кандидатским классам $k$:
$$ \text{Credibility}(x') = \max_k p_k(x') $$
Это измеряет, насколько хорошо новый сценарий «что, если» фактически соответствует базовому распределению реальных обучающих данных.
Однако в мире объяснимого ИИ исправление одного почти всегда ломает другое. Болезненная дилемма, в которую попали предыдущие исследователи, — это борьба между близостью/разреженностью (Proximity/Sparsity) и правдоподобием (Plausibility).
Если вы просто попросите алгоритм найти математически наименьшее расстояние для изменения прогноза (близость) или изменить наименьшее количество признаков (разреженность), математика с радостью удовлетворит это, создав Франкенштейна из данных. Она может сказать вам: «Чтобы получить доход более 50 000 долларов, просто измените свой возраст на 150 лет». Это математически близко, но физически невозможно. Предыдущие исследователи испытывали трудности с генерацией контрфактических данных, которые были бы минимальными, но при этом оставались на истинном «многообразии данных» (data manifold), то есть выглядели бы как реалистичные, правдоподобные люди или сценарии.
Чтобы решить эту проблему, авторы столкнулись с несколькими суровыми, реалистичными препятствиями:
- Ограничение бесконечного пространства поиска: Вы не можете просто перебрать все возможные комбинации чисел, чтобы найти контрфактическое значение. Непрерывное пространство признаков бесконечно велико. Чтобы преодолеть это, авторам пришлось строго ограничить поиск. Сначала они находят «реальное контрфактическое» $x^{\text{real}}$ — фактическую историческую точку данных из калибровочного набора, которая дает другой набор прогнозов. Затем они строят дискретную сетку значений признаков, строго ограниченную между исходным экземпляром $x$ и $x^{\text{real}}$.
- Комбинаторный взрыв: Даже после ограничения поиска этой ограниченной сеткой количество возможных комбинаций признаков растет экспоненциально. Если набор данных имеет много признаков, проверка каждой комбинации вычислительно невозможна. Авторы столкнулись с жестким вычислительным пределом: если количество комбинаций превышает 10 000, исчерпывающий поиск дает сбой или занимает слишком много времени. Им пришлось отказаться от идеальной оптимизации и полагаться на эвристический генетический алгоритм для навигации по пространству.
- Бремя конформных вычислений: В отличие от простых нейронных сетей, где прямой проход выполняется молниеносно, конформное прогнозирование требует вычисления оценок несоответствия (nonconformity scores) и p-значений для каждого кандидатского класса для каждой синтетической точки данных, генерируемой во время поиска. Это создает массивное вычислительное узкое место, делая генерацию этих объяснений в реальном времени чрезвычайно сложной.
Почему этот подход
Чтобы по-настоящему понять прорыв, представленный в данной статье, сначала необходимо рассмотреть, как традиционный искусственный интеллект принимает решения. Большинство моделей машинного обучения являются "точечными предсказателями" — они анализируют ваши данные и выдают один абсолютный ответ, например: "Этот пациент страдает диабетом". Однако в критически важных областях, таких как медицина или финансы, одного предположения недостаточно; лица, принимающие решения, должны знать степень неопределенности модели. Именно здесь на помощь приходит конформное прогнозирование (Conformal Prediction, CP). Вместо одного ярлыка CP выдает набор предсказаний (например, $\{\text{Здоров}, \text{Диабетик}\}$) с математической гарантией того, что истинный ответ содержится в этом наборе с определенной вероятностью, скажем, $95\%$.
Авторы осознали, что традиционные передовые (SOTA) методы объяснения фундаментально не подходят для этих моделей, учитывающих неопределенность. Стандартные контрфактические методы разработаны исключительно для точечных предсказателей. Они отвечают на вопрос: "Каково минимальное изменение, необходимое для изменения предсказания модели с A на B?". Однако, когда модель выдает набор правдоподобных ярлыков вместо одного, существующие методы полностью теряют свою эффективность. Нельзя просто "изменить" набор. Момент осознания наступил, когда авторы увидели, что для объяснения неопределенности модели необходимо объяснить, почему определенный класс был включен или исключен из набора предсказаний при заданном уровне значимости $\epsilon$. Полностью новая математическая структура, адаптированная для конформного прогнозирования, была единственным жизнеспособным решением.
Помимо простых метрик производительности, этот метод качественно превосходит предыдущие благодаря своему структурному преимуществу в обработке правдоподобия. Предыдущий золотой стандарт для контрфактических объяснений в значительной степени опирался на минимизацию расстояния (например, $\ell_2$-нормы) или разреженности (количество измененных признаков). Хотя это математически корректно, часто генерируются "чужеродные" точки данных — предложения, которые совершенно не похожи на реальные экземпляры. Чтобы решить эту проблему, авторы ввели новаторскую метрику: достоверность (credibility).
В конформном прогнозировании достоверность определяется как максимальное p-значение по всем кандидатам на ярлык:
$$ \text{Credibility}(x') = \max_k p_k(x') $$
Оптимизируя по достоверности, метод гарантирует, что сгенерированный контрфактический пример $x'$ идеально соответствует базовому распределению обучающих данных. Вместо того чтобы совершать массивный, нереалистичный скачок через границу принятия решений для изменения точечного предсказания, этот метод находит более мелкие, высокоправдоподобные сдвиги, которые просто расширяют или сужают набор неопределенности. Например, в наборе данных Income, переход от набора предсказаний $\{>\$50\text{K}, \leq\$50\text{K}\}$ к более уверенному одиночному набору $\{>\$50\text{K}\}$ требует гораздо более реалистичных изменений признаков, чем принудительное жесткое изменение класса.
Задача ставила жесткие ограничения: объяснения должны были быть математически обоснованными в рамках конформной структуры, действенными и строго привязанными к калибровочным данным для сохранения гарантий, не зависящих от распределения. Выбранный подход идеально сочетает эти ограничения. Авторы разработали дискретное пространство поиска, ограниченное исходным тестовым экземпляром $x$ и ближайшим реальным контрфактическим примером $x^{\text{real}}$, найденным в калибровочном наборе $Z^c$:
$$ x^{\text{real}} = \arg \min_{x_i \in Z^c} \{ \| x - x_i \|_2 \mid \Gamma^\epsilon(x_i) \neq \Gamma^\epsilon(x) \} $$
Привязывая пространство поиска к фактическим наблюдаемым значениям, алгоритм гарантирует, что синтетический контрфактический пример никогда не выходит за пределы невозможных комбинаций признаков. Если пространство поиска невелико, используется полный перебор; если оно становится вычислительно массивным, элегантно применяется генетический алгоритм. Это идеальное сочетание: строгие статистические границы конформного прогнозирования сохраняются, одновременно предоставляя интуитивно понятные, читаемые человеком объяснения.
Наконец, в статье явно указывается, почему другие популярные подходы потерпели бы неудачу в данном случае. Недавние попытки включить неопределенность в контрфактические объяснения с использованием байесовского моделирования или количественной оценки эпистемической неопределенности полностью упускают суть данной конкретной проблемы. Байесовские модели предоставляют вероятностные оценки, но им не хватает гарантий, не зависящих от распределения. Они предполагают априорное распределение, и если это предположение неверно, гарантии рушатся. Конформное прогнозирование опирается только на предположение об обмениваемости (exchangeability). Следовательно, попытка встроить байесовские контрфактические объяснения или стандартные генеративные модели (такие как GAN или Diffusion) в этот конвейер разрушила бы строгий, математически доказанный уровень ошибок, который делает конформное прогнозирование столь ценным. Авторам пришлось отказаться от этих альтернатив, чтобы сохранить абсолютную статистическую достоверность наборов предсказаний.
 Figure 2. Counterfactual explanation for a conformal prediction set generated by optimizing for distance on the WBC dataset. Changed features are shown in blue
Figure 2. Counterfactual explanation for a conformal prediction set generated by optimizing for distance on the WBC dataset. Changed features are shown in blue
Математический и логический механизм
Чтобы понять прорыв, представленный в данной статье, сначала необходимо установить базовое понимание того, как современные ИИ принимают решения и как измеряется их неопределенность.
В традиционном машинном обучении модель выдает "точечный прогноз" — единственный, наиболее вероятный ответ. Однако в областях с высокими ставками, таких как медицина или финансы, одного предположения недостаточно; нам необходимо знать, насколько уверена модель. Здесь на помощь приходит Конформное Прогнозирование (CP). Вместо одного ответа CP выдает набор прогнозов с математической гарантией. Например, он может сказать: "Я на 95% уверен, что диагноз этого пациента — {Здоров, Диабетик}". Если модель сильно неуверена, набор расширяется. Если она уверена, набор сужается до одного класса.
Мотивация данной статьи проистекает из критического упущения в области Объяснимого ИИ (Explainable AI). Когда ИИ делает точечный прогноз, мы часто используем контрфактические объяснения для его понимания ("Если бы ваш доход был выше, ваш кредит был бы одобрен"). Но как объяснить набор прогнозов? Существующие методы здесь полностью терпят неудачу. Авторы поставили перед собой задачу решить эту проблему, найдя минимальные изменения, необходимые для изменения границы неопределенности модели, эффективно объясняя, почему определенные классы были включены или исключены из набора.
Для этого им пришлось преодолеть несколько ограничений: сгенерированное объяснение должно быть близко к исходным данным (Proximity), оно должно изменять как можно меньше переменных (Sparsity) и, что крайне важно, оно должно выглядеть как реалистичная точка данных, а не математическая галлюцинация (Credibility).
Вот математический механизм, который они построили для решения этой задачи.
Основные Уравнения
Основная логика данной статьи основана на трехкомпонентном математическом механизме: поиск "якоря реальности", максимизация правдоподобия и штрафование сложности.
$$ x^{\text{real}} = \arg \min_{x_i \in Z^c} \left\{ \|x - x_i\|_2 \mid \Gamma^\epsilon(x_i) \neq \Gamma^\epsilon(x) \right\} $$
$$ \text{Credibility}(x') = \max_k p_k(x') $$
$$ \text{Sparsity}(x, x') = \sum_{j=1}^p \mathbf{1}\{x_j \neq x'_j\} $$
Разбор Уравнений
Давайте разберем каждый компонент этого механизма, чтобы понять его физическую и логическую роль.
- $x$: Исходная входная точка данных (например, текущие показатели здоровья пациента). Это наша отправная точка.
- $x_i \in Z^c$: Реальная точка данных из калибровочного набора $Z^c$. Ее логическая роль — служить "проверкой реальности", чтобы модель не выдумывала невозможные сценарии.
- $\|x - x_i\|_2$: L2-норма (Евклидово расстояние). Она действует как резинка, притягивающая поиск обратно к исходному входу. Авторы используют L2-норму здесь, потому что она сильно штрафует большие, нереалистичные отклонения в любой отдельной переменной, заставляя модель находить сбалансированное, близкое решение.
- $\Gamma^\epsilon(x)$: Набор конформных прогнозов при фиксированном уровне значимости $\epsilon$ (обычно 0.05 для 95% доверия). Это представляет собой границу неопределенности модели.
- $\neq$: Оператор неравенства. Это логический триггер всей статьи. Мы не просто хотим сдвинуть базовые вероятности; мы требуем структурного, видимого изменения в конечном наборе прогнозов.
- $\arg \min$: Оператор поиска. Он сканирует данные, чтобы найти путь наименьшего сопротивления — абсолютно ближайший реальный пример, который успешно изменяет набор прогнозов.
- $x'$: Синтетический суррогатный контрфактический объект, который мы генерируем. Это конечное объяснение, которое мы предоставим пользователю.
- $p_k(x')$: p-значение для класса $k$. В конформном прогнозировании оно измеряет, насколько хорошо новая точка соответствует известному распределению данных для данного конкретного класса.
- $\max_k$: Оператор максимума. Принимая максимальное p-значение по всем классам, он гарантирует, что контрфактический объект будет очень правдоподобным для хотя бы одного класса, а не усреднится до посредственного, нереалистичного состояния.
- $\sum_{j=1}^p$: Суммирование по всем $p$ признакам. Почему авторы использовали здесь сумму, а не произведение? Потому что мы хотим аддитивно подсчитать общее количество измененных признаков. Если бы мы использовали умножение, один неизмененный признак (дающий 0) обнулил бы весь штраф, полностью нарушив логику подсчета изменений.
- $\mathbf{1}\{x_j \neq x'_j\}$: Индикаторная функция. Она действует как бинарный переключатель: выдает 1, если признак был изменен, и 0, если он остался без изменений.
Пошаговый Процесс
Проследим за одной абстрактной точкой данных, проходящей через эту механическую сборочную линию:
- Входные данные: Данные пациента $x$ поступают в систему. Модель неуверена и выдает набор прогнозов {Здоров, Диабетик}.
- Якорь реальности: Система сканирует исторические калибровочные данные, чтобы найти $x^{\text{real}}$, ближайшего реального пациента, получившего другой набор прогнозов (например, только {Здоров}).
- Построение сетки: Строится дискретная поисковая сетка. Система извлекает все наблюдаемые значения между $x$ и $x^{\text{real}}$. Это гарантирует, что мы предлагаем только реалистичные промежуточные шаги (например, мы не предложим артериальное давление 10, если оно не существует в данных).
- Сборочная линия: Генерируется синтетический кандидат $x'$ на этой сетке. Он проходит через конформный предиктор, чтобы проверить, действительно ли его набор прогнозов изменяется ($\Gamma^\epsilon(x') \neq \Gamma^\epsilon(x)$).
- Контроль качества: Если набор изменяется, кандидат оценивается. Система рассчитывает его Credibility (является ли он реалистичным пациентом?) и Sparsity (изменили ли мы только несколько вещей, например, только 'Глюкозу' и 'Возраст'?).
- Выходные данные: Кандидат, который наилучшим образом балансирует эти критерии, возвращается в качестве окончательного, действенного объяснения.
Динамика Оптимизации
Как этот механизм фактически обучается, обновляется и сходится?
В традиционных нейронных сетях мы используем градиентный спуск для скольжения вниз по гладкому ландшафту потерь. Однако, поскольку наборы конформных прогнозов создают жесткие, недифференцируемые ступенчатые функции (класс либо строго внутри набора, либо вне его), градиенты здесь не существуют. Ландшафт потерь — это не гладкий холм; это зазубренная скала дискретных, бинарных решений.
Чтобы преодолеть это, авторы используют двухстороннюю стратегию оптимизации. Если пространство поиска невелико (менее 10 000 комбинаций), система использует полный переборный поиск, оценивая каждую точку на сетке, чтобы найти абсолютный математический оптимум.
Если пространство слишком велико, она развертывает Генетический Алгоритм (GA). GA инициализирует популяцию из 100 случайных кандидатов-контрфактических объектов. "Пригодность" каждого кандидата определяется нашими Основными Уравнениями (максимизация Credibility или минимизация Sparsity). Важно отметить, что ландшафт формируется массивной штрафной функцией: если кандидат не изменяет набор прогнозов, его оценка пригодности уничтожается, фактически уничтожая его в следующем поколении. За 1000 итераций кандидаты мутируют (случайно изменяя признак с вероятностью 10%) и скрещиваются (обмениваясь признаками между двумя хорошими кандидатами).
Честно говоря, я не до конца уверен, почему авторы жестко закодировали соотношение элитизма генетического алгоритма ровно на 0.01 без исследования влияния (ablation study), но на практике этого достаточно, чтобы сохранить абсолютно лучшего кандидата на протяжении поколений, не замедляя поиск. Через этот эволюционный процесс система итеративно сходится к минимальному, высокоправдоподобному изменению, которое успешно изменяет границу неопределенности модели.
Результаты, ограничения и заключение
Представьте, что вы обращаетесь к врачу для постановки медицинского диагноза. Если врач говорит: «У вас определенно диабет», это стандартное точечное предсказание. Но что, если врач скажет: «На основании ваших анализов я на 95% уверен, что вы либо полностью здоровы, либо у вас диабет на ранней стадии»? Этот второй сценарий является сутью Конформного Прогнозирования (CP). Вместо того чтобы давать один, потенциально излишне уверенный ответ, CP предоставляет вам набор предсказаний — список возможных исходов, подкрепленный математической гарантией того, что истинный ответ находится внутри этого набора с определенной вероятностью.
Однако это порождает серьезную психологическую и практическую проблему: Почему модель включила «диабет» в этот набор? Что должно измениться в вашем профиле здоровья, чтобы модель уверенно исключила «диабет» и просто сказала «здоров»?
Именно здесь на помощь приходят Контрфактические (CF) Объяснения. Контрфактическое объяснение — это сценарий «что, если». Оно сообщает о минимальном изменении, необходимом для изменения решения модели (например, «Если бы ваше кровяное давление было на 10 пунктов ниже, вы были бы классифицированы как строго здоровый»). Исторически ученые умели генерировать контрфактические объяснения только для стандартных точечных предсказаний. Данная статья решает блестящую, ранее нерешенную проблему: как генерировать контрфактические объяснения для наборов конформных предсказаний?
Предпосылки и Мотивация
Чтобы понять эту статью, необходимо усвоить два понятия:
1. Наборы Конформного Прогнозирования: При заданном уровне значимости $\epsilon$ (например, 0.05 для 95% уровня доверия) конформный классификатор выдает набор меток $\Gamma^\epsilon(x)$. Это делается путем расчета показателя несоответствия для каждой возможной метки, преобразования их в $p$-значения и отклонения любой метки, $p$-значение которой меньше $\epsilon$.
2. Контрфактические объяснения: Это синтетические точки данных $x'$, которые очень близки к исходному входу $x$, но приводят к другому предсказанию.
Мотивация здесь — это чистая доверие и действенность. Лица, принимающие решения, не просто хотят знать неопределенность модели; они хотят знать границы этой неопределенности. Если модель банка говорит, что набор предсказаний для вашей заявки на кредит — $\{\text{Одобрено}, \text{Отклонено}\}$, вы хотите точно знать, что нужно изменить (например, погасить 150 долларов долга по кредитной карте), чтобы этот набор сдвинулся к строго $\{\text{Одобрено}\}$.
Ограничения, Которые Необходимо Преодолеть
Генерация этих сценариев «что, если» чрезвычайно сложна из-за огромного объема высокоразмерных данных. Если просто позволить алгоритму слепо искать математическое решение, он предложит абсурдные вещи, такие как «уменьшить ваш возраст на 15 лет» или «иметь отрицательное кровяное давление».
Следовательно, авторам пришлось ограничить пространство поиска, чтобы генерируемые объяснения были:
* Близкими (Proximate): Изменение должно быть небольшим.
* Разреженными (Sparse): Следует изменять только одну или две характеристики, а не все.
* Правдоподобными (Credible): Синтетическая точка данных должна выглядеть как реальные данные из реального мира.
Математическая Проблема и Решение
Основная математическая проблема, которую решили авторы, заключается в поиске суррогатной выборки $x'$, такой, что набор предсказаний изменится:
$$ \Gamma^\epsilon(x') \neq \Gamma^\epsilon(x) $$
Чтобы решить эту задачу, не генерируя невозможные точки данных, они разработали строго ограниченную трехэтапную архитектуру поиска:
1. Найти «Реальное» Контрфактическое Объяснение: Сначала они рассматривают калибровочный набор данных (реальные исторические данные) и находят ближайшую реальную точку данных $x^{\text{real}}$, которая имеет другой набор предсказаний, чем $x$.
2. Построить Сетку: Они создают дискретное пространство поиска, ограниченное значениями между $x$ и $x^{\text{real}}$. Это гарантирует, что алгоритм не сможет выдумать дикие, выходящие за пределы допустимого числа.
3. Оптимизировать: Они ищут в этой сетке (используя полный перебор для небольших пространств или генетический алгоритм для больших) для поиска синтетической $x'$, которая оптимизирует один из трех критериев:
* Расстояние (Близость): Минимизация $||x - x'||_2$.
* Разреженность: Минимизация количества измененных характеристик $\sum_{j=1}^p \mathbf{1}\{x_j \neq x'_j\}$.
* Достоверность (Credibility): Это мастерский ход авторов. Они определяют достоверность как $\max_k p_k(x')$. Максимизируя наивысшее $p$-значение по всем классам, они заставляют контрфактическое объяснение тесно соответствовать базовому распределению обучающих данных. Это математически заставляет сценарий «что, если» быть очень реалистичным.
Экспериментальная Архитектура и «Жертвы»
Авторы не просто перечислили метрики; они разработали безжалостный эксперимент, чтобы доказать, что их синтетические контрфактические объяснения лучше реальности.
«Жертвы»: Поскольку не существует другого алгоритма для генерации контрфактических объяснений для наборов конформных предсказаний, базовыми методами (которые им пришлось превзойти) были реальные контрфактические объяснения ($x^{\text{real}}$), взятые непосредственно из исторического набора данных.
Доказательства: Они протестировали свой метод на 10 табличных наборах данных. Для каждого набора данных они сгенерировали суррогатные контрфактические объяснения и сравнили их с реальными, используя соотношение.
* При оптимизации по расстоянию их метод достиг среднего соотношения 0.452. Это неоспоримое доказательство того, что их алгоритм нашел действительные объяснения, которые были на 54.8% ближе к исходному входу, чем лучший пример из реального мира.
* При оптимизации по разреженности они достигли соотношения 0.493, что означает, что их объяснения требовали изменения вдвое меньшего количества характеристик, чем их реальные аналоги.
* Наиболее впечатляющим является то, что при оптимизации по достоверности они достигли соотношения 1.157. Это означает, что их синтетические, математически сгенерированные точки данных были фактически на 15.7% более соответствующими распределению данных, чем фактические точки данных из калибровочного набора.
Честно говоря, я не до конца уверен, почему они выбрали относительно простой пакет генетического алгоритма для больших пространств поиска, когда существуют более продвинутые оптимизаторы на основе дискретных градиентов, но эмпирические данные доказывают, что этого было более чем достаточно в качестве доказательства концепции.
Темы для Обсуждения и Будущего Развития
Основываясь на этой блестящей базе, вот несколько критически важных направлений для будущих исследований:
- Причинно-следственные Графы и Строгая Действенность: Текущий метод ограничивает пространство поиска реальными данными, но не понимает причинно-следственных связей. В примере с диабетом алгоритм предложил уменьшить возраст пациента с 30 до 26 лет. Возраст неизменим.
Как можно интегрировать направленные ациклические графы (DAG) в пространство конформного поиска, чтобы алгоритм предлагал только причинно-следственные, действующие вмешательства?
2. Целенаправленное Управление Набором: В настоящее время алгоритм останавливается, как только набор предсказаний изменяется ($\Gamma^\epsilon(x') \neq \Gamma^\epsilon(x)$). Но что, если пользователь хочет направить набор в определенном направлении? Например, перейти от $\{\text{Доброкачественный}, \text{Злокачественный}\}$ строго к $\{\text{Доброкачественный}\}$. Как можно модифицировать целевую функцию для нацеливания на определенные включения/исключения набора?
3. Масштабирование до Неструктурированных Данных: Этот метод опирается на дискретный поиск по сетке между табличными характеристиками. Как развить его для работы с высокоразмерными неструктурированными данными, такими как изображения или текст? Можно ли отобразить конформные $p$-значения в непрерывное латентное пространство в вариационном автоэнкодере (VAE) и выполнить градиентный спуск для поиска контрфактического изображения?
4. Балансирование Трилеммы: Авторы оптимизировали расстояние, разреженность и достоверность по отдельности. Можно ли сформулировать Парето-оптимальную функцию потерь, которая одновременно балансирует все три, возможно, используя многоцелевое обучение с подкреплением, чтобы найти окончательное «идеальное» объяснение?
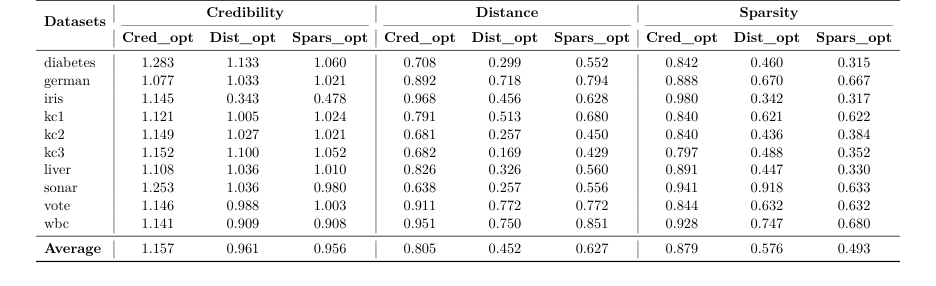 Table 2. Comparison of optimization criteria across datasets
Table 2. Comparison of optimization criteria across datasets
Изоморфизмы с другими полями
Структурный Каркас
Механизм поиска, который находит минимальные возмущения, необходимые для смещения многомерной координаты за статистически гарантированную границу неопределенности, одновременно максимизируя ее соответствие известному эталонному распределению.