등각 예측 집합을 위한 반사실적 설명
New counterfactual explanations make complex "prediction sets" from AI understandable by showing minimal changes that alter the AI's output.
배경 및 학문적 계보
머신러닝 모델은 의료 진단이나 금융 대출 승인과 같이 중대한 환경에 점점 더 많이 배포되고 있다. 이러한 환경에서 150달러의 실수는 사소한 불편함일 수 있지만, 150,000달러의 실수는 치명적일 수 있다. 이러한 중요 영역에서는 단순히 하나의 "최적 추정치"(점 예측)를 제공하는 것만으로는 충분하지 않다. 의사 결정자는 모델의 불확실성을 이해해야 한다.
이를 해결하기 위해 학계에서는 2005년경 Conformal Prediction (CP)을 개발했다. CP는 단일 레이블을 출력하는 대신, 실제 레이블이 포함된다는 수학적 보증과 함께 일련의 가능한 레이블을 출력한다 (예: "환자의 상태가 건강하거나 당뇨병일 확률이 95%입니다").
동시에 머신러닝 모델이 복잡한 "블랙박스"가 되면서 Explainable AI (XAI) 분야가 등장했다. 가장 직관적인 XAI 기법 중 하나는 Counterfactual Explanation (2017년경 대중화)으로, 모델의 결정을 바꾸기 위해 필요한 최소한의 변경 사항을 사용자에게 정확히 알려준다.
본 논문에서 다루는 특정 문제는 이 두 분야의 정확한 교차점에서 발생했다: Conformal Predictor가 생성하는 불확실성 인식 세트를 어떻게 설명할 것인가? 단일 예측을 설명하는 훌륭한 도구와 불확실성을 정량화하는 훌륭한 도구가 있지만, 모델의 불확실성이 특정 레이블을 예측 세트에 포함시키거나 제외할 만큼 왜 변동했는지 설명할 수 있는 연결고리가 부족했다.
이전 접근 방식의 근본적인 한계점, 즉 "고충점"은 기존의 counterfactual explanation 방법이 점 예측기를 위해 엄격하게 설계되었다는 것이다. 이 방법들은 모델이 정확히 하나의 레이블을 출력한다고 가정하며, 전체 수학적 목표는 해당 레이블을 다른 레이블로 바꾸기 위한 가장 작은 특징 조정 값을 찾는 것이다.
Conformal Predictor는 레이블의 세트를 출력하기 때문에 (모델의 신뢰도에 따라 확장되거나 축소됨), 기존 방법들은 완전히 부족하다. 특히 예측 세트 출력의 변화를 설명할 수 없다. 예를 들어, 이전 방법들은 "이 환자의 혈압에 어떤 작은 변화가 있어야 모델이 '당뇨병'을 가능성의 영역에서 제외할 만큼 충분히 확신하게 될까?"라는 질문에 답할 수 없다. 또한, 최근 몇몇 모델들이 counterfactual에 불확실성을 통합하려고 시도했지만, 형식적이고 분포에 독립적인 통계적 보증이 부족했다. 저자들은 보장된 예측 세트 내에서 레이블의 포함 또는 제외를 목표로 하는 새로운 유형의 counterfactual을 발명하기 위해 이 논문을 작성해야 했다.
다음은 논문의 몇 가지 고도로 전문화된 용어를 일상적인 개념으로 번역한 것이다.
- Conformal Prediction Set:
- 비유: 낚시를 상상해 보라. 표준 모델은 작살(점 예측)을 사용한다. 정확히 한 마리의 물고기를 겨냥하지만, 놓치면 아무것도 얻지 못한다. Conformal Predictor는 그물(예측 세트)을 사용한다. 그물은 물고기와 함께 약간의 해초를 잡을 수도 있지만, 95%의 확률로 물고기를 잡을 것을 보장한다. 그물의 크기는 불확실성을 나타낸다. 작은 그물은 높은 확실성을 의미하고, 거대한 그물은 모델이 매우 불확실하다는 것을 의미한다.
- Counterfactual Explanation:
- 비유: GPS 경로 재지정 제안. 단순히 "교통 체증에 갇혔다"고 말하는 것(표준 예측) 대신, counterfactual explanation은 "이전에 나왔던 출구로 갔다면, 지금 속도 제한으로 운전하고 있었을 것이다"라고 말한다. 이는 다른 결과를 얻기 위해 필요한 최소한의 변화를 보여준다.
- Credibility:
- 비유: 고급 클럽의 문지기가 당신의 분위기를 확인하는 것. 이 논문에서 credibility는 새로운 합성 데이터 포인트(counterfactual)가 모델이 학습한 실제 데이터와 얼마나 잘 어울리는지를 측정한다. Credibility가 높으면 새로운 데이터 포인트는 정상적이고 가능한 사람처럼 보인다. 낮으면 데이터 포인트는 모델이 한 번도 본 적 없는 비현실적인 외계인이다.
- Sparsity:
- 비유: 자동차를 수리하는 정비공. 엔진 전체를 재조립하고 타이어를 교체하는 것(낮은 Sparsity) 대신, 고장난 점화 플러그 하나만 교체하기를 원한다(높은 Sparsity). 논문에서 sparse explanation은 가능한 한 적은 변수를 변경하여 사람이 이해하고 조치하기 쉽게 만든다.
| Notation | Description |
|---|---|
| $x$ | 설명이 필요한 원본 입력 인스턴스 (테스트 데이터 포인트). |
| $x'$ | 대리 counterfactual 인스턴스; 예측 세트를 변경하는 새로 생성된 데이터 포인트. |
| $x^{\text{real}}$ | 검색 공간을 고정하는 데 사용되는 보정 데이터셋 내에서 발견된 실제 counterfactual 인스턴스. |
| $\epsilon$ | 허용 가능한 오류율을 나타내는 사전 정의된 유의 수준 (예: $0.05$). |
| $\mathcal{Y}$ | 데이터셋의 모든 가능한 클래스 레이블 집합. |
| $\tilde{y}$ | 예측 세트에 포함될지 여부를 테스트 중인 후보 레이블. |
| $\Gamma^\epsilon(x)$ | 유의 수준 $\epsilon$에서 인스턴스 $x$에 대한 conformal prediction set. 거부되지 않은 모든 레이블을 포함한다. |
| $Z^c$ | 비정상 점수를 계산하는 데 사용되는 별도의 데이터 세트인 보정 데이터셋. |
| $p_k(x)$ | 인스턴스 $x$에서 클래스 $k$에 대해 conformal predictor가 계산한 p-value. |
| $h$ | 기본 예측을 만드는 데 사용되는 기본 머신러닝 알고리즘/분류기. |
| $\alpha_i$ | 알려진 데이터에 비해 인스턴스가 얼마나 "이상한"지를 측정하는 비정상 점수. |
| $d(x, c)$ | 유클리드 거리 또는 Gower 거리와 같이 counterfactual $c$와 원본 입력 $x$ 간의 거리를 측정하는 거리 측정값. |
문제 정의 및 제약 조건
AI를 사용하여 환자를 진단하는 상황을 상상해 보자. 전통적인 AI 모델은 "이 환자는 당뇨병입니다."와 같이 단 하나의 확신에 찬 추측을 제공한다. 하지만 의료나 금융과 같이 결과의 중요성이 높은 분야에서는 단 하나의 추측만으로는 충분하지 않으며, 모델이 얼마나 불확실한지를 알아야 한다. 여기서 conformal prediction이 등장한다. 단일 레이블 대신, conformal classifier는 prediction set을 출력한다. 이는 수학적으로 참값이 95%의 확률로 해당 집합 안에 포함된다는 보증과 함께 가능한 레이블들의 목록(예: {건강함, 당뇨병})이다. AI가 매우 불확실하다면 집합은 커지고, 확신한다면 집합은 단일 레이블로 축소된다.
하지만 여기서 한계에 부딪힌다: AI가 왜 이 특정 집합을 제공했는지 이유를 어떻게 설명할 수 있을까? 전통적인 AI의 경우, 우리는 "반사실적 설명(counterfactual explanations)"을 사용한다. 이는 "만약 이 환자의 BMI가 2점 낮았다면, AI는 '당뇨병' 대신 '건강함'을 예측했을 것입니다."와 같은 "what-if" 시나리오이다.
이 논문의 시작점(Input/Current State)은 이러한 conformal prediction sets와 전통적인 반사실적 방법들의 존재이다. 그러나 전통적인 반사실적 방법들은 단일 점 예측을 뒤집도록 엄격하게 설계되었다. 목표하는 종착점(Output/Goal State)은 완전히 새로운 유형의 설명, 즉 conformal counterfactual이다. 저자들은 고정된 신뢰 수준에서 전체 prediction set을 변경하기 위한 테스트 인스턴스의 최소한의 변경 사항을 찾고자 한다. 예를 들어, 집합에서 "당뇨병"을 완전히 제거하기 위해 무엇이 변경되어야 하는지를 정확히 파악하는 것이다.
이 논문이 연결하는 수학적 간극은 최적화 목표에 있다. 전통적인 반사실적 방법은 다음과 같은 형태의 문제를 해결한다:
$$ \min_{c \in \mathcal{X}} d(x, c) \quad \text{subject to} \quad f(x) \neq f(c) $$
여기서 우리는 원래 입력 $x$로부터의 거리 $d$를 최소화하는 새로운 인스턴스 $c$를 찾고자 하며, 예측 모델 $f$가 다른 단일 레이블을 출력하는 한에서이다.
저자들은 집합에 대해 이 논리를 재작성해야 했다. 단일 레이블 $f(x)$ 대신, 그들은 유의 수준 $\epsilon$에서의 prediction set $\Gamma^\epsilon(x)$를 다룬다. 그들의 새로운 목표는 집합 자체가 변경되도록 하는 대체 인스턴스 $x'$를 찾는 것을 요구한다:
$$ \Gamma^\epsilon(x') \neq \Gamma^\epsilon(x) $$
더 나아가, 그들은 이 탐색을 안내하기 위해 credibility라는 새로운 지표를 도입했다. Credibility는 모든 후보 클래스 $k$에 대한 최대 p-value로 수학적으로 정의된다:
$$ \text{Credibility}(x') = \max_k p_k(x') $$
이는 새로운 "what-if" 시나리오가 실제 훈련 데이터의 근본적인 분포에 얼마나 잘 부합하는지를 측정한다.
그러나 설명 가능한 AI의 세계에서는 한 가지를 고치면 거의 항상 다른 것을 망가뜨린다. 이전 연구자들이 갇혀 있던 고통스러운 딜레마는 근접성/희소성(Proximity/Sparsity)과 타당성(Plausibility) 사이의 줄다리기이다.
단순히 예측을 변경하기 위한 수학적으로 가장 짧은 거리(근접성) 또는 가장 적은 수의 특성 변경(희소성)을 찾도록 알고리즘에 요청하면, 수학은 기꺼이 프랑켄슈타인 데이터 포인트를 생성하여 이를 만족시킬 것이다. 이는 "소득이 50,000달러를 초과하려면, 단순히 나이를 150세로 변경하십시오."라고 말할 수 있다. 수학적으로는 가깝지만 물리적으로는 불가능하다. 이전 연구자들은 최소한이면서도 실제 "데이터 다양체(data manifold)" 상에 존재하는 반사실적 데이터를 생성하는 데 어려움을 겪었다 (즉, 현실적이고 타당한 인간이나 시나리오처럼 보이는 것).
이를 해결하기 위해 저자들은 몇 가지 가혹하고 현실적인 벽에 부딪혔다:
- 무한 탐색 공간 제약: 반사실적 데이터를 찾기 위해 가능한 모든 숫자 조합을 단순히 탐색할 수는 없다. 연속적인 특성 공간은 무한히 크다. 이를 극복하기 위해 저자들은 탐색을 엄격하게 제한해야 했다. 그들은 먼저 "실제 반사실적(real counterfactual)" $x^{\text{real}}$을 찾는다. 이는 다른 예측 집합을 생성하는 보정 데이터셋에서 가져온 실제 과거 데이터 포인트이다. 그런 다음 원래 인스턴스 $x$와 $x^{\text{real}}$ 사이에 엄격하게 제한된 특성 값을 갖는 이산 그리드를 구축한다.
- 조합 폭발(Combinatorial Explosion): 이 제한된 그리드로 탐색을 제한한 후에도 가능한 특성 조합의 수는 기하급수적으로 증가한다. 데이터셋에 특성이 많으면 모든 조합을 확인하는 것은 계산적으로 불가능하다. 저자들은 엄격한 계산 한계에 부딪혔다: 조합 수가 10,000개를 초과하면 완전 탐색이 충돌하거나 너무 오래 걸린다. 그들은 완벽한 최적화를 포기하고 공간을 탐색하기 위해 휴리스틱 유전 알고리즘(Genetic Algorithm)에 의존해야 했다.
- Conformal 계산의 부담: 간단한 신경망에서 순방향 전달(forward pass)이 매우 빠른 것과 달리, conformal prediction은 탐색 중에 생성된 모든 합성 데이터 포인트에 대해 모든 후보 레이블에 대한 비적합성 점수(nonconformity scores)와 p-value를 계산해야 한다. 이는 엄청난 계산 병목 현상을 일으켜 이러한 설명을 실시간으로 생성하는 것을 매우 어렵게 만든다.
이 접근 방식은 왜
이 논문의 혁신을 진정으로 이해하기 위해서는 먼저 전통적인 AI가 어떻게 의사결정을 내리는지 살펴볼 필요가 있다. 대부분의 머신러닝 모델은 "점 예측자(point predictor)"로서, 데이터를 입력받아 "이 환자는 당뇨병이다"와 같이 단 하나의 절대적인 답을 제시한다. 그러나 의학이나 금융과 같이 높은 위험도가 요구되는 분야에서는 단 한 번의 추측만으로는 부족하며, 의사결정자는 모델의 불확실성에 대한 정보를 필요로 한다. 바로 여기서 Conformal Prediction (CP)이 등장한다. CP는 단일 레이블 대신, 특정 확률(예: 95%)로 실제 정답이 해당 집합 안에 포함될 것이라는 수학적 보장을 갖춘 예측 집합(prediction set)을 출력한다 (예: $\{\text{Healthy}, \text{Diabetic}\}$).
저자들은 기존의 최첨단(SOTA) 설명 방법들이 이러한 불확실성 인식 모델에 근본적으로 결함이 있음을 인지하였다. 표준적인 반사실적(counterfactual) 방법들은 점 예측자만을 위해 설계되었다. 이는 "모델의 예측을 A에서 B로 바꾸기 위해 필요한 최소한의 변화는 무엇인가?"라는 질문에 답한다. 그러나 모델이 단일 레이블이 아닌 가능성 있는 레이블들의 집합을 출력할 때, 기존 방법들은 완전히 무너진다. 집합을 단순히 "뒤집는" 것은 불가능하다. 저자들이 결정적인 깨달음을 얻은 순간은, 모델의 불확실성을 설명하기 위해서는 고정된 유의수준 $\epsilon$에서 특정 클래스가 예측 집합에 포함되거나 제외된 이유를 설명해야 한다는 점을 보았을 때였다. Conformal prediction에 맞춰진 완전히 새로운 수학적 프레임워크가 유일하게 실행 가능한 해결책이었다.
단순한 성능 지표를 넘어, 이 방법은 타당성(plausibility)을 다루는 구조적 이점 덕분에 질적으로 우수하다. 반사실적 방법의 이전 표준은 거리(예: $\ell_2$ norm) 최소화 또는 희소성(변경된 특징의 수)에 크게 의존하였다. 이는 수학적으로는 작동하지만, 종종 실제 사례와 전혀 닮지 않은 "이질적인(alien)" 데이터 포인트를 생성한다. 이를 해결하기 위해 저자들은 획기적인 지표인 신뢰도(credibility)를 도입하였다.
Conformal prediction에서 신뢰도는 모든 후보 레이블에 대한 최대 p-value로 정의된다:
$$ \text{Credibility}(x') = \max_k p_k(x') $$
신뢰도를 최적화함으로써, 이 방법은 생성된 반사실적 $x'$가 기본 훈련 데이터 분포에 완벽하게 부합하도록 보장한다. 점 예측을 바꾸기 위해 결정 경계(decision boundary)를 가로지르는 거대하고 비현실적인 도약을 강요하는 대신, 이 방법은 불확실성 집합을 확장하거나 축소하는 작고 매우 타당한 변화를 찾아낸다. 예를 들어, Income 데이터셋에서 예측 집합을 $\{>\$50\text{K}, \leq\$50\text{K}\}$에서 $\{>\$50\text{K}\}$와 같은 더 확신에 찬 단일 집합으로 이동시키기 위해서는, 엄격한 클래스 전환을 강요하는 것보다 훨씬 더 현실적인 특징 변화가 요구된다.
이 문제는 엄격한 제약을 제시하였다: 설명은 conformal framework 하에서 수학적으로 유효해야 하고, 실행 가능해야 하며, 분포 무관(distribution-free) 보장을 유지하기 위해 보정 데이터(calibration data)에 엄격하게 연결되어야 한다. 선택된 접근 방식은 이러한 제약들을 완벽하게 결합한다. 저자들은 원래 테스트 인스턴스 $x$와 보정 집합 $Z^c$에서 찾은 가장 가까운 실제 반사실적 $x^{\text{real}}$에 의해 경계가 설정된 이산 탐색 공간을 설계하였다:
$$ x^{\text{real}} = \arg \min_{x_i \in Z^c} \{ \| x - x_i \|_2 \mid \Gamma^\epsilon(x_i) \neq \Gamma^\epsilon(x) \} $$
탐색 공간을 실제 관찰된 값에 고정함으로써, 알고리즘은 합성 반사실적 값이 불가능한 특징 조합으로 벗어나지 않도록 보장한다. 탐색 공간이 작으면 완전 탐색을 사용하고, 계산적으로 방대해지면 유전 알고리즘(Genetic Algorithm)을 사용하여 우아하게 확장한다. 이는 완벽한 결합이다: conformal prediction의 엄격한 통계적 경계는 유지되면서 직관적이고 사람이 읽을 수 있는 설명을 제공한다.
마지막으로, 이 논문은 왜 다른 인기 있는 접근 방식들이 여기서 실패했을지를 명확히 지적한다. 베이지안 모델링 또는 인식 불확실성 정량화(epistemic uncertainty quantification)를 사용하여 반사실적 설명에 불확실성을 통합하려는 최근 시도들은 이 특정 문제에 대해 완전히 빗나갔다. 베이지안 모델은 확률적 점수를 제공하지만, 분포 무관 보장이 부족하다. 이는 사전 분포를 가정하며, 그 가정이 틀릴 경우 보장이 무너진다. Conformal prediction은 교환성(exchangeability) 가정에만 의존한다. 따라서 베이지안 반사실적 설명이나 표준 생성 모델(GANs 또는 Diffusion과 같은)을 이 파이프라인에 억지로 끼워 넣으려는 시도는 conformal prediction을 매우 가치 있게 만드는 절대적인, 수학적으로 증명된 오류율을 파괴할 것이다. 저자들은 예측 집합의 절대적인 통계적 유효성을 보존하기 위해 이러한 대안들을 거부해야만 했다.
 Figure 2. Counterfactual explanation for a conformal prediction set generated by optimizing for distance on the WBC dataset. Changed features are shown in blue
Figure 2. Counterfactual explanation for a conformal prediction set generated by optimizing for distance on the WBC dataset. Changed features are shown in blue
수학 및 논리 메커니즘
이 논문의 혁신을 이해하기 위해서는 먼저 현대 AI가 어떻게 의사결정을 내리는지, 그리고 그 불확실성을 어떻게 측정하는지에 대한 기준선을 설정해야 한다.
전통적인 머신러닝에서 모델은 "점 예측(point prediction)" 즉, 단 하나의 최적 추정치를 제공한다. 그러나 의학이나 금융과 같이 높은 이해관계가 걸린 분야에서는 단일 추정치만으로는 부족하며, 모델의 확신도를 알아야 한다. 여기서 Conformal Prediction (CP)이 등장한다. CP는 단일 답 대신 수학적 보증이 포함된 예측 집합(prediction set)을 출력한다. 예를 들어, "이 환자의 진단이 {정상, 당뇨병} 중 하나라고 95% 확신한다"고 말할 수 있다. 모델의 불확실성이 높으면 집합이 커지고, 확신도가 높으면 단일 레이블로 축소된다.
본 논문의 동기(motivation)는 설명 가능한 AI(Explainable AI)의 치명적인 맹점에서 비롯된다. AI가 점 예측을 할 때, 우리는 종종 반사실적 설명(counterfactual explanations)을 사용하여 이를 이해한다 ("소득이 더 높았다면 대출이 승인되었을 것입니다"). 하지만 예측 집합은 어떻게 설명할 수 있을까? 기존 방법들은 이 부분에서 완전히 실패한다. 저자들은 모델의 불확실성 경계를 변경하는 데 필요한 최소한의 변화를 찾아, 특정 클래스가 집합에 포함되거나 제외된 이유를 효과적으로 설명함으로써 이 문제를 해결하고자 했다.
이를 위해 저자들은 몇 가지 제약 조건(constraints)을 극복해야 했다. 생성된 설명은 원본 데이터에 가까워야 하고(Proximity), 가능한 한 적은 변수를 변경해야 하며(Sparsity), 결정적으로, 수학적 환각이 아닌 실제 데이터 포인트처럼 보여야 한다(Credibility).
다음은 이를 해결하기 위해 구축한 수학적 엔진이다.
핵심 방정식 (The Master Equations)
본 논문의 핵심 로직은 세 부분으로 구성된 수학적 엔진에 의해 구동된다: 현실 앵커 찾기, 타당성 극대화, 복잡성 페널티 부여.
$$ x^{\text{real}} = \arg \min_{x_i \in Z^c} \left\{ \|x - x_i\|_2 \mid \Gamma^\epsilon(x_i) \neq \Gamma^\epsilon(x) \right\} $$
$$ \text{Credibility}(x') = \max_k p_k(x') $$
$$ \text{Sparsity}(x, x') = \sum_{j=1}^p \mathbf{1}\{x_j \neq x'_j\} $$
방정식 해부하기
이 엔진의 모든 구성 요소를 물리적, 논리적 역할에 따라 분해해 보자.
- $x$: 원본 입력 데이터 포인트 (예: 환자의 현재 건강 지표). 이것이 출발점이다.
- $x_i \in Z^c$: 보정 데이터셋 $Z^c$의 실제 데이터 포인트. 모델이 불가능한 시나리오를 만들어내지 않도록 "현실 검증" 역할을 한다.
- $\|x - x_i\|_2$: L2 노름(유클리드 거리). 검색을 원본 입력 쪽으로 되돌리는 고무줄 역할을 한다. 저자들은 L2 노름을 사용하는데, 이는 단일 변수의 크고 비현실적인 편차에 큰 페널티를 부여하여 모델이 균형 잡히고 가까운 해를 찾도록 강제하기 때문이다.
- $\Gamma^\epsilon(x)$: 고정된 유의 수준 $\epsilon$ (일반적으로 95% 신뢰도의 경우 0.05)에서의 컨포멀 예측 집합. 이는 모델 불확실성의 경계를 나타낸다.
- $\neq$: 부등호 연산자. 이것이 논문 전체의 논리적 트리거이다. 단순히 기저 확률을 이동시키는 것이 아니라, 최종 예측 집합의 구조적이고 가시적인 변화를 요구한다.
- $\arg \min$: 탐색 연산자. 데이터셋을 스캔하여 최소 저항 경로, 즉 예측 집합을 성공적으로 뒤집는 가장 가까운 실제 세계의 예시를 찾는다.
- $x'$: 생성 중인 합성 대체 반사실적 데이터. 이것이 사용자에게 최종적으로 제공될 설명이다.
- $p_k(x')$: 클래스 $k$에 대한 p-값. 컨포멀 예측에서 이는 새로운 포인트가 해당 특정 클래스의 알려진 데이터 분포에 얼마나 잘 부합하는지를 측정한다.
- $\max_k$: 최대 연산자. 모든 클래스에 대한 최대 p-값을 취함으로써, 반사실적 데이터가 평균적으로 어중간하고 비현실적인 상태가 되는 대신, 적어도 하나의 클래스에 대해 매우 타당하도록 보장한다.
- $\sum_{j=1}^p$: 모든 $p$개의 특징에 대한 합계. 저자들이 곱셈 대신 합계를 사용한 이유는 무엇일까? 이는 변경된 특징의 총 개수를 가산적으로 계산하기를 원하기 때문이다. 만약 곱셈을 사용했다면, 변경되지 않은 단일 특징(0을 생성)이 전체 페널티를 무효화하여 특징 변경 횟수를 계산하는 논리를 완전히 깨뜨릴 것이다.
- $\mathbf{1}\{x_j \neq x'_j\}$: 지시 함수. 이진 스위치 역할을 한다. 특징이 변경되면 1을 출력하고, 그대로 두면 0을 출력한다.
단계별 흐름
추상적인 단일 데이터 포인트가 이 기계 조립 라인을 통과하는 과정을 추적해 보자.
- 입력: 환자의 데이터 $x$가 시스템에 입력된다. 모델은 불확실하며 {정상, 당뇨병} 예측 집합을 출력한다.
- 현실 앵커: 시스템은 과거 보정 데이터를 스캔하여 $x^{\text{real}}$, 즉 다른 예측 집합(예: {정상}만)을 받은 가장 가까운 실제 환자를 찾는다.
- 격자 구성: 이산 탐색 격자가 구축된다. 시스템은 $x$와 $x^{\text{real}}$ 사이의 모든 관찰된 값을 추출한다. 이는 현실적인 중간 단계를 제안하도록 보장한다 (예: 데이터에 존재하지 않는 혈압 10을 제안하지 않는다).
- 조립 라인: 합성 후보 $x'$가 이 격자 상에서 생성된다. 이는 컨포멀 예측기를 통과하여 예측 집합이 실제로 뒤집히는지($\Gamma^\epsilon(x') \neq \Gamma^\epsilon(x)$) 확인한다.
- 품질 관리: 집합이 뒤집히면 후보가 평가된다. 시스템은 해당 후보의 타당성(현실적인 환자인가?)과 희소성(단지 '포도당'과 '나이'와 같이 몇 가지 사항만 변경했는가?)을 계산한다.
- 출력: 이러한 기준을 가장 잘 균형 잡는 후보가 최종적이고 실행 가능한 설명으로 반환된다.
최적화 동역학
이 메커니즘은 실제로 어떻게 학습하고, 업데이트하며, 수렴하는가?
전통적인 신경망에서는 경사 하강법을 사용하여 부드러운 손실 지형을 따라 내려간다. 그러나 컨포멀 예측 집합은 딱딱하고 미분 불가능한 계단 함수를 생성하기 때문에 (레이블이 집합 내부에 있거나 외부에 있는 엄격한 결정), 여기서 기울기가 존재하지 않는다. 손실 지형은 부드러운 언덕이 아니라, 이산적이고 이진적인 결정으로 이루어진 들쭉날쭉한 절벽면이다.
이를 극복하기 위해 저자들은 양방향 최적화 전략을 사용한다. 탐색 공간이 작으면 (10,000개 조합 미만), 시스템은 모든 격자 점을 평가하여 절대적인 수학적 최적값을 찾는 완전 탐색(brute-force exhaustive search)을 사용한다.
공간이 너무 크면 유전 알고리즘(Genetic Algorithm, GA)을 배포한다. GA는 100개의 무작위 후보 반사실적 데이터로 구성된 모집단을 초기화한다. 각 후보의 "적합도(fitness)"는 핵심 방정식(타당성 극대화 또는 희소성 최소화)에 의해 결정된다. 결정적으로, 지형은 거대한 페널티 함수에 의해 형성된다. 후보가 예측 집합을 변경하는 데 실패하면, 적합도 점수가 파괴되어 다음 세대에서 사실상 제거된다. 1,000번의 반복을 거치면서 후보들은 돌연변이(10% 확률로 특징을 무작위로 조정)하고 교차(두 개의 좋은 후보 간 특징 교환)한다.
솔직히 말해서, 저자들이 유전 알고리즘의 엘리티즘 비율을 애블레이션 스터디 없이 정확히 0.01로 하드코딩한 이유를 완전히 확신할 수는 없지만, 실제로는 탐색을 멈추지 않으면서 절대적으로 최고의 후보를 세대에 걸쳐 유지하기에 충분하다. 이 진화 과정을 통해 시스템은 예측 집합을 성공적으로 변경하는 최소한의, 매우 타당한 변화를 향해 반복적으로 수렴한다.
결과, 한계점 및 결론
의사가 의료 진단을 위해 병원에 갔다고 상상해 보자. 의사가 "당신은 확실히 당뇨병입니다"라고 말한다면, 이는 표준적인 단일 예측이다. 하지만 만약 의사가 "검사 결과에 따르면, 당신이 완전히 건강하거나 초기 당뇨병일 확률이 95%입니다"라고 말한다면 어떨까? 이 두 번째 시나리오가 바로 Conformal Prediction (CP)의 본질이다. CP는 단일하고 잠재적으로 과신된 답변을 제공하는 대신, 특정 확률로 실제 답이 해당 집합 안에 포함된다는 수학적 보증을 바탕으로 가능한 결과들의 목록인 예측 집합(prediction set)을 제공한다.
하지만 이는 심리적, 실질적인 거대한 문제를 야기한다. 왜 모델이 "당뇨병"을 해당 집합에 포함시켰을까? 모델이 "당뇨병"을 자신 있게 제외하고 단순히 "건강함"이라고 말하기 위해 당신의 건강 프로필에 어떤 변화가 필요할까?
이것이 바로 Counterfactual (CF) Explanations가 등장하는 지점이다. 반사실적 설명(counterfactual)은 "만약 ~라면 어떨까?"라는 시나리오이다. 이는 모델의 결정을 변경하는 데 필요한 최소한의 변화를 알려준다 (예: "혈압이 10포인트 낮았다면, 당신은 엄격하게 건강한 것으로 분류되었을 것입니다"). 역사적으로 과학자들은 표준적인 단일 예측에 대한 반사실적 설명을 생성하는 방법만을 알아냈다. 이 논문은 이전에는 해결되지 않았던 훌륭한 문제를 다룬다: Conformal Prediction Sets에 대한 반사실적 설명을 어떻게 생성할 수 있을까?
배경 및 동기
이 논문을 이해하기 위해서는 두 가지 개념을 파악해야 한다.
1. Conformal Prediction Sets: 유의수준 $\epsilon$ (예: 95% 신뢰 수준의 경우 0.05)이 주어졌을 때, conformal 분류기는 레이블 집합 $\Gamma^\epsilon(x)$를 출력한다. 이는 가능한 모든 레이블에 대해 비순응 점수(nonconformity score)를 계산하고, 이를 $p$-값으로 변환한 후, $p$-값이 $\epsilon$보다 작은 모든 레이블을 거부하는 방식으로 수행된다.
2. Counterfactuals: 이들은 원래 입력 $x$에 매우 가깝지만 다른 예측을 초래하는 합성 데이터 포인트 $x'$이다.
여기서의 동기는 순수한 신뢰와 실행 가능성이다. 의사 결정권자는 단순히 모델의 불확실성을 알고 싶어 하는 것이 아니라, 그 불확실성의 경계를 알고 싶어 한다. 만약 은행의 모델이 당신의 대출 신청 예측 집합이 $\{\text{승인}, \text{거부}\}$라고 말한다면, 당신은 해당 집합을 엄격하게 $\{\text{승인}\}$으로 전환하기 위해 무엇을 변경해야 하는지 (예: 신용카드 부채 150달러 상환) 정확히 알고 싶을 것이다.
극복해야 할 제약 조건
이러한 "만약 ~라면 어떨까?" 시나리오를 생성하는 것은 고차원 데이터의 방대함 때문에 매우 어렵다. 만약 알고리즘이 무작위로 수학적 해를 탐색하도록 내버려 둔다면, "나이를 15세 줄이거나" 또는 "음의 혈압을 가지라"는 터무니없는 제안을 할 것이다.
따라서 저자들은 생성된 설명이 다음과 같도록 탐색 공간을 제약해야 했다.
* 근접성 (Proximate): 변경 사항은 작아야 한다.
* 희소성 (Sparse): 모든 특징을 변경하는 것이 아니라, 하나 또는 두 개의 특징만 변경해야 한다.
* 타당성 (Plausible/Credible): 합성 데이터 포인트는 실제 세계의 실제 데이터처럼 보여야 한다.
수학적 문제 및 해결책
저자들이 해결한 핵심 수학적 문제는 예측 집합이 변경되는 대체 인스턴스 $x'$를 찾는 것이다.
$$ \Gamma^\epsilon(x') \neq \Gamma^\epsilon(x) $$
불가능한 데이터 포인트를 생성하지 않고 이를 해결하기 위해, 그들은 고도로 제약된 3단계 탐색 아키텍처를 설계했다.
1. "실제" 반사실적 설명 찾기: 먼저, 보정 데이터셋(실제 과거 데이터)을 살펴보고 $x$와 다른 예측 집합을 가진 가장 가까운 실제 데이터 포인트 $x^{\text{real}}$을 찾는다.
2. 격자 구축: $x$와 $x^{\text{real}}$ 사이의 값으로 완전히 경계가 지정된 이산 탐색 공간을 구성한다. 이는 알고리즘이 임의의 범위를 벗어난 숫자를 만들어내지 못하도록 보장한다.
3. 최적화: 이 격자를 탐색하여 (작은 공간의 경우 완전 탐색, 더 큰 공간의 경우 유전 알고리즘 사용) 다음 세 가지 기준 중 하나를 최적화하는 합성 $x'$를 찾는다.
* 거리 (근접성): $||x - x'||_2$를 최소화한다.
* 희소성: 변경된 특징의 수를 최소화한다 $\sum_{j=1}^p \mathbf{1}\{x_j \neq x'_j\}$
* 신뢰성 (Credibility): 이것이 저자들의 걸작이다. 그들은 신뢰성을 $\max_k p_k(x')$로 정의한다. 모든 클래스에 걸친 가장 높은 $p$-값을 최대화함으로써, 그들은 반사실적 설명이 훈련 데이터의 기본 분포에 엄격하게 부합하도록 강제한다. 이는 "만약 ~라면 어떨까?" 시나리오가 매우 현실적이도록 수학적으로 강제한다.
실험 아키텍처 및 "희생양"
저자들은 단순히 지표를 나열하는 것이 아니라, 그들의 합성 반사실적 설명이 현실 자체보다 더 낫다는 것을 증명하기 위해 무자비한 실험을 설계했다.
"희생양": Conformal prediction sets에 대한 반사실적 설명을 생성하는 다른 알고리즘이 없기 때문에, 기준선("희생양"으로 삼아야 했던 것)은 과거 데이터셋에서 직접 가져온 실제 반사실적 설명($x^{\text{real}}$)이었다.
증거: 그들은 10개의 테이블형 데이터셋에 걸쳐 그들의 방법을 테스트했다. 각 데이터셋에 대해, 그들은 대체 반사실적 설명을 생성하고 비율을 사용하여 실제 반사실적 설명과 비교했다.
* 거리를 최적화했을 때, 그들의 방법은 평균 비율 0.452를 달성했다. 이는 그들의 알고리즘이 원래 입력보다 54.8% 더 가까운 유효한 설명을 찾았다는 부인할 수 없는 증거이다.
* 희소성을 최적화했을 때, 그들은 0.493의 비율을 달성했는데, 이는 그들의 설명이 실제 세계의 대응물보다 절반의 특징만 변경하면 되었다는 것을 의미한다.
* 가장 인상적인 것은 신뢰성을 최적화했을 때, 그들은 1.157의 비율을 달성했다는 것이다. 이는 그들의 수학적으로 생성된 합성 데이터 포인트가 보정 세트의 실제 데이터 포인트보다 실제로 데이터 분포에 15.7% 더 부합했다는 것을 의미한다.
솔직히 말해서, 더 발전된 이산 기울기 기반 최적화기가 존재함에도 불구하고 왜 더 큰 탐색 공간에 대해 비교적 기본적인 유전 알고리즘 패키지를 선택했는지 완전히 확신할 수는 없지만, 경험적 증거는 이것이 개념 증명으로 충분했음을 증명한다.
향후 발전을 위한 토론 주제
이 훌륭한 기반을 바탕으로, 향후 연구를 위한 몇 가지 중요한 방향은 다음과 같다.
- 인과 그래프 및 엄격한 실행 가능성: 현재 방법은 실제 데이터를 사용하여 탐색 공간을 제한하지만, 인과 관계를 이해하지는 못한다. 당뇨병 예시에서 알고리즘은 환자의 나이를 30세에서 26세로 줄이라고 제안했다. 나이는 불변이다.
방향성 비순환 그래프(DAGs)를 conformal 탐색 공간에 통합하여 알고리즘이 인과적으로 하위 단계에 있고 실행 가능한 개입만을 제안하도록 할 수 있을까? - 표적 집합 조향: 현재 알고리즘은 예측 집합이 변경되는 즉시 ($\Gamma^\epsilon(x') \neq \Gamma^\epsilon(x)$) 중지된다. 하지만 사용자가 특정 방향으로 집합을 조향하기를 원한다면 어떻게 될까? 예를 들어, $\{\text{양성}, \text{악성}\}$에서 엄격하게 $\{\text{양성}\}$으로 이동하는 경우. 특정 집합 포함/제외를 목표로 하도록 목적 함수를 수정할 수 있을까?
- 비정형 데이터로의 확장: 이 방법은 테이블형 특징 간의 이산 격자 탐색에 의존한다. 이를 이미지나 텍스트와 같은 고차원 비정형 데이터에 작동하도록 어떻게 발전시킬 수 있을까? Conformal $p$-값을 변분 자동 인코더(VAE)의 연속적인 잠재 공간에 매핑하고 기울기 하강을 수행하여 반사실적 이미지를 찾을 수 있을까?
- 삼중고 균형: 저자들은 거리, 희소성, 신뢰성을 별도로 최적화했다. 궁극적인 "완벽한" 설명을 찾기 위해 다중 목표 강화 학습을 사용하여 세 가지 모두를 동시에 균형 잡는 파레토 최적 손실 함수를 공식화할 수 있을까?
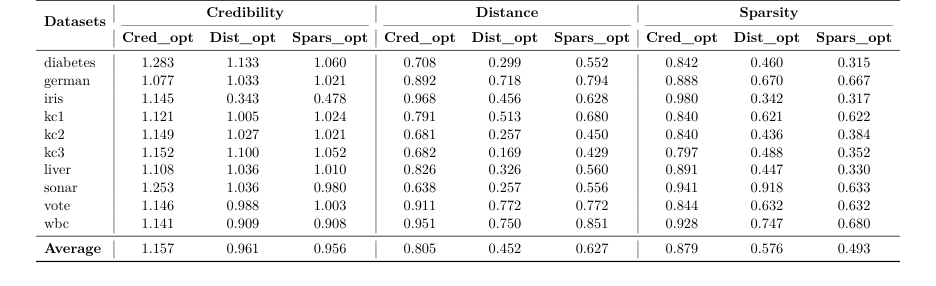 Table 2. Comparison of optimization criteria across datasets
Table 2. Comparison of optimization criteria across datasets