共形予測集合に対する反事実的説明
New counterfactual explanations make complex "prediction sets" from AI understandable by showing minimal changes that alter the AI's output.
背景と学術的系譜
機械学習モデルは、医療診断や金融ローンの承認といった、影響力の大きい環境にますます展開されている。そこでは、150ドルの間違いは些細な不便に過ぎないかもしれないが、15万ドルの間違いは壊滅的な結果をもたらしかねない。これらのクリティカルな領域では、単一の「最良の推測」(点予測)を提供するだけでは不十分である。意思決定者は、モデルの不確実性を理解する必要がある。
この問題を解決するため、学術分野は2005年頃にConformal Prediction (CP) を開発した。 conformal predictor は、単一のラベルを出力する代わりに、真のラベルが含まれるという数学的な保証付きのセットの尤もらしいラベルを出力する(例:「患者の状態が健康か糖尿病かのいずれかであると95%確信している」)。
同時に、機械学習モデルが複雑な「ブラックボックス」になるにつれて、Explainable AI (XAI) の分野が登場した。最も直感的なXAI技術の一つが、モデルの決定を反転させるために必要な最小限の変更をユーザーに正確に伝えるCounterfactual Explanation(2017年頃に普及)である。
本論文で取り上げられた特定の問題は、これら二つの分野のまさに交差点で生じたものである: conformal predictor によって生成された不確実性を考慮したセットを、どのように説明するか? 単一の予測を説明するための優れたツールや、不確実性を定量化するための優れたツールは存在するが、モデルの不確実性が、特定のラベルを予測セットに含めたり除外したりするほど変化した理由を説明するための橋が欠けていた。
以前のアプローチの根本的な限界、あるいは「ペインポイント」は、既存の counterfactual explanation 手法が厳密に点予測器のために設計されていたことである。これらの手法は、モデルが正確に1つのラベルを出力すると仮定しており、その数学的な目的全体は、その1つのラベルを別のラベルに反転させるための最小限の特徴の微調整を見つけることである。
conformal predictor はラベルのセットを出力するため(これはモデルの信頼度に基づいて拡大または縮小する)、既存の手法は完全に不十分である。特に、予測セットの出力の変化を説明することはできない。例えば、古い手法では、「この患者の血圧にどのような小さな変化があれば、モデルは『糖尿病』を可能性の領域から除外するのに十分な確信を持つようになるか?」といった問いに答えることはできない。さらに、少数の最近のモデルが counterfactuals に不確実性を組み込もうと試みたものの、それらは形式的で分布に依存しない統計的保証を欠いていた。著者らは、保証された予測セット内でのラベルの包含または除外をターゲットとする新しいタイプの counterfactual を発明するために、本論文を書くことを余儀なくされた。
以下に、論文中のいくつかの高度に専門的な用語を、日常的な概念に翻訳したものを示す:
- Conformal Prediction Set:
- アナロジー: 釣りを想像してほしい。標準的なモデルは槍(点予測)を使用する。それは正確に1匹の魚を狙うが、外れた場合は何も得られない。conformal predictor は網(予測セット)を使用する。網は魚と一緒に少量の海藻を捕らえるかもしれないが、95%の確率で魚を捕獲することを保証する。網の大きさは不確実性を表す:小さな網は高い確信を意味し、巨大な網はモデルが非常に不確かであることを意味する。
- Counterfactual Explanation:
- アナロジー: GPSの経路変更の提案。単に「渋滞にはまっています」(標準的な予測)と伝えるのではなく、counterfactual explanation は「もし前の出口を利用していれば、あなたは制限速度で走行していたでしょう」と伝える。それは、異なる結果を得るために必要な最小限の変化を示す。
- Credibility:
- アナロジー: 高級クラブの用心棒があなたの雰囲気をチェックする。この論文では、credibility は、新しく合成されたデータポイント(counterfactual)が、モデルが訓練された実際のデータにどれだけうまく溶け込むかを測定する。credibility が高い場合、新しいデータポイントは通常の、尤もらしい人物のように見える。低い場合、そのデータポイントはモデルが一度も見たことのない非現実的なエイリアンである。
- Sparsity:
- アナロジー: 車を修理する整備士。エンジン全体を再構築してタイヤを交換する(低い sparsity)のではなく、壊れたスパークプラグ1本だけを交換してほしい(高い sparsity)と望むだろう。論文では、sparse な説明は可能な限り少ない変数を変更し、人間が理解し行動しやすくする。
| 記号 | 説明 |
|---|---|
| $x$ | 説明が必要な元の入力インスタンス(テストデータポイント)。 |
| $x'$ | サロゲート counterfactual インスタンス;予測セットを変更する新しく生成されたデータポイント。 |
| $x^{\text{real}}$ | 探索空間を固定するために使用される、キャリブレーションデータセット内で見つかった実際の counterfactual インスタンス。 |
| $\epsilon$ | 事前に定義された有意水準(例:$0.05$)、許容されるエラー率を表す。 |
| $\mathcal{Y}$ | データセット内のすべての可能なクラスラベルのセット。 |
| $\tilde{y}$ | 予測セットへの包含がテストされている候補ラベル。 |
| $\Gamma^\epsilon(x)$ | 有意水準 $\epsilon$ におけるインスタンス $x$ の conformal prediction set。拒否されなかったすべてのラベルが含まれる。 |
| $Z^c$ | 非適合度スコアを計算するために使用される、独立したデータセットであるキャリブレーションデータセット。 |
| $p_k(x)$ | インスタンス $x$ におけるクラス $k$ に対して conformal predictor によって計算された p 値。 |
| $h$ | 基本的な予測を行うために使用される、基盤となる機械学習アルゴリズム/分類器。 |
| $\alpha_i$ | 非適合度スコア。既知のデータと比較して、インスタンスがどれほど「奇妙」であるかを測定する。 |
| $d(x, c)$ | カウンターファクチュアル $c$ と元の入力 $x$ との距離を測定する距離尺度(ユークリッド距離またはゴワー距離など)。 |
問題定義と制約
AIを用いて患者の診断を支援している状況を想像してほしい。従来のAIモデルは、「この患者は糖尿病である」という単一で確信度の高い予測を提示する。しかし、医療や金融のような高リスク分野では、単一の予測だけでは不十分であり、モデルが不確実な状況を把握する必要がある。そこで登場するのが「コンフォーマル予測」である。単一のラベルではなく、コンフォーマル分類器は「予測集合」を出力する。これは、真の答えがその集合内に含まれることを数学的に保証された、妥当なラベルのリスト(例:{健康、糖尿病})である。その保証は、例えば95%の時間で成り立つ。AIが非常に不確実な場合、集合は大きくなり、確信度が高い場合は、集合は単一のラベルに縮小する。
しかし、ここで壁にぶつかる。なぜAIがこの特定の集合を提示したのか、その理由をどのように説明すればよいのだろうか。従来のAIでは、「反実仮想説明」が用いられる。「もしこの患者のBMIが2ポイント低ければ、AIは『糖尿病』ではなく『健康』と予測しただろう」といった「もしも」のシナリオである。
本論文の出発点(入力/現在の状態)は、これらのコンフォーマル予測集合と従来の反実仮想手法の存在である。しかし、従来の反実仮想は、単一の点予測を反転させるために厳密に設計されている。望ましい終着点(出力/目標状態)は、全く新しいタイプの説明、すなわち「コンフォーマル反実仮想」である。著者らは、固定された信頼度レベルで予測集合全体を変更するために、テストインスタンスに対する最小限の変更を見つけたいと考えている。例えば、集合から「糖尿病」という可能性を完全に排除するために何を変更する必要があるかを正確に把握することである。
本論文が埋める数学的なギャップは、最適化目的関数にある。従来の反実仮想は、以下のような問題に似たものを解く。
$$ \min_{c \in \mathcal{X}} d(x, c) \quad \text{subject to} \quad f(x) \neq f(c) $$
ここで、$f$が異なる単一ラベルを出力する限り、元の入力$x$からの距離$d$を最小化する新しいインスタンス$c$を見つけたい。
著者らは、集合のためにこの論理を書き直す必要があった。単一のラベル$f(x)$の代わりに、有意水準$\epsilon$における予測集合$\Gamma^\epsilon(x)$を扱っている。新しい目的関数は、集合自体が変化するような代理インスタンス$x'$を見つけることを要求する。
$$ \Gamma^\epsilon(x') \neq \Gamma^\epsilon(x) $$
さらに、著者らはこの探索を導くために「信頼度(credibility)」と呼ばれる新しい指標を導入した。信頼度は、すべての候補クラス$k$にわたる最大p値として数学的に定義される。
$$ \text{Credibility}(x') = \max_k p_k(x') $$
これは、新しい「もしも」のシナリオが、実際の訓練データの基底分布にどれだけよく適合しているかを測定する。
しかし、説明可能なAIの世界では、一つのことを修正すると、ほとんどの場合、別のことが壊れる。過去の研究者を悩ませてきたジレンマは、「近接性/疎性(Proximity/Sparsity)」と「妥当性(Plausibility)」の綱引きである。
単に予測を変更するための数学的に最も短い距離(近接性)や、最も少ない特徴量の変更(疎性)を見つけるようにアルゴリズムに要求した場合、数学はその要求を喜んで満たし、フランケンシュタインのようなデータポイントを作成するだろう。それは、「収入が50,000ドルを超えるためには、年齢を150歳に変更するだけでよい」と述べるかもしれない。それは数学的には近いが、物理的には不可能である。過去の研究者は、最小限でありながらも、真の「データ多様体(data manifold)」上に存在する(つまり、現実的で妥当な人間やシナリオのように見える)反実仮想を生成するのに苦労してきた。
これを解決するために、著者らはいくつかの厳しい現実的な壁に直面した。
- 無限の探索空間の制約: 反実仮想を見つけるために、あらゆる可能な数値の組み合わせを単純に探索することはできない。連続特徴量空間は無限に大きい。これを克服するために、著者らは探索を厳密に制限する必要があった。まず、「実際の反実仮想」$x^{\text{real}}$、すなわち、異なる予測集合をもたらすキャリブレーションデータセットからの実際の過去のデータポイントを見つける。次に、元のインスタンス$x$と$x^{\text{real}}$の間に厳密に境界が設定された特徴量値の離散グリッドを構築する。
- 組み合わせ爆発: この境界設定されたグリッドに探索を制限した後でも、可能な特徴量の組み合わせの数は指数関数的に増加する。データセットに多くの特徴量がある場合、すべての組み合わせをチェックすることは計算上不可能である。著者らは厳しい計算上の限界に直面した。組み合わせの数が10,000を超えると、網羅的な探索はクラッシュするか、時間がかかりすぎる。彼らは完全な最適化を断念し、空間をナビゲートするためにヒューリスティックな遺伝的アルゴリズムに頼らざるを得なかった。
- コンフォーマル計算の負担: 単純なニューラルネットワークではフォワードパスが非常に高速であるのとは異なり、コンフォーマル予測では、探索中に生成されるすべての合成データポイントに対して、すべての候補ラベルの非適合度スコアとp値を計算する必要がある。これは大規模な計算上のボトルネックを生み出し、これらの説明のリアルタイム生成を非常に困難にする。
このアプローチの理由
本論文のブレークスルーを真に理解するためには、まず従来のAIがどのように意思決定を行うかを見る必要がある。ほとんどの機械学習モデルは「点予測子」であり、データを見て「この患者は糖尿病である」といった単一の絶対的な答えを出す。しかし、医療や金融のようなハイリスク分野では、単一の推測だけでは不十分であり、意思決定者はモデルの不確実性を知る必要がある。ここでConformal Prediction (CP)が登場する。CPは単一のラベルではなく、特定の確率(例えば95%)で真の答えがそのセット内に含まれるという数学的な保証付きの予測セット(例:$\{\text{Healthy}, \text{Diabetic}\}$)を出力する。
著者らは、従来の最先端(SOTA)説明手法が、これらの不確実性を考慮したモデルに対して根本的に破綻していることに気づいた。標準的な反事実(counterfactual)手法は、点予測子専用に設計されている。それらは「モデルの予測をAからBに反転させるために必要な最小限の変更は何か?」という問いに答える。しかし、モデルが単一のラベルではなく、 plausibility なラベルのセットを出力する場合、既存の手法は完全に破綻する。セットを単純に「反転」させることはできない。著者らがこの問題に気づいたのは、モデルの不確実性を説明するためには、固定された有意水準 $\epsilon$ において特定のクラスが予測セットに含まれる、あるいは除外される理由を説明する必要があると考えたときだった。Conformal Predictionに特化した全く新しい数学的フレームワークが、唯一実行可能な解決策であった。
単純な性能指標を超えて、この手法は plausibility を扱う上での構造的な優位性により、質的に優れている。反事実における以前のゴールドスタンダードは、距離($\ell_2$ノルムなど)の最小化やスパース性(変更された特徴の数)に大きく依存していた。これは数学的には機能するが、しばしば「エイリアン」なデータポイント、つまり現実世界のインスタンスとは似ても似つかない提案を生成してしまう。これを解決するため、著者らは画期的な指標であるcredibilityを導入した。
Conformal Predictionにおいて、credibilityは全ての候補ラベルにわたる最大p値として定義される:
$$ \text{Credibility}(x') = \max_k p_k(x') $$
credibilityを最適化することで、生成された反事実 $x'$ は基盤となる訓練データ分布に完全に適合することが保証される。点予測を反転させるために、決定境界を越える大規模で非現実的な飛躍を強制するのではなく、この手法は不確実性セットを単純に拡大または縮小する、より小さく、非常に plausibility な操作を見つける。例えば、Incomeデータセットでは、予測セットを $\{\text{>\$50K}, \text{<=\$50K}\}$ から、より確信度の高い単一のセット $\{\text{>\$50K}\}$ にシフトさせるためには、厳格なクラス反転を強制するよりも、はるかに現実的な特徴変更が必要となる。
この問題は厳しい制約を課した。説明はConformal frameworkの下で数学的に有効であり、実行可能であり、かつ分布フリーの保証を維持するためにキャリブレーションデータに厳密に結びついている必要があった。選択されたアプローチは、これらの制約を完璧に融合させた。著者らは、元のテストインスタンス $x$ と、キャリブレーションセット $Z^c$ で見つかった最も近い実際の反事実 $x^{\text{real}}$ によって境界付けられた離散的な探索空間を設計した:
$$ x^{\text{real}} = \arg \min_{x_i \in Z^c} \{ \| x - x_i \|_2 \mid \Gamma^\epsilon(x_i) \neq \Gamma^\epsilon(x) \} $$
探索空間を実際の観測値に固定することで、アルゴリズムは合成反事実が決して不可能な特徴の組み合わせに逸脱しないことを保証する。探索空間が小さい場合は網羅的な探索を使用し、計算量が膨大になる場合は遺伝的アルゴリズムを用いてエレガントにスケーリングする。これは完璧な融合である。Conformal Predictionの厳密な統計的境界が維持されつつ、直感的で人間が読める説明が提供される。
最後に、本論文は他の一般的なアプローチがなぜここで失敗したかを明確に指摘している。ベイジアンモデリングやエピステミック不確実性定量化を用いて反事実への不確実性の組み込みを試みた最近の試みは、この特定の問題に対して的外れである。ベイジアンモデルは確率的なスコアを提供するが、分布フリーの保証を欠いている。それらは事前分布を仮定しており、その仮定が間違っていれば、保証は崩壊する。Conformal Predictionは交換可能性(exchangeability)の仮定のみに依存する。したがって、ベイジアン反事実や標準的な生成モデル(GANsやDiffusionなど)をこのパイプラインに無理に押し込もうとすると、Conformal Predictionを非常に価値あるものにしている厳密で数学的に証明されたエラー率を破壊してしまうだろう。著者らは、予測セットの絶対的な統計的妥当性を維持するために、それらの代替案を却下しなければならなかった。
 Figure 2. Counterfactual explanation for a conformal prediction set generated by optimizing for distance on the WBC dataset. Changed features are shown in blue
Figure 2. Counterfactual explanation for a conformal prediction set generated by optimizing for distance on the WBC dataset. Changed features are shown in blue
数学的・論理的メカニズム
この論文のブレークスルーを理解するためには、まず現代のAIがどのように意思決定を行い、その不確実性をどのように測定するかについてのベースラインを確立する必要がある。
従来の機械学習では、モデルは「点予測」――単一の最良推定値――を提供する。しかし、医療や金融のようなハイリスク分野では、単一の推測だけでは不十分であり、モデルの確信度を知る必要がある。そこで登場するのが Conformal Prediction (CP) である。CPは単一の回答の代わりに、数学的な保証付きの予測集合を出力する。例えば、「この患者の診断が {健康、糖尿病} のいずれかであると95%確信している」と言うかもしれない。モデルが非常に不確実な場合、集合は大きくなる。確信度が高い場合、集合は単一のラベルに縮小する。
本論文の動機は、説明可能なAIにおける重大な盲点に端を発している。AIが点予測を行う場合、それを理解するためにしばしば反実仮想説明(「もしあなたの収入が高ければ、ローンは承認されていたでしょう」)を使用する。しかし、予測集合をどのように説明できるだろうか?既存の方法はここでは完全に失敗する。著者らは、モデルの不確実性境界を変更するために必要な最小限の変更を見つけることで、特定のクラスが集合に含まれたり除外されたりした理由を効果的に説明しようと試みた。
これを達成するために、彼らはいくつかの制約を克服する必要があった。生成される説明は元のデータに近いこと(近接性)、可能な限り少ない変数を変更すること(疎性)、そして最も重要には、数学的な幻覚ではなく現実的なデータポイントのように見えること(信頼性)である。
以下に、彼らがこれを解決するために構築した数学的エンジンを示す。
マスター方程式
本論文の核心的な論理は、3つの部分からなる数学的エンジンによって駆動される。すなわち、現実のアンカーを見つけること、尤度を最大化すること、そして複雑さを罰することである。
$$ x^{\text{real}} = \arg \min_{x_i \in Z^c} \left\{ \|x - x_i\|_2 \mid \Gamma^\epsilon(x_i) \neq \Gamma^\epsilon(x) \right\} $$
$$ \text{Credibility}(x') = \max_k p_k(x') $$
$$ \text{Sparsity}(x, x') = \sum_{j=1}^p \mathbf{1}\{x_j \neq x'_j\} $$
方程式の分解
このエンジンの各コンポーネントを分解し、その物理的および論理的な役割を理解しよう。
- $x$: 元の入力データポイント(例:患者の現在の健康指標)。これが我々の出発点である。
- $x_i \in Z^c$: キャリブレーションデータセット $Z^c$ からの実際のデータポイント。その論理的な役割は、「現実チェック」として機能し、モデルが不可能なシナリオを捏造しないようにすることである。
- $\|x - x_i\|_2$: L2ノルム(ユークリッド距離)。これは、検索を元の入力に向かって引き戻すゴムバンドとして機能する。著者らがここでL2ノルムを使用するのは、単一変数における大きくて非現実的な偏差を強く罰し、モデルにバランスの取れた、近くの解を見つけることを強制するためである。
- $\Gamma^\epsilon(x)$: 固定された有意水準 $\epsilon$(通常は95%信頼度で0.05)における共形予測集合。これはモデルの不確実性の境界を表す。
- $\neq$: 不等号演算子。これは論文全体の論理的なトリガーである。我々は単に基盤となる確率をシフトしたいのではなく、最終的な予測集合における構造的で目に見える変化を要求する。
- $\arg \min$: 検索演算子。これはデータをスキャンし、最小抵抗の経路――予測集合を成功裏に反転させる、絶対的に最も近い実世界の例――を見つける。
- $x'$: 生成される合成代理反実仮想。これがユーザーに提示される最終的な説明である。
- $p_k(x')$: クラス $k$ のp値。共形予測では、これは新しい点がその特定のクラスの既知のデータ分布にどれだけ適合するかを測定する。
- $\max_k$: 最大演算子。すべてのクラスにわたる最大p値を取ることで、反実仮想が平均化されて平凡で非現実的な状態になるのではなく、少なくとも1つのクラスに対して高い尤度を持つことを保証する。
- $\sum_{j=1}^p$: $p$ 個すべての特徴量にわたる合計。著者らが積ではなく合計を使用した理由は何だろうか?なぜなら、我々は変更された特徴量の総数を加算的に数えたいからである。もし積を使用した場合、変更されていない単一の特徴量(0を生成する)がペナルティ全体を消去し、変更を数えるという論理を完全に破綻させるだろう。
- $\mathbf{1}\{x_j \neq x'_j\}$: 指標関数。これはバイナリスイッチとして機能する。特徴量が変更された場合は1を、変更されなかった場合は0を出力する。
ステップバイステップの流れ
抽象的な単一データポイントがこの機械的な組み立てラインをどのように移動するかを追ってみよう。
- 入力: 患者のデータ $x$ がシステムに入る。モデルは不確実であり、予測集合として {健康、糖尿病} を出力する。
- 現実のアンカー: システムは過去のキャリブレーションデータをスキャンし、$x^{\text{real}}$、すなわち異なる予測集合(例:{健康} のみ)を受け取った最も近い実際の患者を見つける。
- グリッド構築: 離散的な検索グリッドが構築される。システムは、$x$ と $x^{\text{real}}$ の間のすべての観測値を抽出する。これにより、現実的な中間ステップのみを提案することが保証される(例:データに存在しない血圧10を提案することはない)。
- 組み立てライン: 合成候補 $x'$ がこのグリッド上で生成される。これは共形予測器を通過し、その予測集合が実際に反転するかどうか ($\Gamma^\epsilon(x') \neq \Gamma^\epsilon(x)$) が確認される。
- 品質管理: 集合が反転した場合、候補は評価される。システムは、その信頼性(現実的な患者か?)と疎性(「グルコース」と「年齢」だけのように、わずかな変更しか加えていないか?)を計算する。
- 出力: これらの基準を最もよくバランスさせた候補が、最終的で実行可能な説明として返される。
最適化ダイナミクス
このメカニズムは実際にどのように学習し、更新し、収束するのだろうか?
従来のニューラルネットワークでは、勾配降下法を使用して滑らかな損失ランドスケープを滑り降りる。しかし、共形予測集合はハードで微分不可能なステップ関数(ラベルは厳密に集合の内側にあるか、外側にあるかのいずれかである)を作成するため、勾配は存在しない。損失ランドスケープは滑らかな丘ではなく、離散的で二値的な決定からなるギザギザの崖の顔である。
これを克服するために、著者らは二重の最適化戦略を使用する。検索空間が小さい場合(10,000組み合わせ未満)、システムは総当たり網羅的検索を使用し、グリッド上のすべてのポイントを評価して絶対的な数学的最適値を見つける。
空間が大きすぎる場合、遺伝的アルゴリズム(GA)を展開する。GAは100個のランダムな候補反実仮想の集団を初期化する。各候補の「適合度」は、マスター方程式(信頼性の最大化または疎性の最小化)によって決定される。極めて重要なのは、ランドスケープは大規模なペナルティ関数によって形成されることである。候補が予測集合を変更できなかった場合、その適合度スコアは破壊され、次の世代で事実上消滅する。1,000回の反復を通じて、候補は突然変異し(10%の確率で特徴量をランダムに微調整する)、交配し(2つの良い候補間で特徴量を交換する)。
正直なところ、著者らが遺伝的アルゴリズムのエリテイズム比率をアブレーションスタディなしで正確に0.01にハードコーディングした理由は完全には不明だが、実際には、検索を停滞させることなく絶対的に最良の候補を世代を超えて維持するのに十分である。この進化プロセスを通じて、システムは、モデルの不確実性境界を成功裏に変更する最小限で、非常に信頼性の高い変更へと反復的に収束する。
結果、限界、および結論
医師のもとで病気の診断を受けると想像してみよう。もし医師が「あなたは間違いなく糖尿病です」と言った場合、それは標準的な点予測である。しかし、もし医師が「検査結果に基づくと、あなたは完全に健康であるか、あるいは初期段階の糖尿病であるかのどちらかであると95%確信しています」と言ったとしたらどうだろうか?この後者のシナリオこそが、Conformal Prediction (CP)の本質である。CPは、単一の、潜在的に過度に確信に満ちた回答を与えるのではなく、数学的な保証に裏打ちされた可能な結果のリストである予測セットを提供する。このセットには、真の答えが特定の確率で含まれることが保証されている。
しかし、これには重大な心理的および実用的な問題が生じる。なぜモデルはそのセットに「糖尿病」を含めたのか?モデルが自信を持って「糖尿病」を除外し、「健康」とだけ言うためには、あなたの健康プロファイルに何が変化する必要があるのだろうか?
ここで、Counterfactual (CF) Explanationsが登場する。反事実とは「もし〜だったら」というシナリオである。これは、モデルの決定を変更するために必要な最小限の変化を教えてくれる(例:「もしあなたの血圧が10ポイント低ければ、あなたは厳密に健康と分類されるでしょう」)。歴史的に、科学者たちは標準的な点予測のための反事実を生成する方法しか見つけられていなかった。本論文は、これまで未解決であった素晴らしい問題に取り組む。すなわち、 conformal prediction sets に対する反事実説明をどのように生成するか?
背景と動機
本論文を理解するためには、2つの概念を把握する必要がある。
1. Conformal Prediction Sets: 有意水準 $\epsilon$(例えば、95%信頼水準であれば0.05)が与えられた場合、 conformal classifier はラベルのセット $\Gamma^\epsilon(x)$ を出力する。これは、あらゆる可能なラベルに対して非適合度スコアを計算し、それらを $p$-value に変換し、 $p$-value が $\epsilon$ より小さいラベルをすべて棄却することによって行われる。
2. Counterfactuals: これらは、元の入力 $x$ に非常に近いが、異なる予測をもたらす合成データ点 $x'$ である。
ここでの動機は、純粋な信頼と実行可能性である。意思決定者は、モデルの不確実性を知りたいだけでなく、その不確実性の境界を知りたいのである。もし銀行のモデルが、あなたのローン申請の予測セットを $\{\text{承認}, \text{否認}\}$ と言うなら、あなたは厳密に $\{\text{承認}\}$ にそのセットを移行させるために、何を(例えば、150ドルのクレジットカード債務を返済する)変更する必要があるのかを正確に知りたいはずだ。
克服すべき制約
これらの「もし〜だったら」というシナリオを生成することは、高次元データの広大さゆえに非常に困難である。アルゴリズムに盲目的に数学的解を探索させると、「年齢を15歳減らす」とか「血圧をマイナスにする」といった不条理な提案をしてしまうだろう。
したがって、著者らは探索空間を制約し、生成される説明が以下のようになるようにした。
* 近接性 (Proximate): 変化は小さくなければならない。
* 疎性 (Sparse): すべての特徴ではなく、1つか2つの特徴のみを変更すべきである。
* 妥当性 (Plausible/Credible): 合成データ点は、現実世界の実際のデータのように見える必要がある。
数学的問題と解決策
著者らが解決した中心的な数学的問題は、予測セットが変化するような代理インスタンス $x'$ を見つけることである。
$$ \Gamma^\epsilon(x') \neq \Gamma^\epsilon(x) $$
不可能なデータ点を生成することなくこれを解決するために、彼らは高度に制約された3段階の探索アーキテクチャを考案した。
1. 「実際の」反事実を見つける: まず、キャリブレーションデータセット(実際の履歴データ)を見て、 $x$ とは異なる予測セットを持つ最も近い実際のデータ点 $x^{\text{real}}$ を見つける。
2. グリッドを構築する: $x$ と $x^{\text{real}}$ の間の値によって完全に境界付けられた離散的な探索空間を構築する。これにより、アルゴリズムが異常な、範囲外の数値を生成できないことが保証される。
3. 最適化する: このグリッドを探索し(小さな空間の場合は網羅的探索、より大きな空間の場合は遺伝的アルゴリズムを使用)、3つの基準のいずれかを最適化する合成 $x'$ を見つける。
* 距離 (近接性): $||x - x'||_2$ を最小化する。
* 疎性: 変更された特徴の数 $\sum_{j=1}^p \mathbf{1}\{x_j \neq x'_j\}$ を最小化する。
* 妥当性 (Credibility): これは著者らの妙技である。彼らは妥当性を $\max_k p_k(x')$ として定義する。すべてのクラスにわたる最も高い $p$-value を最大化することによって、反事実を訓練データの分布に厳密に適合させることを強制する。これは数学的に「もし〜だったら」というシナリオが非常に現実的であることを強制する。
実験アーキテクチャと「犠牲者」
著者らは単にメトリクスをリストアップしただけでなく、彼らの合成反事実が現実そのものよりも優れていることを証明するために、過酷な実験を設計した。
「犠牲者」: conformal prediction sets のための反事実を生成する他のアルゴリズムが存在しないため、ベースライン(彼らが打ち負かさなければならなかった「犠牲者」)は、履歴データセットから直接抽出された実際の反事実 ($x^{\text{real}}$) であった。
証拠: 彼らは10個の表形式データセットで手法をテストした。各データセットについて、合成反事実を生成し、比率を使用して実際の反事実と比較した。
* 距離を最適化した場合、彼らの手法は平均比率 $0.452$ を達成した。これは、彼らのアルゴリズムが、最高の現実世界の例よりも元の入力に54.8%近い有効な説明を見つけたという否定できない証拠である。
* 疎性を最適化した場合、彼らは比率 $0.493$ を達成した。これは、彼らの説明が現実世界の対応物よりも半分の特徴しか変更する必要がなかったことを意味する。
* 最も印象的なのは、妥当性を最適化した場合、彼らは比率 $1.157$ を達成したことである。これは、彼らの合成的、数学的に生成されたデータ点が、キャリブレーションセットからの実際のデータ点よりも、データ分布に15.7%も適合していたことを意味する。
正直なところ、より高度な離散勾配ベースのオプティマイザが存在するにもかかわらず、なぜ彼らがより大きな探索空間に対して比較的基本的な遺伝的アルゴリズムパッケージを選択したのか完全には分からないが、経験的な証拠はそれが概念実証として十分以上であることを証明している。
将来の進化のための議論トピック
この素晴らしい基盤に基づいて、将来の研究のためのいくつかの重要な方向性を以下に示す。
- 因果グラフと厳密な実行可能性: 現在の手法は実際のデータを使用して探索空間を制限するが、因果関係を理解しているわけではない。彼らの糖尿病の例では、アルゴリズムは患者の年齢を30歳から26歳に減らすことを提案した。年齢は不変である。
有向非巡回グラフ (DAG) を conformal 探索空間に統合し、アルゴリズムが因果的に下流の、実行可能な介入のみを提案するようにするにはどうすればよいか?
2. ターゲット付きセットステアリング: 現在、アルゴリズムは予測セットが変化した時点で停止する ($\Gamma^\epsilon(x') \neq \Gamma^\epsilon(x)$)。しかし、ユーザーが特定の方向にセットを誘導したい場合はどうだろうか?例えば、$\{\text{良性}, \text{悪性}\}$ から厳密に $\{\text{良性}\}$ へ移動させる場合などである。特定のセットの包含/除外をターゲットにするために、目的関数をどのように変更できるか?
3. 非構造化データへのスケーリング: この手法は、表形式の特徴間の離散グリッド探索に依存している。これを画像やテキストのような高次元の非構造化データで機能するように進化させるにはどうすればよいか? conformal $p$-value を変分オートエンコーダー (VAE) の連続的な潜在空間にマッピングし、勾配降下法を実行して反事実画像を検索できるだろうか?
4. トライレンマのバランス: 著者らは距離、疎性、妥当性を個別に最適化した。これら3つすべてを同時にバランスさせるパレート最適損失関数を定式化し、おそらく多目的強化学習を使用して、究極の「完璧な」説明を見つけることができるだろうか?
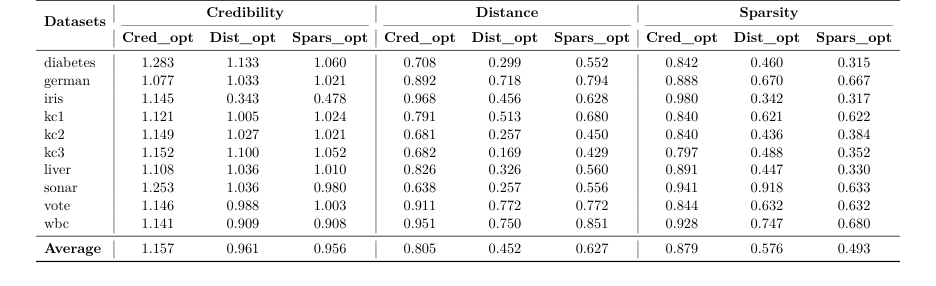 Table 2. Comparison of optimization criteria across datasets
Table 2. Comparison of optimization criteria across datasets