अल्ट्रासाउंड छवियों में संवर्धित मानव शरीर रचना ज्ञान का उपयोग करके एनाटॉमिकल स्ट्रक्चर फ्यू-शॉट डिटेक्शन
चिकित्सा छवि विश्लेषण के क्षेत्र में डीप लर्निंग के कारण भारी प्रगति हुई है। हालाँकि, इस पत्र में संबोधित विशिष्ट समस्या एक गंभीर, वास्तविक दुनिया की बाधा से उत्पन्न होती है: डेटा की भूख। परंपरागत रूप से, अल्ट्रासाउंड...
पृष्ठभूमि और अकादमिक वंश
चिकित्सा छवि विश्लेषण के क्षेत्र में डीप लर्निंग के कारण भारी प्रगति हुई है। हालाँकि, इस पत्र में संबोधित विशिष्ट समस्या एक गंभीर, वास्तविक दुनिया की बाधा से उत्पन्न होती है: डेटा की भूख। परंपरागत रूप से, अल्ट्रासाउंड छवियों में भ्रूण के अंगों का पता लगाने के लिए एआई को प्रशिक्षित करने के लिए विशाल डेटासेट की आवश्यकता होती है। इन डेटासेट को अत्यधिक विशिष्ट डॉक्टरों द्वारा सावधानीपूर्वक एनोटेट किया जाना चाहिए, एक ऐसी प्रक्रिया जो अविश्वसनीय रूप से थकाऊ और महंगी है (विशेषज्ञ श्रम में अक्सर \$150 प्रति घंटे से अधिक की लागत आती है)। इसके अलावा, सख्त नैतिक और गोपनीयता नियम बड़े पैमाने पर रोगी डेटा को इकट्ठा करना और साझा करना लगभग असंभव बना देते हैं।
इस डेटा की कमी को दूर करने के लिए, अकादमिक क्षेत्र "फ्यू-शॉट लर्निंग" की ओर मुड़ गया - एक प्रतिमान जो केवल कुछ उदाहरणों का उपयोग करके मॉडल को प्रशिक्षित करने के लिए डिज़ाइन किया गया है। जबकि फ्यू-शॉट लर्निंग ने एक पूरी छवि को वर्गीकृत करने या एक अंग को रेखांकित करने (सिमेंटिक सेगमेंटेशन) जैसे बुनियादी कार्यों में बड़ी सफलता देखी है, इसने ऐतिहासिक रूप से अल्ट्रासाउंड छवियों में मल्टी-ऑब्जेक्ट डिटेक्शन के बहुत अधिक जटिल कार्य को नजरअंदाज कर दिया है। लेखकों ने इस अंतर को पहचाना और जटिल, मल्टी-ऑर्गन अल्ट्रासाउंड वातावरण में फ्यू-शॉट डिटेक्शन लाने के लिए इस शोध की शुरुआत की।
लेखकों को यह पत्र लिखने के लिए मजबूर होना पड़ा क्योंकि पिछले दृष्टिकोण दो मौलिक सीमाओं से टकराए थे:
1. डोमेन शिफ्ट के प्रति भेद्यता: अल्ट्रासाउंड छवियां कुख्यात रूप से अव्यवस्थित होती हैं। वे मशीन के ब्रांड, ऑपरेटर के प्रोब कोण और अंतर्निहित स्पेकल शोर के आधार पर गंभीर विविधताओं से ग्रस्त हैं। पिछले फ्यू-शॉट मॉडल इन विविधताओं में सामान्यीकरण करने में विफल रहे क्योंकि उनमें अपनी भविष्यवाणियों को एंकर करने के लिए मानव शरीर रचना विज्ञान की एकीकृत समझ का अभाव था।
2. आधुनिक अनुक्रम मॉडल में वास्तुशिल्प अंध बिंदु: हाल ही में, "माम्बा" (स्टेट स्पेस मॉडल पर आधारित) नामक एक अत्यधिक कुशल एआई वास्तुकला लंबे डेटा अनुक्रमों को संसाधित करने के लिए लोकप्रिय हो गई। हालाँकि, पिछले माम्बा-आधारित विधियों ने केवल स्थानिक सहसंबंधों पर ध्यान केंद्रित किया और "चैनल जानकारी" (गहरी, स्तरित सुविधा प्रतिनिधित्व) को पूरी तरह से नजरअंदाज कर दिया। चैनल मिश्रण की इस कमी ने बड़े नेटवर्क में स्थिरता संबंधी समस्याएं पैदा कीं और शारीरिक संरचनाओं के वैश्विक संदर्भ को समझने की मॉडल की क्षमता को गंभीर रूप से सीमित कर दिया।
इस पत्र में अत्यधिक विशिष्ट अवधारणाओं को सहज बनाने के लिए, यहां चार प्रमुख डोमेन शब्दों का रोजमर्रा की उपमाओं में अनुवाद किया गया है:
- फ्यू-शॉट लर्निंग (Few-Shot Learning): कल्पना कीजिए कि आप किसी बच्चे को सिखा रहे हैं कि "प्लेटिपस" क्या है। आपको उन्हें 10,000 तस्वीरें दिखाने की ज़रूरत नहीं है; बस तीन या चार अच्छी तस्वीरें उन्हें जंगल में एक को पहचानने के लिए पर्याप्त हैं। फ्यू-शॉट लर्निंग एआई को विशाल डेटासेट पर निर्भर रहने के बजाय, बहुत सीमित उदाहरणों से सीखने की यह समान मानव-जैसी क्षमता देने की कोशिश करता है।
- डोमेन शिफ्ट (Domain Shift): एक सस्ते, स्थिर-भरे रेडियो पर बजाए गए अपने पसंदीदा गाने को सुनने बनाम एक हाई-एंड कॉन्सर्ट साउंड सिस्टम पर सुनने के बारे में सोचें। अंतर्निहित गीत बिल्कुल वही है, लेकिन ऑडियो गुणवत्ता और विरूपण बहुत भिन्न होते हैं। अल्ट्रासाउंड में, विभिन्न मशीनें और डॉक्टर एक "डोमेन शिफ्ट" बनाते हैं जो मानक एआई मॉडल को आसानी से भ्रमित कर देता है।
- टोपोलॉजिकल रिलेशनशिप रीजनिंग (Topological Relationship Reasoning - TRR): मंद रोशनी वाले कमरे में जिग्सॉ पहेली को एक साथ रखने की कोशिश करने की कल्पना करें। भले ही आप टुकड़ों को स्पष्ट रूप से न देख सकें, आप तार्किक रूप से जानते हैं कि "चिमनी" टुकड़ा "छत" टुकड़े से जुड़ना चाहिए। TRR एआई को एक समान तार्किक मानचित्र देता है: यह मानव अंगों के निश्चित, प्राकृतिक लेआउट (जैसे, हृदय हमेशा फेफड़ों के पास होता है) का उपयोग करके संरचनाओं को ढूंढता है, भले ही अल्ट्रासाउंड छवि धुंधली हो।
- सेलेक्टिव स्टेट स्पेस मॉडल (Selective State Space Models - SSMs): एक व्यस्त वकील की 500-पृष्ठ की कानूनी दस्तावेज़ पढ़ने की तस्वीर। हर एक शब्द को याद रखने के बजाय, वे केवल महत्वपूर्ण खंडों को चुनिंदा रूप से हाइलाइट करते हैं और बेकार भराव पाठ को अनदेखा करते हैं। SSMs डेटा के लिए ऐसा करते हैं, अविश्वसनीय रूप से तेज़ी से और कुशलता से जानकारी को संसाधित करने के लिए अप्रासंगिक शोर को गतिशील रूप से फ़िल्टर करते हैं।
यहां लेखकों के समाधान को तैयार करने के लिए उपयोग किए गए प्रमुख गणितीय नोटेशन का एक ब्रेकडाउन दिया गया है:
| नोटेशन | प्रकार | विवरण |
|---|---|---|
| $x(t), y(t)$ | चर | स्टेट स्पेस मॉडल द्वारा संसाधित एक-आयामी इनपुट और आउटपुट अनुक्रम। |
| $h(t)$ | चर | हिडन स्टेट जो इनपुट अनुक्रम को आउटपुट अनुक्रम पर मैप करता है। |
| $A, B$ | पैरामीटर | रैखिक समय-अपरिवर्तनीय प्रणाली को नियंत्रित करने वाले निरंतर-समय पैरामीटर। |
| $\overline{A}, \overline{B}$ | पैरामीटर | गणना के लिए उनके निरंतर समकक्षों से परिवर्तित असतत-समय पैरामीटर। |
| $\Delta$ | पैरामीटर | निरंतर पैरामीटर को असतत करने के लिए उपयोग किया जाने वाला एक टाइमस्केल पैरामीटर। |
| $X$ | चर | छवि सुविधाओं का प्रतिनिधित्व करने वाला इनपुट टेंसर, जिसे $X \in \mathbb{R}^{B \times C \times H \times W}$ के रूप में परिभाषित किया गया है। |
| $B, C, H, W$ | पैरामीटर | फीचर मैप के आयाम: बैच आकार, चैनलों की संख्या, ऊंचाई और चौड़ाई। |
| $G = \langle \mathcal{N}, \mathcal{E} \rangle$ | चर | एक अप्रत्यक्ष क्षेत्र-से-क्षेत्र ग्राफ जहां नोड्स $\mathcal{N}$ क्षेत्र प्रस्ताव हैं और किनारे $\mathcal{E}$ संबंध हैं। |
| $z_i$ | चर | एक विशिष्ट नोड $i$ के लिए दृश्य सुविधाओं का अव्यक्त स्थान प्रतिनिधित्व। |
| $\omega_m(P(i, j))$ | चर | एक गॉसियन कर्नेल फ़ंक्शन जो दो शारीरिक क्षेत्रों के बीच स्थानिक दूरी और कोण को एन्कोड करता है। |
समस्या परिभाषा और बाधाएँ
अंधेरे, धुंधले कमरे में चाबियों का एक विशिष्ट सेट खोजने की कल्पना करें। अब कल्पना करें कि आपने अपने पूरे जीवन में केवल तीन या पांच बार उन चाबियों को देखा है। यह अनिवार्य रूप से मेडिकल अल्ट्रासाउंड इमेजिंग में फ्यू-शॉट ऑब्जेक्ट डिटेक्शन की चुनौती है।
इस पेपर द्वारा संबोधित की जाने वाली समस्या की भयावहता को समझने के लिए, हमें पहले यह परिभाषित करना होगा कि हम कहाँ से शुरू कर रहे हैं, हम कहाँ जाना चाहते हैं, और उन दो बिंदुओं के बीच की यात्रा इतनी खतरनाक क्यों है।
प्रारंभिक बिंदु और लक्ष्य स्थिति
इनपुट (वर्तमान स्थिति): सिस्टम को एक कच्ची, अत्यधिक शोर वाली अल्ट्रासाउंड छवि फीड की जाती है—विशेष रूप से भ्रूण अल्ट्रासाउंड स्कैन (जैसे मस्तिष्क या हृदय)। इसके साथ ही, मॉडल को उन नवीन शारीरिक संरचनाओं के एनोटेट किए गए उदाहरणों का एक अत्यंत सीमित सेट (जितना कम 1, 3, 5, या 10 "शॉट") दिया जाता है जिसे उसे सीखना है। गणितीय रूप से, इनपुट एक उच्च-आयामी विज़ुअल फ़ीचर टेंसर $X \in \mathbb{R}^{B \times C \times H \times W}$ है, जहाँ $B$ बैच आकार है, $C$ चैनलों की संख्या है, और $H$ और $W$ स्थानिक आयाम हैं।
आउटपुट (लक्ष्य स्थिति): मॉडल को उस धुंधली छवि के भीतर कई शारीरिक संरचनाओं के लिए सटीक बाउंडिंग बॉक्स और वर्गीकरण स्कोर आउटपुट करना होगा। इसे एक क्षेत्रीय भविष्यवाणी मैट्रिक्स $S \in \mathbb{R}^{N \times C}$ के रूप में दर्शाया जाता है, जहाँ $N$ क्षेत्र प्रस्तावों की संख्या है और $C$ वर्गों की संख्या है।
गणितीय अंतर: लुप्त कड़ी एक मजबूत मैपिंग फ़ंक्शन है जो $X$ को $S$ तक ओवरफिटिंग के बिना छोटे प्रशिक्षण डेटासेट तक पहुंचा सकती है। मानक डीप लर्निंग मॉडल बड़े डेटासेट द्वारा संचालित लाखों पैरामीटर अपडेट पर निर्भर होकर इस स्थान को मैप करते हैं। फ्यू-शॉट परिदृश्य में, गणितीय स्थान गंभीर रूप से अंडर-कंस्ट्रेंड होता है। मॉडल के पास उच्च-आयामी स्थान में विभिन्न शारीरिक वर्गों के बीच जटिल, गैर-रेखीय सीमाओं को सीखने के लिए पर्याप्त डेटा बिंदु नहीं होते हैं। लेखकों को पूर्व ज्ञान का उपयोग करके परिकल्पना स्थान को कृत्रिम रूप से बाधित करने की आवश्यकता है ताकि मॉडल तब भी सही अनुमान लगा सके जब उसने बहुत अधिक डेटा नहीं देखा हो।
दर्दनाक दुविधा
कृत्रिम बुद्धिमत्ता में, एक समस्या को ठीक करने से लगभग हमेशा दूसरी समस्या टूट जाती है। धुंधली अल्ट्रासाउंड छवियों में वस्तुओं का पता लगाने के लिए, एक मॉडल को "वैश्विक संदर्भ" की सख्त आवश्यकता होती है—इसे यह समझने के लिए पूरी छवि को देखने की आवश्यकता होती है कि यह कहाँ है, बजाय केवल पिक्सेल के एक छोटे से पैच को देखने के।
ऐतिहासिक रूप से, शोधकर्ताओं ने यहाँ एक क्रूर व्यापार-बंद का सामना किया है:
1. ट्रांसफार्मर मार्ग: आप पूरी छवि में लंबी दूरी की निर्भरताओं को पकड़ने के लिए स्व-ध्यान तंत्र (जैसे ट्रांसफार्मर) का उपयोग कर सकते हैं। हालांकि, कम्प्यूटेशनल जटिलता छवि आकार के साथ द्विघात रूप से बढ़ती है। उच्च-रिज़ॉल्यूशन मेडिकल इमेजिंग में, इसके लिए घातीय रूप से अधिक मेमोरी और कम्प्यूटेशन की आवश्यकता होती है, जिससे यह मानक नैदानिक हार्डवेयर के लिए अव्यवहारिक हो जाता है।
2. माम्बा मार्ग: हाल ही में, शोधकर्ताओं ने स्ट्रक्चर्ड स्टेट स्पेस मॉडल (SSMs), विशेष रूप से "माम्बा" पेश किया, जो इस अनुक्रम मॉडलिंग जटिलता को रैखिक पैमाने तक कम करता है। यह तेज़ और कुशल है। हालांकि, दुविधा वापस आती है: पिछले माम्बा-आधारित तरीके स्थानिक सहसंबंधों पर बहुत अधिक ध्यान केंद्रित करते हैं लेकिन चैनल मिश्रण को पूरी तरह से उपेक्षित करते हैं। तंत्रिका नेटवर्क में, विभिन्न चैनल विभिन्न सीखे गए विशेषताओं (जैसे किनारे, बनावट, या विशिष्ट आकार) का प्रतिनिधित्व करते हैं। इन चैनलों के परस्पर क्रिया करने के तरीके को अनदेखा करके, माम्बा आर्किटेक्चर बड़े नेटवर्क में गंभीर स्थिरता मुद्दों से ग्रस्त है और समृद्ध, वैश्विक सिमेंटिक जानकारी को मॉडल करने की अपनी क्षमता खो देता है।
आप फंसे हुए हैं: ट्रांसफार्मर चुनें और मेमोरी से बाहर हो जाएं, या मानक माम्बा चुनें और एक छोटे से हृदय वाहिका को पृष्ठभूमि शोर से अलग करने के लिए आवश्यक गहरी फ़ीचर इंटरैक्शन खो दें।
कठोर दीवारें
वास्तुशिल्प दुविधा से परे, लेखकों को कई कठोर, यथार्थवादी दीवारों का सामना करना पड़ा है जो इस विशिष्ट समस्या को हल करना अविश्वसनीय रूप से कठिन बनाती हैं:
1. डेटा की अत्यधिक विरलता (नैतिक/श्रम दीवार)
डीप लर्निंग बड़े डेटा पर पनपता है, लेकिन मेडिकल डेटा सख्त नैतिक और गोपनीयता नियमों के पीछे बंद है। भले ही आपको डेटा मिल जाए, इसे लेबल करने के लिए विशेष चिकित्सा विशेषज्ञों की आवश्यकता होती है। आप अल्ट्रासाउंड एनोटेशन को क्राउडसोर्स नहीं कर सकते। यह डेटासेट आकार पर एक कठिन सीमा बनाता है, जिससे मॉडल को लगभग कुछ भी नहीं से सीखना पड़ता है।
2. अल्ट्रासाउंड का भौतिकी (डोमेन शिफ्ट दीवार)
अल्ट्रासाउंड स्वाभाविक रूप से गन्दा है। छवियां आंतरिक भौतिक शोर कलाकृतियों से ग्रस्त हैं, विशेष रूप से कम कंट्रास्ट और स्पेकल शोर। इसके अलावा, मशीन की आवृत्ति/लाभ सेटिंग्स और डॉक्टर के विशिष्ट जांच कोण और दबाव के आधार पर छवियां पूरी तरह से अलग दिखती हैं। यह बड़े पैमाने पर "डोमेन शिफ्ट" बनाता है। अस्पताल ए की कुछ छवियों पर प्रशिक्षित एक मॉडल अस्पताल बी की छवियों पर पूरी तरह से विफल हो जाएगा क्योंकि अंतर्निहित पिक्सेल वितरण मशीन और ऑपरेटर के भौतिकी द्वारा मौलिक रूप से बदल दिया जाता है।
3. मानक एआई की टोपोलॉजिकल अंधापन
मानक ऑब्जेक्ट डिटेक्टर प्रत्येक वस्तु को एक स्वतंत्र इकाई के रूप में मानते हैं। यदि यह "ट्रेकिआ" और "वाहिका" की तलाश करता है, तो यह उन्हें स्वतंत्र रूप से खोजता है। लेकिन मानव शरीर रचना विज्ञान इस तरह काम नहीं करता है। मानव शरीर में स्थानिक-टोपोलॉजिकल संबंध अपरिवर्तनीय हैं—हृदय हमेशा एक विशिष्ट ज्यामितीय लेआउट में विशिष्ट वाहिकाओं से जुड़ा होता है। मानक मॉडल इस जैविक बाधा के "अंधे" हैं। यदि मॉडल गणितीय रूप से उस नियम को एन्कोड नहीं कर सकता है कि "वस्तु ए को वस्तु बी से एक विशिष्ट कोण और दूरी पर होना चाहिए," तो यह अल्ट्रासाउंड के स्पेकल शोर से आसानी से धोखा खा जाएगा, असंभव स्थानों में शारीरिक संरचनाओं की भविष्यवाणी करेगा।
यह दृष्टिकोण क्यों
अल्ट्रासाउंड छवियाँ विश्लेषण के लिए कुख्यात रूप से कठिन होती हैं। वे आंतरिक शोर कलाकृतियों जैसे स्पेकल शोर, निम्न कंट्रास्ट और विभिन्न ऑपरेटरों या मशीन सेटिंग्स के कारण होने वाले बड़े डोमेन शिफ्ट से ग्रस्त हैं। जब आप इस कठोर वातावरण को "फ्यू-शॉट" लर्निंग के साथ जोड़ते हैं - जहाँ मॉडल को सीखने के लिए केवल कुछ लेबल किए गए उदाहरण दिए जाते हैं - तो पारंपरिक डीप लर्निंग विधियाँ बस ढह जाती हैं।
लेखकों ने एक महत्वपूर्ण अहसास किया: मानक अत्याधुनिक (SOTA) मॉडल सब कुछ विशुद्ध रूप से पिक्सेल डेटा से सीखने की कोशिश करते हैं। लेकिन अल्ट्रासाउंड में, पिक्सेल अविश्वसनीय होते हैं। हालाँकि, मानव शरीर रचना अपरिवर्तनीय है। अंगों के बीच स्थानिक संबंध नहीं बदलता है, भले ही अल्ट्रासाउंड प्रोब को अजीब कोण पर रखा गया हो। इससे TRR-CCM का निर्माण हुआ, एक ऐसा मॉडल जो दृश्य सुविधा निष्कर्षण को हार्डकोडेड शारीरिक नियमों के साथ जोड़ता है।
तो, यह विशिष्ट गणितीय दृष्टिकोण ही एकमात्र व्यवहार्य समाधान क्यों था? लेखकों ने पहचाना कि जबकि मैम्बा जैसे हालिया अनुक्रम-मॉडलिंग आर्किटेक्चर लंबी अनुक्रमों से मुख्य अर्थ निकालने में शानदार हैं, मानक मैम्बा में एक घातक दोष है: यह लगभग पूरी तरह से स्थानिक सहसंबंधों पर ध्यान केंद्रित करता है और चैनल जानकारी की उपेक्षा करता है। जटिल चिकित्सा इमेजिंग में, चैनल मिश्रण की यह कमी बड़े नेटवर्क में स्थिरता के मुद्दे पैदा करती है और मॉडल की वैश्विक तस्वीर को समझने की क्षमता को गंभीर रूप से सीमित करती है। इसे ठीक करने के लिए, उन्होंने सर्कुलर चैनल मैम्बा (CCM) डिज़ाइन किया। सेलेक्टिव स्ट्रक्चर्ड स्टेट स्पेस मॉडल (SSM) तंत्र को चैनल आयाम तक विस्तारित करके, CCM अंतर-चैनल सुविधा निर्भरता को कैप्चर करता है। गणितीय रूप से, छिपी हुई स्थिति संक्रमण इस प्रकार परिभाषित किए गए हैं:
$$h_t = \overline{A}h_{t-1} + \overline{B}x_t$$
यह विशिष्ट सूत्रीकरण मॉडल को इनपुट जानकारी को गतिशील रूप से फ़िल्टर करने की अनुमति देता है, जिससे अनुक्रम मॉडलिंग जटिलता को भारी $O(N^2)$ (मानक ट्रांसफार्मर के विशिष्ट) से अत्यधिक कुशल $O(N)$ तक प्रभावी ढंग से कम किया जा सकता है।
इस विधि की तुलनात्मक श्रेष्ठता इसकी दोहरी-इंजन संरचना में निहित है। 9 बेसलाइन विधियों के मुकाबले केवल उच्च माध्य औसत परिशुद्धता (mAP) स्कोर प्राप्त करने से परे, यह गुणात्मक रूप से श्रेष्ठ है क्योंकि यह केवल छवि को "देखता" नहीं है; यह उसके बारे में "तर्क" करता है। अल्ट्रासाउंड के उच्च-आयामी शोर को संभालने के लिए, मॉडल टोपोलॉजिकल रिलेशनशिप रीजनिंग (TRR) का उपयोग करता है। यह एक अप्रत्यक्ष क्षेत्र-से-क्षेत्र ग्राफ $G = \langle \mathcal{N}, \mathcal{E} \rangle$ का निर्माण करता है, जहाँ नोड्स क्षेत्र प्रस्तावों का प्रतिनिधित्व करते हैं और किनारे उनके बीच के संबंधों का प्रतिनिधित्व करते हैं। स्थानिक निर्देशांक को गॉसियन कर्नेल में पास करके, मॉडल संबंध भार की गणना करता है:
$$\omega_m(P(i, j)) = \exp(-\frac{1}{2}(P(i, j) - u_m)^T \Sigma_m^{-1} (P(i, j) - u_m))$$
इसका मतलब है कि भले ही भ्रूण हृदय की दृश्य विशेषताएँ स्पेकल शोर से अस्पष्ट हों, ग्राफ कन्वेन्शनल नेटवर्क (GCN) आसपास की संरचनाओं की स्पष्ट उपस्थिति पर भरोसा करके इसके स्थान और वर्ग का अनुमान लगा सकता है। यह एक संरचनात्मक लाभ है जो इसे पिछले स्वर्ण मानकों की तुलना में अत्यधिक श्रेष्ठ बनाता है जो प्रत्येक बाउंडिंग बॉक्स को अलग-अलग मानते हैं।
यह विधि फ्यू-शॉट मेडिकल डिटेक्शन की कठोर बाधाओं के साथ पूरी तरह से संरेखित होती है। बड़े पैमाने पर चिकित्सा डेटासेट को लेबल करने के लिए विशेष विशेषज्ञों की आवश्यकता होती है, जिसमें प्रति घंटे 150 अमेरिकी डॉलर से अधिक का खर्च आसानी से आ सकता है, जिससे बड़े डेटासेट नैतिक और वित्तीय रूप से प्रतिबंधात्मक हो जाते हैं। यहाँ "विवाह" समस्या की डेटा की कमी और समाधान के अपरिवर्तनीय पूर्व ज्ञान के उपयोग के बीच है। क्योंकि मॉडल TRR मॉड्यूल के माध्यम से मानव शरीर रचना की स्थानिक टोपोलॉजी को पहले से "जानता" है, इसलिए इसे नए वर्गों का पता लगाना सीखने के लिए काफी कम उदाहरणों की आवश्यकता होती है।
ईमानदारी से कहूँ तो, मुझे पूरी तरह से यकीन नहीं है कि लेखकों ने इस विशिष्ट कार्य के लिए GANs या डिफ्यूजन मॉडल जैसे अन्य लोकप्रिय जनरेटिव दृष्टिकोणों को स्पष्ट रूप से अस्वीकार करने पर चर्चा क्यों नहीं की, क्योंकि पेपर में उनका उल्लेख नहीं है। हालाँकि, वे पिछले मैम्बा-आधारित विधियों और मानक CNNs को अस्वीकार करने के पीछे के तर्क को स्पष्ट रूप से समझाते हैं: वे पुराने आर्किटेक्चर या तो चैनल जानकारी को ठीक से मिश्रित करने में विफल रहते हैं या कम्प्यूटेशनल लागतों को बढ़ाए बिना जटिल वैश्विक संदर्भों को कुशलतापूर्वक संसाधित करने के लिए आवश्यक लीनियर-टाइम सेलेक्टिव स्कैनिंग तंत्र की कमी रखते हैं। CCM की लीनियर दक्षता को TRR की शारीरिक बाधाओं के साथ जोड़कर, उन्होंने अल्ट्रासाउंड इमेजिंग के कठोर डोमेन के लिए विशेष रूप से तैयार की गई एक अनूठी मजबूत प्रणाली बनाई।
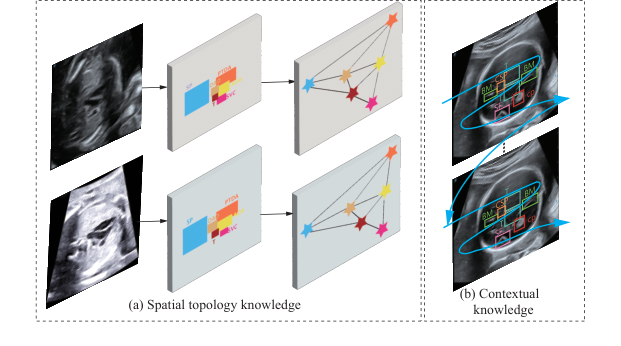 Figure 1. Consistency of two fixed knowledge from human anatomy. (a) Spatial topology knowledge. (b) Contextual knowledge
Figure 1. Consistency of two fixed knowledge from human anatomy. (a) Spatial topology knowledge. (b) Contextual knowledge
गणितीय और तार्किक तंत्र
इस पत्र की प्रतिभा को समझने के लिए, हमें पहले मेडिकल अल्ट्रासाउंड इमेजिंग की मौलिक दुःस्वप्न को समझना होगा। कल्पना कीजिए कि एक रात के आकाश में एक विशिष्ट तारामंडल खोजने की कोशिश कर रहे हैं जो लगातार बदल रहा है, घने बादलों से ढका हुआ है, और एक गंदे टेलीस्कोप से देखा जा रहा है। अल्ट्रासाउंड छवियां कुख्यात रूप से शोरगुल वाली, धुंधली और डॉक्टर द्वारा प्रोब को पकड़े जाने पर अत्यधिक निर्भर होती हैं।
सामान्यतः, डीप लर्निंग इसे लाखों लेबल किए गए उदाहरणों को देखकर हल करता है। लेकिन चिकित्सा के क्षेत्र में, हमारे पास इतना एनोटेट किया गया डेटा नहीं होता है - यह "फ्यू-शॉट" लर्निंग समस्या है। तो, हम AI को केवल कुछ उदाहरणों के साथ भ्रूण के अंगों को खोजना कैसे सिखा सकते हैं?
इस पत्र के लेखकों ने कुछ गहरा महसूस किया: मानव शरीर रचना एक निश्चित नक्शा है। भले ही छवि भयानक रूप से धुंधली हो, हृदय हमेशा रीढ़ के सापेक्ष एक विशिष्ट स्थानिक संबंध में होता है। न्यूरल नेटवर्क को मानव टोपोलॉजी और प्रासंगिक स्मृति के अपरिवर्तनीय नियमों का पालन करने के लिए मजबूर करके, वे डेटा की कमी की भरपाई करते हैं। इसे प्राप्त करने के लिए, उन्होंने एक दोहरे-कोर गणितीय इंजन का निर्माण किया: प्रासंगिक स्मृति के लिए सर्कुलर चैनल मम्बा (CCM), और स्थानिक मैपिंग के लिए टोपोलॉजिकल रिलेशनशिप रीजनिंग (TRR)।
यहां इस प्रणाली के वास्तव में काम करने का विच्छेदन है।
मास्टर समीकरण
इस पत्र का पूर्ण कोर दो परस्पर जुड़े गणितीय इंजनों द्वारा संचालित है।
इंजन 1: प्रासंगिक स्मृति (संरचित अवस्था स्थान मॉडल)
यह समीकरण मॉडल को छवि को स्कैन करने और "याद रखने" की अनुमति देता है जो उसने अभी देखा है, ऊतक की एक प्रासंगिक समझ का निर्माण करता है।
$$h_t = \overline{A}h_{t-1} + \overline{B}x_t$$
$$y_t = Ch_t$$
इंजन 2: शारीरिक टोपोलॉजी (ग्राफ रीजनिंग)
यह पत्र की वास्तविक सफलता है। एक बार जब मॉडल उम्मीदवार अंगों को ढूंढ लेता है, तो यह उनके स्थानिक लेआउट की जांच करने के लिए एक गॉसियन-भारित ग्राफ कनवल्शन का उपयोग करता है कि क्या वे मानव शरीर रचना से मेल खाते हैं।
$$f'_m(i) = \sum_{j \in Neighbour(i)} \omega_m(P(i, j)) x_j e_{ij}$$
$$\omega_m(P(i, j)) = \exp\left(-\frac{1}{2}(P(i, j) - u_m)^T \Sigma_m^{-1} (P(i, j) - u_m)\right)$$
समीकरणों को चीरना
आइए इन समीकरणों में हर गियर और स्प्रिंग को अलग करें।
इंजन 1 से (मम्बा संदर्भ):
* $x_t$: चरण $t$ पर इनपुट। भौतिक रूप से, यह अल्ट्रासाउंड छवि का एक विशिष्ट पैच है जिसे संसाधित किया जा रहा है।
* $h_t, h_{t-1}$: छिपी हुई अवस्थाएं। यह मॉडल की "कार्यशील स्मृति" है। $h_{t-1}$ वर्तमान पैच से ठीक पहले देखे गए छवि पैच के संदर्भ को रखता है।
* $\overline{A}$: असतत अवस्था संक्रमण मैट्रिक्स। इसे "भूलने/धारण द्वार" के रूप में सोचें। यह तय करता है कि पिछले शारीरिक संदर्भ का कितना हिस्सा रखा जाना चाहिए।
* $\overline{B}$: असतत इनपुट मैट्रिक्स। यह एक "ध्यान फिल्टर" के रूप में कार्य करता है, यह तय करता है कि वर्तमान छवि पैच $x_t$ स्मृति को कितना अपडेट करना चाहिए।
* $y_t$: वैश्विक संदर्भ से समृद्ध, उस विशिष्ट पैच के लिए आउटपुट सुविधा प्रतिनिधित्व।
* $C$: आउटपुट प्रोजेक्शन मैट्रिक्स जो छिपी हुई स्मृति को वापस एक प्रयोग करने योग्य दृश्य सुविधा में बदल देता है।
* गुणा के बजाय जोड़ ($+$) क्यों? अवस्था अद्यतन समय के साथ सुचारू रूप से जानकारी जमा करने के लिए जोड़ का उपयोग करता है। गुणा स्मृति को या तो अनंत तक विस्फोट करने या घातीय रूप से तेजी से शून्य तक गायब होने का कारण बनेगा।
इंजन 2 से (टोपोलॉजिकल ग्राफ):
* $f'_m(i)$: एक उम्मीदवार अंग (नोड $i$) के लिए नया अद्यतन, टोपोलॉजी-जागरूक सुविधा वेक्टर।
* $\sum$: योग ऑपरेटर। लेखकों ने मैक्स-पूलिंग या गुणा के बजाय यहां एक इंटीग्रल/योग का उपयोग किया है क्योंकि वे सभी आसपास के अंगों से सहायक साक्ष्य जमा करना चाहते हैं। यदि हृदय, फेफड़े और रीढ़ सभी सहमत हैं कि वे कहां हैं, तो उनके संयुक्त आवाजों को आत्मविश्वास बढ़ाने के लिए एक साथ जोड़ा जाता है।
* $Neighbour(i)$: नोड $i$ के आसपास के शीर्ष-K सबसे प्रासंगिक उम्मीदवार अंग।
* $x_j$: पड़ोसी अंग $j$ का सिमेंटिक फीचर वेक्टर।
* $e_{ij}$: विरल आसन्नता मैट्रिक्स से एज वेट। यह अंग $i$ और अंग $j$ के बीच कच्चे, सीखे गए संबंध की ताकत का प्रतिनिधित्व करता है।
* $\omega_m(P(i, j))$: गॉसियन कर्नेल वेट। यह सिस्टम का "रबर बैंड" है। यदि अंग सही शारीरिक स्थिति में हैं तो यह एक उच्च मान (1 के करीब) आउटपुट करता है, और यदि वे नहीं हैं तो एक निम्न मान (0 के करीब) आउटपुट करता है।
* $P(i, j)$: एक ध्रुवीय निर्देशांक फ़ंक्शन जो $(d, \theta)$ लौटाता है - छवि में अंग $i$ और अंग $j$ के बीच वास्तविक मापी गई दूरी और कोण।
* $\exp(...)$: घातीय फ़ंक्शन। इसका उपयोग एक चिकनी, घंटी के आकार की वक्र बनाने के लिए किया जाता है। यह सुनिश्चित करता है कि यदि कोई अंग अल्ट्रासाउंड प्रोब कोण के कारण थोड़ा स्थानांतरित हो जाता है तो स्थानिक भार अचानक के बजाय धीरे-धीरे कम हो जाता है।
* $-\frac{1}{2}$: गॉसियन वितरण के लिए एक मानक गणितीय स्केलिंग कारक जो सीखने के दौरान कलन (ग्रेडिएंट) को साफ और स्थिर बनाता है।
* $u_m$: एक सीखने योग्य $2 \times 1$ माध्य वेक्टर। भौतिक रूप से, यह AI का "आदर्श ब्लूप्रिंट" है। यह वह सटीक दूरी और कोण है जिसकी AI मानव शरीर रचना के आधार पर दो विशिष्ट अंगों के बीच देखने की अपेक्षा करता है।
* $T$: ट्रांसपोज़ ऑपरेटर, वेक्टर को मैट्रिक्स गुणन के लिए संरेखित करने के लिए आवश्यक है ताकि आउटपुट एक एकल स्केलर दूरी में हल हो जाए।
* $\Sigma_m^{-1}$: एक सीखने योग्य $2 \times 2$ सहप्रसरण मैट्रिक्स का व्युत्क्रम। भौतिक रूप से, यह "विक्षेपण कक्ष" या सहनशीलता है। कुछ अंग भ्रूण की स्थिति (उच्च विचरण) के आधार पर बहुत अधिक घूमते हैं, जबकि अन्य कठोर रूप से तय होते हैं (कम विचरण)। यह मैट्रिक्स दंड को तदनुसार स्केल करता है।
चरण-दर-चरण प्रवाह: असेंबली लाइन
आइए इस वास्तुकला के माध्यम से एक एकल अमूर्त डेटा बिंदु - एक धुंधला धब्बा जो एक भ्रूण हृदय हो सकता है - का पता लगाएं।
- कच्चा निष्कर्षण: अल्ट्रासाउंड छवि बैकबोन नेटवर्क में प्रवेश करती है। हमारे धुंधले धब्बे को एक कच्चे गणितीय टेंसर (संख्याओं का एक ग्रिड) में परिवर्तित किया जाता है।
- प्रासंगिक स्वीपिंग (CCM): टेंसर को अनुक्रमों में काटा जाता है और सर्कुलर चैनल मम्बा में फीड किया जाता है। $\overline{A}$ और $\overline{B}$ मैट्रिक्स छवि पर स्वीप करते हैं। जैसे ही गणित इंजन धब्बे को संसाधित करता है, यह संदर्भ जोड़ता है: "मैं अभी एक रीढ़ जैसी बनावट से गुजरा हूं, इसलिए यह धब्बा संभवतः छाती गुहा में है।" धब्बा $y_t$ बन जाता है।
- ग्राफ निर्माण (TRR): धब्बा अब एक "क्षेत्र प्रस्ताव" (नोड $i$) है। सिस्टम आस-पास के धब्बों (नोड $j$) को देखता है। यह $P(i, j)$ की गणना करता है, यह पाता है कि नोड $j$ 45-डिग्री के कोण पर 5 सेंटीमीटर दूर है।
- शारीरिक पूछताछ: यह $(d, \theta)$ निर्देशांक गॉसियन कर्नेल $\omega_m$ में फीड किया जाता है। कर्नेल इसकी तुलना ब्लूप्रिंट $u_m$ से करता है। क्योंकि एक हृदय और एक रीढ़ को इस विशिष्ट दृश्य में 45-डिग्री के कोण पर होना चाहिए, पद $(P(i, j) - u_m)$ लगभग शून्य हो जाता है।
- साक्ष्य एकत्रीकरण: क्योंकि दूरी शून्य के करीब है, $\exp(0)$ 1 के बराबर हो जाता है। रीढ़ का सिमेंटिक डेटा $x_j$ को 1 से गुणा किया जाता है और हमारे धब्बे $i$ में जोड़ा जाता है ($\sum$)।
- अंतिम आउटपुट: हमारा धुंधला धब्बा अब केवल एक धब्बा नहीं है। यह अब गणितीय रूप से अपने आसपास के शारीरिक पड़ोसियों की पूर्ण निश्चितता के साथ जुड़ा हुआ है। मॉडल आत्मविश्वास से इसे भ्रूण हृदय के रूप में पहचानता है।
अनुकूलन गतिशीलता
यह यांत्रिक जानवर केवल कुछ छवियों से वास्तव में कैसे सीखता है?
मानक फ्यू-शॉट लर्निंग में, हानि परिदृश्य अराजक होता है। क्योंकि बहुत कम डेटा होता है, मॉडल आसानी से ओवरफिट हो जाता है, नकली पैटर्न ढूंढता है (जैसे किसी विशिष्ट अल्ट्रासाउंड मशीन के स्थिर शोर को याद रखना)। ग्रेडिएंट आमतौर पर बेतहाशा उछलते हैं।
हालांकि, TRR मॉड्यूल हानि परिदृश्य पर एक विशाल गुरुत्वाकर्षण लंगर के रूप में कार्य करता है। प्रशिक्षण के दौरान, मॉडल एक मानक SGD (स्टोकेस्टिक ग्रेडिएंट डिसेंट) ऑप्टिमाइज़र का उपयोग करता है। जादू $u_m$ और $\Sigma_m$ में वापस बहने वाले ग्रेडिएंट में होता है।
शुरुआत में, $u_m$ (अपेक्षित अंग स्थान) यादृच्छिक होता है। मॉडल अनुमान लगा सकता है कि हृदय शरीर के बाहर है, जिसके परिणामस्वरूप एक विशाल वर्गीकरण त्रुटि होती है। हानि फ़ंक्शन एक खड़ी ग्रेडिएंट वापस भेजता है, जो कुछ लेबल किए गए उदाहरणों में पाए गए वास्तविक स्थानिक निर्देशांक को प्रतिबिंबित करने के लिए $u_m$ को बलपूर्वक अपडेट करता है।
चूंकि मानव शरीर रचना अत्यधिक सुसंगत है, $u_m$ बहुत जल्दी अभिसरण करता है। एक बार $u_m$ लॉक हो जाने के बाद, $\Sigma_m$ (सहप्रसरण) मैट्रिक्स भ्रूण ऊतक की प्राकृतिक लोच सीखता है। यह मौलिक रूप से अनुकूलन गतिशीलता को नया आकार देता है: न्यूरल नेटवर्क को लाखों पिक्सेल का उपयोग करके खरोंच से यह सीखना कि हृदय क्या दिखता है, को मजबूर करने के बजाय, ग्रेडिएंट को यह सीखने में चैनल किया जाता है कि हृदय अन्य संरचनाओं के सापेक्ष कहां होना चाहिए। यह टोपोलॉजिकल बाधा स्थानीय न्यूनतम को सुचारू बनाती है, जिससे मॉडल विभिन्न अल्ट्रासाउंड मशीनों और रोगियों में खूबसूरती से सामान्यीकृत हो पाता है, भले ही उसने केवल 3 या 5 उदाहरण देखे हों।
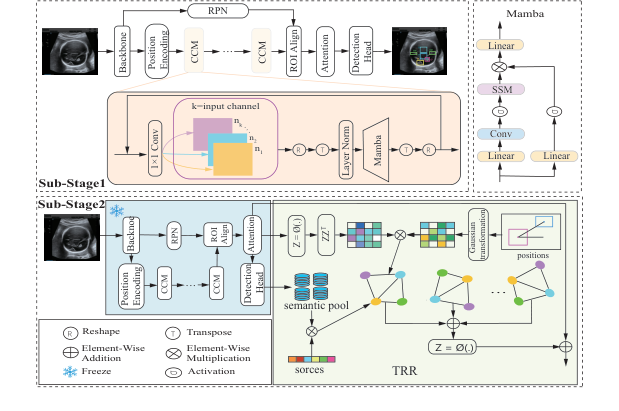 Figure 2. The overall pipeline of the proposed TRR-CCM framework
Figure 2. The overall pipeline of the proposed TRR-CCM framework
परिणाम, सीमाएँ और निष्कर्ष
किसी दानेदार, श्वेत-श्याम टीवी स्थैतिक छवि में एक विशिष्ट, सूक्ष्म संरचना को खोजने का प्रयास करने की कल्पना करें। अब कल्पना करें कि आपके द्वारा इसे सटीकता से खोजने पर किसी का जीवन निर्भर करता है। यह अल्ट्रासाउंड छवि विश्लेषण की दैनिक वास्तविकता है।
इस पत्र की प्रतिभा को समझने के लिए, हमें पहले आधुनिक कृत्रिम बुद्धिमत्ता के बारे में कुछ Ground Truth स्थापित करने की आवश्यकता है। डीप लर्निंग मॉडल अविश्वसनीय रूप से स्मार्ट होते हैं, लेकिन वे डेटा-भूखे भी होते हैं। किसी AI को भ्रूण के हृदय दोष का पता लगाना सिखाने के लिए, आपको आमतौर पर हजारों छवियों की आवश्यकता होती है, जिन्हें चिकित्सा विशेषज्ञों द्वारा सावधानीपूर्वक एनोटेट किया गया हो। यह केवल थकाऊ नहीं है; यह अविश्वसनीय रूप से महंगा है, कभी-कभी एक विशेष रेडियोलॉजिस्ट के समय के लिए प्रति घंटे \$150 से अधिक की लागत आती है। इसके अलावा, सख्त गोपनीयता नियम अक्सर बड़े चिकित्सा डेटासेट एकत्र करना असंभव बना देते हैं।
यह हमें बाधा तक लाता है: Few-Shot Learning (FSL)। FSL एक प्रतिभाशाली छात्र को समस्या के केवल तीन या पांच उदाहरण दिखाने और उनसे अंतिम परीक्षा में उत्कृष्ट प्रदर्शन करने की अपेक्षा करने के AI समकक्ष है। जबकि FSL ने सामान्य छवि वर्गीकरण में सफलता देखी है, इसे अल्ट्रासाउंड छवियों में वस्तु पहचान (कई वस्तुओं के चारों ओर बाउंडिंग बॉक्स ढूंढना) पर लागू करना एक दुःस्वप्न है। अल्ट्रासाउंड गंभीर डोमेन शिफ्ट से पीड़ित होते हैं - विभिन्न मशीनें, विभिन्न प्रोब कोण, और अंतर्निहित स्पेकल शोर।
तो, लेखकों की "आहा!" प्रेरणा क्या थी? उन्होंने महसूस किया कि जबकि अल्ट्रासाउंड छवियां अव्यवस्थित और अप्रत्याशित होती हैं, मानव शरीर रचना विज्ञान नहीं है। स्थानिक टोपोलॉजी (अंग एक-दूसरे के सापेक्ष कहाँ स्थित हैं) और शारीरिक संदर्भ अपरिवर्तनीय हैं। लेखकों ने परिकल्पना की कि यदि वे इस अपरिवर्तनीय मानव शरीर रचना को गणितीय रूप से न्यूरल नेटवर्क में हार्डकोड कर सकते हैं, तो मॉडल शोर से भ्रमित नहीं होगा।
गणितीय व्याख्या: TRR-CCM
इसे हल करने के लिए, लेखकों ने TRR-CCM (Topological Relationship Reasoning with Circular Channel Mamba) नामक एक दोहरे इंजन आर्किटेक्चर को डिजाइन किया। आइए विस्तार से देखें कि उन्होंने जीव विज्ञान को गणित में कैसे अनुवादित किया।
1. सर्कुलर चैनल मैम्बा (CCM)
मानक विजन मॉडल अक्सर भारी कम्प्यूटेशनल शक्ति की आवश्यकता के बिना "बड़ी तस्वीर" देखने में संघर्ष करते हैं। लेखकों ने मैम्बा नामक एक अत्याधुनिक अनुक्रम मॉडलिंग फ्रेमवर्क का रुख किया, जो स्ट्रक्चर्ड स्टेट स्पेस मॉडल (SSMs) पर आधारित है। एक मानक SSM एक छिपी हुई स्थिति $h(t)$ के माध्यम से 1D अनुक्रम $x(t)$ को $y(t)$ पर मैप करता है:
$$h_t = \overline{A}h_{t-1} + \overline{B}x_t, \quad y_t = C h_t$$
जहां $\overline{A}$ और $\overline{B}$ असतत-समय पैरामीटर हैं।
हालांकि, विजन के लिए मानक मैम्बा में एक घातक दोष है: यह चैनल जानकारी (फ़ीचर मैप की गहराई) को अनदेखा करता है। इसे ठीक करने के लिए, लेखकों ने CCM का आविष्कार किया। मैम्बा में छवि को फीड करने से पहले, वे एक कनवल्शनल ऑपरेशन का उपयोग करके क्रॉस-चैनल जानकारी को एकत्रित करने के लिए नेटवर्क को मजबूर करते हैं:
$$\overline{X}(c, m, n) = \sum_{i=0}^{K-1} \sum_{j=0}^{K-1} X_{c, m+i, n+j} \cdot W_{c, i, j}$$
यह समीकरण अनिवार्य रूप से कहता है: "अनुक्रम को देखने से पहले, सभी चैनलों में सुविधाओं को मिश्रित करें ताकि कोई संदर्भ खो न जाए।" फिर वे इस वैश्विक संदर्भ को मैम्बा ब्लॉक के माध्यम से एन्कोड करते हैं:
$$\hat{X} = Mamba(LN(X^T))$$
अंत में, वे एक अवशिष्ट कनेक्शन के माध्यम से इस समृद्ध सुविधा को मूल इनपुट में जोड़ते हैं: $X_{out} = CCM(X + \hat{X}')$।
2. टोपोलॉजिकल रिलेशनशिप रीजनिंग (TRR)
यहीं पर शारीरिक मानचित्र बनाया गया है। लेखक एक ग्राफ कनवल्शनल नेटवर्क (GCN) का उपयोग करते हैं जहां प्रत्येक "नोड" एक संभावित शारीरिक संरचना है। लेकिन AI को कैसे पता चलता है कि ये संरचनाएं एक-दूसरे से कैसे संबंधित हैं?
वे किसी भी दो क्षेत्र प्रस्तावों $(x_i, y_i)$ और $(x_j, y_j)$ के बीच सटीक दूरी $d$ और कोण $\theta$ की गणना के लिए ध्रुवीय निर्देशांक का उपयोग करते हैं:
$$d = \sqrt{(x_i - x_j)^2 + (y_i - y_j)^2}, \quad \theta = \arctan\left(\frac{y_j - y_i}{x_j - x_i}\right)$$
वे इन कच्चे संख्याओं को सीधे नेटवर्क में फीड नहीं करते हैं। वे संबंध भार उत्पन्न करने के लिए इस टोपोलॉजिकल डेटा को गॉसियन कर्नेल से गुजारते हैं:
$$\omega_m(P(i, j)) = \exp\left(-\frac{1}{2}(P(i, j) - u_m)^T \Sigma_m^{-1} (P(i, j) - u_m)\right)$$
यह सुंदर समीकरण एक गतिशील प्रासंगिकता फ़िल्टर के रूप में कार्य करता है। यह गणितीय रूप से निर्धारित करता है कि एक अंग को दूसरे पर उनके अपेक्षित शारीरिक दूरी और कोण के आधार पर कितना ध्यान देना चाहिए। अंत में, जानकारी को ग्राफ में एकत्रित किया जाता है:
$$f'_m(i) = \sum_{j \in Neighbour(i)} \omega_m(P(i, j)) x_j e_{ij}$$
प्रायोगिक क्षेत्र और "पीड़ित"
लेखकों ने केवल यह दावा नहीं किया कि उनका गणित काम करता है; उन्होंने इसे साबित करने के लिए एक क्रूर प्रायोगिक परीक्षण का निर्माण किया। उन्होंने दो अलग-अलग, अत्यधिक जटिल डेटासेट पर अपने मॉडल का परीक्षण किया: TT (भ्रूण मस्तिष्क) और 3VT (भ्रूण हृदय)। उन्होंने मॉडल का मूल्यांकन अत्यधिक भुखमरी की स्थिति में किया: 1, 2, 3, 5, और 10-शॉट सेटिंग्स।
"पीड़ित" 9 अत्याधुनिक फ्यू-शॉट ऑब्जेक्ट डिटेक्शन बेसलाइन थे, जिनमें TFA, FSCE, DeFRCN, और TKR जैसे भारी वजन शामिल थे।
उनकी सफलता का निश्चित, निर्विवाद प्रमाण केवल समग्र लीडरबोर्ड नहीं था—यह एब्लेशन अध्ययन (तालिका 3) था। मॉडल को उसके आधार घटकों तक छीनकर, उन्होंने साबित कर दिया कि केवल CCM या केवल TRR जोड़ने से प्रदर्शन में सुधार हुआ, लेकिन उन्हें संयोजित करने से एक सहक्रियात्मक विस्फोट हुआ। उदाहरण के लिए, 1-शॉट TT डेटासेट में, बेसलाइन ने 67.4% स्कोर किया। CCM जोड़ने से यह 68.8% हो गया, TRR जोड़ने से यह 68.5% हो गया, लेकिन उन्हें संयोजित करने से स्कोर 71.3% तक पहुंच गया।
ईमानदारी से कहूं तो, मुझे पूरी तरह से यकीन नहीं है कि TRR मॉड्यूल ने हृदय डेटासेट (3VT) पर CCM मॉड्यूल की तुलना में मस्तिष्क डेटासेट (TT) की तुलना में इतना भारी प्रदर्शन क्यों किया, लेकिन अगर मुझे अनुमान लगाना पड़े, तो यह संभवतः इस तथ्य से उपजा है कि भ्रूण हृदय के तीन-वाहिनी श्वासनली दृश्य में मस्तिष्क संरचनाओं की तुलना में बहुत अधिक कठोर, अनुमानित स्थानिक ज्यामिति है, जिससे ध्रुवीय-निर्देशांक ग्राफ तर्क वहां असाधारण रूप से घातक हो जाता है।
भविष्य के विकास के लिए चर्चा विषय
इस पत्र में रखी गई शानदार नींव के आधार पर, भविष्य की महत्वपूर्ण सोच और विकास के लिए यहां कई रास्ते दिए गए हैं:
- रोग संबंधी विसंगतियों का विरोधाभास: TRR की मुख्य शक्ति अपरिवर्तनीय मानव शरीर रचना पर इसकी निर्भरता है। लेकिन जब शरीर रचना मौलिक रूप से गलत हो तो क्या होता है? यदि किसी भ्रूण में गंभीर जन्मजात दोष (जैसे, स्थानांतरित वाहिकाएं) हैं, तो क्या TRR का कठोर गॉसियन कर्नेल पता लगाने को दबा देगा क्योंकि संबंध "सामान्य" टोपोलॉजिकल पूर्व को violate करते हैं? हमें चर्चा करनी चाहिए कि ग्राफ तर्क को विसंगतियों का पता लगाने के लिए पर्याप्त लचीला कैसे बनाया जाए, जबकि इसके शोर-फ़िल्टरिंग मजबूती को खोए बिना।
- क्रॉस-मोडेलिटी टोपोलॉजिकल प्रोजेक्शन: क्या हम उच्च-रिज़ॉल्यूशन एमआरआई या सीटी स्कैन से प्राचीन, पूर्ण टोपोलॉजिकल ग्राफ निकाल सकते हैं और उन्हें गणितीय रूप से इस अल्ट्रासाउंड मॉडल के अव्यक्त स्थान में प्रोजेक्ट कर सकते हैं? यदि स्थानिक गणित वास्तव में अपरिवर्तनीय है, तो हमें शोर वाले अल्ट्रासाउंड से ग्राफ सीखने की आवश्यकता नहीं होनी चाहिए; हम एक बेहतर इमेजिंग मोडेलिटी से "ग्राउंड ट्रुथ" ग्राफ आयात कर सकते हैं।
- 2D स्पेस में 1D अनुक्रम मॉडल की सीमाएं: मैम्बा स्वाभाविक रूप से एक 1D अनुक्रम मॉडल है। लेखकों ने CCM में फीड करने के लिए 2D अल्ट्रासाउंड सुविधाओं को समतल किया। जबकि कम्प्यूटेशनल रूप से कुशल, समतल करना मूल 2D स्थानिक निरंतरता को नष्ट कर देता है। एक आकर्षक भविष्य की दिशा एक मूल 2D निरंतर अवस्था-स्थान मॉडल तैयार करना होगा जिसके लिए अनुक्रम समतलीकरण की आवश्यकता नहीं होती है, संभावित रूप से शारीरिक सीमाओं को और भी अधिक सटीकता के साथ कैप्चर किया जा सकता है।
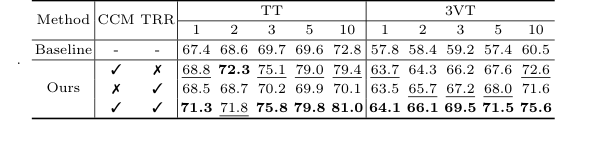 Table 3. shows the ablation studies of the CCM and TRR modules on data split 1 of the TT and 3VT datasets. As shown in Table 3, TRR outperformed CCM on the 3VT dataset, while CCM outperformed TRR on the TT dataset. Both components improve our model’s performance, validating the effectiveness of TRR-CCM. Specifically, the addition of CCM only achieves a significant im- provement over the baseline method by 1.4% to 9.4% on TT dataset, and 5.9% to 12.1% on 3VT dataset, respectively. Only by adding the TRR, it outperforms the baseline on most of the shots of TT, while the 3VT dataset sees an improve- ment of over 5.7% in all cases. When both CCM and TRR are included, our method boosts by 3.9%, 3.2%, 6.1%, 10.2%, and 8.2% in the cases of 1, 2, 3, 5, and 10 shot on data split 1 of TT, respectively
Table 3. shows the ablation studies of the CCM and TRR modules on data split 1 of the TT and 3VT datasets. As shown in Table 3, TRR outperformed CCM on the 3VT dataset, while CCM outperformed TRR on the TT dataset. Both components improve our model’s performance, validating the effectiveness of TRR-CCM. Specifically, the addition of CCM only achieves a significant im- provement over the baseline method by 1.4% to 9.4% on TT dataset, and 5.9% to 12.1% on 3VT dataset, respectively. Only by adding the TRR, it outperforms the baseline on most of the shots of TT, while the 3VT dataset sees an improve- ment of over 5.7% in all cases. When both CCM and TRR are included, our method boosts by 3.9%, 3.2%, 6.1%, 10.2%, and 8.2% in the cases of 1, 2, 3, 5, and 10 shot on data split 1 of TT, respectively
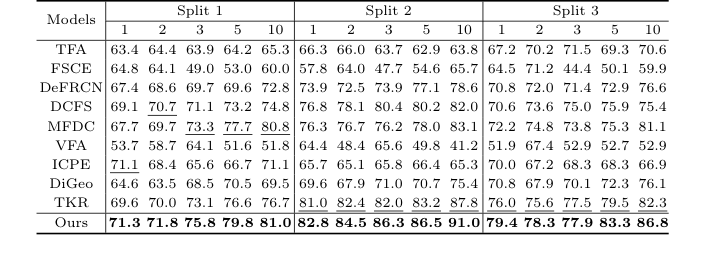 Table 1. Detection results for the TT dataset under the three settings. Bold and underlined numbers denote the 1st and 2nd scores
Table 1. Detection results for the TT dataset under the three settings. Bold and underlined numbers denote the 1st and 2nd scores
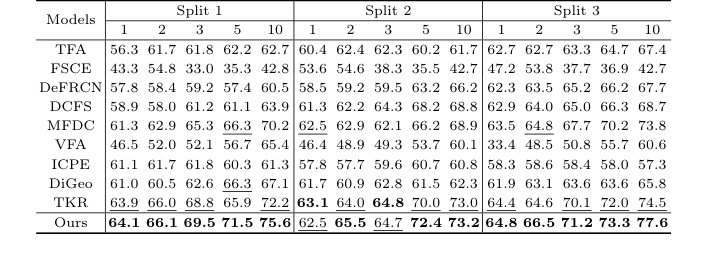 Table 2. Detection results for the 3VT dataset under the three settings. Bold and underlined numbers denote the 1st and 2nd scores
Table 2. Detection results for the 3VT dataset under the three settings. Bold and underlined numbers denote the 1st and 2nd scores
अन्य क्षेत्रों के साथ आइसोमोर्फिज्म
एक हाइब्रिड तंत्र जो रैखिक स्टेट-स्पेस अनुक्रम मॉडलिंग को ज्यामितीय-भारित ग्राफ नेटवर्क के साथ जोड़ता है, ताकि उनके अपरिवर्तनीय स्थानिक संबंधों के आधार पर अत्यधिक शोर वाले वातावरण के भीतर विरल लक्ष्यों की पहचान और स्थान का अनुमान लगाया जा सके।
खगोल भौतिकी और एक्सोप्लैनेट का पता लगाना
एक्सोप्लैनेट या विशिष्ट तारकीय संरचनाओं की खोज में, खगोलविद एक विशाल सिग्नल-टू-नॉइज़ समस्या का सामना करते हैं, जो मेडिकल अल्ट्रासाउंड छवियों में पाए जाने वाले स्पेकल नॉइज़ और कलाकृतियों के समान है। इस संदर्भ में "एनाटॉमी" अपरिवर्तनीय कक्षीय यांत्रिकी या एक तारा प्रणाली के निश्चित टोपोलॉजिकल संबंध हैं। इस पत्र के मुख्य तर्क को लागू करके, एक खगोल भौतिकी मॉडल ब्रह्मांडीय पृष्ठभूमि विकिरण को समय के साथ फ़िल्टर करने के लिए स्टेट-स्पेस तंत्र का उपयोग कर सकता है, जबकि ग्राफ कन्वेन्शनल नेटवर्क खगोलीय पिंडों के बीच अपरिवर्तनीय स्थानिक दूरियों और कोणों को मैप करता है। यह एक ही समस्या का एक आदर्श दर्पण प्रतिबिंब है: अराजक, विषम हस्तक्षेप के घूंघट के पीछे छिपे हुए ज्ञात, संरचित नक्षत्रों को खोजना।
वित्तीय बाज़ार माइक्रोस्ट्रक्चर
उच्च-आवृत्ति ट्रेडिंग में, संपत्तियों के समन्वित संस्थागत संचय का पता लगाना शोर के समुद्र में एक छिपी हुई संरचना खोजने जैसा है। यहाँ "स्थानिक टोपोलॉजी" विभिन्न परिसंपत्ति वर्गों के बीच अपरिवर्तनीय सहसंबंध नेटवर्क में अनुवादित होती है (उदाहरण के लिए, ट्रेजरी यील्ड, अमेरिकी डॉलर और सोने के बीच ऐतिहासिक रूप से निश्चित संबंध)। "अल्ट्रासाउंड नॉइज़" अनियमित, उच्च-आयतन खुदरा ट्रेडिंग है जो वास्तविक बाजार दिशा को अस्पष्ट करती है। इस पत्र के सटीक ढांचे का उपयोग करके, एक वित्तीय मॉडल मैक्रो-आर्थिक बदलाव की "एनाटॉमी" को मैप कर सकता है, ग्राफ नेटवर्क का उपयोग करके परिसंपत्ति मूल्य आंदोलनों में संरचनात्मक स्थिरता को लागू कर सकता है, भले ही ऐतिहासिक डेटा (दुर्लभ बाजार दुर्घटनाओं के लेबल वाले उदाहरण) अत्यंत दुर्लभ हो।
क्या होगा यदि भूभौतिकीविद् जो टेक्टोनिक गतिविधि का अध्ययन कर रहा है, वह कल इस पत्र के सटीक टोपोलॉजिकल तर्क समीकरण को "चोरी" कर ले? विशेष रूप से, यदि वे गॉसियन-भारित ध्रुवीय निर्देशांक ग्राफ का पुन: उपयोग करते हैं:
$$ \omega_m(P(i, j)) = \exp(-\frac{1}{2}(P(i, j) - u_m)^T \Sigma_m^{-1} (P(i, j) - u_m)) $$
भ्रूण हृदय के कक्षों को मैप करने के बजाय, नोड्स $i$ और $j$ भूकंपीय सेंसर स्टेशनों का प्रतिनिधित्व करेंगे, और "एनाटॉमिकल संरचना" पृथ्वी की पपड़ी के भीतर छिपी हुई फॉल्ट लाइनें होंगी। इस फ्यू-शॉट टोपोलॉजिकल तर्क का लाभ उठाकर, वे केवल कुछ विरल भूकंपीय रीडिंग का उपयोग करके अनमैप्ड भूमिगत संरचनाओं को सटीक रूप से मैप कर सकते हैं या दुर्लभ भूकंपीय झुंडों की भविष्यवाणी कर सकते हैं, दशकों के बड़े, एनोटेट किए गए ऐतिहासिक भूकंपीय डेटासेट की आवश्यकता को पूरी तरह से दरकिनार कर सकते हैं।