基于增强人体解剖知识的超声图像解剖结构少样本检测
Deep learning-based models have significantly advanced clinical ultrasound tasks by detecting anatomical structures within vast ultrasound image datasets.
背景与学术传承
医学影像分析领域在深度学习的推动下取得了巨大的飞跃。然而,本文所解决的具体问题源于一个严峻的现实瓶颈:数据饥渴。传统上,训练人工智能以在超声图像中检测胎儿器官需要海量数据集。这些数据集必须由高度专业化的医生进行细致标注,这一过程极其耗时且成本高昂(专家劳动力成本通常远超每小时 150 美元)。此外,严格的伦理和隐私法规使得大规模患者数据的收集和共享几乎不可能。
为了绕过这种数据稀缺性,学术界转向了“少样本学习”(few-shot learning)——一种旨在仅使用少量样本来训练模型的范式。尽管少样本学习在对整个图像进行分类或勾勒单个器官(语义分割)等基本任务上取得了巨大成功,但它在历史上却忽略了超声图像中更复杂的“多目标检测”任务。作者们认识到这一差距,并启动了这项研究,旨在将少样本检测应用于复杂的多器官超声环境。
作者们之所以被迫撰写此文,是因为先前的方法遇到了两个根本性的局限性:
1. 对域偏移的脆弱性: 超声图像以其“混乱”而闻名。它们会因机器品牌、操作者的探头角度以及固有的散斑噪声而产生严重的差异。先前少样本模型未能跨越这些变化进行泛化,因为它们缺乏对人体解剖结构的统一理解来锚定其预测。
2. 现代序列模型中的架构盲点: 近期,一种名为“Mamba”(基于状态空间模型)的高效人工智能架构因处理长序列数据而广受欢迎。然而,先前基于 Mamba 的方法仅关注空间相关性,完全忽略了“通道信息”(即深层、分层的特征表示)。这种通道混合的缺失导致了大型网络中的稳定性问题,并严重限制了模型理解解剖结构全局上下文的能力。
为了使本文高度专业化的概念更直观,以下是四个关键领域术语的日常类比翻译:
- 少样本学习 (Few-Shot Learning): 想象一下教一个孩子什么是“鸭嘴兽”。你不需要给他看 10,000 张照片;只需三四张好的照片就足以让他识别出野外的鸭嘴兽。少样本学习试图赋予人工智能这种与人类相似的能力,从极少的例子中学习,而不是依赖于海量数据集。
- 域偏移 (Domain Shift): 想象一下在廉价、充满静电的收音机上听你最喜欢的歌曲,与在高档音乐会音响系统上听同一首歌。底层的歌曲完全相同,但音频质量和失真差异巨大。在超声领域,不同的机器和医生会造成“域偏移”,很容易混淆标准的人工智能模型。
- 拓扑关系推理 (Topological Relationship Reasoning, TRR): 想象一下在一个光线昏暗的房间里拼拼图。即使你看不清碎片,你也知道从逻辑上讲,“烟囱”碎片必须连接到“屋顶”碎片。TRR 为人工智能提供了一个类似的逻辑地图:它利用人体器官固定的、自然的布局(例如,心脏总是靠近肺部)来寻找结构,即使超声图像模糊不清。
- 选择性状态空间模型 (Selective State Space Models, SSMs): 想象一位忙碌的律师阅读一份 500 页的法律文件。他们不会记住每一个字,而是有选择地只突出关键条款,忽略无用的填充文本。SSMs 对数据也是如此,动态过滤掉不相关的噪声,从而以极快的速度和效率处理信息。
以下是用于构建作者解决方案的关键数学符号的分解:
| 符号 | 类型 | 描述 |
|---|---|---|
| $x(t), y(t)$ | 变量 | 由状态空间模型处理的一维输入和输出序列。 |
| $h(t)$ | 变量 | 将输入序列映射到输出序列的隐藏状态。 |
| $A, B$ | 参数 | 控制线性时不变系统的连续时间参数。 |
| $\overline{A}, \overline{B}$ | 参数 | 从其连续对应物转换而来的离散时间参数,用于计算。 |
| $\Delta$ | 参数 | 用于离散化连续参数的时间尺度参数。 |
| $X$ | 变量 | 代表图像特征的输入张量,定义为 $X \in \mathbb{R}^{B \times C \times H \times W}$。 |
| $B, C, H, W$ | 参数 | 特征图的维度:批次大小、通道数、高度和宽度。 |
| $G = \langle \mathcal{N}, \mathcal{E} \rangle$ | 变量 | 一个无向的区域到区域图,其中节点 $\mathcal{N}$ 是区域提议,边 $\mathcal{E}$ 是关系。 |
| $z_i$ | 变量 | 特定节点 $i$ 的视觉特征的潜在空间表示。 |
| $\omega_m(P(i, j))$ | 变量 | 一个高斯核函数,编码两个解剖区域之间的空间距离和角度。 |
问题定义与约束
想象一下在一个黑暗、有雾的房间里寻找一串特定的钥匙。再想象一下,在你的一生中,你只被展示过这串钥匙的样子三到五次。这本质上就是医学超声成像中少样本目标检测的挑战。
为了理解本文所解决问题的严峻性,我们首先需要明确我们从何处出发、目标何在,以及这两点之间的旅程为何如此艰难。
起点与目标状态
输入(当前状态): 系统接收一张原始的、高度嘈杂的超声图像——特别是胎儿超声扫描(如大脑或心脏)。同时,模型会收到极少量需要学习的新解剖结构的标注示例(少至 1、3、5 或 10 个“样本”)。数学上,输入是一个高维视觉特征张量 $X \in \mathbb{R}^{B \times C \times H \times W}$,其中 $B$ 是批次大小,$C$ 是通道数,$H$ 和 $W$ 是空间维度。
输出(目标状态): 模型必须在该模糊图像中输出多个解剖结构精确的边界框和分类得分。这表示为一个区域预测矩阵 $S \in \mathbb{R}^{N \times C}$,其中 $N$ 是区域提议的数量,$C$ 是类别数量。
数学鸿沟: 缺失的环节是一个鲁棒的映射函数,它可以在不过度拟合微小训练数据集的情况下,将 $X$ 映射到 $S$。标准的深度学习模型通过依赖海量数据集驱动的数百万次参数更新来映射这个空间。在少样本场景下,数学空间严重受限。模型根本没有足够的数据点来学习高维空间中不同解剖类别之间复杂、非线性的边界。作者需要利用先验知识人为地约束假设空间,以便模型即使在数据量很少的情况下也能正确猜测。
痛苦的困境
在人工智能领域,解决一个问题几乎总是会带来另一个问题。为了检测模糊超声图像中的目标,模型迫切需要“全局上下文”——它需要查看整个图像来理解自身所处的位置,而不是仅仅查看一小块像素。
历史上,研究人员在这里面临着一个残酷的权衡:
1. Transformer 路线: 你可以使用自注意力机制(如 Transformer)来捕捉整个图像的长距离依赖关系。然而,计算复杂度会随着图像尺寸的平方而增长。在高分辨率医学成像中,这需要指数级更多的内存和计算资源,使得标准临床硬件无法承受。
2. Mamba 路线: 近期,研究人员引入了结构化状态空间模型(SSM),特别是“Mamba”,它将序列建模的复杂度降低到线性尺度。它快速且高效。然而,困境再次出现:之前的 Mamba 方法严重依赖空间相关性,但完全忽略了通道混合。在神经网络中,不同的通道代表不同的学习特征(如边缘、纹理或特定形状)。通过忽略这些通道如何交互,Mamba 架构在更大的网络中会出现严重的稳定性问题,并丧失其建模丰富、全局语义信息的能力。
你陷入了困境:选择 Transformer 会耗尽内存,选择标准 Mamba 则会失去区分微小的心脏血管与背景噪声所必需的深度特征交互。
严峻的壁垒
除了架构上的困境,作者还遇到了几个严峻的现实壁垒,使得这个问题异常难以解决:
1. 数据的极端稀疏性(伦理/劳动力壁垒)
深度学习依赖于大数据,但医疗数据受到严格的伦理和隐私法规的限制。即使你能获得数据,标注它也需要专业的医学专家。你无法通过众包的方式进行超声标注。这为数据集的大小设置了一个硬性上限,迫使模型几乎从零开始学习。
2. 超声的物理特性(领域迁移壁垒)
超声本质上是混乱的。图像会受到固有的物理噪声伪影的影响,特别是低对比度和散斑噪声。此外,图像的外观会因机器的频率/增益设置以及特定医生探头的角度和压力而完全不同。这会产生巨大的“领域迁移”。在一个医院用少量图像训练的模型,在另一个医院的图像上会完全失效,因为机器和操作员的物理特性从根本上改变了底层的像素分布。
3. 标准 AI 的拓扑盲目性
标准目标检测器将每个对象视为一个独立实体。如果它寻找“气管”和“血管”,它会独立地搜索它们。但人体解剖学并非如此运作。人体中的空间-拓扑关系是不变的——心脏总是以特定的几何布局连接到特定的血管。标准模型对这种生物学约束“视而不见”。如果模型无法在数学上编码“对象 A 必须与对象 B 保持特定的角度和距离”的规则,它很容易被超声的散斑噪声所欺骗,在不可能的位置预测解剖结构。
为何采用此方法
超声图像的分析历来十分困难。它们饱受内在噪声伪影的困扰,例如斑点噪声、低对比度,以及由不同操作员或机器设置引起的巨大域偏移。当将这种严苛的环境与“少样本”学习相结合时——即模型仅获得少量标记示例进行学习——传统的深度学习方法就会彻底失效。
作者们达到了一个关键的认识:标准的state-of-the-art (SOTA) 模型试图纯粹从像素数据中学习一切。但在超声图像中,像素是不可靠的。然而,人体解剖结构是不变的。器官之间的空间关系并不会因为超声探头以奇怪的角度握持而改变。这促成了 TRR-CCM 的创建,该模型将视觉特征提取与硬编码的解剖学规则相结合。
那么,为什么这种特定的数学方法是唯一可行的解决方案呢?作者们认识到,尽管最近的序列建模架构(如 Mamba)在从长序列中提取核心语义方面表现出色,但标准的 Mamba 存在一个致命缺陷:它几乎完全关注空间相关性,而忽略了通道信息。在复杂医学成像中,这种通道混合的缺失会导致大型网络出现稳定性问题,并严重限制模型把握全局图景的能力。为了解决这个问题,他们设计了 Circular Channel Mamba (CCM)。通过将选择性结构化状态空间模型 (SSM) 机制扩展到通道维度,CCM 捕获了通道间的特征依赖性。在数学上,隐藏状态的转换定义为:
$$h_t = \overline{A}h_{t-1} + \overline{B}x_t$$
这种特定的公式允许模型动态地过滤输入信息,有效地将序列建模的复杂度从标准的 $O(N^2)$(通常是标准 Transformer 的复杂度)降低到高效的 $O(N)$。
该方法在比较优势方面体现在其双引擎结构。除了在与 9 种基线方法相比时获得更高的平均精度均值 (mAP) 分数外,它在质量上也更优,因为它不仅仅是“看”图像,而是对图像进行“推理”。为了处理超声图像的高维噪声,该模型采用了拓扑关系推理 (TRR)。它构建了一个无向的区域到区域图 $G = \langle \mathcal{N}, \mathcal{E} \rangle$,其中节点代表区域提议,边代表它们之间的关系。通过将空间坐标输入高斯核,模型计算关系权重:
$$\omega_m(P(i, j)) = \exp(-\frac{1}{2}(P(i, j) - u_m)^T \Sigma_m^{-1} (P(i, j) - u_m))$$
这意味着,即使胎儿心脏的视觉特征被斑点噪声遮挡,图卷积网络 (GCN) 也可以通过依赖于周围结构的清晰存在来推断其位置和类别。这是一个结构性优势,使其在处理每个边界框都孤立对待的先前黄金标准方法上具有压倒性优势。
这种方法完美契合了少样本医学检测的严苛约束。标记海量医学数据集需要专业专家,其成本很容易超过每小时 150 美元,这使得大型数据集在伦理和财务上都受到限制。“联姻”在于问题的样本稀缺性与解决方案利用不变的先验知识。由于模型已经通过 TRR 模块“知道”了人体解剖结构的空间拓扑,因此它只需要极少的样本即可学会检测新类别。
坦白说,我并不完全确定作者们为什么没有明确讨论拒绝像 GAN 或 Diffusion 模型这类流行的生成方法用于此特定任务,因为论文中并未提及它们。然而,他们确实明确解释了拒绝先前基于 Mamba 的方法和标准 CNN 的原因:那些旧的架构要么未能正确混合通道信息,要么缺乏处理复杂全局上下文所需的线性时间选择性扫描机制,而又不至于导致计算成本爆炸。通过结合 CCM 的线性效率和 TRR 的解剖学约束,他们创建了一个独特而强大的系统,专门针对超声成像这一严苛的领域进行了定制。
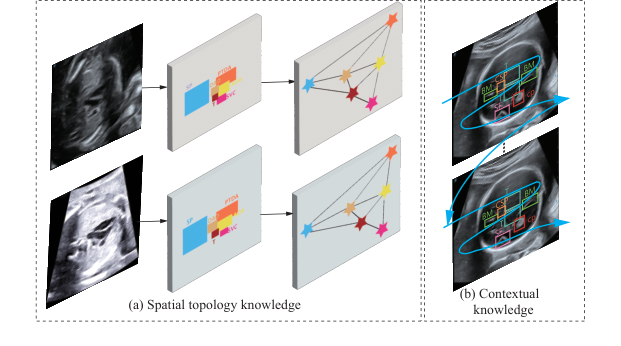 Figure 1. Consistency of two fixed knowledge from human anatomy. (a) Spatial topology knowledge. (b) Contextual knowledge
Figure 1. Consistency of two fixed knowledge from human anatomy. (a) Spatial topology knowledge. (b) Contextual knowledge
数学与逻辑机制
为了理解这篇论文的卓越之处,我们首先需要理解医学超声成像的基本困境。想象一下,在一个不断变化、被厚厚云层笼罩、并通过肮脏的望远镜观察的夜空中寻找特定的星座。超声图像以其固有的噪声大、模糊不清以及高度依赖探头操作者而闻名。
通常情况下,深度学习通过分析数十万个带标签的样本来解决这类问题。但在医学领域,我们根本没有如此大量的标注数据——这就是“少样本学习”问题。那么,我们如何仅凭少量样本教会人工智能识别胎儿器官呢?
本文的作者们认识到了一个深刻的道理:人体解剖结构是一个固定的地图。 即使图像非常模糊,心脏相对于脊柱也始终处于特定的空间关系中。通过强制神经网络遵循人体拓扑结构和上下文记忆的不变性定律,他们弥补了数据量的不足。为了实现这一点,他们构建了一个双核数学引擎:用于上下文记忆的Circular Channel Mamba (CCM),以及用于空间映射的Topological Relationship Reasoning (TRR)。
以下是该系统实际工作原理的剖析。
核心方程
本文的核心由两个相互关联的数学引擎驱动。
引擎 1:上下文记忆(结构化状态空间模型)
该方程允许模型扫描图像并“记住”它刚刚看到的内容,从而建立对组织的上下文理解。
$$h_t = \overline{A}h_{t-1} + \overline{B}x_t$$
$$y_t = Ch_t$$
引擎 2:解剖拓扑(图推理)
这是本文的真正突破。一旦模型找到候选器官,它就会使用高斯加权图卷积来检查其空间布局是否符合人体解剖结构。
$$f'_m(i) = \sum_{j \in Neighbour(i)} \omega_m(P(i, j)) x_j e_{ij}$$
$$\omega_m(P(i, j)) = \exp\left(-\frac{1}{2}(P(i, j) - u_m)^T \Sigma_m^{-1} (P(i, j) - u_m)\right)$$
解析方程
让我们来剖析这些方程中的每一个齿轮和弹簧。
来自引擎 1(Mamba 上下文):
* $x_t$:第 $t$ 步的输入。在物理上,这是正在处理的超声图像的特定块。
* $h_t, h_{t-1}$:隐藏状态。这是模型的“工作记忆”。$h_{t-1}$ 存储了在当前图像块之前看到的图像块的上下文。
* $\overline{A}$:离散化的状态转移矩阵。可以将其视为一个“遗忘/保留门”。它决定了前一个解剖上下文应保留多少。
* $\overline{B}$:离散化的输入矩阵。它充当“注意力过滤器”,决定当前图像块 $x_t$ 应在多大程度上更新记忆。
* $y_t$:特定图像块的输出特征表示,其中融入了全局上下文。
* $C$:输出投影矩阵,将隐藏记忆转换回可用的视觉特征。
* 为何使用加法($+$)而非乘法? 状态更新使用加法来平滑地累积信息。乘法会导致记忆呈指数级增长到无穷大或衰减到零。
来自引擎 2(拓扑图):
* $f'_m(i)$:候选器官(节点 $i$)的、经过拓扑感知后更新的特征向量。
* $\sum$:求和算子。作者在此处使用积分/求和而非最大池化或乘法,是因为他们希望累积来自所有相邻器官的支持证据。如果心脏、肺和脊柱在位置上相互印证,它们的组合信息就会被加在一起以增强置信度。
* $Neighbour(i)$:围绕节点 $i$ 的最相关的 K 个候选器官。
* $x_j$:邻近器官 $j$ 的语义特征向量。
* $e_{ij}$:稀疏邻接矩阵的边权重。它表示器官 $i$ 和器官 $j$ 之间学习到的原始关系强度。
* $\omega_m(P(i, j))$:高斯核权重。这是系统的“橡皮筋”。如果器官处于正确的解剖位置,它会输出一个高值(接近 1);如果不在,则输出一个低值(接近 0)。
* $P(i, j)$:一个极坐标函数,返回 $(d, \theta)$——图像中器官 $i$ 和器官 $j$ 之间的实际测量距离和角度。
* $\exp(...)$:指数函数。它用于创建平滑的钟形曲线。它确保了即使器官由于超声探头角度而略有偏移,空间权重也会平滑下降,而不是突然消失。
* $-\frac{1}{2}$:高斯分布的标准数学缩放因子,使得学习过程中的微积分(梯度)清晰且稳定。
* $u_m$:一个可学习的 $2 \times 1$ 均值向量。在物理上,这是 AI 的“理想蓝图”。它是 AI 根据人体解剖结构预期看到的两个器官之间的精确距离和角度。
* $T$:转置运算符,用于对齐向量以进行矩阵乘法,从而使输出解析为单个标量距离。
* $\Sigma_m^{-1}$:一个可学习的 $2 \times 2$ 协方差矩阵的逆。在物理上,这是“活动空间”或容差。一些器官根据胎儿的位置(高方差)会发生大量移动,而另一些则固定不动(低方差)。该矩阵会相应地调整惩罚。
逐步流程:装配线
让我们追踪一个抽象数据点——一个可能是胎儿心脏的模糊团块——通过这个架构。
- 原始提取: 超声图像进入骨干网络。我们的模糊团块被转换为原始数学张量(数字网格)。
- 上下文扫描(CCM): 张量被切片成序列并输入到 Circular Channel Mamba。$\overline{A}$ 和 $\overline{B}$ 矩阵在图像上扫描。当数学引擎处理团块时,它会添加上下文:“我刚刚经过了一个类似脊柱的纹理,所以这个团块很可能位于胸腔内。”该团块变为 $y_t$。
- 图构建(TRR): 该团块现在是一个“区域提议”(节点 $i$)。系统会查看附近的团块(节点 $j$)。它计算 $P(i, j)$,发现节点 $j$ 距离 5 厘米,角度为 45 度。
- 解剖审问: 这个 $(d, \theta)$ 坐标被输入到高斯核 $\omega_m$ 中。核将其与蓝图 $u_m$ 进行比较。由于在这个特定视图中,心脏和脊柱应该处于 45 度角,因此 $(P(i, j) - u_m)$ 项接近于零。
- 证据聚合: 由于距离接近零,$\exp(0)$ 的计算结果为 1。脊柱的语义数据 $x_j$ 被乘以 1 并加到($\sum$)我们的团块 $i$ 上。
- 最终输出: 我们的模糊团块不再仅仅是一个团块。它现在在数学上与周围解剖邻居的绝对确定性融合在一起。模型自信地将其检测为胎儿心脏。
优化动力学
这个机械巨兽是如何仅凭几张图像就能学会的?
在标准的少样本学习中,损失景观是混乱的。由于数据量极少,模型很容易过拟合,找到虚假的模式(例如,记住特定超声仪器的静态噪声)。梯度通常会剧烈波动。
然而,TRR 模块对损失景观起到了巨大的引力锚定作用。在训练过程中,模型使用标准的 SGD(随机梯度下降)优化器。魔术发生在流回 $u_m$ 和 $\Sigma_m$ 的梯度中。
最初,$u_m$(预期的器官位置)是随机化的。模型可能会猜测心脏位于体外,从而导致巨大的分类错误。损失函数会发送一个陡峭的梯度,强制更新 $u_m$ 以反映在少量标记样本中找到的真实空间坐标。
由于人体解剖结构高度一致,$u_m$ 会非常快速地收敛。一旦 $u_m$ 被锁定,$\Sigma_m$(协方差)矩阵就会学习胎儿组织的自然弹性。这从根本上重塑了优化动力学:梯度被引导去学习心脏相对于其他结构应该在哪里,而不是强迫神经网络从数百万像素中从头开始学习心脏是什么样的。这种拓扑约束平滑了局部最小值,使得模型即使只见过 3 或 5 个样本,也能在不同的超声仪和患者之间实现出色的泛化能力。
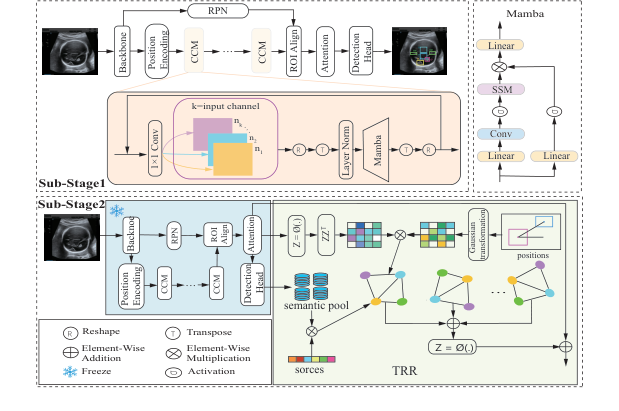 Figure 2. The overall pipeline of the proposed TRR-CCM framework
Figure 2. The overall pipeline of the proposed TRR-CCM framework
结果、局限性与结论
想象一下,在一幅充满噪点的黑白电视静态图像中寻找一个微小而特定的结构。再想象一下,一个人的生命就取决于你是否能准确地找到它。这正是超声图像分析的日常写照。
要理解这篇论文的精妙之处,我们首先需要确立一些关于现代人工智能的基本事实。深度学习模型极其智能,但它们也出了名地“饥渴”于数据。要教会一个AI识别胎儿心脏缺陷,通常需要数千张由医学专家 painstaking 标注的图像。这不仅枯燥乏味,而且成本高昂,有时仅一名专业放射科医生每小时的费用就可能高达150美元。此外,严格的隐私法规常常使得收集海量医疗数据集成为不可能。
这就引出了我们的限制:少样本学习(Few-Shot Learning, FSL)。FSL在AI领域相当于向一位聪明的学生展示三到五个问题示例,并期望他们能在期末考试中取得优异成绩。尽管FSL在通用图像分类领域已取得成功,但将其应用于超声图像的目标检测(在多个目标周围绘制边界框)却是一场噩梦。超声图像会经历严重的域偏移——不同的机器、不同的探头角度以及固有的斑点噪声。
那么,作者的“灵光一闪”的动机是什么呢?他们意识到,尽管超声图像杂乱且不可预测,但人体解剖结构并非如此。空间拓扑(器官相对于彼此的位置)和解剖学上下文是不变的。作者假设,如果他们能将这种不变的人体解剖结构通过数学方式硬编码到神经网络中,模型就不会被噪声所迷惑。
数学解读:TRR-CCM
为了解决这个问题,作者设计了一个名为TRR-CCM(拓扑关系推理与循环通道Mamba)的双引擎架构。让我们详细解析他们如何将生物学转化为数学。
1. 循环通道Mamba (Circular Channel Mamba, CCM)
标准的视觉模型在不要求巨大计算能力的情况下,常常难以把握“全局图景”。作者转向了一个名为Mamba的前沿序列建模框架,该框架基于结构化状态空间模型(Structured State Space Models, SSMs)。一个标准的SSM通过一个隐藏状态 $h(t)$ 将一维序列 $x(t)$ 映射到 $y(t)$:
$$h_t = \overline{A}h_{t-1} + \overline{B}x_t, \quad y_t = C h_t$$
其中 $\overline{A}$ 和 $\overline{B}$ 是离散时间参数。
然而,标准Mamba对于视觉任务存在一个致命缺陷:它忽略了通道信息(特征图的深度)。为了解决这个问题,作者发明了CCM。在将图像输入Mamba之前,他们强制网络使用卷积操作聚合跨通道信息:
$$\overline{X}(c, m, n) = \sum_{i=0}^{K-1} \sum_{j=0}^{K-1} X_{c, m+i, n+j} \cdot W_{c, i, j}$$
这个方程本质上表示:“在观察序列之前,将所有通道的特征融合,以免丢失任何上下文。”然后,他们通过Mamba块编码这种全局上下文:
$$\hat{X} = Mamba(LN(X^T))$$
最后,他们通过残差连接将这个增强的特征加回到原始输入:$X_{out} = CCM(X + \hat{X}')$。
2. 拓扑关系推理 (Topological Relationship Reasoning, TRR)
这是构建解剖学地图的地方。作者使用图卷积网络(Graph Convolutional Network, GCN),其中每个“节点”都是一个潜在的解剖结构。但是,AI如何知道这些结构之间是如何相互关联的呢?
他们使用极坐标计算任意两个区域提议 $(x_i, y_i)$ 和 $(x_j, y_j)$ 之间的精确距离 $d$ 和角度 $\theta$:
$$d = \sqrt{(x_i - x_j)^2 + (y_i - y_j)^2}, \quad \theta = \arctan\left(\frac{y_j - y_i}{x_j - x_i}\right)$$
他们并没有直接将这些原始数字输入网络。他们将这些拓扑数据通过高斯核函数生成关系权重:
$$\omega_m(P(i, j)) = \exp\left(-\frac{1}{2}(P(i, j) - u_m)^T \Sigma_m^{-1} (P(i, j) - u_m)\right)$$
这个精妙的方程充当了一个动态的相关性滤波器。它通过数学方式决定一个器官应该在多大程度上关注另一个器官,这取决于它们预期的解剖距离和角度。最后,信息在图上进行聚合:
$$f'_m(i) = \sum_{j \in Neighbour(i)} \omega_m(P(i, j)) x_j e_{ij}$$
实验竞技场与“牺牲品”
作者并没有仅仅声称他们的数学方法有效,而是设计了一个残酷的实验考验来证明它。他们在两个截然不同、高度复杂的数据集上测试了他们的模型:TT(胎儿大脑)和3VT(胎儿心脏)。他们在极度数据匮乏的条件下进行了评估:1、2、3、5和10-shot设置。
“牺牲品”是9个最先进的少样本目标检测基线,包括TFA、FSCE、DeFRCN和TKR等重量级模型。
他们成功的决定性、不容置疑的证据不仅在于总排行榜,还在于消融研究(表3)。通过将模型剥离到其基本组件,他们证明了仅添加CCM或仅添加TRR就能提高性能,但将它们结合起来却产生了协同爆发。例如,在1-shot TT数据集上,基线得分是67.4%。添加CCM将其提升到68.8%,添加TRR将其提升到68.5%,但结合两者后得分飙升至71.3%。
老实说,我并不完全确定为什么TRR模块在心脏数据集(3VT)上的表现比大脑数据集(TT)上比CCM模块表现得如此出色,但如果非要推测,这很可能源于胎儿心脏的三血管气管视图比大脑结构具有更僵化、更可预测的空间几何形状,这使得极坐标图推理在那里异常致命。
未来演进的讨论话题
基于这篇论文奠定的精妙基础,以下是未来批判性思考和演进的几个方向:
- 病理性异常的悖论: TRR的核心优势在于其对不变人体解剖结构的依赖。但当解剖结构根本错误时会发生什么?如果胎儿患有严重的先天性缺陷(例如,大动脉转位),TRR的僵化高斯核是否会因为实际关系违反了“正常”拓扑先验而抑制检测?我们必须讨论如何使图推理足够灵活,以便在不损失其噪声过滤鲁棒性的情况下检测异常。
- 跨模态拓扑投影: 我们能否从高分辨率MRI或CT扫描中提取出完美无瑕的拓扑图,并将其通过数学方式投影到这个超声模型的潜在空间中?如果空间数学确实是不变的,我们就不需要从嘈杂的超声图像中学习图;我们可以从更优越的成像模态导入“ground truth”图。
- 一维序列模型在二维空间中的局限性: Mamba本质上是一维序列模型。作者将二维超声特征展平以输入CCM。虽然计算效率高,但展平会破坏原生的二维空间连续性。一个引人入胜的未来方向是构建一个原生的二维连续状态空间模型,该模型不需要序列展平,从而可能以更高的精度捕捉解剖边界。
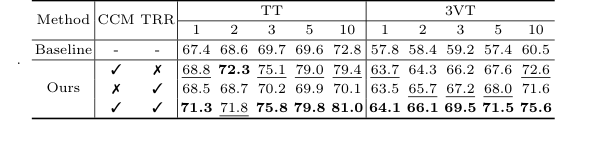 Table 3. shows the ablation studies of the CCM and TRR modules on data split 1 of the TT and 3VT datasets. As shown in Table 3, TRR outperformed CCM on the 3VT dataset, while CCM outperformed TRR on the TT dataset. Both components improve our model’s performance, validating the effectiveness of TRR-CCM. Specifically, the addition of CCM only achieves a significant im- provement over the baseline method by 1.4% to 9.4% on TT dataset, and 5.9% to 12.1% on 3VT dataset, respectively. Only by adding the TRR, it outperforms the baseline on most of the shots of TT, while the 3VT dataset sees an improve- ment of over 5.7% in all cases. When both CCM and TRR are included, our method boosts by 3.9%, 3.2%, 6.1%, 10.2%, and 8.2% in the cases of 1, 2, 3, 5, and 10 shot on data split 1 of TT, respectively
Table 3. shows the ablation studies of the CCM and TRR modules on data split 1 of the TT and 3VT datasets. As shown in Table 3, TRR outperformed CCM on the 3VT dataset, while CCM outperformed TRR on the TT dataset. Both components improve our model’s performance, validating the effectiveness of TRR-CCM. Specifically, the addition of CCM only achieves a significant im- provement over the baseline method by 1.4% to 9.4% on TT dataset, and 5.9% to 12.1% on 3VT dataset, respectively. Only by adding the TRR, it outperforms the baseline on most of the shots of TT, while the 3VT dataset sees an improve- ment of over 5.7% in all cases. When both CCM and TRR are included, our method boosts by 3.9%, 3.2%, 6.1%, 10.2%, and 8.2% in the cases of 1, 2, 3, 5, and 10 shot on data split 1 of TT, respectively
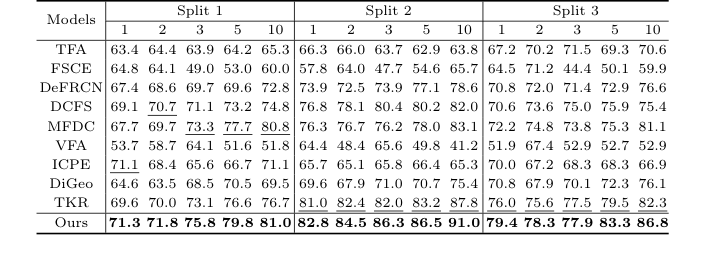 Table 1. Detection results for the TT dataset under the three settings. Bold and underlined numbers denote the 1st and 2nd scores
Table 1. Detection results for the TT dataset under the three settings. Bold and underlined numbers denote the 1st and 2nd scores
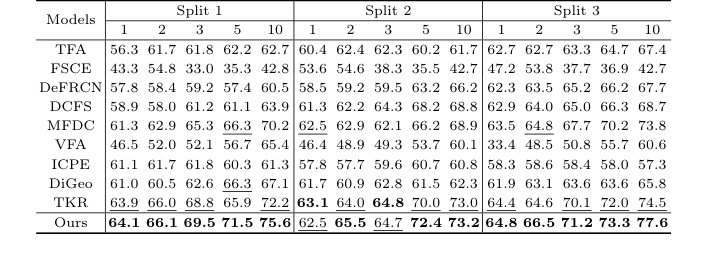 Table 2. Detection results for the 3VT dataset under the three settings. Bold and underlined numbers denote the 1st and 2nd scores
Table 2. Detection results for the 3VT dataset under the three settings. Bold and underlined numbers denote the 1st and 2nd scores
与其他域的同构
一种融合了线性状态空间序列建模与几何加权图网络的混合机制,用于在高度嘈杂的环境中,基于稀疏目标的不变空间关系推断其身份和位置。
天体物理学与系外行星探测
在搜寻系外行星或特定恒星结构时,天文学家面临着巨大的信噪比问题,这与医学超声图像中的斑点噪声和伪影非常相似。在这种情况下,“解剖结构”是不变的轨道力学或恒星系统的固定拓扑关系。通过应用本文的核心逻辑,一个天体物理学模型可以利用状态空间机制随时间过滤宇宙背景辐射,同时图卷积网络则映射天体之间不变的空间距离和角度。这与寻找隐藏在混沌、异质干扰面纱后的已知结构化天体星座的问题,是完美的镜像。
金融市场微观结构
在高频交易中,检测协调一致的机构资产累积,如同在噪声海洋中寻找隐藏结构。这里的“空间拓扑”转化为不同资产类别之间不变的相关性网络(例如,国债收益率、美元和黄金之间历史固定的关系)。“超声噪声”则是掩盖真实市场方向的混乱、大宗散户交易。利用本文的精确框架,一个金融模型可以映射宏观经济变化的“解剖结构”,即使历史数据(罕见市场崩溃的标记样本)极其稀缺,也能利用图网络强制执行资产价格变动中的结构一致性。
如果一位研究构造活动的地质物理学家明天“窃取”了本文的精确拓扑推理方程,会怎么样?具体来说,如果他们重新利用高斯加权极坐标图:
$$ \omega_m(P(i, j)) = \exp(-\frac{1}{2}(P(i, j) - u_m)^T \Sigma_m^{-1} (P(i, j) - u_m)) $$
那么,节点 $i$ 和 $j$ 将代表地震传感器站,而“解剖结构”将是地壳深处的隐藏断层线,而不是映射胎儿心脏的腔室。通过利用这种少样本拓扑推理,他们仅凭少数稀疏的地震读数,就能精确绘制未测绘的地下结构或预测罕见的地震群,完全绕开了对数十年海量标注地震历史数据集的需求。
最终,本文为“万物结构通用图书馆”贡献了一个深刻的蓝图,证明了无论我们是在绘制人心的隐藏腔室、遥远星系之间无形的引力网络,还是我们星球的地下断裂带,不变拓扑推理的数学原理都同样优美地保持不变。