超音波画像における強化された人体解剖知識を利用した解剖学的構造の数ショット検出
Deep learning-based models have significantly advanced clinical ultrasound tasks by detecting anatomical structures within vast ultrasound image datasets.
背景と学術的系譜
深層学習の進歩により、医療画像解析の分野は飛躍的な発展を遂げた。しかし、本論文で取り上げる問題は、現実世界における深刻なボトルネック、すなわち「データ飢餓」に起因する。従来、超音波画像における胎児臓器を検出するAIを訓練するには、膨大なデータセットが必要であった。これらのデータセットは、高度な専門医によって綿密にアノテーションされる必要があり、そのプロセスは極めて煩雑で高価である(専門家の労働時間あたり150ドルをはるかに超える費用がかかることも多い)。さらに、厳格な倫理的およびプライバシー規制により、大規模な患者データの収集と共有はほぼ不可能となっている。
このデータ不足を回避するため、学術分野は「Few-Shot Learning」へと方向転換した。これは、ごくわずかな例のみを使用してモデルを訓練するように設計されたパラダイムである。Few-Shot Learningは、画像全体を分類したり、単一の臓器を輪郭描画したりする(意味セグメンテーション)といった基本的なタスクで大きな成功を収めているが、超音波画像におけるより複雑なマルチオブジェクト検出タスクは、歴史的に無視されてきた。著者らはこのギャップを認識し、複雑なマルチ臓器超音波環境にFew-Shot Detectionをもたらすための研究を開始した。
著者らが本論文を執筆せざるを得なかったのは、従来ののアプローチが2つの根本的な限界に直面していたためである。
1. ドメインシフトへの脆弱性: 超音波画像は、その性質上、非常にノイズが多い。機械のブランド、オペレーターのプローブ角度、および固有のスペックルノイズによって、深刻なばらつきが生じる。従来のFew-Shotモデルは、これらのばらつきに対して統一された人体の解剖学的構造の理解を欠いていたため、汎化に失敗した。
2. 最新シーケンスモデルにおけるアーキテクチャ上の盲点: 最近、Mamba(State Space Modelsに基づく)と呼ばれる非常に効率的なAIアーキテクチャが、長いデータシーケンスの処理に人気を博した。しかし、従来のMambaベースの手法は、空間相関のみに焦点を当て、「チャネル情報」(深層的で階層的な特徴表現)を完全に無視していた。このチャネルミキシングの欠如は、大規模なネットワークにおける安定性の問題を引き起こし、解剖学的構造のグローバルコンテキストを理解するモデルの能力を著しく制限した。
本論文の高度に専門的な概念を直感的に理解するために、ここでは4つの主要なドメイン用語を日常的なアナロジーに置き換えて説明する。
- Few-Shot Learning: 子供に「カモノハシ」とは何かを教えることを想像してほしい。1万枚の写真を見せる必要はない。3〜4枚の良い写真があれば、野生のカモノハシを認識できるようになる。Few-Shot Learningは、大量のデータセットに依存するのではなく、AIにこの人間のような、非常に限られた例から学習する能力を与えることを目指している。
- ドメインシフト: 安価でノイズの多いラジオで好きな曲を聴くのと、ハイエンドのコンサートサウンドシステムで聴くのを想像してほしい。元の曲は全く同じだが、音質や歪みは大きく異なる。超音波では、異なる機械や医師が「ドメインシフト」を作り出し、標準的なAIモデルを容易に混乱させる。
- トポロジカル関係推論 (TRR): 薄暗い部屋でジグソーパズルを組み立てようとしているのを想像してほしい。ピースをはっきりと見ることができなくても、論理的に「煙突」のピースは「屋根」のピースに接続しなければならないと知っている。TRRはAIに同様の論理マップを提供する。それは、超音波画像がぼやけていても、人体の臓器の固定された自然な配置(例:心臓は常に肺の近くにある)を使用して構造を見つける。
- 選択的状態空間モデル (SSM): 忙しい弁護士が500ページの法律文書を読んでいるのを想像してほしい。すべての単語を暗記するのではなく、重要な条項のみを選択的にハイライトし、無駄な詰め込みテキストを無視する。SSMはデータをこのように処理し、関連性のないノイズを動的にフィルタリングして、情報を非常に高速かつ効率的に処理する。
著者らのソリューションを定式化するために使用された主要な数学的記法の内訳を以下に示す。
| 記法 | タイプ | 説明 |
|---|---|---|
| $x(t), y(t)$ | 変数 | State Space Modelによって処理される1次元の入力および出力シーケンス。 |
| $h(t)$ | 変数 | 入力シーケンスを出力シーケンスにマッピングする隠れ状態。 |
| $A, B$ | パラメータ | 線形時不変システムを制御する連続時間パラメータ。 |
| $\overline{A}, \overline{B}$ | パラメータ | 計算のために連続時間パラメータから変換された離散時間パラメータ。 |
| $\Delta$ | パラメータ | 連続時間パラメータを離散化するために使用されるタイムスケールパラメータ。 |
| $X$ | 変数 | 画像特徴を表す入力テンソル。 $X \in \mathbb{R}^{B \times C \times H \times W}$として定義される。 |
| $B, C, H, W$ | パラメータ | 特徴マップの次元:バッチサイズ、チャネル数、高さ、幅。 |
| $G = \langle \mathcal{N}, \mathcal{E} \rangle$ | 変数 | ノード $\mathcal{N}$ が領域提案、エッジ $\mathcal{E}$ が関係である無向領域間グラフ。 |
| $z_i$ | 変数 | 特定のノード $i$ の視覚的特徴の潜在空間表現。 |
| $\omega_m(P(i, j))$ | 変数 | 2つの解剖学的領域間の空間距離と角度をエンコードするガウスカーネル関数。 |
問題定義と制約
暗く霧のかかった部屋で特定の鍵のセットを探そうとしていると想像してほしい。さらに、その鍵が人生で3回か5回しか見たことがないとしたらどうだろうか。これは、医療用超音波画像におけるfew-shotオブジェクト検出の本質的な課題である。
本稿が取り組む問題の規模を理解するために、まず、どこから出発し、どこへ行きたいのか、そしてその2点間の道のりがなぜそれほど危険なのかを正確に定義する必要がある。
出発点と目標状態
入力(現在の状態): システムには、ノイズの多い生の超音波画像、特に胎児の超音波スキャン(脳や心臓など)が供給される。これと同時に、モデルは、学習する必要のある新しい解剖学的構造の非常に限られた注釈付きサンプル(わずか1、3、5、または10「ショット」)を与えられる。数学的には、入力は高次元の視覚特徴テンソル $X \in \mathbb{R}^{B \times C \times H \times W}$ である。ここで、$B$ はバッチサイズ、$C$ はチャネル数、$H$ および $W$ は空間次元である。
出力(目標状態): モデルは、そのぼやけた画像内の複数の解剖学的構造に対して、正確なバウンディングボックスと分類スコアを出力しなければならない。これは、リージョン予測行列 $S \in \mathbb{R}^{N \times C}$ として表される。ここで、$N$ はリージョン提案の数、$C$ はクラスの数である。
数学的なギャップ: 欠けているのは、$X$ から $S$ へ、小さなトレーニングデータセットに過学習することなく橋渡しできる堅牢なマッピング関数である。標準的なディープラーニングモデルは、大規模データセットによって駆動される数百万のパラメータ更新に依存して、この空間をマッピングする。few-shotシナリオでは、数学的空間は著しく制約が少ない。モデルは、高次元空間における異なる解剖学的クラス間の複雑で非線形な境界を学習するには、単にデータポイントが不足している。著者らは、データがあまり見られていない場合でもモデルが正しく推測できるように、事前知識を用いて仮説空間を人工的に制約する必要がある。
苦痛なジレンマ
人工知能において、一つの問題を解決すると、ほぼ必ず別の問題が発生する。ぼやけた超音波画像でオブジェクトを検出するために、モデルは「グローバルコンテキスト」を必死に必要とする。つまり、ピクセルの小さなパッチを見るだけでなく、画像全体を見て自分がどこにいるかを理解する必要がある。
歴史的に、研究者はここで過酷なトレードオフに直面してきた。
1. Transformer経路: 自己注意機構(Transformerなど)を使用して、画像全体の長距離依存関係を捉えることができる。しかし、計算複雑性は画像サイズに対して二次的にスケールする。高解像度の医療画像では、これには指数関数的に多くのメモリと計算が必要となり、標準的な臨床ハードウェアでは実現不可能となる。
2. Mamba経路: 最近、研究者らは構造化状態空間モデル(SSM)、特に「Mamba」を導入し、このシーケンスモデリングの複雑性を線形スケールに削減した。これは高速かつ効率的である。しかし、ジレンマが再び現れる。以前のMambaベースの方法は、空間相関に大きく焦点を当てているが、チャネルミキシングを完全に無視している。ニューラルネットワークでは、異なるチャネルは異なる学習済み特徴(エッジ、テクスチャ、特定の形状など)を表す。これらのチャネルがどのように相互作用するかを無視することで、Mambaアーキテクチャは、より大きなネットワークでの深刻な安定性の問題に悩まされ、リッチなグローバル意味情報をモデル化する能力を失う。
あなたは閉じ込められている。Transformerを選択してメモリ不足になるか、標準的なMambaを選択して、小さな心臓血管を背景ノイズと区別するために必要な深い特徴相互作用を失うかのどちらかである。
過酷な壁
アーキテクチャのジレンマを超えて、著者らは、この特定の問題を解決することを異常に困難にする、いくつかの過酷で現実的な壁にぶつかった。
1. データの極端なスパース性(倫理的・労働的壁)
ディープラーニングはビッグデータで繁栄するが、医療データは厳格な倫理的およびプライバシー規制の背後にある。たとえデータを入手できたとしても、それをラベリングするには専門の医療専門家が必要である。超音波アノテーションをクラウドソーシングすることはできない。これはデータセットサイズにハードシーリングを作成し、モデルはほとんど何も学ばない状態になることを余儀なくされる。
2. 超音波の物理学(ドメインシフト壁)
超音波は本質的に厄介である。画像は、固有の物理的ノイズアーティファクト、特に低コントラストとスペックルノイズに悩まされる。さらに、画像の見た目は、機械の周波数/ゲイン設定や、特定の医師のプローブ角度と圧力によって完全に異なる。これは大規模な「ドメインシフト」を作成する。病院Aの少数の画像でトレーニングされたモデルは、機械とオペレーターの物理学によって基盤となるピクセル分布が根本的に変化しているため、病院Bの画像では完全に失敗する。
3. 標準AIのトポロジカル盲目性
標準的なオブジェクト検出器は、すべてのオブジェクトを独立したエンティティとして扱う。「気管」と「血管」を探す場合、それらを独立して検索する。しかし、人間の解剖学はそのようには機能しない。人体における空間的・トポロジカルな関係は不変である。心臓は常に特定の幾何学的配置で特定の血管に接続されている。標準的なモデルは、この生物学的制約に対して「盲目」である。「オブジェクトAはオブジェクトBから特定の角度と距離になければならない」というルールをモデルが数学的にエンコードできない場合、超音波のスペックルノイズによって容易に騙され、不可能な場所に解剖学的構造を予測してしまうだろう。
このアプローチの理由
超音波画像は解析が困難であることで知られている。それらは、スペックルノイズ、低コントラストといった固有のノイズアーティファクトや、オペレーターや機械設定の違いによる大規模なドメインシフトに悩まされている。このような過酷な環境に、ラベル付けされた少数の例のみを与えて学習させる「few-shot」学習を組み合わせると、従来の深層学習手法は単純に破綻してしまう。
著者らは重要な気づきに至った。標準的なstate-of-the-art (SOTA) モデルは、ピクセルデータからすべてを学習しようとする。しかし、超音波ではピクセルは信頼性が低い。一方で、人間の解剖学的構造は不変である。臓器間の空間的関係は、超音波プローブが奇妙な角度で持たれたからといって変化しない。このことから、視覚的特徴抽出とハードコーディングされた解剖学的ルールを組み合わせたモデル、TRR-CCMが誕生した。
では、なぜこの特定の数学的アプローチが唯一実行可能な解決策だったのだろうか。著者らは、Mambaのような最近のシーケンスモデリングアーキテクチャは、長いシーケンスからコアセマンティクスを抽出するのに優れている一方で、標準的なMambaには致命的な欠陥があることを認識していた。それは、空間的相関にほぼ完全に焦点を当て、チャネル情報を無視してしまうことである。複雑な医用画像処理において、このチャネルミキシングの欠如は、より大きなネットワークで安定性の問題を引き起こし、モデルが全体像を把握する能力を著しく制限する。これを修正するために、Circular Channel Mamba (CCM) を設計した。選択的構造化状態空間モデル (SSM) のメカニズムをチャネル次元に拡張することで、CCMはチャネル間の特徴依存性を捉える。数学的には、隠れ状態遷移は以下のように定義される。
$$h_t = \overline{A}h_{t-1} + \overline{B}x_t$$
この特定の定式化により、モデルは入力情報を動的にフィルタリングすることができ、シーケンスモデリングの複雑さを、標準的なTransformerで典型的な重い $O(N^2)$ から、非常に効率的な $O(N)$ へと効果的に削減する。
この手法の比較優位性は、そのデュアルエンジン構造にある。9つのベースライン手法に対する平均平均精度 (mAP) スコアが高いだけでなく、質的にも優れている。なぜなら、単に画像を「見る」だけでなく、それについて「推論」するからである。超音波の高次元ノイズに対処するため、モデルはトポロジカル関係推論 (TRR) を採用する。これは、ノードが領域提案を表し、エッジがそれらの間の関係を表す無向グラフ $G = \langle \mathcal{N}, \mathcal{E} \rangle$ を構築する。空間座標をガウスカーネルに入力することで、モデルは関係重みを計算する。
$$\omega_m(P(i, j)) = \exp(-\frac{1}{2}(P(i, j) - u_m)^T \Sigma_m^{-1} (P(i, j) - u_m))$$
これは、胎児の心臓の視覚的特徴がスペックルノイズによって不明瞭になっていたとしても、グラフ畳み込みネットワーク (GCN) が周囲の構造の明確な存在に依存することで、その位置とクラスを推測できることを意味する。これは、各バウンディングボックスを個別に扱う以前のゴールドスタンダードに対して圧倒的に優位な構造的利点である。
この手法は、few-shot医療検出の厳しい制約と完全に一致する。大規模な医療データセットのラベリングには専門家が必要であり、1時間あたり150米ドルを超えることも容易であるため、大規模データセットは倫理的にも財政的にも制限的である。ここでの「結婚」は、問題のデータ不足と、ソリューションの不変な事前知識の利用との間にある。モデルはTRRモジュールを通じて人間の解剖学的構造の空間トポロジーを既に「知っている」ため、新しいクラスを検出する方法を学習するために劇的に少ない例で済む。
率直に言って、著者らがなぜこの特定のタスクに対してGANや拡散モデルのような他の一般的な生成アプローチを明確に拒否したのかについては、論文で言及されていないため、完全には確信が持てない。しかし、以前のMambaベースの手法や標準的なCNNを拒否した理由については明確に説明している。それらの古いアーキテクチャは、チャネル情報を適切に混合できないか、計算コストを爆発させることなく複雑なグローバルコンテキストを効率的に処理するために必要な線形時間選択的スキャンメカニズムを欠いているかのいずれかである。CCMの線形効率とTRRの解剖学的制約を組み合わせることで、超音波イメージングの容赦のないドメインに特化して調整された、ユニークに堅牢なシステムを作成した。
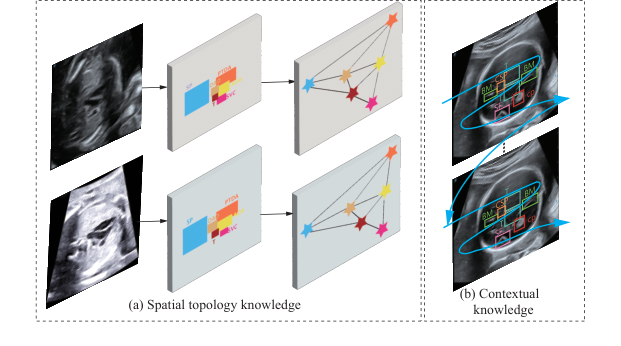 Figure 1. Consistency of two fixed knowledge from human anatomy. (a) Spatial topology knowledge. (b) Contextual knowledge
Figure 1. Consistency of two fixed knowledge from human anatomy. (a) Spatial topology knowledge. (b) Contextual knowledge
数学的・論理的メカニズム
この論文の画期的な点を理解するためには、まず医療用超音波イメージングの根本的な難問を理解する必要がある。絶えず揺れ動き、厚い雲に覆われ、汚れた望遠鏡を通して見ている夜空で、特定の星座を見つけようとしていると想像してほしい。超音波画像は、非常にノイズが多く、ぼやけており、プローブを持つ医師に大きく依存することで知られている。
通常、深層学習はこの問題を、何十万ものラベル付き例を見ることで解決する。しかし、医療分野では、そのようなアノテーション付きデータはほとんど存在しない。これが「few-shot」学習の問題である。では、どのようにして、ごくわずかな例だけでAIに胎児の臓器を見つけさせるように教えるのだろうか?
この論文の著者たちは、ある深遠なことに気づいた。人間の解剖学は固定された地図であるということだ。画像がひどくぼやけていても、心臓は常に脊椎に対して特定の空間的関係にある。ニューラルネットワークに人間のトポロジーと文脈記憶の不変法則を遵守させることで、データの不足を補う。これを達成するために、彼らはデュアルコアの数学エンジンを構築した。文脈記憶のためのCircular Channel Mamba (CCM)と、空間マッピングのためのTopological Relationship Reasoning (TRR)である。
このシステムが実際にどのように機能するのか、その解剖を見てみよう。
マスター方程式
この論文の絶対的な核心は、2つの相互接続された数学エンジンによって駆動されている。
エンジン1:文脈記憶(構造化状態空間モデル)
この方程式は、モデルが画像をスキャンし、見たものを「記憶」して、組織の文脈的な理解を構築することを可能にする。
$$h_t = \overline{A}h_{t-1} + \overline{B}x_t$$
$$y_t = Ch_t$$
エンジン2:解剖学的トポロジー(グラフ推論)
これがこの論文の真のブレークスルーである。モデルが候補となる臓器を見つけると、ガウス重み付きグラフ畳み込みを使用して、それらの空間配置が人間の解剖学と一致するかどうかを確認する。
$$f'_m(i) = \sum_{j \in Neighbour(i)} \omega_m(P(i, j)) x_j e_{ij}$$
$$\omega_m(P(i, j)) = \exp\left(-\frac{1}{2}(P(i, j) - u_m)^T \Sigma_m^{-1} (P(i, j) - u_m)\right)$$
方程式の分解
これらの式の中の、すべての歯車とバネを分解してみよう。
エンジン1(Mambaコンテキスト)から:
* $x_t$: ステップ $t$ における入力。物理的には、処理されている超音波画像の特定のパッチである。
* $h_t, h_{t-1}$: 隠れ状態。これはモデルの「ワーキングメモリ」である。$h_{t-1}$ は、現在のパッチの直前に見た画像パッチのコンテキストを保持している。
* $\overline{A}$: 離散化された状態遷移行列。「忘却/保持ゲート」と考えてほしい。以前の解剖学的コンテキストのどの程度を保持すべきかを決定する。
* $\overline{B}$: 離散化された入力行列。「アテンションフィルター」として機能し、現在の画像パッチ $x_t$ がメモリをどの程度更新すべきかを決定する。
* $y_t$: グローバルコンテキストでリッチになった、特定のパッチの出力特徴表現。
* $C$: 隠れメモリを、使用可能な視覚的特徴に変換する出力射影行列。
* なぜ乗算ではなく加算($+$)なのか? 状態更新は加算を使用して時間とともに情報をスムーズに蓄積する。乗算は、メモリが無限大に爆発するか、指数関数的に速くゼロに消滅する原因となるだろう。
エンジン2(トポロジカルグラフ)から:
* $f'_m(i)$: 候補臓器(ノード $i$)の、新しく更新されたトポロジー認識特徴ベクトル。
* $\sum$: 和演算子。著者たちは、すべての周囲の臓器からの支持的な証拠を蓄積したいと考えているため、max-poolingや乗算ではなく、ここで積分/和を使用している。心臓、肺、脊椎がすべてその位置について合意すれば、それらの結合された声は信頼度を高めるために加算される。
* $Neighbour(i)$: ノード $i$ を囲む、最も関連性の高い上位K個の候補臓器。
* $x_j$: 隣接臓器 $j$ の意味特徴ベクトル。
* $e_{ij}$: 疎な隣接行列からのエッジ重み。臓器 $i$ と臓器 $j$ の間の生の、学習された関係強度を表す。
* $\omega_m(P(i, j))$: ガウスカーネル重み。これはシステムの「ゴムバンド」である。臓器が正しい解剖学的位置にある場合は高い値(1に近い)、そうでない場合は低い値(0に近い)を出力する。
* $P(i, j)$: $(d, \theta)$ を返す極座標関数—画像内の臓器 $i$ と臓器 $j$ の間の実際の測定距離と角度。
* $\exp(...)$: 指数関数。滑らかなベル型の曲線を作成するために使用される。超音波プローブの角度による臓器のわずかなずれに対しても、空間重みが突然ではなく、滑らかに減衰するようにする。
* $-\frac{1}{2}$: ガウス分布の標準的な数学的スケーリング係数であり、学習中に微積分(勾配)をクリーンで安定したものにする。
* $u_m$: 学習可能な $2 \times 1$ の平均ベクトル。物理的には、これはAIの「理想的な青写真」である。人間の解剖学に基づいて、AIが2つの特定の臓器間に期待する正確な距離と角度である。
* $T$: 行列乗算のためにベクトルを整列させるために必要な転置演算子であり、出力が単一のスカラー距離になるようにする。
* $\Sigma_m^{-1}$: 学習可能な $2 \times 2$ 共分散行列の逆行列。物理的には、これは「ゆらぎ」または許容誤差である。一部の臓器は胎児の位置によって大きく変動する(分散が大きい)が、他の臓器は厳密に固定されている(分散が小さい)。この行列は、それに応じてペナルティをスケーリングする。
ステップバイステップフロー:組み立てライン
胎児の心臓かもしれないぼやけた塊という、単一の抽象的なデータポイントを、このアーキテクチャを通してトレースしてみよう。
- 生抽出: 超音波画像がバックボーンネットワークに入る。ぼやけた塊は、生の数学的テンソル(数値のグリッド)に変換される。
- 文脈的走査(CCM): テンソルはシーケンスにスライスされ、Circular Channel Mambaに供給される。$\overline{A}$ および $\overline{B}$ 行列が画像全体を走査する。数学エンジンが塊を処理するにつれて、コンテキストが追加される。「脊椎のようなテクスチャを通過したので、この塊はおそらく胸腔内にあるだろう。」塊は $y_t$ になる。
- グラフ構築(TRR): 塊は「領域提案」(ノード $i$)となる。システムは近くの塊(ノード $j$)を見る。$P(i, j)$ を計算し、ノード $j$ が45度の角度で5センチメートル離れていることを発見する。
- 解剖学的検証: この $(d, \theta)$ 座標がガウスカーネル $\omega_m$ に供給される。カーネルはそれを青写真 $u_m$ と比較する。心臓と脊椎はこの特定のビューで45度の角度にあるはずなので、項 $(P(i, j) - u_m)$ はほぼゼロになる。
- 証拠集約: 距離がゼロに近いので、$\exp(0)$ は1と評価される。脊椎の意味データ $x_j$ は1で乗算され、塊 $i$ に加算($\sum$)される。
- 最終出力: ぼやけた塊はもはや単なる塊ではない。それは、周囲の解剖学的隣接構造の絶対的な確実性と数学的に融合された。モデルはそれを自信を持って胎児の心臓として検出する。
最適化ダイナミクス
この機械的な獣は、わずか数枚の画像からどのように学習するのだろうか?
標準的なfew-shot学習では、損失ランドスケープは混沌としている。データが非常に少ないため、モデルは容易に過学習し、偽のパターンを見つける(特定の超音波装置の静的なノイズを記憶するなど)。勾配は通常、激しく跳ね回る。
しかし、TRRモジュールは、損失ランドスケープに対する巨大な重力アンカーとして機能する。トレーニング中、モデルは標準的なSGD(確率的勾配降下法)オプティマイザを使用する。魔法は、$u_m$ および $\Sigma_m$ に逆流する勾配で起こる。
当初、$u_m$(期待される臓器位置)はランダム化されている。モデルは心臓が体の外にあると推測するかもしれないが、これは巨大な分類誤差につながる。損失関数は急峻な勾配を逆流させ、$u_m$ を、少数のラベル付き例で見つかった真の空間座標を反映するように強制的に更新する。
人間の解剖学は非常に一貫しているため、$u_m$ は非常に速く収束する。一度 $u_m$ が固定されると、$\Sigma_m$(共分散)行列は胎児組織の自然な弾性を学習する。これは最適化ダイナミクスを根本的に再形成する。勾配は、ニューラルネットワークに数百万ピクセルを使ってゼロから心臓がどのように見えるかを学習させるのではなく、他の構造に対する心臓の位置を学習するようにチャネル化される。このトポロジカル制約は局所的最小値を平滑化し、モデルがわずか3つまたは5つの例しか見ていない場合でも、異なる超音波装置や患者間で美しく一般化できるようにする。
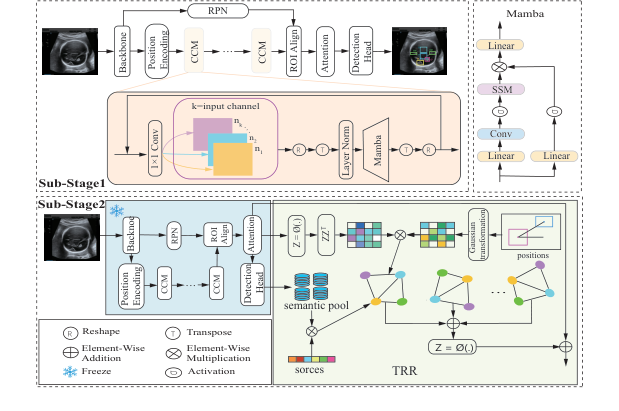 Figure 2. The overall pipeline of the proposed TRR-CCM framework
Figure 2. The overall pipeline of the proposed TRR-CCM framework
結果、限界、および結論
まるで、ざらざらした白黒テレビの砂嵐の中から、特定の微細な構造物を正確に見つけ出そうとするかのようだ。しかも、その発見が人の命を左右するとしたら? これが、超音波画像解析の日常である。
この論文の画期的な点を理解するために、まず現代人工知能(AI)に関するいくつかのground truthを確立する必要がある。ディープラーニングモデルは驚くほど賢いが、同時に膨大なデータを必要とすることでも知られている。胎児の心臓欠損を見つけるAIを訓練するには、通常、医療専門家が丹念にアノテーションを付けた数千枚の画像が必要となる。これは単に手間がかかるだけでなく、極めて高価であり、専門の放射線科医の時間には1時間あたり150ドル以上かかることもある。さらに、厳格なプライバシー規制により、大規模な医療データセットの収集が不可能になる場合が多い。
ここで制約となるのが、Few-Shot Learning (FSL) である。FSLは、優秀な学生に問題の例を3つか5つだけ示して、期末試験で満点を取ることを期待するような、AIにおける等価物である。FSLは一般的な画像分類では成功を収めているが、超音波画像における物体検出(複数の物体にバウンディングボックスを付けること)への応用は悪夢である。超音波は、異なるマシン、異なるプローブ角度、そして固有のスペックルノイズといった、深刻なドメインシフトに悩まされる。
では、著者たちの「アハ!」という動機は何だったのだろうか? 彼らは、超音波画像は雑然として予測不可能である一方で、人間の解剖学的構造はそうではないことに気づいた。空間的トポロジー(臓器がお互いにどのように配置されているか)と解剖学的コンテキストは不変である。著者らは、この不変な人間の解剖学的構造をニューラルネットワークに数学的にハードコードできれば、モデルはノイズに惑わされなくなるだろうと仮説を立てた。
数学的解釈:TRR-CCM
この問題を解決するために、著者らはTRR-CCM(Topological Relationship Reasoning with Circular Channel Mamba)と呼ばれるデュアルエンジンアーキテクチャを考案した。生物学をどのように数学に翻訳したのかを詳しく見ていこう。
1. Circular Channel Mamba (CCM)
標準的なビジョンモデルは、膨大な計算能力を必要とせずに「全体像」を把握するのが難しいことが多い。著者らは、Structured State Space Models (SSMs) に基づく最先端のシーケンスモデリングフレームワークであるMambaに注目した。標準的なSSMは、隠れ状態 $h(t)$ を介して1次元シーケンス $x(t)$ を $y(t)$ にマッピングする:
$$h_t = \overline{A}h_{t-1} + \overline{B}x_t, \quad y_t = C h_t$$
ここで、$\overline{A}$ と $\overline{B}$ は離散時間パラメータである。
しかし、標準的なMambaにはビジョンにおける致命的な欠陥がある。それは、チャネル情報(特徴マップの深さ)を無視することである。これを修正するために、著者らはCCMを発明した。画像をMambaに入力する前に、畳み込み演算を用いてクロスチャネル情報を集約させる:
$$\overline{X}(c, m, n) = \sum_{i=0}^{K-1} \sum_{j=0}^{K-1} X_{c, m+i, n+j} \cdot W_{c, i, j}$$
この方程式は本質的に、「シーケンスを見る前に、コンテキストが失われないように、すべてのチャネルにわたる特徴をブレンドする」と言っている。その後、このグローバルコンテキストをMambaブロックでエンコードする:
$$\hat{X} = Mamba(LN(X^T))$$
最後に、このリッチな特徴を残差接続を介して元の入力に戻す:$X_{out} = CCM(X + \hat{X}')$。
2. Topological Relationship Reasoning (TR)
ここで解剖学的マップが構築される。著者らは、各「ノード」が潜在的な解剖学的構造であるグラフ畳み込みネットワーク(GCN)を使用する。しかし、AIはこれらの構造が互いにどのように関連しているかをどのように知るのだろうか?
極座標を用いて、2つの領域提案 $(x_i, y_i)$ と $(x_j, y_j)$ の間の正確な距離 $d$ と角度 $\theta$ を計算する:
$$d = \sqrt{(x_i - x_j)^2 + (y_i - y_j)^2}, \quad \theta = \arctan\left(\frac{y_j - y_i}{x_j - x_i}\right)$$
これらの生データをネットワークにそのまま入力するわけではない。このトポロジカルデータをガウスカーネルに通して、関係性重み(relationship weights)を生成する:
$$\omega_m(P(i, j)) = \exp\left(-\frac{1}{2}(P(i, j) - u_m)^T \Sigma_m^{-1} (P(i, j) - u_m)\right)$$
この美しい方程式は、動的な関連性フィルターとして機能する。これは、期待される解剖学的距離と角度に基づいて、ある臓器が別の臓器にどれだけ注意を払うべきかを数学的に指示する。最後に、グラフ全体で情報が集約される:
$$f'_m(i) = \sum_{j \in Neighbour(i)} \omega_m(P(i, j)) x_j e_{ij}$$
実験アリーナと「犠牲者」
著者らは単に自分たちの数学が機能すると主張しただけでなく、それを証明するために過酷な実験の連続を設計した。彼らは、TT(胎児脳)と3VT(胎児心臓)という、2つの異なる、非常に複雑なデータセットでモデルをテストした。1-shot、2-shot、3-shot、5-shot、10-shotという極端なデータ不足条件下でモデルを評価した。
「犠牲者」は、TFA、FSCE、DeFRCN、TKRといった有力なモデルを含む、9つの最先端のFew-Shot Object Detectionベースラインであった。
彼らの成功の決定的で否定できない証拠は、単なるリーダーボードの順位だけでなく、アブレーションスタディ(表3)であった。モデルを基本コンポーネントに分解することで、CCM のみ または TRR のみ を追加しても性能が向上したが、それらを組み合わせることで相乗的な爆発が起こることを証明した。例えば、1-shot TTデータセットでは、ベースラインは67.4%を記録した。CCMを追加すると68.8%に、TRRを追加すると68.5%になったが、それらを組み合わせるとスコアは71.3%に急騰した。
正直なところ、なぜTRRモジュールがTTデータセット(脳)と比較して3VTデータセット(心臓)でCCMモジュールよりもはるかに高い性能を発揮したのか完全には確信が持てないが、推測するならば、胎児心臓の三尖弁気管ビューは脳構造よりもはるかに厳格で予測可能な空間幾何学を持っているため、極座標グラフ推論がそこで例外的に致命的になったことに起因する可能性が高い。
将来の進化のための議論トピック
この論文で築かれた画期的な基盤に基づき、将来の批判的思考と進化のためのいくつかの方向性を以下に示す。
- 病理学的異常のパラドックス: TRRの核心的な強みは、不変な人間の解剖学的構造への依存にある。しかし、解剖学的構造が根本的に間違っている場合はどうなるだろうか? もし胎児が重度の先天性欠損(例:大血管転位)を持っている場合、TRRの厳格なガウスカーネルは、関係性が「正常」なトポロジカル事前情報を違反するため、検出を抑制するだろうか? グラフ推論を、ノイズフィルタリングの堅牢性を失うことなく異常を検出できるように柔軟にする方法について議論する必要がある。
- クロスモダリティトポロジカル投影: 高解像度MRIやCTスキャンから、純粋で完璧なトポロジカルグラフを抽出できるだろうか? そして、それをこの超音波モデルの潜在空間に数学的に投影できるだろうか? 空間数学が真に不変であるならば、ノイズの多い超音波からグラフを学習する必要はないかもしれない。より優れたイメージングモダリティから「ground truth」グラフをインポートできる可能性がある。
- 2次元空間における1次元シーケンスモデルの限界: Mambaは本質的に1次元シーケンスモデルである。著者らは、CCMに入力するために2次元超音波特徴量をフラット化した。計算効率は良いが、フラット化はネイティブな2次元空間的連続性を破壊する。興味深い将来の方向性は、シーケンスのフラット化を必要としないネイティブな2次元連続状態空間モデルを定式化することであり、これにより解剖学的境界をさらに高い精度で捉えることができる可能性がある。
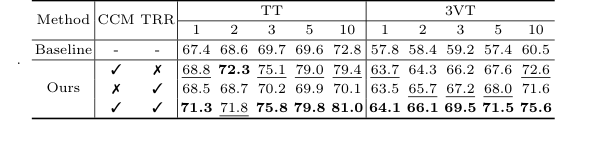 Table 3. shows the ablation studies of the CCM and TRR modules on data split 1 of the TT and 3VT datasets. As shown in Table 3, TRR outperformed CCM on the 3VT dataset, while CCM outperformed TRR on the TT dataset. Both components improve our model’s performance, validating the effectiveness of TRR-CCM. Specifically, the addition of CCM only achieves a significant im- provement over the baseline method by 1.4% to 9.4% on TT dataset, and 5.9% to 12.1% on 3VT dataset, respectively. Only by adding the TRR, it outperforms the baseline on most of the shots of TT, while the 3VT dataset sees an improve- ment of over 5.7% in all cases. When both CCM and TRR are included, our method boosts by 3.9%, 3.2%, 6.1%, 10.2%, and 8.2% in the cases of 1, 2, 3, 5, and 10 shot on data split 1 of TT, respectively
Table 3. shows the ablation studies of the CCM and TRR modules on data split 1 of the TT and 3VT datasets. As shown in Table 3, TRR outperformed CCM on the 3VT dataset, while CCM outperformed TRR on the TT dataset. Both components improve our model’s performance, validating the effectiveness of TRR-CCM. Specifically, the addition of CCM only achieves a significant im- provement over the baseline method by 1.4% to 9.4% on TT dataset, and 5.9% to 12.1% on 3VT dataset, respectively. Only by adding the TRR, it outperforms the baseline on most of the shots of TT, while the 3VT dataset sees an improve- ment of over 5.7% in all cases. When both CCM and TRR are included, our method boosts by 3.9%, 3.2%, 6.1%, 10.2%, and 8.2% in the cases of 1, 2, 3, 5, and 10 shot on data split 1 of TT, respectively
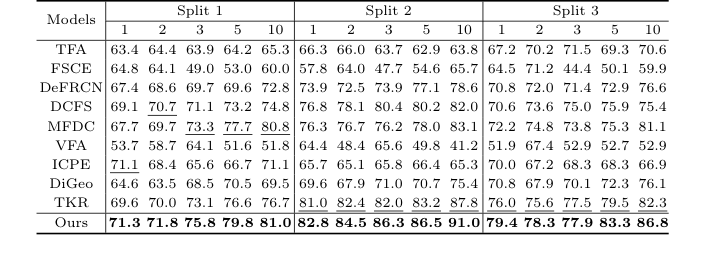 Table 1. Detection results for the TT dataset under the three settings. Bold and underlined numbers denote the 1st and 2nd scores
Table 1. Detection results for the TT dataset under the three settings. Bold and underlined numbers denote the 1st and 2nd scores
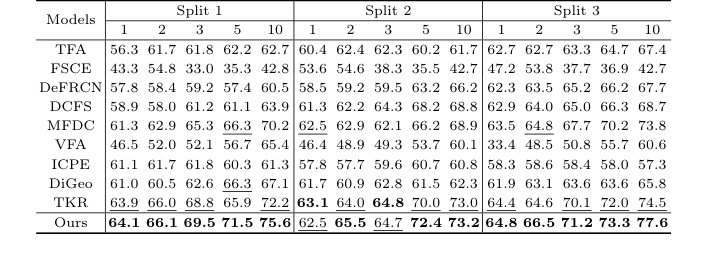 Table 2. Detection results for the 3VT dataset under the three settings. Bold and underlined numbers denote the 1st and 2nd scores
Table 2. Detection results for the 3VT dataset under the three settings. Bold and underlined numbers denote the 1st and 2nd scores
他の体との同型
線形状態空間シーケンスモデリングと幾何学的に重み付けされたグラフネットワークを融合させたハイブリッドメカニズムにより、不変な空間関係に基づき、高ノイズ環境下におけるスパースなターゲットの同一性と位置を推論する。
天体物理学と系外惑星検出
系外惑星や特定の恒星形成の探索において、天文学者は、医療用超音波画像に見られるスペックルノイズやアーティファクトと同様の、大規模な信号対雑音比の問題に直面する。この文脈における「解剖学的構造」とは、不変の軌道力学、あるいは恒星系の固定されたトポロジカル関係である。本論文のコアロジックを適用することで、天体物理学モデルは、状態空間メカニズムを用いて時間経過とともに宇宙背景放射をフィルタリングし、グラフ畳み込みネットワークは、天体間の不変な空間距離と角度をマッピングすることができる。これは、混沌とした異種干渉のベールの陰に隠された、既知の構造化された天体の集合体を見つけるという、全く同じ問題の完璧な鏡像である。
金融市場のミクロ構造
高頻度取引において、協調的な機関投資家による資産の蓄積を検出することは、ノイズの海の中から隠された構造を見つけることに似ている。「空間トポロジー」は、ここでは異なる資産クラス間の不変な相関ネットワーク(例えば、米国債利回り、米ドル、金との歴史的に固定された関係)に相当する。「超音波ノイズ」は、真の市場の方向性を不明瞭にする、予測不能で高ボリュームの個人投資家による取引である。本論文の正確なフレームワークを使用することで、金融モデルはマクロ経済シフトの「解剖学的構造」をマッピングし、たとえ歴史的データ(稀な市場暴落のラベル付き例)が極めて乏しい場合でも、グラフネットワークを用いて資産価格の動き全体にわたる構造的一貫性を強制することができる。
もし地質学者が地殻活動を研究する際に、明日、本論文の正確なトポロジカル推論方程式を「盗用」したらどうなるだろうか?具体的には、ガウス重み付き極座標グラフを再利用した場合:
$$ \omega_m(P(i, j)) = \exp(-\frac{1}{2}(P(i, j) - u_m)^T \Sigma_m^{-1} (P(i, j) - u_m)) $$
ノード $i$ と $j$ が胎児の心臓の部屋をマッピングする代わりに、地震センサー局を表し、「解剖学的構造」は地球の地殻深部の隠された断層線になるとする。この少数ショットのトポロジカル推論を活用することで、彼らは数個のスパースな地震観測データのみを使用して、マッピングされていない地下構造を正確にマッピングしたり、稀な地震群を予測したりすることができ、数十年にわたる大規模な注釈付き地震履歴データセットの必要性を完全に回避できる。
最終的に、本論文は、人間の心臓の隠された部屋、遠方の銀河間の見えない重力網、あるいは我々の惑星の地下の亀裂をマッピングしているかどうかにかかわらず、不変なトポロジカル推論の数学は美しく同じままであることを証明し、構造の普遍的ライブラリに深遠な設計図を提供することに貢献する。