초음파 영상에서 강화된 인체 해부학 지식을 활용한 해부학적 구조 소수샷 탐지
Deep learning-based models have significantly advanced clinical ultrasound tasks by detecting anatomical structures within vast ultrasound image datasets.
배경 및 학문적 계보
의료 영상 분석 분야는 딥러닝 덕분에 비약적인 발전을 경험했다. 그러나 본 논문에서 다루는 특정 문제는 심각한 실제 병목 현상, 즉 데이터 기아(data hunger)에서 비롯된다. 전통적으로 초음파 영상에서 태아 장기를 탐지하는 AI를 훈련시키려면 방대한 데이터셋이 필요하다. 이러한 데이터셋은 고도로 전문화된 의사들이 세심하게 주석을 달아야 하는데, 이 과정은 엄청나게 지루하고 비용이 많이 든다 (전문가 인건비로 시간당 150달러 이상 소요되는 경우가 많다). 더욱이 엄격한 윤리 및 개인 정보 보호 규정으로 인해 대규모 환자 데이터를 수집하고 공유하는 것은 거의 불가능하다.
이러한 데이터 부족을 극복하기 위해 학계는 "퓨샷 학습(few-shot learning)"으로 전환했다. 이는 극소수의 예시만을 사용하여 모델을 훈련하도록 설계된 패러다임이다. 퓨샷 학습은 전체 이미지를 분류하거나 단일 장기의 윤곽을 그리는(semantic segmentation) 것과 같은 기본적인 작업에서 큰 성공을 거두었지만, 초음파 영상에서의 다중 객체 탐지라는 훨씬 더 복잡한 작업은 역사적으로 무시해왔다. 저자들은 이러한 격차를 인지하고 복잡한 다중 장기 초음파 환경에 퓨샷 탐지를 적용하기 위한 연구를 시작했다.
저자들은 이전 접근 방식이 두 가지 근본적인 한계에 부딪혔기 때문에 이 논문을 작성하게 되었다.
1. 도메인 변화에 대한 취약성: 초음파 영상은 기계의 브랜드, 시술자의 프로브 각도, 고유한 스페클 노이즈에 따라 심각한 변화를 겪기 때문에 악명 높게도 잡음이 많다. 이전의 퓨샷 모델은 인간 해부학에 대한 통합된 이해가 부족하여 이러한 변화에 대한 일반화를 실패했다.
2. 현대 시퀀스 모델의 아키텍처적 맹점: 최근에는 "Mamba"(State Space Models 기반)라는 매우 효율적인 AI 아키텍처가 긴 데이터 시퀀스를 처리하는 데 인기를 얻었다. 그러나 이전의 Mamba 기반 방법은 공간적 상관관계에만 초점을 맞추고 "채널 정보"(깊고 계층적인 특징 표현)를 완전히 무시했다. 이러한 채널 혼합의 부족은 더 큰 네트워크에서 안정성 문제를 야기했으며, 모델이 해부학적 구조의 전역적 맥락을 이해하는 능력을 심각하게 제한했다.
본 논문의 고도로 전문화된 개념을 직관적으로 이해할 수 있도록 네 가지 핵심 도메인 용어를 일상적인 비유로 번역했다.
- 퓨샷 학습 (Few-Shot Learning): 아이에게 "오리너구리"가 무엇인지 가르치는 것을 상상해 보라. 10,000장의 사진을 보여줄 필요는 없다. 단 세네 장의 좋은 사진만으로도 야생에서 오리너구리를 인식할 수 있다. 퓨샷 학습은 AI에게 방대한 데이터셋에 의존하는 대신, 매우 제한된 예시로부터 배우는 인간과 유사한 능력을 부여하려고 한다.
- 도메인 변화 (Domain Shift): 저렴하고 잡음이 많은 라디오로 좋아하는 노래를 듣는 것과 고급 콘서트 음향 시스템으로 듣는 것을 비교해 보라. 기본적인 노래는 정확히 같지만, 오디오 품질과 왜곡은 극심하게 달라진다. 초음파에서는 다른 기계와 의사들이 표준 AI 모델을 쉽게 혼란스럽게 하는 "도메인 변화"를 만들어낸다.
- 위상 관계 추론 (Topological Relationship Reasoning, TRR): 어두운 방에서 직소 퍼즐을 맞추려고 하는 것을 상상해 보라. 조각이 명확하게 보이지 않더라도, 논리적으로 "굴뚝" 조각은 "지붕" 조각에 연결되어야 한다는 것을 안다. TRR은 AI에게 유사한 논리적 지도를 제공한다. 즉, 인간 장기의 고정된 자연스러운 배열(예: 심장은 항상 폐 근처에 있음)을 사용하여 초음파 영상이 흐릿하더라도 구조를 찾는다.
- 선택적 상태 공간 모델 (Selective State Space Models, SSMs): 바쁜 변호사가 500페이지 분량의 법률 문서를 읽는 것을 상상해 보라. 모든 단어를 암기하는 대신, 중요한 조항만 선택적으로 강조 표시하고 쓸모없는 채워 넣기 텍스트는 무시한다. SSM은 데이터를 위해 이와 같이 작동하며, 관련 없는 노이즈를 동적으로 필터링하여 정보를 매우 빠르고 효율적으로 처리한다.
저자들의 해결책을 공식화하는 데 사용된 주요 수학적 표기법을 다음과 같이 분석했다.
| 표기 | 유형 | 설명 |
|---|---|---|
| $x(t), y(t)$ | 변수 | State Space Model에서 처리되는 1차원 입력 및 출력 시퀀스. |
| $h(t)$ | 변수 | 입력 시퀀스를 출력 시퀀스로 매핑하는 은닉 상태. |
| $A, B$ | 매개변수 | 선형 시불변 시스템을 제어하는 연속 시간 매개변수. |
| $\overline{A}, \overline{B}$ | 매개변수 | 계산을 위해 연속 시간 매개변수에서 변환된 이산 시간 매개변수. |
| $\Delta$ | 매개변수 | 연속 시간 매개변수를 이산화하는 데 사용되는 시간 스케일 매개변수. |
| $X$ | 변수 | 이미지 특징을 나타내는 입력 텐서, $X \in \mathbb{R}^{B \times C \times H \times W}$로 정의됨. |
| $B, C, H, W$ | 매개변수 | 특징 맵의 차원: 배치 크기, 채널 수, 높이, 너비. |
| $G = \langle \mathcal{N}, \mathcal{E} \rangle$ | 변수 | 노드 $\mathcal{N}$가 영역 제안이고 엣지 $\mathcal{E}$가 관계인 무방향 영역 대 영역 그래프. |
| $z_i$ | 변수 | 특정 노드 $i$의 시각적 특징에 대한 잠재 공간 표현. |
| $\omega_m(P(i, j))$ | 변수 | 두 해부학적 영역 간의 공간 거리와 각도를 인코딩하는 가우시안 커널 함수. |
문제 정의 및 제약 조건
어두컴컴하고 안개가 낀 방에서 특정 열쇠 뭉치를 찾는다고 상상해 보라. 그런데 평생 동안 그 열쇠들이 어떻게 생겼는지 단 세 번 또는 다섯 번만 보았다고 가정해 보자. 이것이 바로 의료 초음파 영상에서 소수샷 객체 탐지(few-shot object detection)의 본질적인 도전 과제이다.
이 논문이 다루는 문제의 규모를 이해하기 위해, 우리는 먼저 정확히 어디에서 시작하고, 어디로 가고 싶으며, 그 두 지점 사이의 여정이 왜 그렇게 험난한지를 정의해야 한다.
시작점과 목표 상태
입력 (현재 상태): 시스템은 잡음이 심한 원시 초음파 영상, 특히 태아 초음파 스캔(뇌 또는 심장 등)을 입력받는다. 이와 함께, 모델은 학습해야 할 새로운 해부학적 구조에 대한 극히 제한된 수의 주석이 달린 예시(단 1, 3, 5, 또는 10개의 "샷")를 제공받는다. 수학적으로, 입력은 고차원 시각 특징 텐서 $X \in \mathbb{R}^{B \times C \times H \times W}$이며, 여기서 $B$는 배치 크기, $C$는 채널 수, $H$와 $W$는 공간 차원이다.
출력 (목표 상태): 모델은 흐릿한 영상 내에서 여러 해부학적 구조에 대한 정확한 경계 상자(bounding boxes)와 분류 점수(classification scores)를 출력해야 한다. 이는 지역 예측 행렬(regional prediction matrix) $S \in \mathbb{R}^{N \times C}$로 표현되며, 여기서 $N$은 지역 제안(region proposals)의 수이고 $C$는 클래스의 수이다.
수학적 간극: 누락된 연결고리는 매우 작은 훈련 데이터셋에 과적합(overfitting)되지 않고 $X$를 $S$로 연결할 수 있는 강력한 매핑 함수이다. 표준 딥러닝 모델은 대규모 데이터셋에 의해 구동되는 수백만 개의 매개변수 업데이트에 의존하여 이 공간을 매핑한다. 소수샷 시나리오에서는 수학적 공간이 심각하게 제약이 부족하다. 모델은 고차원 공간에서 서로 다른 해부학적 클래스 간의 복잡하고 비선형적인 경계를 학습하기에 충분한 데이터 포인트가 없다. 저자들은 모델이 많은 데이터를 보지 못했더라도 올바르게 추측할 수 있도록 사전 지식을 사용하여 가설 공간(hypothesis space)을 인위적으로 제약해야 한다.
고통스러운 딜레마
인공지능에서 한 가지 문제를 해결하면 거의 항상 다른 문제가 발생한다. 흐릿한 초음파 영상에서 객체를 탐지하기 위해 모델은 "전역적 맥락(global context)"을 절실히 필요로 한다. 즉, 작은 픽셀 패치만 보는 것이 아니라 전체 이미지를 보고 자신이 어디에 있는지 이해해야 한다.
역사적으로 연구자들은 여기서 잔인한 트레이드오프에 직면해 왔다.
1. 트랜스포머 경로: 자체 주의 메커니즘(self-attention mechanisms, 예: 트랜스포머)을 사용하여 전체 이미지에 걸친 장거리 의존성(long-range dependencies)을 포착할 수 있다. 그러나 계산 복잡도는 이미지 크기에 따라 이차적으로 증가한다. 고해상도 의료 영상에서는 기하급수적으로 더 많은 메모리와 계산량이 필요하므로 표준 임상 하드웨어에서는 실현 불가능하다.
2. 맘바 경로: 최근 연구자들은 구조화된 상태 공간 모델(Structured State Space Models, SSMs), 특히 "맘바(Mamba)"를 도입하여 시퀀스 모델링 복잡성을 선형적 규모로 줄였다. 이는 빠르고 효율적이다. 그러나 딜레마가 다시 발생한다. 이전 맘바 기반 방법들은 공간적 상관관계에 크게 집중하지만 채널 혼합(channel mixing)을 완전히 무시한다. 신경망에서 서로 다른 채널은 서로 다른 학습된 특징(예: 엣지, 텍스처 또는 특정 모양)을 나타낸다. 이러한 채널 간의 상호 작용을 무시함으로써 맘바 아키텍처는 더 큰 네트워크에서 심각한 안정성 문제를 겪고 풍부하고 전역적인 의미론적 정보를 모델링하는 능력을 잃는다.
당신은 갇혀 있다. 트랜스포머를 선택하면 메모리가 부족해지고, 표준 맘바를 선택하면 작은 심장 혈관을 배경 잡음과 구별하는 데 필요한 깊은 특징 상호 작용을 잃게 된다.
가혹한 벽
아키텍처 딜레마를 넘어, 저자들은 이 특정 문제를 해결하기 매우 어렵게 만드는 몇 가지 가혹하고 현실적인 벽에 부딪혔다.
1. 극심한 데이터 희소성 (윤리/노동의 벽)
딥러닝은 빅데이터에서 번성하지만, 의료 데이터는 엄격한 윤리 및 개인 정보 보호 규제 뒤에 잠겨 있다. 데이터를 얻더라도 주석을 달려면 전문 의료 전문가가 필요하다. 초음파 주석은 크라우드소싱할 수 없다. 이는 데이터셋 크기에 하드 상한선을 만들어 모델이 거의 아무것도 없는 상태에서 학습하도록 강요한다.
2. 초음파의 물리 (도메인 이동의 벽)
초음파는 본질적으로 지저분하다. 영상은 고유한 물리적 잡음 아티팩트, 특히 낮은 대비(low contrast)와 스페클 노이즈(speckle noise)로 고통받는다. 또한, 영상은 기계의 주파수/이득 설정 및 특정 의사의 프로브 각도와 압력에 따라 완전히 다르게 보인다. 이는 엄청난 "도메인 이동(domain shifts)"을 야기한다. 병원 A의 몇몇 영상으로 훈련된 모델은 병원 B의 영상에서는 완전히 실패할 것이다. 왜냐하면 기계와 운영자의 물리적 특성에 의해 근본적으로 변경된 픽셀 분포가 존재하기 때문이다.
3. 표준 AI의 위상학적 맹목성 (Topological Blindness)
표준 객체 탐지기는 모든 객체를 독립적인 개체로 취급한다. "기관지"와 "혈관"을 찾는다면 독립적으로 검색한다. 그러나 인간의 해부학은 그렇게 작동하지 않는다. 인체 내의 공간-위상 관계(spatial-topological relationships)는 불변적이다. 즉, 심장은 항상 특정 기하학적 배치에서 특정 혈관에 연결되어 있다. 표준 모델은 이러한 생물학적 제약에 "눈이 멀었다". 모델이 "객체 A는 객체 B로부터 특정 각도와 거리에 있어야 한다"는 규칙을 수학적으로 인코딩할 수 없다면, 초음파의 스페클 노이즈에 쉽게 속아 불가능한 위치에 해부학적 구조를 예측할 것이다.
이 접근 방식은 왜
초음파 영상은 분석이 매우 어렵다. 이는 스페클 노이즈, 낮은 대비, 그리고 다른 운영자나 기기 설정으로 인한 대규모 도메인 변화와 같은 고유한 노이즈 아티팩트에 시달리기 때문이다. 이러한 열악한 환경에 레이블이 지정된 소수의 예시만으로 학습해야 하는 "퓨샷(few-shot)" 학습을 결합하면, 전통적인 딥러닝 방법은 단순히 붕괴된다.
저자들은 중요한 깨달음에 도달했다. 표준 최신 기술(SOTA) 모델은 픽셀 데이터로부터 모든 것을 학습하려고 시도한다. 그러나 초음파에서는 픽셀이 신뢰할 수 없다. 하지만 인간 해부학은 불변적이다. 초음파 프로브가 이상한 각도로 잡혔다고 해서 장기 간의 공간적 관계가 변하지는 않는다. 이는 시각적 특징 추출과 하드코딩된 해부학적 규칙을 결합한 모델인 TRR-CCM의 탄생으로 이어졌다.
그렇다면 왜 이 특정 수학적 접근 방식이 유일하게 실행 가능한 해결책이었을까? 저자들은 Mamba와 같은 최근의 시퀀스 모델링 아키텍처가 긴 시퀀스로부터 핵심 의미론을 추출하는 데 뛰어나지만, 표준 Mamba는 치명적인 결함을 가지고 있음을 인식했다. 즉, 공간적 상관관계에 거의 전적으로 집중하고 채널 정보를 무시한다는 것이다. 복잡한 의료 영상에서 이러한 채널 혼합의 부족은 더 큰 네트워크에서 안정성 문제를 야기하며, 모델이 전역적인 그림을 파악하는 능력을 심각하게 제한한다. 이를 해결하기 위해 저자들은 Circular Channel Mamba(CCM)를 설계했다. 선택적 구조화 상태 공간 모델(SSM) 메커니즘을 채널 차원으로 확장함으로써, CCM은 채널 간 특징 의존성을 포착한다. 수학적으로, 은닉 상태 전이는 다음과 같이 정의된다.
$$h_t = \overline{A}h_{t-1} + \overline{B}x_t$$
이 특정 공식은 모델이 입력 정보를 동적으로 필터링할 수 있게 하여, 시퀀스 모델링 복잡성을 표준 트랜스포머의 일반적인 $O(N^2)$에서 매우 효율적인 $O(N)$으로 효과적으로 줄인다.
이 방법의 비교 우위는 이중 엔진 구조에 있다. 9가지 기준선 방법 대비 더 높은 평균 평균 정밀도(mAP) 점수를 달성하는 것 외에도, 단순히 이미지를 "보는" 것이 아니라 "추론"하기 때문에 질적으로 우수하다. 초음파의 고차원 노이즈를 처리하기 위해, 모델은 위상 관계 추론(Topological Relationship Reasoning, TRR)을 사용한다. 이는 노드가 영역 제안을 나타내고 엣지가 그들 간의 관계를 나타내는 비방향성 영역 대 영역 그래프 $G = \langle \mathcal{N}, \mathcal{E} \rangle$를 구성한다. 공간 좌표를 가우시안 커널에 통과시킴으로써, 모델은 관계 가중치를 계산한다.
$$\omega_m(P(i, j)) = \exp(-\frac{1}{2}(P(i, j) - u_m)^T \Sigma_m^{-1} (P(i, j) - u_m))$$
이는 태아 심장의 시각적 특징이 스페클 노이즈에 의해 가려지더라도, 그래프 컨볼루션 네트워크(GCN)가 주변 구조의 명확한 존재에 의존하여 그 위치와 클래스를 추론할 수 있음을 의미한다. 이는 모든 바운딩 박스를 개별적으로 취급했던 이전의 골드 스탠다드보다 압도적으로 우수한 구조적 이점이다.
이 방법은 퓨샷 의료 탐지의 열악한 제약 조건과 완벽하게 일치한다. 대규모 의료 데이터셋에 레이블을 지정하는 것은 전문적인 전문가를 필요로 하며, 시간당 150달러 이상이 쉽게 소요될 수 있어 대규모 데이터셋은 윤리적으로나 재정적으로 제한적이다. 여기서의 "결합"은 문제의 데이터 부족과 해결책의 불변적 사전 지식 사용 간의 결합이다. 모델은 이미 TRR 모듈을 통해 인간 해부학의 공간적 위상 구조를 "알고" 있기 때문에, 새로운 클래스를 탐지하는 방법을 학습하는 데 훨씬 적은 예시가 필요하다.
솔직히 말해서, 저자들이 이 특정 작업에 대해 GAN이나 확산 모델과 같은 다른 인기 있는 생성적 접근 방식을 명시적으로 거부한 이유에 대해 완전히 확신할 수 없다. 왜냐하면 논문에서 이를 언급하지 않기 때문이다. 그러나 저자들은 이전의 Mamba 기반 방법과 표준 CNN을 거부한 이유를 명확하게 설명한다. 즉, 이러한 이전 아키텍처는 채널 정보를 제대로 혼합하지 못하거나, 계산 비용이 폭발하지 않으면서 복잡한 전역 컨텍스트를 효율적으로 처리하는 데 필요한 선형 시간 선택적 스캐닝 메커니즘이 부족하다는 것이다. CCM의 선형 효율성과 TRR의 해부학적 제약을 결합함으로써, 저자들은 초음파 영상의 용서받지 못하는 도메인에 특화된 독특하게 강력한 시스템을 만들었다.
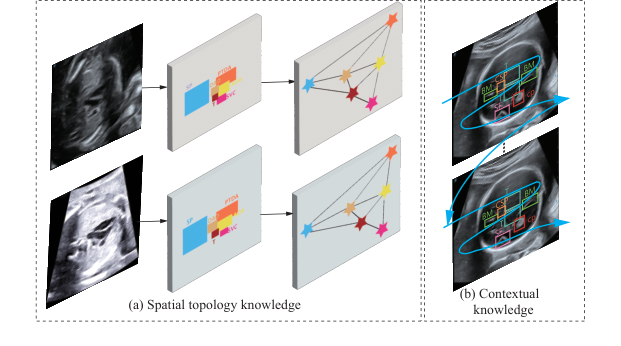 Figure 1. Consistency of two fixed knowledge from human anatomy. (a) Spatial topology knowledge. (b) Contextual knowledge
Figure 1. Consistency of two fixed knowledge from human anatomy. (a) Spatial topology knowledge. (b) Contextual knowledge
수학 및 논리 메커니즘
이 논문의 탁월함을 이해하기 위해서는 먼저 의료 초음파 영상의 근본적인 난제를 파악해야 한다. 끊임없이 흔들리고, 짙은 구름에 가려져 있으며, 더러운 망원경으로 바라보는 밤하늘에서 특정 별자리를 찾는다고 상상해보라. 초음파 영상은 악명 높게 노이즈가 많고 흐릿하며, 프로브를 잡고 있는 의사에 따라 크게 달라진다.
일반적으로 딥러닝은 수십만 개의 레이블이 지정된 예제를 통해 이를 해결한다. 그러나 의료 분야에서는 그렇게 많은 주석이 달린 데이터를 확보하기 어렵다. 이것이 바로 "few-shot" 학습 문제이다. 그렇다면 소수의 예제만으로 AI에게 태아 장기를 찾는 방법을 어떻게 가르칠 수 있을까?
이 논문의 저자들은 심오한 사실을 깨달았다: 인체 해부학은 고정된 지도이다. 이미지가 극도로 흐릿하더라도 심장은 척추와 항상 특정 공간적 관계를 유지한다. 신경망이 인체 위상학 및 맥락 기억의 불변 법칙을 따르도록 강제함으로써, 데이터 부족을 보완한다. 이를 달성하기 위해 그들은 이중 코어 수학 엔진을 구축했다. 맥락 기억을 위한 Circular Channel Mamba (CCM)와 공간 매핑을 위한 Topological Relationship Reasoning (TRR)이다.
이 시스템이 실제로 어떻게 작동하는지 해부해보자.
핵심 방정식
이 논문의 핵심은 두 개의 상호 연결된 수학 엔진에 의해 구동된다.
엔진 1: 맥락 기억 (구조화된 상태 공간 모델)
이 방정식은 모델이 이미지를 스캔하고 방금 본 것을 "기억"하여 조직에 대한 맥락적 이해를 구축할 수 있도록 한다.
$$h_t = \overline{A}h_{t-1} + \overline{B}x_t$$
$$y_t = Ch_t$$
엔진 2: 해부학적 위상학 (그래프 추론)
이것이 이 논문의 진정한 돌파구이다. 모델이 후보 장기를 찾으면, 가우시안 가중치 그래프 컨볼루션을 사용하여 공간적 배치가 인체 해부학과 일치하는지 확인한다.
$$f'_m(i) = \sum_{j \in Neighbour(i)} \omega_m(P(i, j)) x_j e_{ij}$$
$$\omega_m(P(i, j)) = \exp\left(-\frac{1}{2}(P(i, j) - u_m)^T \Sigma_m^{-1} (P(i, j) - u_m)\right)$$
방정식을 분해하다
이 방정식들의 모든 기어와 스프링을 해부해보자.
엔진 1 (Mamba 맥락)에서:
* $x_t$: 단계 $t$에서의 입력. 물리적으로, 이는 처리 중인 초음파 이미지의 특정 패치이다.
* $h_t, h_{t-1}$: 은닉 상태. 이것은 모델의 "작업 기억"이다. $h_{t-1}$은 현재 패치 바로 전에 본 이미지 패치의 맥락을 보유한다.
* $\overline{A}$: 이산화된 상태 전이 행렬. 이를 "망각/유지 게이트"로 생각하라. 이전 해부학적 맥락의 어느 정도를 유지할지 결정한다.
* $\overline{B}$: 이산화된 입력 행렬. 이는 "주의 필터" 역할을 하며, 현재 이미지 패치 $x_t$가 메모리를 얼마나 업데이트해야 하는지 결정한다.
* $y_t$: 전역 맥락으로 풍부해진 특정 패치에 대한 출력 특징 표현.
* $C$: 은닉 메모리를 다시 사용 가능한 시각적 특징으로 변환하는 출력 투영 행렬.
* 곱셈 대신 덧셈($+$)을 사용하는 이유는 무엇인가? 상태 업데이트는 시간 경과에 따라 정보를 부드럽게 축적하기 위해 덧셈을 사용한다. 곱셈은 메모리가 무한대로 폭발하거나 지수적으로 빠르게 0으로 사라지게 할 것이다.
엔진 2 (위상학적 그래프)에서:
* $f'_m(i)$: 후보 장기(노드 $i$)에 대한 새로 업데이트된, 위상학적으로 인식하는 특징 벡터.
* $\sum$: 합계 연산자. 저자들은 최대 풀링이나 곱셈 대신 적분/합계를 사용하는데, 이는 모든 주변 장기로부터의 지지 증거를 축적하기를 원하기 때문이다. 심장, 폐, 척추가 모두 자신의 위치에 대해 동의한다면, 그들의 결합된 목소리가 합쳐져 신뢰도를 높인다.
* $Neighbour(i)$: 노드 $i$ 주변의 가장 관련성 높은 상위 K개 후보 장기.
* $x_j$: 이웃 장기 $j$의 의미론적 특징 벡터.
* $e_{ij}$: 희소 인접 행렬의 엣지 가중치. 이는 장기 $i$와 장기 $j$ 사이의 학습된 관계 강도를 나타낸다.
* $\omega_m(P(i, j))$: 가우시안 커널 가중치. 이것은 시스템의 "고무줄"이다. 장기가 올바른 해부학적 위치에 있으면 높은 값(1에 가까움)을 출력하고, 그렇지 않으면 낮은 값(0에 가까움)을 출력한다.
* $P(i, j)$: 이미지에서 장기 $i$와 장기 $j$ 사이의 실제 측정된 거리와 각도를 반환하는 극좌표 함수 $(d, \theta)$.
* $\exp(...)$: 지수 함수. 부드러운 종 모양 곡선을 만들기 위해 사용된다. 장기가 초음파 프로브 각도로 인해 약간 이동하더라도 공간 가중치가 갑자기 떨어지는 대신 부드럽게 감소하도록 보장한다.
* $-\frac{1}{2}$: 가우시안 분포에 대한 표준 수학적 스케일링 계수로, 학습 중에 미적분(기울기)을 깨끗하고 안정적으로 만든다.
* $u_m$: 학습 가능한 $2 \times 1$ 평균 벡터. 물리적으로, 이것은 AI의 "이상적인 청사진"이다. 이는 AI가 인체 해부학을 기반으로 두 특정 장기 사이에 볼 것으로 예상하는 정확한 거리와 각도이다.
* $T$: 전치 연산자. 출력이 단일 스칼라 거리로 해결되도록 행렬 곱셈을 위해 벡터를 정렬하는 데 필요하다.
* $\Sigma_m^{-1}$: 학습 가능한 $2 \times 2$ 공분산 행렬의 역행렬. 물리적으로, 이것은 "여유 공간" 또는 허용 오차이다. 일부 장기는 태아의 위치에 따라 많이 이동하고(높은 분산), 다른 장기는 엄격하게 고정되어 있다(낮은 분산). 이 행렬은 페널티를 적절하게 조정한다.
단계별 흐름: 조립 라인
추상적인 단일 데이터 포인트, 즉 태아 심장일 수 있는 흐릿한 덩어리를 이 아키텍처를 통해 추적해보자.
- 원시 추출: 초음파 이미지가 백본 네트워크로 들어간다. 우리의 흐릿한 덩어리는 원시 수학 텐서(숫자 그리드)로 변환된다.
- 맥락 스위핑 (CCM): 텐서는 시퀀스로 슬라이스되어 Circular Channel Mamba에 공급된다. $\overline{A}$ 및 $\overline{B}$ 행렬이 이미지 전체를 스캔한다. 수학 엔진이 덩어리를 처리함에 따라 맥락이 추가된다: "나는 방금 척추와 유사한 질감을 통과했으므로, 이 덩어리는 흉강 내에 있을 가능성이 높다." 덩어리는 $y_t$가 된다.
- 그래프 구성 (TRR): 덩어리는 이제 "영역 제안"(노드 $i$)이다. 시스템은 주변 덩어리(노드 $j$)를 살펴본다. $P(i, j)$를 계산하여 노드 $j$가 45도 각도로 5센티미터 떨어져 있음을 발견한다.
- 해부학적 심문: 이 $(d, \theta)$ 좌표는 가우시안 커널 $\omega_m$에 공급된다. 커널은 이를 청사진 $u_m$과 비교한다. 심장과 척추는 이 특정 뷰에서 45도 각도를 이루어야 하므로, 항 $(P(i, j) - u_m)$은 거의 0이 된다.
- 증거 집계: 거리가 0에 가깝기 때문에 $\exp(0)$은 1로 평가된다. 척추의 의미론적 데이터 $x_j$는 1과 곱해지고 우리의 덩어리 $i$에 더해진다($\sum$).
- 최종 출력: 우리의 흐릿한 덩어리는 더 이상 단순한 덩어리가 아니다. 이제 주변 해부학적 이웃의 절대적인 확실성과 수학적으로 융합되었다. 모델은 이를 태아 심장으로 자신 있게 감지한다.
최적화 역학
이 기계적인 괴물은 어떻게 단 몇 장의 이미지로 학습하는가?
표준 few-shot 학습에서 손실 지형은 혼란스럽다. 데이터가 너무 적기 때문에 모델은 쉽게 과적합되어 잘못된 패턴을 찾는다(특정 초음파 기계의 정적 노이즈를 암기하는 것과 같음). 기울기는 보통 격렬하게 요동친다.
그러나 TRR 모듈은 손실 지형에 대한 거대한 중력 앵커 역할을 한다. 훈련 중에 모델은 표준 SGD(Stochastic Gradient Descent) 최적화 프로그램을 사용한다. 마법은 $u_m$과 $\Sigma_m$으로 다시 흐르는 기울기에서 발생한다.
초기에 $u_m$(예상 장기 위치)은 무작위로 설정된다. 모델은 심장이 몸 밖에 있다고 추측할 수 있으며, 이는 엄청난 분류 오류를 초래한다. 손실 함수는 $u_m$을 업데이트하여 소수의 레이블이 지정된 예제에서 발견된 실제 공간 좌표를 반영하도록 강력하게 업데이트한다.
인체 해부학은 매우 일관성이 있기 때문에 $u_m$은 매우 빠르게 수렴한다. $u_m$이 고정되면 $\Sigma_m$(공분산) 행렬은 태아 조직의 자연스러운 탄성을 학습한다. 이는 최적화 역학을 근본적으로 재편한다: 신경망이 수백만 픽셀을 사용하여 처음부터 심장이 어떻게 보이는지 학습하도록 강제하는 대신, 기울기는 심장이 다른 구조물에 비해 어디에 있어야 하는지를 학습하는 데 집중된다. 이러한 위상학적 제약은 지역 최소값을 완만하게 만들어, 모델이 3개 또는 5개의 예제만 보았더라도 다른 초음파 기계 및 환자에 걸쳐 아름답게 일반화할 수 있도록 한다.
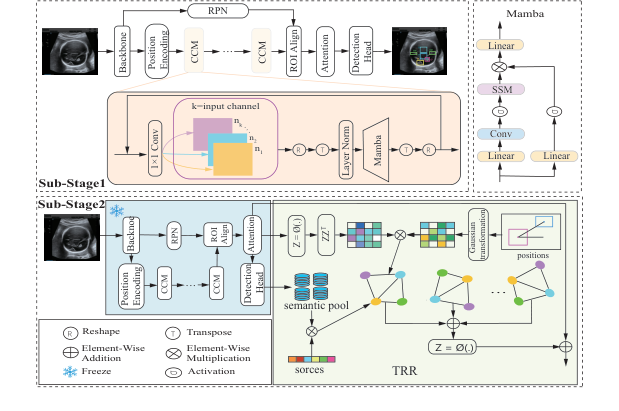 Figure 2. The overall pipeline of the proposed TRR-CCM framework
Figure 2. The overall pipeline of the proposed TRR-CCM framework
결과, 한계점 및 결론
마치 흑백 TV 잡음 속에서 아주 작고 특정한 구조물을 찾아내려 애쓰는 상황을 상상해 보십시오. 그런데 그 구조물을 정확히 찾아내는 것이 누군가의 생명과 직결된다고 가정해 봅시다. 이것이 바로 초음파 영상 분석의 일상적인 현실입니다.
이 논문의 탁월함을 이해하기 위해서는 먼저 현대 인공지능에 대한 몇 가지 Ground Truth를 확립해야 합니다. 딥러닝 모델은 놀랍도록 똑똑하지만, 동시에 데이터에 대한 갈증이 매우 심한 것으로 악명 높습니다. AI에게 태아 심장 결함을 찾도록 가르치려면 일반적으로 수천 장의 이미지가 필요하며, 이는 의료 전문가들이 공들여 주석을 단 것입니다. 이는 단순히 지루한 작업일 뿐만 아니라 엄청나게 비용이 많이 들며, 때로는 전문 방사선과 의사의 시간당 비용이 150달러를 초과하기도 합니다. 더욱이 엄격한 개인 정보 보호 규정으로 인해 방대한 의료 데이터셋을 수집하는 것이 불가능한 경우가 많습니다.
여기서 우리는 Few-Shot Learning (FSL)이라는 제약 조건에 도달합니다. FSL은 뛰어난 학생에게 문제의 예시를 세 개 또는 다섯 개만 보여주고 최종 시험을 잘 치르기를 기대하는 것과 같은 AI의 동등물입니다. FSL은 일반적인 이미지 분류에서 성공을 거두었지만, 초음파 영상에서 객체 탐지(여러 객체 주위에 경계 상자를 찾는 것)에 적용하는 것은 악몽과 같습니다. 초음파는 심각한 Domain Shift, 즉 서로 다른 장비, 다른 프로브 각도, 그리고 내재된 스페클 노이즈로 인해 어려움을 겪습니다.
그렇다면 저자들의 "아하!" 동기는 무엇이었을까요? 그들은 초음파 영상이 지저분하고 예측 불가능하지만, 인간의 해부학은 그렇지 않다는 점을 깨달았습니다. 공간적 위상(장기가 서로 상대적으로 어디에 위치하는지)과 해부학적 맥락은 불변(invariant)합니다. 저자들은 이러한 불변의 인간 해부학을 신경망에 수학적으로 하드코딩할 수 있다면, 모델이 노이즈에 혼란스러워하지 않을 것이라고 가정했습니다.
수학적 해석: TRR-CCM
이를 해결하기 위해 저자들은 TRR-CCM(Topological Relationship Reasoning with Circular Channel Mamba)이라는 이중 엔진 아키텍처를 설계했습니다. 생물학을 수학으로 어떻게 변환했는지 자세히 살펴보겠습니다.
1. Circular Channel Mamba (CCM)
표준 비전 모델은 막대한 계산 능력을 요구하지 않고는 "큰 그림"을 보는 데 어려움을 겪는 경우가 많습니다. 저자들은 Structured State Space Models (SSMs)에 기반한 최첨단 시퀀스 모델링 프레임워크인 Mamba를 활용했습니다. 표준 SSM은 은닉 상태 $h(t)$를 통해 1D 시퀀스 $x(t)$를 $y(t)$로 매핑합니다.
$$h_t = \overline{A}h_{t-1} + \overline{B}x_t, \quad y_t = C h_t$$
여기서 $\overline{A}$와 $\overline{B}$는 이산 시간 파라미터입니다.
그러나 비전을 위한 표준 Mamba에는 치명적인 결함이 있습니다. 바로 채널 정보(특징 맵의 깊이)를 무시한다는 것입니다. 이를 해결하기 위해 저자들은 CCM을 발명했습니다. 이미지를 Mamba에 입력하기 전에, 컨볼루션 연산을 사용하여 네트워크가 교차 채널 정보를 집계하도록 강제합니다.
$$\overline{X}(c, m, n) = \sum_{i=0}^{K-1} \sum_{j=0}^{K-1} X_{c, m+i, n+j} \cdot W_{c, i, j}$$
이 방정식은 본질적으로 "시퀀스를 보기 전에 모든 채널의 특징을 혼합하여 컨텍스트가 손실되지 않도록 합니다."라고 말합니다. 그런 다음 Mamba 블록을 통해 이 전역 컨텍스트를 인코딩합니다.
$$\hat{X} = Mamba(LN(X^T))$$
마지막으로 잔차 연결을 통해 이 풍부해진 특징을 원래 입력에 다시 추가합니다. $X_{out} = CCM(X + \hat{X}')$.
2. Topological Relationship Reasoning (TRR)
이것이 해부학적 지도가 구축되는 곳입니다. 저자들은 각 "노드"가 잠재적인 해부학적 구조인 Graph Convolutional Network (GCN)을 사용합니다. 하지만 AI는 이러한 구조들이 서로 어떻게 관련되어 있는지 어떻게 알 수 있을까요?
극좌표계를 사용하여 두 영역 제안 $(x_i, y_i)$와 $(x_j, y_j)$ 사이의 정확한 거리 $d$와 각도 $\theta$를 계산합니다.
$$d = \sqrt{(x_i - x_j)^2 + (y_i - y_j)^2}, \quad \theta = \arctan\left(\frac{y_j - y_i}{x_j - x_i}\right)$$
이러한 원시 숫자를 단순히 네트워크에 입력하는 것이 아닙니다. 이 위상 데이터를 가우시안 커널을 통과시켜 관계 가중치를 생성합니다.
$$\omega_m(P(i, j)) = \exp\left(-\frac{1}{2}(P(i, j) - u_m)^T \Sigma_m^{-1} (P(i, j) - u_m)\right)$$
이 아름다운 방정식은 동적 관련성 필터 역할을 합니다. 이는 예상되는 해부학적 거리와 각도를 기반으로 한 장기가 다른 장기에 얼마나 주의를 기울여야 하는지를 수학적으로 결정합니다. 마지막으로, 정보는 그래프 전체에 집계됩니다.
$$f'_m(i) = \sum_{j \in Neighbour(i)} \omega_m(P(i, j)) x_j e_{ij}$$
실험 환경 및 "희생양"
저자들은 자신의 수학이 작동한다고 주장하는 데 그치지 않고, 이를 증명하기 위해 가혹한 실험 과정을 설계했습니다. 그들은 두 가지 독특하고 매우 복잡한 데이터셋, 즉 TT(태아 뇌)와 3VT(태아 심장)에 대해 모델을 테스트했습니다. 그들은 1, 2, 3, 5, 10-shot 설정과 같은 극심한 데이터 부족 조건에서 모델을 평가했습니다.
"희생양"은 TFA, FSCE, DeFRCN, TKR과 같은 강력한 모델을 포함한 9개의 최첨단 Few-Shot Object Detection 기준선이었습니다.
그들의 성공에 대한 결정적이고 부인할 수 없는 증거는 단순히 종합 순위표뿐만 아니라, ablation study(표 3)였습니다. 모델을 기본 구성 요소로 축소함으로써, CCM 또는 TRR 단독을 추가하는 것만으로도 성능이 향상되었지만, 이를 결합했을 때 시너지 효과가 폭발적으로 나타났음을 입증했습니다. 예를 들어, 1-shot TT 데이터셋에서 기준선은 67.4%를 기록했습니다. CCM을 추가하면 68.8%로 상승했고, TRR을 추가하면 68.5%로 상승했지만, 이를 결합하자 점수는 71.3%로 급등했습니다.
솔직히 말해서, TRR 모듈이 뇌 데이터셋(TT)에 비해 심장 데이터셋(3VT)에서 CCM 모듈보다 훨씬 더 높은 성능을 보인 이유를 완전히 확신할 수는 없지만, 추측하자면 태아 심장의 삼혈관 기관지(three-vessel trachea) 뷰가 뇌 구조보다 훨씬 더 엄격하고 예측 가능한 공간 기하학을 가지고 있어, 극좌표 그래프 추론이 그곳에서 특히 치명적이었기 때문일 가능성이 높습니다.
향후 발전을 위한 논의 주제
이 논문에서 제시된 탁월한 기초를 바탕으로, 향후 비판적 사고와 발전을 위한 몇 가지 방안은 다음과 같습니다.
- 병리학적 이상 현상의 역설: TRR의 핵심 강점은 불변의 인간 해부학에 의존한다는 것입니다. 하지만 해부학이 근본적으로 잘못되었다면 어떻게 될까요? 태아가 심각한 선천성 결함(예: 혈관 전위증)을 가지고 있다면, TRR의 엄격한 가우시안 커널이 "정상" 위상 사전(prior)을 위반하기 때문에 탐지를 억제할까요? 우리는 그래프 추론을 노이즈 필터링 견고성을 잃지 않으면서 이상 현상을 탐지할 수 있도록 충분히 유연하게 만드는 방법에 대해 논의해야 합니다.
- 교차 양식 위상 투영: 고해상도 MRI 또는 CT 스캔에서 깨끗하고 완벽한 위상 그래프를 추출하여 이 초음파 모델의 잠재 공간으로 수학적으로 투영할 수 있을까요? 공간 수학이 진정으로 불변이라면, 노이즈가 많은 초음파에서 그래프를 학습할 필요가 없을 것입니다. 우리는 더 우수한 영상 양식에서 "Ground Truth" 그래프를 가져올 수 있습니다.
- 2D 공간에서 1D 시퀀스 모델의 한계: Mamba는 본질적으로 1D 시퀀스 모델입니다. 저자들은 CCM에 입력하기 위해 2D 초음파 특징을 평탄화했습니다. 계산적으로 효율적이지만, 평탄화는 네이티브 2D 공간 연속성을 파괴합니다. 흥미로운 미래 방향은 시퀀스 평탄화가 필요하지 않은 네이티브 2D 연속 상태 공간 모델을 공식화하는 것이며, 이는 해부학적 경계를 훨씬 더 정확하게 포착할 수 있을 것입니다.
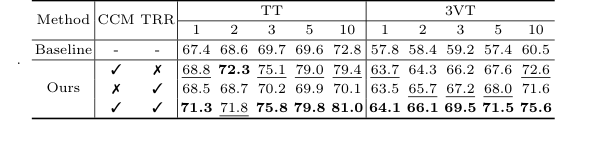 Table 3. shows the ablation studies of the CCM and TRR modules on data split 1 of the TT and 3VT datasets. As shown in Table 3, TRR outperformed CCM on the 3VT dataset, while CCM outperformed TRR on the TT dataset. Both components improve our model’s performance, validating the effectiveness of TRR-CCM. Specifically, the addition of CCM only achieves a significant im- provement over the baseline method by 1.4% to 9.4% on TT dataset, and 5.9% to 12.1% on 3VT dataset, respectively. Only by adding the TRR, it outperforms the baseline on most of the shots of TT, while the 3VT dataset sees an improve- ment of over 5.7% in all cases. When both CCM and TRR are included, our method boosts by 3.9%, 3.2%, 6.1%, 10.2%, and 8.2% in the cases of 1, 2, 3, 5, and 10 shot on data split 1 of TT, respectively
Table 3. shows the ablation studies of the CCM and TRR modules on data split 1 of the TT and 3VT datasets. As shown in Table 3, TRR outperformed CCM on the 3VT dataset, while CCM outperformed TRR on the TT dataset. Both components improve our model’s performance, validating the effectiveness of TRR-CCM. Specifically, the addition of CCM only achieves a significant im- provement over the baseline method by 1.4% to 9.4% on TT dataset, and 5.9% to 12.1% on 3VT dataset, respectively. Only by adding the TRR, it outperforms the baseline on most of the shots of TT, while the 3VT dataset sees an improve- ment of over 5.7% in all cases. When both CCM and TRR are included, our method boosts by 3.9%, 3.2%, 6.1%, 10.2%, and 8.2% in the cases of 1, 2, 3, 5, and 10 shot on data split 1 of TT, respectively
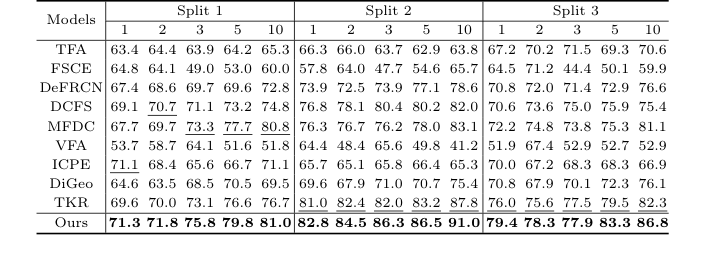 Table 1. Detection results for the TT dataset under the three settings. Bold and underlined numbers denote the 1st and 2nd scores
Table 1. Detection results for the TT dataset under the three settings. Bold and underlined numbers denote the 1st and 2nd scores
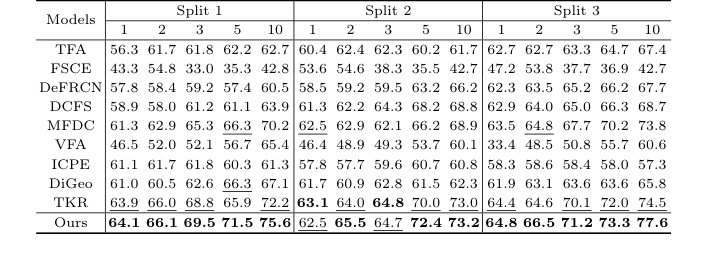 Table 2. Detection results for the 3VT dataset under the three settings. Bold and underlined numbers denote the 1st and 2nd scores
Table 2. Detection results for the 3VT dataset under the three settings. Bold and underlined numbers denote the 1st and 2nd scores
다른 필드와의 동형 사상
선형 상태-공간 시퀀스 모델링과 기하학적 가중치 그래프 네트워크를 융합하여, 불변의 공간적 관계를 기반으로 고도로 노이즈가 많은 환경 내에서 희소 타겟의 정체와 위치를 추론하는 하이브리드 메커니즘.
천체물리학 및 외계 행성 탐지
외계 행성 또는 특정 항성 구조를 탐색하는 과정에서 천문학자들은 의료 초음파 이미지에서 발견되는 스페클 노이즈 및 아티팩트와 유사한, 막대한 신호 대 잡음비 문제를 마주한다. 이 맥락에서의 "해부학"은 불변의 궤도 역학 또는 항성계의 고정된 위상 관계이다. 본 논문의 핵심 논리를 적용함으로써, 천체물리학 모델은 상태-공간 메커니즘을 사용하여 시간 경과에 따른 우주 배경 복사를 필터링할 수 있으며, 그래프 컨볼루션 네트워크는 천체 간의 불변 공간 거리 및 각도를 매핑할 수 있다. 이는 알려진 구조화된 객체 군집을 혼란스럽고 이질적인 간섭의 베일 뒤에서 찾아내는 문제와 완벽하게 대칭적인 관계를 이룬다.
금융 시장 미시구조
고빈도 거래에서 조직적인 자산 축적을 탐지하는 것은 노이즈의 바다 속에서 숨겨진 구조를 찾는 것과 같다. 여기서 "공간적 위상"은 서로 다른 자산군 간의 불변 상관관계 네트워크(예: 국채 수익률, 미국 달러, 금 간의 역사적으로 고정된 관계)로 번역된다. "초음파 노이즈"는 진정한 시장 방향을 가리는 불규칙하고 대량의 개인 투자자 거래이다. 본 논문의 정확한 프레임워크를 사용하여, 금융 모델은 거시 경제 변화의 "해부학"을 매핑할 수 있으며, 희귀한 시장 붕괴의 레이블이 지정된 예시인 역사적 데이터가 극도로 부족한 경우에도 그래프 네트워크를 사용하여 자산 가격 변동 전반에 걸쳐 구조적 일관성을 강제할 수 있다.
지구물리학자가 지각 활동을 연구하며 내일 이 논문의 정확한 위상 추론 방정식을 "훔친다면" 어떻게 될까? 구체적으로, 만약 그들이 가우시안 가중 극좌표 그래프를 재활용한다면:
$$ \omega_m(P(i, j)) = \exp(-\frac{1}{2}(P(i, j) - u_m)^T \Sigma_m^{-1} (P(i, j) - u_m)) $$
이때 노드 $i$와 $j$는 태아 심장의 방을 매핑하는 대신 지진 감지기 스테이션을 나타낼 것이며, "해부학적 구조"는 지구 지각 깊숙한 곳의 숨겨진 단층선이 될 것이다. 이러한 소수 샘플 위상 추론을 활용함으로써, 수십 년간의 방대한 주석이 달린 지진 역사 데이터셋의 필요성을 완전히 우회하고, 단 몇 개의 희소한 지진 측정값만을 사용하여 지도화되지 않은 지하 구조를 정확하게 매핑하거나 희귀한 지진 군집을 예측할 수 있다.
궁극적으로, 본 논문은 인간의 심장 내부의 숨겨진 방, 멀리 떨어진 은하계 간의 보이지 않는 중력 웹, 또는 우리 행성의 지하 균열을 매핑하든, 불변의 위상 추론의 수학은 아름답게 동일하게 유지된다는 것을 증명하며, 보편적 구조 라이브러리에 심오한 청사진을 기여한다.