Анатомическая структура малопримерочного обнаружения с использованием расширенных знаний человеческой анатомии на ультразвуковых изображениях
В области анализа медицинских изображений достигнут значительный прогресс благодаря глубокому обучению.
Предыстория и академическая родословная
В области анализа медицинских изображений достигнут значительный прогресс благодаря глубокому обучению. Однако специфическая проблема, рассматриваемая в данной статье, проистекает из серьезного реального узкого места: "голода" по данным. Традиционно для обучения ИИ обнаружению фетальных органов на ультразвуковых изображениях требуются обширные наборы данных. Эти наборы данных должны быть тщательно аннотированы высококвалифицированными врачами, что является чрезвычайно трудоемким и дорогостоящим процессом (часто превышающим 150 долларов США в час экспертного труда). Кроме того, строгие этические нормы и правила конфиденциальности делают сбор и обмен большими объемами данных пациентов практически невозможными.
Чтобы обойти эту нехватку данных, академическое сообщество переключилось на "обучение с малым числом примеров" (few-shot learning) — парадигму, разработанную для обучения моделей с использованием лишь небольшого количества примеров. Хотя обучение с малым числом примеров добилось больших успехов в базовых задачах, таких как классификация всего изображения или выделение одного органа (семантическая сегментация), оно исторически игнорировало гораздо более сложную задачу обнаружения нескольких объектов на ультразвуковых изображениях. Авторы признали этот пробел и инициировали данное исследование, чтобы применить обучение с малым числом примеров для обнаружения объектов в сложных мультиорганных ультразвуковых средах.
Авторы были вынуждены написать эту статью, поскольку предыдущие подходы столкнулись с двумя фундаментальными ограничениями:
1. Уязвимость к сдвигам домена: Ультразвуковые изображения известны своей "шумностью". Они подвержены сильным вариациям в зависимости от марки аппарата, угла наклона датчика оператором и присущего им спекл-шума. Предыдущие модели обучения с малым числом примеров не смогли обобщить эти вариации, поскольку им не хватало единого понимания анатомии человека для привязки своих предсказаний.
2. Архитектурные "слепые зоны" в современных последовательных моделях: Недавно высокоэффективная архитектура ИИ под названием "Mamba" (основанная на моделях пространства состояний) стала популярной для обработки длинных последовательностей данных. Однако предыдущие методы на основе Mamba фокусировались только на пространственных корреляциях и полностью игнорировали "канальную информацию" (глубокие, многослойные представления признаков). Этот недостаток смешивания каналов вызывал проблемы со стабильностью в более крупных сетях и серьезно ограничивал способность модели понимать глобальный контекст анатомических структур.
Чтобы сделать высокоспециализированные концепции данной статьи интуитивно понятными, здесь приведены четыре ключевых термина из предметной области, переведенные в повседневные аналогии:
- Обучение с малым числом примеров (Few-Shot Learning): Представьте, что вы учите ребенка, что такое "утконос". Вам не нужно показывать ему 10 000 картинок; достаточно трех или четырех хороших фотографий, чтобы он смог распознать его в дикой природе. Обучение с малым числом примеров пытается дать ИИ эту же способность, подобную человеческой, учиться на очень ограниченном количестве примеров, вместо того чтобы полагаться на огромные наборы данных.
- Сдвиг домена (Domain Shift): Подумайте о прослушивании вашей любимой песни, воспроизводимой на дешевом радио с помехами, по сравнению с высококачественной концертной звуковой системой. Сама песня остается той же, но качество звука и искажения сильно различаются. На ультразвуковых изображениях различные аппараты и врачи создают "сдвиг домена", который легко сбивает с толку стандартные модели ИИ.
- Рассуждение о топологических отношениях (Topological Relationship Reasoning, TRR): Представьте, что вы пытаетесь собрать пазл в тускло освещенной комнате. Даже если вы не видите кусочки четко, вы логически знаете, что кусочек "дымохода" должен соединяться с кусочком "крыши". TRR дает ИИ подобную логическую карту: он использует фиксированное, естественное расположение человеческих органов (например, сердце всегда находится рядом с легкими), чтобы находить структуры, даже когда ультразвуковое изображение размыто.
- Селективные модели пространства состояний (Selective State Space Models, SSMs): Представьте себе занятого юриста, читающего 500-страничный юридический документ. Вместо того чтобы запоминать каждое слово, он выборочно выделяет только критические положения и игнорирует бесполезный наполнительный текст. SSMs делают это с данными, динамически отфильтровывая нерелевантный шум для чрезвычайно быстрой и эффективной обработки информации.
Ниже приведено описание ключевых математических обозначений, использованных при формулировании решения авторов:
| Обозначение | Тип | Описание |
|---|---|---|
| $x(t), y(t)$ | Переменная | Одномерные входные и выходные последовательности, обрабатываемые моделью пространства состояний. |
| $h(t)$ | Переменная | Скрытое состояние, которое отображает входную последовательность в выходную. |
| $A, B$ | Параметр | Параметры непрерывного времени, управляющие линейной инвариантной по времени системой. |
| $\overline{A}, \overline{B}$ | Параметр | Параметры дискретного времени, полученные из их непрерывных аналогов для вычислений. |
| $\Delta$ | Параметр | Параметр временного масштаба, используемый для дискретизации непрерывных параметров. |
| $X$ | Переменная | Входной тензор, представляющий признаки изображения, определенный как $X \in \mathbb{R}^{B \times C \times H \times W}$. |
| $B, C, H, W$ | Параметр | Размеры карты признаков: размер пакета (Batch size), количество каналов (Channels), высота (Height) и ширина (Width). |
| $G = \langle \mathcal{N}, \mathcal{E} \rangle$ | Переменная | Неориентированный граф "регион-к-региону", где узлы $\mathcal{N}$ — это предложения регионов, а ребра $\mathcal{E}$ — отношения. |
| $z_i$ | Переменная | Представление латентного пространства визуальных признаков для конкретного узла $i$. |
| $\omega_m(P(i, j))$ | Переменная | Функция Гауссова ядра, которая кодирует пространственное расстояние и угол между двумя анатомическими областями. |
Определение проблемы и ограничения
Представьте, что вы пытаетесь найти определенный набор ключей в темной, туманной комнате. А теперь представьте, что вы видели, как эти ключи выглядят, всего три или пять раз за всю свою жизнь. Это, по сути, задача обнаружения объектов в условиях малого количества примеров (few-shot object detection) при анализе медицинских ультразвуковых изображений.
Чтобы понять масштаб проблемы, которую решает данная статья, нам сначала необходимо точно определить, где мы находимся, куда хотим попасть и почему путь между этими двумя точками столь опасен.
Исходная точка и целевое состояние
Входные данные (текущее состояние): Системе подается необработанное, сильно зашумленное ультразвуковое изображение, в частности, фетальные ультразвуковые снимки (например, мозга или сердца). Вместе с этим модель получает чрезвычайно ограниченный набор аннотированных примеров (всего 1, 3, 5 или 10 "выстрелов") новых анатомических структур, которые ей необходимо изучить. Математически входные данные представляют собой высокоразмерный тензор визуальных признаков $X \in \mathbb{R}^{B \times C \times H \times W}$, где $B$ — размер пакета (batch size), $C$ — количество каналов, а $H$ и $W$ — пространственные размеры.
Выходные данные (целевое состояние): Модель должна выдать точные ограничивающие рамки (bounding boxes) и оценки классификации для множества анатомических структур на этом размытом изображении. Это представлено в виде матрицы региональных предсказаний $S \in \mathbb{R}^{N \times C}$, где $N$ — количество предложенных областей (region proposals), а $C$ — количество классов.
Математический разрыв: Отсутствующим звеном является надежная функция отображения, которая может связать $X$ с $S$ без переобучения на крошечном обучающем наборе данных. Стандартные модели глубокого обучения отображают это пространство, полагаясь на миллионы обновлений параметров, управляемых массивными наборами данных. В сценарии с малым количеством примеров математическое пространство сильно недоопределено. У модели просто недостаточно точек данных для изучения сложных, нелинейных границ между различными анатомическими классами в высокоразмерном пространстве. Авторам необходимо искусственно ограничить пространство гипотез с использованием априорных знаний, чтобы модель могла правильно угадывать, даже когда она видела мало данных.
Мучительная дилемма
В искусственном интеллекте решение одной проблемы почти всегда нарушает другую. Для обнаружения объектов на размытых ультразвуковых изображениях модели отчаянно нужен "глобальный контекст" — ей необходимо рассматривать все изображение целиком, чтобы понять, где она находится, а не просто смотреть на небольшой участок пикселей.
Исторически исследователи сталкивались здесь с жестоким компромиссом:
1. Путь Трансформеров: Можно использовать механизмы самовнимания (self-attention mechanisms), такие как Трансформеры, для захвата дальних зависимостей по всему изображению. Однако вычислительная сложность растет квадратично с размером изображения. В высокоразрешающей медицинской визуализации это требует экспоненциально больше памяти и вычислений, что делает его непрактичным для стандартного клинического оборудования.
2. Путь Mamba: Недавно исследователи представили модели структурированного пространства состояний (Structured State Space Models, SSM), в частности "Mamba", которые снижают сложность моделирования последовательностей до линейного масштаба. Это быстро и эффективно. Однако дилемма возвращается: предыдущие методы на основе Mamba сильно фокусируются на пространственных корреляциях, но полностью пренебрегают смешиванием каналов. В нейронных сетях различные каналы представляют различные изученные признаки (например, края, текстуры или специфические формы). Игнорируя взаимодействие этих каналов, архитектура Mamba страдает от серьезных проблем со стабильностью в более крупных сетях и теряет способность моделировать богатую, глобальную семантическую информацию.
Вы в ловушке: выбирайте Трансформеры и исчерпайте память, или выбирайте стандартную Mamba и потеряйте глубокие взаимодействия признаков, необходимые для отличия крошечного сосуда сердца от фонового шума.
Жесткие стены
Помимо архитектурной дилеммы, авторы столкнулись с несколькими суровыми, реалистичными препятствиями, которые делают эту конкретную проблему невероятно сложной для решения:
1. Экстремальная разреженность данных (стена этики/трудоемкости)
Глубокое обучение процветает на больших данных, но медицинские данные заблокированы строгими этическими нормами и правилами конфиденциальности. Даже если вы получите данные, их разметка требует участия специализированных медицинских экспертов. Аннотировать ультразвуковые изображения с помощью краудсорсинга невозможно. Это создает жесткий потолок для размера набора данных, заставляя модель учиться почти ничему.
2. Физика ультразвука (стена сдвига домена)
Ультразвук по своей природе несовершенен. Изображения страдают от внутренних артефактов физического шума, в частности, от низкого контраста и спекл-шума. Более того, изображения выглядят совершенно по-разному в зависимости от настроек частоты/усиления аппарата, а также от конкретного угла наклона и давления датчика врача. Это создает массивные "сдвиги домена". Модель, обученная на нескольких изображениях из Больницы А, полностью откажет на изображениях из Больницы Б, потому что лежащее в основе распределение пикселей фундаментально изменено физикой аппарата и оператором.
3. Топологическая слепота стандартного ИИ
Стандартные детекторы объектов рассматривают каждый объект как независимую сущность. Если он ищет "трахею" и "сосуд", он ищет их независимо. Но человеческая анатомия так не работает. Пространственно-топологические отношения в человеческом теле инвариантны — сердце всегда связано с определенными сосудами в определенной геометрической конфигурации. Стандартные модели "слепы" к этому биологическому ограничению. Если модель не может математически закодировать правило, что "Объект А должен находиться под определенным углом и на определенном расстоянии от Объекта Б", она легко будет обманута спекл-шумом ультразвука, предсказывая анатомические структуры в невозможных местах.
Почему этот подход
Анализ ультразвуковых изображений традиционно представляет собой сложную задачу. Они подвержены внутренним артефактам, таким как спекл-шум, низкий контраст и значительные сдвиги домена, вызванные различными операторами или настройками аппарата. В сочетании с "few-shot" обучением, когда модель получает лишь небольшое количество размеченных примеров для обучения, традиционные методы глубокого обучения просто не справляются.
Авторы пришли к критически важному осознанию: стандартные state-of-the-art (SOTA) модели пытаются изучить все исключительно на основе пиксельных данных. Однако в ультразвуке пиксели ненадежны. В то же время, человеческая анатомия инвариантна. Пространственные взаимоотношения между органами не меняются только потому, что ультразвуковой датчик был расположен под странным углом. Это привело к созданию TRR-CCM — модели, которая сочетает извлечение визуальных признаков с жестко закодированными анатомическими правилами.
Итак, почему именно этот математический подход оказался единственным жизнеспособным решением? Авторы признали, что, хотя современные архитектуры моделирования последовательностей, такие как Mamba, отлично справляются с извлечением ключевой семантики из длинных последовательностей, стандартная Mamba имеет фатальный недостаток: она почти полностью фокусируется на пространственных корреляциях и пренебрегает информацией о каналах. В сложной медицинской визуализации такое отсутствие смешивания каналов вызывает проблемы со стабильностью в более крупных сетях и серьезно ограничивает способность модели охватить общую картину. Для решения этой проблемы они разработали Circular Channel Mamba (CCM). Расширяя механизм Selective Structured State Space Model (SSM) на размерность каналов, CCM улавливает межканальные зависимости признаков. Математически переходы скрытого состояния определяются как:
$$h_t = \overline{A}h_{t-1} + \overline{B}x_t$$
Эта конкретная формулировка позволяет модели динамически фильтровать входную информацию, эффективно снижая сложность моделирования последовательностей с тяжелой $O(N^2)$ (типичной для стандартных Трансформеров) до высокоэффективной $O(N)$.
Сравнительное превосходство этого метода заключается в его двухдвигательной структуре. Помимо достижения более высоких показателей mean average precision (mAP) по сравнению с 9 базовыми методами, он качественно превосходит их, поскольку не просто "смотрит" на изображение, а "рассуждает" о нем. Для обработки высокоразмерного шума ультразвука модель использует Topological Relationship Reasoning (TRR). Она строит неориентированный граф "область к области" $G = \langle \mathcal{N}, \mathcal{E} \rangle$, где узлы представляют предложенные области, а ребра — взаимоотношения между ними. Пропуская пространственные координаты через Gaussian kernel, модель вычисляет веса взаимоотношений:
$$\omega_m(P(i, j)) = \exp(-\frac{1}{2}(P(i, j) - u_m)^T \Sigma_m^{-1} (P(i, j) - u_m))$$
Это означает, что даже если визуальные признаки плода скрыты спекл-шумом, Graph Convolutional Network (GCN) может определить его местоположение и класс, полагаясь на четкое присутствие окружающих структур. Это структурное преимущество делает его подавляюще превосходящим предыдущие золотые стандарты, которые рассматривают каждую ограничивающую рамку изолированно.
Этот метод идеально соответствует жестким ограничениям few-shot детектирования в медицине. Разметка массивных медицинских наборов данных требует специализированных экспертов, что может легко стоить более 150 долларов США в час, делая большие наборы данных этически и финансово ограниченными. Здесь "брак" заключается между дефицитом данных в задаче и использованием моделью инвариантных априорных знаний. Поскольку модель уже "знает" пространственную топологию человеческой анатомии через модуль TRR, ей требуется значительно меньше примеров для обучения обнаружению новых классов.
Честно говоря, я не до конца уверен, почему авторы не обсуждали явно отказ от других популярных генеративных подходов, таких как GANs или Diffusion models, для данной конкретной задачи, поскольку в статье они не упоминаются. Однако они явно объясняют причины отказа от предыдущих методов на основе Mamba и стандартных CNN: эти более старые архитектуры либо не смешивают информацию о каналах должным образом, либо не имеют механизма линейного сканирования, необходимого для эффективной обработки сложных глобальных контекстов без взрывного роста вычислительных затрат. Объединив линейную эффективность CCM с анатомическими ограничениями TRR, они создали уникально надежную систему, специально адаптированную для беспощадной области ультразвуковой визуализации.
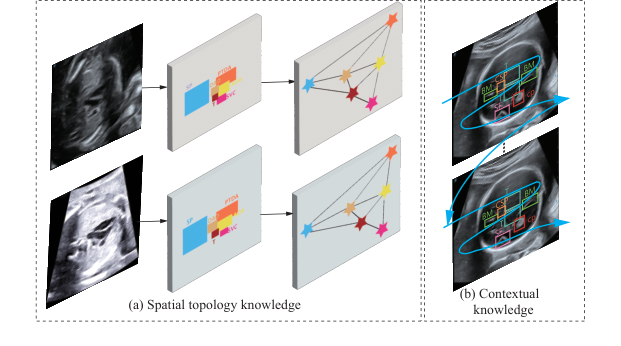 Figure 1. Consistency of two fixed knowledge from human anatomy. (a) Spatial topology knowledge. (b) Contextual knowledge
Figure 1. Consistency of two fixed knowledge from human anatomy. (a) Spatial topology knowledge. (b) Contextual knowledge
Математический и логический механизм
Чтобы понять гениальность данной работы, сначала необходимо осознать фундаментальную проблему медицинской ультразвуковой визуализации. Представьте, что вы пытаетесь найти определенное созвездие на ночном небе, которое постоянно меняется, скрыто густыми облаками и наблюдается через грязный телескоп. Ультразвуковые изображения, как известно, зашумлены, размыты и сильно зависят от врача, держащего датчик.
Обычно глубокое обучение решает эту проблему, анализируя сотни тысяч размеченных примеров. Однако в медицинской сфере у нас просто нет такого количества аннотированных данных — это проблема обучения на малом числе примеров (few-shot learning). Так как же научить ИИ находить органы плода всего по нескольким примерам?
Авторы этой работы осознали нечто глубокое: анатомия человека — это фиксированная карта. Даже если изображение ужасно размыто, сердце всегда находится в определенном пространственном отношении к позвоночнику. Принуждая нейронную сеть подчиняться инвариантным законам человеческой топологии и контекстной памяти, они компенсируют недостаток данных. Для достижения этой цели они создали двуядерный математический движок: Circular Channel Mamba (CCM) для контекстной памяти и Topological Relationship Reasoning (TRR) для пространственного картирования.
Далее следует подробный разбор того, как эта система работает на самом деле.
Основные уравнения
Основная часть этой работы обеспечивается двумя взаимосвязанными математическими движками.
Движок 1: Контекстная память (Structured State Space Model)
Это уравнение позволяет модели сканировать изображение и "запоминать", что она только что видела, формируя контекстное понимание ткани.
$$h_t = \overline{A}h_{t-1} + \overline{B}x_t$$
$$y_t = Ch_t$$
Движок 2: Анатомическая топология (Graph Reasoning)
Это настоящий прорыв данной работы. Как только модель находит кандидатные органы, она использует свертку графа с Гауссовым взвешиванием для проверки соответствия их пространственного расположения анатомии человека.
$$f'_m(i) = \sum_{j \in Neighbour(i)} \omega_m(P(i, j)) x_j e_{ij}$$
$$\omega_m(P(i, j)) = \exp\left(-\frac{1}{2}(P(i, j) - u_m)^T \Sigma_m^{-1} (P(i, j) - u_m)\right)$$
Разбираем уравнения
Разберем каждый винтик и пружинку в этих уравнениях.
Из Движка 1 (Контекст Mamba):
* $x_t$: Входные данные на шаге $t$. Физически это конкретный участок ультразвукового изображения, который обрабатывается.
* $h_t, h_{t-1}$: Скрытые состояния. Это "рабочая память" модели. $h_{t-1}$ хранит контекст участков изображения, увиденных непосредственно перед текущим.
* $\overline{A}$: Дискретизированная матрица перехода состояний. Представьте это как "вентиль забывания/сохранения". Она определяет, какая часть предыдущего анатомического контекста должна быть сохранена.
* $\overline{B}$: Дискретизированная входная матрица. Она действует как "фильтр внимания", определяя, насколько текущий участок изображения $x_t$ должен обновить память.
* $y_t$: Выходное представление признаков для данного конкретного участка, обогащенное глобальным контекстом.
* $C$: Матрица выходной проекции, которая преобразует скрытую память обратно в используемые визуальные признаки.
* Почему сложение ($+$), а не умножение? Обновление состояния использует сложение для плавного накопления информации во времени. Умножение привело бы к тому, что память либо экспоненциально быстро уходила бы в бесконечность, либо в ноль.
Из Движка 2 (Топологический граф):
* $f'_m(i)$: Новый обновленный, учитывающий топологию вектор признаков для кандидатного органа (узла $i$).
* $\sum$: Оператор суммирования. Авторы используют здесь интеграл/сумму, а не max-pooling или умножение, потому что они хотят накопить подтверждающие свидетельства от всех окружающих органов. Если сердце, легкие и позвоночник согласны относительно своего положения, их объединенные голоса складываются для повышения уверенности.
* $Neighbour(i)$: Топ-K наиболее релевантных кандидатных органов, окружающих узел $i$.
* $x_j$: Вектор семантических признаков соседнего органа $j$.
* $e_{ij}$: Вес ребра из разреженной матрицы смежности. Он представляет собой сырую, выученную силу связи между органом $i$ и органом $j$.
* $\omega_m(P(i, j))$: Вес Гауссова ядра. Это "резиновая лента" системы. Он выдает высокое значение (близкое к 1), если органы находятся в правильном анатомическом положении, и низкое значение (близкое к 0), если нет.
* $P(i, j)$: Функция полярных координат, возвращающая $(d, \theta)$ — фактическое измеренное расстояние и угол между органом $i$ и органом $j$ на изображении.
* $\exp(...)$: Экспоненциальная функция. Она используется для создания гладкой кривой в форме колокола. Она гарантирует, что пространственный вес плавно убывает, а не резко падает, если орган немного смещен из-за угла ультразвукового датчика.
* $-\frac{1}{2}$: Стандартный математический коэффициент масштабирования для Гауссовых распределений, который обеспечивает чистоту и стабильность вычислений (градиентов) во время обучения.
* $u_m$: Обучаемый вектор среднего размера $2 \times 1$. Физически это "идеальный чертеж" ИИ. Это точное расстояние и угол, которые ИИ ожидает увидеть между двумя конкретными органами на основе анатомии человека.
* $T$: Оператор транспонирования, необходимый для выравнивания векторов для матричного умножения, чтобы результат был одним скалярным расстоянием.
* $\Sigma_m^{-1}$: Обратная матрица ковариационной матрицы размера $2 \times 2$, которая также обучается. Физически это "зона колебаний" или допуск. Некоторые органы сильно смещаются в зависимости от положения плода (высокая дисперсия), в то время как другие жестко зафиксированы (низкая дисперсия). Эта матрица соответствующим образом масштабирует штраф.
Пошаговый поток: сборочная линия
Проследим за одним абстрактным элементом данных — размытым пятном, которое может быть сердцем плода — через эту архитектуру.
- Извлечение сырых данных: Ультразвуковое изображение поступает в базовую сеть. Наше размытое пятно преобразуется в сырой математический тензор (сетку чисел).
- Контекстное сканирование (CCM): Тензор нарезается на последовательности и подается в Circular Channel Mamba. Матрицы $\overline{A}$ и $\overline{B}$ сканируют изображение. По мере обработки пятна математическим движком добавляется контекст: "Я только что прошел мимо текстуры, похожей на позвоночник, поэтому это пятно, вероятно, находится в грудной полости." Пятно становится $y_t$.
- Построение графа (TRR): Пятно теперь является "предложением региона" (узел $i$). Система рассматривает соседние пятна (узел $j$). Она вычисляет $P(i, j)$, обнаруживая, что узел $j$ находится на расстоянии 5 сантиметров под углом 45 градусов.
- Анатомический опрос: Эта координата $(d, \theta)$ подается в Гауссово ядро $\omega_m$. Ядро сравнивает ее с чертежом $u_m$. Поскольку сердце и позвоночник должны находиться под углом 45 градусов в этом конкретном ракурсе, член $(P(i, j) - u_m)$ становится почти нулевым.
- Агрегация свидетельств: Поскольку расстояние близко к нулю, $\exp(0)$ оценивается как 1. Семантические данные $x_j$ позвоночника умножаются на 1 и добавляются ($\sum$) к нашему пятну $i$.
- Финальный вывод: Наше размытое пятно больше не просто пятно. Оно теперь математически слито с абсолютной уверенностью своих окружающих анатомических соседей. Модель уверенно определяет его как сердце плода.
Динамика оптимизации
Как этот механический зверь на самом деле учится всего на нескольких изображениях?
В стандартном обучении на малом числе примеров ландшафт потерь хаотичен. Из-за малого количества данных модель легко переобучается, находя ложные закономерности (например, запоминая статичный шум конкретного ультразвукового аппарата). Градиенты обычно скачут дико.
Однако модуль TRR действует как массивный гравитационный якорь на ландшафте потерь. Во время обучения модель использует стандартный оптимизатор SGD (Stochastic Gradient Descent). Магия происходит в градиентах, которые возвращаются в $u_m$ и $\Sigma_m$.
Изначально $u_m$ (ожидаемые положения органов) рандомизирован. Модель может предположить, что сердце находится вне тела, что приводит к огромной ошибке классификации. Функция потерь посылает крутой градиент обратно, принудительно обновляя $u_m$ для отражения истинных пространственных координат, найденных в нескольких размеченных примерах.
Поскольку анатомия человека очень последовательна, $u_m$ сходится очень быстро. Как только $u_m$ зафиксирован, матрица ковариации $\Sigma_m$ изучает естественную эластичность тканей плода. Это фундаментально изменяет динамику оптимизации: вместо того, чтобы заставлять нейронную сеть учиться тому, как выглядит сердце с нуля, используя миллионы пикселей, градиенты направляются на изучение где сердце должно находиться относительно других структур. Это топологическое ограничение сглаживает локальные минимумы, позволяя модели прекрасно обобщаться на различные ультразвуковые аппараты и пациентов, даже если она видела всего 3 или 5 примеров.
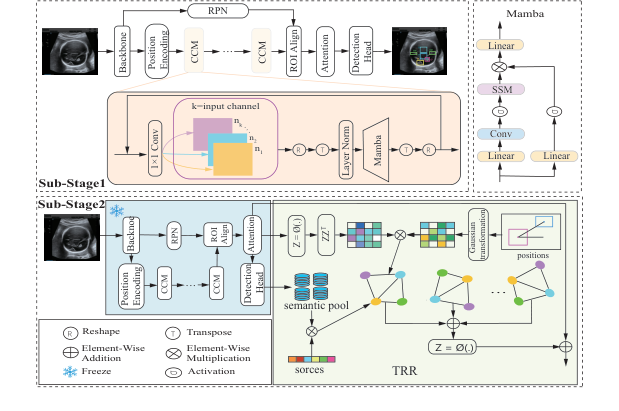 Figure 2. The overall pipeline of the proposed TRR-CCM framework
Figure 2. The overall pipeline of the proposed TRR-CCM framework
Результаты, ограничения и заключение
Представьте, что вы пытаетесь найти определенную, крошечную структуру на зернистом черно-белом изображении телевизионных помех. А теперь представьте, что от вашей точности зависит чья-то жизнь. Это ежедневная реальность анализа ультразвуковых изображений.
Чтобы понять гениальность этой статьи, сначала необходимо установить некоторые базовые истины о современном искусственном интеллекте. Модели глубокого обучения чрезвычайно умны, но они также печально известны своей "голодностью" к данным. Чтобы научить ИИ находить врожденный порок сердца у плода, обычно требуются тысячи изображений, тщательно аннотированных медицинскими экспертами. Это не только утомительно, но и невероятно дорого, иногда стоимость часа работы специализированного рентгенолога достигает 150 долларов. Более того, строгие правила конфиденциальности часто делают сбор массивных медицинских наборов данных невозможным.
Это подводит нас к ограничению: обучение на малом количестве примеров (Few-Shot Learning, FSL). FSL — это эквивалент в мире ИИ, когда вы показываете блестящему студенту всего три или пять примеров задачи и ожидаете, что он сдаст финальный экзамен на отлично. Хотя FSL добился успеха в общей классификации изображений, применение его к обнаружению объектов (поиску ограничивающих рамок вокруг нескольких объектов) на ультразвуковых изображениях — это кошмар. Ультразвуковые исследования страдают от сильных сдвигов домена — разные аппараты, разные углы датчика и присущий им спекл-шум.
Итак, какова была мотивация авторов, их "Эврика!"? Они поняли, что, хотя ультразвуковые изображения шумны и непредсказуемы, человеческая анатомия таковой не является. Пространственная топология (расположение органов относительно друг друга) и анатомический контекст инвариантны. Авторы предположили, что если бы они смогли математически "закодировать" эту инвариантную человеческую анатомию в нейронную сеть, модель не сбивалась бы с толку шумом.
Математическая интерпретация: TRR-CCM
Для решения этой задачи авторы разработали архитектуру с двойным движком под названием TRR-CCM (Topological Relationship Reasoning with Circular Channel Mamba — Рассуждение о топологических отношениях с циклическим канальным Mamba). Давайте разберем, как именно они перевели биологию в математику.
1. Циклический канальный Mamba (CCM)
Стандартные модели зрения часто испытывают трудности с восприятием "общей картины" без значительных вычислительных ресурсов. Авторы обратились к передовой системе моделирования последовательностей под названием Mamba, основанной на структурированных моделях пространства состояний (SSM). Стандартная SSM отображает одномерную последовательность $x(t)$ в $y(t)$ через скрытое состояние $h(t)$:
$$h_t = \overline{A}h_{t-1} + \overline{B}x_t, \quad y_t = C h_t$$
где $\overline{A}$ и $\overline{B}$ — параметры дискретного времени.
Однако стандартный Mamba имеет фатальный недостаток для зрения: он игнорирует информацию о каналах (глубину карт признаков). Чтобы исправить это, авторы изобрели CCM. Перед подачей изображения в Mamba они заставляют сеть агрегировать межканальную информацию с помощью операции свертки:
$$\overline{X}(c, m, n) = \sum_{i=0}^{K-1} \sum_{j=0}^{K-1} X_{c, m+i, n+j} \cdot W_{c, i, j}$$
Это уравнение по сути означает: "Прежде чем рассматривать последовательность, смешайте признаки по всем каналам, чтобы не потерять контекст". Затем они кодируют этот глобальный контекст через блок Mamba:
$$\hat{X} = Mamba(LN(X^T))$$
Наконец, они добавляют этот обогащенный признак обратно к исходному входу через остаточное соединение: $X_{out} = CCM(X + \hat{X}')$.
2. Рассуждение о топологических отношениях (TRR)
Здесь строится анатомическая карта. Авторы используют графовую сверточную сеть (GCN), где каждый "узел" является потенциальной анатомической структурой. Но как ИИ узнает, как эти структуры связаны друг с другом?
Они используют полярные координаты для расчета точного расстояния $d$ и угла $\theta$ между любыми двумя предложенными областями $(x_i, y_i)$ и $(x_j, y_j)$:
$$d = \sqrt{(x_i - x_j)^2 + (y_i - y_j)^2}, \quad \theta = \arctan\left(\frac{y_j - y_i}{x_j - x_i}\right)$$
Они не просто подают эти сырые числа в сеть. Они пропускают эти топологические данные через гауссовское ядро для генерации весов отношений:
$$\omega_m(P(i, j)) = \exp\left(-\frac{1}{2}(P(i, j) - u_m)^T \Sigma_m^{-1} (P(i, j) - u_m)\right)$$
Это элегантное уравнение действует как динамический фильтр релевантности. Оно математически диктует, сколько внимания один орган должен уделять другому, основываясь на их ожидаемом анатомическом расстоянии и угле. Наконец, информация агрегируется по графу:
$$f'_m(i) = \sum_{j \in Neighbour(i)} \omega_m(P(i, j)) x_j e_{ij}$$
Экспериментальная арена и "Жертвы"
Авторы не просто заявили, что их математика работает; они создали безжалостный экспериментальный полигон, чтобы доказать это. Они протестировали свою модель на двух различных, чрезвычайно сложных наборах данных: TT (мозг плода) и 3VT (сердце плода). Они оценили модель в условиях экстремального дефицита данных: в режимах 1, 2, 3, 5 и 10 примеров.
"Жертвами" стали 9 передовых базовых моделей для обнаружения объектов на малом количестве примеров (Few-Shot Object Detection), включая тяжеловесов, таких как TFA, FSCE, DeFRCN и TKR.
Окончательным, неоспоримым доказательством их успеха стала не просто общая таблица лидеров, а абликационное исследование (Таблица 3). Разбирая модель на составные части, они доказали, что добавление только CCM или только TRR улучшило производительность, но их комбинация привела к синергетическому взрыву. Например, на наборе данных TT с 1 примером базовая модель показала результат 67,4%. Добавление CCM повысило его до 68,8%, добавление TRR — до 68,5%, но их комбинация подтолкнула результат до 71,3%.
Честно говоря, я не до конца уверен, почему модуль TRR показал себя значительно лучше модуля CCM на наборе данных сердца (3VT) по сравнению с набором данных мозга (TT), но если бы мне пришлось предположить, это, вероятно, связано с тем, что вид трехсосудистой трахеи сердца плода имеет гораздо более жесткую, предсказуемую пространственную геометрию, чем структуры мозга, что делает рассуждение на основе полярных координат чрезвычайно эффективным в данном случае.
Темы для обсуждения в контексте дальнейшего развития
Основываясь на блестящем фундаменте, заложенном в этой статье, вот несколько направлений для дальнейших критических размышлений и развития:
- Парадокс патологических аномалий: Основная сила TRR заключается в его опоре на инвариантную человеческую анатомию. Но что происходит, когда анатомия фундаментально нарушена? Если у плода есть тяжелый врожденный дефект (например, транспозиция сосудов), подавит ли жесткое гауссовское ядро TRR обнаружение, поскольку отношения нарушают "нормальный" топологический априорный признак? Мы должны обсудить, как сделать графовые рассуждения достаточно гибкими для обнаружения аномалий, не теряя при этом робастности фильтрации шума.
- Проекция топологии между модальностями: Можем ли мы извлечь чистые, идеальные топологические графы из высокоразрешающих МРТ или КТ-сканов и математически спроецировать их в латентное пространство этой ультразвуковой модели? Если пространственная математика действительно инвариантна, нам не нужно будет изучать граф по шумным ультразвуковым изображениям; мы могли бы импортировать "истинный" граф из более совершенной модальности визуализации.
- Пределы одномерных моделей последовательностей в двумерном пространстве: Mamba по своей сути является одномерной моделью последовательностей. Авторы "сплющили" двумерные ультразвуковые признаки, чтобы подать их в CCM. Хотя это вычислительно эффективно, "сплющивание" разрушает нативную двумерную пространственную связность. Интересным направлением для будущих исследований было бы создание нативной двумерной непрерывной модели пространства состояний, которая не требует "сплющивания" последовательности и потенциально может захватывать анатомические границы с еще большей точностью.
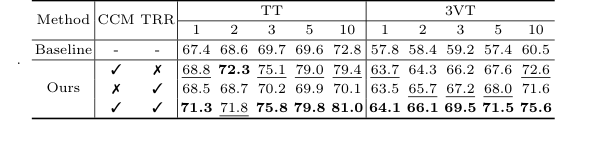 Table 3. shows the ablation studies of the CCM and TRR modules on data split 1 of the TT and 3VT datasets. As shown in Table 3, TRR outperformed CCM on the 3VT dataset, while CCM outperformed TRR on the TT dataset. Both components improve our model’s performance, validating the effectiveness of TRR-CCM. Specifically, the addition of CCM only achieves a significant im- provement over the baseline method by 1.4% to 9.4% on TT dataset, and 5.9% to 12.1% on 3VT dataset, respectively. Only by adding the TRR, it outperforms the baseline on most of the shots of TT, while the 3VT dataset sees an improve- ment of over 5.7% in all cases. When both CCM and TRR are included, our method boosts by 3.9%, 3.2%, 6.1%, 10.2%, and 8.2% in the cases of 1, 2, 3, 5, and 10 shot on data split 1 of TT, respectively
Table 3. shows the ablation studies of the CCM and TRR modules on data split 1 of the TT and 3VT datasets. As shown in Table 3, TRR outperformed CCM on the 3VT dataset, while CCM outperformed TRR on the TT dataset. Both components improve our model’s performance, validating the effectiveness of TRR-CCM. Specifically, the addition of CCM only achieves a significant im- provement over the baseline method by 1.4% to 9.4% on TT dataset, and 5.9% to 12.1% on 3VT dataset, respectively. Only by adding the TRR, it outperforms the baseline on most of the shots of TT, while the 3VT dataset sees an improve- ment of over 5.7% in all cases. When both CCM and TRR are included, our method boosts by 3.9%, 3.2%, 6.1%, 10.2%, and 8.2% in the cases of 1, 2, 3, 5, and 10 shot on data split 1 of TT, respectively
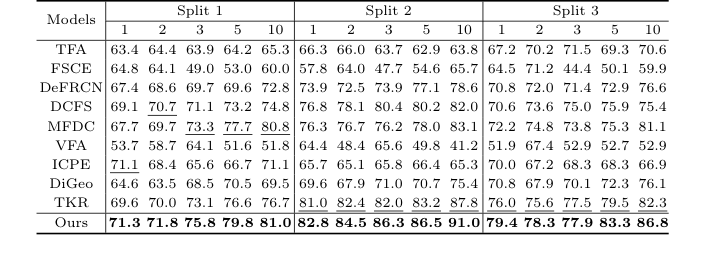 Table 1. Detection results for the TT dataset under the three settings. Bold and underlined numbers denote the 1st and 2nd scores
Table 1. Detection results for the TT dataset under the three settings. Bold and underlined numbers denote the 1st and 2nd scores
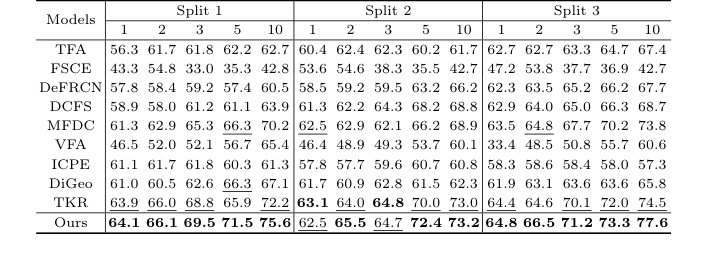 Table 2. Detection results for the 3VT dataset under the three settings. Bold and underlined numbers denote the 1st and 2nd scores
Table 2. Detection results for the 3VT dataset under the three settings. Bold and underlined numbers denote the 1st and 2nd scores
Изоморфизмы с другими полями
Гибридный механизм, объединяющий моделирование последовательностей в линейном пространстве состояний с графовой сетью с геометрическим взвешиванием для выявления идентичности и местоположения разреженных целей в сильно зашумленных средах на основе их инвариантных пространственных отношений.
Астрофизика и обнаружение экзопланет
В поиске экзопланет или специфических звездных формаций астрономы сталкиваются с масштабной проблемой соотношения сигнал/шум, подобно шуму и артефактам, обнаруживаемым в медицинских ультразвуковых изображениях. "Анатомия" в данном контексте представляет собой инвариантную орбитальную механику или фиксированные топологические отношения звездной системы. Применяя основную логику данной статьи, астрофизическая модель могла бы использовать механизмы пространства состояний для фильтрации космического фонового излучения во времени, в то время как сверточная графовая сеть отображала бы инвариантные пространственные расстояния и углы между небесными телами. Это идеальное отражение той же проблемы: поиск известной, структурированной совокупности объектов, скрытой за покровом хаотических, гетерогенных помех.
Микроструктура финансовых рынков
В высокочастотной торговле обнаружение скоординированного институционального накопления активов подобно поиску скрытой структуры в море шума. "Пространственная топология" здесь переводится в инвариантные корреляционные сети между различными классами активов (например, исторически фиксированное отношение между доходностью казначейских облигаций, долларом США и золотом). "Ультразвуковой шум" представляет собой непредсказуемую, высокообъемную розничную торговлю, которая затуманивает истинное направление рынка. Используя точный фреймворк данной статьи, финансовая модель могла бы отобразить "анатомию" макроэкономического сдвига, используя графовую сеть для обеспечения структурной согласованности движений цен активов, даже когда исторические данные (размеченные примеры редких рыночных крахов) крайне скудны.
Что, если бы геофизик, изучающий тектоническую активность, "позаимствовал" точное уравнение топологического рассуждения из этой статьи завтра? В частности, что, если бы они перепрофилировали гауссово-взвешенный граф в полярных координатах:
$$ \omega_m(P(i, j)) = \exp(-\frac{1}{2}(P(i, j) - u_m)^T \Sigma_m^{-1} (P(i, j) - u_m)) $$
Вместо отображения камер плода, узлы $i$ и $j$ представляли бы сейсмические датчики, а "анатомическая структура" — скрытые разломы глубоко в земной коре. Используя это маловыборочное топологическое рассуждение, они могли бы точно картировать некартографированные подземные структуры или прогнозировать редкие рои землетрясений, используя лишь горстку разреженных сейсмических показаний, полностью обходя необходимость десятилетий массивных, аннотированных исторических сейсмических данных.
В конечном итоге, данная статья представляет собой глубокий план для Универсальной Библиотеки Структур, доказывая, что независимо от того, отображаем ли мы скрытые камеры человеческого сердца, невидимые гравитационные сети между далекими галактиками или подземные разломы нашей планеты, математика инвариантного топологического рассуждения остается неизменно прекрасной.