वेसल सेगमेंटेशन के लिए वन-शॉट एक्टिव लर्निंग
चिकित्सा इमेजिंग के क्षेत्र में, मस्तिष्क की रक्त वाहिकाओं का मानचित्रण जिसे वाहिका विभाजन (vessel segmentation) के रूप में जाना जाता है मस्तिष्क के कार्यों को समझने और स्ट्रोक जैसे गंभीर न्यूरोलॉजिकल विकारों का निदान...
पृष्ठभूमि और अकादमिक वंश
चिकित्सा इमेजिंग के क्षेत्र में, मस्तिष्क की रक्त वाहिकाओं का मानचित्रण - जिसे वाहिका विभाजन (vessel segmentation) के रूप में जाना जाता है - मस्तिष्क के कार्यों को समझने और स्ट्रोक जैसे गंभीर न्यूरोलॉजिकल विकारों का निदान करने के लिए एक महत्वपूर्ण कदम है। ऐतिहासिक रूप से, जैसे ही डीप लर्निंग मॉडल इस कार्य के लिए स्वर्ण मानक (gold standard) बने, एक बड़ी बाधा उत्पन्न हुई: ये मॉडल अविश्वसनीय रूप से डेटा-भूखे होते हैं। उन्हें चिकित्सा विशेषज्ञों द्वारा सावधानीपूर्वक एनोटेट किए गए हजारों 3D मस्तिष्क स्कैन की आवश्यकता होती है। जटिल, सूक्ष्म संवहनी नेटवर्क का मैन्युअल रूप से पता लगाना न केवल थकाऊ है, बल्कि निषेधात्मक रूप से महंगा भी है, कभी-कभी प्रति स्कैन विशेषज्ञ श्रम के \$150 या उससे अधिक के बराबर लागत आती है।
इसे कम करने के लिए, क्षेत्र एक्टिव लर्निंग (Active Learning - AL) की ओर मुड़ा, एक प्रतिमान जहां AI सबसे जानकारीपूर्ण अनलेबल नमूनों की पहचान करता है और मानव विशेषज्ञ से केवल उन्हीं को लेबल करने के लिए कहता है। हालांकि, क्लासिकल AL अत्यधिक पुनरावृत्तीय (iterative) है। इसके लिए मॉडल को प्रशिक्षित करने, विशेषज्ञ से लेबल मांगने के लिए रुकने, मॉडल को फिर से प्रशिक्षित करने और फिर से पूछने के चक्र की आवश्यकता होती है। इस निरंतर आगे-पीछे की प्रक्रिया के लिए नैदानिक विशेषज्ञों की निरंतर उपलब्धता की आवश्यकता होती है और भारी कम्प्यूटेशनल ओवरहेड होता है, जिससे वास्तविक समय नैदानिक अनुप्रयोग लगभग असंभव हो जाता है।
मौलिक सीमा जिसने लेखकों को यह पेपर लिखने के लिए मजबूर किया, वह अगले विकासवादी कदम की खामियों में निहित है: वन-शॉट एक्टिव लर्निंग (One-Shot Active Learning - OSAL)। जबकि OSAL एक ही पास में नमूनों का एक न्यूनतम सेट चुनने का प्रयास करता है (आगे-पीछे की प्रक्रिया को समाप्त करता है), पिछले OSAL मॉडल अनिवार्य रूप से "ब्लैक बॉक्स" थे। वे सामान्य डेटा ऑग्मेंटेशन या कंट्रास्टिव लर्निंग पर निर्भर थे, बिना मस्तिष्क की वास्तविक शारीरिक रचना को समझने के किसी स्पष्ट तंत्र के। विशेष रूप से, उन्होंने रक्त वाहिकाओं की आवर्ती, वृक्ष-जैसी संरचनाओं को पूरी तरह से नजरअंदाज कर दिया। क्योंकि ये पुराने मॉडल यह व्याख्या नहीं कर सके कि वे कुछ डेटा बिंदुओं का चयन क्यों कर रहे थे, उन्होंने अक्सर गैर-प्रतिनिधित्व वाले नमूने चुने। इससे ऐसे मॉडल बने जो नए, अनदेखे रोगी डेटा पर सामान्यीकरण (generalize) करने में विफल रहे। लेखकों ने महसूस किया कि इसे ठीक करने के लिए, उन्हें एक OSAL फ्रेमवर्क की आवश्यकता थी जो विशेष रूप से मस्तिष्क वाहिकाओं की अद्वितीय, आवर्ती ज्यामिति के अनुरूप हो।
लेखकों ने इसे सहज रूप से समझने में आपकी सहायता के लिए, यहां मुख्य अवधारणाएं अत्यधिक विशिष्ट डोमेन शब्दों से रोजमर्रा की उपमाओं में अनुवादित की गई हैं:
- वन-शॉट एक्टिव लर्निंग (OSAL): कल्पना कीजिए कि आप एक विशाल, जटिल दावत के लिए किराने का सामान खरीद रहे हैं, लेकिन आपको केवल एक बार स्टोर जाने की अनुमति है। हर बार जब आपको किसी लापता सामग्री का एहसास होता है तो स्टोर पर वापस दौड़ने के बजाय (जो कि पुनरावृत्तीय एक्टिव लर्निंग कैसे काम करती है), आप पहले से ही अपने नुस्खे का सावधानीपूर्वक विश्लेषण करते हैं और एक ही, अत्यधिक कुशल यात्रा में सामग्री का एक पूरी तरह से विविध, न्यूनतम सेट खरीदते हैं।
- डिक्शनरी लर्निंग और एटम (Dictionary Learning & Atoms): इसे एक मास्टर बिल्डर के लेगो सेट की तरह सोचें। कभी बनाए गए हर एकल खिलौना महल या अंतरिक्ष यान के सटीक आकार को याद रखने की कोशिश करने के बजाय, AI केवल मौलिक लेगो ईंटों (जिन्हें "एटम" कहा जाता है) का एक छोटा सेट सीखता है। इन बुनियादी ईंटों को विभिन्न तरीकों से जोड़कर, AI किसी भी जटिल रक्त वाहिका आकार का पुनर्निर्माण कर सकता है जिसका वह सामना करता है।
- लेटेंट स्पेस (Latent Space): एक विशाल, जादुई पुस्तकालय की कल्पना करें जहां किताबें वर्णानुक्रम में क्रमबद्ध नहीं हैं, बल्कि उनके कथानक कितने समान हैं। एक लेटेंट स्पेस एक गणितीय "कमरा" है जहां AI छवि पैच रखता है। समान वाहिका पैटर्न वाले पैच एक-दूसरे के बगल में रखे जाते हैं, जबकि पूरी तरह से अलग पैटर्न दूर धकेल दिए जाते हैं, जिससे डेटा की बड़ी तस्वीर देखना आसान हो जाता है।
- सियामीस एनकोडर (Siamese Encoder): एक ही मामले पर काम कर रहे जुड़वां जासूसों की कल्पना करें। उन्हें दो अलग-अलग सुराग (छवि पैच) दिए जाते हैं। यदि सुराग एक ही संदिग्ध (समान वाहिका पैटर्न) से संबंधित हैं, तो जासूस उन्हें एक छोटी स्ट्रिंग से बांध देते हैं। यदि वे विभिन्न संदिग्धों से संबंधित हैं, तो वे उन्हें दूर धकेल देते हैं। यह एल्गोरिथम सुनिश्चित करता है कि लेटेंट स्पेस पूरी तरह से व्यवस्थित और अत्यधिक विभेदक (discriminative) हो।
यहां समस्या को तैयार करने और हल करने के लिए उपयोग किए गए प्रमुख गणितीय नोटेशन का विवरण दिया गया है:
| नोटेशन | विवरण |
|---|---|
| $\mathcal{I}$ | लेबल किया गया डेटासेट जिसमें छवियां और उनके संबंधित विशेषज्ञ एनोटेशन शामिल हैं। |
| $\mathbf{I}$ | डेटासेट से एक विशिष्ट 3D वॉल्यूमेट्रिक छवि (जैसे, एक एमआरआई मस्तिष्क स्कैन)। |
| $\mathbf{L}$ | छवि $\mathbf{I}$ से जुड़ा ग्राउंड-ट्रुथ लेबल मैप। |
| $H \times W \times S$ | छवि के आयाम (ऊंचाई, चौड़ाई और स्लाइस की संख्या)। |
| $X_k, Y_k$ | गैर-ओवरलैपिंग 2D छवि पैच और उनके संबंधित लेबल पैच। |
| $\mathcal{Y}_{\mathcal{I}}$ | डेटासेट से निकाले गए बाइनरी वाहिका एनोटेट पैच का सेट। |
| $\mathbf{B}$ | एक ओवर-कंप्लीट डिक्शनरी जिसमें वृक्ष-जैसी शाखाओं के पैटर्न के मौलिक निर्माण खंड (एटम) शामिल हैं। |
| $\mathbf{z}$ | प्रतिनिधित्व गुणांक (यह निर्धारित करता है कि कौन से एटम सक्रिय होते हैं) युक्त एक विरल वेक्टर। |
| $\hat{\mathbf{B}}, \hat{\mathbf{Z}}$ | अनुकूलन के बाद प्राप्त सीखा हुआ डिक्शनरी और सीखा हुआ विरल लेटेंट वेक्टर। |
| $\lambda$ | एक नियमितीकरण पैरामीटर जो प्रतिनिधित्व वैक्टर की विरलता को नियंत्रित करता है (मॉडल को यथासंभव कम एटम का उपयोग करने के लिए मजबूर करता है)। |
| $c_i$ | एक विशिष्ट एनोटेशन और उसके संबंधित छवि पैच को सौंपा गया के-मीन्स क्लस्टर लेबल। |
| $\mathcal{E}_1, \mathcal{R}_1$ | पैच को विरल लेटेंट वैक्टर पर मैप करने और उन्हें पुनर्निर्मित करने के लिए उपयोग किया जाने वाला रैखिक एनकोडर और डिकोडर। |
| $\mathcal{E}_s$ | एमआरआई पैच के लिए अंतिम जानकारीपूर्ण लेटेंट स्पेस उत्पन्न करने के लिए उपयोग किया जाने वाला सियामीस एनकोडर नेटवर्क। |
| $\mathcal{I}^U$ | अनलेबल छवियों का एक नया डेटासेट जिससे मॉडल को नमूना लेने की आवश्यकता है। |
| $n$ | फ्रेमवर्क द्वारा मानव विशेषज्ञ को एनोटेशन के लिए भेजे जाने वाले मस्तिष्क पैच का न्यूनतम उपसमुच्चय। |
| $\Phi$ | नए एनोटेट किए गए पैच का उपयोग करके प्रशिक्षित अंतिम मस्तिष्क वाहिका विभाजन मॉडल। |
इन तत्वों को मिलाकर, लेखकों ने सफलतापूर्वक V-DiSNet बनाया, एक ऐसी प्रणाली जो रक्त वाहिकाओं के आवर्ती पैटर्न को गणितीय रूप से मॉडल करती है $$ \mathbf{Y} = \mathbf{B}\mathbf{z} $$ और इस समझ का उपयोग मानव द्वारा लेबल किए जाने वाले सबसे अच्छे $n$ पैच को चुनने के लिए करती है, केवल 30% डेटा लेबल होने के साथ लगभग पूर्ण-डेटासेट प्रदर्शन प्राप्त करती है।
समस्या परिभाषा और बाधाएं
इस पत्र द्वारा संबोधित की जाने वाली समस्या को समझने के लिए, हमें पहले प्रारंभिक बिंदु और अंतिम बिंदु पर विचार करना होगा।
इनपुट (वर्तमान स्थिति): हम 3डी मस्तिष्क स्कैन के एक विशाल, बिना लेबल वाले डेटासेट से शुरुआत करते हैं - विशेष रूप से मैग्नेटिक रेजोनेंस एंजियोग्राफी (MRA) छवियां। गणितीय रूप से, यह बिना लेबल वाली वॉल्यूमेट्रिक छवियों का एक सेट है $I^U = \{I_j\}_{j=1}^M \subset \mathbb{R}^{H \times W \times S}$।
आउटपुट (लक्ष्य स्थिति): लक्ष्य एक पूरी तरह से प्रशिक्षित, अत्यधिक सटीक डीप लर्निंग मॉडल है जो मस्तिष्क में जटिल, वृक्ष-जैसी रक्त वाहिकाओं को सेगमेंट (सटीक रूप से रेखांकित) करने में सक्षम है। हालांकि, एक पकड़ है: हम इसे मूल डेटा के केवल एक छोटे, सावधानीपूर्वक चयनित अंश (उदाहरण के लिए, केवल 30% या उससे भी कम) को मैन्युअल रूप से एनोटेट करने के लिए मानव चिकित्सा विशेषज्ञों से प्राप्त करके प्राप्त करना चाहते हैं।
लुप्त कड़ी: इनपुट और लक्ष्य के बीच गणितीय अंतर चयन तंत्र है। आप गणितीय रूप से कैसे गारंटी दे सकते हैं कि आप डॉक्टरों को लेबल करने के लिए जिन छवियों का छोटा समूह मांगते हैं, वे सबसे अधिक जानकारीपूर्ण हैं, इससे पहले कि आप वास्तव में जानते हैं कि उनके अंदर क्या है? लेखक परिकल्पना करते हैं कि मस्तिष्क वाहिकाएं आवर्ती, पदानुक्रमित शाखाकरण पैटर्न से निर्मित होती हैं। इसलिए, किसी भी संवहनी वृक्ष छवि $\mathbf{Y}$ को मौलिक निर्माण खंडों (एक शब्दकोश $\mathbf{B}$) और विरल गुणांक ($\mathbf{z}$) के एक रैखिक संयोजन के रूप में मॉडल किया जा सकता है, जैसे कि $\mathbf{Y} = \mathbf{B}\mathbf{z}$। इस पत्र द्वारा पुल की गई लुप्त कड़ी यह पता लगाना है कि वाहिका पैटर्न के इस छिपे हुए शब्दकोश को कैसे सीखा जाए और बिना लेबल वाली छवियों को एक लेटेंट स्पेस में कैसे मैप किया जाए जहां हम एक ही पास में सबसे विविध, प्रतिनिधि पैच को गणितीय रूप से नमूना ले सकें।
यह हमें उस दर्दनाक दुविधा तक ले जाता है जिसने पिछले शोधकर्ताओं को फंसाया है।
मशीन लर्निंग की दुनिया में, मानव लेबल की आवश्यकता को कम करना आमतौर पर एक्टिव लर्निंग (AL) पर निर्भर करता है। पारंपरिक AL एक पुनरावृत्तीय प्रक्रिया है: मॉडल कुछ छवियों पर प्रशिक्षित होता है, पता लगाता है कि वह किस बारे में सबसे अधिक भ्रमित है, एक मानव ओरेकल से उन विशिष्ट भ्रमित करने वाली छवियों को लेबल करने के लिए कहता है, और फिर पुनः प्रशिक्षित करता है।
* समझौता: आपको कुछ लेबल के साथ उच्च सटीकता मिलती है, लेकिन मॉडल को लगातार पुनः प्रशिक्षित करने से आपको भारी कम्प्यूटेशनल लागत आती है। इससे भी बदतर, इसके लिए एक चिकित्सा विशेषज्ञ को एल्गोरिथम के प्रश्नों का उत्तर देने के लिए लगातार स्टैंडबाय पर रहने की आवश्यकता होती है, जो वास्तविक नैदानिक सेटिंग्स में व्यावहारिक रूप से असंभव है।
इसे ठीक करने के लिए, शोधकर्ताओं ने वन-शॉट एक्टिव लर्निंग (OSAL) का आविष्कार किया, जो पूरे सूचनात्मक नमूनों के बैच को एक ही बार में चुनने का प्रयास करता है, जिससे पुनरावृत्तीय पुनः प्रशिक्षण लूप समाप्त हो जाता है।
* नई दुविधा: मौजूदा OSAL विधियां सामान्य, "ब्लैक-बॉक्स" गणित (जैसे कंट्रास्टिव लर्निंग या वेरिएशन ऑटोएनकोडर) पर निर्भर करती हैं जो मस्तिष्क की वास्तविक भौतिक शरीर रचना के प्रति पूरी तरह से अंधी हैं। वे यह नहीं समझते हैं कि रक्त वाहिकाएं निरंतर, आवर्ती ट्यूबलर संरचनाएं हैं। यदि आप एक शॉट में नमूने चुनने के लिए इन सामान्य विधियों का उपयोग करते हैं, तो आप छवियों के एक बैच का चयन करने का जोखिम उठाते हैं जो महत्वपूर्ण शारीरिक विविधताओं को पूरी तरह से चूक जाता है। आप एक ऐसे मॉडल के लिए कम्प्यूटेशनल दक्षता का व्यापार करते हैं जो अनदेखे डेटा पर सामान्यीकरण करने में विफल रहता है क्योंकि इसका प्रशिक्षण सेट जटिल संवहनी वृक्ष का वास्तव में प्रतिनिधि नहीं था।
इसे हल करने के लिए, लेखकों ने कई कठोर, यथार्थवादी बाधाओं का सामना किया:
- छिपा हुआ शब्दकोश बाधा: मस्तिष्क वाहिकाओं के मौलिक निर्माण खंड ( "परमाणु") सीधे तौर पर देखे नहीं जाते हैं। उन्हें खोजने के लिए, लेखकों को पुनर्निर्माण त्रुटि को कम करने के लिए एक अत्यधिक बाधित अनुकूलन समस्या को हल करना पड़ा, जबकि प्रतिनिधित्व को विरल बनाने के लिए मजबूर किया गया। उन्हें इसे गणितीय रूप से इस प्रकार परिभाषित करना पड़ा:
$$ \hat{\mathbf{B}}, \hat{\mathbf{Z}} = \min_{\mathbf{B}, \mathbf{Z}} \|\mathcal{Y}_{\mathcal{I}} - \mathbf{B}\mathbf{Z}\|_2^2 $$
सख्त विरलता बाधा $\|\mathbf{Z}\|_1 < \lambda$ के अधीन। इसे हल करने के लिए सीखे गए इटरेटिव श्रिंकेज थ्रेशोल्डिंग एल्गोरिथम (LISTA) जैसे विशेष, जटिल एल्गोरिदम की आवश्यकता होती है। - चरम डेटा विरलता और जटिलता: आसपास के मस्तिष्क ऊतक की तुलना में रक्त वाहिकाएं अविश्वसनीय रूप से पतली, जटिल और विरल होती हैं। उनकी कनेक्टिविटी और ट्यूबलर आकार को कैप्चर करने का मतलब है कि मानक पिक्सेल-दर-पिक्सेल विश्लेषण पर्याप्त नहीं है; मॉडल को किसी तरह एक शाखा वाले वृक्ष की ज्यामिति को समझना चाहिए।
- हार्डवेयर और आयामीता सीमाएं: 3डी वॉल्यूमेट्रिक मस्तिष्क स्कैन विशाल होते हैं। इन विरल शब्दकोशों को सीखने के लिए पूर्ण 3डी पैच को संसाधित करना अविश्वसनीय रूप से मेमोरी-गहन है। ईमानदारी से कहूं तो, मुझे पूरी तरह से यकीन नहीं है कि यह सख्ती से जीपीयू मेमोरी सीमा थी या गणितीय जटिलता सीमा, लेकिन लेखकों ने स्पष्ट रूप से एक कठोर समझौता स्वीकार किया: उन्हें शब्दकोश सीखने को सुगम बनाने के लिए 3डी वॉल्यूम को 2डी पैच में काटना पड़ा। 2डी पैच पर यह निर्भरता का मतलब है कि वे संवहनी वृक्ष की कुछ वैश्विक 3डी स्थानिक कनेक्टिविटी खोने का जोखिम उठाते हैं - एक भौतिक बाधा जिसे उन्होंने उचित कम्प्यूटेशनल सीमाओं के भीतर गणित को काम करने के लिए स्वीकार करना पड़ा।
यह तरीका क्यों
इस पत्र के लेखकों को एक महत्वपूर्ण "आह!" क्षण का अनुभव हुआ जब उन्होंने महसूस किया कि मौजूदा अत्याधुनिक (SOTA) वन-शॉट एक्टिव लर्निंग (OSAL) फ्रेमवर्क मौलिक रूप से मानव शरीर रचना विज्ञान के प्रति अंधे थे। पारंपरिक विधियाँ सामान्य स्व-पर्यवेक्षित शिक्षण, वेरिएशनल ऑटोएनकोडर (VAEs), या कंट्रास्टिव लर्निंग पर बहुत अधिक निर्भर करती हैं। जबकि ये दृष्टिकोण मानक छवि डेटासेट में सांख्यिकीय आउटलायर्स को खोजने में उत्कृष्ट हैं, वे मस्तिष्क स्कैन को सामान्य पिक्सेल वितरण के रूप में मानते हैं। वे मस्तिष्क वाहिकाओं की आवर्ती, वृक्ष-जैसी, नलिकाकार संरचनाओं को ध्यान में रखने में पूरी तरह से विफल रहते हैं।
इस शारीरिक अंधापन के कारण, मानक डीप लर्निंग मॉडल यह गारंटी नहीं दे सकते थे कि चयनित नमूने वास्तव में सार्थक या पूर्ण संवहनी वृक्ष का प्रतिनिधि थे। लेखकों ने पहचाना कि इसे हल करने के लिए, उन्हें एक गणितीय मॉडल की आवश्यकता थी जो स्वाभाविक रूप से पदानुक्रमित शाखाओं को समझता हो। यही कारण है कि डिक्शनरी लर्निंग को स्पार्स कोडिंग के साथ जोड़ना एकमात्र व्यवहार्य समाधान था। इस सैद्धांतिक आधार पर कि एक संवहनी वृक्ष को मौलिक निर्माण खंडों के रैखिक संयोजन के रूप में मॉडल किया जा सकता है, उन्होंने इन छिपे हुए "परमाणुओं" को वाहिका पैटर्न निकालने की समस्या को तैयार किया।
गणितीय रूप से, उन्होंने इस निष्कर्षण को निम्नलिखित अनुकूलन समस्या को हल करके परिभाषित किया:
$$ \hat{\mathbf{B}}, \hat{\mathbf{Z}} = \min_{\mathbf{B},\mathbf{Z}} \|\mathcal{Y}_{\mathcal{I}} - \mathbf{B}\mathbf{Z}\|_2^2 $$
स्पार्सिटी बाधा $\|\mathbf{Z}\|_1 < \lambda$ के अधीन। यहाँ, $\mathcal{Y}_{\mathcal{I}}$ प्रेक्षित वाहिका पैच का प्रतिनिधित्व करता है, $\mathbf{B}$ वाहिका पैटर्न का ओवर-कंप्लीट डिक्शनरी है, और $\mathbf{Z}$ स्पार्स प्रतिनिधित्व गुणांक रखता है। सीखे गए Iterative Shrinkage Thresholding Algorithm (LISTA) का उपयोग करके, वे इसे कुशलतापूर्वक हल कर सकते थे, जिससे नेटवर्क को एक अत्यधिक संपीड़ित, स्पार्स लेटेंट वेक्टर सीखने के लिए मजबूर किया जा सकता था जहाँ प्रत्येक सक्रिय तत्व रक्त वाहिका के एक विशिष्ट भौतिक लक्षण (जैसे उसका आकार, माप, या कनेक्टिविटी) से मेल खाता है।
जब इस दृष्टिकोण को पिछले स्वर्ण मानकों के मुकाबले बेंचमार्क किया गया, तो V-DiSNet की तुलनात्मक श्रेष्ठता डाइस स्कोर जैसे सरल प्रदर्शन मेट्रिक्स से कहीं आगे जाती है। वास्तविक संरचनात्मक लाभ इसकी व्याख्यात्मकता और दक्षता में निहित है। मानक OSAL विधियाँ ब्लैक बॉक्स हैं; वे यह नहीं समझा सकते कि एक डेटा बिंदु को दूसरे पर क्यों प्राथमिकता दी जाती है। इसके विपरीत, V-DiSNet का स्पार्स लेटेंट स्पेस पूरी तरह से पारदर्शी है। यदि आप लेटेंट वेक्टर में एक विशिष्ट "परमाणु" को निष्क्रिय करते हैं, तो वाहिका का एक विशिष्ट भाग पुनर्निर्माण में भौतिक रूप से बदल जाता है या गायब हो जाता है। इसके अलावा, उच्च-आयामी वॉल्यूमेट्रिक मस्तिष्क पैच को इस स्पार्स लेटेंट स्पेस में मैप करके और के-मीन्स क्लस्टरिंग लागू करके, मॉडल खोज स्थान जटिलता को काफी कम कर देता है। लाखों उच्च-आयामी पैच के बीच की दूरी का अंधाधुंध मूल्यांकन करने के बजाय, सिस्टम उन्हें संरचनात्मक समानता के आधार पर समूहित करता है और ठीक वही चुनता है जिसकी उसे आवश्यकता है, पारंपरिक नमूनाकरण के भारी कम्प्यूटेशनल ओवरहेड को प्रभावी ढंग से बायपास करते हुए, एक स्तरीकृत Farthest Point Sampling (FPS) एल्गोरिथम का उपयोग करता है।
यह चुनी गई विधि चिकित्सा क्षेत्र की कठोर बाधाओं के साथ पूरी तरह से संरेखित होती है। एक नैदानिक सेटिंग में, डॉक्टरों और विशेषज्ञ एनोटेटर्स के पास बहुत सीमित समय होता है। Iterative Active Learning—जिसमें एक मानव को कुछ छवियों को लेबल करने, मॉडल के पुनः प्रशिक्षित होने की प्रतीक्षा करने और फिर अधिक लेबल करने की आवश्यकता होती है—अपने निरंतर ओवरहेड के कारण व्यावहारिक रूप से बेकार है। समस्या के लिए एक "वन-शॉट" समाधान (एकल लेबलिंग राउंड) की मांग की गई थी जो अभी भी मस्तिष्क वाहिकाओं की विशाल विविधता को पकड़ सके। यहाँ का "विवाह" सुंदर है: शून्य पुनरावृत्ति प्रतिक्रिया की कठोर बाधा को डिक्शनरी लर्निंग की अनूठी क्षमता से दूर किया जाता है, जो यह गारंटी देता है कि ओरेकल को भेजे गए पैच का न्यूनतम उपसमुच्चय संवहनी वृक्ष के हर संभव संरचनात्मक भिन्नता को कवर करता है।
यदि लेखकों ने GANs या मानक डिफ्यूजन मॉडल जैसे अन्य लोकप्रिय जनरेटिव दृष्टिकोणों का उपयोग करने का प्रयास किया होता, तो वे विफल हो जाते। जबकि एक GAN अत्यधिक यथार्थवादी सिंथेटिक रक्त वाहिकाएं उत्पन्न कर सकता है, यह एक अनलेबल डेटासेट की संरचनात्मक विविधता को मापने के लिए एक स्पष्ट, व्याख्यात्मक तंत्र प्रदान नहीं करता है। GANs और डिफ्यूजन मॉडल डेटा को निरंतर, अक्सर उलझे हुए लेटेंट स्पेस में मैप करते हैं जहाँ एक विशिष्ट "ब्रांचिंग पैटर्न" को अलग करना अविश्वसनीय रूप से कठिन होता है। स्पार्स डिक्शनरी लर्निंग के पक्ष में इन ब्लैक-बॉक्स जनरेटिव मॉडल को अस्वीकार करके, लेखकों ने सुनिश्चित किया कि उनकी नमूनाकरण रणनीति अपारदर्शी सांख्यिकीय भिन्नता के बजाय वास्तविक, सत्यापन योग्य संवहनी शरीर रचना विज्ञान द्वारा संचालित थी।
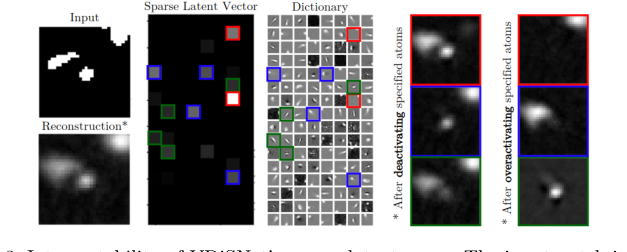 Figure 3. Interpretability of VDiSNet’s sparse latent space. The input patch is en- coded into a sparse representation using learned dictionary atoms. Deactivating or overactivating specific atoms alters specific vessel components, highlighting their role in the reconstruction
Figure 3. Interpretability of VDiSNet’s sparse latent space. The input patch is en- coded into a sparse representation using learned dictionary atoms. Deactivating or overactivating specific atoms alters specific vessel components, highlighting their role in the reconstruction
गणितीय और तार्किक तंत्र
इस पत्र के मूल में एक गणितीय इंजन है जिसे मस्तिष्क रक्त वाहिकाओं की अराजक, शाखित जटिलता को मौलिक आकृतियों की एक स्वच्छ, प्रबंधनीय शब्दावली में आसुत करने के लिए डिज़ाइन किया गया है। इसे प्राप्त करने के लिए, लेखक विरल शब्दकोश सीखने (sparse dictionary learning) के एक क्लासिक सूत्रीकरण पर भरोसा करते हैं, जिसे यहां एक व्याख्यात्मक अव्यक्त स्थान (interpretable latent space) बनाने के लिए एक पूर्व-कार्य (pretext task) के रूप में अनुकूलित किया गया है।
यहां वह मास्टर समीकरण है जो फ्रेमवर्क को शक्ति प्रदान करता है:
$$ \hat{\mathcal{B}}, \hat{\mathbf{Z}} = \min_{\mathcal{B}, \mathbf{Z}} \|\mathcal{Y}_{\mathcal{I}} - \mathcal{B}\mathbf{Z}\|_2^2 $$
इस बाधा के अधीन:
$$ \|\mathbf{Z}\|_1 < \lambda $$
यह समझने के लिए कि यह समीकरण वास्तव में क्या कर रहा है, आइए इसे एक-एक करके तोड़ें:
- $\hat{\mathcal{B}}, \hat{\mathbf{Z}}$: ये इंजन के अंतिम, अनुकूलित आउटपुट हैं। $\hat{\mathcal{B}}$ सीखा हुआ "शब्दकोश" है—इसे मौलिक, आवर्ती वाहिका निर्माण खंडों (जैसे एक सीधी नली, एक तेज वक्र, या एक Y-आकार का द्विशाखन) की एक सूची के रूप में सोचें। $\hat{\mathbf{Z}}$ विरल गुणांक मैट्रिक्स है, जो एक विशिष्ट नुस्खा के रूप में कार्य करता है जो सिस्टम को बताता है कि प्रत्येक छवि के लिए किन खंडों का उपयोग करना है।
- $\min_{\mathcal{B}, \mathbf{Z}}$: यह अनुकूलन निर्देश है। यह गणितीय इंजन को शब्दकोश $\mathcal{B}$ और व्यंजनों $\mathbf{Z}$ दोनों को तब तक लगातार समायोजित करने के लिए कहता है जब तक कि इसके दाईं ओर की अभिव्यक्ति सबसे कम संभव मान तक नहीं पहुंच जाती।
- $\mathcal{Y}_{\mathcal{I}}$: इनपुट डेटा मैट्रिक्स। भौतिक रूप से, ये डेटासेट से निकाले गए मस्तिष्क वाहिकाओं के वास्तविक, देखे गए बाइनरी छवि पैच हैं।
- $-$ (घटाव): यहां अवशिष्ट (residual) की गणना के लिए उपयोग किया जाता है। यह वास्तविक वाहिका पैच और इसे फिर से बनाने के मॉडल के कृत्रिम प्रयास के बीच सटीक अंतर को मापता है।
- $\mathcal{B}\mathbf{Z}$: पुनर्निर्मित डेटा। लेखक यहां मैट्रिक्स गुणन का उपयोग करते हैं क्योंकि यह एक रैखिक संयोजन (linear combination) को पूरी तरह से मॉडल करता है। मैट्रिक्स गुणन $\mathcal{B}$ में प्रत्येक शब्दकोश परमाणु (dictionary atom) को $\mathbf{Z}$ में निर्दिष्ट तीव्रता भार (intensity weight) से स्केल करता है, और फिर उन सभी को एक साथ जोड़ता है। अंतिम जटिल वाहिका संरचना बनाने के लिए इन मौलिक आकृतियों को एक-दूसरे पर ओवरले करने के लिए जोड़ का उपयोग किया जाता है।
- $\| \cdot \|_2^2$: वर्गित L2 नॉर्म (squared L2 norm)। गणितीय रूप से, यह वास्तविक और नकली पैच के बीच सभी पिक्सेल के वर्गित अंतरों का योग करता है। भौतिक रूप से, यह मॉडल को उच्च निष्ठा (high fidelity) की ओर खींचने वाले एक रबर बैंड के रूप में कार्य करता है। लेखकों ने यहां एक पूर्ण L1 नॉर्म के बजाय एक वर्गित L2 नॉर्म का उपयोग किया है क्योंकि वर्गण बड़े, स्पष्ट त्रुटियों (जैसे मोटी वाहिका को पूरी तरह से याद करना) को भारी दंडित करता है, जिससे मॉडल को समग्र मैक्रो-संरचना को सटीक रूप से कैप्चर करने के लिए मजबूर किया जाता है।
- $\|\mathbf{Z}\|_1 < \lambda$: L1 नॉर्म का उपयोग करके विरलता बाधा (sparsity constraint)। गणितीय रूप से, यह नुस्खे में गुणांकों के निरपेक्ष मानों का योग करता है। भौतिक रूप से, यह एक सख्त बजट के रूप में कार्य करता है। यह मॉडल को छवि को पुनर्निर्मित करने के लिए शब्दकोश परमाणुओं की न्यूनतम संख्या का उपयोग करने के लिए मजबूर करता है।
- $\lambda$: नियमितीकरण पैरामीटर (regularization parameter)। यह ट्यूनिंग नॉब है जो निर्धारित करता है कि विरलता बजट कितना सख्त है। एक उच्च $\lambda$ एक विरल प्रतिनिधित्व को मजबूर करता है, जिसका अर्थ है कि मॉडल प्रति पैच केवल कुछ ही परमाणुओं को चुन सकता है।
चरण-दर-चरण प्रवाह
एक स्वचालित असेंबली लाइन की कल्पना करें जिसे सरल लेगो ईंटों से जटिल संवहनी वृक्ष (vascular trees) बनाने के लिए डिज़ाइन किया गया है।
सबसे पहले, एक मस्तिष्क वाहिका का एक कच्चा, लेबल रहित छवि पैच $Y_i$ कारखाने में प्रवेश करता है। इसे एक रैखिक एनकोडर (एक स्कैनर के रूप में कार्य करने वाले) में फीड किया जाता है। यह स्कैनर जटिल वाहिका को देखता है और एक विरल ब्लूप्रिंट वेक्टर $\hat{z}_i$ उत्पन्न करता है। जैसा कि हमने चर्चा की, सख्त L1 बजट के कारण, यह ब्लूप्रिंट ज्यादातर शून्य होता है—इसे अत्यधिक चयनात्मक होने के लिए मजबूर किया जाता है, केवल कुछ आवश्यक घटकों को सक्रिय करता है।
इसके बाद, यह ब्लूप्रिंट शब्दकोश $\mathcal{B}$ को भेजा जाता है, जो मौलिक वाहिका भागों को संग्रहीत करने वाला गोदाम है। $\hat{z}_i$ में गैर-शून्य मान यांत्रिक लीवर के रूप में कार्य करते हैं। यदि ब्लूप्रिंट में स्थिति 5 पर $0.8$ का मान है, तो यह गोदाम से "परमाणु 5" (शायद एक विशिष्ट Y-शाखा आकार) खींचता है और इसकी तीव्रता को $0.8$ से स्केल करता है।
अंत में, इन चयनित, स्केल किए गए भागों को अंतिम पुनर्निर्मित पैच $\hat{Y}_i$ बनाने के लिए एक-दूसरे पर स्टैक किया जाता है। सिस्टम तब मूल पैच और इस नई रचना के बीच के अंतर को देखता है, त्रुटि की गणना करता है, और अगले दौर के लिए स्कैनर और गोदाम की सूची को समायोजित करने के लिए लाइन की शुरुआत में एक संकेत भेजता है।
अनुकूलन गतिशीलता (Optimization Dynamics)
यह तंत्र वास्तव में कैसे सीखता है और अभिसरण (converge) करता है? यहां अनुकूलन परिदृश्य एक क्लासिक रस्साकशी (tug-of-war) है। L2 नॉर्म छवि को पूरी तरह से फिर से बनाना चाहता है, जिसके लिए आमतौर पर हर उपलब्ध उपकरण का उपयोग करने की आवश्यकता होती है (जिसके परिणामस्वरूप एक सघन $\mathbf{Z}$ होता है)। लेकिन L1 बाधा एक सख्त प्रबंधक है जो दक्षता की मांग करता है, $\mathbf{Z}$ के अधिकांश हिस्से को शून्य पर मजबूर करता है।
इस गैर-तुच्छ अनुकूलन समस्या को हल करने के लिए, लेखक केवल मानक ग्रेडिएंट डिसेंट (gradient descent) का उपयोग नहीं करते हैं। वे LISTA (Learned Iterative Shrinkage Thresholding Algorithm) का उपयोग करते हैं। LISTA एक पारंपरिक गणितीय सॉल्वर लेता है और उसके पुनरावृत्त चरणों को एक तंत्रिका नेटवर्क (neural network) की परतों में खोलता है।
प्रशिक्षण के दौरान, हानि परिदृश्य (loss landscape) एक चिकनी, बहु-आयामी कटोरे (L2 नॉर्म से) के रूप में आकार लेता है जो एक तेज, बहु-आयामी हीरे (L1 नॉर्म से) के साथ प्रतिच्छेद करता है। जैसे ही ग्रेडिएंट्स खुले हुए LISTA नेटवर्क के माध्यम से पीछे की ओर प्रवाहित होते हैं, "सिकुड़न" (shrinkage) ऑपरेशन कैंची की एक जोड़ी की तरह कार्य करता है। यह ग्रेडिएंट अपडेट को देखता है और छोटे, महत्वहीन भारों को ठीक शून्य पर क्लिप करता है।
समय के साथ, यह गतिशीलता शब्दकोश $\mathcal{B}$ को बेकार शोर को त्यागने और केवल सबसे सार्वभौमिक रूप से लागू वाहिका आकृतियों को रखने के लिए मजबूर करती है। साथ ही, एनकोडर इस हीरे के आकार के हानि परिदृश्य को नेविगेट करना सीखता है ताकि सबसे कुशल संयोजनों को तुरंत चुना जा सके। एक बार जब यह अव्यक्त स्थान पूरी तरह से बन जाता है और क्लस्टर हो जाता है, तो सक्रिय शिक्षण फ्रेमवर्क (active learning framework) विभिन्न क्लस्टर से आसानी से नमूना ले सकता है, यह गारंटी देता है कि मानव एनोटेटर को लेबल करने के लिए वाहिका ज्यामिति का एक पूरी तरह से विविध सेट प्राप्त होता है।
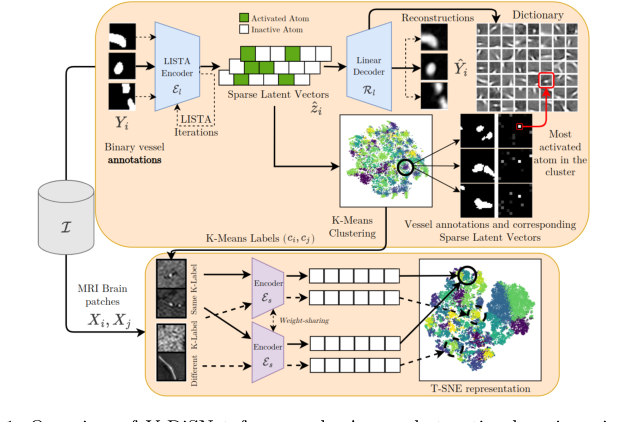 Figure 1. Overview of V-DiSNet framework: A one-shot active learning pipeline that leverages dictionary learning to capture intrinsic vessel patterns, constructs an informative latent space via a Siamese encoder, and applies diversity-based sampling to select a minimal yet representative set of vessel patches for efficient brain vessel segmentation
Figure 1. Overview of V-DiSNet framework: A one-shot active learning pipeline that leverages dictionary learning to capture intrinsic vessel patterns, constructs an informative latent space via a Siamese encoder, and applies diversity-based sampling to select a minimal yet representative set of vessel patches for efficient brain vessel segmentation
परिणाम, सीमाएँ और निष्कर्ष
एक विशाल, जटिल शहर की जटिल नलसाजी प्रणाली का नक्शा बनाने का कार्य आपको सौंपा गया है। आप पाइपों को सीधे नहीं देख सकते; आपके पास केवल धुंधले रडार स्कैन हैं। एक सटीक नक्शा बनाने के लिए, आपको एक विशेषज्ञ प्लंबर की आवश्यकता है जो स्कैन को देखे और हर एक पाइप को हाथ से ट्रेस करे। यह अविश्वसनीय रूप से महंगा है—विशेषज्ञ चिकित्सा समय में प्रति स्कैन शायद \$500 का खर्च आता है—और दर्दनाक रूप से धीमा है।
मेडिकल इमेजिंग के क्षेत्र में, यह "नलसाजी प्रणाली" मानव मस्तिष्क का संवहनी नेटवर्क है, और "रडार स्कैन" मैग्नेटिक रेजोनेंस एंजियोग्राफी (MRA) छवियां हैं। डीप लर्निंग मॉडल इन वाहिकाओं को मैप करने में शानदार हैं, लेकिन वे कुख्यात रूप से डेटा-भूखे होते हैं। उन्हें सीखने के लिए पूरी तरह से लेबल किए गए डेटासेट की आवश्यकता होती है, जिसका अर्थ है कि मानव डॉक्टरों को 3D मस्तिष्क स्कैन को वोक्सेल दर वोक्सेल एनोटेट करने में अनगिनत घंटे बिताने पड़ते हैं।
इस बाधा को दूर करने के लिए, वैज्ञानिक एक्टिव लर्निंग (AL) का उपयोग करते हैं। सब कुछ लेबल करने के बजाय, AI डेटा को देखता है और मानव से केवल सबसे भ्रमित करने वाले या सूचनात्मक भागों को लेबल करने के लिए कहता है। हालांकि, पारंपरिक AL पुनरावृत्त है: AI कुछ लेबल मांगता है, खुद को प्रशिक्षित करता है, महसूस करता है कि उसे और अधिक की आवश्यकता है, और फिर से पूछता है। व्यस्त नैदानिक सेटिंग्स में यह निरंतर आगे-पीछे होना अत्यधिक अव्यावहारिक है। वन-शॉट एक्टिव लर्निंग (OSAL) यहाँ प्रवेश करता है, जहाँ AI को एक बार में लेबल करने के लिए डेटा का एक एकल, न्यूनतम बैच चुनता है।
इस पेपर के लेखकों को जिस बाधा को दूर करना था, वह यह है कि मौजूदा OSAL विधियाँ अनिवार्य रूप से शरीर रचना विज्ञान के प्रति अंधी हैं। वे सांख्यिकीय विसंगतियों या पिक्सेल भिन्नताओं के आधार पर डेटा बिंदुओं को चुनते हैं, इस मौलिक वास्तविकता को पूरी तरह से अनदेखा करते हैं कि रक्त वाहिकाएं निरंतर, वृक्ष-जैसी, नलिकाकार संरचनाएं हैं। यदि एक OSAL मॉडल केवल यादृच्छिक "कठिन" पैच चुनता है, तो यह आवर्ती शाखाकरण पैटर्न को याद कर सकता है जो संवहनी प्रणाली को परिभाषित करते हैं, जिससे एक AI बनता है जो सामान्यीकरण में विफल रहता है।
गणितीय मूल: शरीर रचना विज्ञान को डिकोड करना
इसे हल करने के लिए, लेखकों ने V-DiSNet (वेसल-डिक्शनरी सिलेक्शन नेट) बनाया। उनकी शानदार अंतर्दृष्टि जटिल संवहनी वृक्ष को पिक्सेल के यादृच्छिक वर्गीकरण के रूप में नहीं, बल्कि बुनियादी आकृतियों—जैसे सीधी नलियों, वाई-जंक्शनों और वक्रों—के एक सीमित वर्णमाला से निर्मित भाषा के रूप में मानना था।
गणितीय रूप से, उन्होंने एक संवहनी छवि पैच $\mathcal{Y}$ को इन बुनियादी निर्माण खंडों के रैखिक संयोजन के रूप में मॉडल किया। उन्होंने एक अति-पूर्ण "शब्दकोश" $\mathcal{B}$ (आकृतियों का वर्णमाला) और एक विरल वेक्टर $\mathbf{Z}$ (कौन सी आकृतियों का उपयोग करना है और उन्हें कितनी मजबूती से भारित करना है, इसकी विशिष्ट विधि) को परिभाषित किया।
चूंकि वे पहले से शब्दकोश नहीं जानते थे, उन्हें इसे मौजूदा लेबल वाले डेटासेट से सीखना पड़ा। उन्होंने इसे एक अनुकूलन समस्या के रूप में तैयार किया:
$$ \hat{\mathcal{B}}, \hat{\mathbf{Z}} = \min_{\mathcal{B}, \mathbf{Z}} \|\mathcal{Y}_{\mathcal{I}} - \mathcal{B}\mathbf{Z}\|_2^2 $$
इस बाधा के अधीन:
$$ \|\mathbf{Z}\|_1 < \lambda $$
यहाँ इसका सुरुचिपूर्ण अर्थ है: एल्गोरिथम इष्टतम शब्दकोश ($\hat{\mathcal{B}}$) और इष्टतम विधि ($\hat{\mathbf{Z}}$) खोजने का प्रयास करता है ताकि जब आप उन्हें एक साथ गुणा करते हैं, तो पुनर्निर्मित छवि और वास्तविक एनोटेट की गई छवि ($\mathcal{Y}_{\mathcal{I}}$) के बीच का अंतर शून्य के जितना करीब हो सके (वर्गित L2 मानदंड द्वारा न्यूनतम)।
महत्वपूर्ण हिस्सा बाधा $\|\mathbf{Z}\|_1 < \lambda$ है। यह एक विरलता बाधा है। यह मॉडल को वाहिका को पुनर्निर्मित करने के लिए शब्दकोश से "सामग्री" की पूर्ण न्यूनतम संख्या का उपयोग करने के लिए मजबूर करता है। विरलता को मजबूर करके, मॉडल केवल छवि को याद नहीं कर सकता; इसे वास्तविक, अंतर्निहित, आवर्ती शारीरिक पैटर्न ( "परमाणु" ) की खोज करने के लिए मजबूर किया जाता है।
एक बार जब ये परमाणु सीख लिए जाते हैं, तो लेखक नए, बिना लेबल वाले एमआरआई पैच को एक लेटेंट स्पेस (एक गणितीय प्रतिनिधित्व स्थान) में मैप करने के लिए एक सियामी तंत्रिका नेटवर्क आर्किटेक्चर का उपयोग करते हैं। समान संवहनी संरचनाओं वाले पैच एक-दूसरे के करीब खींचे जाते हैं, जबकि भिन्न संरचनाओं वाले पैच एक-दूसरे से दूर धकेल दिए जाते हैं। अंत में, वे इस स्थान पर समान रूप से फैले हुए पैच के एक छोटे, अत्यधिक विविध सेट का चयन करने के लिए एक फारथेस्ट पॉइंट सैंपलिंग (FPS) एल्गोरिथम का उपयोग करते हैं। यह गारंटी देता है कि मानव विशेषज्ञ से मस्तिष्क में मौजूद हर प्रकार की वाहिका ज्यामिति के पूरी तरह से प्रतिनिधि क्रॉस-सेक्शन को लेबल करने के लिए कहा जाता है।
प्रयोगात्मक वास्तुकला: क्रूर अवधारणा का प्रमाण
लेखकों ने केवल अपने मॉडल को एक डेटासेट पर नहीं फेंका और मामूली सटीकता वृद्धि की रिपोर्ट नहीं की। उन्होंने अपने नमूना तंत्र को मौजूदा प्रतिमानों से कहीं बेहतर साबित करने के लिए एक कठोर तनाव परीक्षण की वास्तुकला तैयार की।
उनके "पीड़ित" मानक रैंडम सैंपलिंग (R-W) और तीन अत्याधुनिक OSAL बेसलाइन थे: RA (प्रतिनिधि एनोटेशन), CA (कंट्रास्टिव एक्टिव लर्निंग), और AET (एपिस्टेमिक और एलिटोरिक अनिश्चितता के माध्यम से सक्रिय सीखना)। उन्होंने परिणामों को एक विशिष्ट स्कैनर प्रकार का संयोग न बनाने के लिए तीन अलग-अलग, सार्वजनिक रूप से उपलब्ध 3D MRA डेटासेट (OASIS-3, SMILE-UHURA, और CAS) पर इन मॉडलों को तैनात किया।
V-DiSNet की श्रेष्ठता का निश्चित प्रमाण अल्ट्रा-लो डेटा व्यवस्था में पाया गया। लेखकों ने मॉडलों को भूखा रखा, उन्हें केवल 0.1%, 1%, 5%, और 10% लेबल किए गए डेटा तक पहुंच प्रदान की। इन चरम स्थितियों में, V-DiSNet ने व्यवस्थित रूप से बेसलाइन को कुचल दिया।
इसके अलावा, उन्होंने केवल मानक पिक्सेल ओवरलैप (Dice score) को नहीं मापा। उन्होंने clDice मीट्रिक का उपयोग किया, जो विशेष रूप से नलिकाकार संरचनाओं की टोपोलॉजिकल शुद्धता और कनेक्टिविटी को मापता है। इसने साबित कर दिया कि V-DiSNet केवल पिक्सेल को बेहतर ढंग से अनुमानित नहीं कर रहा था; यह वास्तव में रक्त वाहिकाओं की निरंतर, पाइप-जैसी अखंडता को संरक्षित कर रहा था। उनके डेटा में अंतिम माइक्रो-ड्रॉप क्षण यह है कि केवल 30% डेटासेट लेबल होने के साथ, V-DiSNet ने 100% पूरी तरह से एनोटेट किए गए डेटा पर प्रशिक्षित मॉडल के समान सेगमेंटेशन प्रदर्शन प्राप्त किया।
यह साबित करने के लिए कि उनका गणितीय लेटेंट स्पेस सिर्फ एक ब्लैक बॉक्स नहीं था, उन्होंने एक व्याख्यात्मकता प्रयोग किया। अपने सीखे हुए शब्दकोश $\mathbf{Z}$ में विशिष्ट "परमाणुओं" को मैन्युअल रूप से निष्क्रिय करके, उन्होंने दिखाया कि पुनर्निर्मित रक्त वाहिकाओं की विशिष्ट भौतिक विशेषताएं (जैसे एक विशिष्ट शाखा या वक्र) गायब हो जाएंगी। इसने निर्विवाद रूप से साबित कर दिया कि उनके गणित ने मानव संवहनी की भौतिक ज्यामिति को सफलतापूर्वक अलग कर दिया था।
भविष्य के विकास के लिए चर्चा के विषय
इस पेपर के गहन निहितार्थों के आधार पर, भविष्य के अन्वेषण और महत्वपूर्ण विचार के लिए कई रास्ते यहाँ दिए गए हैं:
-
2D पैच से 3D वैश्विक टोपोलॉजी तक:
वर्तमान ढांचा 3D वॉल्यूम से निकाले गए 2D पैच पर संचालित होता है। जबकि स्थानीय रूप से प्रभावी, यह संवहनी वृक्ष की वैश्विक निरंतरता को खोने का जोखिम उठाता है (जैसे, एक लंबी धमनी जो कई पैच तक फैली हुई है)। हम शब्दकोश सीखने के समीकरण को 3D वॉल्यूमेट्रिक ग्राफ़ को मूल रूप से संसाधित करने के लिए कैसे विकसित कर सकते हैं, बिना कम्प्यूटेशनल लागत को विस्फोट किए? क्या हम नमूनाकरण चरण के दौरान वैश्विक कनेक्टिविटी बाधाओं को लागू करने के लिए टोपोलॉजिकल डेटा विश्लेषण (TDA) को एकीकृत कर सकते हैं? -
क्रॉस-मोडेलिटी एनाटॉमिकल ट्रांसफरेबिलिटी:
V-DiSNet MRA स्कैन से अपना शब्दकोश सीखता है। हालांकि, रक्त वाहिकाओं का मौलिक आकार वही रहता है, चाहे वह MRA, CT एंजियोग्राफी (CTA), या अल्ट्रासाउंड के माध्यम से देखा जाए। क्या एक सार्वभौमिक "वेसल डिक्शनरी" को एक बार प्रशिक्षित किया जा सकता है और फिर पूरी तरह से अलग इमेजिंग तौर-तरीकों में स्थानांतरित किया जा सकता है? यह एक अस्पताल को सस्ते, प्रचुर मात्रा में MRA डेटा से सीखे गए शब्दकोश का उपयोग करके दुर्लभ, महंगे, या उपन्यास इमेजिंग प्रकारों पर वन-शॉट एक्टिव लर्निंग करने की अनुमति देगा। -
भौतिकी और हेमोडायनामिक्स का एकीकरण:
वर्तमान में, शब्दकोश परमाणु विशुद्ध रूप से स्थिर स्थानिक ज्यामिति से सीखे जाते हैं। लेकिन रक्त वाहिकाएं उनके माध्यम से बहने वाले रक्त की द्रव गतिकी से आकार लेती हैं। यदि हम लेटेंट स्पेस जनरेशन में फिजिक्स-इन्फॉर्म्ड न्यूरल नेटवर्क (PINNs) इंजेक्ट करते हैं, तो क्या हम सियामी नेटवर्क को न केवल आकार के आधार पर, बल्कि उनके हेमोडायनामिक गुणों (जैसे, कतरनी तनाव या प्रवाह वेग) के आधार पर वाहिकाओं को क्लस्टर करने के लिए मजबूर कर सकते हैं? यह एन्यूरिज्म या स्ट्रोक की भविष्यवाणी के लिए डेटा के नमूनाकरण के तरीके में क्रांति ला सकता है।
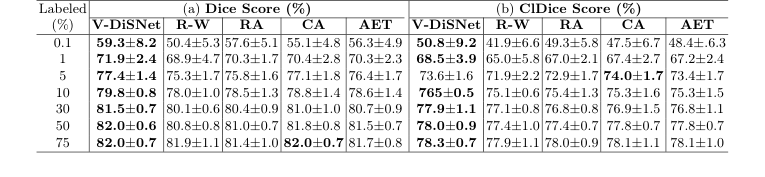 Table 1. Segmentation performance on 15 CAS dataset test patients at various labeling percentages. Eight experiments with distinct random seeds were run for each fraction and model. Results were averaged and standard deviations computed across test patients
Table 1. Segmentation performance on 15 CAS dataset test patients at various labeling percentages. Eight experiments with distinct random seeds were run for each fraction and model. Results were averaged and standard deviations computed across test patients
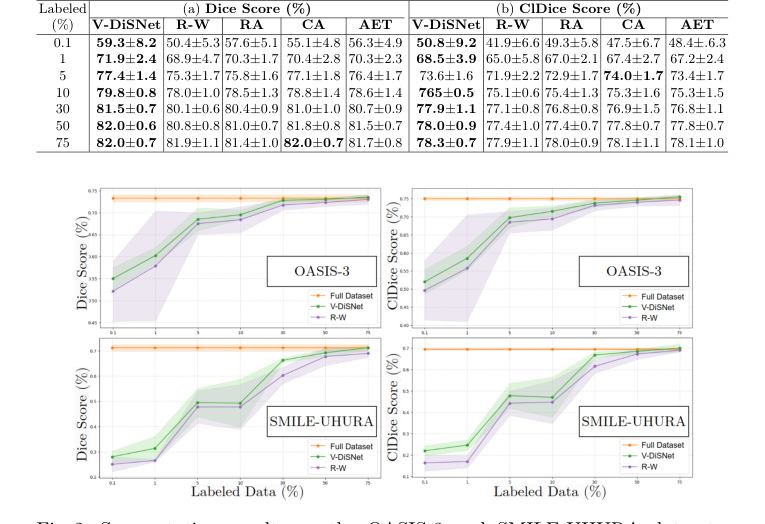 Figure 2. Segmentation results on the OASIS-3 and SMILE-UHURA datasets, showing Dice scores (left) and ClDice scores (right) for different percentages of sample and annotated patches
Figure 2. Segmentation results on the OASIS-3 and SMILE-UHURA datasets, showing Dice scores (left) and ClDice scores (right) for different percentages of sample and annotated patches
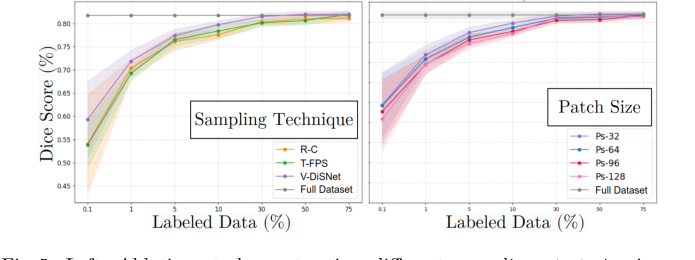 Figure 5. Left: Ablation study contrasting different sampling strategies in our learned latent space. Right: Evaluation of the impact of the patch size
Figure 5. Left: Ablation study contrasting different sampling strategies in our learned latent space. Right: Evaluation of the impact of the patch size