Однократное активное обучение для сегментации сосудов
В области медицинской визуализации картирование кровеносных сосудов головного мозга, процесс, известный как сегментация сосудов, является критически важным этапом для понимания функций мозга и диагностики тяжелых...
Предыстория и академическое происхождение
В области медицинской визуализации картирование кровеносных сосудов головного мозга, процесс, известный как сегментация сосудов, является критически важным этапом для понимания функций мозга и диагностики тяжелых неврологических расстройств, таких как инсульты. Исторически сложилось так, что с появлением глубоких нейронных сетей, ставших золотым стандартом для этой задачи, возникла серьезная проблема: эти модели чрезвычайно требовательны к данным. Им требуются тысячи 3D-сканов мозга, тщательно аннотированных медицинскими экспертами. Ручное отслеживание сложных, микроскопических сосудистых сетей не только утомительно, но и непомерно дорого, иногда стоимость экспертного труда на один скан эквивалентна 150 долларам США или более.
Для решения этой проблемы область обратилась к активному обучению (Active Learning, AL) — парадигме, в которой ИИ идентифицирует наиболее информативные неразмеченные образцы и просит человека-эксперта разметить только их. Однако классическое AL является высокоитеративным. Оно требует цикла обучения модели, паузы для получения метки от эксперта, переобучения модели и повторного запроса. Этот постоянный обмен информацией требует постоянной доступности клинических экспертов и влечет за собой огромные вычислительные затраты, что делает применение в реальном времени практически невозможным.
Фундаментальное ограничение, которое побудило авторов написать эту статью, заключается в недостатках следующего эволюционного шага: однопроходное активное обучение (One-Shot Active Learning, OSAL). Хотя OSAL пытается выбрать минимальный набор образцов за один проход (устраняя необходимость обмена информацией), предыдущие модели OSAL были по сути «черными ящиками». Они полагались на общую аугментацию данных или контрастное обучение без какого-либо явного механизма для понимания фактической анатомии мозга. В частности, они полностью игнорировали повторяющиеся, древовидные структуры кровеносных сосудов. Поскольку эти старые модели не могли интерпретировать, почему они выбирают определенные точки данных, они часто выбирали нерепрезентативные образцы. Это приводило к моделям, которые не могли обобщаться на новые, ранее не встречавшиеся данные пациентов. Авторы поняли, что для исправления этого им нужна структура OSAL, специально разработанная для уникальной, повторяющейся геометрии сосудов мозга.
Чтобы помочь вам интуитивно понять, как авторы решили эту проблему, ниже приведены основные концепции, переведенные из узкоспециализированных терминов в повседневные аналогии:
- Однопроходное активное обучение (OSAL): Представьте, что вы ходите по магазинам за огромным, сложным угощением, но вам разрешено посетить магазин ровно один раз. Вместо того чтобы возвращаться в магазин каждый раз, когда вы понимаете, что вам не хватает ингредиента (как это работает при итеративном активном обучении), вы заранее тщательно анализируете свой рецепт и покупаете идеально разнообразный, минимальный набор ингредиентов за одну, высокоэффективную поездку.
- Обучение по словарю и атомы: Думайте об этом как о наборе Lego у мастера-строителя. Вместо того чтобы пытаться запомнить точную форму каждого когда-либо построенного замка или космического корабля, ИИ просто изучает небольшой набор фундаментальных кирпичиков Lego (называемых «атомами»). Комбинируя эти базовые кирпичики различными способами, ИИ может реконструировать любую сложную форму кровеносного сосуда, с которой он сталкивается.
- Скрытое пространство (Latent Space): Представьте себе огромную волшебную библиотеку, где книги сортируются не по алфавиту, а по сходству их сюжетов. Скрытое пространство — это математическая «комната», куда ИИ помещает фрагменты изображений. Фрагменты со схожими узорами сосудов располагаются рядом друг с другом, в то время как совершенно разные узоры отодвигаются далеко, что позволяет легко увидеть общую картину данных.
- Сиамский энкодер (Siamese Encoder): Представьте себе близнецов-детективов, работающих над одним делом. Им дают две разные улики (фрагменты изображений). Если улики принадлежат одному и тому же подозреваемому (один и тот же узор сосудов), детективы связывают их короткой нитью. Если они принадлежат разным подозреваемым, они их разделяют. Этот алгоритм гарантирует, что скрытое пространство будет идеально организовано и высокодискриминативно.
Ниже приведено описание ключевых математических обозначений, использованных для формулировки и решения этой проблемы:
| Обозначение | Описание |
|---|---|
| $\mathcal{I}$ | Размеченный набор данных, содержащий изображения и соответствующие им аннотации экспертов. |
| $\mathbf{I}$ | Конкретное 3D объемное изображение (например, МРТ головного мозга) из набора данных. |
| $\mathbf{L}$ | Карта истинных меток, соответствующая изображению $\mathbf{I}$. |
| $H \times W \times S$ | Размеры изображения (высота, ширина и количество срезов). |
| $X_k, Y_k$ | Непересекающиеся 2D фрагменты изображений и соответствующие им фрагменты меток. |
| $\mathcal{Y}_{\mathcal{I}}$ | Набор бинарных аннотированных фрагментов сосудов, извлеченных из набора данных. |
| $\mathbf{B}$ | Сверхопределенный словарь, содержащий фундаментальные строительные блоки (атомы) древовидных разветвляющихся структур. |
| $\mathbf{z}$ | Разреженный вектор, содержащий коэффициенты представления (определяющие, какие атомы активированы). |
| $\hat{\mathbf{B}}, \hat{\mathbf{Z}}$ | Обученный словарь и обученные разреженные скрытые векторы, полученные после оптимизации. |
| $\lambda$ | Параметр регуляризации, контролирующий разреженность векторов представления (заставляя модель использовать как можно меньше атомов). |
| $c_i$ | Метка кластера k-средних, присвоенная конкретной аннотации и соответствующему ей фрагменту изображения. |
| $\mathcal{E}_1, \mathcal{R}_1$ | Линейный энкодер и декодер, используемые для отображения фрагментов в разреженные скрытые векторы и их реконструкции. |
| $\mathcal{E}_s$ | Сеть сиамского энкодера, используемая для генерации окончательного информативного скрытого пространства для фрагментов МРТ. |
| $\mathcal{I}^U$ | Новый набор неразмеченных изображений, из которого модели необходимо выбирать образцы. |
| $n$ | Минимальный поднабор фрагментов мозга, выбранный структурой для отправки человеку-эксперту для аннотации. |
| $\Phi$ | Окончательная модель сегментации сосудов головного мозга, обученная с использованием вновь аннотированных фрагментов. |
Объединив эти элементы, авторы успешно создали V-DiSNet — систему, которая математически моделирует повторяющиеся узоры кровеносных сосудов как $$ \mathbf{Y} = \mathbf{B}\mathbf{z} $$ и использует это понимание для выбора абсолютно лучших $n$ фрагментов для разметки человеком, достигая почти полного объема данных при разметке только 30% данных.
Определение проблемы и ограничения
Чтобы понять точную проблему, которую решает данная статья, необходимо сначала рассмотреть начальную и конечную точки.
Входные данные (текущее состояние): Мы начинаем с массивного неразмеченного набора данных 3D-сканов мозга, в частности, изображений магнитно-резонансной ангиографии (МРА). Математически это набор неразмеченных объемных изображений $I^U = \{I_j\}_{j=1}^M \subset \mathbb{R}^{H \times W \times S}$.
Выходные данные (целевое состояние): Целью является полностью обученная, высокоточная модель глубокого обучения, способная сегментировать (точно очерчивать) сложные, древовидные кровеносные сосуды в мозге. Однако есть нюанс: мы хотим достичь этого, имея лишь крошечную, тщательно отобранную долю исходных данных, вручную аннотированную медицинскими экспертами (например, всего 30% или даже меньше).
Связующее звено: Математический разрыв между входными данными и целью заключается в механизме отбора. Как математически гарантировать, что небольшое количество изображений, которые вы просите врачей разметить, являются наиболее информативными, прежде чем вы фактически узнаете, что в них содержится? Авторы выдвигают гипотезу, что сосуды мозга состоят из повторяющихся иерархических ветвящихся структур. Следовательно, любое изображение сосудистого дерева $\mathbf{Y}$ может быть смоделировано как линейная комбинация фундаментальных строительных блоков (словаря $\mathbf{B}$) и разреженных коэффициентов ($\mathbf{z}$), таким образом, что $\mathbf{Y} = \mathbf{B}\mathbf{z}$. Связующим звеном, которое преодолевает данная статья, является определение того, как изучить этот скрытый словарь паттернов сосудов и отобразить неразмеченные изображения в латентное пространство, где мы можем математически выбрать наиболее разнообразные и репрезентативные участки за один проход.
Это подводит нас к мучительной дилемме, которая ставила в тупик предыдущих исследователей.
В мире машинного обучения снижение потребности в человеческих метках обычно опирается на активное обучение (Active Learning, AL). Традиционное AL — это итеративный процесс: модель обучается на нескольких изображениях, определяет, в чем она больше всего путается, просит человеческий оракул разметить эти конкретные запутанные изображения, а затем переобучается.
* Компромисс: Вы получаете высокую точность при малом количестве меток, но несете огромные вычислительные затраты из-за постоянного переобучения модели. Хуже того, это требует, чтобы медицинский эксперт постоянно находился наготове, чтобы отвечать на запросы алгоритма, что практически невозможно в реальных клинических условиях.
Чтобы решить эту проблему, исследователи изобрели однократное активное обучение (One-Shot Active Learning, OSAL), которое пытается выбрать всю партию информативных образцов за один раз, устраняя цикл итеративного переобучения.
* Новая дилемма: Существующие методы OSAL опираются на общую "черноящичную" математику (например, контрастное обучение или вариационные автокодировщики), которая совершенно не учитывает фактическую физическую анатомию мозга. Они не понимают, что кровеносные сосуды являются непрерывными, повторяющимися трубчатыми структурами. Если использовать эти общие методы для выбора образцов за один проход, существует риск выбора партии изображений, которая полностью упускает критические анатомические вариации. Вы жертвуете вычислительной эффективностью ради модели, которая не может обобщаться на невиданные данные, потому что ее обучающий набор не был по-настоящему репрезентативным для сложного сосудистого дерева.
Чтобы решить эту проблему, авторы столкнулись с несколькими суровыми, реалистичными препятствиями:
- Ограничение скрытого словаря: Фундаментальные строительные блоки ("атомы") сосудов мозга напрямую не наблюдаются. Чтобы найти их, авторам пришлось решить задачу сильно ограниченной оптимизации для минимизации ошибки реконструкции, одновременно заставляя представление быть разреженным. Им пришлось математически определить это как:
$$ \hat{\mathbf{B}}, \hat{\mathbf{Z}} = \min_{\mathbf{B}, \mathbf{Z}} \|\mathcal{Y}_{\mathcal{I}} - \mathbf{B}\mathbf{Z}\|_2^2 $$
при строгом ограничении разреженности $\|\mathbf{Z}\|_1 < \lambda$. Решение этой задачи требует специализированных, сложных алгоритмов, таких как обученный итеративный алгоритм пороговой обработки (learned Iterative Shrinkage Thresholding Algorithm, LISTA). - Экстремальная разреженность и сложность данных: Кровеносные сосуды чрезвычайно тонкие, сложные и разреженные по сравнению с окружающей тканью мозга. Захват их связности и трубчатой формы означает, что стандартного попиксельного анализа недостаточно; модель должна каким-то образом понимать геометрию ветвящейся структуры.
- Ограничения аппаратного обеспечения и размерности: 3D объемные сканы мозга огромны. Обработка полных 3D участков для изучения этих разреженных словарей требует огромного количества памяти. Честно говоря, я не до конца уверен, было ли это строго ограничением памяти GPU или ограничением математической сложности, но авторы явно признают суровый компромисс: им пришлось разрезать 3D объемы на 2D участки, чтобы сделать изучение словаря осуществимым. Эта зависимость от 2D участков означает, что они рискуют потерять некоторую глобальную 3D пространственную связность сосудистого дерева — физическое ограничение, которое им пришлось принять, чтобы математика работала в разумных вычислительных пределах.
Почему этот подход
Авторы данной статьи достигли критического момента "озарения", когда осознали, что существующие передовые (SOTA) фреймворки для однократного активного обучения (One-Shot Active Learning, OSAL) фундаментально игнорируют анатомию человека. Традиционные методы в значительной степени полагаются на общее самообучение (self-supervised learning), вариационные автокодировщики (Variational Autoencoders, VAEs) или контрастное обучение (contrastive learning). Хотя эти подходы превосходно выявляют статистические выбросы в стандартных наборах изображений, они рассматривают снимки мозга как общие распределения пикселей. Они полностью упускают из виду повторяющиеся, древовидные, трубчатые структуры сосудов мозга.
Из-за этой анатомической слепоты стандартные модели глубокого обучения не могли гарантировать, что выбранные образцы действительно являются значимыми или репрезентативными для всего сосудистого дерева. Авторы признали, что для решения этой проблемы им нужна математическая модель, которая изначально понимает иерархическое ветвление. Именно поэтому обучение по словарю (Dictionary Learning) в сочетании с разреженным кодированием (sparse coding) стало единственным жизнеспособным решением. Основываясь на теоретическом положении о том, что сосудистое дерево может быть смоделировано как линейная комбинация фундаментальных строительных блоков, они сформулировали задачу извлечения этих скрытых "атомов" сосудистых паттернов.
Математически они определили это извлечение, решив следующую задачу оптимизации:
$$ \hat{\mathbf{B}}, \hat{\mathbf{Z}} = \min_{\mathbf{B},\mathbf{Z}} \|\mathcal{Y}_{\mathcal{I}} - \mathbf{B}\mathbf{Z}\|_2^2 $$
при условии ограничения на разреженность $\|\mathbf{Z}\|_1 < \lambda$. Здесь $\mathcal{Y}_{\mathcal{I}}$ представляет наблюдаемые фрагменты сосудов, $\mathbf{B}$ — переполненный словарь сосудистых паттернов, а $\mathbf{Z}$ содержит коэффициенты разреженного представления. Используя обученный итеративный алгоритм сжатия с порогом (Iterative Shrinkage Thresholding Algorithm, LISTA), они смогли эффективно решить эту задачу, заставив сеть обучить высокосжатый, разреженный латентный вектор, где каждый активный элемент соответствует определенной физической характеристике кровеносного сосуда (например, его форме, размеру или связности).
При тестировании этого подхода на фоне предыдущих золотых стандартов сравнительное превосходство V-DiSNet выходит далеко за рамки простых метрик производительности, таких как оценки Dice. Истинное структурное преимущество заключается в его интерпретируемости и эффективности. Стандартные методы OSAL являются "черными ящиками"; они не могут объяснить, почему один объект данных имеет приоритет над другим. В отличие от них, разреженное латентное пространство V-DiSNet полностью прозрачно. Если деактивировать определенный "атом" в латентном векторе, соответствующая часть сосуда физически изменяется или исчезает при реконструкции. Кроме того, отображая высокоразмерные объемные фрагменты мозга в это разреженное латентное пространство и применяя кластеризацию k-средних (k-means clustering), модель значительно снижает сложность пространства поиска. Вместо того чтобы слепо оценивать расстояние между миллионами высокоразмерных фрагментов, система группирует их по структурному сходству и использует стратифицированный алгоритм выборки ближайших точек (Farthest Point Sampling, FPS), чтобы выбрать именно то, что ей нужно, эффективно обходя массивные вычислительные накладные расходы традиционной выборки.
Этот выбранный метод идеально соответствует жестким ограничениям медицинской области. В клинических условиях врачи и эксперты-аннотаторы имеют крайне ограниченное время. Итеративное активное обучение (Iterative Active Learning), которое требует от человека разметки нескольких изображений, ожидания переобучения модели, а затем разметки большего количества, практически бесполезно из-за постоянных накладных расходов. Задача требовала "однократного" решения (один раунд разметки), которое тем не менее охватывало бы огромное разнообразие сосудов мозга. Здесь "брак" прекрасен: жесткое ограничение отсутствия итеративной обратной связи преодолевается уникальной способностью обучения по словарю гарантировать, что минимальный поднабор фрагментов, отправленных оракулу, охватывает все возможные структурные вариации сосудистого дерева.
Если бы авторы попытались использовать другие популярные генеративные подходы, такие как GANs или стандартные диффузионные модели (Diffusion models), они бы потерпели неудачу. Хотя GAN может генерировать высокореалистичные синтетические кровеносные сосуды, он не предоставляет явного, интерпретируемого механизма для измерения структурного разнообразия неразмеченного набора данных. GAN и диффузионные модели отображают данные в непрерывные, часто запутанные латентные пространства, где выделение определенного "паттерна ветвления" чрезвычайно затруднено. Отказавшись от этих генеративных моделей "черного ящика" в пользу разреженного обучения по словарю, авторы гарантировали, что их стратегия выборки была обусловлена фактической, проверяемой сосудистой анатомией, а не непрозрачной статистической вариацией.
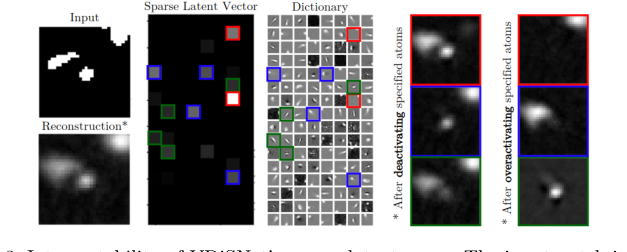 Figure 3. Interpretability of VDiSNet’s sparse latent space. The input patch is en- coded into a sparse representation using learned dictionary atoms. Deactivating or overactivating specific atoms alters specific vessel components, highlighting their role in the reconstruction
Figure 3. Interpretability of VDiSNet’s sparse latent space. The input patch is en- coded into a sparse representation using learned dictionary atoms. Deactivating or overactivating specific atoms alters specific vessel components, highlighting their role in the reconstruction
Математический и логический механизм
В основе данной работы лежит математический аппарат, предназначенный для преобразования хаотичной, разветвленной сложности сосудов головного мозга в четкий, управляемый словарь фундаментальных форм. Для достижения этой цели авторы опираются на классическую формулировку обучения разреженных словарей, адаптированную здесь в качестве предварительной задачи для построения интерпретируемого латентного пространства.
Основное уравнение, лежащее в основе данного подхода:
$$ \hat{\mathcal{B}}, \hat{\mathbf{Z}} = \min_{\mathcal{B}, \mathbf{Z}} \|\mathcal{Y}_{\mathcal{I}} - \mathcal{B}\mathbf{Z}\|_2^2 $$
при условии:
$$ \|\mathbf{Z}\|_1 < \lambda $$
Разберем это уравнение по частям, чтобы точно понять его суть:
- $\hat{\mathcal{B}}, \hat{\mathbf{Z}}$: Это конечные, оптимизированные выходные данные аппарата. $\hat{\mathcal{B}}$ представляет собой обученный "словарь" — каталог фундаментальных, повторяющихся строительных блоков сосудов (например, прямой участок трубки, резкий изгиб или Y-образное разветвление). $\hat{\mathbf{Z}}$ — это разреженная матрица коэффициентов, которая действует как конкретный рецепт, указывающий системе, какие блоки использовать для каждого изображения.
- $\min_{\mathcal{B}, \mathbf{Z}}$: Это директива оптимизации. Она указывает математическому аппарату непрерывно настраивать как словарь $\mathcal{B}$, так и рецепты $\mathbf{Z}$ до тех пор, пока выражение справа не достигнет минимально возможного значения.
- $\mathcal{Y}_{\mathcal{I}}$: Матрица входных данных. Физически это реальные, наблюдаемые бинарные фрагменты изображений сосудов головного мозга, извлеченные из набора данных.
- $-$ (Вычитание): Используется здесь для расчета остатка. Оно измеряет точный разрыв между реальным фрагментом сосуда и искусственной попыткой модели его воссоздать.
- $\mathcal{B}\mathbf{Z}$: Реконструированные данные. Авторы используют матричное умножение, поскольку оно идеально моделирует линейную комбинацию. Матричное умножение масштабирует каждый атом словаря в $\mathcal{B}$ на весовое значение интенсивности, указанное в $\mathbf{Z}$, а затем суммирует их. Сложение используется для наложения этих фундаментальных форм друг на друга с целью построения финальной сложной структуры сосуда.
- $\| \cdot \|_2^2$: Квадрат L2-нормы. Математически он суммирует квадраты разностей всех пикселей между реальным и сгенерированным фрагментами. Физически он действует как резинка, притягивающая модель к высокой точности. Авторы использовали квадрат L2-нормы вместо абсолютной L1-нормы, поскольку возведение в квадрат сильно штрафует большие, явные ошибки (например, полное отсутствие толстого сосуда), заставляя модель точно улавливать общую макроструктуру.
- $\|\mathbf{Z}\|_1 < \lambda$: Ограничение разреженности с использованием L1-нормы. Математически оно суммирует абсолютные значения коэффициентов в рецепте. Физически оно действует как строгий бюджет. Оно заставляет модель использовать минимально возможное количество атомов словаря для реконструкции изображения.
- $\lambda$: Параметр регуляризации. Это ручка настройки, определяющая строгость бюджета разреженности. Более высокое значение $\lambda$ требует более разреженного представления, что означает, что модель может выбрать лишь небольшое количество атомов на фрагмент.
Пошаговый процесс
Представьте себе автоматизированную сборочную линию, предназначенную для построения сложных сосудистых деревьев из простых деталей Lego.
Сначала на фабрику поступает необработанный, неразмеченный фрагмент изображения сосуда головного мозга $Y_i$. Он подается в линейный кодер (действующий как сканер). Этот сканер анализирует сложный сосуд и генерирует разреженный вектор чертежа $\hat{z}_i$. Благодаря строгому бюджету L1, обсуждавшемуся ранее, этот чертеж состоит в основном из нулей — он вынужден быть очень избирательным, активируя лишь несколько основных компонентов.
Затем этот чертеж отправляется в словарь $\mathcal{B}$, который представляет собой склад, хранящий фундаментальные части сосудов. Ненулевые значения в $\hat{z}_i$ действуют как механические рычаги. Если в чертеже значение $0.8$ находится в пятой позиции, это означает, что "Атом 5" (возможно, специфическая форма Y-образного разветвления) извлекается со склада и его интенсивность масштабируется на $0.8$.
Наконец, эти выбранные, масштабированные части накладываются друг на друга для построения финального реконструированного фрагмента $\hat{Y}_i$. Затем система сравнивает исходный фрагмент с этой новой конструкцией, вычисляет ошибку и отправляет сигнал обратно в начало линии для корректировки сканера и инвентаря склада для следующего цикла.
Динамика оптимизации
Как этот механизм фактически обучается и сходится? Ландшафт оптимизации здесь представляет собой классическое перетягивание каната. L2-норма стремится идеально воссоздать изображение, что обычно означает использование всех доступных инструментов (что приводит к плотному $\mathbf{Z}$). Однако ограничение L1 является строгим менеджером, требующим эффективности, и заставляет большую часть $\mathbf{Z}$ становиться нулевой.
Для решения этой нетривиальной задачи оптимизации авторы используют не просто стандартный градиентный спуск. Они применяют LISTA (Learned Iterative Shrinkage Thresholding Algorithm). LISTA берет традиционный математический решатель и "разворачивает" его итеративные шаги в слои нейронной сети.
Во время обучения ландшафт потерь имеет форму гладкой, многомерной чаши (от L2-нормы), пересекающейся с острой, многомерной ромбовидной фигурой (от L1-нормы). По мере того как градиенты проходят обратно через развернутую сеть LISTA, операция "сжатия" действует как пара ножниц. Она анализирует обновления градиента и буквально обрезает малые, незначительные веса до ровно нуля.
Со временем эта динамика заставляет словарь $\mathcal{B}$ отбрасывать бесполезный шум и сохранять только наиболее универсально применимые формы сосудов. Одновременно кодер учится перемещаться по этому ромбовидному ландшафту потерь, чтобы мгновенно выбирать наиболее эффективные комбинации. Как только это латентное пространство полностью сформировано и кластеризовано, фреймворк активного обучения может легко выбирать образцы из различных кластеров, гарантируя, что аннотатор получит идеально разнообразный набор геометрий сосудов для маркировки.
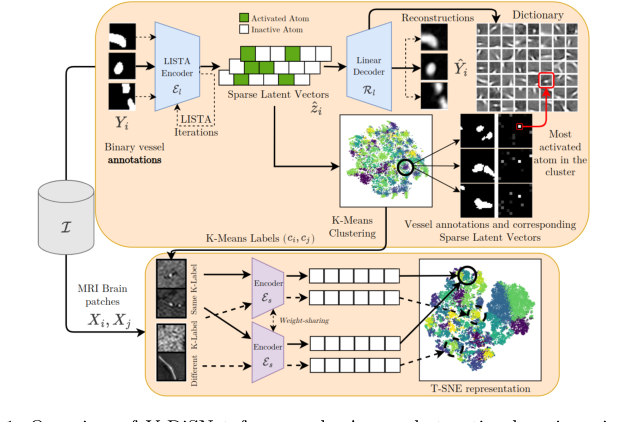 Figure 1. Overview of V-DiSNet framework: A one-shot active learning pipeline that leverages dictionary learning to capture intrinsic vessel patterns, constructs an informative latent space via a Siamese encoder, and applies diversity-based sampling to select a minimal yet representative set of vessel patches for efficient brain vessel segmentation
Figure 1. Overview of V-DiSNet framework: A one-shot active learning pipeline that leverages dictionary learning to capture intrinsic vessel patterns, constructs an informative latent space via a Siamese encoder, and applies diversity-based sampling to select a minimal yet representative set of vessel patches for efficient brain vessel segmentation
Результаты, ограничения и заключение
Представьте, что вам поручено составить карту сложной и разветвленной системы водоснабжения огромного города. Вы не можете видеть трубы напрямую; у вас есть только нечеткие радарные снимки. Чтобы построить точную карту, вам нужен опытный сантехник, который рассмотрит снимки и вручную проследит каждую трубу. Это невероятно дорого — около 500 долларов за снимок, учитывая время медицинских экспертов, — и мучительно медленно.
В области медицинской визуализации эта «система водоснабжения» представляет собой сосудистую сеть человеческого мозга, а «радарные снимки» — это изображения магнитно-резонансной ангиографии (МРА). Модели глубокого обучения отлично справляются с картированием этих сосудов, но они крайне требовательны к данным. Им требуются полностью размеченные наборы данных для обучения, что означает, что врачи-люди должны потратить бесчисленные часы на аннотирование 3D-снимков мозга воксель за вокселем.
Чтобы обойти это узкое место, ученые используют активное обучение (Active Learning, AL). Вместо того чтобы размечать все, ИИ просматривает данные и просит человека разметить только наиболее сложные или информативные части. Однако традиционное AL итеративно: ИИ запрашивает несколько меток, обучается, понимает, что ему нужно больше, и запрашивает снова. Этот постоянный обмен информацией крайне непрактичен в условиях загруженных клиник. Здесь на помощь приходит однократное активное обучение (One-Shot Active Learning, OSAL), когда ИИ выбирает одну минимальную партию данных для одновременной разметки.
Ограничение, которое пришлось преодолеть авторам этой статьи, заключается в том, что существующие методы OSAL по сути слепы к анатомии. Они выбирают точки данных на основе статистических аномалий или вариаций пикселей, полностью игнорируя фундаментальную реальность того, что кровеносные сосуды являются непрерывными, древовидными, трубчатыми структурами. Если модель OSAL просто выбирает случайные «сложные» участки, она может упустить повторяющиеся закономерности ветвления, которые определяют сосудистую систему, что приведет к тому, что ИИ не сможет обобщать.
Математическое ядро: Декодирование анатомии
Чтобы решить эту проблему, авторы создали V-DiSNet (Vessel-Dictionary Selection Net). Их блестящая идея заключалась в том, чтобы рассматривать сложную сосудистую сеть не как случайный набор пикселей, а как язык, построенный из конечного алфавита основных форм — таких как прямые трубки, Y-образные разветвления и изгибы.
Математически они смоделировали участок сосудистого изображения $\mathcal{Y}$ как линейную комбинацию этих основных строительных блоков. Они определили избыточный «словарь» $\mathcal{B}$ (алфавит форм) и разреженный вектор $\mathbf{Z}$ (конкретный рецепт того, какие формы использовать и с какой силой их взвешивать).
Поскольку они не знали словарь заранее, им пришлось изучить его на существующем размеченном наборе данных. Они сформулировали это как задачу оптимизации:
$$ \hat{\mathcal{B}}, \hat{\mathbf{Z}} = \min_{\mathcal{B}, \mathbf{Z}} \|\mathcal{Y}_{\mathcal{I}} - \mathcal{B}\mathbf{Z}\|_2^2 $$
при условии:
$$ \|\mathbf{Z}\|_1 < \lambda $$
Вот что это элегантно означает: алгоритм пытается найти оптимальный словарь ($\hat{\mathcal{B}}$) и оптимальный рецепт ($\hat{\mathbf{Z}}$) таким образом, чтобы при их умножении разница между реконструированным изображением и реальным аннотированным изображением ($\mathcal{Y}_{\mathcal{I}}$) была как можно ближе к нулю (минимизируется квадратом L2-нормы).
Ключевым моментом является ограничение $\|\mathbf{Z}\|_1 < \lambda$. Это ограничение разреженности. Оно заставляет модель использовать абсолютный минимум «ингредиентов» из словаря для реконструкции сосуда. Принуждая к разреженности, модель не может просто запомнить изображение; она вынуждена обнаружить истинные, лежащие в основе, повторяющиеся анатомические закономерности («атомы»).
После изучения этих атомов авторы используют архитектуру сиамской нейронной сети для отображения новых, неразмеченных участков МРТ в латентное пространство (пространство математических представлений). Участки со схожими сосудистыми структурами притягиваются друг к другу, в то время как участки с различными структурами отталкиваются. Наконец, они используют алгоритм Farthest Point Sampling (FPS) для выбора крошечного, высокоразнообразного набора участков, равномерно распределенных по этому пространству. Это гарантирует, что эксперту-человеку будет предложено разметить идеально репрезентативную выборку каждого типа геометрии сосудов, присутствующей в мозге.
Экспериментальная архитектура: Бескомпромиссное доказательство концепции
Авторы не просто бросили свою модель на набор данных и сообщили о незначительном повышении точности. Они разработали строгий стресс-тест, чтобы доказать, что их механизм выборки значительно превосходит существующие парадигмы.
Их «жертвами» стали стандартная случайная выборка (Random Sampling, R-W) и три передовых базовых метода OSAL: RA (Representative Annotation), CA (Contrastive Active Learning) и AET (Active Learning via Epistemic and Aleatoric Uncertainty). Они развернули эти модели на трех различных общедоступных 3D-наборах данных МРА (OASIS-3, SMILE-UHURA и CAS), чтобы гарантировать, что результаты не являются случайностью одного конкретного типа сканера.
Окончательное доказательство превосходства V-DiSNet было обнаружено в режимах с крайне малым объемом данных. Авторы «морили голодом» модели, предоставляя им доступ только к 0,1%, 1%, 5% и 10% размеченных данных. В этих экстремальных условиях V-DiSNet систематически превосходил базовые методы.
Более того, они измеряли не только стандартное перекрытие пикселей (показатель Dice). Они использовали метрику clDice, которая специально измеряет топологическую корректность и связность трубчатых структур. Это доказало, что V-DiSNet не просто лучше угадывал пиксели; он фактически сохранял непрерывную, трубообразную целостность кровеносных сосудов. Окончательным моментом, демонстрирующим их успех, является то, что при разметке всего 30% набора данных V-DiSNet достиг почти такой же производительности сегментации, как и модель, обученная на 100% полностью аннотированных данных.
Чтобы доказать, что их математическое латентное пространство не было просто «черным ящиком», они провели эксперимент по интерпретируемости. Вручную деактивируя определенные «атомы» в их изученном словаре $\mathbf{Z}$, они показали, что определенные физические особенности реконструированных кровеносных сосудов (например, определенная ветвь или изгиб) исчезали. Это недвусмысленно доказало, что их математика успешно выделила физическую геометрию человеческой васкулятуры.
Темы для обсуждения для дальнейшего развития
Исходя из глубоких последствий этой статьи, вот несколько направлений для дальнейших исследований и критического осмысления:
-
От 2D-патчей к 3D-глобальной топологии:
Текущая структура работает с 2D-патчами, извлеченными из 3D-объемов. Хотя это эффективно локально, это может привести к потере глобальной непрерывности сосудистого дерева (например, длинной артерии, охватывающей несколько патчей). Как можно развить уравнение обучения словаря для нативной обработки 3D-объемных графов без взрывного роста вычислительных затрат? Можно ли интегрировать топологический анализ данных (TDA) для обеспечения глобальных ограничений связности на этапе выборки? -
Переносимость анатомии между модальностями:
V-DiSNet изучает свой словарь на основе снимков МРА. Однако фундаментальная форма кровеносных сосудов остается неизменной, независимо от того, рассматриваются ли они через МРА, КТ-ангиографию (КТА) или ультразвук. Можно ли один раз обучить универсальный «Словарь сосудов» и затем переносить его между совершенно разными методами визуализации? Это позволило бы больнице использовать словарь, изученный на дешевых, широко доступных данных МРА, для выполнения однократного активного обучения на редких, дорогих или новых типах визуализации. -
Интеграция физики и гемодинамики:
В настоящее время атомы словаря изучаются исключительно на основе статической пространственной геометрии. Но кровеносные сосуды формируются под воздействием гидродинамики протекающей по ним крови. Если бы мы внедрили физически-информированные нейронные сети (PINNs) в генерацию латентного пространства, могли бы мы заставить сиамскую сеть кластеризовать сосуды не только по форме, но и по их гемодинамическим свойствам (например, сдвиговому напряжению или скорости потока)? Это могло бы революционизировать то, как мы отбираем данные для прогнозирования аневризм или инсультов.
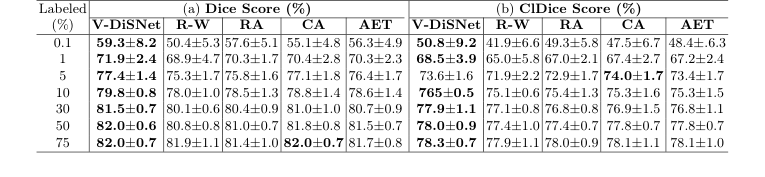 Table 1. Segmentation performance on 15 CAS dataset test patients at various labeling percentages. Eight experiments with distinct random seeds were run for each fraction and model. Results were averaged and standard deviations computed across test patients
Table 1. Segmentation performance on 15 CAS dataset test patients at various labeling percentages. Eight experiments with distinct random seeds were run for each fraction and model. Results were averaged and standard deviations computed across test patients
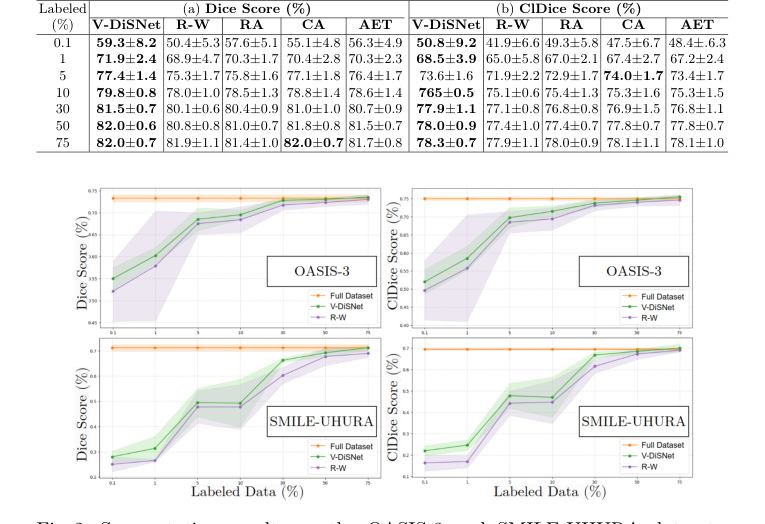 Figure 2. Segmentation results on the OASIS-3 and SMILE-UHURA datasets, showing Dice scores (left) and ClDice scores (right) for different percentages of sample and annotated patches
Figure 2. Segmentation results on the OASIS-3 and SMILE-UHURA datasets, showing Dice scores (left) and ClDice scores (right) for different percentages of sample and annotated patches
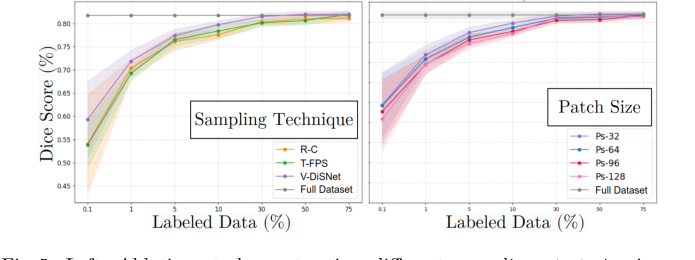 Figure 5. Left: Ablation study contrasting different sampling strategies in our learned latent space. Right: Evaluation of the impact of the patch size
Figure 5. Left: Ablation study contrasting different sampling strategies in our learned latent space. Right: Evaluation of the impact of the patch size