血管セグメンテーションのためのワンショットアクティブラーニング
New AI learns from tiny, smart samples, saving time & resources for better disease insights.
背景と学術的系譜
医療画像処理の分野において、脳の血管をマッピングするプロセス、すなわち血管セグメンテーションは、脳機能の理解や脳卒中などの重篤な神経疾患の診断において極めて重要なステップである。歴史的に、このタスクにおいてディープラーニングモデルがゴールドスタンダードとなるにつれて、巨大なボトルネックが出現した。すなわち、これらのモデルは膨大なデータを必要とするのである。数千もの3D脳スキャンに医療専門家による綿密なアノテーションが要求される。複雑で微細な血管網を手動でトレースすることは、単に疲労を伴うだけでなく、法外に高価であり、単一スキャンあたり専門家の労力として150ドル以上、あるいはそれと同等の費用がかかる場合もある。
これを緩和するため、この分野はアクティブラーニング(AL)というパラダイムに転向した。ALは、AIが最も情報量の多いラベルなしサンプルを特定し、人間が専門家にそれらのみをラベル付けするように要求するものである。しかし、古典的なALは非常に反復的である。モデルのトレーニング、専門家へのラベル要求のための停止、モデルの再トレーニング、そして再び要求するというサイクルが必要となる。この絶え間ない往復は、臨床専門家の継続的な可用性を要求し、膨大な計算オーバーヘッドを発生させるため、リアルタイムの臨床応用はほぼ不可能である。
著者らが本稿を執筆するに至った根本的な限界は、次の進化段階であるワンショットアクティブラーニング(OSAL)の欠陥にある。OSALは、単一パスで最小限のサンプルセットを選択しようとする(往復を排除する)が、従来のOSALモデルは本質的に「ブラックボックス」であった。これらは、脳の実際の解剖学的構造を理解するための明示的なメカニズムなしに、一般的なデータ拡張やコントラスティブラーニングに依存していた。具体的には、血管の繰り返し現れる樹状構造を完全に無視していた。これらの古いモデルは、なぜ特定のデータポイントを選択しているのかを解釈できなかったため、代表性のないサンプルをしばしば選択した。これにより、新しい、未知の患者データに汎化できないモデルが生じた。著者らは、これを修正するためには、脳血管のユニークで繰り返し現れる幾何学的構造に特化したOSALフレームワークが必要であると認識した。
著者らがこれをどのように解決したかを直感的に理解するために、高度に専門的なドメイン用語を日常的なアナロジーに翻訳したコアコンセプトを以下に示す。
- ワンショットアクティブラーニング(OSAL): 巨大で複雑な祝宴のために食料品店で買い物をしていると想像してほしい。しかし、あなたは店にちょうど一度だけしか行くことが許されない。足りない材料に気づくたびに店に駆け戻るのではなく(これは反復的なアクティブラーニングの仕組みである)、事前にレシピを注意深く分析し、単一の非常に効率的な旅行で、完全に多様で最小限の材料セットを購入する。
- 辞書学習とアトム: これは熟練した建築家のレゴセットのようなものだと考えてほしい。AIは、これまで建てられたあらゆるおもちゃの城や宇宙船の正確な形状を記憶しようとするのではなく、基本的なレゴブロックの小さなセット(「アトム」と呼ばれる)を学習するだけである。これらの基本的なブロックをさまざまな方法で組み合わせることで、AIは遭遇するあらゆる複雑な血管形状を再構築できる。
- 潜在空間: 本がアルファベット順ではなく、プロットの類似性によってソートされている、巨大で魔法のような図書館を想像してほしい。潜在空間は、AIが画像パッチを配置する数学的な「部屋」である。類似した血管パターンを持つパッチは互いのすぐ近くに配置され、完全に異なるパターンは遠くに押しやられるため、データの全体像を容易に把握できる。
- サイアミーズエンコーダー: 同じ事件に取り組む双子の探偵を想像してほしい。彼らは2つの異なる手がかり(画像パッチ)を渡される。手がかりが同じ容疑者に属する場合(同じ血管パターン)、探偵は短い紐でそれらを結びつける。異なる容疑者に属する場合、それらを離す。このアルゴリズムは、潜在空間が完全に整理され、非常に識別性の高いものであることを保証する。
以下に、この問題を定式化し解決するために使用された主要な数学的記法の内訳を示す。
| 記法 | 説明 |
|---|---|
| $\mathcal{I}$ | 画像とその対応する専門家のアノテーションを含むラベル付きデータセット。 |
| $\mathbf{I}$ | データセット内の特定の3Dボリューム画像(例:MRI脳スキャン)。 |
| $\mathbf{L}$ | 画像 $\mathbf{I}$ に関連付けられたグラウンドトゥルースラベルマップ。 |
| $H \times W \times S$ | 画像の次元(高さ、幅、スライス数)。 |
| $X_k, Y_k$ | 重なり合わない2D画像パッチとその対応するラベルパッチ。 |
| $\mathcal{Y}_{\mathcal{I}}$ | データセットから抽出されたバイナリ血管アノテーション付きパッチのセット。 |
| $\mathbf{B}$ | 樹状分岐パターンの基本的な構成要素(アトム)を含むオーバーコンプリート辞書。 |
| $\mathbf{z}$ | 表現係数(どのアトムがアクティブ化されるかを決定する)を含むスパースベクトル。 |
| $\hat{\mathbf{B}}, \hat{\mathbf{Z}}$ | 最適化後に得られた学習済み辞書と学習済みスパース潜在ベクトル。 |
| $\lambda$ | 表現ベクトルのスパース性を制御する正則化パラメータ(モデルにできるだけ少ないアトムを使用させる)。 |
| $c_i$ | 特定のアノテーションとその対応する画像パッチに割り当てられたk-meansクラスタラベル。 |
| $\mathcal{E}_1, \mathcal{R}_1$ | パッチをスパース潜在ベクトルにマッピングし、それらを再構築するために使用される線形エンコーダーとデコーダー。 |
| $\mathcal{E}_s$ | MRIパッチの最終的な情報量の多い潜在空間を生成するために使用されるサイアミーズエンコーダーネットワーク。 |
| $\mathcal{I}^U$ | モデルがサンプリングする必要があるラベルなし画像の新しいデータセット。 |
| $n$ | フレームワークによって選択され、人間がアノテーションのために専門家に送信する脳パッチの最小サブセット。 |
| $\Phi$ | 新しくアノテーションされたパッチを使用してトレーニングされた最終的な脳血管セグメンテーションモデル。 |
これらの要素を組み合わせることで、著者らは血管の繰り返し現れるパターンを $$ \mathbf{Y} = \mathbf{B}\mathbf{z} $$ として数学的にモデル化し、この理解を利用して人間がラベル付けするのに最適な $n$ 個のパッチを選択するシステムであるV-DiSNetを成功裏に作成した。これにより、データセットの30%のみをラベル付けすることで、ほぼ完全なデータセットのパフォーマンスを達成した。
問題定義と制約
この論文が取り組む正確な問題を理解するためには、まず出発点と到達点に目を向ける必要がある。
入力(現状): 我々は、ラベル付けされていない大量の3D脳スキャンデータ、具体的には磁気共鳴血管造影(MRA)画像から出発する。数学的には、これはラベルなし体積画像 $I^U = \{I_j\}_{j=1}^M \subset \mathbb{R}^{H \times W \times S}$ の集合である。
出力(目標状態): 目標は、脳内の複雑で樹状の血管を正確に輪郭描画する(セグメンテーションする)ことが可能な、完全に学習された高精度な深層学習モデルである。しかし、条件がある。元のデータのごく一部、例えば30%あるいはそれ以下にすぎない、注意深く選択されたデータのみを人間の医療専門家が手動でアノテーションすることによって、これを達成したいのである。
失われた環: 入力と目標の間の数学的なギャップは、選択メカニズムである。実際に画像の内容を知る前に、医師にラベル付けを依頼する少数の画像が最も情報量の多いものであると、数学的にどのように保証できるだろうか。著者らは、脳血管は繰り返し現れる階層的な分岐パターンから構築されていると仮説を立てている。したがって、任意の血管樹画像 $\mathbf{Y}$ は、基本的な構成要素(辞書 $\mathbf{B}$)と疎な係数($\mathbf{z}$)の線形結合としてモデル化できる。すなわち、$\mathbf{Y} = \mathbf{B}\mathbf{z}$ である。この論文が埋める失われた環は、この隠された血管パターンの辞書を学習し、ラベルなし画像を、単一パスで最も多様で代表的なパッチを数学的にサンプリングできる潜在空間にマッピングする方法を見出すことである。
ここで、以前の研究者を悩ませてきた痛ましいジレンマにたどり着く。
機械学習の世界では、人間のラベルの必要性を減らすことは、通常、アクティブラーニング(AL)に依存する。従来のALは反復的なプロセスである。モデルは少数の画像で学習し、最も混乱している点を把握し、人間(オラクル)にそれらの特定の混乱している画像をラベル付けするように依頼し、その後再学習する。
* トレードオフ: 少数のラベルで高い精度を得られるが、モデルの継続的な再学習によって膨大な計算コストがかかる。さらに、アルゴリズムの問い合わせに常に応答するために、医療専門家が常に待機している必要があるが、これは実際の臨床現場では事実上不可能である。
これを解決するために、研究者たちはOne-Shot Active Learning(OSAL)を発明した。これは、情報量の多いサンプルのバッチ全体を一度に選択し、反復的な再学習ループを排除しようとするものである。
* 新たなジレンマ: 既存のOSAL手法は、脳の実際の物理的な解剖学には全く無頓着な、一般的な「ブラックボックス」数学(コントラスティブラーニングや変分オートエンコーダーなど)に依存している。それらは、血管が連続的で繰り返し現れる管状構造であることを理解していない。これらの一般的な手法を用いて一度にサンプルを選択すると、重要な解剖学的変異を完全に捉え損ねた画像のバッチを選択するリスクがある。計算効率と引き換えに、学習セットが複雑な血管樹を真に代表していなかったため、未知のデータに汎化できないモデルを得ることになる。
これを解決するために、著者らはいくつかの厳しい現実的な壁に直面した。
- 隠された辞書の制約: 脳血管の基本的な構成要素(「原子」)は直接観測されない。それらを見つけるために、著者らは再構成誤差を最小化しつつ、表現を疎にするように強制する、高度に制約された最適化問題を解決する必要があった。彼らはこれを数学的に次のように定義する必要があった。
$$ \hat{\mathbf{B}}, \hat{\mathbf{Z}} = \min_{\mathbf{B}, \mathbf{Z}} \|\mathcal{Y}_{\mathcal{I}} - \mathbf{B}\mathbf{Z}\|_2^2 $$
ただし、厳密な疎性制約 $\|\mathbf{Z}\|_1 < \lambda$ を課す。これを解決するには、学習されたIterative Shrinkage Thresholding Algorithm(LISTA)のような特殊で複雑なアルゴリズムが必要である。 - 極端なデータの疎性と複雑さ: 脳血管は、周囲の脳組織と比較して、信じられないほど細く、複雑で、疎である。それらの接続性と管状の形状を捉えることは、標準的なピクセルごとの分析では不十分であることを意味する。モデルは、分岐する樹木の幾何学的構造を何らかの方法で理解する必要がある。
- ハードウェアと次元性の限界: 3D体積脳スキャンは巨大である。これらの疎な辞書を学習するために完全な3Dパッチを処理することは、メモリを大量に消費する。正直なところ、GPUメモリの制限なのか、数学的な複雑さの制限なのか、厳密には確信が持てないが、著者らは明確に厳しい妥協を認めている。彼らは、辞書学習を扱いやすくするために、3D体積を2Dパッチにスライスする必要があった。この2Dパッチへの依存は、血管樹のグローバルな3D空間接続性の一部を失うリスクを意味する。これは、合理的な計算量で数学を機能させるために受け入れなければならなかった物理的な制約である。
このアプローチの理由
本論文の著者らは、既存の最先端(SOTA)One-Shot Active Learning(OSAL)フレームワークが人間の解剖学的構造を根本的に見落としていることに気づいた際に、決定的な「ひらめき」を得た。従来の手法は、汎用的な自己教師あり学習、変分オートエンコーダー(VAE)、または対照学習に大きく依存している。これらのアプローチは標準的な画像データセットにおける統計的異常値の検出に優れているが、脳スキャンを一般的なピクセル分布として扱っている。それらは、脳血管の繰り返し現れる樹状の管状構造を全く考慮に入れていない。
この解剖学的構造に対する盲点のために、標準的な深層学習モデルでは、選択されたサンプルが実際に意味のあるものか、あるいは血管樹全体の代表的なものであるかを保証できなかった。著者らは、これを解決するためには、階層的な分岐を本質的に理解する数学的モデルが必要であると認識した。このため、Dictionary Learningとスパースコーディングの組み合わせが唯一実行可能な解決策であった。血管樹は基本的な構成要素の線形結合としてモデル化できるという理論的基盤に基づき、彼らはこれらの隠れた血管パターンの「原子」を抽出する問題を設定した。
数学的には、この抽出を以下の最適化問題を解くことで定義した。
$$ \hat{\mathbf{B}}, \hat{\mathbf{Z}} = \min_{\mathbf{B},\mathbf{Z}} \|\mathcal{Y}_{\mathcal{I}} - \mathbf{B}\mathbf{Z}\|_2^2 $$
ただし、スパース性制約 $\|\mathbf{Z}\|_1 < \lambda$ を課す。ここで、$\mathcal{Y}_{\mathcal{I}}$ は観測された血管パッチを表し、$\mathbf{B}$ は血管パターンの過剰完備辞書、$\mathbf{Z}$ はスパース表現係数を含む。学習されたIterative Shrinkage Thresholding Algorithm(LISTA)を使用することで、これを効率的に解くことができ、ネットワークは高度に圧縮されたスパースな潜在ベクトルを学習することを強制される。この潜在ベクトルにおいて、各アクティブな要素は、血管の特定の物理的特性(形状、サイズ、接続性など)に対応する。
このアプローチを以前のゴールドスタンダードと比較してベンチマークした際、V-DiSNetの比較優位性は、Diceスコアのような単純な性能指標をはるかに超えている。真の構造的利点は、その解釈可能性と効率性にある。標準的なOSAL手法はブラックボックスであり、なぜあるデータポイントが別のデータポイントよりも優先されるのかを説明できない。対照的に、V-DiSNetのスパース潜在空間は完全に透明である。潜在ベクトル内の特定の「原子」を非アクティブ化すると、再構成において血管の特定の部分が物理的に変化または消失する。さらに、高次元の体積脳パッチをこのスパース潜在空間にマッピングし、k-meansクラスタリングを適用することで、モデルは検索空間の複雑さを劇的に削減する。数百万の高次元パッチ間の距離を盲目的に評価する代わりに、システムは構造的類似性によってそれらをグループ化し、階層化されたFarthest Point Sampling(FPS)アルゴリズムを使用して必要なものを正確に選択し、従来のサンプリングにおける大規模な計算オーバーヘッドを効果的に回避する。
この選択された方法は、医療分野の厳しい制約と完全に一致している。臨床現場では、医師や専門のアノテーターは時間が極めて限られている。反復的なアクティブ学習(人間がいくつかの画像をラベル付けし、モデルの再学習を待ち、さらにラベル付けする)は、その継続的なオーバーヘッドのために実質的に役に立たない。この問題は、脳血管の広大な多様性を捉えつつ、「ワンショット」ソリューション(単一のラベリングラウンド)を要求した。ここで美しいのは「結婚」である。反復的なフィードバックがゼロという厳しい制約は、辞書学習が持つ、オリクルに送られるパッチの最小サブセットが血管樹のあらゆる可能な構造的バリエーションを網羅することを保証する独自の能力によって克服される。
もし著者らがGANや標準的な拡散モデルのような他の一般的な生成アプローチを使用しようとしたならば、失敗していただろう。GANは非常にリアルな合成血管を生成するかもしれないが、ラベル付けされていないデータセットの構造的多様性を測定するための明示的で解釈可能なメカニズムを提供しない。GANと拡散モデルは、データを連続的でしばしば絡み合った潜在空間にマッピングし、特定の「分岐パターン」を分離することは非常に困難である。スパースなDictionary Learningを支持してこれらのブラックボックス生成モデルを拒否することにより、著者らはサンプリング戦略が不透明な統計的変動ではなく、実際の検証可能な血管解剖学によって駆動されることを保証した。
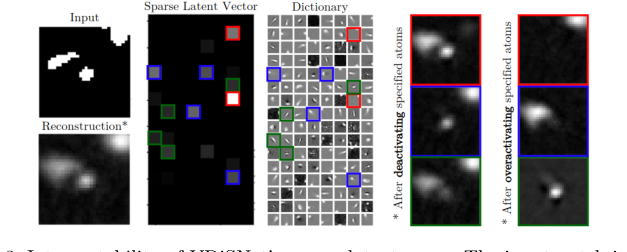 Figure 3. Interpretability of VDiSNet’s sparse latent space. The input patch is en- coded into a sparse representation using learned dictionary atoms. Deactivating or overactivating specific atoms alters specific vessel components, highlighting their role in the reconstruction
Figure 3. Interpretability of VDiSNet’s sparse latent space. The input patch is en- coded into a sparse representation using learned dictionary atoms. Deactivating or overactivating specific atoms alters specific vessel components, highlighting their role in the reconstruction
数学的・論理的メカニズム
本論文の中心には、脳血管の混沌とした分岐構造の複雑さを、基本的形状の明瞭で管理可能な語彙へと抽出するための数学的エンジンが存在する。この目的を達成するため、著者らはスパース辞書学習の古典的な定式化に依拠しており、これを解釈可能な潜在空間を構築するための事前タスクとして適用している。
このフレームワークを駆動するマスター方程式は以下の通りである。
$$ \hat{\mathcal{B}}, \hat{\mathbf{Z}} = \min_{\mathcal{B}, \mathbf{Z}} \|\mathcal{Y}_{\mathcal{I}} - \mathcal{B}\mathbf{Z}\|_2^2 $$
制約条件は以下の通りである。
$$ \|\mathbf{Z}\|_1 < \lambda $$
この方程式を細部まで分解し、その正確な動作を理解しよう。
- $\hat{\mathcal{B}}, \hat{\mathbf{Z}}$: これらはエンジンの最終的な最適化された出力である。$\hat{\mathcal{B}}$ は学習された「辞書」であり、基本的な繰り返し現れる血管の構成要素(直線管、鋭いカーブ、Y字分岐など)のカタログと考えることができる。$\hat{\mathbf{Z}}$ はスパース係数行列であり、各画像に対してどの構成要素を使用するかを示す具体的なレシピとして機能する。
- $\min_{\mathcal{B}, \mathbf{Z}}$: これは最適化の指示である。数学的エンジンに対し、右辺の式が可能な限り最小の値に達するまで、辞書 $\mathcal{B}$ とレシピ $\mathbf{Z}$ の両方を継続的に調整するように指示する。
- $\mathcal{Y}_{\mathcal{I}}$: 入力データ行列である。物理的には、データセットから抽出された脳血管の実際の観測された二値画像パッチである。
- $-$ (減算): ここでは残差を計算するために使用される。これは、実際の血管パッチと、それを再構築しようとするモデルの人工的な試みとの間の正確な差を測定する。
- $\mathcal{B}\mathbf{Z}$: 再構築されたデータである。著者らは、行列乗算が線形結合を完全にモデル化するため、ここでそれを使用している。行列乗算は、$\mathbf{Z}$ で指定された強度重みによって $\mathcal{B}$ の各辞書原子をスケーリングし、それらをすべて加算する。加算は、これらの基本的な形状を互いに重ね合わせて最終的な複雑な血管構造を構築するために使用される。
- $\| \cdot \|_2^2$: 二乗L2ノルムである。数学的には、実際のパッチと偽のパッチ間のすべてのピクセルの二乗差の合計である。物理的には、モデルを高忠実度へと引き寄せるゴムバンドとして機能する。著者らは、絶対値L1ノルムの代わりに二乗L2ノルムを使用した。なぜなら、二乗は大きな、明白な誤差(太い血管を完全に欠落させるなど)に強くペナルティを課し、モデルに全体的なマクロ構造を正確に捉えることを強制するためである。
- $\|\mathbf{Z}\|_1 < \lambda$: L1ノルムを用いたスパース性制約である。数学的には、レシピ内の係数の絶対値の合計である。物理的には、厳格な予算として機能する。これは、モデルが画像を再構築するために、最小限の辞書原子数を使用することを強制する。
- $\lambda$: 正則化パラメータである。スパース性予算の厳格さを決定するチューニングノブである。$\lambda$ が高いほど、よりスパースな表現が強制され、モデルはパッチごとにごくわずかな原子しか選択できなくなる。
ステップごとのフロー
単純なレゴブロックから複雑な血管樹を構築するために設計された自動組立ラインを想像してほしい。
まず、脳血管の生でラベル付けされていない画像パッチ $Y_i$ が工場に入ってくる。これは線形エンコーダー(スキャナーとして機能)に供給される。このスキャナーは複雑な血管を調べ、スパースなブループリントベクトル $\hat{z}_i$ を生成する。前述の厳格なL1予算のため、このブループリントはほとんどがゼロであり、少数の必須コンポーネントのみをアクティブにするように強制される。
次に、このブループリントが、基本的な血管部品を保管する倉庫である辞書 $\mathcal{B}$ に送られる。$\hat{z}_i$ の非ゼロ値は機械的なレバーとして機能する。ブループリントの5番目の位置に $0.8$ という値がある場合、それは倉庫から「原子5」(おそらく特定のY字分岐形状)を引き出し、その強度を $0.8$ でスケーリングする。
最後に、これらの選択されスケーリングされた部品が積み重ねられ、最終的な再構築パッチ $\hat{Y}_i$ が構築される。システムは、元のパッチとこの新しい構築物との差を調べ、誤差を計算し、次のラウンドのためにスキャナーと倉庫の在庫を調整するようにラインの開始点に信号を戻す。
最適化ダイナミクス
このメカニズムは実際にどのように学習し、収束するのだろうか?ここでの最適化ランドスケープは、古典的な綱引きである。L2ノルムは画像を完全に再構築したいと考えており、これは通常、利用可能なすべてのツールを使用することを意味する(結果として密な $\mathbf{Z}$ になる)。しかし、L1制約は効率を要求する厳格な管理者であり、$\mathbf{Z}$ のほとんどをゼロに強制する。
この非自明な最適化問題を解決するために、著者らは標準的な勾配降下法を使用するだけではない。彼らはLISTA(Learned Iterative Shrinkage Thresholding Algorithm)を使用する。LISTAは、従来の数学的ソルバーを取り込み、その反復ステップをニューラルネットワークのレイヤーに展開する。
トレーニング中、損失ランドスケープは、滑らかな多次元ボウル(L2ノルムから)と、シャープな多次元ダイヤモンド(L1ノルムから)の交差として形状付けられる。勾配が展開されたLISTAネットワークを逆方向に流れるにつれて、「シュリンケージ」操作はハサミのように機能する。これは勾配更新を調べ、小さく、重要でない重みを文字通りゼロにクリップする。
時間の経過とともに、このダイナミクスは、辞書 $\mathcal{B}$ が無用なノイズを破棄し、最も普遍的に適用可能な血管形状のみを保持することを強制する。同時に、エンコーダーは、このダイヤモンド形状の損失ランドスケープをナビゲートして、最も効率的な組み合わせを即座に選択することを学習する。この潜在空間が完全に形成され、クラスタリングされると、アクティブラーニングフレームワークは異なるクラスタから容易にサンプリングでき、人間のアノテーターがラベル付けするための血管形状の完全に多様なセットを受け取ることを保証する。
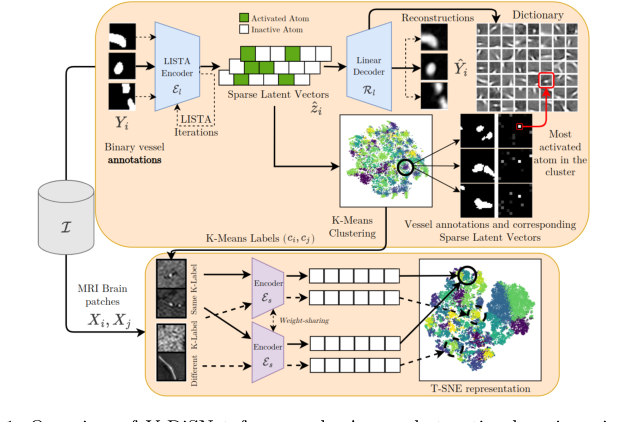 Figure 1. Overview of V-DiSNet framework: A one-shot active learning pipeline that leverages dictionary learning to capture intrinsic vessel patterns, constructs an informative latent space via a Siamese encoder, and applies diversity-based sampling to select a minimal yet representative set of vessel patches for efficient brain vessel segmentation
Figure 1. Overview of V-DiSNet framework: A one-shot active learning pipeline that leverages dictionary learning to capture intrinsic vessel patterns, constructs an informative latent space via a Siamese encoder, and applies diversity-based sampling to select a minimal yet representative set of vessel patches for efficient brain vessel segmentation
結果、限界、および結論
巨大で複雑な都市の配管システムをマッピングするタスクを想像してほしい。配管を直接見ることはできず、ぼやけたレーダースキャンしか手元にない。正確な地図を作成するには、熟練した配管工がスキャンを見て、すべての配管を手作業でトレースする必要がある。これは非常に高価であり、専門医の時間を1スキャンあたり約500ドルも費やし、そして痛いほど遅い。
医療画像処理の分野では、この「配管システム」は人間の脳の血管ネットワークであり、「レーダースキャン」は磁気共鳴血管造影(MRA)画像である。ディープラーニングモデルはこれらの血管のマッピングに優れているが、データ飢餓であることは周知の事実である。学習には完全にラベル付けされたデータセットが必要であり、これは人間の医師が3D脳スキャンをボクセルごとに数え切れないほどの時間をかけてアノテーションしなければならないことを意味する。
このボトルネックを回避するために、科学者はアクティブラーニング(AL)を使用する。すべてにラベルを付ける代わりに、AIはデータを見て、最も混乱している、または情報量の多い部分のみをラベル付けするように人間に要求する。しかし、従来のALは反復的である。AIはいくつかのラベルを要求し、自己学習し、さらに必要であると認識し、再び要求する。この絶え間ない往復は、忙しい臨床現場では非常に非現実的である。そこで登場するのがワンショットアクティブラーニング(OSAL)であり、AIは一度にラベル付けされる単一の最小限のデータバッチを選択する。
本論文の著者らが克服しなければならなかった制約は、既存のOSAL手法が本質的に解剖学に盲目であることである。それらは統計的異常またはピクセル変動に基づいてデータポイントを選択し、血管が連続した、樹状の、管状の構造であるという根本的な現実を完全に無視している。OSALモデルがランダムな「難しい」パッチを選択するだけでは、血管系を定義する繰り返し現れる分岐パターンを見逃す可能性があり、汎化に失敗するAIにつながる。
数学的コア:解剖学の解読
これを解決するために、著者らはV-DiSNet(Vessel-Dictionary Selection Net)を作成した。彼らの素晴らしい洞察は、複雑な血管樹をランダムなピクセルの集合としてではなく、直線管、Y字分岐、曲線などの基本的な形状の有限なアルファベットから構築された言語として扱うことだった。
数学的には、血管画像パッチ $\mathcal{Y}$ をこれらの基本的な構成要素の線形結合としてモデル化した。過剰完備な「辞書」 $\mathcal{B}$(形状のアルファベット)と疎ベクトル $\mathbf{Z}$(どの形状を使用し、どの程度強く重み付けするかという特定のレシピ)を定義した。
辞書が事前にわからなかったため、既存のラベル付きデータセットから学習する必要があった。これを最適化問題として定式化した。
$$ \hat{\mathcal{B}}, \hat{\mathbf{Z}} = \min_{\mathcal{B}, \mathbf{Z}} \|\mathcal{Y}_{\mathcal{I}} - \mathcal{B}\mathbf{Z}\|_2^2 $$
制約の下で:
$$ \|\mathbf{Z}\|_1 < \lambda $$
これがエレガントに意味するところは次のとおりである。アルゴリズムは、最適な辞書($\hat{\mathcal{B}}$)と最適なレシピ($\hat{\mathbf{Z}}$)を見つけようとする。それらを掛け合わせたときに、再構築された画像と実際のアノテーションされた画像($\mathcal{Y}_{\mathcal{I}}$)との差が可能な限りゼロに近くなるように(二乗L2ノルムによって最小化される)。
重要な部分は、制約 $\|\mathbf{Z}\|_1 < \lambda$ である。これはスパース性制約である。これにより、モデルは再構築された血管に辞書から絶対最小限の「材料」を使用することを強制される。スパース性を強制することにより、モデルは画像を単に記憶することはできず、真の、根底にある、繰り返し現れる解剖学的パターン(「原子」)を発見することを強制される。
これらの原子が学習された後、著者らはサイアミーズニューラルネットワークアーキテクチャを使用して、新しいラベル付けされていないMRIパッチを潜在空間(数学的表現空間)にマッピングする。同様の血管構造を持つパッチは互いに引き寄せられ、異なる構造を持つパッチは互いに離される。最後に、Farthest Point Sampling(FPS)アルゴリズムを使用して、この空間全体に均等に分散された、非常に多様な小さなパッチのセットを選択する。これにより、人間の専門家は、脳内に存在するあらゆる種類の血管形状の完全に代表的な断面をラベル付けするように要求されることが保証される。
実験的アーキテクチャ:徹底的な概念実証
著者らは単にモデルをデータセットに投入してわずかな精度向上を報告したわけではない。彼らは、サンプリングメカニズムが既存のパラダイムよりもはるかに優れていることを証明するために、厳格なストレステストを設計した。
彼らの「犠牲者」は、標準的なランダムサンプリング(R-W)と、3つの最先端のOSALベースラインであるRA(Representative Annotation)、CA(Contrastive Active Learning)、およびAET(Active Learning via Epistemic and Aleatoric Uncertainty)であった。彼らは、結果が特定のスキャナタイプの偶然ではないことを保証するために、3つの異なる、公開されている3D MRAデータセット(OASIS-3、SMILE-UHURA、およびCAS)にこれらのモデルを展開した。
V-DiSNetの優位性の決定的な証拠は、超低データレジームで見つかった。著者らはモデルを飢餓状態にし、ラベル付きデータへのアクセスを0.1%、1%、5%、および10%のみに制限した。これらの極端な条件下で、V-DiSNetはベースラインを体系的に打ち砕いた。
さらに、標準的なピクセルオーバーラップ(Diceスコア)を測定しただけではない。彼らは、管状構造のトポロジー的な正確さと接続性を特に測定するclDiceメトリックを利用した。これは、V-DiSNetが単にピクセルをより良く推測しているだけでなく、実際には血管の連続したパイプ状の完全性を維持していることを証明した。彼らのデータにおける究極の「マイクドロップ」の瞬間は、データセットのわずか30%がラベル付けされただけで、V-DiSNetが100%の完全にアノテーションされたデータでトレーニングされたモデルとほぼ同じセグメンテーションパフォーマンスを達成したことである。
彼らの数学的な潜在空間が単なるブラックボックスではないことを証明するために、解釈可能性実験を行った。学習された辞書 $\mathbf{Z}$ の特定の「原子」を個別に無効にすることにより、再構築された血管の特定の物理的特徴(特定の分岐や曲線など)が消滅することを示した。これは、彼らの数学が人間の血管系の物理的な形状を正常に分離したことを否定できないほど証明した。
将来の進化のための議論トピック
本論文の深遠な意味合いに基づき、将来の探求と批判的思考のためのいくつかの方向性を以下に示す。
-
2Dパッチから3Dグローバルトポロジーへ:
現在のフレームワークは、3Dボリュームから抽出された2Dパッチで動作する。局所的には効果的であるが、血管樹のグローバルトポロジーの連続性を失うリスクがある(例:複数のパッチにまたがる長い動脈)。計算コストを爆発させることなく、3Dボリュームグラフをネイティブに処理するように辞書学習方程式を進化させるにはどうすればよいか?サンプリングフェーズ中にグローバル接続性制約を強制するために、トポロジーデータ解析(TDA)を統合できるか? -
クロスモダリティ解剖学的転移性:
V-DiSNetはMRAスキャンから辞書を学習する。しかし、MRA、CT血管造影(CTA)、または超音波で観察されても、血管の基本的な形状は同じである。普遍的な「血管辞書」を一度トレーニングし、完全に異なるイメージングモダリティ間で転送できるか?これにより、病院は安価で豊富なMRAデータから学習された辞書を使用して、希少で高価な、または新しいイメージングタイプに対してワンショットアクティブラーニングを実行できるようになる。 -
物理学と血行動態の統合:
現在、辞書原子は静的な空間形状から純粋に学習されている。しかし、血管はそれらを流れる血液の流体力学によって形成される。もし物理情報ニューラルネットワーク(PINNs)を潜在空間生成に注入した場合、サイアミーズネットワークに形状だけでなく、血行動態特性(例:せん断応力または流速)によって血管をクラスタリングするように強制できるか?これは、動脈瘤や脳卒中の予測のためのデータサンプリング方法に革命をもたらす可能性がある。
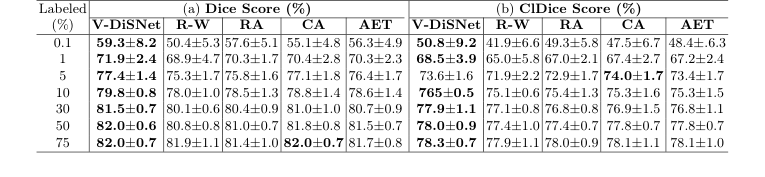 Table 1. Segmentation performance on 15 CAS dataset test patients at various labeling percentages. Eight experiments with distinct random seeds were run for each fraction and model. Results were averaged and standard deviations computed across test patients
Table 1. Segmentation performance on 15 CAS dataset test patients at various labeling percentages. Eight experiments with distinct random seeds were run for each fraction and model. Results were averaged and standard deviations computed across test patients
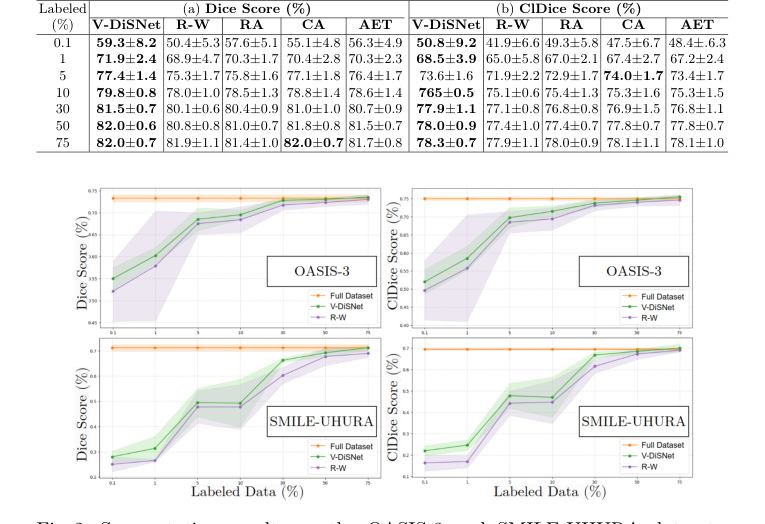 Figure 2. Segmentation results on the OASIS-3 and SMILE-UHURA datasets, showing Dice scores (left) and ClDice scores (right) for different percentages of sample and annotated patches
Figure 2. Segmentation results on the OASIS-3 and SMILE-UHURA datasets, showing Dice scores (left) and ClDice scores (right) for different percentages of sample and annotated patches
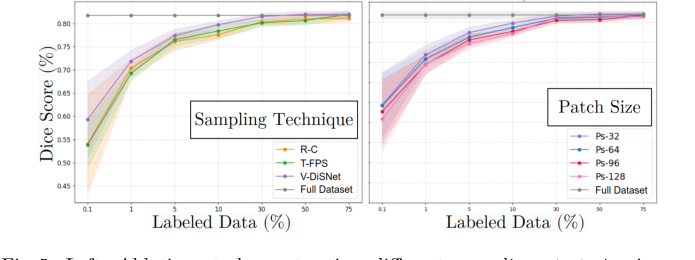 Figure 5. Left: Ablation study contrasting different sampling strategies in our learned latent space. Right: Evaluation of the impact of the patch size
Figure 5. Left: Ablation study contrasting different sampling strategies in our learned latent space. Right: Evaluation of the impact of the patch size